
YOLOX: Exceeding YOLO Series in 2021(原文翻译)
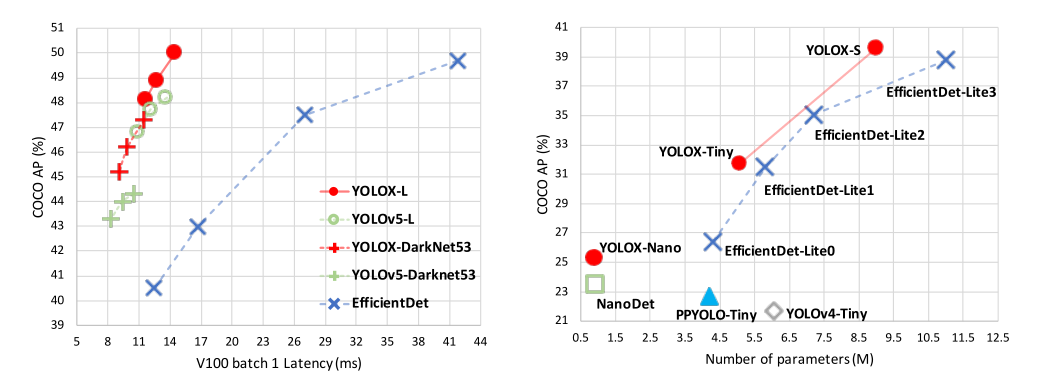
图1:YOLOX和其他最先进的物体检测器在移动设备上精确模型的速度-精度权衡(上)和精简模型的尺寸-精度曲线(下)。
在本报告中,我们介绍了对YOLO系列进行了有经验的改进,形成了一种新的高性能检测器——YOLOX。我们将YOLO检测器切换到无锚方式,并进行其他先进的检测技术,即解耦头和领先的标签分配策略SimOTA,让模型在目前大尺度物体检测中取得最好的结果:对于YOLO-Nano仅用0.91M参数和1.08G FLOPs,我们在COCO上获得25.3%的AP,超过NanoDet 1.8%的AP;对于工业上应用最广泛的探测器之一YOLOv3,我们在COCO上将其提升至47.3% AP,比目前的最佳实践高出3.0% AP;对于参数量与YOLOv4CSP、YOLOv5-L大致相同的YOLOX-L,我们在COCO上实现了50.0%的AP,在特斯拉 V100上的速度为68.9 FPS,超过YOLOv5-L 1.8%的AP。此外,还凭借YOLOX-L模型赢得了流媒体感知挑战赛(2021 CVPR自动驾驶研讨会)的第一名。希望这份报告能为开发者和研究人员在实际场景中提供有益的经验,我们还提供了支持ONNX、TensorRT、NCNN和Openvino的部署版本。源代码:https://github.com/Megvii-BaseDetection/YOLOX。
1、引言
随着目标检测的发展,YOLO系列[23,24,25,1,7]始终追求实时应用的最佳速度和精度平衡。他们提取当时可用的最先进的检测技术(例如,针对YOLOv2 [24]的锚[26]、针对YOLOv3 [25]的残差网络[9]),并针对最佳实践优化实施。目前,YOLOv5 [7]在13.7 ms的COCO上以48.2%的AP保持了最佳的折衷性能。
然而,在过去的两年中,目标检测学术界的主要进展集中在无锚检测器[29,40,14],高级标签分配策略[37,36,12,41,22,4]和端到端(无NMS)检测器[2,32,39]。这些尚未融入YOLO家庭,如YOLOv4和YOLOv5仍然是基于锚的检测器,具有手工制作的训练分配规则。
这就是我们来到这里的原因,通过经验丰富的优化为YOLO系列带来了最新的进步。考虑到YOLOv4和YOLOv5对于基于锚点的通道可能有些过度优化,我们选择YOLOv3 [25]作为我们的起点(我们将YOLOv3-SPP设置为默认的YOLOv3)。事实上,由于各种实际应用中的计算资源有限和软件支持不足,YOLOv3仍然是行业中使用最广泛的检测器之一。
如图1所示,随着上述技术的经验更新,我们在COCO上以640 × 640的分辨率将YOLOv3提升到47.3% AP (YOLOX-DarkNet53),大大超过了目前YOLOv3的最佳实践(44.3% AP,ultralytics版)。此外,当切换到采用先进CSPNet [31]主干和额外PAN [19]头的先进YOLOv5架构时,YOLOX-L在640 × 640分辨率的COCO上实现了50.0%的AP,比对应的YOLOv5-L高出1.8%的AP。我们也在小尺寸的模型上测试我们的设计策略。YOLOX-Tiny和YOLOX-Nano(仅0.91M参数和1.08G FLOPs)的性能分别比对应的YOLOv4-Tiny和NanoDet3by高出10% AP和1.8% AP。
我们已经在https://github.com/Megvii-BaseDetection/YOLOX上发布了我们的代码。支持ONNX、TensorRT、NCNN和Openvino。还有一点值得一提,我们使用一款YOLOX-L车型赢得了流媒体感知挑战赛(2021 CVPR自动驾驶研讨会)的第一名。
2、YOLOX
2.1 YOLOX-DarkNet53
我们选择YOLOv3 [25],以Darknet53为基线。在接下来的部分,我们将一步一步地在YOLOX中遍历整个系统设计。
