数据挖掘导论 第二章 知识总结
第二章数据相关内容主要就是一下四个(需要熟练掌握)
1.数据属性与对象
2.数据性质与类型
3.数据质量
4.数据相似性与相异性度量
一.数据概念
数据:是数据对象的集合。
数据对象又称作记录,点,向量,模式,事件,样本,观测,实体。数据对象用一组刻画其基本性质的属性描述。
(1).属性
属性是对象的性质或特征。eg:人的体重身高,眼睛颜色
属性值:为分析属性而赋予属性以数字或符号,称为属性值。
属性与属性值的区别:
—同一属性可以映射到不同的属性值
—同一属性值可以映射到不同属性值
(2).属性类型:离散型和连续型(用值的个数描述属性)任何测量标度类型都可以与基于值个数的的任意类型来组合。
离散型:以符号和整数作为属性值,具有有限个或无限个可数个值,eg:人的年龄,性别,成绩等级。注意:二进制属性是离散属性。
连续属性:以实数作为属性值。eg:温度,体重,身高。连续属性一般表示为浮点变量。
(3).非对称属性:只重视少数非零属性值才有意义,则称为非对称属性。
二.数据性质和类型
(1).数据一般特性
1.维数:数据集属性的数目。分析高纬度数据时容易陷入维度灾害。数据预处理的一个重要动机就是减少维度,即维归约。那么什么维度灾害?
维度灾难:是指在样本容量大小不变的情况下,不断的增加特征维数时,模型的效果反而下降
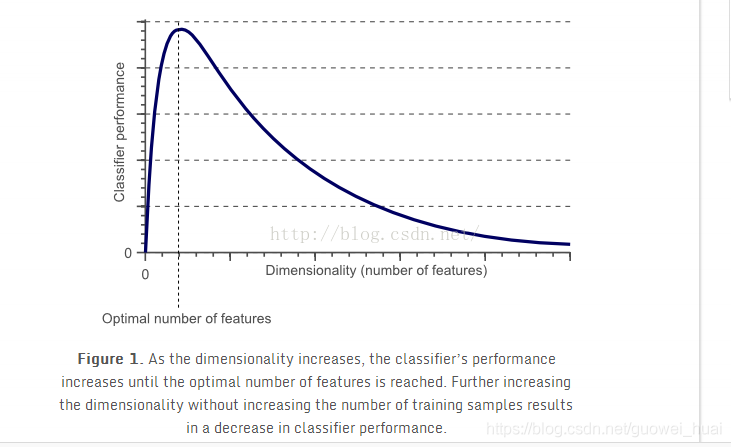
也就是说要实现相同的模型效果,高纬度数据模型所需样本数量远大于低纬度数据模型所需要的样本数量。
如何理解维度灾害?
随着维度的增加,数据在特征空间中越来越稀疏,导致了过拟合,学习了噪声和异常值。
怎样解决维度灾害?
在处理维度灾难的时候,我们可以通过增加数据集、正则化、降低维度等方法来解决。
但是增加数据集需要我们指数型增加,使得数据密度合理,这样是比较困难的,所以我们一般采用降低维度的方法。
如何避免维度灾难?
使用不同算法使得维度平衡
党模型较为复杂的时候,不要选择太高的维度;当模型简单的时候。可以选择较高的维度。主要考虑是否需要增加维度,提供非线性的问题。
——非线性决策边界的分类器(例如神经网络、KNN分类器、决策树等)分类效果好但是泛化能力差且容易发生过拟合。因此,维度不能太高。
——使用泛化能力好的分类器(例如贝叶斯分类器、线性分类器),可以使用更多的特征,因为分类器模型并不复杂。
泛化能力:机器学习算法对新鲜样本的适应能力。
因此,过拟合只在高维空间中预测相对少的参数和低维空间中预测多参数这两种情况下发生。
2.稀疏性:有点数据集如非对称属性的数据集,这样可以只存储非零值,大大减少了存储空间(稀疏矩阵)
3.分辨率:数据对象依赖分辨率,分辨率太小,数据对象可能不出现,分辨率太大,数据对象可能看不出来。
4.数据集类型:记录,图,序列
三.数据质量
常见数据质量问题:
—噪声
—异常值:是极少数数据对象的特征值与数据集中大多数对象由显著不用
—缺失值:数据并总不是完备的,原因:
—没有收集到信息
—属性不一定适用于所有情况,如:收入不适用于儿童
可能需要推测去补全
—重复值:数据来源不同导致数据重复。
—不一致值:同一属性值格式编码不一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号