
找到一篇论文 Spatial: A Language and Compiler for Application Accelerators 机翻了一下
spatial:一种用于应用程序的语言和编译器加速器
| David Koeplinger美国斯坦福大学dkoeplin@stanford.edu | 马修·费尔德曼美国斯坦福大学mattfel@stanford.edu | Raghu Prabhakar美国斯坦福大学raghup17@stanford.edu |
|---|---|---|
| zhang yaqi美国斯坦福大学yaqiz@stanford.edu | 斯特凡·哈吉斯美国斯坦福大学shadjis@stanford.edu | 鲁本·菲泽尔瑞士EPFLrfiszel@stanford.edu |
| zhao tian美国斯坦福大学tianzhao@stanford.edu | 路易吉·纳尔迪美国斯坦福大学lnardi@stanford.edu | 阿尔达万·佩德拉姆美国斯坦福大学perdavan@stanford.edu |
克里斯托斯·科齐拉基斯,美国斯坦福大学kozyraki@stanford.edu
昆勒·奥卢科顿
美国斯坦福大学
kunle@stanford.edu
摘要
为提升性能和能效,业界正越来越多地采用FPGA和CGRAs等可重构架构。但这些架构的应用却因编程模型的局限性而受限。硬件描述语言(HDL)缺乏提升效率的抽象层级,且难以通过高级语言进行优化。虽然硬件级语言(HLS)工具能提高开发效率,但其采用软硬件混合的临时性抽象模型,导致性能优化困难重重。
在本研究中,我们开发了一种名为Spatial的新型领域特定语言及编译器,专门用于对应用加速器进行高层次描述。我们详细阐述了Spatial以硬件为中心的抽象设计,既提升了程序员的工作效率,又优化了系统设计性能,并总结了实现这些抽象所需的编译器流程,包括流水线调度、自动内存共享机制以及基于主动机器学习的自动化设计调优。通过实验证明,该语言能够直接从通用源代码生成FPGA和CGRAs架构。当在亚马逊EC2 F1实例上部署Xilinx UltraScale+ VU9P FPGA时,采用Spatial编写的应用程序平均代码量比SDAccel HLS缩短42%,并实现了2.9×倍的平均加速效果。
概念•硬件→硬件加速器;可重构逻辑应用;•软件及其工程→数据流语言;源代码生成;
关键词:领域特定语言、编译器、硬件加速器、高级综合、可重构架构、现场可编程门阵列(FPGA)、可重构图形处理器(CGRAs)
ACM参考格式:
1前言
近年来,技术规模化的趋势、海量数据的获取以及新型算法突破,推动了加速器架构研究的发展。诸如现场可编程门阵列(FPGA)和粗粒度可重构架构(CGRAs)等可重构架构,因其相较于传统CPU在性能潜力和能效优势方面表现突出,重新获得了学术界和产业界的广泛关注。目前微软和百度的数据中心已采用FPGA加速网络搜索[29,34],亚马逊将FPGA实例纳入AWS服务[4],英特尔则推出了封装式至强-FPGA系统[18]和FPGA加速存储系统[21]等产品。与此同时,多个最新研究原型[17,30-32,40]和初创企业[6,7]也在不同粒度下探索各类CGRAs的应用。这类可重构架构的使用正日益广泛。
现在,架构比以往任何时候都更容易被程序员使用。
可重构设备能够加速应用程序运行,部分得益于其通过定制数据管道和内存架构实现的多层级嵌套并行性和数据局部性。然而,正是这些提升可重构架构效率的特性,也使得编程复杂度大幅增加。加速器设计必须统筹处理流水线信号时序与目标设备物理限制下的计算内存资源,同时还要管理本地缓存与片外存储器之间的数据分配以实现良好数据局部性。这些复杂因素的叠加,导致加速器设计方案空间变得难以驾驭[13]。
这些技术难题使得可编程性成为制约连续格结构阵列(CGRAs)和现场可编程门阵列(FPGAs)广泛应用的关键瓶颈[10,15]。当前CGRAs的可编程领域存在碎片化问题,各厂商采用的编程模型不仅互不兼容,还存在架构依赖性。目前FPGA编程的主流方案需要整合厂商提供的专用IP模块、通过低级RTL或高级综合工具开发的手动调优硬件模块,以及与DRAM等片外组件通信的架构专用逻辑。而像Verilog和VHDL这类硬件描述语言(HDL)专为显式硬件设计,却将算法实现的复杂性转嫁给了用户,迫使他们不得不自行解决硬件实现的难题。
诸如SDAccel [42]、Vi- vado HLS [3]和英特尔OpenCL软件开发工具包[5]等高级综合(HLS)工具,相较于传统硬件描述语言(HDL),显著提升了抽象层次。例如,这些工具允许程序员通过无时间限制的嵌套循环编写加速器设计方案,并提供CPU主机与FPGA间数据传输等常见操作的库函数。然而,现有的商用HLS工具均基于C语言、OpenCL和Matlab等软件平台构建。这些软件平台主要针对基于指令集的处理器(如CPU和GPU)进行优化。因此,尽管现有HLS工具提升了可重构架构的抽象层次,但其混合的软硬件抽象往往缺乏明确规范。以SDAccel为例,虽然能将嵌套循环转换为硬件状态机,但其语言本身不支持架构内存层次结构,也无法实现任意层级的循环流水处理[2]。程序员必须牢记:即便采用软件级编程抽象,仍需运用硬件而非软件优化技术。这种双重标准使得开发出完全优化的HLS代码面临巨大挑战[26]。
在本研究中,我们首先系统梳理了从零开始构建新型高级综合语言所需的核心语言抽象体系,涵盖可重构架构中内存管理、控制逻辑及加速器与主机接口的语法设计。我们提出这种“全新起点”
采用高级综合语言设计的方法,能够生成在语义上更简洁的可重构架构语言,特别是在优化数据局部性和并行性时。这些抽象特性有助于提高程序员的工作效率,并使用户和编译器都能更轻松地优化设计以提升性能。
我们随后介绍了一种名为Spatial的新型领域特定语言(DSL)及编译器框架,该框架通过实现这些抽象概念来支持更高层次、面向性能的硬件加速器设计。图1展示了Spatial中矩阵乘法的基础实现示例。如图所示,Spatial代码与现有硬件级语言(HLS)类似,其程序具有非时序特性,且语言本身我们鼓励将加速器设计以嵌套循环的形式进行表达。然而,与现有硬件描述语言(HLS)工具不同,Spatial通过提供片上和片外存储器模板库(如图1所示的DRAM和SRAM),让用户能更直观地控制内存层次结构。默认情况下,Spatial会根据并行访问模式自动为用户生成任意嵌套循环、存储库、缓冲区及重复存储器的流水线。这与现代HLS工具形成鲜明对比——后者通常需要用户在代码中添加显式指令才能实现此类优化。Spatial还支持通过自动化设计spatial探索(DSE)对参数化设计进行调优。不同于以往方法[22]采用易产生偏差的启发式随机搜索,Spatial采用了名为Hy-hyperMapper[11]的主动机器学习框架来驱动探索过程。这种调优方式使得单个加速器设计能够轻松跨目标架构和厂商快速移植。
在针对FPGA进行优化时,Spatial不仅能生成经过优化的、可大规模集成的Chisel代码,还能提供可在宿主机CPU上运行的C++代码,用于管理加速器在目标FPGA上的初始化和执行。目前该工具支持亚马逊EC2 F1实例上的Xilinx Ultrascale+ VU9P FPGA、Xilinx Zynq-7000及Ultrascale+ ZCU102片上系统,以及Altera DE1和Arria 10片上系统。Spatial的架构设计具有通用性,适用于各类可重构架构,这意味着其程序同样可以用于针对CGRAs的优化。本文通过最新提出的Plasticine CGRA [32]进行优化演示,验证了这一特性。
本文的贡献如下:
•我们讨论了描述可重构体系结构中目标无关加速器设计所需的抽象概念(第2节)。接着,我们描述了Spatial对这些构造的实现(第3节),以及这些抽象在Spatial编译器中所支持的优化(第4节)。
我们描述了一种改进的快速、自动化的设计参数spatial探索方法,使用HyperMapper(第4.6节)。该方法在第5节中进行了评估。
•我们评估了Spatial在高效表达多样化应用场景及从同一源代码实现多架构适配方面的表现。通过实验证明,Spatial可同时适配两种FPGA架构和Plasticine计算图形处理器(CGRA)。在VU9P FPGA平台上,我们对Spatial与SDAccel进行了多基准测试的定量对比(第5节),结果显示Spatial以42%的代码量缩减实现了2.9×的几何级加速。第6节则对Spatial与其他相关技术成果进行了定性比较分析。
2语言标准
对于具有硬件设计抽象目的的语言来说,关键是要在提高程序员生产力的高级构造和用于优化性能的低级语法。在此,我们通过概述实现生产力与可实现性能之间良好平衡的要求来阐述我们对Spatial的讨论动机。
2.1控制
对于大多数应用程序而言,控制流通常可以用抽象化的术语来描述。数据依赖分支(例如if语句)和嵌套循环几乎存在于所有应用场景中,而这些循环在常见情况下都具有可静态计算的起始区间。这类循环对应着层次化的流水线结构,在多数情况下编译器能够自动进行优化。因此,定义这些控制结构的工作应当由编译器承担,用户仅需在编译器缺乏优化循环调度所需信息时进行干预。
2.2存储器层次结构
在大多数可重构架构中,内存层次结构至少包含三个层级:片外存储器(DRAM)、片上临时存储区(例如FPGA中的“块RAM”)以及寄存器。与CPU将内存呈现为统一可访问地址空间不同,可重构架构需要程序员显式管理内存层次结构。Sequoia等早期编程语言[16]已证明,在编程语言设计中明确内存层次结构的概念具有显著优势。此外,循环展开和流水线优化对提升性能和面积利用率至关重要,但这些优化需要对片上内存进行分区、分库和缓冲处理,以满足并发访问所需的带宽需求。这些决策需通过静态分析循环迭代器的内存访问模式来实现。因此,加速器设计语言应向用户提供目标内存层次结构的可视化视图,并引入循环迭代器概念,从而实现针对片上带宽的自动内存分区、分库及缓冲优化。
除了片上内存管理之外,加速器设计还需明确管理片外与片内内存之间的数据传输。这就需要创建一个软内存控制器来管理片外存储器。不同目标架构和厂商的内存控制器实现方式差异显著,但这些架构都有一个共同点——都需要根据访问模式优化内存控制器。不可预测且依赖数据的请求,比可预测的线性访问需要更专业的内存控制器逻辑。与其纠结于特定目标的细节,这种语言应该让用户专注于根据访问模式优化每次数据传输。因此,加速器语言应尽可能抽象化这些传输操作,同时提供基于访问模式的专用构造函数。
2.3主机接口
spatial架构通常用作加速器,以卸载主处理器的应用程序计算任务。在这种运行模型中,主机通常负责分配内存、准备数据结构,并通过大型异构网络进行数据收发。数据准备完成后,主机会调用加速器,要么等待其完成任务(“阻塞式执行”),要么以轮询或中断方式与持续运行的加速器交互(“非阻塞式执行”)。尽管通信管理和加速器执行功能通常得到支持,但不同平台和厂商提供的相关库及函数调用存在显著差异,导致代码难以移植或比较。为了实现与CPU主机的通信,用于加速器设计的高级语言应尽可能抽象化目标架构。
2.4设计空间探索
与所有硬件设计类似,加速器设计空间往往极其庞大且难以探索。尽管循环流水线和内存组等优化手段能自动提升效率,但这些改进仍使编译器面临资源分配的多重选择。这些决策会形成庞大的性能/面积权衡空间,且随着应用复杂度增加呈指数级增长。在通用矩阵乘法的固定实现中,设计空间包含多个维度:包括存储完整矩阵片段的片上Tile(内存块)尺寸、对遍历Tile(内存块)的循环并行化方案以及Tile(内存块)内部迭代循环的设计。图1第17-21行所示参数仅展示了众多设计空间参数中的几个。已有研究[22]表明,通过让编译器感知流水线、展开因子和Tile(内存块)尺寸等设计参数,可有效加速并自动化参数空间探索。因此,抽象硬件语言应同时支持设计空间参数的语言表达与编译器实现。
3 spatial 语言
Spatial是一种专为可重构spatial架构(包括现场可编程门阵列FPGA和可重构栅极阵列CGRAs)设计加速器的领域特定语言。该语言旨在简化加速器设计流程,使领域专家能够快速完成硬件加速器的开发、测试、优化和部署工作——既可通过直接实现高级硬件设计方案,也可通过从其他更高层级语言转译至Spatial进行开发。
在本节中,我们将描述Spatial包含的抽象概念,以平衡生产效率和性能导向的细节。由于篇幅所限,无法完整说明该语言,但表1提供了Spatial核心语法子集的概览。
(a) Control Structures
(a) 控制结构
min* until max by stride* par factor*
min* 至 max,步长 stride,并行因子 factor
A counter over [min,max) ([0,max) if min is unspecified).
