

sd5
1、Align your latent
改造2DUNET,把原来的每个层叫做spatial layer,当视频进来的时候就把时间维度映射到batchsize维度。为了让模型有时间概念,spatial layer 每层后面新增 temporal mixing layer,把空间层输出的结果(batchsize维度的格式)转为视频格式再输入时间层,时间层的输出也要再转成batchsize维度的格式,然后再和空间层输出的结果做安全相加得到时间层的最终结果。在训练文本视频对的时候,固定空间层,只训练时间层。
长视频生成:
假定共T帧,先训练一个prediction model:给定S帧,预测剩下的T-S帧,用Ms掩码去遮掩T帧,然后和Ms做拼接作为条件。S一般取0/1/2。然后使用 prediction model 预测一帧,拿这一帧做条件再预测一个帧序列。在这个帧序列中,每两个相邻帧作为条件,去预测中间的3帧,这样的话,视频帧率就从T提高到了4T。在采样过程中使用 classifier-free guidance 技巧。
为了提高分辨率,采用级联的扩散模型。
2、Video-P2P
视频编辑
类似tune,把 self-attentions 替换为 frame-attentions:当前帧做Q,第一帧做K和V,只训练Q的权重。首先专门对Q进行微调。
对视频所有帧应用Null-text Inversion
把 Prompt-to-Prompt 改一下用于视频编辑,DM用上面微调好的。当用到原始文本计算时,使用优化中的""向量。当用到新文本计算时,使用初始化的""向量。最后将旧文本算出的zt-1和新文本算出的zt-1*按照掩码相融合。掩码是旧单词和新单词的平均注意力权重图二进制化之后的并集。这是因为对编辑文本使用优化中的""向量会降低它的编辑效果,所以最后的效果就是在可编辑区域用初始化的""向量+新文本来采样,不可编辑区域(如背景)就用旧文本+优化中的""向量来采样:

3、PVDM
将像素空间的视频 x 首先使用video Transformer(比如 TimeSformer) 转为1个3d向量(还有逆过程的解码),然后再通过一个Transformer 结构 分解成3个平面向量 z=[zs,zh,zw],三个向量拼接起来,然后用2dunet 去处理,这样大大缓解了计算量。为了生成长视频,训练的时候联合有条件和无条件损失一起训,训练集:针对视频x取出两个挨着的部分clip :x2,x1,有条件的训练就是x2|x1,无条件的训练就是 x2| 空帧,这里把无条件转为特殊的有条件,这样训练的模型只用1个就行了,无条件的意义就是为了产生初始帧。
长视频生成:先通过无条件产生初始帧,而后面帧的采样都是在前一帧上的有条件的采样
4、Pix2Video
