ragflow知识库- chat中的 "提示引擎"参数

- 系统提示词:当LLM回答问题时,你需要LLM遵循的说明,比如角色设计、答案长度和答案语言等。如果您的模型原生支持在问答中推理,可以通过 //no_thinking 关闭自动推理。
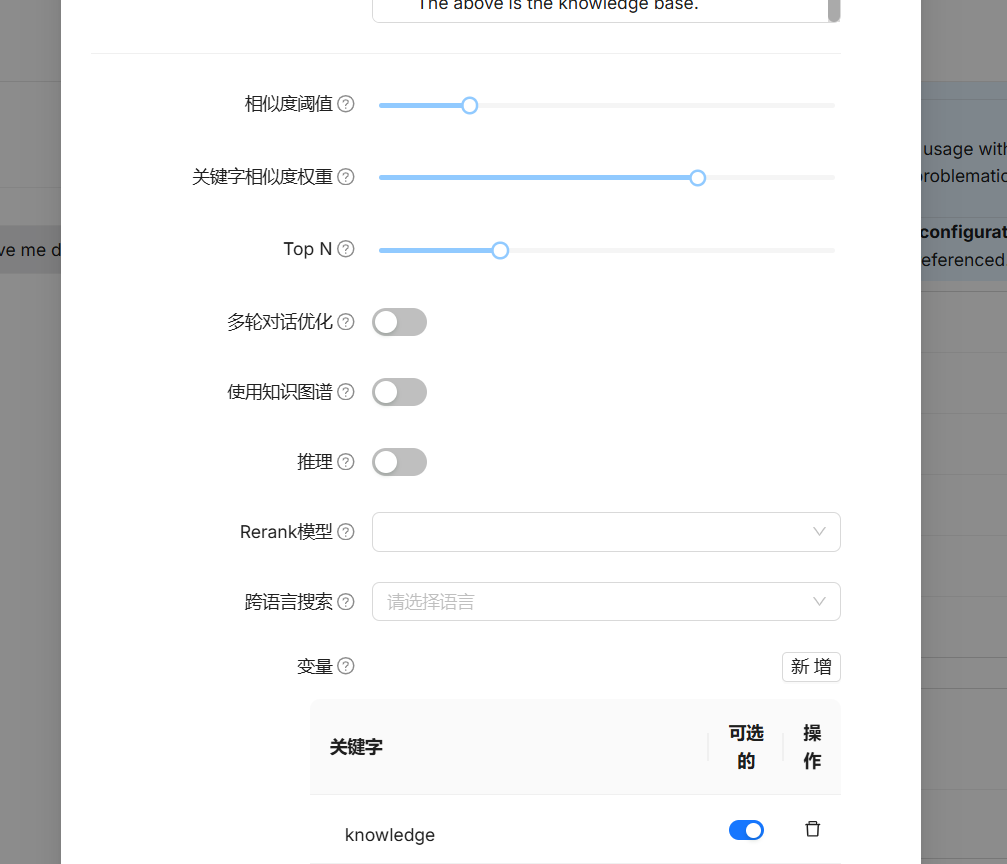
- 相似度阈值(Similarity threshold):如果查询语句和分块之间的相似度小于此阈值,则该分块将被过滤掉,默认设置为 0.2,也就是说文本块的相似度得分至少 20 才会被召回;
- 关键字相似度权重(Keyword similarity weight):RAGFlow 使用混合相似度得分来评估两行文本之间的距离,它结合了关键词相似度和向量相似度,这个参数用于设置关键词相似度在混合相似度得分中的权重,默认情况下,该值为 0.7,使得另一个组成部分的权重为 0.3,两个权重之和为 1.0;
- Top N: 并非所有相似度得分高于“相似度阈值”的块都会被提供给大语言模型。 LLM 只能看到这些“Top N”块。
- 多轮对话优化:在多轮对话的中,对去知识库查询的问题进行优化。会调用大模型额外消耗token。
- 推理:在问答过程中是否启用推理工作流,例如Deepseek-R1或OpenAI o1等模型所采用的方式。启用后,该功能允许模型访问外部知识,并借助思维链推理等技术逐步解决复杂问题。通过将问题分解为可处理的步骤,这种方法增强了模型提供准确回答的能力,从而在需要逻辑推理和多步思考的任务上表现更优。
- 重排序模型(Rerank model):上面提到混合相似度得分结合了关键词相似度和向量相似度,这其实是没有配置重排序模型时的算法,当配置了重排序模型,那么混合相似度得分中的向量相似度将由重排序分数替代,混合相似度得分将结合关键词相似度和重排序分数;
- 使用知识图谱(Use knowledge graph):启用该配置前,确保知识图谱已成功构建,它会检索知识图谱相关文本块,以处理复杂的多跳问题。在知识图谱中,实体描述、关系描述或社区报告各自作为独立的片段存在,因此启用该配置将涉及对实体、关系和社区报告文本块的多次检索,会显著延长检索时间;
- 跨语言搜索(Cross-language search):选择一种或多种语言进行跨语言搜索,如果未选择任何语言,系统将使用原始查询进行搜索。
RAGflow的多轮对话优化解析
RAGflow中的"多轮对话优化"指的是对基于检索增强生成(Retrieval-Augmented Generation)系统的对话能力进行改进,使其在连续对话交互中表现更好。具体来说,这包含以下几个方面的优化:
主要优化方向
-
上下文保持能力
-
让系统能够记住和理解对话历史
-
正确处理对话中的指代和省略
-
-
检索策略优化
-
根据多轮对话调整检索查询
-
动态更新检索范围以匹配对话进展
-
-
生成质量提升
-
基于完整对话历史生成更连贯的回复
-
避免重复或矛盾的回答
-
-
状态管理
-
有效跟踪对话状态和用户意图演变
-
处理话题转换和嵌套问题
-
技术实现方式
-
对话历史编码:将之前的对话内容编码到当前查询中
-
查询重写:基于上下文重写用户当前查询以获得更好检索结果
-
记忆机制:选择性保留重要对话信息
-
意图识别:在多轮中持续识别和更新用户意图
这种优化使得RAG系统不再局限于单轮问答,而能处理更复杂的多轮交互场景,如深度探讨、问题澄清、逐步推理等。
RAGflow中的打开"多轮对话优化,是不是会更耗费tokens:
的,在RAGflow中打开"多轮对话优化"功能通常会消耗更多的tokens,主要原因如下:
1. 对话历史包含
-
系统需要将之前的对话内容作为上下文传入模型
-
每轮对话都会累积更多的历史文本
-
典型的实现方式会将最近N轮对话附加到当前查询中
2. 更复杂的查询处理
-
查询重写(Query Rewriting)会增加token使用
-
可能生成多个搜索查询变体以提高召回率
-
上下文感知的检索需要更详细的输入
3. 增强的生成过程
-
生成回复时会考虑更多上下文信息
-
可能需要更长的输出以保证连贯性
-
可能包含对之前内容的引用或总结
优化建议:
-
设置合理的对话历史长度
-
只保留最近几轮关键对话
-
使用摘要代替完整历史
-
-
启用智能截断功能
-
自动截断不相关的历史部分
-
优先保留最近和最相关的信息
-
-
监控token使用
-
观察开启前后的token消耗变化
-
根据业务需求平衡效果与成本
-
虽然会消耗更多tokens,但多轮对话优化能显著提升用户体验,特别是在复杂问答、深度咨询等场景中,通常这种成本增加是值得的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号