一个在区间 [min, max) 上的计数器(若未指定 min,则为 [0, max))。
stride: optional counter stride, default is 1
stride:可选的计数器步长,默认为 1
factor: optional counter parallelization, default is 1
factor:可选的计数器并行化因子,默认为 1
FSM(init){continue}{action}{next}
有限状态机(初始状态){继续条件}{动作}{下一状态}
An arbitrary finite state machine, similar to a while loop.
一个任意的有限状态机,类似于 while 循环。
init: the FSM’s initial state
init:有限状态机的初始状态。
continue: the “while” condition for the FSM
continue:有限状态机的 "while" 继续条件。
action: arbitrary expression, executed each iteration
action:任意表达式,每次迭代执行。
next: function calculating the next state
next:计算下一状态的函数。
Foreach(counter+){body}
循环遍历(计数器+){循环体}
A parallelizable for loop.
一个可并行化的 for 循环。
counter: counter(s) defining the loop’s iteration domain
counter:定义循环迭代域的计数器。
body: arbitrary expression, executed each loop iteration
body:任意表达式,每次循环迭代执行。
*foreach 就是简单并行的,各执行之间是完全独立的。
一般来说,输入,输出数据,中间状态数据都是相互独立的,没有执行先后的要求,也没有状态保留的要求。
Reduce(accum)(counter+){func}{reduce}
规约(累加器)(计数器+){映射函数}{规约操作}
A scalar reduction loop, parallelized as a tree.
一个标量规约循环,以树形方式并行化。
accum: the reduction’s accumulator register
accum:规约的累加器寄存器。
counter: counter(s) defining the loop’s iteration domain
counter:定义循环迭代域的计数器。
func: arbitrary expression which produces a scalar value
func:产生标量值的任意表达式。
reduce: associative reduction between two scalar values
reduce:两个标量值之间的结合性规约操作。
*reduce的话,结果数据是聚合的,也就是归拢到一点,但是,中间的过程是可以交换的,比如累加。
这种情况下,编译器可以进行树形并行计算,最大限度地通过并行计算来减少总的计算时间。
MemReduce(accum)(counter+){func}{reduce}
内存规约(累加内存)(计数器+){映射函数}{规约操作}
Reduction over addressable memories.
对可寻址内存的规约操作。
accum: an addressable, on-chip memory for accumulation
accum:用于累加的可寻址片上内存。
counter: counter(s) defining the loop’s iteration domain
counter:定义循环迭代域的计数器。
func: arbitrary expression returning an on-chip memory
func:返回一个片上内存的任意表达式。
reduce: associative reduction between two scalar values
reduce:两个标量值之间的结合性规约操作。
* Reduce: 将 一个集合 归约成 一个标量值。
* MemReduce: 将 多个集合 并行地归约成 多个标量值,或者更一般地说,对 多个归约操作 进行并行化。
Stream(*){body}
流(*){循环体}
A streaming loop which never terminates.
一个永不终止的流循环。
body: arbitrary expression, executed each loop iteration
body:任意表达式,每次循环迭代执行。
*Foreach 和 Reduce 是关于空间并行性,那么 Stream 更多的是关于时间并行性。
*Stream 的主要目的是创建生产者-消费者流水线,让数据在计算单元之间流动,从而实现:
* 任务级流水线并行
* 重叠计算和数据移动
* 处理无限或大型数据流
Parallel{body}
并行{代码体}
Overrides normal compiler scheduling. All statements
覆盖正常的编译器调度。
in the body are instead scheduled in a fork-join fashion.
代码体中的所有语句将以 fork-join 方式调度。
body: arbitrary sequence of controllers
body:任意的控制器序列。
* Parallel 用于创建一组完全独立、可以并行执行的任务块。这些任务块之间通常没有数据依赖。
*Parallel = 任务并行 → "同时做不同的事情"
* Foreach = 数据并行 → "同时对不同数据做相同的事情"
DummyPipe{body}
虚拟管道{代码体}
A “loop” with exactly one iteration.
一个只有一次迭代的"循环"。
Inserted by the compiler, generally not written explicitly.
通常由编译器插入,一般不显式编写。
body: arbitrary expression
body:任意表达式。
(b) Optional Scheduling Directives
(b) 可选的调度指令
Sequential.(Foreach|Reduce|MemReduce)
顺序.(循环遍历|规约|内存规约)
Sets loop to run sequentially.
设置循环顺序执行。
*Sequential 用来显式控制执行顺序的, 用于强制代码块按顺序执行,与 Parallel 正好相反。因为有些场景必须顺序执行。
Pipe(ii*).(Foreach|Reduce|MemReduce)
流水线(ii*).(循环遍历|规约|内存规约)
Sets loop to be pipelined.
设置循环为流水线执行。
ii: optional overriding initiation interval
ii:可选的重写初始化间隔。
Stream.(Foreach|Reduce|MemReduce)
流.(循环遍历|规约|内存规约)
Sets loop to be streaming.
设置循环为流式执行。
(c) Shared Host/Accelerator Memories
(c) 主机/加速器共享内存
ArgIn[T]
参数输入[T]
Accelerator register initialized by the host
由主机初始化的加速器寄存器。
ArgOut[T]
参数输出[T]
Accelerator register visible to host after accelerator execution
加速器执行后对主机可见的加速器寄存器。
HostIO[T]
主机输入输出[T]
Accelerator register the host may read and write at any time.
主机可在任何时间读写的加速器寄存器。
DRAMT
片外内存T
Burst-addressable, host-allocated off-chip memory.
支持突发访问、由主机分配的片外内存。
(d) External Interfaces
(d) 外部接口
StreamInT
流输入T
Streaming input from a bus of external pins.
从外部引脚总线来的流输入。
StreamOutT
流输出T
Streaming output to a bus of external pins.
向外部引脚总线的流输出。
(e) Host Interfaces
(e) 主机接口
Accel{body}
加速器{代码体}
A blocking accelerator design.
一个阻塞式加速器设计。
Accel(*){body}
加速器(*){代码体}
A non-blocking accelerator design.
一个非阻塞式加速器设计。
*Accel 是 Spatial 设计的顶层容器,它定义了哪些代码应该在 FPGA/硬件加速器 上执行,而不是在 CPU/主机上执行。
Accel 明确划分了硬件和软件的界限:
Accel 块内的所有内容都会映射到实际的硬件资源:
Accel { // 顶层:硬件加速器
↓
Pipe { // 中层:流水线控制
↓
Foreach { ... } // 底层:并行计算
Reduce { ... }
MemReduce { ... }
Stream { ... }
}
Sequential { ... }
Parallel { ... }
}
Accel 是必需的 - 每个Spatial设计都必须有一个Accel块
Accel 是顶层容器 - 所有其他Spatial结构都在Accel内部
Accel 定义硬件范围 - 块内的所有东西都会变成硬件
Accel 管理数据移动 - 通过DRAM接口与主机内存通信
没有 Accel → 只是普通的Scala软件
有 Accel → 变成了硬件加速器设计
(f) Design Space Parameters
(f) 设计空间参数
default (min,max)
默认 (最小值, 最大值)
default (min,stride,max)
默认 (最小值, 步长, 最大值)
A compiler-aware design parameter with given default value.
一个编译器可知的设计参数,带有给定的默认值。
DSE explores the range [min, max] with optional stride.
设计空间探索在范围 [min, max] 内进行,可指定步长。
表1
Pipe vs Sequential vs Parallel vs Foreach
特性 Sequential Parallel Foreach Pipe
执行方式 完全顺序 完全并行 空间并行 时间并行(流水线)
吞吐量 低 高 高 中等至高
延迟 高 低 低 中等
资源使用 低 高 高 中等
数据依赖 容易处理 难以处理 迭代内独立 阶段间依赖
| 特性 | Pipe | Stream |
|---|---|---|
| 数据源 | 内存(SRAM/DRAM) | 流接口(StreamIn/StreamOut) |
| 执行触发 | 循环迭代 | 数据可用性 |
| 数据移动 | 显式加载/存储 | 隐式流式传输 |
3.1控制结构
Spatial语言提供了一套混合控制结构,既帮助用户更简洁地表达程序逻辑,又能让编译器识别并行化机会。这些结构可以无限制地任意嵌套,使用户能够轻松定义层次化的数据流和嵌套式并行计算。表1a列举了该语言中部分控制结构的示例。除了Foreach循环和状态机外,Spatial还借鉴了并行模式[35,39]的思想,为归约提供了简洁的功能语法。虽然可以用纯命令式方式表达归约操作,但通过Reduce指令可告知编译器该归约函数具有结合性。类似地,使用MemReduce对多内存进行归约时,相比命令式实现能展现更多层级的并行性。例如在图1中,第45行的MemReduce指令允许编译器对参数PAR_K进行并行处理。这将导致多个tileC数据块被并行填充,随后通过归约树将它们合并到累加器accum中。
Foreach、Reduce和MemReduce可以通过为各自的计数器设置并行化因子来实现并行化。当编译器需要对循环进行并行化时,会分析这种并行化是否能保证与顺序执行具有等效性。如果验证失败,编译器将抛出错误提示。spatial机制确保并行化体在开始下一次并行迭代前能够完整执行完毕,但无法保证单批次展开迭代中各操作的相对时间顺序。
spatial控制结构的实体具有非时序特性。编译器会自动调度操作,确保功能行为不会发生改变。编译器选择的调度方式可分为流水线式、顺序式或流式执行。在流水线式执行中,循环迭代的执行过程会进行重叠。对于最内层循环,其重叠程度取决于控制器的平均启动间隔;而对于外层循环,其重叠量则由控制器的“深度”决定。所谓深度,是指一个阶段在启动其消费级阶段之前,允许执行的外层循环迭代的最大次数。
在顺序执行模式下,循环体的单次迭代会在下一次迭代开始前完整执行完毕。这种顺序调度机制相当于流水线技术——其启动间隔等于循环体的延迟时间,对于外部控制器而言,其深度为1。流式执行则通过允许内部控制器在输入可用时异步运行,进一步实现阶段间的重叠。只有当控制器之间的通信通过流式接口或队列进行时,流式执行才能形成完善的控制方案。
3.2 存储器
spatial提供多种内存模板,使用户能够以抽象但明确的方式控制数据的分配表1.Spatial语法的子集说明。方括号(如[T])表示模板的类型参数。参数后跟‘+’表示可被多次赋值的参数,而‘*’则表示该参数为可选参数。DRAM、Foreach、Reduce和MemReduce等操作均可支持任意维度。
跨加速器的异构内存。spatial编译器了解所有这些内存类型,并能够自动优化其中的每一个。
