Python爬虫-Feapder框架
前言
曾以为:风有约,花不误,年年岁岁不相负。
后来明白:半生花开,半世落,回首过往半生路,七分酸楚三分甜。
最后懂得:给时间时间,放过去过去,让开始开始。听风吟,看雪落,等花开,待春来。
⚠️声明:本文所涉及的爬虫技术及代码仅用于学习、交流与技术研究目的,禁止用于任何商业用途或违反相关法律法规的行为。若因不当使用造成法律责任,概与作者无关。请尊重目标网站的
robots.txt协议及相关服务条款,共同维护良好的网络环境。
1.Feapder
1.1简介
Feapder 是一个基于 Scrapy 和 Requests 设计的 高性能、分布式爬虫框架,相较于 Scrapy,Feapder 更适合大规模数据采集,并具备 断点续爬、分布式调度、数据存储管理 等功能。
Feapder 主要特点
- 支持 Scrapy 和 Requests 语法,结合两者优点。
- 断点续爬,不必担心爬取中断。
- 分布式爬取,适用于高并发、大数据采集。
- 内置 MySQL、MongoDB、Redis、Elasticsearch 支持,数据存储方便。
- 去重功能,避免重复爬取。
- 支持 Airflow 调度,可定时启动任务。
官方文档:https://feapder.com

1.2架构
| 模块名称 | 模块功能 |
|---|---|
spider |
框架调度核心 |
parser_control模版控制器 |
模版控制器,负责调度parser |
collector任务收集器 |
任务收集器,负责从任务队里中批量取任务到内存,以减少爬虫对任务队列数据库的访问频率及并发量 |
parser |
数据解析器 |
start_request |
初始任务下发函数 |
item_buffer数据缓冲队列 |
数据缓冲队列,批量将数据存储到数据库中 |
request_buffer请求任务缓冲队列 |
请求任务缓冲队列,批量将请求任务存储到任务队列中 |
request数据下载器 |
数据下载器,封装了requests,用于从互联网上下载数据 |
response请求响应 |
请求响应,封装了response, 支持xpath、css、re等解析方式,自动处理中文乱码 |


1.3执行流程
spider调度start_request生产任务start_request下发任务到request_buffer中spider调度request_buffer批量将任务存储到任务队列数据库中spider调度collector从任务队列中批量获取任务到内存队列spider调度parser_control从collector的内存队列中获取任务parser_control调度request请求数据request请求与下载数据request将下载后的数据给response,进一步封装- 将封装好的
response返回给parser_control(图示为多个parser_control,表示多线程) parser_control调度对应的parser,解析返回的response(图示多组parser表示不同的网站解析器)parser_control将parser解析到的数据item及新产生的request分发到item_buffer与request_bufferspider调度item_buffer与request_buffer将数据批量入库
+------------------+
| 任务管理 (Task) |
+------------------+
↓
+---------------------+
| 任务调度器 (Scheduler) |
+---------------------+
↓
+--------------------+
| 爬虫引擎 (Engine) |
+--------------------+
↓
+--------------------+
| 下载器 (Downloader) |
+--------------------+
↓
+--------------------+
| 解析器 (Parser) |
+--------------------+
↓
+----------------------+
| 数据存储 (Pipeline) |
+----------------------+
1.4环境搭建
Feapder 自带 scrapy,但可能是修改过的版本(不同于官方 Scrapy)。
Scrapy-Redis 需要原生 scrapy,如果版本不匹配,可能导致 ImportError 或 AttributeError。
隔离环境 让它们各自使用合适的 Scrapy 版本,避免 pip install scrapy 时版本被覆盖。
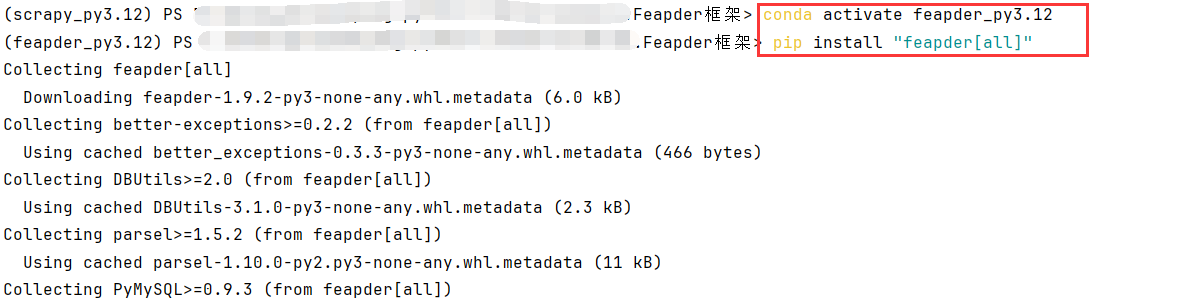
这里使用conda为Feapder创建独立的环境
# 创建一个名为 feapder_py3.12 的 Conda 环境,并指定 Python 版本为 3.12
conda create -n feapder_py3.12 python=3.12
# 激活 feapder_py3.12 这个 Conda 环境
conda activate feapder_py3.12
# 安装 Feapder 及其所有可选依赖
pip install "feapder[all]"

