
Python爬虫-Requests包详解
前言
我姑且举灰黑的手装作喝干一杯酒
我将在不知道时候的时候独自远行
鲁迅《野草》
⚠️声明:本文所涉及的爬虫技术及代码仅用于学习、交流与技术研究目的,禁止用于任何商业用途或违反相关法律法规的行为。若因不当使用造成法律责任,概与作者无关。请尊重目标网站的
robots.txt协议及相关服务条款,共同维护良好的网络环境。
1.Requests介绍
requests 是 Python 中一个非常流行的 HTTP 库,专门用于简化发送 HTTP 请求和处理响应的操作。它支持所有 HTTP 方法(如 GET、POST、PUT、DELETE 等),并且提供了简洁、易用的接口来处理 HTTP 请求、响应、头部、数据等。
中文文档:https://requests.readthedocs.io/projects/cn/zh-cn/latest/
2.模块安装
安装requests
pip install requests
查看requests包详细信息
pip show requests
3.requests功能特性
Keep-Alive& 连接池- 国际化域名和
URL - 带持久
Cookie的会话 - 浏览器式的
SSL认证 - 自动内容解码
- 基本/摘要式的身份认证
- 优雅的
key/value Cookie - 自动解压
Unicode响应体HTTP(S)代理支持- 文件分块上传
- 流下载
- 连接超时
- 分块请求
- 支持
.netrc
4.requests发送网络请求以及常用的响应属性
常用的响应属性
status_code:获取响应的 HTTP 状态码。常见的状态码包括 200(成功)、404(未找到页面)、500(服务器错误)等。text:返回响应的内容,以字符串形式表示。对于文本类型的响应(如 HTML、JSON 字符串),可以使用text来获取响应内容。json:解析响应体中的 JSON 数据,返回一个字典对象。如果响应的内容是 JSON 格式的数据,可以直接使用该方法将响应体解析为 Python 字典。content:返回响应的内容,以字节流的形式表示。它通常用于处理二进制数据(如图片、文件等)。headers:返回响应的头信息。它是一个字典,包含了所有的响应头信息。cookies:返回服务器返回的 cookies,返回的是一个RequestsCookieJar对象,类似于字典。url:返回实际请求的 URL。在某些情况下,重定向后,返回的 URL 可能与原请求 URL 不同。encoding:返回响应的字符编码。requests会自动根据响应头中的Content-Type字段设置编码方式,但你也可以手动修改。elapsed:返回请求完成所花费的时间,单位为秒。返回一个timedelta对象,可以方便地查看请求的时长。raise_for_status:用于判断请求是否成功。如果请求失败(例如状态码为 4xx 或 5xx),会抛出HTTPError异常。iter_content:用于处理响应体中的大文件或二进制数据,支持分块获取内容,避免一次性加载过多数据到内存。iter_lines:用于处理响应中的逐行数据。对于响应体较大的文本文件(如日志文件),可以使用该方法逐行读取。
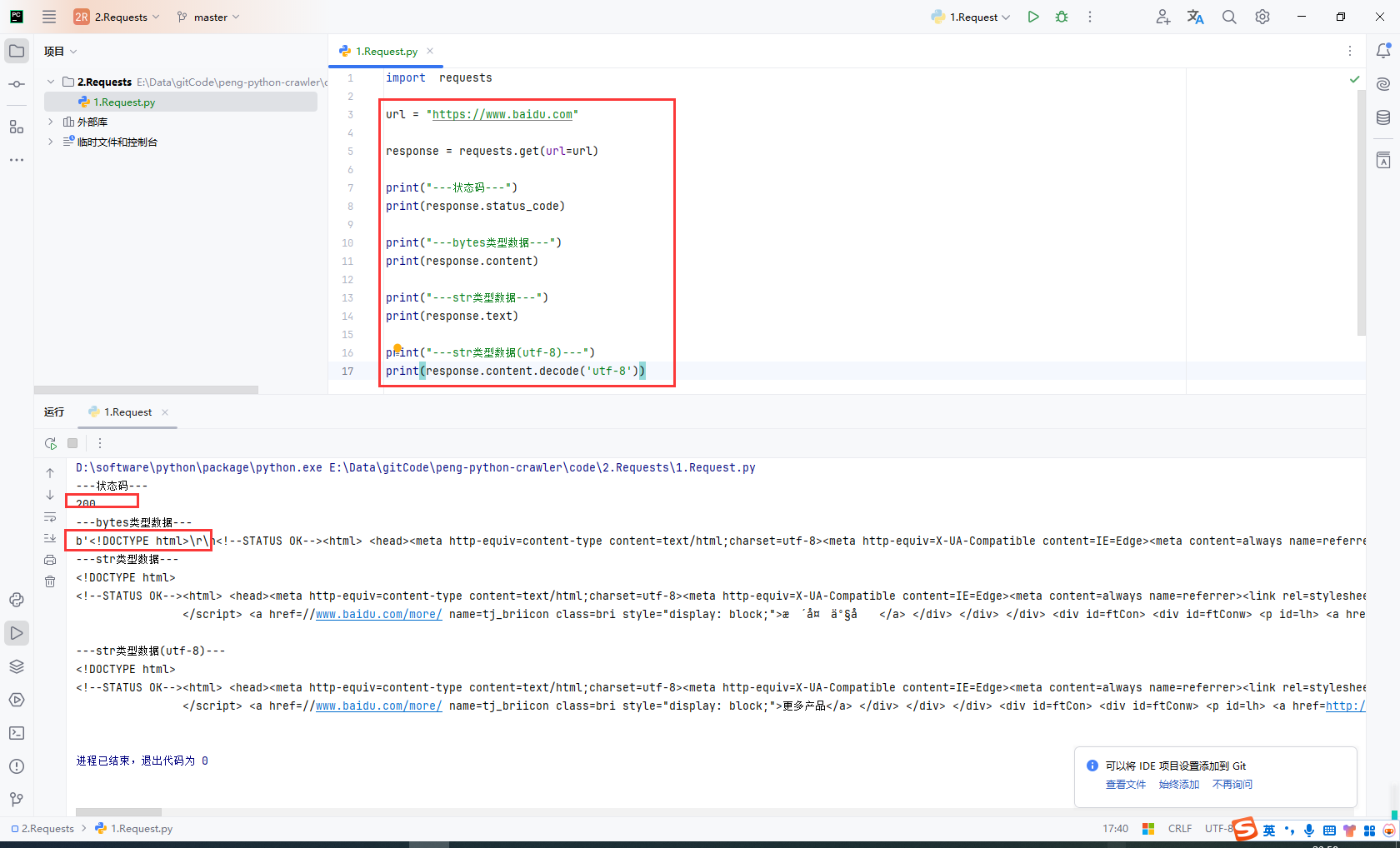
通过requests向百度首页发送请求,获取百度首页数据
import requests
url = "https://www.baidu.com"
response = requests.get(url=url)
print("---状态码---")
print(response.status_code)
print("---bytes类型数据---")
print(response.content)
print("---str类型数据---")
print(response.text)
print("---str类型数据(utf-8)---")
print(response.content.decode('utf-8'))
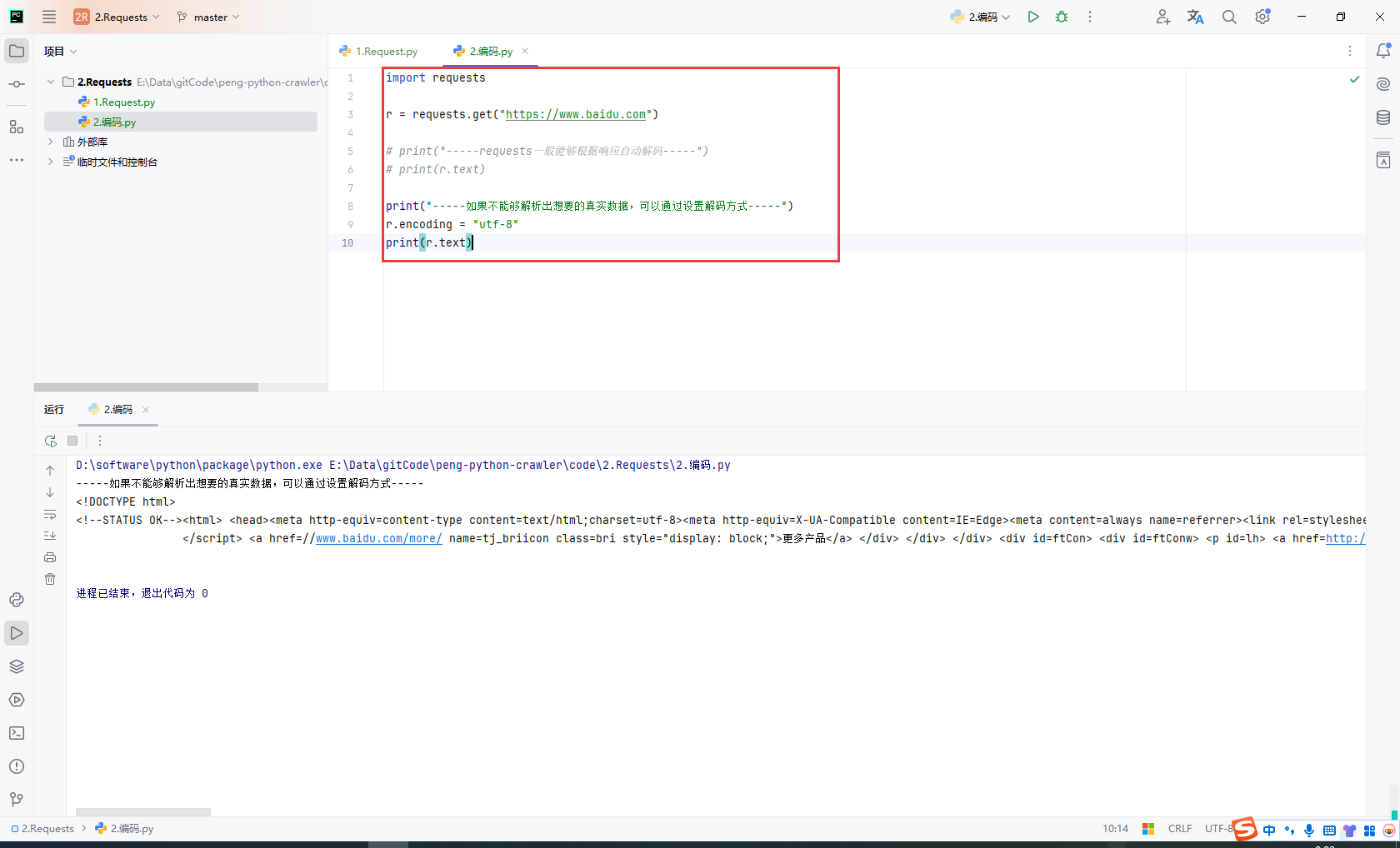
获取网页源码的通用方式
以下三种方式从前往后依次尝试,百分百可以解决网页编码问题。