unet 的 cross-attention 是用于把条件(如文本)嵌入进去,自注意力机制能决定图片的整体结构。第一个改进是对自注意力机制的改进以引入帧间关系。对于当前帧,Q还是原来的,K和V是由[上一帧的特征图片,初始帧的特征图]决定的,初始帧的作用是在长视频生成时能够始终提供全局的结构信息。
改进2是为了提高时间上的稳定性(避免temporal flickering),在采样的时候,当由xt算出xt-1,算一下当前帧的预测x0和上一帧的预测x0,两者算mse作为指导来更新下xt-1,注意这种更新只会在DDIM初期才有:

5.1、PHENAKI(vq系列)
能实现:文生长视频
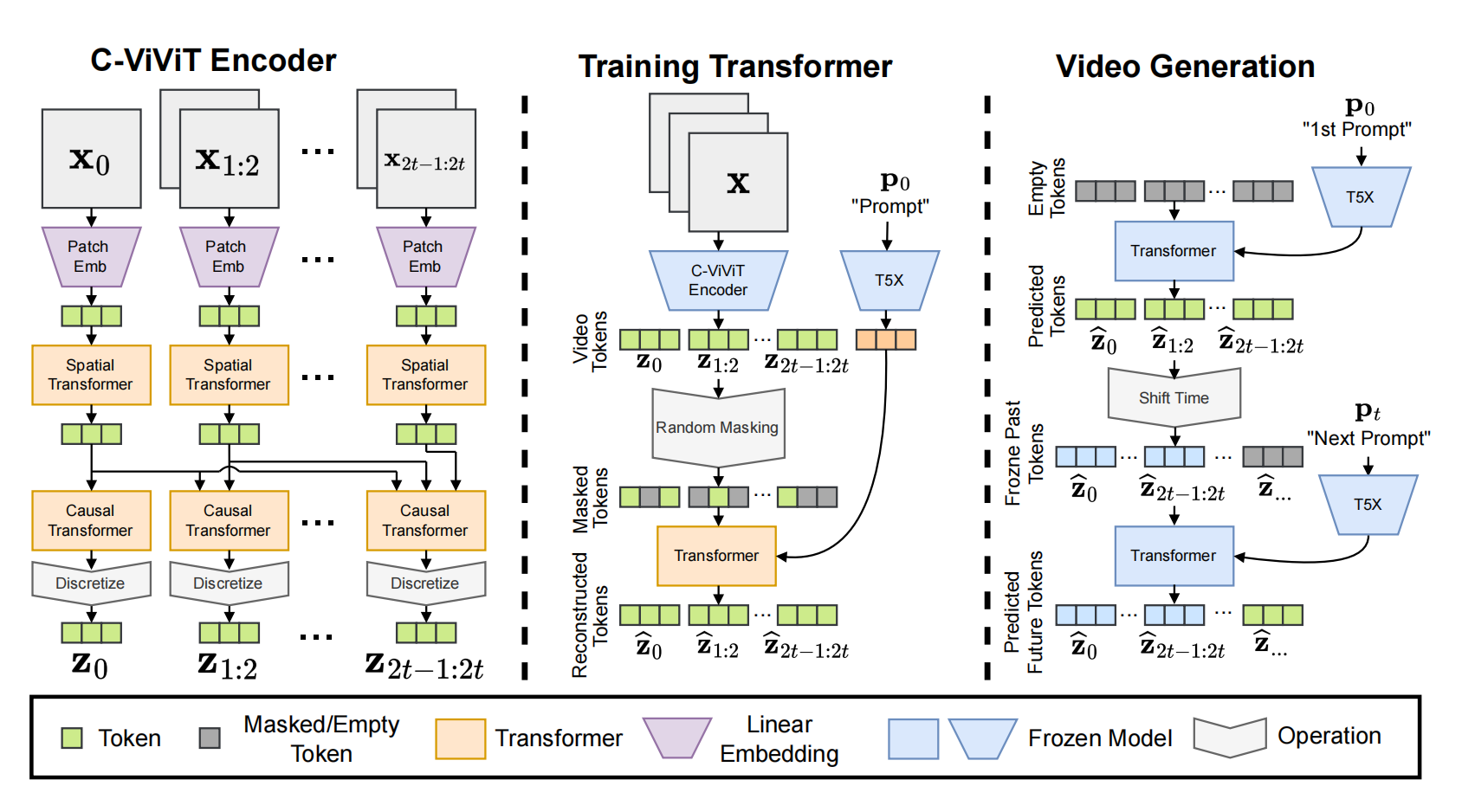
设计了C-ViViT encoder 作为Encoder结构,能够实现生图像和生视频的联合训练,x0为视频第一帧或者图像,后面的xi是视频剩余帧,先通过patch网络,然后分别经过spatial Transformer(时间维度)在空间上实现全注意力,然后是casual Transformer,能够让后面的帧注意到前面的所有帧(时间维度),最后通过codebook 实现 tokenizer;decoder的结构是encoder完全反过来;第一步就是训练encoder+decoder+codebook,损失函数包括codebook loss, image perceptual loss;video perceptual loss;Gan 损失;l2损失;
第二步就是训练中间的Transformer:视频通过编码+tokenizer后作为GT,随机mask token作为Transformer的输入,文本作为条件。
推理:采用MaskGIT机制,对于长视频生成,生成完一个视频的token 序列后,后面补多个空token,预测空的token,此时的prompt可以换,如此可以实现长的 story 生成。
5.2、MAGVIT(vq系列)
能实现条件生视频,条件不仅包括文本,还有帧预测、帧差值等,一个模型就能完成
模型结构改进了 VQGAN encoder和decoder ,2D卷积沿着时间轴改为3D 变成3D-VQ,2DVQGAN的权重来初始化,LeCam regularization提高GAN训练的稳定性,判别器改为StyleGAN结构并扩展到3D
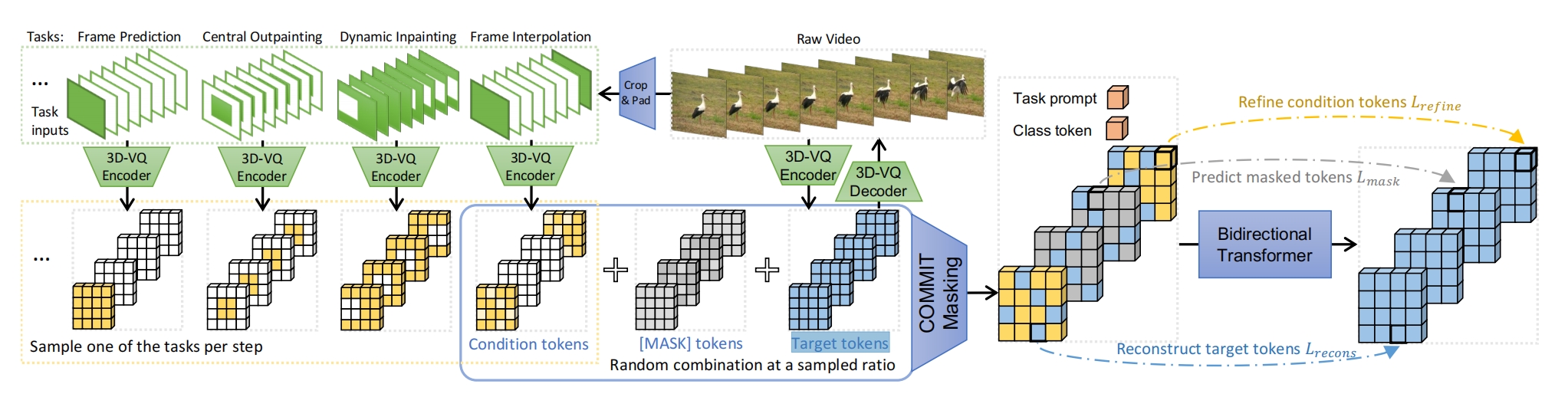
训练:将视频生成任务拆成10个子任务进行多任务训练,每次训练时就随机选一个任务。每个任务对应1种条件输入,如帧预测任务的条件输入图就是只要原视频的第一帧,然后后面的帧都用空帧(pad)代替;插帧预测任务就是取视频的头尾帧,中间插空白帧。然后 3D-VQ encoder 将此条件输入图转为 Condition tokens ,图中的每个小方块都是1个 token 向量。3D-VQ encoder 还将原视频转为 Target tokens。