数据预处理——分类(线性可分SVM与决策树)
[toc]
## 第二次作业
#### 第一题
<b>题目描述</b><br>
1.如下表数据,前四列是天气情况(阴晴outlook,气温temperature,湿度humidity,风windy);最后一列是类标签,表示根据天气情况是否出去玩。
(1)“信息熵”是度量样本集合纯度最常用的一种指标,假定当前样本集合D中第k类样本所占的比例为 (k=1, 2, …, K),请问当什么条件下,D的信息熵Ent(D)取得最大,最大值为多少?
(2)根据表中训练数据,基于信息增益决策树应该选哪个属性作为第一个分类属性?
(3)对于含有连续型属性的样本数据,决策树和朴素贝叶斯分类能有哪些处理方法?
(4)在分类算法的评价指标中,recall和precision分别是什么含义?
(5)若一批数据中有3个属性特征,2个类标记,则最多可能有多少种不同的决策树?(不同决策树指同一个样本在两个两个决策下可能得到不同的类标记)
| outlook | temperature | humidity | windy | play |
| ---- | ---- | ---- | ---- | ---- |
| sunny | hot | high | FALSE | no |
| sunny | hot | high | TRUE | no |
| rainy | cool | normall | TRUE | no |
| sunny | mild | high | FALSE | no |
| sunny | cool | normal | FALSE | yes |
| rainy | mild | normal | FALSE | yes |
| overcast | cool | normal | TRUE | yes |
| rainy | cool | normal | FALSE | yes |
