Python爬虫-selenium框架
前言
蜕变的过程虽然很痛苦,但却藏着成长的奇迹和惊喜。
勇于尝试未知,是成长;
挑战不愿意之事,是改变;
追求你害怕的东西,是突破。
⚠️声明:本文所涉及的爬虫技术及代码仅用于学习、交流与技术研究目的,禁止用于任何商业用途或违反相关法律法规的行为。若因不当使用造成法律责任,概与作者无关。请尊重目标网站的
robots.txt协议及相关服务条款,共同维护良好的网络环境。
1.Miniconda
1.1简介
Miniconda 是 Anaconda 的一个轻量版,主要用于环境和包的管理。与 Anaconda 相比,Miniconda 安装包非常小,只有大约 400 MB,而 Anaconda 包含了大量的库和工具,安装包大约为 3 GB。Miniconda 让你能够从零开始创建自定义环境并按需安装所需的包。
Miniconda:
- 包含最基础的功能:Conda 包管理器和 Python 解释器。
- 没有预装其他包,只有 Conda 和基础 Python,安装后可以根据需求安装各种包。
- 适合希望定制环境的用户,减少不必要的安装包和依赖。
Anaconda:
- 包含了 Conda、Python 以及大多数常用的科学计算和数据分析库(如 NumPy、Pandas、SciPy、Matplotlib 等)。
- 安装包较大,适合希望快速开始的数据科学和机器学习项目。
Miniconda 的优点
- 体积小:只有 Anaconda 的一小部分,可以节省磁盘空间。
- 按需安装:只安装你需要的包,避免不必要的依赖。
- 灵活性高:让用户有更多控制权来管理环境和安装包。
1.2安装
参考:https://gis-xh.github.io/my-note/python/01conda/Win11-Miniconda-install/
地址:https://www.anaconda.com/download/success
Miniconda在下面,点击下载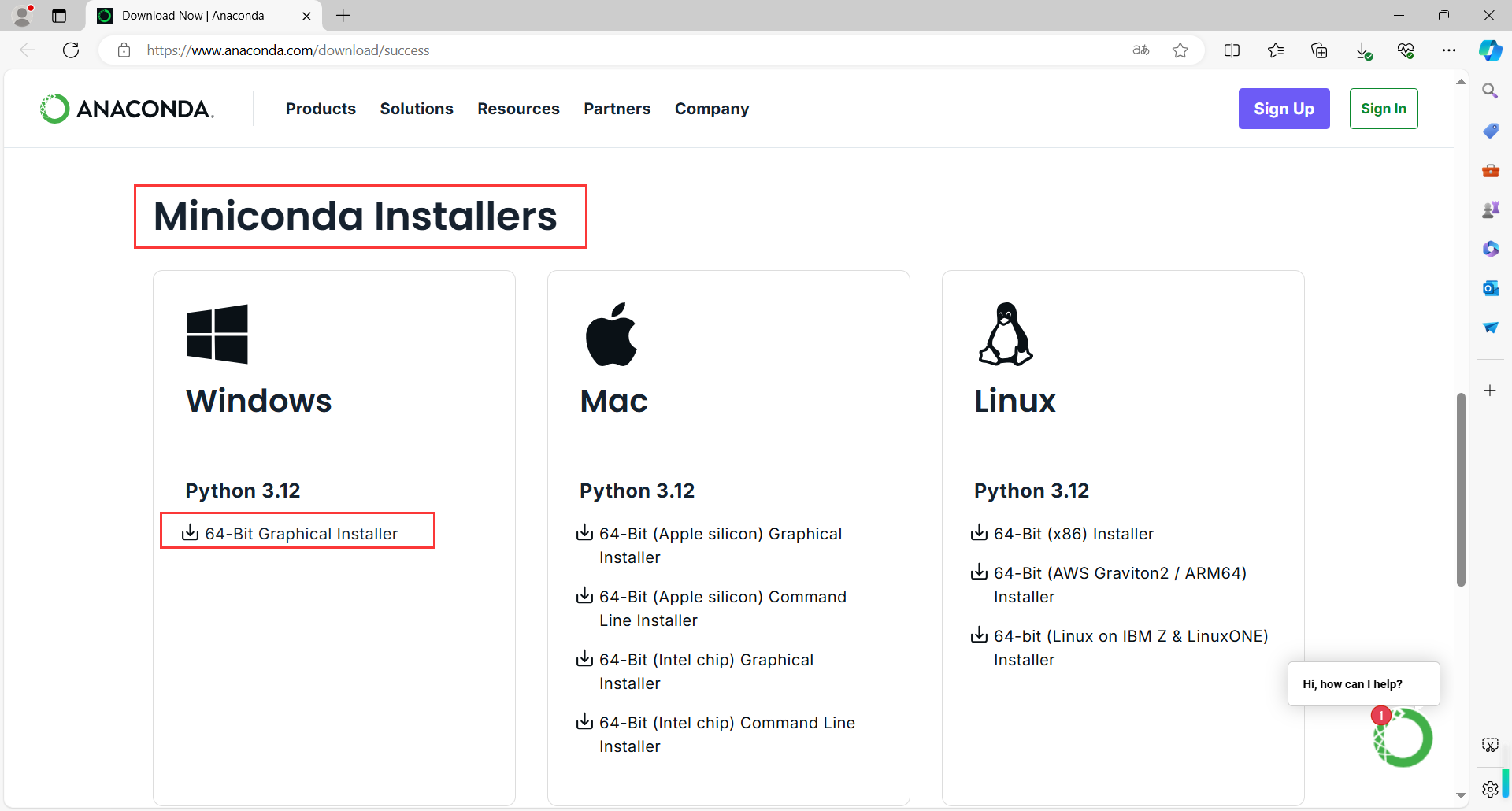
建议选择修改安装目录
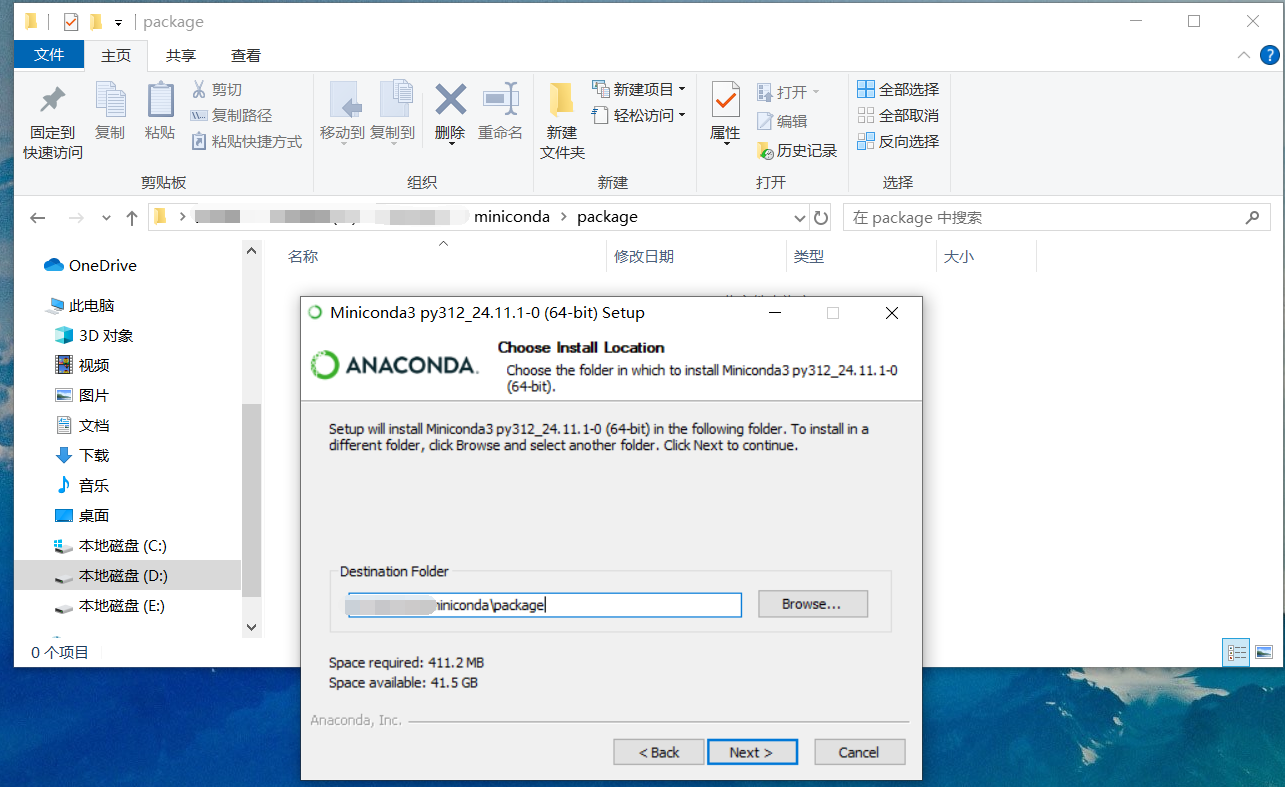
我这里为了方便都选上了
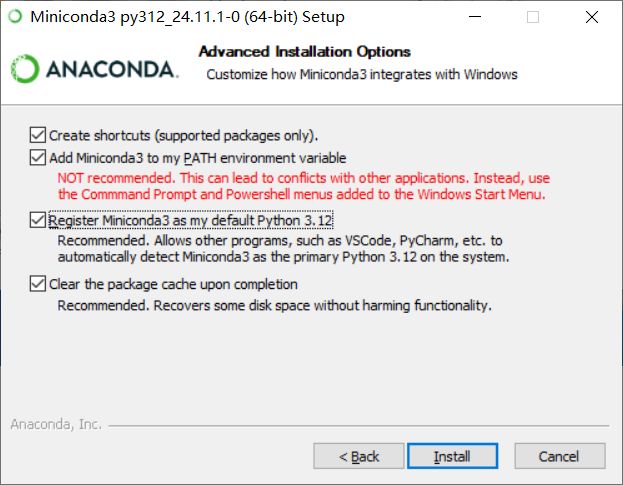
- 创建快捷方式(仅支持包)。
- 将Miniconda3添加到PATH环境变量中不推荐。这可能导致与其他应用程序的冲突。代替。使用Windows开始菜单中添加的命令提示符和Powershell菜单。
- 注册Miniconda3作为我默认的Python 3.12推荐。允许其他程序,如VsCode, PyCharm等自动检测Miniconda3作为系统上的主Python 3.12。
- 完成后清除包缓存建议使用。恢复部分磁盘空间而不损害功能。
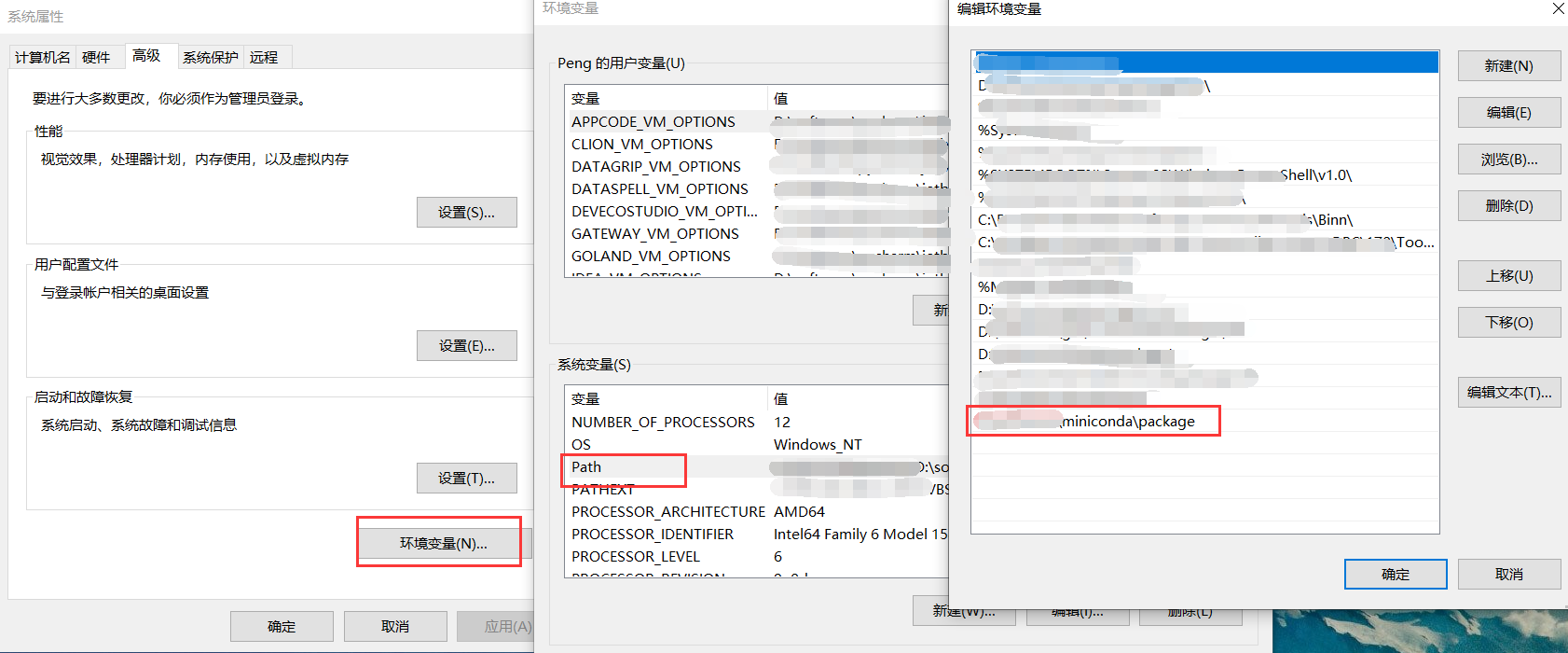
配置Miniconda3环境变量
验证
# 初始化
conda init
# 版本
conda --version
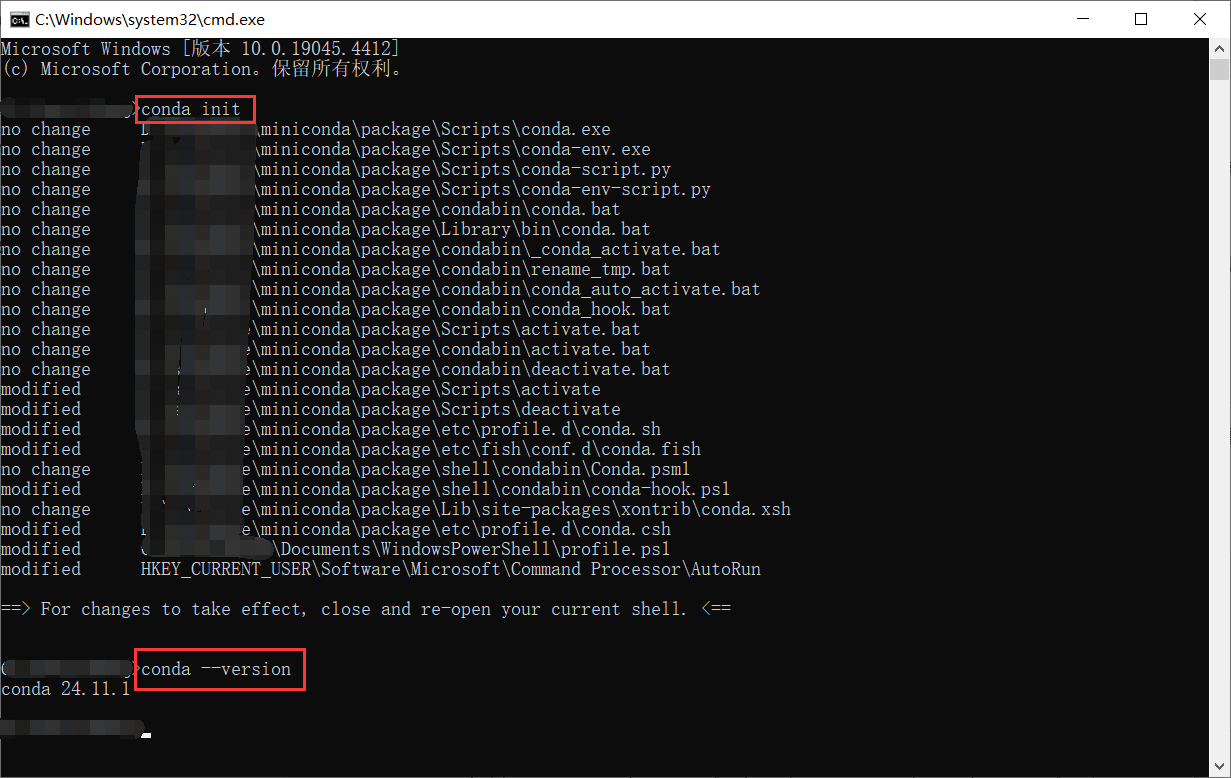
打开一个新的 cmd 窗口,输入下方指令
conda config --set show_channel_urls yes

随后在 C 盘的用户目录下会生成一个 .condarc 文件。
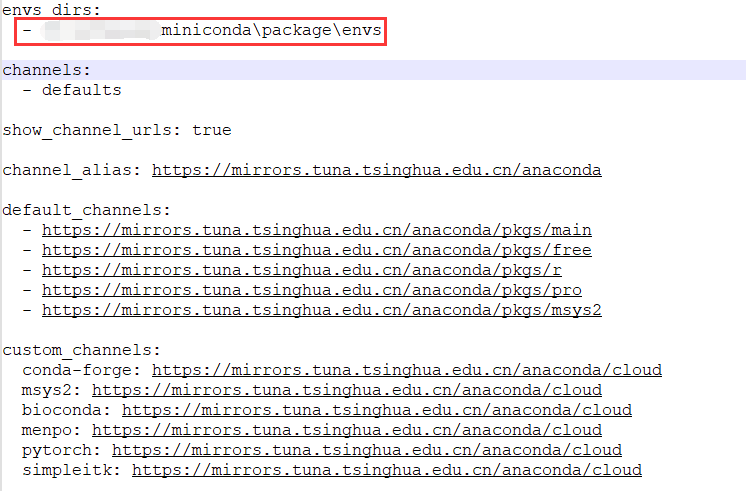
记事本打开,并修改如下配置
需要修改你自己的miniconda3安装路径
envs_dirs:
- 你的miniconda安装路径\envs
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
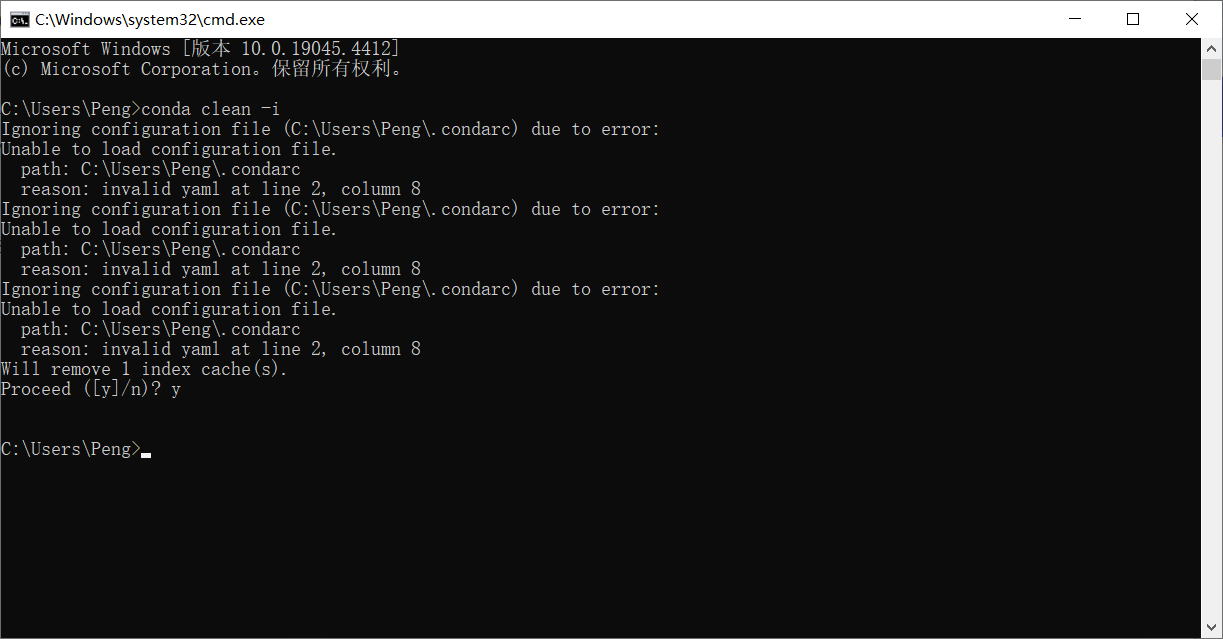
清理索引缓存
conda clean -i
修改虚拟环境默认安装位置
找到 miniconda 目录下的 envs 文件夹,右击打开属性。
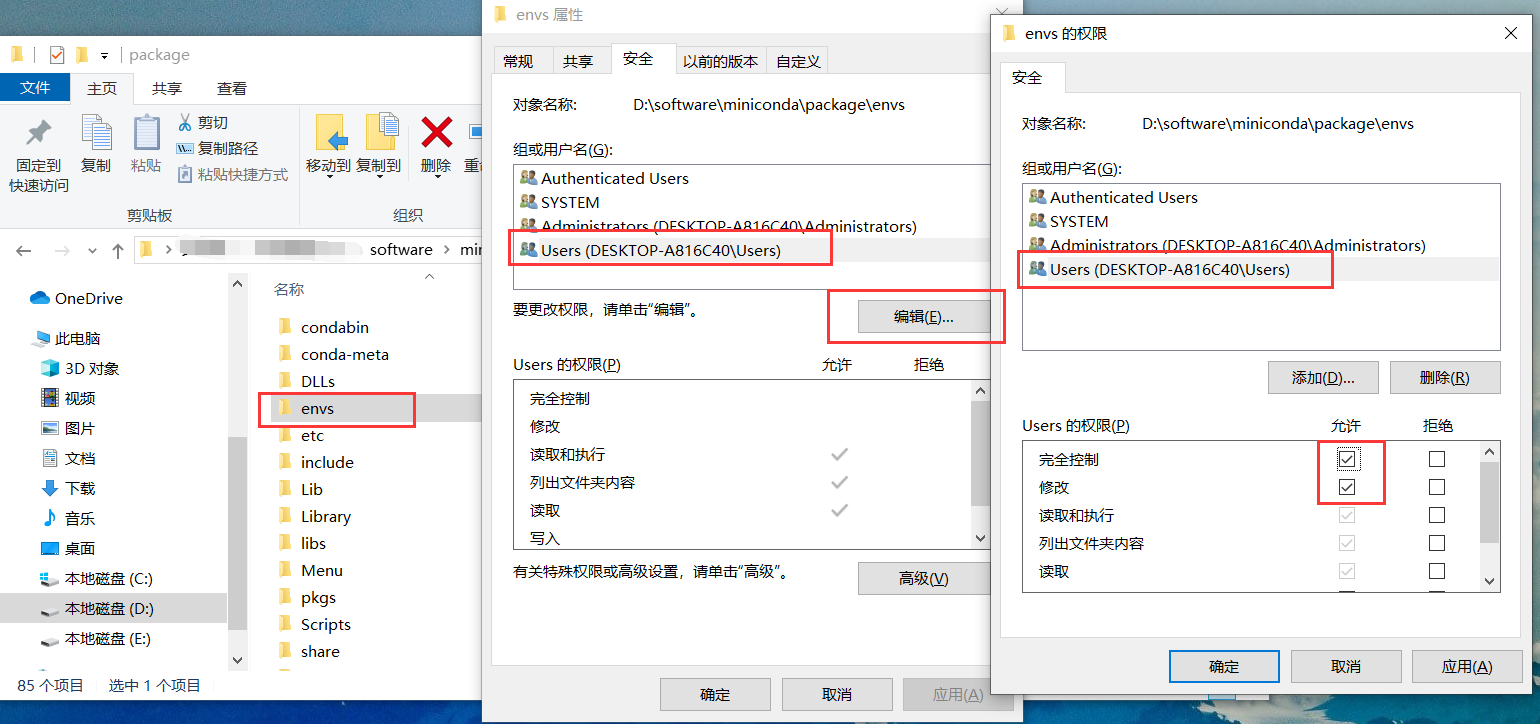
检查当前环境信息
conda info

创建一个新的环境(例如:python_3.12)并安装 Python 3.12:
conda create --name python_3.12 python=3.12
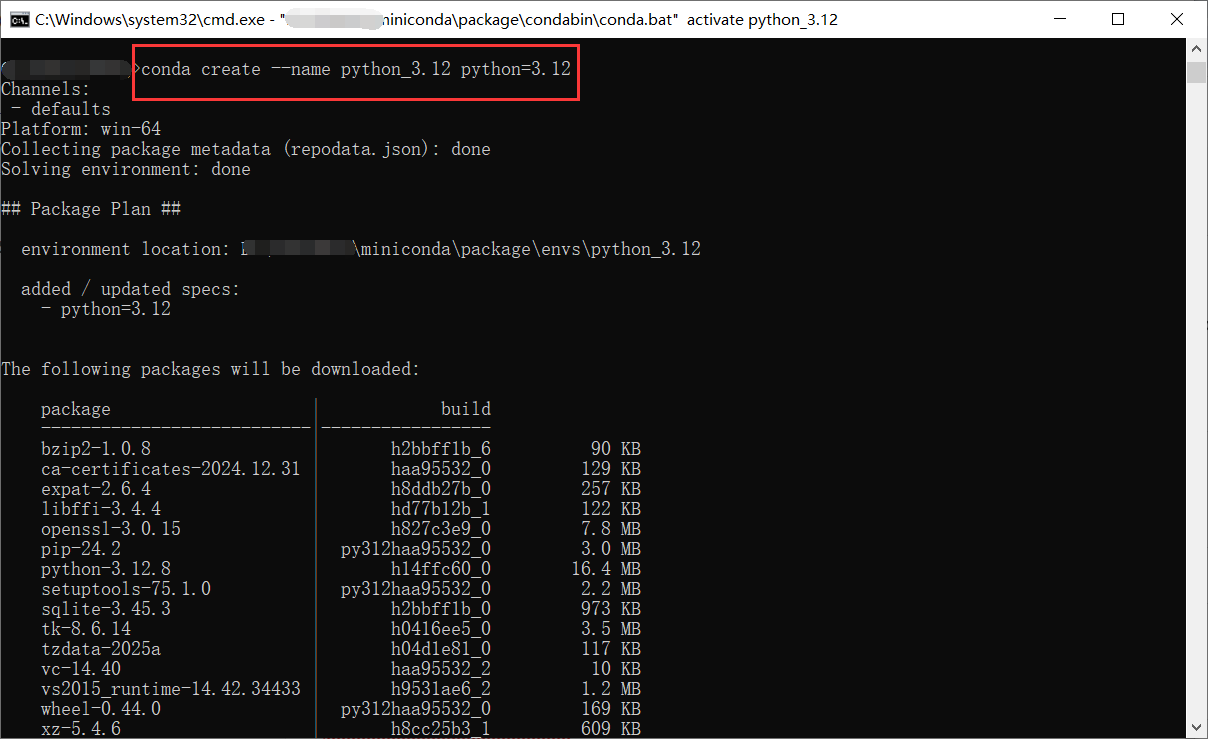
查看已创建的虚拟环境
conda info -e
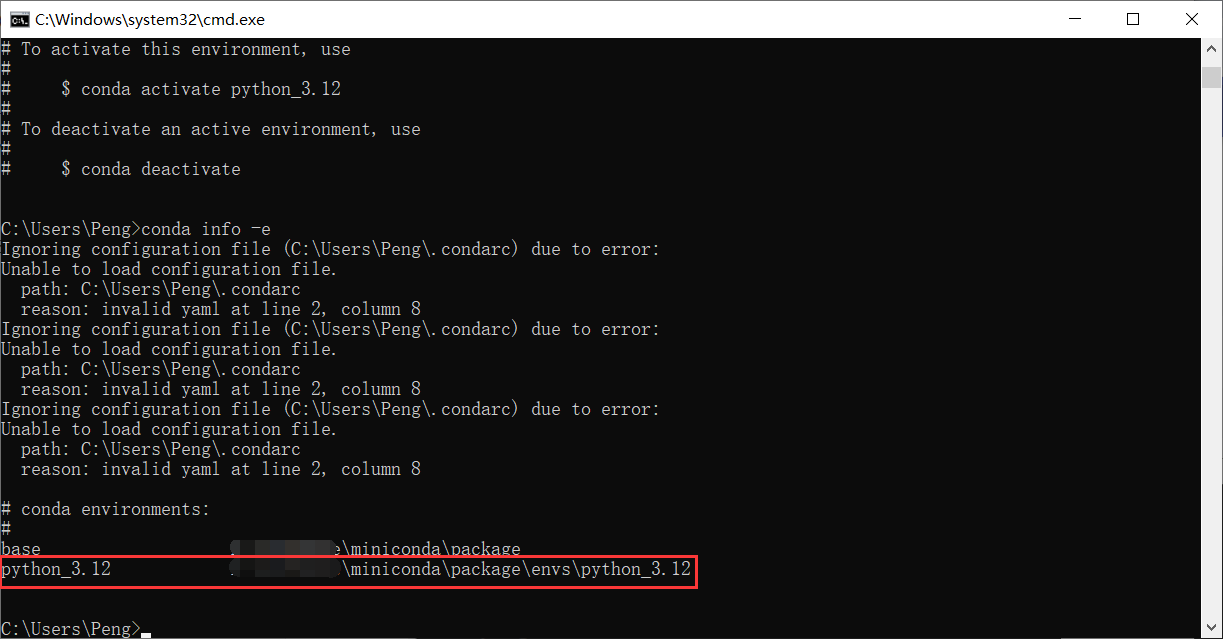
激活新环境
conda activate python_3.12

移除名为 python_3.12 的虚拟环境。
conda remove -n python_3.12 --all
关闭名为 python_3.12 的虚拟环境
conda deactivate python_3.12
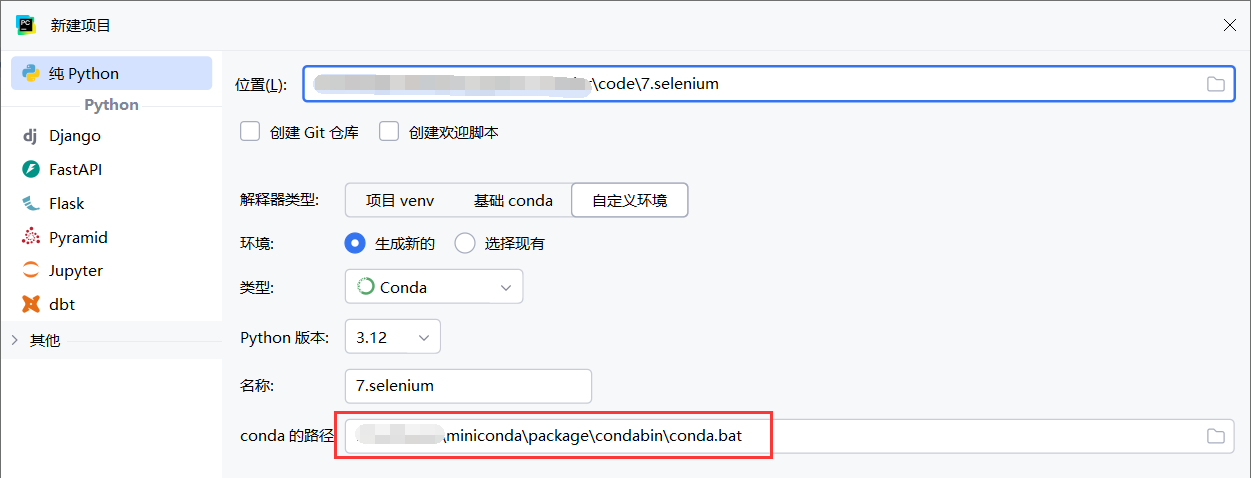
1.3基于conda创建项目
2.Selenium框架
2.1简介
Selenium 是一个广泛使用的开源自动化测试框架,主要用于Web应用的自动化测试。它可以模拟用户与浏览器的交互,进行自动化操作,比如点击按钮、填写表单、抓取数据等。Selenium 支持多种编程语言,包括 Python、Java、C#、Ruby、JavaScript 等。
官方网站:https://www.selenium.dev/
中文参考网址:http://www.selenium.org.cn/
其他参考网址:https://selenium-python.readthedocs.io/
