


20211301 郑润芃 实验四
------------恢复内容开始------------
20211301 郑润芃 实验四
实验信息
|作业要求|https://edu.cnblogs.com/campus/besti/2021-2022-2-PythonPrograming/homework/12518
|作业目标|<Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等>|
实验内容:使用爬虫对雪球股票信息进行爬取,并用pandas模块进行可视化处理
1.分析实验目的,明确流程,先对数据进行爬取,在进行可视化,制作柱状图。
- 找到爬取网站 并对数据进行分析 找到需要的数据的url
![]()
3.用requests发送请求,访问网站
url = f'https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=30&order=desc&order_by=current&exchange=CN&market=CN&type=kcb&_=1653896675948'
# 防止反爬
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
4.获取数据
json_data = response.json()
print(json_data)
5.提取数据
data_list = json_data['data']['list']
for data in data_list:
data1 = data['symbol']
data2 = data['name']
data3 = data['current']
data4 = data['chg']
data5 = data['percent']
data6 = data['current_year_percent']
data7 = data['volume']
data8 = data['amount']
data9 = data['turnover_rate']
data10 = data['pe_ttm']
data11 = data['dividend_yield']
data12 = data['market_capital']
print(data1, data2, data3, data4, data5, data6, data7, data8, data9, data10, data11, data12)
data_dict = {
'股票代码': data1,
'股票名称': data2,
'当前价': data3,
'涨跌额': data4,
'涨跌幅': data5,
'年初至今': data6,