| rainy | mild | high | FALSE | yes |
| overcast | hot | high | FALSE | yes |
<b>解答</b><br>
<b>(1)</b>

<b>(2)</b>

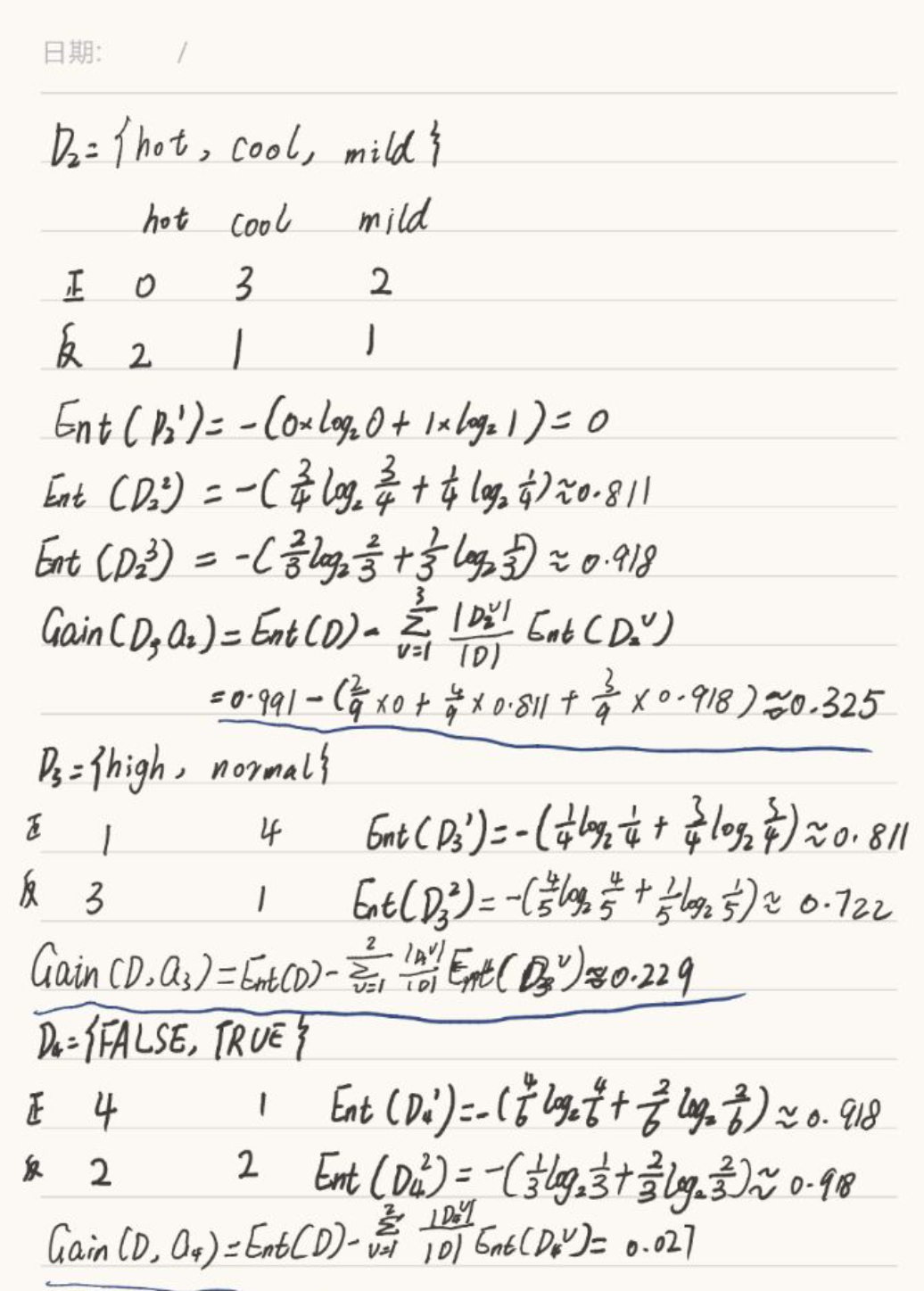

<b>(3)</b><br>
对于决策树来说,当含有连续型属性样本数据时,可以进行如下操作:
离散化,假如连续属性出现的n(假设出现了n中不同的值),那么可排序为(a1, a2, ..., an);这样就形成了n - 1个区间;对于每个区间来说,可以设(a(i) + a(i + 1)) / 2来代表整个区间;从而将这些连续型的样本数据转化成了n - 1个划分点的数据集合,从而可以像计算离散数据那样去计算连续型数据样本。
<b>(4)</b><br>
recall:召回率;recall = 预测为正样本且预测正确的样本数 / 真实的正样本数目;recall = TP / TP + FN<br>
precision:准确率;precision = 预测为正样本且预测正确的样本数 / 预测为正样本的数目;TP / TP + FP<br>
<b>(5)</b><br>
3个特征,2个类别;构造出的决策树一共有三层,第i层由第i个特征进行划分,这样决策树的种类树是P(3, 3) = 6种。<br>
#### 第二题
<b>题目描述</b><br>
2. 已知正例点 x1 = (2,3)T,x2 = (3, 2)T,负例点 x3 = (1, 1)T
(1) 试用 SVM 对其进行分类,求最大间隔分离超平面,并指出所有的支持向量。<br>
(2) 现额外有一个点能被 SVM 正确分类且远离决策边界,如果将该点加入到训练集,SVM 的决策边界会受影响吗?为什么?<br>