实现细节 从基线到最终模型,我们的训练设置基本一致。我们在COCO train2017上对模型进行了总共300个时期的训练,其中包括5个时期的预热[17]。我们使用随机梯度下降进行训练。我们使用的学习速率为lr×BatchSize/64(线性缩放[8]),初始化lr = 0.01,lr随着时间余弦变化。权重衰减为0.0005,SGD动量为0.9。默认情况下,典型的8-GPU设备的批处理大小为128。包括单个GPU训练在内的其他批处理大小也运行良好。输入大小从448到832均匀绘制,步长32。本报告中的FPS和延迟都是在单个特斯拉V100上用FP16-precision和 batch=1测量的。
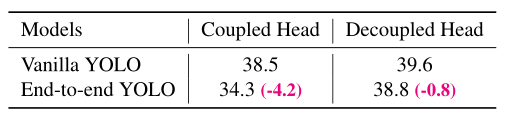
表1:以AP (%)表示的端到端YOLO解耦头对COCO的影响。
YOLOv3基准线 我们的基线采用了DarkNet53主干和SPP层的架构,在一些论文中被称为yolov3-SPP[1,7]。与最初的实现相比,我们稍微改变了一些训练策略[25],增加了均线权重更新、余弦lr调度、IoU损失和IoU感知分支。我们将BCE损失用于训练cls和obj分支,将IoU损失用于训练reg分支。这些常规训练技巧与YOLOX的关键改进是正交的,因此我们将其放在基线上。我们只进行RandomHorizontalFlip、ColorJitter和多尺度数据增强,并放弃RandomResizedCrop策略,因为我们发现RandomResizedCrop与计划的镶嵌增强有点重叠。通过这些增强,我们的基线在COCO val上实现了38.5%的AP,如表2显示。
解耦头 在目标检测中,分类和回归任务之间的冲突是一个众所周知的问题[27,34]。因此,用于分类和定位的解耦头广泛用于大多数单级和两级检测器[16,29,35,34]。然而,作为YOLO系列的主干和特征金字塔(例如,FPN [13],PAN[20])。)不断发展,它们的检测头保持耦合,如图2所示。
我们的两个分析实验表明,耦合探测头可能会损害性能。1).如图3所示,用解耦的头代替YOLO的头大大提高了收敛速度。2).解耦的头部对于端到端版本的YOLO是必不可少的(将在下面描述)。从表1就能看出来。端对端特性随着耦合头降低4.2%的AP,而对于解耦合头降低到0.8%的AP。因此,我们用如图2所示的lite去耦头代替YOLO检测头。具体来说,它包含一个1 × 1 卷积层以减小通道尺寸,其后是两个平行分支,分别有两个3 × 3 卷积层。我们在表2的V100上报告batch=1的推断时间,lite去耦头带来额外的1.1 ms (11.6 ms v.s. 10.5 ms)
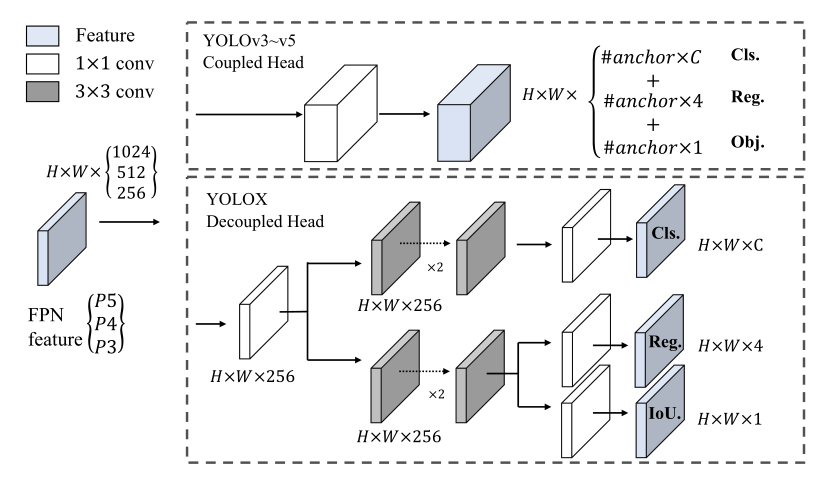
图2:说明YOLOv3头部和建议的去耦头部之间的差异。对于每一级FPN特征,我们首先采用1 × 1 卷积层将特征通道减少到256个,然后添加两个平行分支,每个分支有两个3 × 3 卷积层,分别用于分类和回归任务。在回归分支上增加了IoU分支。
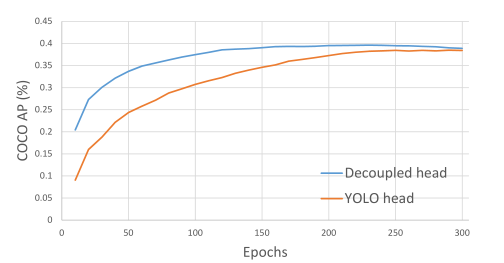
图3:带有YOLOv3头或去耦头的检测器的训练曲线。我们每10个时代在COCO val上评估一次AP。解耦磁头比YOLOv3磁头收敛得更快,最终获得更好的结果。
强数据增强 我们将Mosaic和MixUp添加到我们的增强策略中,以提高YOLOX的性能。Mosaic是ultralytics-YOLOv3提出的一种有效的扩增策略。然后,它被广泛用于YOLOv4 [1]、YOLOv5 [7]和其他检测器[3]。MixUp [10]最初是为图像分类任务而设计的,但在对象检测训练中,MixUp[38]的任务是很复杂的。我们在模型中采用了MixUp和Mosaic实现,并在过去15个时期关闭了它,在表2中实现了42.0%的AP。在使用强大的数据增强后,我们发现ImageNet预训练不再有任何益处,因此我们从头开始训练以下所有模型。
无锚框 YOLOv4 [1]和YOLOv5 [7]都遵循YOLOv3 [25]的基于锚的原始管道。然而,锚机制有许多已知的问题。首先,为了获得最佳检测性能,需要在训练之前进行聚类分析以确定一组最佳锚。这些群集锚是特定于领域的,不太一般化。第二,锚机制增加了检测头的复杂性,以及每个图像的预测数量。在一些边缘人工智能系统中,在设备之间移动如此大量的预测(例如,从NPU到中央处理器)可能会成为总延迟的潜在瓶颈。
