
m9
0、语义分析
发展过程:依存句法分析-》语义角色标注-》依存语义分析-》抽象语义表示
【依存句法分析,Dependency Parsing, DP】
分析句子里的词语之间的依存关系,如SBV主语关系,VOB动宾关系,ATT修饰关系,常用标记:
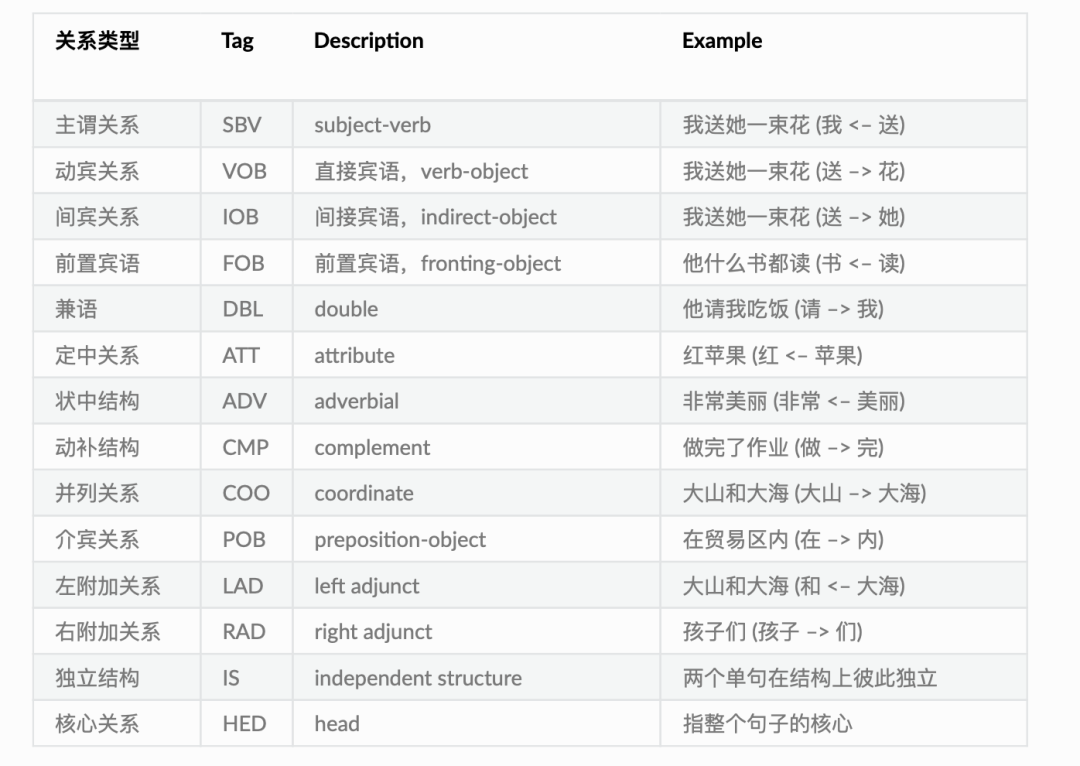
例子:
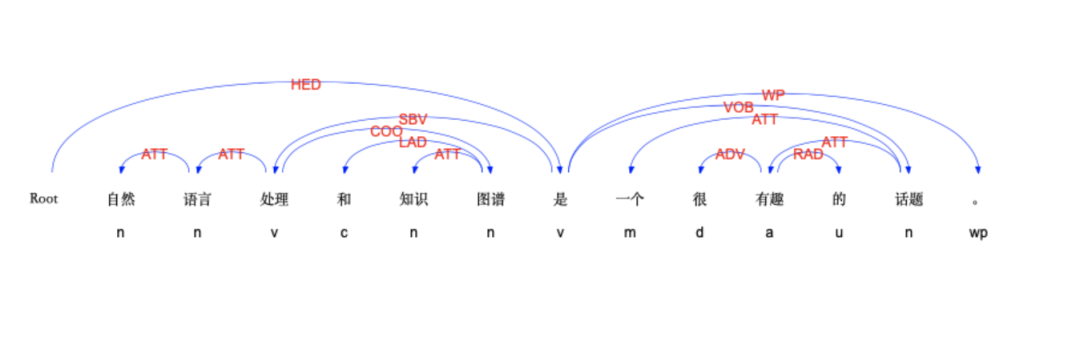
from ltp import LTP ltp = LTP() seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"]) dep = ltp.dep(hidden) [['他', '叫', '汤姆', '去', '拿', '外衣', '。']] [ [ (1, 2, 'SBV'), # 他(1) --|SBV|--> 叫(2) (2, 0, 'HED'), # 叫(2) --|HED|--> ROOT(0) (3, 2, 'DBL'), (4, 2, 'VOB'), (5, 4, 'COO'), (6, 5, 'VOB'), (7, 2, 'WP') ] ]
【语义角色标注,Semantic Role Labeling,简称 SRL】
分析词语的角色,标记:
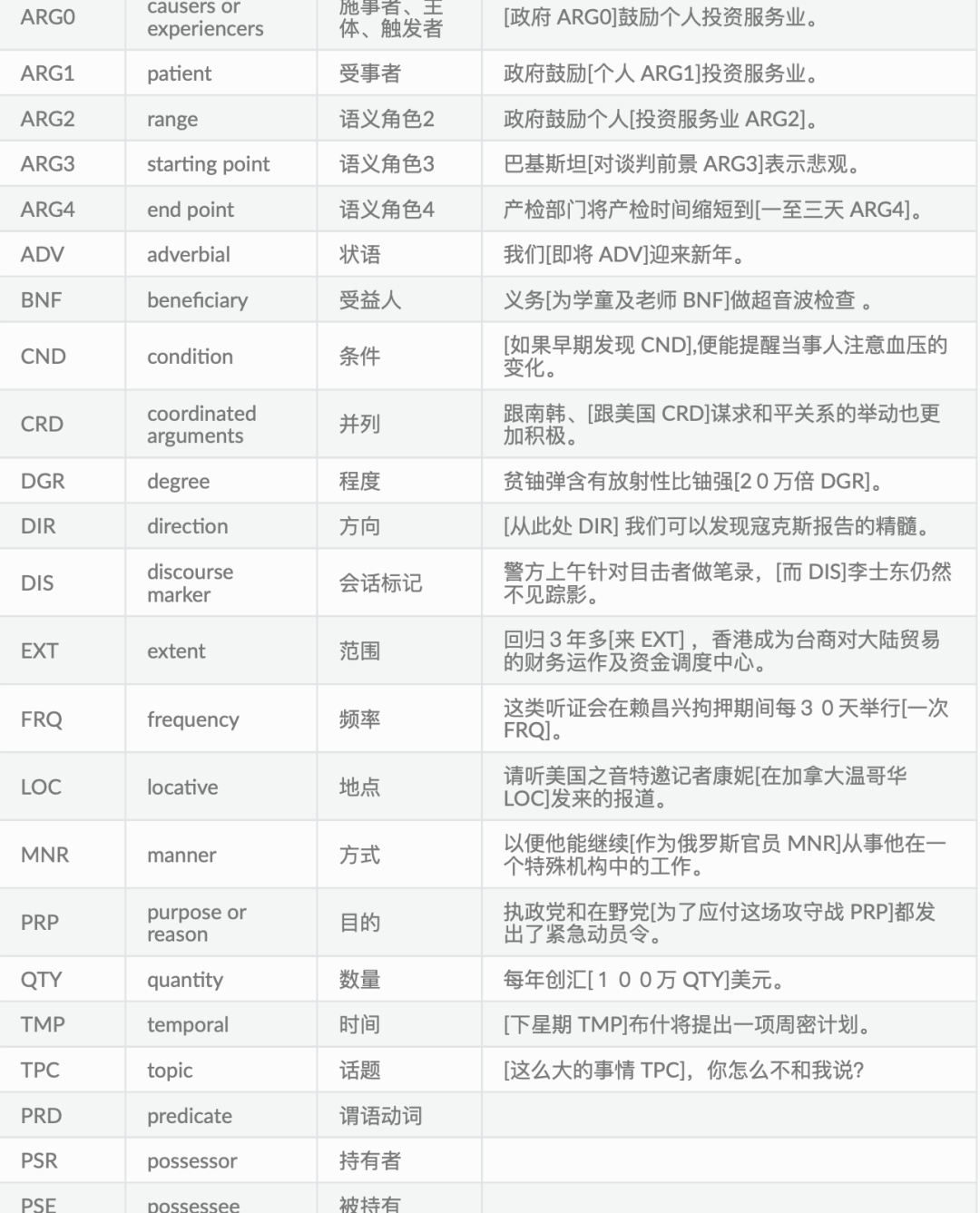
例子:
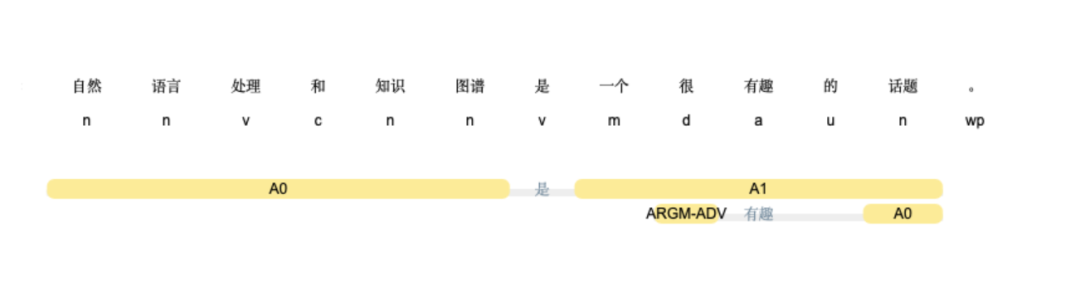
from ltp import LTP ltp = LTP() seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"]) srl = ltp.srl(hidden) [['他', '叫', '汤姆', '去', '拿', '外衣', '。']] [ [ [], # 他 [('ARG0', 0, 0), ('ARG1', 2, 2), ('ARG2', 3, 5)], # 对于“叫”而言 -> [ARG0: 他(列表的索引0-0), ARG1: 汤姆(索引2-2), ARG2: 去拿外衣(索引3-5)]
[], # 汤姆 [], # 去 [('ARG0', 2, 2), ('ARG1', 5, 5)],# 对于“拿”而言 -> [ARG0: 汤姆, ARG1: 外衣] [], # 外衣 [] # 。 ] ] srl = ltp.srl(hidden, keep_empty=False) # 简化显示 [ [ (1, [('ARG0', 0, 0), ('ARG1', 2, 2), ('ARG2', 3, 5)]), # 叫 -> [ARG0: 他, ARG1: 汤姆, ARG2: 去拿外衣] (4, [('ARG0', 2, 2), ('ARG1', 5, 5)]) # 拿 -> [ARG0: 汤姆, ARG1: 外衣]
【语义依存分析 (Semantic Dependency Parsing, SDP)】
分析词语语义之间的关系,标记:
例子:
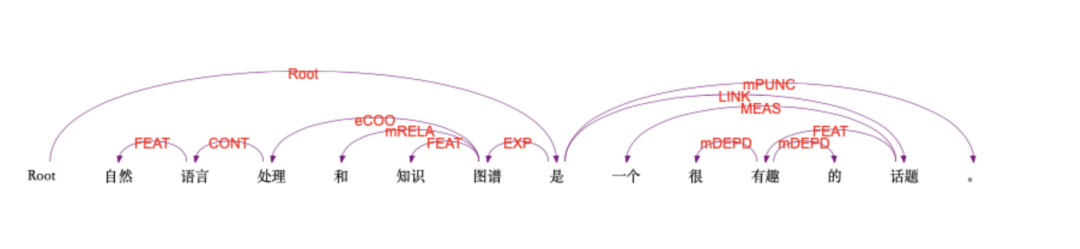
from ltp import LTP ltp = LTP() seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"]) sdp = ltp.sdp(hidden, mode='tree') [['他', '叫', '汤姆', '去', '拿', '外衣', '。']] [ [ (1, 2, 'Agt'), # 他 -- AGT-- 叫 (2, 0, 'Root'), # 叫 --|Root|--> ROOT (3, 2, 'Datv'), (4, 2, 'eEfft'), (5, 4, 'eEfft'), (6, 5, 'Pat'), (7, 2, 'mPunc') ] ]
