
六:协程创建与并发请求
一:PHP-FPM的运作模式
PHP-FPM 是一个多进程的 FastCGI 管理程序,我们使用 Nginx 提供 HTTP 服务(Apache 同理),所有客户端发起的请求最先抵达的都是 Nginx,然后 Nginx 通过 FastCGI 协议将请求转发给 PHP-FPM 处理,PHP-FPM 的 Worker 进程 会抢占式的获得 CGI 请求进行处理,这个处理指的就是,等待 PHP 脚本的解析,等待业务处理的结果返回,完成后回收子进程,这整个的过程是阻塞等待的,也就意味着 PHP-FPM 的进程数有多少能处理的请求也就是多少,假设 PHP-FPM 有 200 个 Worker 进程,一个请求将耗费 1 秒的时间,那么简单的来说整个服务器理论上最多可以处理的请求也就是 200 个,QPS 即为 200/s,在高并发的场景下,这样的性能往往是不够的,尽管可以利用 Nginx 作为负载均衡配合多台 PHP-FPM 服务器来提供服务,但由于 PHP-FPM 的阻塞等待的工作模型,一个请求会占用至少一个 MySQL 连接,多节点高并发下会产生大量的 MySQL 连接,而 MySQL 的最大连接数默认值为 100,尽管可以修改,但显而易见该模式没法很好的应对高并发的场景;

二:协程
协程是一种轻量级的线程,由用户代码来调度和管理,而不是由操作系统内核来进行调度,也就是在用户态进行。什么时候切换由用户自己来实现,而不是由操作系统分配 CPU 时间决定;具体来说,Swoole 的每个 Worker 进程 会存在一个协程调度器来调度协程,协程切换的时机就是遇到 I/O 操作或代码显性切换时,进程内以单线程的形式运行协程,也就意味着一个进程内同一时间只会有一个协程在运行且切换时机明确,也就无需处理像多线程编程下的各种同步锁的问题。
假设为请求 A 创建了 协程 A,为 请求 B 创建了 协程 B,那么在处理 协程 A 的时候代码跑到了查询 MySQL 的语句上,这个时候 协程 A 则会触发协程切换,协程 A 就继续等待 I/O 设备返回结果,那么此时就会切换到 协程 B,开始处理 协程 B 的逻辑,当又遇到了一个 I/O 操作便又触发协程切换,再回过来从 协程 A 刚才切走的地方继续执行,如此反复,遇到 I/O 操作就切换到另一个协程去继续执行而非一直阻塞等待。
这里可以发现一个问题就是,*协程 A 的 MySQL 查询操作必须得是一个异步非阻塞的操作,否则会由于阻塞导致协程调度器没法切换到另一个协程继续执行*,这个也是要在协程编程下需要规避的问题之一。
都说协程是一个轻量级的线程,协程和线程都适用于多任务的场景下,从这个角度上来说,协程与线程很相似,都有自己的上下文,可以共享全局变量,但不同之处在于,在同一时间可以有多个线程处于运行状态,但对于 Swoole 协程来说只能有一个,其它的协程都会处于暂停的状态。此外,普通线程是抢占式的,哪个线程能得到资源由操作系统决定,而协程是协作式的,执行权由用户态自行分配。
四:协程编程注意事项
4.1:不能存在阻塞代码
协程内代码的阻塞会导致协程调度器无法切换到另一个协程继续执行代码,所以我们绝不能在协程内存在阻塞代码,假设我们启动了 4 个 Worker 来处理 HTTP 请求(通常启动的 Worker 数量与 CPU 核心数一致或 2 倍),如果代码中存在阻塞,暂且理论的认为每个请求都会阻塞 1 秒,那么系统的 QPS 也将退化为 4/s ,这无疑就是退化成了与 PHP-FPM 类似的情况,所以我们绝对不能在协程中存在阻塞代码。
那么到底哪些是阻塞代码呢?我们可以简单的认为绝大多数你所熟知的非 Swoole 提供的异步函数的 MySQL、Redis、Memcache、MongoDB、HTTP、Socket等客户端,文件操作、sleep/usleep 等均为阻塞函数,这几乎涵盖了所有日常操作,那么要如何解决呢?Swoole 提供了 MySQL、PostgreSQL、Redis、HTTP、Socket 的协程客户端可以使用,同时 Swoole 4.1 之后提供了一键协程化的方法 \Swoole\Runtime::enableCoroutine(),只需在使用协程前运行这一行代码,Swoole 会将 所有使用 php_stream 进行 socket 操作均变成协程调度的异步 I/O,可以理解为除了 curl 绝大部分原生的操作都可以适用,关于此部分可查阅 Swoole 文档 获得更具体的信息。
在 Hyperf 中我们已经为您处理好了这一切,您只需关注 \Swoole\Runtime::enableCoroutine() 仍无法协程化的阻塞代码即可。
4.2:不能通过全局变量储存状态
在 Swoole 的持久化应用下,一个 Worker 内的全局变量是 Worker 内共享的,而从协程的介绍我们可以知道同一个 Worker 内还会存在多个协程并存在协程切换,也就意味着一个 Worker 会在一个时间周期内同时处理多个协程(或直接理解为请求)的代码,也就意味着如果使用了全局变量来储存状态可能会被多个协程所使用,也就是说不同的请求之间可能会混淆数据,这里的全局变量指的是 $_GET/$_POST/$_REQUEST/$_SESSION/$_COOKIE/$_SERVER等$_开头的变量、global 变量,以及 static 静态属性。
那么当我们需要使用到这些特性时应该怎么办?