然后 Condition tokens 和 Target tokens 按照 mask 再 加上任务条件 来融合到一起。损失函数就是根据预测融合后的特征图通过 transformer 之后再和Target tokens 的MSE。可以看到这个损失分为三部分,预测没有被mask的部分,预测被mask的部分,预测条件区域部分。mask方法:每个 token 都有1个自己的 mask 分数,然后再按照某种调度函数得到阈值,小于这个阈值的 token都被mask掉,在被mask掉的这部分tokens当中,如果被masked 的 token 在 Condition tokens 当中属于有效 token(不是空帧对应的 token ),则替换为 Condition tokens 当中的那个 token。最后的序列前面加上task prompt和class token,也就是文本和参考的帧
推理:采用MaskGIT机制,即任务条件 + 全0特征图(表示被全体 mask),通过 transformer 预测所有 token,然后按照最高概率保留一部分的预测 token 作为最终token。然后再迭代下一步,只针对没有保留的 tokens 的做下一次预测。最终预测的结果通过VQGAN decoder解码出视频
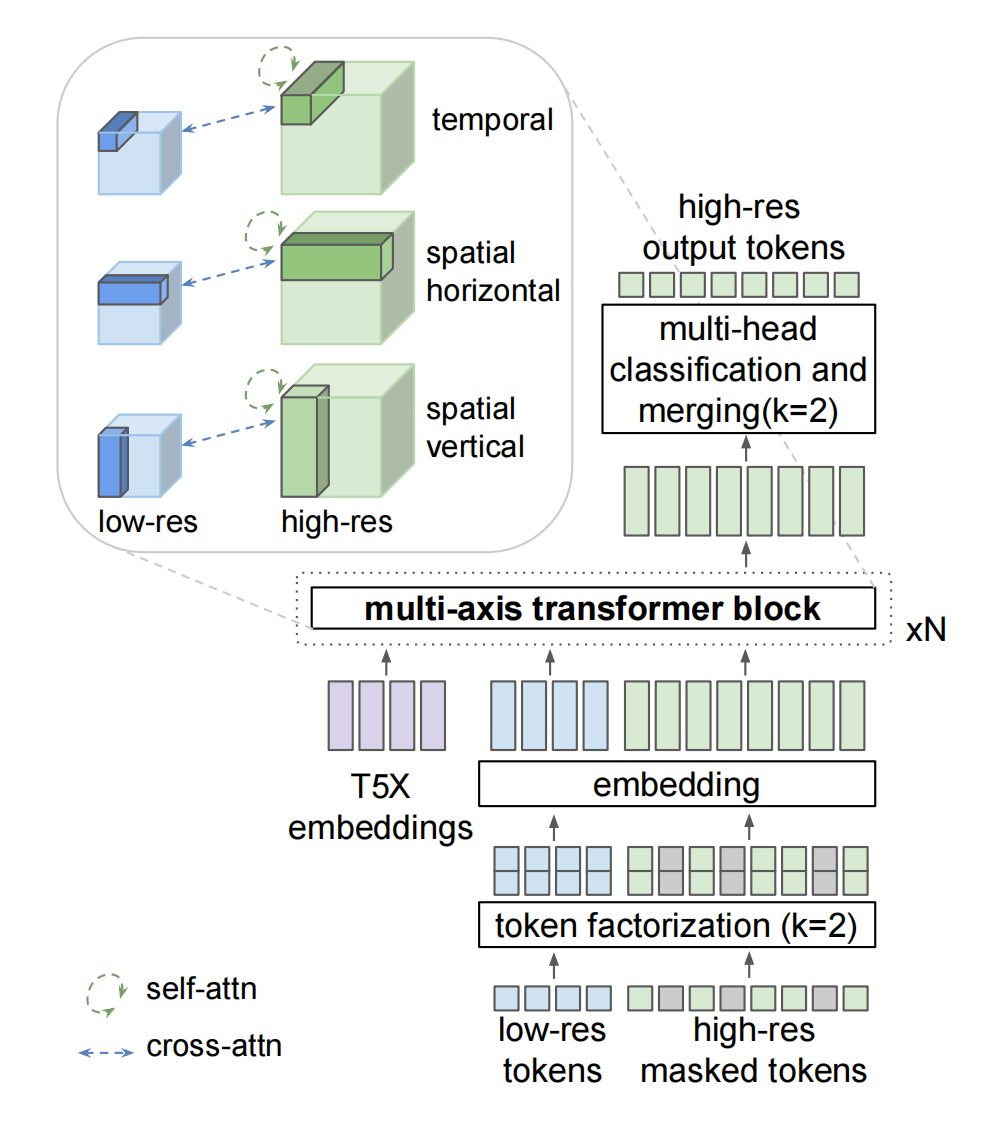
5.3、MAGVIT-v2(vq系列)
改进了MAGVIT:改进1是tokenizer的codebook特征维度变为1,实现了Lookup-Free Quantization (LFQ);改进2是编码器采用 Causal 3D CNN 结构,一个卷积核作用于前k-1帧,而普通的3D卷积作用于当前帧和前(k/2-1)帧和后(k/2)帧,所以无法独立处理第一帧,而 casual 可以:

Token factorization:一个token变为2个token emb的和,这样1个大的codebook变为了2个子codebook
6、controlVideo1
动作序列(从参考视频抽出)和文本输入 controlnet 得到新视频
所有帧的XT都是一样的随机噪声
认为 sparser cross-frame mechanisms 让所有帧都关注第一帧,导致Q和K差距比较大,所以提出 Fully cross-frame interaction ,就是将2D卷积沿着时间轴扩展到3D,并整体的去处理所有帧。
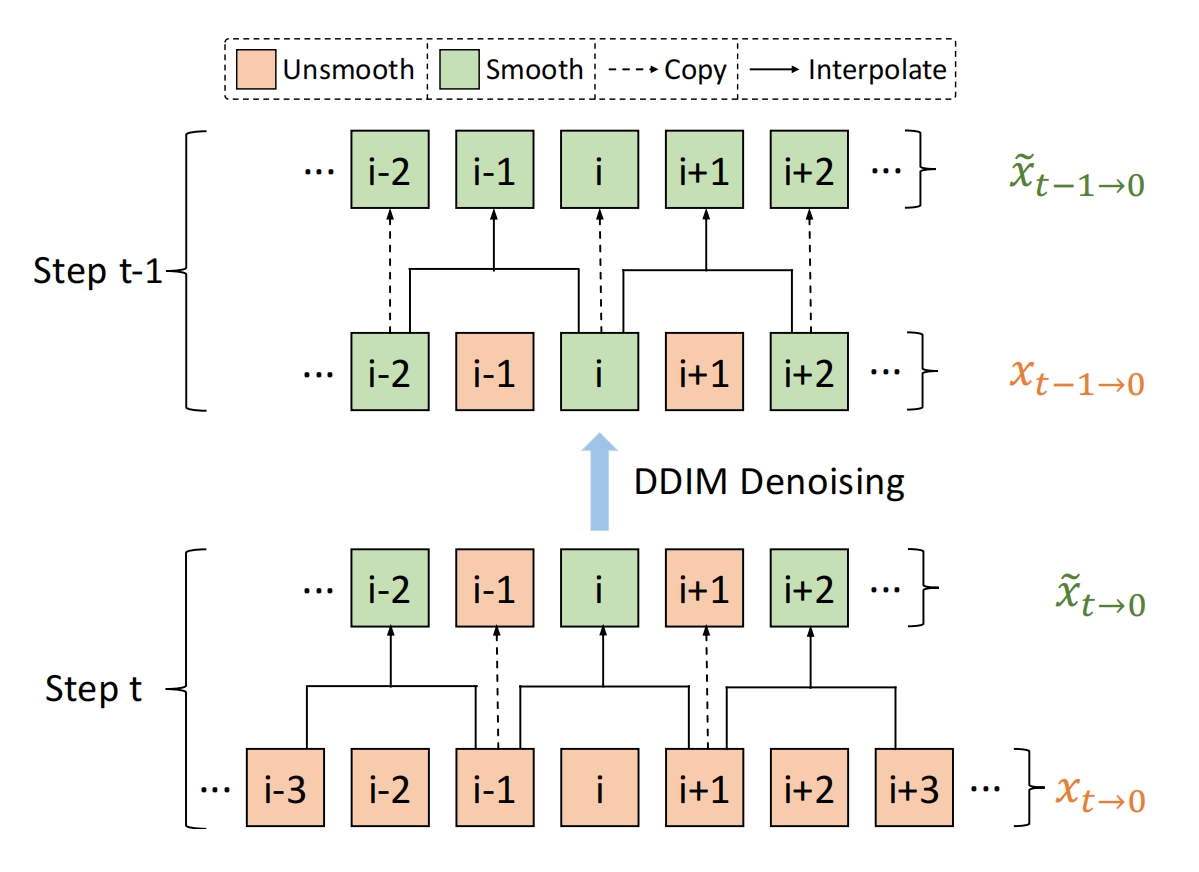
为了避免 flickering in structure,提出了在采样的中间阶段使用 Interleaved-frame smoother:
xt->xt-1:
对 t 时刻的 xt 算出预测xt->0再vae解码为视频,将视频分解为多帧。奇数帧复制,偶数帧替换为两帧的差值结果,差值方法是将两个帧输入到IFNET中得到一帧。