'成交量': data7,
'成交额': data8,
'换手率': data9,
'市盈率(TTM)': data10,
'股息率': data11,
'市值': data12,
}
csv_write.writerow(data_dict)
6.翻页 提取大量数据
for page in range(1, 16):
url = f'https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=current&exchange=CN&market=CN&type=kcb&_=1653896675948'
7.数据处理,利用pandas制作柱状图
df = data_df.dropna()
df1 = df[['股票名称','成交量']]
df2 = df1.iloc[:20]
list(df2['股票名称'].values)
c = (
Bar()
.add_xaxis(list(df2['股票名称'].values))
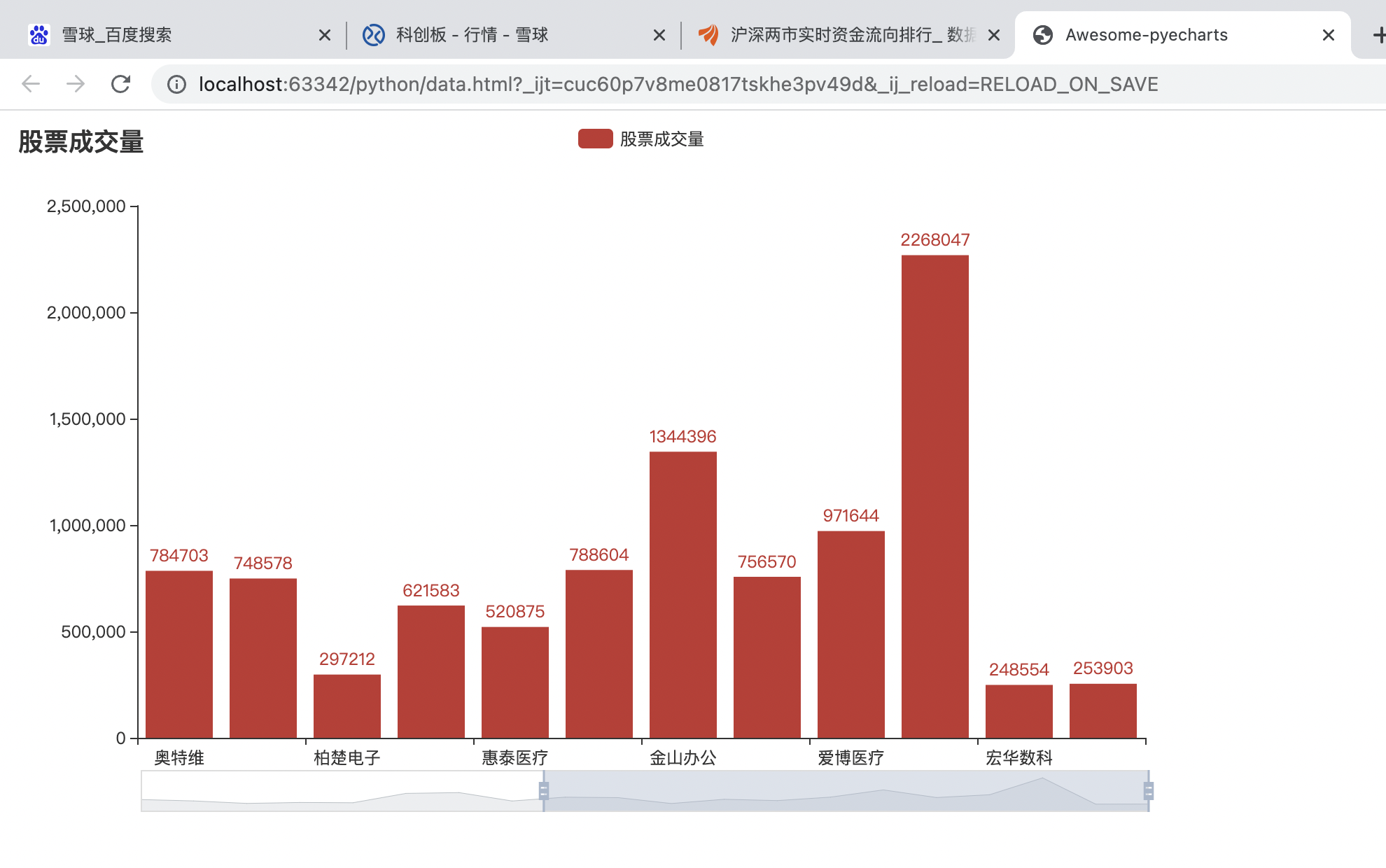
.add_yaxis('股票成交量',df2['成交量'].values.tolist())
.set_global_opts(
title_opts = opts.TitleOpts(title="股票成交量"),
datazoom_opts=opts.DataZoomOpts()
)
)
c.render('data.html')
8.在本机运行结果
9.可视化运行结果
10.在华为云上运行
(1) 通过forklift上传代码
(2)用pip下载需要用到的模块(requests,pandas)
(3)运行代码
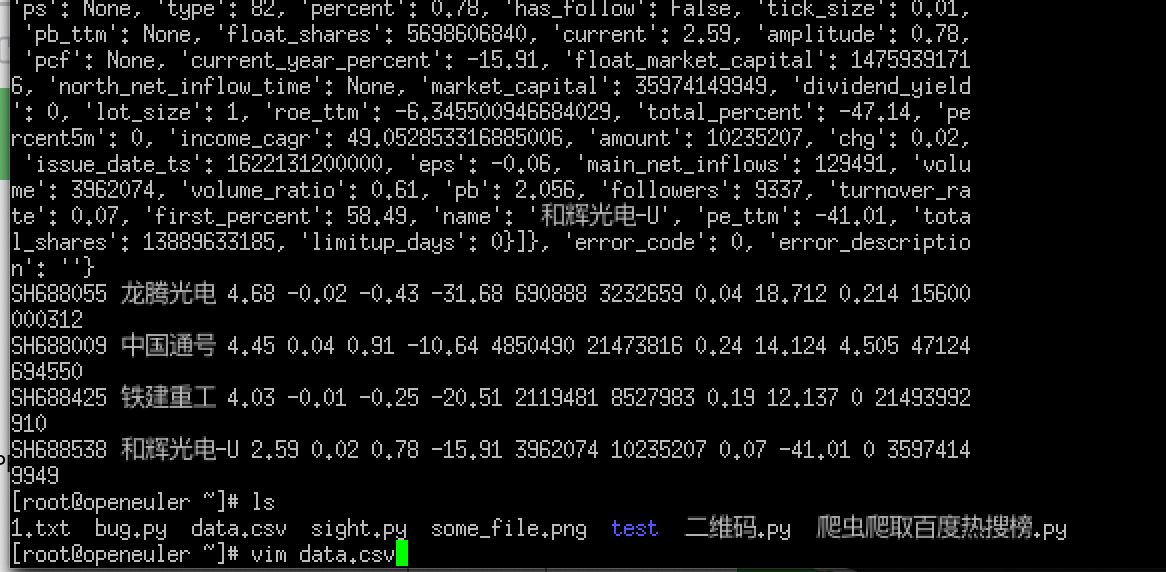
(4) 查看csv文件

(5) 运行可视化文件

代码调试中的问题和解决过程
- 问题1:无法进行爬取,返回403
- 问题1解决方案:网站识别到这是一个爬虫程序,采取了反爬措施,所以要进行伪装,添加header。
- 问题2:可视化制作的图表无法看到
- 问题2解决方案:此方法制作的图表自动生成了一个网址需要用浏览器才可以查看。
- 问题2:华为云上一直报错
- 问题2解决方案:第一个原因:程序中有中文,linux下的中文需要在Python文件的开头加注释;第二个原因:自带的事Python2,有模块与Python3不兼容,所以要用Python3运行。
感想
大一上的时候信安导论主要学习的就是Python,那个时候主要是自学,加上一些惰性,导致我并没有真正入门这个编程语言。在这个学期的选修课上,王志强老师讲的每一个知识点都很细致,由浅入深,有理论,有实践,每次遇到不会的问题老师都会耐心的帮助解决。印象很深的是,有一次晚课下课后,我的c语言编译器出了问题,找老师寻求帮助,老师耐心的帮我调试,帮我找解决办法,一直持续到十点多,很感谢志强老师一学期的倾情讲解!!!