response.encoding = 'utf-8'response.content.decode('utf-8')response.text
5.下载网络图片
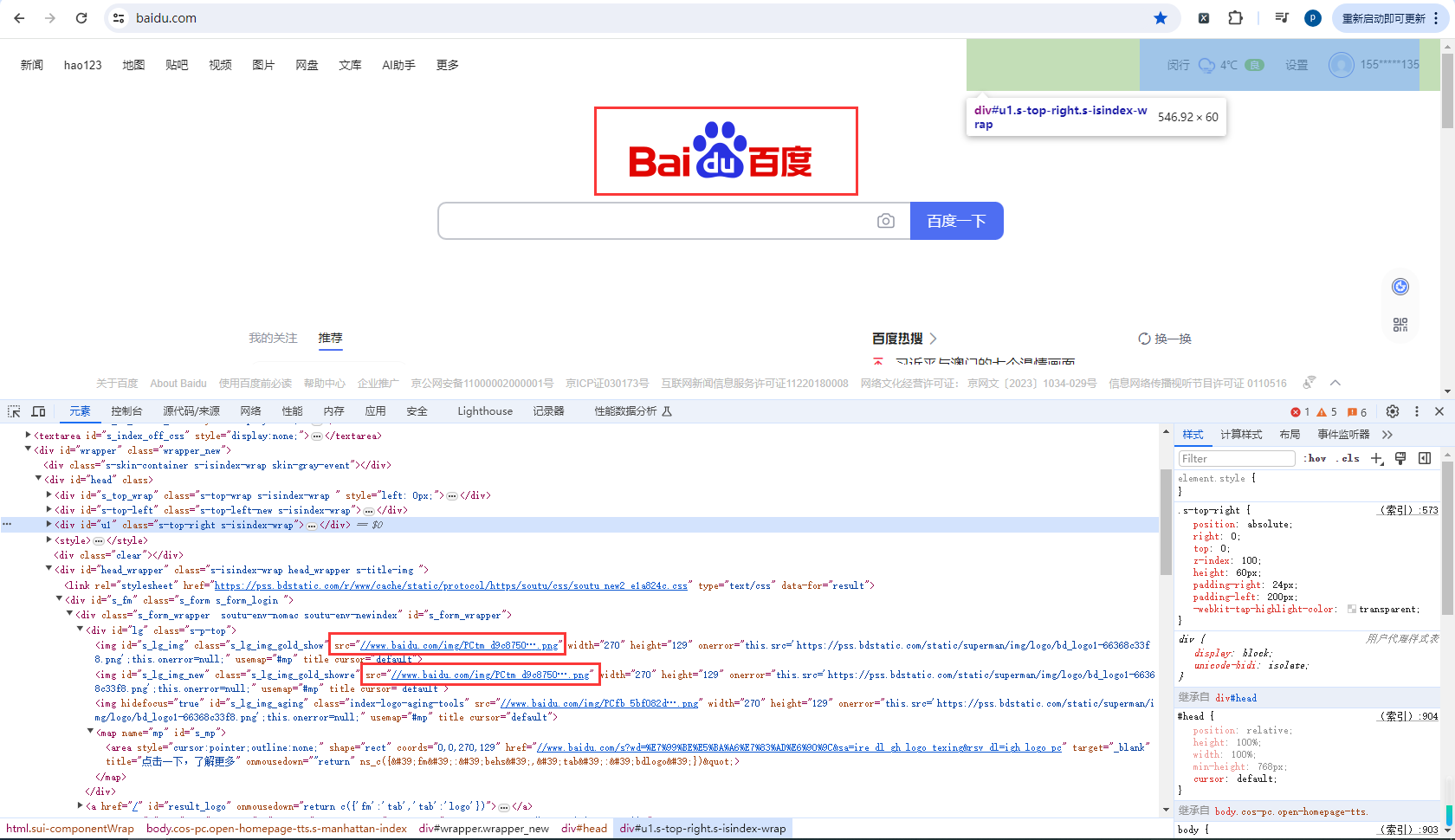
将百度logo下载到本地
找到百度图片的地址:https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png
利用requests模块发送请求并获取响应
使用二进制写入的方式打开文件并将response响应内容写入文件内
import requests
# 图片的url
url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
# 响应本身就是一个图片,并且是二进制类型
r = requests.get(url)
print(r.content)
# 以二进制+写入的方式打开文件
with open('baidu.png', 'wb') as f:
# r.content bytes二进制类型
f.write(r.content)
6.iter_content
用于处理响应体中的大文件或二进制数据,支持分块获取内容,避免一次性加载过多数据到内存。
将百度网页下载到本地
-
stream=True:
当你向服务器发送请求时,requests默认会将响应的所有内容一次性下载到内存中。通过设置stream=True,你告诉requests仅仅获取响应头,响应体的内容会逐步下载并逐块传输给你。适用于处理大文件或下载大数据量时,避免占用过多内存。 -
r.iter_content(chunk_size=100):
iter_content()是一个迭代器方法,它会按块(chunk)返回响应体的内容。你可以通过设置chunk_size参数来定义每次读取的数据量,单位为字节。这里设置chunk_size=100,意味着每次读取 100 字节数据,然后将这些数据写入文件。这样你就可以避免一次性加载整个文件到内存中,节省内存资源。 -
with open('test.html', 'wb'):
使用with语句打开文件,这样当文件写入完成后,文件会自动关闭。'wb'模式表示以二进制写入文件,适用于写入图片、HTML 文件等二进制数据。 -
f.write(chunk):
将每个读取的块chunk写入到本地文件中。
import requests
r = requests.get('https://www.baidu.com', stream=True)
with open('test.html', 'wb') as f:
for chunk in r.iter_content(chunk_size=100):
f.write(chunk)
7.关于抖音视频地址加密
查看抖音视频地址的时候发现api返回的不是json对象了,而是json转义字符串
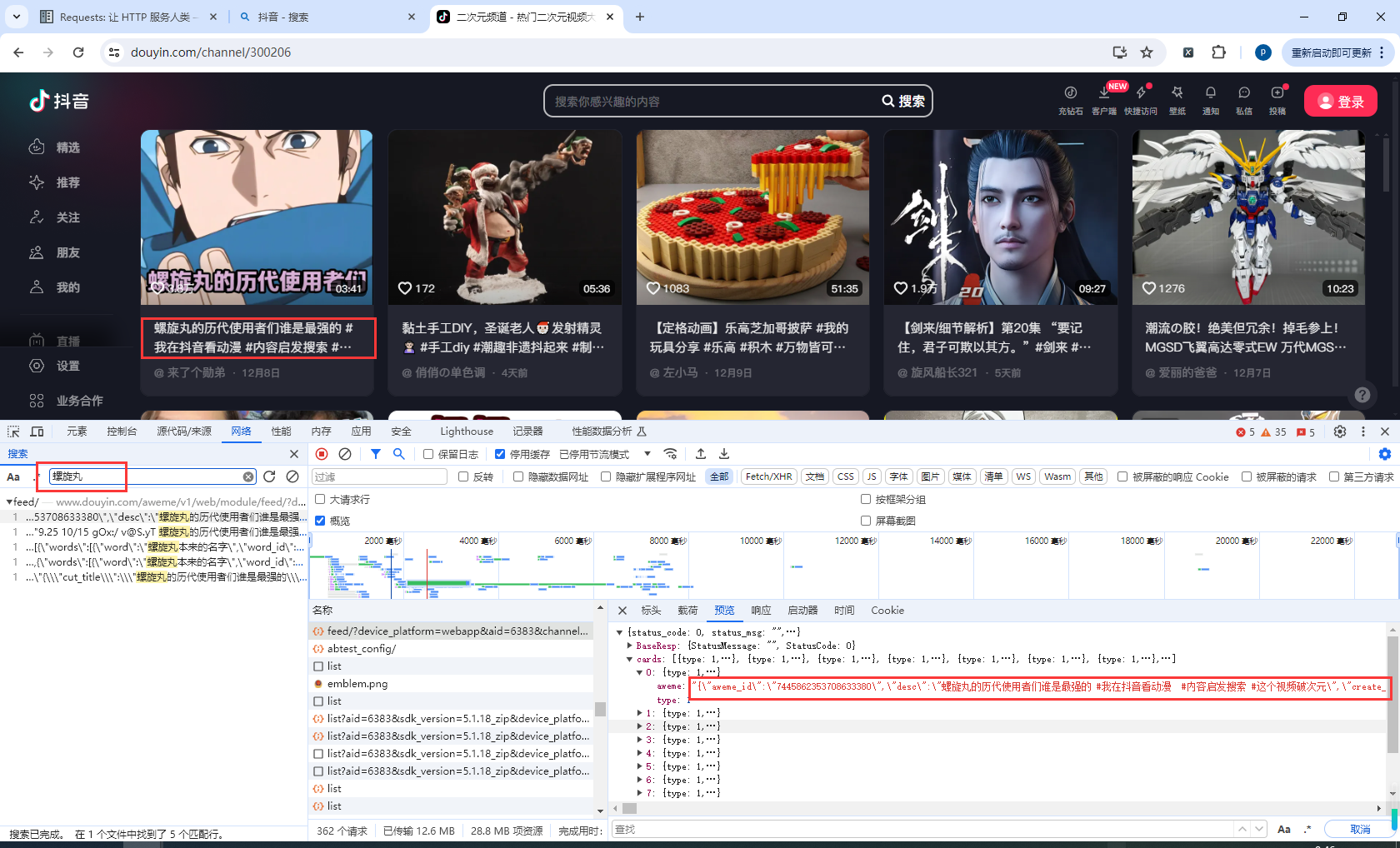
我们把这一段json转义字符拷贝下来
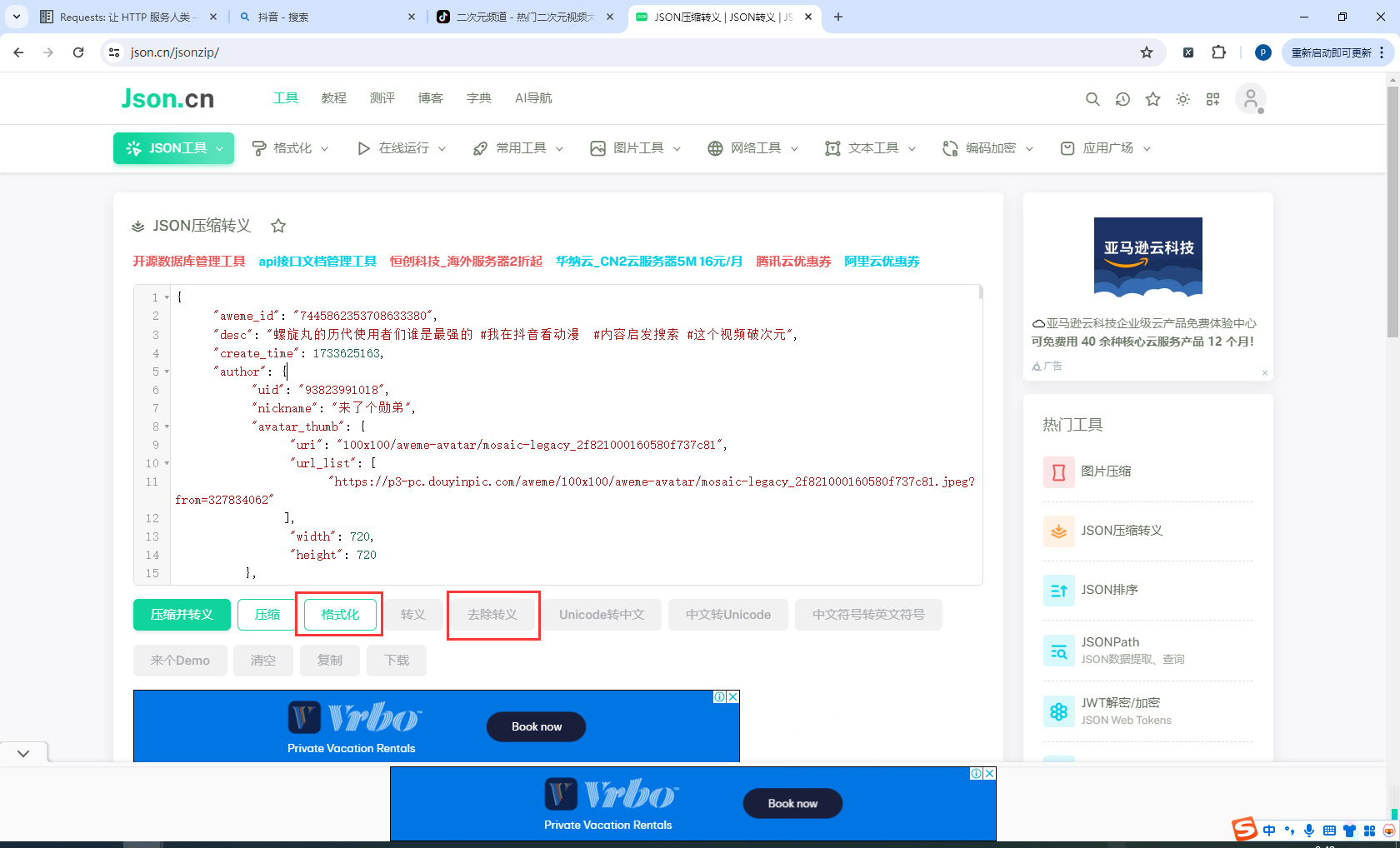
拷贝到:https://www.json.cn/jsonzip/,然后删除开始结尾的分号("")
然后先点击去除转义,再点击格式化
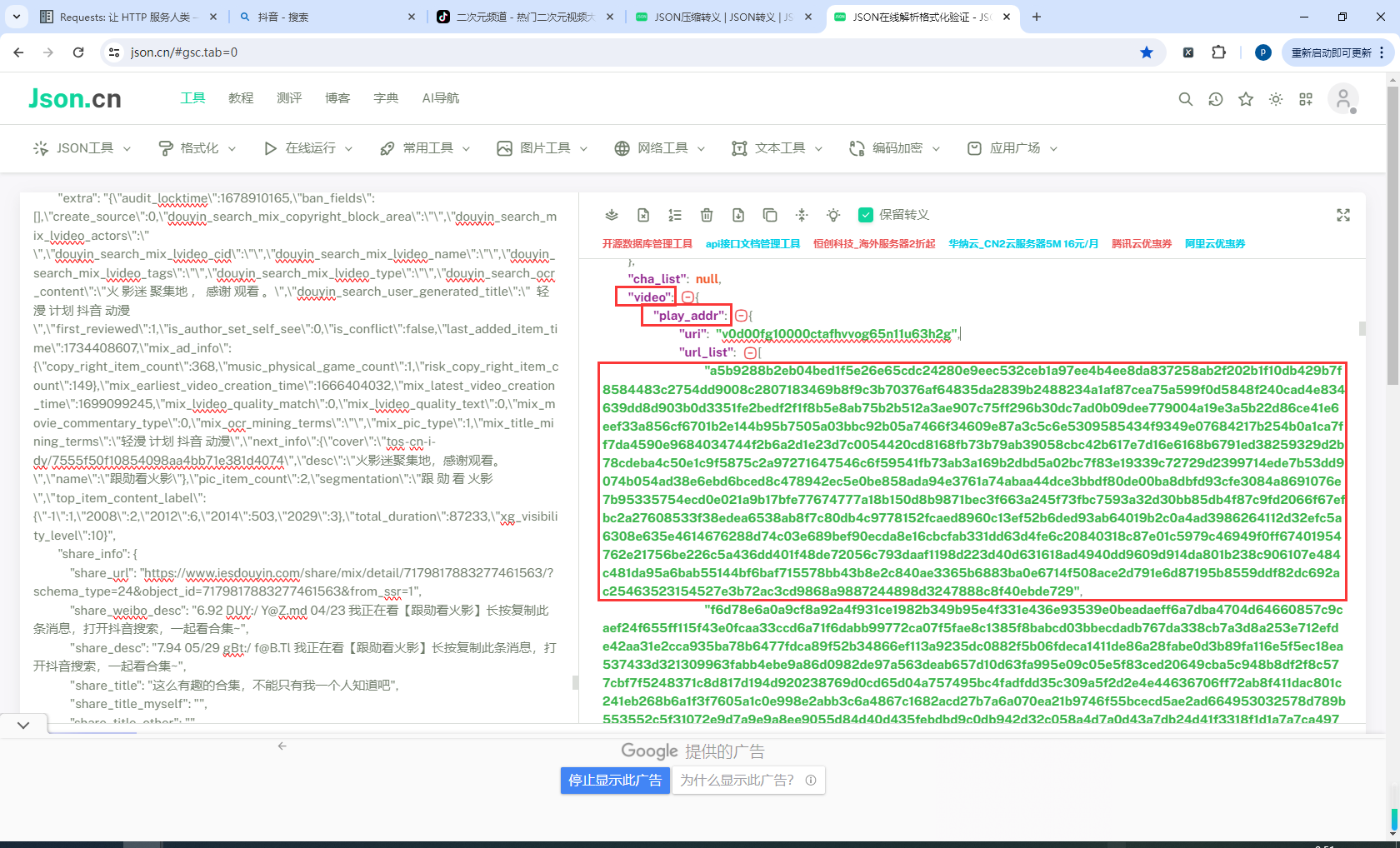
拷贝到https://www.json.cn,然后找到video相关信息,发现地址已被加密了
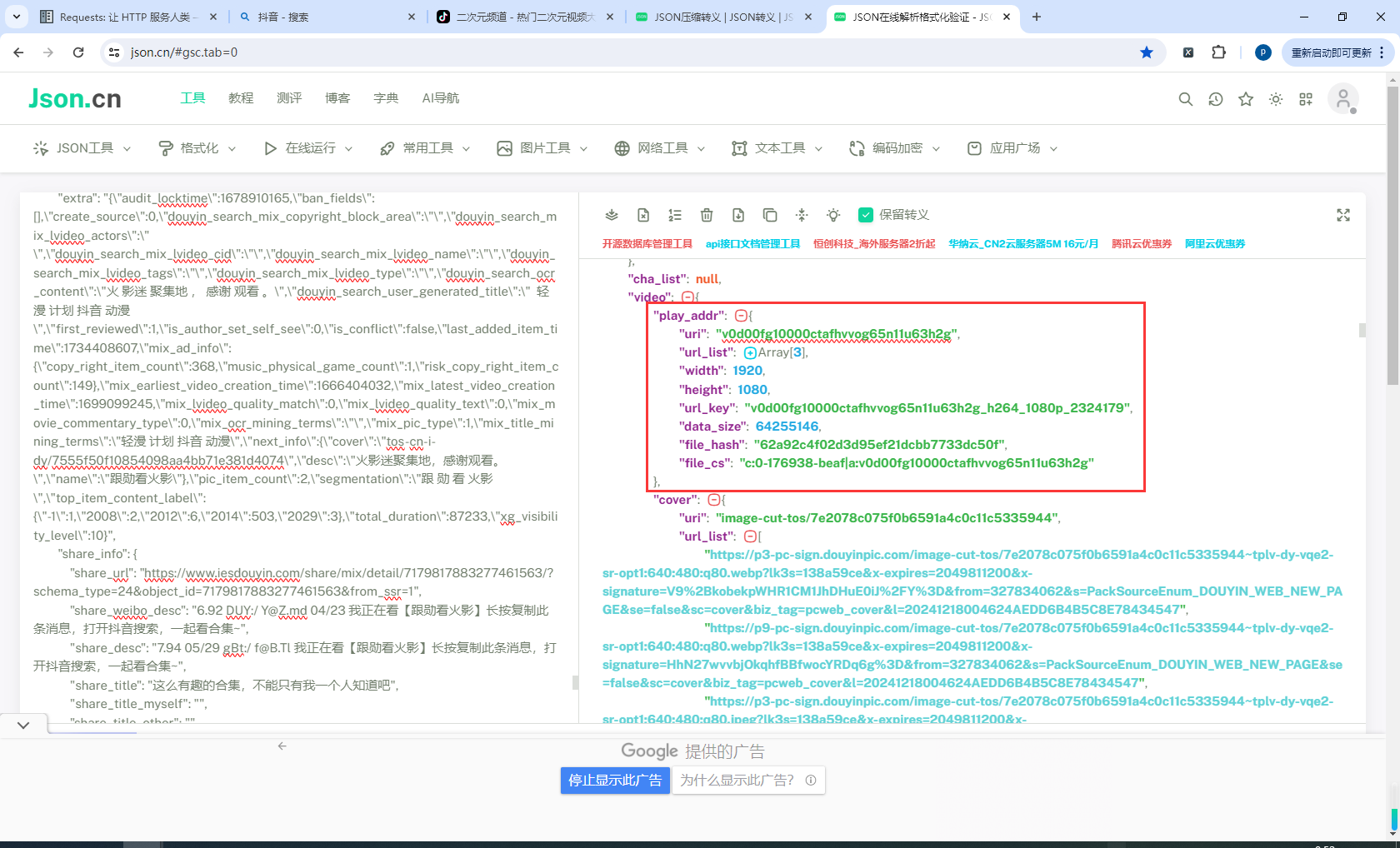
这里确实不造怎么办,但是我先记录下
8.下载视频显示进度
import requests
# 视频URL
video_url = ""
# 发送请求
r = requests.get(url=video_url, stream=True)
response_body_length = int(r.headers.get("Content-Length"))
print("body的数据长度为:", response_body_length)
# 获取响应内容存储到文件
with open("抖音.mp4", 'wb') as fd:
write_length = 0
for chunk in r.iter_content(chunk_size=100):
write_length += fd.write(chunk) # write的返回值为写入到文件内容的多少
print("下载进度: %02.2f%%" % (100 * write_length / response_body_length))
9.设置请求头发送请求
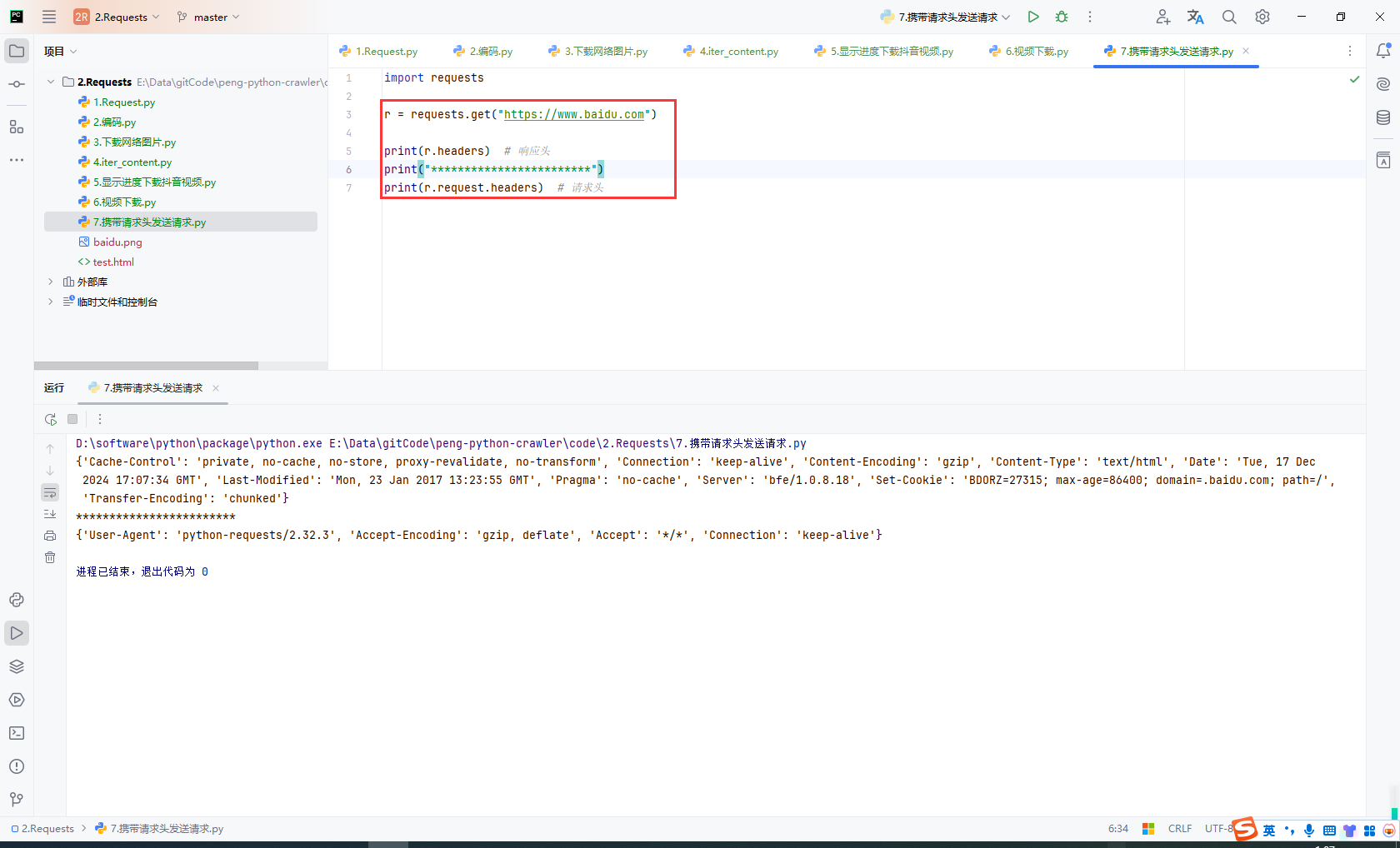
查看请求头和响应头
import requests
r = requests.get("https://www.baidu.com")
print(r.headers) # 响应头
print("************************")
print(r.request.headers) # 请求头
携带User-Agent请求百度
查看自己访问百度的时候携带的User-Agent
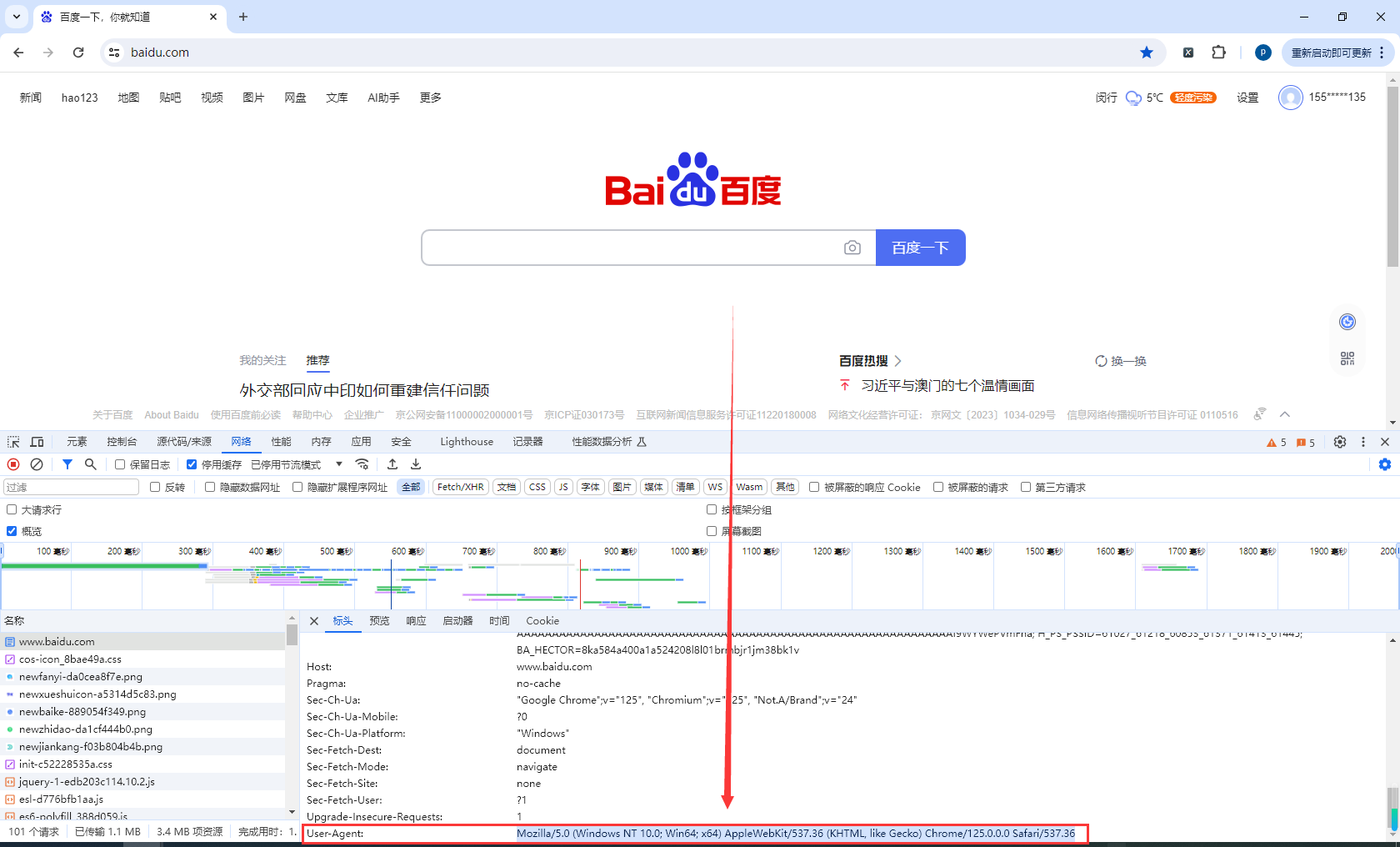
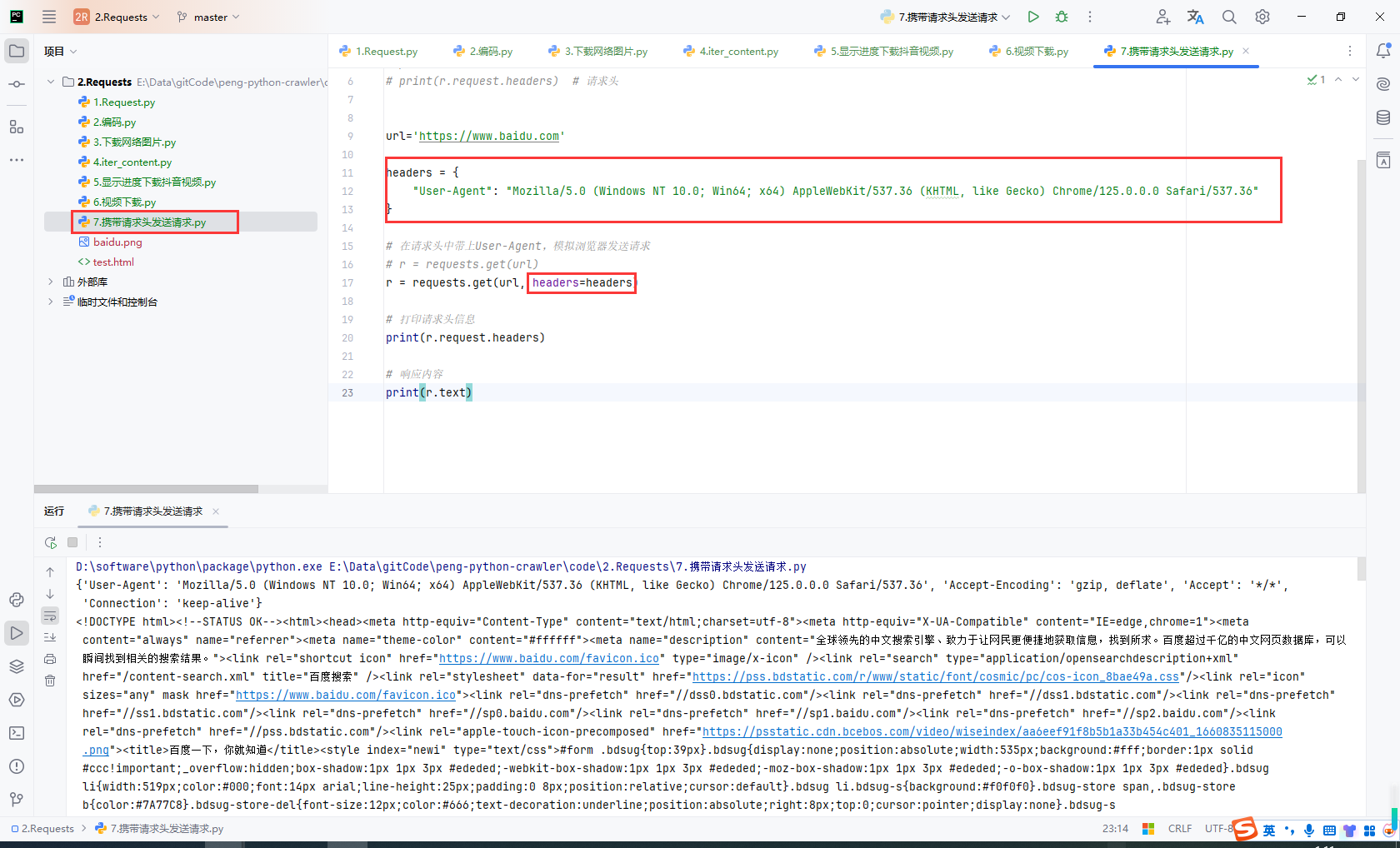
设置User-Agent,请求百度
url='https://www.baidu.com'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
}
# 在请求头中带上User-Agent,模拟浏览器发送请求
# r = requests.get(url)
r = requests.get(url, headers=headers)
# 打印请求头信息
print(r.request.headers)
# 响应内容
print(r.text)
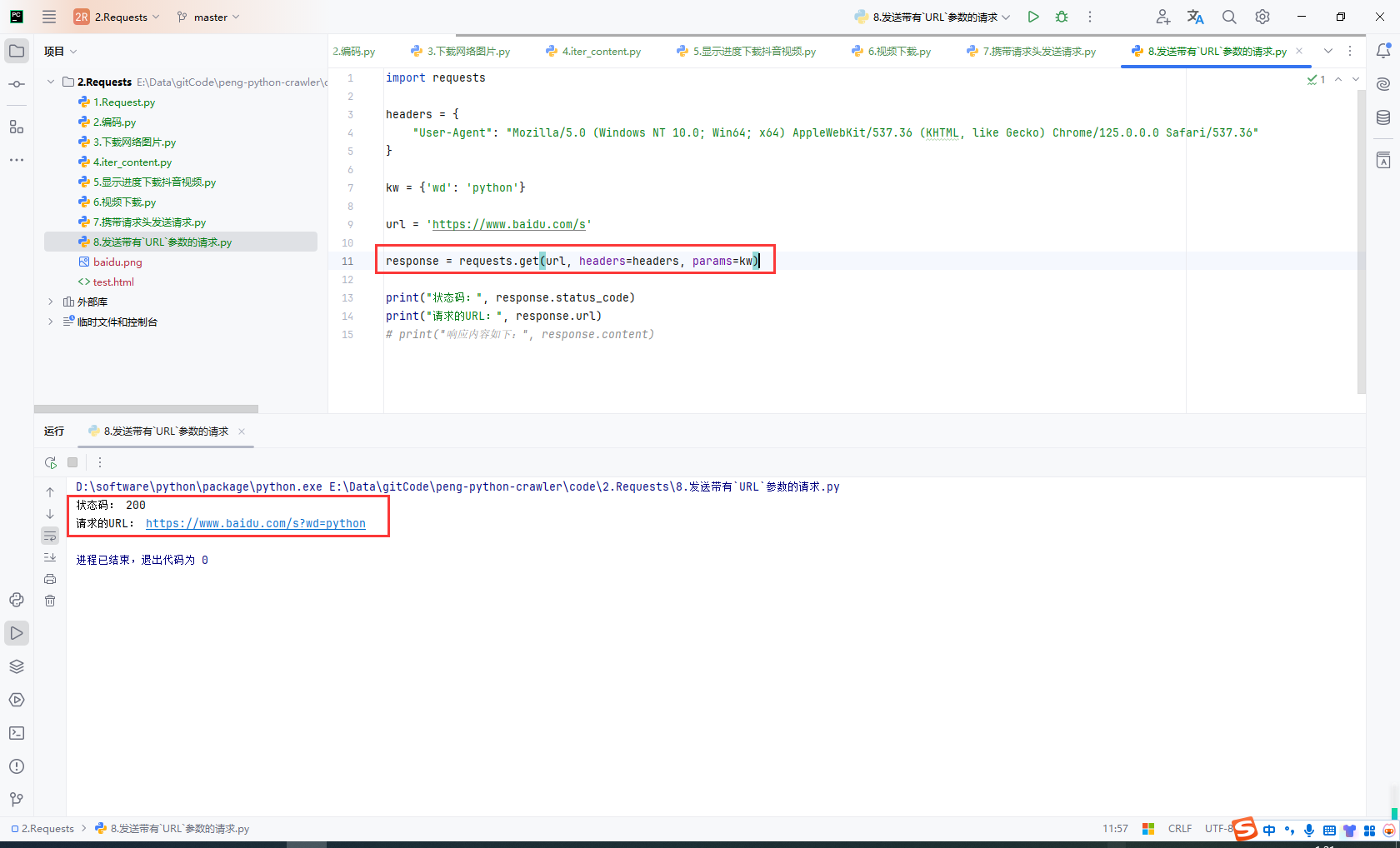
10.带有URL参数的请求
我们使用百度搜索的时候发现请求地址中带有搜索的关键字,比如这里是python,地址栏上有https://www.baidu.com/s?wd=python
https://www.baidu.com/s?wd=python&rsv_spt=1&rsv_iqid=0x9aea423800793a45&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=7&rsv_sug1=5&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=1301&rsv_sug4=1936

当前查询字符串参数可以直接写到url地址中:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
}
kw = {'wd': 'python'}
url = 'https://www.baidu.com/s'
response = requests.get(url, headers=headers, params=kw)
print("状态码:", response.status_code)
print("请求的URL:", response.url)
# print("响应内容如下:", response.content)
11.豆瓣电影Top250-获取请求头
豆瓣地址:https://movie.douban.com/top250
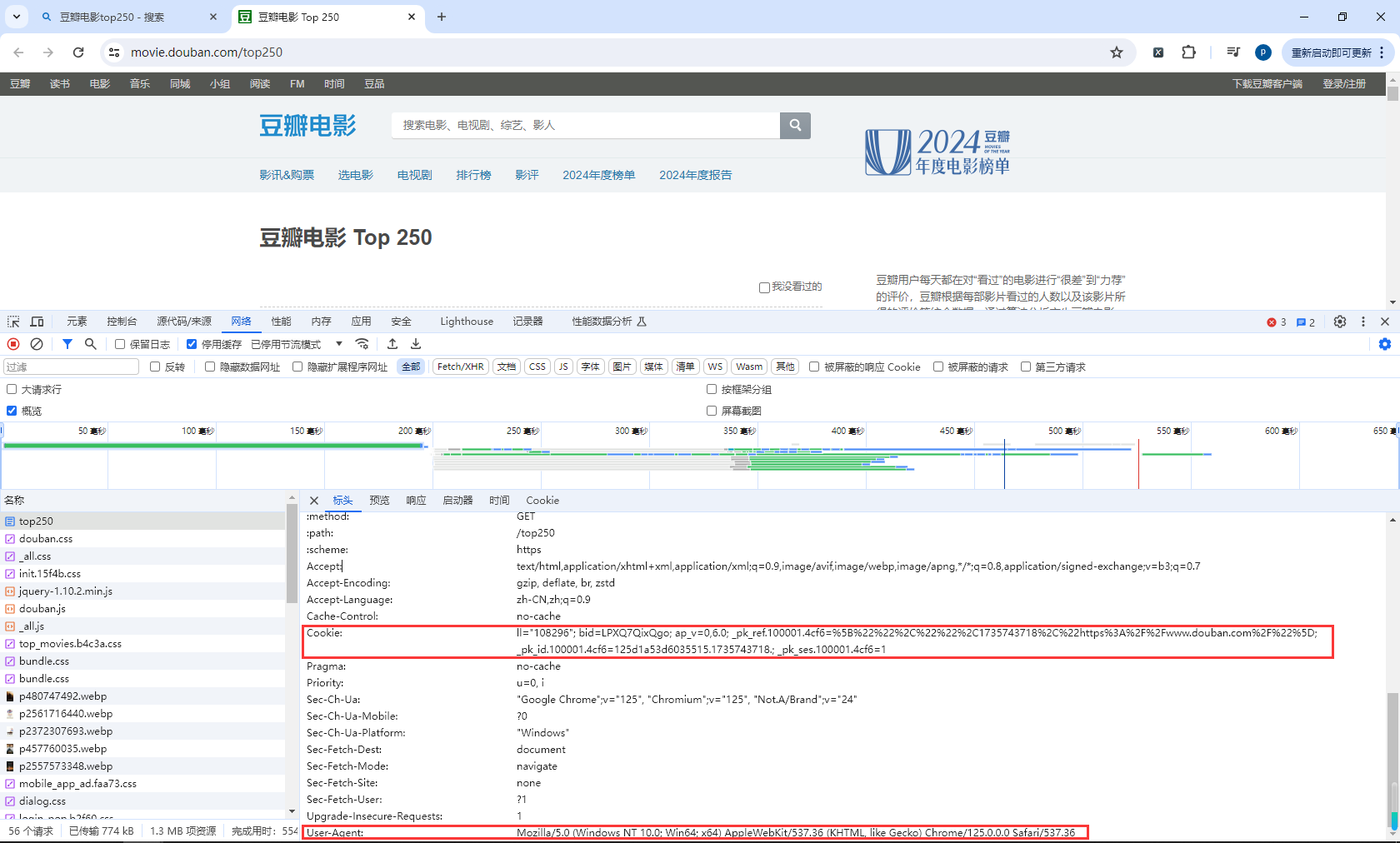
代码
import requests
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
"Cookie": 'll="108296"; bid=LPXQ7QixQgo; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1735743718%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_id.100001.4cf6=125d1a53d6035515.1735743718.; _pk_ses.100001.4cf6=1'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url, headers=headers)
