

02-k8s部署环境
前言
心有山水不造作,静而不争远是非
7.集群
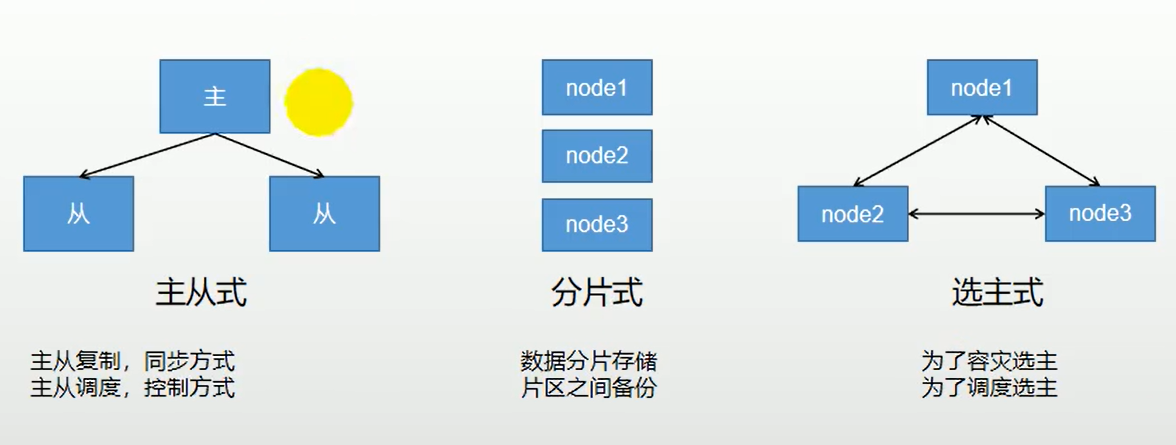
7.1集群常见的基本形式
集群的目标
-
高可用:主机宕机对业务无影响。
- 宕机原因:网卡、路由器、机房、CPU负载过高、内存溢出、自然灾害等不可预期的原因导致,也称单点问题
- 解决方案:【选主式(双主、raft选举)】重新创建主节点
-
单点性能限制:当单点数据量过大导致性能降低,所以需要多台分担共同存储整个集群数据,并且做好互相备份保证即使单点故障,也能在其他节点找到数据
- 解决方案:【分片式(分库分表)】
-
数据备份容灾:单点故障后,存储的数据仍然可以在别的地方拉起
- 解决方案:【主从复制】
-
压力分担:避免单点压力过高,例如单节点几千亿条数据读取很慢,分离操作,各单点完成自己的工作完成整个工作
- 解决方案:【读写分离】
-
主从复制、读写分离可以一起实现
集群的基础形式
- 主从式:
- 主从复制:从节点复制主节点数据,保持一致(mysql)
- 主从调度:所有请求由主节点调度,挑一个从节点响应请求(k8s)
- 分片式:(可以看作有多套主从构成分片)
- 数据分片存储,突破单点限制
- 分片之间互相备份,保证数据不丢失
- 客户端分片:由客户端计算实际请求的分片地址(mycat)
- 服务端分片:由服务端计算实际请求的分片地址(redis)
- 例:订单表,按地区分片,按时间分表
- 选主式:
- 为了容灾选主
- 为了调度选主
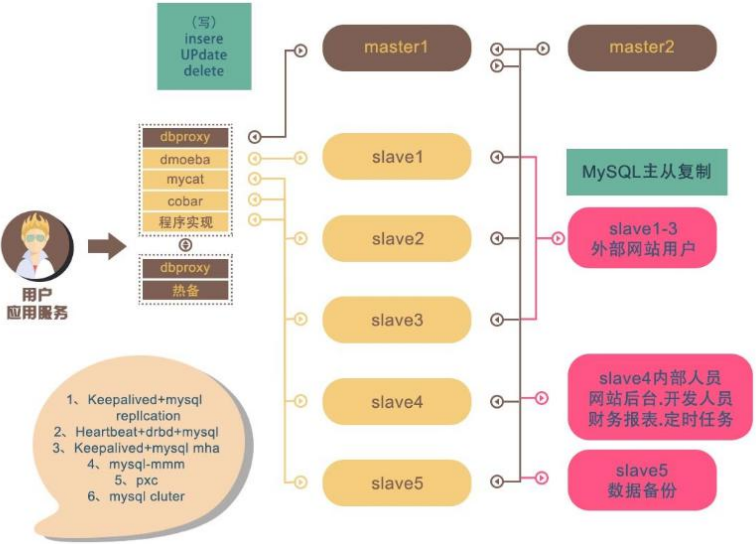
7.2MySQL-常见集群形式
集群原理
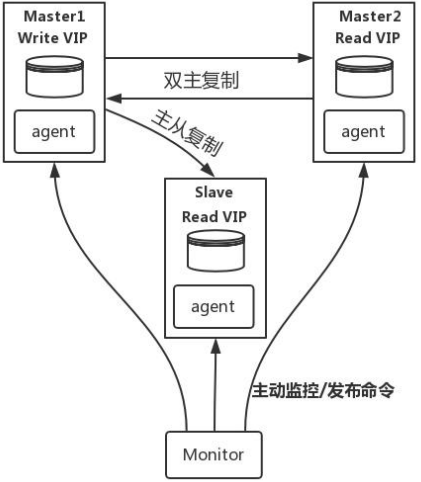
MySQL-MMM 是 Master-Master Replication Manager for MySQL(mysql 主主复制管理 器)的简称,是 Google 的开源项目 (Perl 脚本)。MMM 基于 MySQL Replication 做的扩展架构,主要用 来监控 mysql 主主复制并做失败转 移。其原理是将真实数据库节点的 IP(RIP)映射为虚拟 IP(VIP)集。 mysql-mmm 的监管端会提供多个 虚拟 IP(VIP),包括一个可写 VIP, 多个可读 VIP,通过监管的管理,这 些 IP 会绑定在可用 mysql 之上,当 某一台 mysql 宕机时,监管会将 VIP 迁移至其他 mysql。在整个监管过 程中,需要在 mysql 中添加相关授 权用户,以便让 mysql 可以支持监 理机的维护。授权的用户包括一个mmm_monitor 用户和一个 mmm_agent 用户,如果想使用 mmm 的备份工具则还要添 加一个 mmm_tools 用户。
MHA(Master High Availability)目前在 MySQL 高可用方面是一个相对成熟的解决方案, 由日本 DeNA 公司 youshimaton(现就职于 Facebook 公司)开发,是一套优秀的作为 MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中, MHA 能做到在 0~30 秒之内自动完成数据库的故障切换操作(以 2019 年的眼光来说太 慢了),并且在进行故障切换的过程中,MHA 能在最大程度上保证数据的一致性,以 达到真正意义上的高可用。
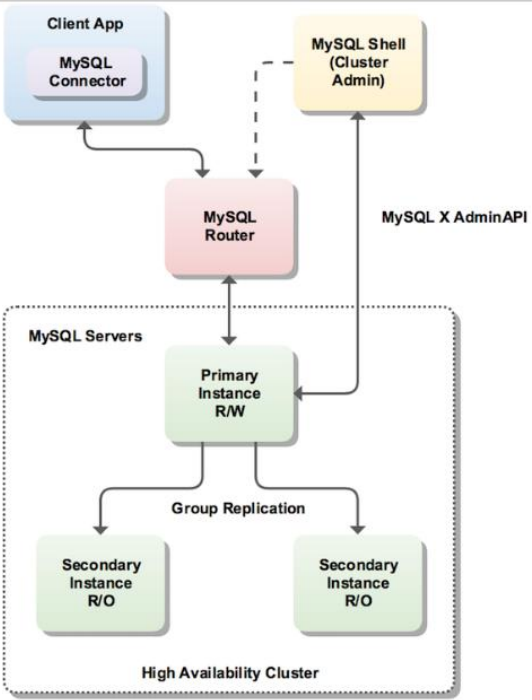
InnoDB Cluster 支持自动 Failover、强一致性、读写分离、读库高可用、读请求负载均 衡,横向扩展的特性,是比较完备的一套方案。但是部署起来复杂,想要解决 router 单点问题好需要新增组件,如没有其他更好的方案可考虑该方案。 InnoDB Cluster 主 要由 MySQL Shell、MySQL Router 和 MySQL 服务器集群组成,三者协同工作,共同为 MySQL 提供完整的高可用性解决方案。MySQL Shell 对管理人员提供管理接口,可以 很方便的对集群进行配置和管理,MySQL Router 可以根据部署的集群状况自动的初始 化,是客户端连接实例。如果有节点 down 机,集群会自动更新配置。集群包含单点写 入和多点写入两种模式。在单主模式下,如果主节点 down 掉,从节点自动替换上来, MySQL Router 会自动探测,并将客户端连接到新节点。
7.3MySQL-主从同步
| 主机 | ip |
|---|---|
| mysql-master | 192.168.188.180:3317 |
| mysql-slaver-01 | 192.168.188.180:3327 |
Master
运行一个mysql实例
参数说明
- -p 3307:3306:将容器的 3306 端口映射到主机的 3307 端口 -v
/mydata/mysql/master/conf:/etc/mysql:将配置文件夹挂在到主机 -v/mydata/mysql/master/log:/var/log/mysql:将日志文件夹挂载到主机 -v/mydata/mysql/master/data:/var/lib/mysql:将配置文件夹挂载到主机 -eMYSQL_ROOT_PASSWORD=root:初始化 root 用户的密码
# 删除目录 如果需要清除环境
docker stop mysql-master
docker rm -f mysql-master
rm -rf /mydata/mysql/master/data
rm -rf /mydata/mysql/master/log
rm -rf /mydata/mysql/master/conf
# 创建目录
mkdir -p /mydata/mysql/master/{data,log}
mkdir -p /mydata/mysql/master/conf/{conf.d,mysql.conf.d}
# 运行
docker run -p 3317:3306 --name mysql-master \
-v /mydata/mysql/master/log:/var/log/mysql \
-v /mydata/mysql/master/data:/var/lib/mysql \
-v /mydata/mysql/master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
修改 master 基本配置
# rm -f /mydata/mysql/master/conf/my.cnf
vim /mydata/mysql/master/conf/my.cnf
my.cnf
注意:skip-name-resolve 一定要加,不然连接 mysql 会超级
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 添加 master 主从复制部分配置
server_id=1
log-bin=mysql-bin
# 读写
read-only=0
# 只同步业务库
binlog-do-db=mall_ums
binlog-do-db=mall_pms
binlog-do-db=mall_oms
binlog-do-db=mall_sms
binlog-do-db=mall_wms
binlog-do-db=mall_admin
# 不同步mysql基础库
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
重启master
docker restart mysql-master
docker logs mysql-master
Slave
运行一个mysql实例
# 删除目录 如果需要清除环境
docker stop mysql-slaver-01
docker rm -f mysql-slaver-01
rm -rf /mydata/mysql/slaver/data
rm -rf /mydata/mysql/slaver/log
rm -rf /mydata/mysql/slaver/conf