2.豆瓣电影250(Feapder)
2.1创建项目
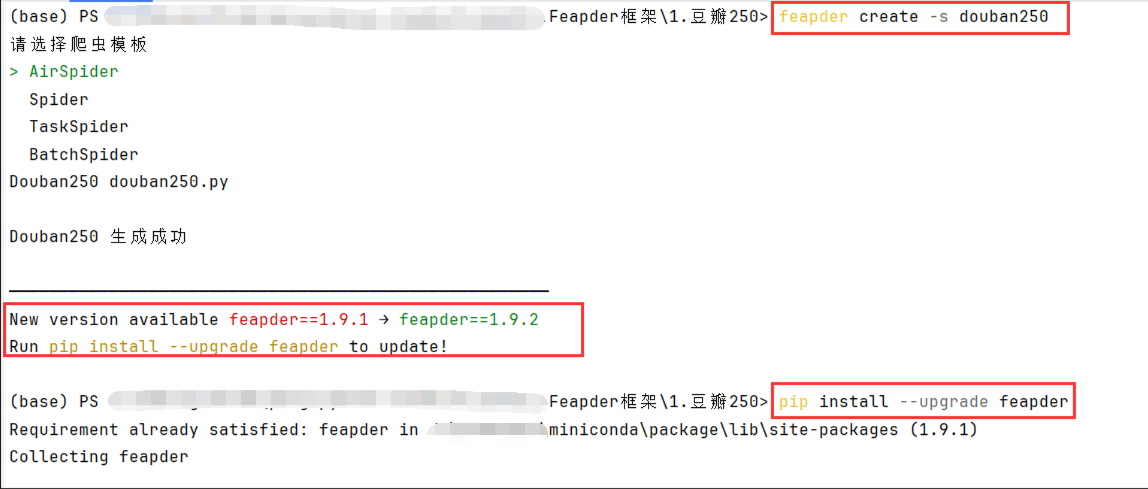
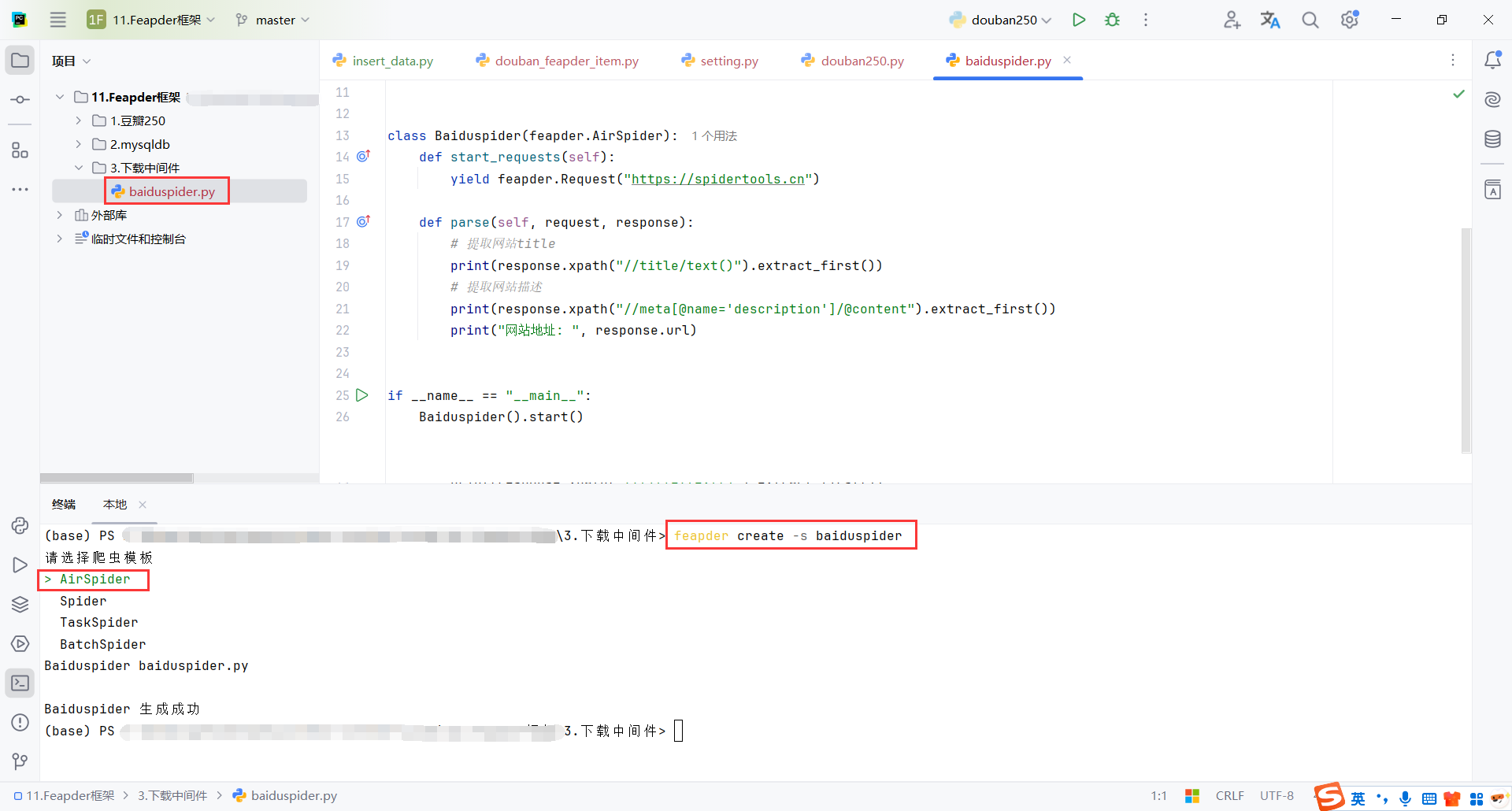
创建命令,然后选择AirSpider
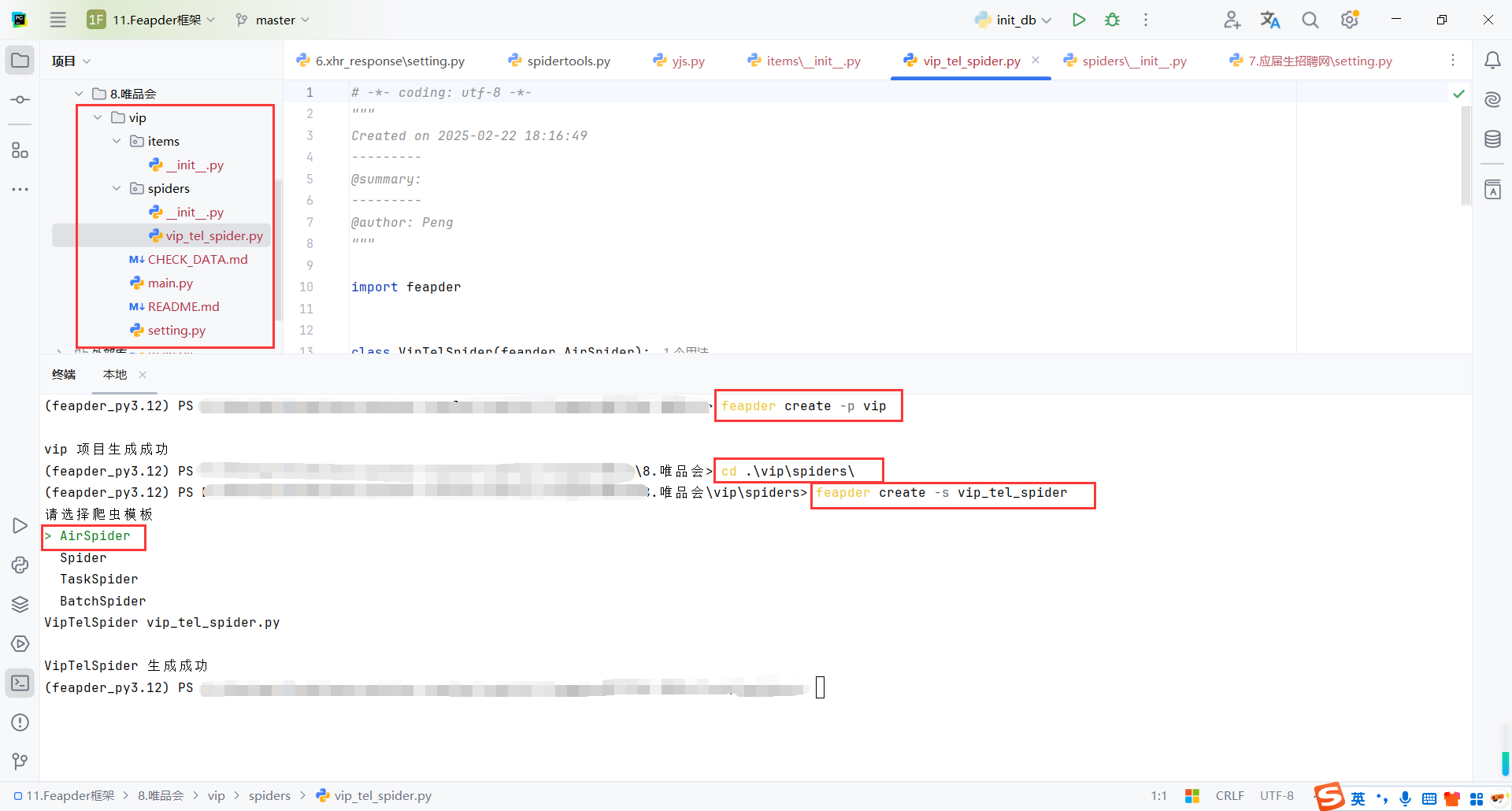
AirSpider:适合常规的单个爬虫任务,执行简单、快速且高效,适用于大多数数据抓取的场景。
Spider:这是 Feapder 的基础爬虫模板,适合需要定期调度或者一些复杂功能的场景。
TaskSpider:专门用于定时任务,适合需要任务调度、分布式抓取的场景。
BatchSpider:用于批量抓取数据,适合需要处理大量数据且能分批次处理的任务。
feapder create -s douban250
创建完项目提示我更新,我这里就更新一下
pip install --upgrade feapder
再次创建

2.2项目结构
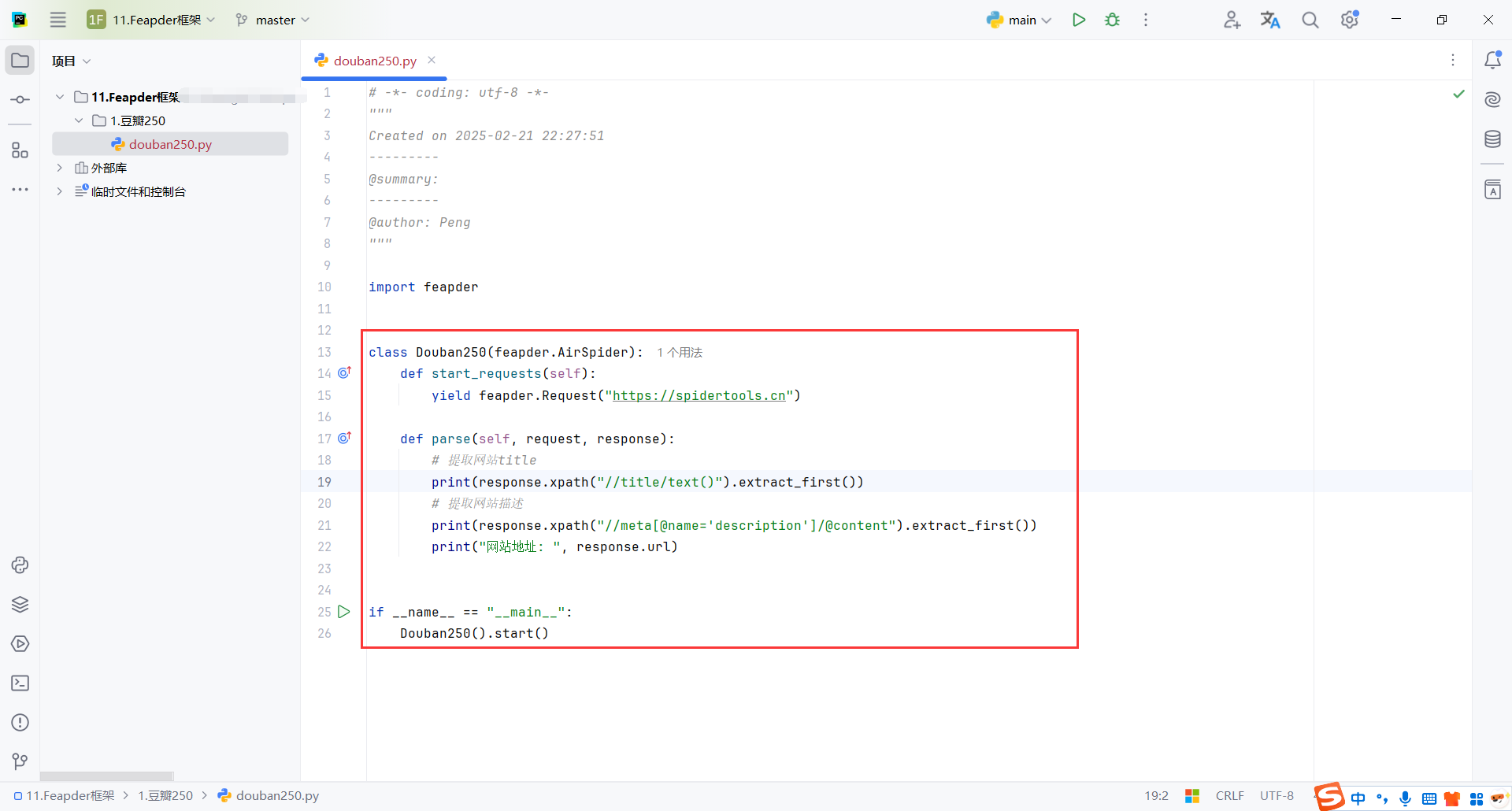
feapder.AirSpider:AirSpider 是 Feapder 中一种高效的爬虫基类,专门用于爬取普通网页数据。
start_requests :定义了爬虫的起始请求。
feapder .Request :基于requests库类似,表示一个请求,支持requests所有参数,同时也可携带些自定义的参数
parse :数据解析函数,是一个回调方法,负责处理每个请求的响应。
response:请求响应的返回体,支持xpath、re、css等解析方式
2.3代码
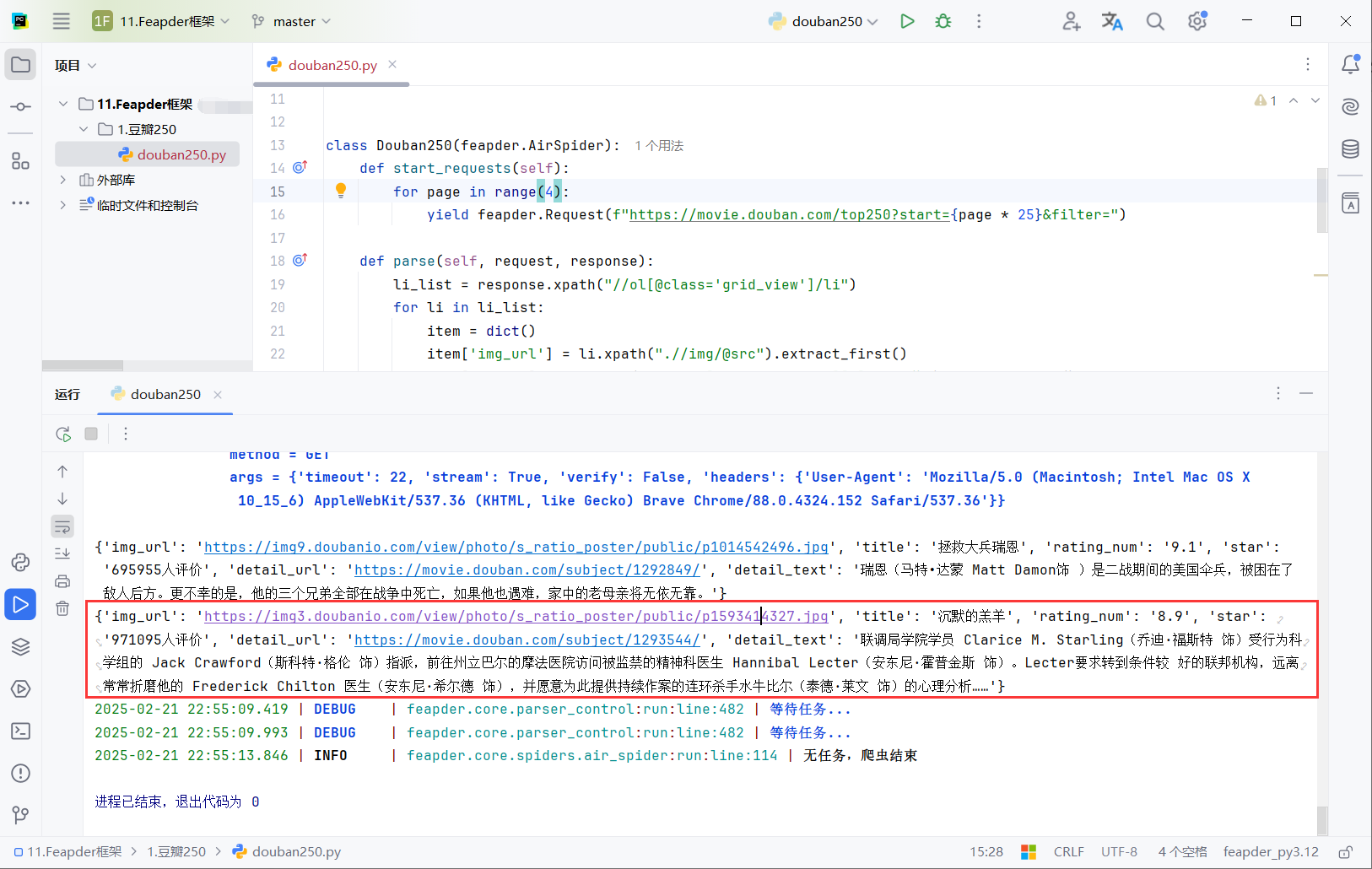
feapder.Request 用于发起请求,构造了每个页面的 URL,其中 start 参数控制分页,filter 参数为空。
yield feapder.Request(item['detail_url'], callback=self.parse_detail, item=item) 发起了对电影详细页面的请求,响应会传递给 parse_detail 方法处理,同时将当前提取的 item 信息一并传递。
request.item:在 Feapder 或 Scrapy 中,Request 对象可以携带额外的数据,这样你就可以在不同的回调函数之间传递数据。request.item 是一个便捷的方式来传递这些数据。例如,在 parse 方法中提取了电影的基本信息,并通过 request.item 将这些信息传递给 parse_detail 方法,从而在该方法中继续操作和处理这些数据。
import feapder
class Douban250(feapder.AirSpider):
def start_requests(self):
for page in range(4):
yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=")
def parse(self, request, response):
li_list = response.xpath("//ol[@class='grid_view']/li")
for li in li_list:
item = dict()
item['img_url'] = li.xpath(".//img/@src").extract_first()
item['title'] = li.xpath(".//span[@class='title'][1]/text()").extract_first()
item['rating_num'] = li.xpath(".//span[@class='rating_num']/text()").extract_first()
item['star'] = li.xpath(".//div[@class='star']/span[4]/text()").extract_first()
item['detail_url'] = li.xpath('./div/div[@class="info"]/div/a/@href').extract_first()
# 请求图片链接,进行下载图片
yield feapder.Request(item['detail_url'], callback=self.parse_detail, item=item)
def parse_detail(self, request, response):
if response.xpath('//div[@class="indent"]/span[@class="all hidden"]//text()'):
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[@class="all hidden"]//text()').extract_first().strip()
else:
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[1]//text()').extract_first().strip()
print(request.item)