将新视频做 vae 编码作为新的预测x0,利用新的预测x0采样出xt-1。图示:
长视频生成:
对条件长视频平均分成 k 个clip,取每个 clip 的始终帧组成关键帧条件序列,以 T->T-1 采样为例:
根据关键帧条件序列采样得到 T-1 时刻的关键帧隐向量,然后以每两帧为条件生成clip内部的 T-1 时刻的帧隐向量,这样就得到了 T-1 时刻所有帧的隐向量。
比如两个关键帧是帧0和帧4,要生成帧123的隐向量:
7、controlVideo2
将 sd 编码器向量hu 和 controlnet 多个条件向量hc 相加实现多条件控制,每个条件向量有自己的控制力度 λ:
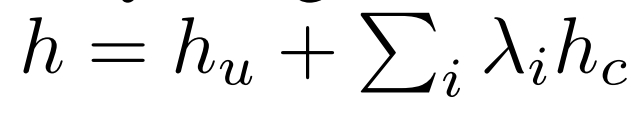
self-attention 转为 key-frame attention:当前帧做Q,第一帧做K,V
sd当中新增 temporal attention module + 零卷积层,注意力机制采用 key-frame attention
8、tryondiffusion
让目标人person穿另一个人的衣服garment
训练数据是同一个人穿一样的衣服但是姿势不同(一对)
Parallel-Unet 由2部分组成,上面是 person-UNet ,下面是 garment-UNet,garment-UNet到了上采样的第一块(32*32)就停止
为了将要穿的衣服warp到目标人的姿态: garment-UNet采用cross attention,Q是加噪的zt,KV都是Ic,此处的相关性是目标人和所要穿的衣服的相关性
pose 向量作为guide,它传给person-UNet,传的方式是把自己和自注意力层的kv拼起来。pose emb还要和temb结合去控制Parallel-Unet 的整体特征。

9、InstructPix2Pix
图片+编辑指令=》根据指令编辑后的图片

首先制作训练数据集:(原图片,编辑指令,编辑图片):已知(原图片,原始标题input caption),做一个小的数据集(取700个标题,人为的标出对应的编辑指令和新标题)来微调GPT3,使得GPT3能够根据原始标题自动输出:编辑指令和新标题。利用 Prompt-to-Prompt 根据(原始图片,原始标题,新标题)变换相似性参数 p (采样的步数比例)分别产生100个新标题所对应的图片,并从中挑选一张图片,该图片和原始图片的距离 要与 新标题和原始标题的距离相等(就是之前说的 Directional CLIP loss )。由此就产生了(原图片,编辑指令,编辑图片)
然后根据(原图片,编辑指令,编辑图片)改造 sd 模型,编辑指令作为cross attention 的 unet 输入,原图片作为视觉条件经过vae编码到隐空间之后和 t步的噪声 进行拼接,然后初始化为 sd 参数,新增的权重初始化为0。