Spatial的“片上”存储器代表静态尺寸的逻辑内存空间。支持的存储类型包括只读查找表(LUT)、暂存区(SRAM)、行缓冲器(LineBuffer)、固定大小队列与栈(FIFO和LIFO)、寄存器(Reg)以及寄存器文件(RegFile)。这些存储器始终通过加速器资源进行分配,默认情况下无法被主机访问。虽然每个存储器对程序员而言都保证具有一致性,但实现每个存储器时使用的资源数量和类型不受限制。除具有显式初始值的LUT和寄存器外,存储器在分配时内容是未定义的。这些规则使得spatial编译器在优化整个应用程序上下文中的内存访问延迟和资源利用率方面具有最大的自由度。根据访问模式,编译器可以自动复制、存储库或缓冲内存,只要最终逻辑内存的行为不变。
共享内存由主机CPU分配,可同时供主机和加速器访问。这类内存通常用于卸载模型中实现主机与加速器之间的数据传输。DRAM模板代表层次结构中最慢且容量最大的层级。为帮助用户优化内存控制器,DRAM通过显式读写操作与片上存储器进行交互。这些传输操作专门针对可预测的读写模式(如加载和存储)以及数据依赖型访问模式(如分散与聚集)进行优化。
3.3接口
Spatial提供了几个专门的接口,用于与主机和连接到加速器的其他外部设备进行通信。与内存模板一样,Spatial能够优化对这些接口的操作。
ArgIn、ArgOut和HostIO是CPU主机上具有内存映射的专用寄存器。ArgIn仅在设备初始化时可由主机写入,而ArgOut只能被主机读取,无法进行写操作。HostIO则允许主机在加速器运行期间随时进行读写。此外,当标量值(包括DRAM尺寸)在Accel作用域内使用时,会隐式创建ArgIn实例。例如图1中,矩阵A、B、C的维度通过隐式ArgIn传递给加速器,因为这些维度用于生成循环边界(如A行数、B列数)。
// Custom floating point format
// 11 mantissa, 5 exponent bits
type Half = FltPt[11, 5]
def main(args: Array[String])
{
// Load data from files
val a:
Matrix[Half] = loadMatrix[Half](args(0))
val b:
Matrix[Half] = loadMatrix[Half](args(1))
// Allocate space on accelerator DRAM
val A = DRAM[Half](a.rows, a.cols)
val B = DRAM[Half](b.rows, b.cols)
val C = DRAM[Half](a.rows, b.cols)
// Create explicit design parameters
val M = 128(64, 1024) // Tile size for output rows
val N = 128(64, 1024) // Tile size for output cols
val P = 128(64, 1024) // Tile size for common
val PAR_K = 2(1, 8) // Unroll factor of k
val PAR_J = 2(1, 16) // Unroll factor of j
// Transfer data to accelerator DRAM
sendMatrix(A, a)
sendMatrix(B, b)
// Specify the accelerator design
Accel
{
// Produce C in M x N tiles
Foreach(A.rows by M, B.cols by N)
{
(ii, jj) =>
val tileC = SRAM[Half](M, N)
// Combine intermediates across common dimension
MemReduce(tileC)(A.cols by P)
{
kk =>
// Allocate on-chip scratchpads
val tileA = SRAM[Half](M, P)
val tileB = SRAM[Half](P, N)
val accum = SRAM[Half](M, N)
// Load tiles of A and B from DRAM
tileA load A(ii::ii + M, kk::kk + P) // M x P
tileB load B(kk::kk + P, jj::jj + N) // P x N
// Combine intermediates across a chunk of P
MemReduce(accum)(P by 1 par PAR_K)
{ k =>
val partC = SRAM[Half](M, N)
Foreach(M by 1, N by 1 par PAR_J)
{
(i, j) => partC(i, j) = tileA(i, k) * tileB(k, j)
}
partC
// Combine intermediates with element-wise add
} { (a, b) => a + b }
} { (a, b) => a + b }
// Store the tile of C to DRAM
C(ii::ii + M, jj::jj + N)store tileC
}
}
// Save the result to another file
saveMatrix(args(2), getMatrix(C))
}
矩阵乘法示例见图1。
图1.在Spatial中实现的基本参数化矩阵-矩阵乘法(C = A·B)。
Spatial中的StreamIn和StreamOut用于创建与外部接口的连接。通过在目标设备上指定输入/输出引脚总线即可创建流。外部外设的连接采用面向对象的方式实现。每个可用的Spatial目标设备都定义了一组常用外部总线,可用于分配StreamIn或StreamOut。
Spatial语言允许开发者在同一程序中同时编写主机代码和加速器代码,从而实现设备间的无缝通信。该语言的数据结构与运算操作被划分为“可加速”和“主机”两类,其中只有可加速操作才对应Spatial架构的映射关系。这种区分机制旨在帮助开发者构建最适合可重构架构的算法框架。例如,那些过度依赖动态内存分配的程序,在可重构架构上通常表现欠佳,但通过算法层面的优化转换,往往能获得更优的性能表现。
spatial程序通过Accel作用域明确划分主机与加速器之间的计算任务。如表1e所示,这些调用被定义为阻塞或非阻塞类型。图1展示了一个阻塞调用的示例:在加速器中完成两个矩阵的乘积运算后,才会将结果传递给主机。该作用域内的所有操作都会分配到目标硬件加速器,而外部操作则由主机处理。因此,Accel作用域内的所有操作都必须支持加速功能。
主机上的操作包括分配主机与加速器之间的共享内存、向加速器传输数据以及访问主机的文件系统。数组通过DRAM进行复制,如图1所示的操作包括sendMatrix和getMatrix,用于在共享内存之间传输数据。标量则通过ArgIn和ArgOut进行传输,使用setArg和getArg函数。
在spatial编译完成后,主机操作会被生成为C++代码。从主机的角度来看,Accel作用域
双引号用于生成目标特定的库调用以运行加速器。此语法可完全抽象出初始化和运行加速器时繁琐的目标特定细节。
目前spatial架构假设系统具有一个目标可重构的体系结构。如果程序定义了多个加速器作用域,这些作用域将按照声明顺序依次加载和运行。然而,这一限制在未来的工作中可以很容易地放宽。
3.4参数
spatial参数的创建需遵循表1f所示的语法规范。由于每个参数在编译器生成代码前必须具有固定值,因此提供的取值范围必须能够被静态计算。这些参数可用于定义片上存储器和动态随机存取存储器(DRAM)的可寻址维度,在创建计数器时可指定参数化的步长或并行化因子,也可用于设定外部控制器的流水线深度。应用程序的隐式与显式应用参数共同构成了设计空间,编译器后续可自动探索该设计空间。
3.5例子
我们通过两个示例来总结spatial语言的讨论。图2展示了一个有限冲激响应(FIR)滤波器的流式实现。该示例表明,当使用Stream()时,spatial语言的语义与其他数据流导向的流式语言相似。每当有效元素出现在StreamIn输入端时,第24行的循环主体就会被运行一次。spatial语言通过流水线处理该主体以最大化吞吐量。
def FIR_Filter(args: Array[String]) {
val input = StreamIn[Int](target.In)
val output = StreamOut[Int](target.Out)
val weights = DRAM[Int](32)
val width = ArgIn[Int]
val P = 16 (1,1,32)
// Initialize width with the first console argument
setArg(width, min(32, args(0).to[Int]) )
// Transfer weights from the host to accelerator
sendArray(weights, loadData[Int]("weights.csv"))
Accel {
val wts = RegFile[Int](32)
val ins = RegFile[Int](32)
val sum = Reg[Int]
// Load weights from DRAM into local registers
wts load weights(0::width)
Stream(*) { // Stream continuously
// Shift in the most recent input
ins <<= input
// Create a reduce-accumulate tree with P inputs
Reduce(sum)(0 until width par P){i =>
wts(i) * ins(i)
}{(a,b) => a + b }
// Stream out the computed average
output := sum / width
}
}
}
图2.有限脉冲响应(FIR)滤波器。
虽然基础FIR滤波器即使在硬件描述语言(HDL)中也易于编写和调试,但Spatial平台让扩展基础设计变得更加轻松。本示例中的权重数量和抽头数可在设备初始化阶段设置,无需重新综合整个设计。此外,滤波器中并行组合的元件数量被定义为参数。通过设计spatial探索功能,系统可自动优化设计以实现最小面积或最低延迟。
图3展示了Spatial语言中固定大小合并排序的简易实现方案。该方案将数据加载到片上暂存区进行排序后,再回写至主内存。得益于该语言对片上与片外存储器的区分机制,这类分块设计的编写和逻辑推演显得更加自然。具体实现采用静态容量的SRAM和两个先进先出队列,通过逐步拆分并排序本地数据块来实现分块处理。块大小由第8行最外层循环决定,且以2的幂次方递增。这种设计在Spatial语言中最适合用状态机(FSM)来表达。
def Merge_Sort(offchip: DRAM[Int], offset: Int) {
val N = 1024 // Static size of chunk to sort
Accel {
val data = SRAM[Int](N)
data load offchip(offset::N+offset)
FSM(1){m => m < N}{ m =>
Foreach(0 until N by 2*m){ i =>
val lower = FIFO[Int](N/2).reset()
val upper = FIFO[Int](N/2).reset()
val from = i
val end = min(i + 2*m - 1, N) + 1
// Split data into lower and upper FIFOs
Foreach(from until i + m){ x =>
lower.enq(data(x))
}
Foreach(i + m until end){ y =>
upper.enq(data(y))
}
// Merge of the two FIFOs back into data
Foreach(from until end){ k =>
val low = lower.peek() // Garbage if empty
val high = upper.peek() // Garbage if empty
data(k) = {
if (lower.empty) { upper.deq() }
else if (upper.empty) { lower.deq() }
else if (low < high) { lower.deq() }
else { upper.deq() }
}
}
}
}{ m => 2*m /* Next state logic */ }
offchip(offset::offset+N) store data
}
}
图3.就地合并排序设计的一部分。
4 spatial编译器
spatial编译器能够将spatial语言应用程序的源代码转换为可综合的Chisel RTL硬件描述[9]。本节将详细阐述编译器的中间表示方法及其核心处理流程(如图4所示)。除生成Chisel代码外,这些处理流程同样适用于FP-GA和Plasticine CGRA两种架构。关于Plasticine架构的具体实现细节,已有研究[32]进行了深入探讨。

图4.spatial编译器针对FPGA进行优化的流程总结。
4.1中间表示
编译器内部将spatial程序表示为分层数据流图(DFG)。该图中的节点代表控制结构、数据操作和内存分配,边则表示数据依赖关系与效果依赖关系。控制器的嵌套关系会直接映射到中间表示的层级结构中。设计参数以图元数据形式存在,这样即使不修改图本身,也能独立更新这些参数。
在讨论DFG转换与优化时,将图结构视为控制器/访问树往往能带来显著优势。如图5所示,该图展示了spatial代码示例中内存Tile(内存块)B的控制器树结构。值得注意的是,片上与片外存储器之间的数据传输扩展为控制节点,通过迭代器e和f实现对片上存储器的线性访问。这种树状结构抽象化了大多数基础操作,仅保留关键的控制器层级架构及特定内存的访问逻辑。