# 获取请求头
# response.request.cookies 错误的
print(response.request.headers.get('Cookie'))
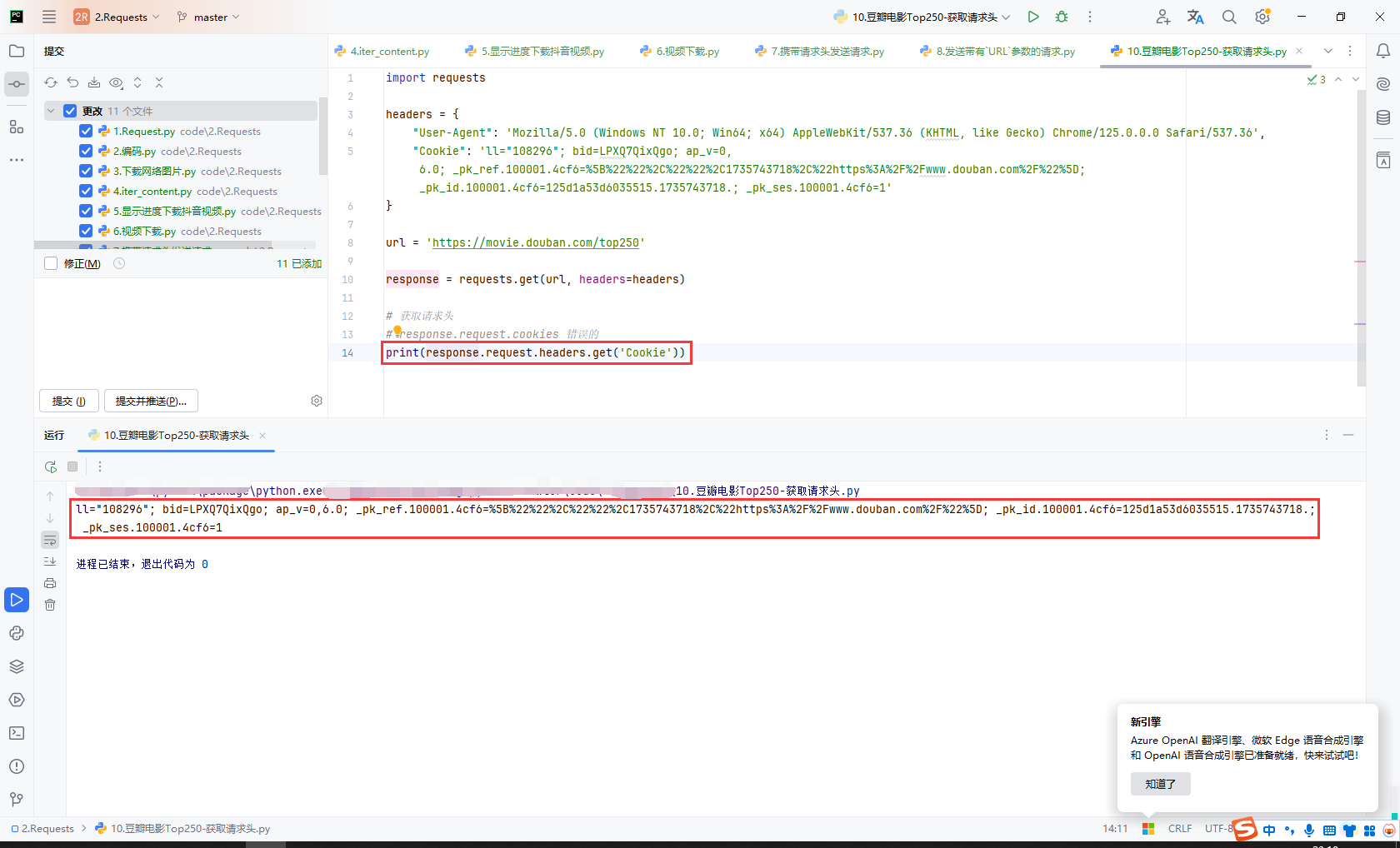
12.巨潮资讯网-POST请求
巨潮资源网地址:http://www.cninfo.com.cn/new/index.jsp
我们发现首页请求是Get查询
右侧有条件查询,点击查询吗,进入查询页面
查看请求地址
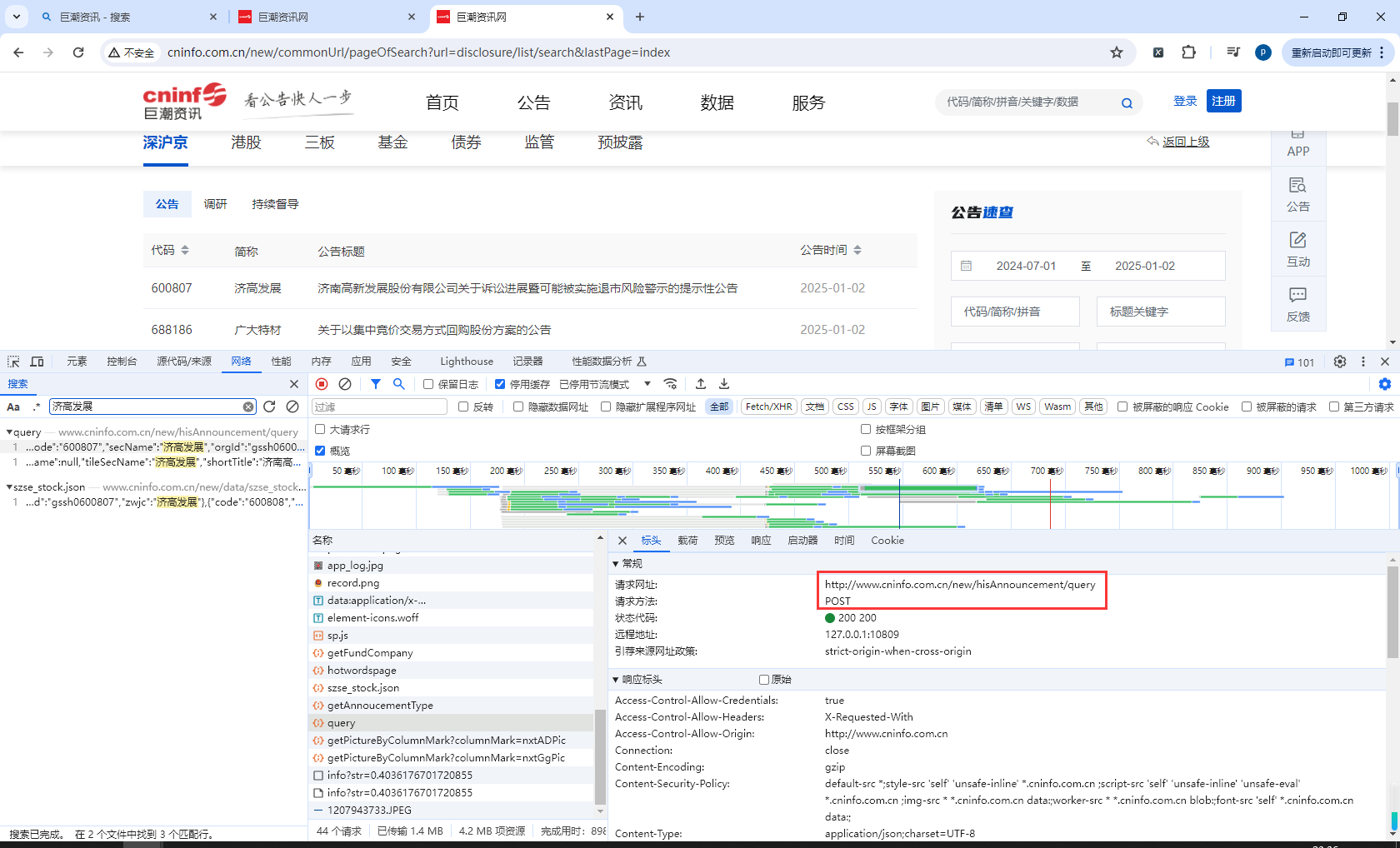
查看请求参数
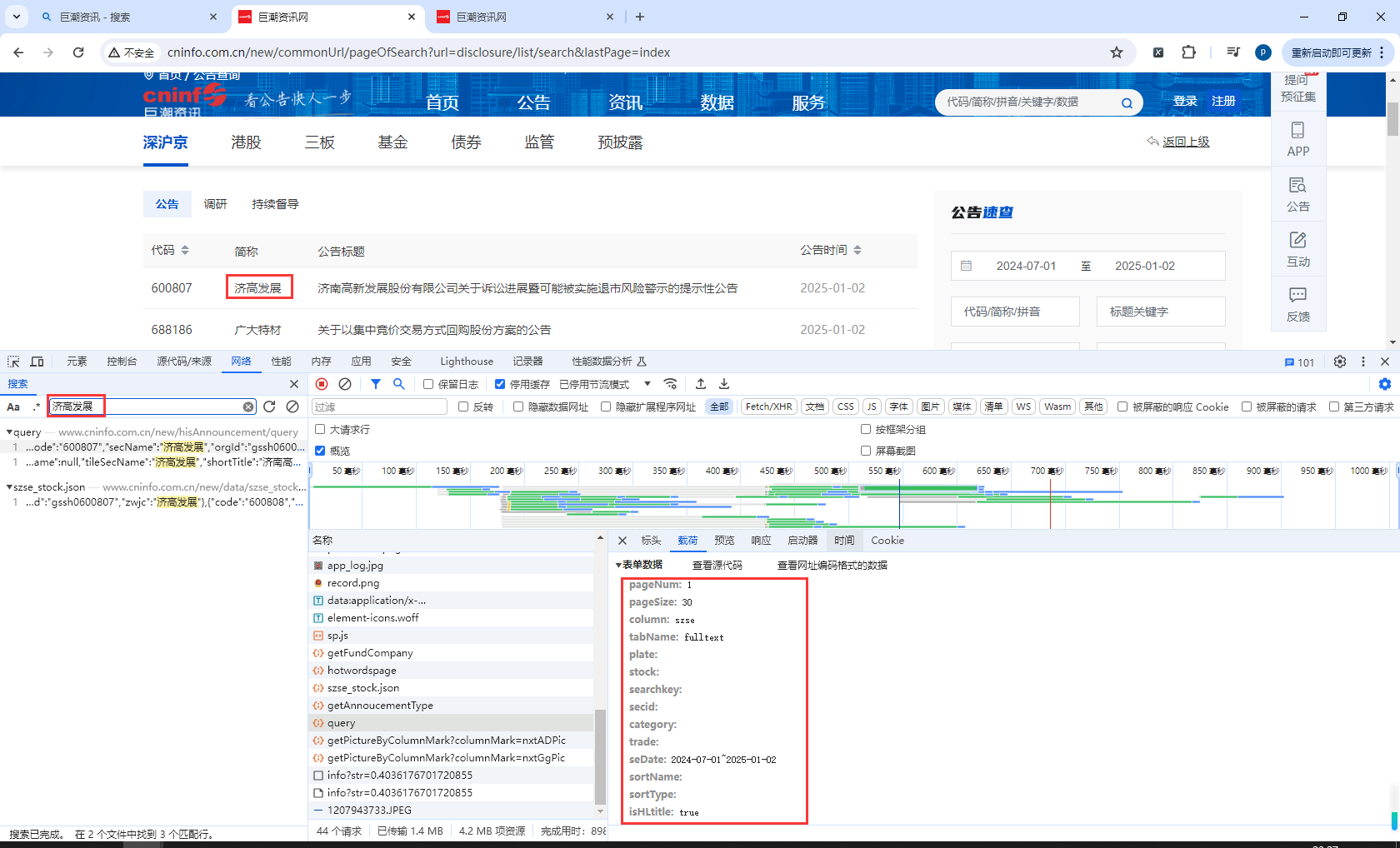
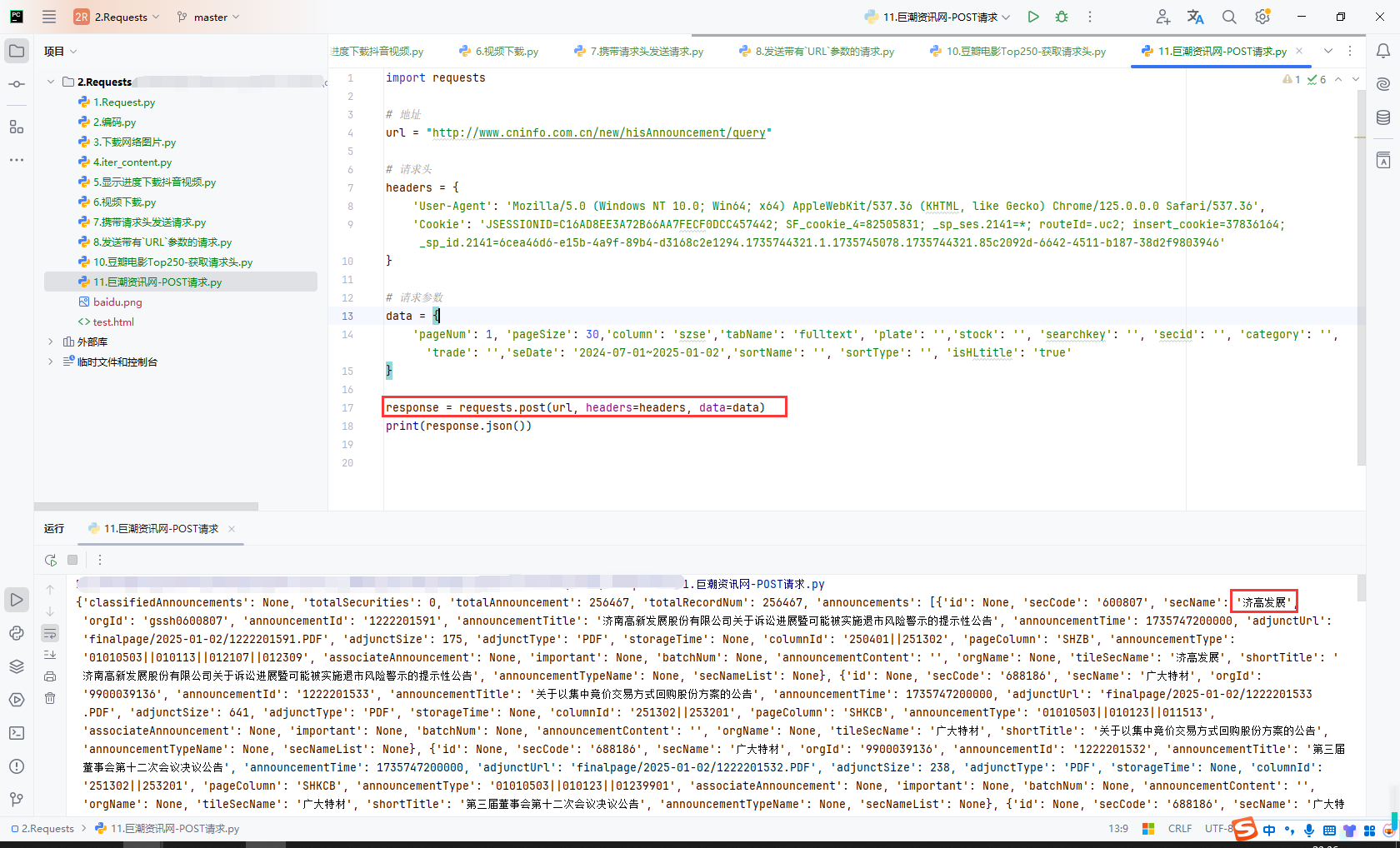
实现
import requests
# 地址
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
'Cookie': 'JSESSIONID=C16AD8EE3A72B66AA7FECF0DCC457442; SF_cookie_4=82505831; _sp_ses.2141=*; routeId=.uc2; insert_cookie=37836164; _sp_id.2141=6cea46d6-e15b-4a9f-89b4-d3168c2e1294.1735744321.1.1735745078.1735744321.85c2092d-6642-4511-b187-38d2f9803946'
}
# 请求参数
data = {
'pageNum': 1, 'pageSize': 30,'column': 'szse','tabName': 'fulltext', 'plate': '','stock': '', 'searchkey': '', 'secid': '', 'category': '', 'trade': '','seDate': '2024-07-01~2025-01-02','sortName': '', 'sortType': '', 'isHLtitle': 'true'
}
response = requests.post(url, headers=headers, data=data)
print(response.json())
13.百度翻译
百度PC端接口
不要使用PC端,使用移动端,PC端接口访问不通
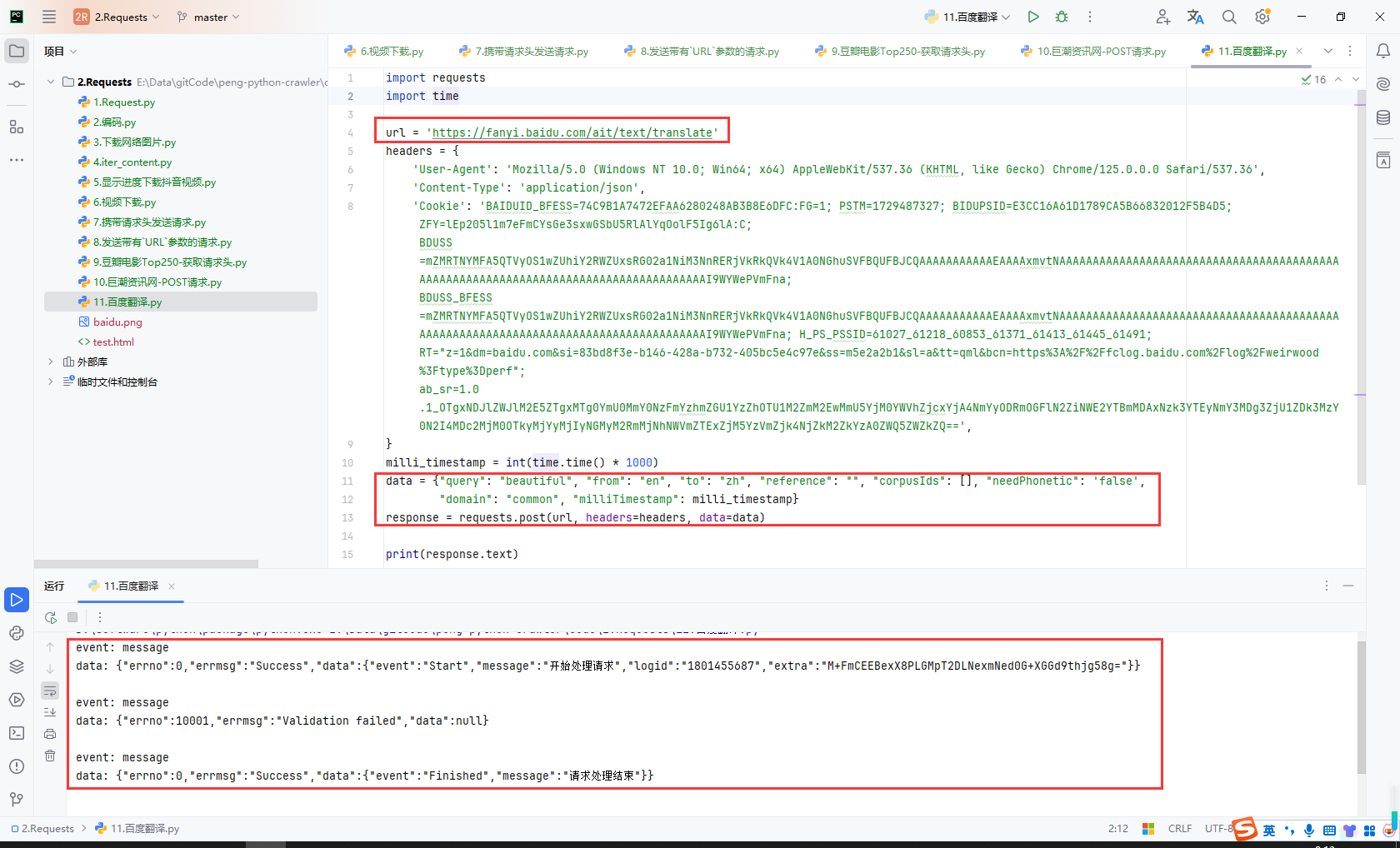
调试PC端接口
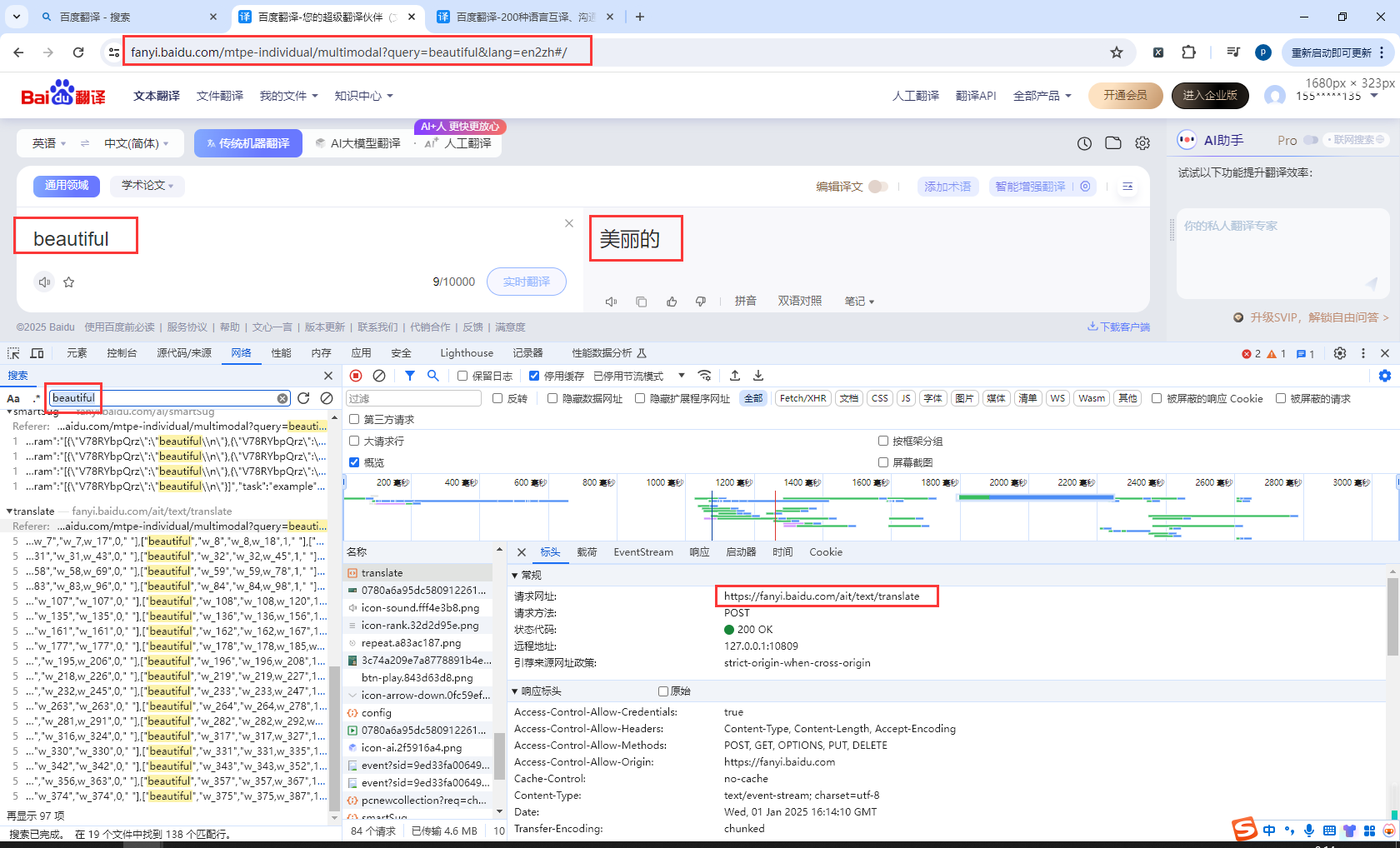
模拟请求百度PC端翻译接口,验证失败
百度移动端接口
- 把浏览器设置成移动端界面
- 需要获取接口的地址
User-Agent、Cookie参数 - 每个单词不同,
sign参数值不同,这里是固定的,所以暂时没法动态查询翻译接口(js逆向解决)

代码
import requests
url = 'https://fanyi.baidu.com/basetrans'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Mobile Safari/537.36',
'Cookie': 'BAIDUID_BFESS=74C9B1A7472EFAA6280248AB3B8E6DFC:FG=1; PSTM=1729487327; BIDUPSID=E3CC16A61D1789CA5B66832012F5B4D5; ZFY=lEp205l1m7eFmCYsGe3sxwGSbU5RlAlYqOolF5Ig6lA:C; BDUSS=mZMRTNYMFA5QTVyOS1wZUhiY2RWZUxsRG02a1NiM3NnRERjVkRkQVk4V1A0NGhuSVFBQUFBJCQAAAAAAAAAAAEAAAAxmvtNAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI9WYWePVmFna; BDUSS_BFESS=mZMRTNYMFA5QTVyOS1wZUhiY2RWZUxsRG02a1NiM3NnRERjVkRkQVk4V1A0NGhuSVFBQUFBJCQAAAAAAAAAAAEAAAAxmvtNAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAI9WYWePVmFna; H_PS_PSSID=61027_61218_60853_61371_61413_61445_61491; RT="z=1&dm=baidu.com&si=83bd8f3e-b146-428a-b732-405bc5e4c97e&ss=m5e2a2b1&sl=d&tt=yc7&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&r=1gi9v57sl&ul=12v5j&hd=12vvm"; ab_sr=1.0.1_MWRhZDFiNmM4Njg4MjYzOTdkMWZjYWY3OGE3YTZhY2M1ODMwYzE1ZDcxMTUyZmJhN2EyNzg5ZjMzNWJjMDM3NGZiNmY1NjRmZWYxYzU0ZDliYjZmNGNiYjQ0NTJjNzNjODUyMzRjNzk4NmQ5NTc5ZmNhODkwZWIxZTVkZTZmYjFmOTJhYmE5YTYwOGEyYmQ5MTdkMjMxNmE2MzIxOWI1ZGE3ZTI1YjE4MmFjZTQ2NTg5NDI0N2Q4MzEwODcwNzll',
}
data = {'query': 'beautiful','from': 'en', 'to': 'zh', 'token': 'c9befe93b56b60b978d4016119b83caf', 'sign': 395688.191129}
response = requests.post(url, headers=headers, data=data).json()
print(response['trans'][0]['dst'])
print(response)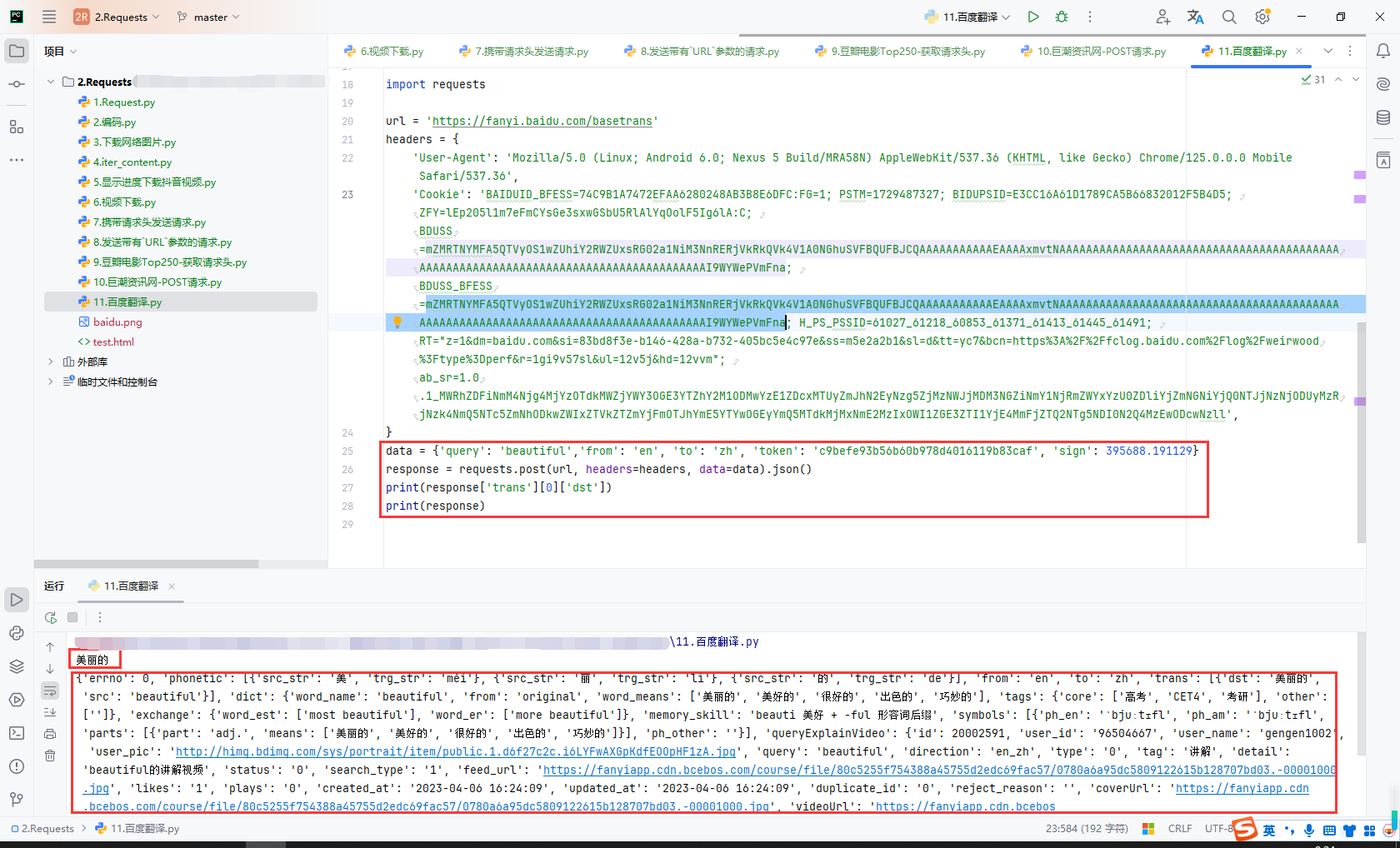
14.Cookie
爬虫中使用cookie的利弊:
优点:
- 访问受保护的内容:某些网站的内容对未登录用户不可见,使用 Cookie 可以模拟已登录用户访问这些内容。
- 提高效率:利用已有的会话信息避免重复登录,可以减少不必要的登录操作和网络请求。
- 个性化数据爬取:Cookie 保存了用户偏好、语言设置等信息,可以爬取与特定用户相关的个性化内容。
- 模拟真实用户行为:带 Cookie 的请求更接近真实用户操作,可能更难被反爬机制察觉。
缺点:
- Cookie 有效期问题:Cookie 通常有时效性,过期后需要重新获取有效的 Cookie。
- 涉及隐私和法律问题:爬取带有 Cookie 的内容可能涉及用户隐私或违反网站的使用条款,需要特别注意法律和道德问题。
- 反爬检测:许多网站会监测 Cookie 使用是否异常,例如同一 Cookie 是否过于频繁使用,导致 IP 或账户被封禁。
- 依赖性强:如果网站更新了验证机制或修改了 Cookie 的生成方式,爬虫可能无法正常工作,需要重新调整。
- 技术复杂性:需要管理 Cookie 的获取、更新和持久化,增加了开发和维护成本。
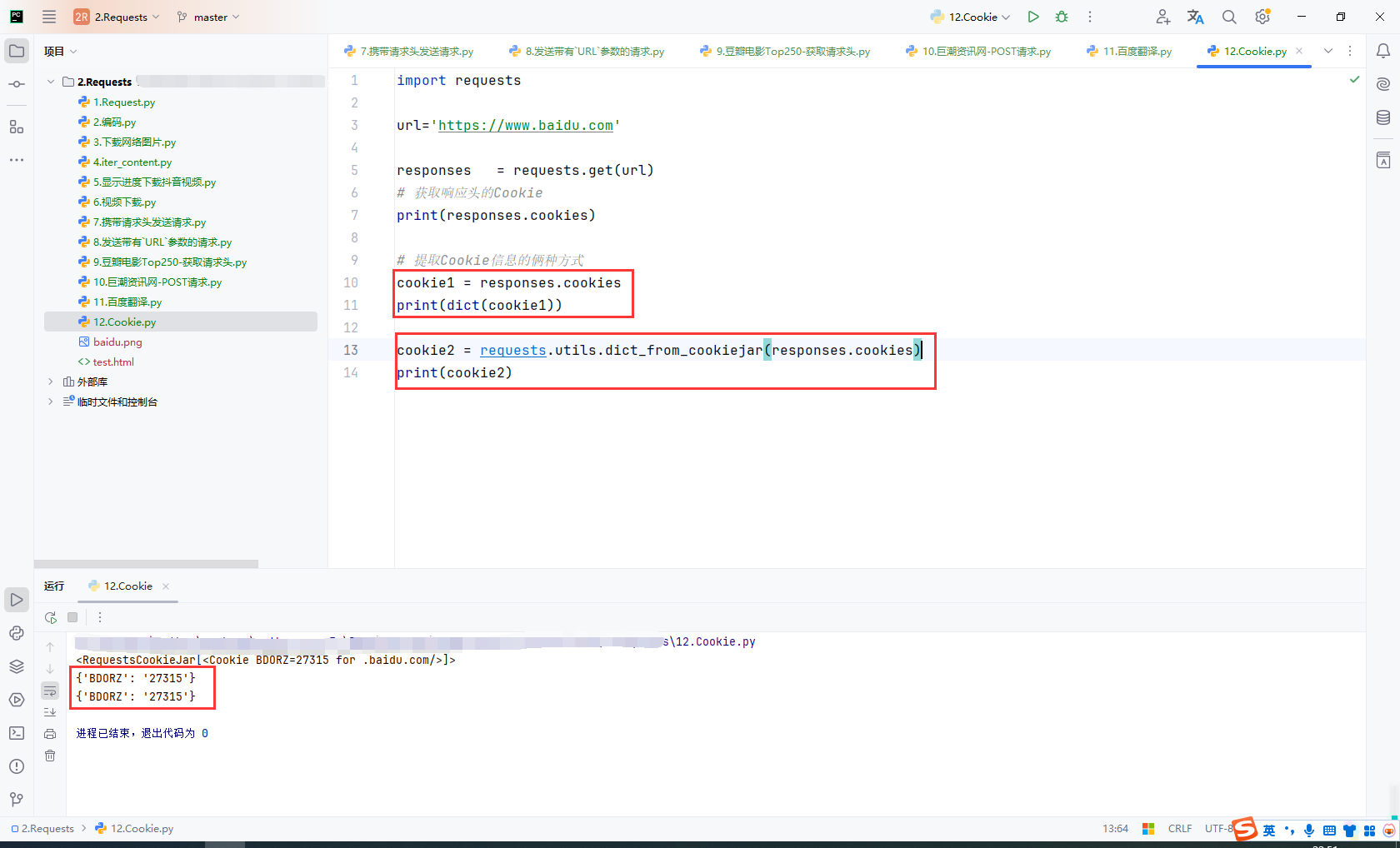
获取响应头的Cookie:
import requests
url='https://www.baidu.com'
responses = requests.get(url)
# 获取响应头的Cookie
print(responses.cookies)
# 提取Cookie信息的俩种方式
cookie1 = responses.cookies
print(dict(cookie1))
cookie2 = requests.utils.dict_from_cookiejar(responses.cookies)
print(cookie2)
15.重定向
重定向的状态码
-
301 和 308:永久重定向,适用于资源长期迁移或重命名。
-
