


m11
1、强化学习
1️⃣概念
状态转移概率矩阵(已知状态s和动作a,下一个状态是s‘ 的概率):
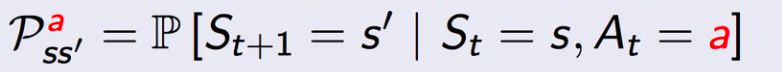
状态 s 采取动作 a 能获得的奖励期望:
![]()
策略:状态s下采取动作a的概率:
![]()
执行策略 后,状态从s转移至 s' 的概率:
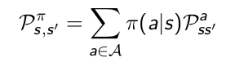
奖励函数:
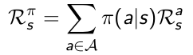
return :从 t 时刻开始往后所有的奖励的有衰减的和:

行为价值函数:在遵循策略 π 时,衡量在状态 s 执行行为a的价值:
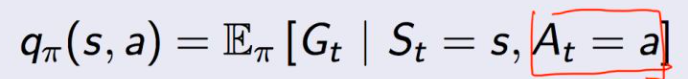
![]()
value function:在执行策略π时,在状态 s 的价值:
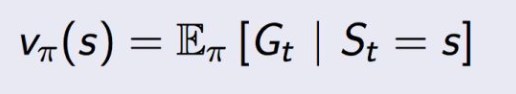
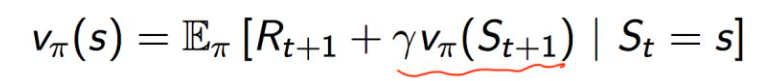
根据q和v的关系:
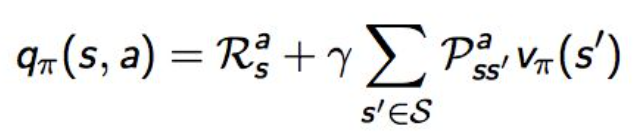
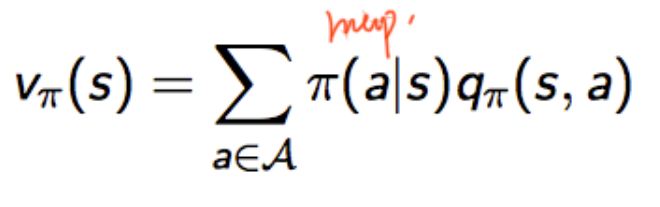
可以推导出(该式又叫 bellman期望方程,由于bellman方程没考虑动作,此处略) :
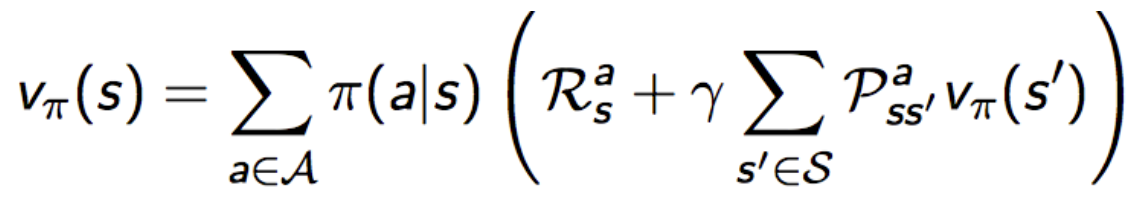
(Bellman期望方程)矩阵形式:
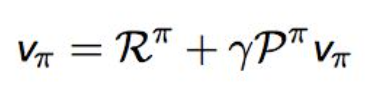
( Bellman期望方程)举例:
节点是状态,节点的数值是价值,边是动作和奖励
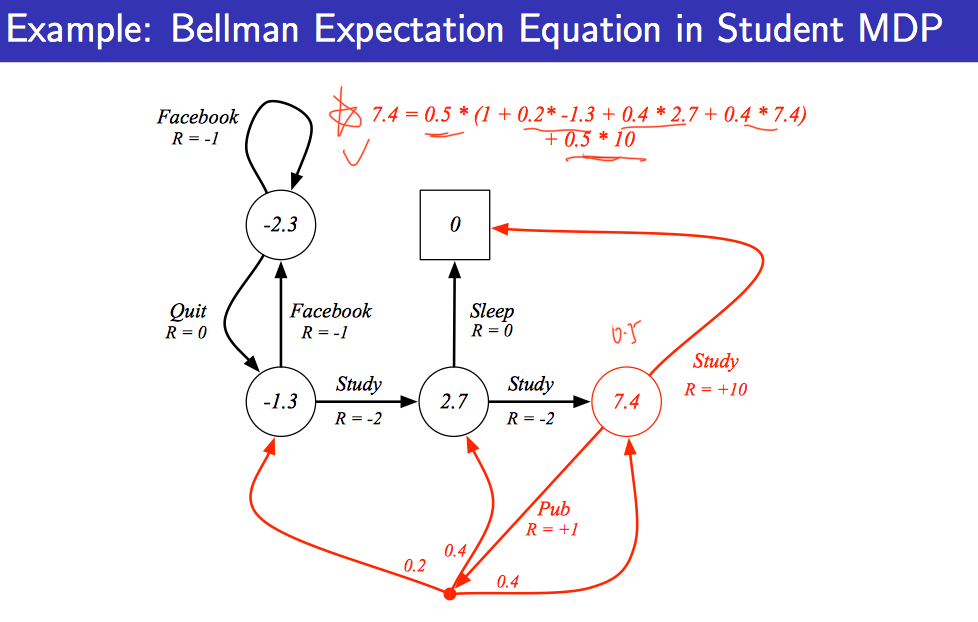
解释:从A状态(设7.4那个状态为A状态)出来有两动作,一个是study一个是Pub,每个动作的概率为0.5,则对应上上面公式是 ,我们先看通过Study的action,发现它转移到了终止状态,