对于全局变量,均是跟随着一个 请求(Request) 而产生的,而 Hyperf 的 请求(Request)/响应(Response) 是由 hyperf/http-message 通过实现 PSR-7 处理的,故所有的全局变量均可以在 请求(Request) 对象中得到相关的值;
对于 global 变量和 static 变量,在 PHP-FPM 模式下,本质都是存活于一个请求生命周期内的,而在 Hyperf 内因为是 CLI 应用,会存在 全局周期 和 请求周期(协程周期) 两种长生命周期。
- 全局周期,我们只需要创建一个静态变量供全局调用即可,静态变量意味着在服务启动后,任意协程和代码逻辑均共享此静态变量内的数据,也就意味着存放的数据不能是特别服务于某一个请求或某一个协程;
- 协程周期,由于
Hyperf会为每个请求自动创建一个协程来处理,那么一个协程周期在此也可以理解为一个请求周期,在协程内,所有的状态数据均应存放于Hyperf\Utils\Context类中,通过该类的get、set来读取和存储任意结构的数据,这个Context(协程上下文)类在执行任意协程时读取或存储的数据都是仅限对应的协程的,同时在协程结束时也会自动销毁相关的上下文数据。
4.3:最大协程数限制
对 Swoole Server 通过 set 方法设置 max_coroutine 参数,用于配置一个 Worker 进程最多可存在的协程数量。因为随着 Worker 进程处理的协程数目的增加,其对应占用的内存也会随之增加,为了避免超出 PHP 的 memory_limit 限制,请根据实际业务的压测结果设置该值,Swoole 的默认值为 100000( Swoole 版本小于 v4.4.0-beta 时默认值为 3000 ), 在 hyperf-skeleton 项目中默认设置为 100000。