Selenium 的主要功能
- 浏览器自动化:Selenium 可以控制浏览器执行常见的任务,如点击链接、提交表单、滚动页面、获取页面内容等。
- 跨平台支持:支持多种操作系统(如 Windows、macOS 和 Linux)以及多个浏览器(如 Chrome、Firefox、Safari、Edge)。
- 支持多种语言:可以使用多种编程语言(如 Python、Java、C#)来编写自动化脚本。
- 等待机制:提供显式等待和隐式等待机制,以应对网页加载延迟的问题。
- 元素定位:支持多种方式定位网页元素,如通过 ID、name、class、标签名、XPath、CSS 选择器等。
- 截图与日志:能够在自动化操作中截图并记录日志。
- 模拟用户行为:模拟用户行为,包括点击、输入文本、移动鼠标、键盘操作等。
Selenium 组件
Selenium WebDriver:
- WebDriver 是 Selenium 中的核心组件,提供了一个接口,用于与浏览器进行交互。它能够模拟用户与浏览器的所有操作。
- 支持多种浏览器的驱动,如 ChromeDriver、GeckoDriver(Firefox)、EdgeDriver、SafariDriver 等。
Selenium IDE:
- IDE 是一个浏览器插件,提供了一个简单的界面,用于录制和回放浏览器操作,适合快速录制一些简单的测试脚本。
Selenium Grid:
- Grid 用于并行运行多个测试。可以在多台机器上运行不同浏览器的测试,从而加快测试速度。
2.2安装包
安装命令
pip install selenium
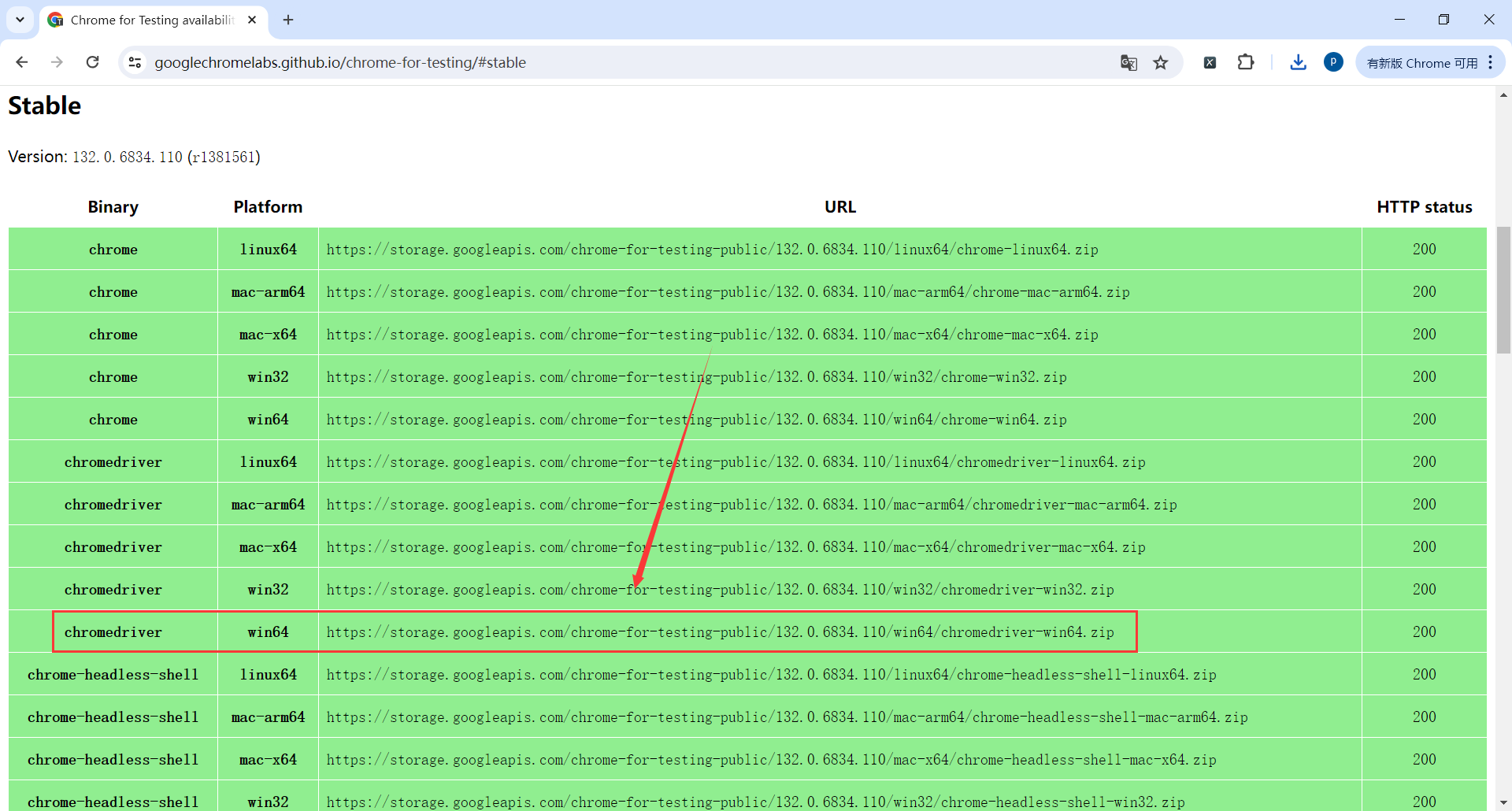
2.3安装驱动
Google浏览器安装selenium驱动
地址:https://googlechromelabs.github.io/chrome-for-testing/#stable
这里什么环境的都有,找自己系统环境的驱动就可以
我这里是win64
下载完成后解压,然后chromedriver.exe移动到miniconda3安装目录
测试代码
import time
from selenium import webdriver
browser = webdriver.Chrome()
time.sleep(3)
我这里运行代码报了一个错误
大致意思是chromedriver 版本和现有的google浏览器版本不一致
我这里安装的最新的chromedriver ,google浏览器版本可能低了
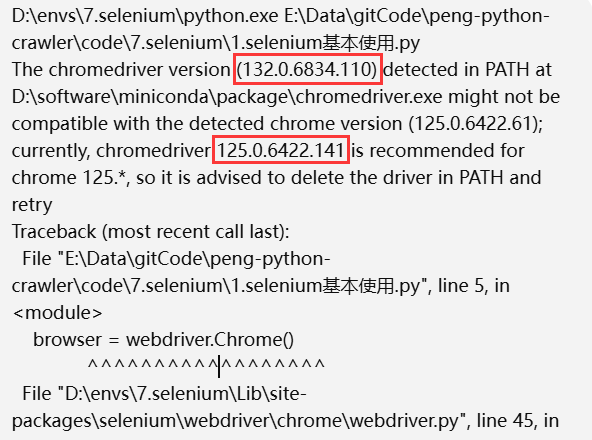
打开以下地址,升级一下google浏览器即可
chrome://settings/help
在运行一下测试代码,google浏览器弹出来即可
除了可以配置谷歌浏览器之外也可以配置火狐浏览器,配置方式与谷歌浏览器大致相同。
火狐驱动下载地址:https://github.com/mozilla/geckodriver/releases
2.4基本使用
2.4.1加载网页
time.sleep(3):程序运行结束后,Python 进程会退出,同时会清理 Selenium 创建的资源,包括关闭浏览器。主要是延时一下,能够让代码执行完成,看到效果
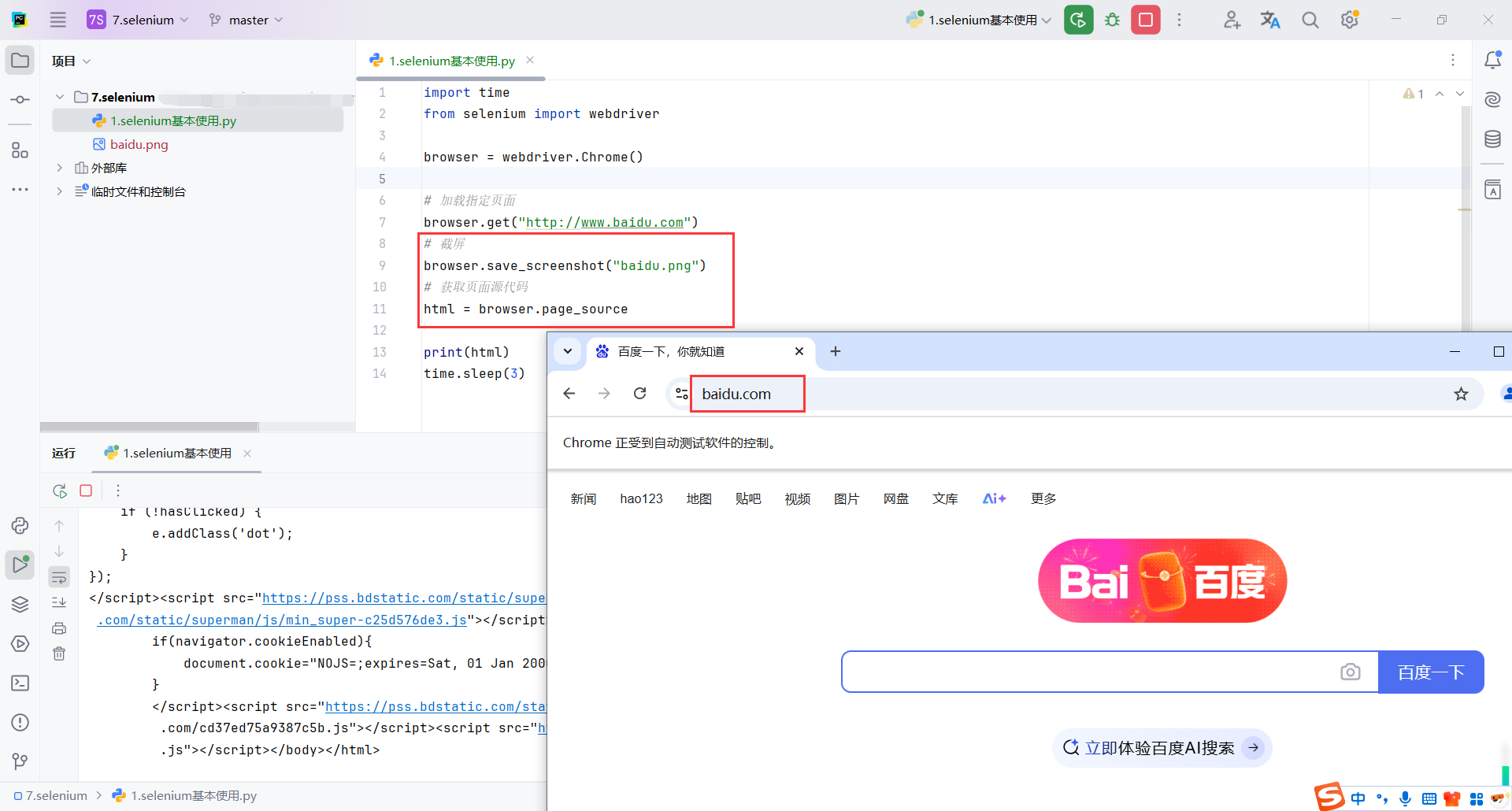
import time
from selenium import webdriver
browser = webdriver.Chrome()
# 加载指定页面
browser.get("http://www.baidu.com")
# 截屏
browser.save_screenshot("baidu.png")
# 获取页面源代码
html = browser.page_source
print(html)
time.sleep(3)
2.4.2页面定位与操作
主要步骤
-
打开百度首页。
-
在搜索框中输入“python”。
-
点击“百度一下”按钮。
-
程序暂停 3 秒,让搜索结果页面保持可见。
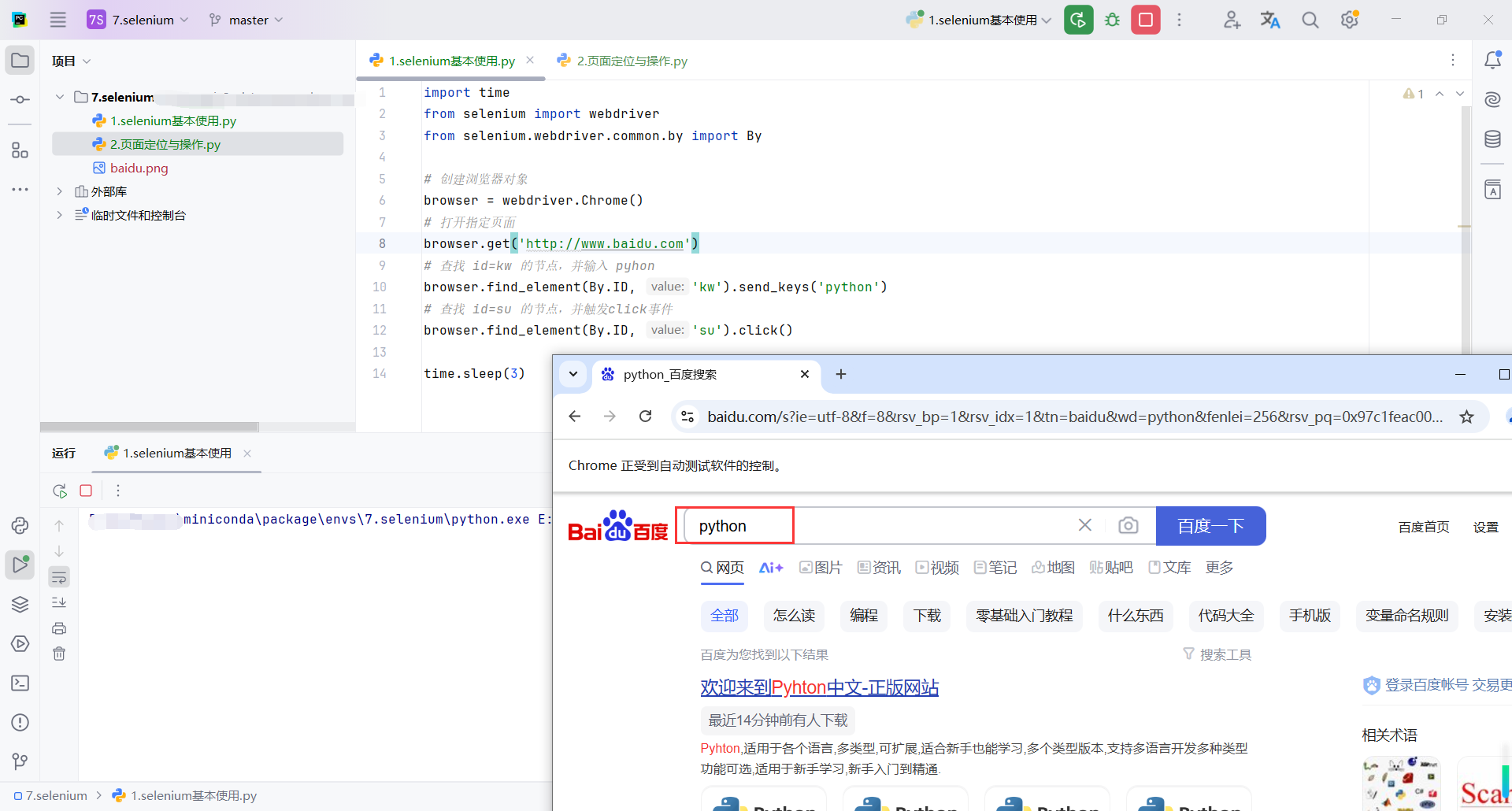
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建浏览器对象
browser = webdriver.Chrome()
# 打开指定页面
browser.get('http://www.baidu.com')
# 查找 id=kw 的节点,并输入 pyhon
browser.find_element(By.ID, 'kw').send_keys('python')
# 查找 id=su 的节点,并触发click事件
browser.find_element(By.ID, 'su').click()
time.sleep(3)
2.4.3查询请求信息
主要步骤
- 启动 Chrome 浏览器并打开百度首页。
- 打印百度页面中的 cookies。
- 跳转到
https://www.360buy.com,但是此链接会重定向到https://www.jd.com/ - 打印当前浏览器访问的地址,也就是
https://www.jd.com/
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
print(browser.get_cookies())
browser.get('https://www.360buy.com')
print(browser.current_url)
input("回车结束程序...")