# 创建目录
mkdir -p /mydata/mysql/slaver/{data,log}
mkdir -p /mydata/mysql/slaver/conf/{conf.d,mysql.conf.d}
docker run -p 3327:3306 --name mysql-slaver-01 \
-v /mydata/mysql/slaver/log:/var/log/mysql \
-v /mydata/mysql/slaver/data:/var/lib/mysql \
-v /mydata/mysql/slaver/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
修改 slave 基本配置
vim /mydata/mysql/slaver/conf/my.cnf
my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 添加 master 主从复制部分配置
server-id=2
log-bin=mysql-bin
# 只读
read-only=1
# 只同步业务库
binlog-do-db=mall_ums
binlog-do-db=mall_pms
binlog-do-db=mall_oms
binlog-do-db=mall_sms
binlog-do-db=mall_wms
binlog-do-db=mall_admin
# 不同步mysql基础库
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
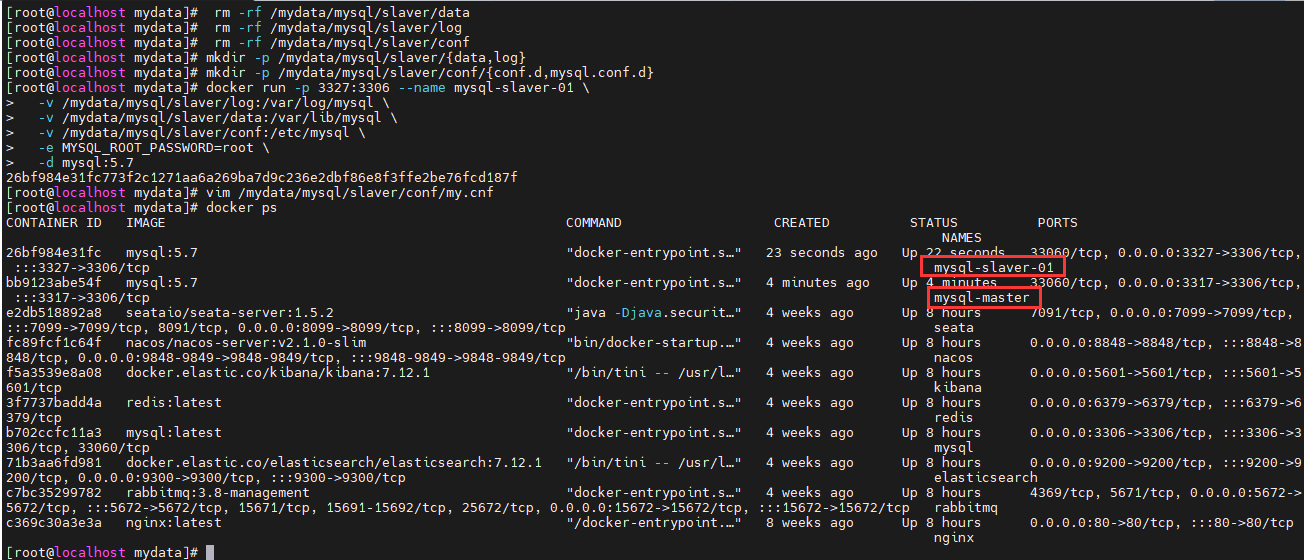
重启mysql-slaver-01
docker restart mysql-slaver-01

查看容器
docker ps
为 master 授权用户来他的同步数据
进入 master 容器
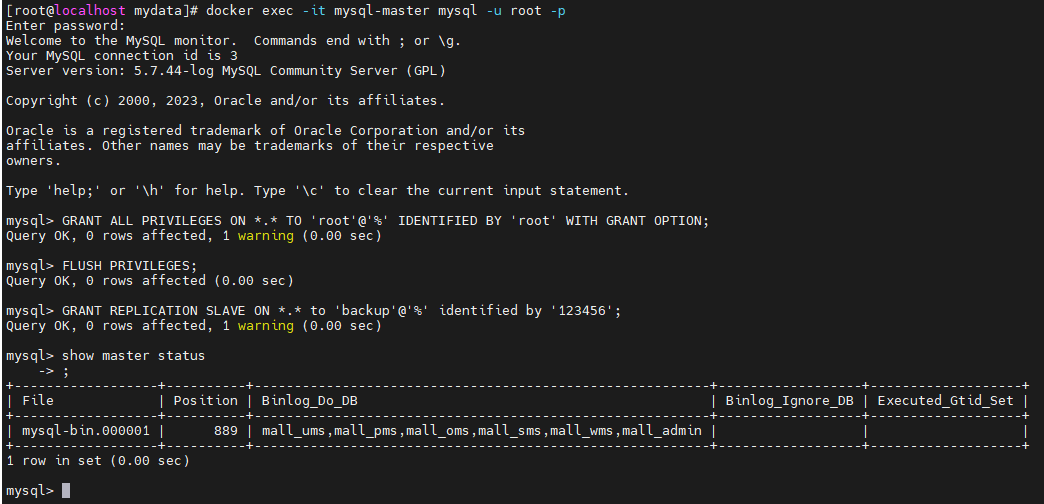
docker exec -it mysql-master mysql -u root -p
进入 mysql 内部
# 授权 root 可以远程访问( 主从无关,为了方便我们远程连接 mysql)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
# 添加用来同步的用户
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
# 查看 master状态
show master status;
配置 slaver 同步 master 数据
进入 slaver 容器
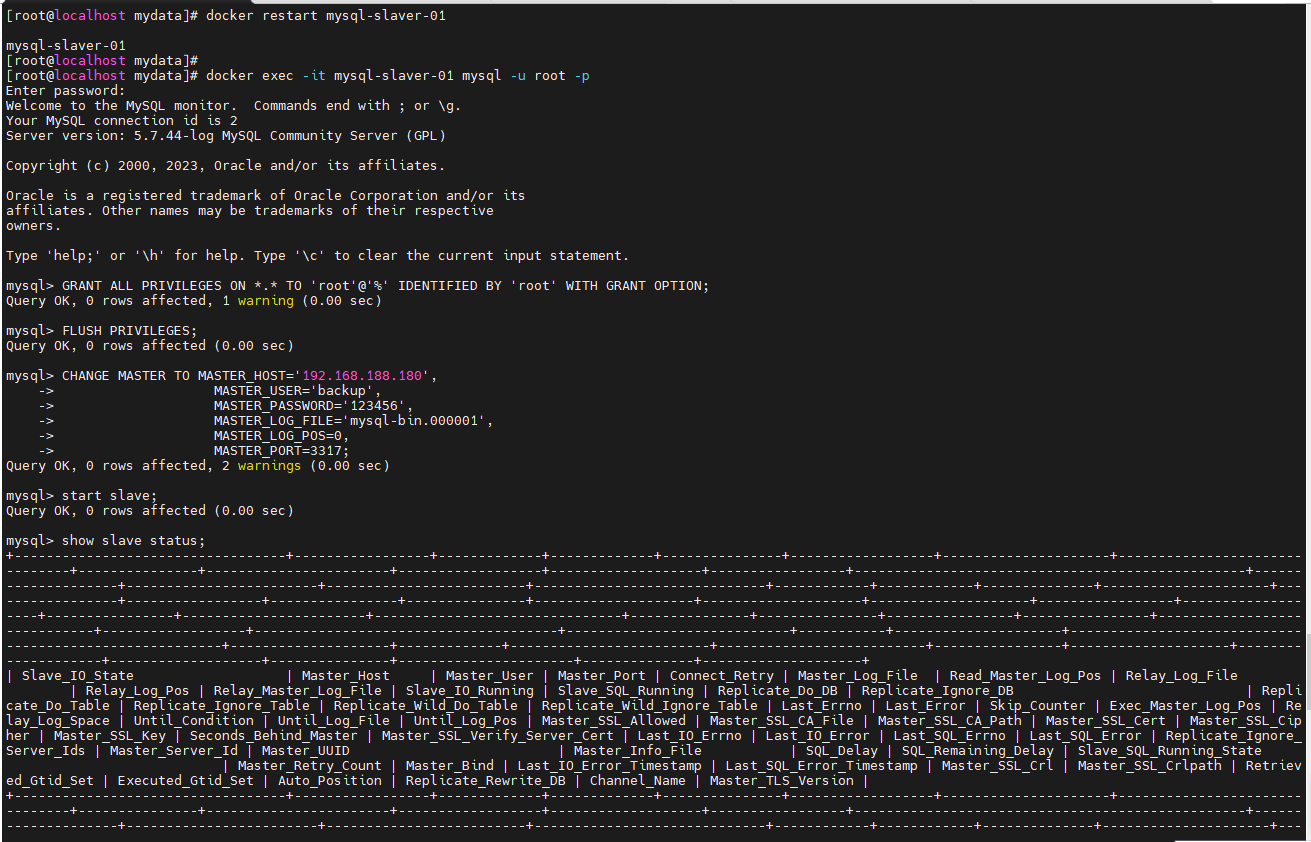
docker exec -it mysql-slaver-01 mysql -u root -p
进入 mysql 内部
# 授权 root 可以远程访问( 主从无关,为了方便我们远程连接 mysql)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
# 设置主库连接
# MASTER_LOG_FILE是show master status;查master的File字段
CHANGE MASTER TO MASTER_HOST='192.168.188.180',
MASTER_USER='backup',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=0,
MASTER_PORT=3317;
# 启动从库同步
start slave;
# 查看从库状态
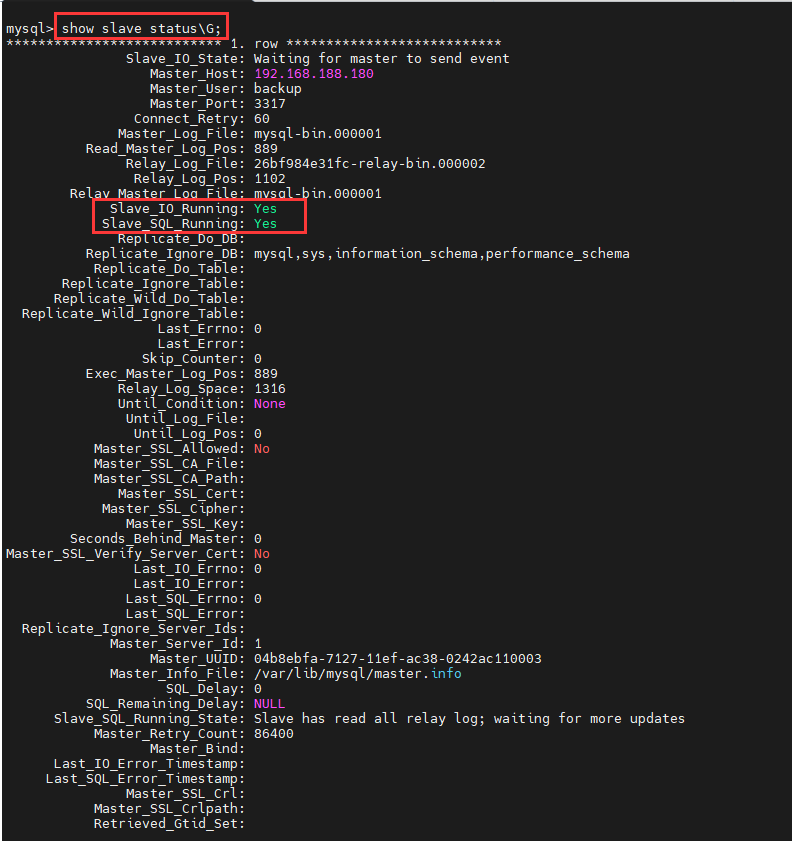
show slave status;
查看从库状态
show slave status\G;
测试
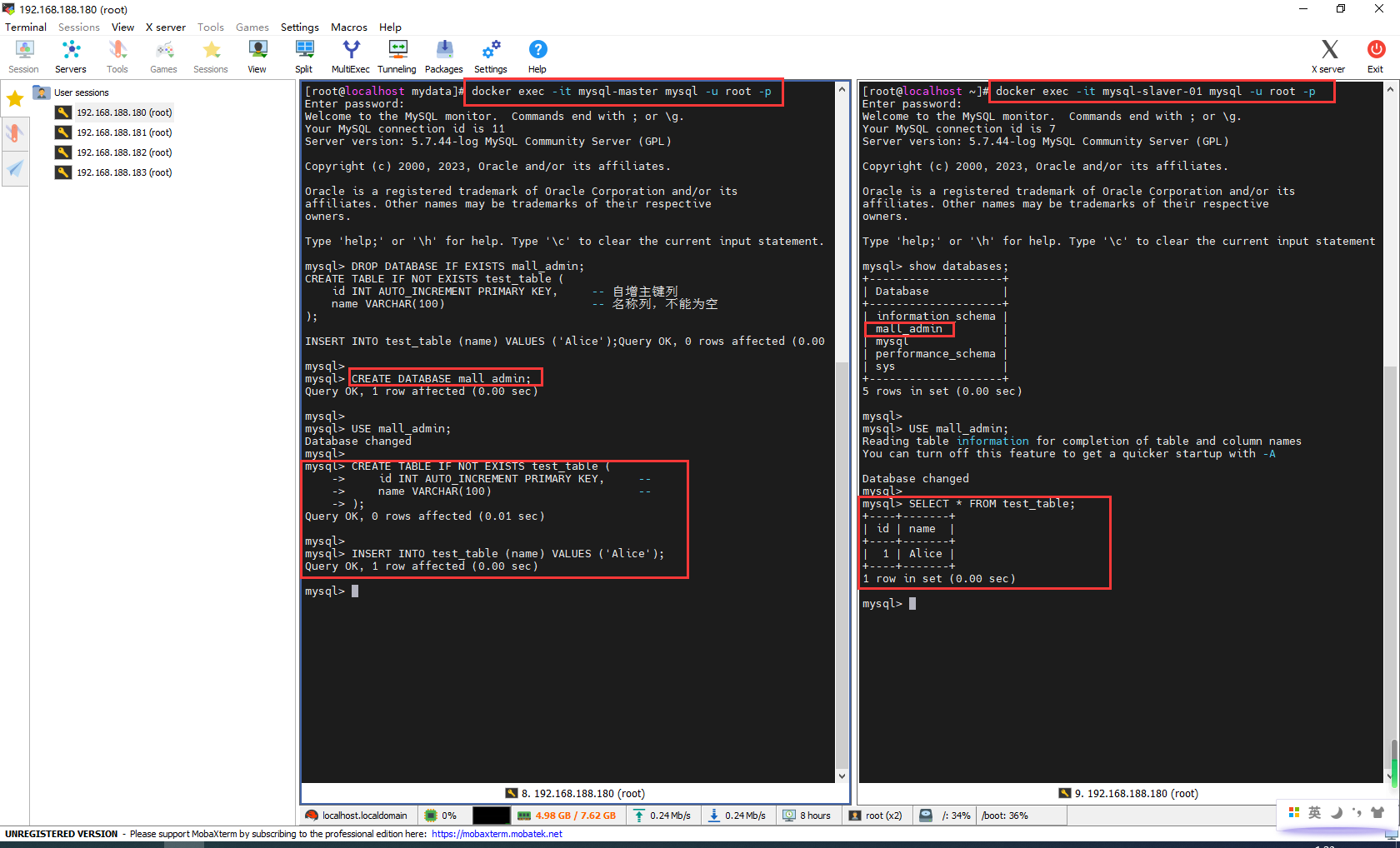
登录mysql-master,创建测试mall_admin
这里创建的表名字只能是my.cnf配置的binlog-do-db
docker exec -it mysql-master mysql -u root -p
DROP DATABASE IF EXISTS mall_admin;
CREATE DATABASE mall_admin;
USE mall_admin;
CREATE TABLE IF NOT EXISTS test_table (
id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键列
name VARCHAR(100) -- 名称列,不能为空
);
INSERT INTO test_table (name) VALUES ('Alice');
登录mysql-slaver-01,发现库和表成功同步
docker exec -it mysql-slaver-01 mysql -u root -p
show databases;
USE mall_admin;
SELECT * FROM test_table;
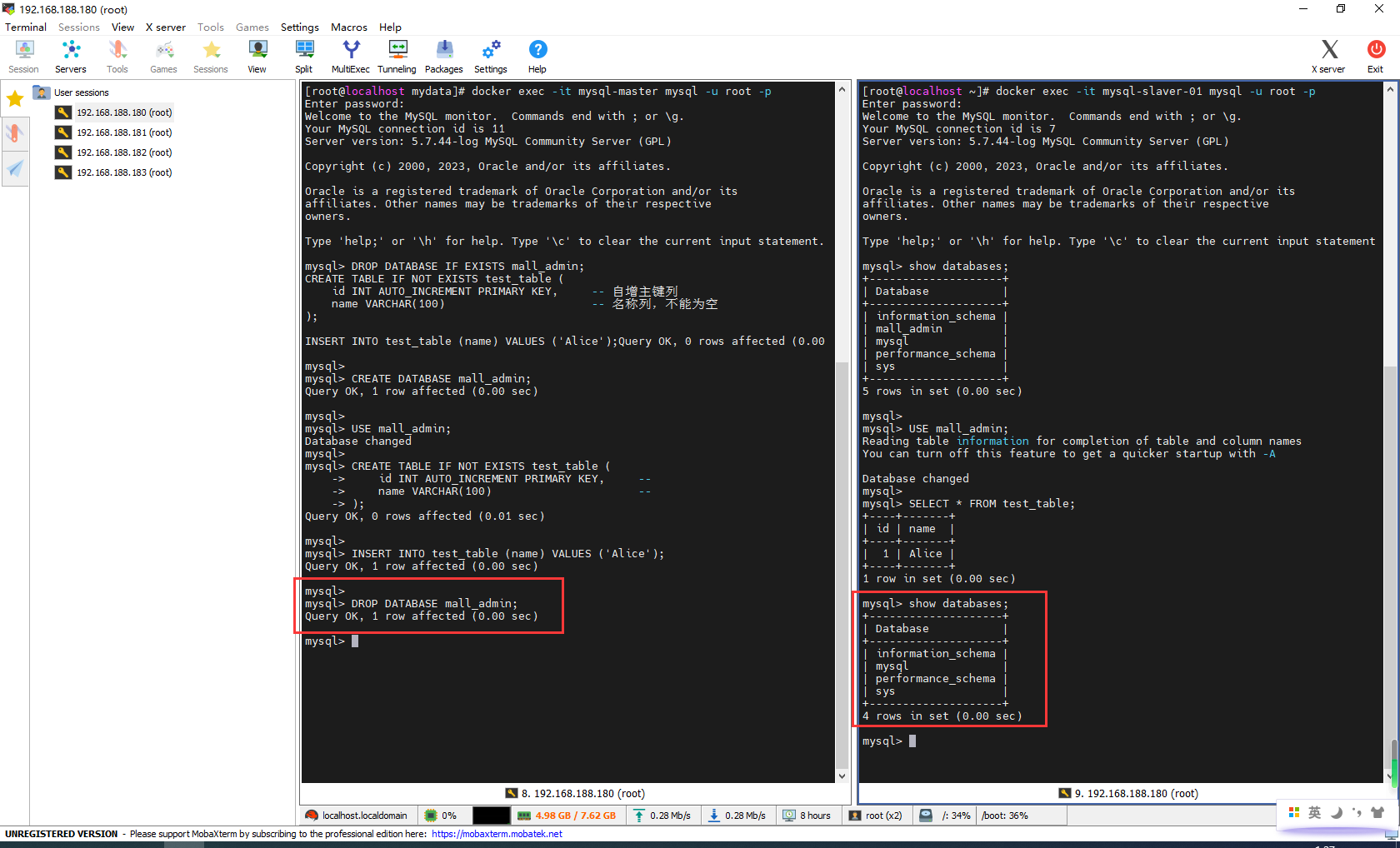
主库再删除,从库已同步
DROP DATABASE mall_admin;
7.4ShardingSphere-简介
官网地址:https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/
7.5ShardingSphere-分库分表&读写分离配置
解压
下载mysql驱动包
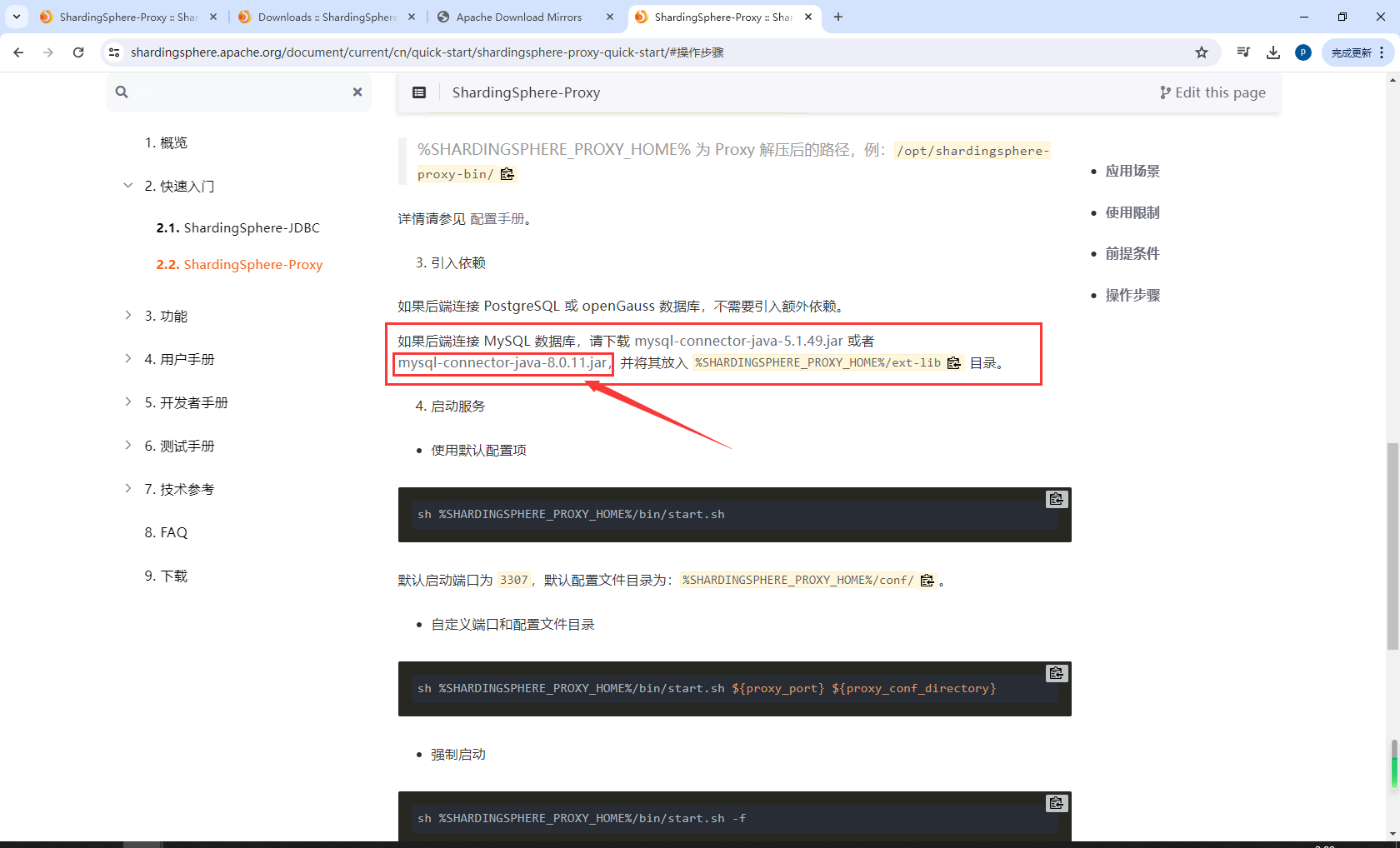
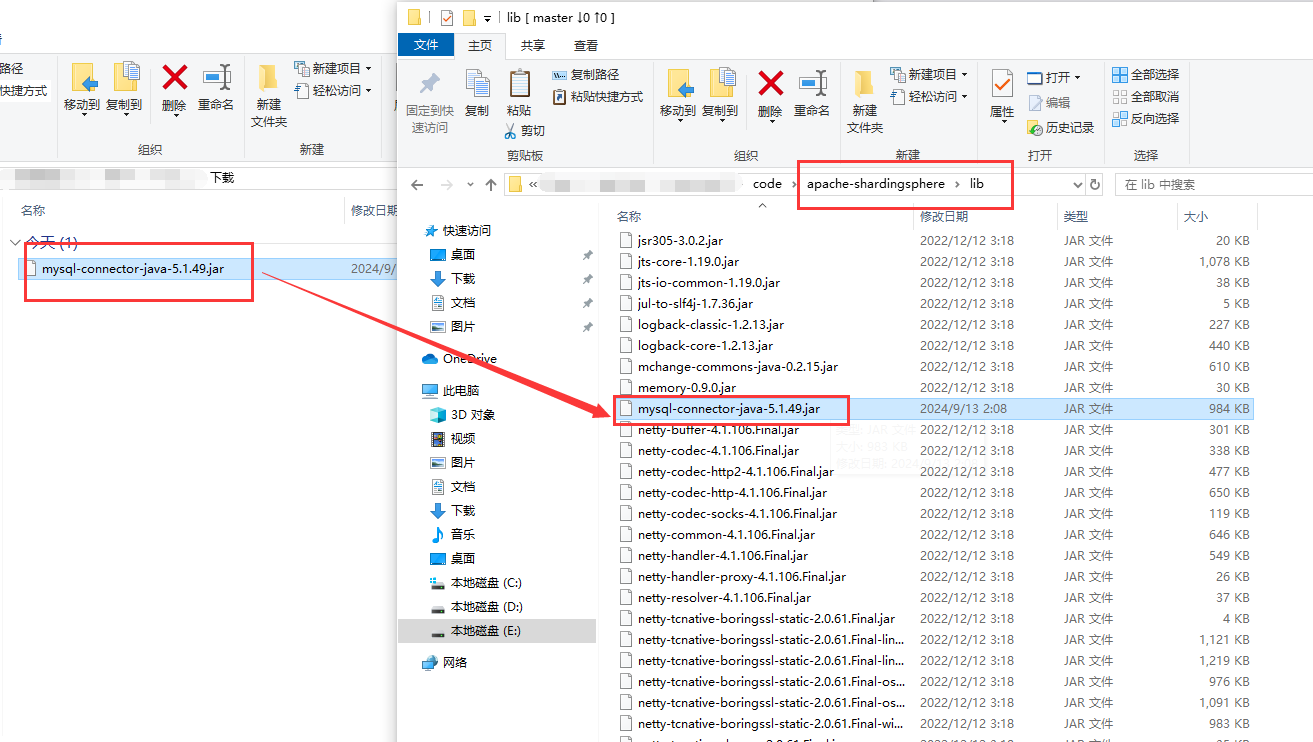
mysql-connector-java-5.1.49.jar放到apache-shardingsphere\lib目录下
配置认证授权
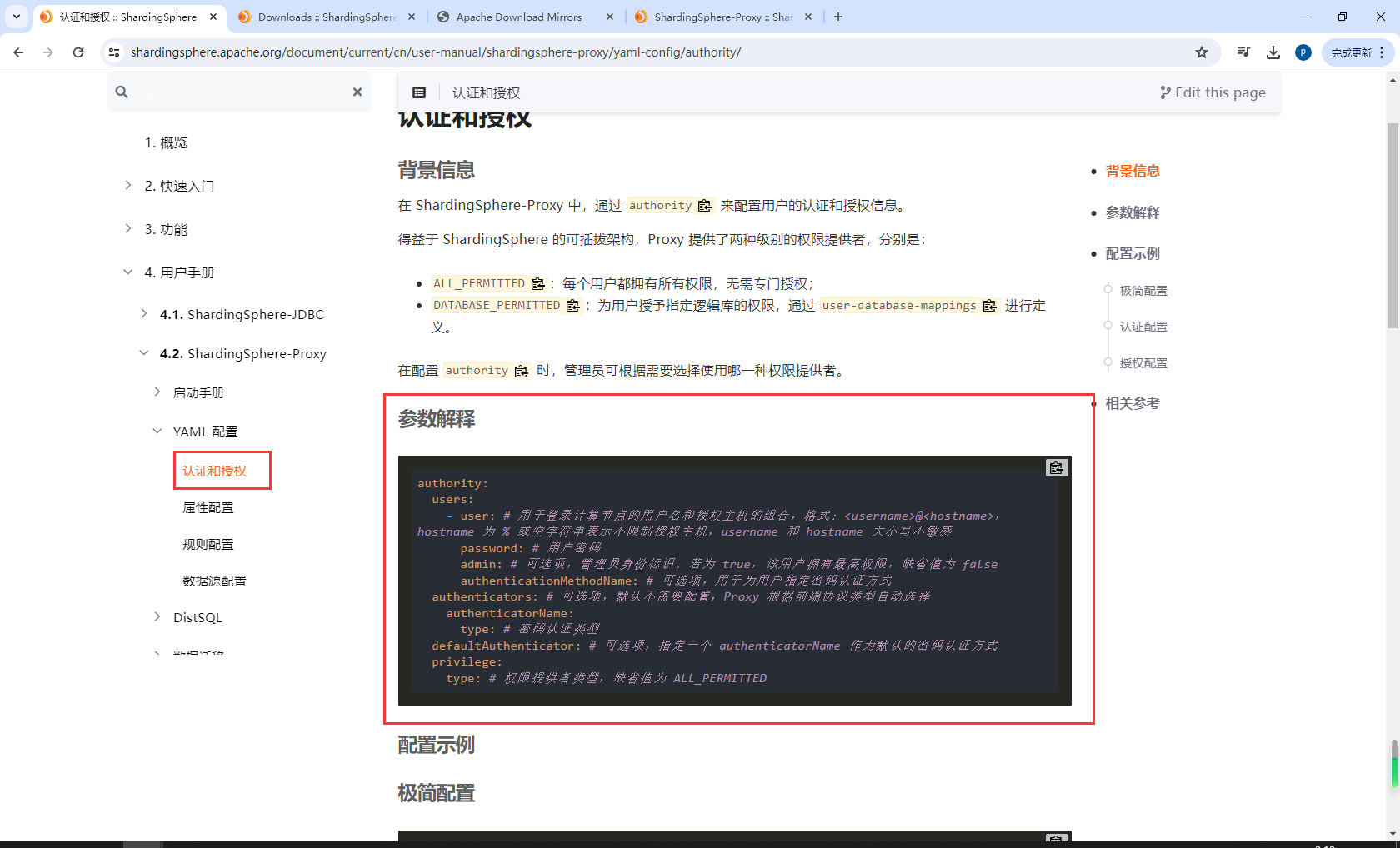
配置apache-shardingsphere\conf的global.yaml
authority:
users:
- user: root@%
password: root
- user: sharding
password: sharding
privilege:
type: ALL_PERMITTED
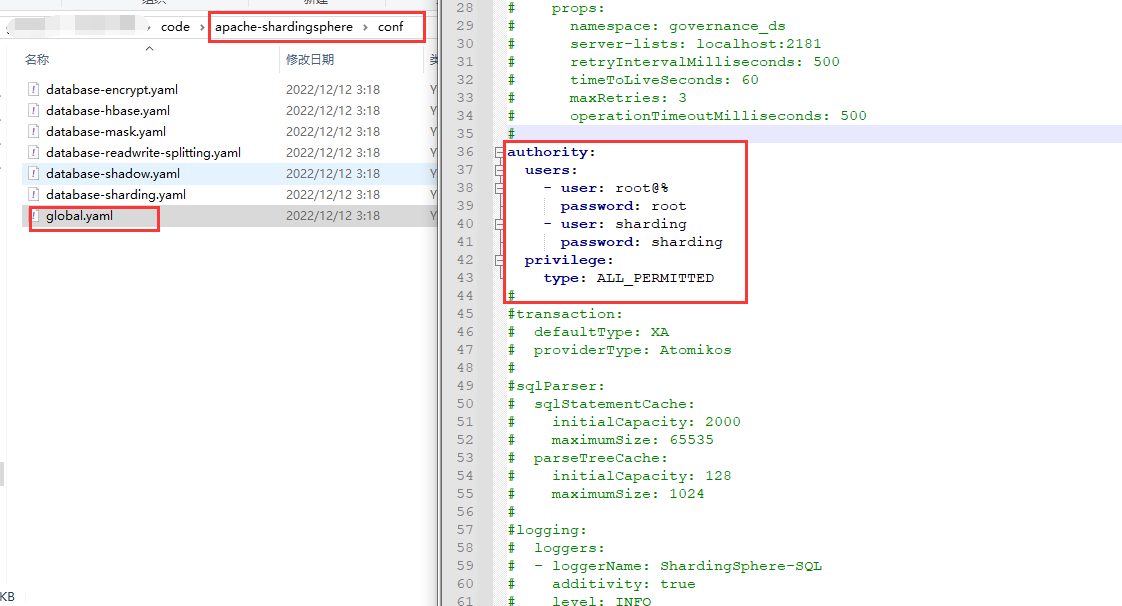
配置database-sharding.yaml
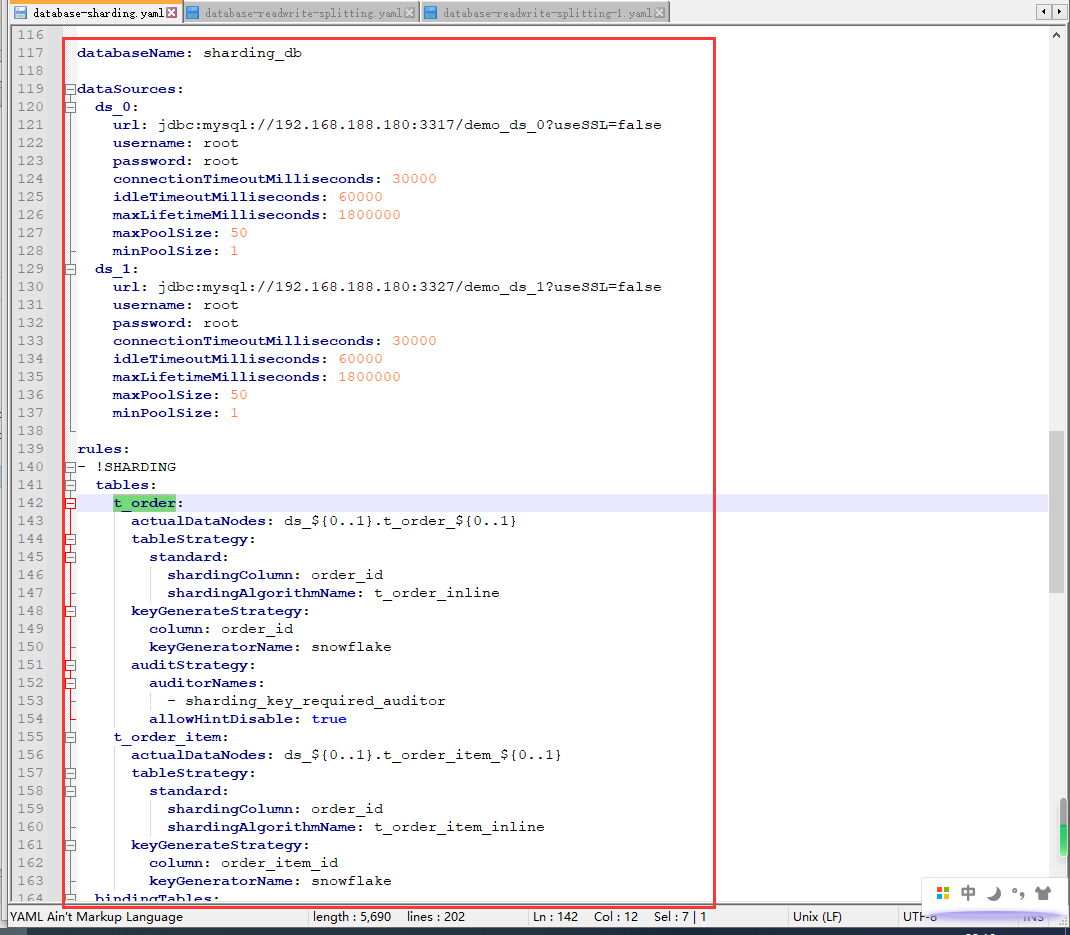
配置database-readwrite-splitting.yaml
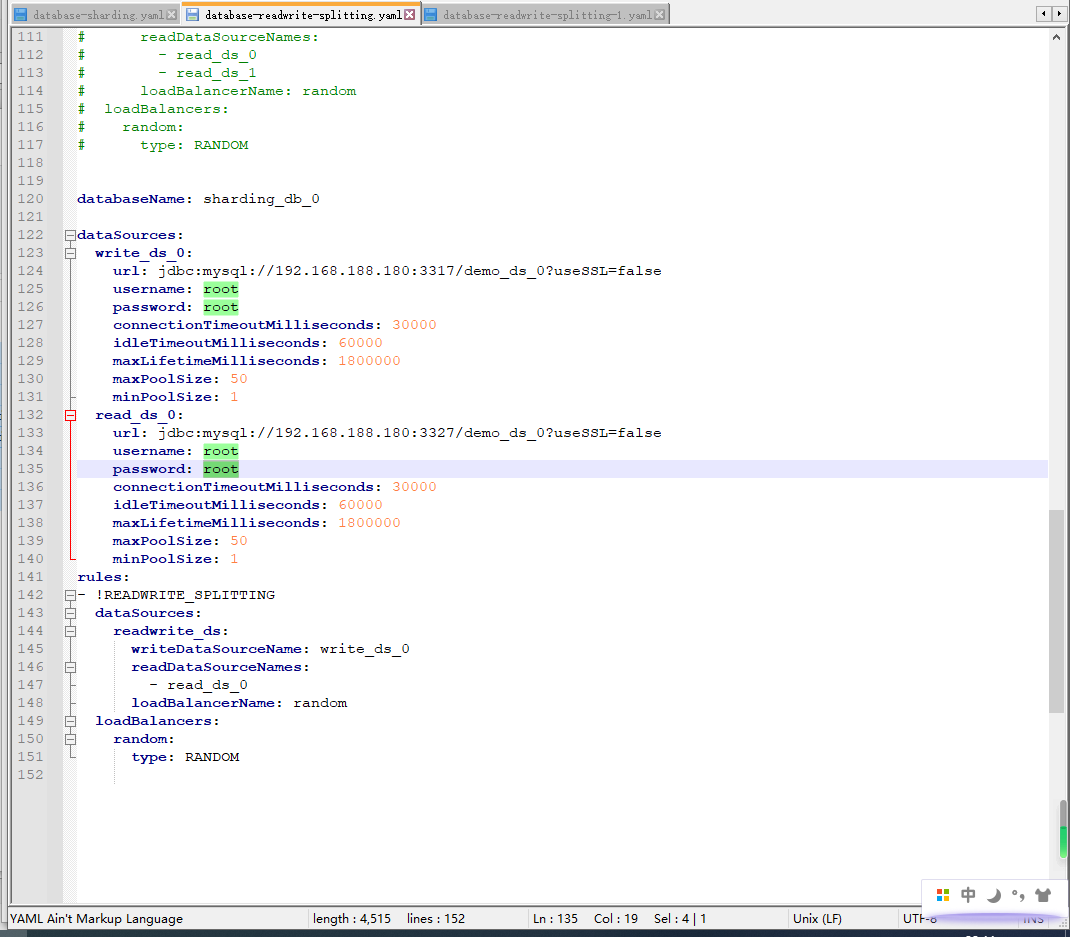
添加database-readwrite-splitting-1.yaml
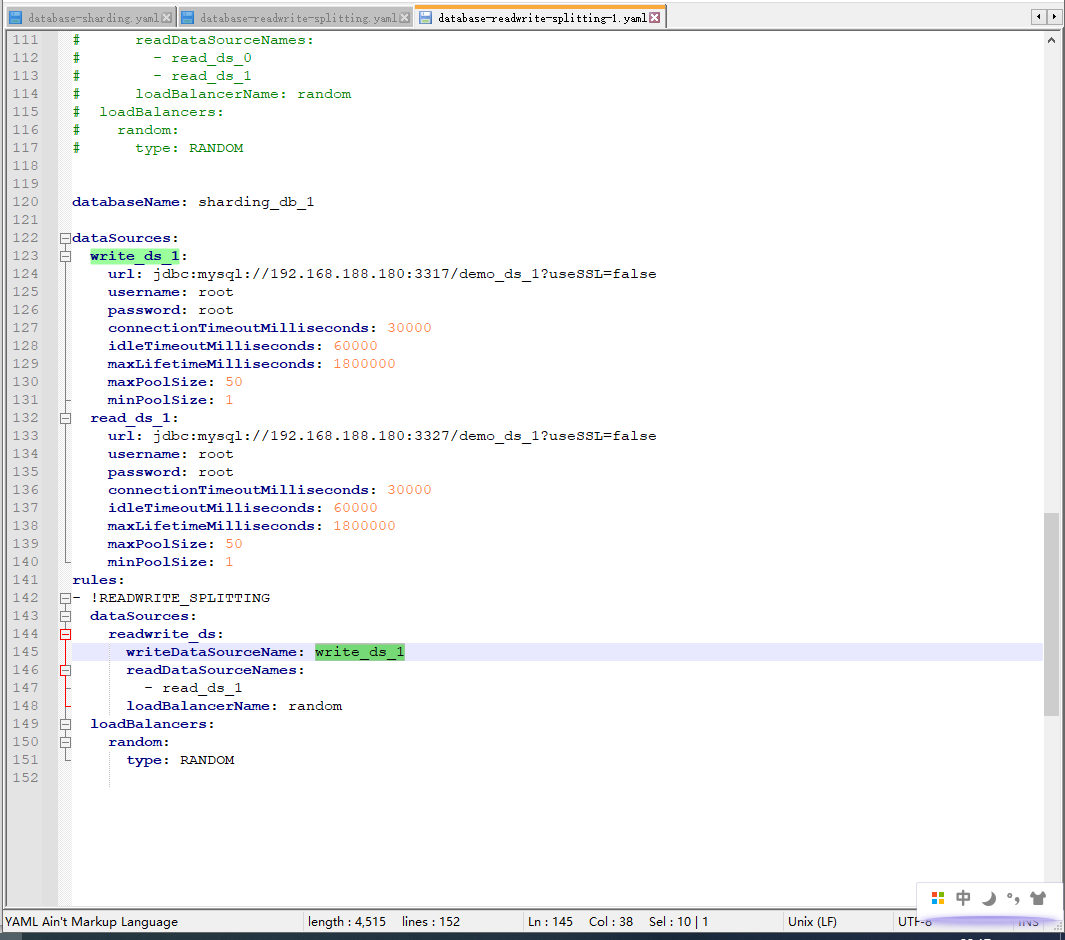
在master节点 创建demo_ds_0、demo_ds_1
CREATE DATABASE `demo_ds_0` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci */;
CREATE DATABASE `demo_ds_1` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci */;
修改master和slaver的my.cnf
vim /mydata/mysql/master/conf/my.cnf
vim /mydata/mysql/slaver/conf/my.cnf
把demo_ds_0、demo_ds_1添加到主从同步
binlog-do-db=demo_ds_0
binlog-do-db=demo_ds_1

启动ShardingSphere
start.bat 3388
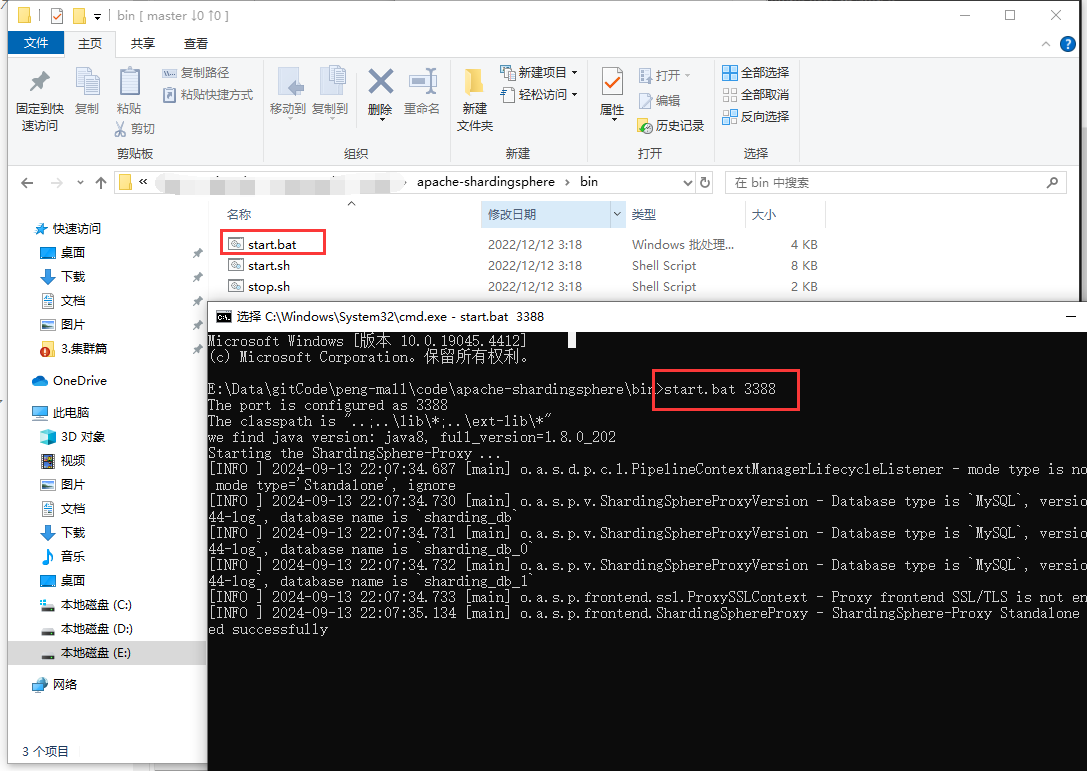
在3388链接下创建表