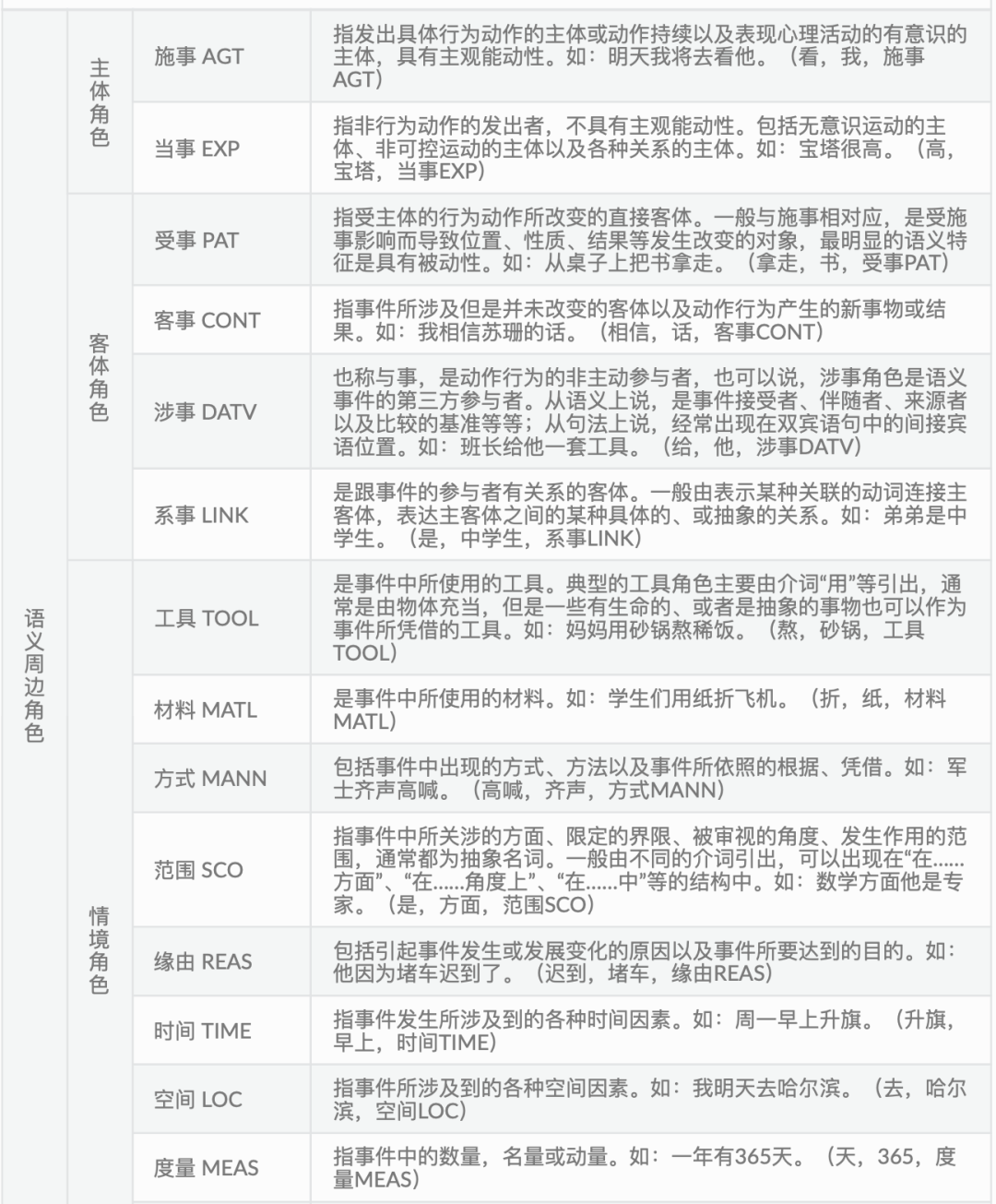
【抽象语义表示 Abstract Meaning Representation (AMR)】
将表示同一个意思的英文句子(不管语法如何),映射到AMR图,AMR的基本结构是“单根有向无环图”,CAMR是针对中文提出的,句子中的词抽象为概念节点,词之间的关系抽象为带有语义关系标签的有向弧,同时忽略虚词和形态变化体现的较虚的语义(如the、单复数、时、体等等),图中的节点不再是单词而是概念,还可以自由引入句子表面不存在的概念
AMR 解析的就是对给定的输入句子,输出一个相应的 AMR图结构
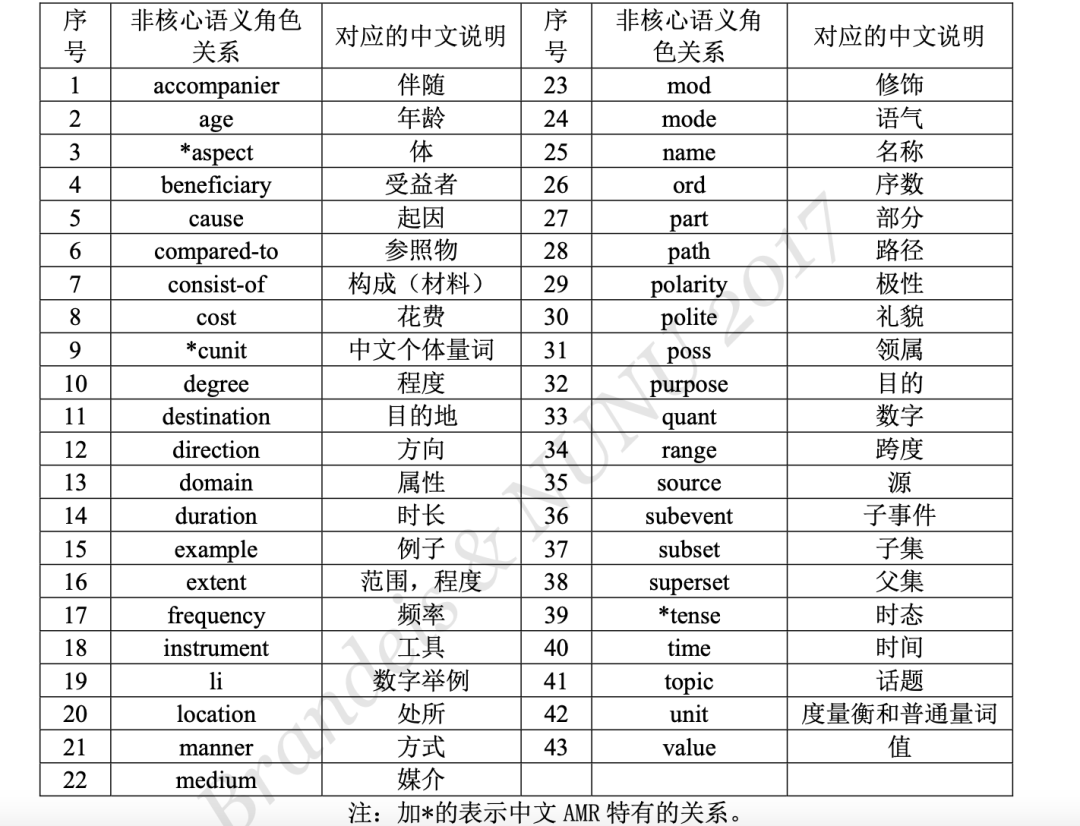
在关系上,语义关系分为两种,核心语义角色关系和非核心语义角色关系。用形如 “Argx(x∈[0,4])”的标签来表示核心语义角色关系,用形如“cost(花费)”等的语义标 签来表示非核心的语义角色关系。
核心语义关系,沿用 OntoNotes 的体系,共5个,即:ARG0(原型施事)、ARG1(原 型受事)、ARG2(间接宾语、工具等)、ARG3(出发点、受益者等)、ARG4(终点);
非核心语义关系表示除核心语义之外的关系类型:
评估预测的arm和人工arm的方法:smatch,在对两个 AMR图进行匹配度计算时,首先将每个 AMR图转化成一个逻辑三元组的集合,其中每个三元组表示图中的一个顶点或一条边;然后计算两个三元组集合之间的匹配或重叠程度,以 F1 值呈现
