ML.NET学习
重点参考:官网 ML.NET 文档 ,以下每一步具体的解释查看“操作指南”
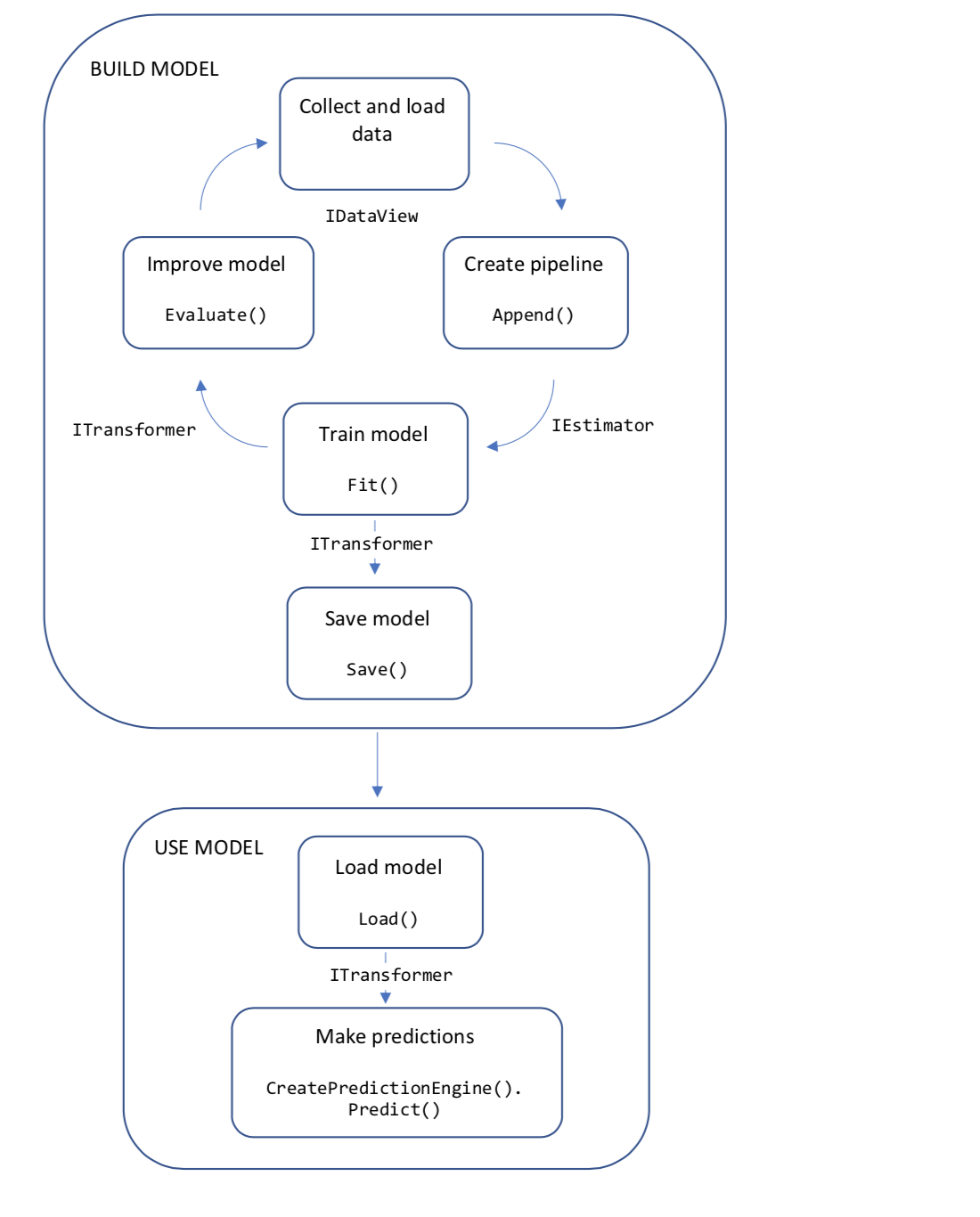
开发流程
以下关系图表示应用程序代码结构,以及模型开发的迭代过程:
- 将训练数据收集并加载到 IDataView 对象中
- 指定操作的管道【数据转换】,以提取特征并应用机器学习算法
- 通过在管道上调用 Fit() 来训练模型
- 评估模型并通过迭代进行改进
- 将模型保存为二进制格式,以便在应用程序中使用
- 将模型加载回 ITransformer 对象
- 通过调用 CreatePredictionEngine.Predict() 进行预测
在实际应用程序中,模型训练和评估代码将与预测分离。 事实上,这两项活动通常由单独的团队执行。 模型开发团队可以保存模型以便用于预测应用程序。
mlContext.Model.Save(model, trainingData.Schema,"model.zip");
但是在简单的应用中 也可以是直接使用模型,流程图如下:

参考资料
关于ML.NET v1.0 的发布说明 【20190507】
数据转化
- 文本转换
FeaturizeText 将文本列转换为规范化 ngram 和 char-gram 计数的浮点数组。即字符串列【特征列,可能多个】转化为数字向量。
- 列映射和分组
Concatenate 将一个或多个输入列 连接到新输出列中。。//将所有特征列(能用于训练的所有的向量)合并到"Features"列
- 数据类型转换
MapValueToKey 通过从输入数据创建映射,将值映射到键(类别)【分类算法所接受的格式】
MapKeyToValue 将键转换回原始值
参考:键值类型编码与独热编码
MapValueToKey功能是将(字符串)值类型转换为KeyTpye类型。
有时候某些输入字段用来表示类型(类别特征),但本身并没有特别的含义,比如编号、电话号码、行政区域名称或编码等,这里需要把这些类型转换为1到一个整数如1-300来进行重新编号。
举个简单的例子,我们进行图片识别的时候,目标结果可能是“猫咪”、“小狗”、“人物”这些分类,需要把这些分类转换为1、2、3这样的整数。但本文的标签值本身就是1、2、3,为什么还要转换呢?因为我们这里的一二三其实不是数学意义上的数字,而是一种标志,可以理解为壹、贰、叁,所以要进行编码。
MapKeyToValue和MapValueToKey相反,它把将键类型转换回其原始值(字符串)。就是说标签是文本格式,在运算前已经被转换为数字枚举类型了,此时预测结果为数字,通过MapKeyToValue将其结果转换为对应文本。
MapValueToKey一般是对标签值进行编码,一般不用于特征值,如果是特征值为字符串类型的,建议采用独热编码。独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。例如:
自然状态码为:0,1,2,3,4,5
独热编码为:000001,000010,000100,001000,010000,100000
怎么理解这个事情呢?举个例子,假如我们要进行人的身材的分析,但我们希望加入地域特征,比如:“黑龙江”、“山东”、“湖南”、“广东”这种特征,但这种字符串机器学习是不认识的,必须转换为浮点数,刚才提到MapKeyToValue可以把字符串转换为数字,为什么这里要采用独热编码呢?简单来说,假设把地域名称转换为1到10几个数字,在欧氏几何中1到3的欧拉距离和1到9的欧拉距离是不等的,但经过独热编码后,任意两点间的欧拉距离都是相等的,而我们这里的地域特征仅仅是想表达分类关系,彼此之间没有其他逻辑关系,所以应该采用独热编码。
- 自定义转换
CustomMapping 使用用户定义映射(mapAction)将现有列转换为新列。eg:对文本进行jieba分词;对图片进行像素处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号