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE `t_order_item` (
`order_item_id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`content` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`status` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`order_item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
添加测试数据
insert into t_order(user_id,status) values(1,2);
insert into t_order(user_id,status) values(2,2);
insert into t_order(user_id,status) values(3,2);
7.6Redis-Cluster基本原理
7.6.1Redis集群形式
1.数据分区方案
1.1客户端分区
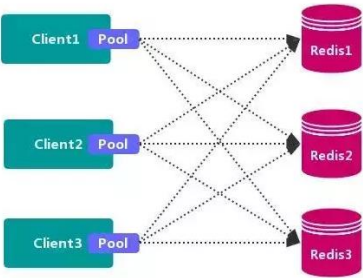
客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前,业 界普遍使用的 Redis 多实例集群 方法。Java 的 Redis 客户端驱动库 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool。
优点 :
- 不使用 第三方中间件,分区逻辑 可控,配置 简单,节点之间无关联,容易 线性扩展,灵 活性强。
缺点 :
- 客户端 无法 动态增删 服务节点,客户端需要自行维护 分发逻辑,客户端之间 无连接共享, 会造成 连接浪费。
1.2代理分区
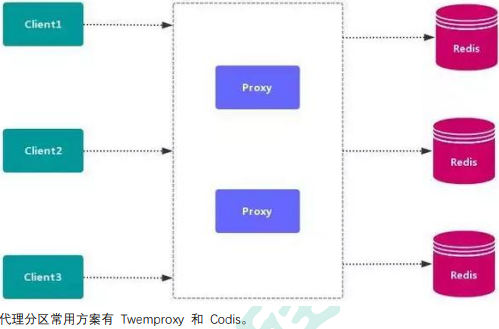
1.3redsi-cluster
2.高可用方式
2.1Sentinel( 哨兵机制)支持高可用
前面介绍了主从机制,但是从运维角度来看,主节点出现了问题我们还需要通过人工干预的 方式把从节点设为主节点,还要通知应用程序更新主节点地址,这种方式非常繁琐笨重, 而 且主节点的读写能力都十分有限,有没有较好的办法解决这两个问题,哨兵机制就是针对第 一个问题的有效解决方案,第二个问题则有赖于集群!哨兵的作用就是监控 Redis 系统的运 行状况,其功能主要是包括以下三个
- 监控(Monitoring): 哨兵(sentinel) 会不断地检查你的 Master 和 Slave 是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当主数据库出现故障时自动将从数据库转换为主数 据库。
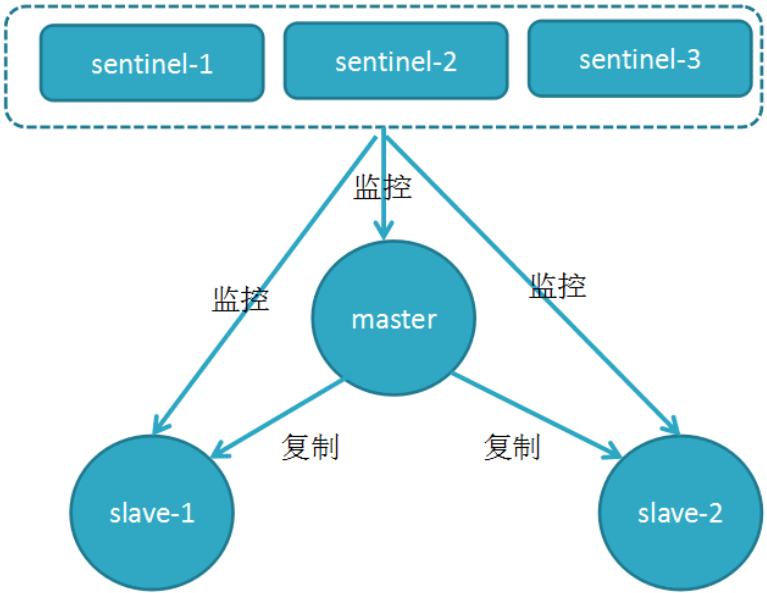
哨兵的原理 Redis 哨兵的三个定时任务,Redis 哨兵判定一个 Redis 节点故障不可达主要就是通过三个定 时监控任务来完成的:
- 每隔 10 秒每个哨兵节点会向主节点和从节点发送"info replication" 命令来获取最新的 拓扑结构
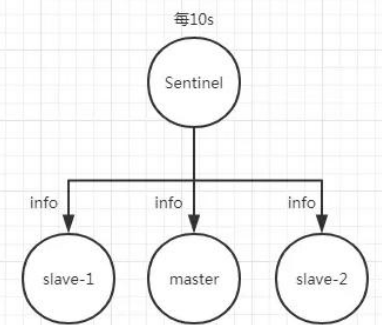
- 每隔 2 秒每个哨兵节点会向 Redis 节点的_sentinel_:hello 频道发送自己对主节点是否故 障的判断以及自身的节点信息,并且其他的哨兵节点也会订阅这个频道来了解其他哨兵 节点的信息以及对主节点的判断
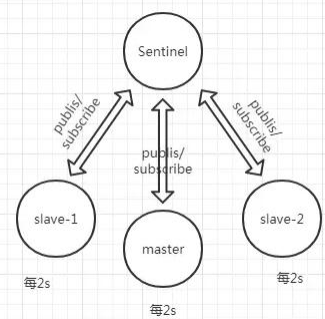
- 每隔 1 秒每个哨兵会向主节点、从节点、其他的哨兵节点发送一个 “ping” 命令来做心 跳检测
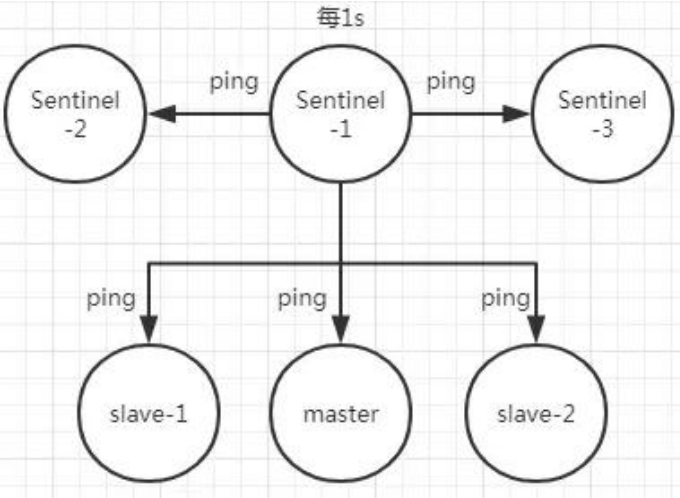
如果在定时 Job3 检测不到节点的心跳,会判断为“主观下线”。如果该节点还是主节点那么 还会通知到其他的哨兵对该主节点进行心跳检测,这时主观下线的票数超过了数 时,那么这个主节点确实就可能是故障不可达了,这时就由原来的主观下线变为了“客观下 线”。
故障转移和 Leader 选举 如果主节点被判定为客观下线之后,就要选取一个哨兵节点来完成后面的故障转移工作,选 举出一个 leader,这里面采用的选举算法为 Raft。选举出来的哨兵 leader 就要来完成故障转 移工作,也就是在从节点中选出一个节点来当新的主节点,这部分的具体流程可参考引用.
2.2Redis-Cluster
https://redis.io/topics/cluster-tutorial/
7.6.2Redis-Cluster
https://redis.io/topics/cluster-tutorial/
Redis 的官方多机部署方案,Redis Cluster。一组 Redis Cluster 是由多个 Redis 实例组成,官 方推荐我们使用 6 实例,其中 3 个为主节点,3 个为从结点。一旦有主节点发生故障的时候, Redis Cluster 可以选举出对应的从结点成为新的主节点,继续对外服务,从而保证服务的高 可用性。那么对于客户端来说,知道知道对应的 key 是要路由到哪一个节点呢?Redis Cluster 把所有的数据划分为 16384 个不同的槽位,可以根据机器的性能把不同的槽位分配给不同 的 Redis 实例,对于 Redis 实例来说,他们只会存储部分的 Redis 数据,当然,槽的数据是 可以迁移的,不同的实例之间,可以通过一定的协议,进行数据迁移。
1.槽
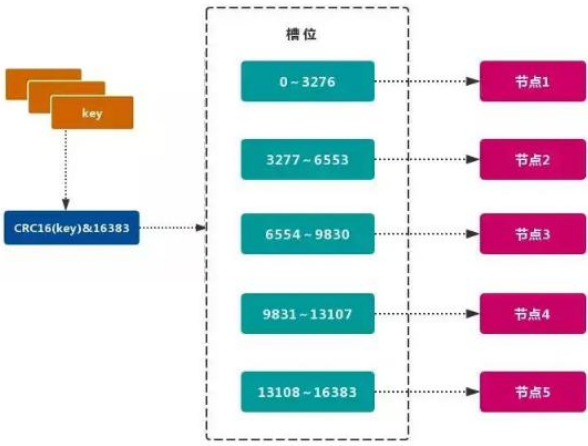
Redis 集群的功能限制;Redis 集群相对 单机 在功能上存在一些限制,需要 开发人员 提前 了解,在使用时做好规避。JAVA CRC16 校验算法
- key 批量操作 支持有限。
- 类似 mset、mget 操作,目前只支持对具有相同 slot 值的 key 执行 批量操作。 对于 映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节 点上,因此不被支持。
- key 事务操作 支持有限。
- 只支持 多 key 在 同一节点上 的 事务操作,当多个 key 分布在 不同 的节点上 时 无法 使用事务功能。
- key 作为 数据分区 的最小粒度
- 不能将一个 大的键值 对象如 hash、list 等映射到 不同的节点。
- 不支持 多数据库空间
- 单机 下的 Redis 可以支持 16 个数据库(db0 ~ db15),集群模式 下只能使用 一 个 数据库空间,即 db0。
- 复制结构 只支持一层
- 从节点 只能复制 主节点,不支持 嵌套树状复制 结构。
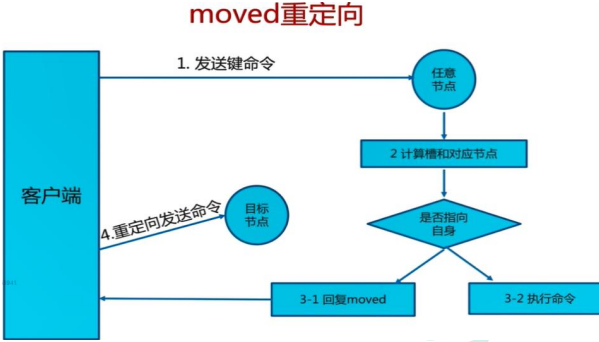
- 命令大多会重定向,耗时多
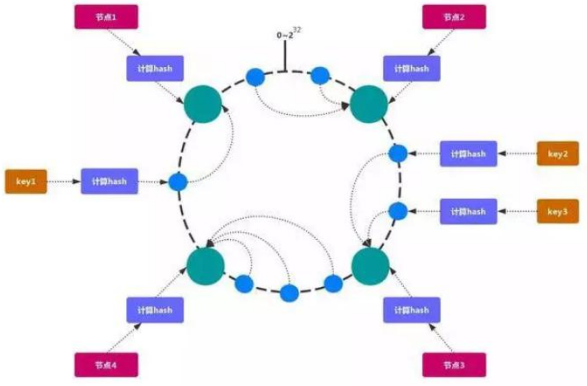
2.一致性 hash
一致性哈希 可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 收尾相接 的 Hash 环上,每个 key 在计算 Hash 后会 顺时针 找到 临接 的 存储节点 存放。而当有节 点 加入 或 退出 时,仅影响该节点在 Hash 环上 顺时针相邻 的 后续节点。
Hash 倾斜
如果节点很少,容易出现倾斜,负载不均衡问题。一致性哈希算法,引入了虚拟节点,在整 个环上,均衡增加若干个节点。比如 a1,a2,b1,b2,c1,c2,a1 和 a2 都是属于 A 节点 的。解决 hash 倾斜问题。
7.7Redis-Cluster集群搭建
安装redis
下载redis:5.0.7镜像
docker pull redis:5.0.7
运行6个redis
for port in $(seq 7001 7006); \
do \
mkdir -p /mydata/redis/node-${port}/conf
touch /mydata/redis/node-${port}/conf/redis.conf