在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点是那些可能消耗但不会产生控制信号的操作,包括片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。 在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点是那些可能消耗但不会产生控制信号的操作,包括片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。 在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点是那些可能消耗但不会产生控制信号的操作,包括片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录状态的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。 在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点是那些可能消耗但不会产生控制信号的操作,包括片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。 在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点指那些可能消耗但不会产生控制信号的操作,例如片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录状态的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。 在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点是那些可能消耗但不会产生控制信号的操作,包括片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。 在Spatial的加速器子系统中,节点被正式划分为三大类:控制节点、内存分配节点和基础节点。控制节点对应状态机结构,例如第3.1节所述的Foreach和Reduce操作。基础节点是那些可能消耗但不会产生控制信号的操作,包括片上内存访问。这些基础节点进一步细分为需要硬件资源的“物理”操作和仅用于编译器记录状态的“临时”操作。例如,位选择和字组结构化操作虽然不需要硬件资源,但用于追踪生成代码中的必要连线。
4.2控制插入
为简化控制信号的推理,Spatial要求控制节点不能同时包含物理原语节点和其他控制节点。唯一的例外是条件if语句,只要其自身不包含控制节点而仅包含条件判断,即可与原语在相同作用域内使用。这一要求通过DFG转换得以满足——该转换会在控制体中包含控制节点的原始逻辑周围插入“虚拟管道”控制节点。虚拟管道是一种记录控制结构,其逻辑等效于仅含一次迭代的循环。此后,包含原语节点的控制节点称为“内部”控制节点,而包含其他嵌套控制器的控制器则称为“外部”节点。
4.3控制器调度
控制器插入后,编译器将对每个控制器内的操作进行调度。默认情况下,无论嵌套级别如何,编译器总是会尝试对循环进行流水线处理。用户可以使用表1b中列出的指令来覆盖编译器调度器的行为。
内部流水线调度基于资源启动间隔进行规划。编译器首先根据内部目标依赖查找表,为控制器中每个基本节点收集资源启动间隔。当资源启动间隔为1时,大多数基本操作会采用流水线处理。随后,编译器通过数据流图计算流水线内所有循环承载的依赖关系。对于不可寻址存储器,总启动间隔取所有依赖读取与写入之间的路径长度最大值;对于可寻址存储器,循环承载依赖的路径长度还需乘以写入地址与读取地址的差值。若地址间不存在循环依赖,则启动间隔取路径长度(可能相等时取相同值,已知不相等时取1);若无法静态确定地址间距,则启动间隔设为无限大,意味着必须按顺序执行循环。总启动间隔定义为所有循环承载依赖的启动间隔与所有资源启动间隔的最大值。
编译器同样尝试采用类似流水线技术处理外部控制节点的主体结构,但其数据流调度策略是以内部控制节点和阶段数量为考量对象,而非原始节点与循环结构。例如图1第34行所示的外部MemReduce操作包含四个子控制器:向Tile(内存块)A加载(第41行)、向Tile(内存块)B加载(42行)、内部MemReduce(45行),以及整合中间Tile(内存块)的归约阶段(53行)。基于数据依赖关系,编译器推断这两个加载操作可以并行执行,随后是内部MemReduce和Tile(内存块)缩减。它还将确定该外循环的多次迭代也可以通过这些阶段进行流水线处理。
4.4内存分析
循环并行化只有在芯片具备足够带宽支持重复计算时才能真正提升性能。Spatial公司通过内存分析技术,将内存划分为多个存储库和缓冲区,从而最大化可用的片上读写带宽。这种内存分库技术(又称数据分区)通过将内存地址spatial分配到多个物理实例中,为同一控制器内的并发访问创建额外端口。当访问模式具有静态可预测性且能确保不同访问不会冲突同一端口/存储库时,即可实现这种分区。虽然单个端口可以采用时分复用技术,但这会增加整个流水线的启动间隔时间,完全抵消了并行化的优势。需要说明的是,尽管通过内存复制就能轻松实现分库,但Spatial公司还致力于最大限度减少整体内存资源的消耗。
spatial算法基于王等人[41]提出的冲突多面体空性测试内存分区策略进行改进。我们通过考虑随机访问模式和嵌套循环中的内存访问行为,对该策略进行了扩展。将随机访问建模为冲突多面体中的额外维度,如同新增的循环迭代器一般。spatial算法通过识别随机值的仿射组合,最大限度减少此类随机访问符号的使用量。例如,对地址x和x + 1的内存访问仅需一个随机变量x,因为第二个地址是第一个地址的可预测仿射函数。此外,spatial算法还支持按维度配置存储库,以应对某些维度访问具有可预测性的场景。
像先进先出(FIFO)和后进先出(FILO)这类非寻址存储器,其建模方式与寻址存储器相同。每次访问这类存储器时,都会根据内存定义,对所有循环迭代器进行线性访问操作。spatial限制禁止在外围循环中对非寻址访问进行并行化处理,因为这会破坏与顺序执行等效行为的保证机制。
为了在外部循环中处理多个流水线访问,Spatial还会自动在片上存储器中创建缓冲区。这种缓冲机制会生成同一数据的多个副本。
用于在重叠循环迭代之间维护数据版本的内存。如果没有这种优化,粗粒度流水线中不同阶段对同一内存的并行访问将无法并发运行。有关如何计算银行和缓冲区的详细信息,请参见附录A.1。
例如,如图5所示,Tile(内存块)B包含两个并行访问操作:对第42行的加载和对第48行的读取。若将所有(隐式和显式)并行化因子均设为2,则相当于每个循环包含4次访问。Spatial随后会构建与每个循环中所有访问对应的多面体,并确定适用于两个循环的存储策略。在此示例中,这意味着SRAM将采用双缓冲存储策略,使得2x2正方形内的每个单元都存放在不同的物理存储库中,从而实现完全并行访问。若对第34行的MemReduce操作进行流水线处理,Tile(内存块)B将采用双缓冲机制,以保护外循环某次迭代中的读取操作(第48行)免受下一次迭代中写入操作(第42行)的影响。
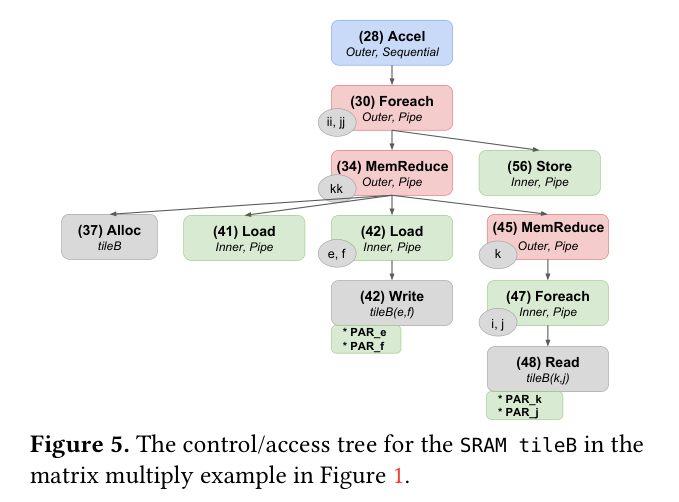
图5.SRAMTile(内存块)B的控制/访问树
4.5区域和运行时间估算
Spatial通过执行两轮估算流程来评估给定参数集,从而近似计算应用程序的面积和运行时间。这些估算过程基于与我们先前在Delite硬件定义语言(DHDL)[22]研究中使用的分析资源模型和运行时模型相似的方法,但Spatial在此基础上进行了扩展,能够处理流式吞吐量、任意控制流以及有限状态机等复杂场景。运行时和面积利用率模型均基于每个目标平台约2000次一次性特征化测试构建而成。
4.6设计spatial探索
编译器识别的调度与内存银行选项,结合循环并行化和Tile(内存块)大小参数,共同构成了应用程序的设计spatial。设计调优阶段作为可选编译器流程,能够快速探索该设计spatial以实现面积与运行时间之间的权衡。启用设计调优后,系统会反复选取设计方案点,并通过重新运行控制调度、内存分析和估算分析等流程进行评估。该搜索过程的输出结果是从帕累托前沿中筛选出的一组参数组合。
遗憾的是,应用设计spatial往往极其庞大,对整个spatial进行穷举搜索通常难以实现。在第5节讨论的基准测试中,仅有布莱克-斯科尔斯模型的spatial规模相对较小,约8万个参数点。虽然Spatial工具能在几分钟内完成该spatial的穷举搜索,但其他spatial的规模要大得多,参数点数从106到1010不等,需要耗费数小时甚至数天才能完成全面搜索。例如,即使仅考虑图1代码中显式展示的设计参数,结合隐式流水线和并行化参数后,这段代码已包含约2.6×10^8种潜在设计方案。DHDL [22]采用启发式剪枝后的随机搜索方法,进一步优化了搜索效率。
总spatial的大小要缩小两到三个数量级。但是,这种方法在较大的设计spatial上具有较高的方差,并且可能会无意中剪去一些理想的点。
为降低大规模设计spatial的方差,Spatial的设计spatial探索流程集成了基于主动学习的自动调优器HyperMapper [11,27,36]。HyperMapper是一种多目标无导数优化器(DFO),已在SLAMBench基准测试框架[28]上得到验证。该工具通过随机森林回归器构建代理模型,并预测参数spatial内的性能表现。初始阶段仅使用数百个随机设计点样本构建回归器,后续通过主动学习步骤逐步迭代优化。
4.7展开
在确定设计参数值后,Spatial通过单一图转换完成参数优化:根据前期分析结果展开循环并复制内存。Reduce和MemReduce模式也会被分解为命令式实现,硬件缩减树将基于给定的缩减函数进行实例化。例如,图1中的两个MemReduce循环将分别被分解为展开的Foreach循环,其中包含显式的银行化内存访问和显式的重复乘法运算。对应的Tile(内存块)间归约操作(第52-53行)则被分解为Foreach循环的第二阶段,其对应的缩减树与循环并行化相匹配。
4.8重定时
展开后,编译器会对每个内部流水线进行重新计时,确保数据和控制信号正确对齐,并满足目标时钟频率要求。为此,编译器会根据效果依赖关系和数据流顺序,在各流水线内对基础运算进行排序。该排序通过逆向深度优先搜索沿数据依赖和效果依赖计算得出,随后再通过正向深度优先搜索来最小化归约周期中的延迟。基于此排序结果,编译器会根据映射基础运算节点到对应延迟的查找表,插入流水线寄存器和延迟线寄存器。对于延迟不足完整周期的依赖节点,保持组合运算形式,仅在最后一个操作之后插入寄存器。这种寄存器插入策略既最大化了控制器的时钟频率,又有效缩短了所需的启动间隔。
4.9代码生成
在代码生成之前,编译器首先为每个ArgIn、ArgOut和HostIO分配寄存器名称。在对中间表示进行最终遍历时,代码生成器会从Chisel语言编写的自定义参数化RTL模板库中实例化硬件模块,并推导生成将这些模块组合在一起所需的逻辑。这些模板包括表2.SDAccel和Spatial在单个VU9P FPGA上的代码行数(LOC)、面积利用率和运行时间比较。作为参考,第一行列出可用的FPGA资源总数。LOC改进是相对于SDAccel的百分比改进。其余改进系数按(SDAccel/Spatial)计算。
LOC LUT和BRAM DSP的时间(毫秒)
| 基 | 数据大小 | DSE尺寸 | 容量 | — | 914400 | 1680 | 5640 | — |
|---|---|---|---|---|---|---|---|---|
| BS布莱克-斯科尔斯期权定价 | 96万份期权 | 7 .7 × 104 | SDAccelspatial改进 | 1759346.8% | 3633686988850.52× | 5504931.12× | 2909450.31× | 6 . 183 .79 1.63× |
| GDA高斯判别分析 | 1024行96个尺寸 | 3 .0 × 1010 | SDAccelspatial改进 | 736412.3% | 3568573781300.94× | 5948580.69× | 1082160.50× | 10 .751 .27 8.48× |
| 通用电子维护模型矩阵乘积 | A: 1024×1024B: 1024×1024 | 2 .6 × 108 | SDAccelspatial改进 | 1104460.0% | 3418944262950.80× | 6745001.35× | 2067980.26× | 1207 .26878 .451.37× |
| K均值法k-均值聚 | 200次迭代320×32元素点 | 2 . 1 × 106 | SDAccelspatial改进 | 1468144.5% | 3563823693480.96× | 6574531.45× | 5391055.13× | 73 .0453 .25 1.37× |
| 页面排名节点排序算法 | DIMACS10 Chesapeake 10000次迭代 | 4 . 1 × 103 | SDAccelspatial改进 | 1127731.2% | 3371024181280.81× | 5498620.64× | 1781 0.21× | 2041 .62587 .353.48× |
| 软件史密斯-沃特曼DNA比对 | 256个碱基对 | 2 . 1 × 106 | SDAccelspatial改进 | 2408265.8% | 5416173300631.64× | 5474701.16× | 129 1.33× | 8 .670 .61 14.15× |
| TQ6TPC-H Q6过滤器减压 | 6,400,000条记录 | 3 .5 × 109 | SDAccelspatial改进 | 744835.1% | 3569784728680.75× | 5485740.95× | 153930.04× | 18 .6113 .97 1.33× |
| 平均值 | 改进 | 42.3% | 0.87× | 1.01× | 0.42× | 2.90× |
