
cv2
检索:输入一张图片,找出类似图片
迁移学习:用别人已经训练好的网络解决我们的问题
数据预处理:
归一化是去掉量纲

去相关的目的是降维,去掉不同维度的相关性,白化是在之前的基础上去均值
3层神经网络:除了输入层以外有3层;2隐层神经网络:有2个隐层(蓝色的),输入层是特征数或维度

如果没有激活函数,神经网络就退化为线性分类器
常用激活函数:

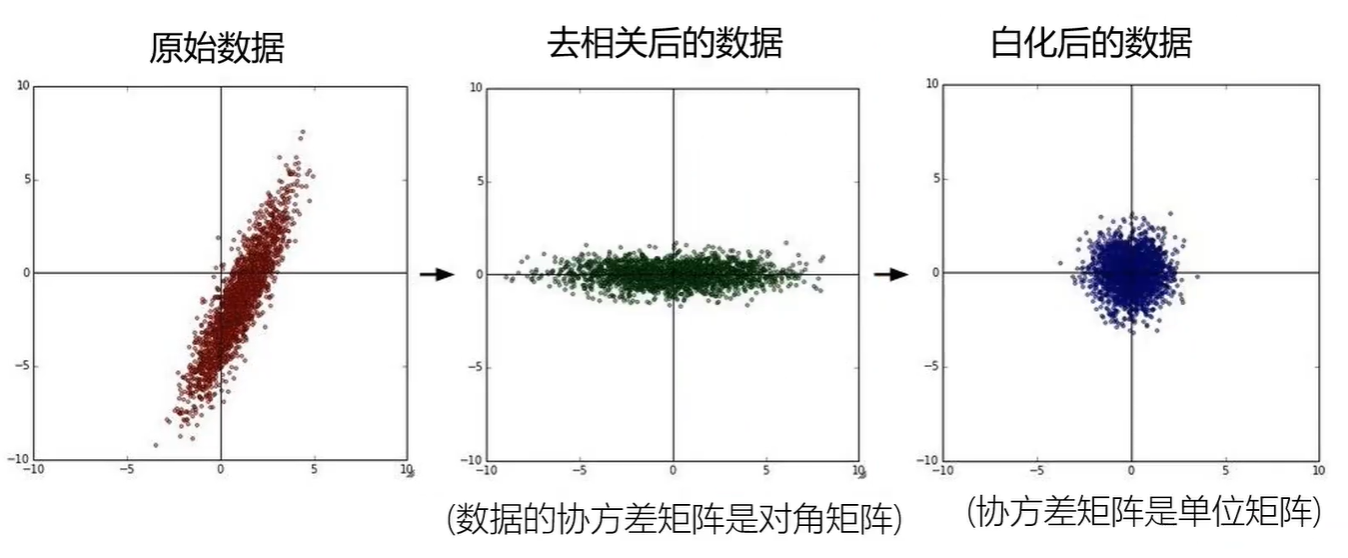
若增加隐层神经元个数:
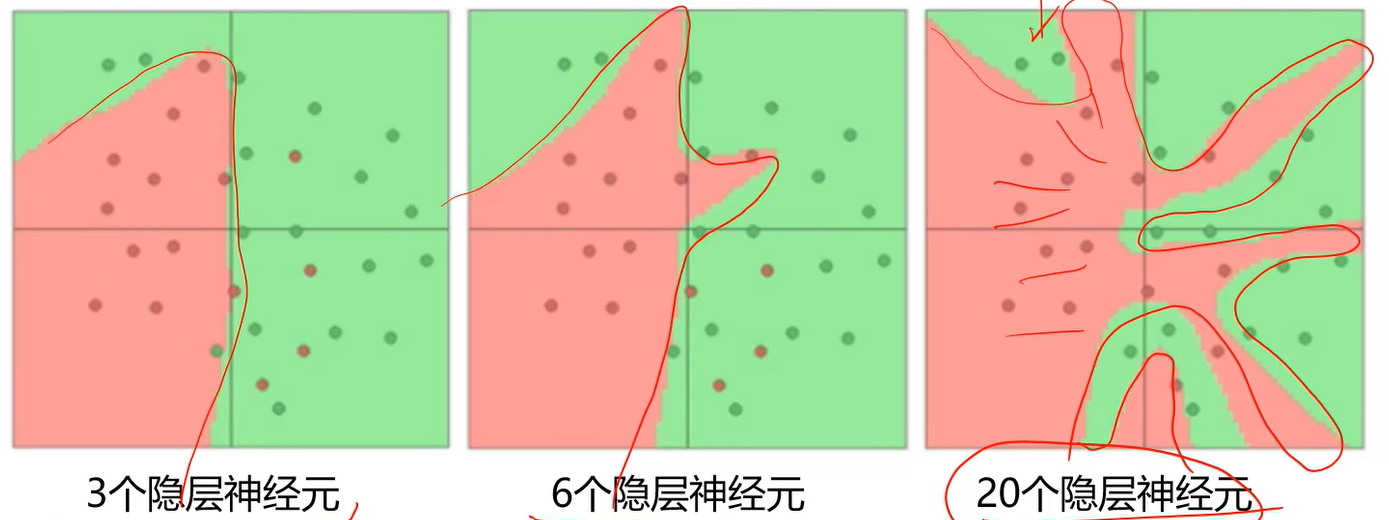
softmax层:把数映射到0-1之间,经过softmax层后,每一个输出可以视为属于对应类别的概率,这些概率和为1
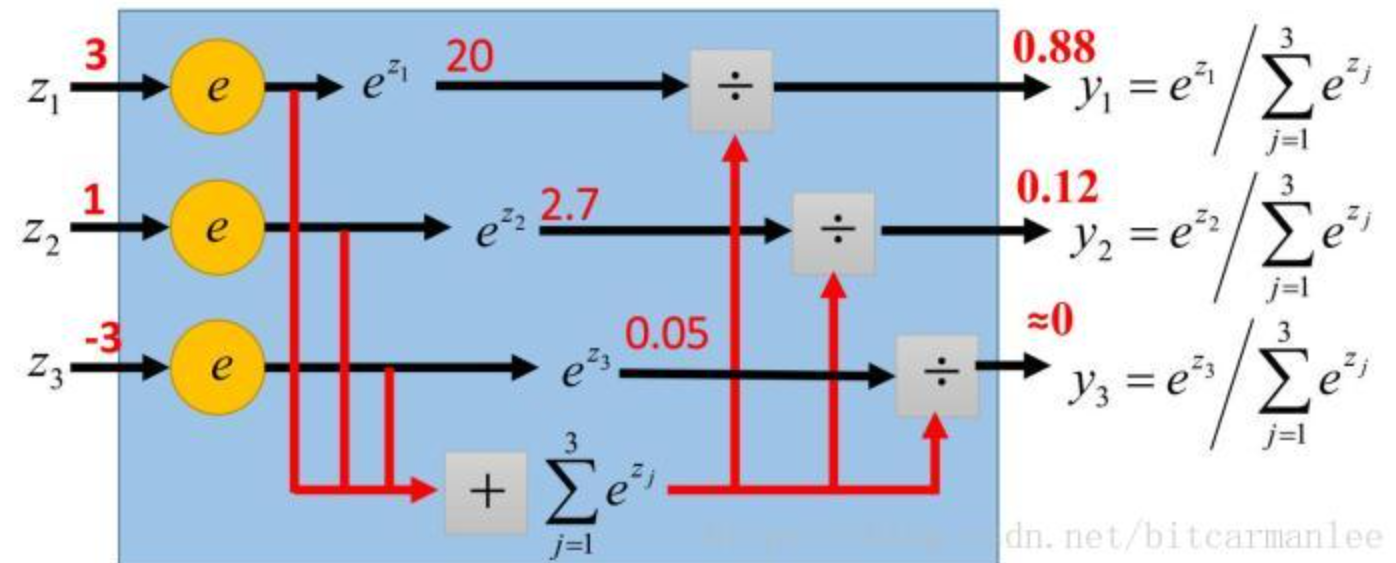
若输出层再加个softmax层:

比如:
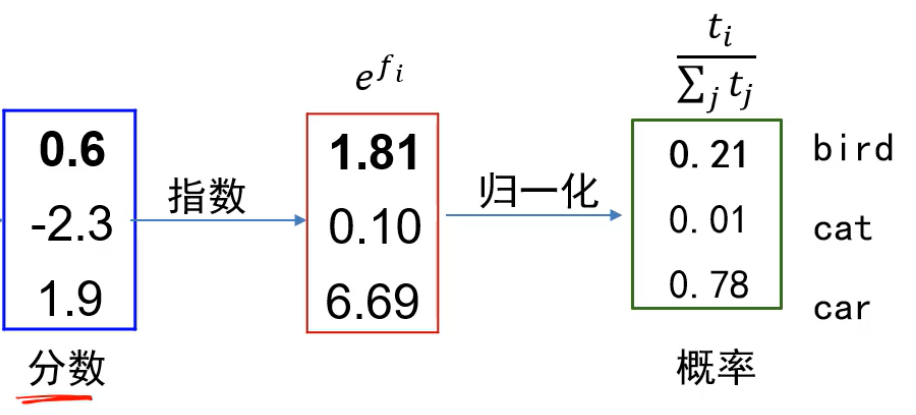
熵越大,包含的信息量越多。
p是真实值,q是预测
应当用相对熵来计算损失,但是由于一些问题中,当p使用one-hot形式,H(p)=0,所有直接用交叉熵计算损失就可以了,继续简化后= - log(该样本真实类别的预测概率)

2种损失计算的例子:
使用交叉熵损失能够使得对正确类别的预测分数更高,对其他类别的预测分数更低,多类...可能无法反应这样的情况。

优化算法:

根据计算图使用反向传播的方法来计算 f 对 各个自变量的导数,从输出往回走,最终结果为一系列梯度的乘积
也可以把多个圆圈联合起来看成一个整体,这样颗粒度就比较大了

梯度爆炸:连乘的中间有个式子值很大,导致最后结果很大,可以对算出来的值进行范围约束(梯度裁剪)
梯度消失:最后结果很小,趋于0
由于其他激活函数的导数更容易造梯度消失现象,所以使用relu或Leakly Relu
普通梯度下降算法的损失函数可能导致在某个方向上变化迅速,但在另一个方向变化缓慢,使得
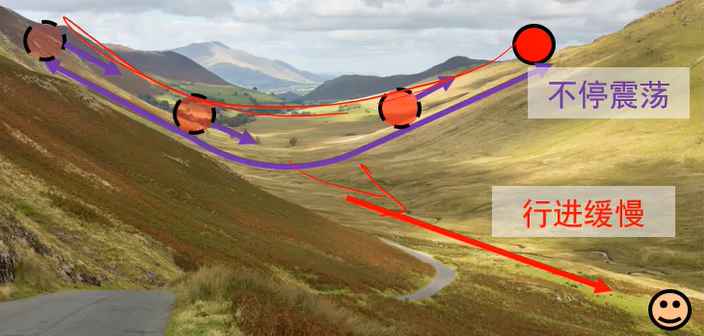
动量法可以解决,在累加过程中震荡方向相互抵消,平坦方向会加强,它是整体调节的:


若μ=1,则衰减不下来

自适应梯度法也可以解决,是分开在两个方向上调节,震荡方向调小点,平缓方向调大点:


由于当 r 很大的时候就失去调节作用了,因此可以用RMSProp,增大ρ则考虑历史值多一点,若ρ=0,则只考虑当前值了

Adam更加智能:
冷启动:刚运行,参数更新很慢,若干次后,第5个修正的步骤就可以忽略了

批归一化BN能够解决前向传播过程中的梯度消失和梯度消失
用于全连接之后,激活函数之前:

他能将小梯度区域的数据映射到正常梯度的区域内:
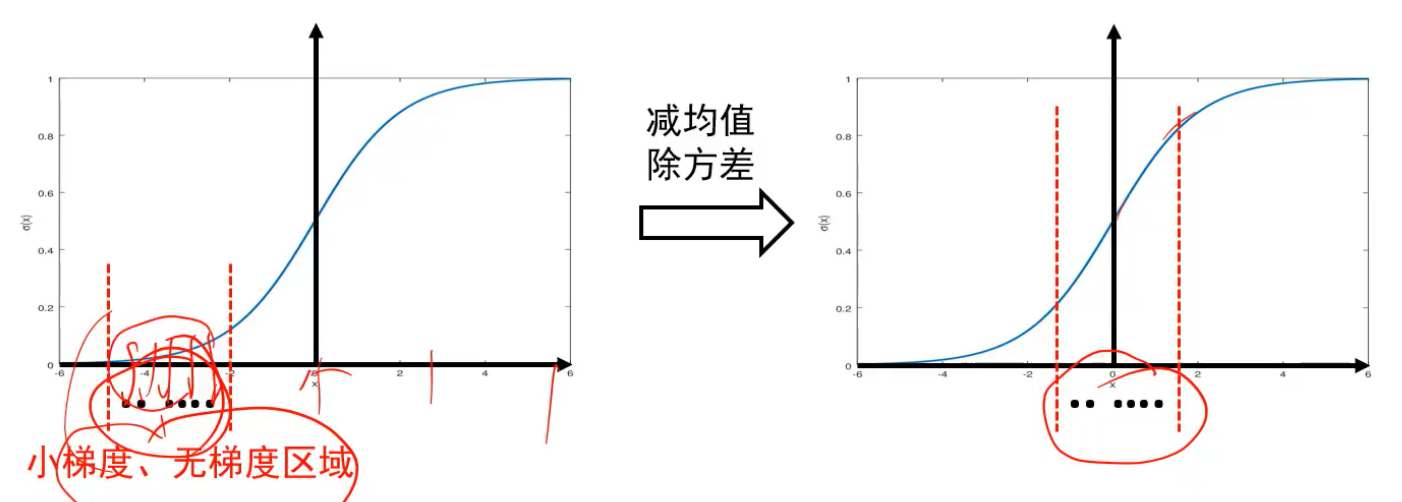
过程:
其中平移和缩放是为了使得网络自行决定均值和方差