302 和 307:临时重定向,适用于临时变更或维护。
-
303:用于 POST 请求后的重定向,避免表单重复提交。
-
304:用于缓存控制,客户端可以使用缓存资源。
-
305:已被弃用,不推荐使用。
重定向
www.360buy.com 是京东早期的域名,之所以会跳转到京东的主域名 www.jd.com,主要是因为京东在发展过程中进行了品牌升级和域名优化。
京东实现跳转的方式是通过 HTTP 301 重定向。这可以通过以下方法实现:
- DNS 设置:将
360buy.com的访问请求指向主站服务器。 - 服务器配置:在服务器(如 Nginx 或 Apache)中配置重定向规则,将所有访问
360buy.com的请求转发到jd.com。
server {
server_name www.360buy.com;
return 301 https://www.jd.com$request_uri;
}
代码
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
r = requests.get("http://www.360buy.com")
print(r.url)
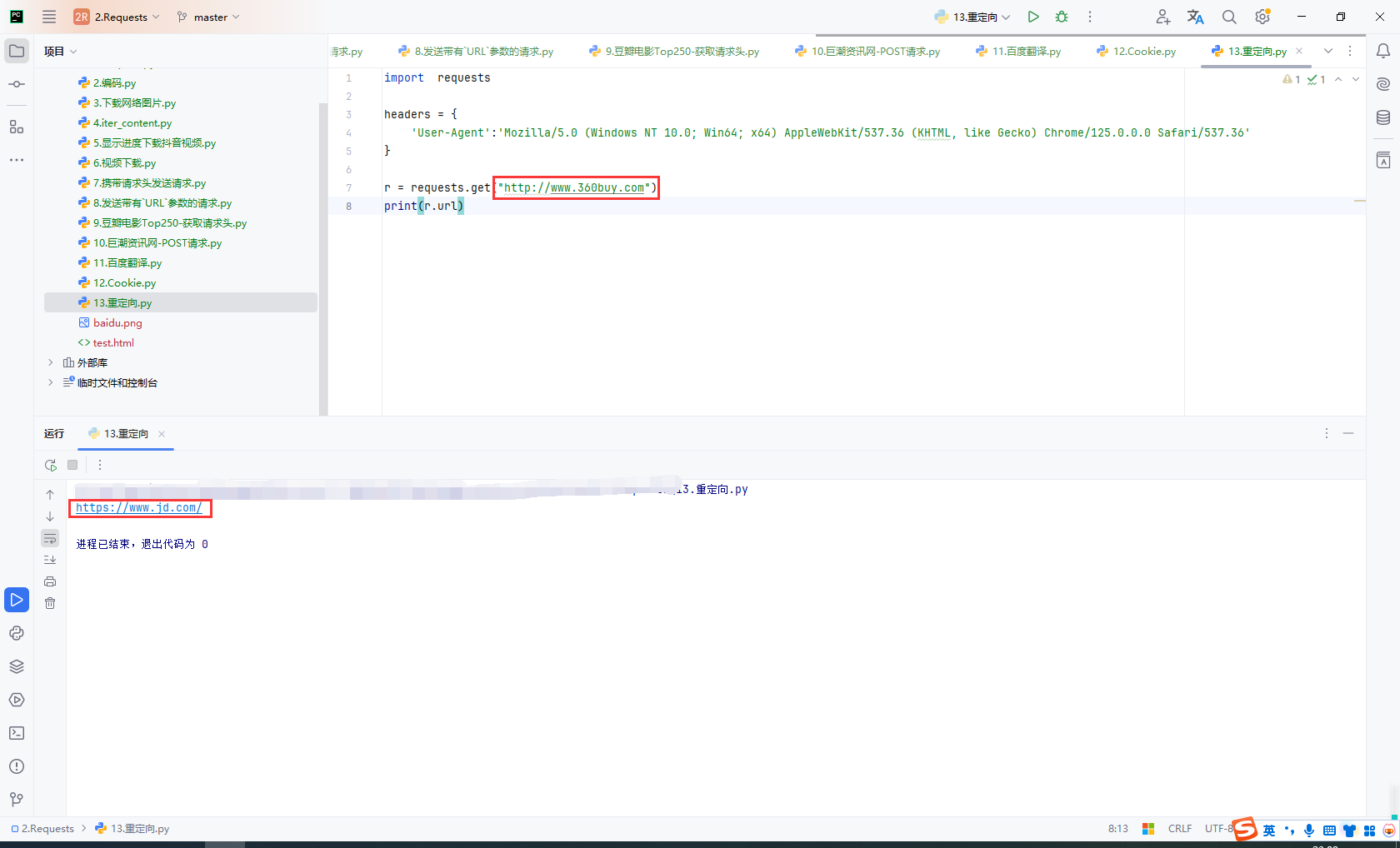
取消重定向:allow_redirects
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
# r = requests.get("http://www.360buy.com")
r = requests.get("http://www.360buy.com", allow_redirects=False)
print(r.url)
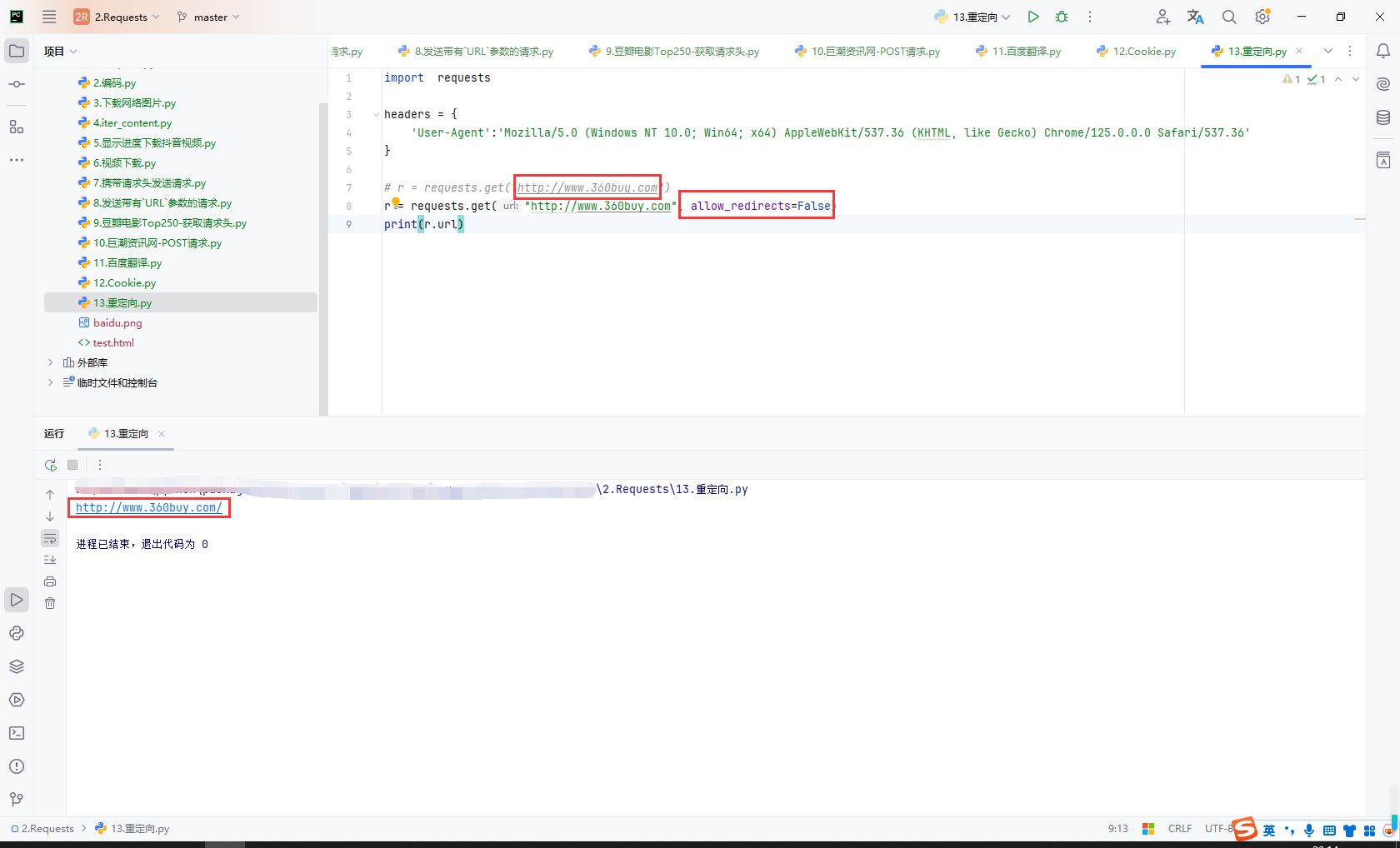
历史请求
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
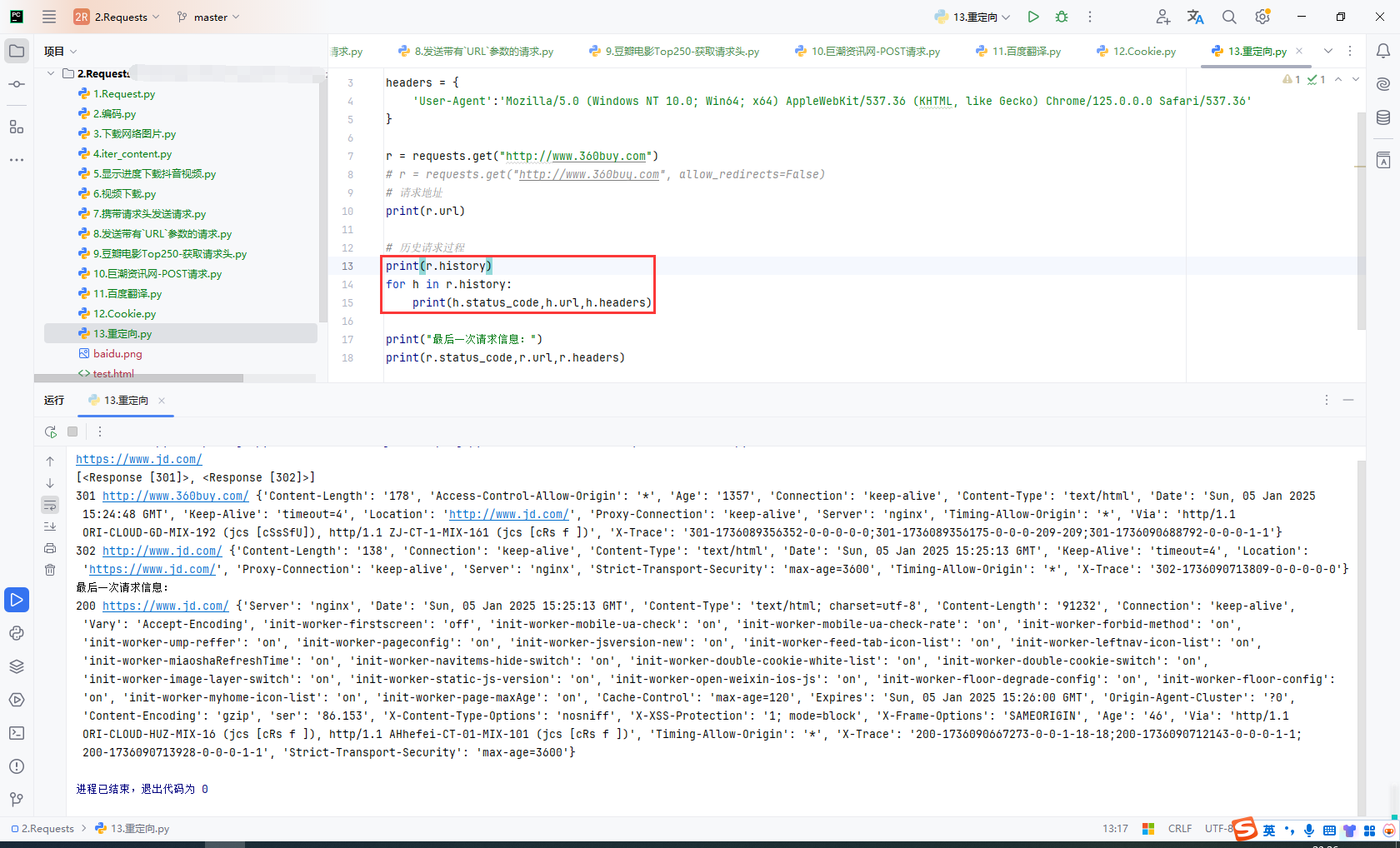
r = requests.get("http://www.360buy.com")
# r = requests.get("http://www.360buy.com", allow_redirects=False)
# 请求地址
print(r.url)
# 历史请求过程
print(r.history)
for h in r.history:
print(h.status_code,h.url,h.headers)
print("最后一次请求信息:")
print(r.status_code,r.url,r.headers)
16.SSL
在浏览网页时,可能遇到以下情况
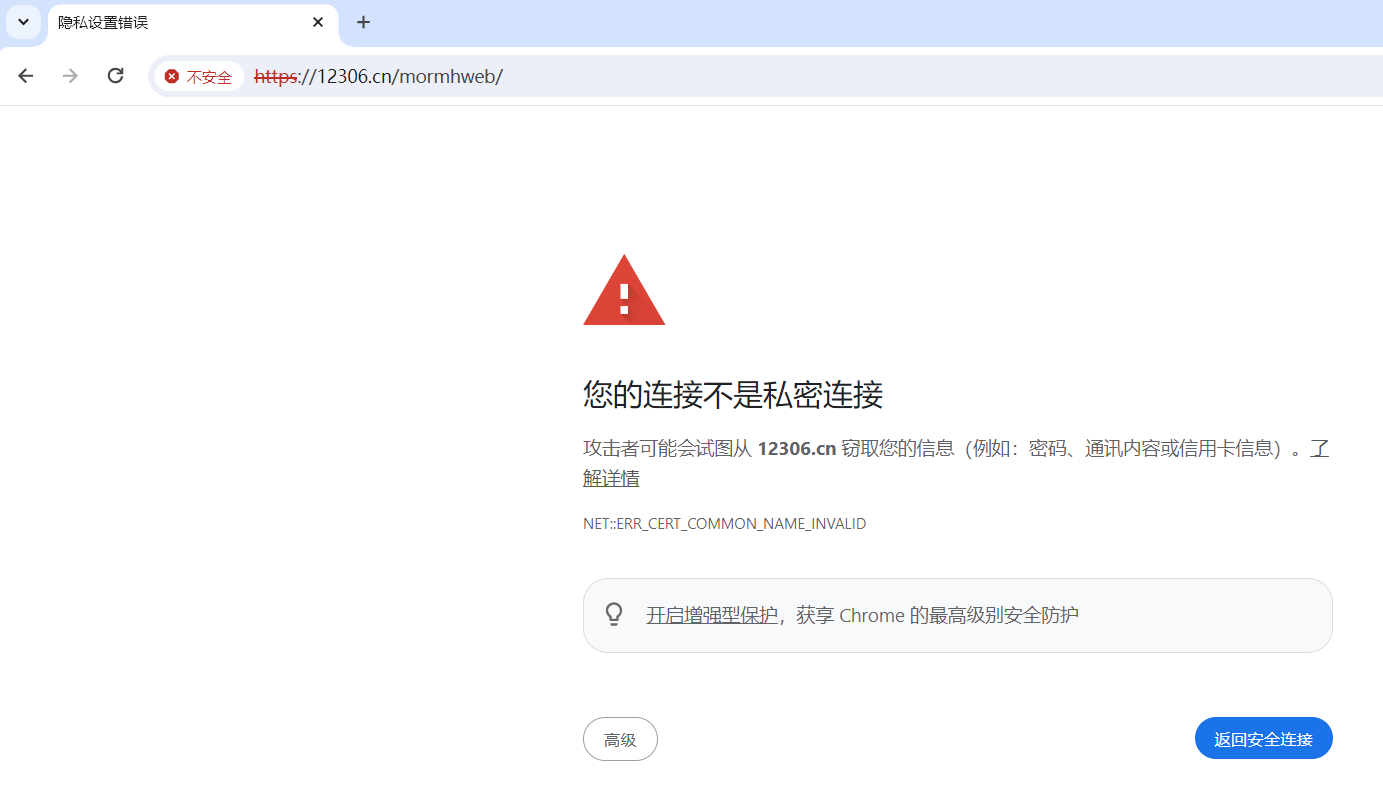
出现这个问题的原因是:ssl的证书不安全导致。
解决方案
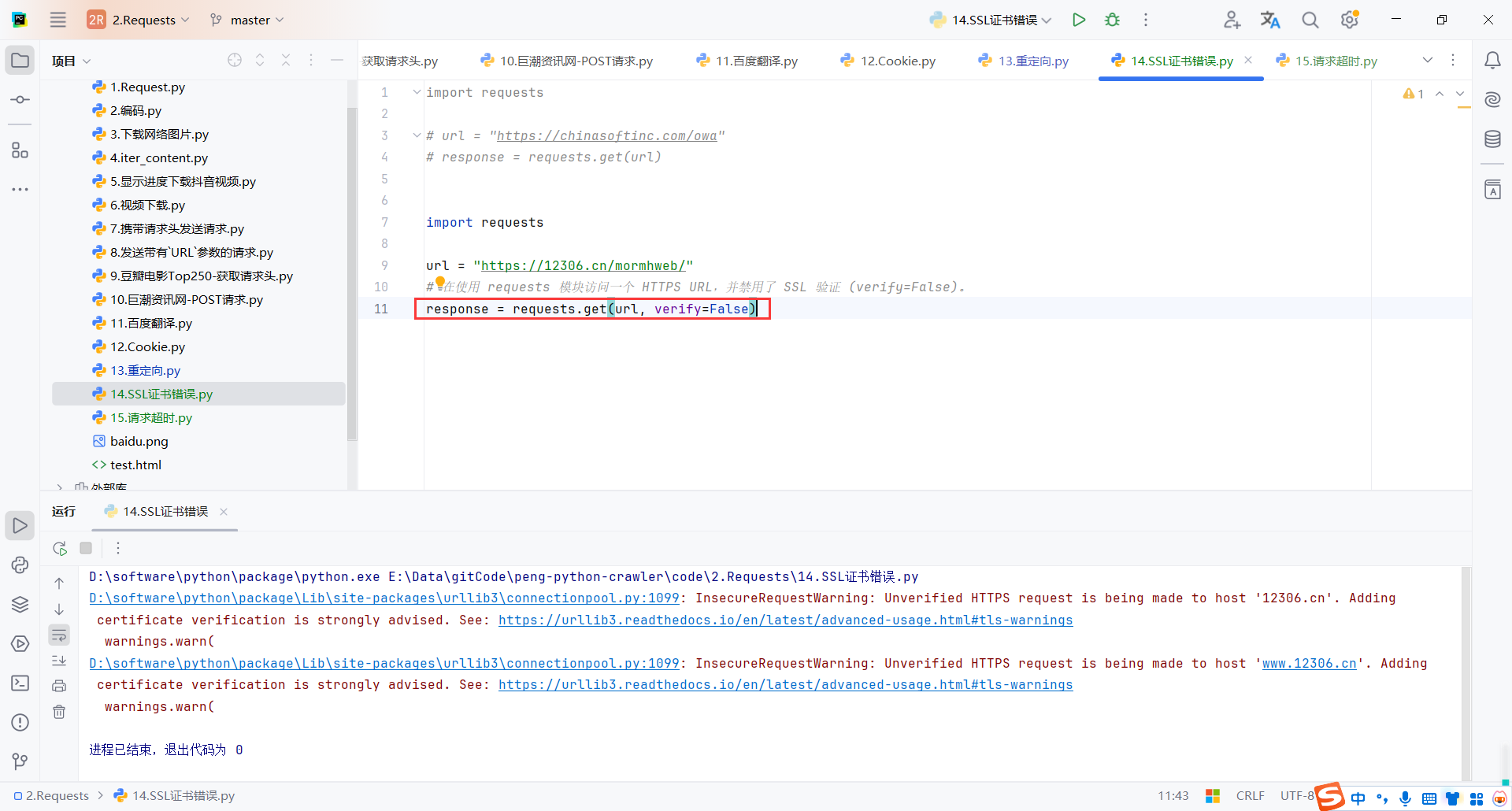
在使用 requests 模块访问一个 HTTPS URL,并禁用了 SSL 验证 (verify=False)。
import requests
url = "https://12306.cn/mormhweb/"
response = requests.get(url, verify=False)
17.请求超时
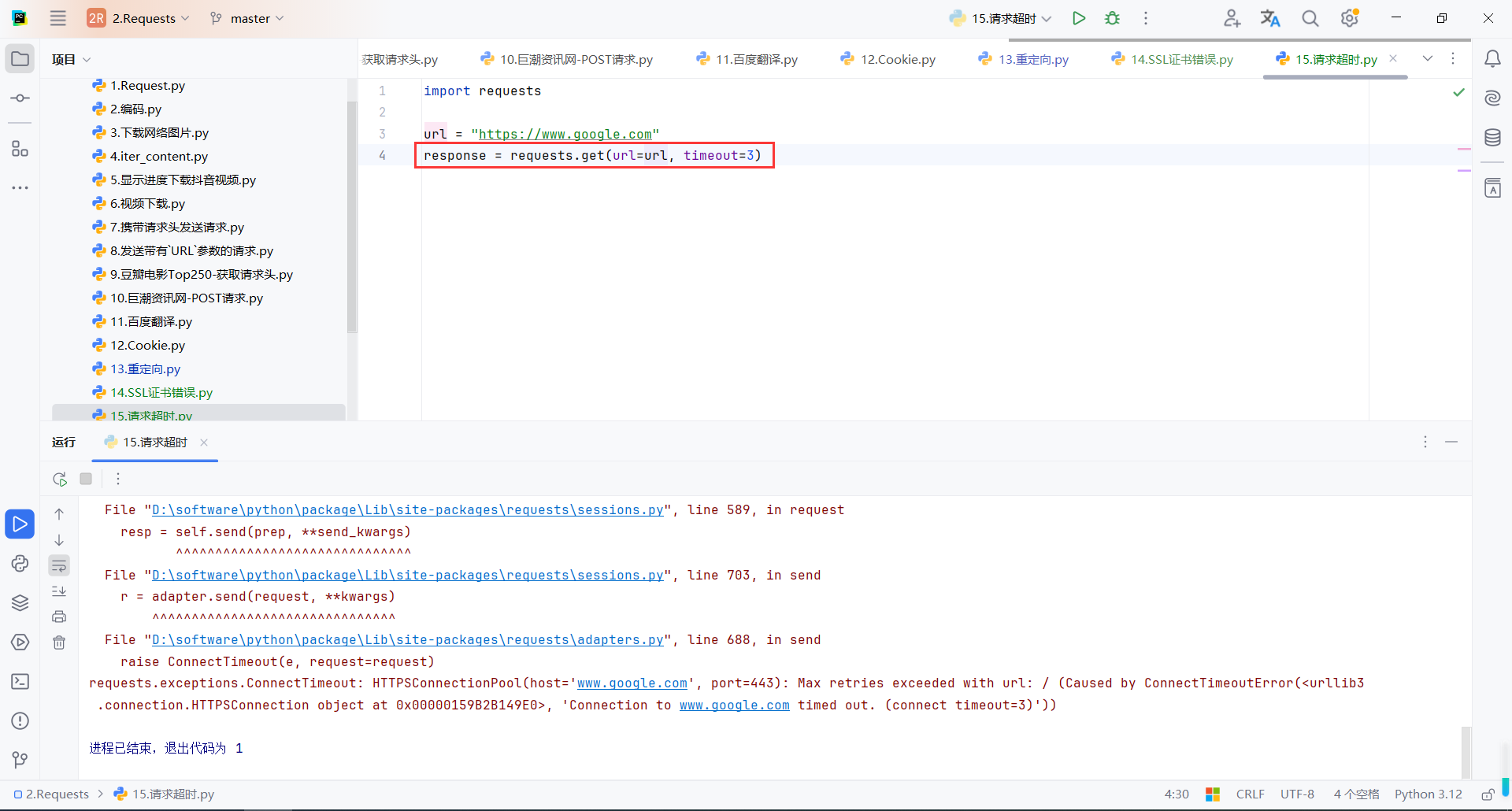
timeout=3:设置了请求的超时时间为 3 秒。如果服务器未能在 3 秒内响应,程序会抛出 requests.exceptions.ConnectTimeout 异常
import requests
url = "https://www.google.com"
response = requests.get(url=url, timeout=3)
18.retrying模块
retrying
地址:https://pypi.org/project/retrying/
安装retrying
pip install retrying
事例
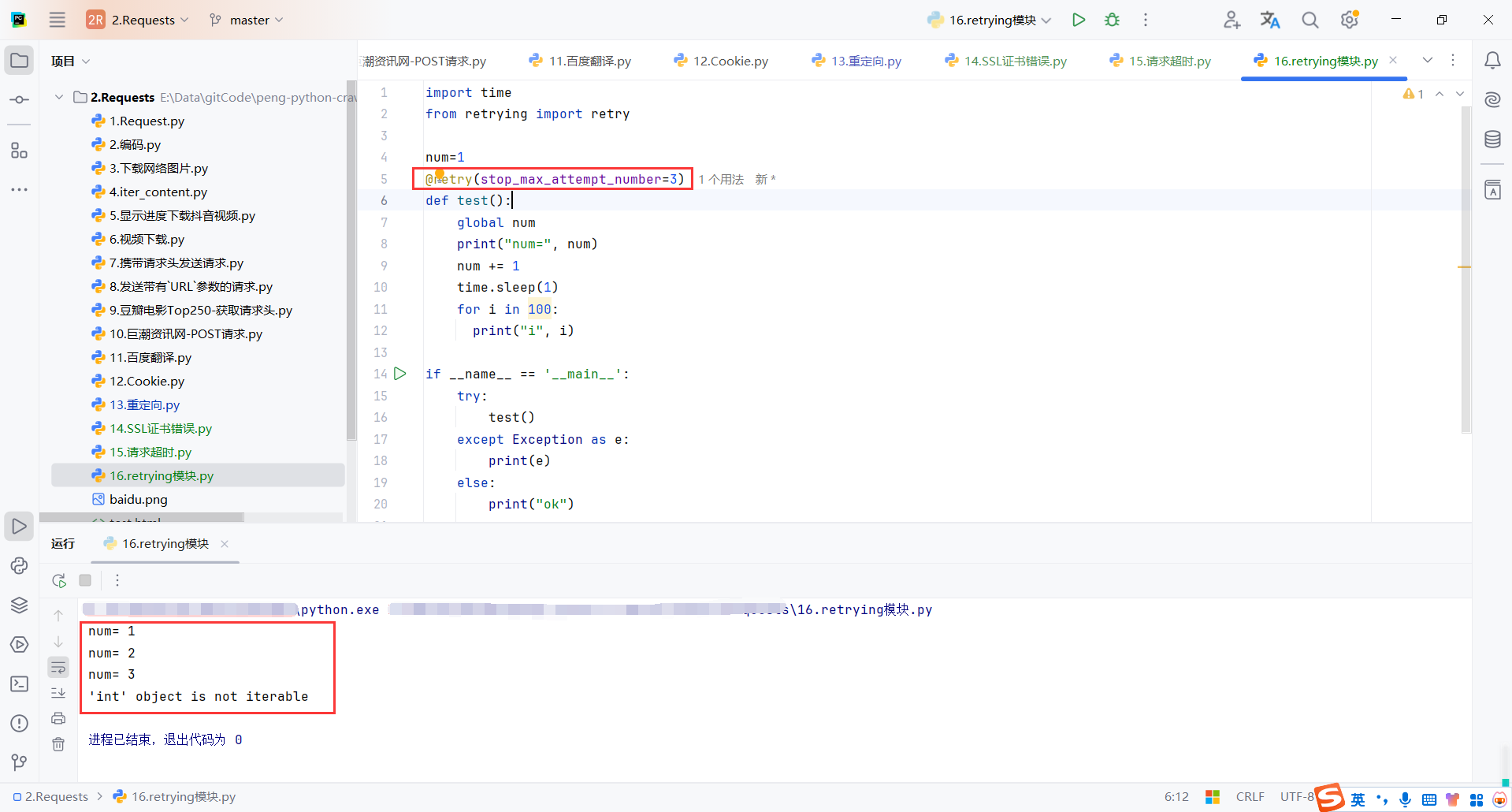
