
mysql 索引 零记
索引算法
二分查找法/折半查找法
伪算法 :
1. 前提,数据需要有序
2. 确定数据中间元素 K
3. 比如目标元素 A与K的大小
3.1 相等则找到
3.2 小于时在左区间
3.3 大于时在右区间
4. 重复以上过程,直到找到或遍历完所有数据
优点:比较次数少,查找速度快,总体性能好
缺点:要求数据有序,插入数据困难(因为有序,插入时要先找到位置)
二叉树
每个节点最多有两个子树
左节点永远小于右节点
最大层数为树的高度,无层数限制
下面文章有更详细的说明
https://www.jianshu.com/p/bf73c8d50dc2
平衡二叉树
当数据量大时,二叉树高度较大,查询复杂度上升,于是有了平衡二叉树,特点如下
左右两个子树的高度差的绝对值不超过1,依旧是二叉树
不满足上述条件时,会通过自旋,达到上述条件,故该二叉树不存在严重的数据倾斜现象,查询最坏/最好的时间复杂度都维持在O(logN)。
详细可参考
https://www.cnblogs.com/zhangbaochong/p/5164994.html
B树,平衡多叉树,又叫B-tree/B-树
一个结点的子树节点个数不限
可满足大量数据的读写,普遍运用于数据库、文件系统
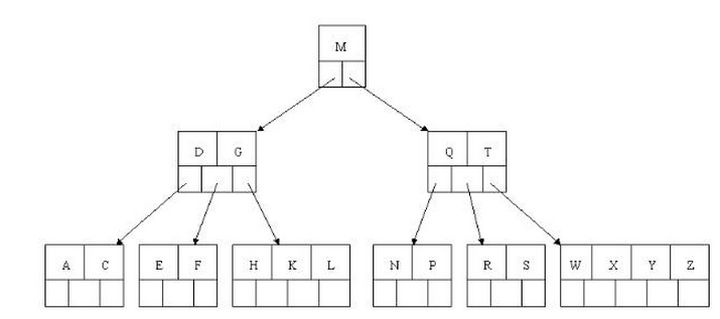
排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
有N个子结点的非叶子结点包含N-1个键值(索引节点),比如上图中DG所在结点有两个键值(D与G)、三个叶子结点
详细参考
https://zhuanlan.zhihu.com/p/27700617
B+树
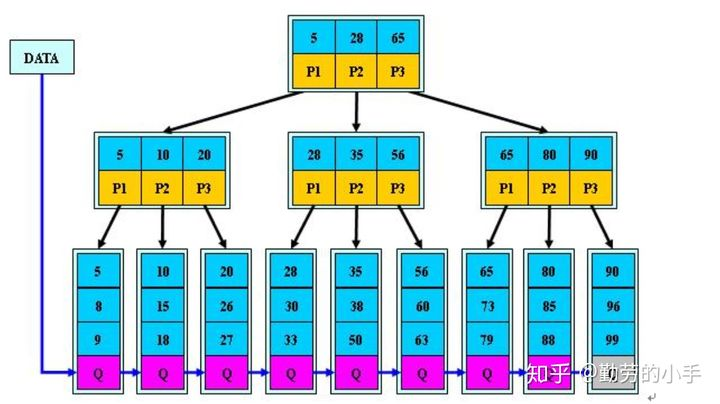
非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
所有数据都保存在叶子结点
B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
详细参考
https://my.oschina.net/u/4116286/blog/3107389
B*树
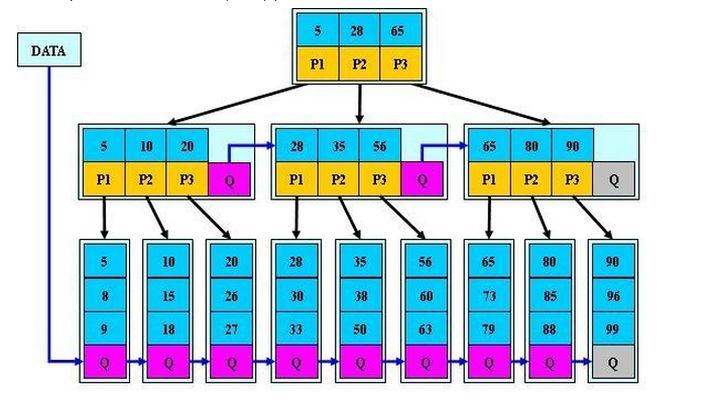
B*树是B+树的变种,相对于B+树他们的不同之处如下:
首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b*树的初始化个数为(cei(2/3*m))
B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来;
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树额分解次数变得更少;
哈希索引/散列索引
mysql> select crc32(11); +------------+ | crc32(11) | +------------+ | 3596227959 | +------------+ 1 row in set (0.00 sec)
通过对键值key进行hash运算得到一个code,该code指向数据行;
innodb中不常用, NDB中使用
大量、唯一、等值查询,HASH索引效率高于B+Tree,原因是IO次数少,HASH索引一次就能找到数据,B+Tree需要2-3次
联合索引时,所有列必须同时出现,并且都是等值查询
HASH索引不支持范围、排序、模糊查询
HASH索引只能显式应用于HEAP/MEMORY/NDB表
在等值查询这一领域里,HASH算法优于B+Tree,综合性不如B+Tree
HASH索引与innodb内部的自应用HASH索引是两个概念

 浙公网安备 33010602011771号
浙公网安备 33010602011771号