
缓存常见问题
热点key,大key,过期key删除策略:
过期key的删除策略:
1、定时删除:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
1.若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key;
2.定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
2、懒汉式删除: key过期的时候不删除,每次通过key获取值的时候去检查是否过期,若过期,则删除,返回null。
优点:删除操作只发生在通过key取值的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了
每隔一段时间执行一次删除过期key操作(从所有过期的key中随机抽取一部分)
优点:1.通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点;2)定期删除过期key--处理"懒汉式删除"的缺点
缺点:
1.在内存友好方面,不如"定时删除"(会造成一定的内存占用,但是没有懒汉式那么占用内存)
2.在CPU时间友好方面,不如"懒汉式删除"(会定期的去进行比较和删除操作,cpu方面不如懒汉式,但是比定时好)
难点: 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了),每次执行时间太长,或者执行频率太高对cpu都是一种压力,每次进行定期删除操作执行之后,需要记录遍历循环到了哪个标志位,以便下一次定期时间来时,从上次位置开始进行循环遍历
memcached只是用了惰性删除,而redis同时使用了惰性删除与定期删除,这也是二者的一个不同点(可以看做是redis优于memcached的一点);
Redis采用懒汉式+定期删除策略:
redis淘汰策略,例:redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧
热点key删除策略:
缓存中的某些Key(可能对应用与某个促销商品)对应的value存储在集群中一台机器,使得所有流量涌向同一机器,成为系统的瓶颈,该问题的挑战在于它无法通过增加机器容量来解决。(当key失效的时候,大量的线程构建缓存,导致负载增加)
解决方案:
1.客户端热点key缓存:将热点key对应value并缓存在客户端本地,并且设置一个失效时间。对于每次读请求,将首先检查key是否存在于本地缓存中,如果存在则直接返回,如果不存在再去访问分布式缓存的机器。
2.将热点key分散为多个子key,然后存储到缓存集群的不同机器上,这些子key对应的value都和热点key是一样的。当通过热点key去查询数据时,通过某种hash算法随机选择一个子key,然后再去访问缓存机器,将热点分散到了多个子key上。
3.为每个 value 设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。缓存层面没有设置过期时间(这种方案可以解决大量线程等待的问题,但它可能导致数据不一致的问题)
4.针对热点key失效,大量线程构建缓存(使用互斥锁,只让一个线程构建缓存,可以解决这个问题)。
bigkey删除:
string类型10kb以内,hash,list,set,zset元素个数不要超过5000。
bigkey发现:
1.应用方异常(超时或者各种异常)
2.redis-cli --bigkeys(去扫描所有的key,不能自己设定参数)
3.scan + debug object
4.主动报警:网络流量监控,客户端监控
bigkey删除:会阻塞线程
redis-4.0 提供了lazy delete 会在后台为我们再创建一个线程去做删除操作,不会阻塞我们的主线程。
bigkey预防:
命令的优化,尽量使用hmget不要使用hgetall
运维监控报警,即时反馈给业务端,来进行优化
优化数据结构:例如二级拆分,把一个月的list,转换为一天天的list
缓存穿透
查询一个数据库中不存在的数据,比如商品详情,查询一个不存在的ID,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成过大地压力。
解决方案:
1.当通过某一个key去查询数据的时候,如果对应在数据库中的数据都不存在,我们将此key对应的value设置为一个默认的值,比如“NULL”,并设置一个缓存的失效时间,这时在缓存失效之前,所有通过此key的访问都被缓存挡住了。后面如果此key对应的数据在DB中存在时,缓存失效之后,通过此key再去访问数据,就能拿到新的value了。
2.常见的则是采用布隆过滤器(可以用很小的内存保留很多的数据),将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
缓存雪崩
缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
1.将系统中key的缓存失效时间均匀地错开,防止统一时间点有大量的key对应的缓存失效;
2.重新设计缓存的使用方式,当我们通过key去查询数据时,首先查询缓存,如果此时缓存中查询不到,就通过分布式锁进行加锁,取得锁的进程查DB并设置缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回缓存数据或者再次查询DB。
3.尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上
4.本地memcache缓存 + hystrix限流&降级,避免MySQL崩掉
如果已经崩溃了:也可以利用redis的持久化机制将保存的数据尽快恢复到缓存里。
缓存无底洞:
为了满足业务大量加节点,但是性能没提升反而下降。
当客户端增加一个缓存的时候,只需要 mget 一次,但是如果增加到三台缓存,这个时候则需要 mget 三次了(网络通信的时间增加了),每增加一台,客户端都需要做一次新的 mget,给服务器造成性能上的压力。
同时,mget 需要等待最慢的一台机器操作完成才能算是完成了 mget 操作。这还是并行的设计,如果是串行的设计就更加慢了。
通过上面这个实例可以总结出:更多的机器!=更高的性能
但是并不是没办法,一般在优化 IO 的时候可以采用以下几个方法。
- 命令的优化。例如慢查下 keys、hgetall bigkey。
- 我们需要减少网络通讯的次数。这个优化在实际应用中使用次数是最多的,我们尽量减少通讯次数。
- 降低接入成本。比如使用客户端长连接或者连接池、NIO 等等。
缓存不一致问题:
一个服务调用的过程:
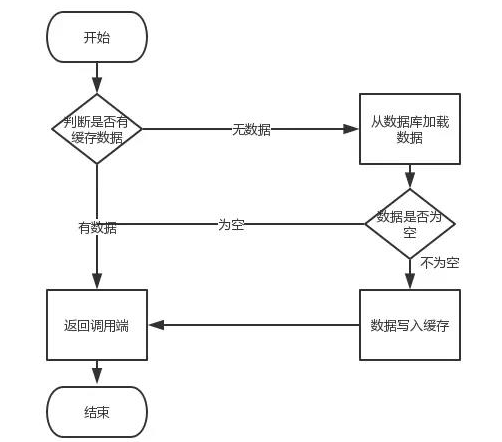
1.先更新数据库,再更新缓存。
A更新数据库->B更新数据库->B更新缓存->A更新缓存(导致不一致)
2.先删除缓存再更新数据库。
A写入数据库,先删除缓存->B去查询,缓存没有数据->B去查询数据库读取旧值并更新缓存->A写入数据库(导致不一致)
延时双删策略:
A删除缓存->A写入数据库->睡眠1s再删除缓存
3.先更新再删除
缓存刚好失效->A查询数据库得到旧值->B更新数据库->B删除缓存->A更新缓存(导致不一致)
出现这种的情况很低,写很慢。
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/10693626.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号