五:使用协程
5.1:创建一个协程
只需通过 co(callable $callable) 或 go(callable $callable) 函数或 Hyperf\Utils\Coroutine::create(callable $callable) 即可创建一个协程,协程内可以使用协程相关的方法和客户端。
如何使用协程在一个代码块内创建多个协程去并行的进行I/O请求;
模拟客户端发起请求;每次请求停顿两秒;总公四秒;
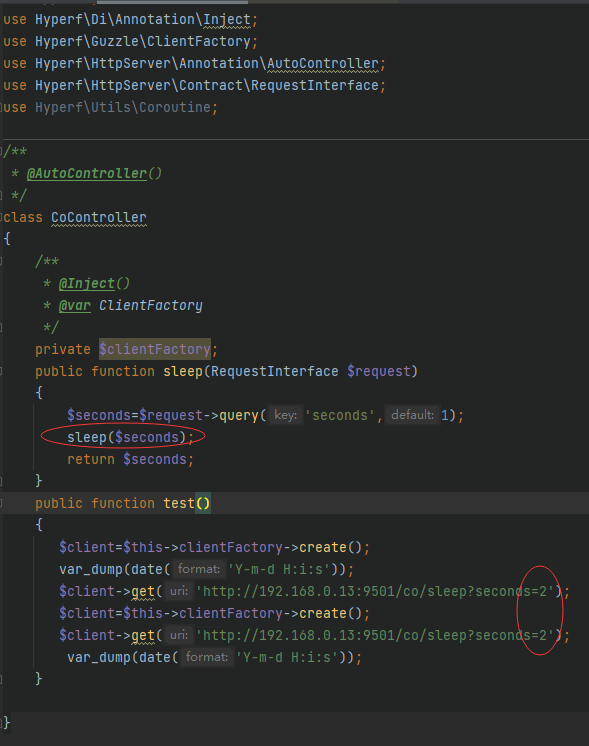
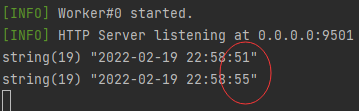
如何并行的发起请求?改造如下:
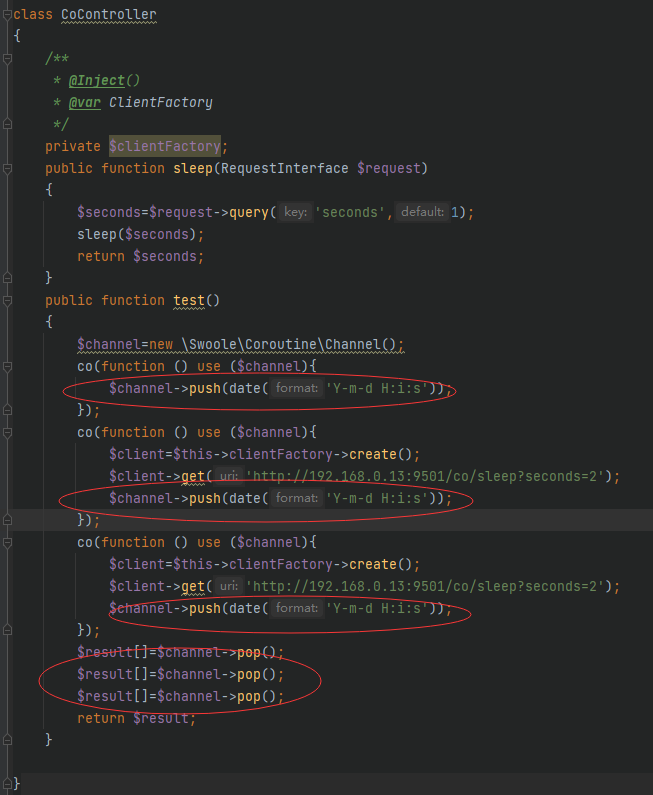
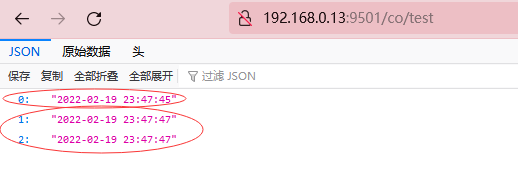
改为协程的方式,之前一共用了4秒,现在一共只用了2秒;
WaitGroup 的案例在下面;
5.2:判断当前是否处于协程环境内
在一些情况下我们希望判断一些当前是否运行于协程环境内,对于一些兼容协程环境与非协程环境的代码来说会作为一个判断的依据,我们可以通过 Hyperf\Utils\Coroutine::inCoroutine(): bool 方法来得到结果。
5.3:获得当前协程的 ID