cat << EOF >/mydata/redis/node-${port}/conf/redis.conf
port ${port}
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 192.168.188.180
cluster-announce-port ${port}
cluster-announce-bus-port 1${port}
appendonly yes
EOF
docker run -p ${port}:${port} -p 1${port}:1${port} --name redis-${port} \
-v /mydata/redis/node-${port}/data:/data \
-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \
-d redis:5.0.7 redis-server /etc/redis/redis.conf
done
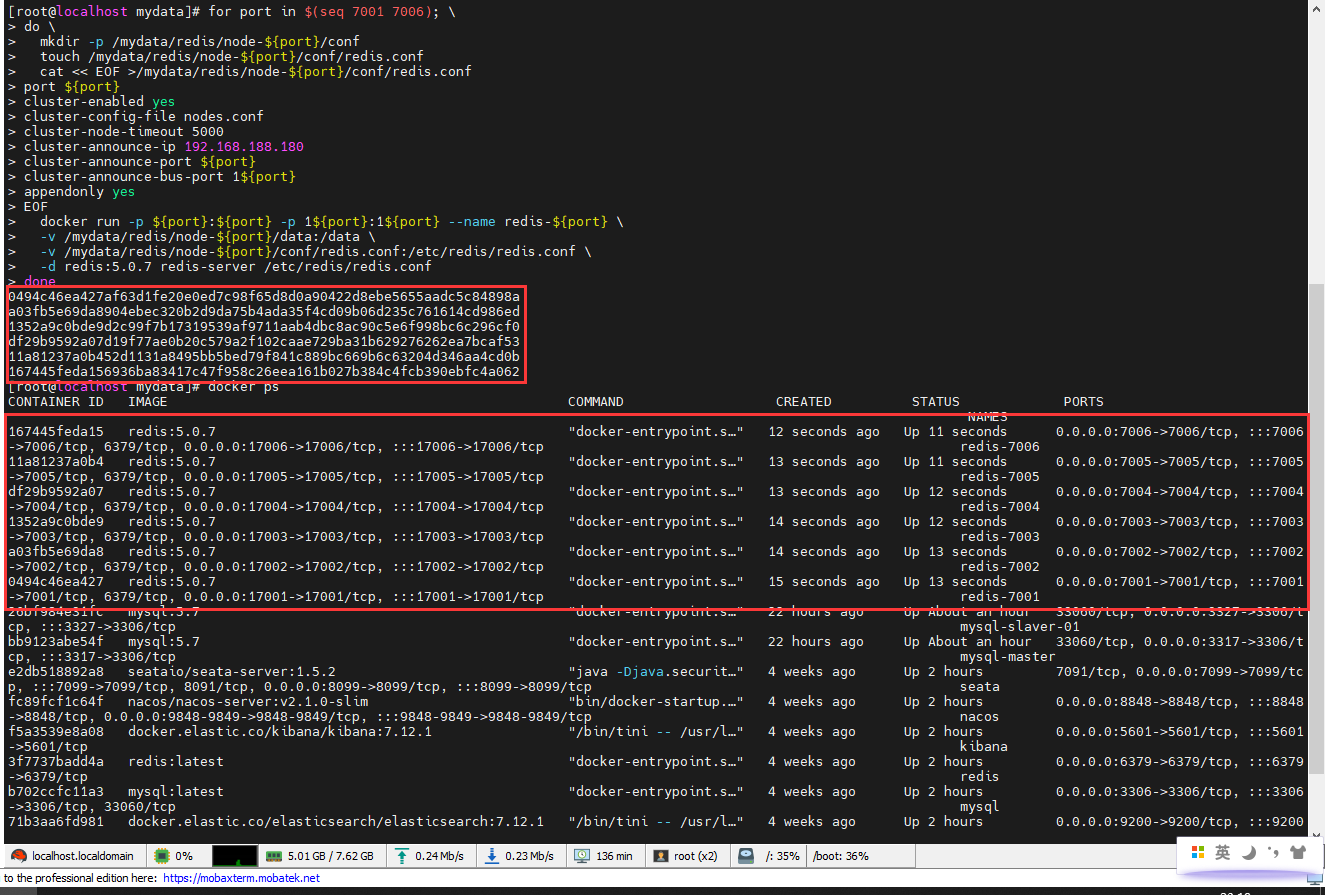
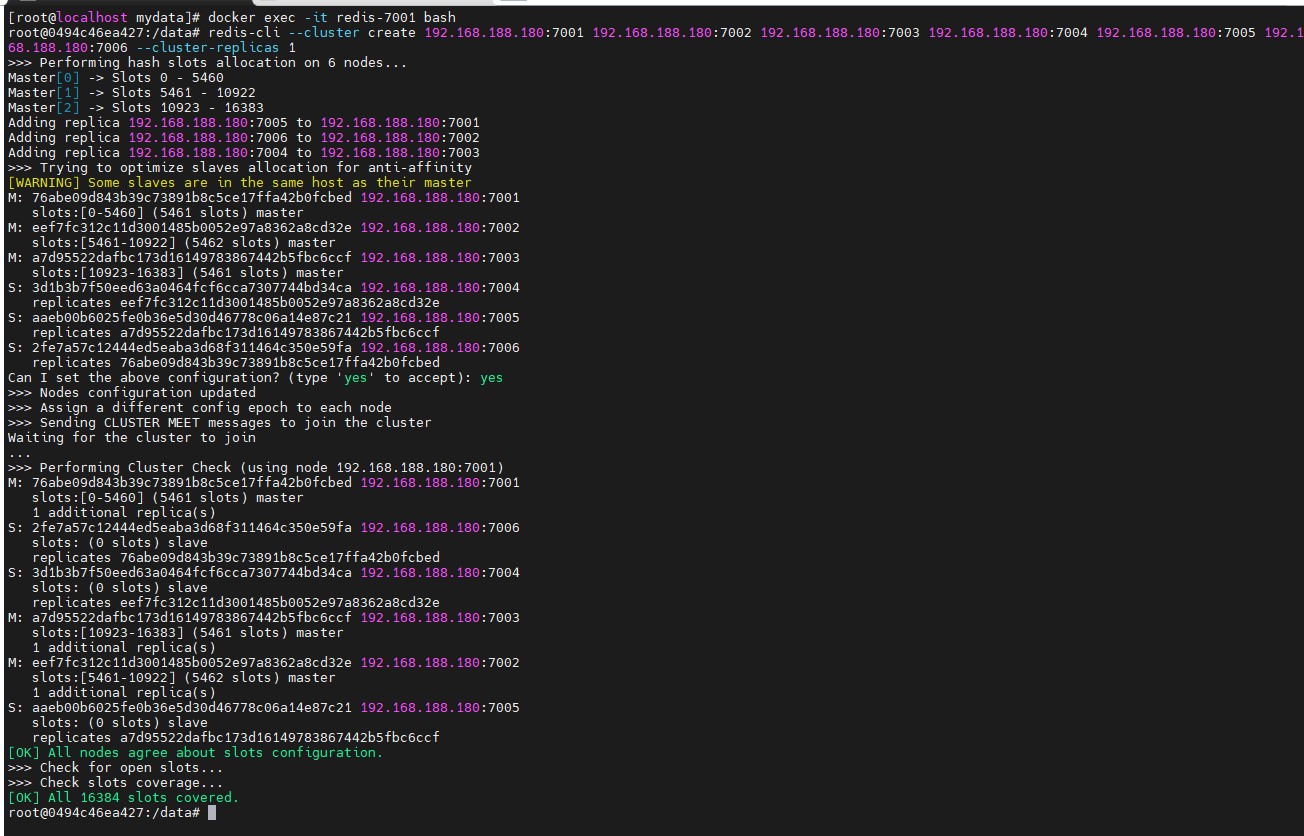
使用 redis 建立集群
# 进入 Redis 容器
docker exec -it redis-7001 bash
# 执行 redis-cli 创建 Redis 集群的命令
redis-cli --cluster create 192.168.188.180:7001 192.168.188.180:7002 192.168.188.180:7003 192.168.188.180:7004 192.168.188.180:7005 192.168.188.180:7006 --cluster-replicas 1
# 主
7001 76abe09d843b39c73891b8c5ce17ffa42b0fcbed
# 从
7006 2fe7a57c12444ed5eaba3d68f311464c350e59fa
# 主
7002 eef7fc312c11d3001485b0052e97a8362a8cd32e
# 从
7004 3d1b3b7f50eed63a0464fcf6cca7307744bd34ca
# 主
7003 a7d95522dafbc173d16149783867442b5fbc6ccf
# 从
7005 aaeb00b6025fe0b36e5d30d46778c06a14e87c21
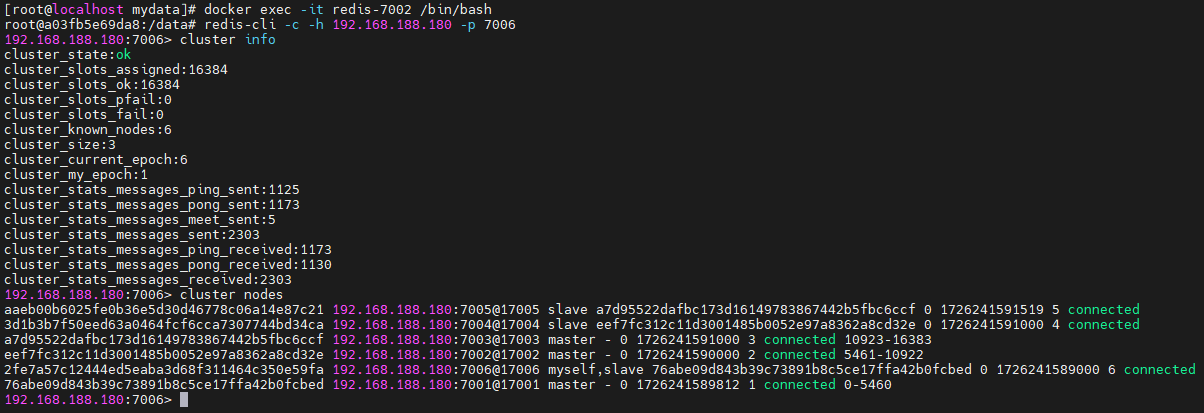
测试
随便进入某个redis容器
docker exec -it redis-7002 /bin/bash
使用 redis-cli 的 cluster 方式进行连接
redis-cli -c -h 192.168.188.180 -p 7006
获取集群信息
cluster info
获取集群节点
cluster nodes
7.8ElasticSearch-集群原理
集群原理
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/distributed-cluster.html
elasticsearch 是天生支持集群的,他不需要依赖其他的服务发现和注册的组件,如 zookeeper 这些,因为他内置了一个名字叫 ZenDiscovery 的模块,是 elasticsearch 自己实现的一套用 于节点发现和选主等功能的组件,所以 elasticsearch 做起集群来非常简单,不需要太多额外 的配置和安装额外的第三方组件。
1.单节点

- 一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群 中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
- 当一个节点被选举成为 主节点时, 它将负责管理集群范围内的所有变更,例如增加、 删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索 等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主 节点。
- 作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知 道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数 据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
2.集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健 康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
GET /_cluster/health
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green:所有的主分片和副本分片都正常运行。
- yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- red:有主分片没能正常运行。
3.分片
- 一个 分片 是一个底层的 工作单元 ,它仅保存了全部数据中的一部分。我们的文档被 存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。分片就认为 是一个数据区
- 一个分片可以是 主 分片或者 副本 分片。索引内任意一个文档都归属于一个主分片, 所以主分片的数目决定着索引能够保存的最大数据量。
- 在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
- 让我们在包含一个空节点的集群内创建名为 blogs 的索引。 索引在默认情况下会被分 配 5 个主分片, 但是为了演示目的,我们将分配 3 个主分片和一份副本(每个主分片 拥有一个副本分片):
PUT /blogs{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}}
此时集群的健康状况为 yellow 则表示全部 主分片都正常运行(集群可以正常服务所有请 求),但是 副本 分片没有全部处在正常状态。 实际上,所有 3 个副本分片都是 unassigned —— 它们都没有被分配到任何节点。在同一个节点上既保存原始数据又保存副本是没有意 义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。 当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险。
4.新增节点
当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配 置,它就会自动发现集群并加入到其中。 但是在不同机器上启动节点的时候,为了加入到 同一集群,你需要配置一个可连接到的单播主机列表。 详细信息请查看最好使用单播代替 组播

此时,cluster-health 现在展示的状态为 green ,这表示所有 6 个分片(包括 3 个主分片和 3 个副本分片)都在正常运行。我们的集群现在不仅仅是正常运行的,并且还处于 始终可 用 的状态。
5.水平扩容-启动第三个节点

Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥 有 2 个分片,而不是之前的 3 个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少 的分片所共享,每个分片的性能将会得到提升。
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把副本 数从默认的 1 增加到 2
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