泛化:训练好的模型能适用于很多前所有与的数据上
随机失活dropout也能对抗过拟合,因为它减少了模型参数,分散权重,让每个神经元记录了更多的信息:

dropout 例子:
注意,由于测试阶段每个神经元都会工作,所以为了保证测试阶段和训练阶段的期望一致,就要 / p

参数是神经网络要学习的,超参数是设计网络时提前想好的,如隐层神经元个数、网络层数、非线性单元、学习率、dropout比率、正则项强度,学习率可以在中间训练的过程中再做调整
超参数优化:
两个参数可以形成多个组合,由于随机搜索能尝试更多的学习率,所以建议随机搜索
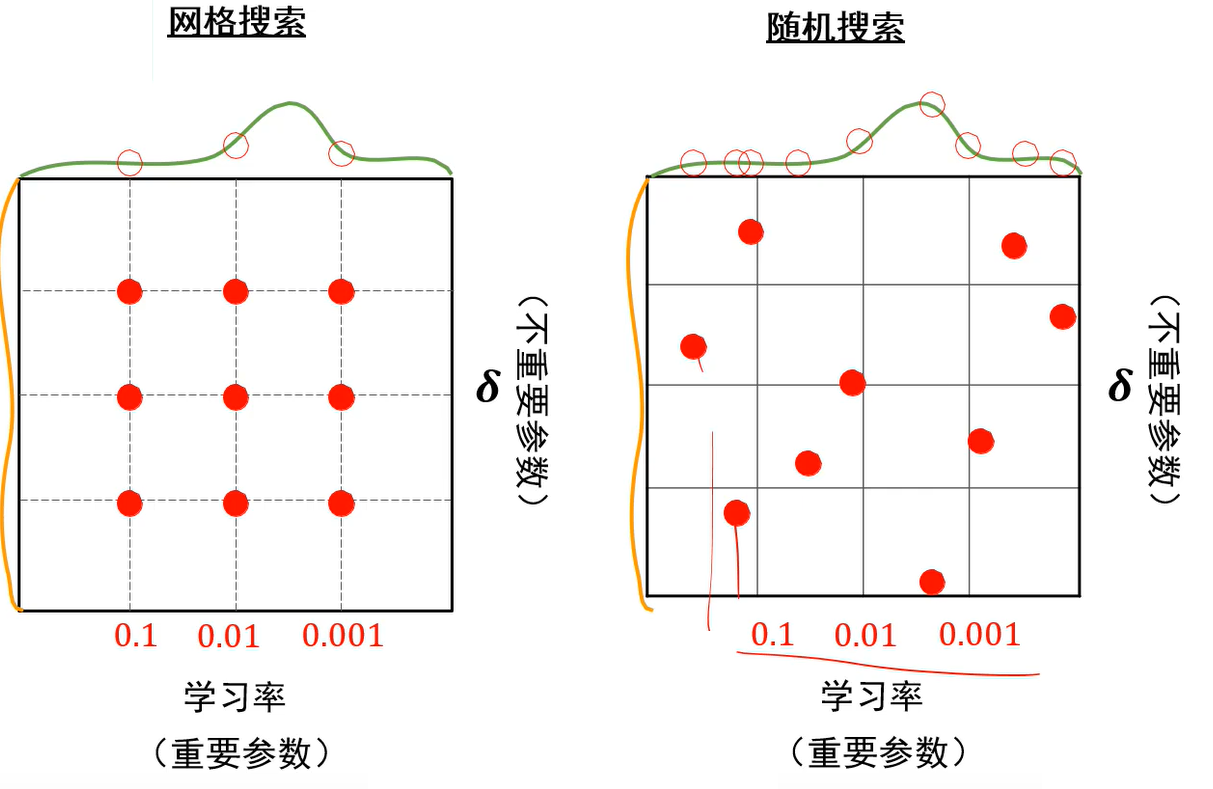
超参数搜索可以先粗搜索,即在较大范围内找到几个好的超参数,借此将搜索范围缩小,然后在小范围内寻找最好的超参数
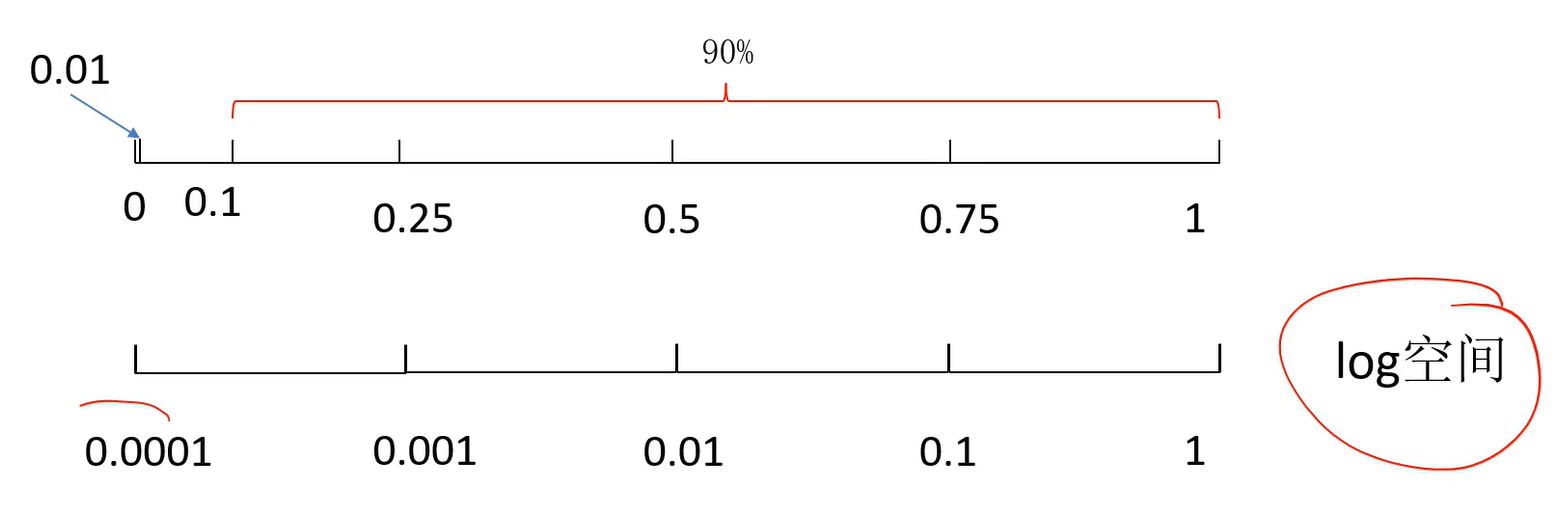
若在[0.0001 , 1]内采样,可以将该范围设置为对数空间,然后在对数空间采样才能更加均匀:
全连接神经网络只有神经元,而且前一层的每个神经元都与后一层的每个神经元都连接,参数非常多,训练麻烦,无法很好的处理复杂的图片数据,而CNN由输入层、卷积层、池化层、全连接层、Softmax层组成,本质上减少了参数数量。
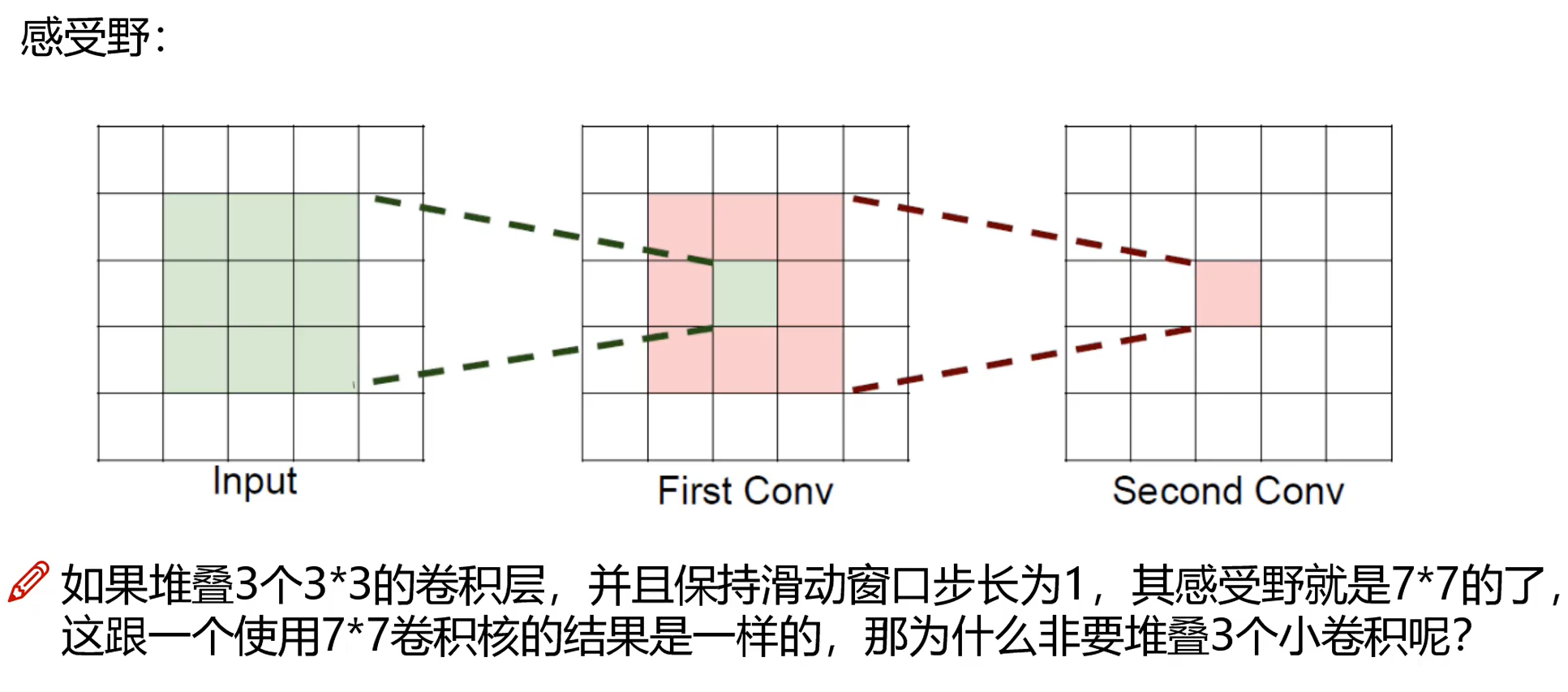
感受野=感受域:每层输出的特征图上的一个点对应原图上的区域,越大越好
非线性变换指的是relu

公式 : 后一层感受野 = 前一层感受野 + (核尺寸大小 - 1)*步长,stride越大感受野越大,feature map保留的信息越少
局部信息:几何信息比较丰富,能搜集更多的点线面的信息,有助于分割尺寸较小的目标,感受野较小
全局信息:空间信息比较丰富,有助于分割尺寸较大的目标
两层3*3卷积核操作之后,其中卷积核(filter)的步长(stride)为1、padding为0
第一层感受野是1+(3-1)*1 =3;
第二层感受野是3+(3-1)*1 =5;

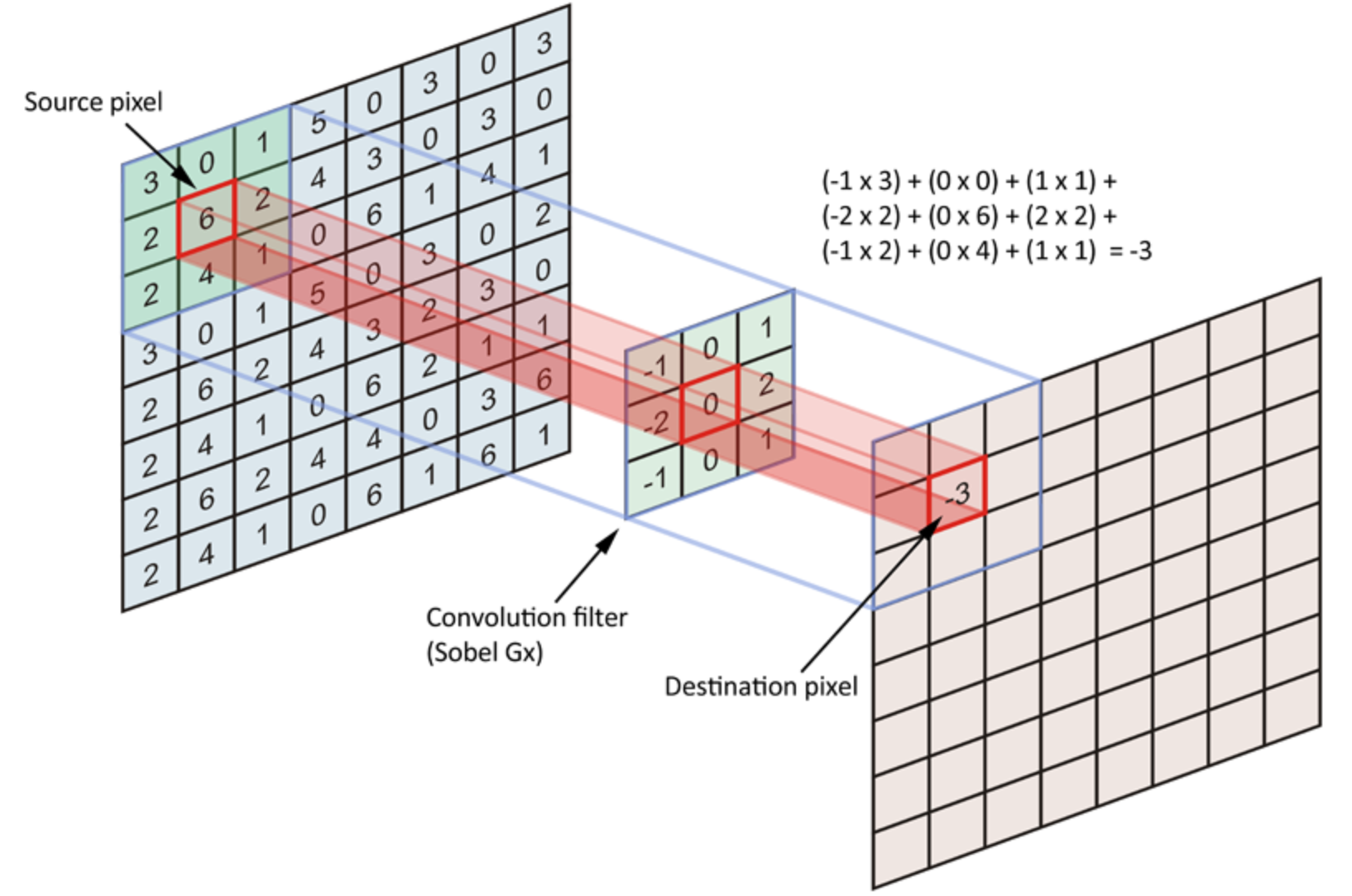
卷积:
将输入图像填充后,然后将卷积核旋转180度,在填充后的图像上挪动(卷积核每个点对应相乘,然后相加),每次挪动1下算出一个新值。
性质:

为了使得卷积后的结果和输入一样大,卷积时需要对原图像进行填充,有常数填充,拉伸,镜像
卷积结果:



由于:

所以:
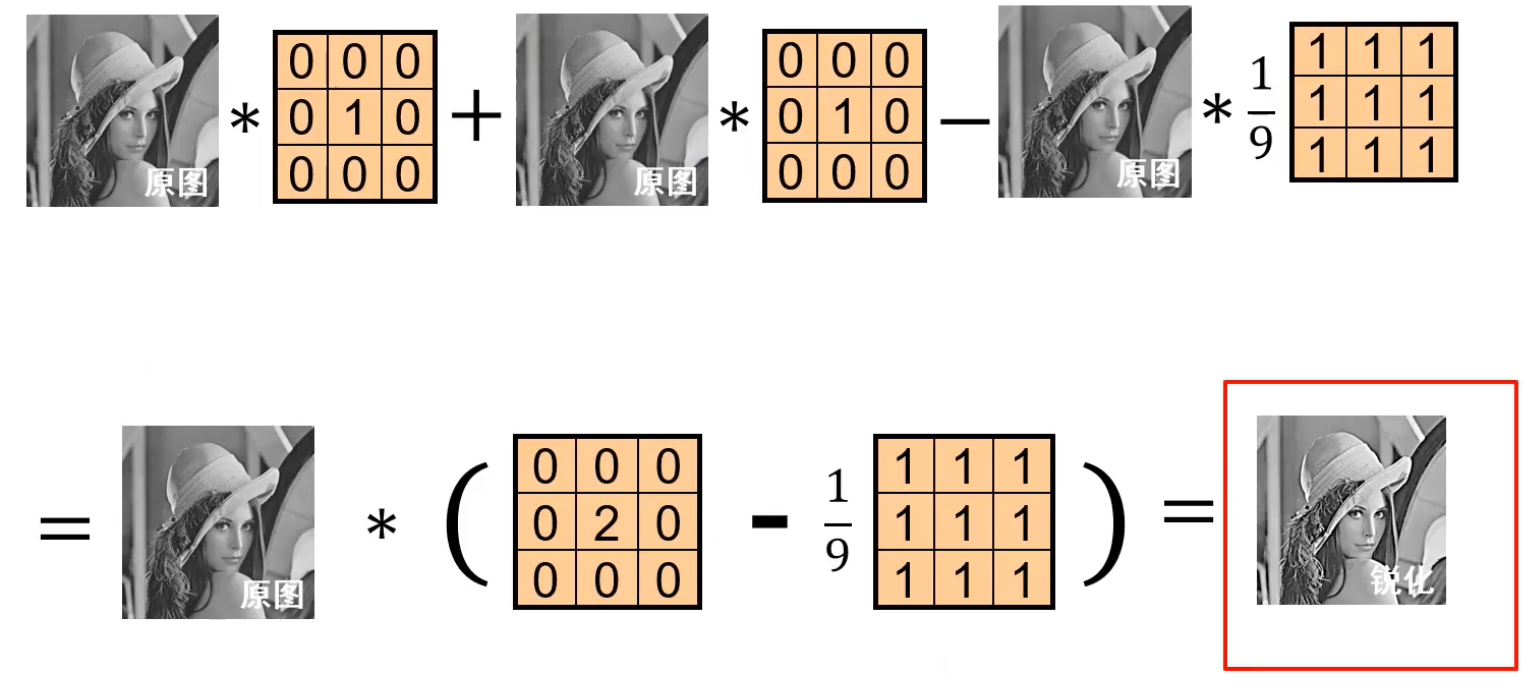
高斯卷积核是一个线性操作,中值滤波是非线性:
中心值大,边缘值小

生成:
其中诡归一化是将当前元素 / 全部元素之和,使得所有元素之和=1,这样不会对原像素衰减和增强


方差:
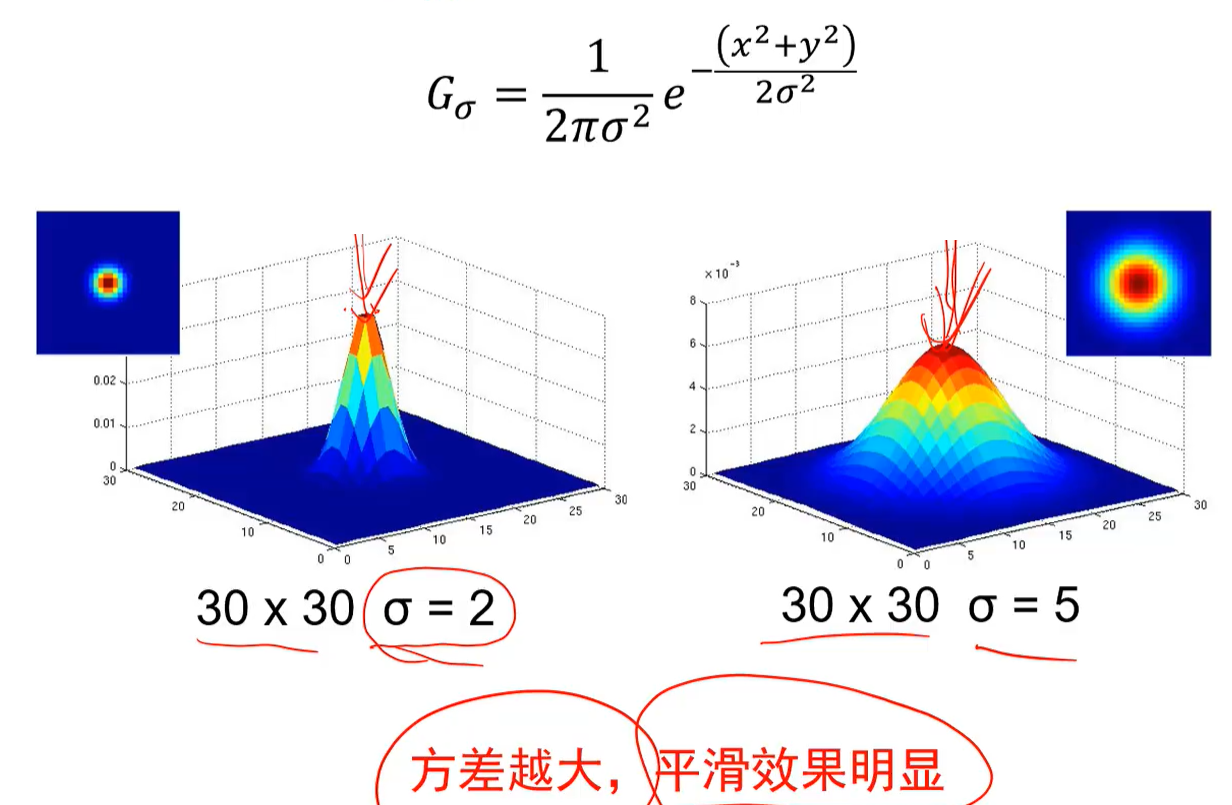
卷积核尺寸大,则由第四部可知各个元素的值偏小,使得权重分数,平滑效果增强。
卷积核参数:

卷积结果:

作用:平滑,作为低通滤波器,过滤掉图中的高频成分,如噪点;

将二维卷积核分离成多个一维核能够降低复杂度;将大卷积分解成多个小卷积能降低复杂度
高斯噪声:
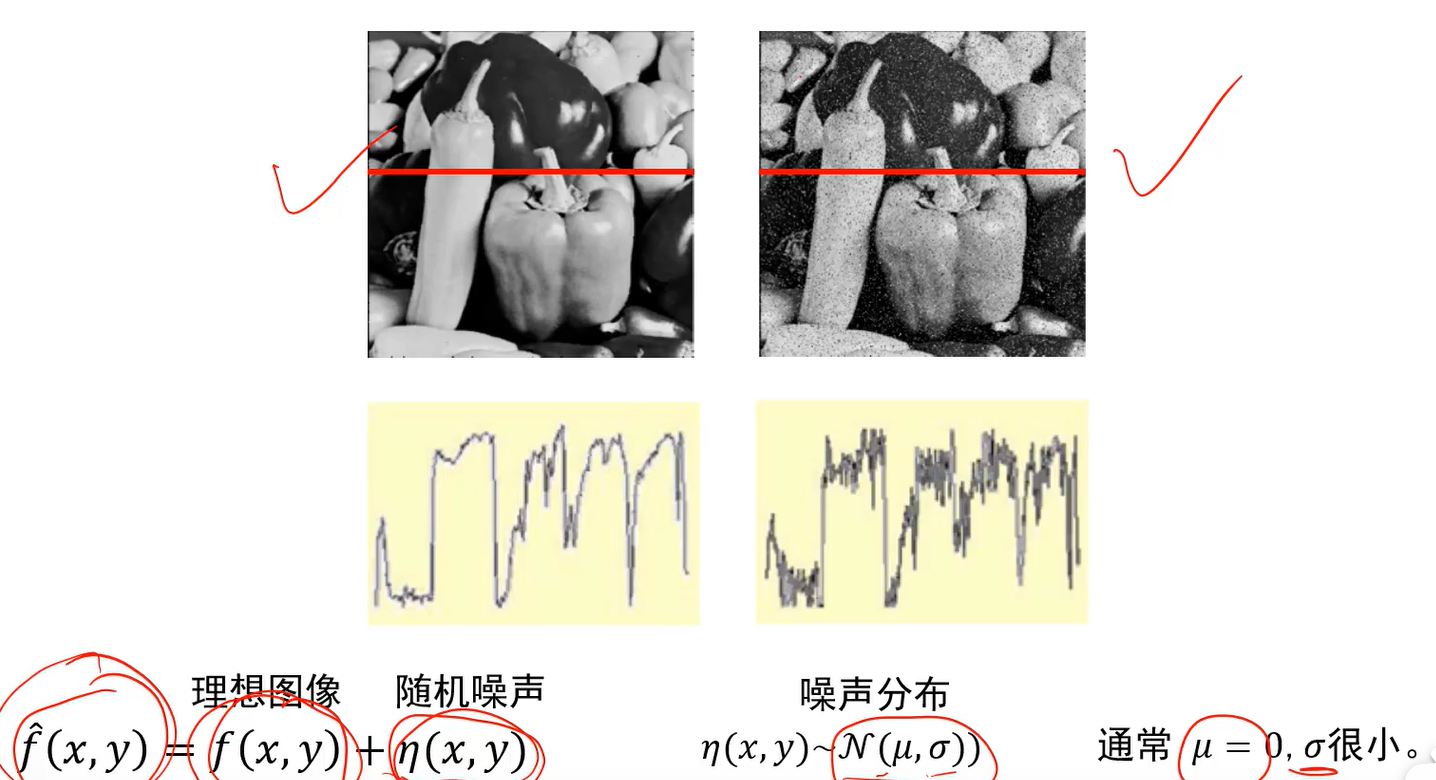
若高斯噪声大,则使用大方差或者大尺寸卷积核
椒盐噪声:黑色白色像素随机出现;脉冲噪声:白色像素随机出现,这两个不适合高斯滤波,但适合中值滤波(使用中值代替)
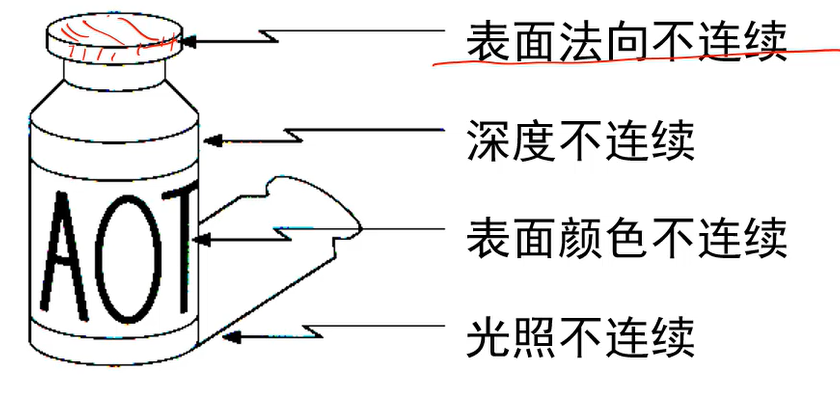
边缘种类:
通过信号中的导数可以提取边缘,导数可以近似为旁边的像素减去自己的像素,即把卷积核作用上去。
图像梯度指向灰度变化最快的方向(由暗到明),梯度的模可以反应图像的边缘信息,该点梯度的模长越大越有可能是边缘:

真实处理前要先平滑去噪,再求导找边缘:

简化操作:
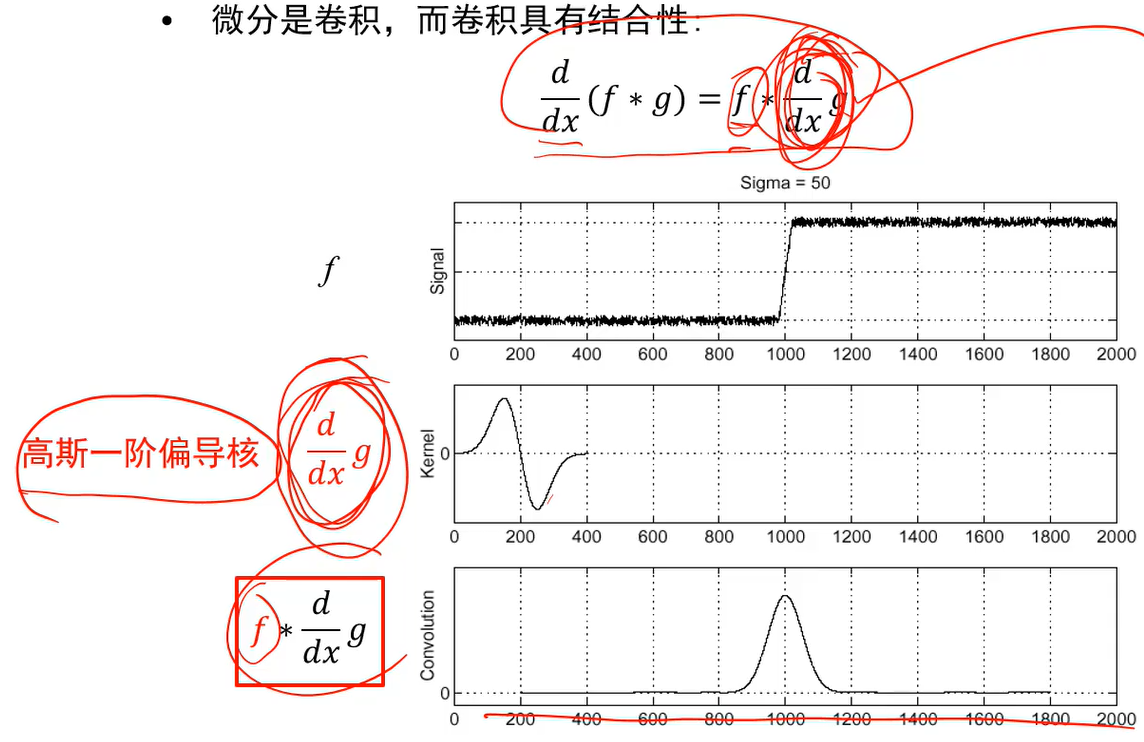
与方差的关系,方差越大提取的边缘越粗犷:


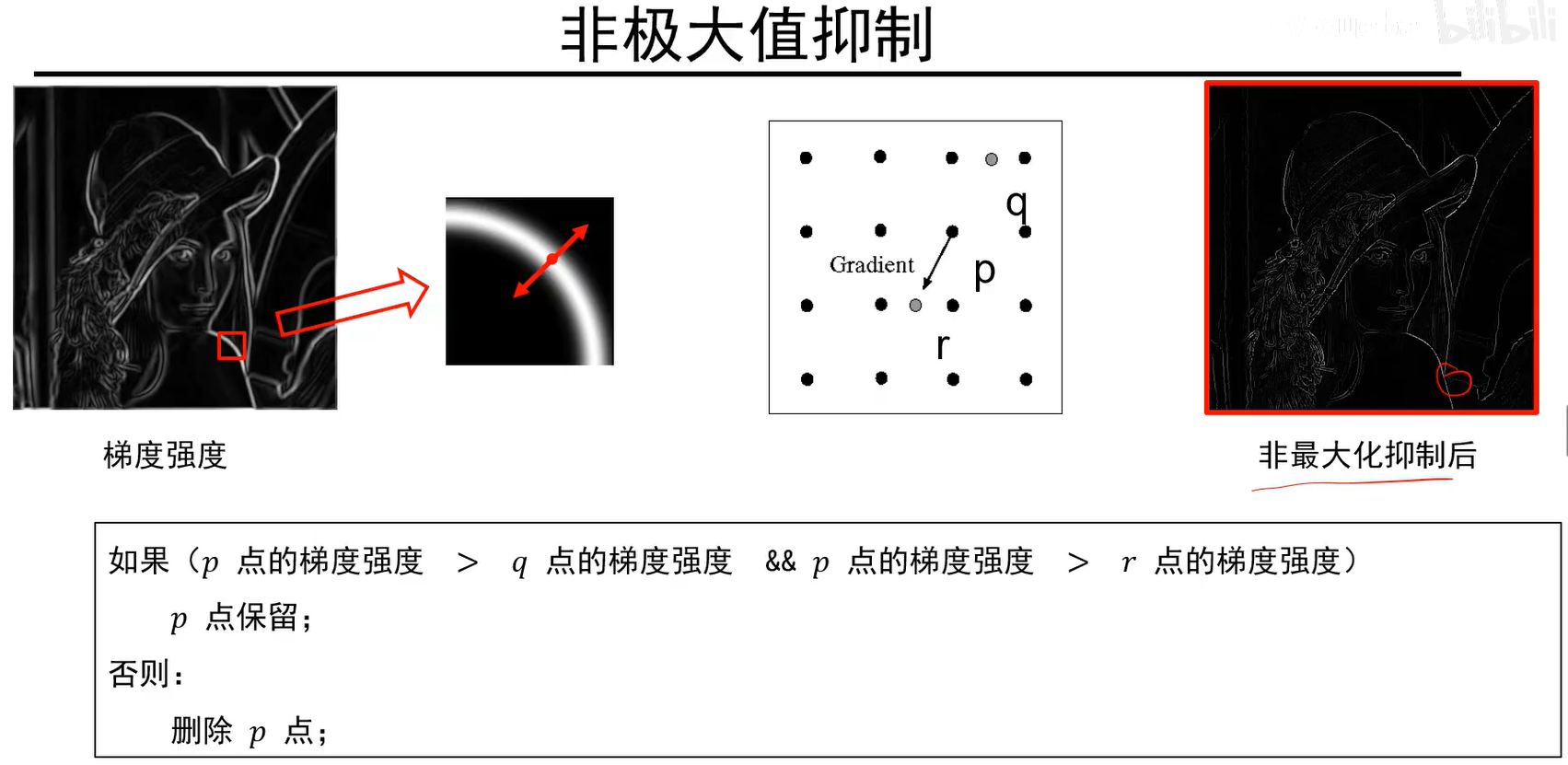
非极大值抑制能把较粗的边缘进行突出细化,q和r点得在p点的梯度向量上,若它们的像素值不是整数,则可以用差值求出:
canny边缘检测器:
第四步是保留高阈值边以及和高阈值边有连接关系的低阈值边

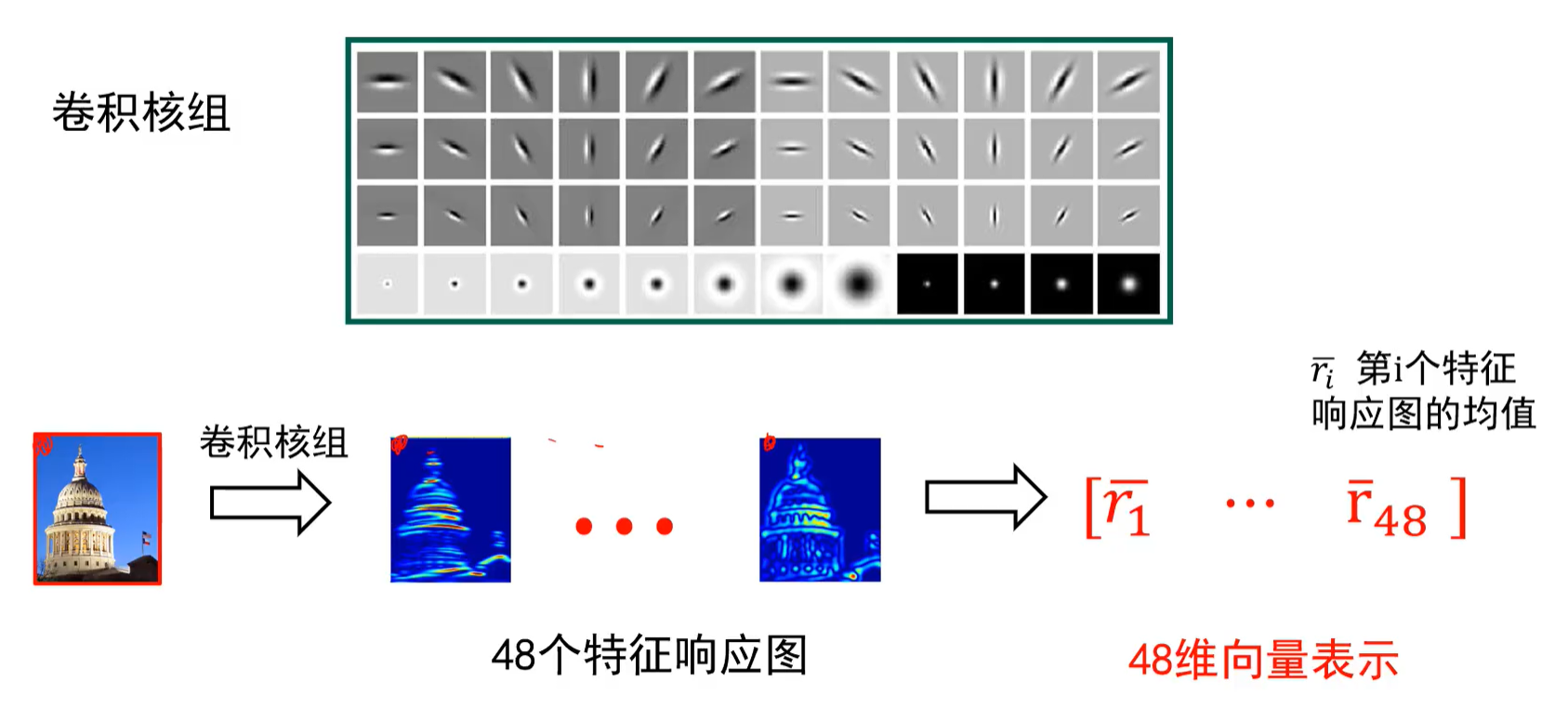
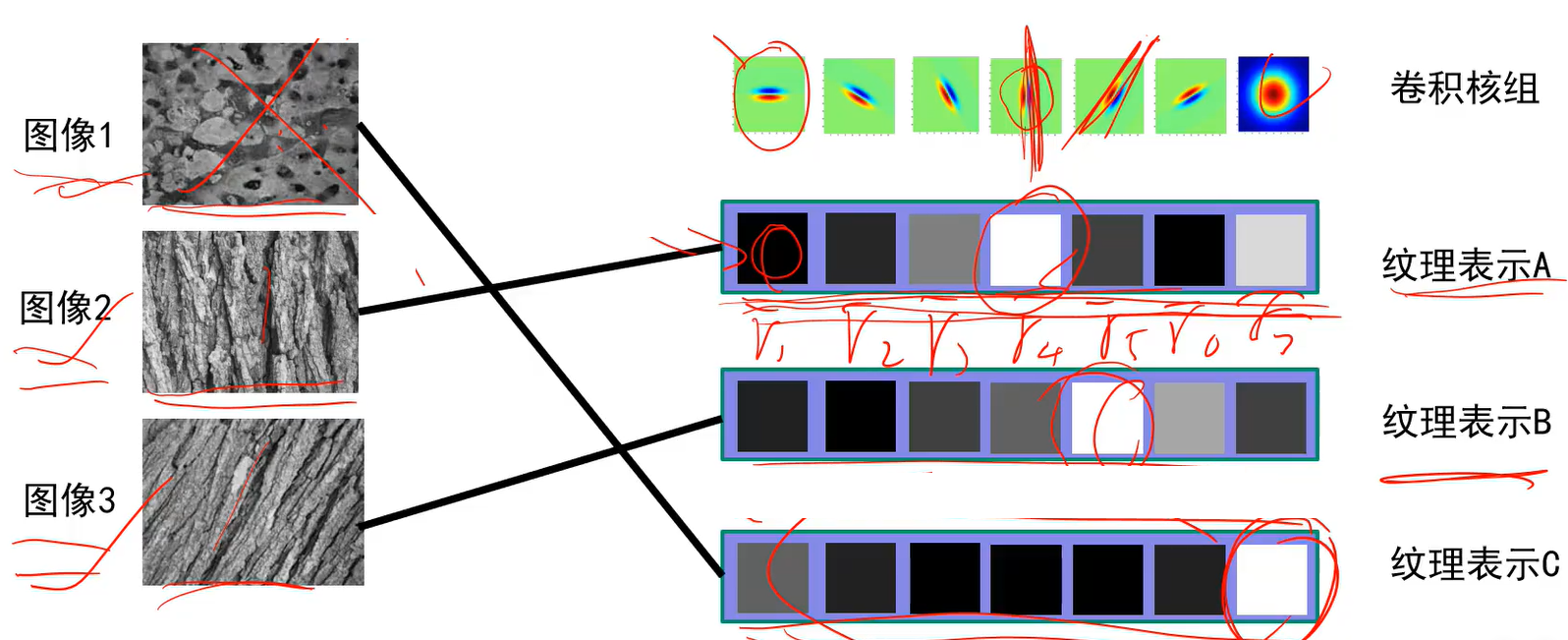
纹理:
将48个卷积核分别作用到图像上会得到48个对应的特征响应图,每个特征相应图对应一个均值,最后用48个均值所构成的48维向量来表示图像纹理。
在这个向量中,如果第二个值很大,则表示图中有很多斜向下的边(看第二个卷积核)
对于图中的某个像素也可以有48维向量,若第二维数值大,则该像素含有斜向下的边的信息多。
纹理由基元组成,一个卷积核可以描述一个1个基元
例子:
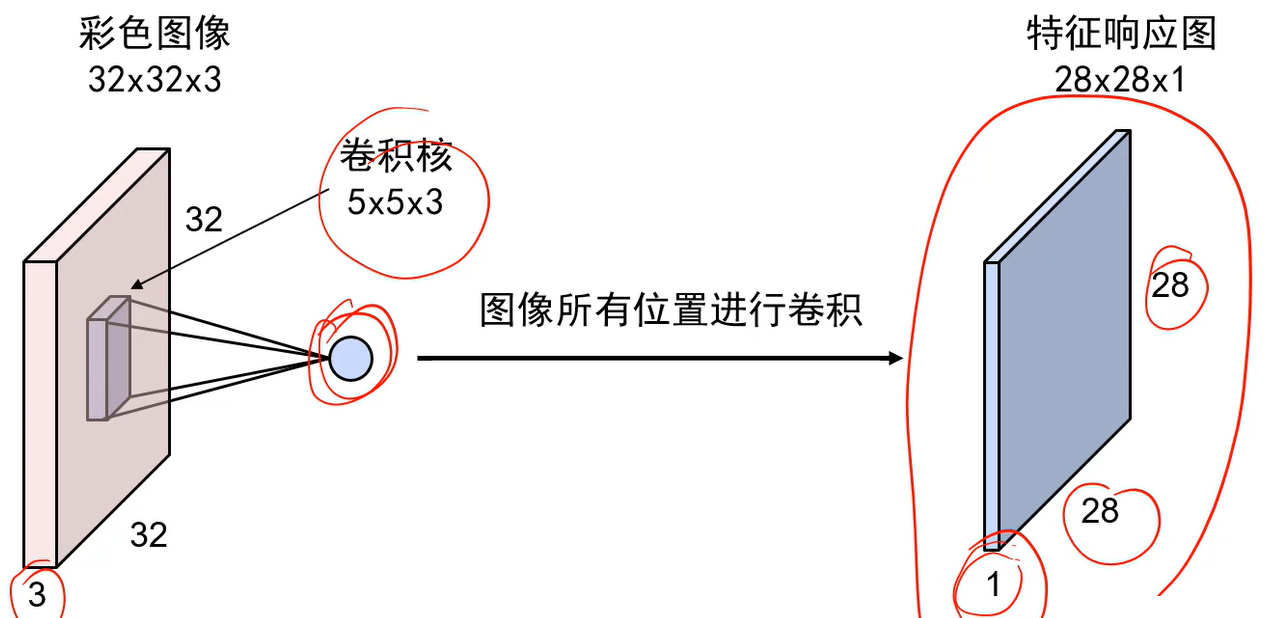
全连接神经网络隐层的每个神经元的权重个数 = 图的长*宽*通道数+1,+1是偏置,因此不能直接处理大图像
卷积神经网络的卷积核是立体的,点乘后还要再加个偏值项:
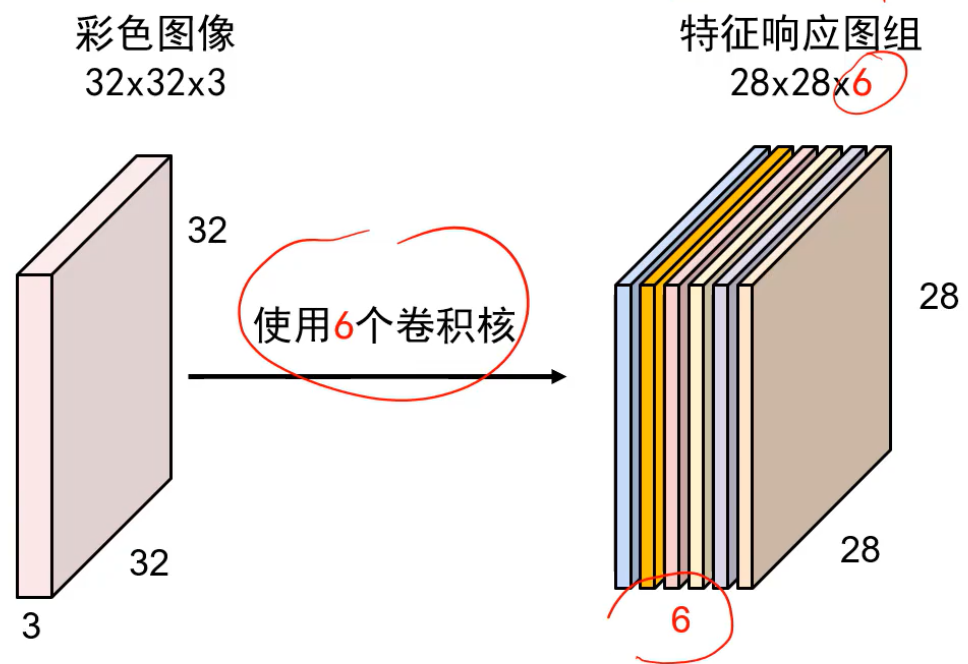
1个卷积核对1个特征图,卷积核个数 = 特征图个数
若第6个特征图的左上角的值大,表示原图像的左上角含有较多的圆圈信息(假设第六个卷积核是圆圈)
卷积步长就是卷积核每次挪动几格
输入与输出(经过卷积核)的关系式:

若给图像填充后,输入与输出的关系(更完整),p是单边的像素长度:

池化为了降低特征图的尺度(不改变厚度),同时卷积核就相对变大了,使得能提取更多粗矿的信息:
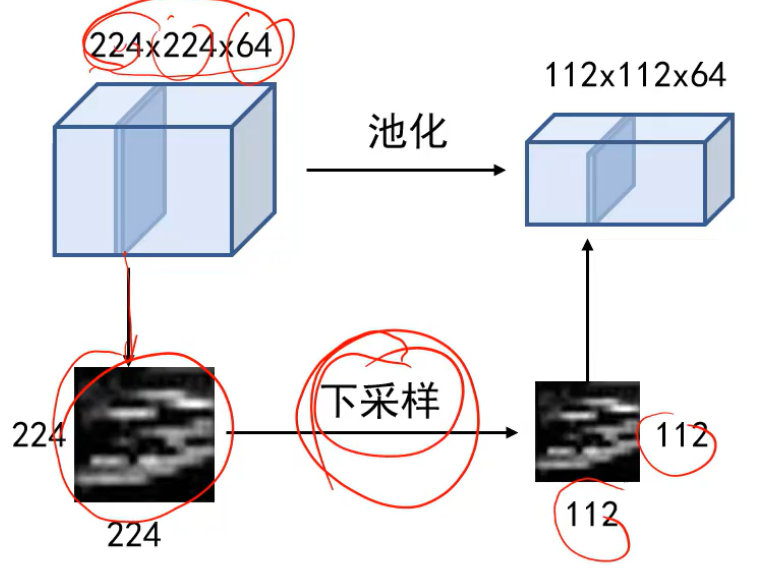
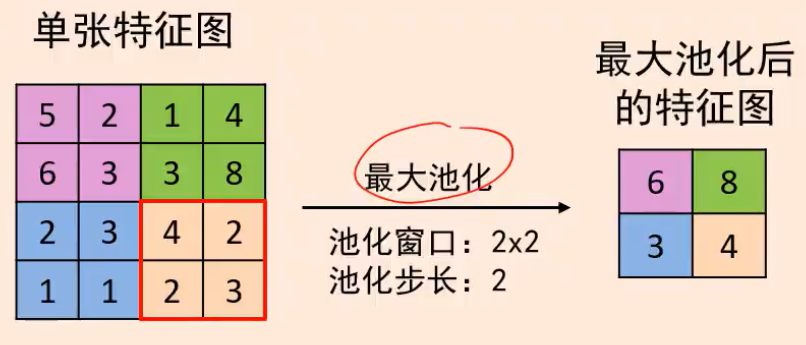
下采样方法有最大池化,平均池化是取均值
最大池化是保留下来最强响应信息:
卷积神经网络:
后面的卷积层记录的是前一层的信息
后面的卷积层拿到的图像小了点,所以看的图像更粗犷

样本增强,如翻转,缩放,色彩范围,旋转,拉伸,裁剪,例子:

经典网络:
Alexnet:


它的去均值化:先统计所有样本的均值,结果是一个平均化的样本,然后用输入的图像减去该平均化的样本
卷积核越多描述的能力越强。
可以将卷积层看成是256个卷积核,若某个特征图的某个位置相应值高,则原图像的对应位置含有较多的该边缘(对应卷积核):

ZFnet:
改小卷积核是为了一开始就提取图像更加细粒度的信息;步长=2是为了一点一点的降低尺寸,而不是一下子就降低很多,这样会损失很多信息;增加卷积核的个数是为了提取更多语义信息

VGG16:
参数过多的话容易过拟合
去均值与前面2个网络不同,算出所有图像的R,G,B均值,形成一个三维向量,然后输入图像每个点减去它;
前面卷积核少,后面核多的原因:前面图像大,为了降低运算量大,而且前面主要提取基元信息,实际没有那么多基元,后面核多是为了提取更多的语义信息;


小卷积核优势:

Googlenet:
采用了inception模块,避免了单一单元提取输入图像容易造成提取信息不全面,inception将各个单元收集到的信息按照深度方向拼起来
前面的2个1x1卷积是为了降深度,以减少后面的单元的运算量
输入到全连接层之前采用平均池化,每个产生的特征图对应一个平均值,这些平均值输入到 fc 中,这样丢掉了空间信息,但是不大影响分类任务效果
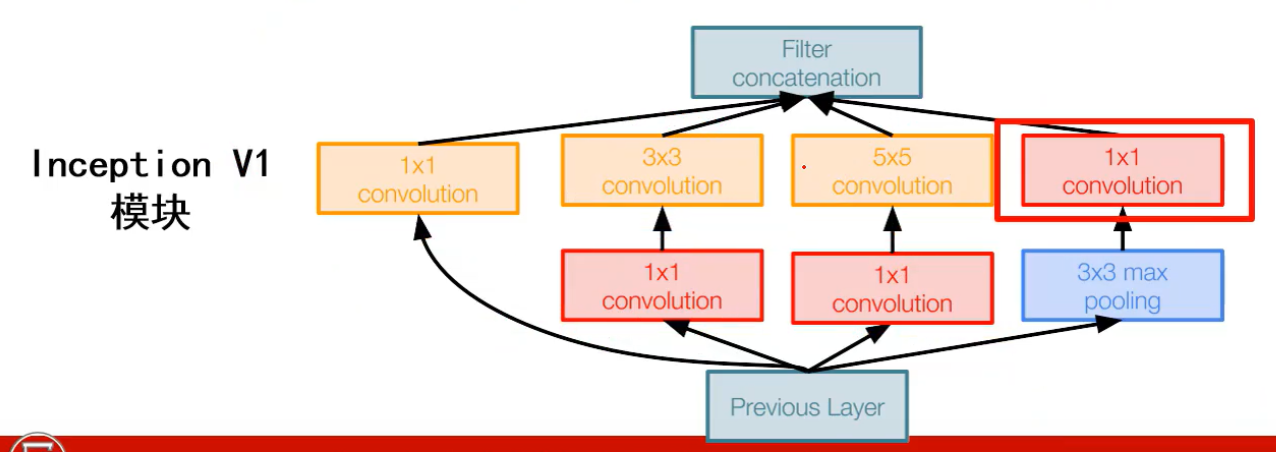
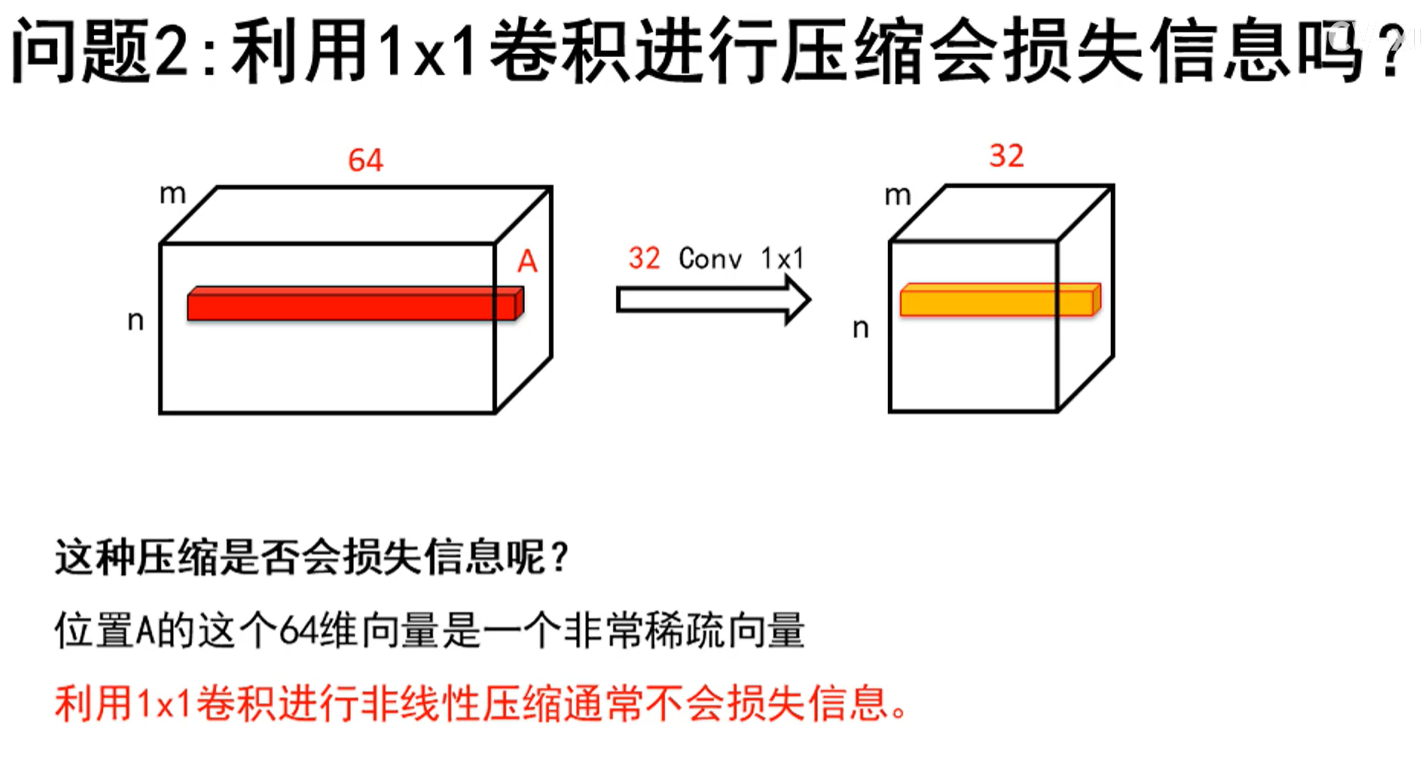
1*1卷积:
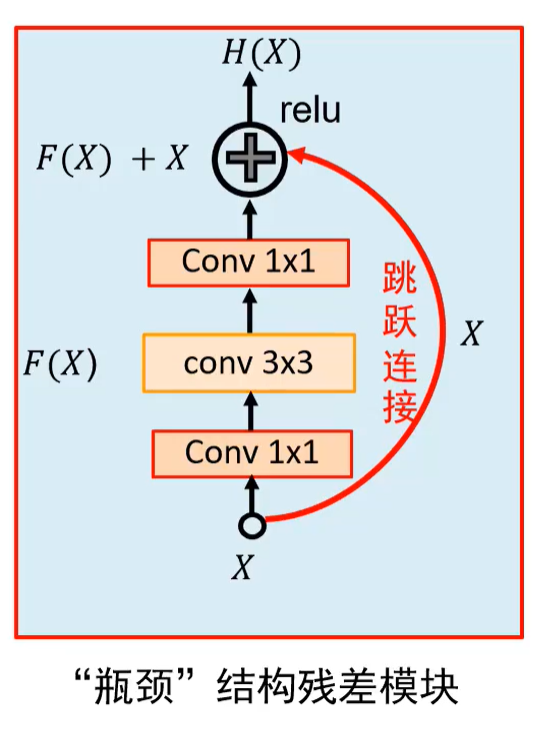
Resnet:
若层数增加性能反而下降,则说明训练不够
使用残差模块中的X,保留了上一层的信息,即使本层没学到东西,也不会下降性能(+X);同时反向梯度流更加顺畅(+X)
第一个的1*1卷积是为了降低厚度, 第二个1*1是为了还原厚度,以便和X相加,而且3*3的卷积核个数就不需要很多,可以降低 3*3 卷积计算量
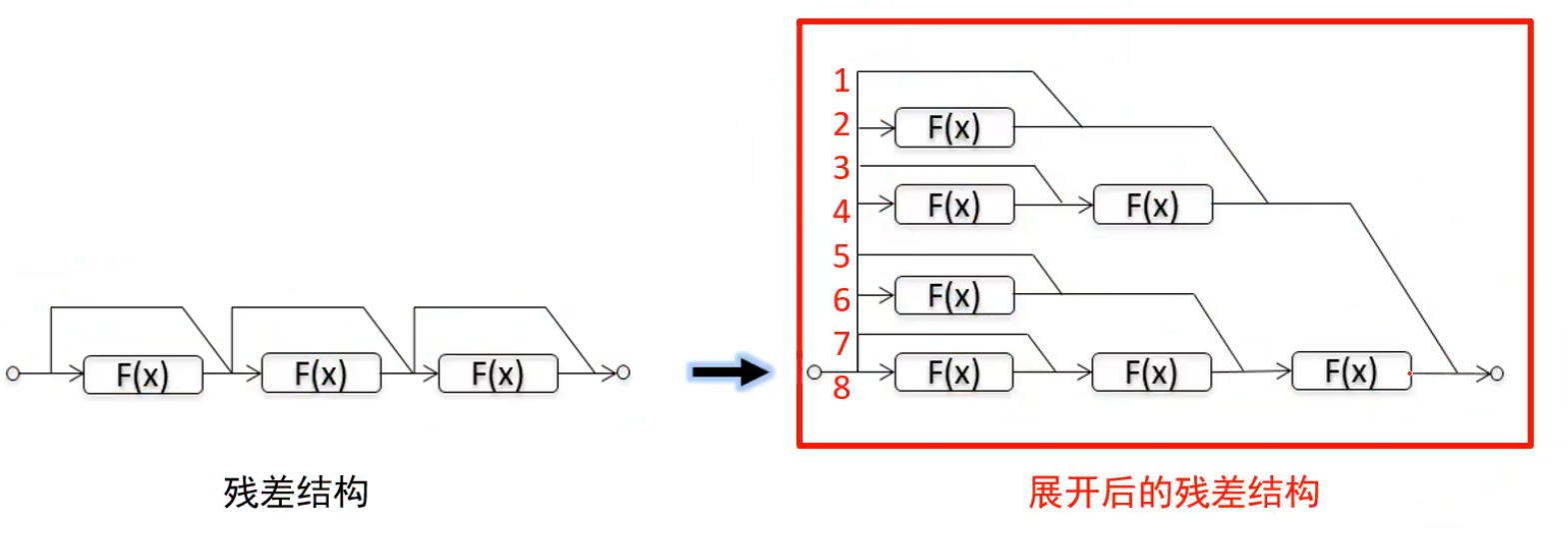
多个残差模块连起来相当于多个模型集成,这样就使得模型性能很好:
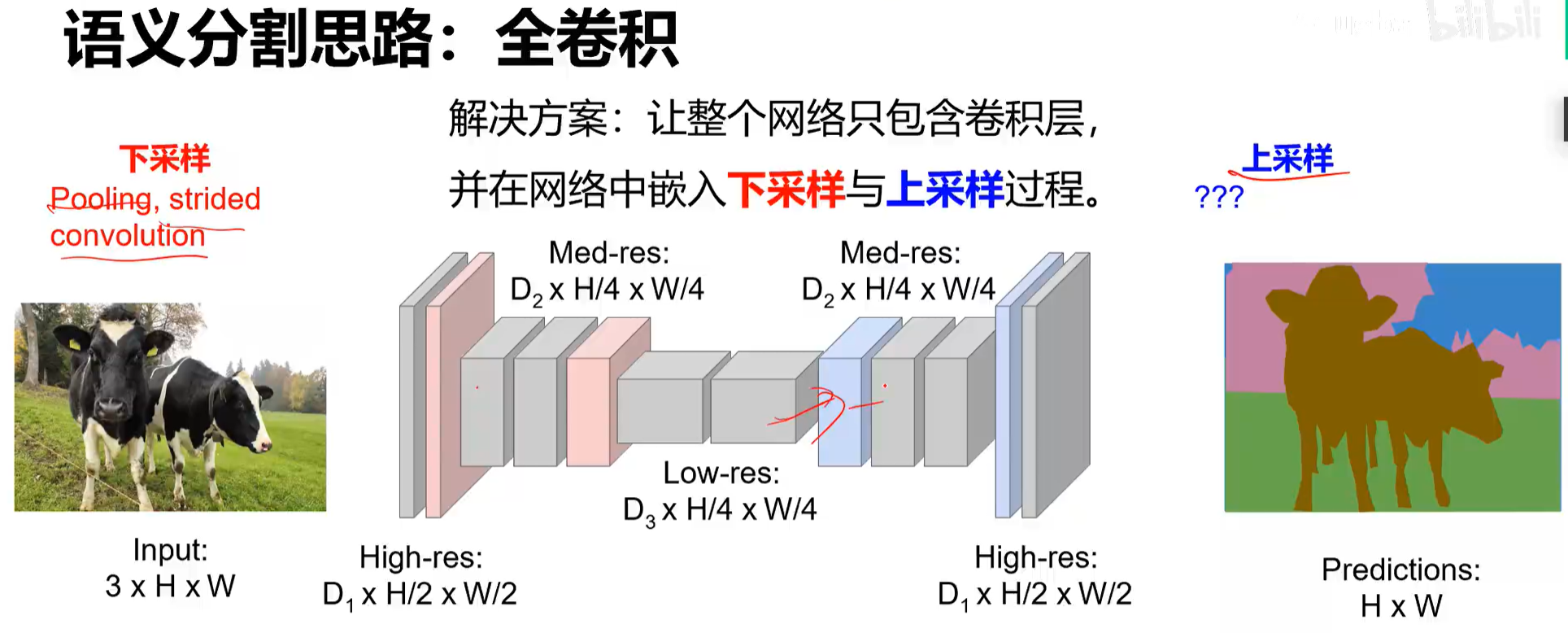
语义分割:
FCN(包含基于此的改进 SegNet、DeconvNet、DeepLab)+ 后端 CRF/MRF (条件随机场/马尔科夫随机场)优化
下采样是为了缩小图像减少运算量,上采样用来恢复尺寸。
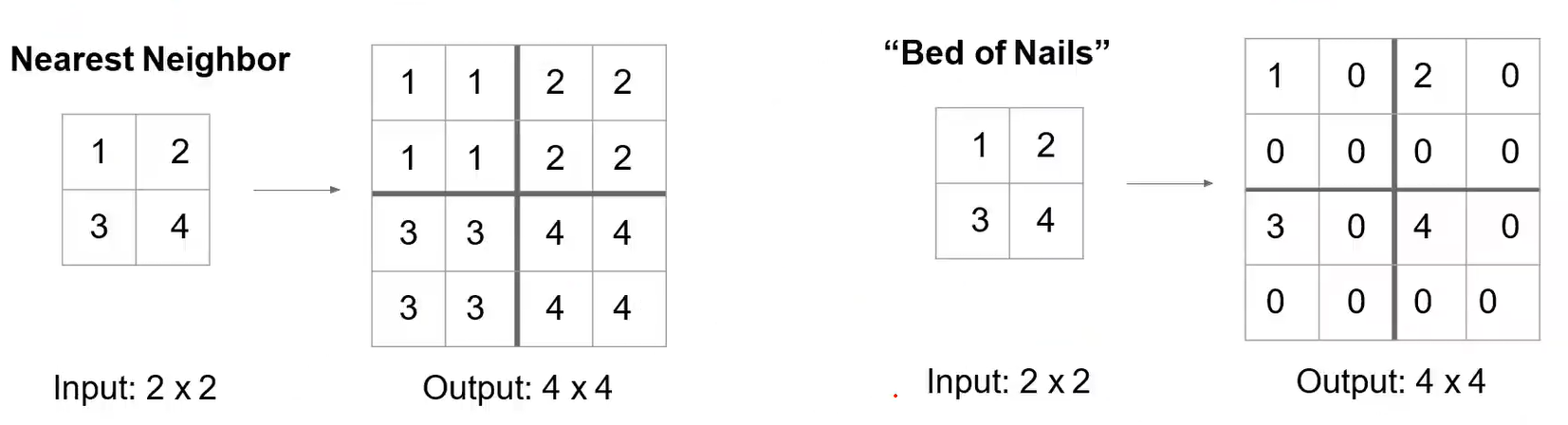
上采样包括Nearest Neighbor、Bed of Nailds、max unpooling、转置卷积=反卷积:
max unpooling:记住5原来在哪,然后恢复的时候,1就放到5的位置。