由于 classifier-free guidance 能够使得图片更偏向条件,作者仿照它将原来单条件的改为了多条件的 classifier-free guidance,CI是原图片(条件1),CT是编辑指令(条件2):
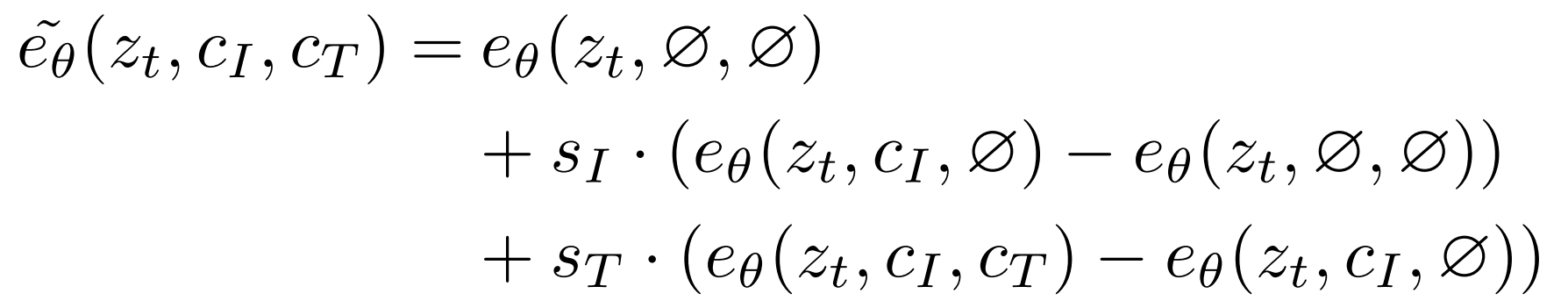
10、Rerender A Video
原始video + text ->新 video
(1)认为自注意力可以看成是单帧内部的 patch 之间按照相似性的融合, cross-frame 可以看成是多帧的 patch 之间按照相似性的融合 ,但是只使用 cross-frame 无法保持 low-level consistency(结构和纹理的一致性),它只会保持风格(Style-aware)。首先将自注意力替换为 cross-frame 以实现 Style-aware,K和V是前一帧和第一帧。
(2)在采样早期,更新 t 时刻的预测x0 以保持旧视频的shape (Shape-aware cross-frame):
![]()
其中
wij:旧视频帧 Ij 到帧 Ii 的 optical flow(经验发现j=0效果好,模糊现象减轻)
Mij:旧视频帧 Ij 到帧 Ii 的 occlusion mask
x~it->0:第 i 新帧(采样帧)在 t 时刻的预测x0
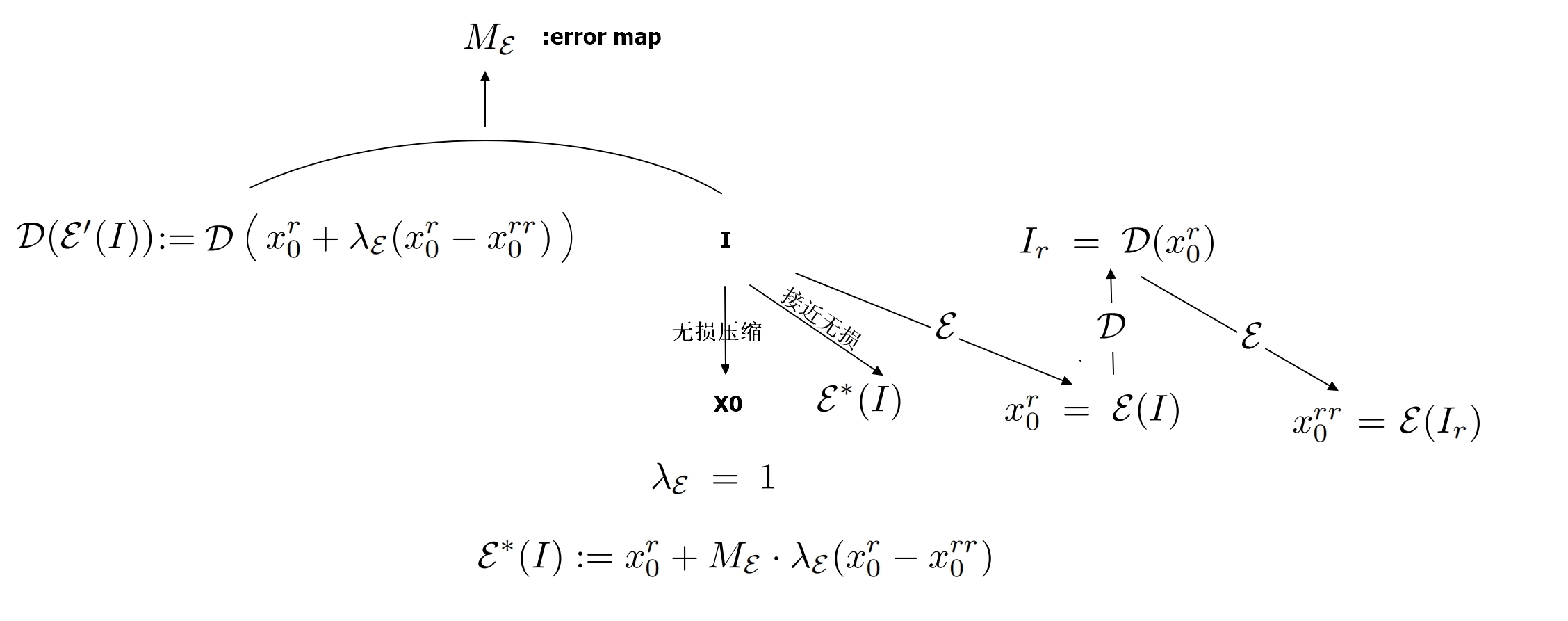
(3)构造了接近无损的图片编码器,下图的 I 是图片
在中间的采样步骤,引入 Structure-guided inpainting 以保持纹理特征
(4)后期采样步骤应用了 Color-aware adaptive latent adjustment 以保持与第一帧颜色风格一致:应用AdaIN到 时间t 的 第i帧的预测x0与时间t 的 第1帧的预测x0 的均值和方差一致
(5)新视频生成:先生成一堆关键帧,然后每隔K个帧取一一个关键帧:I0,IK,I2K,...。然后对两个相邻的关键帧进行插帧,比如I0和Ik,先根据I0得到中间的一堆插帧,再根据IK得到中间的一堆插帧,最后两堆插帧融合。由于普通的插帧会导致新内容无法生成。作者引入了 Patch-based propagation:先找到关键帧和要插入的帧之间的映射图,根据这个图来扭曲关键帧作为插帧。混合方法是通过掩码M混合,比如要混合根据第0帧产生的第 i 帧 I'0i 和第k帧产生的第 i 帧 I'ki 的 第p个像素 :如果 I'0i 帧第p个像素的 patch match error 比I'ki 的第p个像素的 patch match error (根据该帧和产生该帧的关键帧来计算)小就用 I'0i 帧素:
![]()
