Elasticsearch-head使用及ES相关概念
elasticsearch-head安装和介绍已在上一篇讲了。
在浏览器访问http://localhost:9100,可看到如下界面,表示启动成功:

仔细观察,我们会发现客户端默认连接的是我们elasticsearch的默认路径。而此时elasticsearch服务未启动,所以集群健康值是未连接
集群健康值的几种状态如下:
绿色,最健康的状态,代表所有的分片包括备份都可用
黄色,基本的分片可用,但是备份不可用(也可能是没有备份),下文有提到
红色,部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好
灰色,未连接到elasticsearch服务
此时,我们启动elasticsearch服务,重新刷新浏览器,发现集群健康值变成了黄色,如下:
集群名字:xwj。在配置文件(elasticsearch.yml)中设置 cluster.name:
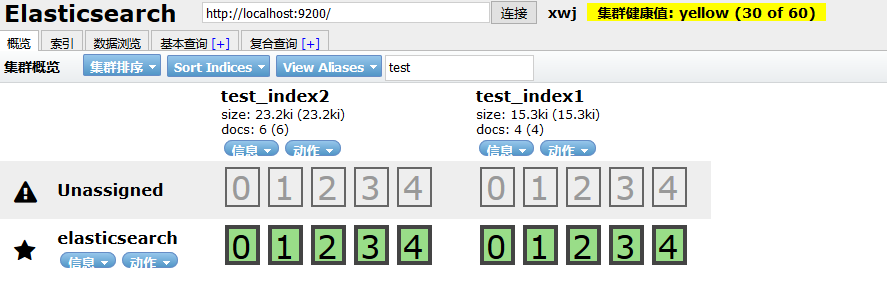
1、概览
通过上图可以看到我们的节点名称为elasticsearch,并且该节点下有两个索引test_index1、test_index2
在test_index2下,选择 信息-->索引信息,可以查看该索引的所有信息,包括mappings、setting等等
在test_index2下,选择 动作-->关闭/开启,可以关闭/开启该索引,关闭后的索引如图:
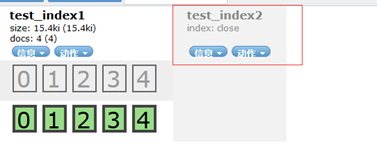
在该界面也可以模糊查询索引、设置刷新频率等操作。如下图:

几个查询
集群健康:localhost:9200/_cat/health?v
集群的节点列表:localhost:9200/_cat/nodes?v
查看全部索引:localhost:9200/_cat/indices?v
2、索引
在这里,可以查看到所有的索引,并且还可以创建一个新的索引,如下图:
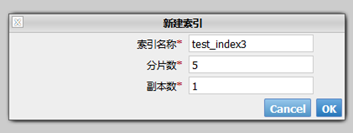
创建结构化索引
上图创建的索引,点开索引信息,mapping是空的,表示该索引的字段并没有指定,我们可以在创建索引的时候直接指定其字段名来创建。通过发送http请求来实现。
使用Head的符合查询 或者postman工具进行创
请求路径:localhost:9200/book --》ES服务的ip:端口/要创建的索引名,请求方法:PUT
请求体:


{
"settings":{
"number_of_shards":5, //分片数
"number_of_replicas":1 //备份数
},
//映射文件
"mappings":{
//类型名
"novel":{
//文档的所有字段以及类型
"properties":{
"name":{
"type":"text"
},
"author":{
"type":"keyword"
},
"word_count":{
"type":"integer"
},
"publish_date":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd" //日期格式化允许的类型
}
}
}
}
}
关于结构化索引和非结构化索引的区别:
结构化索引,类似MySQL,我们会对索引结构做预定义,包括字段名,字段类型等;那么,非结构化索引,就类似Mongo,索引结构未知,根据具体的数据来update索引的mapping。