状态机负责管理应用程序中各类控制结构与基础组件之间的通信,同时协调银行化存储器、缓冲存储器结构以及高效的算术运算。最终,所有生成的硬件模块都会封装在特定于目标架构的参数化Chisel模块中,该模块能够协调加速器与目标FPGA上的外围设备之间的片外访问操作。
5评估
在本节中,我们通过将程序员的生产力和生成的设计性能与赛灵思的商用HLS工具SDAccel进行比较来评估Spatial。随后,我们评估了HyperMapper设计调优方法,并展示了Spatial在FPGA和Plasticine CGRA之间可移植性的优势。
5.1 FPGA性能和生产率
我们首先评估了Spatial与赛灵思公司商用C语言编程工具SDAccel在FPGA性能和生产效率方面的差异。研究选用SDAccel是因为其性能目标与Spatial相近,支持主流的OpenCL编程模型,并具备循环流水线优化、展开优化及内存分区优化等多项功能[42]。表2中基准测试的基线实现均基于这些基准测试方案既包含赛灵思公司公开的SDAccel基准测试套件[45],也有手工编写的版本。每个基准测试方案都通过使用HLS实用程序[43]进行手动调优,具体包括选择循环流水线化、展开操作和阵列银行因子,并启用数据流优化功能。Spatial的设计要点则是根据第4.6节所述的DSE流程来确定的。
我们通过统计描述FPGA内核(不含主机代码)所使用的源代码行数来衡量生产效率。性能评估则基于Xilinx-inx超大规模+VU9P板卡(总线时钟频率125 MHz,部署于亚马逊EC2 F1实例)上的基准测试运行时间及FPGA资源消耗。针对每个基准测试,我们使用Spatial和SDAccel工具生成VU9P架构的FPGA比特流,并从布局布线后的报告中获取资源利用率数据。随后在FPGA上运行并验证两种设计方案,测量板卡执行时间。需要特别说明的是,CPU配置代码与CPU-FPGA间的数据传输时间均未计入两种工具的运行时间统计。
表2展示了输入数据集的规模,以及在SDAccel和Spatial中实现的基准测试在源代码行数、资源利用率和运行时间方面的全面对比。就生产效率而言,Spatial中的语言结构(如用于从DRAM传输密集型稀疏数据的加载和存储操作)能有效减少代码臃肿并提升可读性。此外,通过隐式推断诸如并行化因子和循环起始间隔,spatial代码基本上没有注释和实用程序。
在BlackScholes和TPC-H Q6基准测试中,Spatial的加速性能分别比SDAccel提升了1.63×和1.33×。这两个基准测试都采用深度流水线数据路径从DRAM传输数据流,这种设计非常适合FPGA加速。SDAccel通过Dataflow指令集[44]实现数据流支持,而Spatial则具备流式传输能力,两者都能高效加速这类工作负载。在InK-Means算法中,Spatial通过粗粒度流水线支持,在减少1.5×个BRAM单元的情况下,其性能表现与SDAccel基本持平。针对PageRank任务,Spatial凭借专用DRAM分散/聚合支持,实现了3.48×的加速效果。
我们在计算密集型工作负载GDA、GEMM和SW中分别观察到8.48×、1.37×和14.15×的加速效果。SW基准测试由赛灵思采用脉动阵列实现,而Spatial实现方案则使用嵌套控制器架构。GEMM和GDA的工作负载中存在适合粗粒度流水线化的操作机会,这些机会在Spatial方案中得到了充分利用。例如,GDA包含外积运算,在此过程中需要反复访问并重用同一缓冲区的数据。虽然这种操作可以通过生成数组的前置循环进行流水线化处理,但SDAccel的数据流指令集不支持此类涉及数据重用的操作模式。因此,SDAccel需要更大的数组分区和循环展开因子来抵消性能损失,但这会增加FPGA BRAM的占用量。此外,GEMM中的嵌套控制器可在Spatial方案中独立并行化和流水线化,而SDAccel会在外层循环并行化时自动展开所有内层循环。这使得Spatial能够探索SDAccel难以表达的设计点。最后,由于Spatial编译器对参数化中间表示进行分析,无需扩展中间表示图即可推断更大并行化因子。SDAccel则将中间表示图作为预处理步骤展开,
因此当展开和数组分区因子较大时会产生更庞大的图结构。这显著增加了编译器的内存占用和编译时间,使得优化设计变得困难甚至无法实现。
Spatial为FPGA编程提供了高效的开发平台,在所有基准测试中平均代码行数较SDAccel减少了42%。在本次研究的基准测试中,Spatial相比工业级HLS工具实现了2.9×的几何平均加速比。
5.2设计spatial探索
接下来,我们对HyperMapper进行初步评估,以快速估算设计时长与FPGA逻辑利用率(LUT)这两个设计目标的帕累托前沿。为此,我们使用多个随机初始样本种子运行HyperMapper,样本数量R从1到6000个设计方案不等,并进行5次主动学习迭代,每次最多处理100个样本。作为对比,文献[22]中提出的启发式搜索方法采用了剪枝策略
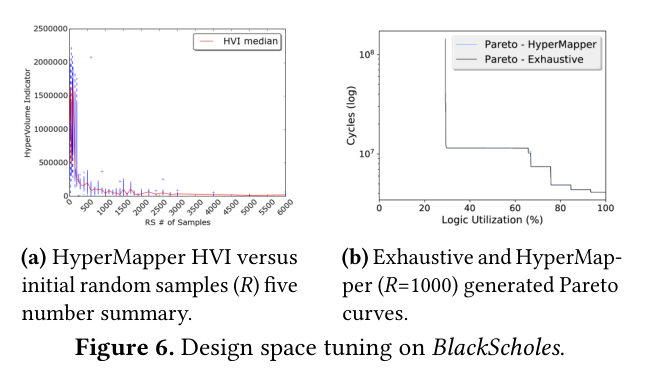
图6.BlackScholes上的设计空间调整。
使用简单的启发式方法,然后随机采样最多10万个点。对于这两种方法,设计调优最多需要1-2分钟,具体时间因基准测试的复杂度而略有不同。
图6展示了黑斯科尔斯基准模型的超体积指标(HVI)随初始随机样本数量变化的函数关系。该指标通过计算估计帕累托前沿与通过穷举搜索获得的真实帕累托曲线之间的面积来量化模型性能。在主动学习阶段增加随机样本数量进行自举时,我们观察到HVI指标提升了两个数量级。此外,随着随机样本数量的增加,整体方差呈现快速下降趋势。这表明自动调参器对随机性具有鲁棒性,仅需少量随机样本即可完成主动学习阶段的自举。如图6b所示,HyperMapper模型仅需不到1500个设计点即可实现对真实帕累托前沿的近似逼近。
在GDA这类设计spatial较为稀疏的基准测试中,HyperMapper需要耗费大量时间评估那些无法适配FPGA的无效设计方案区域。因此,其在这些基准测试中的准确率反而低于启发式方法。基于此,我们计划在后续工作中为HyperMapper添加有效设计方案预测机制,并在更广泛的基准测试类别上验证这种调优方案的有效性。
5.3spatial可移植性
接下来,我们通过针对两种不同的FPGA架构来展示Spatial代码的可移植性:(1)Zynq ZC706 SoC板,以及(2)部署在亚马逊EC2 F1上的Virtex超大规模+VU9P。VU9P上的设计采用单个DRAM通道,其峰值带宽为19.2 GB/s。ZC706在FPGA资源方面比VU9P小得多,其DRAM带宽也更小,仅为4.26 GB/s。对于表2中列出的所有基准测试,我们均使用同一Spatial代码针对ZC706和VU9P进行测试。每个目标都通过自动DSE的特定模型进行调优。两种FPGA的时钟频率均固定为125 MHz。
表3显示了在VU9P上相对于ZC706实现的加速。结果表明,不仅能够以相同表3.在ZC706上经过调优的设计的运行时间(毫秒),随后是将这些设计直接移植到VU9P上的运行时间和加速比(×),然后是针对VU9P调优的移植设计的运行时间和连续加速比。总计列显示累积加速比。
FPGA ZC706 VU9P总计 FPGA ZC706 VU9P总计 FPGA ZC706 VU9P总计 FPGA ZC706 VU9P总计
设计调谐移植调谐 设计调谐移植调谐 设计调谐移植调谐 设计调谐移植调谐
| 时间 | 时间 | × | 时间 | × | × | |
|---|---|---|---|---|---|---|
| BS | 89 .0 | 35 .6 | 2 .5 | 3 .8 | 9 .4 | 23 .4 |
| GDA | 8 .4 | 3 .4 | 2 .5 | 1 .3 | 2 .6 | 6 .5 |
| 通用电子维护模型 | 2226 .5 | 1832 .6 | 1 .2 | 878 .5 | 2.1 | 2 .5 |
| K均值法 | 358 .4 | 143 .4 | 2 .5 | 53 .3 | 2 .7 | 6 .7 |
| 页面排名 | 1299 .5 | 1003 .3 | 1 .3 | 587 .4 | 1 .7 | 2 .2 |
| 软件† | 1 .3 | 0 .5 | 2 .5 | 0 .5 | 1 .0 | 2 .5 |
| TQ6 | 69 .4 | 15 .0 | 4 .6 | 14 .0 | 1.1 | 5 .0 |
†基于160个碱基对的软件,这是ZC706上能安装的最大软件。
表4. Plasticine DRAM带宽、资源利用率、
运行时,以及速度(×)相比VU9P FPGA。
| 应用 | 平均DRAMBW (%)装载仓库 | 资源利用率(%)PCU PMU AG | 时间****(ms) | × |
|---|---|---|---|---|
| BS | 77 .4 12 .9 | 73.4 10 .9 20 .6 | 2 .33 | 1.6 |
| GDA | 24 .0 0 .2 | 95.3 73 .4 38 .2 | 0 . 13 | 9.8 |
| 通用电子维护模型 | 20 .5 2 . 1 | 96.8 64 . 1 11 .7 | 15 .98 | 55.0 |
| K均值法 | 8 .0 0 .4 | 89.1 57 .8 17 .6 | 8 .39 | 6.3 |
| TQ6 | 97.2 0 .0 | 29 .7 37 .5 70.6 | 8 .60 | 1.6 |
当spatial源代码移植到不同性能的架构时,应用程序还能自动优化以充分利用各目标平台的资源。针对计算密集型基准测试(如布莱克-舒尔斯算法、GDA、GEMM和K均值聚类),在VU9P平台上相比ZC706处理器可实现最高23×倍的加速。若仅将这些设计移植到VU9P平台,由于主内存带宽提升带来的优势可达1.2×至2.5×倍,但FPGA容量更大的主要优势在于通过调整并行化参数来释放更多资源。虽然软件层面同样存在计算瓶颈,但数据集规模受限于较小的FPGA。在这种情况下,VU9P的更大容量并未提升运行效率,反而使其能够处理更庞大的数据集。
内存带宽受限的基准测试TPC-H Q6得益于VU9P平台更高的DRAM带宽。移植该基准测试后,由于主内存带宽更大,运行时间直接提升了4.6×倍。同时通过并行化控制器生成更多并行地址流到DRAM,使应用程序能更高效地利用带宽资源。PageRank同样存在带宽限制,但VU9P平台的主要优势在于其专用内存控制器,能针对稀疏访问场景最大化带宽利用率。
最后,我们通过扩展编译器来映射spatial架构,证明了spatial架构在FPGA之外的可移植性。
spatial 中间指令(Spatial IR)旨在实现我们提出的可重构CGRA [32]。可重构架构采用二维阵列结构,由计算单元(PCU)和存储单元(PMU)Tile(内存块)组成,外围配置静态可配置互连模块及地址生成器(AG),用于执行DRAM访问操作。该架构与现场可编程门阵列(FPGA)存在显著差异,其对内存组和计算单元的约束更为严格,包括固定尺寸设计、流水线SIMD通道等特性。
我们使用由64个计算单元和64个存储单元组成的16×8阵列来模拟Plasticine,其时钟频率为1 GHz,主内存采用具有12.8 GB/s峰值带宽的DDR3-1600通道。表4展示了Plasticine CGRA在部分基准测试中相对于VU9P的DRAM带宽、资源利用率、运行时间和加速比。
在带宽受限的流式应用中,TPC-H Q6芯片能高效利用约97%的DRAM带宽资源。而计算密集型应用GDA、GEMM和K均值算法,则可充分利用Plasticine芯片约90%的计算单元。得益于该芯片更高的片上带宽,这些应用能更高效地利用计算资源,分别获得9.9×倍、55.0×倍和6.3×倍的加速效果。类似地,BlackScholes芯片的深度计算流水线经过多单元分割后,可占用73.4%的计算资源,实现1.6×倍的加速性能。
6相关工作
我们以定性比较Spatial与相关工作作为结尾,从第2节的标准中得出结论。
硬件描述语言(HDL)如Verilog和VHDL专为任意电路设计,为实现最大通用性,需要用户手动管理时序、控制信号和局部存储器。在扁平化RTL中,循环通过状态机表达。唯一的例外是Bluespec SystemVerilog [8],它支持从嵌套while循环进行状态机推断。近年来HDL的发展主要集中在元编程优化和硬件模块库规模扩展上。Chisel [9]、My- HDL [1]和VeriScala [23]等语言通过将HDL嵌入软件语言(如Scala或Python),简化了电路的程序化生成流程。类似地,Genesis2 [37]为SystemVerilog添加Perl脚本支持,助力程序化生成。尽管这些改进相比Verilog生成语句实现了更强大的元编程能力,但用户仍需在时序电路层面编写程序。
Lime Lime是IBM公司基于Java开发的编程模型与运行时环境,致力于为异构架构提供统一编程语言。该框架原生支持自定义位精度,并内置集合操作功能,其并行性由编译器自动推断。通过“任务”机制实现粗粒度流水线与数据并行处理,同时支持粗粒度流式计算。
计算图可通过内置的连接、分割和合并等构造函数进行构建。Lime运行时系统负责处理流图的缓冲、分区和调度任务。但该系统不支持偏离流式模型的粗粒度管道架构,开发者若需处理带有反馈循环的粗粒度图结构,必须通过底层消息传递API进行操作。此外,编译器未提供自动设计优化功能。最后需要指出的是,由于编译器对多维数据结构的银行化缓存实现细节未作具体说明(即如何针对任意访问模式进行缓存管理),其在实例化银行化存储器和缓冲内存方面的具体能力尚不明确。
诸如LegUp [12]、Vivado HLS [3]、英特尔OpenCL专用FPGA软件开发工具包[5]和SDAccel [42]等高级综合工具,允许用户使用C/C++语言和OpenCL编写FPGA设计方案。通过这些工具,应用程序可以采用数组和非时序嵌套循环的高层次表达方式。然而,尽管编译器负责处理内部循环流水线化、展开操作以及内存银行与缓冲机制,但通常仍需用户显式调用指令。虽然已有研究利用多面体工具实现了单个循环嵌套中仿射访问的自动银行决策[41],但尚未解决非仿射访问场景或多个循环嵌套中对同一内存进行访问的情况。尽管像Vivado HLS的DATAFLOW指令能有限支持嵌套循环流水线化,但目前仍无法实现任意层级循环嵌套的流水线化[2]。虽然Aladdin [38]等工具已开发用于自动化优化HLS程序中的指令调用,但HLS设计仍需人工进行硬件优化[26]。