blogs 索引现在拥有 9 个分片:3 个主分片和 6 个副本分片。 这意味着我们可以将集群扩 容到 9 个节点,每个节点上一个分片。相比原来 3 个节点时,集群搜索性能可以提升3 倍。

6.应对故障

- 我们关闭的节点是一个主节点。而集群必须拥有一个主节点来保证正常工作,所以发生 的第一件事情就是选举一个新的主节点: Node 2 。
- 在我们关闭 Node 1 的同时也失去了主分片 1 和 2 ,并且在缺失主分片的时候索引 也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为 red :不是所 有主分片都在正常工作。
- 幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这 些分片在 Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会 为 yellow 。 这个提升主分片的过程是瞬间发生的,如同按下一个开关一般。
- 为什么我们集群状态是 yellow 而不是 green 呢? 虽然我们拥有所有的三个主分片, 但是同时设置了每个主分片需要对应 2 份副本分片,而此时只存在一份副本分片。 所 以集群不能为 green 的状态,不过我们不必过于担心:如果我们同样关闭了 Node 2 , 我们的程序 依然 可以保持在不丢任何数据的情况下运行,因为 Node 3 为每一个分 片都保留着一份副本。
- 如果我们重新启动 Node 1 ,集群可以将缺失的副本分片再次进行分配。如果 Node 1依然拥有着之前的分片,它将尝试去重用它们,同时仅从主分片复制发生了修改的数据 文件。
7.问题与解决
1、主节点
主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch 中的主节点的工作量相对较轻,用户的请求可以发往集群中任何一个节点,由该节点负责分 发和返回结果,而不需要经过主节点转发。而主节点是由候选主节点通过 ZenDiscovery 机 制选举出来的,所以要想成为主节点,首先要先成为候选主节点。
2、候选主节点
在 elasticsearch 集群初始化或者主节点宕机的情况下,由候选主节点中选举其中一个作为主 节点。指定候选主节点的配置为:node.master: true。 当主节点负载压力过大,或者集中环境中的网络问题,导致其他节点与主节点通讯的时候, 主节点没来的及响应,这样的话,某些节点就认为主节点宕机,重新选择新的主节点,这样 的话整个集群的工作就有问题了,比如我们集群中有 10 个节点,其中 7 个候选主节点,1 个候选主节点成为了主节点,这种情况是正常的情况。但是如果现在出现了我们上面所说的 主节点响应不及时,导致其他某些节点认为主节点宕机而重选主节点,那就有问题了,这剩 下的 6 个候选主节点可能有 3 个候选主节点去重选主节点,最后集群中就出现了两个主节点 的情况,这种情况官方成为“脑裂现象”; 集群中不同的节点对于 master 的选择出现了分歧,出现了多个 master 竞争,导致主分片 和副本的识别也发生了分歧,对一些分歧中的分片标识为了坏片。
3、数据节点
数据节点负责数据的存储和相关具体操作,比如 CRUD、搜索、聚合。所以,数据节点对机 器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统 CPU、 Memory 和 IO 的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高 可用性。指定数据节点的配置:node.data: true。 elasticsearch 是允许一个节点既做候选主节点也做数据节点的,但是数据节点的负载较重, 所以需要考虑将二者分离开,设置专用的候选主节点和数据节点,避免因数据节点负载重导 致主节点不响应。
4、客户端节点
客户端节点就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等等, 但是这样的工作,其实任何一个节点都可以完成,因为在 elasticsearch 中一个集群内的节点 都可以执行任何请求,其会负责将请求转发给对应的节点进行处理。所以单独增加这样的节 点更多是为了负载均衡。指定该节点的配置为: node.master: false node.data: false
5、脑裂”问题可能的成因
1.网络问题:集群间的网络延迟导致一些节点访问不到 master,认为 master 挂掉了从而选 举出新的 master,并对 master 上的分片和副本标红,分配新的主分片
2.节点负载:主节点的角色既为 master 又为 data,访问量较大时可能会导致 ES 停止响应造 成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
3.内存回收:data 节点上的 ES 进程占用的内存较大,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。
- 脑裂问题解决方案:
- 角色分离:即 master 节点与 data 节点分离,限制角色;数据节点是需要承担存储 和搜索的工作的,压力会很大。所以如果该节点同时作为候选主节点和数据节点, 那么一旦选上它作为主节点了,这时主节点的工作压力将会非常大,出现脑裂现象 的概率就增加了。
- 减少误判:配置主节点的响应时间,在默认情况下,主节点 3 秒没有响应,其他节 点就认为主节点宕机了,那我们可以把该时间设置的长一点,该配置是: discovery.zen.ping_timeout: 5
- 选举触发:discovery.zen.minimum_master_nodes:1(默认是 1),该属性定义的是 为了形成一个集群,有主节点资格并互相连接的节点的最小数目。
- 一 个 有 10 节 点 的 集 群 , 且 每 个 节 点 都 有 成 为 主 节 点 的 资 格 , discovery.zen.minimum_master_nodes 参数设置为 6。
- 正常情况下,10 个节点,互相连接,大于 6,就可以形成一个集群。
- 若某个时刻,其中有 3 个节点断开连接。剩下 7 个节点,大于 6,继续运行之 前的集群。而断开的 3 个节点,小于 6,不能形成一个集群。
- 该参数就是为了防止”脑裂”的产生。
- 建议设置为(候选主节点数 / 2) + 1,
8.集群结构
以三台物理机为例。在这三台物理机上,搭建了 6 个 ES 的节点,三个 data 节点,三个 master 节点(每台物理机分别起了一个 data 和一个 master),3 个 master 节点,目的是达到(n/2) +1 等于 2 的要求,这样挂掉一台 master 后(不考虑 data),n 等于 2,满足参数,其他两 个 master 节点都认为 master 挂掉之后开始重新选举,
master 节点上
node.master = true
node.data = false
discovery.zen.minimum_master_nodes = 2
data 节点上
node.master = false
node.data = true
7.9ElasticSearch-集群搭建
设置max_map_count
vm.max_map_count 是一个内核参数,表示一个进程可以拥有的最大内存映射区域数量。将其设置为 262144 增加了该限制,这在需要大量内存映射的应用程序(如某些数据库或大型应用程序)中可能会有所帮助。
所有之前先运行
sysctl -w vm.max_map_count=262144

我们只是测试,所以临时修改。永久修改使用下面
#防止 JVM 报错
echo vm.max_map_count=262144 >> /etc/sysctl.conf
sysctl -p
准备 docker 网络
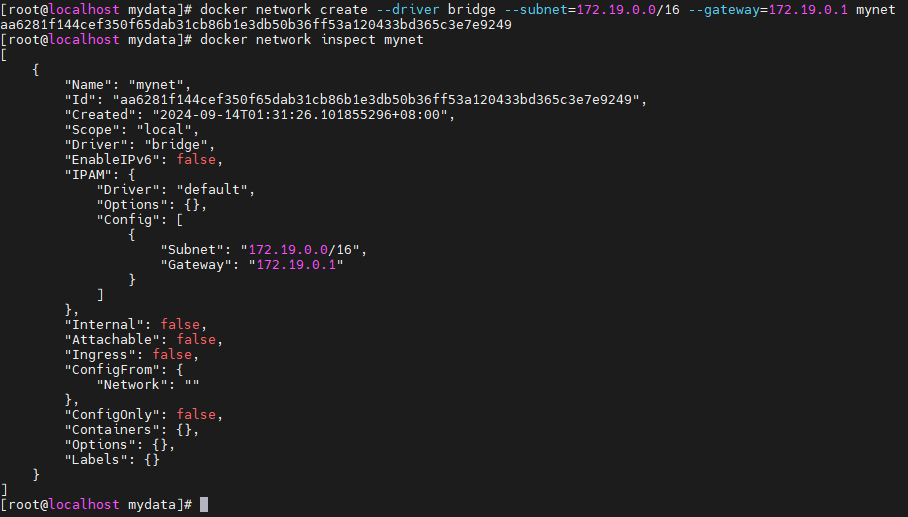
创建一个新的 bridge 网络
docker network create --driver bridge --subnet=172.19.0.0/16 --gateway=172.19.0.1 mynet