无锚探测器[29,40,14]在过去两年中发展迅速。这些工作表明,无锚探测器的性能可以与基于锚的探测器相媲美。无锚机制显著减少了需要启发式调整的设计参数数量和涉及的许多技巧(例如,锚聚类[24],网格敏感[11])。)为了获得良好的性能,使检测器,尤其是其训练和解码阶段变得相当简单[29]。
将YOLO切换到无锚模式非常简单。我们将每个位置的预测从3减少到1,并使它们直接预测四个值,即网格左上角的两个偏移量,以及预测框的高度和宽度。我们将指派每个对象的中心位置作为正样本,并预先定义一个标度范围,如[29]中所做的,以指定每个对象的FPN水平。这种修改减少了检测器的参数和GFLOPs,使其更快,但获得了更好的性能:42.9%的AP,如表2所示。

表2:YOLOX-Darknet 53在COCO val上的AP (%)路线图。所有模型均以640×640分辨率进行测试,在特斯拉V100上的FP16-precision和batch=1。该表中的延迟和FPS是在没有后处理的情况下测量的。
多正样本 为了与YOLOv3的分配规则保持一致,上述无锚点版本只为每个对象选择一个正样本(中心位置),同时忽略其他高质量预测。然而,优化那些高质量的预测也可能带来有益的梯度,这可能缓解训练期间正/负采样的极端不平衡。我们简单地将中心3×3区域指定为正样本,在FCOS也称为“中心采样”。检测器的性能提高到45.0% AP,如表2所示,已经超过了ultralytics-YOLOv3的当前最佳实践(44.3% AP)。
SimOTA 高级标签分配是近年来目标检测的又一重要进展。基于我们自己的研究OTA [4],我们总结了高级标签分配的四个关键见解:1)损失/质量意识,2)居中在先,3)每个真实地面的正锚点的动态数量4(缩写为动态top-k),4)全局视图。OTA满足上述四个规则,因此我们选择它作为候选标签分配策略。
具体而言,OTA [4]从全局角度分析标签分配,并将分配过程公式化为最优传输(OT)问题,产生当前分配策略中的SOTA性能[12,41,36,22,37]。然而,在实践中我们发现通过sinkorn-Knopp算法解决OT问题会带来25%的额外训练时间,这对于训练300个纪元来说是相当昂贵的。因此,我们将其简化为动态top-k策略,命名为SimOTA,以获得近似解。
我们在这里简单介绍一下SimOTA。SimOTA首先计算成对匹配度,由每个预测gt对的成本[4,5,12,2]或质量[33]表示。例如,在SimOTA中,gt gi和预测pj之间的成本计算如下:
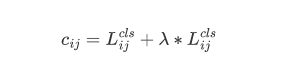
其中λ是平衡系数。L_{ij}^{cls}和L_{ij}^{reg}是gt g_i和预测p_j之间的分类损失和回归损失。然后,对于gt g_i,我们选择固定中心区域内成本最小的前k个预测作为其正样本。最后,那些正预测的对应网格被指定为正,而其余网格为负。请注意,k值因不同的基本事实而异。详情请参考OTA [4]中的动态k估计策略。
SimOTA不仅减少了训练时间,而且避免了Sinkhorn-Knopp算法中额外的求解超参数。如表2所示,SimOTA将探测器从45.0% AP提高到47.3% AP,比SOTA ultralytics-YOLOv3高3.0% AP,展示了高级分配策略的威力。
端到端YOLO 我们按照[39]添加两个额外的conv层,一对一的标签分配和停止梯度。这些使检测器能够以端到端的方式执行,但会略微降低性能和推理速度,如表2中所列。因此,我们将其作为一个可选模块,不包含在最终模型中。
2.2 其他骨干网络
除了DarkNet53,我们还在其他不同大小的主干上测试YOLOX,其中YOLOX相对于所有对应的主干实现了一致的改进。
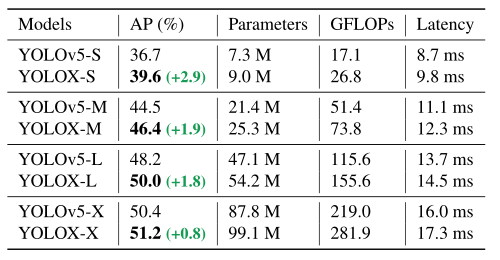
表3:在COCO上用AP (%)比较YOLOX和YOLOv5。所有模型均以640 × 640分辨率进行测试,在特斯拉V100上的FP16-precision和batch=1。