=0,则这条路贡献了0.5*10,同理action为Pub的那条路,R为1,然后各自有0.2,0.4,0.4的概率转移到下一个状态,所以另一条路为:0.5*(1+0.2*-1.3+0.4*2.7+0.4*7.4)
解法:反复迭代计算v,最终会收敛,式子里面后面的v用的是上次迭代的结果,
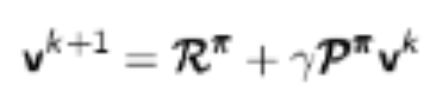
2️⃣引入最优的概念
最优状态价值函数:状态s的最大价值:
最优行为价值函数:在状态 s 执行 a 的最大价值
最优策略:遵循策略 π 的价值都>=遵循策略 π' 下的价值,对任何状态s都成立:
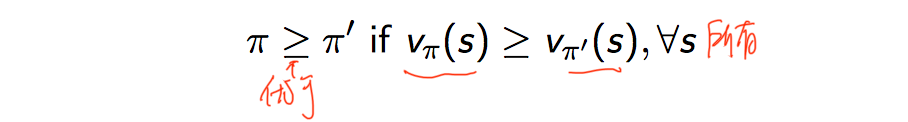
根据v*和q*的关系:
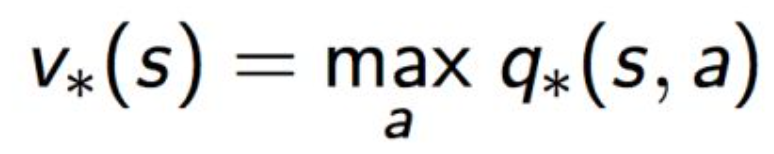
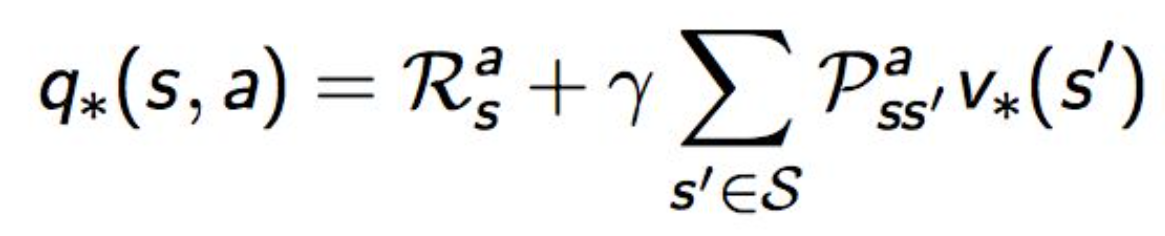
可以推导出(被称为 Bellman最优方程):
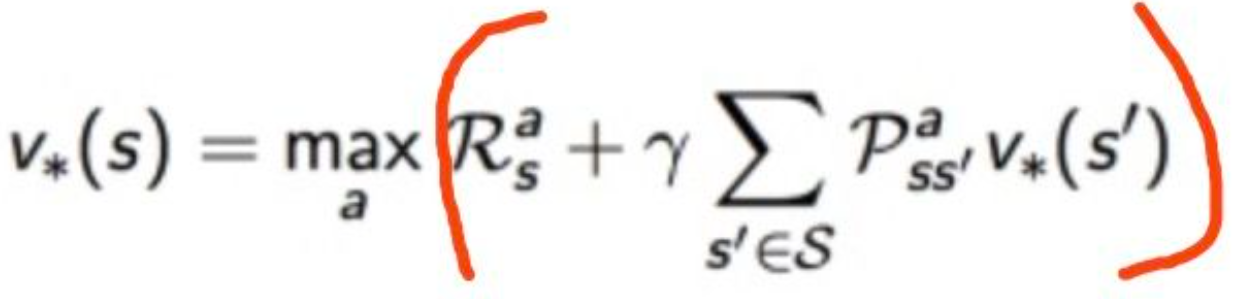
举例:
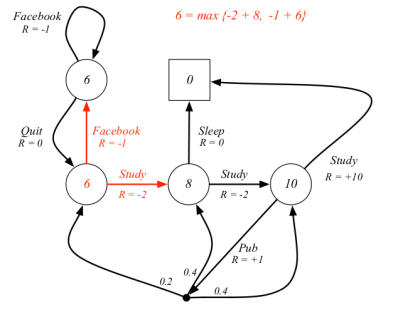
解释:它有两个action一个是Study对应的立即奖励是R=-2,一个是Facebook对应的是R=-1,我们要求 ,则是从这两个动作挑一个能得到最大值的action,又因为
,这里默认
都为1,而且从Study和Facebook动作出去之后都只能到达一个状态,于是
,于是6={-2+8*1, -1+6*1}
解法:要求出V*s的话,由于式子(Bellman最优方程)是非线性的(因为max运算在里面),没有固定的解决方案。但是有通过一些迭代方法来解决:价值迭代、策略迭代、Q学习、Sarsa等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号