2.4.4标签页操作
只会在当前标签先打开https://www.taobao.com/,再打开https://www.jd.com/
from selenium import webdriver
import time
# 创建浏览器
browser = webdriver.Chrome()
# 打开淘宝
browser.get("https://www.taobao.com/")
time.sleep(1)
# 打开京东
browser.get("https://www.jd.com/")
time.sleep(1)
# 关闭浏览器
browser.quit()
2.4.5js代码打开新标签页
打开淘宝网站,然后通过 JavaScript 脚本 window.open() 打开京东网站。
browser.execute_script(js_script):使用 Selenium 的 execute_script 方法执行 JavaScript 脚本。在这里,window.open() 被用来打开新标签页并加载京东页面。
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.taobao.com/")
time.sleep(1)
# js脚本
js_script = 'window.open("https://www.jd.com/")'
# 执行js脚本
browser.execute_script(js_script)
time.sleep(3)
browser.quit()
2.4.6切换标签页
browser.execute_script(js_script):execute_script 方法执行 window.open,在新标签页中打开京东。
browser.switch_to.window(browser.window_handles[0]):切换到第一个标签页
browser.window_handles是一个列表,包含当前所有标签页的句柄。[0]表示第一个标签页(淘宝)。switch_to.window()切换到指定的标签页。
browser.switch_to.window(browser.window_handles[1]):切换到第二个标签页
browser.close() :关闭当前活动的标签页。
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.taobao.com/")
time.sleep(1)
js_script = 'window.open("https://www.jd.com/")'
browser.execute_script(js_script)
time.sleep(1)
# 切换第一个标签页
browser.switch_to.window(browser.window_handles[0])
time.sleep(3)
browser.switch_to.window(browser.window_handles[1])
time.sleep(3)
# 关闭当前标签页
browser.close()
time.sleep(1)
# 切换第一个标签页
browser.switch_to.window(browser.window_handles[0])
browser.close()
# 退出浏览器
browser.quit()
2.4.7退出浏览器
close() :
- 关闭当前活动的标签页。
- 如果只有一个标签页调用
close()将关闭整个浏览器窗口。
quit():
quit()方法关闭浏览器窗口及其关联的所有标签页,同时释放WebDriver资源。- 即使已调用
close(),仍需调用quit()以确保完全退出。
import time
from selenium import webdriver
browser = webdriver.Chrome()
# 打开https://www.taobao.com/
browser.get("https://www.taobao.com/")
time.sleep(1)
# 关闭当前活动标签页
browser.close()
# quit() 方法关闭浏览器窗口及其关联的所有标签页,同时释放 WebDriver 资源。
browser.quit()
3.元素定位
3.1获取单个节点
find_element(by: str, value: str):方法仅返回匹配的第一个元素。如果页面上有多个匹配的元素,其他元素将被忽略。
by:指定定位方式,通常用By枚举类的属性。By.ID: 根据元素的id属性定位。By.CLASS_NAME: 根据元素的class属性定位。By.NAME: 根据元素的name属性定位。By.TAG_NAME: 根据 HTML 标签名定位。By.CSS_SELECTOR: 使用 CSS 选择器定位。By.XPATH: 使用 XPath 表达式定位。
value:按照by参数指定的方式,传入具体的定位值。
打开百度新闻,获取一下搜索框
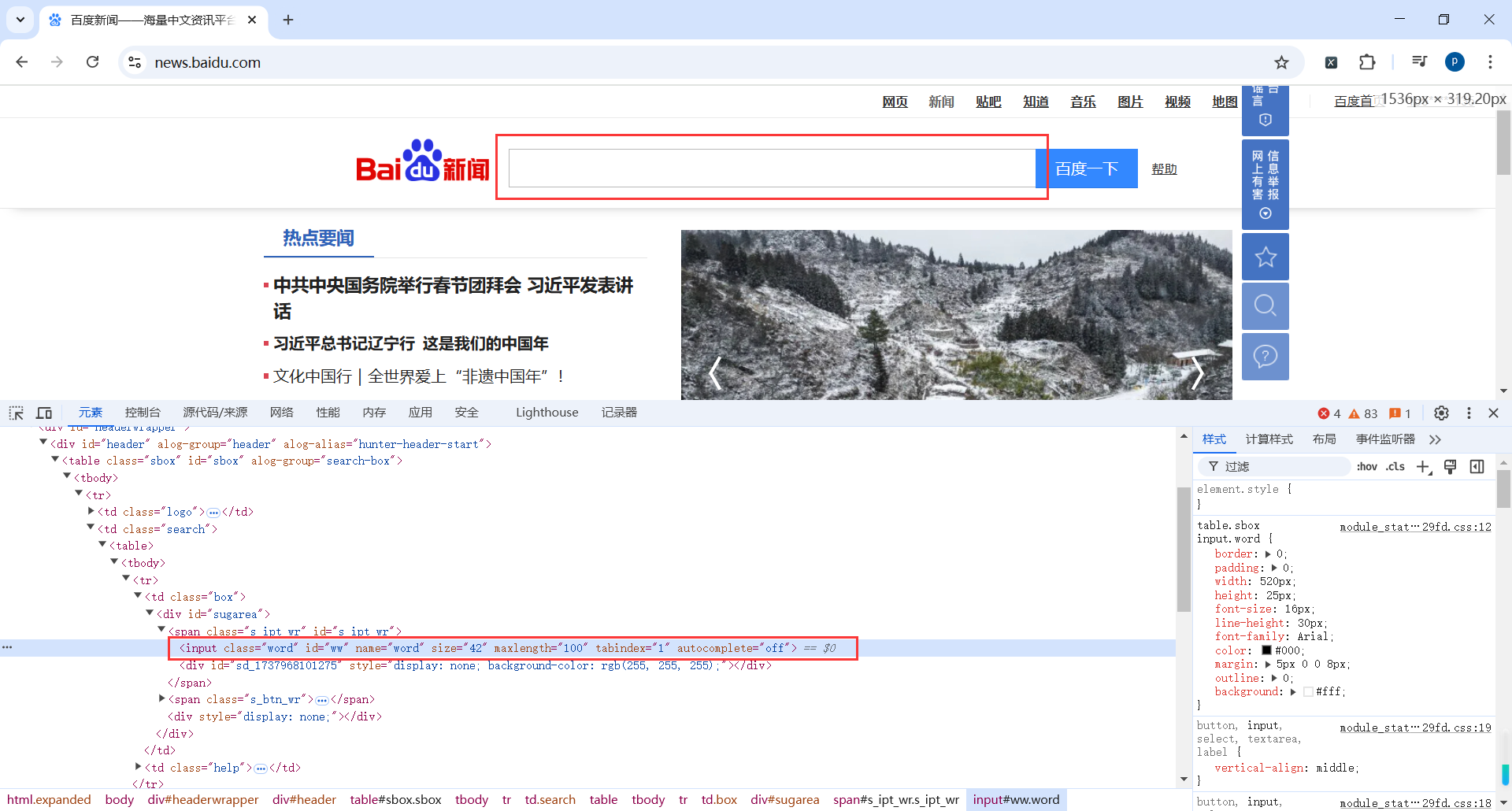
代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://news.baidu.com/')
# 按照元素的 id 属性值进行定位
ele_obj_1 = browser.find_element(By.ID,'ww')
print(ele_obj_1)
# 使用 CSS 选择器语法定位
ele_obj_2 = browser.find_element(By.CSS_SELECTOR,'#ww')
print(ele_obj_2)
# 使用 CSS 选择器 .word 定位元素
ele_obj_3 = browser.find_element(By.CSS_SELECTOR,'.word')
print(ele_obj_3)
# 使用 XPath 表达式定位元素
ele_obj_4 = browser.find_element(By.XPATH,'//*[@id="ww"]')
print(ele_obj_4)
# 使用 name 定位
ele_obj_5 = browser.find_element(By.NAME,'word')
print(ele_obj_5)
# 使用 tag 定位
ele_obj_6 = browser.find_element(By.TAG_NAME,'input')
print(ele_obj_6)
3.2获取多个节点
打开豆瓣电影 Top 250 页面,定位电影信息
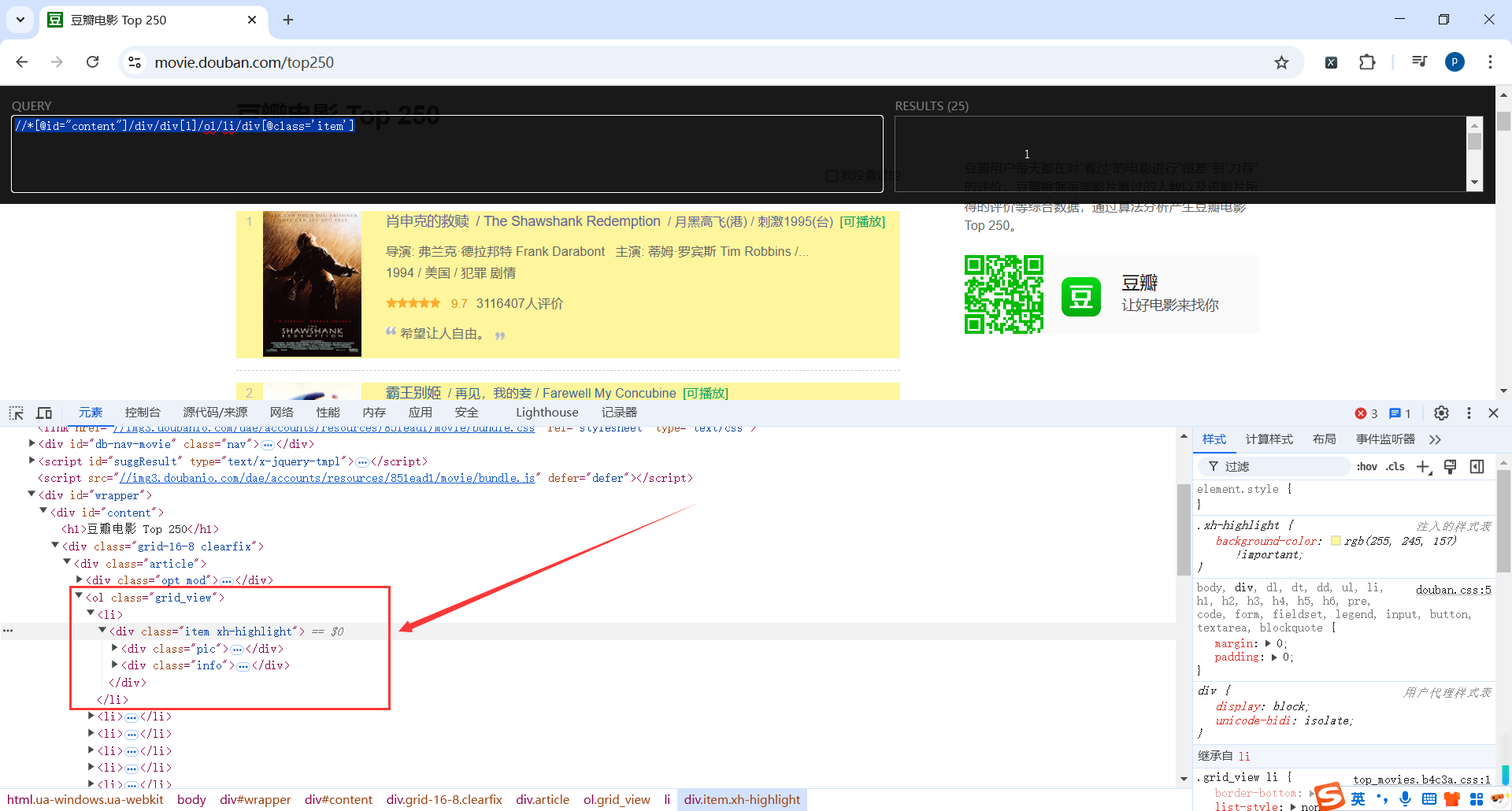
代码
find_elements:
-
查找页面上符合条件的所有元素,返回一个包含
WebElement对象的列表。 -
与
find_element不同,find_elements不会抛出异常,如果未找到元素,会返回空列表。
res1 = browser.find_elements(By.CSS_SELECTOR,'.item'):
- 使用 CSS 选择器
.item定位所有带有类名为item的元素。 - 这里的
.item是标准 CSS 语法,表示选择类名为item的所有元素。
[@id='content']/div/div[1]/ol/li/div[@class='item']"):
- 使用 XPath 表达式定位。
//*[@id='content']/div/div[1]/ol/li/div[@class='item']表示从页面根节点开始,找到 ID 为content的元素,然后逐级定位到其子元素,最终选择class="item"的div元素。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
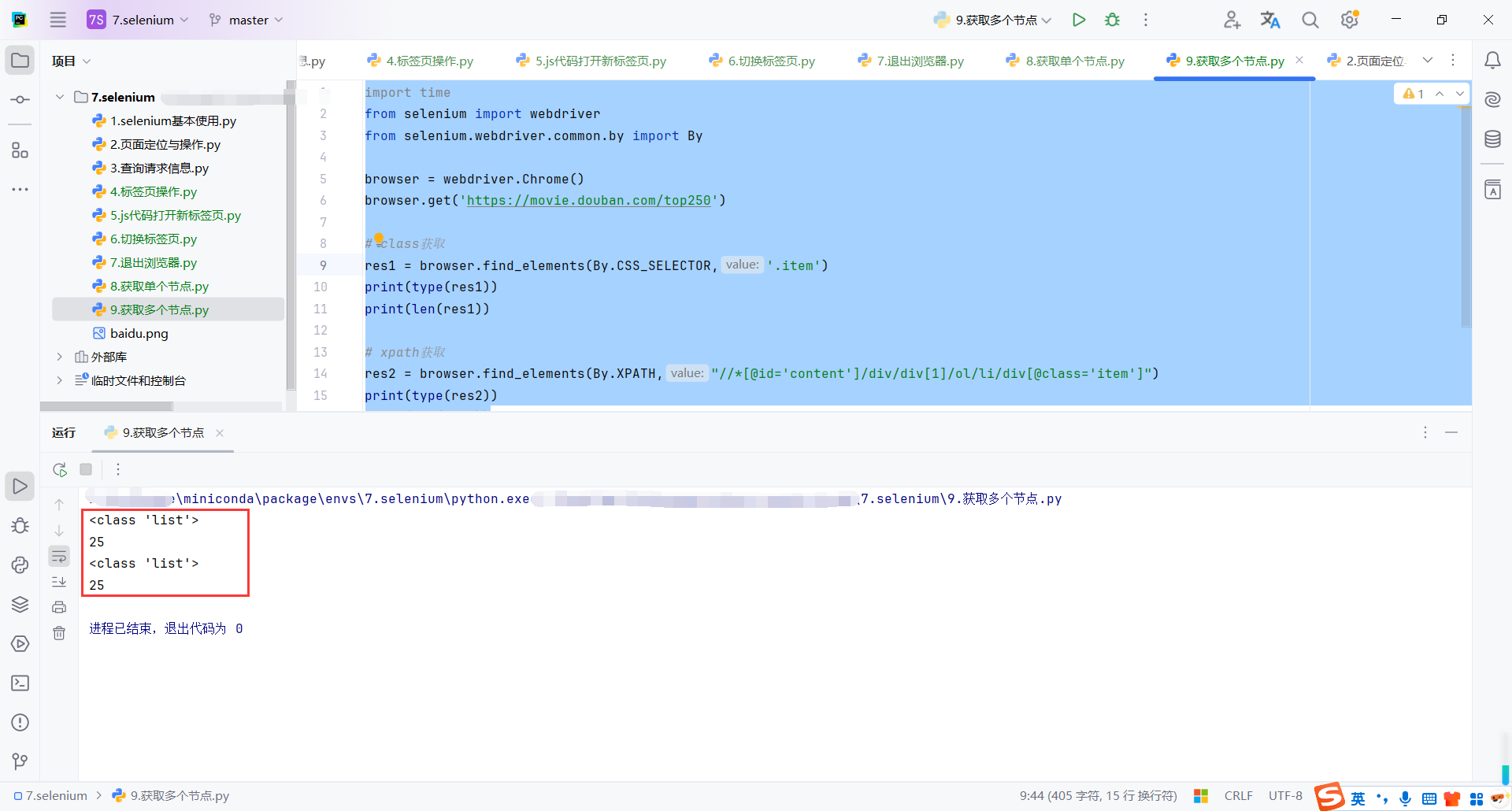
browser.get('https://movie.douban.com/top250')
# class获取
res1 = browser.find_elements(By.CSS_SELECTOR,'.item')
print(type(res1))
print(len(res1))
# xpath获取
res2 = browser.find_elements(By.XPATH,"//*[@id='content']/div/div[1]/ol/li/div[@class='item']")
print(type(res2))
print(len(res2))
4.其他方法
4.1获取标签内容和属性
代码
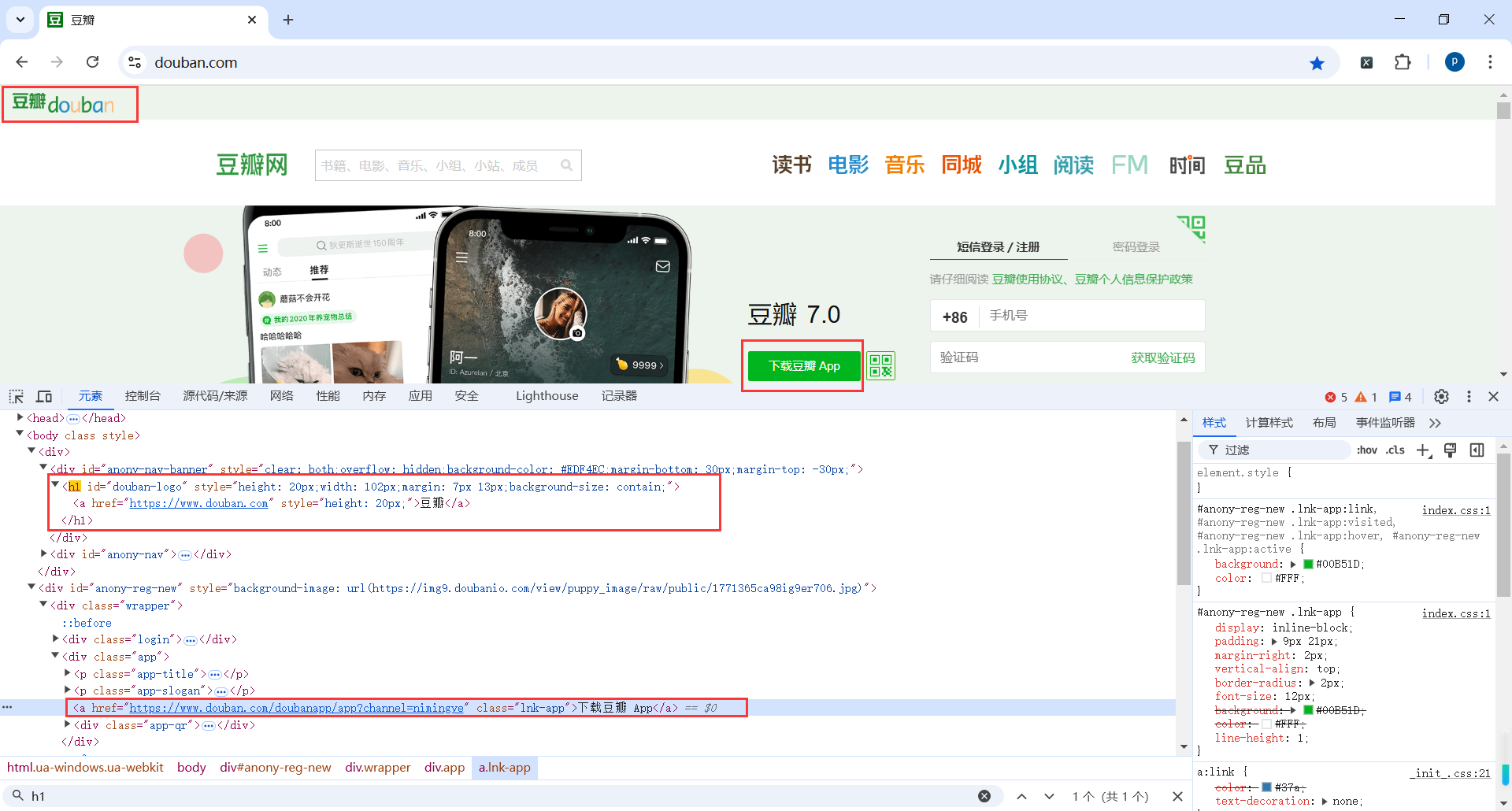
browser.find_element(By.TAG_NAME, 'h1'):定位页面中第一个匹配指定 HTML 标签(如 <h1>)的元素。这里定位到页面中的 <h1> 标签。
res1.text:获取定位元素的文本内容。
get_attribute('属性名'):
- 获取 HTML 元素中指定属性的值。
id: 获取<h1>元素的id属性值。style: 获取<h1>元素的style属性值,如果未设置则返回None。
browser.find_element(By.LINK_TEXT, '下载豆瓣 App'):通过链接文本的完整内容定位超链接元素。定位页面中显示文本为“下载豆瓣 App”的 <a> 标签。
res2.get_attribute('href'):获取超链接的 href 属性值
res2.get_attribute('class'):获取超链接的 class 属性值
区别
| 特性 | get_attribute |
get_property |
|---|---|---|
| 获取的内容 | 返回 HTML 属性值 | 返回 DOM 属性值 |
| 动态内容的支持 | 不一定返回最新值(取决于 HTML 属性是否变化) | 返回最新的 DOM 属性值 |
| 适用场景 | 适用于获取初始 HTML 属性,如 href、class 等 |
适用于获取动态属性值,如 value、checked 等 |
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.douban.com/')
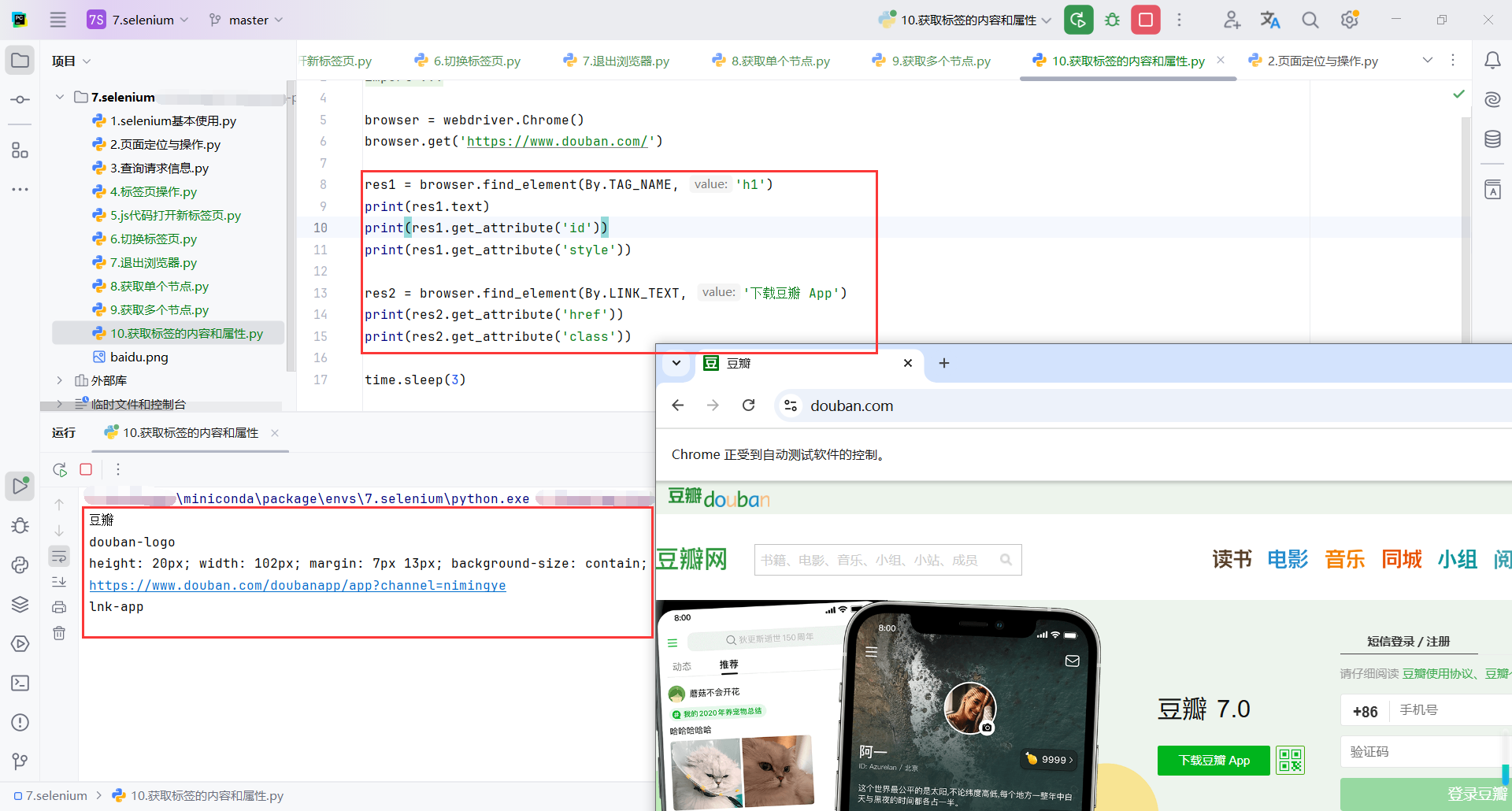
res1 = browser.find_element(By.TAG_NAME, 'h1')
print(res1.text)
print(res1.get_attribute('id'))
print(res1.get_attribute('style'))
res2 = browser.find_element(By.LINK_TEXT, '下载豆瓣 App')
print(res2.get_attribute('href'))
print(res2.get_attribute('class'))