if __name__ == "__main__":
Douban250(thread_count=2).start()
3.豆瓣电影250(mysqldb)
3.1创建项目
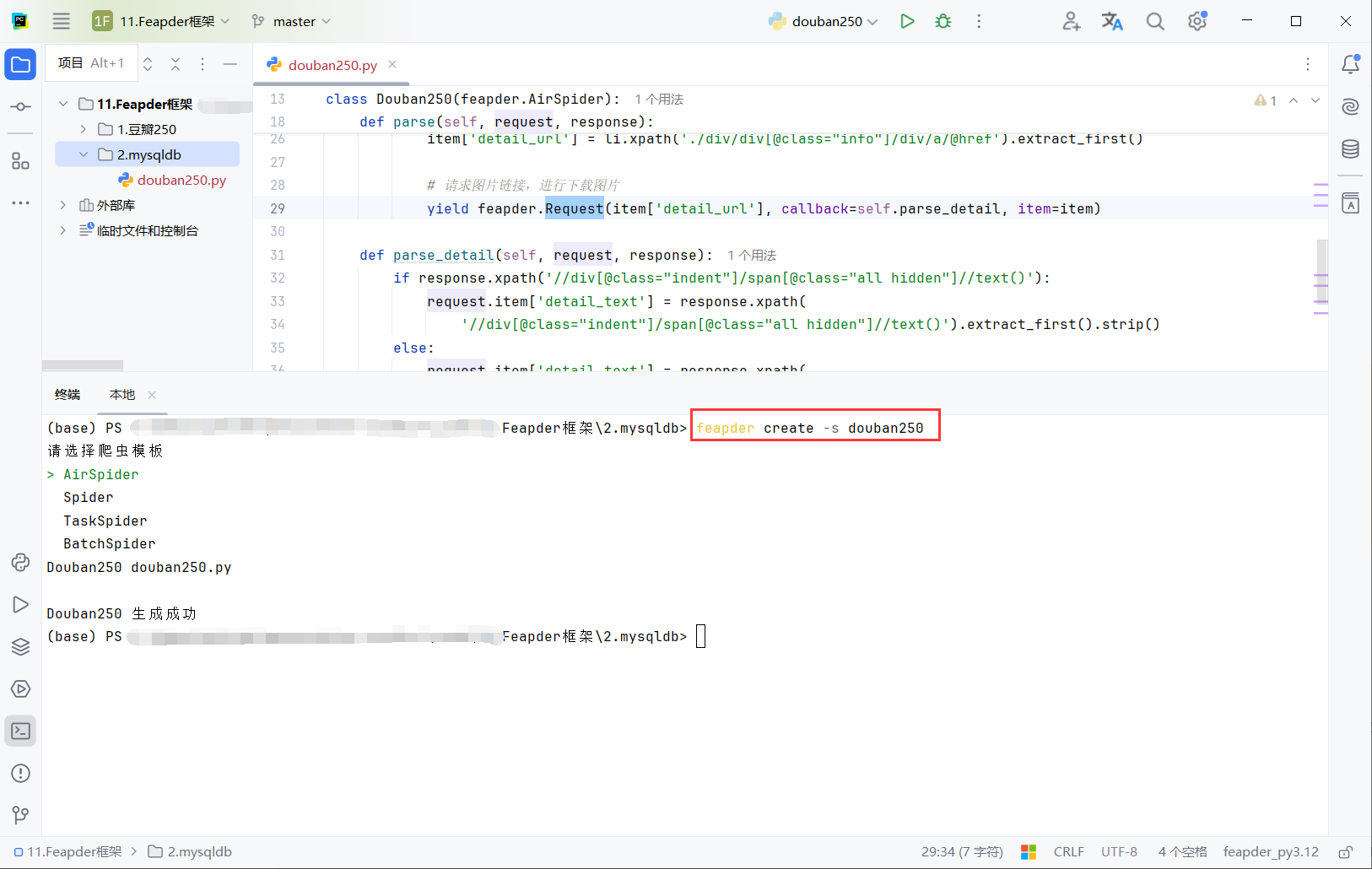
重新创建目录2.mysqldb,并创建脚本douban250
feapder create -s douban250
3.2配置文件(setting)
创建配置文件
feapder create --setting

配置线程数,防止IP封禁
配置MySQL账户
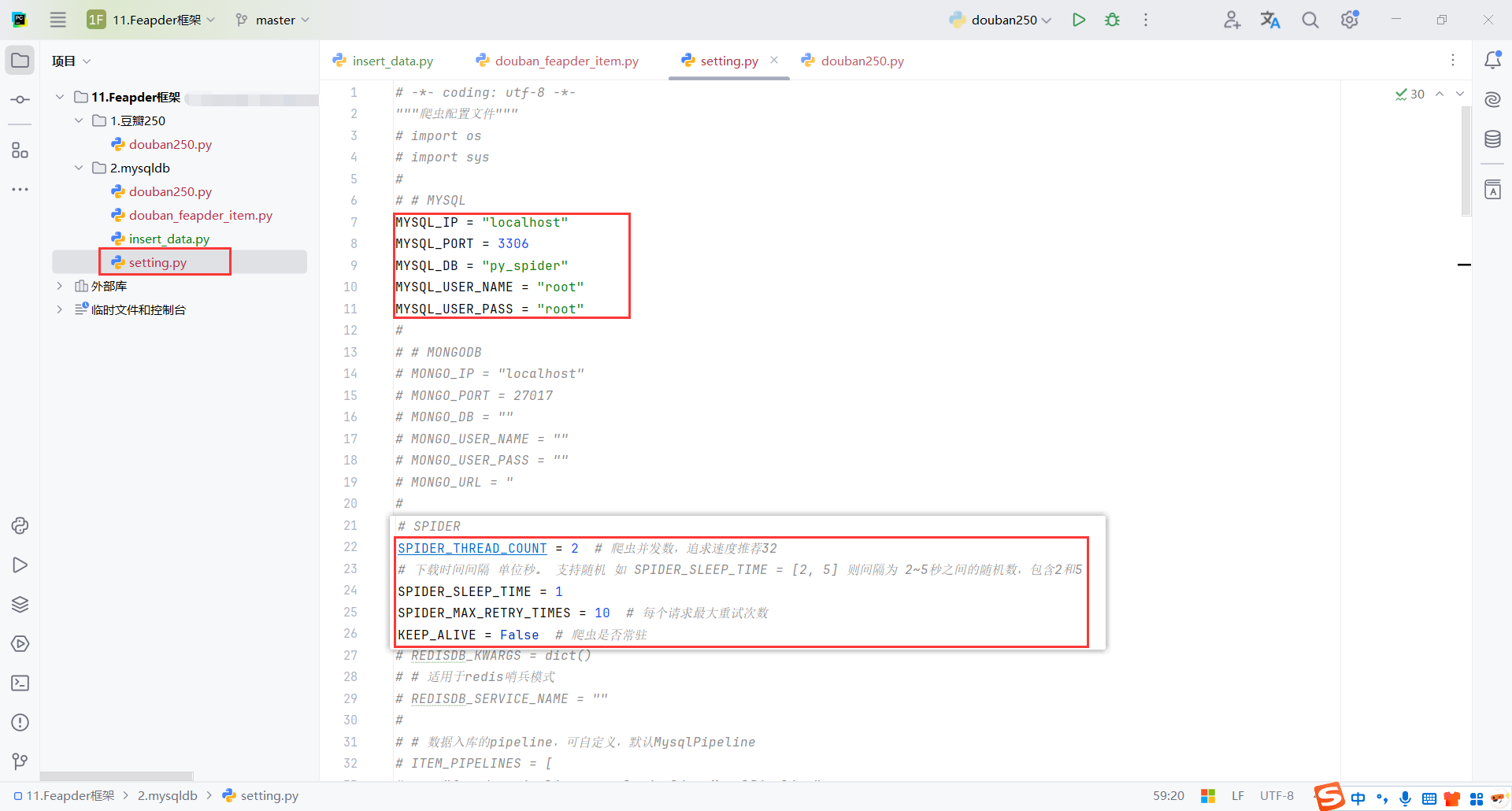
3.3数据模型(Item)
创建数据模型
字段命名一致性:Item 类中的字段名必须符合你爬取的目标数据的结构。如果抓取的数据结构有所改变,记得更新 Item 类中的字段。
表名映射(如果使用数据库存储):如果你使用 Feapder 的数据库功能,__table_name__ 会映射到数据库表。在数据库中,你需要确保表的结构和 Item 类一致。对于不同的数据库,你可能需要进行字段类型的转换。
feapder create -i douban_feapder
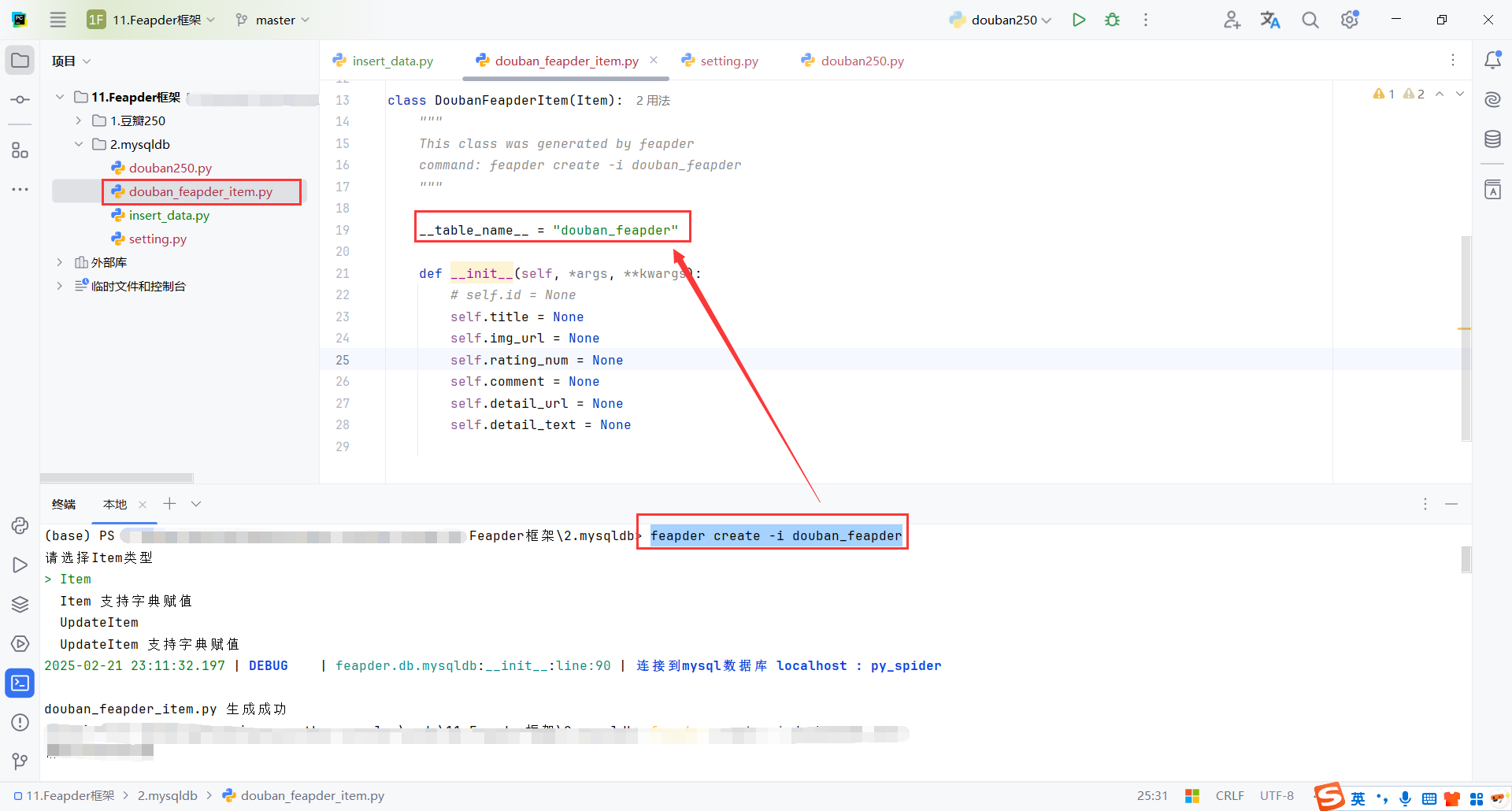
表已经自动生成
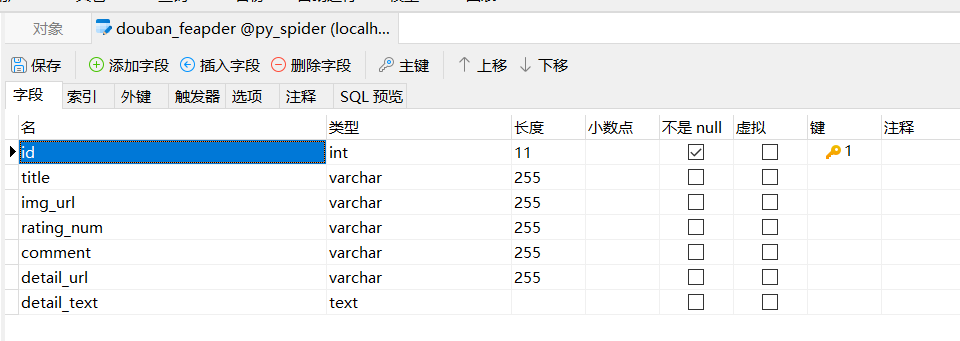
3.4自动入库
yield request.item 自动入库:
- Item 自动存储机制: 在 Feapder 中,每个
Item都是与数据库表关联的。通过继承feapder.Item类的DoubanFeapderItem,Feapder 框架会根据Item类中的字段自动将数据存储到数据库表(通常是__table_name__所指定的表)。在没有明确指定存储方式的情况下,Feapder 会默认使用数据库存储。 - 数据库连接配置: Feapder 会自动处理数据库连接。在你设置了数据库连接的情况下,当
yield request.item被执行时,Feapder 会根据__table_name__属性将数据插入到数据库的指定表中。通常,Feapder 会在Item类中设置__table_name__来与数据库表进行关联。 - 回调机制:
yield在 Feapder 中用于异步处理请求。request.item被yield后,Feapder 会将其传递给后续的处理器(例如存储或输出处理),并根据配置进行存储(如数据库、文件等)。所以,只要你的爬虫任务正常执行并且数据库连接正确,yield返回的Item就会被 Feapder 自动入库。
import feapder
from douban_feapder_item import DoubanFeapderItem
class Douban250(feapder.AirSpider):
def start_requests(self):
for page in range(3):
yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=")
def parse(self, request, response):
li_list = response.xpath("//ol[@class='grid_view']/li")
for li in li_list:
item = DoubanFeapderItem()
item['img_url'] = li.xpath(".//img/@src").extract_first()
item['title'] = li.xpath(".//span[@class='title'][1]/text()").extract_first()
item['rating_num'] = li.xpath(".//span[@class='rating_num']/text()").extract_first()
item['comment'] = li.xpath(".//div[@class='star']/span[4]/text()").extract_first()
item['detail_url'] = li.xpath('./div/div[@class="info"]/div/a/@href').extract_first()
# 请求图片链接,进行下载图片
yield feapder.Request(item['detail_url'], callback=self.parse_detail, item=item)
def parse_detail(self, request, response):
if response.xpath('//div[@class="indent"]/span[@class="all hidden"]//text()'):
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[@class="all hidden"]//text()').extract_first().strip()
else:
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[1]//text()').extract_first().strip()