表4:YOLX-Tiny和YOLX-Nano与COCO val上对应的AP (%)的比较。所有模型均以416 × 416分辨率进行测试。
修改YOLOv5里的CSPNet 为了进行公平的比较,我们采用了精确的YOLOv5主干,包括修改的CSPNet [31]、路斯激活和PAN [19]头。我们也遵循其缩放规则来生产YOLOXS、YOLOX-M、YOLOX-L和YOLOX-X型号。与选项卡中的YOLOv5相比。3、我们的模型获得了一致的改进,从3.0%到1.0%,只有边际时间增加(来自解耦的头部)。
Tiny和Nano检测器 我们将我们的模型进一步缩小为YOLOX-Tiny,以与YOLOv4-Tiny进行比较[30]。对于移动设备,我们采用深度方向卷积构建了一个YOLOX-Nano模型,该模型只有0.91M的参数和1.08G的FLOPs。如表4所示,YOLOX性能良好,模型尺寸甚至比同类产品更小。
模型大小和数据增强 在我们的实验中,所有的模型保持几乎相同的学习进度和优化参数,如2.1所示。然而,我们发现不同尺寸的模型中,合适的增强策略是不同的。如表5显示,虽然对YOLOX-L应用MixUp可以提高0.9%的AP,但对YOLOX-Nano这样的小型号来说,削弱增强效果更好。具体来说,我们在训练小模型,即YOLOX-S、YOLOX-Tiny和YOLOX-Nano时,去掉了混叠增强,弱化了马赛克(将比例范围从[0.1,2.0]缩小到[0.5,1.5])。这样的修改将YOLOX-Nano的AP从24.0%提高到25.3%。
对于大型模型,我们还发现增强更强更有帮助。事实上,我们的MixUp实现是比[38]中的原始版本更重的一部分。受复制粘贴[6]的启发,我们在混合图像之前,通过随机采样的比例因子对两幅图像进行抖动。为了理解混合和缩放抖动的威力,我们将其与YOLOX-L上的复制粘贴进行比较。注意,复制粘贴需要额外的实例掩码注释,而混合不需要。但是如表5所示,这两种方法实现了有竞争力的性能,这表明当没有实例掩码注释可用时,带有比例抖动的MixUp是copy pastewhen的一个合格的位置。
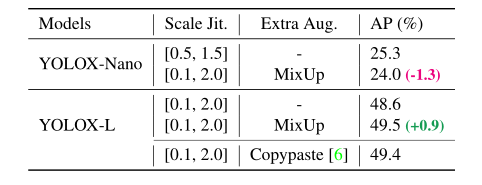
表5:不同模型规模下数据扩充的效果。“规模准时。”代表镶嵌图像的比例抖动范围。当采用复制粘贴时,使用来自COCO trainval的实例掩码注释。
3、和SOTA比较
有一个传统,显示SOTA比较表,如表6.但是,请记住,此表中模型的推断速度通常不受控制,因为速度因软件和硬件而异。因此,我们对图1中的所有YOLO系列使用相同的硬件和代码库,绘制了稍微受控的速度/精度曲线。
我们注意到有一些高性能的YOLO系列具有更大的模型尺寸,如Scale-YOLOv4 [30]和YOLOv5-P6 [7]。基于电流互感器的检测器[21]将精度-SOTA推到了∨60ap。由于时间和资源的限制,我们没有探索那些重要的壮举。
4、流媒体感知挑战第一名(CVPR2021 WAD)
WAD 2021上的流感知挑战是通过最近提出的指标:流准确性对准确性和延迟进行的联合评估[15]。这个度量标准的关键洞察是在每个时刻联合评估整个感知堆栈的输出,迫使堆栈考虑在进行计算时应该忽略的流数据量[15]。我们发现在30 FPS数据流上度量的最佳折衷点是推理时间≤ 33ms的强大模型。因此,我们采用了带有TensorRT的YOLOX-L模型来生产我们的最终模型,以应对赢得第一名的挑战。有关更多详细信息,请参考挑战网
5、结论
在本报告中,我们介绍了YOLO系列的一些经验丰富的更新,它形成了一个高性能的无锚探测器,称为YOLOX。YOLOX配备了一些最新的先进检测技术,即去耦头、无锚和先进的标签分配策略,在速度和精度之间取得了比所有模型尺寸的其他同类产品更好的平衡。值得注意的是,我们将YOLOv3的架构提升到COCO上的47.3% AP,比当前的最佳实践高出3.0% AP,yolov 3由于其广泛的兼容性,仍然是业界使用最广泛的检测器之一。我们希望这份报告能够帮助开发者和研究人员在实际场景中获得更好的体验。
参考