那么如何选择两种索引呢,还是跟具体的使用场景有关,结构化相比非结构化,更易优化,性能好些,非结构化相较灵活,只是频繁update索引mapping会有一定的性能损耗。
重点:需要特别特别注意的是:如果你的索引后期要修改,那么你只能重建一个你要修改成的索引,然后将数据复制到新的索引中,代码如下
POST localhost:9200/_reindex
{
"source": {
"index": "people"
},
"dest": {
"index": "book"
}
}
参考:Elasticsearch index fields 重命名
3、数据浏览及相关概念
这里可看到索引、类型、字段、数据信息,如下图所示:
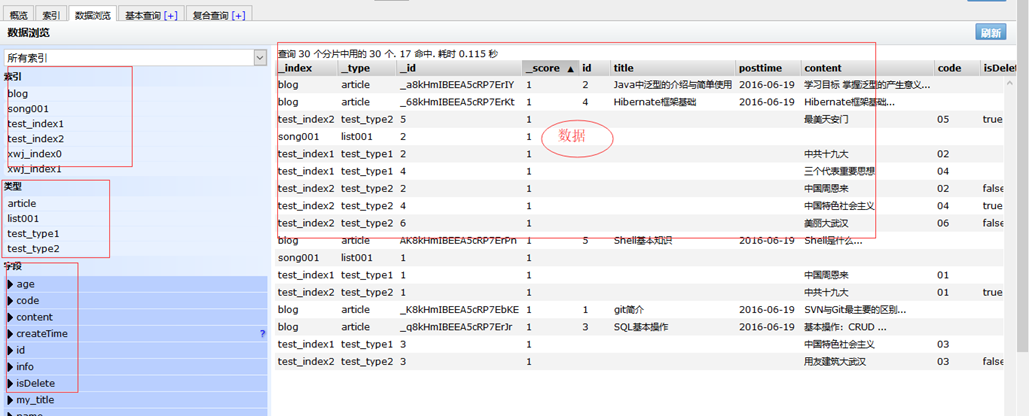
集群(Cluster):
ES是一个分布式的搜索引擎,一般由多台物理机组成。这些物理机,通过配置一个相同的cluster name,互相发现,把自己组织成一个集群。
节点(Node):
同一个集群中的一个Elasticsearch实例就是一个Node。一个机器可以有多个实例,所以并不能说一台机器就是一个node。不过大多数情况下每个node运行在一个独立的环境或虚拟机上。
Node类型:
1)data node: 存储index数据。Data nodes hold data and perform data related operations such as CRUD, search, and aggregations.
2)client node: 不存储index,处理转发客户端请求到Data Node。
3)master node: 不存储index,集群管理,如管理路由信息(routing infomation),判断node是否available,当有node出现或消失时重定位分片(shards),当有node failure时协调恢复。
(所有的master node会选举出一个master leader node)
详情参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
分片(shard):
分片,ES是分布式搜索引擎,每个索引有一个或多个分片,索引的数据被分配到各个分片上,相当于一桶水用了N个杯子装,分片有助于横向扩展,N个分片会被尽可能平均地(rebalance)分配在不同的节点上(例如你有2个节点,4个主分片(不考虑备份),那么每个节点会分到2个分片,后来你增加了2个节点,那么你这4个节点上都会有1个分片,这个过程叫relocation,ES感知后自动完成),分片是独立的,对于一个Search Request的行为,每个分片都会执行这个Request.
主分片(Primary shard):
索引(下文介绍)的一个物理子集。同一个索引在物理上可以切多个分片,分布到不同的节点上。分片的实现是Lucene 中的索引。
注意:ES中一个索引的分片个数是建立索引时就要指定的,建立后不可再改变。所以开始建一个索引时,就要预计数据规模,将分片的个数分配在一个合理的范围。
副本分片(Replica shard):
可以理解为备份分片。每个主分片可以有一个或者多个副本,个数是用户自己配置的。ES会尽量将同一索引的不同分片分布到不同的节点上,提高容错性。对一个索引,只要不是所有shards所在的机器都挂了,就还能用。主分片和备分片不会出现在同一个节点上(防止单点故障),默认情况一个索引创建5个分片一个副本(一个副本是指复制一次,有几个分片复制几个)(即5 primary+5 replica=10个分片)。如果你只有一个节点,那么5个replica都无法分配(unassigned),此时cluster status会变成Yellow。