<b>解答</b><br>
<!-- <b>问题</b> -->
<!-- SVC(kernel = 'linear') or LinearSVC 的区别? -->
<b>(1)</b><br>
<b>答案</b><br>
支持向量:(1, 1), (2, 3), (3, 2);即三个里超平面最近的三个点。
<b>推导</b>





<b>代码</b>
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# 线性可分;导入数据
array = np.random.randn(20,2)
X= np.array([[2, 3], [3, 2], [1, 1]])
y = [1, 1, -1]
# 建立svm模型并训练
clf = svm.SVC(kernel='linear')
clf.fit(X,y)
w = clf.coef_
b = clf.intercept_
print("w:\n", w)
print("b:\n", b)
print("支持向量:\n", clf.support_vectors_)
# 画图
X1 = []
X2 = []
for i in range(5):
X1.append(i + 1)
X2.append(((-1) * b - w[0][0] * (i + 1)) / w[0][1])
X3 = [2, 3, 1]
X4 = [3, 2, 1]
plt.plot(X1, X2, c = "blue")
plt.scatter(X3, X4, c = "red")
plt.show()
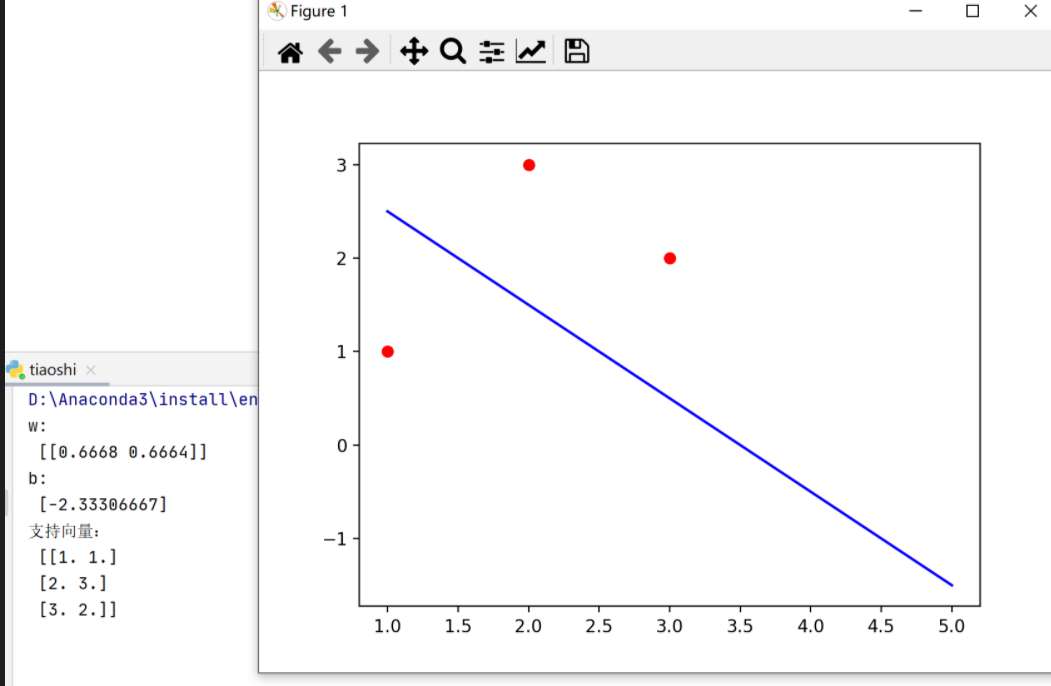
<b>(2)</b><br>