[1] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Y uan Mark Liao. Y olov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020. 1,2, 3, 6
[2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020. 1,4
[3] Qiang Chen, Yingming Wang, Tong Yang, Xiangyu Zhang,Jian Cheng, and Jian Sun. Y ou only look one-level feature.In CVPR, 2021. 3
[4] Zheng Ge, Songtao Liu, Zeming Li, Osamu Y oshie, and Jian Sun. Ota: Optimal transport assignment for object detection.In CVPR, 2021. 1, 4
[5] Zheng Ge, Jianfeng Wang, Xin Huang, Songtao Liu, and Os-amu Y oshie. Lla: Loss-aware label assignment for dense pedestrian detection. arXiv preprint arXiv:2101.04307,2021,4
[6] Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. In CVPR, 2021. 5
[7] glenn jocher et al. yolov5. https://github.com/ultralytics/yolov5, 2021. 1, 2, 3, 5, 6
[8] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noord-huis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch,Yangqing Jia, and Kaiming He. Accurate, large mini-batch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017. 2
[9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. In CVPR,2016.1
[10] Zhang Hongyi, Cisse Moustapha, N. Dauphin Yann, and David Lopez-Paz. mixup: Beyond empirical risk minimization. ICLR, 2018. 3
[11] Xin Huang, Xinxin Wang, Wenyu Lv, Xiaying Bai, Xiang Long, Kaipeng Deng, Qingqing Dang, Shumin Han, Qiwen Liu, Xiaoguang Hu, et al. Pp-yolov2: A practical object detector. arXiv preprint arXiv:2104.10419, 2021. 3, 6
[12] Kang Kim and Hee Seok Lee. Probabilistic anchor assignment with iou prediction for object detection. In ECCV,2020.1, 4
[13] Seung-Wook Kim, Hyong-Keun Kook, Jee-Y oung Sun,Mun-Cheon Kang, and Sung-Jea Ko. Parallel feature pyra-mid network for object detection. In ECCV, 2018. 2
[14] Hei Law and Jia Deng. Cornernet: Detecting objects aspaired keypoints. In ECCV, 2018. 1, 3