print(request.item)
# 进行数据入库
yield request.item
if __name__ == "__main__":
Douban250(
thread_count=2 # 设置爬虫的线程数为 2
).start()
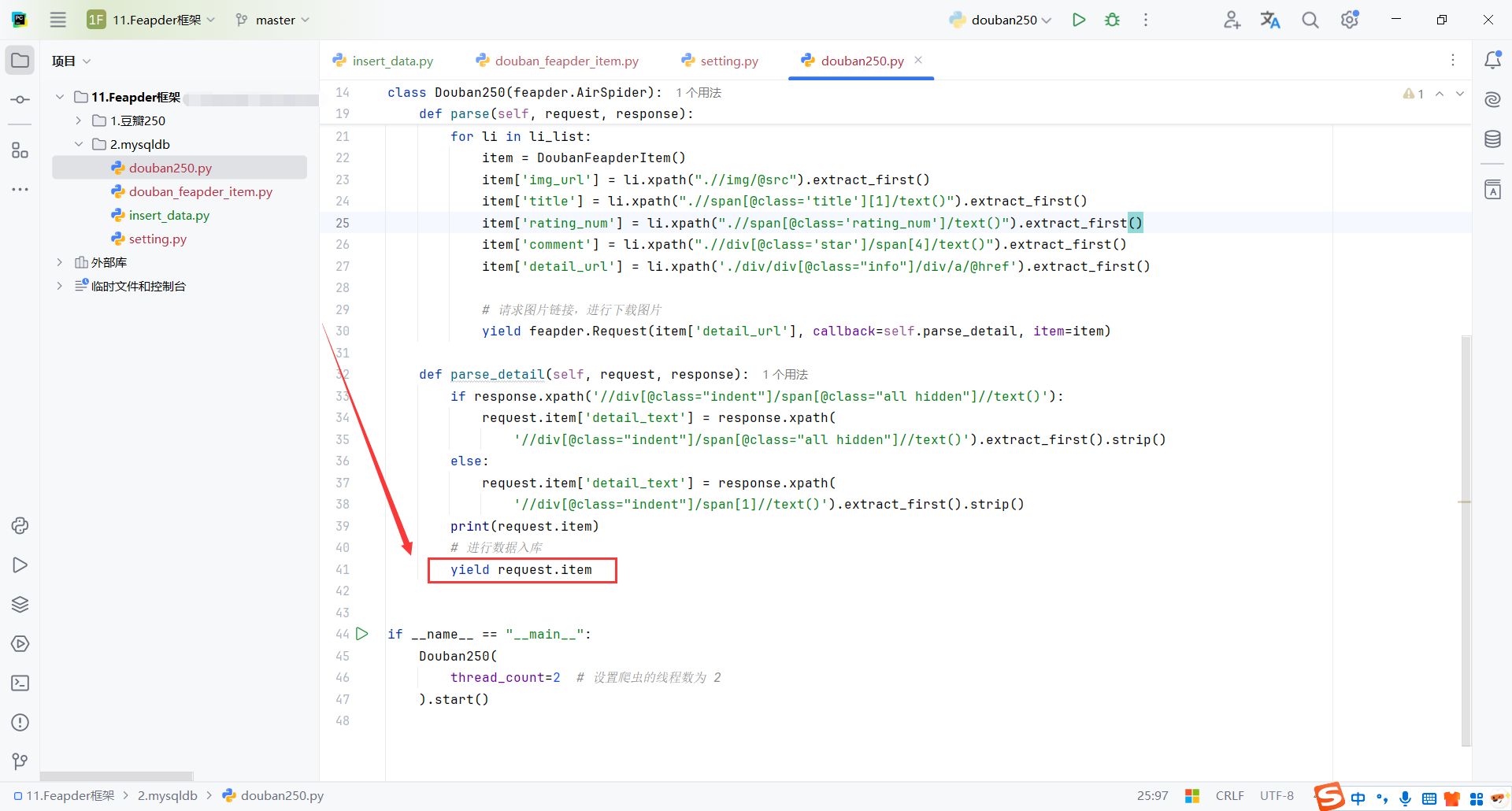
4.下载中间件
4.1创建项目
创建命令
feapder create -s baiduspider
4.2download_midware
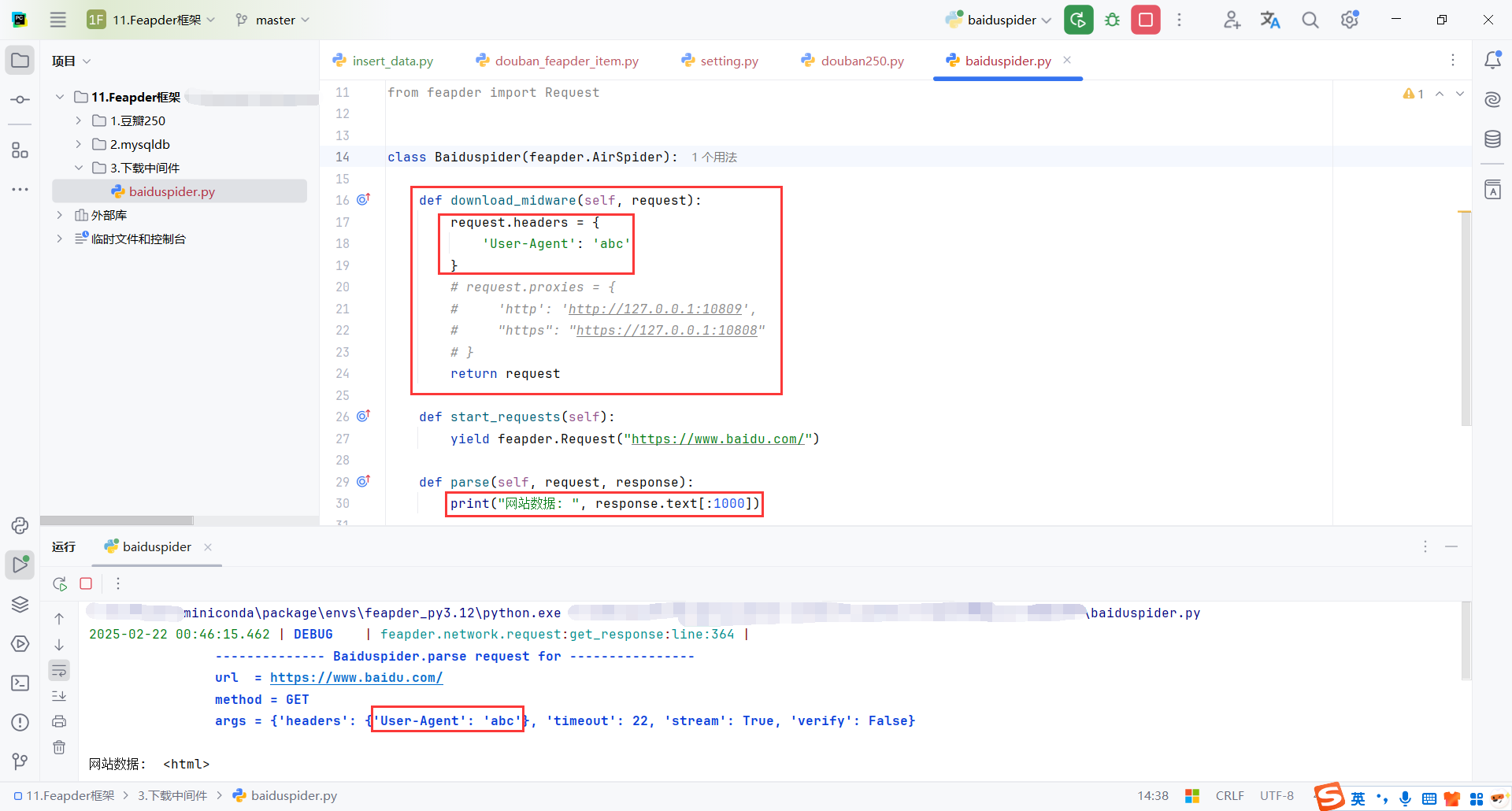
download_midware 是 Feapder 框架中提供的一种方法,用于定制请求的处理过程。具体来说,download_midware 是用于修改请求(request)的请求头、代理、或其他与请求相关的设置。它会在 Feapder 发起请求之前调用,从而让你可以灵活地调整每一个请求的内容。
最后需要return request
import feapder
from feapder import Request
class Baiduspider(feapder.AirSpider):
def download_midware(self, request):
request.headers = {
'User-Agent': 'abc'
}
return request
def start_requests(self):
yield feapder.Request("https://www.baidu.com/")
def parse(self, request, response):
print("网站数据: ", response.text[:1000])
if __name__ == "__main__":
Baiduspider().start()
4.3自定义中间件
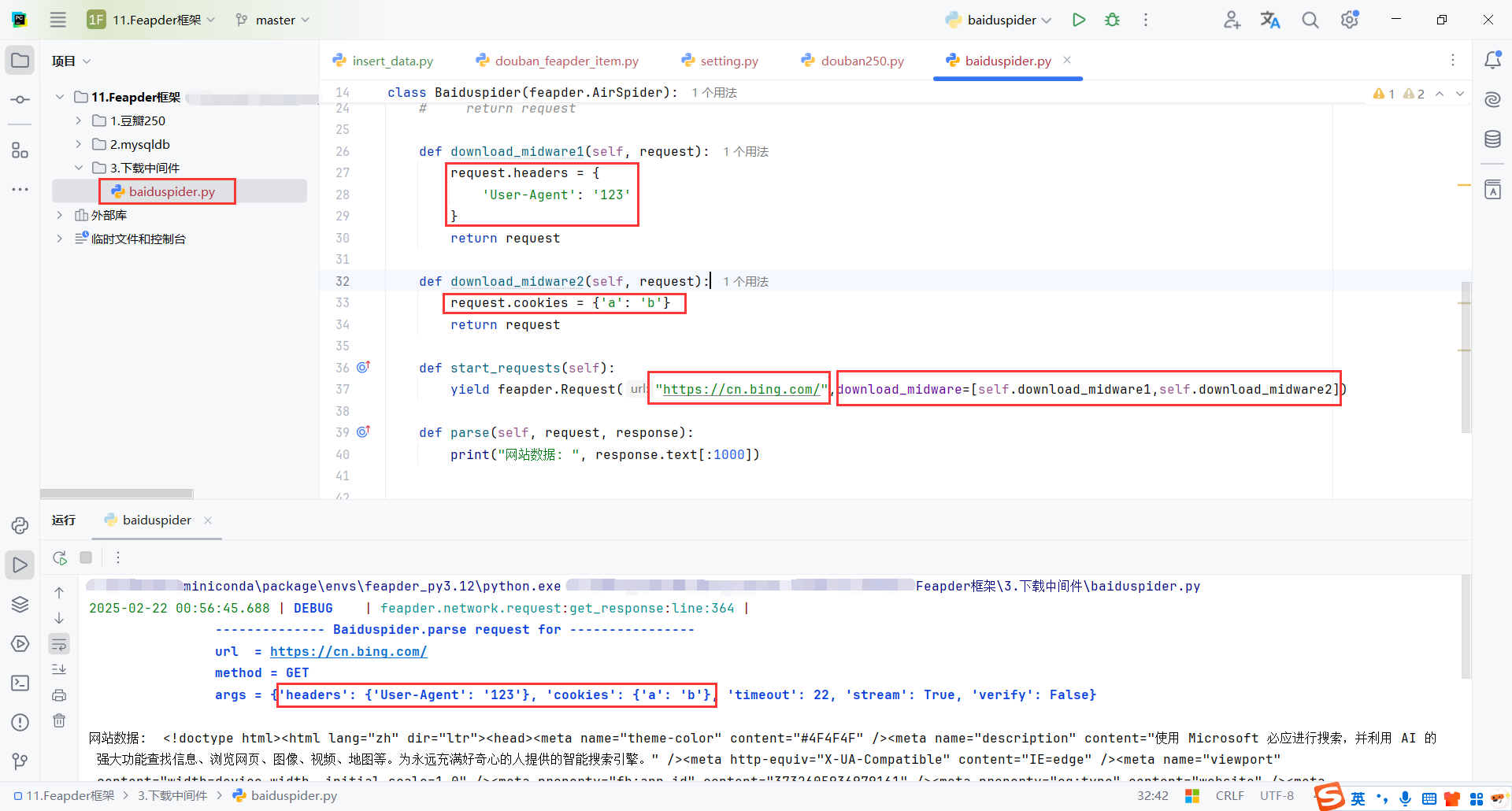
通过 download_midware=[self.download_midware1, self.download_midware2] 参数传递了你自定义的两个中间件方法。Feapder 会在请求发送之前依次调用这两个方法,修改请求的 User-Agent 和 cookies。
import feapder
from feapder import Request
class Baiduspider(feapder.AirSpider):
def download_midware1(self, request):
request.headers = {
'User-Agent': '123'
}
return request
def download_midware2(self, request):
request.cookies = {'a': 'b'}
return request
def start_requests(self):
yield feapder.Request("https://cn.bing.com/",download_midware=[self.download_midware1,self.download_midware2])
def parse(self, request, response):
print("网站数据: ", response.text[:1000])
if __name__ == "__main__":
Baiduspider().start()
5.校验响应对象
5.1创建项目
feapder create -s douban250

5.2校验(validate)
在 Feapder 中,validate 方法是一个自定义验证方法,用来检查爬虫请求的响应内容是否符合预期。如果响应的状态码、内容或者其他因素不符合要求,可以通过 validate 方法进行处理。通常,validate 方法用于进行 异常处理 和 请求重试。
validate 方法的参数:
- request: 当前的请求对象(
feapder.Request),它包含了请求的所有信息,如 URL、请求头、请求参数等。 - response: 当前的响应对象(
feapder.Response),它包含了服务器返回的响应内容,如 HTTP 状态码、响应头、响应体等。
validate 方法的功能:
validate方法的主要作用是 验证响应 是否符合要求。在实际的爬虫中,常常需要对 HTTP 响应的状态码、返回数据或其他信息进行检查,确保返回的内容是有效的。如果检测到异常,validate方法可以决定是否重试当前请求(raise Exception('请求重试'))或者丢弃这个请求(return False)。
import feapder
class Douban250(feapder.AirSpider):
def download_midware(self, request):
# 错误代理 validate会重试
request.proxies = {
'http': 'http://127.0.0.1:10809'
}
def start_requests(self):