查看网络信息,以后使用--network=mynet --ip 172.18.12.x 指定 ip
docker network inspect mynet
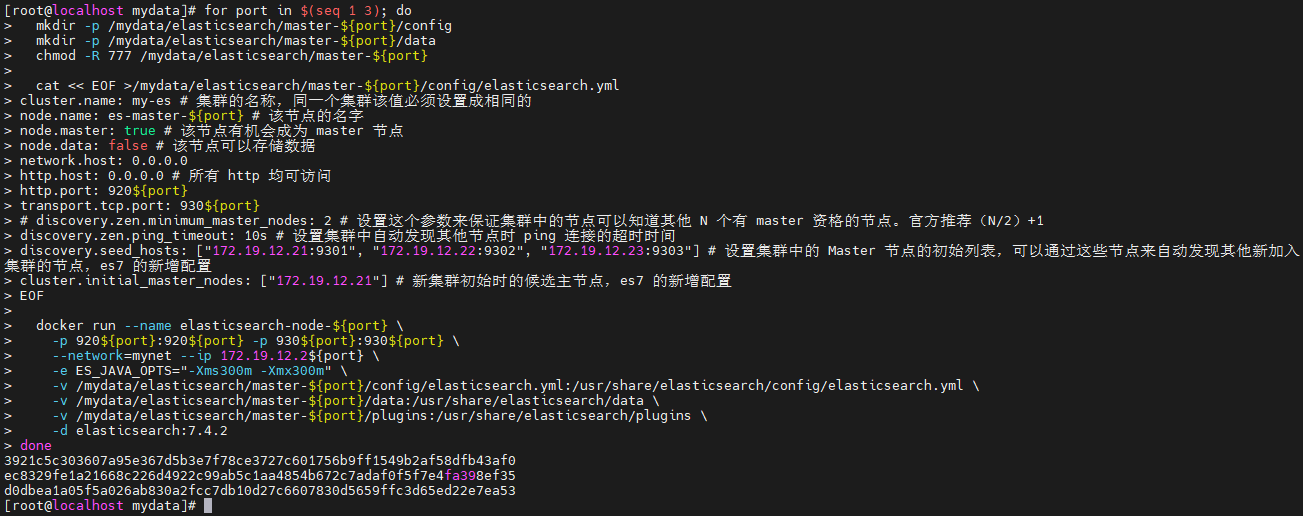
创建Master节点
for port in $(seq 1 3); do
mkdir -p /mydata/elasticsearch/master-${port}/config
mkdir -p /mydata/elasticsearch/master-${port}/data
chmod -R 777 /mydata/elasticsearch/master-${port}
cat << EOF >/mydata/elasticsearch/master-${port}/config/elasticsearch.yml
cluster.name: my-es # 集群的名称,同一个集群该值必须设置成相同的
node.name: es-master-${port} # 该节点的名字
node.master: true # 该节点有机会成为 master 节点
node.data: false # 该节点可以存储数据
network.host: 0.0.0.0
http.host: 0.0.0.0 # 所有 http 均可访问
http.port: 920${port}
transport.tcp.port: 930${port}
# discovery.zen.minimum_master_nodes: 2 # 设置这个参数来保证集群中的节点可以知道其他 N 个有 master 资格的节点。官方推荐(N/2)+1
discovery.zen.ping_timeout: 10s # 设置集群中自动发现其他节点时 ping 连接的超时时间
discovery.seed_hosts: ["172.19.12.21:9301", "172.19.12.22:9302", "172.19.12.23:9303"] # 设置集群中的 Master 节点的初始列表,可以通过这些节点来自动发现其他新加入集群的节点,es7 的新增配置
cluster.initial_master_nodes: ["172.19.12.21"] # 新集群初始时的候选主节点,es7 的新增配置
EOF
docker run --name elasticsearch-node-${port} \
-p 920${port}:920${port} -p 930${port}:930${port} \
--network=mynet --ip 172.19.12.2${port} \
-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \
-v /mydata/elasticsearch/master-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/master-${port}/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/master-${port}/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
done
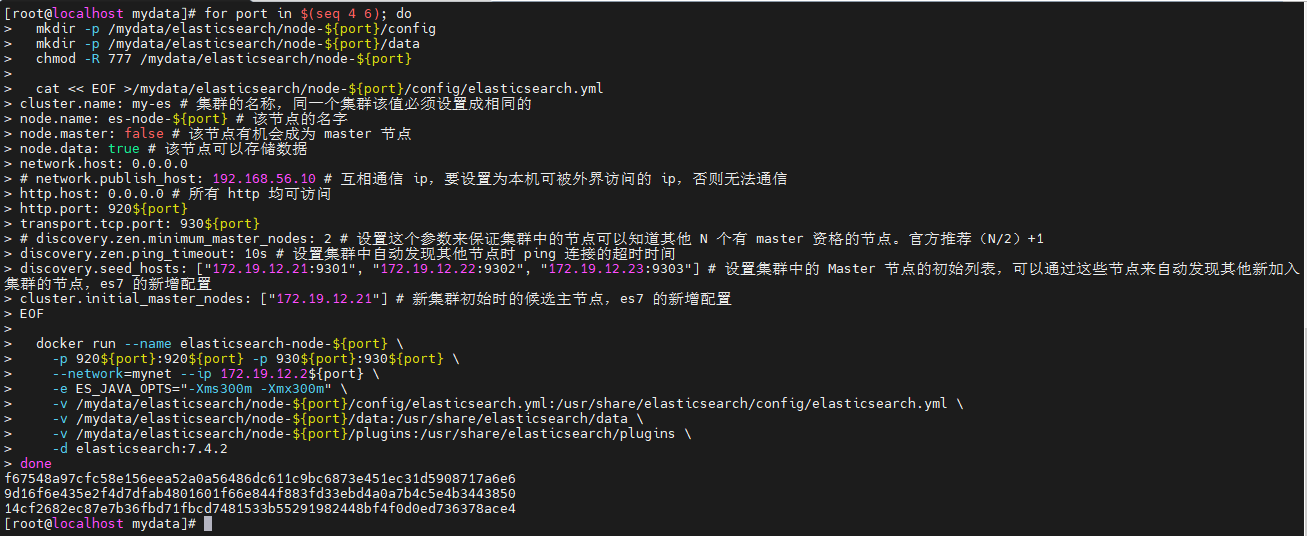
创建Data-Node节点
for port in $(seq 4 6); do
mkdir -p /mydata/elasticsearch/node-${port}/config
mkdir -p /mydata/elasticsearch/node-${port}/data
chmod -R 777 /mydata/elasticsearch/node-${port}
cat << EOF >/mydata/elasticsearch/node-${port}/config/elasticsearch.yml
cluster.name: my-es # 集群的名称,同一个集群该值必须设置成相同的
node.name: es-node-${port} # 该节点的名字
node.master: false # 该节点有机会成为 master 节点
node.data: true # 该节点可以存储数据
network.host: 0.0.0.0
# network.publish_host: 192.168.56.10 # 互相通信 ip,要设置为本机可被外界访问的 ip,否则无法通信
http.host: 0.0.0.0 # 所有 http 均可访问
http.port: 920${port}
transport.tcp.port: 930${port}
# discovery.zen.minimum_master_nodes: 2 # 设置这个参数来保证集群中的节点可以知道其他 N 个有 master 资格的节点。官方推荐(N/2)+1
discovery.zen.ping_timeout: 10s # 设置集群中自动发现其他节点时 ping 连接的超时时间
discovery.seed_hosts: ["172.19.12.21:9301", "172.19.12.22:9302", "172.19.12.23:9303"] # 设置集群中的 Master 节点的初始列表,可以通过这些节点来自动发现其他新加入集群的节点,es7 的新增配置
cluster.initial_master_nodes: ["172.19.12.21"] # 新集群初始时的候选主节点,es7 的新增配置
EOF
docker run --name elasticsearch-node-${port} \
-p 920${port}:920${port} -p 930${port}:930${port} \
--network=mynet --ip 172.19.12.2${port} \
-e ES_JAVA_OPTS="-Xms300m -Xmx300m" \
-v /mydata/elasticsearch/node-${port}/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/node-${port}/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/node-${port}/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
done
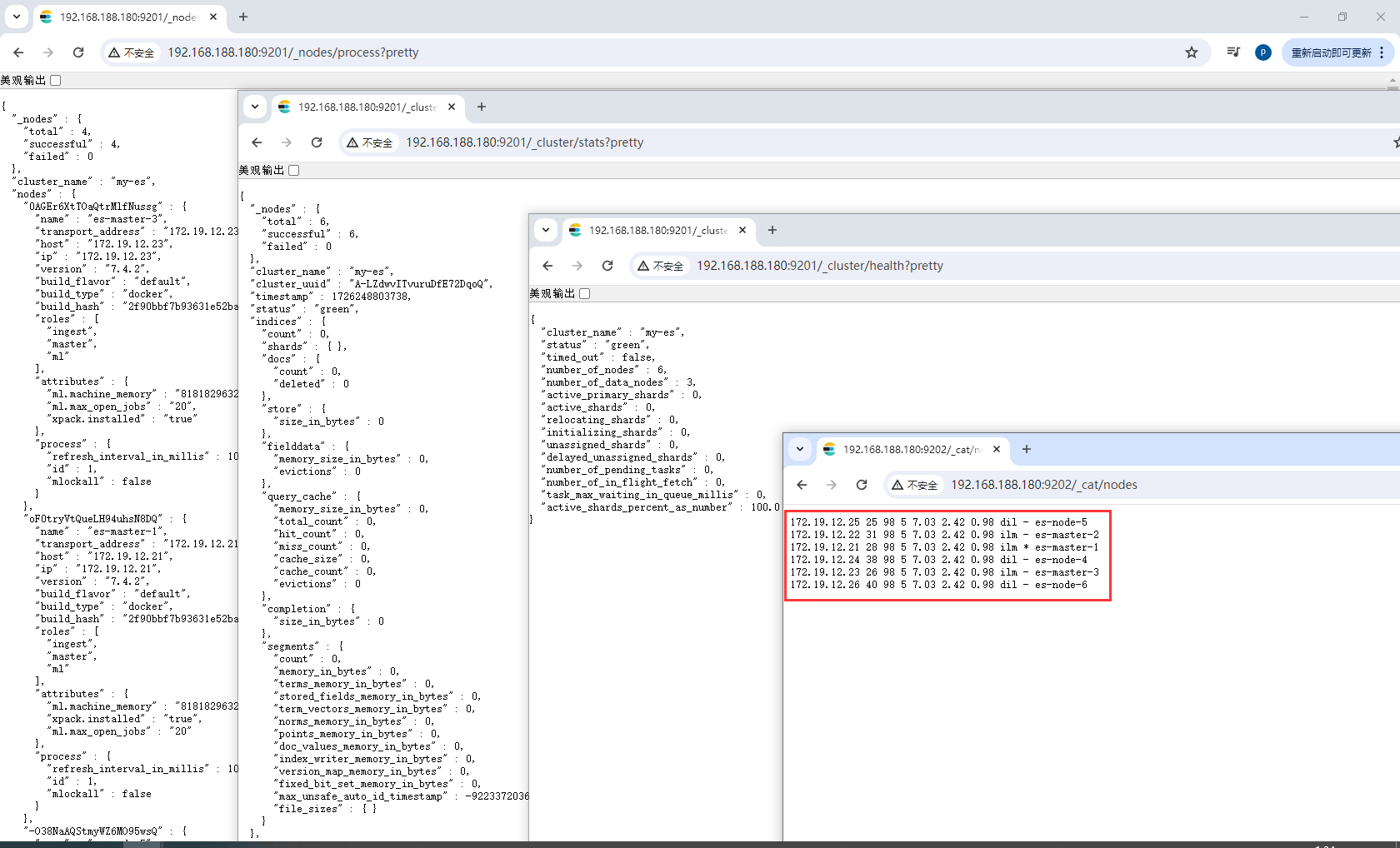
测试集群
http://192.168.188.180:9201/_nodes/process?pretty 查看节点状况
http://192.168.188.180:9201/_cluster/stats?pretty 查看集群状态
http://192.168.188.180:9201/_cluster/health?pretty 查看集群健康状况
http://192.168.188.180:9202/_cat/nodes 查看各个节点信息
$ curl localhost:9200/_cat
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
7.10RabbitMQ-镜像集群搭建
7.10.1集群形式
RabbiMQ 是用 Erlang 开发的,集群非常方便,因为 Erlang 天生就是一门分布式语言,但其 本身并不支持负载均衡。
RabbitMQ 集群中节点包括内存节点(RAM)、磁盘节点(Disk,消息持久化),集群中至少有 一个 Disk 节点。
- 普通模式(默认)
对于普通模式,集群中各节点有相同的队列结构,但消息只会存在于集群中的一个节 点。对于消费者来说,若消息进入 A 节点的 Queue 中,当从 B 节点拉取时,RabbitMQ 会 将消息从 A 中取出,并经过 B 发送给消费者。 应用场景:该模式各适合于消息无需持久化的场合,如日志队列。当队列非持久化,且 创建该队列的节点宕机,客户端才可以重连集群其他节点,并重新创建队列。若为持久化, 只能等故障节点恢复。