[15] Mengtian Li, Y uxiong Wang, and Deva Ramanan. Towards streaming perception. In ECCV, 2020. 5, 6
[16] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV,2017,2
[17] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 2
[18] Songtao Liu, Di Huang, and Y unhong Wang. Learning spatial fusion for single-shot object detection. arXiv preprintarXiv:1911.09516, 2019. 6
[19] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia.Path aggregation network for instance segmentation. In CVPR, 2018. 2, 5
[20] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia.Path aggregation network for instance segmentation. In CVPR, 2018. 2
[21] Ze Liu, Y utong Lin, Y ue Cao, Han Hu, Yixuan Wei,Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030, 2021. 5
[22] Y uchen Ma, Songtao Liu, Zeming Li, and Jian Sun. Iqdet:Instance-wise quality distribution sampling for object detec-tion. In CVPR, 2021. 1, 4
[23] Joseph Redmon, Santosh Divvala, Ross Girshick, and AliFarhadi. Y ou only look once: Unified, real-time object de-tection. In CVPR, 2016. 1 [24] Joseph Redmon and Ali Farhadi. Y olo9000: Better, faster,stronger. In CVPR, 2017. 1, 3
[25] Joseph Redmon and Ali Farhadi. Y olov3: An incrementalimprovement. arXiv preprint arXiv:1804.02767, 2018. 1, 2,3 [26] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015. 1
[27] Guanglu Song, Y u Liu, and Xiaogang Wang. Revisiting the sibling head in object detector. In CVPR, 2020. 2
[28] Mingxing Tan, Ruoming Pang, and Quoc V Le. Efficientdet:Scalable and efficient object detection. In CVPR, 2020. 6
[29] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos:Fully convolutional one-stage object detection. In ICCV,2019.1, 2, 3, 4
[30] Chien-Yao Wang, Alexey Bochkovskiy, and HongY uan Mark Liao. Scaled-yolov4: Scaling cross stage partial network. arXiv preprint arXiv:2011.08036, 2020. 1, 5, 6