time.sleep(3)
4.2cookie数据处理
Cookie
什么是 Cookie:
- Cookie 是浏览器用来存储用户信息的小型文本文件。
- 通常由服务器设置,用于保存会话状态、用户偏好等信息。
Cookies 的常见属性:
name: Cookie 的名称。value: Cookie 的值。domain: 适用的域名。path: Cookie 的作用路径。expiry: Cookie 的过期时间(时间戳格式)。httpOnly: 是否只能通过 HTTP 协议访问。secure: 是否仅通过 HTTPS 传输。
代码
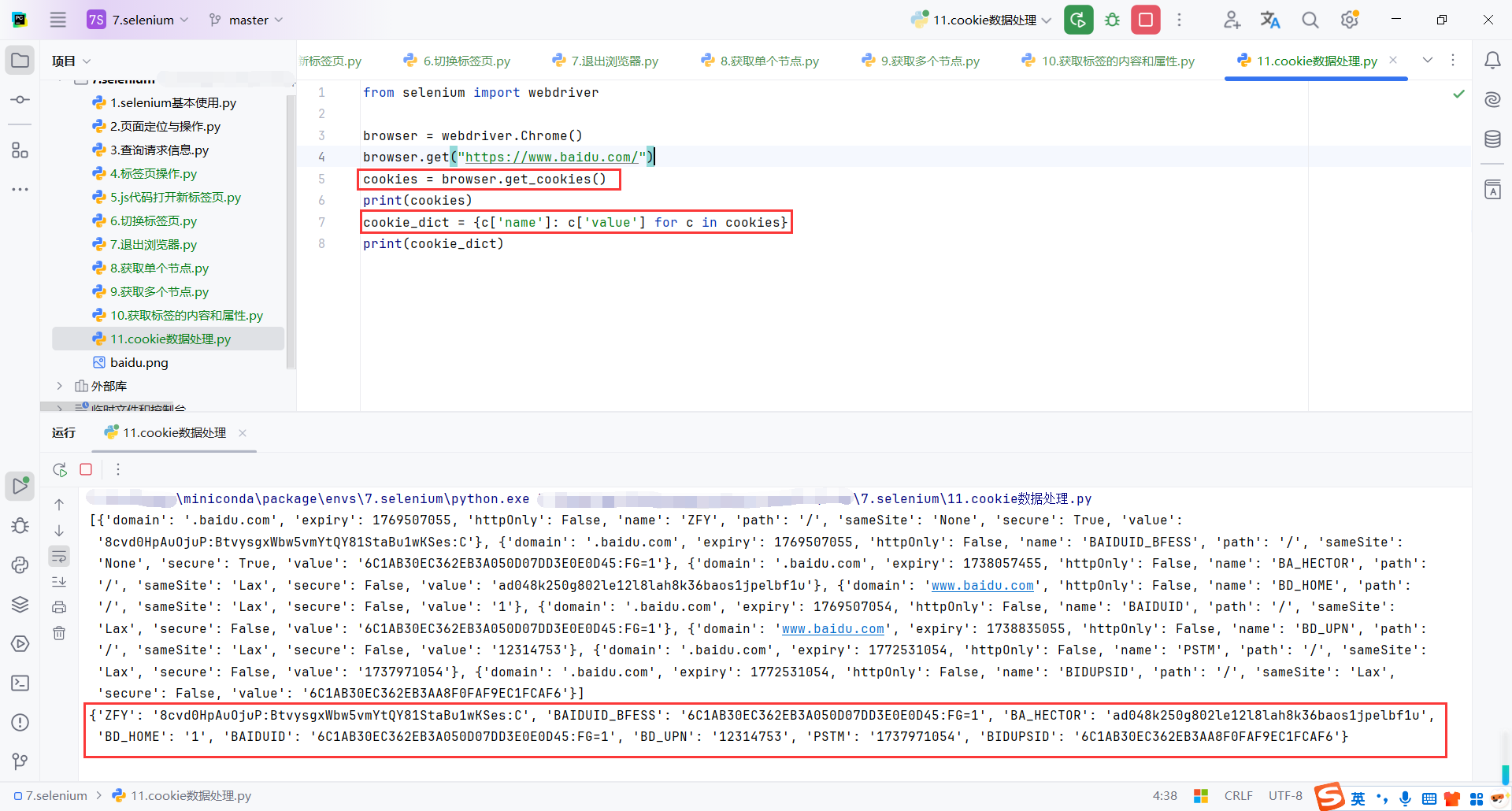
browser.get_cookies():
- 返回浏览器当前页面的所有 cookies 信息。
- 返回值是一个列表,每个元素是一个字典,包含 cookies 的详细信息
{c['name']: c['value'] for c in cookies}:将 cookies 转化为简单的键值对形式。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
cookies = browser.get_cookies()
print(cookies)
cookie_dict = {c['name']: c['value'] for c in cookies}
print(cookie_dict)
4.3页面显式等待
WebDriverWait 详解
-
WebDriverWait是 Selenium 提供的用于显式等待的一种方式,可以让 WebDriver 在进行某些操作之前等待某个条件发生,避免因页面加载缓慢或元素未及时出现导致的操作失败。 -
WebDriverWait可以被用于等待直到某个条件(如元素可点击、元素可见等)被满足。 -
WebDriverWait(driver, timeout):-
driver: 传入一个 WebDriver 实例,如webdriver.Chrome()。 -
timeout: 最大等待的秒数。如果在这个时间内条件没有被满足,WebDriverWait会抛出TimeoutException。
-
常见的 Expected Conditions(预期条件):
expected_conditions 包含了多种常用的等待条件。常见的有:
presence_of_element_located: 等待某个元素存在于 DOM 树中。visibility_of_element_located: 等待某个元素可见。element_to_be_clickable: 等待某个元素可点击。text_to_be_present_in_element: 等待某个元素的文本内容变化。
wait_obj.until 详解
wait_obj.untilwait_obj.until()是等待某个条件满足,直到最大超时为止。- 它返回条件满足时的元素对象,或者抛出超时异常。
EC.presence_of_element_located((By.ID, 'key')): 这表示我们期望通过ID="key"定位到某个元素,并且要等待这个元素的存在。wait_obj.until()会等待直到条件满足(即元素加载完成),然后返回这个元素对象。否则会抛出TimeoutException。
流程说明:
- Selenium 会每隔 500 毫秒检查一次条件是否成立。
- 如果超时仍未满足条件,则会抛出
TimeoutException。
代码
wait_obj = WebDriverWait(browser, 10):WebDriverWait 是 Selenium 提供的显式等待工具,10 是等待的最大秒数。
wait_obj.until(EC.presence_of_element_located((By.ID, 'key'))):这里使用了 EC.presence_of_element_located 条件,它会等待页面中具有 ID="key" 的元素存在(即搜索框元素加载完成)。
search_input.send_keys('手机'):使用 send_keys() 方法向搜索框中输入文本“手机”。
serch_btn = wait_obj.until(EC.presence_of_element_located((By.XPATH, '//*[@id="search"]/div/div[2]/button'))):等待搜索按钮(通过 XPath 定位)加载完成。
serch_btn.click():使用 click() 方法点击搜索按钮。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
wait_obj = WebDriverWait(browser, 10)
time.sleep(3)
browser.get('https://www.jd.com')
search_input = wait_obj.until(EC.presence_of_element_located((By.ID, 'key')))
print(search_input)
search_input.send_keys('手机')
serch_btn = wait_obj.until(EC.presence_of_element_located((By.XPATH, '//*[@id="search"]/div/div[2]/button')))
print(search_input)
serch_btn.click()
time.sleep(3)
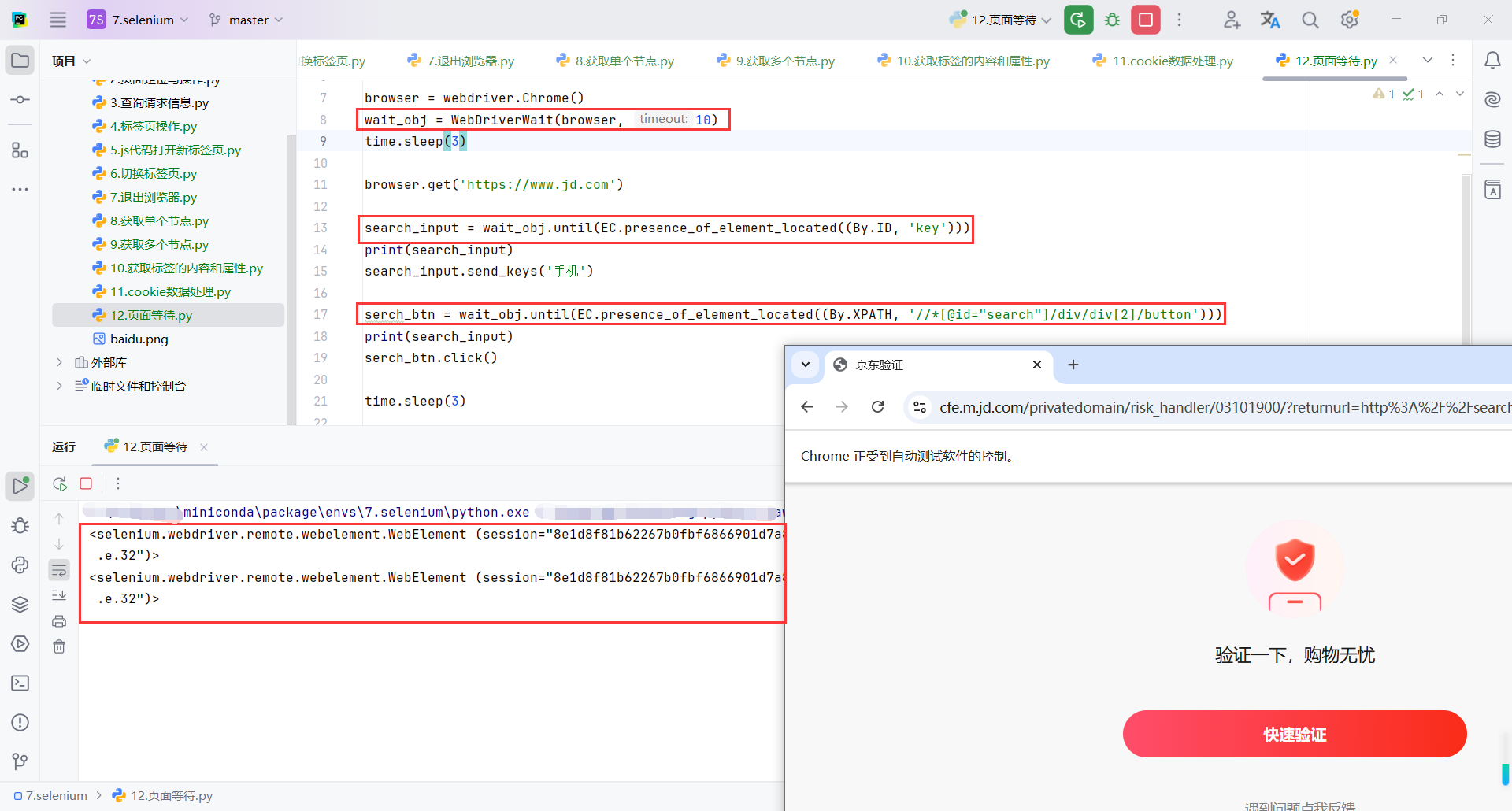
4.4前进和后退
browser.back():
back()方法用于模拟浏览器的“后退”按钮。当你需要回到上一个页面时使用这个方法。back()是浏览器的历史记录操作,会使浏览器回到上一个访问的页面。
browser.forward():
forward()方法用于模拟浏览器的“前进”按钮。当你需要从当前页面前进到之前的页面时使用此方法。- 这与
back()方法是互相配对的,back()后,你可以使用forward()再返回原页面。
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('https://www.jd.com')
time.sleep(2)
browser.get('https://www.taobao.com')
time.sleep(2)
browser.back()
time.sleep(1)
browser.forward()
time.sleep(1)
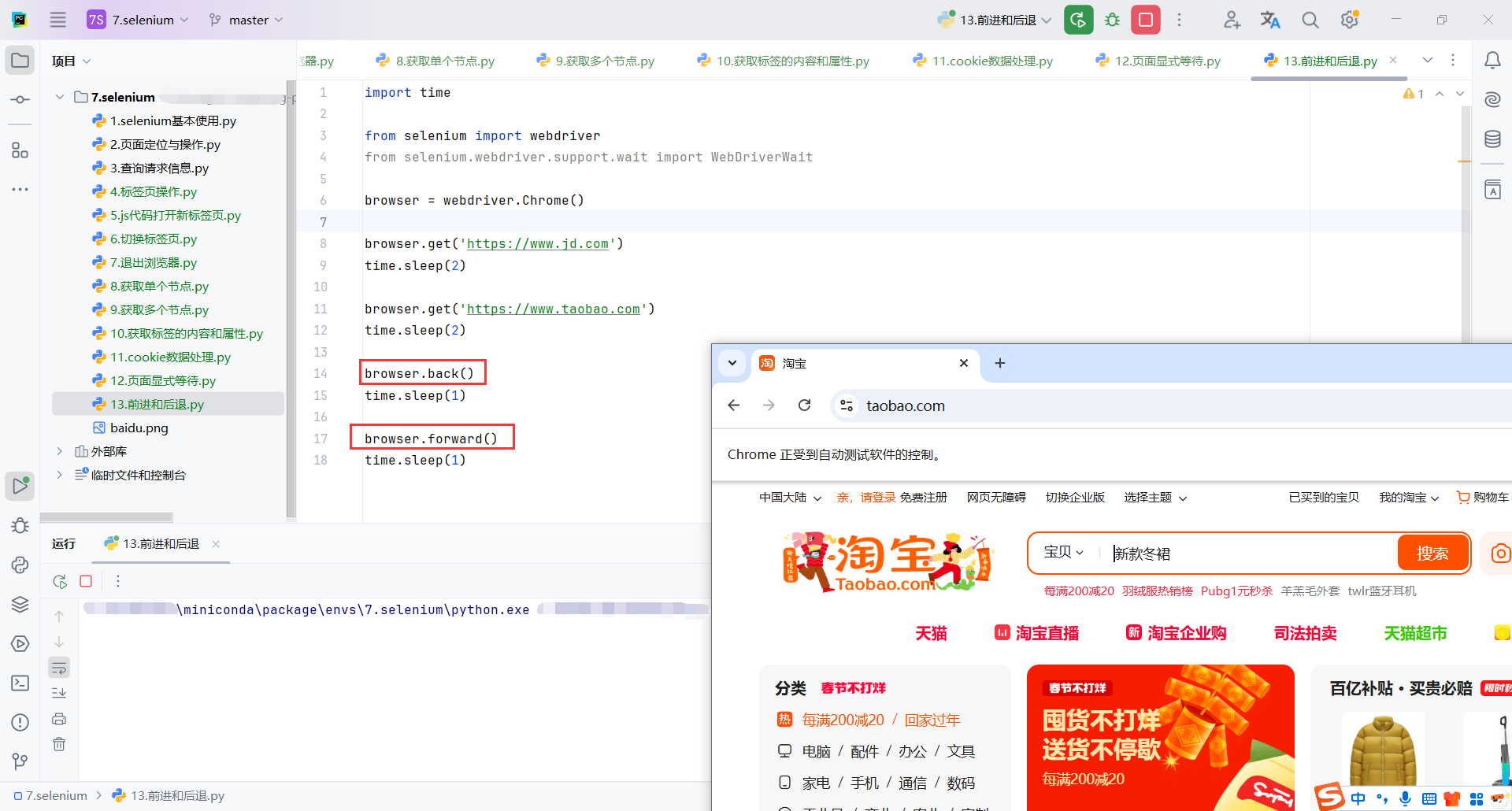
4.5登录163邮箱
4.5.1分析
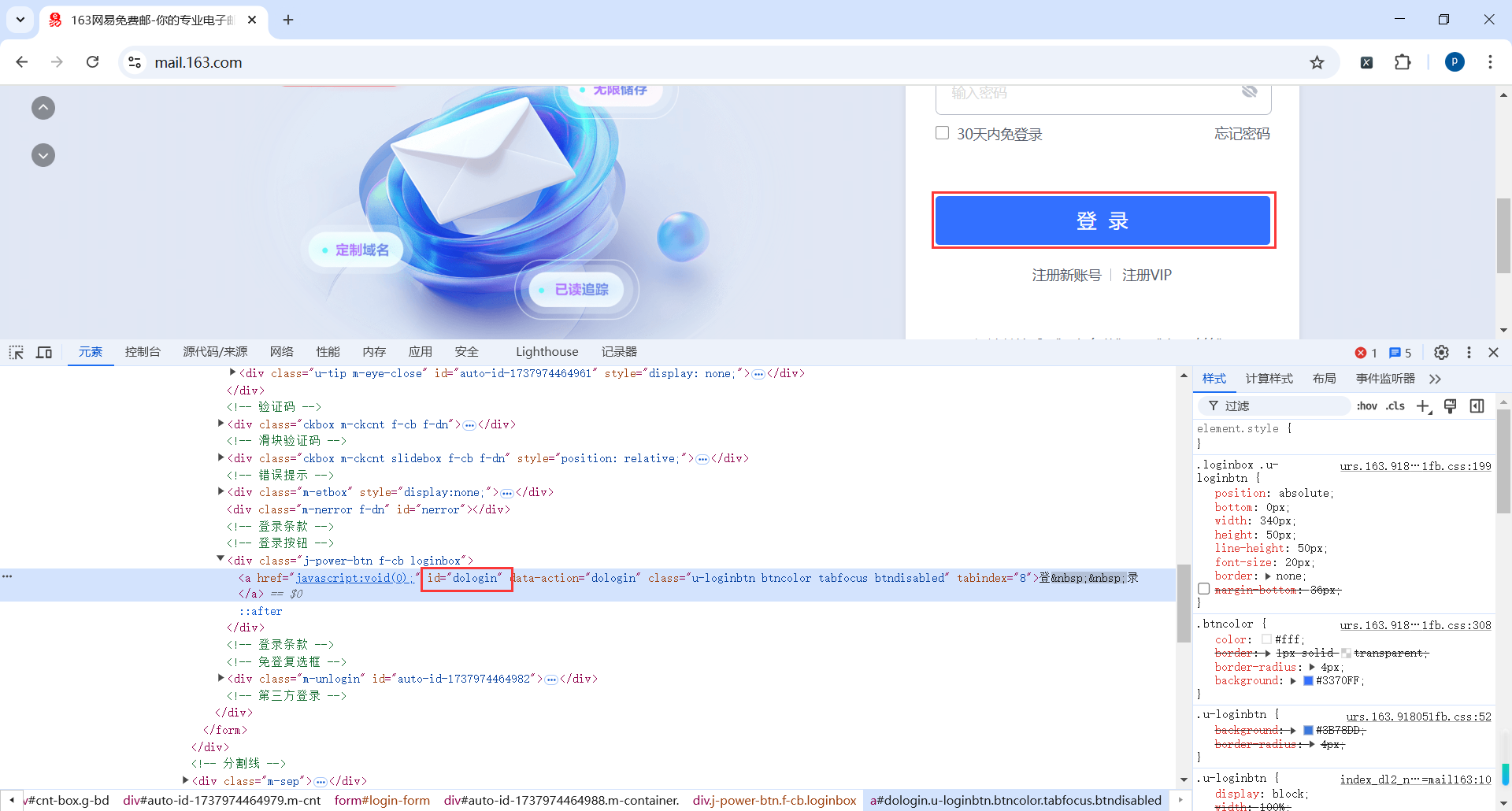
登录表单是一个嵌套的iframe
通常来说尽量使用id来匹配元素,但是这个iframe的id像是动态生成的,每次获取页面可能不一样,所以我们换一种定位方式,使用属性方式定位
//*[@id="x-URS-iframe1737972908104.6643"]
//div[@id="loginDiv"]/iframe[@scrolling = "no"]
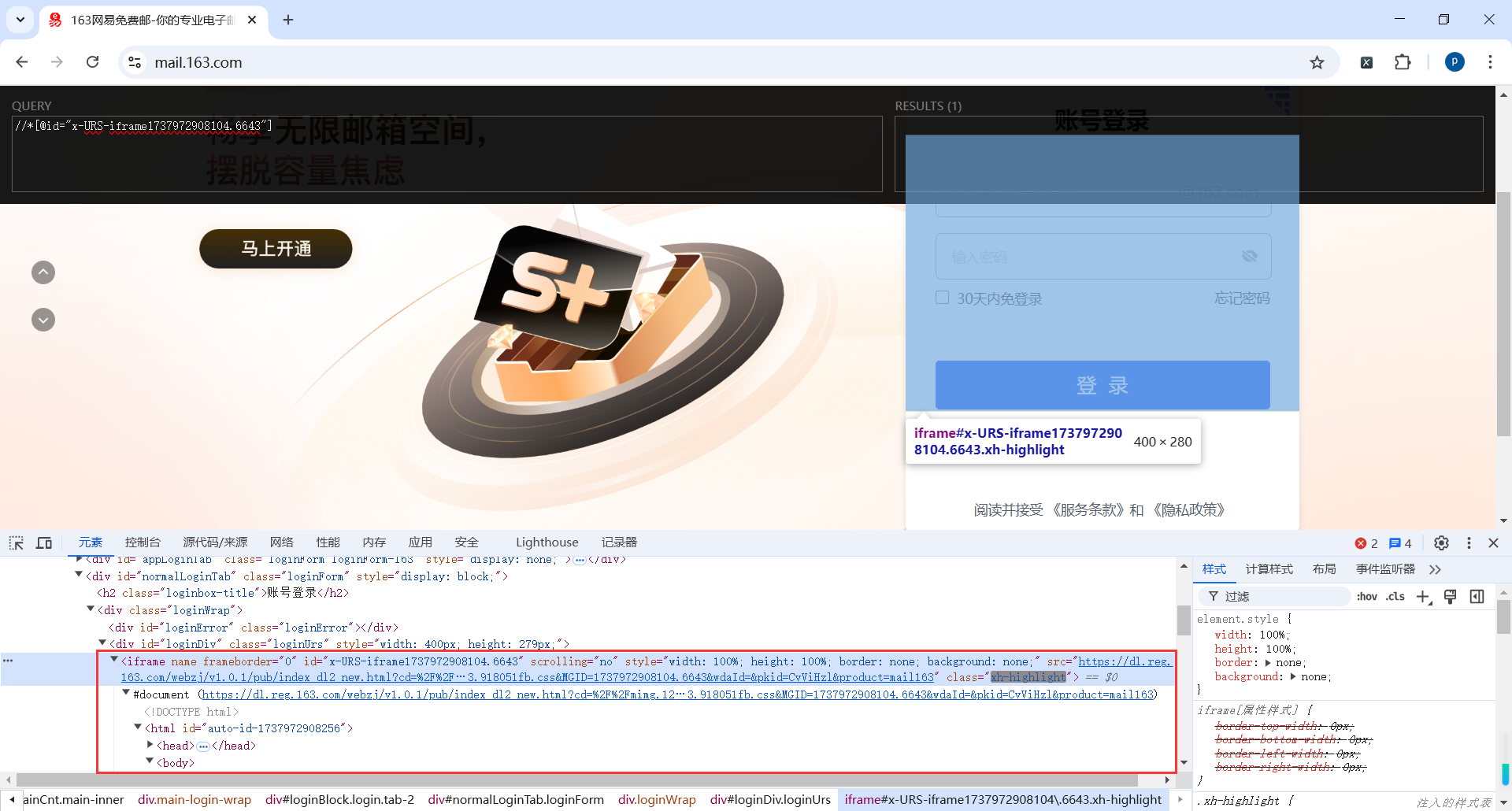
我们发现用户名和密码也是类似动态生成的Id,每次获取页面可能不一样,因此不建议使用Id选择器匹配元素
self.driver.find_element(By.XPATH, '//div[@class="u-input box"]//input[@name="email"]').send_keys(userinfo['name'])
self.driver.find_element(By.XPATH, '//div[@class="u-input box"]//input[@name="password"]').send_keys(userinfo['pwd'])
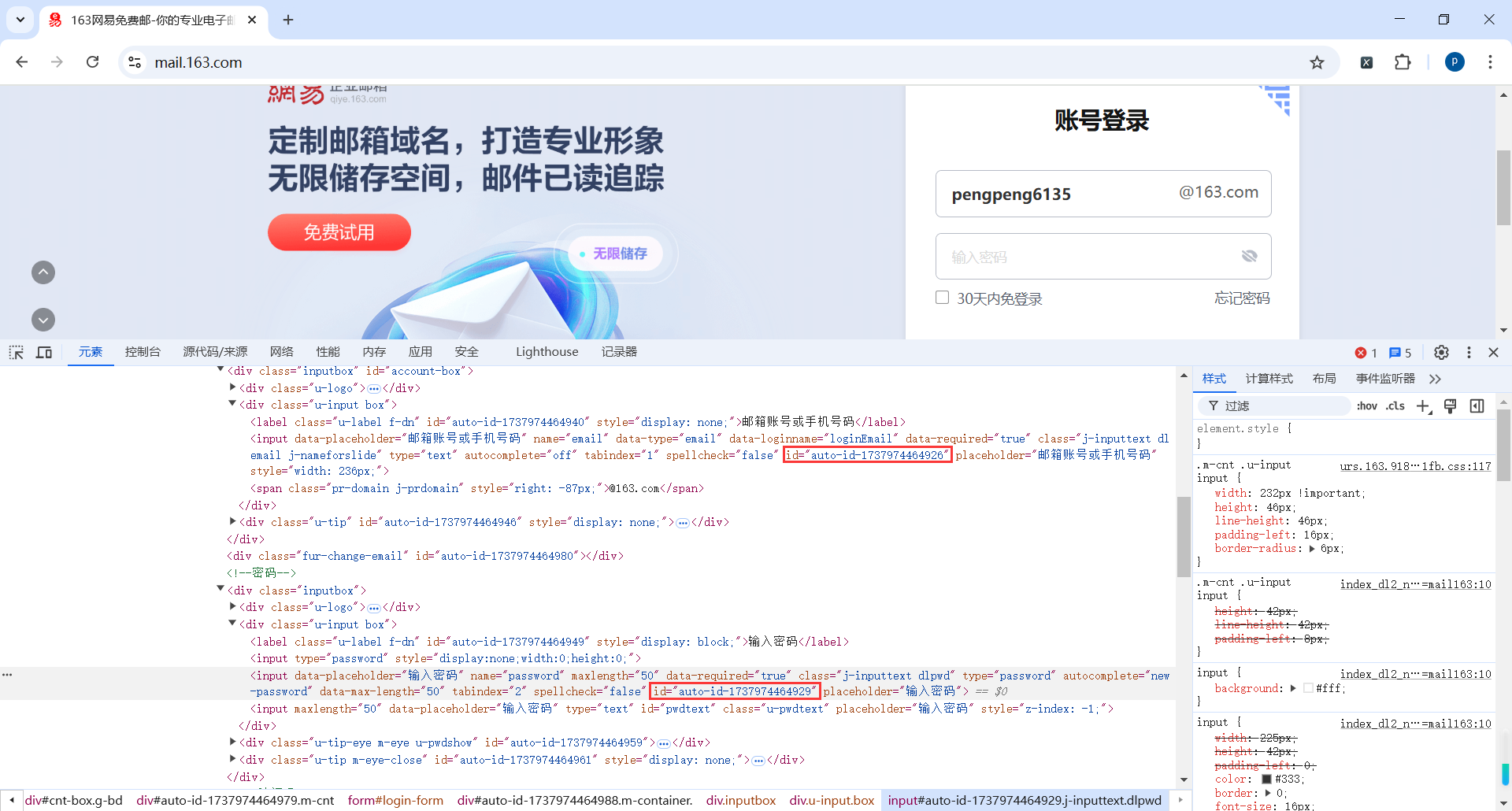
按钮的Id应该是固定的,所以可以使用Id选择器
//*[@id="dologin"]
4.5.2代码
iframe_tag = self.wait_obj.until(EC.presence_of_element_located((By.XPATH, '//div[@id="loginDiv"]/iframe[@scrolling = "no"]'))):等待登录 iframe 元素的加载完成。iframe的id是动态生成的,每次请求可能不一样,所以不要使用id选择器
self.driver.switch_to.frame(iframe_tag):将操作切换到 iframe 内部,确保后续元素的定位都在 iframe 内部。 iframe 是一个嵌套的 HTML 文档,它包含在主页面中。默认情况下,Selenium 的 WebDriver 只会与主页面中的元素进行交互。如果你需要操作 iframe 中的元素,必须切换到这个 iframe,否则无法找到 iframe 内的元素。
send_keys :输入用户名和密码
click:点击登录按钮
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class WYMail:
# 初始化
def __init__(self):
self.driver = webdriver.Chrome()
self.wait_obj = WebDriverWait(self.driver, 10)
# 打开邮箱地址
def open_email(self,url):
self.driver.get(url)
self.wait_obj.until(EC.presence_of_element_located((By.XPATH, "//iframe[contains(@id, 'x-URS-iframe')]")))
time.sleep(1)
def login_email(self,userinfo):