# request对象支持载入多个自定义中间件, 将download_midware的参数设置为一个列表即可
# 但是一般不使用, 在一个中间件中配置好所有的request参数即可
yield feapder.Request("https://movie.douban.com/top250?start=0&filter=")
def validate(self, request, response):
# print('响应状态码:', response.status_code)
if response.status_code != 200:
print('响应状态码异常:', response.status_code)
# return False # 抛弃当前请求
raise Exception('请求重试')
if __name__ == "__main__":
Douban250().start()

6.浏览器渲染(selenium)
6.1创建项目
命令
feapder create -s baidu
feapder create --setting
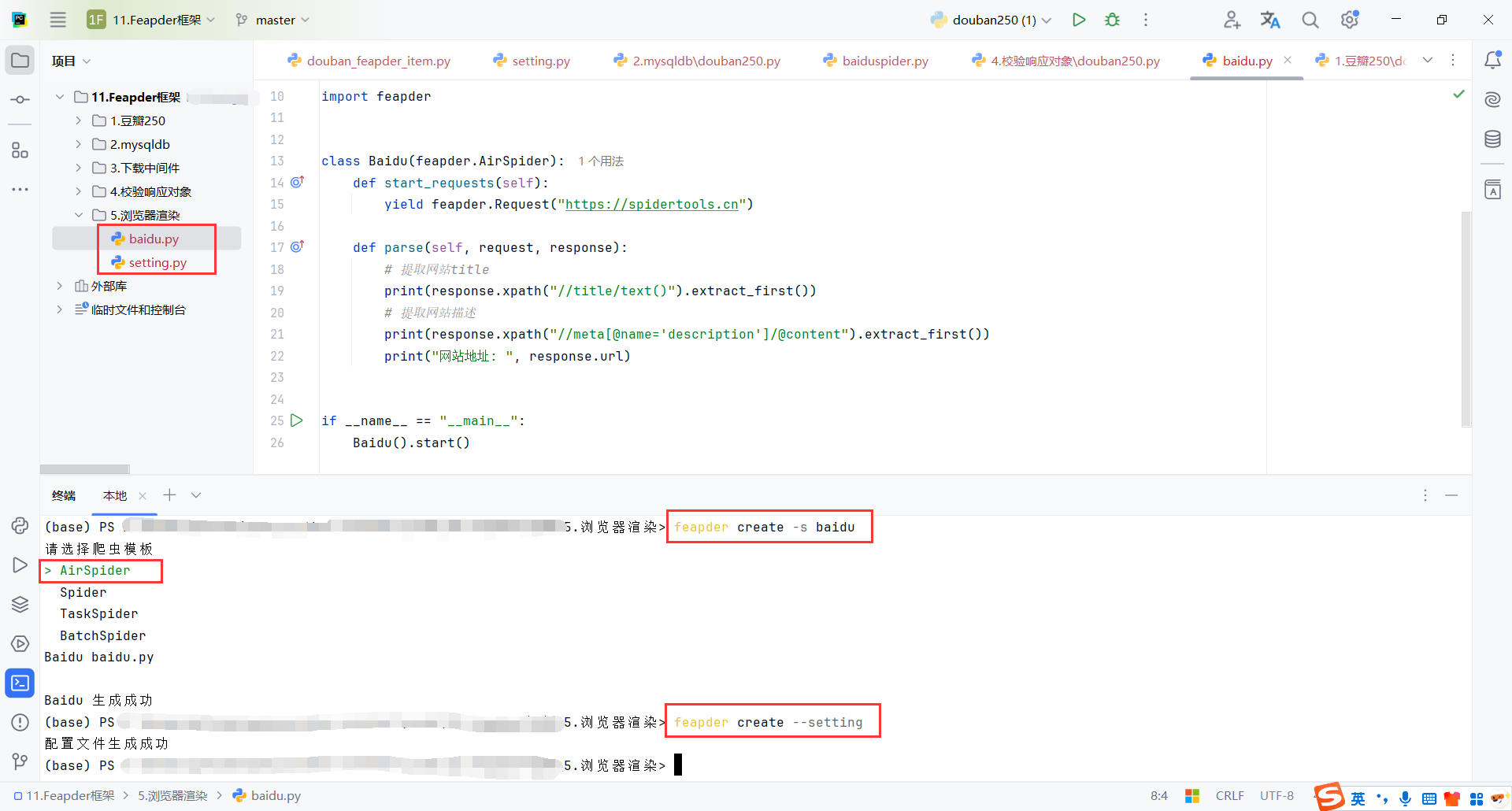
6.2配置(setting)
需要确定conda安装目录下存在浏览器的驱动,否则需要配置download_path
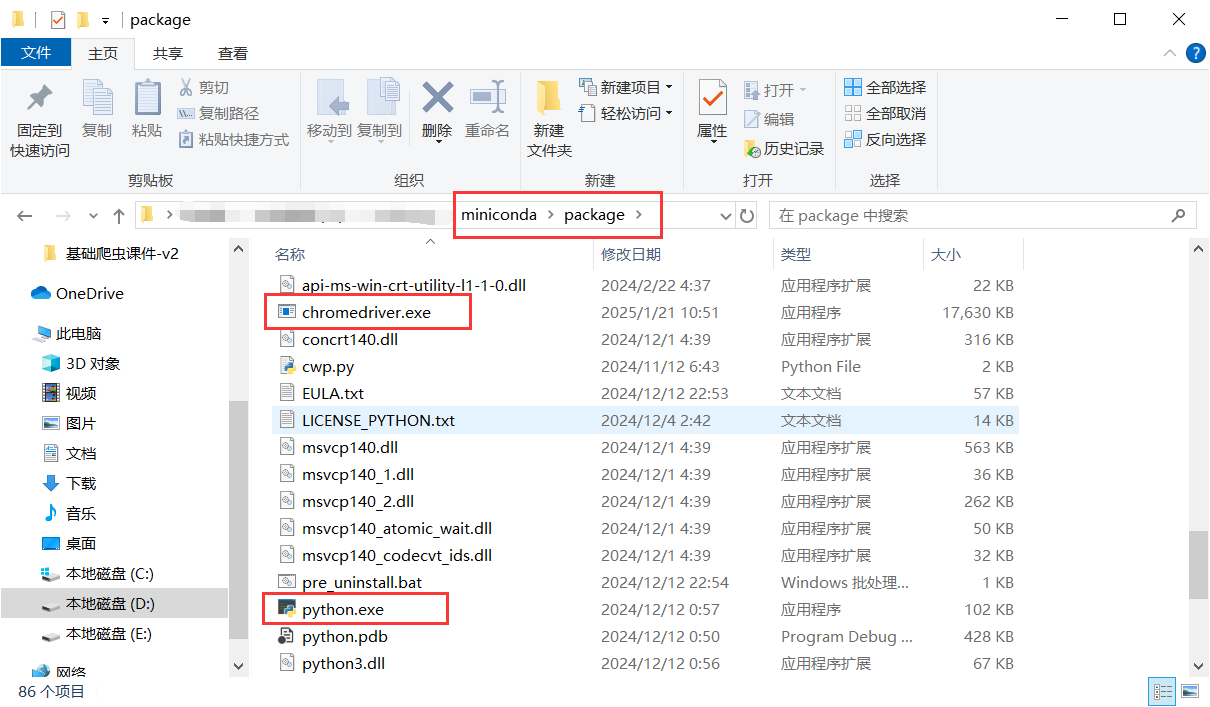
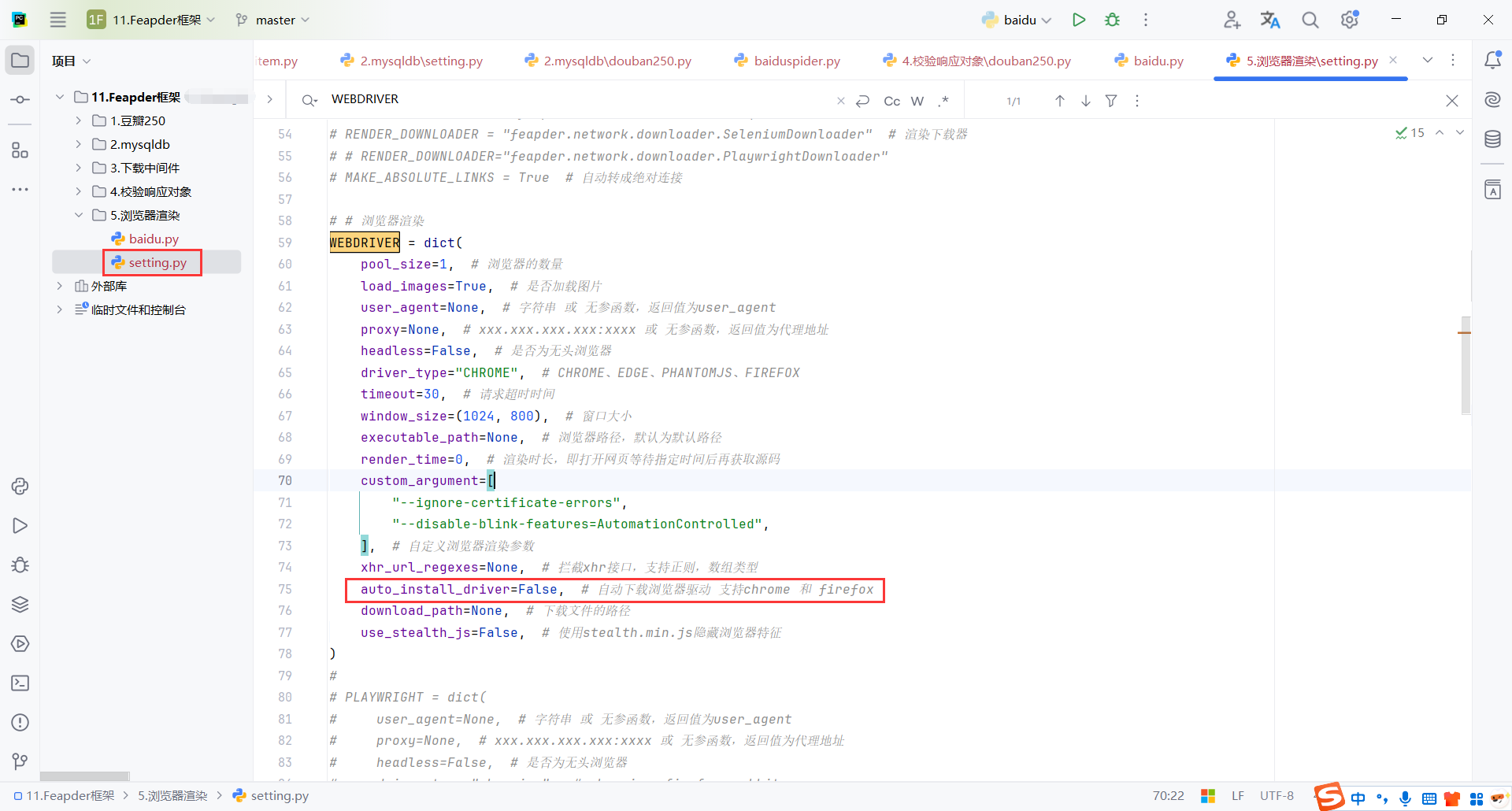
selenium配置
auto_install_driver=False取消自动下载驱动配置,其他保持默认即可
6.3代码
代码比较简单,之前学习过了selenium
这里就是打开https://www.baidu.com,然后搜索feapder
render=True :
- 启用页面渲染:当你在请求中传递
render=True时,feapder会使用浏览器(通常是通过 Selenium)来加载并渲染页面,执行页面中的 JavaScript 代码,最终获取完全加载后的 HTML。 - 动态内容抓取:通过这种方式,可以获取那些需要 JavaScript 执行后的动态内容(例如异步加载的图片、列表等),而不是仅仅返回初始的 HTML 代码。
xhr_url_regex 参数:在 xhr_json() 方法中传递一个正则表达式,匹配你想要抓取的XHR请求URL。在这里,xhr_url_regex 被设置为匹配百度搜索的请求。
import feapder
from feapder.utils.webdriver import WebDriver
from selenium.webdriver.common.by import By
class Baidu(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com", render=True)
def parse(self, request, response):
browser: WebDriver = response.browser
browser.find_element(By.ID, 'kw').send_keys('feapder')
browser.find_element(By.ID, 'su').click()
if __name__ == "__main__":
Baidu().start()
7.xhr_response
7.1拦截xhr数据
官方文档:https://feapder.com/#/source_code/浏览器渲染-Selenium?id=拦截xhr数据

官方接口:https://www.spidertools.cn/#/
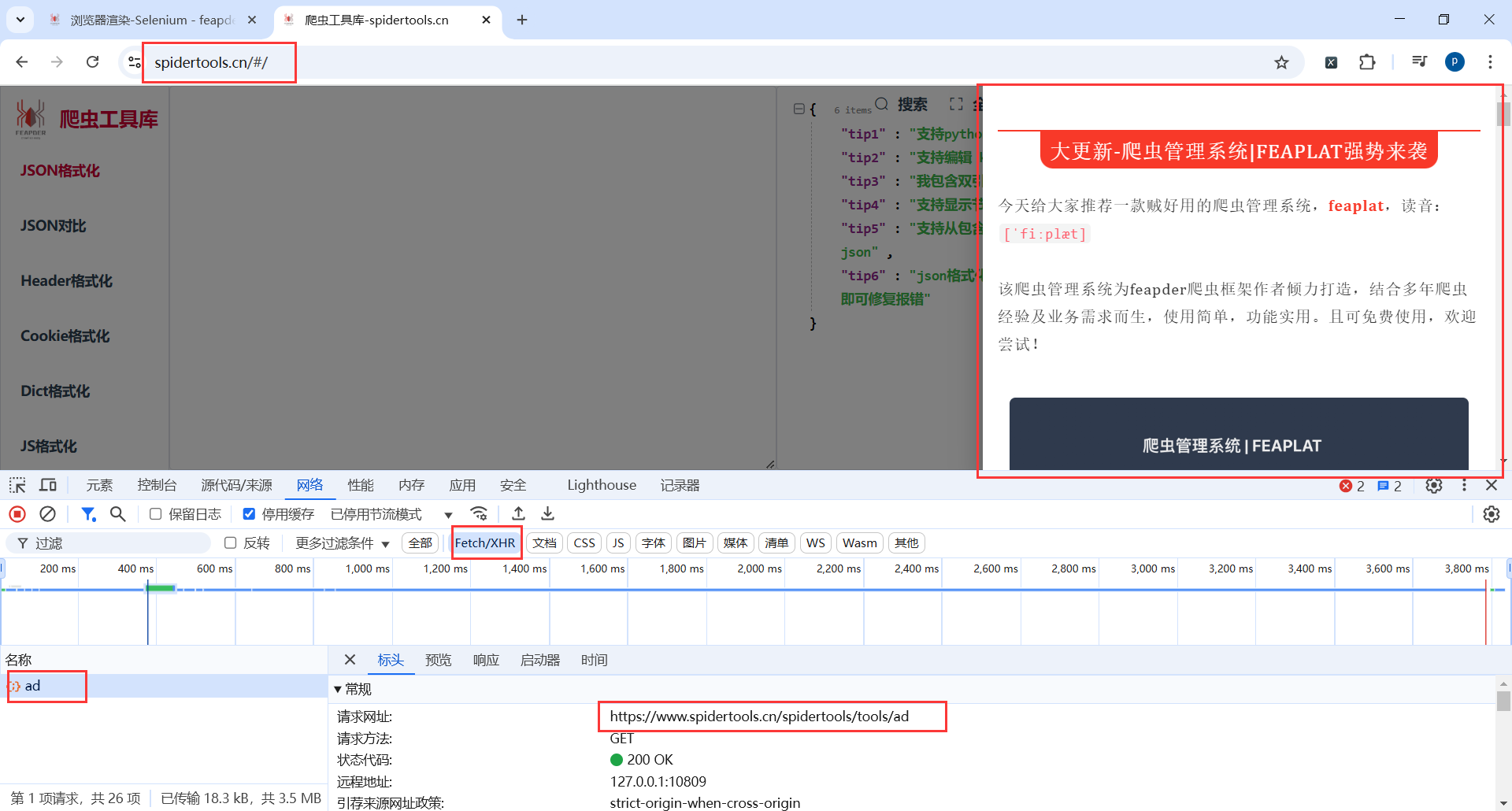
7.2创建项目
feapder create -s spidertools
feapder create --setting
修改配置
# # 浏览器渲染
WEBDRIVER = dict(
xhr_url_regexes=['/ad'], # 拦截xhr接口,支持正则,数组类型
auto_install_driver=False, # 自动下载浏览器驱动 支持chrome 和 firefox
)

7.3代码
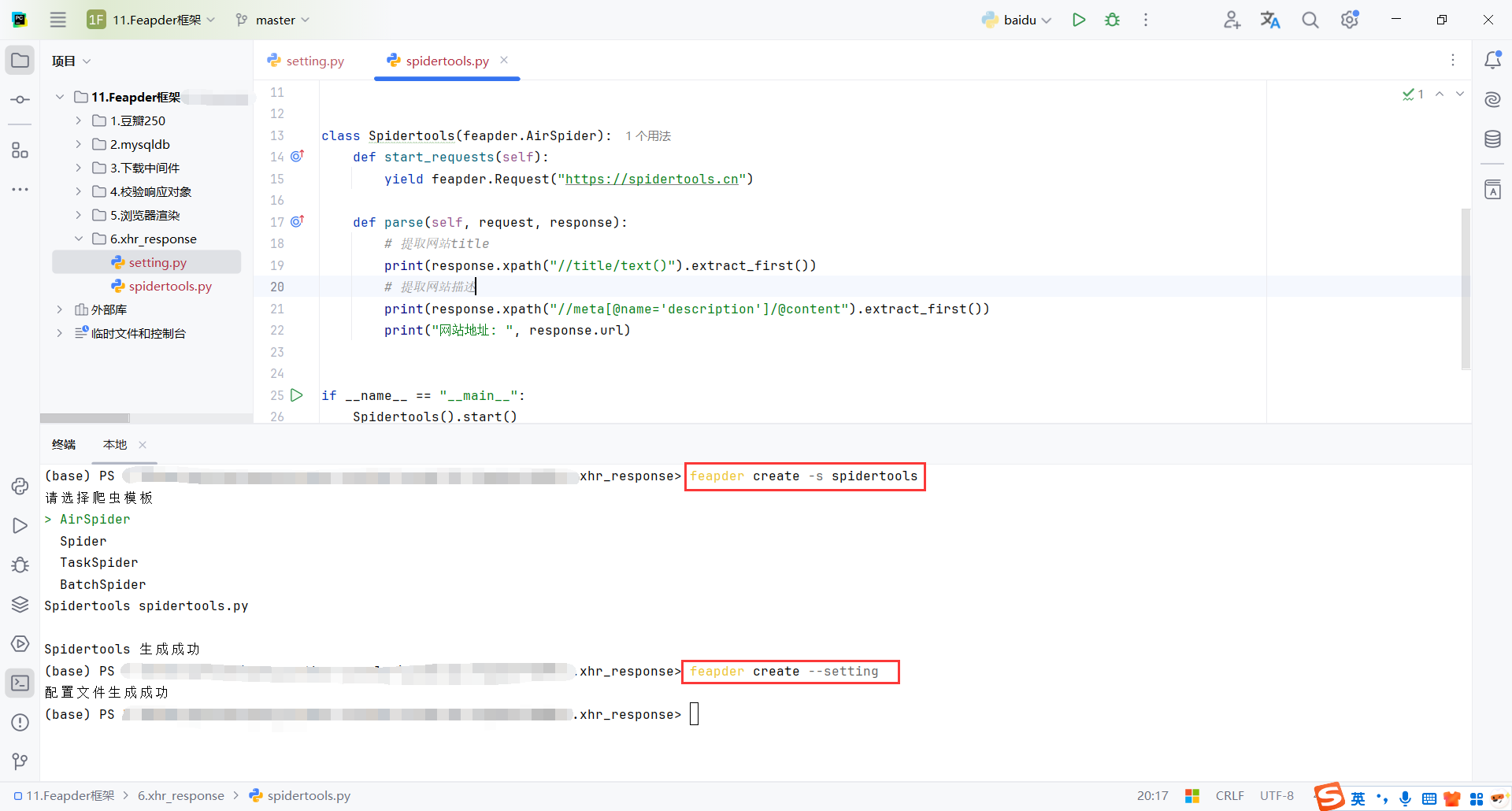
browser.xhr_response() 方法的作用:
xhr_response = browser.xhr_response("/ad")会让SeleniumDriver查找并返回匹配指定 URL(或 URL 路径)的 XHR 请求的响应。- 这个方法是抓取 JavaScript 动态请求返回的数据的关键工具,它帮助你获取浏览器通过 JavaScript 发起的网络请求的数据。
class Spidertools(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://spidertools.cn", render=True)
def parse(self, request, response):
browser: WebDriver = response.browser