在一些情况下,我们需要根据 协程 ID 去做一些逻辑,比如 协程上下文 之类的逻辑,可以通过 Hyperf\Utils\Coroutine::id(): int 获得当前的 协程 ID,如不处于协程环境下,会返回 -1。
5.4:Channel 通道
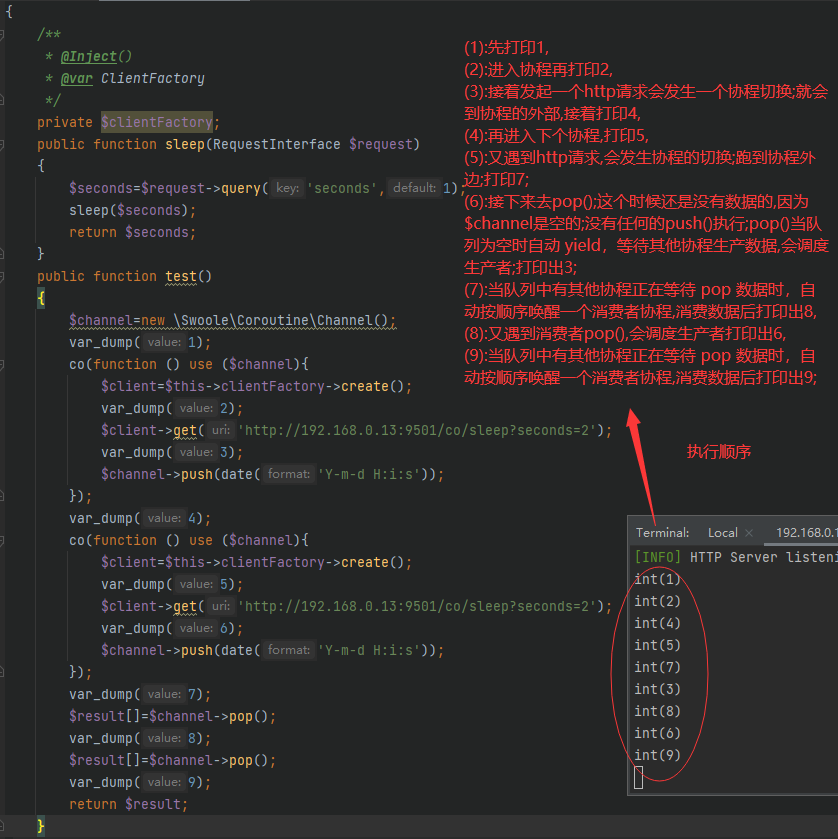
类似于 Go 语言的 chan,Channel 可为多生产者协程和多消费者协程模式提供支持。底层自动实现了协程的切换和调度。 Channel 与 PHP 的数组类似,仅占用内存,没有其他额外的资源申请,所有操作均为内存操作,无 I/O 消耗,使用方法与 SplQueue 队列类似。Channel 主要用于协程间通讯,当我们希望从一个协程里返回一些数据到另一个协程时,就可通过 Channel 来进行传递
Channel->push:当队列中有其他协程正在等待pop数据时,自动按顺序唤醒一个消费者协程。当队列已满时自动yield让出控制权,等待其他协程消费数据Channel->pop:当队列为空时自动yield,等待其他协程生产数据。消费数据后,队列可写入新的数据,自动按顺序唤醒一个生产者协程。
下面是一个协程间通讯的简单例子:

5.5:Defer 特性
当我们希望在协程结束时运行一些代码时,可以通过 defer(callable $callable) 函数或 Hyperf\Coroutine::defer(callable $callable) 将一段函数以 栈(stack) 的形式储存起来,栈(stack) 内的函数会在当前协程结束时以 先进后出 的流程逐个执行。
5.6:WaitGroup 特性
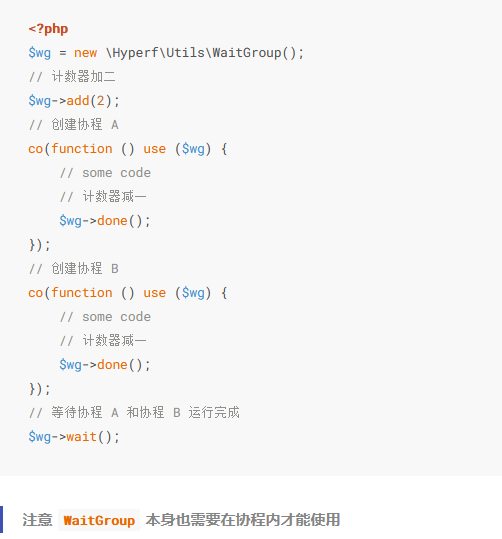