100不能被遍历,所以会报错,但是使用@retry(stop_max_attempt_number=3)会重试3次,全局num最后是3
import time
from retrying import retry
num=1
@retry(stop_max_attempt_number=3)
def test():
global num
print("num=", num)
num += 1
time.sleep(1)
for i in 100:
print("i", i)
if __name__ == '__main__':
try:
test()
except Exception as e:
print(e)
else:
print("ok")
retrying和timeout案例
- 全局变量
num: 用于记录请求尝试的次数,在_parse_url方法中打印重试次数。 - 装饰器
@retry:stop_max_attempt_number=3在函数_parse_url失败后最多重试 3 次(包含初始调用)。 - 设置超时时间
timeout=3。
import requests
from retrying import retry
num = 1
@retry(stop_max_attempt_number=3)
def _parse_url(url):
global num
print("第%d次尝试" % num)
num += 1
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
}
# 超时的时候会报错并重试
response = requests.get(url, headers=headers, timeout=3)
# 状态码不是200,也会报错并重试
assert response.status_code == 200 # 此语句是"断言",如果assert 后面的条件为True则呈现继续运行,否则抛出异常
return response
def parse_url(url):
# 进行异常捕获
try:
response = _parse_url(url)
except Exception as e:
print("产生异常:", e)
# 报错返回None
response = None
return response
if __name__ == '__main__':
url = "https://chinasoftinc.com/owa"
print("----开始----")
r = parse_url(url=url)
print("----结束----", "响应内容为:", r)

19.发送json格式数据
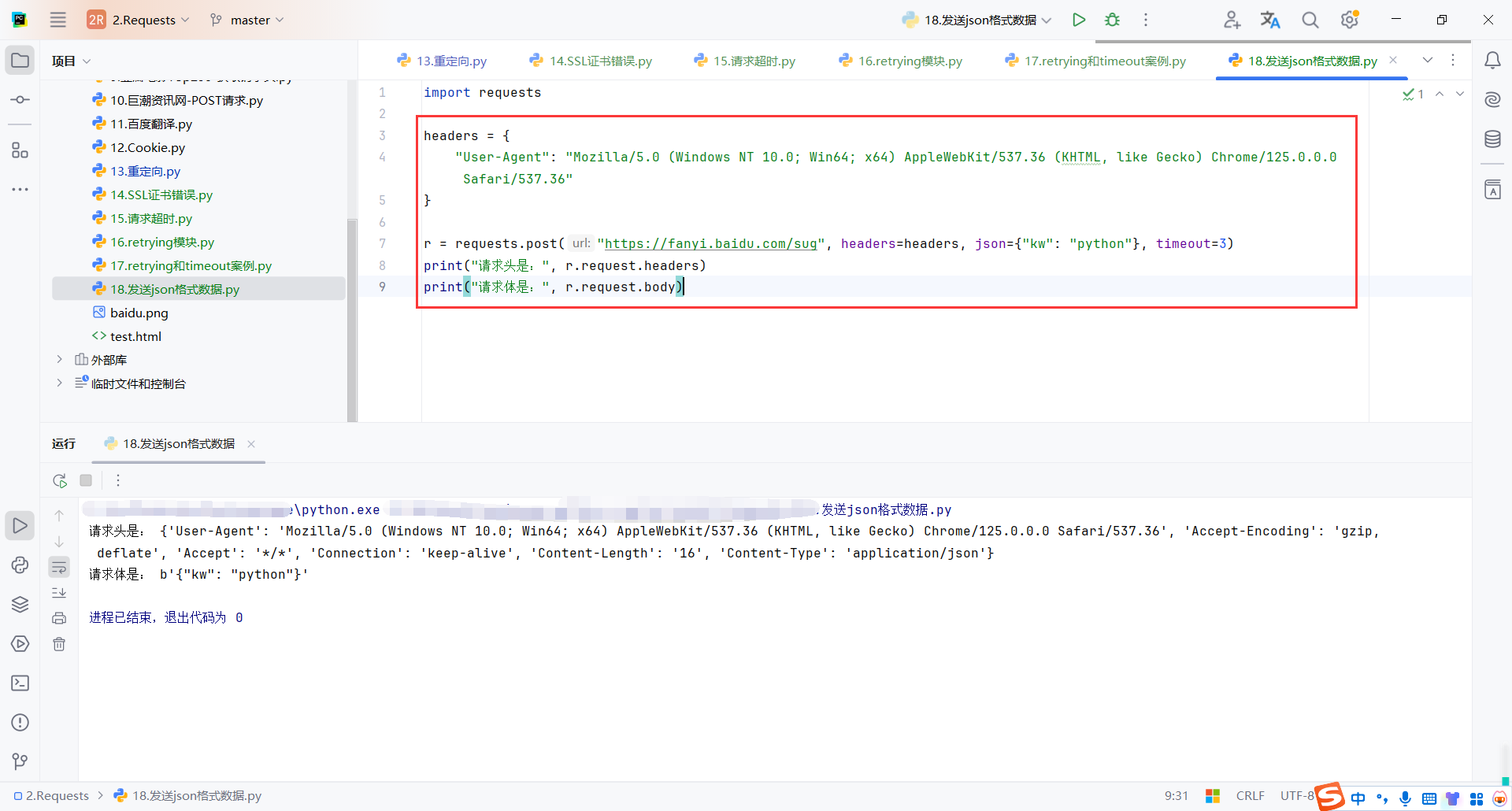
{"kw": "python"} 是发送给服务器的 JSON 数据
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
}
r = requests.post("https://fanyi.baidu.com/sug", headers=headers, json={"kw": "python"}, timeout=3)
print("请求头是:", r.request.headers)
print("请求体是:", r.request.body)
20.session会话
Session会话
当我们在爬取某些页面的时候,服务器往往会需要cookie,而想要得到cookie就需要先访问某个URL进行登录,服务器接收到请求之后验证用户名以及密码在登录成功的情况下会返回一个响应,这个响应的header中一般会有一个set-cookie的信息,它对应的值就是要设置的cookie信息。
虽然我们再之前可以通过requests.utils.dict_from_cookiejar(r.cookies)提取到这个响应信息中设置的新cookie,但在下一个请求中再携带这个数据的过程较为麻烦,所以requests有个高级的方式 - 会话Session
Session的作用
- 保存
cookie,下一次请求会自动带上前一次的cookie - 实现和服务端的长连接,加快请求速度
事例