xhr_response = browser.xhr_response("/ad")
print("请求接口", xhr_response.request.url)
# 请求头目前获取的不完整
print("请求头", xhr_response.request.headers)
print("请求体", xhr_response.request.data)
print("返回头", xhr_response.headers)
print("返回地址", xhr_response.url)
print("返回内容", xhr_response.content)
if __name__ == "__main__":
Spidertools().start()
8.应届生招聘网(Feapder)

8.1创建项目
创建项目和配置文件
feapder create -s yjs
feapder create --setting
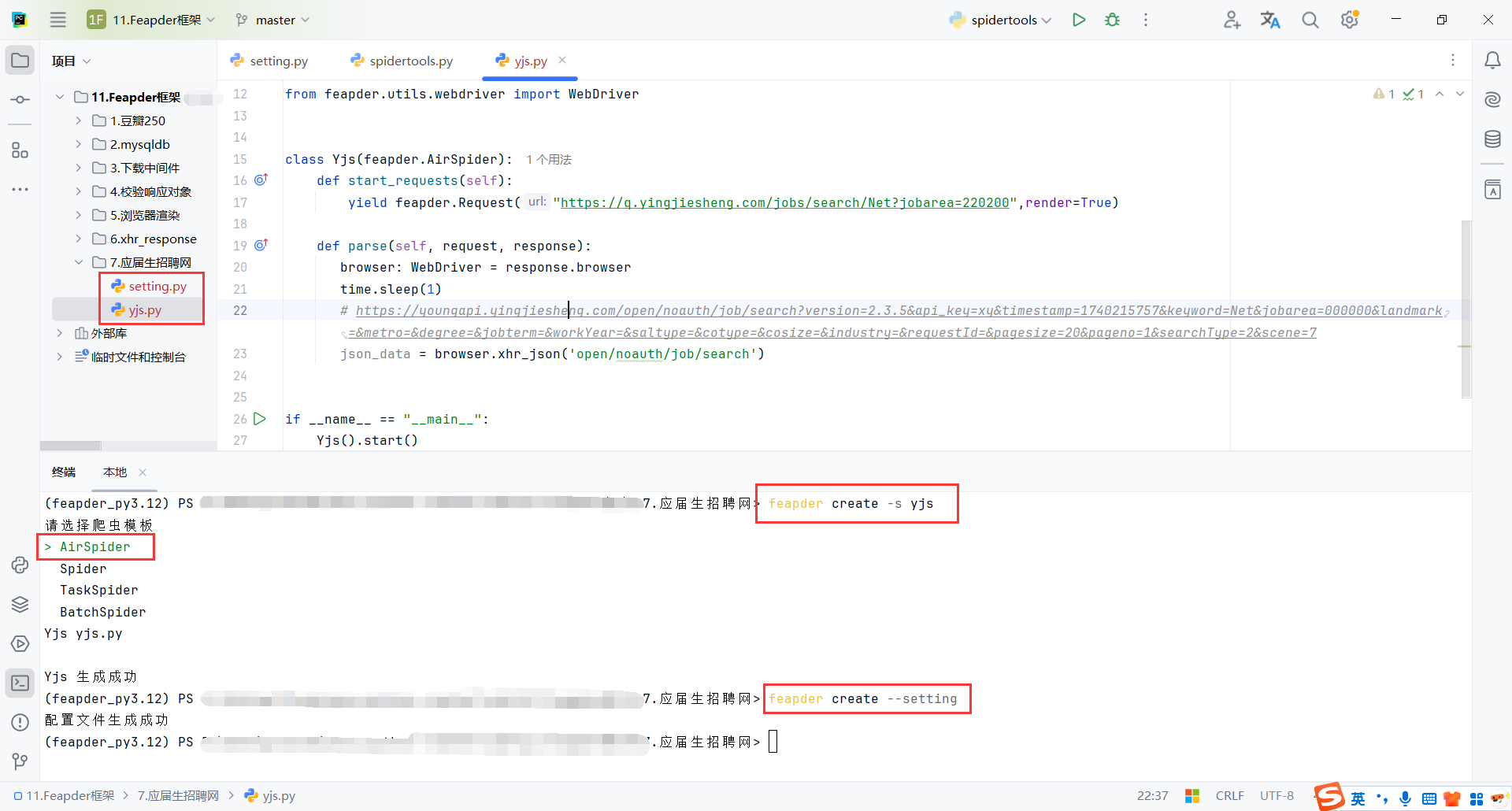
8.2配置(setting)
SPIDER_SLEEP_TIME:主要是防止请求太快,防止ip封禁。
auto_install_driver=False:自己的miniconda目录下有驱动即可,不用下载,自己配置好环境
xhr_url_regexes=['open/noauth/job/search']:配置xhr接口
8.3页面异步加载(xhr_json)
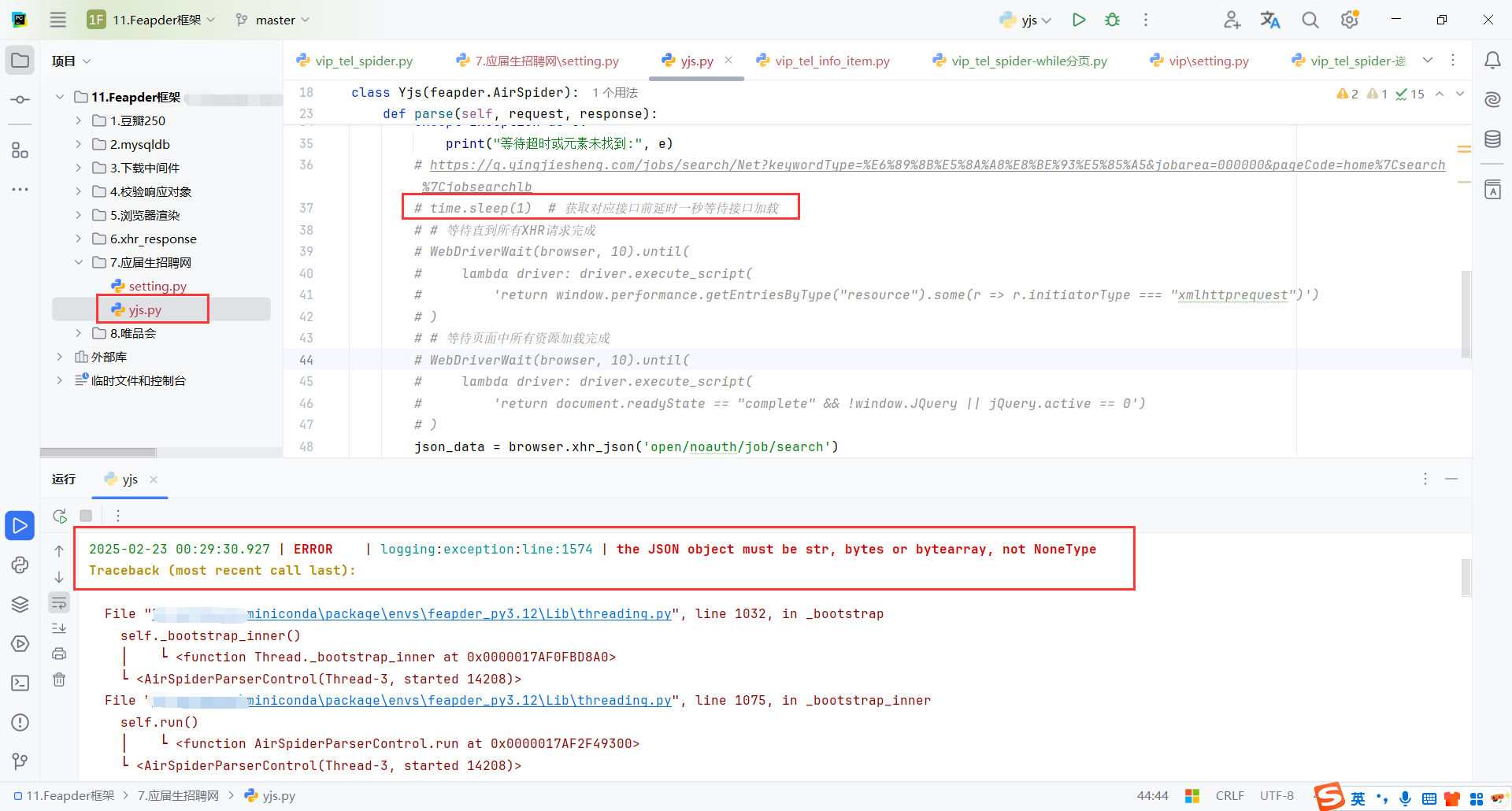
如果不延迟发现接口返回的数据不对,表明 返回 的值为 None,这不是 json.loads() 的有效参数
原因:xhr_json() 是通过 Selenium 获取页面发出的异步请求的数据,而异步请求本质上是异步执行的,这意味着它们的响应时间是不确定的。由于页面可能还没有完全加载,当你调用 xhr_json() 时,页面的数据请求(例如:获取职位列表的数据)可能还没有返回结果,导致 xhr_json() 返回 None,从而触发你遇到的 TypeError 错误。(xhr_json() 是异步的 我获取数据的时候页面可能没加载完成 所以是None)
页面动态加载数据:爬虫代码是基于 Selenium 驱动的,Selenium 在模拟浏览器时会等待页面的元素加载完成。但是有时候某些数据是通过异步请求(如 AJAX)动态加载的。如果在页面完全加载之前就尝试获取这些数据,可能会出现没有数据或者获取到错误的结果。
接口请求的延迟:() 是通过 Selenium 获取由页面发出的异步请求的返回数据。如果你在页面数据还没有完全加载的时候调用该接口,它可能会返回 None 或空数据,导致你遇到 TypeError 错误。这是因为数据请求的时间可能比较长,特别是如果接口的响应时间波动较大,爬虫就可能在数据未准备好时就尝试解析。
解决方案:延迟 1秒,可以确保页面至少完成了大部分的加载,尤其是动态数据的加载。通过这种方式,你可以提高爬取的稳定性,避免请求空的或未完全加载的数据。
不过,使用 time.sleep(1) 并不是最优的解决方案,原因如下:
- 延迟时间过长会浪费时间,导致爬取效率降低。
- 如果页面加载特别快,延迟时间可能显得不必要。
可以延迟和等待页面加载一起使用
# 等待直到所有XHR请求完成
WebDriverWait(browser, 10).until(
lambda driver: driver.execute_script(
'return window.performance.getEntriesByType("resource").some(r => r.initiatorType === "xmlhttprequest")')
)
# 等待页面中所有资源加载完成
WebDriverWait(browser, 10).until(
lambda driver: driver.execute_script(
'return document.readyState == "complete" && !window.JQuery || jQuery.active == 0')
)
time.sleep(1) # 获取对应接口前延时一秒等待接口加载
8.4代码
主要注意页面的异步加载,需要等待页面所有资源都加载完成,包括异步请求,才能使用xhr_json
# -*- coding: utf-8 -*-
"""
Created on 2025-02-22 17:12:10
---------
@summary:
---------
@author: Peng
"""
import json
import time
import feapder
from feapder.utils.webdriver import WebDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class Yjs(feapder.AirSpider):
def start_requests(self):
yield feapder.Request(
"https://q.yingjiesheng.com/jobs/search/Net?keywordType=%E6%89%8B%E5%8A%A8%E8%BE%93%E5%85%A5&jobarea=000000&pageCode=home%7Csearch%7Cjobsearchlb",