import hanlp hanlp.pretrained.amr.ALL # 语种见名称最后一个字段或相应语料库 amr = hanlp.load('MRP2020_AMR_ENG_ZHO_XLM_BASE') graph = amr(["男孩", "希望", "女孩", "相信", "他", "。"]) print(graph) # 谓词在中心,论元在子部分,然后针对论元,再对论元分解为谓词和论元,括号内是一个整体块,下面的显示也能转成图的形式 (x2 / 希望-01 :arg1 (x4 / 相信-01 :arg0 (x3 / 女孩) :arg1 x1) :arg0 (x1 / 男孩))
1、关系抽取
【概念】论元:与谓词搭配的名词,如“老张走了”,是由一个谓词“走”和一个名词性论元“老张”组成的论元结构
即抽取两个或多个实体之间的联系,比如给定输入 : 句子 “Steve Jobs was the co-founder of Apple Inc” 和两个实体 Steve Jobs 和 Apple Inc。
需要输出:实体之间关系 :/business/company/founder
【基于模板的关系抽取方法】
人工定义关系涉及到的所有模板,
比如,假设 X 和 Y 都表示公司实体,那么可以使用下述模板表示“收购”关系:X is acquired by Y; X is purchased by Y; X is bought by Y;
当句子中所出现的实体匹配其中一个模板时,就可以认为这两个实体具备“收购”的语义关系。
显然,凡是涉及到需要人工去总结归纳的,都不可避免的无法穷举所有模板,这就导致关系抽取的召回率特别低;另外,凡是涉及到模板的,它都是针对特定领域的高度定制化的,不具有可扩展性。
【基于特征工程的机器学习方法】
先人工定义关系的特征,然后使用特征抽取工具来提取所列举的特征,同时特征抽取的过程是一个串联的(Pipeline)过程,前一步的输出要作为后一步的输入,显然,这不可避免的造成错误的累积和传递,导致抽取的特征不精准,当然最终的关系抽取效果就大打折扣了。