转置卷积=反卷积:
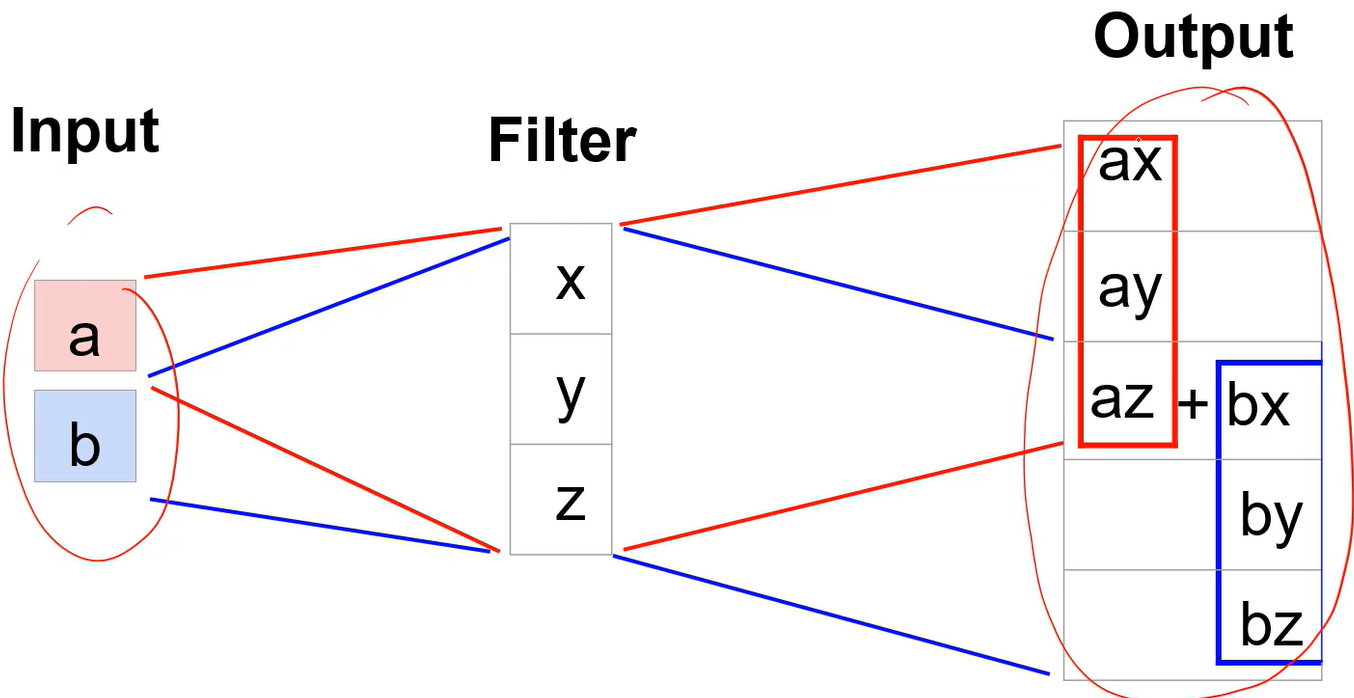
卷积可以写成矩阵乘法,这样更快,后面再通过转置矩阵来恢复图像尺寸,a,b是输入,x,y,z是权重,网络会学习:

FCN:
FCN 在结构上将 CNN 网络最后的全连接层换成了上采样中的反卷积操作。
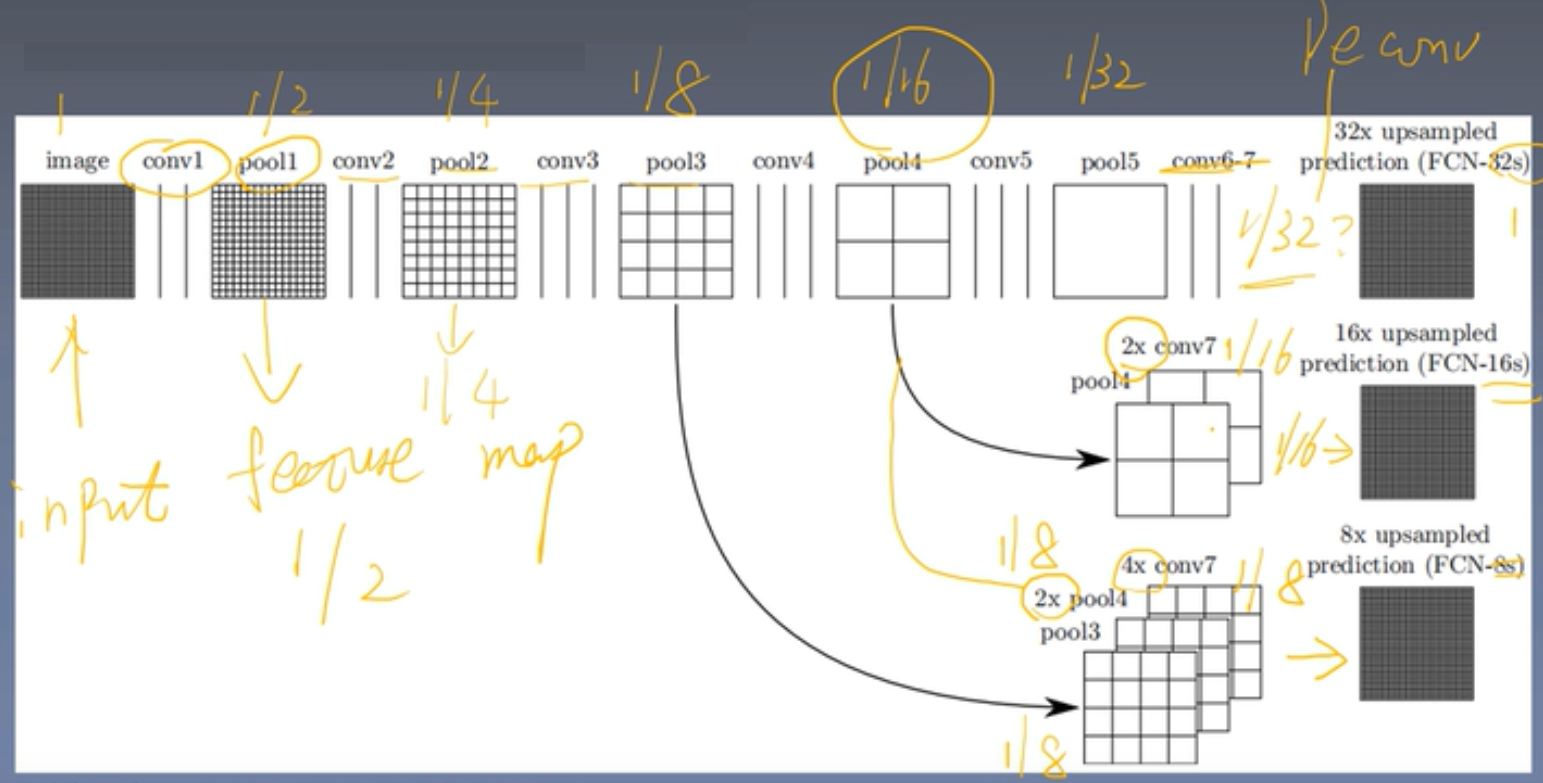
架构:
当最后卷积层输出后,特征图为原图的1/32
32s模式:将特征图32倍上采样恢复到原图尺寸
16s模式:将特征图上采样2倍到1/16,然后和pool4的结果等大小融合(引入跳跃结构,意义是使得后面学到的全局信息能够结合前面层搜集到局部信息),结果还是1/16,再上采样到16倍
8s模式(更精细):将特征图上采样4倍成为1/8,pool4的结果上采样2倍成1/8,再和pool3的1/8,3者融合,最后再上采样8倍
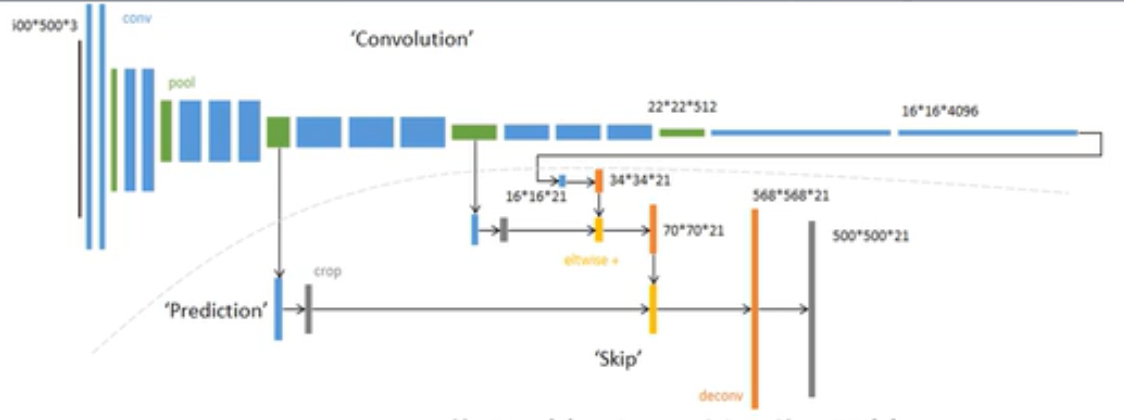
8s具体例子:
损失函数:对每个像素预测类别,单个像素的预测结果与真实类别做交叉熵,最后求和。
unet:
UNet基于FCN,对FCN的基本结构进行了更精细的设计,更为高效,是可以替代FCN的方案
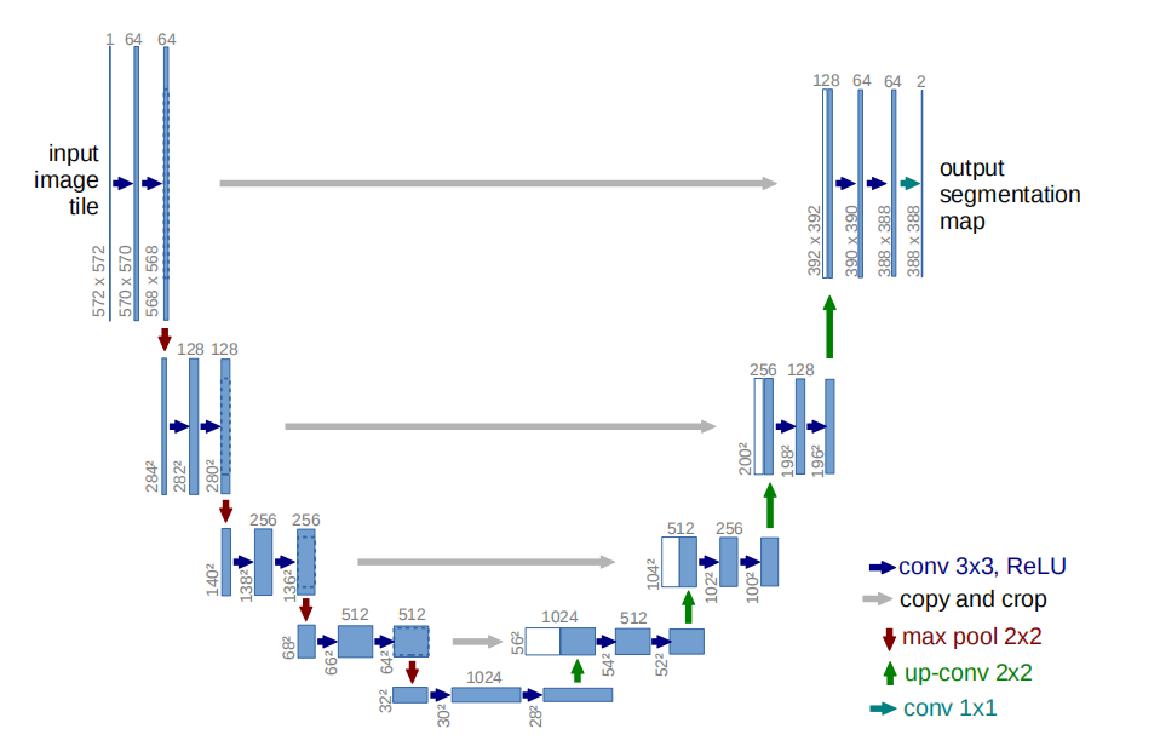
结构:
Unet包括两部分,可以看右图,第一部分,特征提取,VGG类似。第二部分上采样部分。由于网络结构像U型,所以叫Unet网络。特征提取部分,每经过一个池化层就一个尺度,包括原图尺度一共有5个尺度。上采样部分,每上采样一次,就和特征提取部分对应的通道数相同尺度融合,但是融合之前要将其crop。这里的融合是拼接。可以看到,输入是572x572的,但是输出变成了388x388,这说明经过网络以后,输出的结果和原图不是完全对应的。蓝色箭头代表3x3的卷积操作,并且stride是1,padding策略是vaild,因此,每个该操作以后,featuremap的大小会减2。红色箭头代表2x2的maxpooling操作,需要注意的是,此时的padding策略也是vaild,这就会导致如果pooling之前featuremap的大小是奇数,会损失一些信息 。所以要选取合适的输入大小,因为2*2的max-pooling算子适用于偶数像素点的图像长宽。绿色箭头代表2x2的反卷积操作,这个只要理解了反卷积操作,就没什么问题,操作会将featuremap的大小乘2。灰色箭头表示复制和剪切操作,可以发现,在同一层左边的最后一层要比右边的第一层要大一些,这就导致了,想要利用浅层的feature,就要进行一些剪切。输出的最后一层,使用了1x1的卷积层做了分类。输出的最后一层,使用了1x1的卷积层做了分类
特点:
U-net与其他常见的分割网络有一点非常不同的地方:U-net采用了完全不同的特征融合方式:拼接,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征。
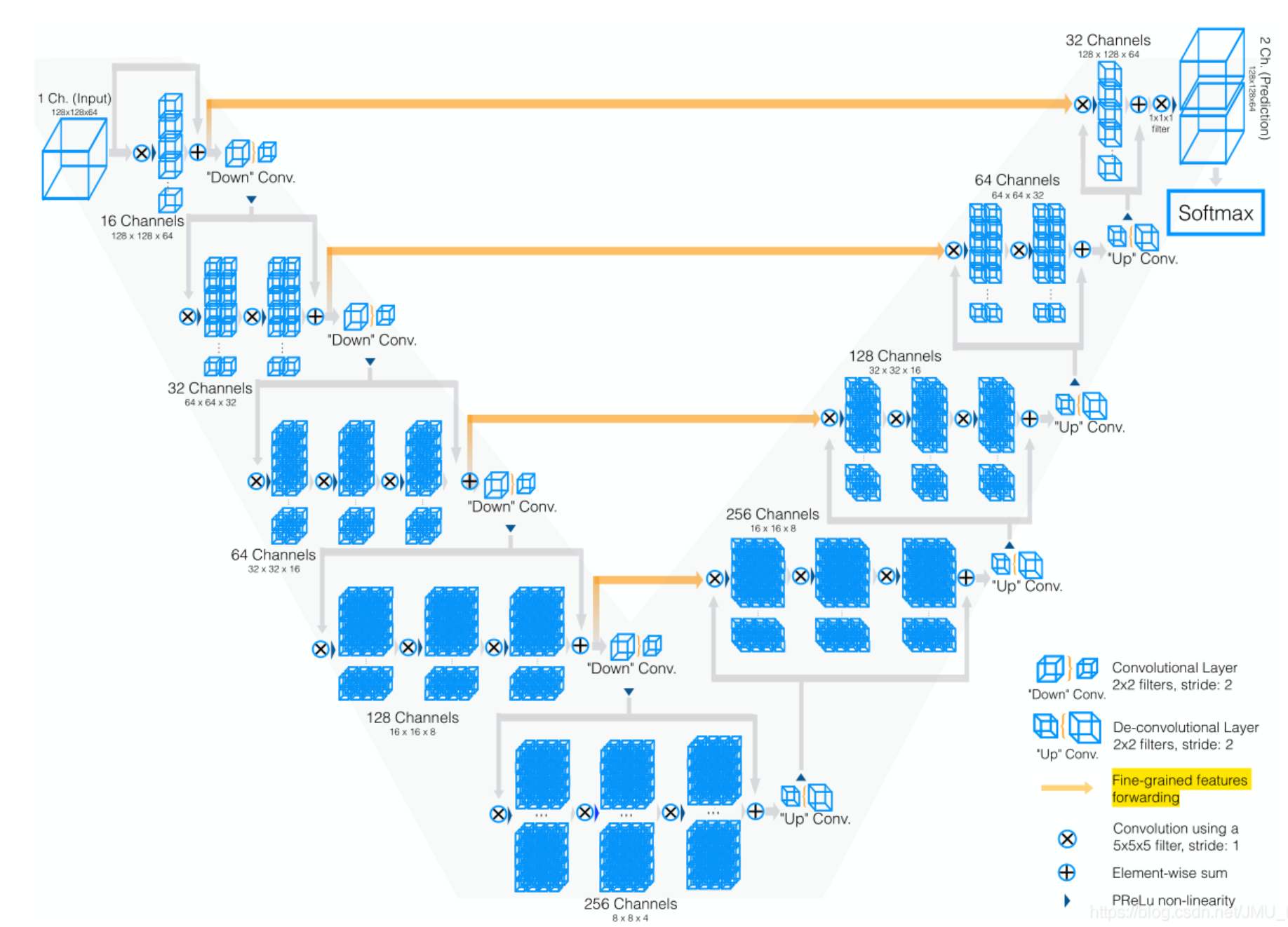
Vnet:
Vnet其实就是Unet的一个变型,Vnet论文主要是针对医学图像提出的,使用的数据集是三维图像,而不是二维
Vnet 网络:也可以分为两部分,第一个部分对图像进行下采样,第二个部分对图像进行上采样。共做了四次下采样和四次上采样,下采样采用卷积的方法,步长为 2,因此图像大小减半(相比于池化的方法,使用卷积下采样,内存占用更小,因为在反向传播的时候最大值池化需要存储最大值所在的位置)上采样采用反卷积的方法。在下采样过程中,通道数是不断翻倍,上采样过程,通道数是不断减半。同时将相对应的下采样过程中的特征图添加至上采样的特征图中,来弥补分割的细节度。Vnet 网络在卷积的过程中采样激活函数为 PReLU
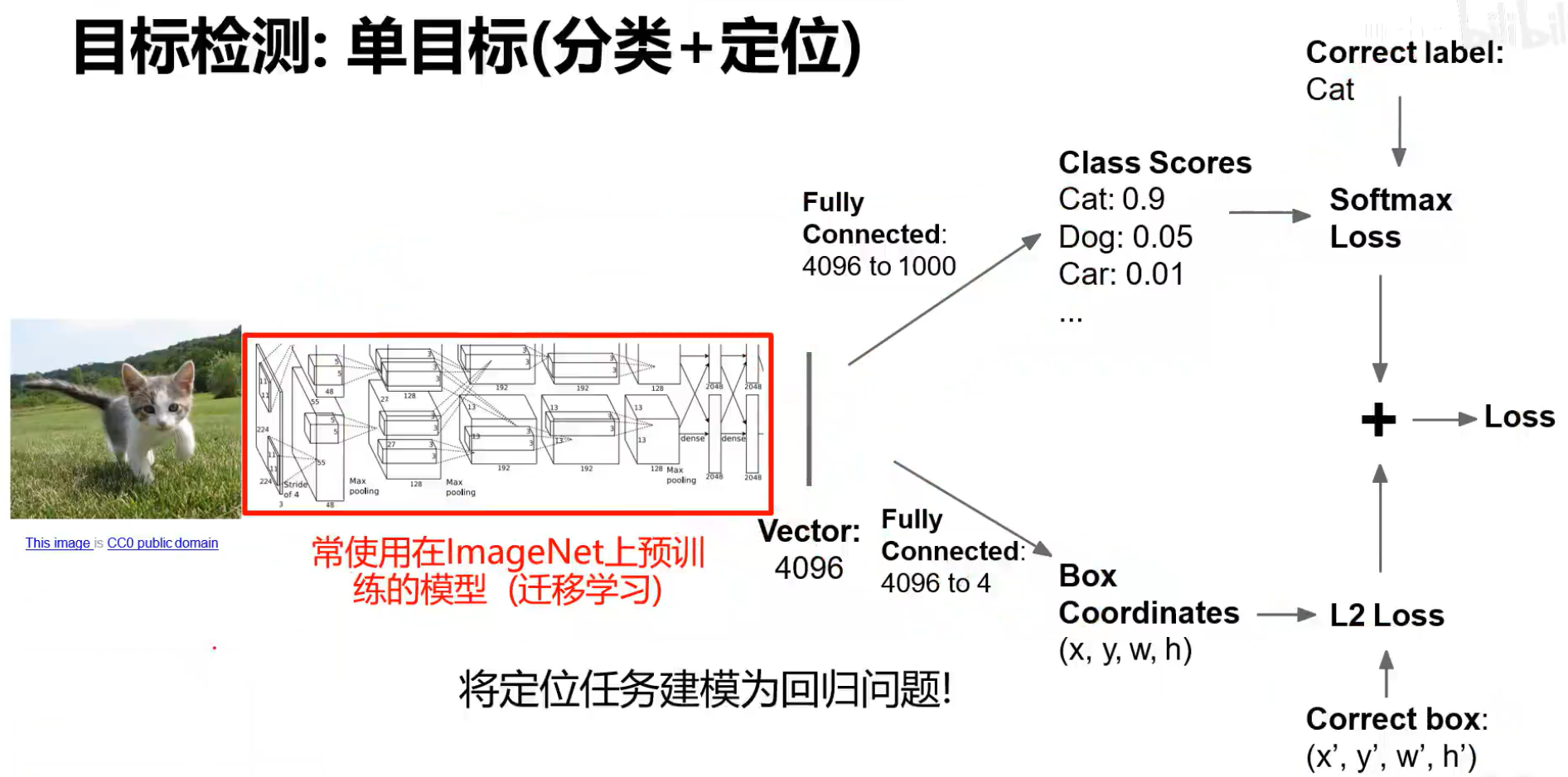
单目标检测:
神经网络有2个输出,一个是预测所属类别,并计算损失函数,另一个是预测该物体的位置,并计算损失,然后2个损失相加(可以按照权重相加)
下图中,可以先训练分类,再训练位置,最后训练整体
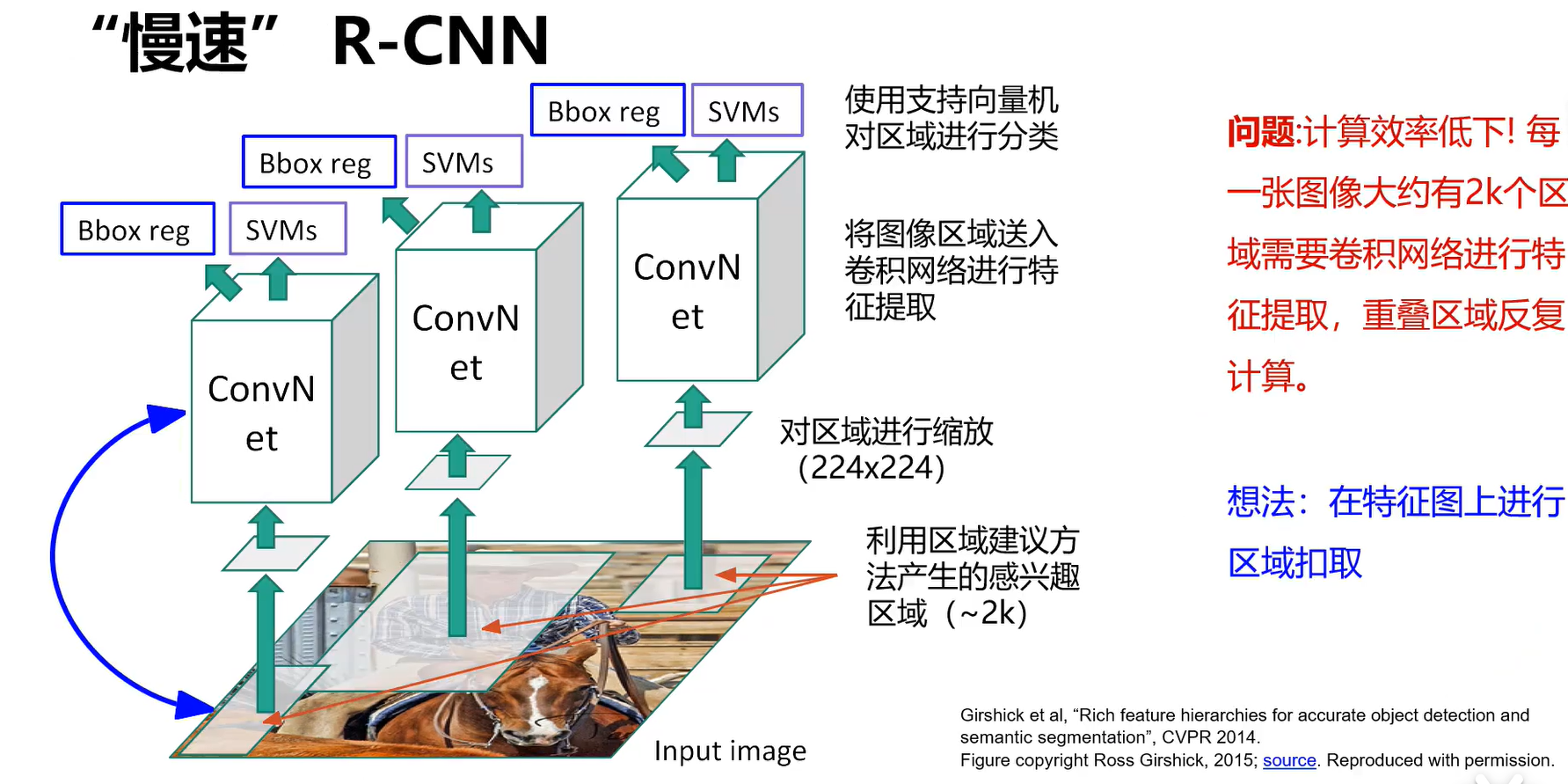
RCNN:
先产生大概2k个候选区域,对每个区域分别进行缩放,然后用卷积网络对它特征提取,然后使用SVMs预测一个类别,Bbox reg预测该物体的位置(修正原来感兴趣的区域)
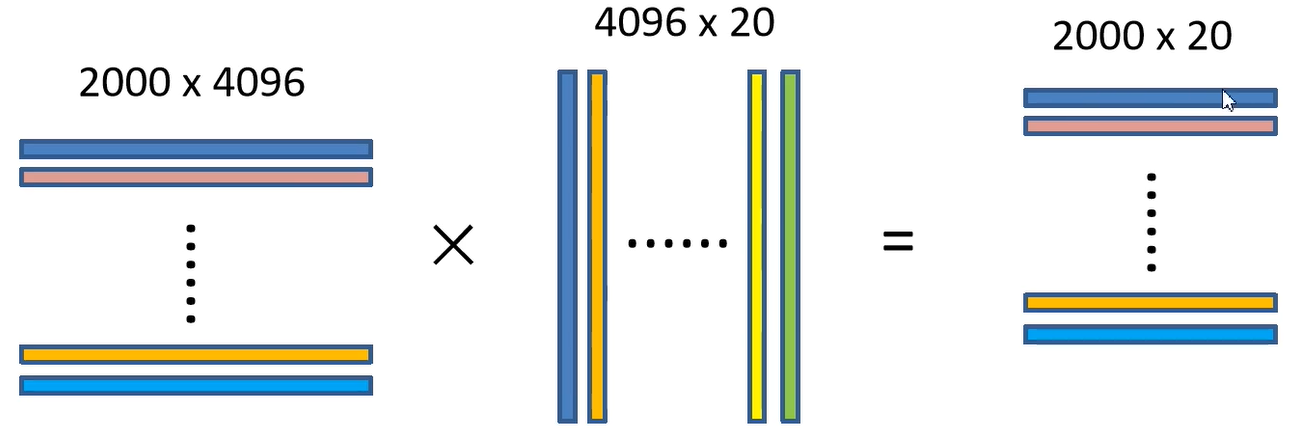
假定有2000个区域,20个类别,cnn输出的向量是4096维,最后的矩阵大小是:2000*4096 ,与svm权值矩阵相乘,它的每一列对应那类的权值,相乘后的结果中,Aij表示第 i 个区域属于第 j 个类别的概率
由于此时对于某个物体而言,有很多冗余的区域,采用非极大值抑制的方法去掉某些重复区域:
从结果的第一列开始,找到概率最大的那行(假定第二行),然后计算其他区域与该区域的IOu(该值越大则两者的重复度越高):
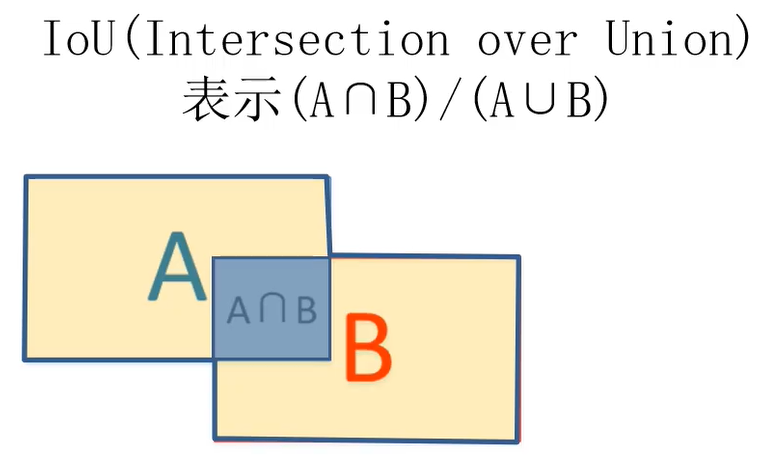
若Iou高出某个阈值则删掉对应的区域,然后把第二行保存下来,找到其他行里面概率次大的(假定第三行), 然后计算剩余行与第三行的Iou(不包括第二行)....
第一列结束后,对第二列进行,直到结束
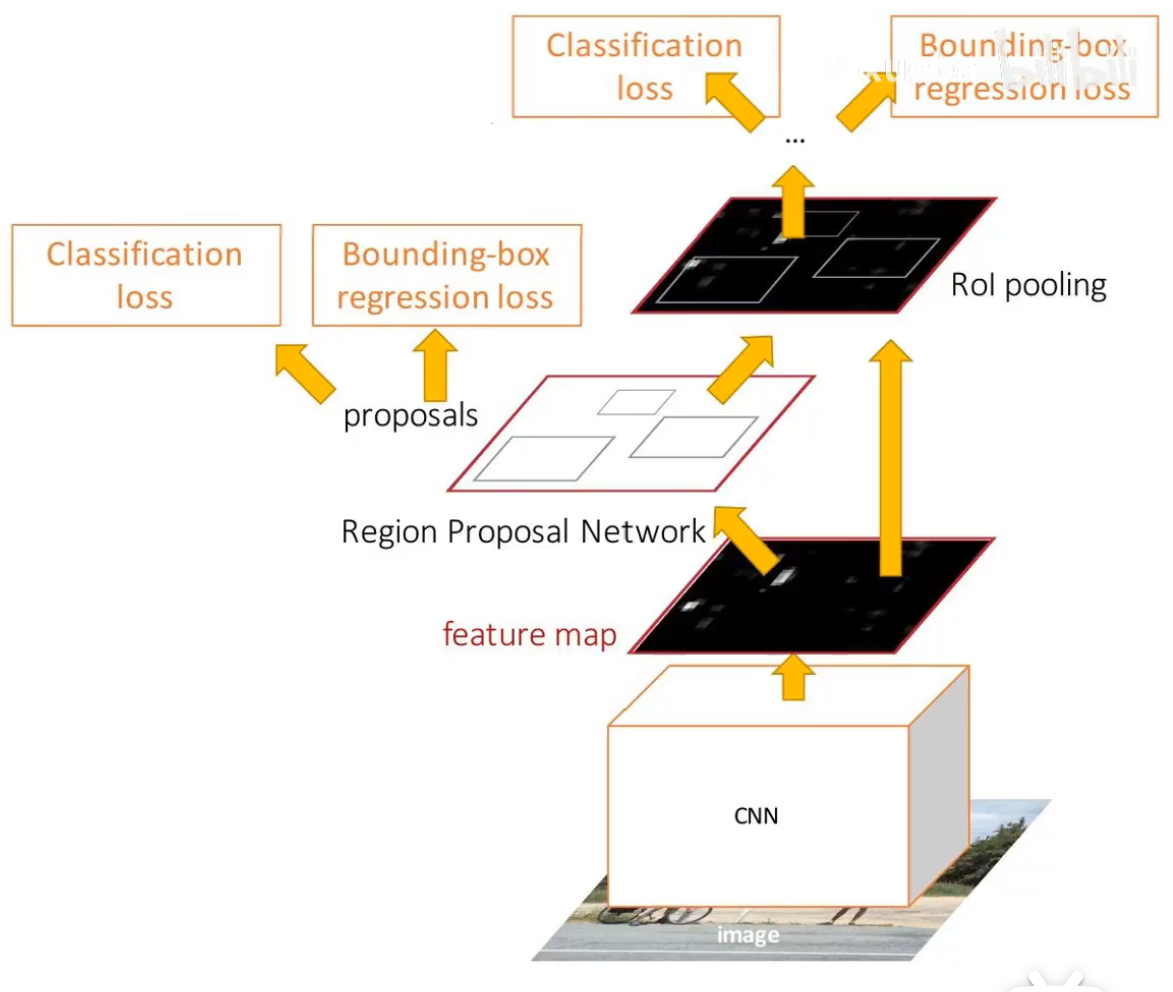
fast RCNN:
先用卷积网络提取特征,再产生候选区域,然后对区域裁剪和缩放成统一尺度的输出,然后分别输入到fcs,对每个区域预测类别和边界框
训练时候并不是训练所有产生的区域,而是训练其中的一部分
目标类别是一个向量,包含该区域属于所有类别的概率,边界框偏差也是个向量, 有4*类别数维度