答:如果将该点加入到训练集中,SVM的决策边界不会受到影响,因为SVM在去寻找超平面的时候,其最大化的是数据集中几何间隔最小的那个;因此添加一个正确分类且远离决策边界的并不会产生影响。(新加入的点的几何间隔小于最小的几何间隔)
#### 第三题
<b>题目描述</b>
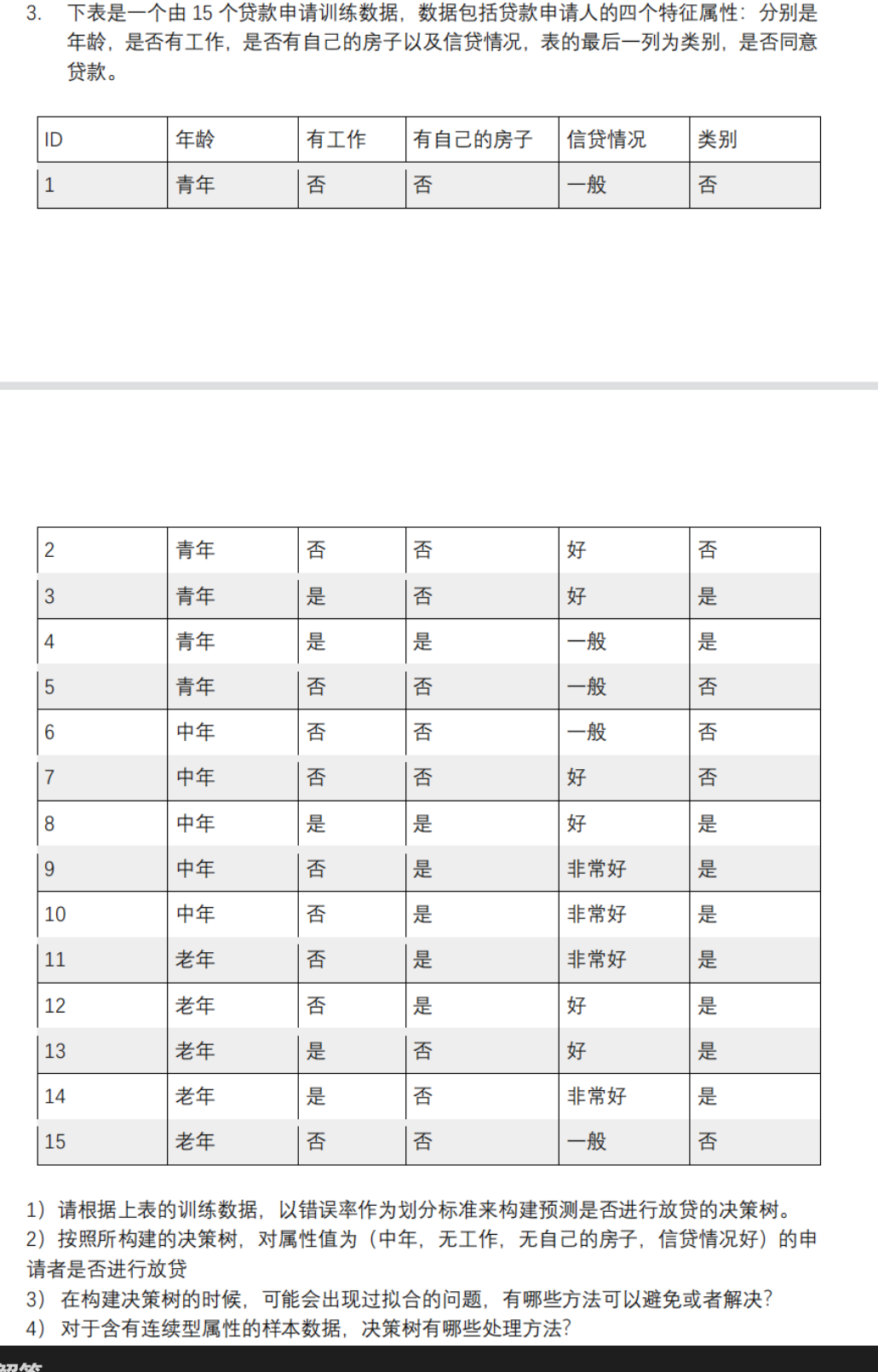
<b>解答</b><br>
<br><b>(1)</b><br>
错误率最低的特征为当前的划分标准<br>
年龄:青年和中年 同意贷款;错误率;<br>
工作:有工作 同意贷款;错误率:<br>
房子:有房子 同意贷款:<br>
信贷情况:非常好与好 同意贷款:<br>
第一次划分:信贷情况<br>
(节点1)
| 特征 | 错误率 |
| ---- | ---- |
| 年龄 | 3/5 |
| 工作 | 4/15 |
| 房子 | 4/15 |
| 信贷情况 | 1/5 |
第二次划分:房子<br>
(节点3)
| 特征 | 错误率 |
| ---- | ---- |
| 年龄 | 6/10 |
| 工作 | 4/10 |
| 房子 | 3/10 |
第三次划分:年龄<br>
(节点5)
| 特征 | 错误率 |
| ---- | ---- |
| 年龄 | 2/5 |
| 工作 | 4/5 |
第四次划分:工作<br>
(节点7)<br>
有工作则贷款<br>
无工作则不贷款<br>
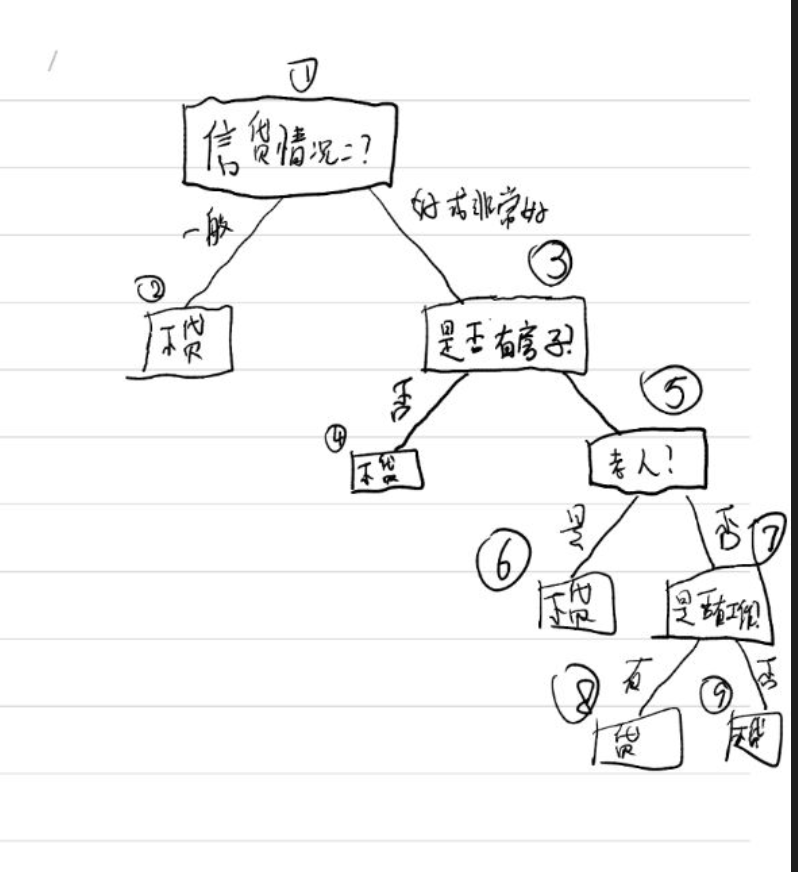
<br><b>(2)</b>
答:对属性值为(中年,无工作,无自己的房子,信贷情况好)的申请者不进行放贷。
<br><b>(3)</b>
1. 进行预剪枝;可以预先设定一份阈值,当熵或者某种目标函数值小于这个阈值的时候就停止继续创建分支,例如给XGBoos的目标函数值设置阈值;
2. 进行后剪枝;例如REP,错误率降低剪枝。(这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止)