- 镜像模式
与普通模式不同之处是消息实体会主动在镜像节点间同步,而不是在取数据时临时拉 取,高可用;该模式下,mirror queue 有一套选举算法,即 1 个 master、n 个 slaver,生产 者、消费者的请求都会转至 master。
应用场景:可靠性要求较高场合,如下单、库存队列。
缺点:若镜像队列过多,且消息体量大,集群内部网络带宽将会被此种同步通讯所消 耗。
(1)镜像集群也是基于普通集群,即只有先搭建普通集群,然后才能设置镜像队列。
(2)若消费过程中,master 挂掉,则选举新 master,若未来得及确认,则可能会重复消费。
7.10.2搭建集群
搭建集群
创建目录
mkdir /mydata/rabbitmq
cd rabbitmq/
mkdir rabbitmq01 rabbitmq02 rabbitmq03

运行rabbitmq01、rabbitmq02、rabbitmq03
docker run -d --hostname rabbitmq01 --name rabbitmq01 \
-v /mydata/rabbitmq/rabbitmq01:/var/lib/rabbitmq \
-p 15673:15672 -p 5673:5672 \
-e RABBITMQ_ERLANG_COOKIE='peng' \
rabbitmq:management
docker run -d --hostname rabbitmq02 --name rabbitmq02 \
-v /mydata/rabbitmq/rabbitmq02:/var/lib/rabbitmq \
-p 15674:15672 -p 5674:5672 \
-e RABBITMQ_ERLANG_COOKIE='peng' \
--link rabbitmq01:rabbitmq01 \
rabbitmq:management
docker run -d --hostname rabbitmq03 --name rabbitmq03 \
-v /mydata/rabbitmq/rabbitmq03:/var/lib/rabbitmq \
-p 15675:15672 -p 5675:5672 \
-e RABBITMQ_ERLANG_COOKIE='peng' \
--link rabbitmq01:rabbitmq01 \
--link rabbitmq02:rabbitmq02 \
rabbitmq:management
节点加入集群
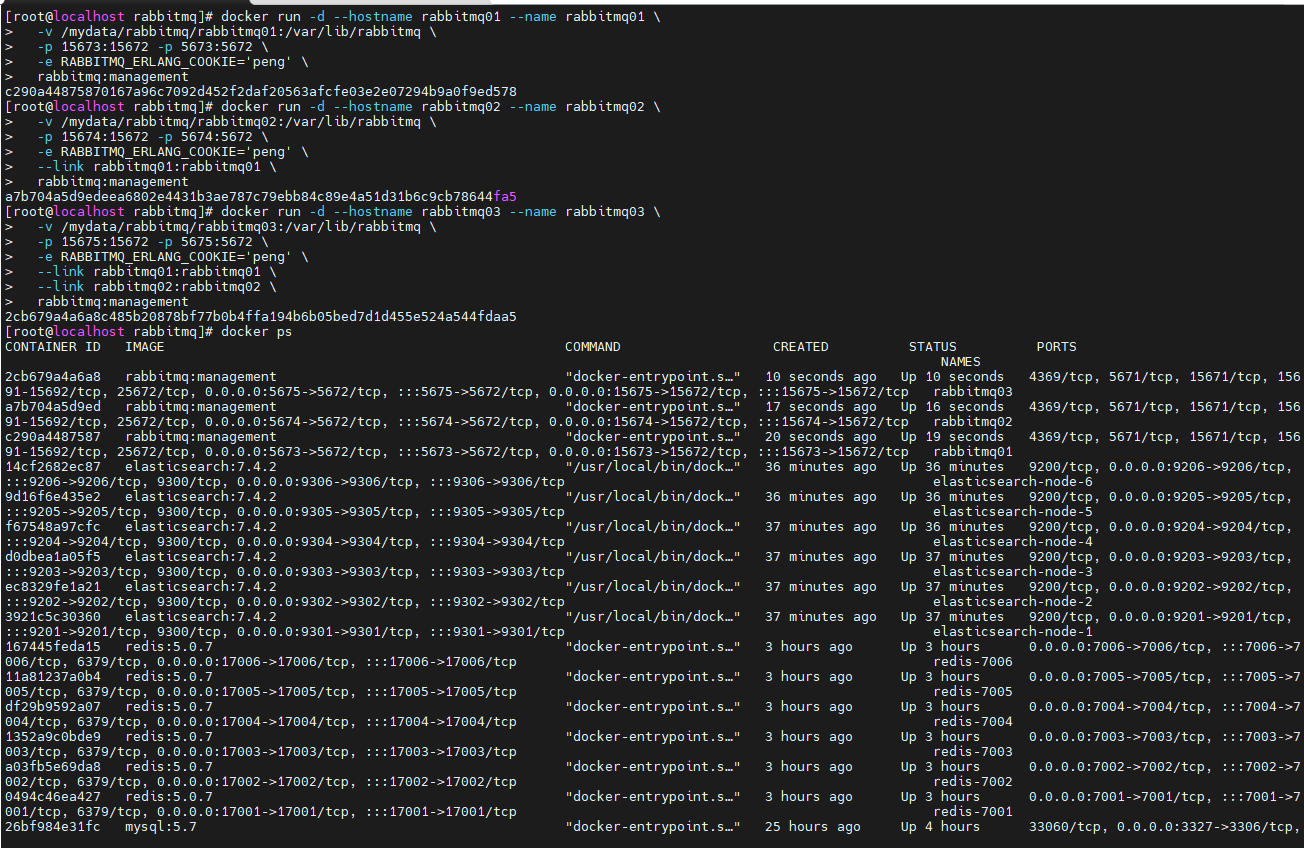
进入rabbitmq01
docker exec -it rabbitmq01 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exit
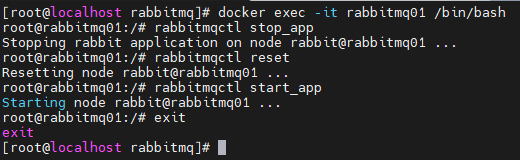
进入rabbitmq02
docker exec -it rabbitmq02 /bin/bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit
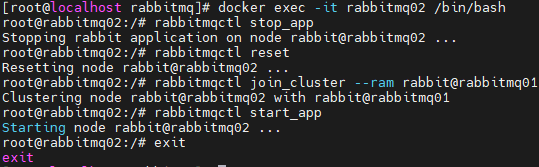
进入rabbitmq03
docker exec -it rabbitmq03 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbitmq01
rabbitmqctl start_app
exit
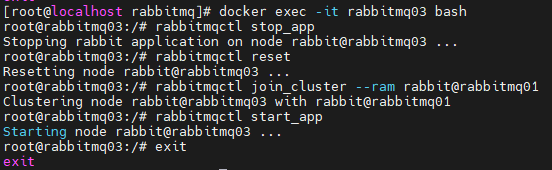
实现镜像集群
在 cluster 中任意节点启用策略,策略会自动同步到集群节点 rabbitmqctl set_policy-p/ha-all"^"’{“ha-mode”:“all”}’ 策略模式 all 即复制到所有节点,包含新增节点,策略正则表达式为 “^” 表示所有匹配所有队列名称。“^hello”表示只匹配名为 hello 开始的队列。
docker exec -it rabbitmq01 bash
rabbitmqctl set_policy -p / ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
#查看 vhost/下面的所有 policy
rabbitmqctl list_policies -p /;

测试
在http://192.168.188.180:15673/#/queues创建节点,剩下2个从节点自动同步
8.k8s部署
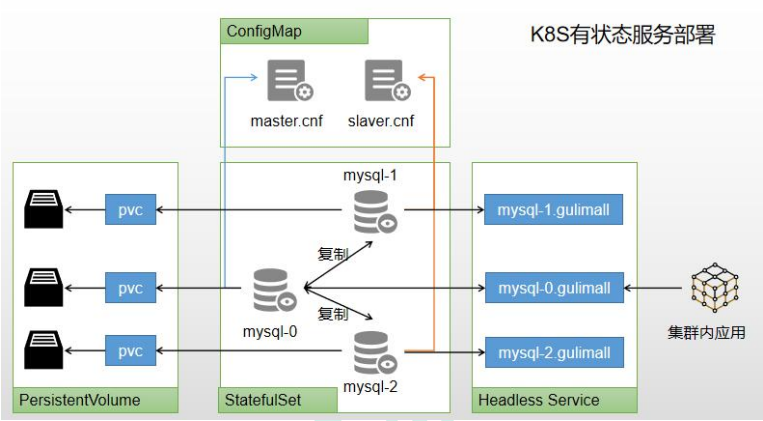
8.1如何在k8s上部署有状态应用
可以使用 kubesphere,快速搭建 MySQL 环境。
-
有状态服务抽取配置为 ConfigMap
-
有状态服务必须使用 pvc 持久化数据
-
服务集群内访问使用 DNS
8.2k8s部署MySQL
常用命令
# 创建目录
mkdir -p /mydata/mysql/master/{data,log}
mkdir -p /mydata/mysql/master/conf/{conf.d,mysql.conf.d}
# 运行
docker run -p 3317:3306 --name mysql-master \
-v /mydata/mysql/master/log:/var/log/mysql \
-v /mydata/mysql/master/data:/var/lib/mysql \
-v /mydata/mysql/master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
kubectl get statefulsets -n peng-mall
kubectl edit statefulset mysql-master-v1 -n peng-mall
kubectl get pods -n peng-mall
8.2.1部署mysql主节点
安装
- 创建配置
mysql-master-cnf - 创建存储卷
mysql-master-pvc - 创建有状态服务
创建配置mysql-master-cnf
基本信息

配置设置
my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 添加 master 主从复制部分配置
server_id=1
log-bin=mysql-bin
# 读写
read-only=0
# 只同步业务库
binlog-do-db=mall_ums
binlog-do-db=mall_pms
binlog-do-db=mall_oms
binlog-do-db=mall_sms
binlog-do-db=mall_wms
binlog-do-db=mall_admin
# 不同步mysql基础库
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
创建存储卷mysql-master-pvc
基本信息
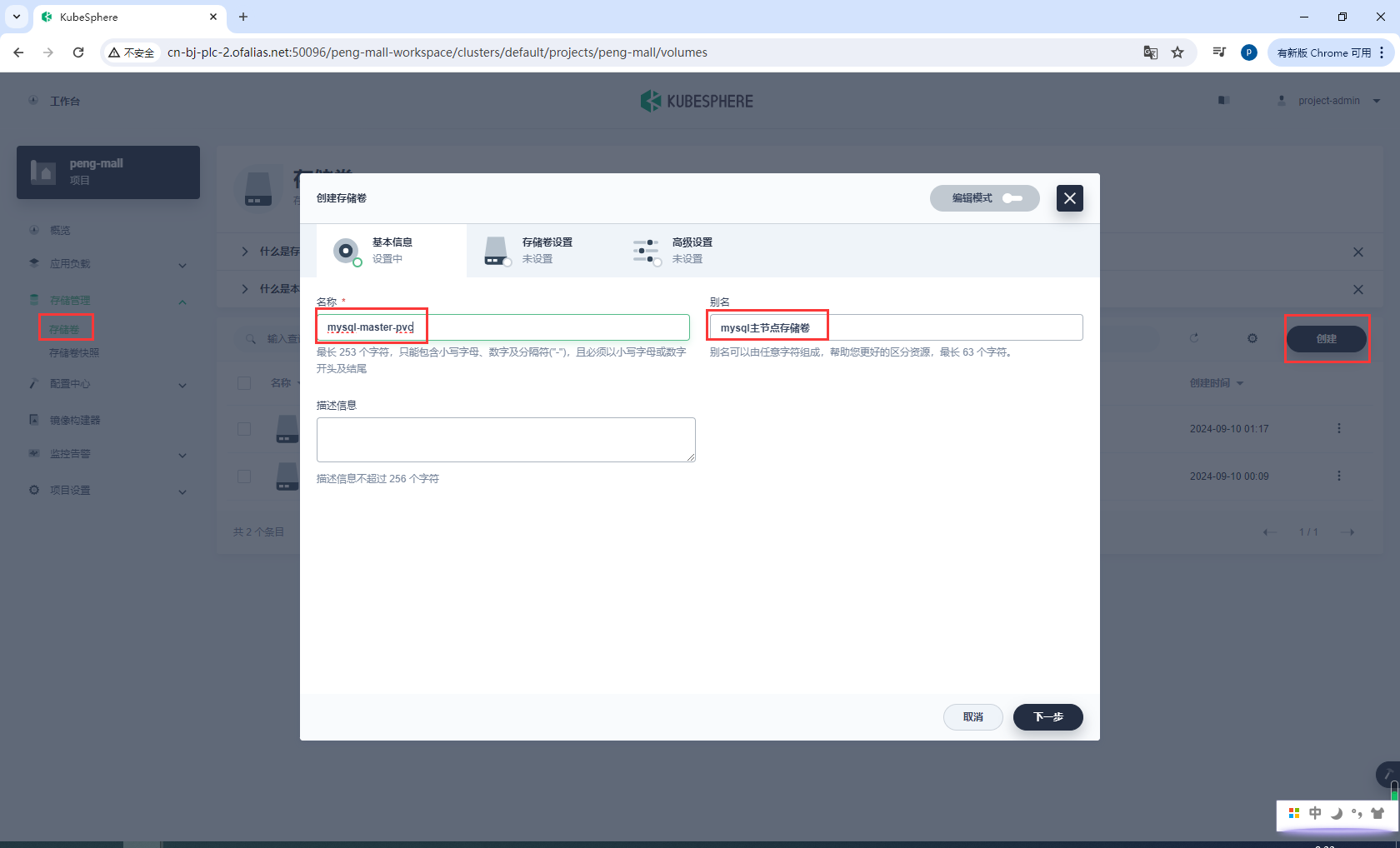
存储卷设置
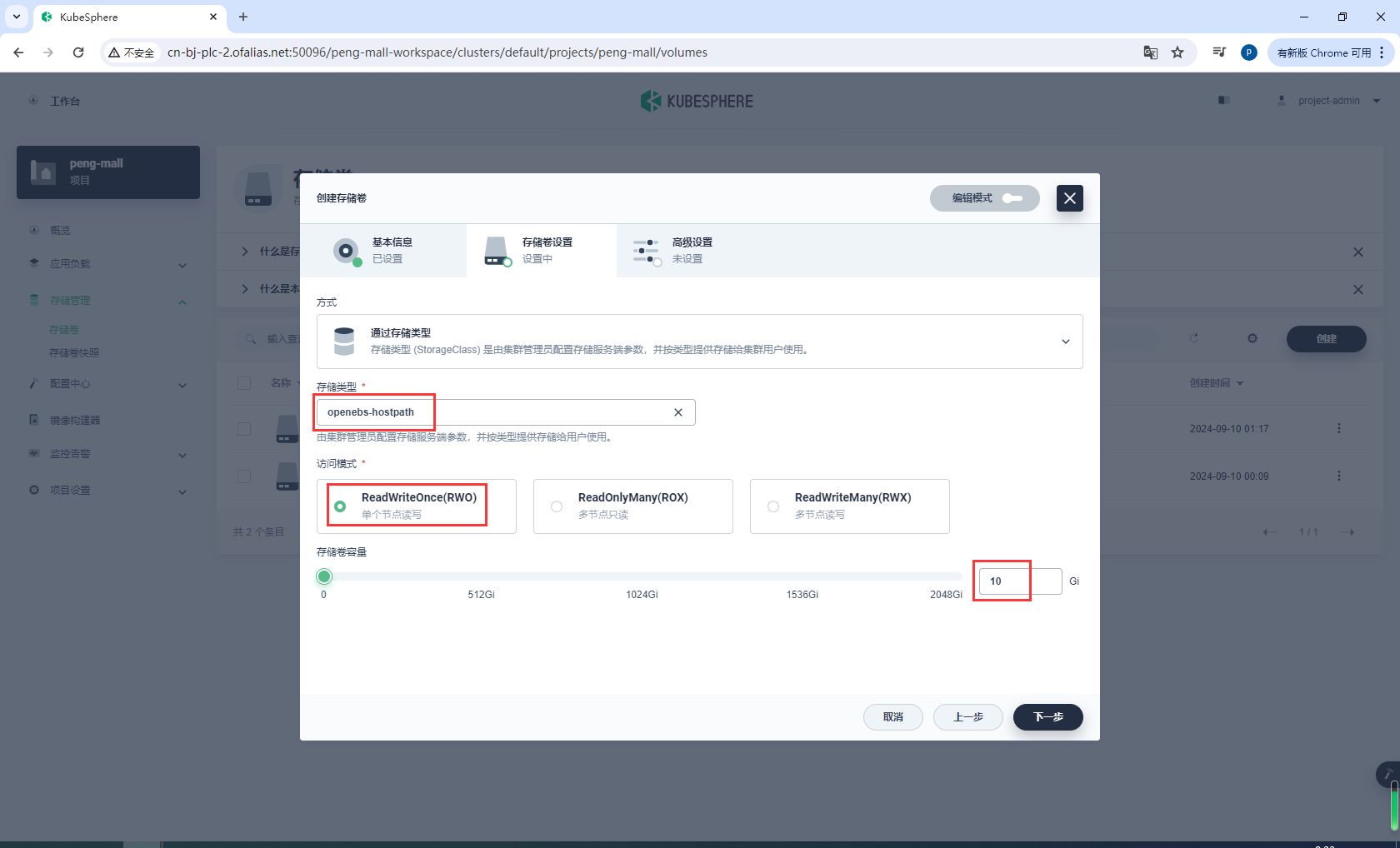
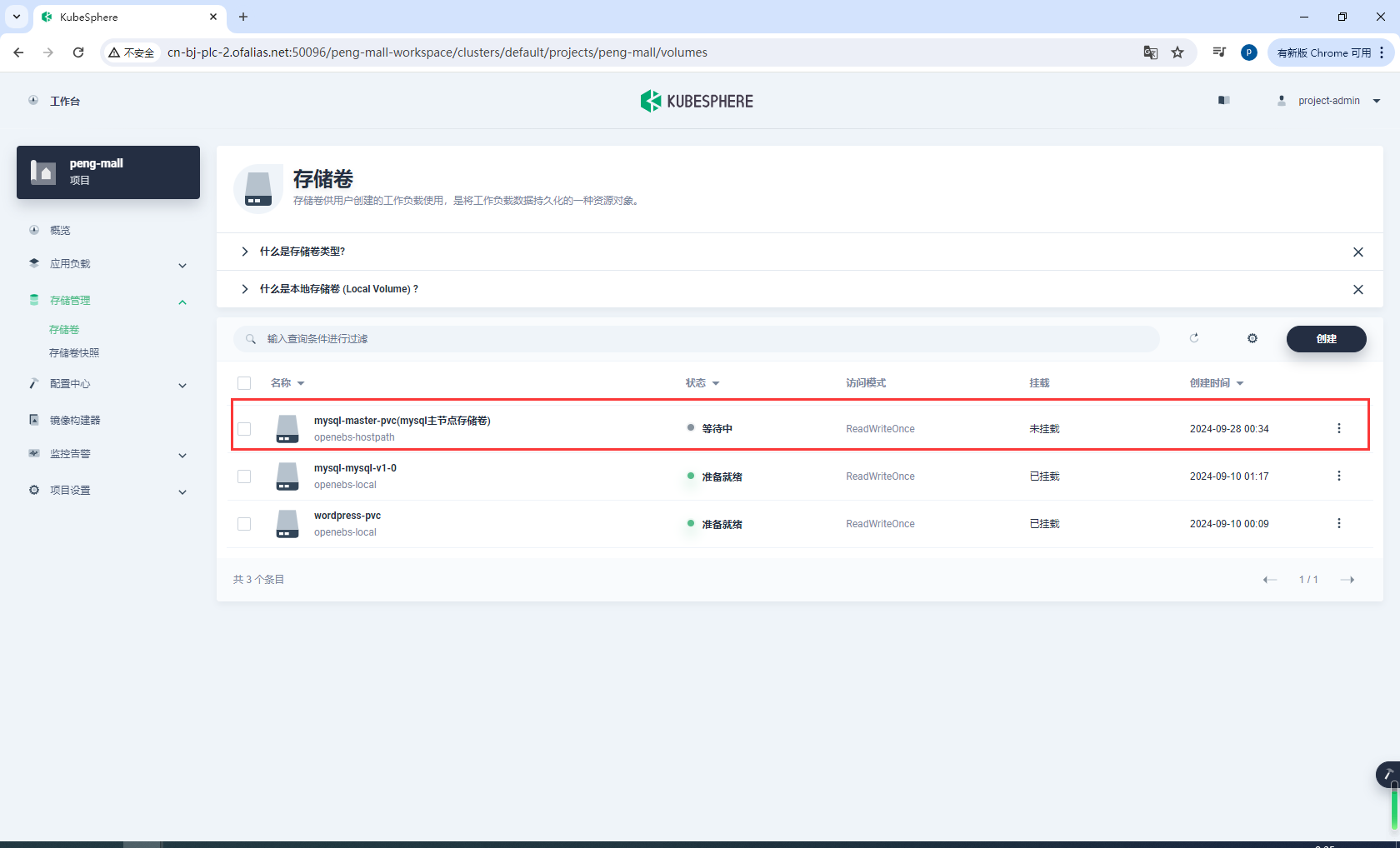
创建有状态服务
基本信息
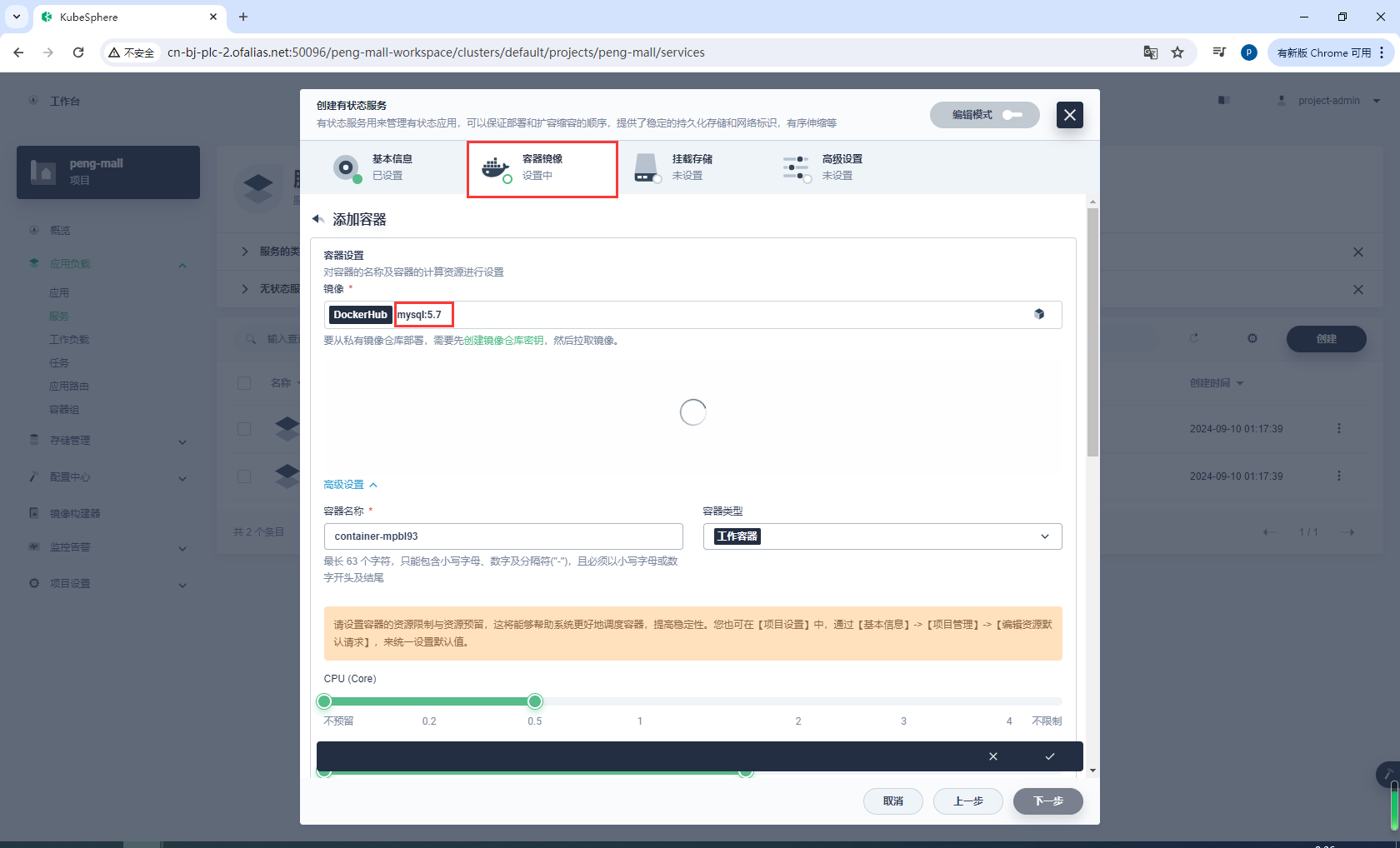
镜像设置
如果一直查询不出来mysql:5.7,使用命令行工具docker search mysql:5.7查询一下,我学习的这几个月docker地址老是被墙
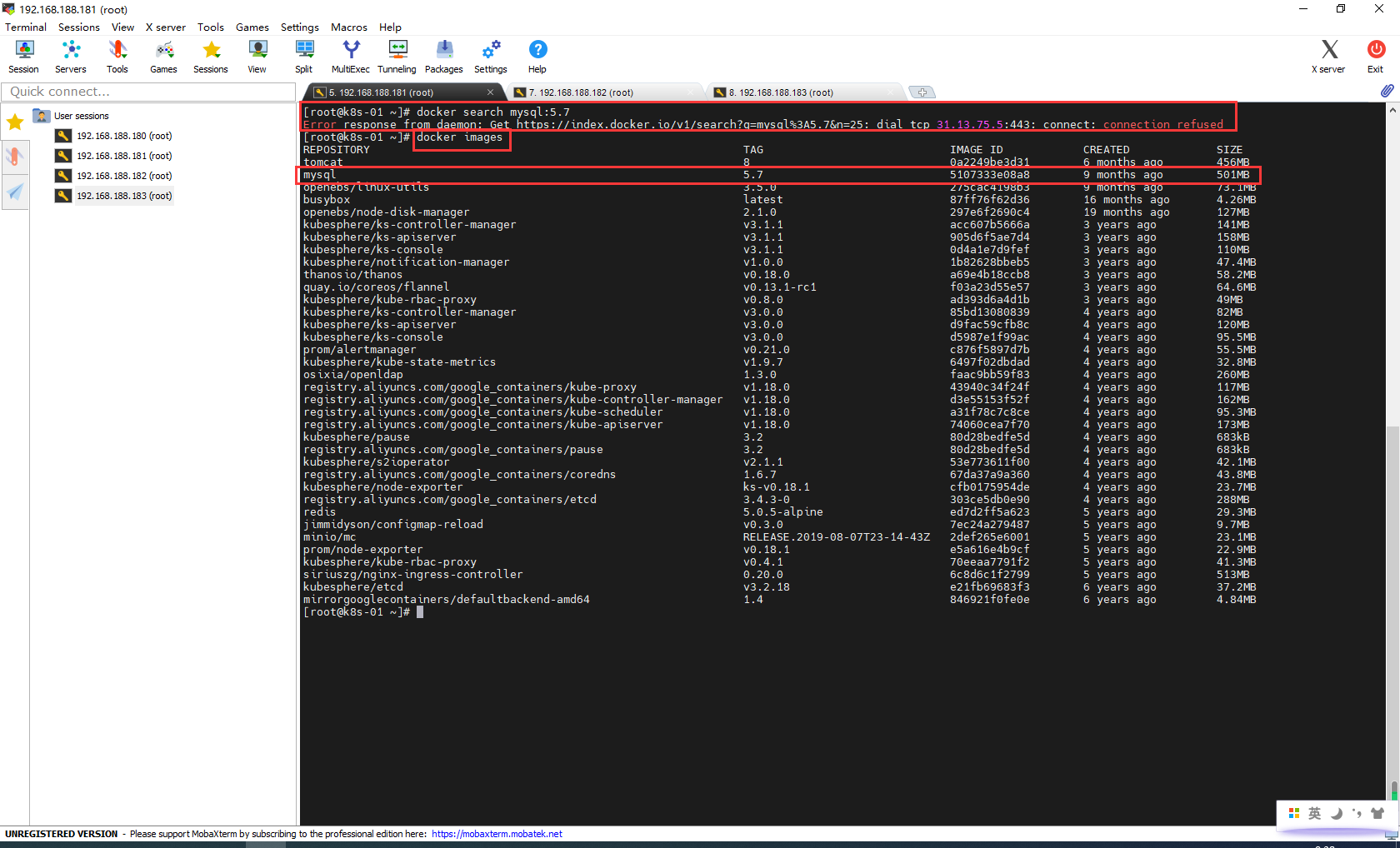
解决办法:
docker search不能使用镜像加速,但是pull可以下载镜像,提前把mysql:5.7镜像下载下来
分享我的daemon.json,如果后面还不能用,自己上网再查找即可