[31] Chien-Yao Wang, Hong-Y uan Mark Liao, Y ueh-Hua Wu,Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. Cspnet:A new backbone that can enhance learning capability of cnn.In CVPR workshops, 2020. 2, 5 [32] Jianfeng Wang, Lin Song, Zeming Li, Hongbin Sun, JianSun, and Nanning Zheng. End-to-end object detection with fully convolutional network. In CVPR, 2020. 1
[33] Jianfeng Wang, Lin Song, Zeming Li, Hongbin Sun, JianSun, and Nanning Zheng. End-to-end object detection withfully convolutional network. In CVPR, 2021. 4
[34] Y ue Wu, Yinpeng Chen, Lu Y uan, Zicheng Liu, LijuanWang, Hongzhi Li, and Y un Fu. Rethinking classificationand localization for object detection. In CVPR, 2020. 2
[35] Y ue Wu, Yinpeng Chen, Lu Y uan, Zicheng Liu, LijuanWang, Hongzhi Li, and Y un Fu. Rethinking classificationand localization for object detection. In CVPR, 2020. 2
[36] Shifeng Zhang, Cheng Chi, Y ongqiang Yao, Zhen Lei, and Stan Z Li. Bridging the gap between anchor-based andanchor-free detection via adaptive training sample selection.In CVPR, 2020. 1, 4
[37] Xiaosong Zhang, Fang Wan, Chang Liu, Rongrong Ji, andQixiang Ye. Freeanchor: Learning to match anchors for visual object detection. In NeurIPS, 2019. 1, 4
[38] Zhi Zhang, Tong He, Hang Zhang, Zhongyuan Zhang, Jun-yuan Xie, and Mu Li. Bag of freebies for training object detection neural networks. arXiv preprint arXiv:1902.04103,2019.3, 5
[39] Qiang Zhou, Chaohui Y u, Chunhua Shen, Zhibin Wang,and Hao Li. Object detection made simpler by eliminating heuristic nms. arXiv preprint arXiv:2101.11782, 2021. 1, 4
[40] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. arXiv preprint arXiv:1904.07850, 2019. 1,3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号