<br><b>(4)</b>
1. 对连续的数据进行离散化,去每个区间的中间值代表这个区间,这样就把连续数据变成了离散的一个一个点;
2. 对条件进行变化,例如在实数范围内,设置条件为 是否小于4,这样也可以进行划分。
#### 第四题
<b>题目描述</b><br>
4. 请评价两个分类器 M1 和 M2 的性能。所选择的测试集包含 26 个二值属性,记作 A 到 Z。 表中是模型应用到测试集时得到的后验概率(图中只显示正类的后验概率)。因为这是二类问题,所以 P(-)=1-P(+),P(-|A,…,Z)=1-P(+|A,…,Z)。假设需要从正类中检测实例
1) 画出 M1 和 M2 的 ROC 曲线(画在一幅图中)。哪个模型更多?给出理由。
2) 对模型 M1,假设截止阈值 t=0.5。换句话说,任何后验概率大于 t 的测试实例都被看作正例。计算模型在此阈值下的 precision,recall 和 F-score。
3) 对模型 M2 使用相同的截止阈值重复(2)的分析。比较两个模型的 F-score,哪个模型更好?所得结果与从 ROC 曲线中得到的结论一致吗?
4) 使用阈值 t=0.1 对模型 M2 重复(2)的分析。t=0.5 和 t=0.1 哪一个阈值更好?该结果和你从 ROC 曲线中得到的一致吗?

<br><b>(1)</b>
从图中可以看到M1的ROC围成的面积(AUC)是大于M2的;而AUC考虑的是样本预测的排序质量,其loss定义为:
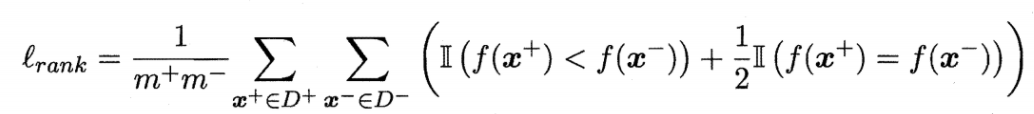
而AUC是计算围成的多个梯形的面积之和,有:
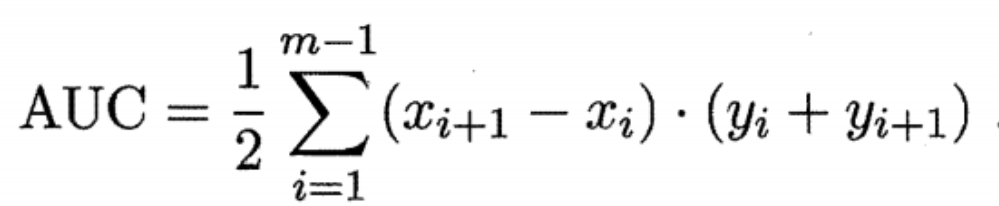
即有:AUC = 1 - loss;
***
所以AUC面积越大,说明Loss越小,所以AUC面积更大的模型性能更好,所以M1模型的性能更好。