# 定位到登录表单的iframe
# iframe_tag = self.driver.find_element(By.XPATH,'//*[@id="x-URS-iframe1737972908104.6643"]')
# 等待最大时间为 10 秒
# iframe_tag = self.wait_obj.until(EC.presence_of_element_located((By.XPATH, '//div[@id="loginDiv"]/iframe[@scrolling = "no"]')))
# 登录表单是一个嵌套的子页面 需要切入到这个子页面
# self.driver.switch_to.frame(iframe_tag)
# 输入用户名
# self.driver.find_element(By.XPATH,'//*[@id="auto-id-1737972908201"]').send_keys(userinfo['name'])
# 输入密码
# self.driver.find_element(By.XPATH,'//*[@id="auto-id-1737972908204"]').send_keys(userinfo['pwd'])
# 触发登录按钮click
# self.driver.find_element(By.XPATH,'//*[@id="dologin"]').click()
iframe_tag = self.wait_obj.until(EC.presence_of_element_located((By.XPATH, '//div[@id="loginDiv"]/iframe[@scrolling = "no"]')))
self.driver.switch_to.frame(iframe_tag)
self.driver.find_element(By.XPATH, '//div[@class="u-input box"]//input[@name="email"]').send_keys(userinfo['name'])
self.driver.find_element(By.XPATH, '//div[@class="u-input box"]//input[@name="password"]').send_keys(userinfo['pwd'])
self.driver.find_element(By.XPATH, '//*[@id="dologin"]').click()
time.sleep(5)
def __del__(self):
self.driver.quit()
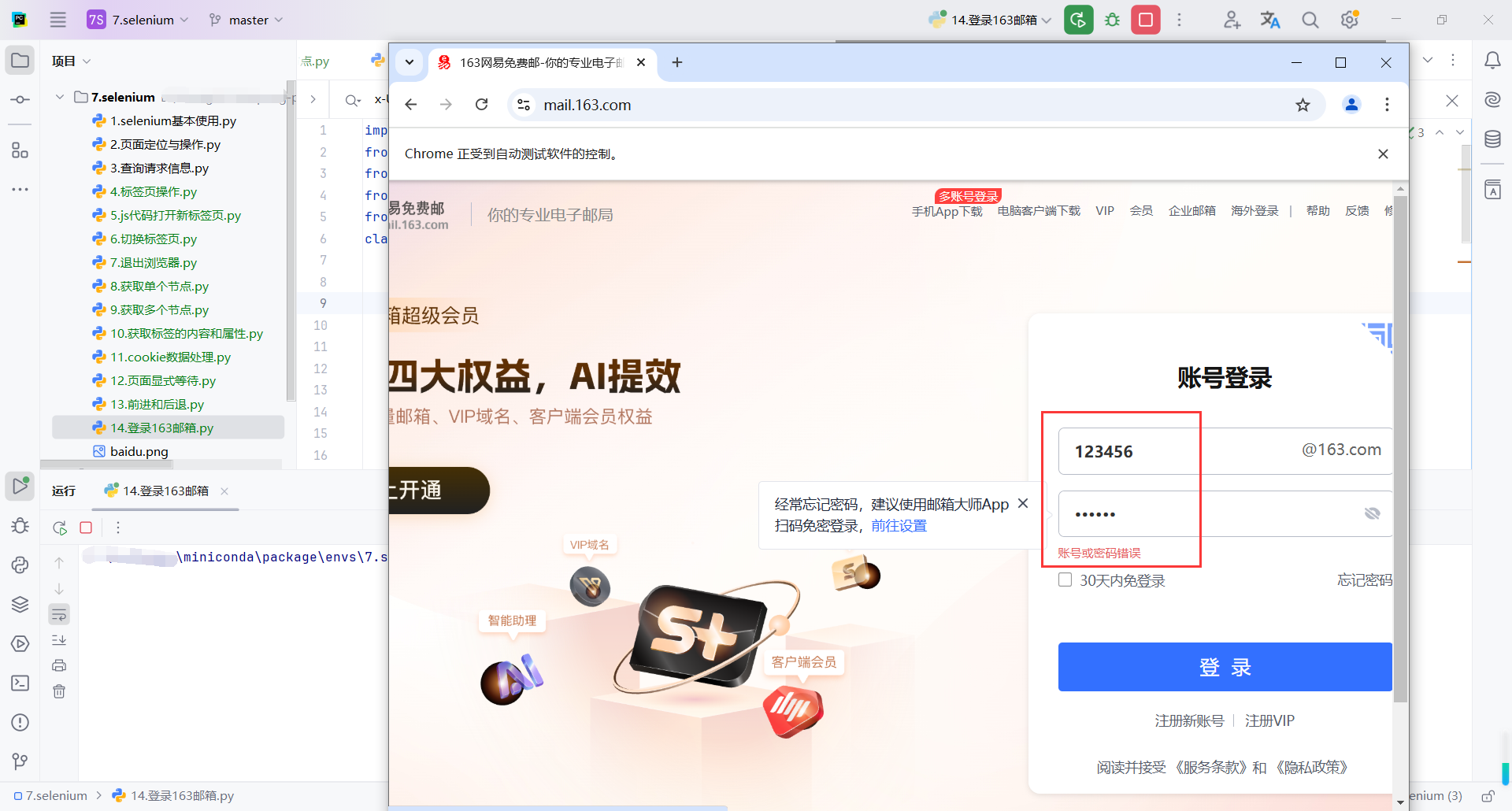
if __name__ == '__main__':
wymail = WYMail()
wymail.open_email('https://mail.163.com/')
wymail.login_email({
'name': '123456',
'pwd': '123456'
})
我这里故意输错用户名密码,输入你自己的就可以了
4.6页面滚动
代码
browser.execute_script(f"window.scrollTo(0, {i * 700});"):
browser.execute_script是 Selenium 提供的接口,用于在浏览器中直接执行 JavaScript 脚本。window.scrollTo(x, y):- 将页面滚动到指定的绝对位置。
- 参数
(x, y)表示滚动到的具体像素点。 x是水平滚动距离(向右为正值)。y是垂直滚动距离(向下为正值)。{i * 700}表示垂直方向滚动到从页面顶部开始的 绝对位置
window.scrollBy(0, {i * 700}):
- 将页面滚动一个相对距离。
- 每次滚动的最终位置取决于 当前页面位置 和 滚动增量。
主要区别
| 方法 | 滚动方式 | 滚动位置 | 适用场景 |
|---|---|---|---|
window.scrollTo |
滚动到绝对位置 | 从页面顶部开始的固定像素位置,例如 (0, 1400)。 |
精确滚动到页面某一位置,例如滚动到特定段落或元素处。 |
window.scrollBy |
滚动到相对位置 | 从当前页面位置开始的偏移,例如 +700 像素向下滚动。 |
动态、连续滚动,例如模拟用户的滚动行为(无限加载)。 |
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://36kr.com/")
for i in range(1, 10):
# 绝对位置
# browser.execute_script(f"window.scrollTo(0, {i * 700});")
# 相对位置
browser.execute_script(f"window.scrollBy(0, {i * 700});")
time.sleep(1)
4.7绕过检测
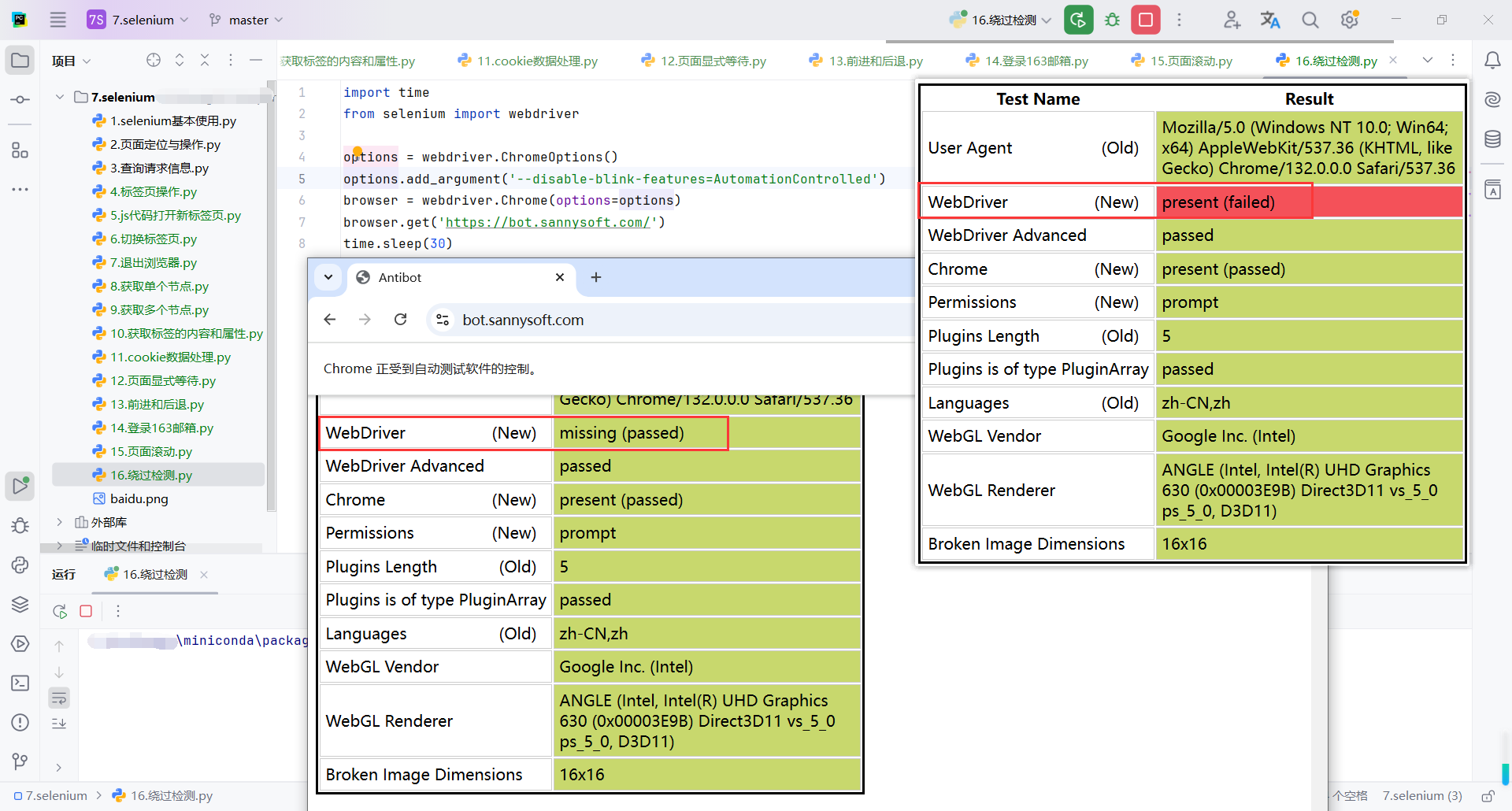
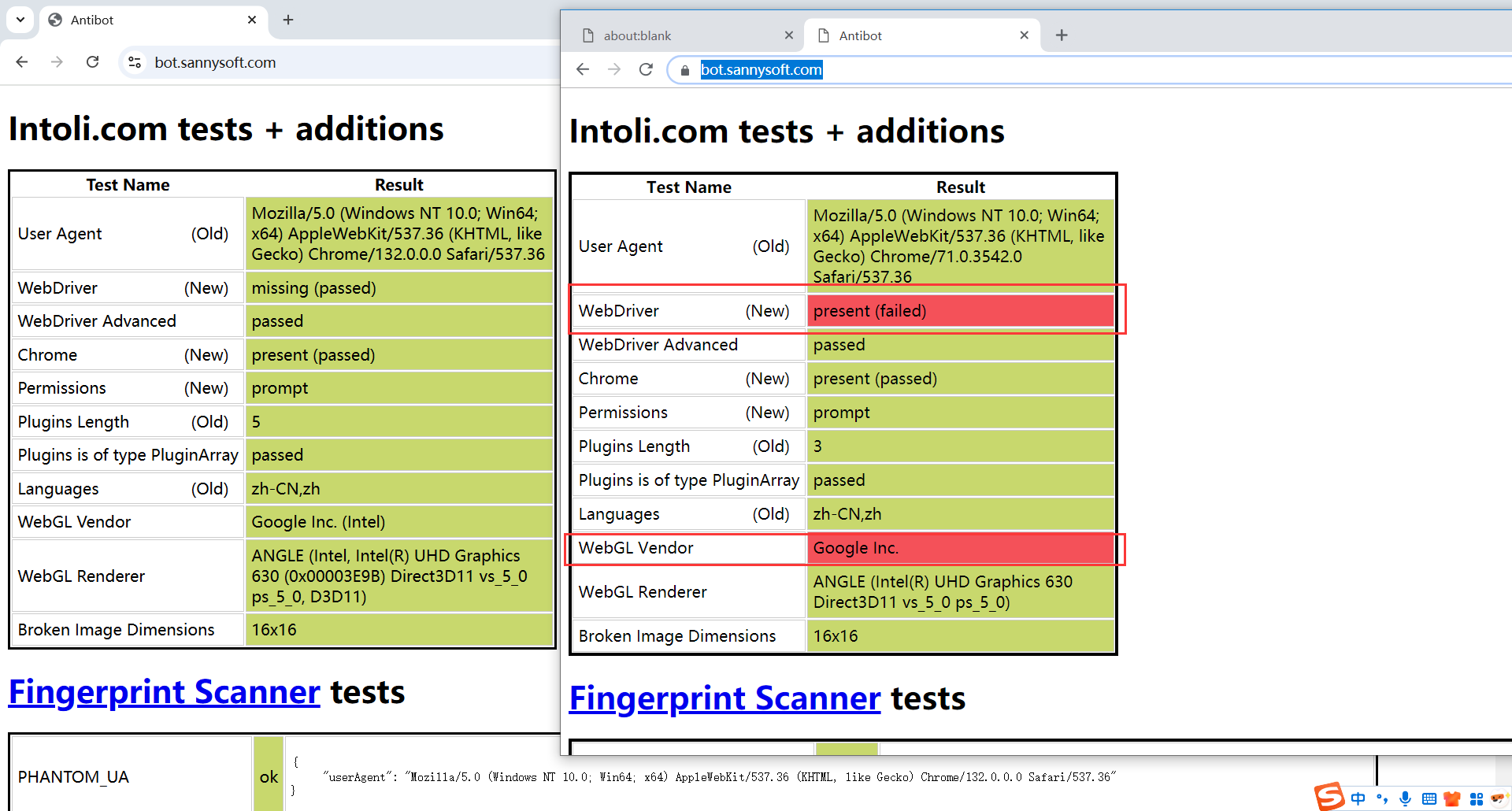
https://bot.sannysoft.com/:这是一个用于检测浏览器是否由自动化工具(如 Selenium)控制的网站。
代码
options = webdriver.ChromeOptions():创建一个 Chrome 浏览器选项对象,允许自定义浏览器的启动参数(如无头模式、禁用自动化标志等)。
options.add_argument('--disable-blink-features=AutomationControlled'):
-
options.add_argument向浏览器选项对象添加配置 -
--disable-blink-features=AutomationControlled是一个 Chrome 参数,用于隐藏 Selenium 的特征(如navigator.webdriver设置为false)。
import time
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
browser = webdriver.Chrome(options=options)
browser.get('https://bot.sannysoft.com/')
time.sleep(30)
4.8浏览器配置
add_argument和add_experimental_option区别
| 特性 | add_argument |
add_experimental_option |
|---|---|---|
| 配置方式 | 通过命令行参数配置浏览器行为。 | 配置实验性或内部功能,通常是 JSON 格式的选项。 |
| 使用场景 | 简单的功能,如窗口设置、代理、自定义 UA。 | 高级设置,如隐藏自动化痕迹、首选项配置。 |
| 底层机制 | 调用 Chrome 的命令行接口。 | 调用 Chrome 的内部配置接口。 |
| 灵活性 | 适用于所有支持的命令行参数。 | 适用于特定的实验性功能或扩展功能。 |
| 示例配置内容 | "--headless", "--proxy-server=..." |
"prefs", "excludeSwitches", "useAutomationExtension" |
代码
webdriver.ChromeOptions():创建一个 ChromeOptions 对象,用于配置 Chrome 浏览器的启动参数。
prefs = {"profile.managed_default_content_settings.images": 2}:阻止浏览器加载图片,以减少网络资源的消耗,提高页面加载速度。
prefs是一个字典,用于存储浏览器首选项。"images": 2表示禁止加载图片。
add_experimental_option:将自定义选项传递给浏览器。
options.add_argument(f'user-agent={user_agent}'):修改浏览器的 User-Agent 字段,伪装为指定的客户端请求。add_argument:添加一个命令行启动参数。
options.add_experimental_option('useAutomationExtension', False) options.add_experimental_option('excludeSwitches', ['enable-automation']): 隐藏 Selenium 操控浏览器时可能出现的 "Chrome is being controlled by automated test software" 警告。
useAutomationExtension: False:禁用默认的自动化扩展。excludeSwitches: ['enable-automation']: 禁用会暴露自动化行为的浏览器启动开关。
options.add_argument("--proxy-server=http://127.0.0.1:10809"):使用代理服务器拦截和转发请求。
import time
from selenium import webdriver
options = webdriver.ChromeOptions()
# 禁止加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
# 设置UA
user_agent = '123456'
options.add_argument(f'user-agent={user_agent}')
# 隐藏浏览器开发者警告
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 代理配置
options.add_argument("--proxy-server=http://127.0.0.1:10809")
browser = webdriver.Chrome(options=options)
browser.get('https://www.taobao.com')
time.sleep(100)
4.9.动作链
地址:https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
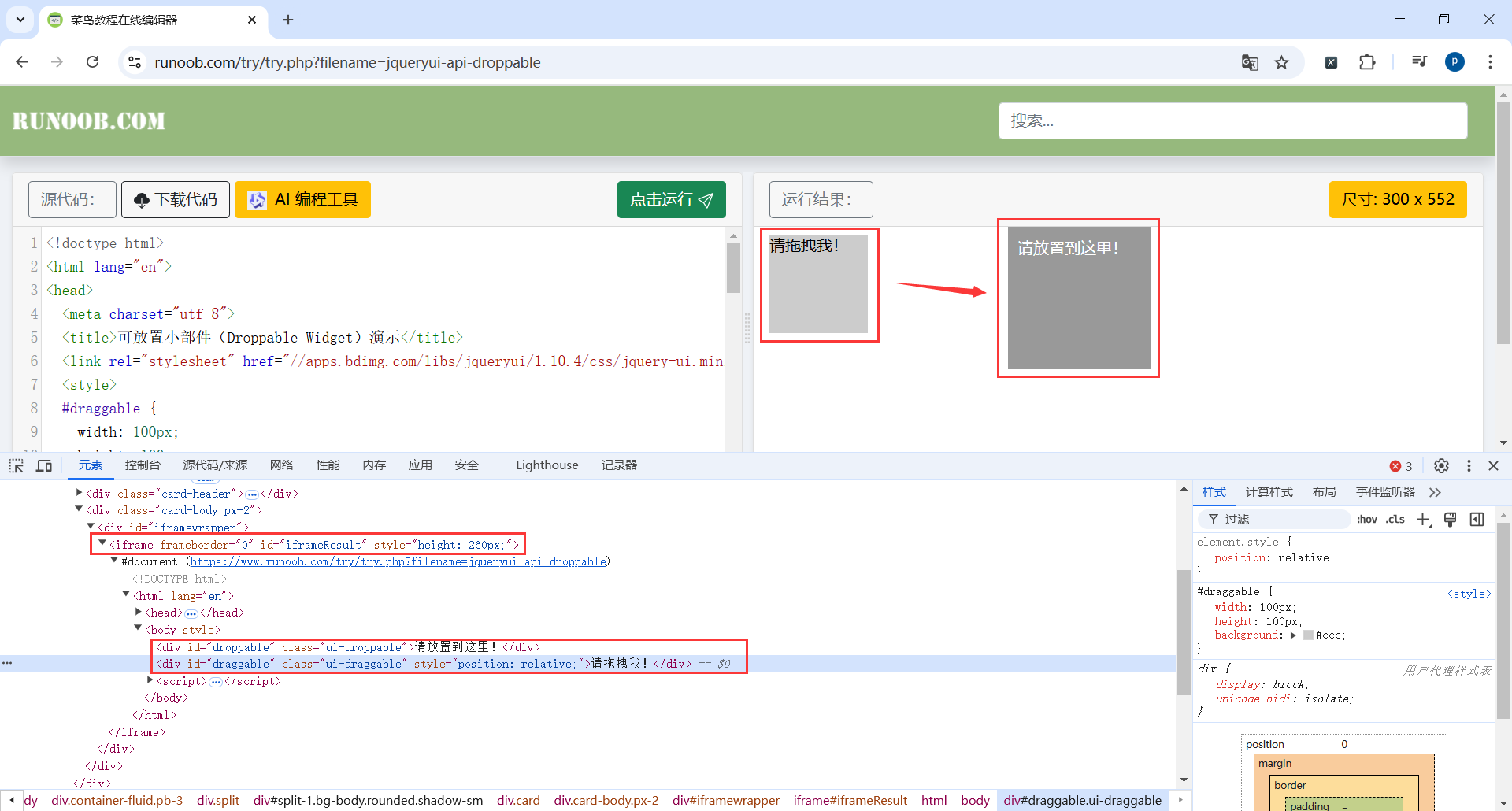
代码
iframe_tag = browser.find_element(By.XPATH, '//div[@id="iframewrapper"]/iframe'):使用 find_element 方法,通过 XPath 定位页面中的 iframe。
browser.switch_to.frame(iframe_tag):切换到 iframe 中。如果页面中包含 iframe,必须先切换到目标 iframe,否则 Selenium 无法定位其中的元素。
source = browser.find_element(By.ID, 'draggable'):定位可拖动的元素(id="draggable")。
target = browser.find_element(By.ID, 'droppable'):定位目标区域(id="droppable")。
actions = ActionChains(browser):创建一个 ActionChains 对象,用于存储和执行用户交互操作。ActionChains 提供了多种交互操作方法,如点击、双击、拖拽等,支持组合复杂操作。
actions.drag_and_drop(source, target).perform():
actions.drag_and_drop(source, target)定义拖拽操作,将source元素拖动到target元素上。perform(): 执行定义的操作链。