WaitGroup 是基于 Channel 衍生出来的一个特性,如果接触过 Go 语言,我们都会知道 WaitGroup 这一特性,在 Hyperf 里,WaitGroup 的用途是使得主协程一直阻塞等待直到所有相关的子协程都已经完成了任务后再继续运行,这里说到的阻塞等待是仅对于主协程(即当前协程)来说的,并不会阻塞当前进程。
我们通过一段代码来演示该特性
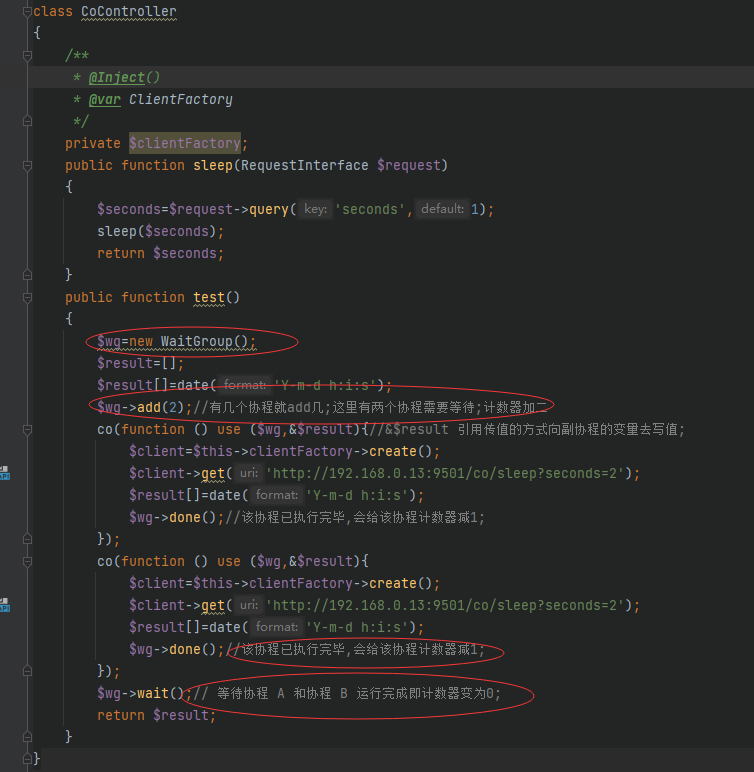
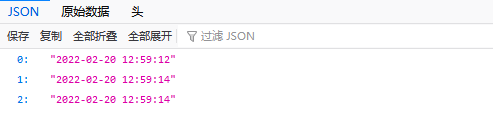
WaitGroup的灵活度很高的api,但是它不是最方便使用的,Parallel 特性更加方便;如下:
5.7:Parallel 特性
Parallel 特性是 Hyperf 基于 WaitGroup 特性抽象出来的一个更便捷的使用方法,我们通过一段代码来演示一下。

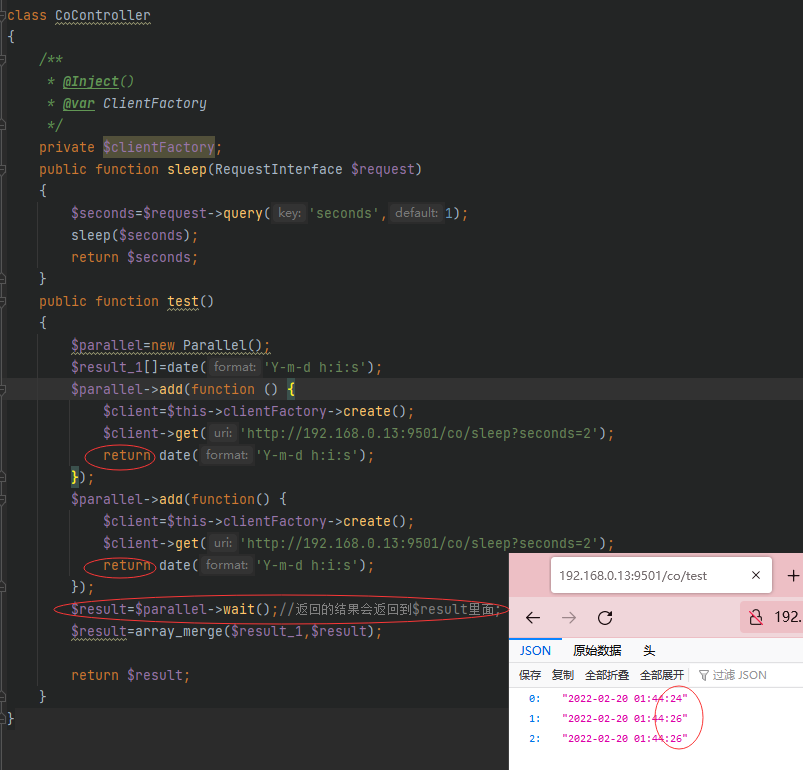
通过上面的代码我们可以看到仅花了 1 秒就得到了两个不同的协程的 ID,在调用 add(callable $callable) 的时候 Parallel 类会为之自动创建一个协程,并加入到 WaitGroup 的调度去。
不仅如此,我们还可以通过 parallel(array $callables) 函数进行更进一步的简化上面的代码,达到同样的目的,下面为简化后的代码。


Hyperf\Utils\Coroutine\Concurrent 基于 Swoole\Coroutine\Channel 实现,用来控制一个代码块内同时运行的最大协程数量的特性。