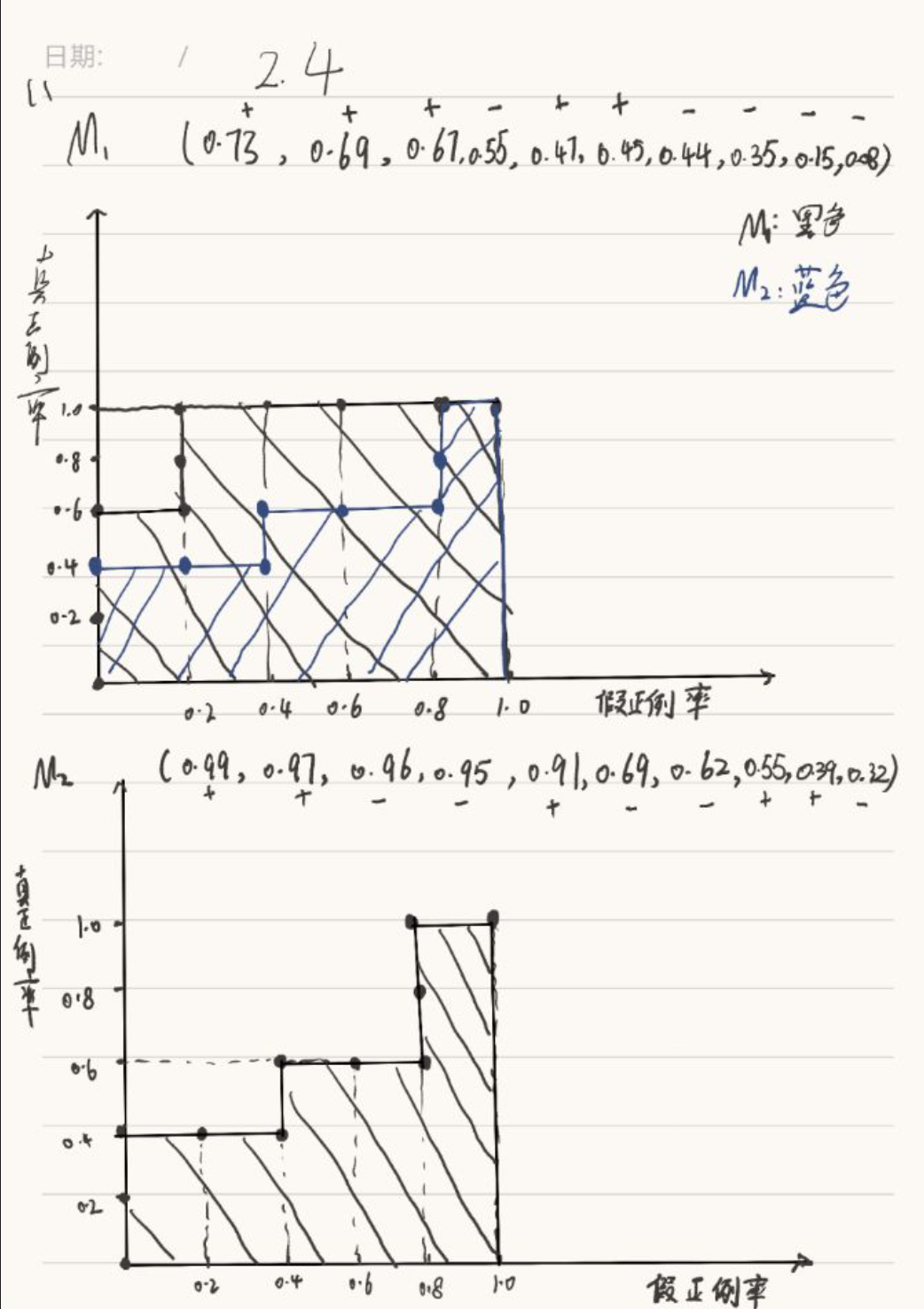
<b>(2)</b><br>
当 t = 0.5时,对模型M1进行分析<br>
precision = TP / TP + FP = 3 / 4<br>
recall = TP / TP + NF = 3 / 5<br>
F-score = 2 * P * R / (P + R) = 2 / 3<br>
<br><b>(3)</b>
当 t = 0.5时,对模型M2进行分析<br>
precision = TP / TP + FP = 1 / 2<br>
recall = TP / TP + NF = 1 / 5<br>
F-score = 2 * P * R / (P + R) = 2 / 7<br>
***
模型M1的F1值大于M2的F1数值,表示模型M1性能更好;所得结果和ROC曲线中得到的结论是一致的。<br>
<b>(4)</b><br>
当t = 0.1时,对模型M2进行恩熙<br>
precision = TP / TP + FP = 2 / 5<br>
recall = TP / TP + NF = 2 / 5<br>
F-score = 2 * P * R / (P + R) = 2 / 5<br>
***
对模型M2分析,当t = 0.5与t = 0.1的时候,t = 0.1的时候更好,因为F1数值更高了;当对t = 0.1时来分析M2模型,还是比不上M1模型的F1数值,和ROC曲线的结果是一样。<br>
这个地方,阈值的大小,其实要看是更看重查准率还是查全率;当更看重查全率的时候,可以把阈值设置为(从小到大)排序后更靠左边的位置;若是更看重查准率,设置为靠右边的位置。
#### 第五题
<b>题目描述</b>

<b>解答</b><br>