MaxJ是由Maxeler公司开发的专有编程语言,允许用户通过Java库实现数据流算法,其核心优势在于采用“时钟周期”而非传统“周期”来精确描述有效流元素的运行时序[24]。当编写嵌套循环结构时,开发者仍需使用类似HDL的扁平化语法处理状态机。该语言通过相对流偏移量推断内存布局,这种设计虽然便于流处理操作,却将硬件实现细节对用户隐藏,而这些信息本可助力优化流程。此外,MaxJ的兼容性存在局限,目前仅支持在Maxeler FPGA平台进行开发。
DHDL精密硬件定义语言(DHDL)
[22] 是Spatial的前身,因为它允许程序员描述无时序、嵌套且可并行化的硬件流水线,并将其编译为硬件。虽然DHDL支持编译器感知的设计参数和自动设计调优,但它不支持数据依赖的控制流、流式处理或内存控制器专门化。DHDL也不支持通用内存组或缓冲技术,其重定时和启动间隔计算依赖于后端MaxJ。
图像处理专用语言(DSL)最近提出的图像处理专用语言为针对多种加速器平台(包括GPU和FPGA)提供了高层次的规范。
窄域允许这些DSL提供更简洁的服务
用于指定模板操作的抽象。在针对加速器进行优化时,这些语言通常依赖于源到源的转换。例如,HIPACC [25]使用基于类C前端的源到源编译器,生成CUDA、OpenCL和Renderscript以适配GPU。近期研究在Halide[35]上已证实具有目标异质性系统,包括Xilinx Zynq的FPGA和ARM内核,通过生成中间C++和Vivado HLS [33]。Rigel [20]和Darkroom [19]用于生成Verilog代码,而PolyMage [14]则通过OpenMP和C++进行高级综合设计。Rigel和暗盒支持在FPGA上生成专用存储结构(如行缓冲器),以实现资源复用。HIPACC可通过固定访问模式推断GPU上的内存层次结构。这些专用存储结构(DSL)能够捕捉给定模板中的并行性,通常涉及图像通道间及图像处理流水线的并行操作。
相较于图像处理专用软件开发工具包(DSL),Spatial框架具有更通用的特性,提供较低层次的抽象化设计。该框架能够为任意层级的循环结构实现流水线优化与展开操作,并在自动存储器组、缓冲区和结构复制的同时,显式呈现内存层次结构以适应各种访问模式。这些功能特性,结合Spatial独特的设计调优能力,使其成为图像处理专用软件开发工具包进行优化的天然后端目标平台。
7结论
在本研究中,我们提出了Spatial——一种专为可重构架构设计应用加速器开发的领域特定语言。该语言包含针对控制、内存和设计调优的硬件专用抽象层,有助于在生产效率与性能驱动型加速器设计之间取得平衡。我们已证明Spatial能够通过单一源代码适配多种可重构架构,并且相比SDAccel实现了平均2.9倍的加速效果,同时代码量减少42%。
spatial语言和编译器是斯坦福大学正在进行的开源项目。相关文档和发布内容可在https://spatial.stanford.edu找到。
A附录
A.1存储库和缓冲
图7展示了Spatial算法的伪代码,该算法通过循环嵌套机制对指定内存m进行访问缓存与缓冲。针对每次对m的访问操作,我们首先为该访问定义一个迭代域D。这个域是包含所有可能值的多维spatial,其中包含所有存在a但不存在m的循环迭代器。
然后,我们将m上的读写访问分组到“兼容”集合中,这些集合与同一物理地址并行出现。
function GroupAccesses:
input: A → set of reads or writes to m
G = ∅ set of sets of compatible accesses
for all accesses a in A:
for all sets of accesses д in G:
if IComp(a, a′) for all a′ in д then
add a to д
break
else add {a} to G
return G
end function
function ConfigureMemory:
input: Ar → set of reads of m
input: Aw → set of writes to m
Gr= GroupAccesses(Ar )
Gw = GroupAccesses(Aw )
I = ∅ set of memory instances
for all read sets R in Gr :
= {R}
Iw = ReachingWrites(Gw , Ir )
i = BankAndBuffer(Ir , Iw )
for each inst in I :
I ′r
= ReadSets[inst] + R
I ′w = ReachingWrites(Gw , I ′r )
if OComp(A1,A2) ∀A1 � A2 ∈ (Gw ∪ I ′r ) then:
i′ = BankAndBuffer(I ′r , I ′w )
if Cost(i′) < Cost(i) + Cost(inst) then:
remove inst from I
add i′ to I
break
if i has not been merged then add i to I
return I
end function
图7.用于计算片上存储器m的实例的银行和缓冲算法。
端口,但可以被银行化在一起(第1-14行)。如果两个访问a1和a2在迭代域D1和D2内是银行化兼容的(IComp),则
IComp (a1, a2) = ∃ ∈ (D1 ∪ D2) s.t. a1 () = r2 i(→)()i(→)i(→)
其中a(i)是对应于访问a的多维地址,该地址由迭代器值向量i生成。此检查可通过多面体空性测试来实现。
完成分组后,每个子组可以直接映射到m的某个连贯的“实例”或副本。不过这种方法通常会消耗超出实际需求的资源。为最大限度减少内存实例数量,我们接下来采用贪心算法进行合并操作(第25-39行)。当合并实例的成本低于为该子组单独创建连贯实例的成本时,就会执行合并操作。系统会生成两组
如果满足以下条件,A1和A2入口允许合并(OComp)
OComp(A1,A2)=∃(a1∈A1,a2∈A2),其中满足LCA(a1,a2)∈并行∪(管道∩内部)。
其中,Parallel、Pipe和Inner分别表示程序中的并行控制器、流水线控制器和内部控制器集合。若此条件成立,则两个实例之间的所有访问要么以顺序方式发生,要么作为粗粒度流水线的一部分发生。顺序访问可以进行时间复用,而流水线访问则会被缓冲。
Reaching writes返回每个集合中可能对给定读取集合中的任何读取可见的所有写入。如果写入可以在读取之前执行并且具有重叠的地址spatial,则可以实现可见性。
BankAndBuffer函数通过内存读写操作生成单一内存实例。在此机制中,每组访问操作都是对内存实例单个端口的并行读写操作。不同访问集之间被确保不会同时对同一端口进行操作。因此,我们发现了一种通用的银行策略,该策略能确保任何访问集都不会发生银行冲突。这种银行策略是通过王等人[41]提出的迭代多面体空性测试方法实现的。针对每个提出的访问策略,都会对每组并行访问操作单独执行空性测试。
一对访问a1和a2到m所需的缓冲深度d的计算方式为
其中dist表示最近公共祖先(LCA)的深度与包含a1和a2的两个直接子节点数据流距离中的较小值。Seq、Stream和Pipe分别代表顺序控制器、流式控制器和流水线控制器。当前暂不支持跨流访问时缓冲可寻址存储器的操作。读取操作集R与写入操作集W的深度则为
深度(R,W) = max{d(w,a)∀(w,a)∈W×(W∪R)}
缓冲区中每个访问的端口由所有缓冲访问之间的相对距离确定。spatial要求合并实例中最多只能包含一个粗粒度控制器或流式控制器。贪婪搜索的最终输出是内存m所需的一组物理内存实例。
致谢
作者谨此感谢匿名审稿人提供的宝贵意见。本研究部分由美国国防高级研究计划局(DARPA)通过协议号FA8750-17-2-0095、FA8750-12-2-0335和FA8750-14-2-0240,以及美国国家科学基金会(NSF)的SHF-1563078和IIS-1247701项目资助。根据美国政府授权,允许为官方用途复制及分发本论文摘要,即使存在版权标注亦不作影响。文中观点与结论仅代表作者立场,不应被解读为DARPA、NSF或美国政府的官方政策或认可,无论明示或暗示。
参考文献
[1] 2015. MyHDL. http://www.myhdl.org/.
[2] 2015. Vivado设计套件2015.1用户指南。
[3] 2016. Vivado高级综合。http://www.xilinx.com/products/ design-tools/vivado/integration/esl-design.html.
[4] 2017. [4] 2017年。配备FPGA的EC2 F1实例现已全面推出。aws.amazon.com/blogs/aws/ ec2-f1-instances-with-fpgas-now-generally-available/. [4] 2017年。配备FPGA的EC2 F1实例现已全面推出。aws.amazon.com/blogs/aws/ ec2-f1-instances-with-fpgas-now-generally-available/.
[5] 2017.英特尔开放CL专用FPGA软件开发工具包。https://www.altera.com/products/ design-software/embedded-software-developers/opencl/overview. html。
[6] 2017. Neon 2.0:针对英特尔架构优化。https://www. intelnervana.com/neon-2-0-optimized-for-intel-architectures/.
[7] 2017. [7] 2017年。Wave Computing推出机器学习设备。https://www.top500.org/news/ wave-computing-launches-machine-learning-appliance/. [7] 2017年。Wave Computing推出机器学习设备。https://www.top500.org/news/ wave-computing-launches-machine-learning-appliance/.
[8]阿文德(Arvind)。2003年。《Bluespec:一种用于硬件设计、仿真、综合与验证的语言》特邀报告。收录于首届ACM与IEEE联合举办的共设计形式化方法与模型国际会议(MEMOCODE‘03)论文集,IEEE计算机学会,美国华盛顿特区,第249页。http://dl.acm.org/citation.cfm?id=823453.823860
[9]贾·巴赫拉克、武辉、理查兹、李云硕、沃特曼、阿维齐尼斯、瓦夫日涅克与阿萨诺维奇。2012年。《Chisel:基于Scala嵌入式语言构建硬件》。收录于《设计自动化会议(DAC)》(第49届ACM/EDAC/IEEE会议),2012年,第1212–1221页。
[10] David Bacon,Rodric Rabbah和Sunil Shukla,2013年。面向大众的FPGA编程。Queue 11,2,Article 40(2013年2月),13页。
https://doi.org/10.1145/2436696.2443836
[11]布鲁诺·博丹、路易吉·纳尔迪、M·泽山·齐亚、哈里·瓦格斯塔夫、戈文德·斯里卡尔·谢诺伊、穆拉利·埃马尼、约翰·莫尔、克里斯托斯·科特塞利迪斯、安迪·尼斯贝特、米克尔·卢扬、比约恩·弗兰克、保罗·H·J·凯利和迈克尔·奥博伊尔。2016年。《将算法参数整合到三维场景理解的基准测试与设计spatial探索中》。收录于PACT会议论文集。
[12]安德鲁·卡尼斯、崔宗硕、马克·奥尔德姆、张维克、艾哈迈德·卡穆纳、杰森·H·安德森、斯蒂芬·布朗与托马什·查伊科夫斯基。2011年。《LegUp:基于FPGA的处理器/加速器系统高级综合方案》。收录于第十九届ACM/SIGDA国际现场可编程门阵列研讨会论文集(FPGA‘11)。美国纽约州纽约市,ACM出版社,第33-36页。https://doi.org/10.1145/1950413.1950423
[13] C. Cascaval,S. Chatterjee,H. Franke,K. J. Gildea和P. Pattnaik。
2010年。加速器体系结构及其编程模型的分类。IBM研究与发展期刊54,5(2010年9月),5:1-5:10。
[14] Nitin Chugh,Vinay Vasista,Suresh Purini和Uday Bondhugula。
2016年,发表《用于加速FPGA上图像处理流水线的DSL编译器》一文于《并行体系结构与编译技术》期刊(PACT),该论文收录于2016年国际会议论文集,IEEE出版,第327-338页。
[15] Bjorn De Sutter,Praveen Raghavan和Andy Lambrechts。2013年。
粗粒度可重构阵列架构。纽约:Springer出版社,第553-592页。https://doi.org/10.1007/978-1-4614-6859-2_ 18
[16]凯文·法塔哈里安、丹尼尔·赖特·霍恩、蒂莫西·J·奈特、拉尔洪·李姆、迈克·休斯顿、朴智英、马坦·埃雷兹、任曼曼、亚历克斯·艾肯、威廉·J·达利和帕特·汉拉汉。2006年。《红杉:内存层次结构编程》。收录于2006年ACM/IEEE超级计算会议(SC‘06)论文集。美国纽约ACM出版社,第83篇论文。https://doi.org/10.1145/1188455.1188543
[17] V.戈文达拉朱、C. H.何、T.诺瓦茨基、J.楚加尼、N.萨蒂什、K.桑卡-阿林甘和C.金。2012年。DySER:统一功能与并行化专门化以实现节能计算。IEEE Micro 32,5(2012年9月),38–51。https://doi.org/10.1109/MM.2012.51
[18] Prabhat K.古普塔.2015年.数据中心的Xeon+FPGA平台.http://www.ece.cmu.edu/~calcm/carl/lib/exe/fetch.php?media= carl15-gupta.pdf.