【基于神经网络的方法】
PCNN(Piece-Wise-CNN)模型=TextCNN + Position Embedding:
输入一句话,输出这句话两个实体之间的关系,如As we known,Steve Jobs was the co-founder of Apple Inc which is a great company in America,这两个实体之间的关系是co-founder
由于句子中有2个实体,所以这条句子就会产生两个和句子长度相同的编码向量,含有其他单词与实体之间的相对距离。
-
pos_1:[-4,-3,-2,-1,0,1,2,3......] ,其中0就是 Steve Jobs 的位置。
-
pos_2:[-9,-8,-7,-6,-5,-4,-3,-2,-1,0,1,2,3......] 其中0就是 Apple Inc 的位置。
因为entities之间有关系的词一般会出现在两个entity之间,左侧,或者右侧,集中注意力分别关注这三部分,所以进行切分:在两个实体处各切一刀将文本分成了3段,2个位置向量也同样切割,上述例句可以切分成这样:
-
1. As we known,Steve Jobs,-4,-3,-2,-1,0,-9,-8,-7,-6,-5
-
2. Steve Jobs was the co-founder of Apple Inc,....,....
-
3. Apple Inc which is a great company in America.,.....,....
3个部分并行处理, 以1为例,把单词、位置1索引、位置2索引映射为词向量:
As的词向量,-4的词向量,-9的词向量
we的词向量,-3的词向量,-8的词向量
...