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
iframe_tag = browser.find_element(By.XPATH, '//div[@id="iframewrapper"]/iframe')
browser.switch_to.frame(iframe_tag)
source = browser.find_element(By.ID,'draggable')
target = browser.find_element(By.ID,'droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target).perform()
time.sleep(3)
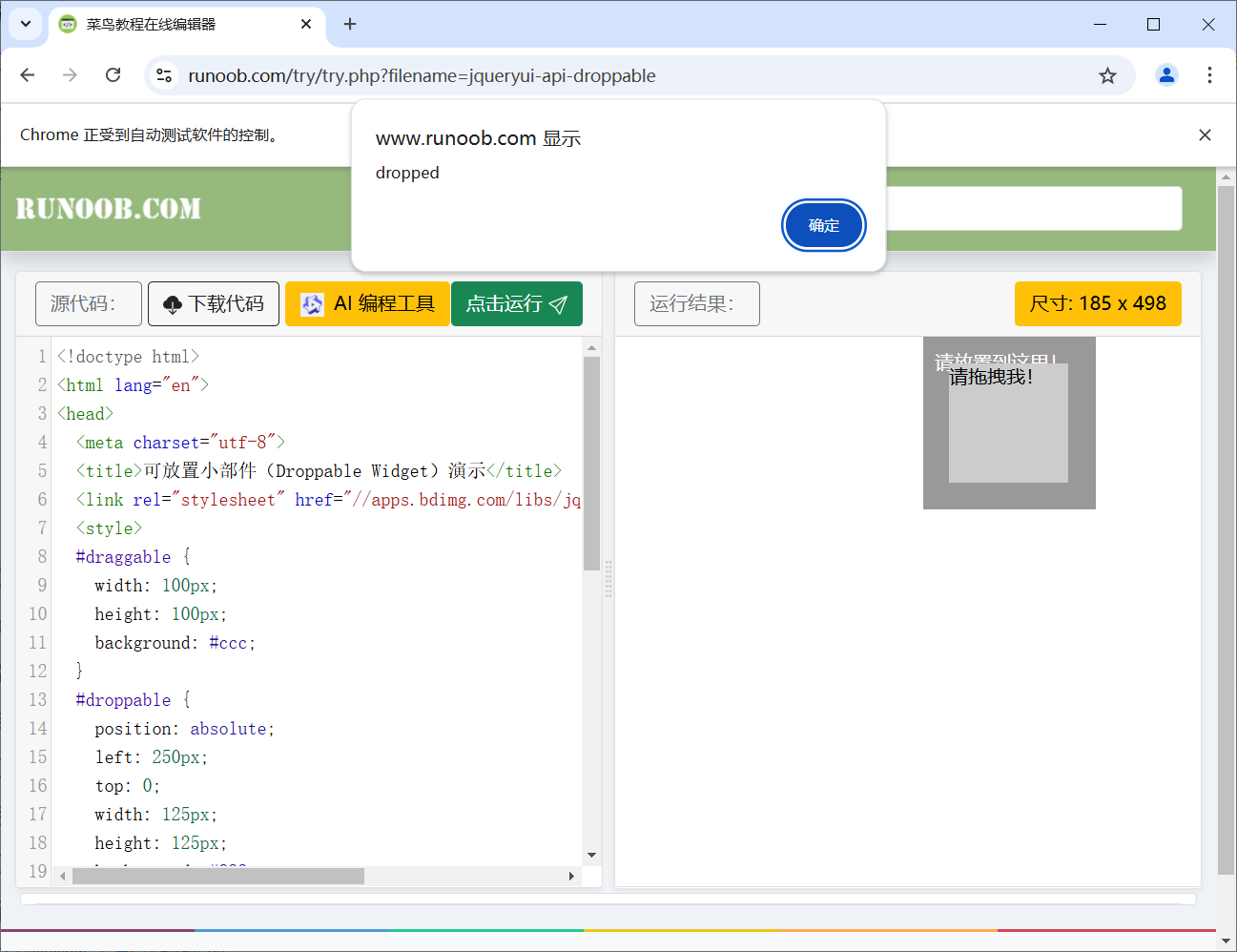
4.10selenium异常类
browser.set_page_load_timeout(3):
- 设置页面加载超时时间为 3 秒。
- 如果超过 3 秒网页仍未完全加载,抛出
TimeoutException。
TimeoutException:捕获页面加载超时的异常。
NoSuchElementException:捕获未找到元素时的异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
try:
browser.set_page_load_timeout(3)
browser.get('https://www.google.com')
except Exception as e:
print("请求超时:", e)
try:
browser.find_element(By.ID, '#abc')
except Exception as e:
print("元素标签未找到:", e)
7.唯品会商品数据抓取
7.1Cookie
目前不登录搜索商品会跳转到登录页面
而且需要点击图形码验证,这部分比较难

简单方法就是自己登录后,获取登录的token
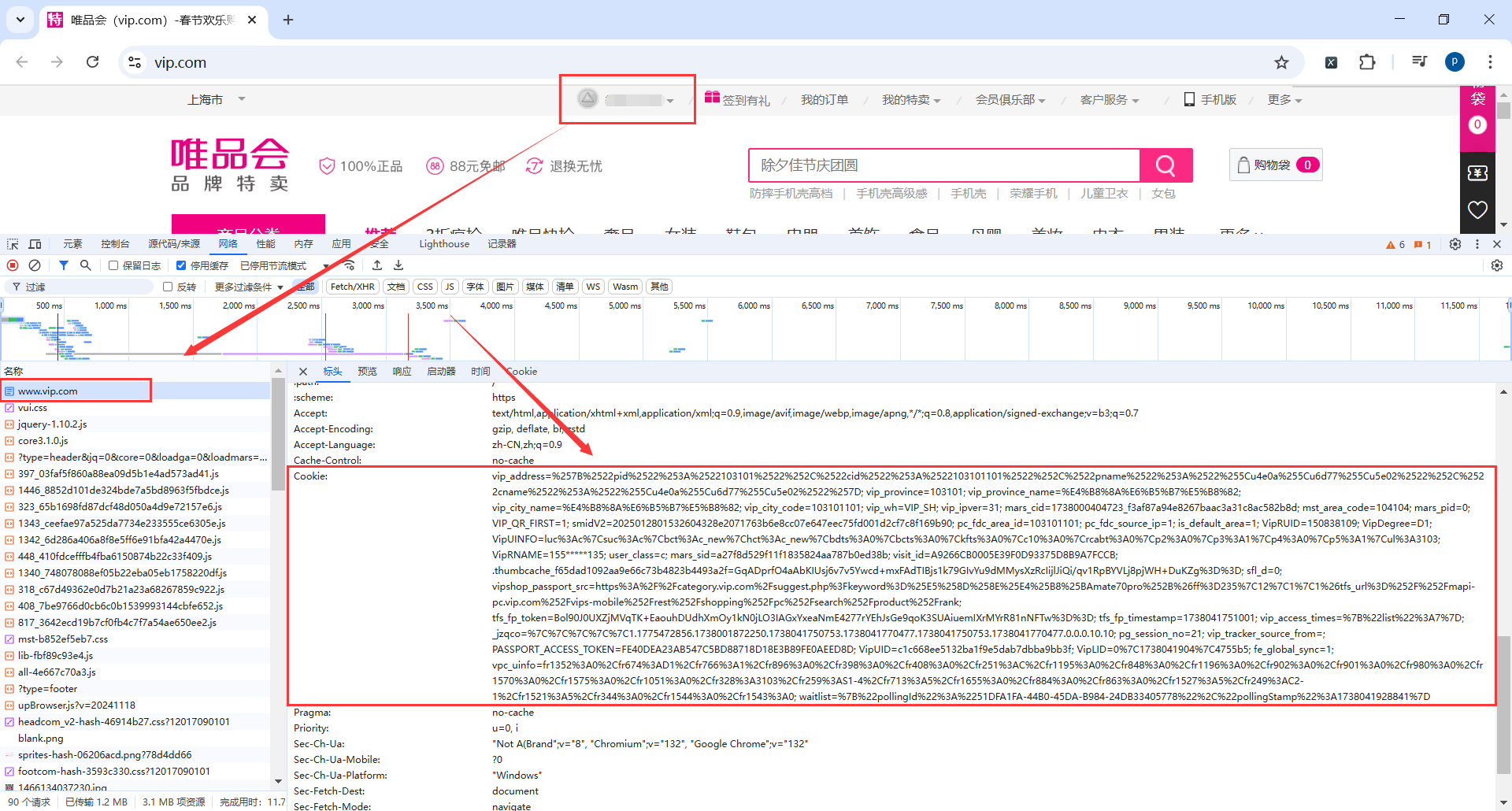
使用selenium打开页面时带上token
方法比较笨,但是目前可以解决问题,后面能够破解验证码了再优化
self.browser.get(url="https://www.vip.com/")
# 需要设置的 cookies 字符串
cookie_string = "你的token"
# 分割 cookie 字符串
cookies = cookie_string.split(';')
# 将 cookie 添加到浏览器
for cookie in cookies:
# 获取 cookie 的 name 和 value
name, value = cookie.split('=', 1)
# 添加 cookie
self.browser.add_cookie({
'name': name.strip(),
'value': value.strip(),
'domain': 'vip.com' # 根据实际情况调整
})
self.browser.get(url="https://www.vip.com/")
7.2元素遮挡
第一种方式:隐藏遮挡元素
元素被遮掩时,调用click()方法会报错,但是会告诉你被什么元素遮挡了,可以直接使用js隐藏元素
self.browser.execute_script("document.querySelector('img.main-img').style.display = 'none';")
self.browser.execute_script("document.querySelector('div#J_asset_have').style.display = 'none';")
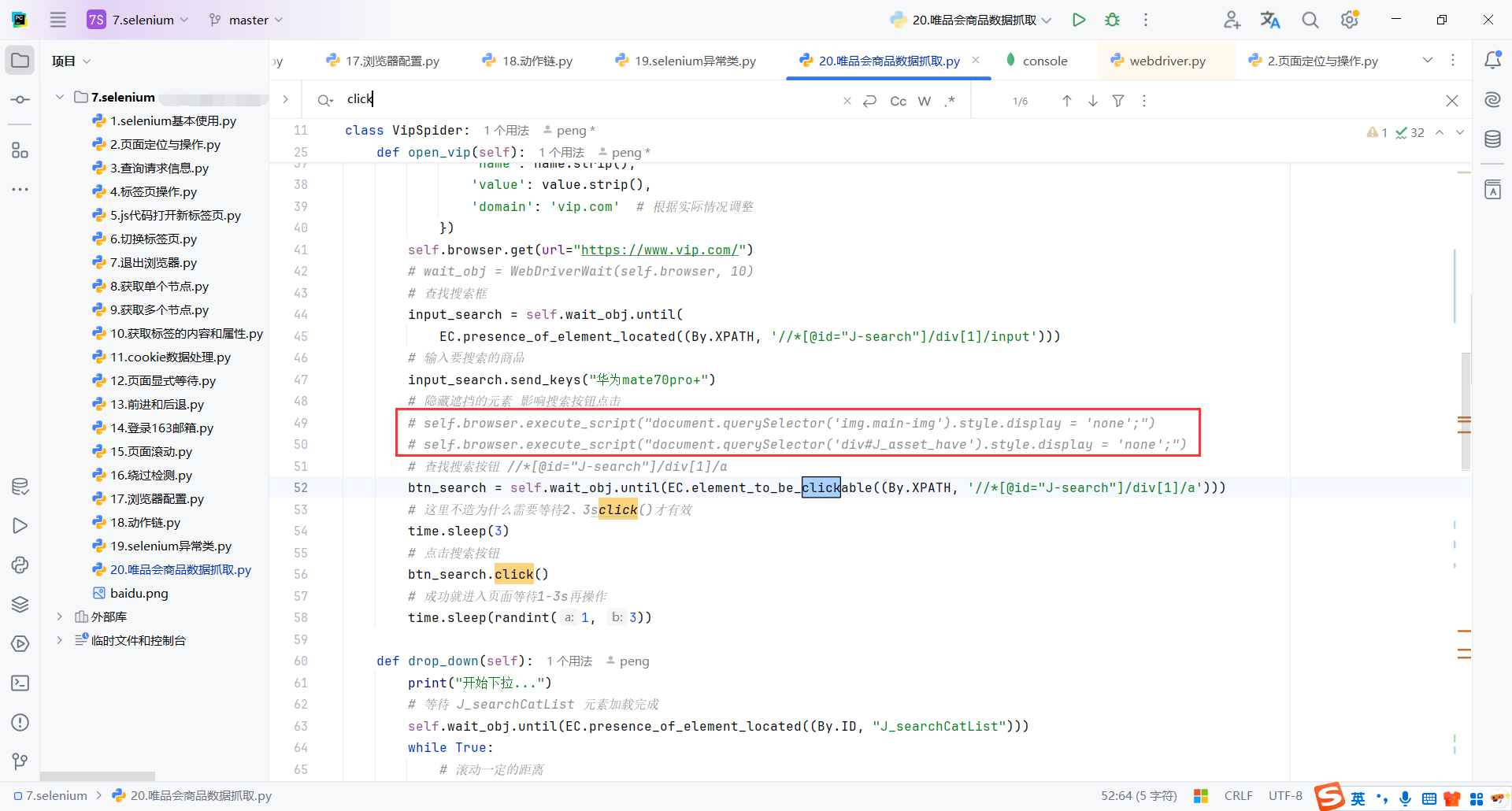
第二种方式:使用 JavaScript 执行点击
这种方式也是执行js,相对简单点
self.browser.execute_script("arguments[0].click();", next_page_button)
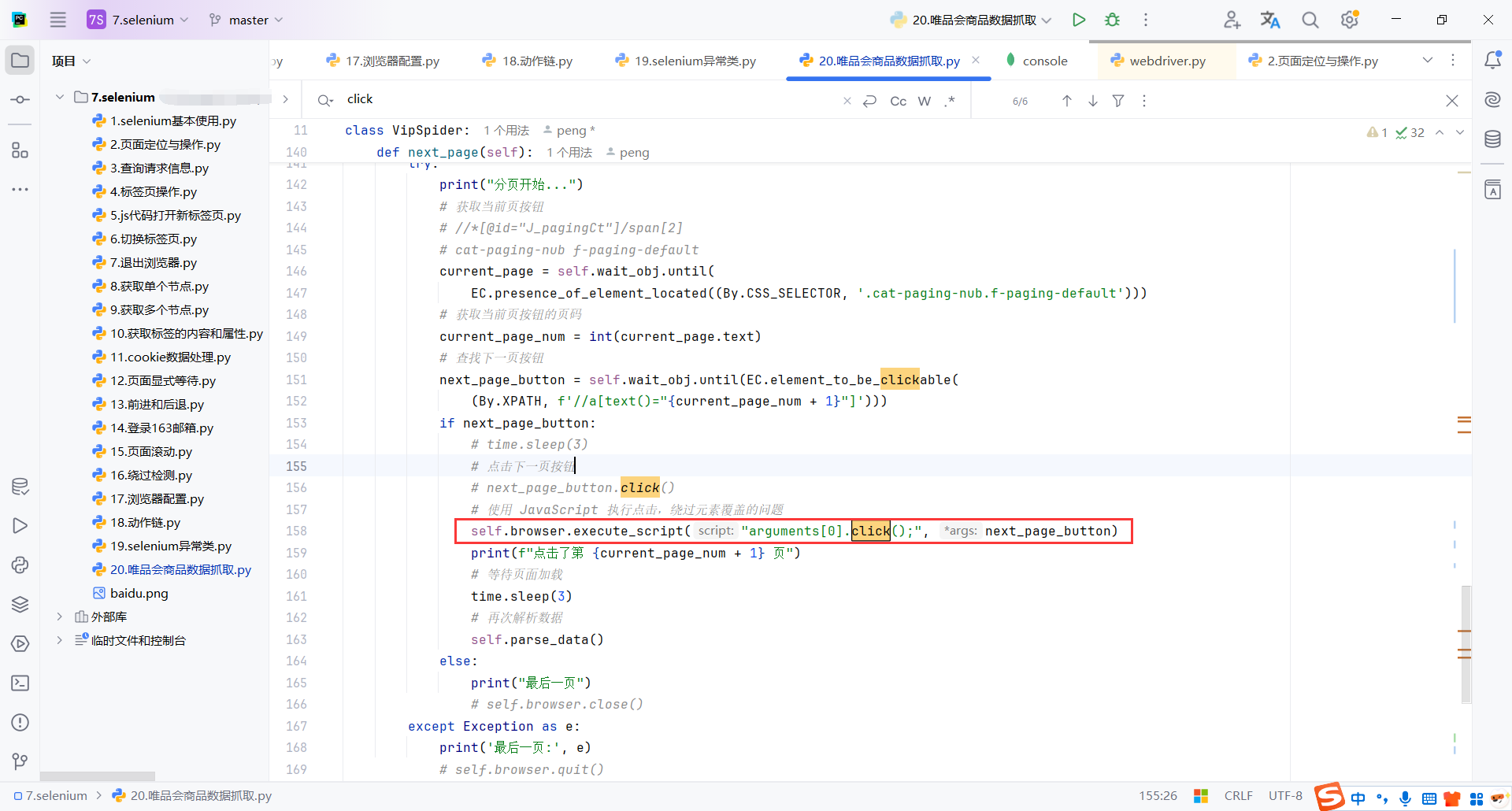
还有很多其他方式,问题不难,解决即可,这里记录一下
7.3滚动页面底部
搜索完商品,到商品列表页,每次需要向下拖动才可以加载数据,而且需要拖动到最底部
所以需要模拟浏览器页面的下拉操作

使用range遍历需要计算页面的大致大小,我觉得这样做不太好,每次都要计算页面大小
for i in range(1, 13):
js_code = f'window.scrollTo(0, {i * 1000})'
self.browser.execute_script(js_code)
time.sleep(randint(1, 3))
这里使用return (window.innerHeight + window.scrollY) >= document.body.scrollHeight;判断页面是否到达底部,这样感觉灵活些,不用每次调整页面,具体代码如下:
self.wait_obj.until(EC.presence_of_element_located((By.ID, "J_searchCatList"))):确保页面中带有 id="J_searchCatList" 的元素已经加载完成。就是商品列表加载完成再进行拖动
while True:表示下拉操作会持续执行,直到达到页面底部。
self.browser.execute_script("window.scrollBy(0, 1000);"):
- 使用 JavaScript 命令向下滚动页面。
"window.scrollBy(0, 1000);":让页面纵向滚动 1000 像素。
time.sleep(randint(1, 3)):
- 暂停 1-3 秒之间的随机时间,模拟人类行为,防止被识别为机器人。
- 防止速度太快,页面反应不过来,代码不生效。
randint(1, 3):从 1 到 3 秒随机生成整数。
is_end = self.browser.execute_script( "return (window.innerHeight + window.scrollY) >= document.body.scrollHeight;"):window.innerHeight + window.scrollY 表示滚动条当前位置的底部位置。如果其大于或等于页面总高度,则说明已经到达页面底部。
self.browser.execute_script:运行 JavaScript 脚本。window.innerHeight:浏览器窗口的视口高度。window.scrollY:页面已滚动的距离。document.body.scrollHeight:页面的总高度。is_end=True表示已到达页面底部。退出循环。
def drop_down(self):
# 使用window.scrollTo模拟拖动
# for i in range(1, 13):
# js_code = f'window.scrollTo(0, {i * 1000})'
# self.browser.execute_script(js_code)
# time.sleep(randint(1, 3))
print("开始下拉...")
# 等待 J_searchCatList 元素加载完成
self.wait_obj.until(EC.presence_of_element_located((By.ID, "J_searchCatList")))
while True:
# 滚动一定的距离
self.browser.execute_script("window.scrollBy(0, 1000);")
# 等待页面加载
time.sleep(randint(1, 3))
# 检查页面是否已经滚动到底部,如果是则退出循环
is_end = self.browser.execute_script(
"return (window.innerHeight + window.scrollY) >= document.body.scrollHeight;")
if is_end:
break
print("下拉结束...")
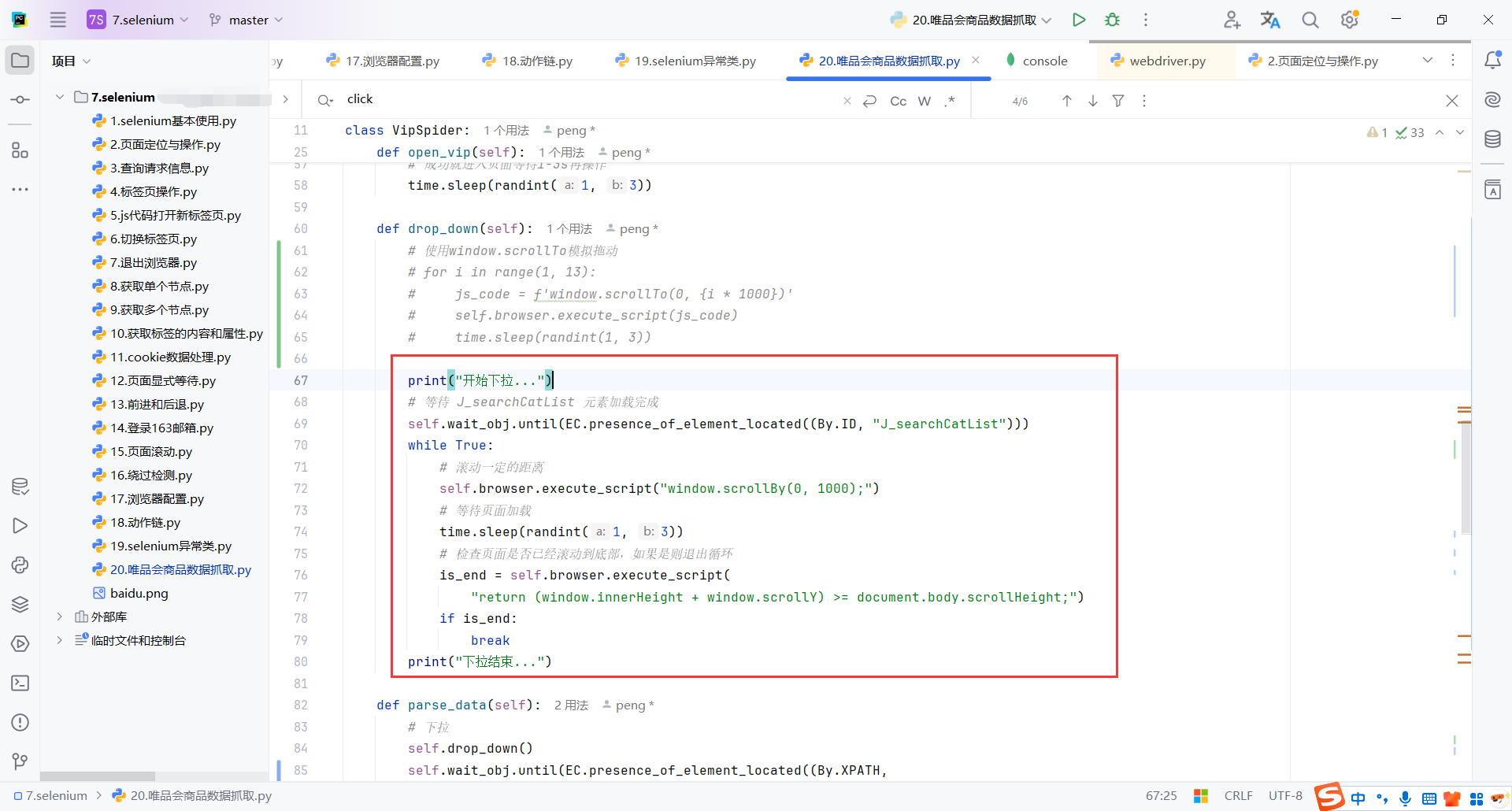
7.4分页
到达页面底部后并完成当前页面数据解析,就需要点击下一页,解析下一页数据
这里只有页码,没有下一页,页码什么时候都存在,下一页可能可有可无,所以考虑匹配页码实现此功能
从页码实现感觉也更加灵活一些
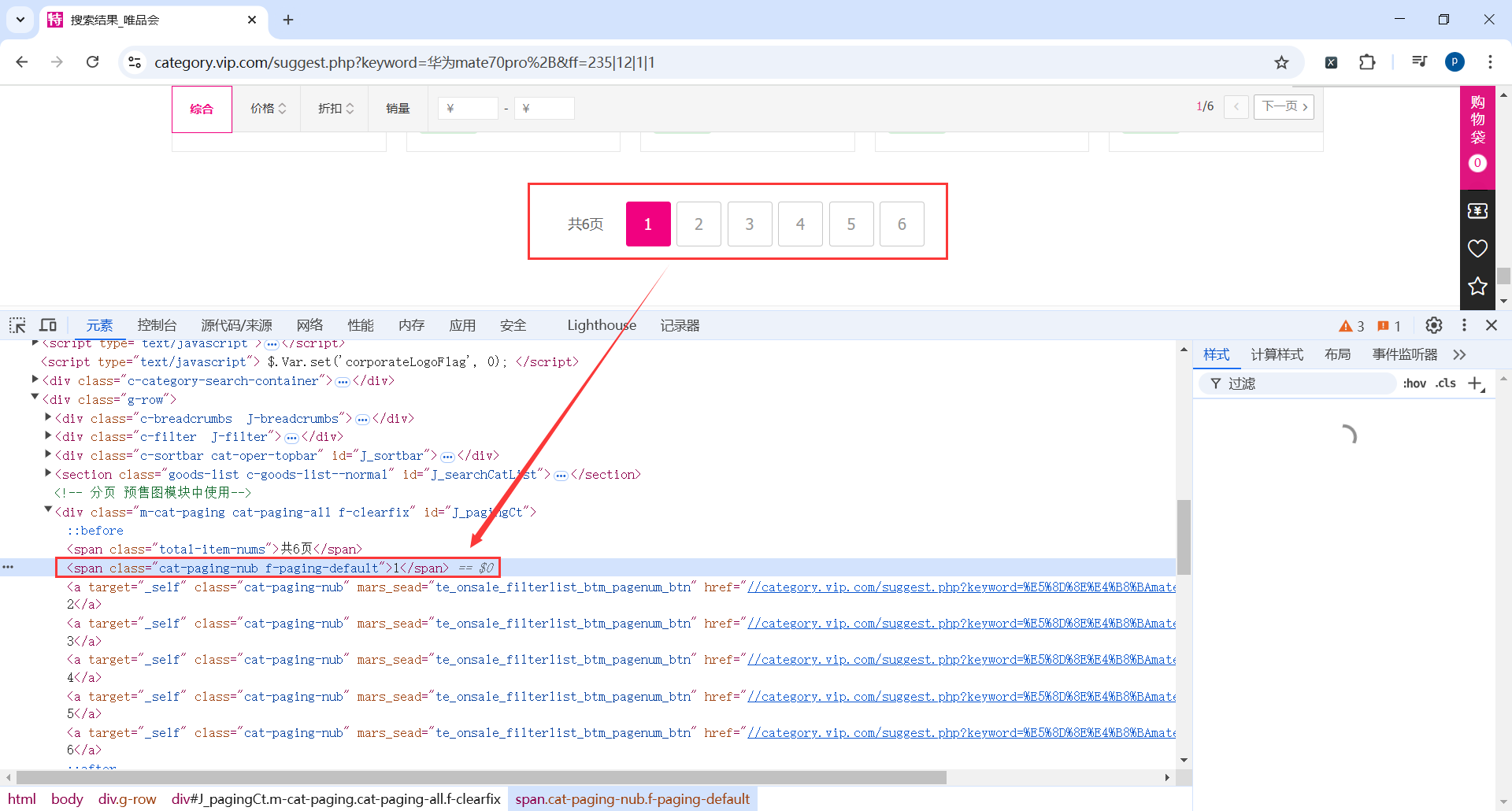
current_page = self.wait_obj.until( EC.presence_of_element_located((By.CSS_SELECTOR, '.cat-paging-nub.f-paging-default'))):
-
显式等待当前页按钮加载完成。
-
确保操作发生在元素已经渲染的情况下,避免
NoSuchElementException。 -
使用
By.CSS_SELECTOR和类选择器.cat-paging-nub.f-paging-default,定位当前页码的按钮。
current_page_num = int(current_page.text):提取当前页按钮的文本内容,通常是当前页的页码。
next_page_button = self.wait_obj.until(EC.element_to_be_clickable( (By.XPATH, f'//a[text()="{current_page_num + 1}"]'))):
- 显式等待
current_page_num + 1的页码按钮变为可点击状态。也就是等待下一页按钮可点击。 f'//a[text()="{current_page_num + 1}"]':动态生成下一页的页码按钮的XPath。这里根据文本匹配元素。- 如果没有找到下一页按钮,说明当前页面是最后一页。可以直接退出。
if next_page_button: self.browser.execute_script("arguments[0].click();", next_page_button):
- 如果
next_page_button存在,执行点击操作。 arguments[0].click()使用 JavaScript 点击指定元素。避免因按钮被其他元素遮挡而导致点击失败。
time.sleep(3):
- 暂停 3 秒,确保新页面完全加载。
- 其实
self.parse_data()开始已经显示等待页面加载完成了,这里还是习惯性慢一点。
def next_page(self):
try:
print("分页开始...")