以下样例,当同时执行 10 个子协程时,会在循环中阻塞,但只会阻塞当前协程,直到释放出一个位置后,循环继续执行下一个子协程。

六:协程上下文
由于同一个进程内协程间是内存共享的,但协程的执行/切换是非顺序的,也就意味着我们很难掌控当前的协程是哪一个*(事实上可以,但通常没人这么干)*,所以我们需要在发生协程切换时能够同时切换对应的上下文。
在 Hyperf 里实现协程的上下文管理将非常简单,基于 Hyperf\Utils\Context 类的 set(string $id, $value)、get(string $id, $default = null)、has(string $id)、override(string $id, \Closure $closure) 静态方法即可完成上下文数据的管理,通过这些方法设置和获取的值,都仅限于当前的协程,在协程结束时,对应的上下文也会自动跟随释放掉,无需手动管理,无需担忧内存泄漏的风险;
6.1:Hyperf\Utils\Context::set()

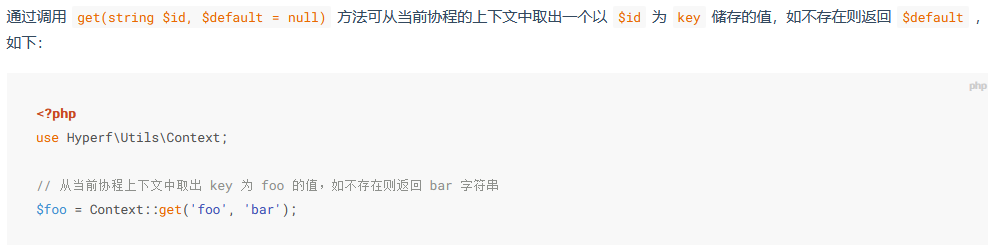
6.2:Hyperf\Utils\Context::get()
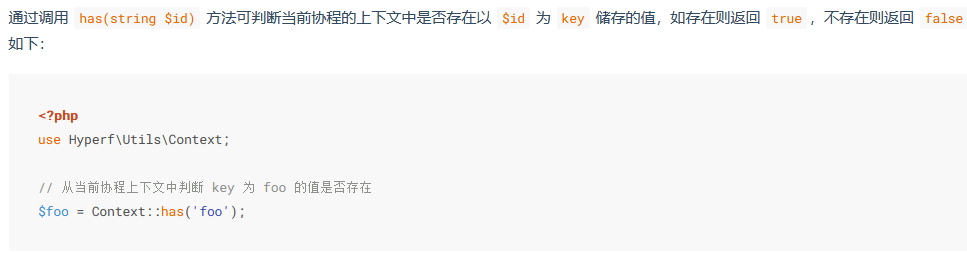
6.3:Hyperf\Utils\Context::has()
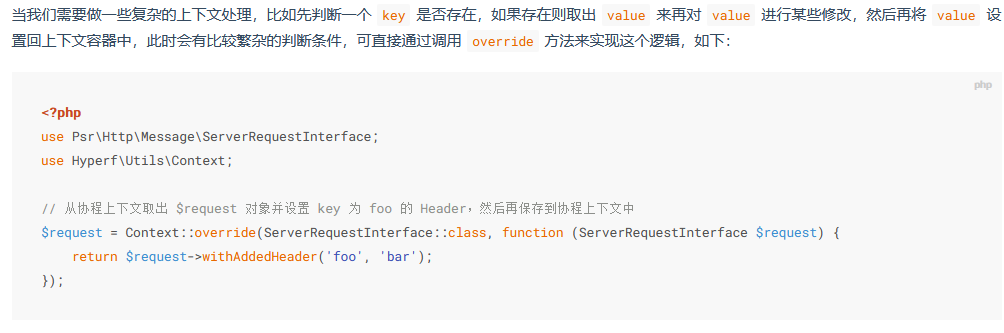
6.4:Hyperf\Utils\Context::override()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号