分别通过20(举例)个卷积核,每个卷积核宽度=3,生成n*1*20的长方体,再通过池化,变成1*1*20的向量
3个部分拼接,形成1*1*30的向量,然后通过多层神经网络和softmax层,此时的类别个数就是所有关系的个数
【基于RoBERTa的模型,硕士论文】
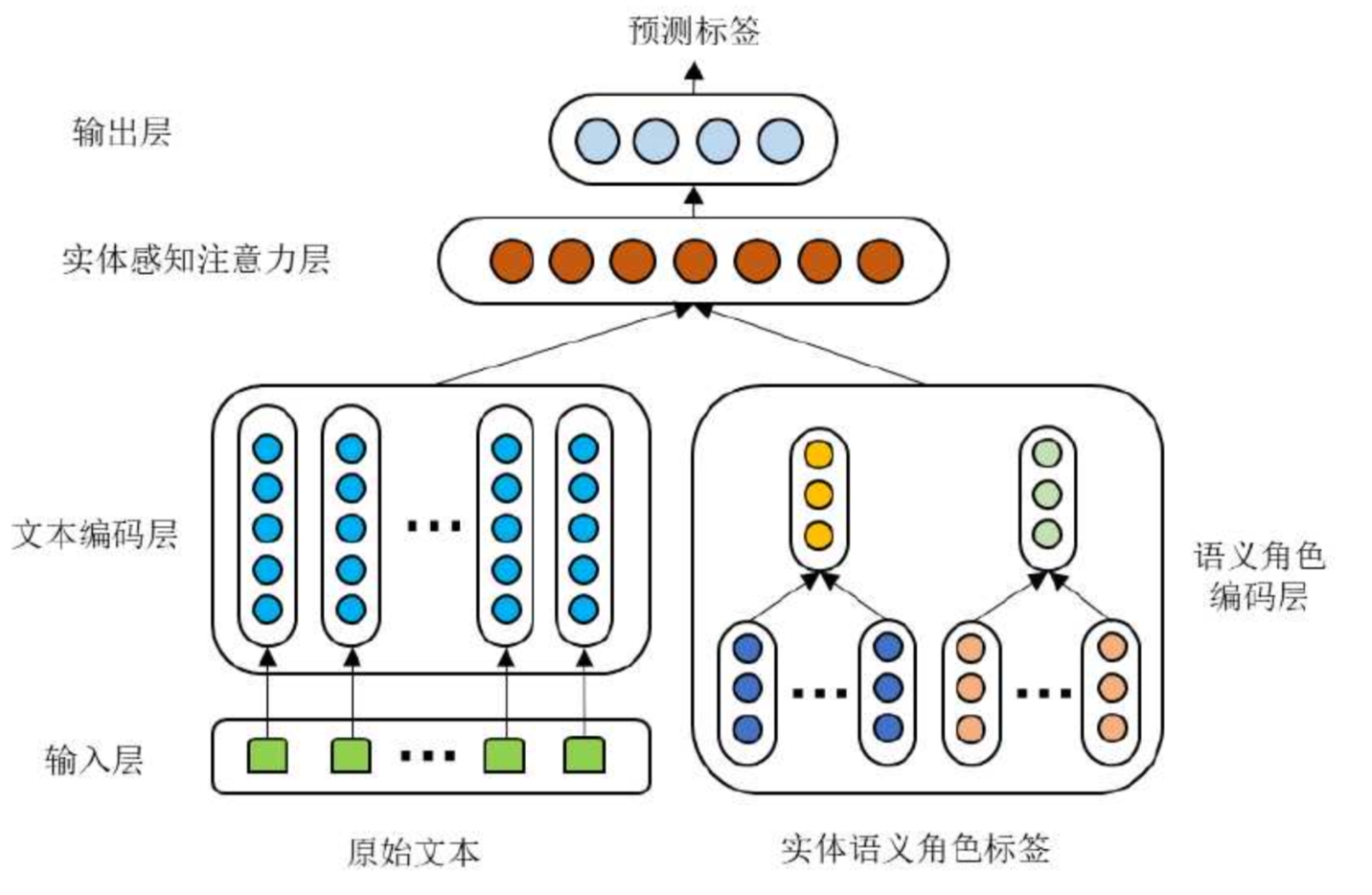
输入层:将包含两个实体的一句话做格式处理,头实体的前后加{,尾实体的前后加}
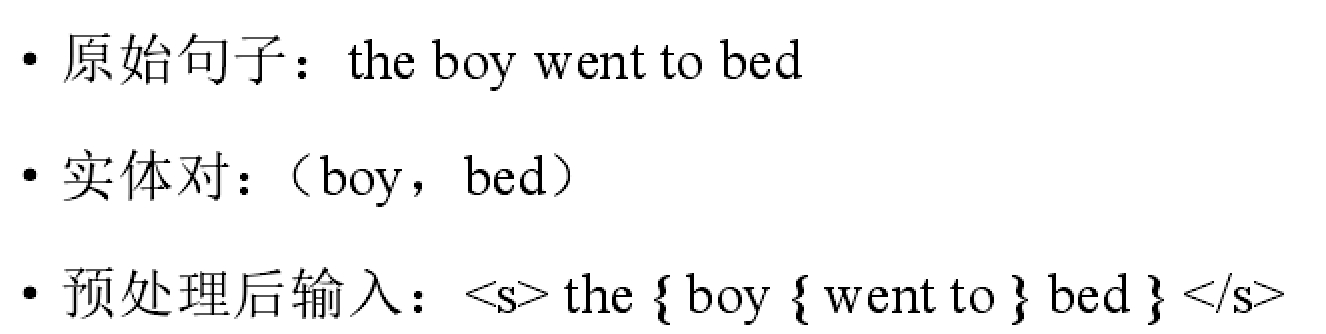
文本编码层:roberta,针对这2个实体,若某个实体包括多个词,则取多个词向量的平均得到该实体向量h1~,h2~
实体语义角色标签(我改进):roberta的输出加上 crf 层,得到每个词的语义角色标签,如B-Arg0,只看这2个实体的语义角色标签,然后将2个实体的标签转换成对应的标签向量,最后得到2个实体的语义角色标签向量s1,s2
实体感知注意力层:
将实体向量和对应的语义角色标签向量做融合,得到2个实体的融合向量:
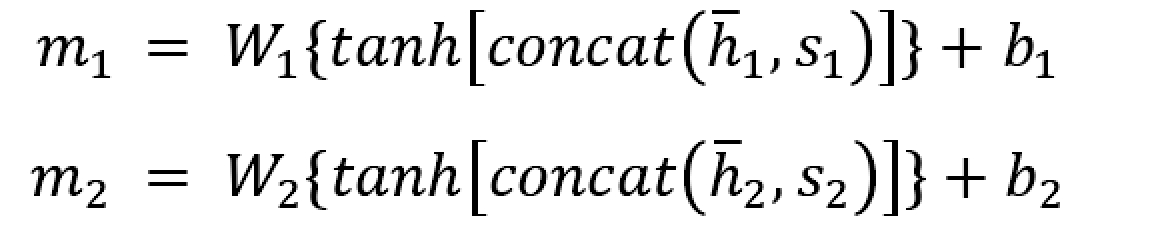
然后用(m1+m2)/2做q,代表实体对,k 和 v 都 = roberta输出{h1,h2,...hn},用q分别点乘 hi 得到相似度,然后通过softmax得到每个词的权重,然后和hi做加权和得到最终句子向量mh,这个句子向量就是实体对对其每个单词做了重要性分配的结果