# 获取当前页按钮
# //*[@id="J_pagingCt"]/span[2]
# cat-paging-nub f-paging-default
current_page = self.wait_obj.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.cat-paging-nub.f-paging-default')))
# 获取当前页按钮的页码
current_page_num = int(current_page.text)
# 查找下一页按钮
next_page_button = self.wait_obj.until(EC.element_to_be_clickable(
(By.XPATH, f'//a[text()="{current_page_num + 1}"]')))
if next_page_button:
# time.sleep(3)
# 点击下一页按钮
# next_page_button.click()
# 使用 JavaScript 执行点击,绕过元素覆盖的问题
self.browser.execute_script("arguments[0].click();", next_page_button)
print(f"点击了第 {current_page_num + 1} 页")
# 等待页面加载
time.sleep(3)
# 再次解析数据
self.parse_data()
else:
print("最后一页")
# self.browser.close()
except Exception as e:
print('最后一页:', e)
# self.browser.quit()
7.5代码
大部分需要注意的地方上面都讲完了,就剩下解析数据了
这部分应该是最简单的了,主要注意3点:
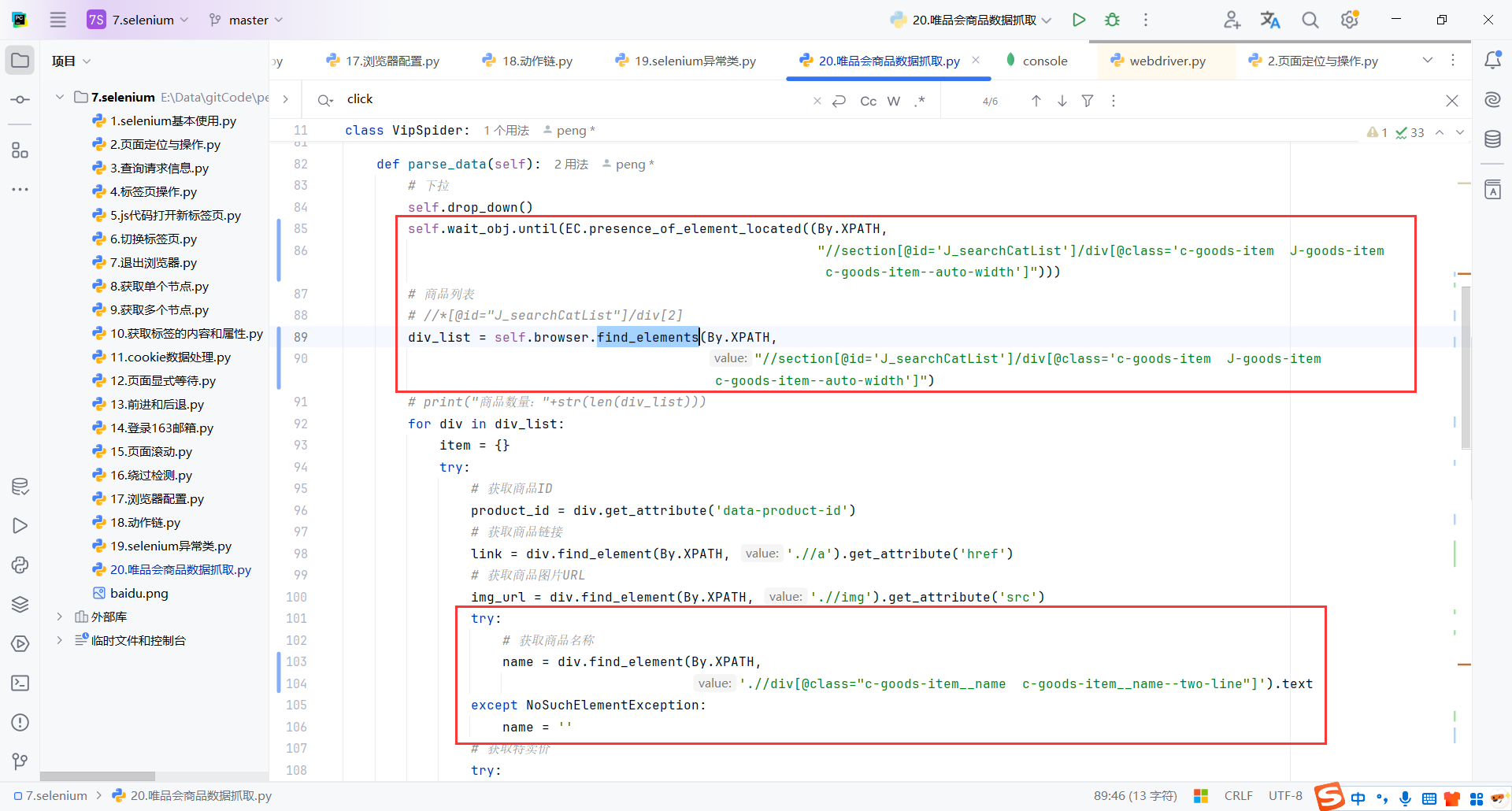
self.wait_obj.until(EC.presence_of_element_located((By.XPATH,"//section[@id='J_searchCatList']/div[@class='c-goods-item J-goods-item c-goods-item--auto-width']"))):显示等待页面加载完成NoSuchElementException:如果需要匹配的可能不存在,使用NoSuchElementException捕获selenium异常,可以让程序继续运行,尤其是在批量抓取中,避免因为单个元素的缺失导致整个抓取任务失败。self.save_data(item):存储数据,我这里是存储mongodb
import time
from random import randint
from pymongo import MongoClient
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class VipSpider:
mongo_client = MongoClient()
collection = mongo_client['py_spider']['wp_shop']
# 创建浏览器配置对象
options = webdriver.ChromeOptions()
# 禁止加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
# 创建浏览器对象
browser = webdriver.Chrome(options=options)
# 创建 WebDriverWait 对象
wait_obj = WebDriverWait(browser, 10)
# 打开唯品会首页
def open_vip(self):
self.browser.get(url="https://www.vip.com/")
# 需要设置的 cookies 字符串
cookie_string = "vip_address=%257B%2522pid%2522%253A%2522103101%2522%252C%2522cid%2522%253A%2522103101101%2522%252C%2522pname%2522%253A%2522%255Cu4e0a%255Cu6d77%255Cu5e02%2522%252C%2522cname%2522%253A%2522%255Cu4e0a%255Cu6d77%255Cu5e02%2522%257D; vip_province=103101; vip_province_name=%E4%B8%8A%E6%B5%B7%E5%B8%82; vip_city_name=%E4%B8%8A%E6%B5%B7%E5%B8%82; vip_city_code=103101101; vip_wh=VIP_SH; vip_ipver=31; mars_cid=1738000404723_f3af87a94e8267baac3a31c8ac582b8d; mst_area_code=104104; mars_pid=0; VIP_QR_FIRST=1; smidV2=2025012801532604328e2071763b6e8cc07e647eec75fd001d2cf7c8f169b90; pc_fdc_area_id=103101101; pc_fdc_source_ip=1; is_default_area=1; VipRUID=150838109; VipDegree=D1; VipUINFO=luc%3Ac%7Csuc%3Ac%7Cbct%3Ac_new%7Chct%3Ac_new%7Cbdts%3A0%7Cbcts%3A0%7Ckfts%3A0%7Cc10%3A0%7Crcabt%3A0%7Cp2%3A0%7Cp3%3A1%7Cp4%3A0%7Cp5%3A1%7Cul%3A3103; VipUID=c1c668ee5132ba1f9e5dab7dbba9bb3f; VipRNAME=155*****135; user_class=c; mars_sid=a27f8d529f11f1835824aa787b0ed38b; visit_id=A9266CB0005E39F0D93375D8B9A7FCCB; .thumbcache_f65dad1092aa9e66c73b4823b4493a2f=GqADprfO4aAbKIUsj6v7v5Ywcd+mxFAdTIBjs1k79GIvYu9dMMysXzRcIijlJiQi/qv1RpBYVLj8pjWH+DuKZg%3D%3D; sfl_d=0; vip_access_times=%7B%22list%22%3A5%7D; vipshop_passport_src=https%3A%2F%2Fcategory.vip.com%2Fsuggest.php%3Fkeyword%3D%25E6%2589%258B%25E6%259C%25BA%26ff%3D235%7C12%7C1%7C1%26tfs_url%3D%252F%252Fmapi-pc.vip.com%252Fvips-mobile%252Frest%252Fshopping%252Fpc%252Fsearch%252Fproduct%252Frank; tfs_fp_token=Bi+QekQsx/yhBURVIKsFaZcuFQW3ExCrbDa+rrnwnp0jQjjvu/CNXlsGX2+jEBiyIZ+G4Tngi076v3XLeodF+0A%3D%3D; tfs_fp_timestamp=1738040803945; _jzqco=%7C%7C%7C%7C%7C1.1775472856.1738001872250.1738002211593.1738040814493.1738002211593.1738040814493.0.0.0.8.8; PASSPORT_ACCESS_TOKEN=67DE74BAF8F0B373FA0390111B52FE5477CAEE24; VipLID=0%7C1738040818%7C1d74d2; fe_global_sync=1; vpc_uinfo=fr1352:0,fr674:D1,fr766:1,fr896:0,fr398:0,fr408:0,fr251:C,fr1195:0,fr848:0,fr1196:0,fr902:0,fr901:0,fr980:0,fr1570:0,fr1575:0,fr1051:0,fr328:3103,fr259:S1-4,fr713:5,fr1655:0,fr884:0,fr863:0,fr1527:5,fr249:C2-1,fr1521:5,fr344:0,fr1544:0,fr1543:0; pg_session_no=13; vip_tracker_source_from=; waitlist=%7B%22pollingId%22%3A%22CAFB5BA3-83ED-4456-B38D-C456BAD9278C%22%2C%22pollingStamp%22%3A1738040830041%7D"
# 分割 cookie 字符串
cookies = cookie_string.split(';')
# 将 cookie 添加到浏览器
for cookie in cookies:
# 获取 cookie 的 name 和 value
name, value = cookie.split('=', 1)
# 添加 cookie
self.browser.add_cookie({
'name': name.strip(),
'value': value.strip(),
'domain': 'vip.com' # 根据实际情况调整
})
self.browser.get(url="https://www.vip.com/")
# wait_obj = WebDriverWait(self.browser, 10)
# 查找搜索框
input_search = self.wait_obj.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="J-search"]/div[1]/input')))
# 输入要搜索的商品
input_search.send_keys("华为mate70pro+")
# 隐藏遮挡的元素 影响搜索按钮点击
# self.browser.execute_script("document.querySelector('img.main-img').style.display = 'none';")
# self.browser.execute_script("document.querySelector('div#J_asset_have').style.display = 'none';")
# 查找搜索按钮 //*[@id="J-search"]/div[1]/a
btn_search = self.wait_obj.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="J-search"]/div[1]/a')))
# 这里不造为什么需要等待2、3sclick()才有效
time.sleep(3)
# 点击搜索按钮
btn_search.click()
# 成功就进入页面等待1-3s再操作
time.sleep(randint(1, 3))
def drop_down(self):
print("开始下拉...")
# 等待 J_searchCatList 元素加载完成
self.wait_obj.until(EC.presence_of_element_located((By.ID, "J_searchCatList")))
while True:
# 滚动一定的距离
self.browser.execute_script("window.scrollBy(0, 1000);")
# 等待页面加载
time.sleep(randint(1, 3))
# 检查页面是否已经滚动到底部,如果是则退出循环
is_end = self.browser.execute_script(
"return (window.innerHeight + window.scrollY) >= document.body.scrollHeight;")
if is_end:
break
print("下拉结束...")
def parse_data(self):
# 下拉
self.drop_down()
self.wait_obj.until(EC.presence_of_element_located((By.XPATH,
"//section[@id='J_searchCatList']/div[@class='c-goods-item J-goods-item c-goods-item--auto-width']")))
# 商品列表
# //*[@id="J_searchCatList"]/div[2]
div_list = self.browser.find_elements(By.XPATH,
"//section[@id='J_searchCatList']/div[@class='c-goods-item J-goods-item c-goods-item--auto-width']")
# print("商品数量:"+str(len(div_list)))
for div in div_list:
item = {}
try:
# 获取商品ID
product_id = div.get_attribute('data-product-id')
# 获取商品链接
link = div.find_element(By.XPATH, './/a').get_attribute('href')
# 获取商品图片URL
img_url = div.find_element(By.XPATH, './/img').get_attribute('src')
try:
# 获取商品名称
name = div.find_element(By.XPATH,
'.//div[@class="c-goods-item__name c-goods-item__name--two-line"]').text
except NoSuchElementException:
name = ''
# 获取特卖价
try:
# sale_price = div.find_element(By.XPATH, './/div[@class="c-goods-item__sale-price J-goods-item__sale-price"]').text.strip()
sale_price = div.find_element(By.XPATH,
'.//div[@class="c-goods-item__sale-price J-goods-item__sale-price"]').text.strip()
except NoSuchElementException:
sale_price = '' # 如果特卖价不存在,设为N/A
# 获取市场价
try:
# c-goods-item__market-price J-goods-item__market-price
# market_price = div.find_element(By.XPATH,'.//div[@class="c-goods-item__market-price J-goods-item__market-price"]').text.strip()
market_price = div.find_element(By.XPATH,