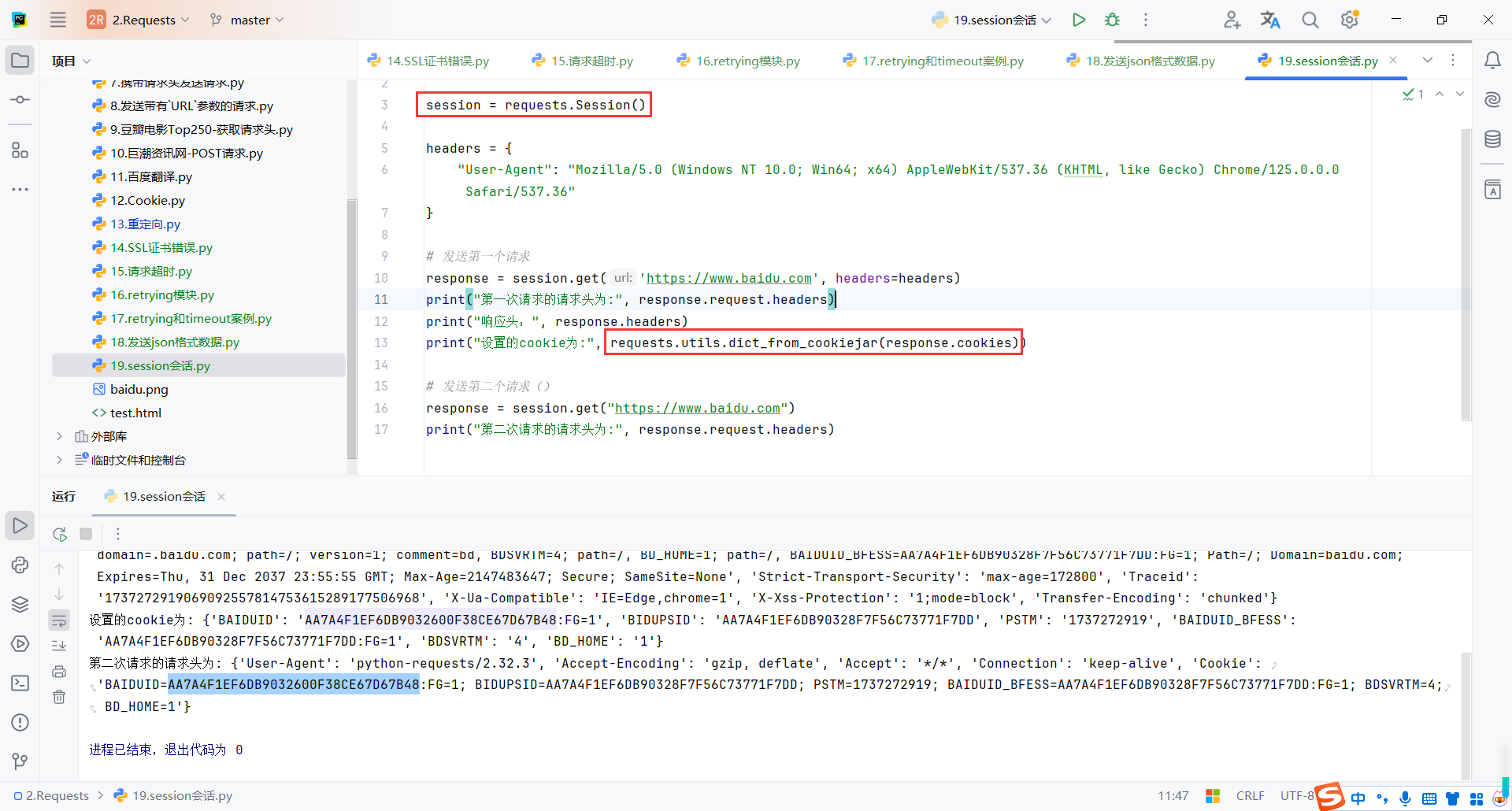
- 携带自定义的
headers,发送到https://www.baidu.com - 响应后,提取
Cookie并存储到session对象中。 - 再次访问
https://www.baidu.com,session会自动附加第一个请求中设置的Cookie。
import requests
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
}
# 发送第一个请求
response = session.get('https://www.baidu.com', headers=headers)
print("第一次请求的请求头为:", response.request.headers)
print("响应头:", response.headers)
print("设置的cookie为:", requests.utils.dict_from_cookiejar(response.cookies))
# 发送第二个请求()
response = session.get("https://www.baidu.com")
print("第二次请求的请求头为:", response.request.headers)
21.代理
为什么使用代理
-
绕过访问限制:访问受地理限制或封锁的网站。
-
隐藏真实 IP:保护隐私,避免泄露用户的真实 IP 地址。
-
突破频率限制:避免因高频请求被封禁,使用代理 IP 轮换。
-
提高安全性:过滤恶意内容,监控和防止攻击。
-
加速访问:通过缓存静态资源提高加载速度。
-
调试与测试:模拟不同地区的访问,捕获网络流量进行分析。
-
负载均衡:分配请求到不同服务器,减轻单点压力。
-
访问内部服务:通过反向代理访问内网服务,提升安全性。
-
合规需求:记录和审计网络访问,满足行业合规要求。
代理基本原理
代理的基本原理是通过一个中间服务器(代理服务器)转发客户端请求和响应,以实现隐匿用户身份、加速访问或安全过滤等功能。代理服务器充当客户端与目标服务器之间的中介,处理请求并将响应返回给客户端。
基本使用
将代理地址与端口配置成字典并使用proxies参数传递
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("https://example.org", proxies=proxies)
如何获取代理
- 使用搜索引擎搜索查询“免费代理ip”,但一般情况下都不太好用
- 付费代理:
事例
http://httpbin.org/ip是一个提供公共 IP 地址信息的 HTTP API,访问此 URL时,服务器会返回一个包含你当前公共 IP 地址的 JSON 格式响应。- 检查自己的代理客户端配置的端口号

- 将本机设置为代理服务器
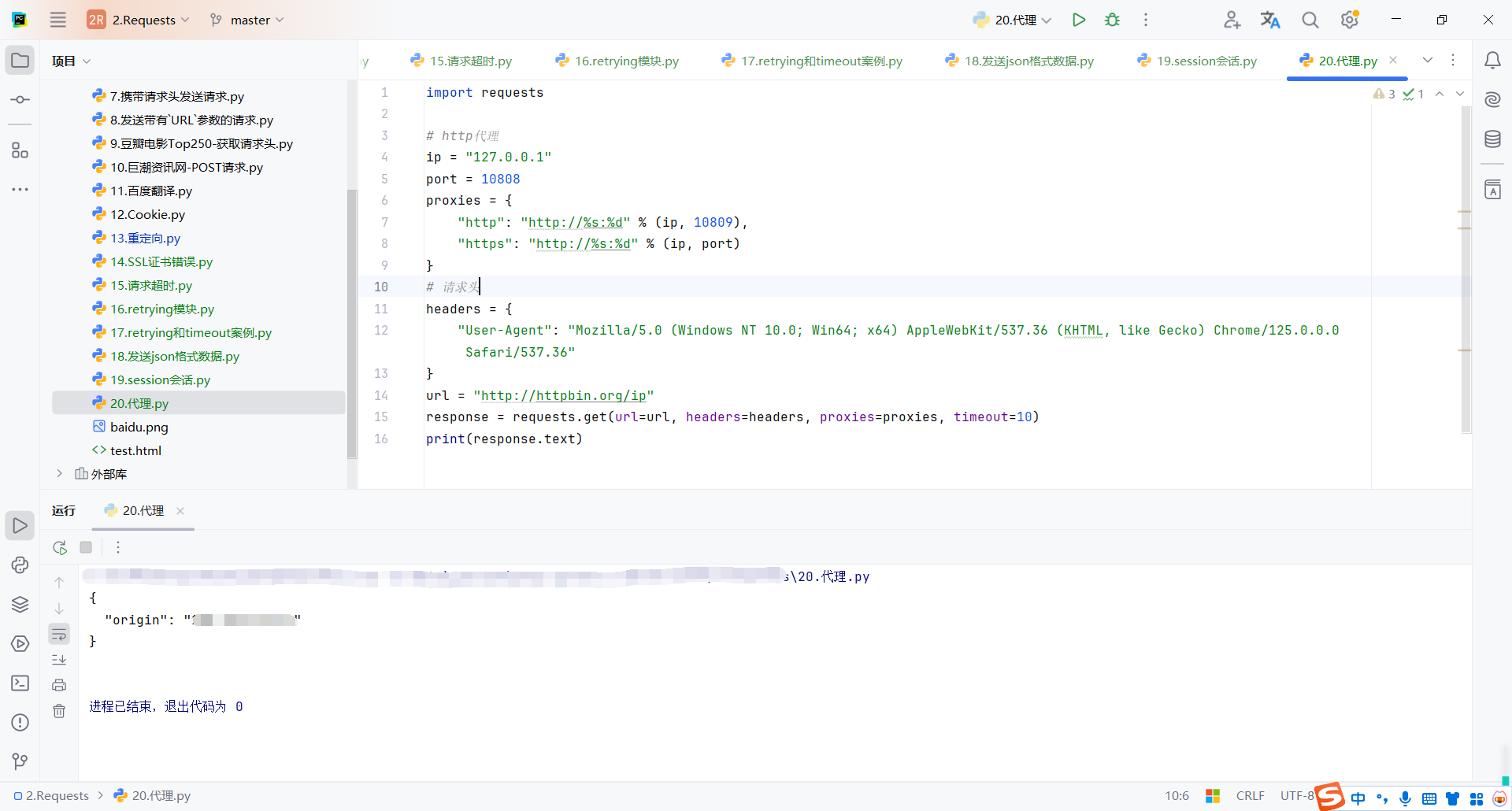
import requests
# http代理
ip = "127.0.0.1"
port = 10808
proxies = {
"http": "http://%s:%d" % (ip, 10809),
"https": "http://%s:%d" % (ip, port)
}
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
}
url = "http://httpbin.org/ip"
response = requests.get(url=url, headers=headers, proxies=proxies, timeout=10)
print(response.text)
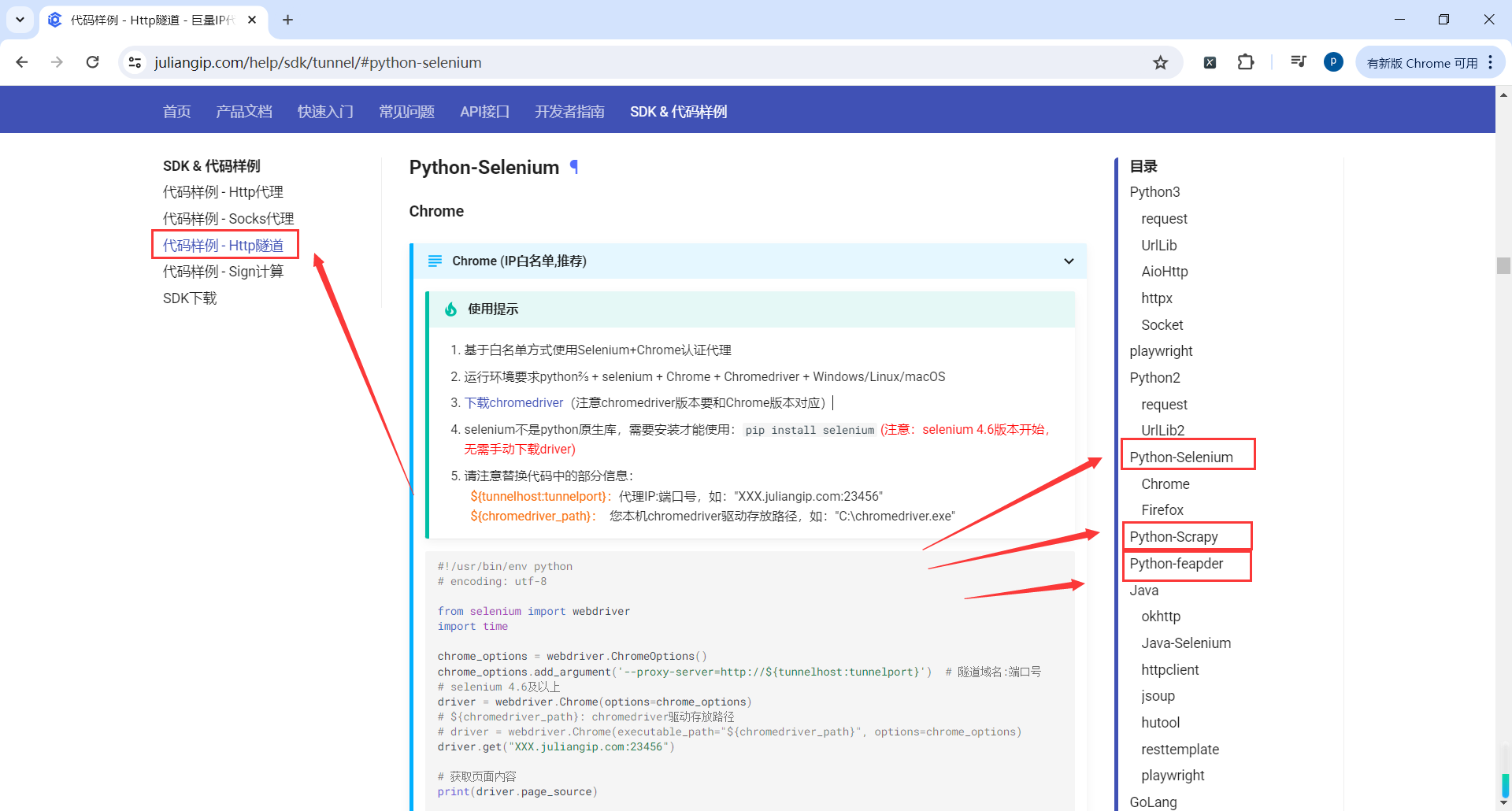
快代理
python文档
地址:https://www.juliangip.com/help/sdk/http/#python3
📌 创作不易,感谢支持!
每一篇内容都凝聚了心血与热情,如果我的内容对您有帮助,欢迎请我喝杯咖啡☕,您的支持是我持续分享的最大动力!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号