否则对上一针的mask 用 optical flow 扭曲来得到新的mask,用新的mask来融合。
11、LVDM
将视频映射到隐空间操作,AE的编码器和解码器都进行训练
长视频生成:在每一帧的通道维度加入一层掩码m,取值为0/1,每当预测完前面的视频 clip,就拿预测好的 clip 作为条件去预测后面的 clip。用两个模型去做生成,第一个模型生成稀疏帧,第二个模型生成稀疏帧中间的插帧;为了降低由先前所预测视频所导致错误积累,针对条件帧,加入t步的噪声扰动作为条件;由于积累的预测错误并没有影响到无条件生成,所以加入无条件指导以提高视频质量,所有帧的掩码置为0能得到无条件的噪声估计εu,把前 k 帧的掩码置为1,其余的掩码置为0得到有条件的噪声估计εc:
![]()
12、LFDM
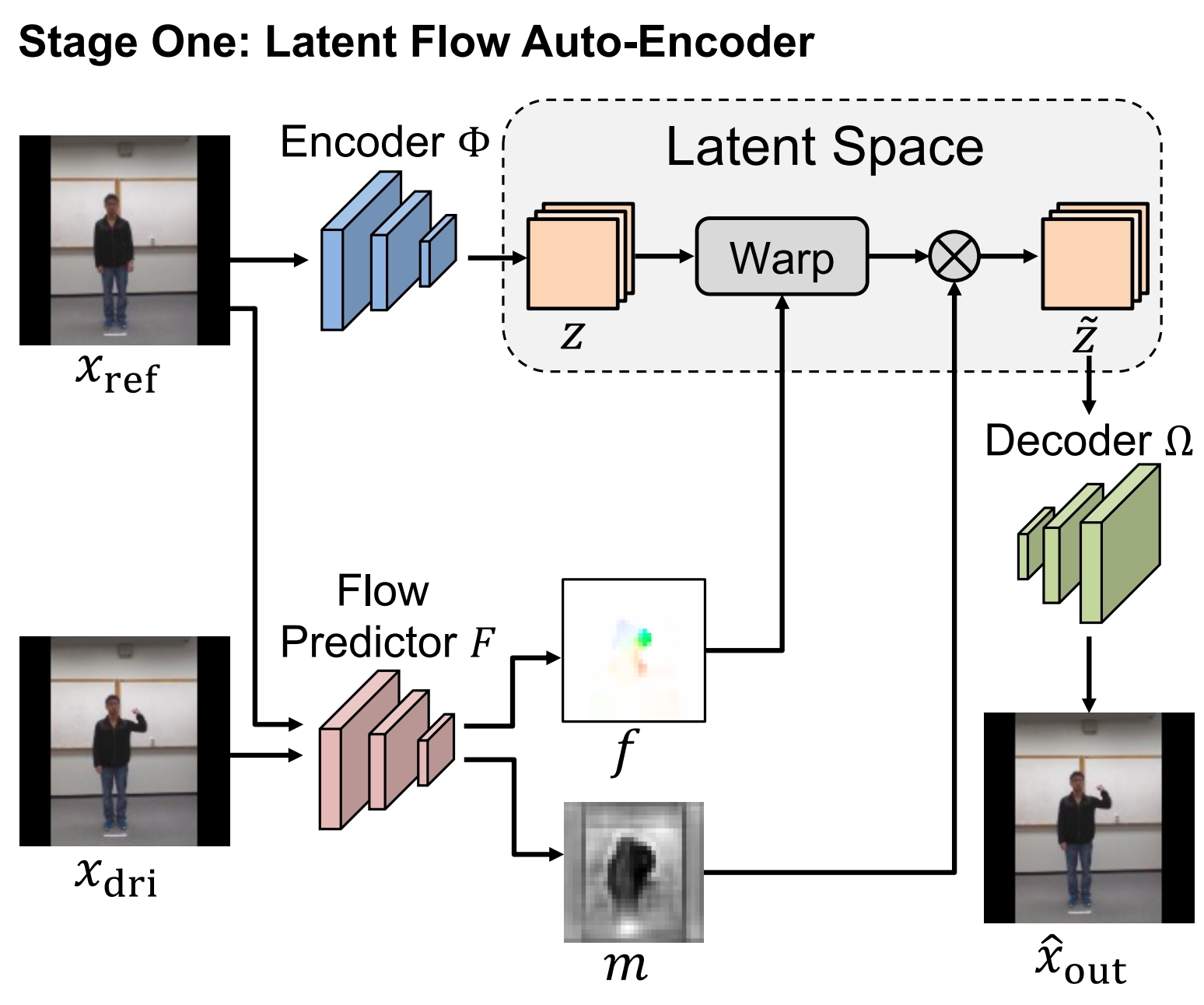
图 + 文=》视频
训练包括两个阶段,第一阶段训练Flow predictor F,F输入初始帧xref和目标帧xdri(视频里面随便抽2帧),输出光流 f(motion)和 occlusion map m,f 用于 warp xref 的隐向量,m 用于提示哪些区域不用warp,公式:

损失是 decoder 后的图片和xdri 的距离损失
第二阶段训练一个dm,能够根据文本和初始帧生成光流 f(motion)和 occlusion map m:先根据上面训练好的 F 生成视频中每一帧对应的光流和m,按厚度拼接作为dm的x0,dm以初始帧的隐向量和文本向量作为条件对其加噪再解噪。
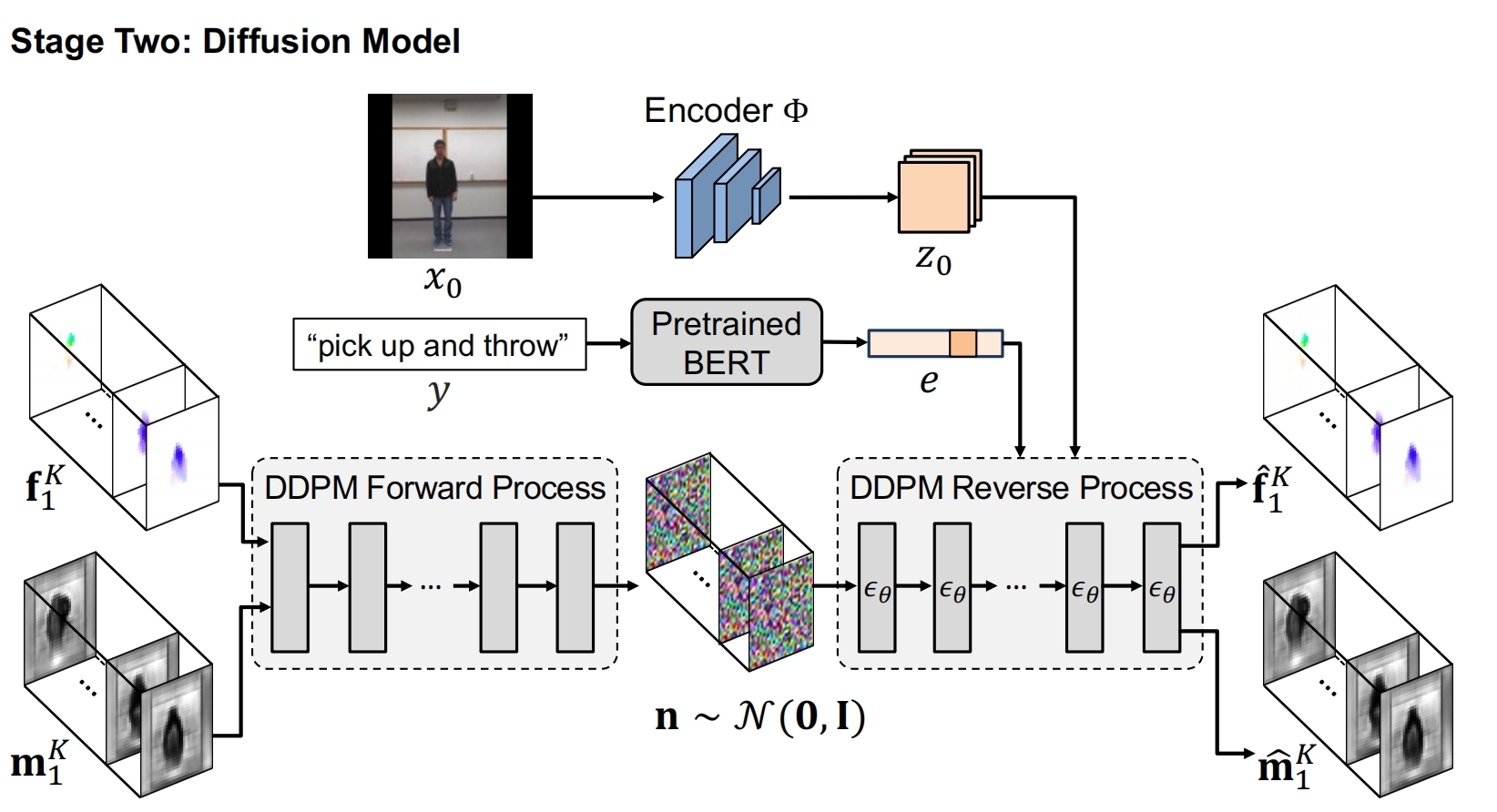
预测:训练好的dm根据初始帧和文本向量生成光流和m,然后扭曲x0和解码得到对应的视频
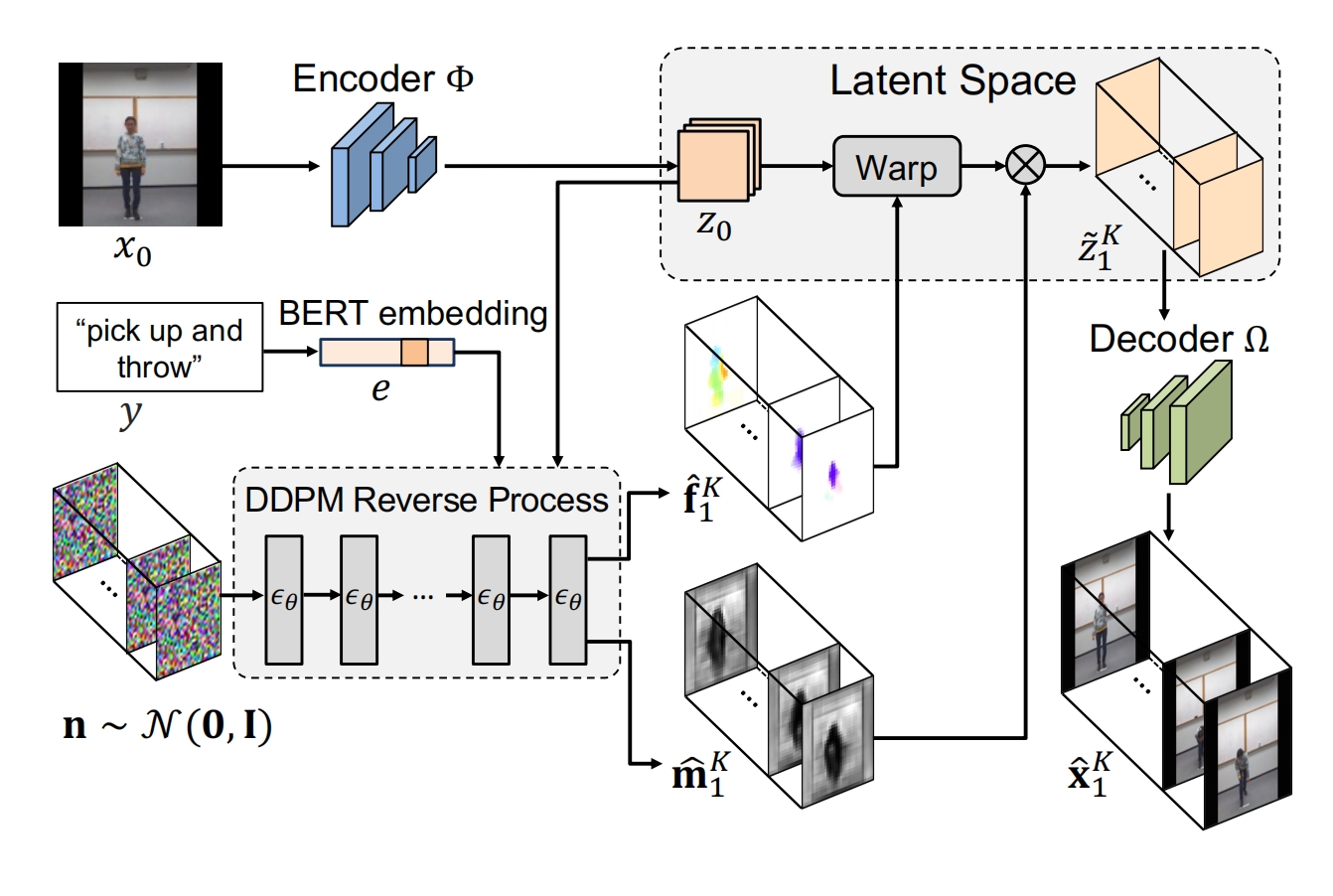
13、dragnuwa
图+文+轨迹=》视频
就是给sd 3 个条件:图片,文本,轨迹,然后生成视频
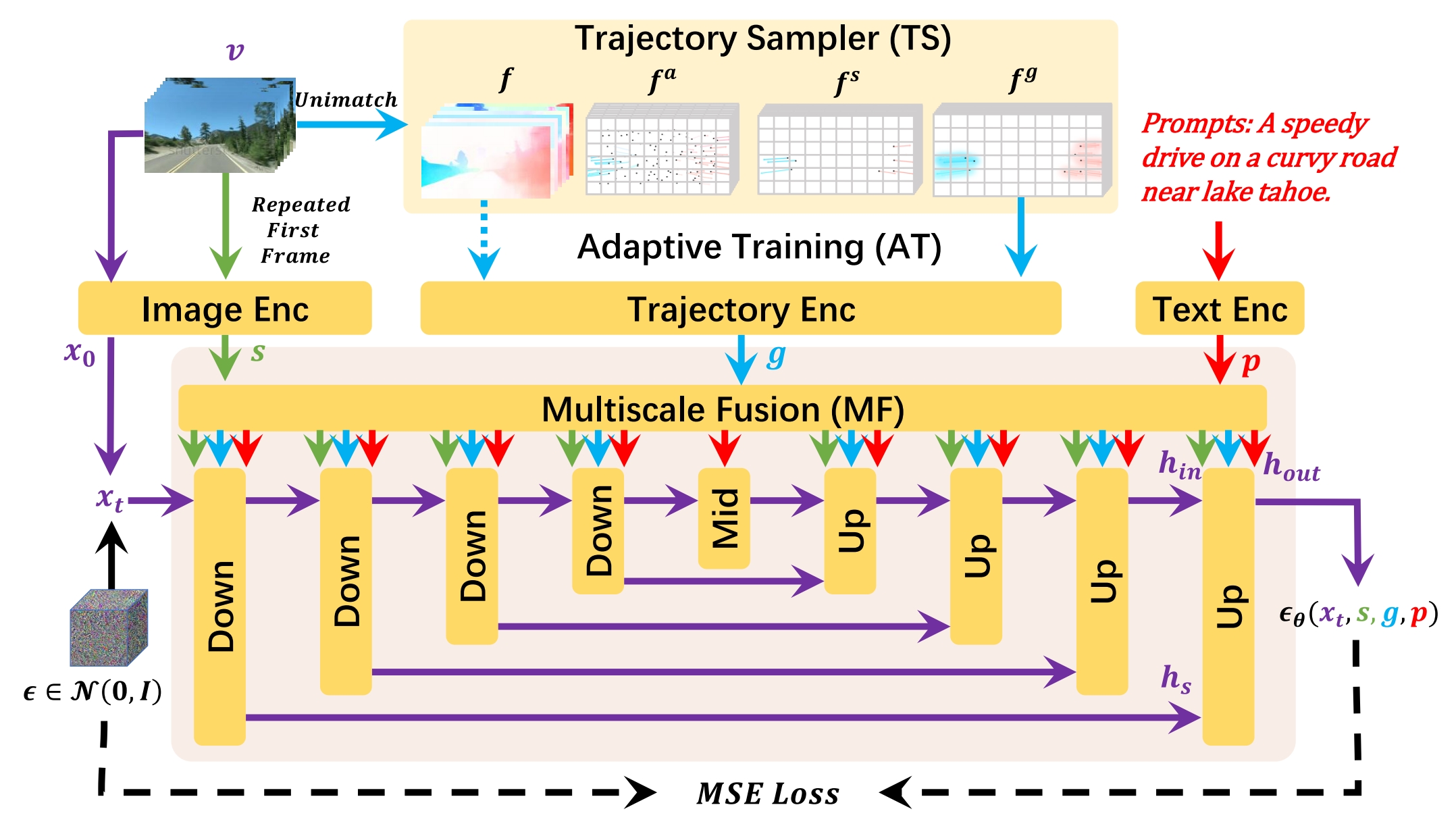
训练:
图片条件:视频的第一帧复制帧数次,再通过编码器得到s;
轨迹条件:视频通过 unimatch 得到视频的光流 f,由于光流的密集程度不同可能导致模型过于关注较大行为的物体,因此 f 取间隔的点+点小范围随机扰动 得到稀释的 fa,从fa中再根据光流的稀疏性采样N个点作为N个轨迹初始点,然后根据光流 f 可以得到这N个完整的轨迹fs,最后应用 Gaussian Filter 降低fs的稀疏性得到 fg 以便模型学习轨迹。训练第一阶段用 f ,第二阶段用 fg 以提高学习难度。光流的作用只是拿来得到轨迹的。
文本条件:文本通过clip text model。