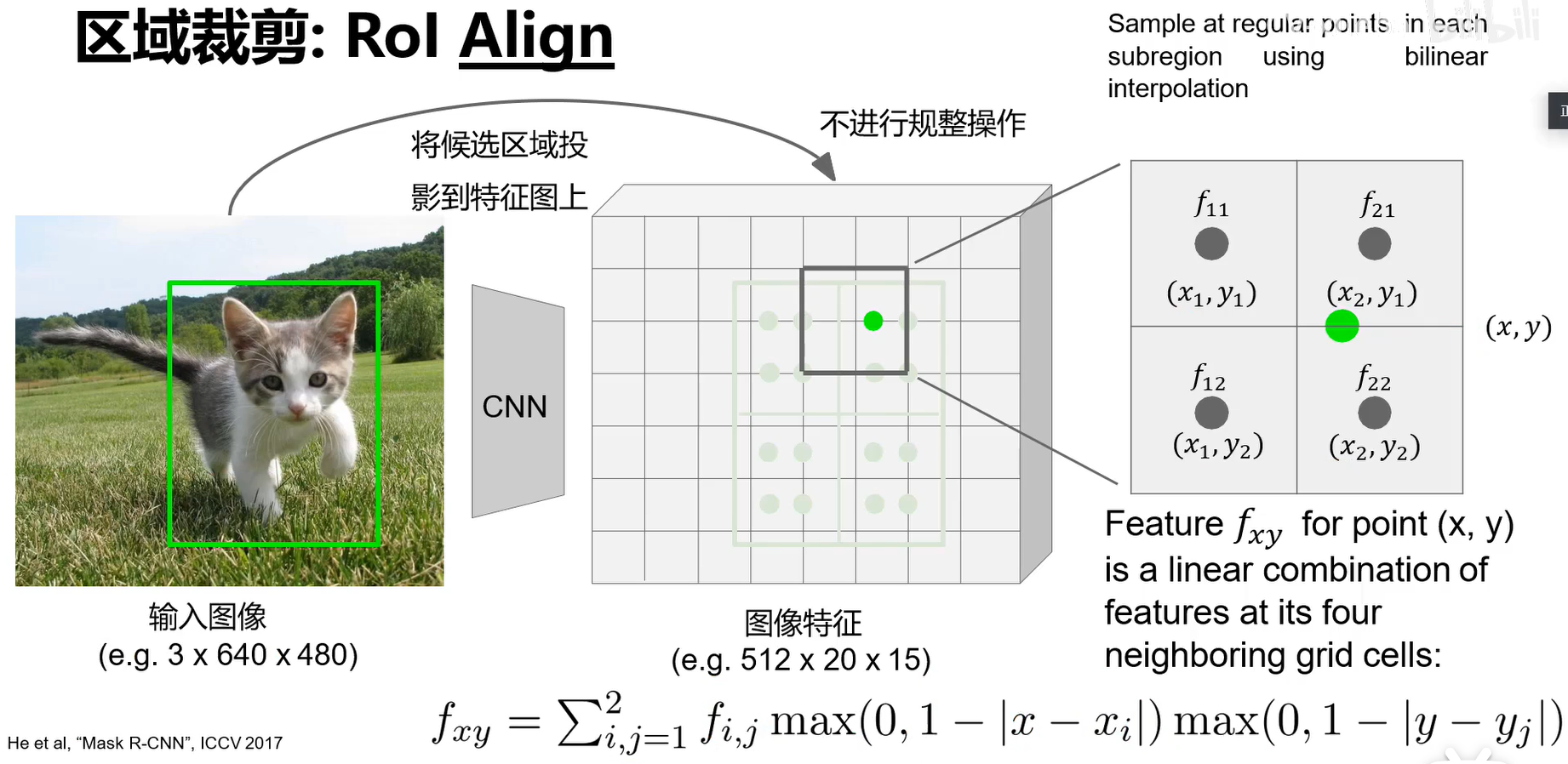
裁剪:

ROI Align能实现对齐:
将大区域划分为几块以后,每块取中间4个绿点,每个绿色点的值采用双线性差值计算,下图的那个绿色点的周围4个黑点就是它所在黑框的四个顶点,公式使用图底下的公式
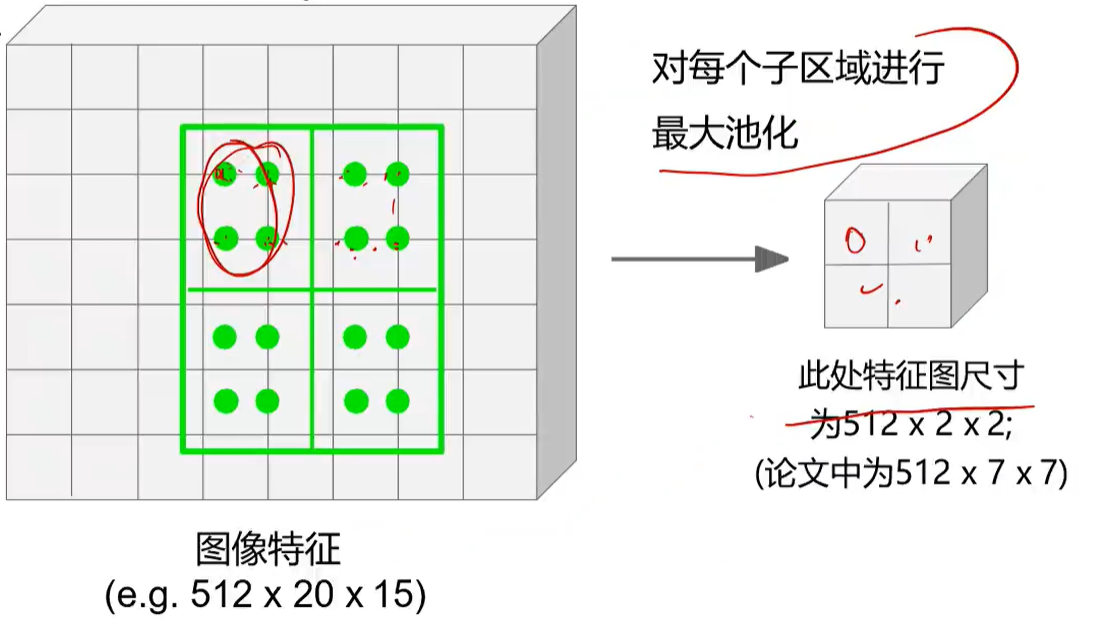
最后最大池化(对每个区域内的4个点取最大的一个):
faster rcnn:
rpn:用CNN来做区域建议
对feature map的每一个点产生包含它的9个框(9个锚点),再忽略掉越过边界的框,再利用非极大值抑制去掉重复框,最后的框就是建议框
每个框对应2个类别:是背景还是要检测的类别
mask RCNN是在faster rcnn的基础上改造,能实现实例分割
神经网络倒数第二层输出的向量可视化后,表示某一类的模板,最后预测的属于该类的图片会与模板像
不同的卷积核关注图像的不同区域
反向可视化计算出梯度图像,可以看出神经网络有没有学对:

可视化方法:梯度上升:将输入图像转成0图,然后前向传播,反向计算梯度时只算某个类别的,其他类的梯度不要,然后回传到第一层再叠加到图像上去,再前向传播...,最后观察图像
神经网络的脆弱性:若在输入图像上加上一点某个类别反向传递的信息,则会误激活该类别的神经元,从而误判定是该类
前面卷积层会记录原图很多细节信息,后面的会记录更多轮廓信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号