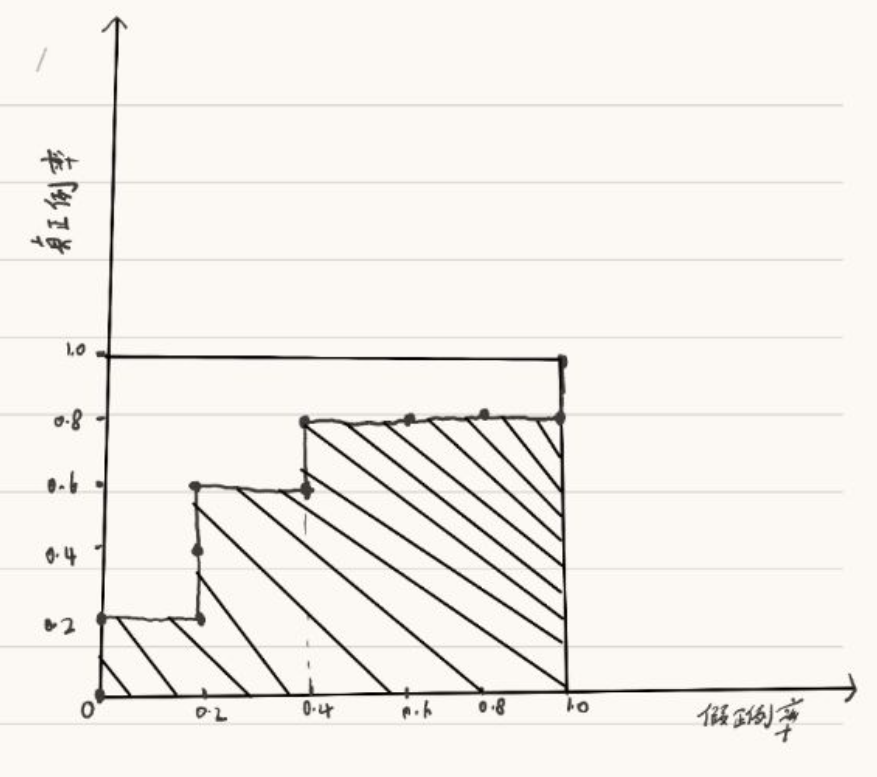
<b>计算TPR与FPR</b><br>
TP: {1, 3, 4, 6}<br>
FP: {2, 5, 7, 8, 9}<br>
TN: 空集<br>
FN: {10}<br>
所以它们各自的数目为:<br>
TP: 4; FP: 5; TN: 0; FN: 1;<br>
<b>(阈值为0.5)</b><br>
TPR = TP / (TP + FN) = 4 / 4 + 1 = 4 / 5<br>
FPR = FP / (TN + FP) = 1 / 0 + 5 = 1 / 5<br>
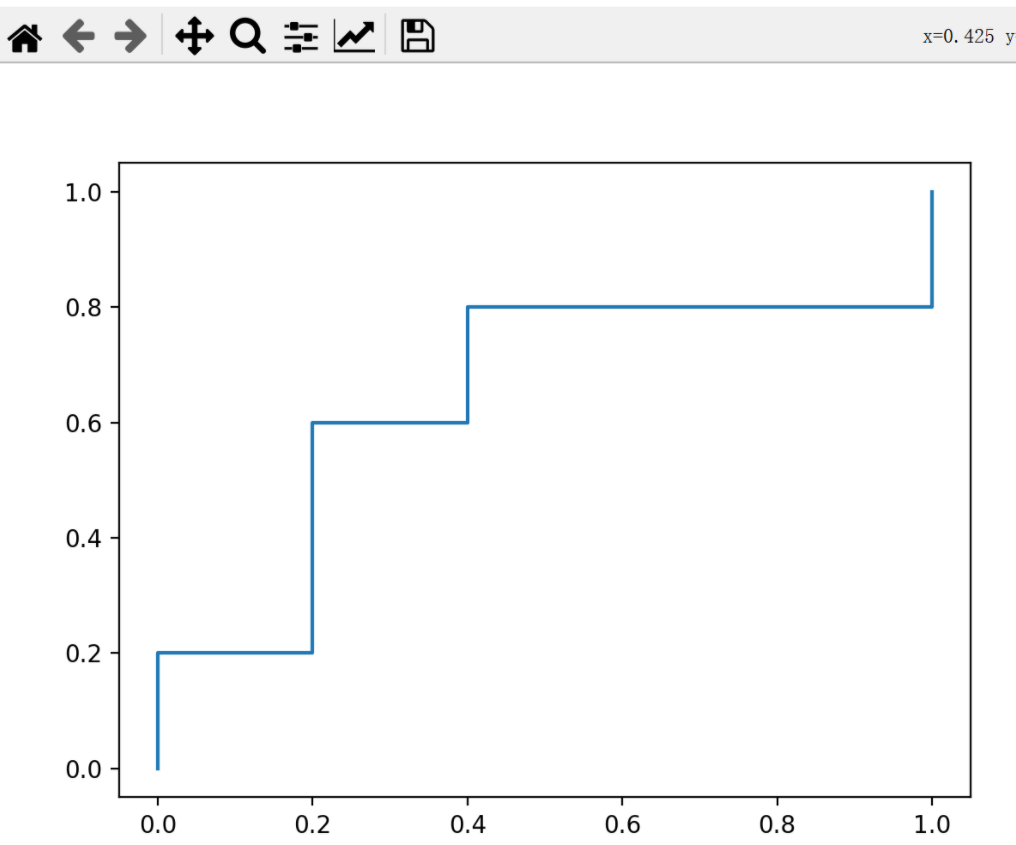
<b>手绘ROC曲线</b>
<b>程序画的ROC曲线</b>
import matplotlib.pyplot as plt X = [0, 0, 0.2, 0.2, 0.2, 0.4, 0.4, 0.6, 0.8, 1.0, 1.0] Y = [0, 0.2, 0.2, 0.4, 0.6, 0.6, 0.8, 0.8, 0.8, 0.8, 1.0] plt.plot(X, Y) plt.show()
#### 第六题
<b>题目描述</b><br>
6. 假设两个预测模型 M 和 N 之间进行选择。已经在每个模型上做了 10 轮 10-折交叉验证,其中在第 i 轮,M 和 N 都是用相同的数据划分。M 得到的错误率为 30.5、32.2、 20.7、20.6、31.0、41.0、27.7、28.0、21.5、28.0。N 得到的错误率为 22.4、14.5、22.4、 19.6、20.7、20.4、22.1、19.4、18.2、35.0。评述在 1%的显著水平上,一个模型是否显著地比另一个好。<br>
<b>解答</b><br>
<b>这两个模型的性能没有明显的显著差异</b><br>

M = [30.5, 32.2, 20.7, 20.6, 31.0, 41.0, 27.7, 28.0, 21.5, 28.0]
N = [22.4, 14.5, 22.4, 19.6, 20.7, 20.4, 22.1, 19.4, 18.2, 35.0]
X = []
for i, j in zip(M, N):
X.append(i - j)
def get_u(X):
num = 0
for i in X:
num += i
return num / len(X)
def get_variance(X, u):
sum = 0
for i in X:
sum += (i - u) * (i - u)
sum = sum / len(X)
return sum
def get_T(u, variance, k):
sum = (k ** 0.5) * u / (variance ** 0.5)
return abs(sum)
#计算均值与方差,t以及两个模型的平均值
u = get_u(X)
variance = get_variance(X, u)
T = get_T(u, variance, len(X))
t = 3.25
M_average = get_u(M)
N_average = get_u(N)
print("T: ", T)
if(T < t):
print("两个模型没有显著差别")
elif(M_average > N_average):
print("模型N性能更优")
else:
print("模型M性能更优")

#### 存在的问题
1. SMO算法还需要去手推一下;
2. SVM的核函数需要去学习一下,这次作业没有涉及到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号