mh再和m1,m2做拼接得到该层输出
输出层:实体感知注意力层的输出向量接了一个输出层,神经元的个数=所有可能的关系数,用于预测这两个实体包含什么关系
【Roberta实体关系联合抽取,期刊】
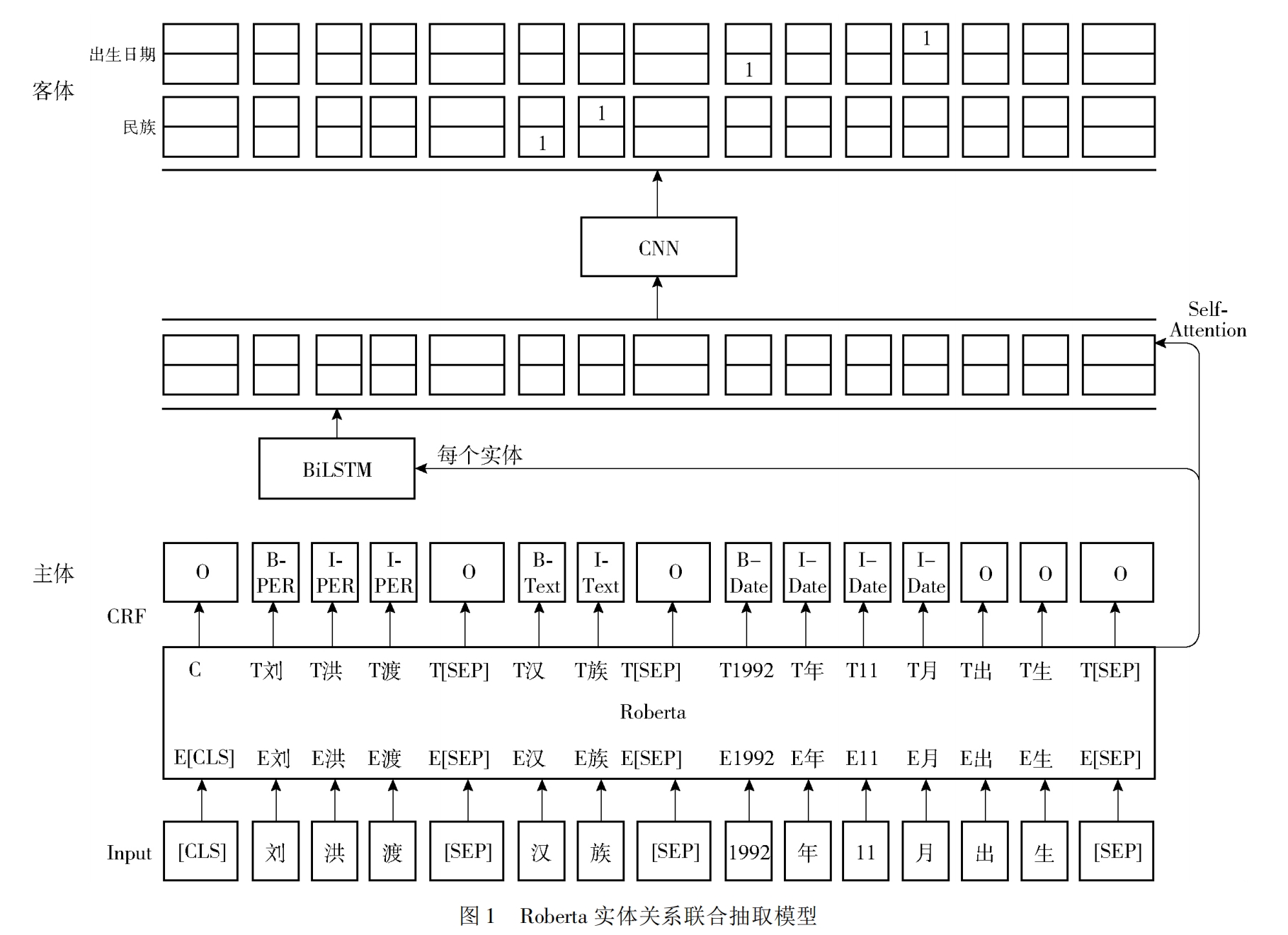
从下面的主体模块开始,将一段话输入到roberta中,roberta的输出再接一个crf层,得到每个词的标签预测结果,此时能得到一个 crf 损失:预测某个词是该标签的概率,然后将每个词的概率相乘,再加上(第0个词的标签O转移到第1个词的标签B-PER的概率 * 第1个....转移到第2个....),最后取 -log
通过 crf 的预测结果从中提取所有的主体,遍历每个主体,此例只有刘洪波,该主体通过 BiLSTM 聚合一下主体内的信息,得到的输出向量和实体位置向量拼接,得到该实体向量
遍历所有可能的关系,比如对于关系“民族”,得到关系向量,再把 roberta 的输出结果拿来,把每个词向量做拼接,得到 {实体向量 | 词向量 | 关系向量},然后我改进了一下:
每个词接一个神经网络输出该词是起始和结束的概率,通过预测结果确定一个客体,如果这个客体合法(词起始预测位置<词终点预测位置),我们就能从该段落中预测了一个三元组:主体->关系->客体,通过遍历就可以得到这段话中所有的三元组,其中 客体的开始结尾损失 加上 crf 损失可以作为总损失
其他模型详细: https://mp.weixin.qq.com/s?__biz=MzAwOTgwMjQ4OQ==&mid=2649990154&idx=1&sn=7a0057b32c988792f728313776d60c95&chksm=835d039cb42a8a8a681468f54d21f04789970a5ad586254351379bb9dc1125cecce97ce6dc4c&cur_album_id=2370685926617645061&scene=189#wechat_redirect
2、共指消解
目前思路:先找到所有可能的span(连续的词,如a big dog),然后mention detection检测他是不是mention(比如a big就不是mention),然后通过mention pair detection判定两两mention是不是共指(如果只有1个共指,则叫singleton,共指中前面的mention叫antecedent,后面的叫作 anaphor)
# 叫(2) --|HED|--> ROOT(0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号