[19]詹姆斯·赫加蒂、约翰·布鲁纳弗、扎卡里·德维托、乔纳森·拉根-凯利、诺伊·科恩、史蒂文·贝尔、阿尔捷姆·瓦西里耶夫、马克·霍罗威茨和帕特·汉拉汉。2014年。《暗室:将高级图像处理代码编译为硬件流水线》。ACM图形学汇刊33卷4期(2014),第144–1页。
[20]詹姆斯·赫加蒂、罗斯·戴利、扎卡里·德维托、乔纳森·拉根-凯利、马克·霍罗威茨和帕特·汉拉汉。2016年。Rigel:灵活多速率图像处理硬件。ACM图形学汇刊(TOG)35卷4期(2016),第85页。
[21]英特尔公司。2015年。先进NAND闪存单芯片存储解决方案。<_ga=2.108749825.2041564619.1502344247-21903935.1501673108.1>-flash-memory-controller.html?_ga=2.108749825.2041564619.1502344247-21903935.1501673108.
[22]大卫·科普林格、拉古·普拉巴卡尔、张亚奇、克里斯蒂娜·德利米特鲁、克里斯托斯·科齐拉基斯和昆勒·奥卢科顿。2016年。可重构硬件高效加速器的自动生成。收录于国际计算机体系结构研讨会(ISCA)。
[23]刘燕强、李瑶、熊伟伦、赖梦、陈成、齐正伟、管海兵. 2017.基于Scala的FPGA设计流程.收录于《2017年ACM/SIGDA国际现场可编程门阵列研讨会论文集》.ACM,286–286.
[24] Maxeler Technologies. 2011. MaxCompiler白皮书。
[25]理查德·门巴特、奥利弗·赖歇、弗兰克·汉尼格、于尔根·泰希、马里奥·科纳与维尔兰德·埃克特。2016年。《Hipa cc:专为图像处理设计的领域特定语言及编译器》。IEEE并行与分布式系统汇刊第27卷第1期(2016),210-224页。
[26]拉兹万·纳内、弗拉德-米哈伊·西马、克里斯蒂安·皮拉托、崔宗硕、布莱尔·福特、安德鲁·卡尼斯、陈玉婷、黄献孝、斯蒂芬·布朗、法布里齐奥·费兰迪等学者。2016年发表于《IEEE集成电路与系统计算机辅助设计汇刊》第35卷第10期(2016年)的论文《PGA高阶综合工具综述与评估》,页码1591–1604。
[27]路易吉·纳尔迪、布鲁诺·博丹、萨贾德·赛义迪、埃马努埃莱·韦斯帕、安德鲁·J。
戴维森与保罗·H·J·凯利。2017年。基于HyperMapper的三维视觉应用算法性能与精度权衡研究。收录于iWAPT- IPDPS会议论文集。http://arxiv.org/abs/1702.00505
[28]路易吉·纳尔迪、布鲁诺·博丹、齐山·齐亚教授、约翰·莫尔、安迪·尼斯贝特、保罗·H·J·凯利、安德鲁·J·戴维森、米克尔·卢扬、迈克尔·FP·奥博伊尔、格雷厄姆·莱利等学者于2015年在ICRA会议上共同发布了《SLAMBench性能与精度基准测试方法论》。
[29]建欧阳、林世定、魏琦、王勇、余波和宋江。
2014年:SDA:用于大规模DNN系统的软件定义加速器(Hot Chips 26)。
[30]安格苏曼·帕拉沙尔、迈克尔·佩劳尔、迈克尔·阿德勒、布什拉·阿桑、尼尔·克拉戈、丹尼尔·卢斯蒂格、弗拉基米尔·帕夫洛夫、安东尼亚·柴、莫希特·甘比尔、阿米尔·贾利尔、兰迪·奥尔蒙、拉希德·雷耶斯、斯蒂芬·马雷什和乔尔·埃默。2013年。触发式指令:spatial编程架构的控制范式。收录于第40届国际计算机体系结构研讨会论文集(ISCA‘13)。美国纽约ACM出版社,142–153页。https://doi.org/10.1145/2485922.2485935
[31]安格苏曼·帕拉沙尔、敏苏·鲁、阿努拉格·穆卡拉、安东尼奥·普利耶利、兰加拉詹·文卡泰桑、布鲁斯克·凯拉尼、乔尔·埃默、斯蒂芬·W·凯克勒和威廉·J·达利。2017年。SCNN:压缩稀疏卷积神经网络加速器。收录于第44届国际计算机体系结构年会论文集,ACM出版社,27-40页。
[32]拉古·普拉巴卡尔、张亚奇、大卫·科普林格、马修·费尔德曼、赵天、斯特凡·哈吉斯、阿尔达万·佩德拉姆、克里斯托斯·科齐拉基斯和昆乐·奥卢科顿。2017年。Plasticine:一种用于并行模式的可重构架构。收录于第44届国际计算机体系结构年会(ISCA 2017)论文集,加拿大安大略省多伦多市,2017年6月24日至28日。389–402页。https://doi.org/10.1145/3079856.3080256
[33]石景普、史蒂文·贝尔、杨璇、杰夫·塞特、斯蒂芬·理查森、乔纳森·拉根-凯利与马克·霍罗威茨。2016年。基于图像处理领域特定语言编程异构系统。CoRR abs/1610.09405(2016)。arXiv:1610.09405http://arxiv.org/abs/1610. 09405
[34]安德鲁·普特南、阿德里安·M·考尔菲尔德、埃里克·S·钟、德里克·邱、基普罗斯·康斯坦丁尼德斯、约翰·德米、哈迪·伊斯梅尔扎德、杰里米·福尔斯、戈皮·普拉山特·戈帕尔、简·格雷、迈克尔·哈塞尔曼、斯科特·豪克、斯蒂芬·海尔、阿米尔·霍尔马蒂、金周永、西塔拉姆·兰卡、詹姆斯·拉勒斯、埃里克·彼得森、西蒙·波普、亚伦·史密斯、杰森·通、菲利普·易·肖和道格·伯格。2014年。一种可重构架构以加速大规模数据中心服务。收录于第41届国际计算机体系结构研讨会论文集(ISCA‘14)。IEEE出版社,美国新泽西州皮斯卡塔韦,13–24页。http://dl.acm.org/citation.cfm?id= 2665671.2665678
[35]乔纳森·拉根-凯利、康奈利·巴恩斯、安德鲁·亚当斯、西尔万·帕里斯、弗雷多·杜兰德与萨曼·阿马拉辛格。2013年。《Halide:一种用于优化图像处理流水线并行性、局部性和重计算的语言与编译器》。收录于第34届ACM SIGPLAN编程语言设计与实现会议论文集(PLDI‘13)。美国纽约州纽约市,ACM出版社,519–530页。
https://doi.org/10.1145/2491956.2462176
[36]萨贾德·赛义迪、路易吉·纳尔迪、爱德华·约翰斯、布鲁诺·博丹、保罗·凯利和安德鲁·戴维森。2017年。面向应用的SLAM算法设计spatial探索。见ICRA会议论文集。
[37]奥弗·沙查姆. 2011.芯片多处理器生成器:自动生成定制和异构计算平台.斯坦福大学。
[38] Yakun Sophia Shao,Brandon Reagen,Gu-Yeon Wei和David Brooks。
2014年。《阿拉丁:一种基于RTL前的功耗性能加速器模拟器,支持定制架构的大规模设计spatial探索》发表于《计算机体系结构(ISCA)》期刊,收录于第41届ACM/IEEE国际研讨会论文集,IEEE出版,第97-108页。
[39] Arvind K.苏吉特, 凯文·J·布朗, 李炯中, 蒂亚克·罗姆普夫, 哈桑·查菲, 马丁·奥德斯基与昆勒·奥卢科顿.2014年.《Delite:面向性能的嵌入式领域特定语言编译器架构》.收录于《TECS‘14:ACM嵌入式计算系统汇刊》.
[40]斯瓦加斯·文卡塔拉马尼、阿什什·兰詹、苏巴尔诺·班纳吉、迪潘卡尔·达斯、萨西坎特·阿万查、阿肖克·贾格纳坦、阿贾亚·杜尔格、迪曼斯·纳加拉杰、巴拉特·考尔、普拉迪普·杜贝和阿南德·拉古纳桑。2017年。ScaleDeep:一种用于学习和评估深度网络的可扩展计算架构。收录于第44届国际计算机体系结构研讨会论文集(ISCA‘17)。美国纽约ACM,2017年10月13-26日。https://doi.org/10.1145/3079856.3080244
[41]王玉欣、李鹏与曾杰森. 2014.高级综合中广义存储器分区的理论与算法.收录于《2014年ACM/SIGDA现场可编程门阵列国际研讨会论文集》(FPGA‘14),美国纽约州纽约市ACM出版社,第199-208页。https://doi.org/10.1145/2554688.2554780
[42] Xilinx. 2014. The Xilinx SDAccel Development En-viro-men-t.https://www.xilinx.com/publications/prod_mktg/sdx/sdaccel-backgrounder.pdf. [42] Xilinx. 2014. The Xilinx SDAccel Development En-viro-men-t.https://www.xilinx.com/publications/prod_mktg/sdx/sdaccel-backgrounder.pdf. [42] Xilinx. 2014. The Xilinx SDAccel Development En-viro-men-t.https://www.xilinx.com/publications/prod_mktg/sdx/sdaccel-backgrounder.pdf.
[43]希捷公司。2017。HLS指令集。https://www.xilinx.com/html_docs/ xilinx2017_2/sdaccel_doc/topics/pragmas/concept-Intro_to_HLS_ pragmas.html。
[44]希捷科技。2017年。SDAccel数据流指令。https://www.xilinx.com/ html_docs/xilinx2017_2/sdaccel_doc/topics/pragmas/ref-pragma_ HLS_dataflow.html。
[45] Xilinx. 2017. SDAccel示例库。https://github.com/Xilinx/ SDAccel_Examples。
[1] 2015. MyHDL. http://www.myhdl.org/.
[2] 2015. Vivado design suite 2015.1 user guide.
[3] 2016. Vivado High-Level Synthesis. http://www.xilinx.com/products/
design-tools/vivado/integration/esl-design.html.
[4] 2017. EC2 F1 Instances with FPGAs âĂŞ Now Generally Available.
aws.amazon.com/blogs/aws/ec2-f1-instances-with-fpgas-now-generally-available/.
[5] 2017. Intel FPGA SDK for OpenCL. https://www.altera.com/products/
design-software/embedded-software-developers/opencl/overview.html.
[6] 2017.Neon 2.0: Optimized for Intel Architectures.
https://www.intelnervana.com/neon-2-0-optimized-for-intel-architectures/.
[7] 2017.Wave Computing Launches Machine Learn-ing Appliance.
https://www.top500.org/news/
wave-computing-launches-machine-learning-appliance/.
[8] Arvind. 2003. Bluespec: A Language for Hardware Design, Simulation,
Synthesis and Verification. Invited Talk. In Proceedings of the First ACM
and IEEE International Conference on Formal Methods and Models for
Co-Design (MEMOCODE ’03). IEEE Computer Society, Washington,
DC, USA, 249–. http://dl.acm.org/citation.cfm?id=823453.823860
[9] J. Bachrach, Huy Vo, B. Richards, Yunsup Lee, A. Waterman, R. Avizie-
nis, J. Wawrzynek, and K. Asanovic. 2012. Chisel: Constructing hard-
ware in a Scala embedded language. In Design Automation Conference
(DAC), 2012 49th ACM/EDAC/IEEE. 1212–1221.
[10] David Bacon, Rodric Rabbah, and Sunil Shukla. 2013. FPGA Program-
ming for the Masses. Queue 11, 2, Article 40 (Feb. 2013), 13 pages.
https://doi.org/10.1145/2436696.2443836
[11] Bruno Bodin, Luigi Nardi, M. Zeeshan Zia, Harry Wagstaff, Govind
Sreekar Shenoy, Murali Emani, John Mawer, Christos Kotselidis, Andy
Nisbet, Mikel Lujan, Björn Franke, Paul H.J. Kelly, and Michael O’Boyle.
