
第二讲:Redis的基本了解以及高性能的原因
一:Redis的基本了解以及高性能的原因
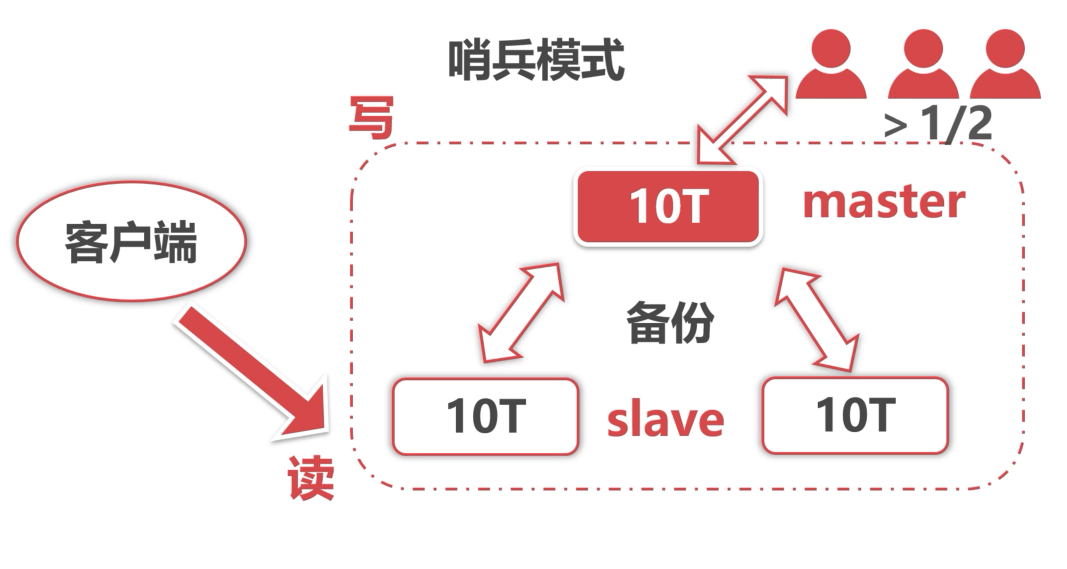
1:redis支持数据的备份主从模式(master-slave)与集群(分片存储),以及拥有哨兵监控机制;
总结:10万并发以下可以使用单节点模式,但是往往也要考虑节点的高可用,并发比较高的情况下,如果读写数据都从单节点势必造成性能的大大降低;
这个时候可以使用Redis提供的主从模式(master-slave)进行读写分离;
当数据不多的时候也要考虑数据的备份,配置选项里有个配置从节点是否为只读模式;那么就可以写入数据到主节点,从从节点读取数据
但是这里有个问题,一旦主节点故障那么就没法写入数据了;所以redis提供了哨兵的机制,如果哨兵是单个机器监控主节点,一旦主机点故障了,
它就会将请求转到一个slave 节点上,将此slave从节点升为master;这样做太草率了,因为有可能在网络波动的情况下,哨兵可能认为主节点故障了,
进而进行故障转移,实际上这个主节点并没有故障;所以一般会选择搭建奇数台的哨兵,这些哨兵都会监控主节点,当监控故障数目大于1/2的时候,
就认为这个主节点故障了,从而进行故障转移的操作;
每次主节点写入数据了,从节点是一个复制的过程;那么也就意味着从节点也会拥有实际的数据;那么这个时候数据越来越多;每个节点都会存在着大量的相同数据;对服务器就会造成压力;
所以我们要考虑到节点存入数据的压力;可以利用集群(分片存储的方式)来解决这个问题;
2:支持事务;
3:性能极高:
3.1:官方测试50个并发执行100000个请求,设置和获取的值是一个256字节的字符串,redis能读的速度是110000次/s,写的速度是81000次/s,如果10万+可以采用主从复制模式;
3.2:纯内存数据库无磁盘的I/O操作,速度快,如果机器故障了数据就丢了,所以支持数据的持久化;
3.3:redis使用的是非阻塞I/O,I/O多路复用,减少了线程切换时上下文的切换和竞争;保障了高吞吐量;
3.4:redis存储结构的多样化,:redis不仅仅支持简单的key-value类型的数据,同时还提供了Lists,Hashes,Sets,Sorted Sets等多种数据的存储;不同的数据结构对数据存储进行了优化加快读取的速度;
4:丰富的特性--redis还支持publish/subscribe,通知,key过期等特性;
5:redis的单线程
5.1:不需要各种锁的性能消耗
5.2:单线程多进程的集群方案
5.3:保证了每个操作的原子性;同时还支持对几个操作合并后的原子性执行(事务),减少了线程的上下文切换和竞争;CPU的消耗大大降低;
5.4:虽然无法发挥多核的CPU性能,但是可以通过在单机多开Redis实例来完善;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号