MF 用将每个条件分别映射到unet 对应的不同分辨率上,然后通过卷积映射得到 scale 和 shift ,根据 scale 和 shift 和 unet 原来的隐状态进行融合。各层融合各层的。
损失函数还是 sd 的噪声损失。
推理:轨迹条件是把用户提供的轨迹通过 Gaussian Filter + 0帧 padding 到 fg 的形式
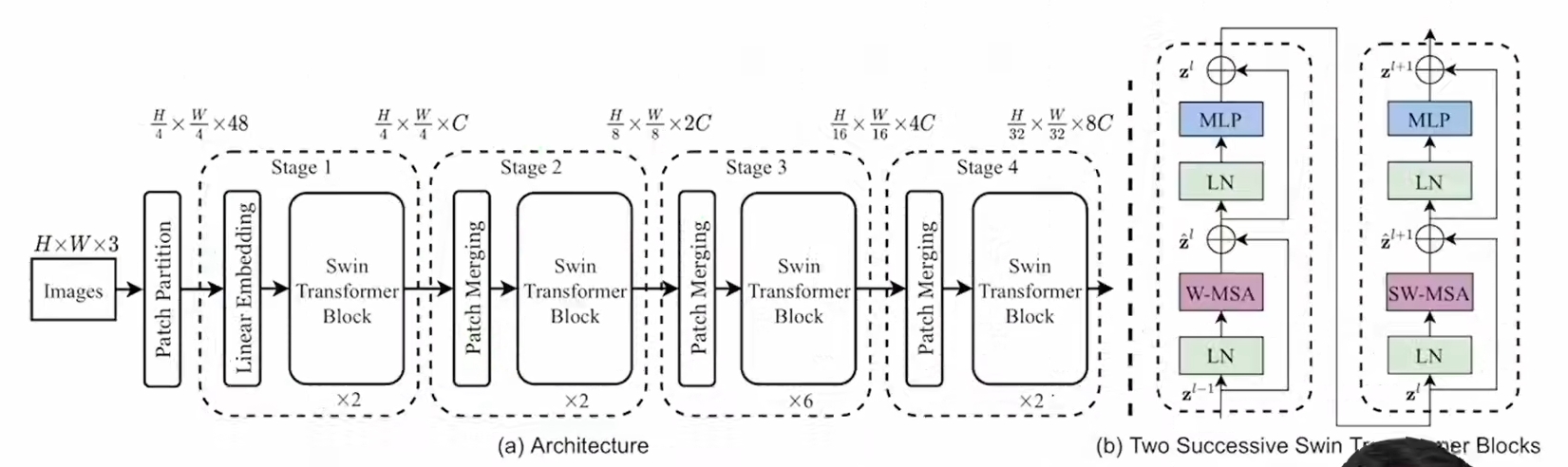
14、swin Transform
对VIT的改进:VIT是先对对特征图划一堆patch,全图的 patch 做自注意力。swin 是对特征图划分了4(举例)个窗口,每个窗口内部先做自注意力(swin Transformer block1),然后把窗口挪动一下位置(shift),产生了9个窗口,窗口内再做自注意机制(swin Transformer block2),这就相当于原来窗口先做自注意力,然后再和周围窗口做个通信(cross-window connections),这种窗口的做法降低了运算复杂度。为了降低操作难度,作者巧妙的挪动了特征图的位置,并采用了掩码的方式遮掩了无需相互计算的部分。
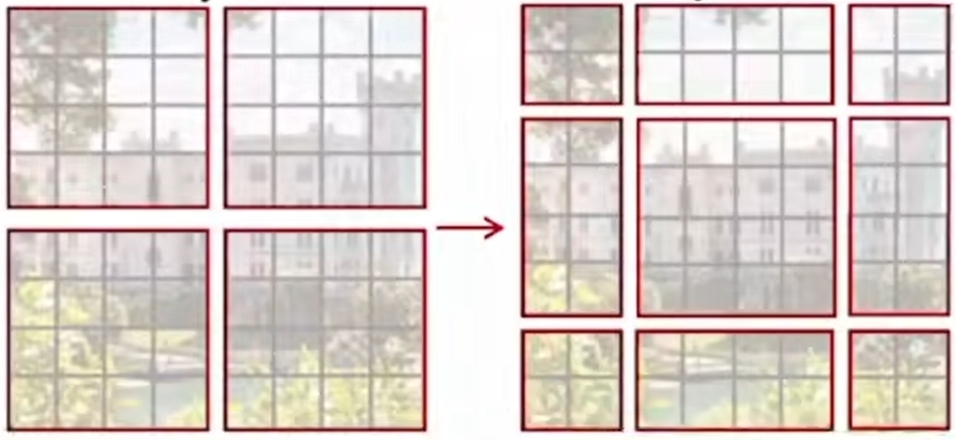
swin 整体分为了多层,这是为了实现多尺度特征提取,然后在每层当中堆叠了多个 swin Transformer block1+swin Transformer block2:
15、GUIGEN
文 + grounding text (optional) + grounding box/keypoint/conditional map (optional) =》 图
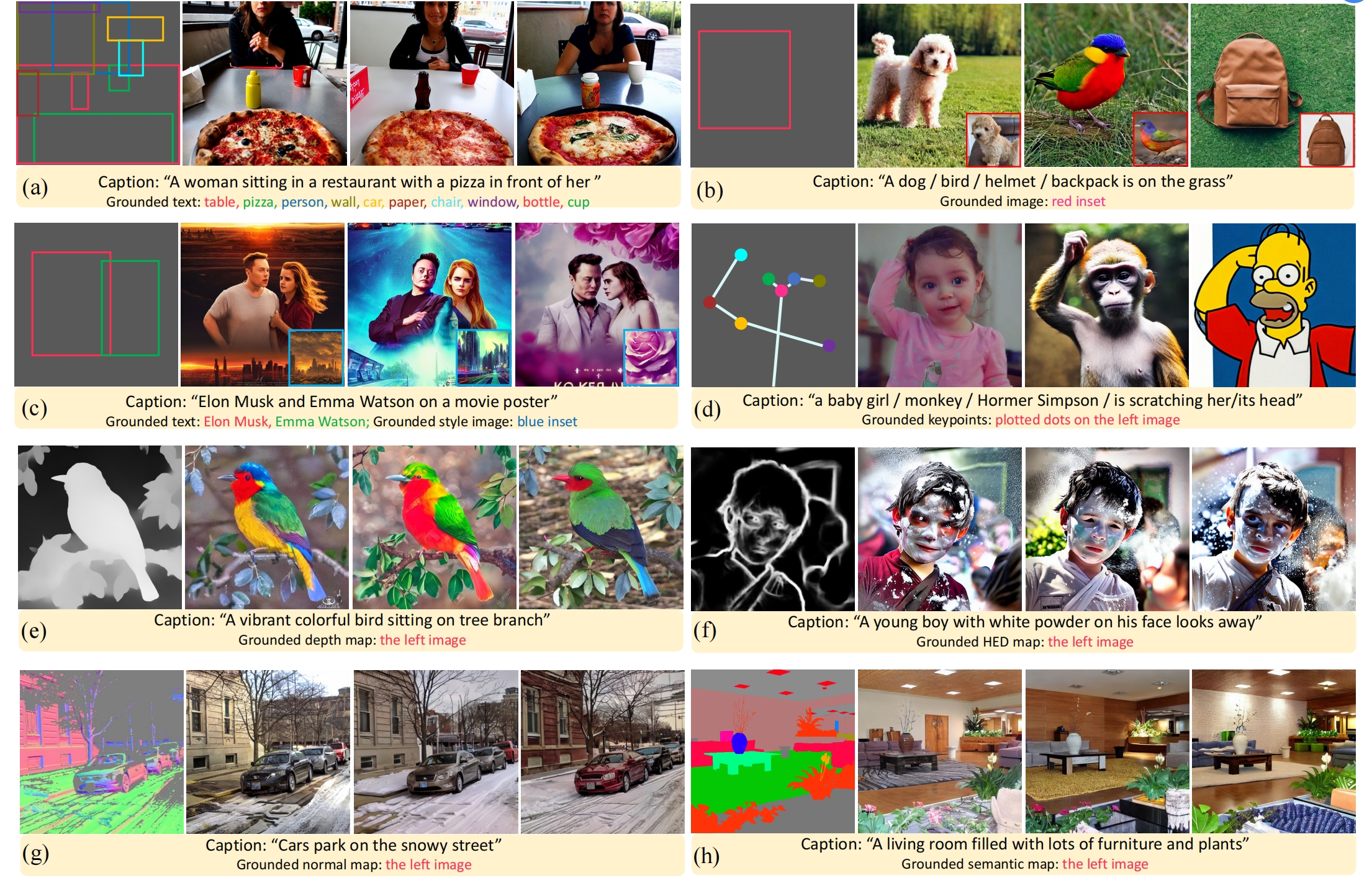
针对groundding text 和groundding box的编码:每个entity text经过text encoder后得到的向量和groundding box向量(Fourier embedding)拼接后再通过MLP,这样每个entity就对应1个向量了,叫做grounding token(lhe)。而caption经过text encoder后的每个token被叫做caption token。
sd改造:在self-attn和cross-attn中间新增了gated-attn。训练只训练gated-attn和grounding token的编码
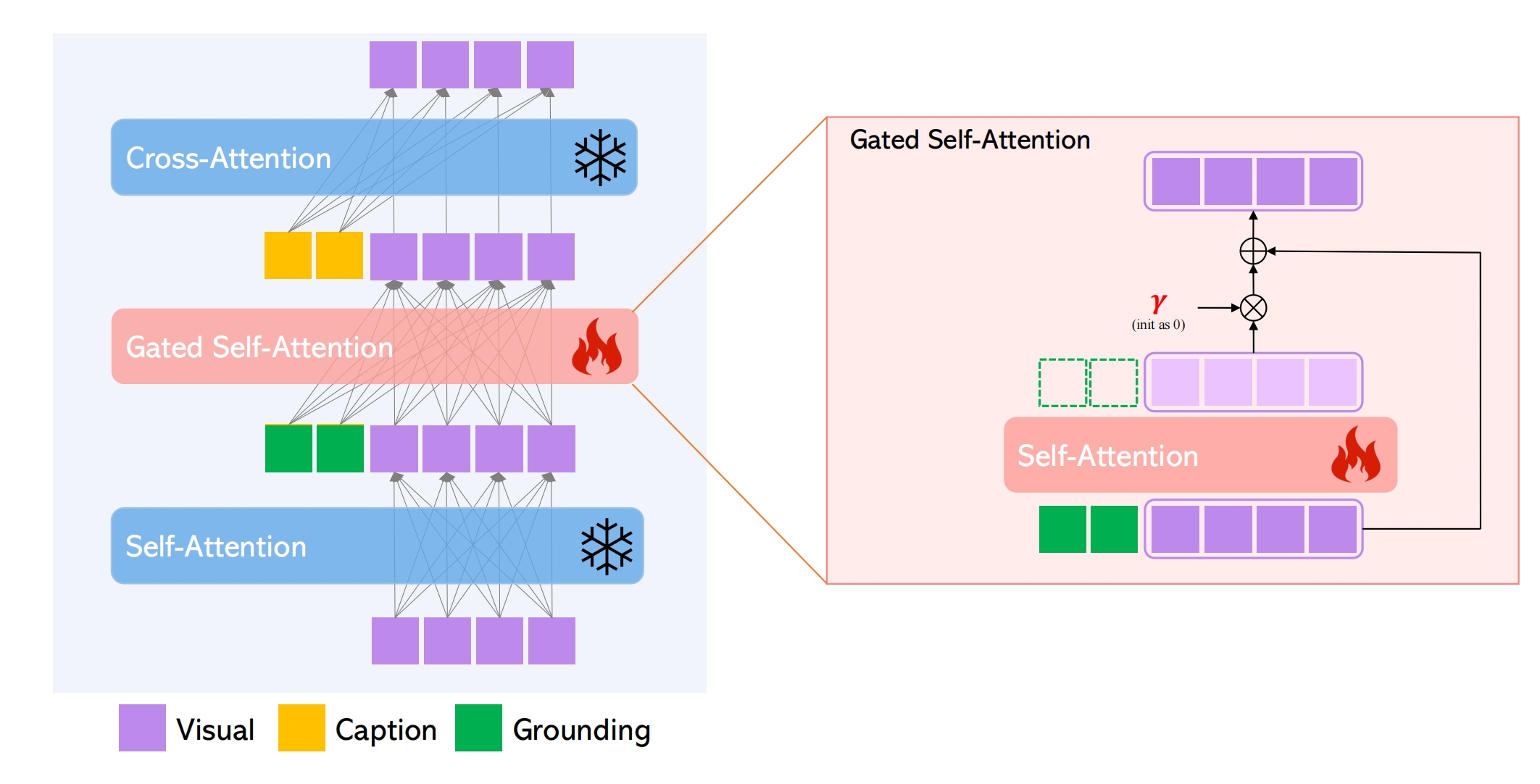
grounding token和visual token先经过self-attn,然后只要visual token的向量(TS),然后乘以一个可学习的系数γ(初始化为0),β在训练时恒定1,推理时为了兼顾图片质量,一开始为1,后来为0:
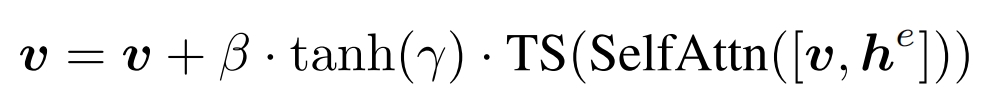
