


Java流操作
Stream接口
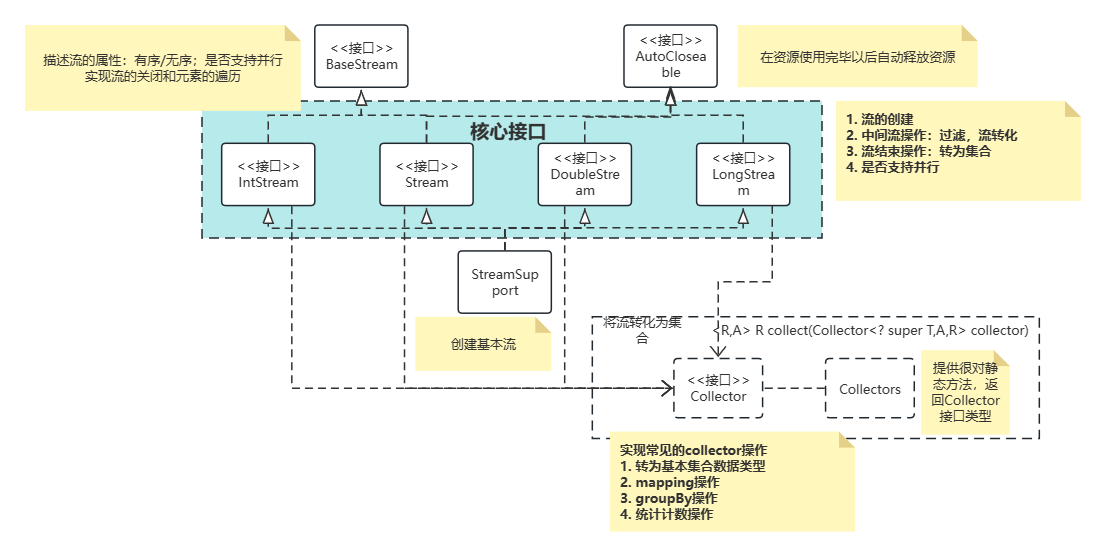
- Stream接口的继承关系:BaseStream=🡺AutoClosed
- Stream简单介绍:源,中间流,结束操作
- 使用流注意事项
- 同一个数据源不能同时使用两个不同的流进行处理
- 除非使用的流和IO有关,通常情况下的使用:Most streams are backed by collections, arrays, or generating functions, which require no special resource management. (If a stream does require closing, it can be declared as a resource in a try-with-resources statement.)
- 封装基本数据类型的流:IntStream, LongStream, DoubleStream
内部类:

里面有三个方法:accept,add,build

创建流的静态方法:

iterate方法,借助一元函数生成无穷流
generate方法创建无穷流,适合返回常量流以及随机数流
动态创建流
核心方法:
- 过滤操作
- map流转化
//创建Object流,元素类型可以不一致
Stream<Object> strings = Stream.builder().add("123").add("456").add(789).build();
//将Object流转化为String流
//传入String参数,调用Object.toString方法,返回对应的String值
//map函数接收的参数 Function<? super T,? extends R> mapper
//Object::toString
Stream<String> stream = strings.map(Object::toString);
- flatMap,将流中每一个元素一变多,变成一个新的流以后,再将所有的流进行合并得到一个完整的流:
Stream<String> lines = Files.lines(path, StandardCharsets.UTF_8);//行流
Stream<String> words = lines.flatMap(line -> Stream.of(line.split(" +")));//单词流:由行流转化成行流,转化的思路是行流中的每一行按照空格进行划分为单词流
flatMapTo***:转化为具体的流,如IntStream flatMapToInt(Function<? super T,? extends IntStream> mapper)
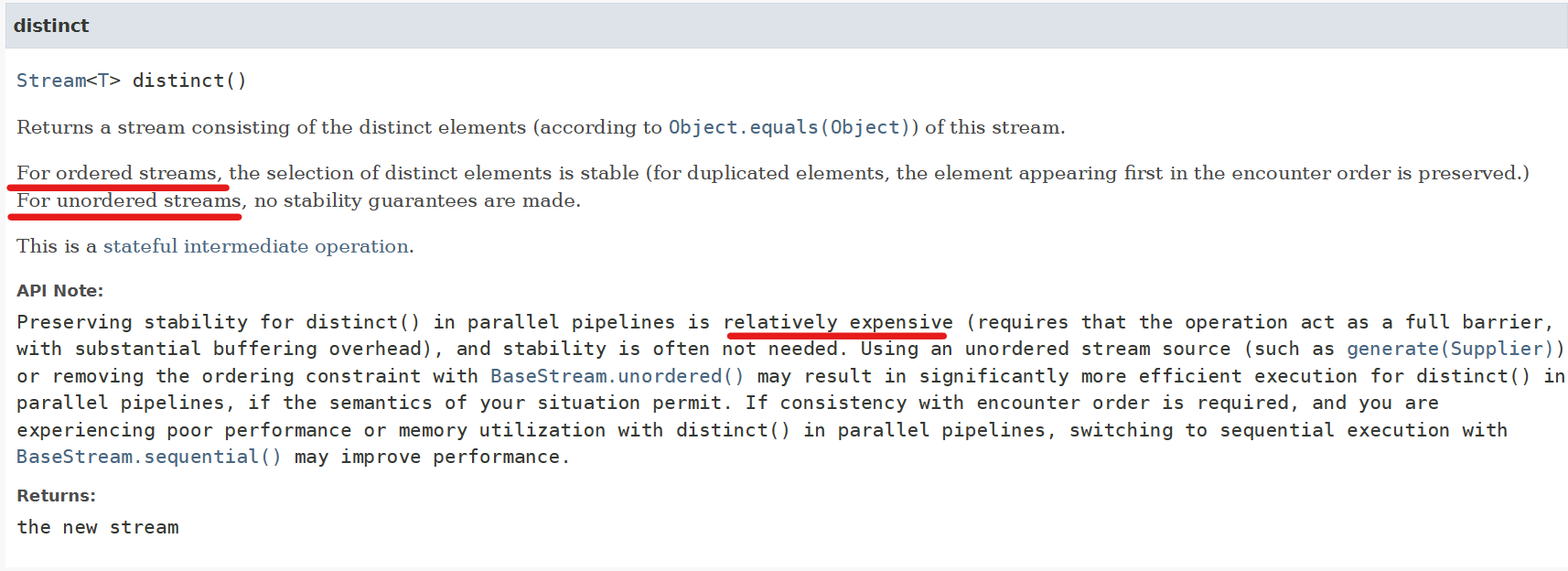
- Stream<T> distinct()
- Stream<T> sorted()
注意其流操作类型为有状态流
Stream operations are divided into intermediate and terminal operations, and are combined to form stream pipelines. A stream pipeline consists of a source (such as a Collection, an array, a generator function, or an I/O channel); followed by zero or more intermediate operations such as Stream.filter or Stream.map; and a terminal operation such as Stream.forEach or Stream.reduce.
Intermediate operations return a new stream. They are always lazy; executing an intermediate operation such as filter() does not actually perform any filtering, but instead creates a new stream that, when traversed, contains the elements of the initial stream that match the given predicate. Traversal of the pipeline source does not begin until the terminal operation of the pipeline is executed.
Terminal operations, such as Stream.forEach or IntStream.sum, may traverse the stream to produce a result or a side-effect. After the terminal operation is performed, the stream pipeline is considered consumed, and can no longer be used; if you need to traverse the same data source again, you must return to the data source to get a new stream. In almost all cases, terminal operations are eager, completing their traversal of the data source and processing of the pipeline before returning. Only the terminal operations iterator() and spliterator() are not; these are provided as an "escape hatch" to enable arbitrary client-controlled pipeline traversals in the event that the existing operations are not sufficient to the task.
Processing streams lazily allows for significant efficiencies; in a pipeline such as the filter-map-sum example above, filtering, mapping, and summing can be fused into a single pass on the data, with minimal intermediate state. Laziness also allows avoiding examining all the data when it is not necessary; for operations such as "find the first string longer than 1000 characters", it is only necessary to examine just enough strings to find one that has the desired characteristics without examining all of the strings available from the source. (This behavior becomes even more important when the input stream is infinite and not merely large.)
Intermediate operations are further divided into stateless and stateful operations. Stateless operations, such as filter and map, retain no state from previously seen element when processing a new element -- each element can be processed independently of operations on other elements. Stateful operations, such as distinct and sorted, may incorporate state from previously seen elements when processing new elements.
Stateful operations may need to process the entire input before producing a result. For example, one cannot produce any results from sorting a stream until one has seen all elements of the stream. As a result, under parallel computation, some pipelines containing stateful intermediate operations may require multiple passes on the data or may need to buffer significant data. Pipelines containing exclusively stateless intermediate operations can be processed in a single pass, whether sequential or parallel, with minimal data buffering.
Further, some operations are deemed short-circuiting operations. An intermediate operation is short-circuiting if, when presented with infinite input, it may produce a finite stream as a result. A terminal operation is short-circuiting if, when presented with infinite input, it may terminate in finite time. Having a short-circuiting operation in the pipeline is a necessary, but not sufficient, condition for the processing of an infinite stream to terminate normally in finite time.
- Stream<T> peek(Consumer<? super T> action)
在返回流的同时,对流中的每一个元素进行action处理,通常用来调试,在调试过程中输出流的处理过程:
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
- Stream<T> limit(long maxSize)
限制流中元素的个数不超过最大值maxSize,其中该操作为short-circuiting stateful intermediate operation.改方法适合无序流,在有序流中使用时,花费较高,通常使用Using an unordered stream source (such as generate(Supplier)) or removing the ordering constraint with BaseStream.unordered() may result in significant speedups of limit() in parallel pipelines
- skip跳过流中指定的元素
- forEach流处理结束时遍历操作
- Object[] toArray():将流以Object数组的形式返回
- <A> A[] toArray(IntFunction<A[]> generator):将流以数组类型为A的形式返回
- reduce操作
- collect操作:将流转化为collection

 浙公网安备 33010602011771号
浙公网安备 33010602011771号