
mysql order by语句流程是怎么样的
order by流程是怎么样的
注意点:
select id, name,age,city from t1 where city='杭州' order by age limit 1000;
order by 和limit一般共同出现使用。他的流程是什么呢?
-
首先依然会走连接器,分析器,优化器选择索引。查看sql语句执行计划,一定要多使用explain sql语句。能发现很多事情。
-
排序避免全表扫描,我们排序字段需要尽可能有索引,explain sql语句由
Using filesort字段,代表需要使用排序。 -
排序需要先读出数据,读出的数据需要在内存里面开辟一个空间来存数据。这块空间叫
sort_buffer,由参数sort_buffer_size控制。 -
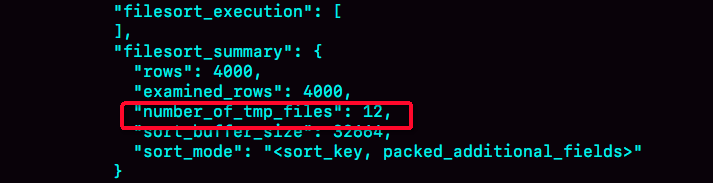
如果排序数据量过大。超过了自己sort_buffer空间的大小,怎么办?这是就会用额外的磁盘临时文件来辅助排序。这种情况下,性能就会非常低。通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。12代表使用了12个磁盘文件,这种外部排序一般使用归并排序算法。
-
sort_buffer空间的数据,每行长度也有限制,排序后查询的结果字段太多,就会存在放不下,这种情况下,mysql会使用rowid排序算法。这个算法在sort_buffer空间不用取出全部字段,只取排序字段age。排序后查询limit限制的100。然后根据主机id再去索引树上取得其他字段的值。
-
排序过程中需要排序这个过程,如果我们索引字段上排序,索引本来就有顺序,就不需要排序了。这样explain里面就没有user filesort关键字了。
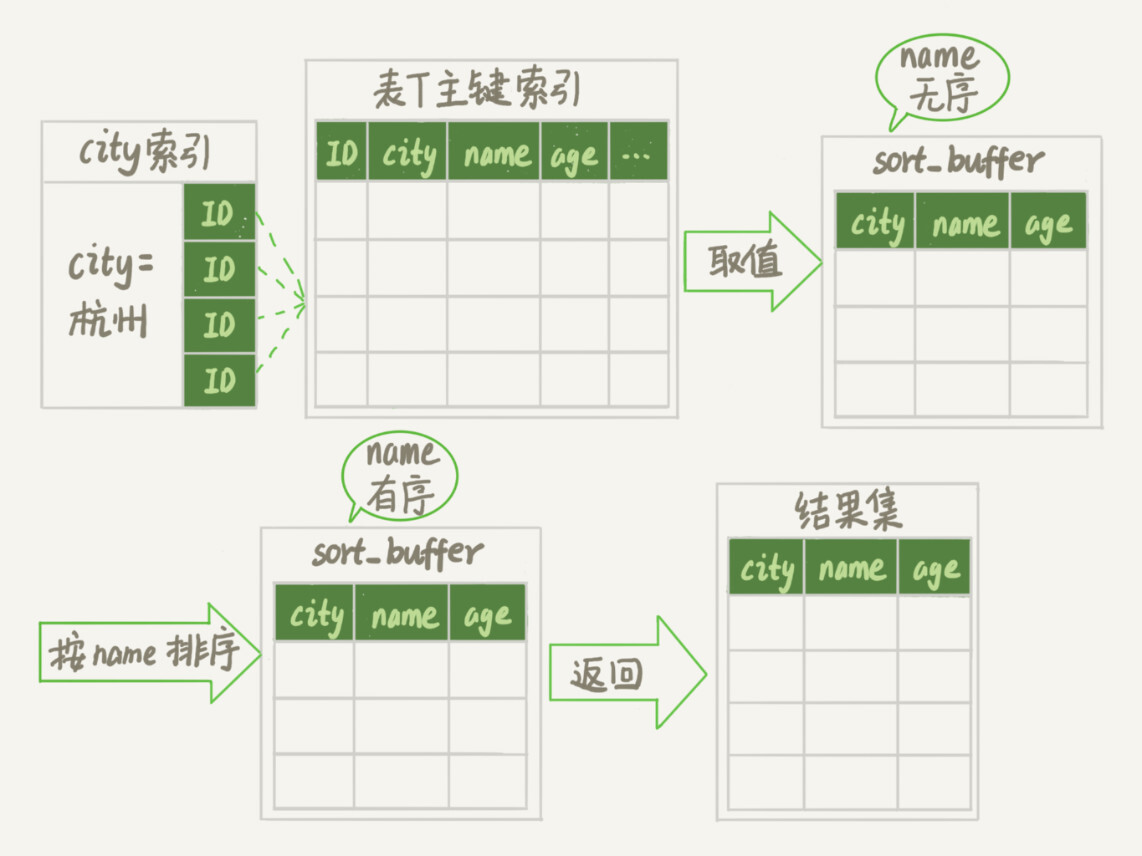
排序流程:
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;按照排序结果取前 1000 行返回给客户端。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号