Integrating Algorithmic Parameters into Benchmarking and
Design Space Exploration in 3D Scene Understanding. In PACT.
[12] Andrew Canis, Jongsok Choi, Mark Aldham, Victor Zhang, Ahmed
Kammoona, Jason H. Anderson, Stephen Brown, and Tomasz Cza-
jkowski. 2011. LegUp: High-level Synthesis for FPGA-based Proces-
sor/Accelerator Systems. In Proceedings of the 19th ACM/SIGDA Interna-
tional Symposium on Field Programmable Gate Arrays (FPGA ’11). ACM,
New York, NY, USA, 33–36. https://doi.org/10.1145/1950413.1950423
[13] C. Cascaval, S. Chatterjee, H. Franke, K. J. Gildea, and P. Pattnaik.
A taxonomy of accelerator architectures and their programming models. IBM Journal of Research and Development 54, 5 (Sept 2010), 5:1–5:10.
[14] Nitin Chugh, Vinay Vasista, Suresh Purini, and Uday Bondhugula.
A DSL compiler for accelerating image processing pipelines on
FPGAs. In Parallel Architecture and Compilation Techniques (PACT),
2016 International Conference on. IEEE, 327–338.
[15] Bjorn De Sutter, Praveen Raghavan, and Andy Lambrechts. 2013.
Coarse-Grained Reconfigurable Array Architectures. Springer New York,
New York, NY, 553–592. https://doi.org/10.1007/978-1-4614-6859-2_18
[16] Kayvon Fatahalian, Daniel Reiter Horn, Timothy J. Knight, Larkhoon
Leem, Mike Houston, Ji Young Park, Mattan Erez, Manman Ren, Alex
Aiken, William J. Dally, and Pat Hanrahan. 2006. Sequoia: Program-
ming the Memory Hierarchy. In Proceedings of the 2006 ACM/IEEE
Conference on Supercomputing (SC ’06). ACM, New York, NY, USA,
Article 83. https://doi.org/10.1145/1188455.1188543
[17] V. Govindaraju, C. H. Ho, T. Nowatzki, J. Chhugani, N. Satish, K. Sankar-
alingam, and C. Kim. 2012. DySER: Unifying Functionality and Paral-
lelism Specialization for Energy-Efficient Computing. IEEE Micro 32,
5 (Sept 2012), 38–51. https://doi.org/10.1109/MM.2012.51
[18] Prabhat K. Gupta. 2015. Xeon+FPGA Platform for the Data Cen-
ter. http://www.ece.cmu.edu/~calcm/carl/lib/exe/fetch.php?media=
carl15-gupta.pdf.
[19] James Hegarty, John Brunhaver, Zachary DeVito, Jonathan Ragan-
Kelley, Noy Cohen, Steven Bell, Artem Vasilyev, Mark Horowitz, and
Pat Hanrahan. 2014. Darkroom: compiling high-level image processing
code into hardware pipelines. ACM Trans. Graph. 33, 4 (2014), 144–1.
[20] James Hegarty, Ross Daly, Zachary DeVito, Jonathan Ragan-Kelley,
Mark Horowitz, and Pat Hanrahan. 2016. Rigel: Flexible multi-rate
image processing hardware. ACM Transactions on Graphics (TOG) 35,
4 (2016), 85.
[21] Intel. 2015. Advanced NAND Flash Memory Single-Chip Storage
Solution. www.altera.com/b/nand-flash-memory-controller.html?
_ga=2.108749825.2041564619.1502344247-21903935.1501673108.
[22] David Koeplinger, Raghu Prabhakar, Yaqi Zhang, Christina Delimitrou,
Christos Kozyrakis, and Kunle Olukotun. 2016. Automatic Generation
of Efficient Accelerators for Reconfigurable Hardware. In International
Symposium in Computer Architecture (ISCA).
[23] Yanqiang Liu, Yao Li, Weilun Xiong, Meng Lai, Cheng Chen, Zheng-
wei Qi, and Haibing Guan. 2017. Scala Based FPGA Design Flow.
In Proceedings of the 2017 ACM/SIGDA International Symposium on
Field-Programmable Gate Arrays. ACM, 286–286.
[24] Maxeler Technologies. 2011. MaxCompiler white paper.
[25] Richard Membarth, Oliver Reiche, Frank Hannig, Jürgen Teich, Mario
Körner, and Wieland Eckert. 2016. Hipa cc: A domain-specific language
and compiler for image processing. IEEE Transactions on Parallel and
Distributed Systems 27, 1 (2016), 210–224.
[26] Razvan Nane, Vlad-Mihai Sima, Christian Pilato, Jongsok Choi, Blair
Fort, Andrew Canis, Yu Ting Chen, Hsuan Hsiao, Stephen Brown,
Fabrizio Ferrandi, et al. 2016. A survey and evaluation of fpga high-
level synthesis tools. IEEE Transactions on Computer-Aided Design of
Integrated Circuits and Systems 35, 10 (2016), 1591–1604.
[27] Luigi Nardi, Bruno Bodin, Sajad Saeedi, Emanuele Vespa, Andrew J.
Davison, and Paul H. J. Kelly. 2017. Algorithmic Performance-Accuracy
Trade-off in 3D Vision Applications Using HyperMapper. In iWAPT-
IPDPS. http://arxiv.org/abs/1702.00505
[28] Luigi Nardi, Bruno Bodin, M Zeeshan Zia, John Mawer, Andy Nisbet,
Paul HJ Kelly, Andrew J Davison, Mikel Luján, Michael FP O’Boyle,
Graham Riley, et al. 2015. Introducing SLAMBench, a Performance
and Accuracy Benchmarking Methodology for SLAM. In ICRA.
[29] Jian Ouyang, Shiding Lin, Wei Qi, Yong Wang, Bo Yu, and Song Jiang.
SDA: Software-Defined Accelerator for LargeScale DNN Systems (Hot Chips 26).
[30] Angshuman Parashar, Michael Pellauer, Michael Adler, Bushra Ah-
san, Neal Crago, Daniel Lustig, Vladimir Pavlov, Antonia Zhai, Mohit
Gambhir, Aamer Jaleel, Randy Allmon, Rachid Rayess, Stephen Maresh,
and Joel Emer. 2013. Triggered Instructions: A Control Paradigm for
Spatially-programmed Architectures. In Proceedings of the 40th Annual
International Symposium on Computer Architecture (ISCA ’13). ACM,
New York, NY, USA, 142–153. https://doi.org/10.1145/2485922.2485935
[31] Angshuman Parashar, Minsoo Rhu, Anurag Mukkara, Antonio
Puglielli, Rangharajan Venkatesan, Brucek Khailany, Joel Emer,
Stephen W Keckler, and William J Dally. 2017. SCNN: An Accelerator
for Compressed-sparse Convolutional Neural Networks. In Proceedings
of the 44th Annual International Symposium on Computer Architecture.
ACM, 27–40.
[32] Raghu Prabhakar, Yaqi Zhang, David Koeplinger, Matthew Feldman,
Tian Zhao, Stefan Hadjis, Ardavan Pedram, Christos Kozyrakis, and
Kunle Olukotun. 2017. Plasticine: A Reconfigurable Architecture For
Parallel Paterns. In Proceedings of the 44th Annual International Sympo-
sium on Computer Architecture, ISCA 2017, Toronto, ON, Canada, June
24-28, 2017. 389–402. https://doi.org/10.1145/3079856.3080256
[33] Jing Pu, Steven Bell, Xuan Yang, Jeff Setter, Stephen Richardson, Jonathan Ragan-Kelley, and Mark Horowitz. 2016.
Programming Heterogeneous Systems from an Image Processing DSL. CoRR abs/1610.09405 (2016).
arXiv:1610.09405 http://arxiv.org/abs/1610.09405
[34] Andrew Putnam, Adrian M. Caulfield, Eric S. Chung, Derek Chiou,
Kypros Constantinides, John Demme, Hadi Esmaeilzadeh, Jeremy Fow-
ers, Gopi Prashanth Gopal, Jan Gray, Michael Haselman, Scott Hauck,
Stephen Heil, Amir Hormati, Joo-Young Kim, Sitaram Lanka, James
Larus, Eric Peterson, Simon Pope, Aaron Smith, Jason Thong, Phillip Yi
Xiao, and Doug Burger. 2014. A Reconfigurable Fabric for Accelerat-
ing Large-scale Datacenter Services. In Proceeding of the 41st Annual
International Symposium on Computer Architecuture (ISCA ’14). IEEE
Press, Piscataway, NJ, USA, 13–24. http://dl.acm.org/citation.cfm?id=
2665671.2665678
[35] Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain
Paris, Frédo Durand, and Saman Amarasinghe. 2013. Halide: A Lan-
guage and Compiler for Optimizing Parallelism, Locality, and Re-
computation in Image Processing Pipelines. In Proceedings of the
34th ACM SIGPLAN Conference on Programming Language Design
and Implementation (PLDI ’13). ACM, New York, NY, USA, 519–530.
https://doi.org/10.1145/2491956.2462176
[36] Sajad Saeedi, Luigi Nardi, Edward Johns, Bruno Bodin, Paul Kelly, and
Andrew Davison. 2017. Application-oriented Design Space Exploration
for SLAM Algorithms. In ICRA.
[37] Ofer Shacham. 2011. Chip multiprocessor generator: automatic genera-tion of custom and heterogeneous compute platforms. Stanford Univer-sity.
[38] Yakun Sophia Shao, Brandon Reagen, Gu-Yeon Wei, and David Brooks.
Aladdin: A pre-RTL, power-performance accelerator simulator
enabling large design space exploration of customized architectures.
In Computer Architecture (ISCA), 2014 ACM/IEEE 41st International
Symposium on. IEEE, 97–108.
[39] Arvind K. Sujeeth, Kevin J. Brown, HyoukJoong Lee, Tiark Rompf, Hassan Chafi, Martin Odersky, and Kunle Olukotun. 2014. Delite: A Compiler Architecture for Performance-Oriented Embedded Domain-Specific Languages. In TECS’14: ACM Transactions on Embedded Com-puting Systems.
[40] Swagath Venkataramani, Ashish Ranjan, Subarno Banerjee, Dipankar
Das, Sasikanth Avancha, Ashok Jagannathan, Ajaya Durg, Dheemanth
Nagaraj, Bharat Kaul, Pradeep Dubey, and Anand Raghunathan. 2017.
ScaleDeep: A Scalable Compute Architecture for Learning and Evalu-
ating Deep Networks. In Proceedings of the 44th Annual International
Symposium on Computer Architecture (ISCA ’17). ACM, New York, NY,
USA, 13–26. https://doi.org/10.1145/3079856.3080244
[41] Yuxin Wang, Peng Li, and Jason Cong. 2014. Theory and Algorithm
for Generalized Memory Partitioning in High-level Synthesis. In Pro-
ceedings of the 2014 ACM/SIGDA International Symposium on Field-
programmable Gate Arrays (FPGA ’14). ACM, New York, NY, USA,
199–208. https://doi.org/10.1145/2554688.2554780
[42] Xilinx. 2014.
The Xilinx SDAccel Development Environment.
https://www.xilinx.com/publications/prod_mktg/sdx/sdaccel-backgrounder.pdf.
[43] Xilinx. 2017. HLS Pragmas.
https://www.xilinx.com/html_docs/xilinx2017_2/sdaccel_doc/topics/pragmas/concept-Intro_to_HLS_
pragmas.html.
[44] Xilinx. 2017. SDAccel DATAFLOW pragma. https://www.xilinx.com/
html_docs/xilinx2017_2/sdaccel_doc/topics/pragmas/ref-pragma_
HLS_dataflow.html.
[45] Xilinx. 2017. SDAccel Example Repository. https://github.com/Xilinx/
SDAccel_Examples.
允许为个人或课堂教学目的制作本作品全部或部分内容的数字或实体副本,无需支付费用。但须遵守以下条件:不得以盈利或商业利益为目的进行复制或分发,并且所有副本需在首页标注版权声明及完整引用信息。对于非作者方持有的作品组成部分版权,必须予以尊重。允许在注明出处的情况下进行摘要引用。如需以其他方式复制、重新发布、上传至服务器或向邮件列表转发,需事先获得特别授权并/或支付费用。相关授权申请请咨询permissions@acm.org。PLDI‘18会议于2018年6月18日至22日在美国宾夕法尼亚州费城举行。
®2018版权所有,由所有者/作者(s)持有。出版权利授权给计算机协会。
ACM ISBN 978-1-4503-5698-5/18/06... $15.00

 浙公网安备 33010602011771号
浙公网安备 33010602011771号