render=True)
# yield feapder.Request("https://q.yingjiesheng.com/jobs/search/Python?jobarea=220200", render=True)
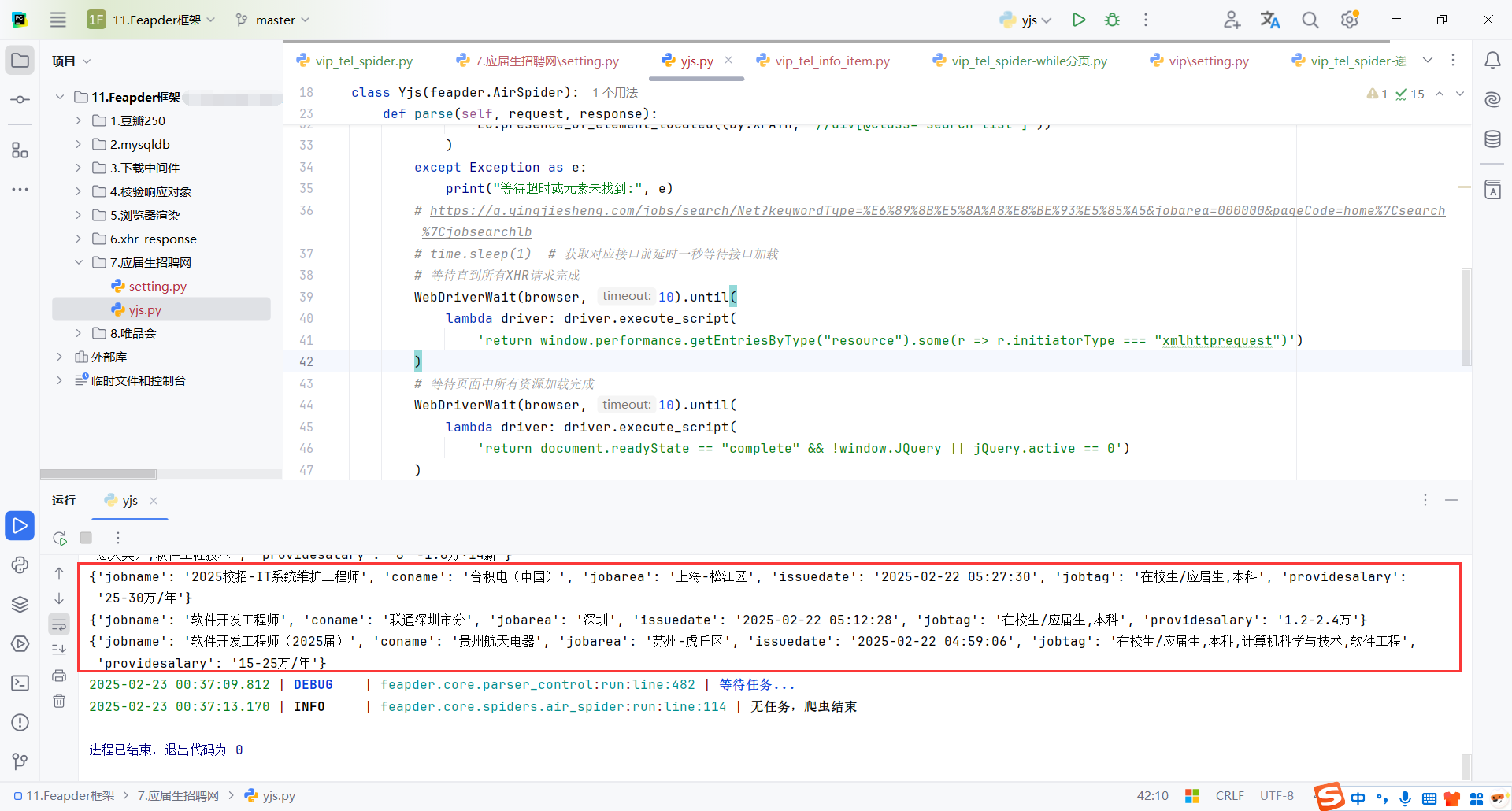
def parse(self, request, response):
browser: WebDriver = response.browser
# 隐式等待
# time.sleep(1)
# 显式等待直到某个元素加载完毕
# 等待页面加载完成
try:
WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.XPATH, "//div[@class='search-list']"))
)
except Exception as e:
print("等待超时或元素未找到:", e)
# https://q.yingjiesheng.com/jobs/search/Net?keywordType=%E6%89%8B%E5%8A%A8%E8%BE%93%E5%85%A5&jobarea=000000&pageCode=home%7Csearch%7Cjobsearchlb
# 等待直到所有XHR请求完成
WebDriverWait(browser, 10).until(
lambda driver: driver.execute_script(
'return window.performance.getEntriesByType("resource").some(r => r.initiatorType === "xmlhttprequest")')
)
# 等待页面中所有资源加载完成
WebDriverWait(browser, 10).until(
lambda driver: driver.execute_script(
'return document.readyState == "complete" && !window.JQuery || jQuery.active == 0')
)
time.sleep(1) # 获取对应接口前延时一秒等待接口加载
json_data = browser.xhr_json('open/noauth/job/search')
print(f"sssss:{json_data}")
for temp in json_data['resultbody']['searchData']['joblist']['items']:
item = dict()
item['jobname'] = temp['jobname']
item['coname'] = temp['coname']
item['jobarea'] = temp['jobarea']
item['issuedate'] = temp['issuedate']
item['jobtag'] = temp['jobtag']
item['providesalary'] = temp['providesalary']
print(item)
if __name__ == "__main__":
Yjs().start()
9.唯品会(Feapder)
9.1feapder create命令
基本语法:
-
[options]:是一些可选的命令行参数,用于配置创建的项目类型、配置等。-p或--project:用来指定项目的模板类型。-s或--spider:用来指定项目中要创建的蜘蛛(Spider)的名称。
-
[name]:是你要创建的项目名称,即生成的文件夹名称,项目的目录结构将以这个名称命名。
feapder create [options] [name]
假设你创建一个名为 my_crawler 的项目,使用 vip 模板,项目目录可能如下:
-
spiders/:存放爬虫文件,每个爬虫都应该是一个 Python 文件,定义了如何从网站中获取数据。 -
settings.py:设置 Feapder 项目的一些默认参数,比如请求头、爬取深度等。 -
items.py:定义爬虫抓取的数据结构,通常会用到 Feapder 的Item类。 -
pipelines.py:定义了爬取后如何处理数据(如存储到数据库或文件系统中)。 -
middlewares.py:用于处理请求和响应的中间件,比如添加代理、处理重试等。
my_crawler/
spiders/
spider.py # 默认的蜘蛛(爬虫)模板
settings.py # 项目的设置配置文件
items.py # 定义爬取的数据结构
pipelines.py # 数据处理管道
middlewares.py # 中间件配置
__init__.py # 项目初始化文件
9.2创建项目
创建一个Spider
# 创建项目
feapder create -p vip
# 进入spiders目录
cd .\vip\spiders\
# 创建脚本
feapder create -s vip_tel_spider
9.3配置(setting)
数据库配置
# MYSQL
MYSQL_IP = "localhost"