eg:新建两个索引testshards和testa,选择的 分片数和副本数分别为(5,2)和(1,1),建索引时分片数指 主分片数。
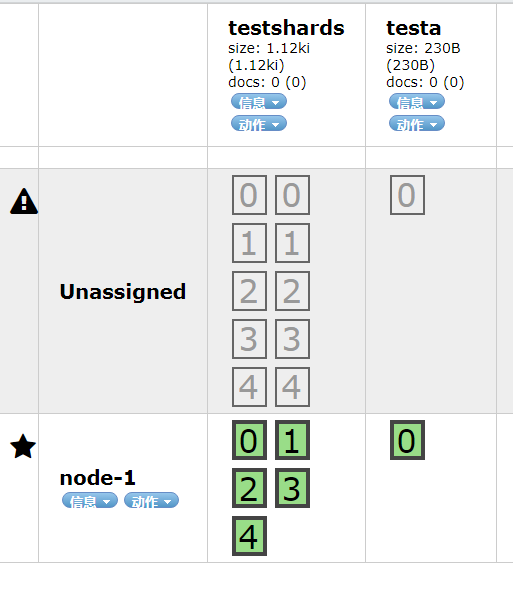
replica的作用主要包括:
1.容灾:primary分片丢失,replica分片就会被顶上去成为新的主分片,同时根据这个新的主分片创建新的replica,集群数据安然无恙
2.提高查询性能:replica和primary分片的数据是相同的,所以对于一个query既可以查主分片也可以查备分片,在合适的范围内多个replica性能会更优(但要考虑资源占用也会提升[cpu/disk/heap]),另外index request只能发生在主分片上,replica不能执行index request。
对于一个索引,除非重建索引否则不能调整分片的数目(主分片数, number_of_shards),但可以随时调整replica数(number_of_replicas)。
索引(Index):
逻辑概念,一个可检索的文档对象(documents)的集合。类似与DB中的database概念。同一个集群中可建立多个索引。比如,生产环境常见的一种方法,对每个月产生的数据建索引,以保证单个索引的量级可控。
类型(Type):
索引的下一级概念,相当于数据库中的table。同一个索引里可以包含多个 Type。 数据浏览tab中,选中某个索引或者类型,都可以看它对应的类型或索引。
文档(Document):
即搜索引擎中的文档概念,也是ES中一个可以被检索的基本单位,相当于数据库中的row,一条记录。
字段(Field):
相当于数据库中的column。ES中,每个文档,其实是以json形式存储的。而一个文档可以被视为多个字段的集合。比如一篇文章,可能包括了主题、摘要、正文、作者、时间等信息,每个信息都是一个字段,最后被整合成一个json串,落地到磁盘。
映射(Mapping):
相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以不显示地指定、自动根据文档数据创建。
ES比传统关系型数据库,对一些概念上的理解:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields参考:
4、基本查询
在这个页签,可以做数据项简单的查询(只能做查询)。
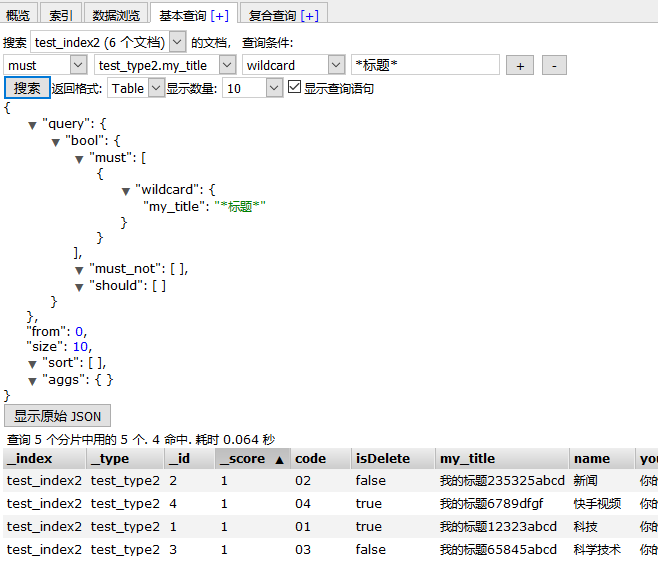
选择一个索引,然后再选择不同的查询条件,勾选“显示查询语句”,最后点击搜索,可以看到具体的查询json和查询结果
至于不同组合的查询条件表示的意思 -> ElasticSearch查询
5、复合查询
在这个页签,可以使用json进行复杂的查询,也可发送put请求新增及跟新索引,使用delete请求删除索引等等。如图所示:
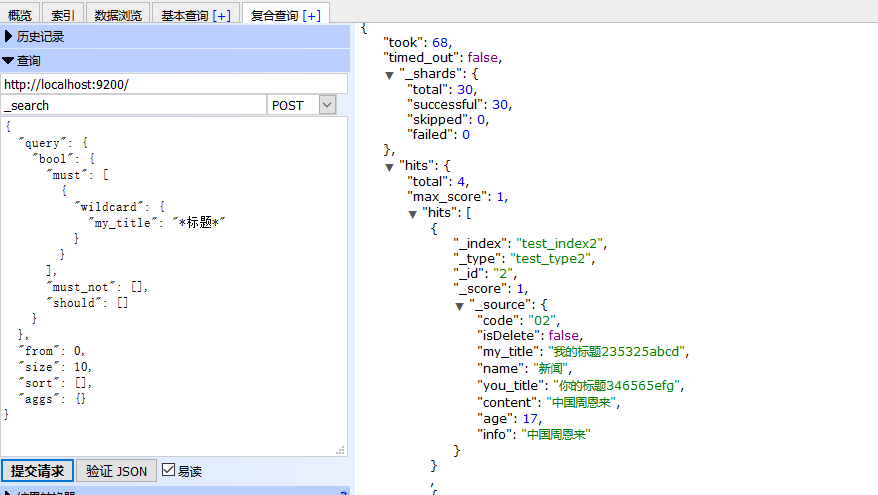
该页签的简单使用 -> ElasticSearch索引文档的增删改查
当然也可以采用postman去执行这些操作 -> ElasticSearch数据导入By Postman

 浙公网安备 33010602011771号
浙公网安备 33010602011771号