对于这一学期Python课的学习,我有以下几点感悟。
首先这是一门实践出真知的课程,所有编程语言都是这样的,不是学会理论知识就可以当好一个程序员,而是在无数的报错和几百几千行的代码中摸索、探寻规律。编程语言不像生活中的语言,哪怕表述不清楚,不合逻辑,也可以被人听懂,但是编程语言,不止是Python,还有c、c++、Java都需要严密的逻辑,哪怕一个括号没写全,拼错了一个字母都是错误的,都无法编程、运行。
其次,Python是一种高级动态、完全面向对象的语言,函数、模块、数字、字符串都是对象,并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。Python是一种计算机程序设计语言(解释型语言),具有代码少、简单、运行速度慢的特点。我在这门课上知识的收获也很多:
- 字符串
- 变量赋值命名规则
- 列表、数组、字典、集合的常用功能
- 循环、条件语句
- 运算符及优先级
- 正则表达式
- 函数生成
- 面向对象的程序设计
- 异常处理
- 爬虫
通过这几次实验我也发现,听懂和掌握完全不一样,每次觉得上课的知识都吸收了,过了几天再去完成实验代码,就发现会有很多问题,少了冒号,少了条件,随机数带零不带零,小问题总是反反复复出现。有的时候不报错但是就是运行不出来,而且代码较长找错误还很麻烦,所以就看出单步调试和函数的重要性了,把一个完整的程序分散化,每一个小程序单独调试,每写完一个步骤就调试一下,而且学会使用debug可以解决很多问题!!
这门课的优点我觉得就在于这几次实验上,自己动手才能知道不足在哪,实践才是最大的考察,实践中难免会遇到不懂的问题,会遇到一些想要更加完善的程序,这样就需要自己动脑,上网,找资料,设计程序,修改,完善。从外观、实用性、可读性等等方面自己操作,设计,完成。尤其是最后一次实验,前面因为基础还比较薄弱,对于程序的设计,编程语言还不熟悉,所以前面三次实验都是老师带着一步一步做的,难度也相对较低。最后一次实验是自己根据兴趣和擅长的方面自己选择想设计的程序,可以选择课上讲过的,也可以选择课上没讲过的,自己感兴趣的东西。在最后一次实验中,我学习到了很多东西,哪个代码怎么用,语法是怎么样的,都是一步一步通过自己完成的,有很大的成就感,看着自己爬取的数据和制作的柱状图,而且在这个探索的过程中,也增加了对编程语言的兴趣,更增加了对Python的兴趣,甚至在结课之后,我也有想要继续深入学习的想法!!
------------恢复内容结束------------


 浙公网安备 33010602011771号
浙公网安备 33010602011771号