16、Dragdiffusion
图+ 文 + mask + drag 坐标 => drag 后的图
首先用lora技巧微调db 以便记住(图,文),然后对原图 ddim inversion t 步得到zt,根据drag坐标对zt进行拖拽变换,然后再ddim采样生成拖拽后的图片
拖拽变换要对 zt 进行多次优化,对于第k次要优化ztk,假设start和tar分别是拖拽起始和拖拽终点,Ftar(ztk):F是让ztk通过unet倒数第二层,然后取围绕tar的3*3区域的小特征图,sg代表不回传梯度,m是mask,值为0的区域代表要保持不变:
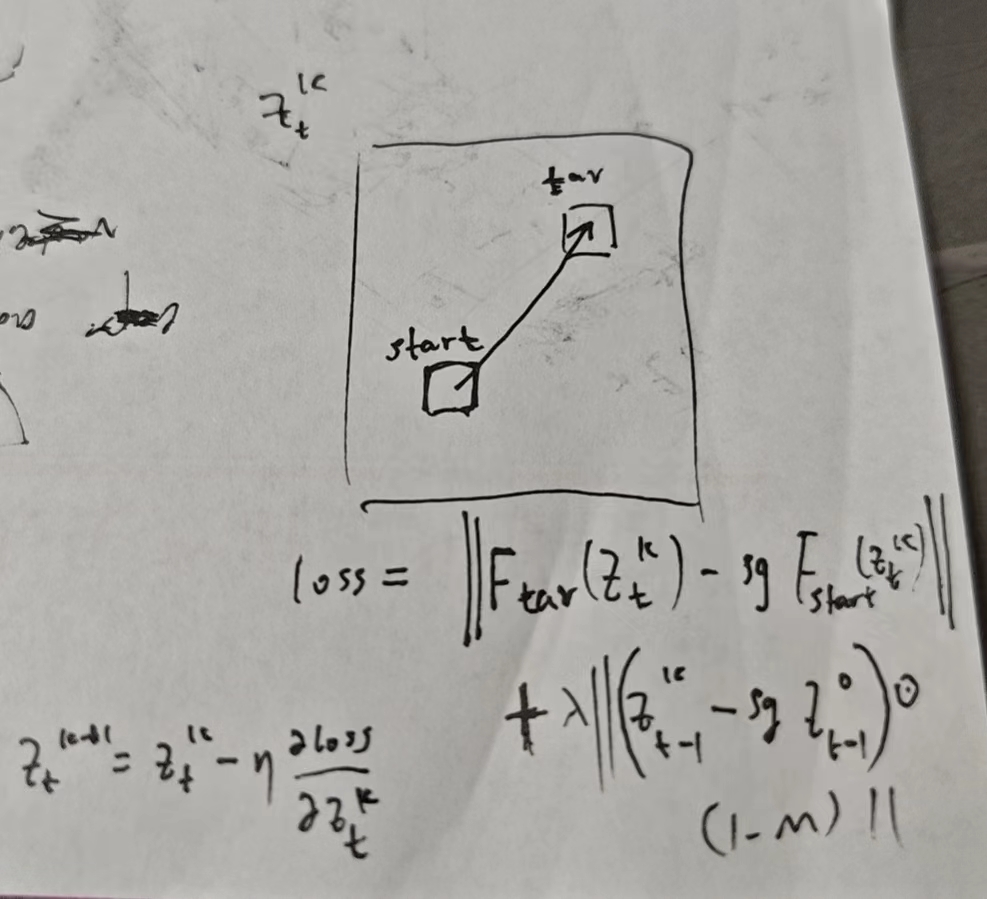
每一次优化后,特征图都进行了某些拖拽了,所以拖拽的起点h都会更新一次,这是为了一直跟着原来的起始像素点:
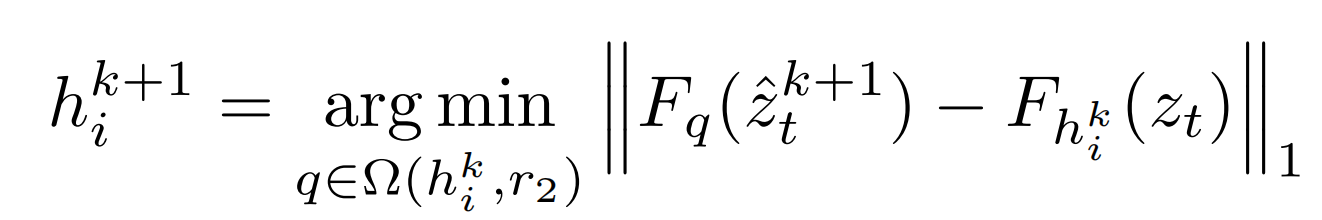
17、fastcomposer
文+几个参考人的图=》多人的图

推理:将参考物体通过图片编码器分别通过MLP注入到实体“man”的文本向量中,此时 man 就记住了这个人id。一开始推理的时候用注入前的文本向量生成layout,过一会再用注入后的向量(delayed subject conditioning)
训练:

给一个图(多人图)文对,提取文的所有实体,如“woman”,“man”,再对图片分割出所有人,把人注入到对应实体向量中。另外一个trick,把实体对应的cross attention map 逼近对应人的分割图以防止多人生成的时候 id混合,方法是把map和分割mask做mse loss,加到扩散模型噪声上。仅训练image encoder ,mlp,unet。
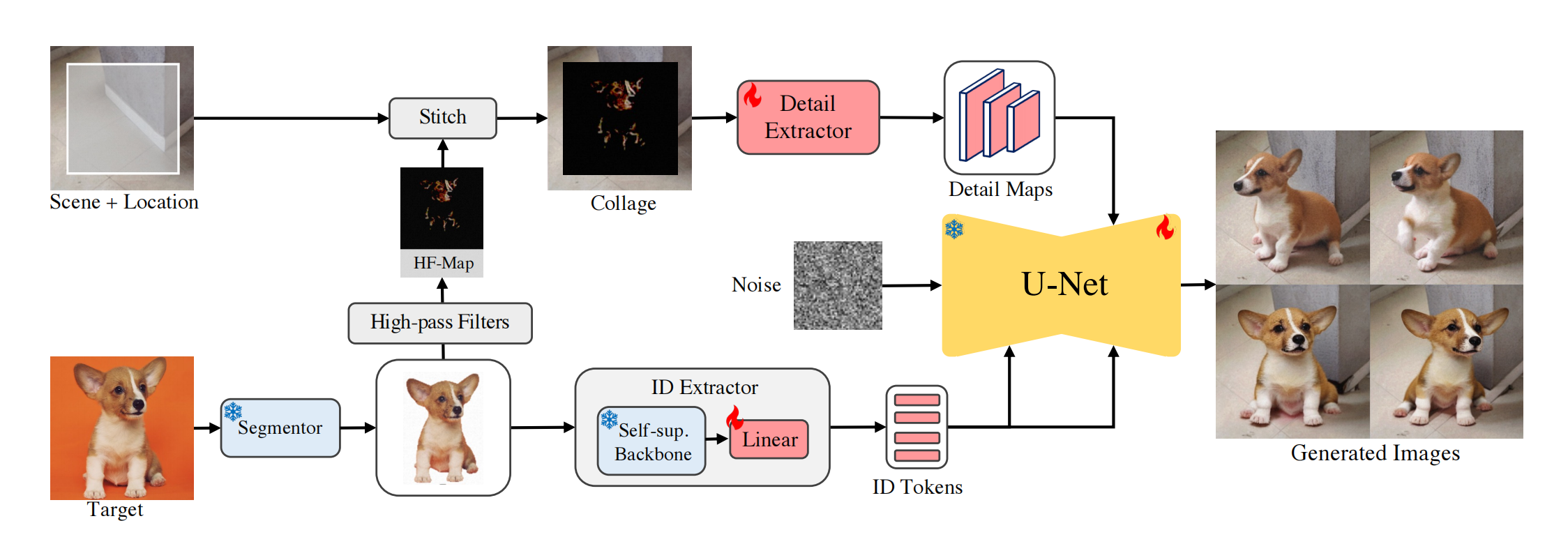
18、AnyDoor
目标图+mask+参考图=>目标图mask区域内的物品换成参考图
下面分支提取语义信息:目标图通过segmentor去掉背景,再通过ID Extractor(DINOV2+linear)得到序列向量257*1024,序列向量当作cross attn注入到unet,但是这个分支没有空间细节特征
上面分支补充空间细节特征:把collage通过一个 UNet encoder 得到多个分辨率特征,然后和dm的unet 的 UNet decoder 每层拼接,训练的时候 unet encoder 冻住,decoder 放开
训练集制作:
除了Multi-view Image数据集,还有通过视频生成的数据集

由于视频数据通常分辨率低,图片分辨率高,所以训练的时候如果用的是视频数据,则加噪步骤多点,图片则少点,因为早期解噪主要是轮廓生产,后期是细节生成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号