
第二十七讲:nginx 事件循环
在我们了解了网络事件以及事件分发收集器以后,我们再来看nginx是怎样来处理事件的?
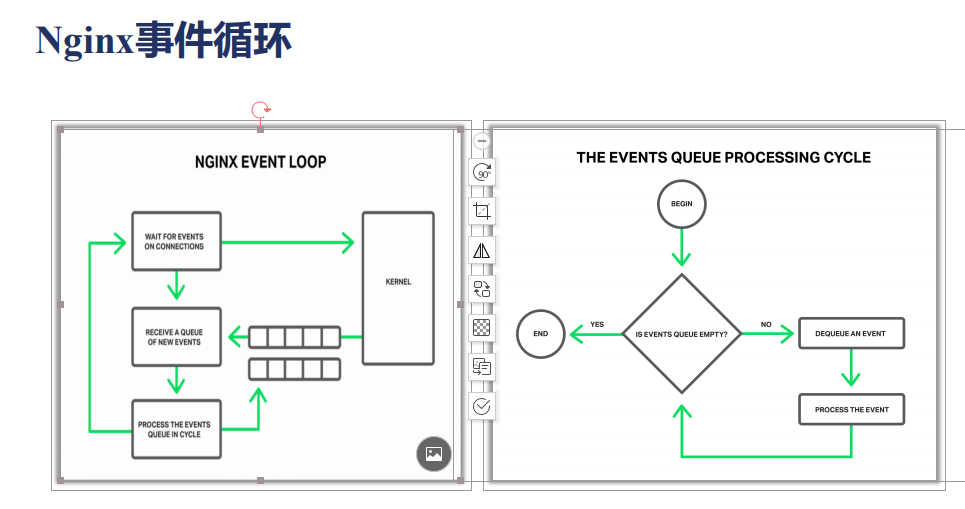
当我们nginx刚刚启动的时候,实际上,在第一步wait for events on connections,也就是说我们打开了80或443端口;这个时候我们在等待新的事件进来,什么样的事件尼?比如新的客户端连上了我们的nginx,它向我们发起了连接;我们在等这样的事件,这样一步尼,往往对应着我们epool中的 epoolwait这么一个方法;这个时候我们的nginx其实是处于sleep这样的一个状态;而当操作系统收到了一个建立TCP连接的握手报文,并且处理完握手流程以后尼,操作系统就会通知我们的epoolwait这个阻塞方法,到此时它可以往下走了,同时唤醒我们的nginx的worker进程;我们往下走以后尼,就会向操作系统要事件;这里的KERNEL就是我们操作系统的内核;那么操作系统会把它准备好的事件 放到事件队列中,从事件队列中我们可以获取到我们要处理的一个个事件receive a queue of events ,比如建立连接,比如建立一个TCP的请求报文;我们都可以从这里取出来,取出来以后尼,我们就会处理这么一个事件,我们看右边的图 就是处理事件的一个循环;就是我们发现队列中事件不为空,就把事件取出来;开始处理这个事件,在处理事件的过程中尼,我可能又会生成新的事件;比如说我发现一个连接新建立了,那么我可能要添加一个操作时间,比如说默认的60秒,也就是说在60秒之内,如果浏览器不向我发送请求的话,我就会把这个连接关掉,又比如说当我发现我收集完了完整的HTTP请求以后,我已经可以生成HTTP响应了,那么这个新生响应尼是需要我可以向操作系统的写缓存区里面把响应写进去;要求操作系统尽快的把响应的内容发到浏览器上,那么这里我实际上期待一个写事件,也就是说我们在处理事件的过程中有可能会生成新的事件,也就是下面的一个队列,它会新生成新的一个队列放到这里,等待下一次来处理,如果所有的事件都处理完成以后 尼,我们就又会返回到wait for events on connections 这样的一个流程,那么知道了nginx的事件循环有什么好处,这个时候再去理解我们使用的第三方模块,有时候使用的第三方模块可能会做大量的CPU运算,这样的计算任务尼会导致我处理一个事件的时间会非常非常的长,在我们刚刚所说的流程图里,我们就可看到,它会导致后续队列中的大量事件长时间得不到处理,从而引发恶心循环,也即是它们的操作时间已经到了,那么我们大量的CPU和Nginx的任务都消耗在处理连接不正常的断开,所以Nginx往往不能容忍有些第三方模块长时间的消耗大量的CPU进行计算任务,就是这么一个原因;我们可以看到如gizp等这样的模块,它们都是不会一次使用大量的CPU,而是分段使用,都与这是有关系的;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号