MYSQL_PORT = 3306
MYSQL_DB = "py_spider"
MYSQL_USER_NAME = "root"
MYSQL_USER_PASS = "root"
并发配置低点,防止被封
# SPIDER
SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐32
# 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
SPIDER_SLEEP_TIME = 1
SPIDER_MAX_RETRY_TIMES = 10 # 每个请求最大重试次数
KEEP_ALIVE = False # 爬虫是否常驻
关闭自动下载浏览器驱动
如果没有配置好浏览器驱动,可以指定绝对路径
9.4初始化数据库
我这里提前建好了数据库,所以这里就只建了表
init_db.py
from feapder.db.mysqldb import MysqlDB
db = MysqlDB(ip='localhost', user_name='root', user_pass='root', db='py_spider')
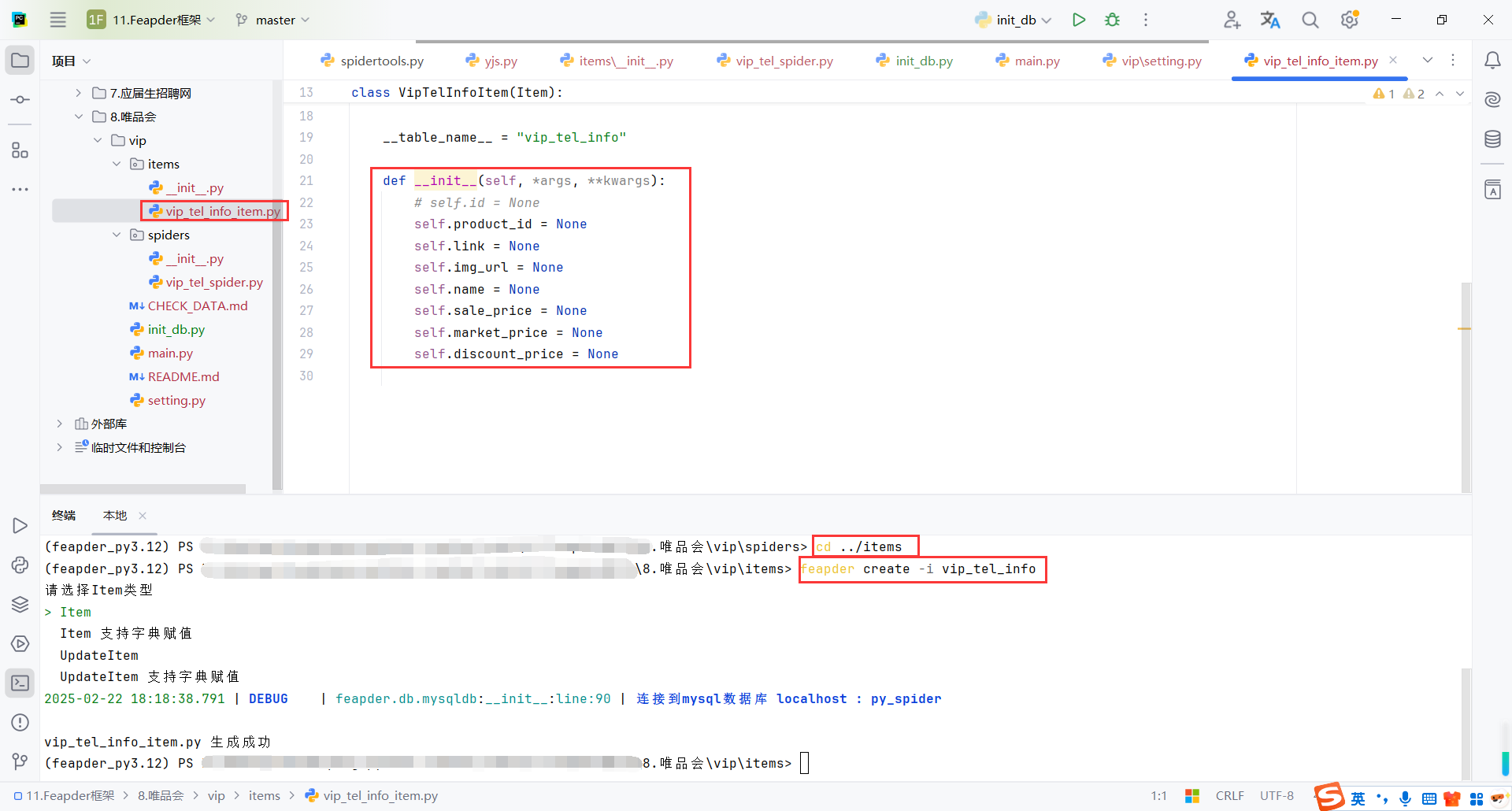
create_table_sql = """
create table vip_tel_info(
id int primary key auto_increment,
product_id varchar(255) ,
link varchar(255) ,
img_url varchar(255) ,
name varchar(255) ,
sale_price varchar(255) ,
market_price varchar(255) ,
discount_price varchar(255)
);
"""
db.execute(create_table_sql)
9.5创建数据模型(Item)
在项目/items目录下创建
还需要确定表vip_tel_info已存在
cd ../items
feapder create -i vip_tel_info
9.6配置cookie
首先使用自己的账号登录,获取cookie
如果不使用登录的cookie,搜索完成跳转到搜索列标签会跳转到登录页
9.6.1获取Cookies
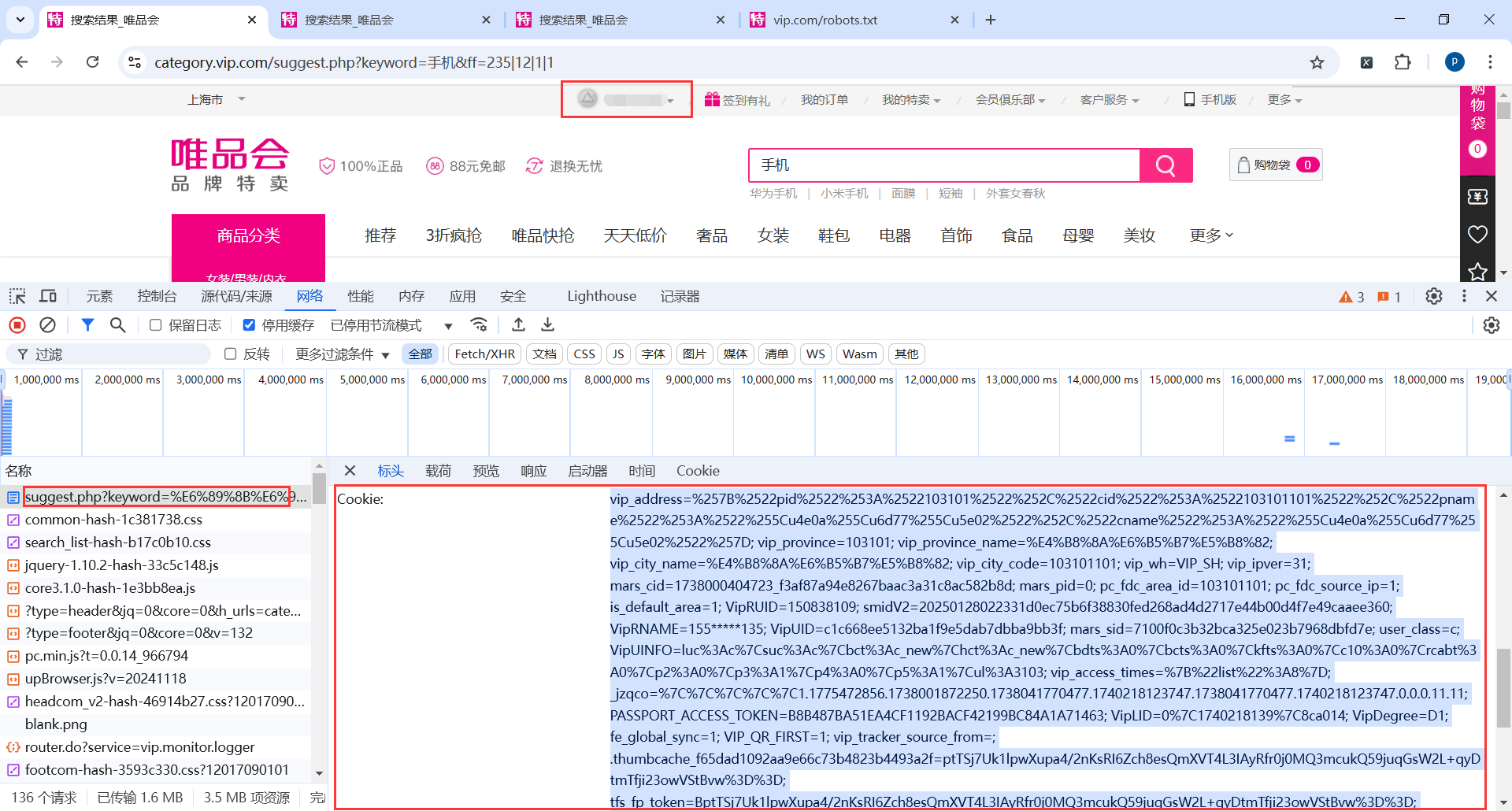
9.6.2feapder.Request配置cookie
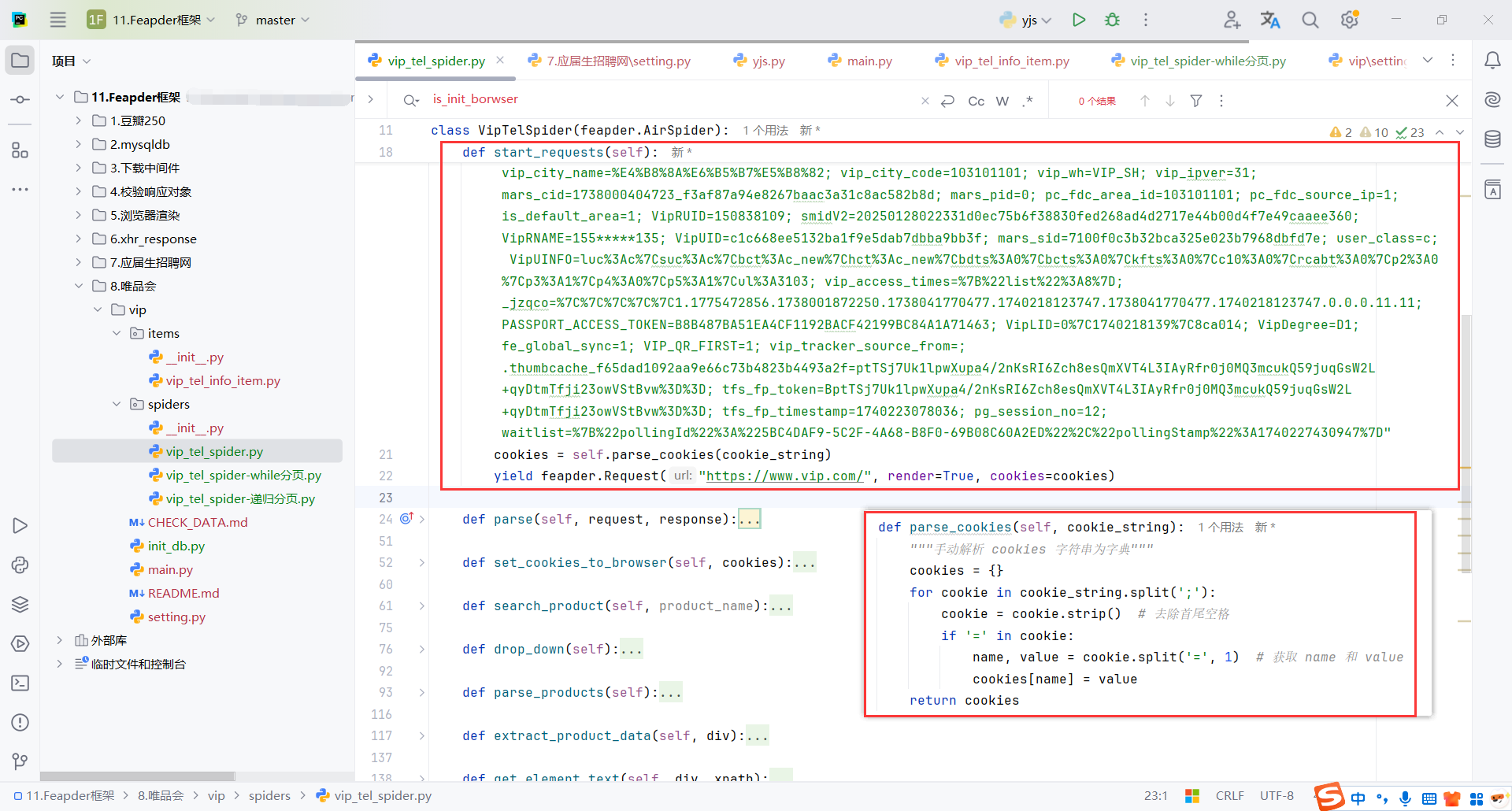
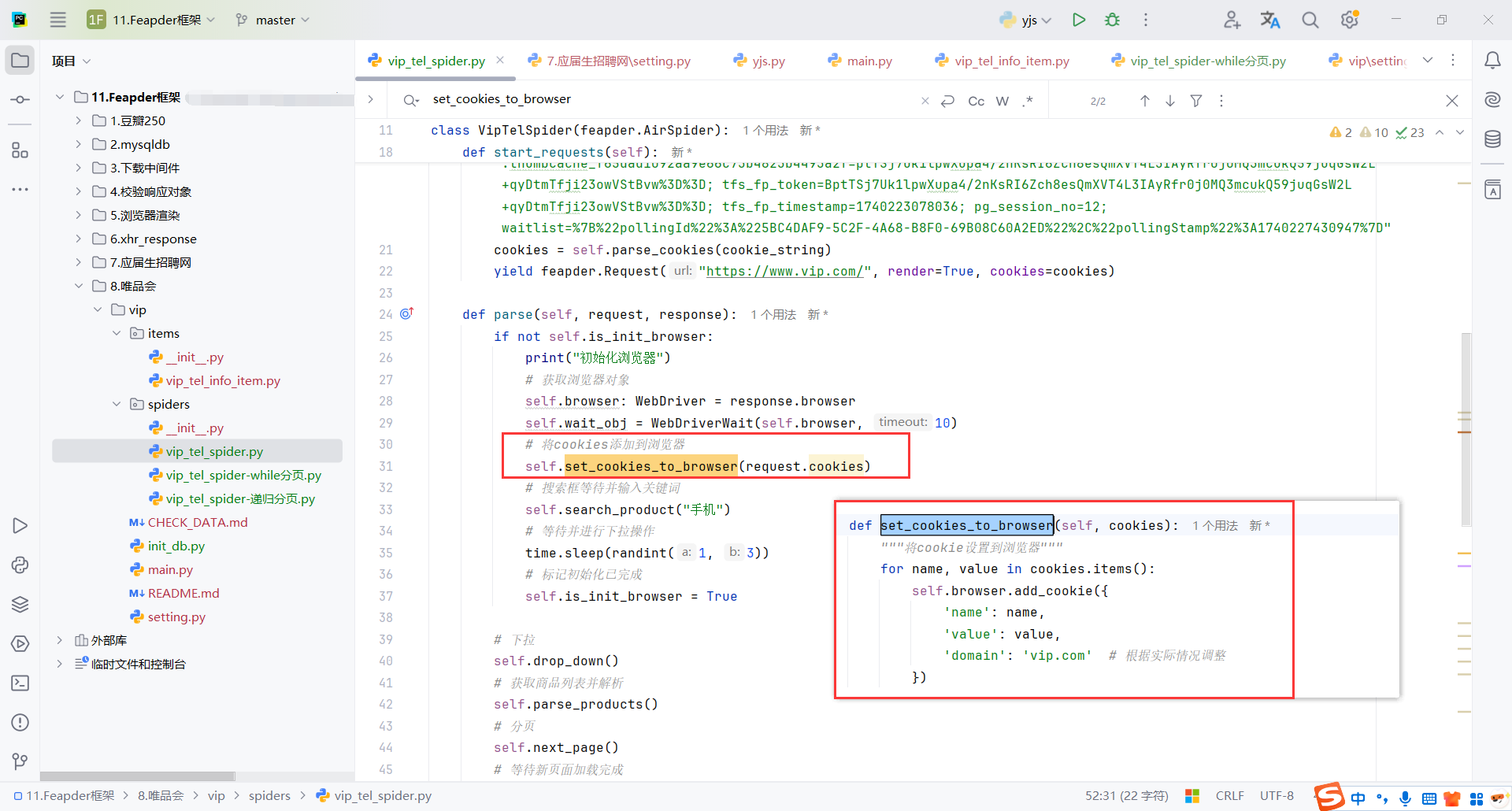
9.6.2WebDriver配置cookie
因为也需要selenium从页面发送请求,所以这里WebDriver也需要配置
9.7分页
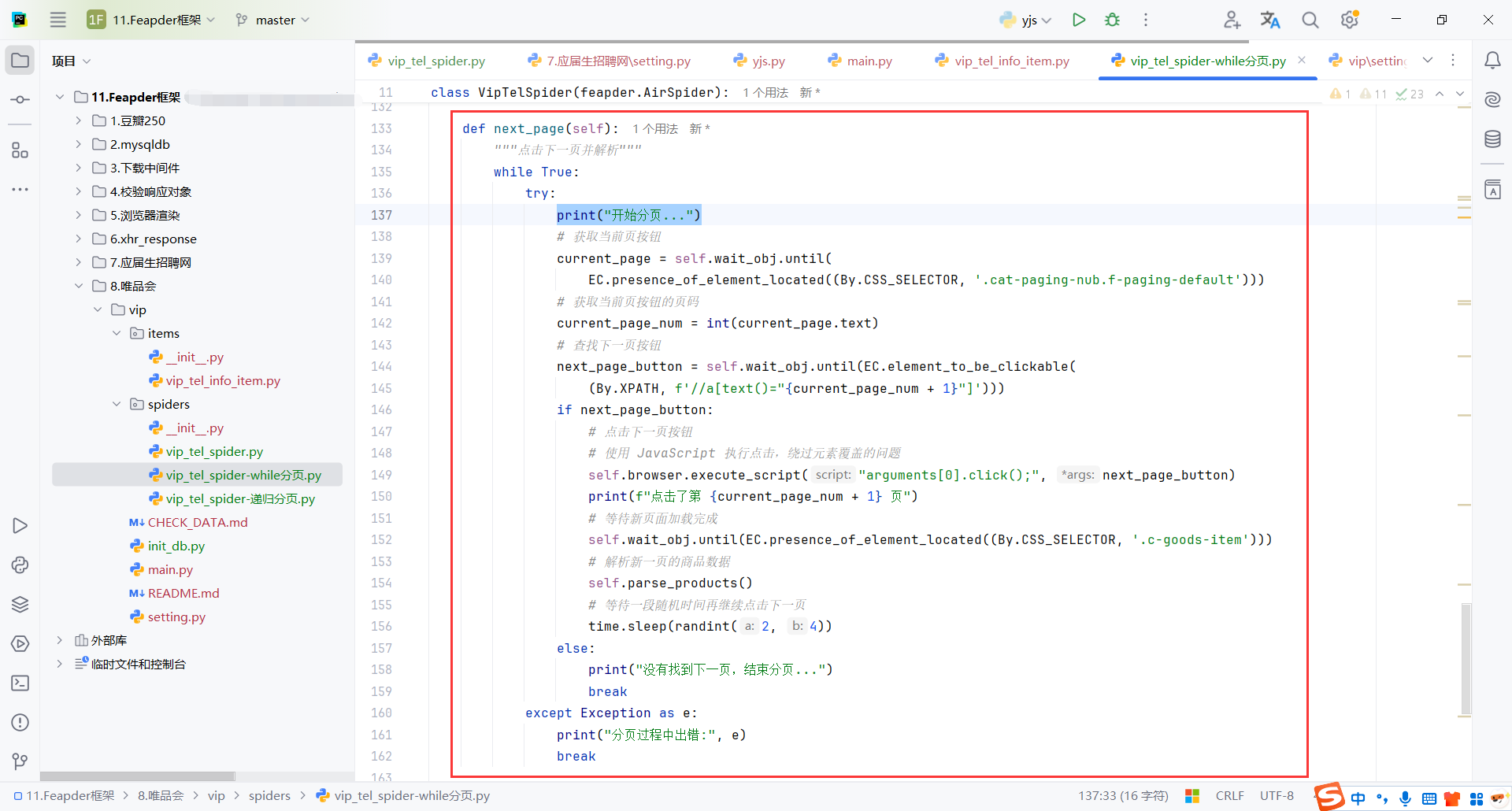
9.7.1While分页
在while循环里循环获取页码按钮,没有获取到就意味最后一页,退出即可
9.7.2递归分页
和while原理类似
需要注意第一页的时候已经执行了self.drop_down()
当没有找到页码的时候意味最后一页,每次递归传入当前页码 + 1
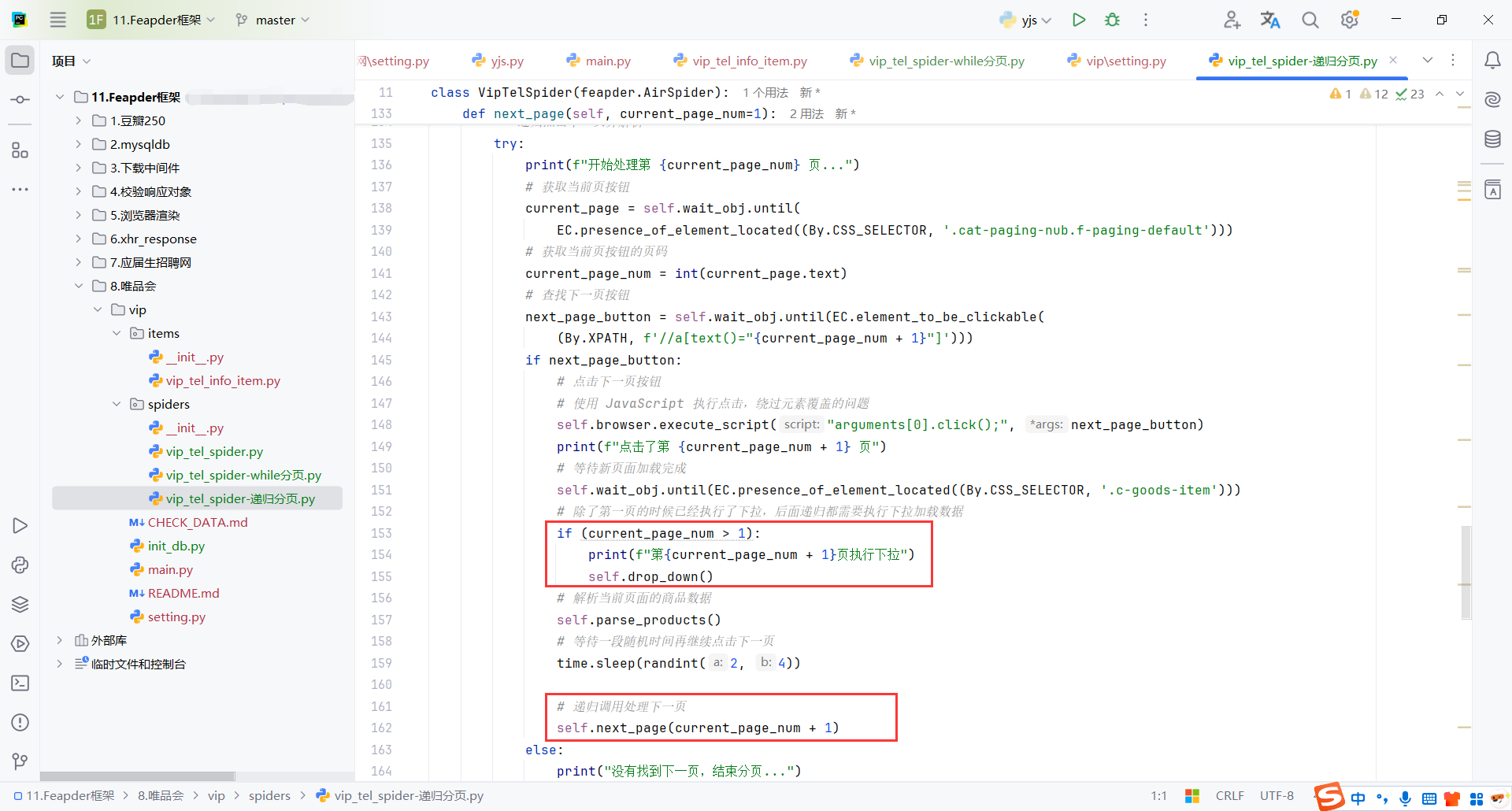
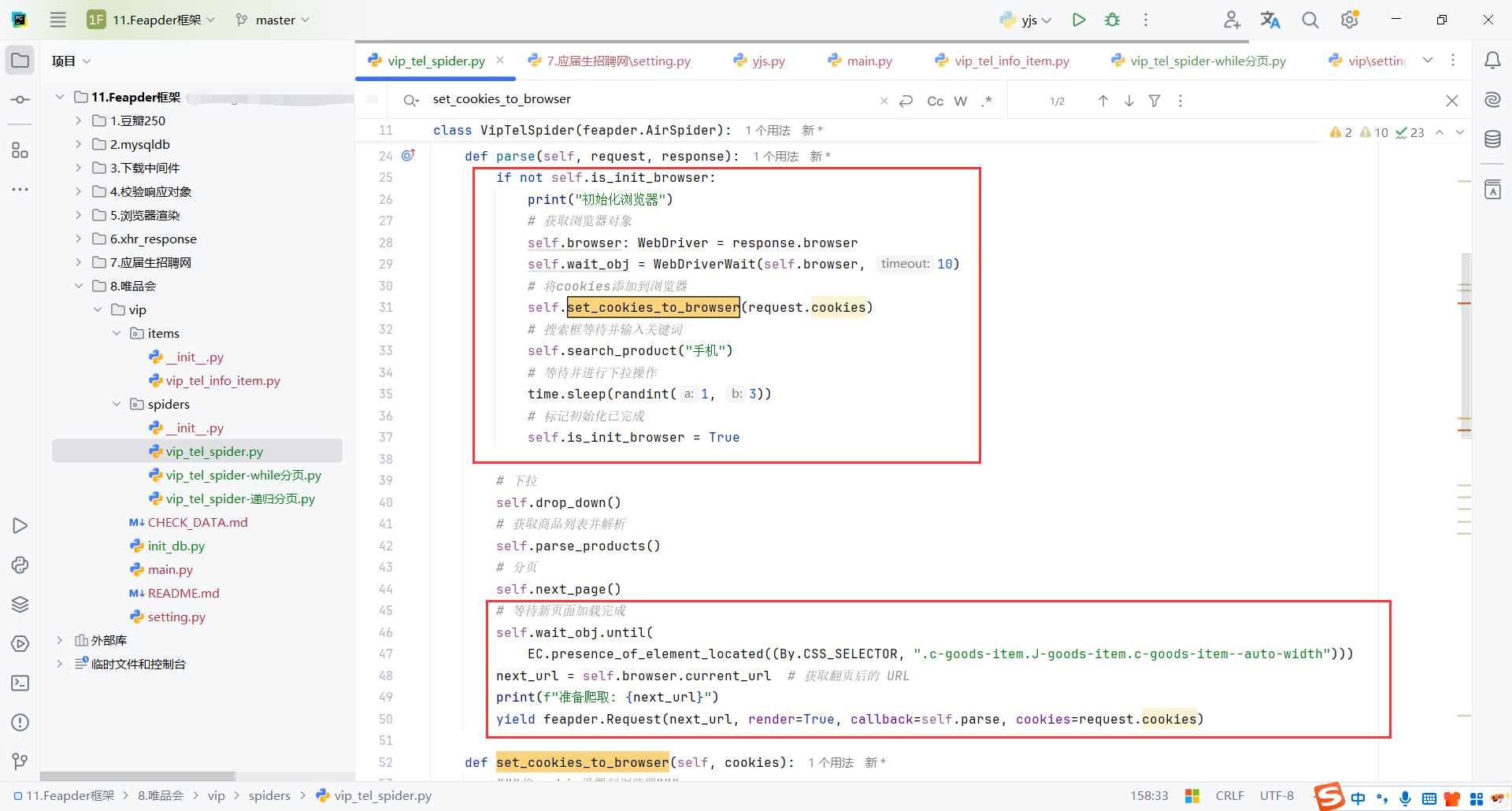
9.7.3feapder.Request分页
因为会回调调用parse,所以初始化browser、cookie、self.search_product("手机")这些逻辑只用执行一次,通过全局变量判断第二次parse就不执行了
feapder.Request的请求地址可以通过WebDriver获取,parse方法还包括request、response
比较推荐这种方式,框架切合度比较高
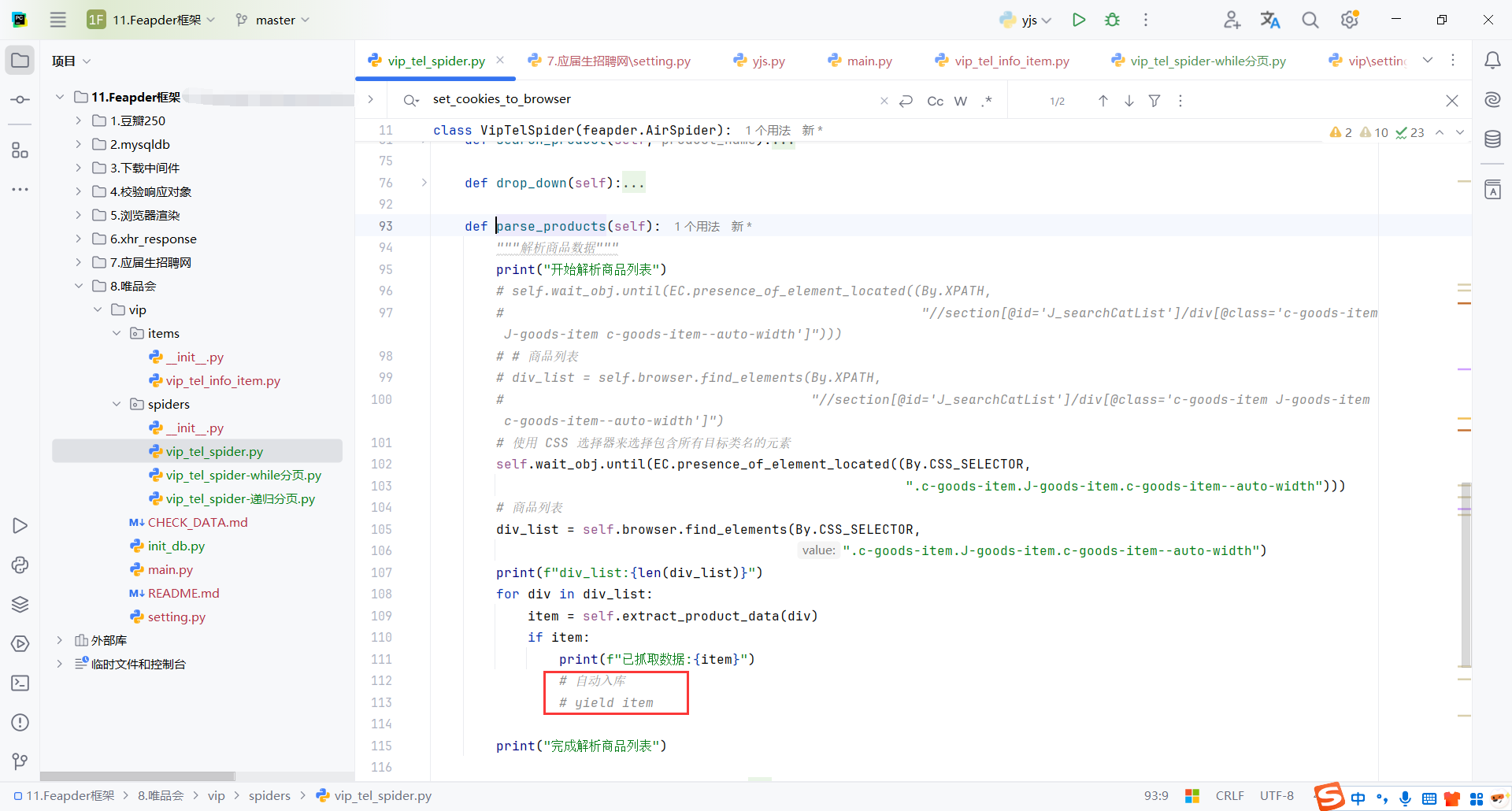
9.8数据保存
框架支持自动入库,配置好数据库配置和数据模型就可以了
9.9main.py
具体来说,__init__.py 文件有以下几个常见用途:
- 标记目录为包:它使得 Python 知道这个目录应该被视为一个包,而不仅仅是一个普通的文件夹。这意味着你可以通过
import语句导入包内的模块和子模块。 - 初始化代码:可以在
__init__.py文件中放置一些包初始化时需要执行的代码。比如,你可以在包导入时执行某些操作,或者定义一些公共函数/变量。 - 简化导入路径:可以通过
__init__.py文件中的导入语句来定义包内的模块或子模块的公共接口,使得用户在导入包时不需要了解包内的具体实现结构。
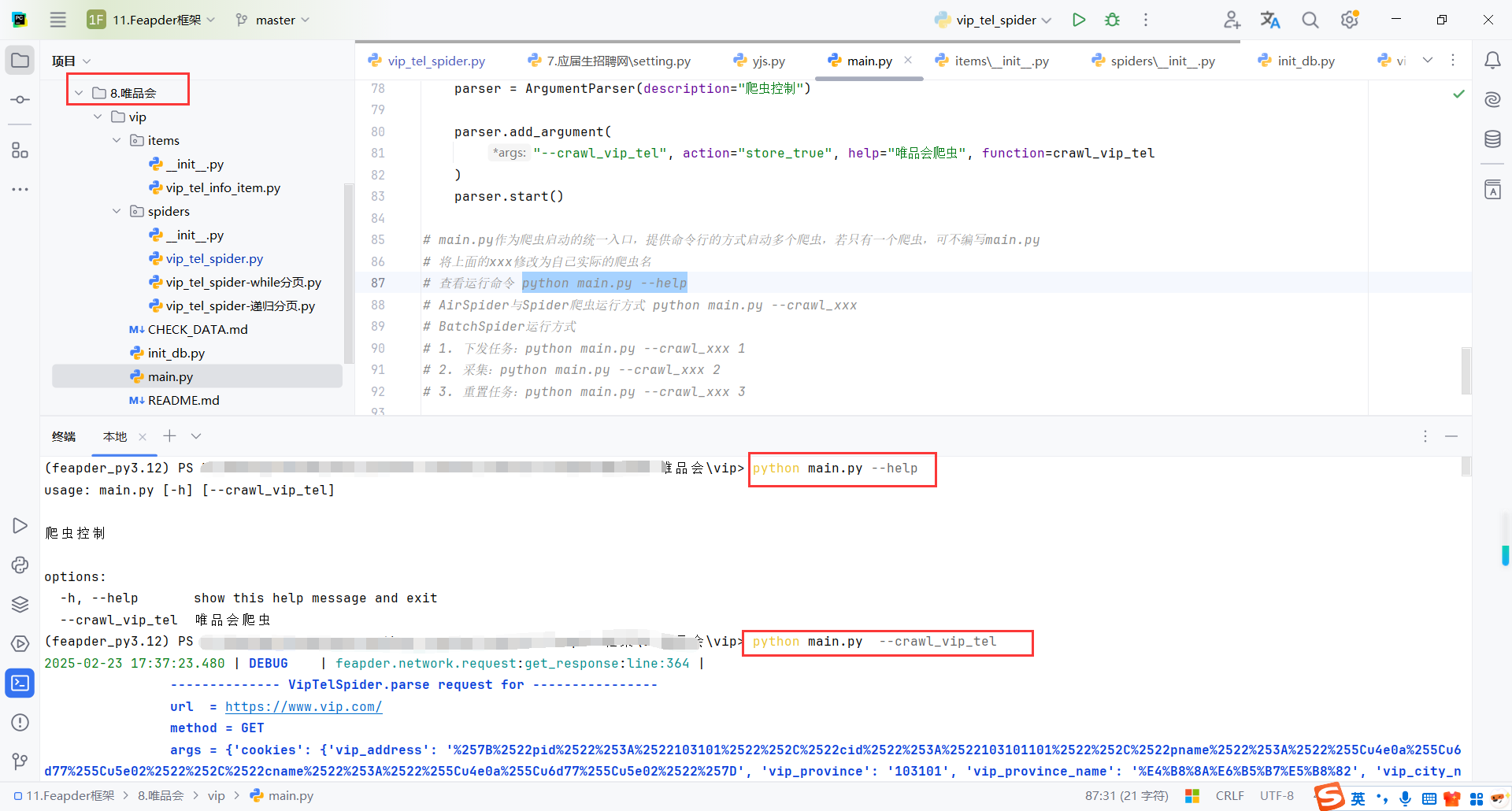
使用命令执行爬虫
python main.py --help
python main.py --crawl_vip_tel
📌 创作不易,感谢支持!
每一篇内容都凝聚了心血与热情,如果我的内容对您有帮助,欢迎请我喝杯咖啡☕,您的支持是我持续分享的最大动力!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号