'.//div[@class="c-goods-item__market-price J-goods-item__market-price"]').text.strip()
except NoSuchElementException:
market_price = '' # 如果市场价不存在,设为N/A
# 折扣
try:
discount_price = div.find_element(By.XPATH,
'.//div[@class="c-goods-item__discount J-goods-item__discount"]').text
except NoSuchElementException:
discount_price = '' # 如果市场价不存在,设为N/A
# 将数据添加到字典
item['product_id'] = product_id
item['link'] = link
item['img_url'] = img_url
item['name'] = name
item['sale_price'] = sale_price
item['market_price'] = market_price
item['discount_price'] = discount_price
# 打印或存储商品数据
print(item)
self.save_data(item)
# time.sleep(100)
except Exception as e:
print("Error parsing item:", e)
# 分页
self.next_page()
def next_page(self):
try:
print("分页开始...")
# 获取当前页按钮
# //*[@id="J_pagingCt"]/span[2]
# cat-paging-nub f-paging-default
current_page = self.wait_obj.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.cat-paging-nub.f-paging-default')))
# 获取当前页按钮的页码
current_page_num = int(current_page.text)
# 查找下一页按钮
next_page_button = self.wait_obj.until(EC.element_to_be_clickable(
(By.XPATH, f'//a[text()="{current_page_num + 1}"]')))
if next_page_button:
# time.sleep(3)
# 点击下一页按钮
# next_page_button.click()
# 使用 JavaScript 执行点击,绕过元素覆盖的问题
self.browser.execute_script("arguments[0].click();", next_page_button)
print(f"点击了第 {current_page_num + 1} 页")
# 等待页面加载
time.sleep(3)
# 再次解析数据
self.parse_data()
else:
print("最后一页")
# self.browser.close()
except Exception as e:
print('最后一页:', e)
# self.browser.quit()
def save_data(self, item):
self.collection.insert_one(item)
def main(self):
self.open_vip()
self.parse_data()
def __del__(self):
self.browser.quit()
if __name__ == '__main__':
spider = VipSpider()
spider.main()
mongdb
8.Pyppeteer框架
8.1简介
Pyppeteer
Pyppeteer 是 Python 语言的一个异步库,它是 Puppeteer(一个为 Node.js 提供的自动化工具)在 Python 中的移植。Puppeteer 本质上是一个用于控制 headless Chrome(无头浏览器)的库,通常用于网页自动化、爬虫、截图、生成PDF等任务。
Pyppeteer 作为 Puppeteer 的 Python 版本,能够提供类似的功能,并允许开发者使用 Python 编写自动化脚本。
框架特点以及环境配置
- 支持
chromium浏览器 - 支持
asyncio
Chromium是一款独立的浏览器,是Google为发展自家的浏览器Google Chrome而开启的计划,相当于Chrome的实验版,且Chromium是完全开源的。二者基于相同的源代码构建,Chrome所有的新功能都会先在Chromium上实现,待验证稳定后才会移植,因此Chromium的版本更新频率更高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium的用户群体要小众得多。两款浏览器"同根同源",它们有着同样的Logo,但配色不同,Chrome由蓝红绿黄四种颜色组成,而 Chromium由不同深度的蓝色构成。
安装
pip install pyppeteer
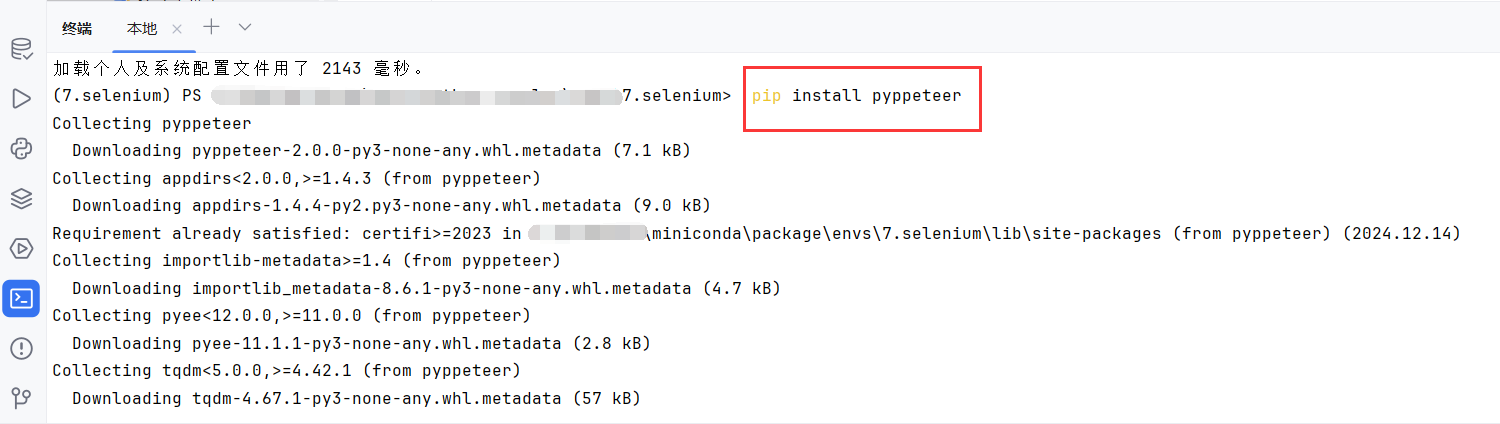
8.2Pyppeteer2.0.0下载Chromium失败
第一次运行Pyppeteer基本代码时,Pyppeteer会自动下载Chromium浏览器。
但是我这里一直下载失败。
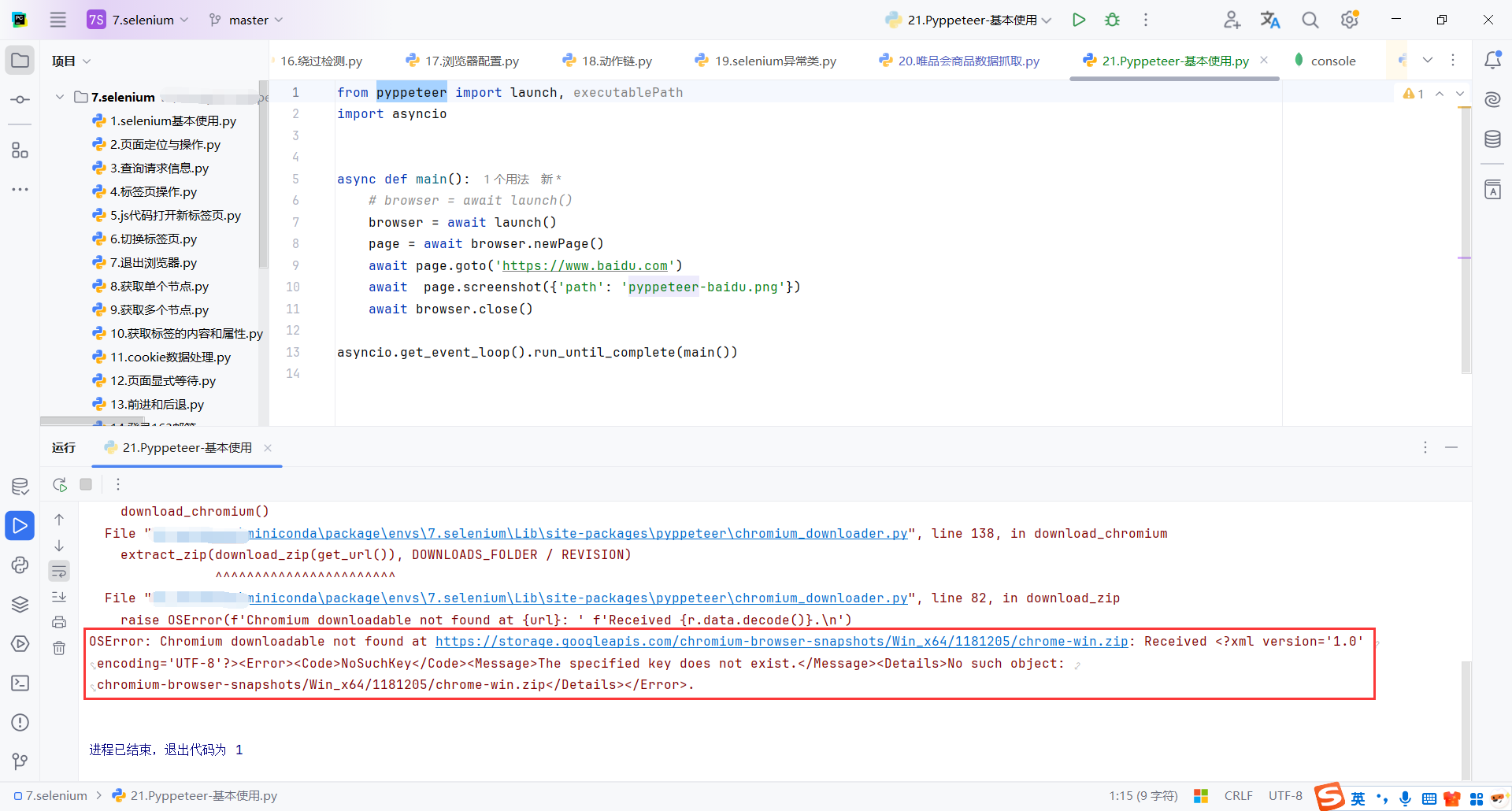
点击报错的链接,发现链接也不可用
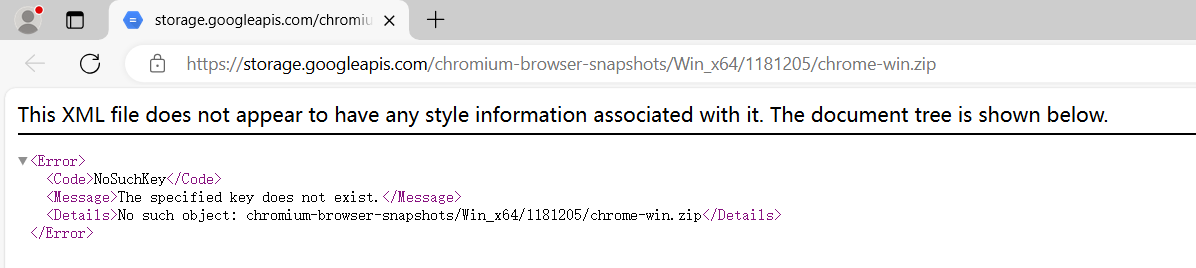
查看Pyppeteer版本是2.0.0,Pyppeteer已经不维护了,网上查了一下回退一下版本即可
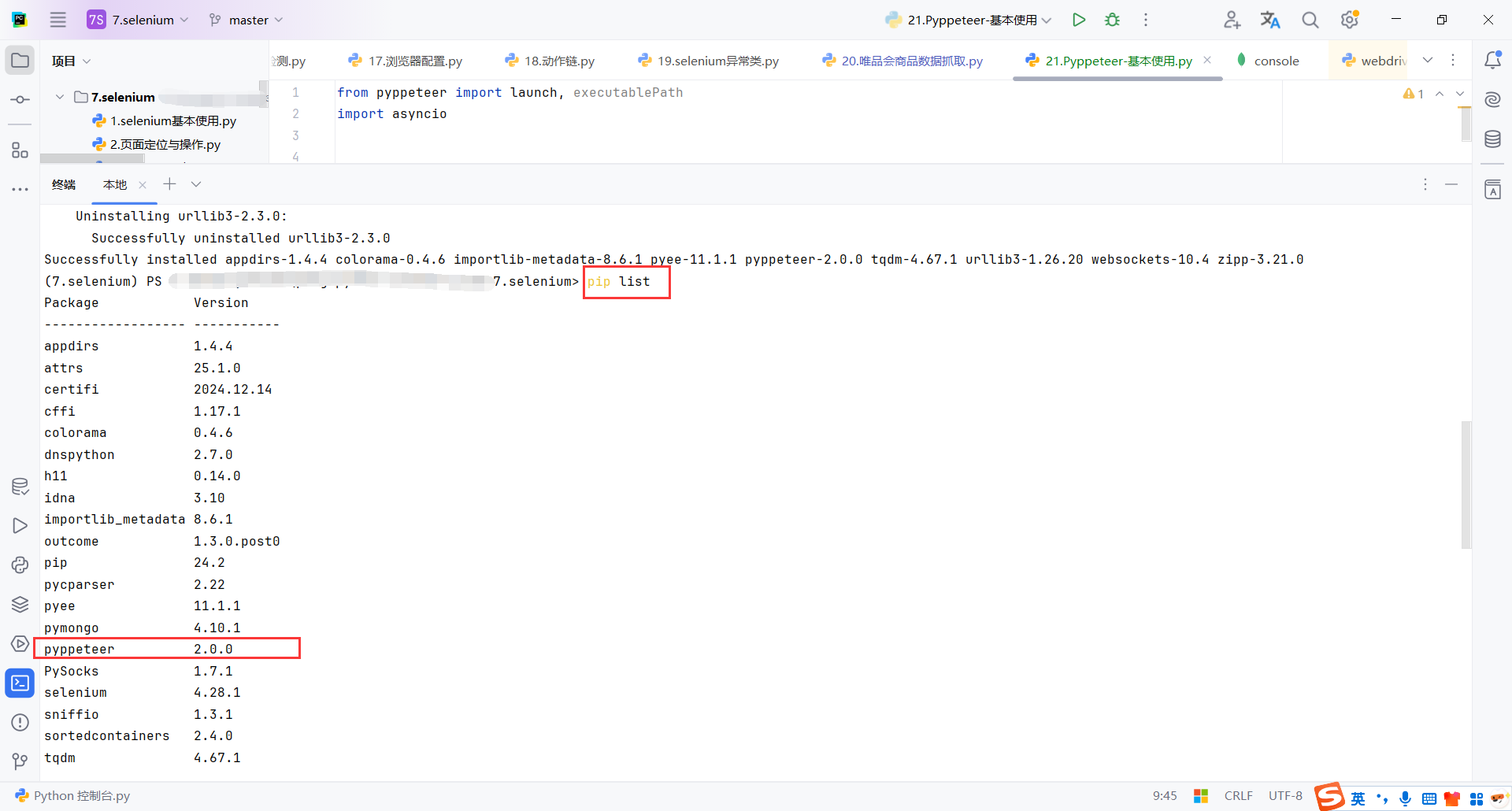
回退到1.0.2
pip install pyppeteer==1.0.2
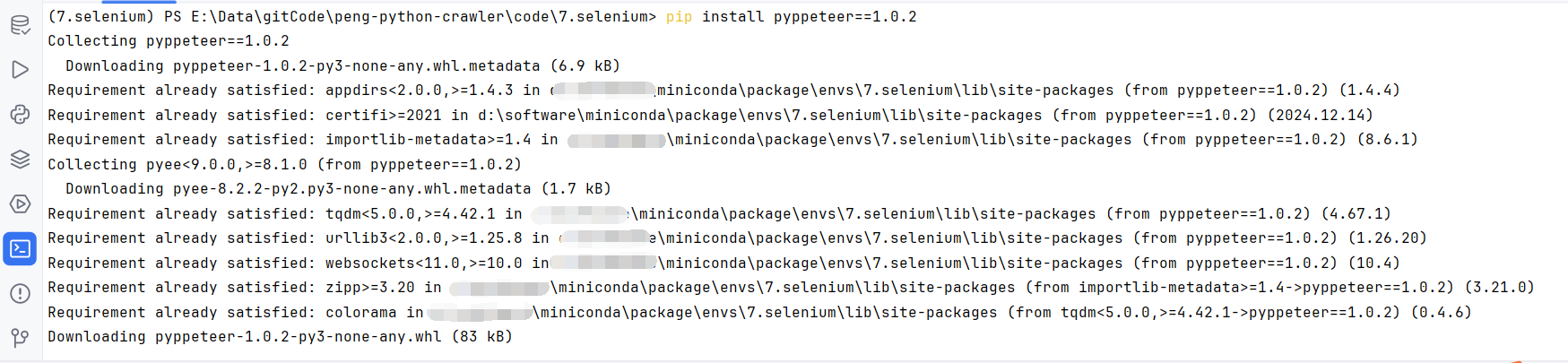
再次运行,执行成功了,并且首次执行会自动下载Chromium浏览器。
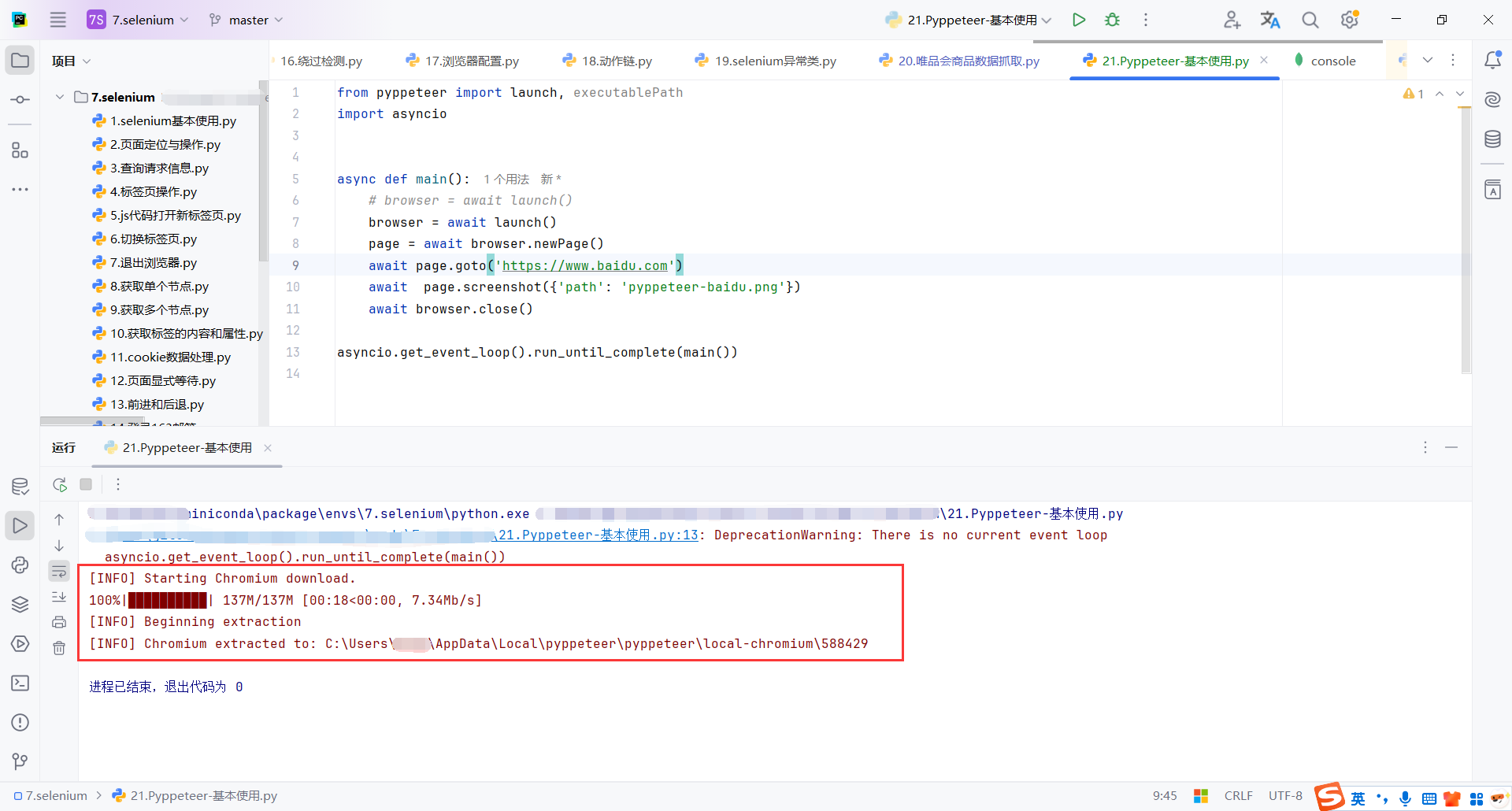
8.3基本使用
browser = await launch():
launch():启动 Chromium 浏览器的核心方法。这里使用await来调用它,这样浏览器会在后台启动,但不会阻塞主线程。- 默认情况下,
launch()会自动下载 Chromium 并启动它,除非我们指定浏览器路径。
page = await browser.newPage():创建一个新的浏览器页面(标签页)。同样使用 await 等待页面被创建。
await page.goto('https://www.baidu.com'):让浏览器打开指定的网址(这里是百度)。await 会等待页面加载完毕后才继续执行下一步。
await page.screenshot({'path': 'pyppeteer-baidu.png'}):让浏览器截图。这里传入一个字典 {'path': 'pyppeteer-baidu.png'},指定截图保存的文件路径(当前目录下的 pyppeteer-baidu.png 文件)。截图是异步操作,因此需要使用 await 等待操作完成。
from pyppeteer import launch, executablePath
import asyncio
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await page.screenshot({'path': 'pyppeteer-baidu.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
8.4打开浏览器页面
launch({"headless": False}):launch() 用来启动 Chromium 浏览器,headless=False 参数意味着浏览器将以可视化模式启动(即你可以看到浏览器界面,而不是无头模式)。如果是无头模式(默认值 True),浏览器在后台运行,不会显示界面。
time.sleep(30):这行代码会让程序暂停 30 秒,目的是给你足够的时间在浏览器中查看加载的页面。需要注意的是,time.sleep() 是同步阻塞操作,它会阻止后续代码执行,直到延迟结束。
import time
from pyppeteer import launch, executablePath
import asyncio
async def main():
browser = await launch({"headless": False})
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await page.screenshot({'path': 'pyppeteer-baidu.png'})
time.sleep(30)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
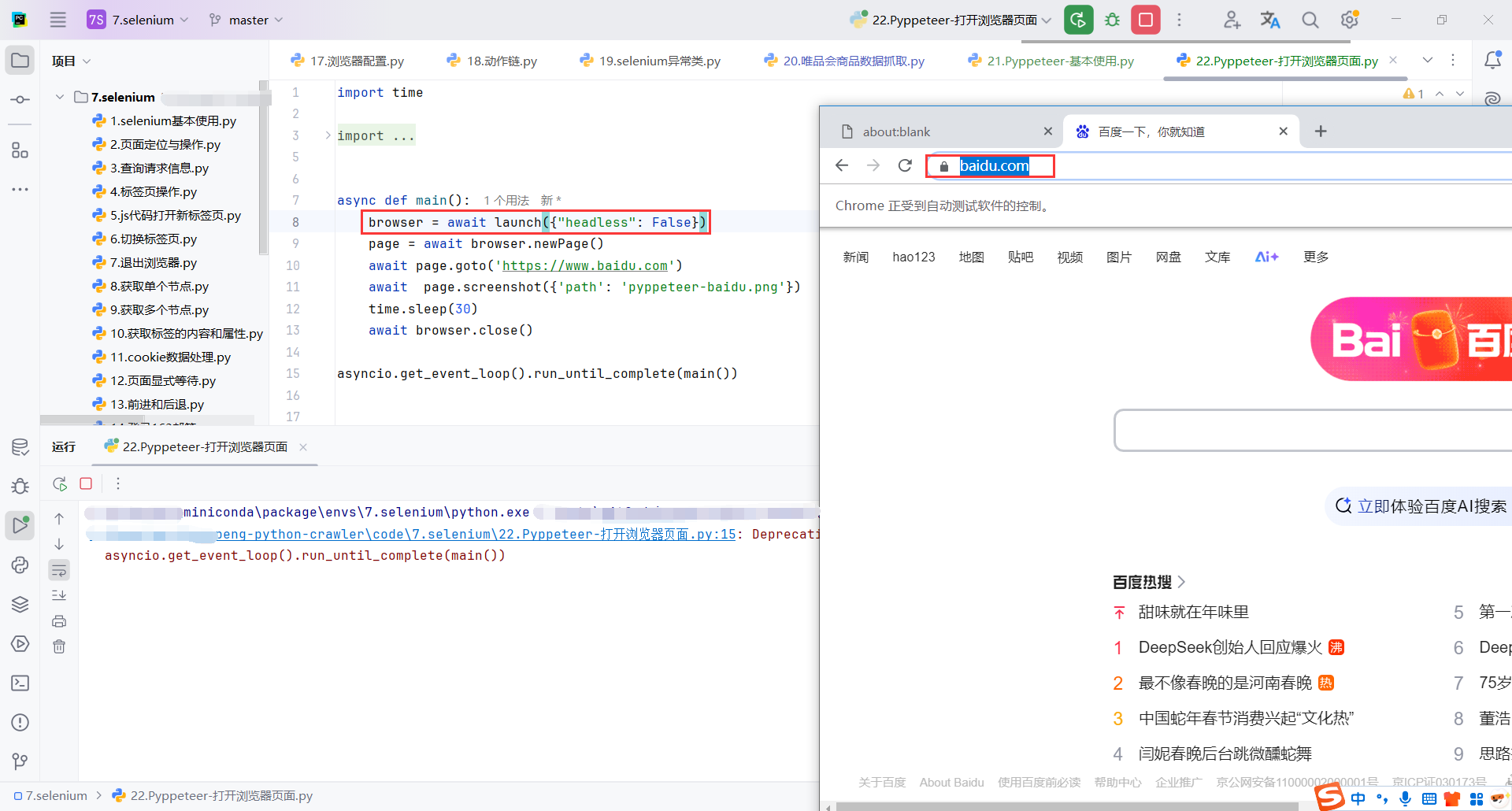
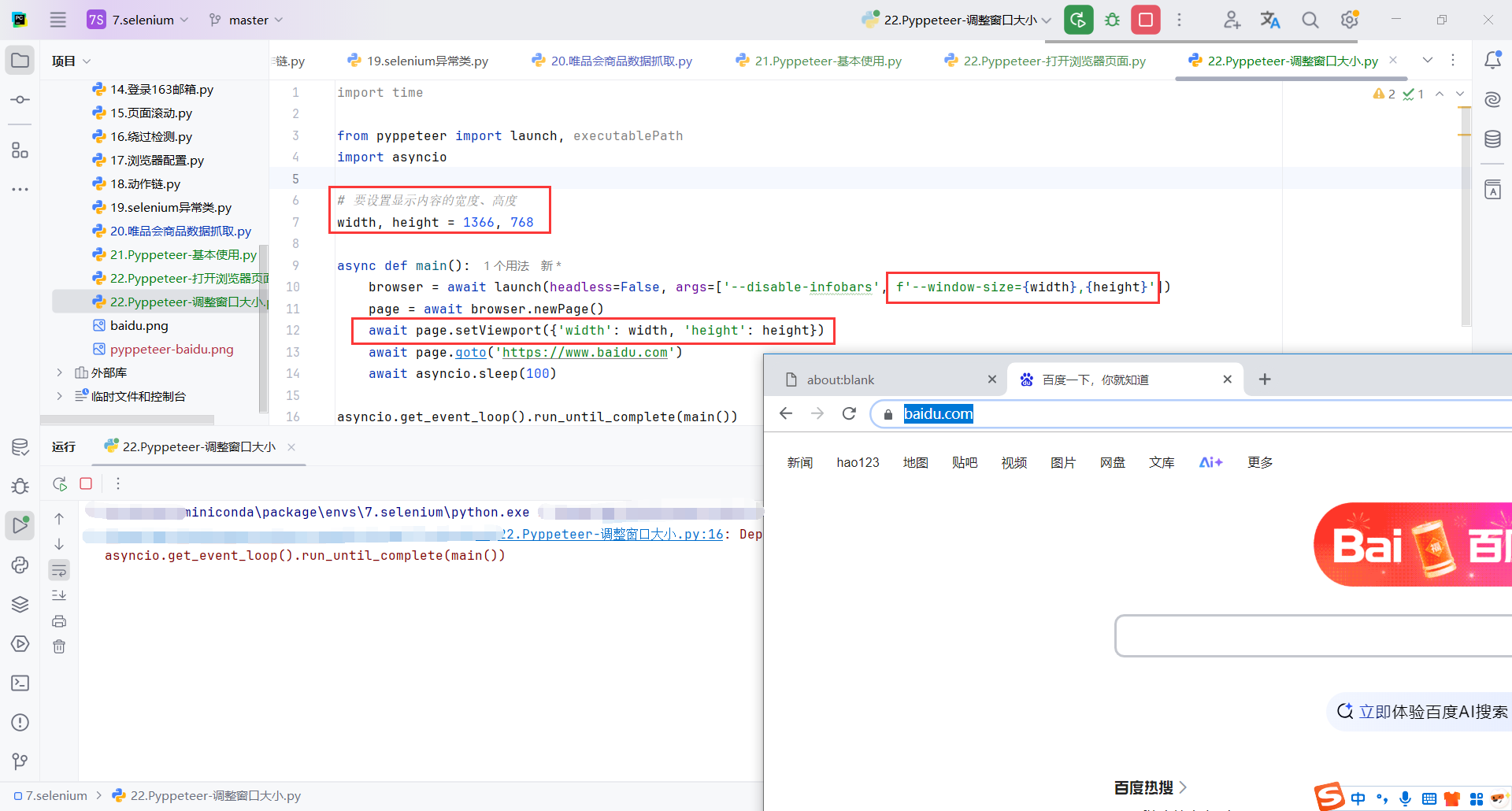
8.5调整窗口大小
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}']):
launch(headless=False):启动 Chromium 浏览器,headless=False表示浏览器将以可视化的方式运行,而不是在后台运行(无头模式)。如果设置为headless=True,浏览器会在后台运行而没有图形界面。args=['--disable-infobars', f'--window-size={width},{height}']:通过args参数传递浏览器启动时的额外命令行参数:--disable-infobars:禁用 Chrome 浏览器中的一些信息条(如“自动化测试”提示)。--window-size={width},{height}:设置浏览器窗口的尺寸,width和height是在前面定义的。
await page.setViewport({'width': width, 'height': height}):设置浏览器页面的视口大小,width 和 height 是你之前定义的窗口尺寸。视口大小是浏览器内显示网页内容的区域大小。
import time
from pyppeteer import launch, executablePath
import asyncio
# 要设置显示内容的宽度、高度
width, height = 1366, 768
async def main():
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
8.6绕过检测
await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }'''):
evaluate():此方法允许在浏览器中执行 JavaScript 代码。在这行代码中,它修改了navigator.webdriver的属性。navigator.webdriver是浏览器用来标识自动化工具(如 Selenium 或 Puppeteer)的一种标志,通常自动化脚本会将其设置为trueObject.defineProperties(navigator, { webdriver: { get: () => false } }):此代码通过 JavaScript 修改navigator对象,将webdriver属性的值设置为false,从而绕过网站的自动化检测。
asyncio.sleep(60):使得程序暂停 60 秒。由于 asyncio.sleep() 是非阻塞的,其他异步任务仍然可以并发执行。这里的等待使得浏览器页面保持打开状态,方便用户查看。
import time
from pyppeteer import launch, executablePath
import asyncio
# 要设置显示内容的宽度、高度
width, height = 1366, 768
async def main():
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
# await page.goto('https://kyfw.12306.cn/otn/resources/login.html')
await page.goto('https://bot.sannysoft.com/')
await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
await asyncio.sleep(60)
asyncio.get_event_loop().run_until_complete(main())
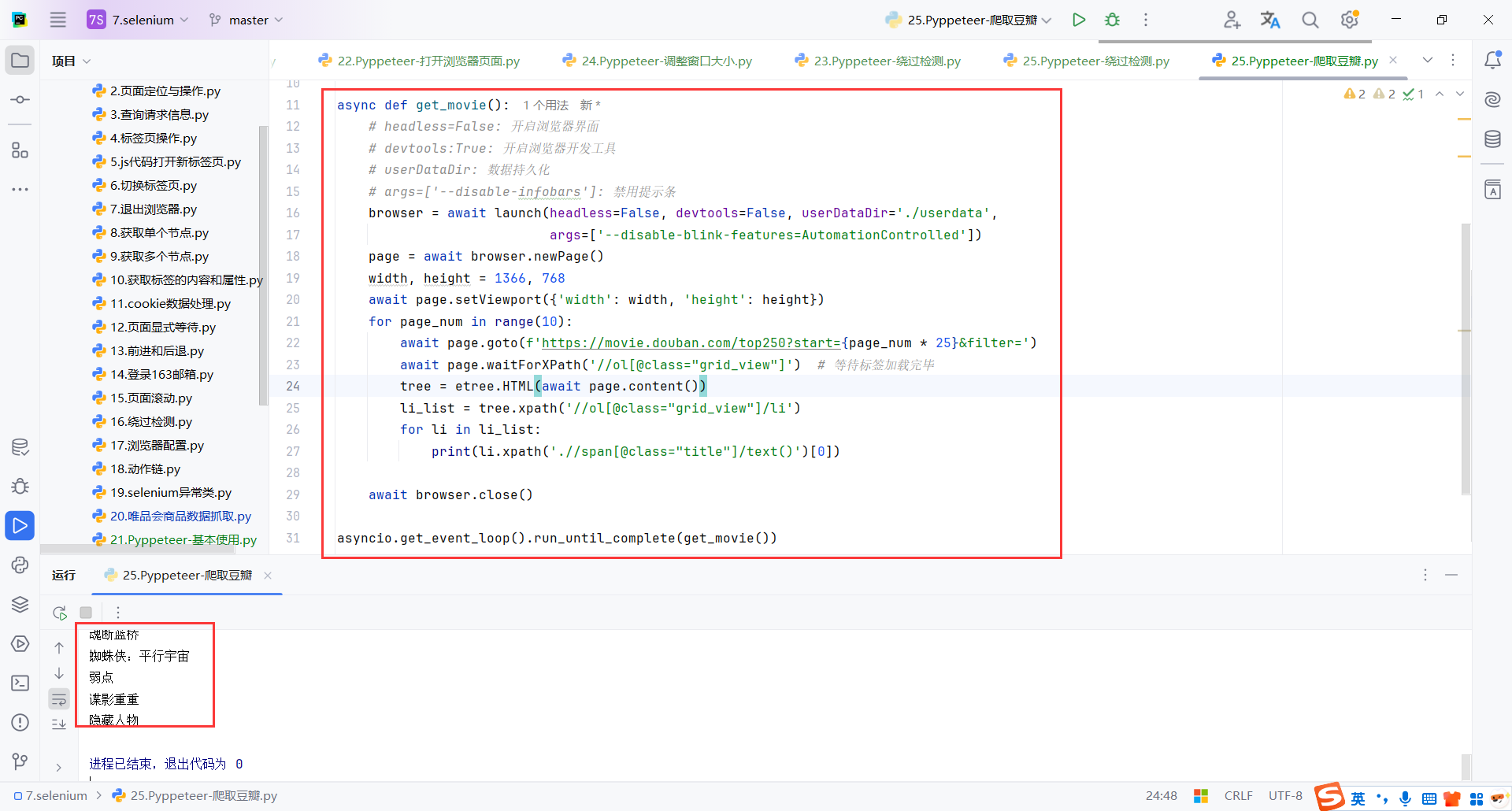
8.7爬取豆瓣
import asyncio
import time
from lxml import etree
from pyppeteer import launch, executablePath
# 要设置显示内容的宽度、高度
width, height = 1366, 768
async def get_movie():
# headless=False: 开启浏览器界面
# devtools:True: 开启浏览器开发工具
# userDataDir: 数据持久化
# args=['--disable-infobars']: 禁用提示条
browser = await launch(headless=False, devtools=False, userDataDir='./userdata',
args=['--disable-blink-features=AutomationControlled'])
page = await browser.newPage()
width, height = 1366, 768
await page.setViewport({'width': width, 'height': height})
for page_num in range(10):
await page.goto(f'https://movie.douban.com/top250?start={page_num * 25}&filter=')
await page.waitForXPath('//ol[@class="grid_view"]') # 等待标签加载完毕
tree = etree.HTML(await page.content())
li_list = tree.xpath('//ol[@class="grid_view"]/li')
for li in li_list:
print(li.xpath('.//span[@class="title"]/text()')[0])
await browser.close()
asyncio.get_event_loop().run_until_complete(get_movie())
📌 创作不易,感谢支持!
每一篇内容都凝聚了心血与热情,如果我的内容对您有帮助,欢迎请我喝杯咖啡☕,您的支持是我持续分享的最大动力!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号