cat << EOF > /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://dockerproxy.cn",
"https://docker.rainbond.cc",
"https://docker.udayun.com",
"https://docker.211678.top",
"https://hub.rat.dev",
"https://docker.wanpeng.top",
"https://doublezonline.cloud",
"https://docker.mrxn.net",
"https://lynn520.xyz",
"https://ginger20240704.asia",
"https://docker.wget.at",
"https://dislabaiot.xyz",
"https://dockerpull.com",
"https://docker.fxxk.dedyn.io",
"https://docker.m.daocloud.io"
],
"live-restore": true,
"log-driver": "json-file",
"log-opts": {"max-size": "500m", "max-file": "3"},
"storage-driver": "overlay2"
}
EOF
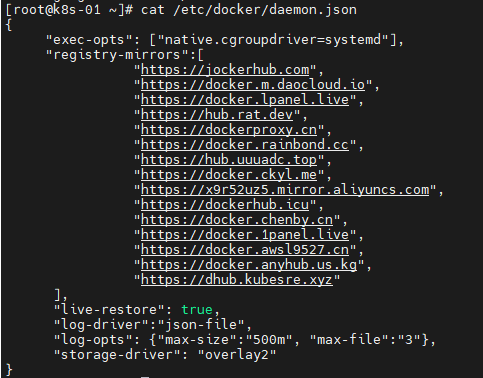
然后重启
sudo systemctl daemon-reload
sudo systemctl restart docker
我这里三个节点都下载了mysql:5.7,你也不知道mysql会安装在那个子节点上
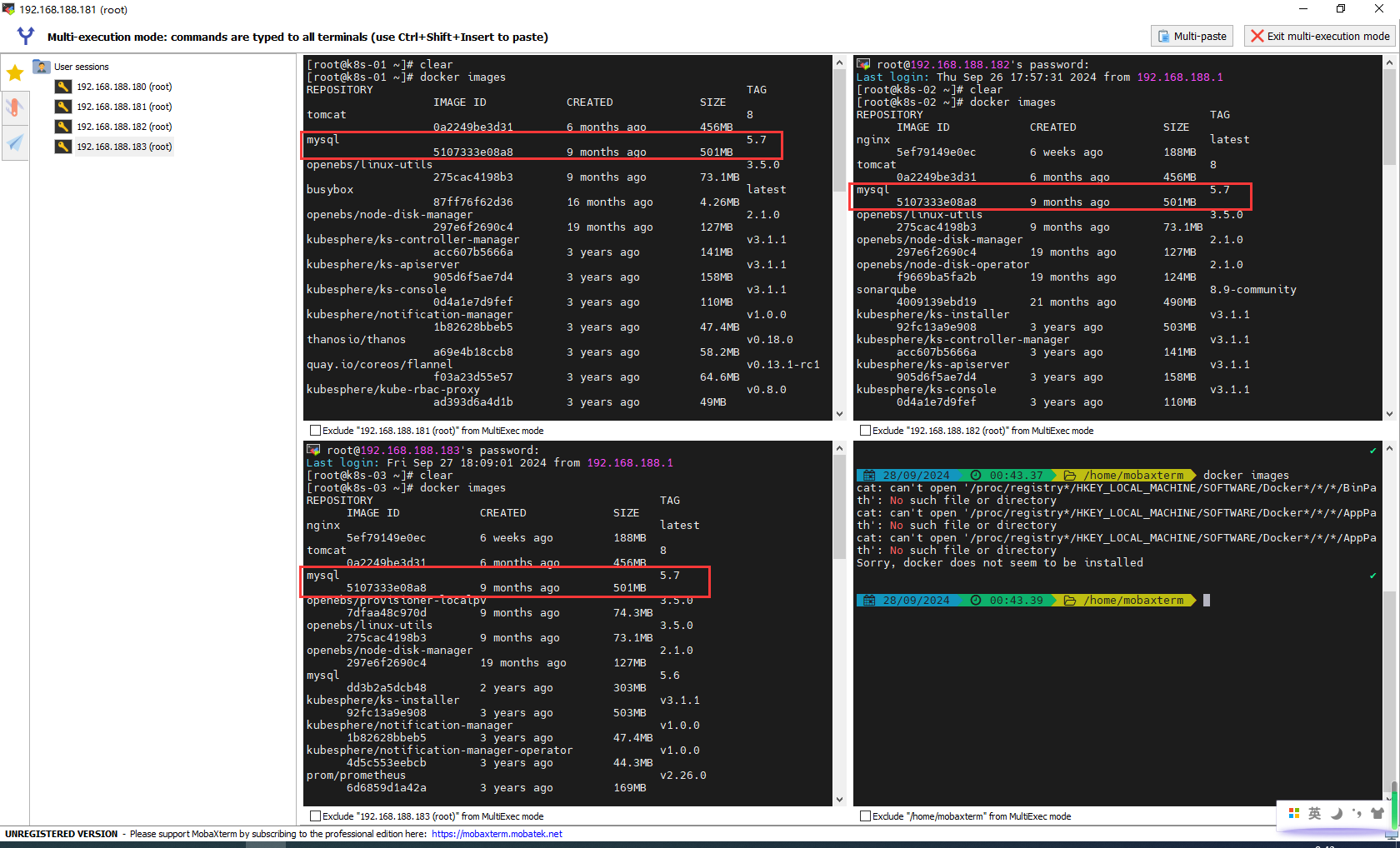
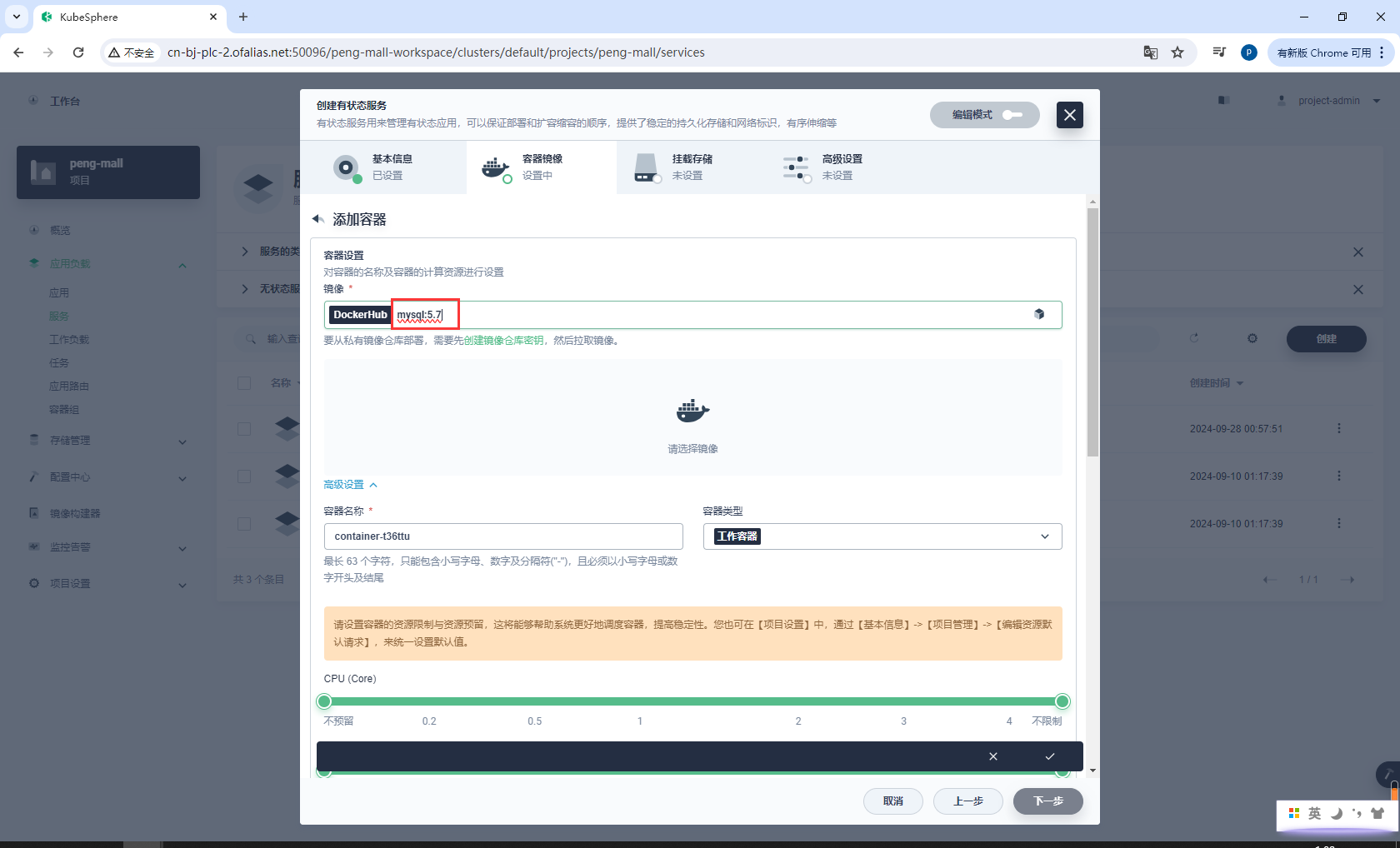
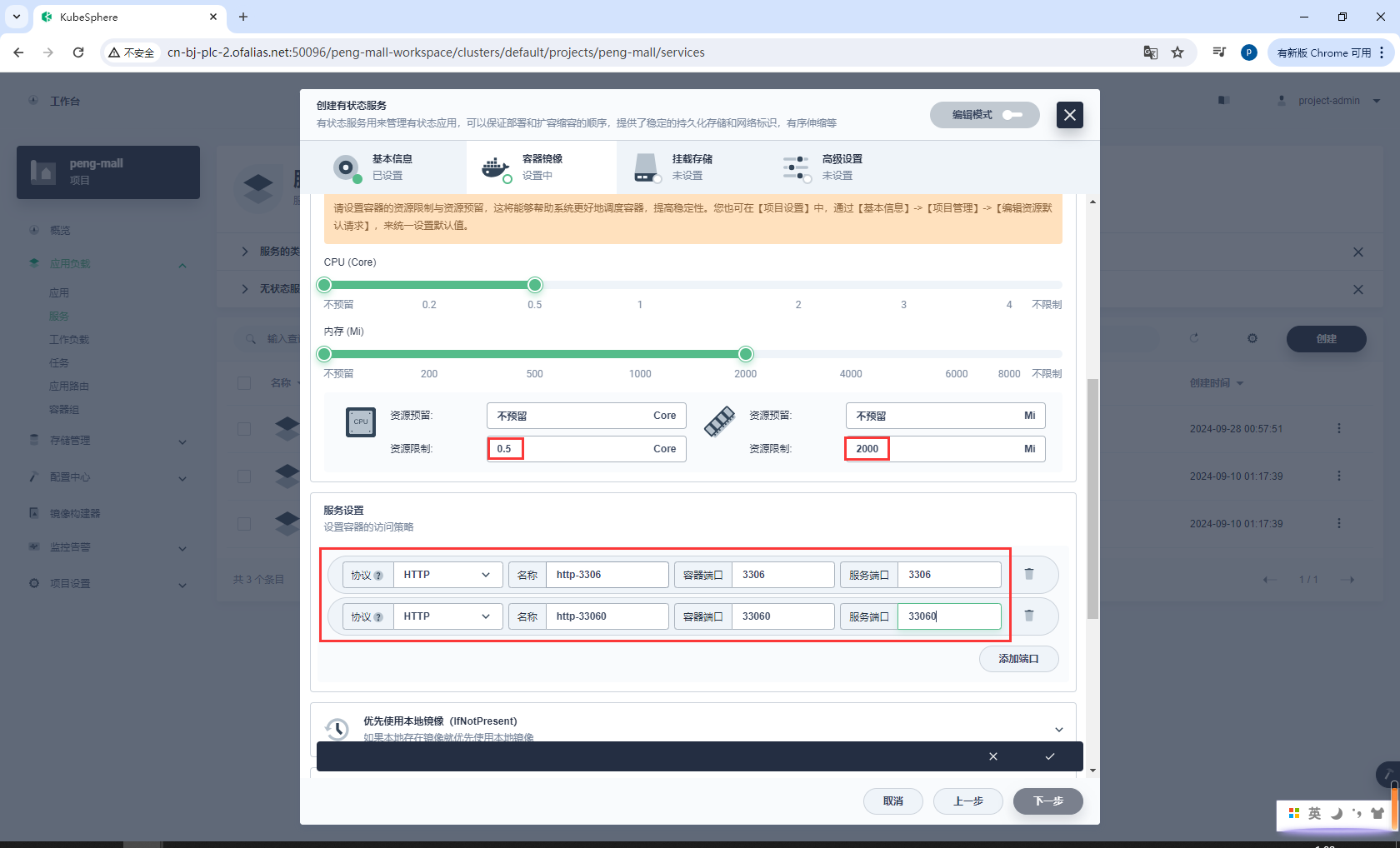
服务设置资源、端口
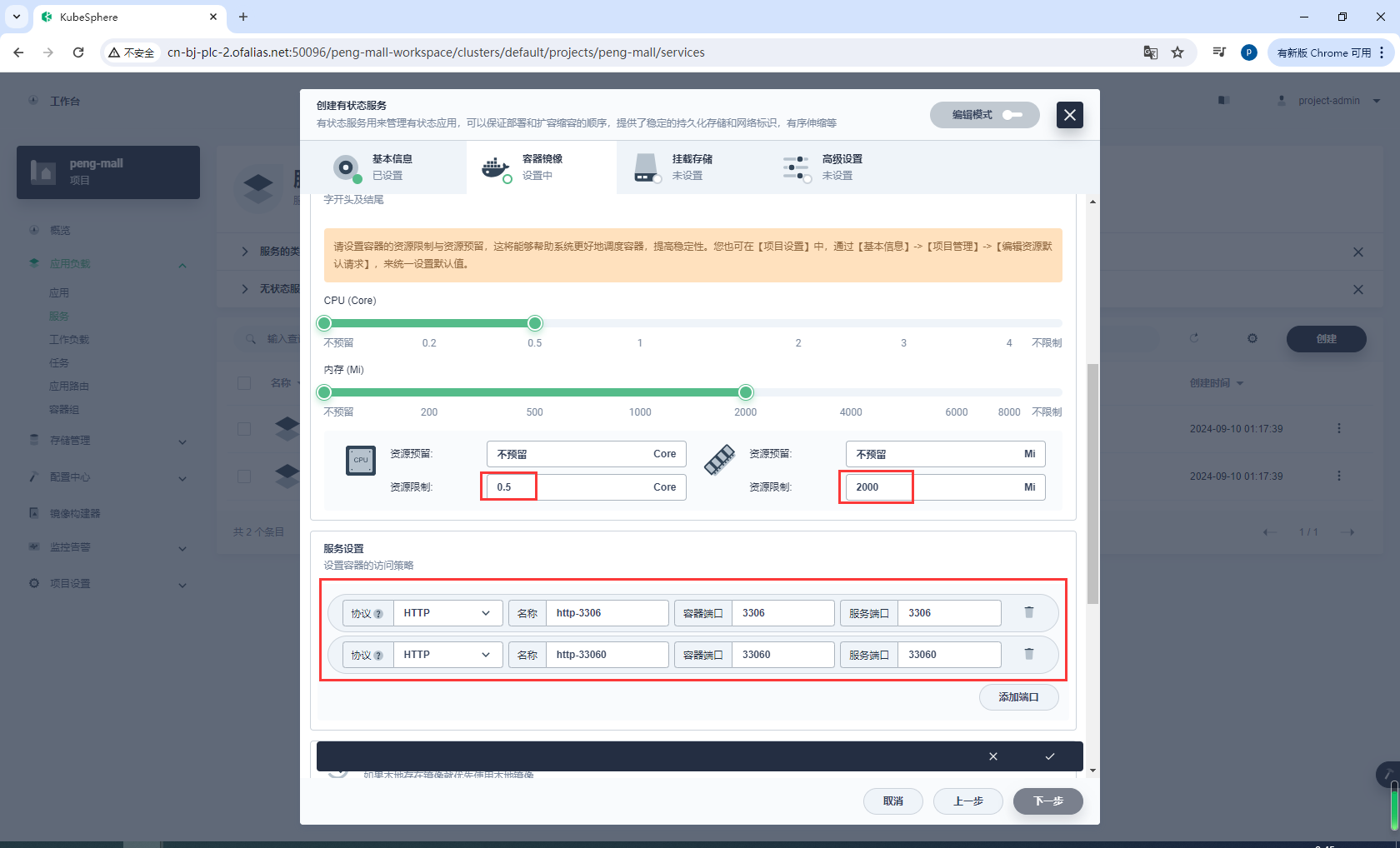
镜像下载完成后记得选择优先使用本地镜像
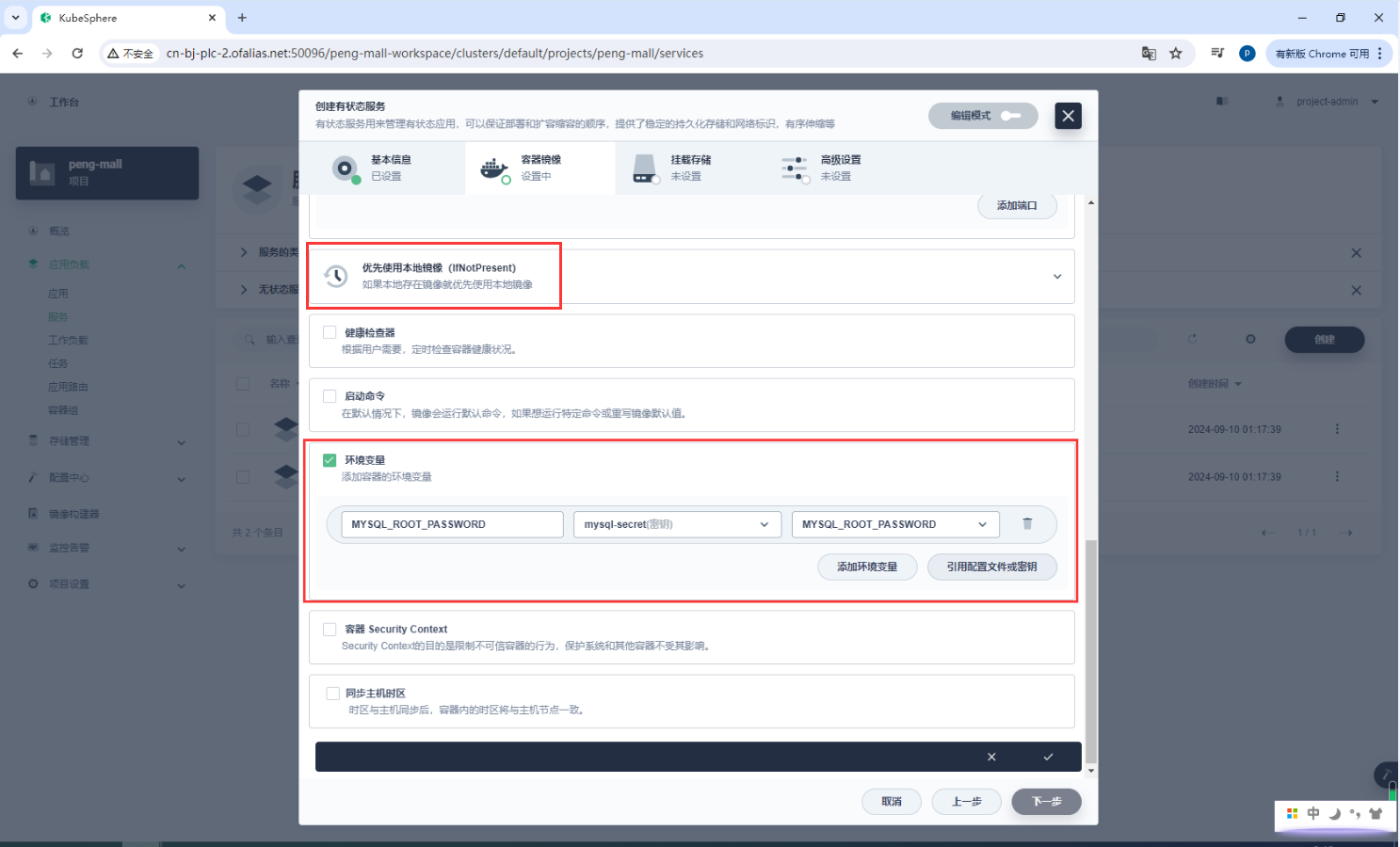
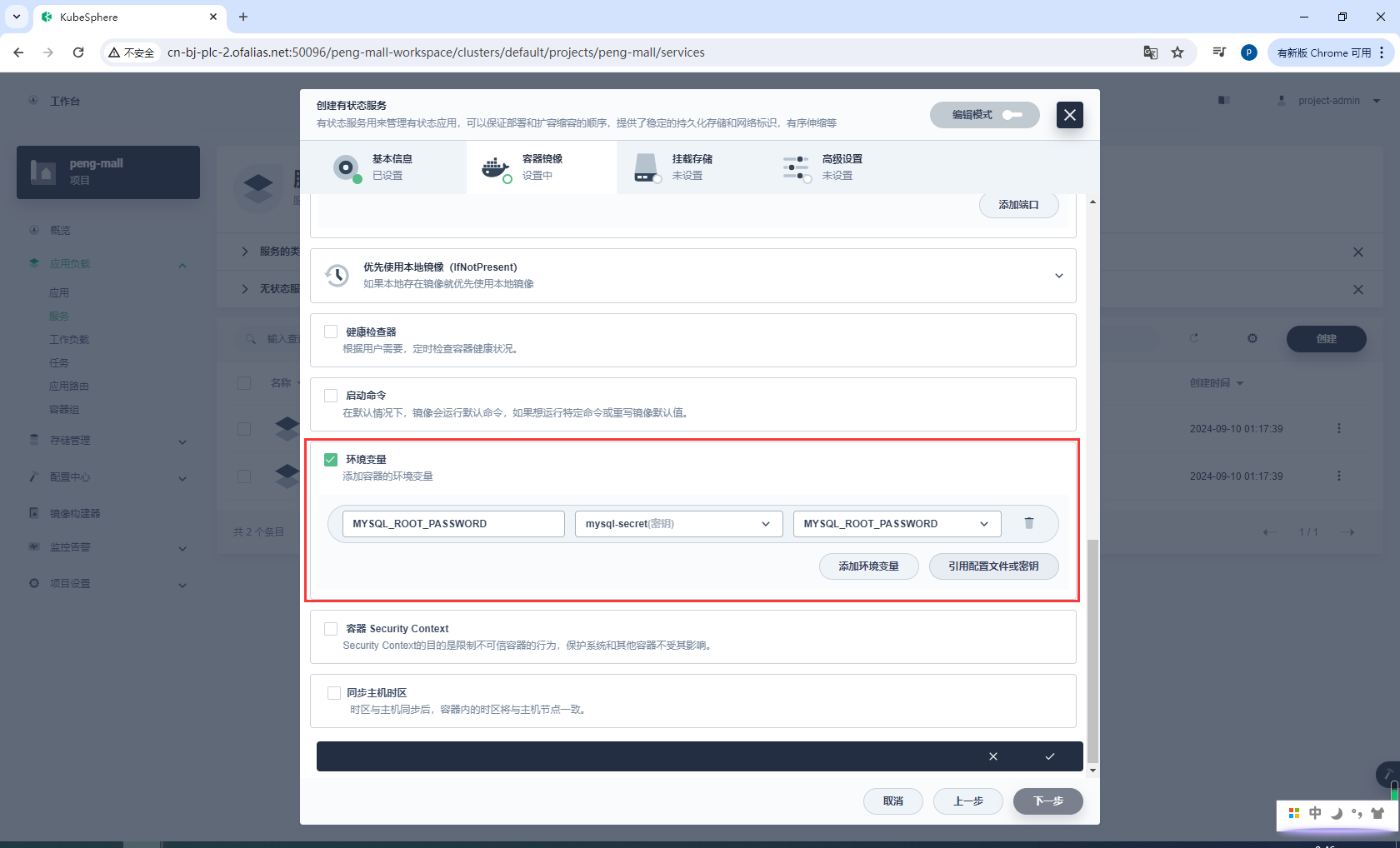
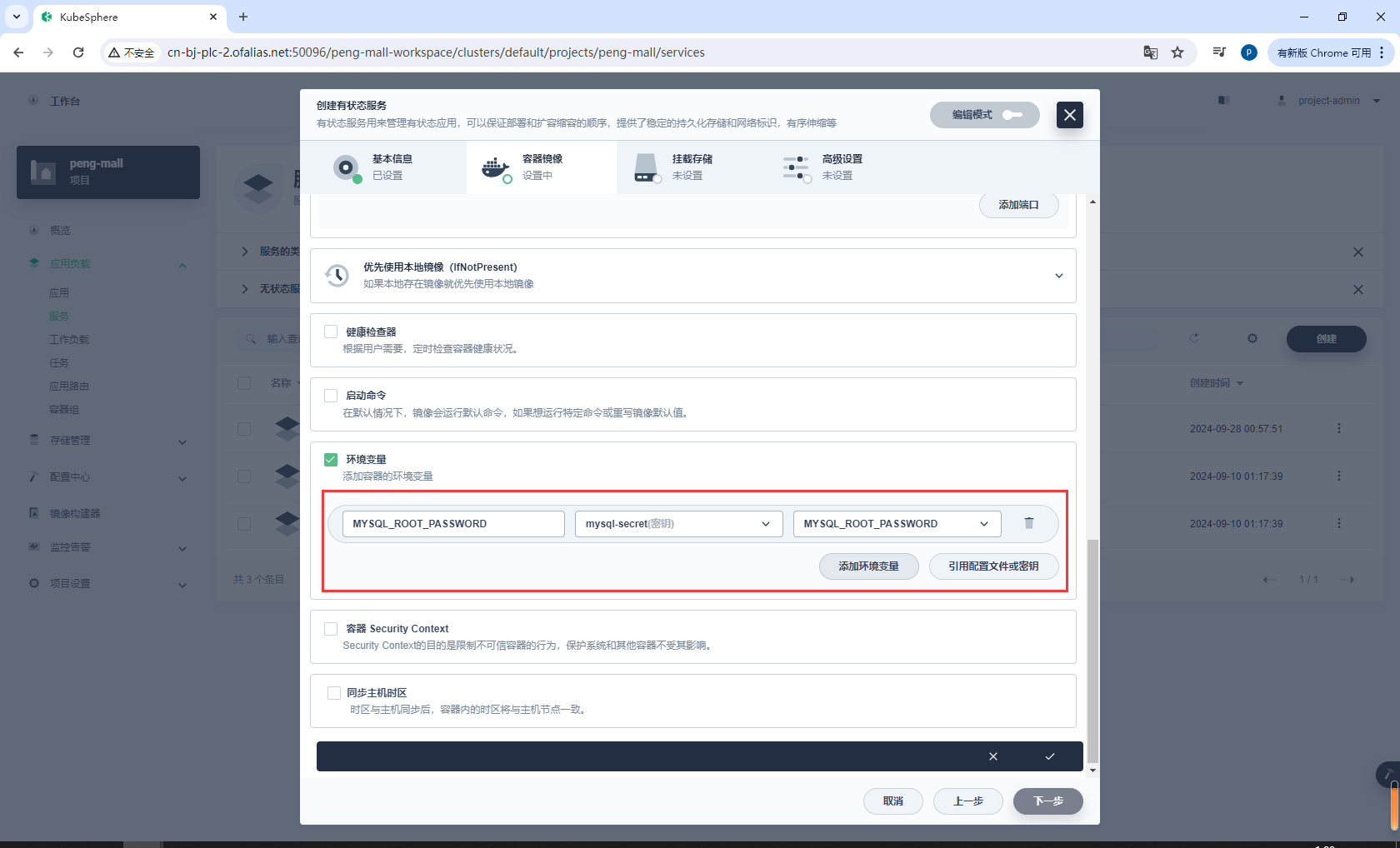
环境配置,设置数据库密码,这里的mysql-secret之前都配置过了
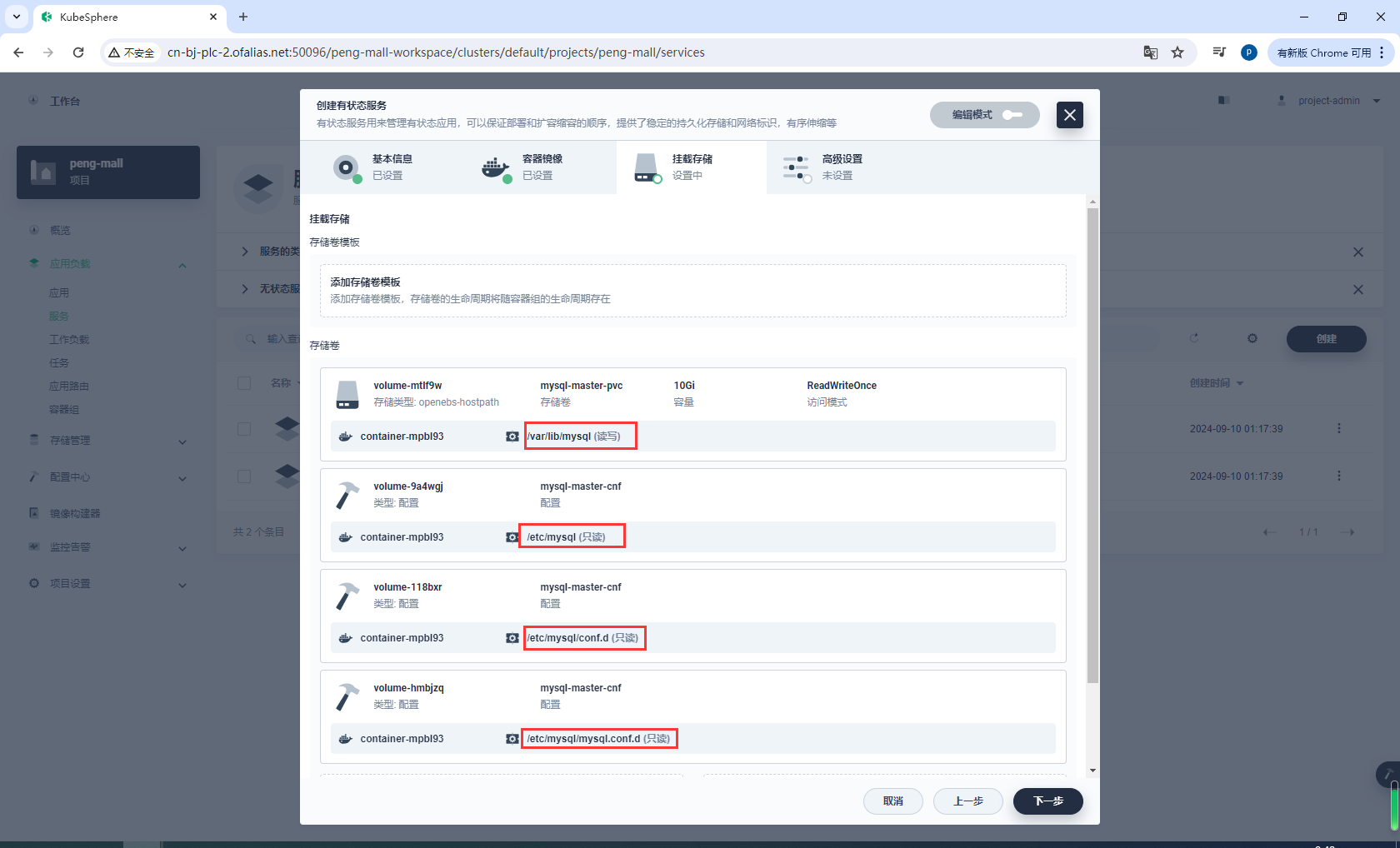
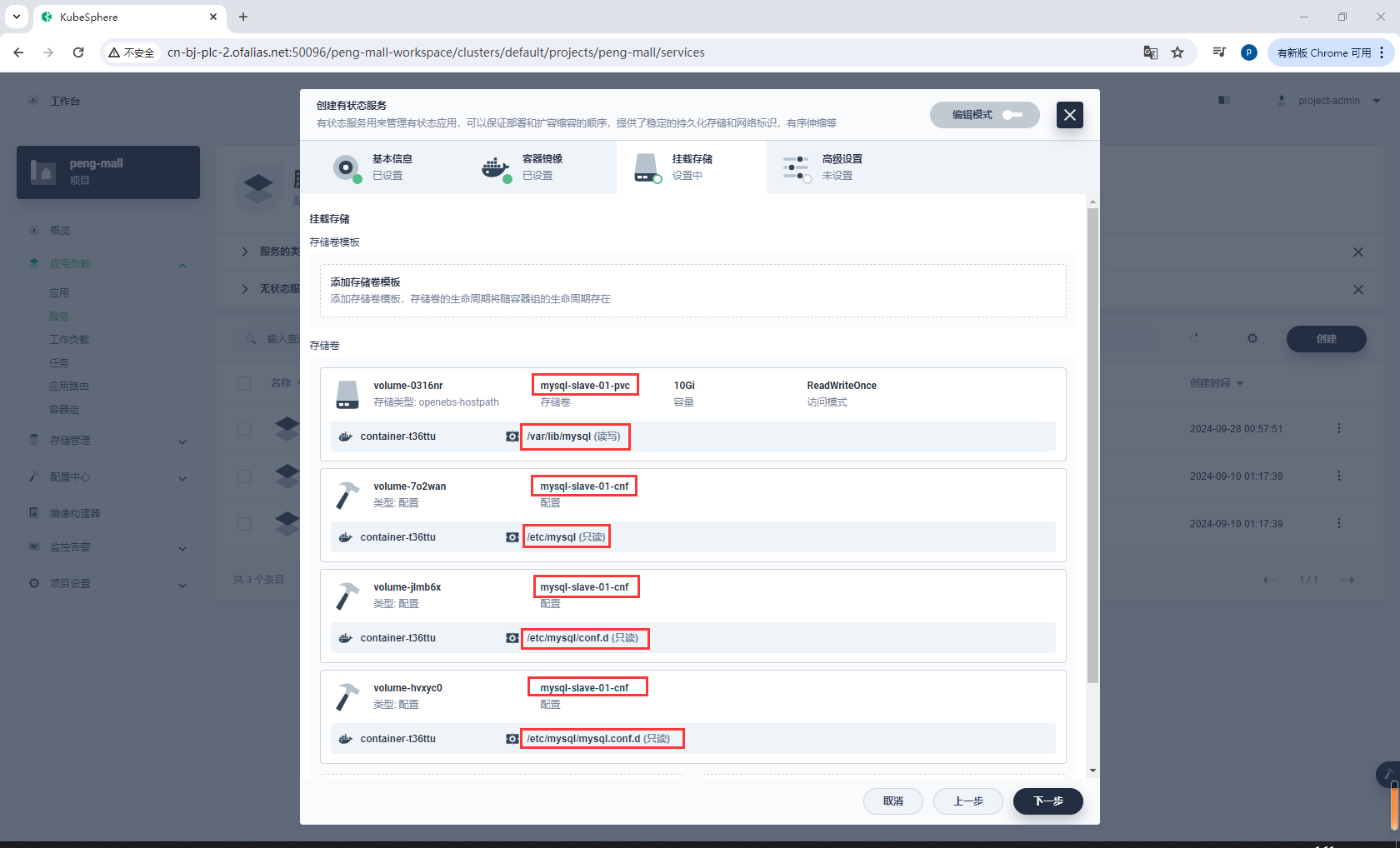
挂载存储
注意我这里配置了1个存储卷和3个配置文件
/var/lib/mysql
/etc/mysql
/etc/mysql/conf.d
/etc/mysql/mysql.conf.d
按理说只需要配置/etc/mysql,但我这里运行时会报错,说是找不到/etc/mysql/conf.d和/etc/mysql/mysql.conf.d,所以直接在这2个路径下也添加配置文件
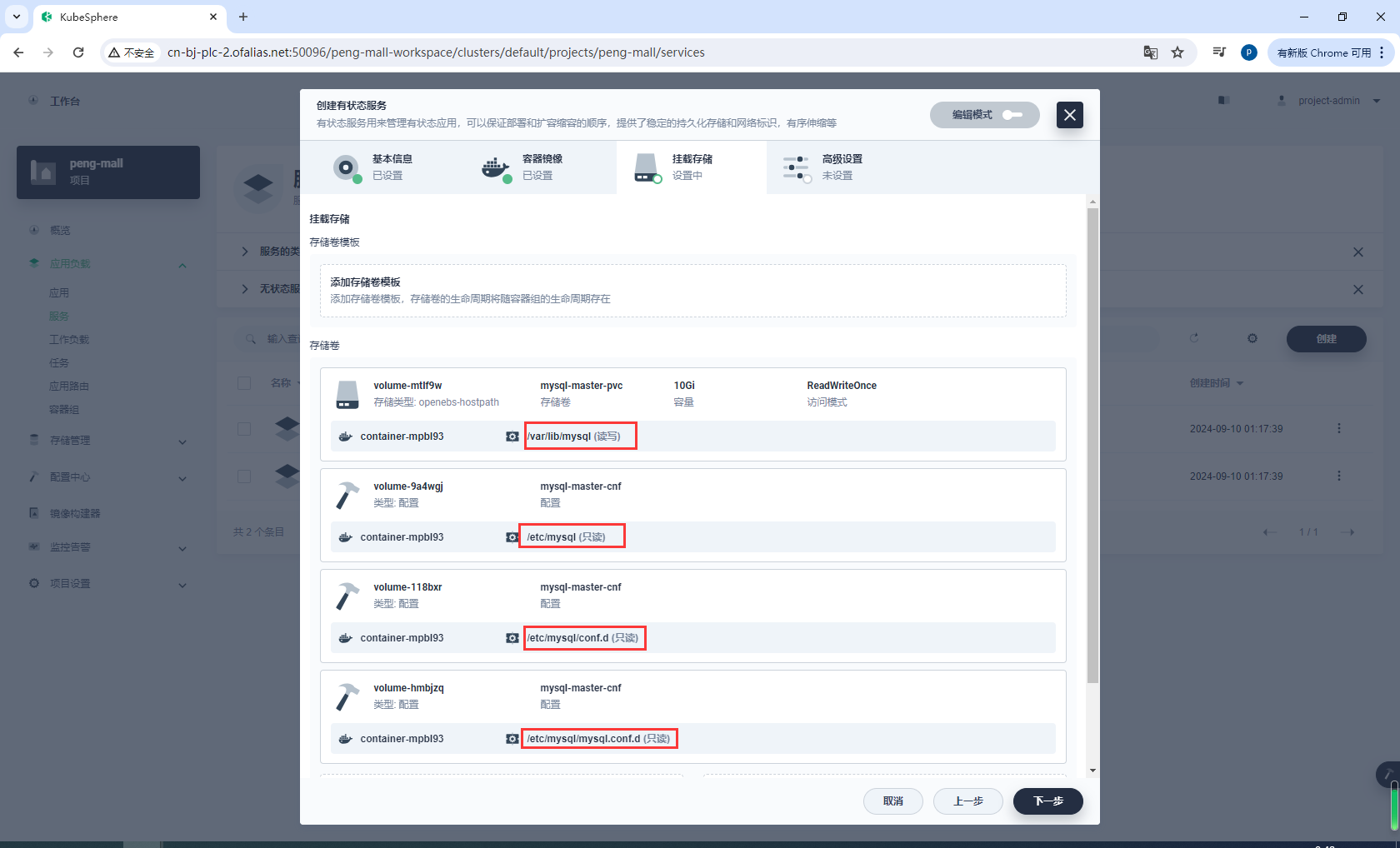
mysqld: Can't read dir of '/etc/mysql/conf.d/

高级设置
8.2.2部署mysql子节点
安装
- 创建配置
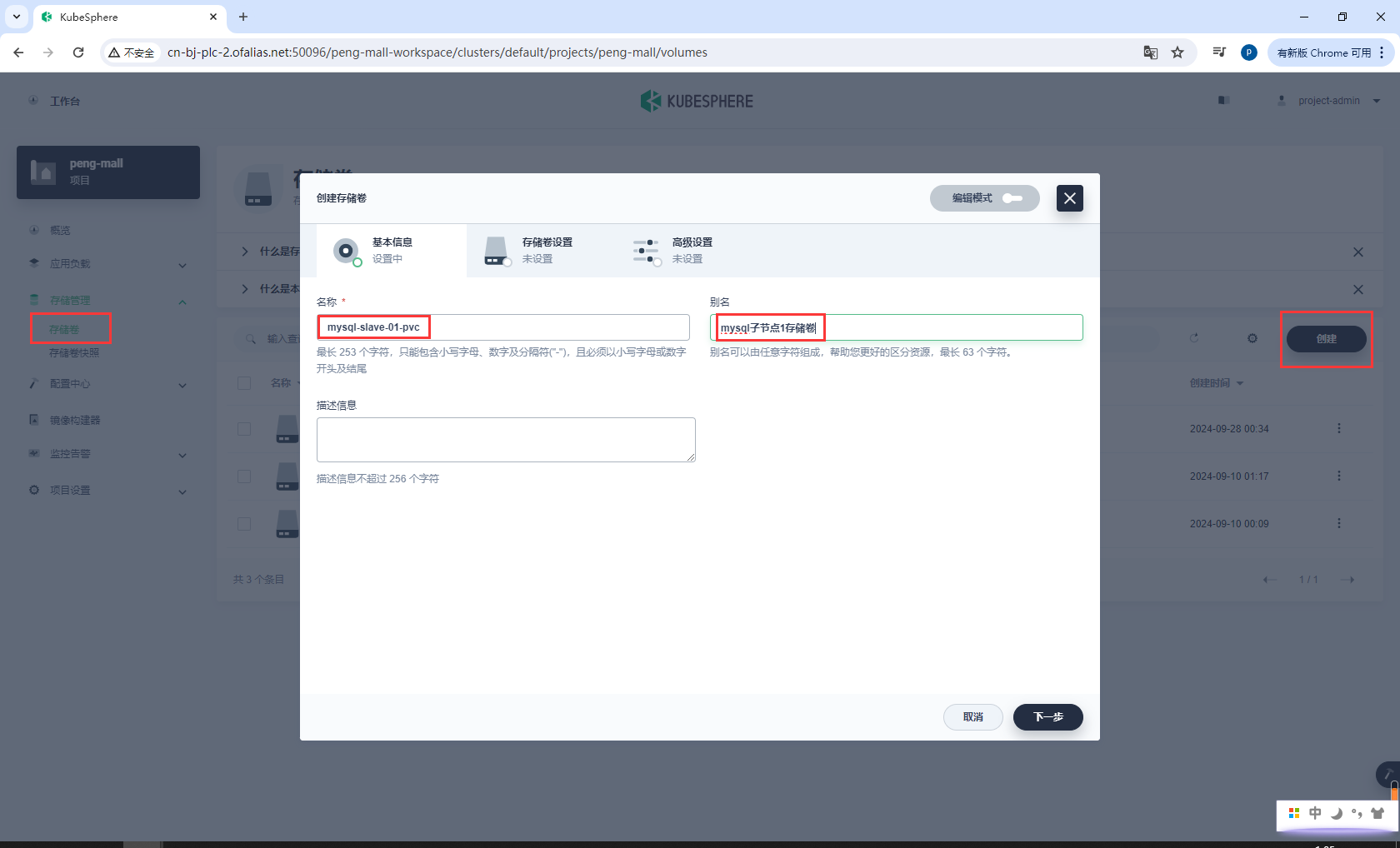
mysql-slave-01-cnf - 创建存储卷
mysql-slave-01-pvc - 创建有状态服务
创建配置mysql-slave-01-cnf
基本信息
配置设置
配置项
my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
# 添加 master 主从复制部分配置
server-id=2
log-bin=mysql-bin
# 只读
read-only=1
# 只同步业务库
binlog-do-db=mall_ums
binlog-do-db=mall_pms
binlog-do-db=mall_oms
binlog-do-db=mall_sms
binlog-do-db=mall_wms
binlog-do-db=mall_admin
# 不同步mysql基础库
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
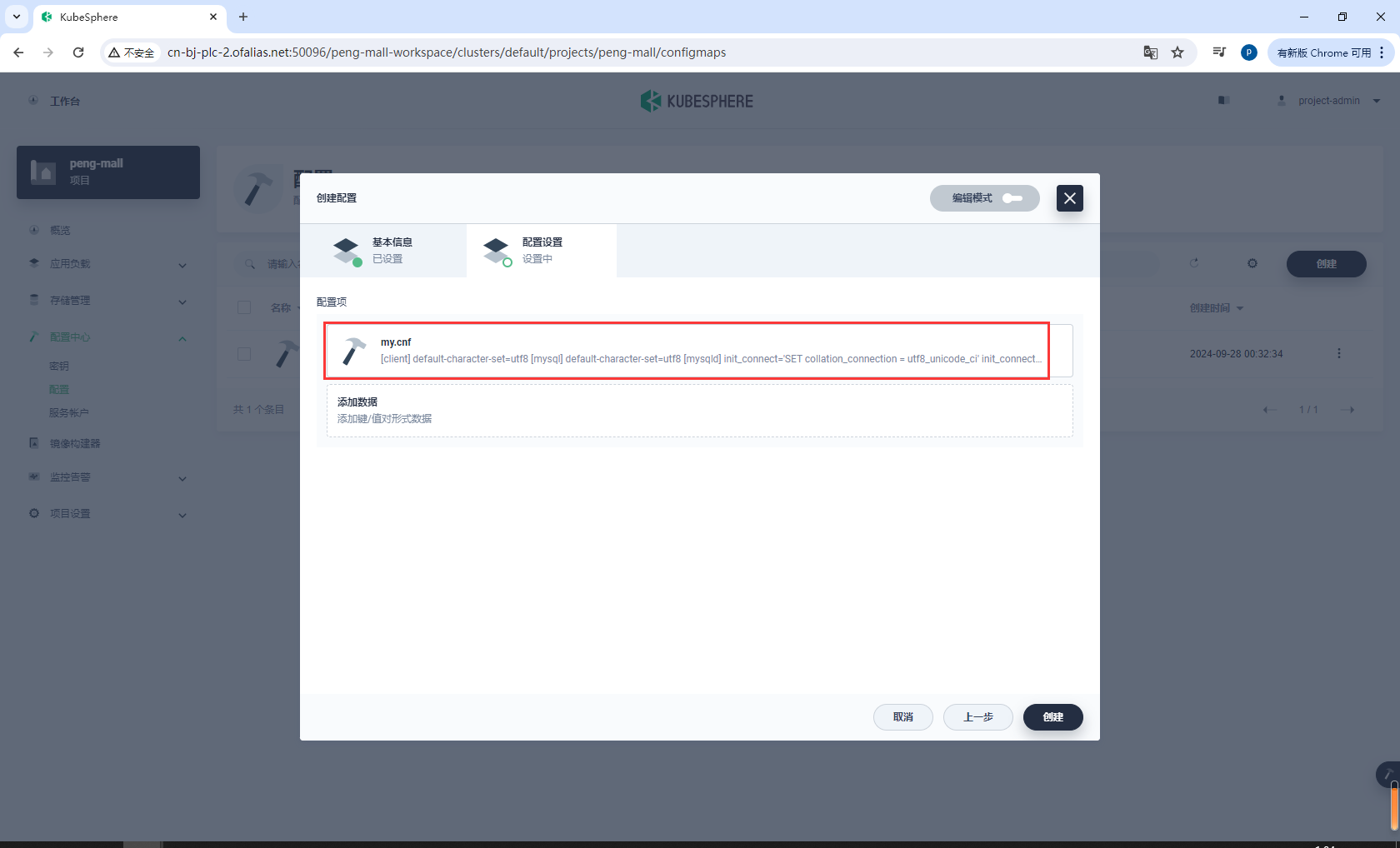
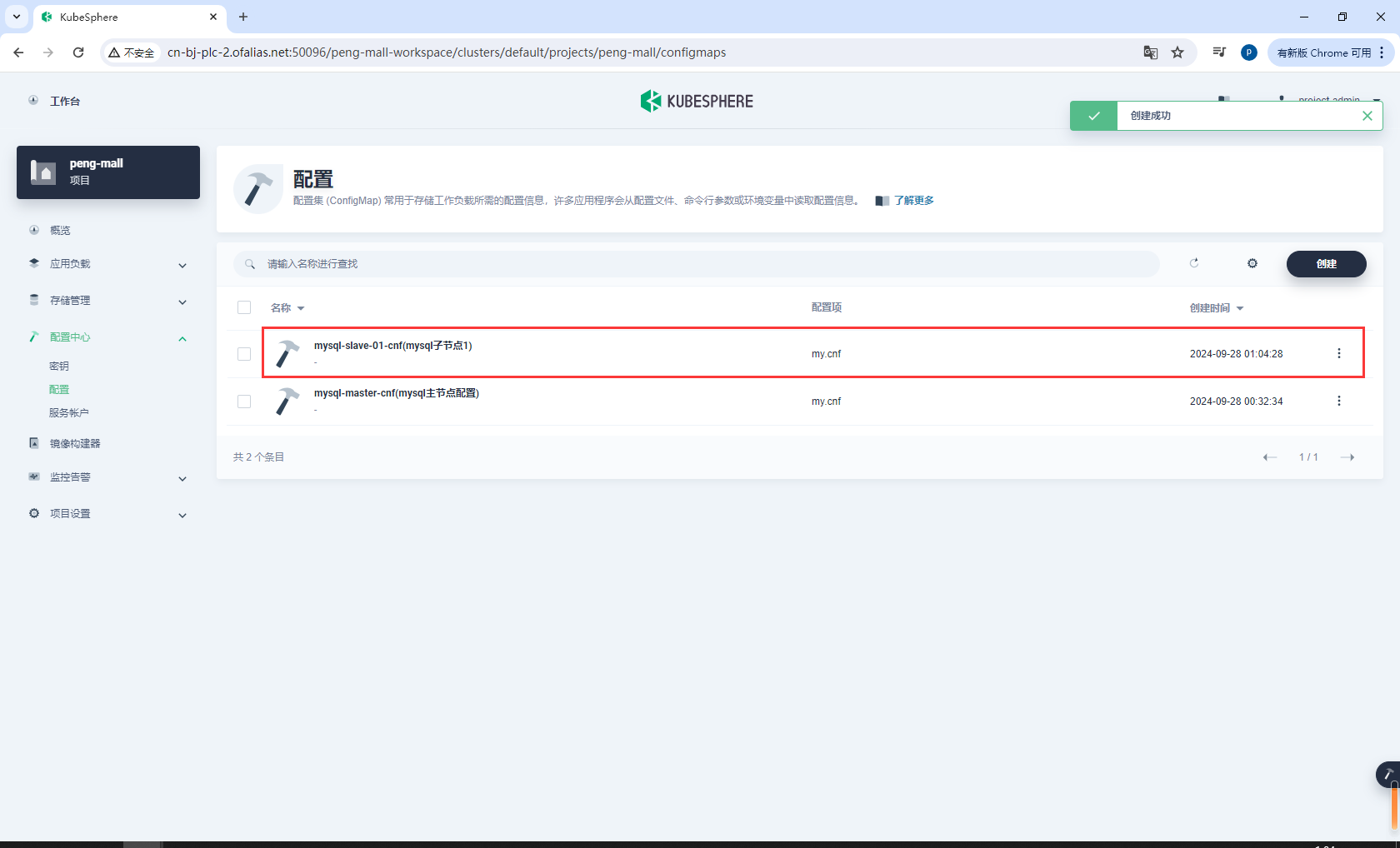
创建完成
创建存储卷mysql-slave-01-pvc
基本信息
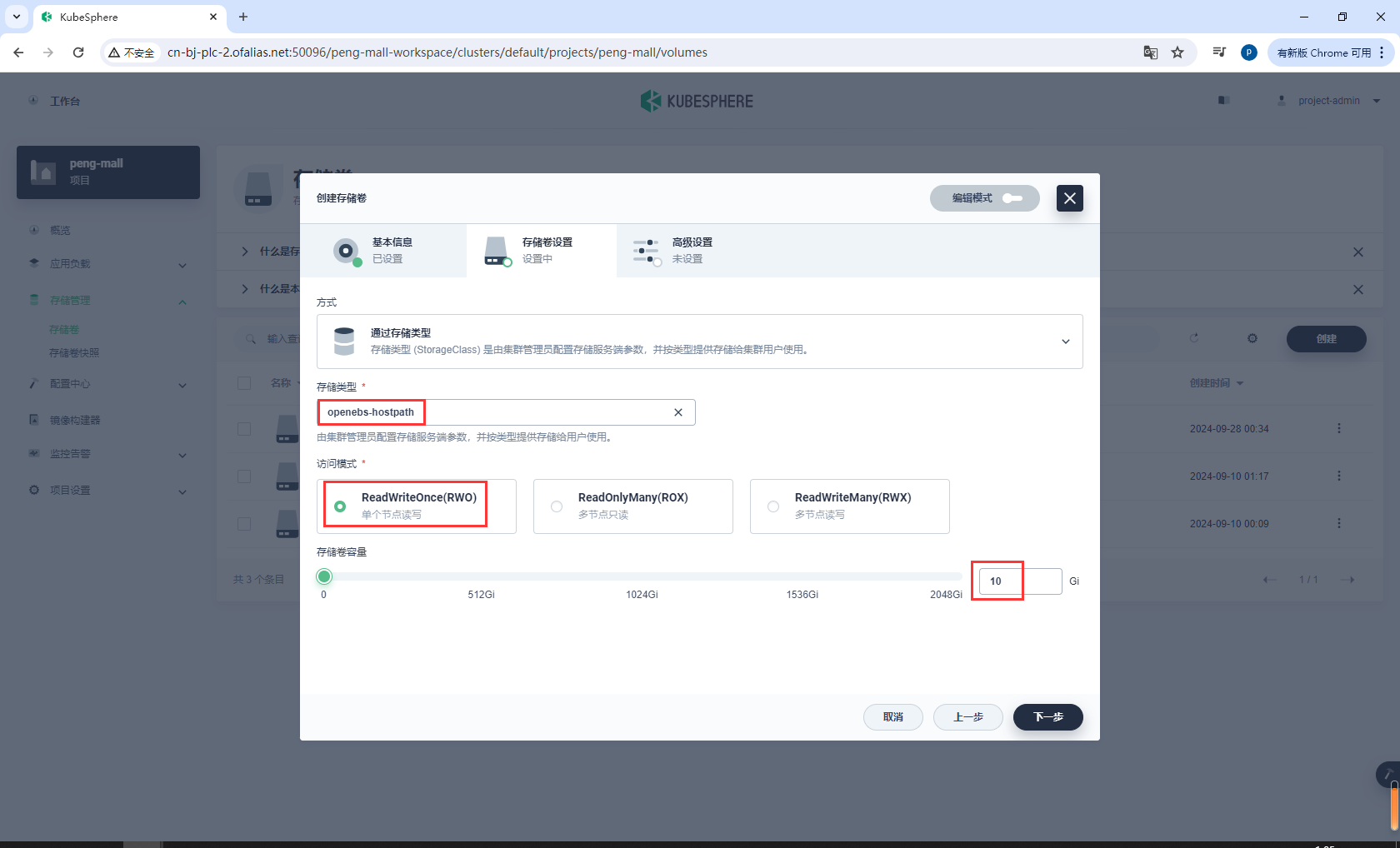
存储卷设置
点击创建
创建完成
创建有状态服务
基本信息
镜像
资源配置
环境变量
挂在存储,注意我们挂载的是子节点的存储卷**mysql-slave-01-pvc**和配置文件mysql-slave-01-cnf
/var/lib/mysql
/etc/mysql
/etc/mysql/conf.d
/etc/mysql/mysql.conf.d
高级设置
创建完成
8.2.3配置mysql主从
进入mysql-master(mysql主节点)容器组

进入容器
为 master 授权用户来他的同步数据
进入 master 容器
mysql -u root -p
进入 mysql 内部
# 授权 root 可以远程访问( 主从无关,为了方便我们远程连接 mysql)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
# 添加用来同步的用户
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
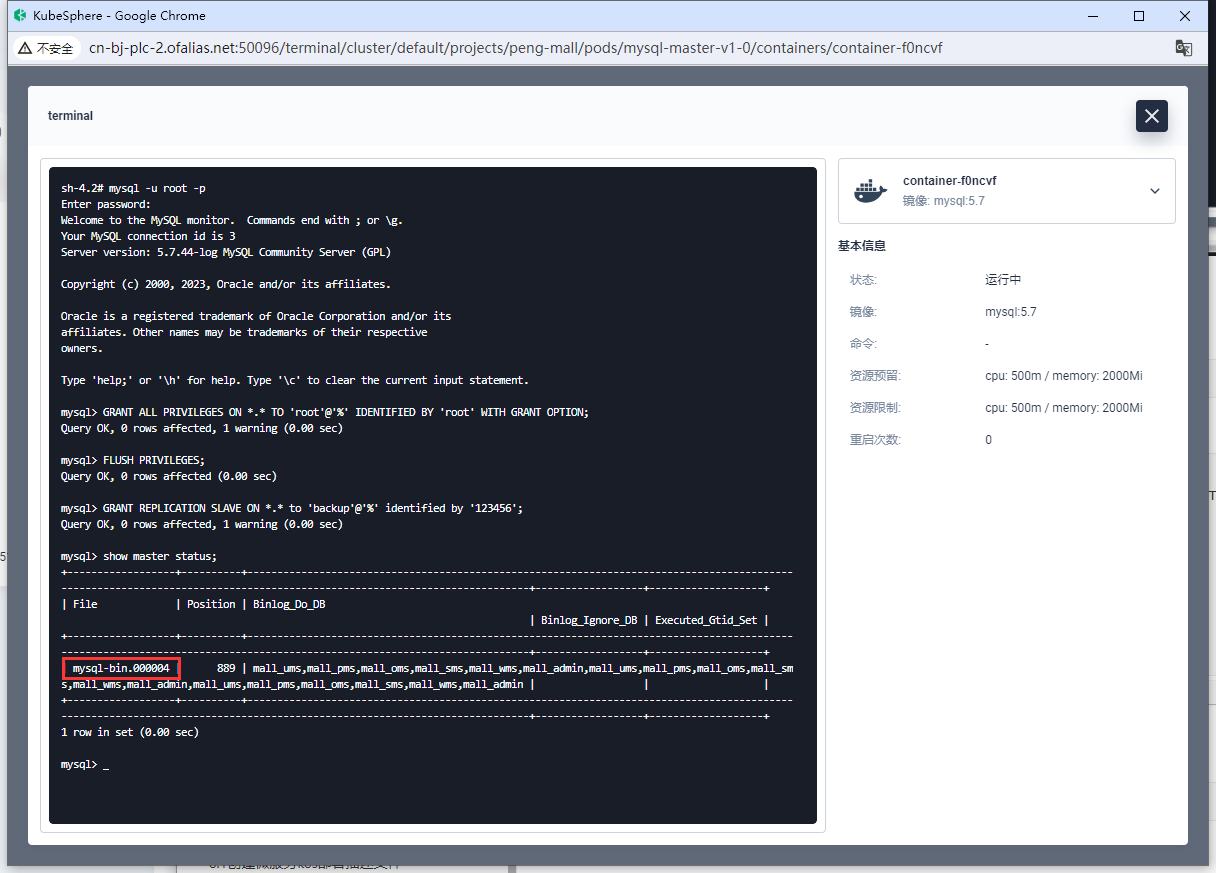
# 查看 master状态
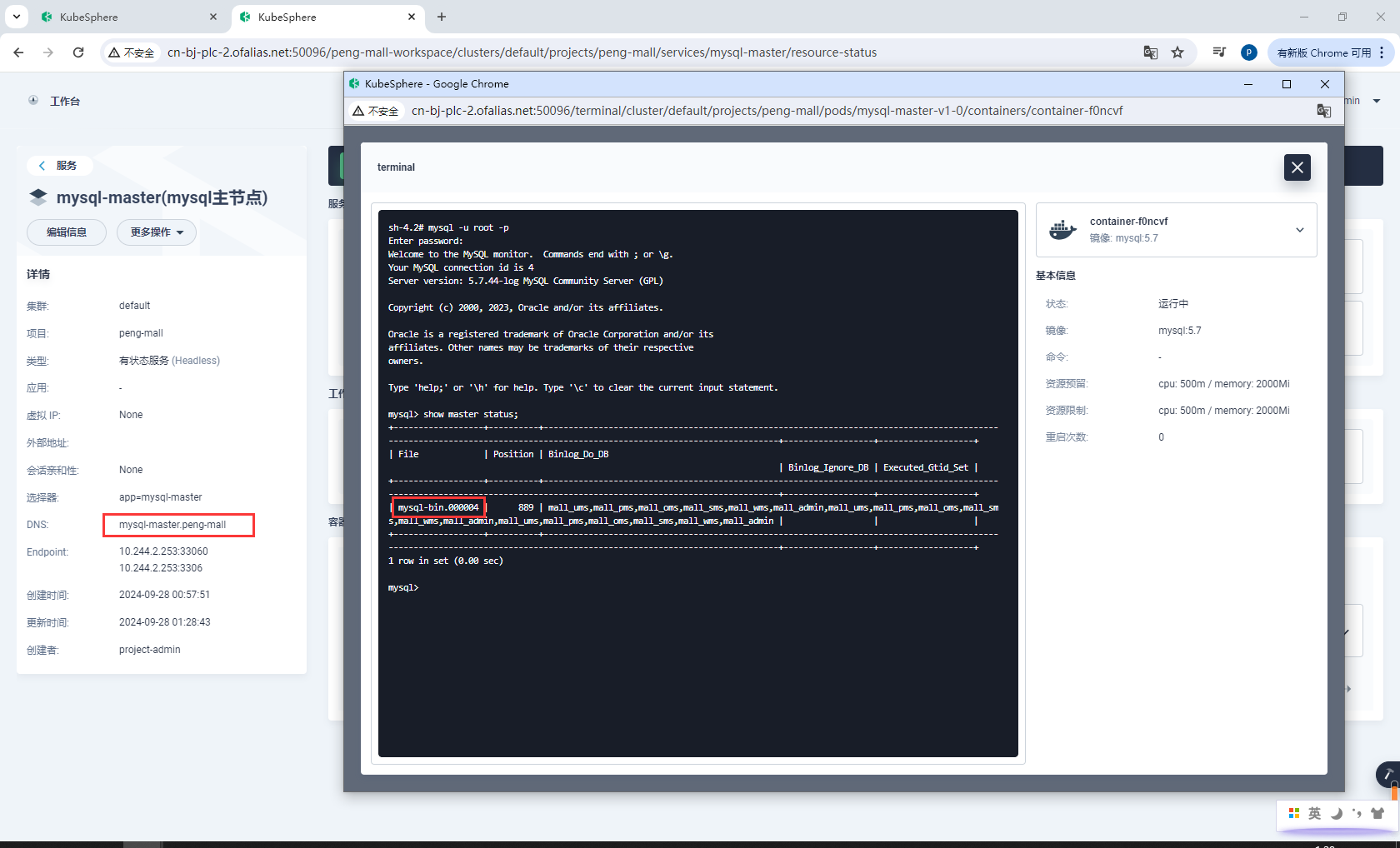
show master status;
记住mysql-bin.000004这个地址,一会同步从库的时候要从mysql-bin.000004同步
配置 slaver 同步 master 数据
进入从库容器组mysql-slave-01-v1-0
进入 slaver 容器
mysql -u root -p
mysql-master域名是mysql-master.peng-mall,数据同步位置是mysql-bin.000004,端口号是3306,所以同步命令
CHANGE MASTER TO MASTER_HOST='mysql-master.peng-mall',
MASTER_USER='backup',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=0,
MASTER_PORT=3306;
进入mysql内部
# 授权 root 可以远程访问( 主从无关,为了方便我们远程连接 mysql)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
# 设置主库连接
# MASTER_LOG_FILE是show master status;查master的File字段
CHANGE MASTER TO MASTER_HOST='mysql-master.peng-mall',
MASTER_USER='backup',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000004',
MASTER_LOG_POS=0,
MASTER_PORT=3306;
# 启动从库同步
start slave;
# 查看从库状态
show slave status\G;
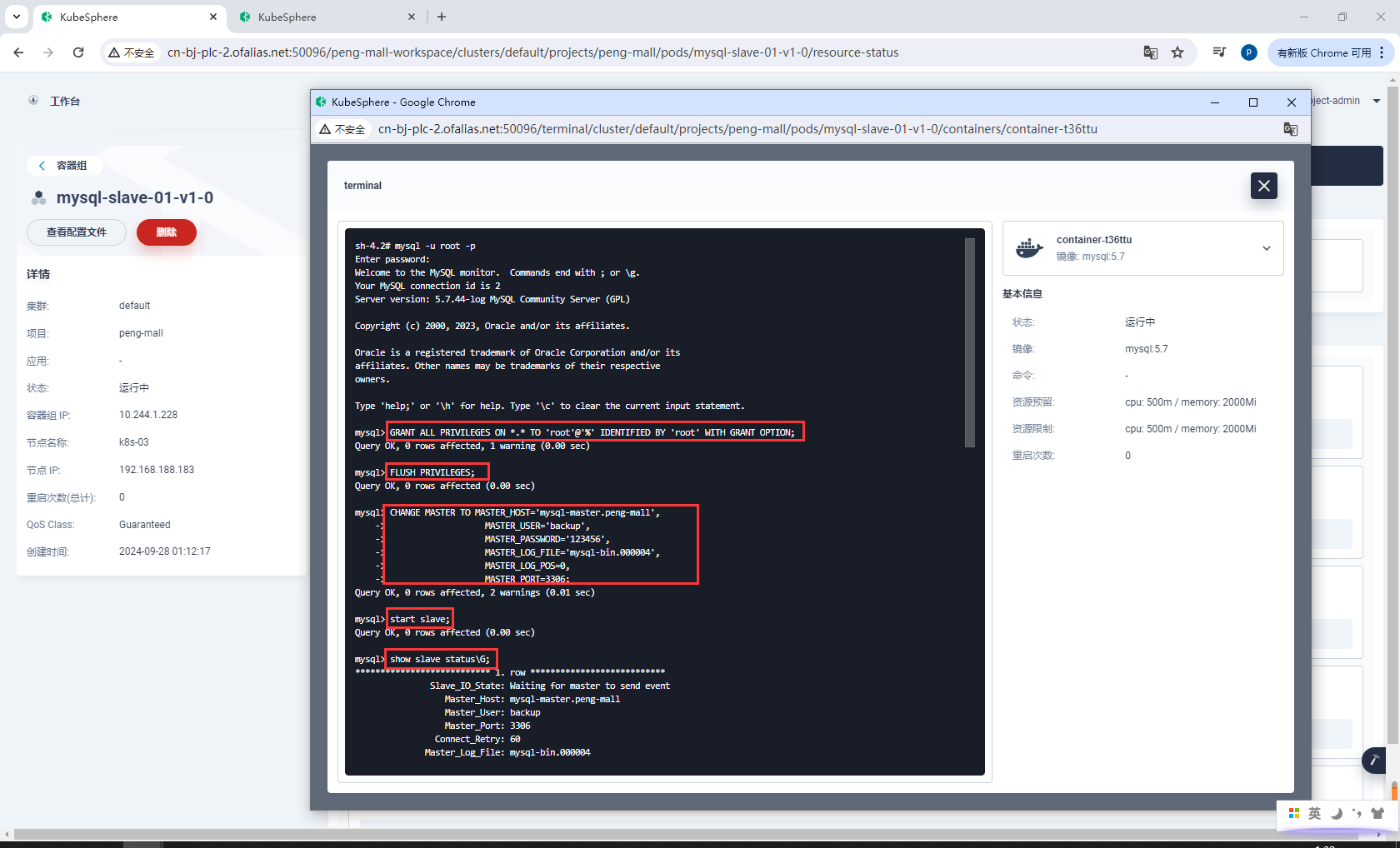
从库配置完成
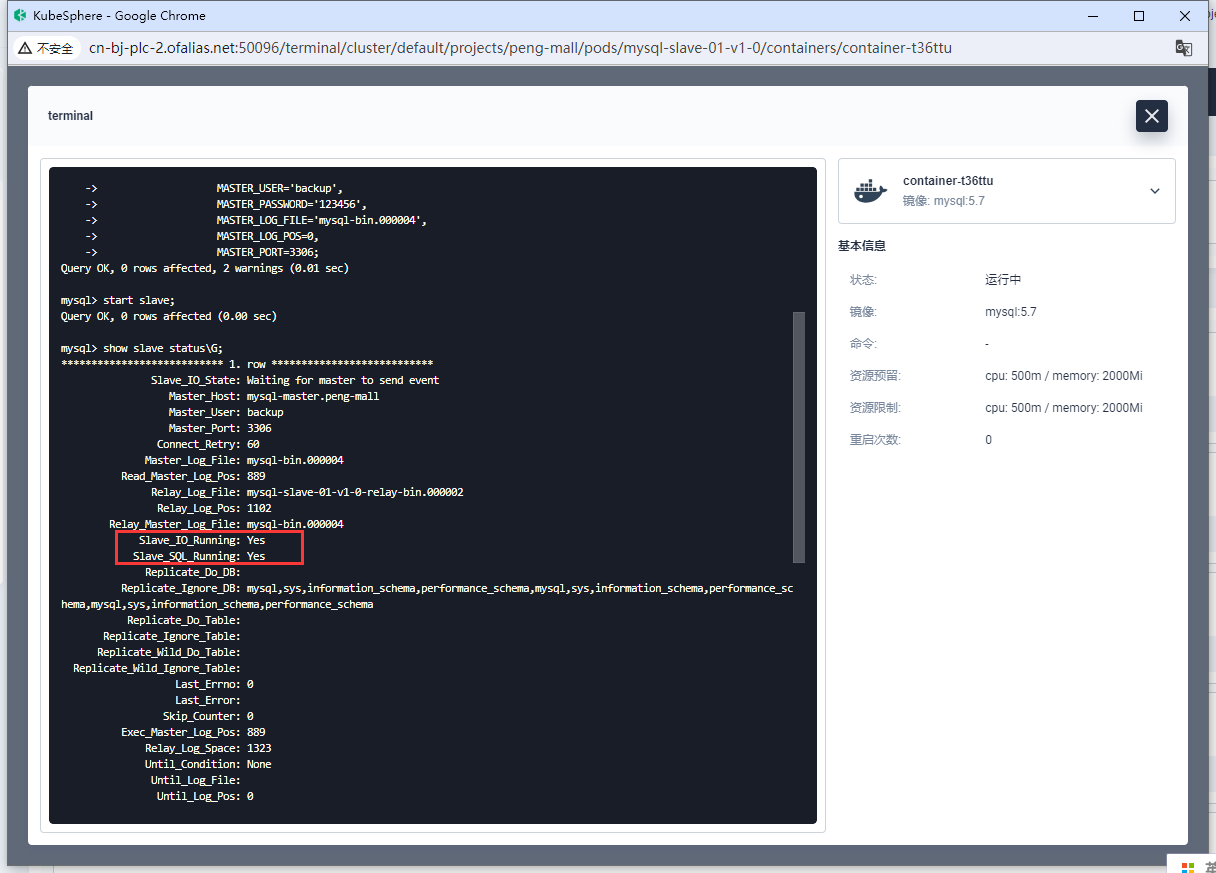
8.2.4测试
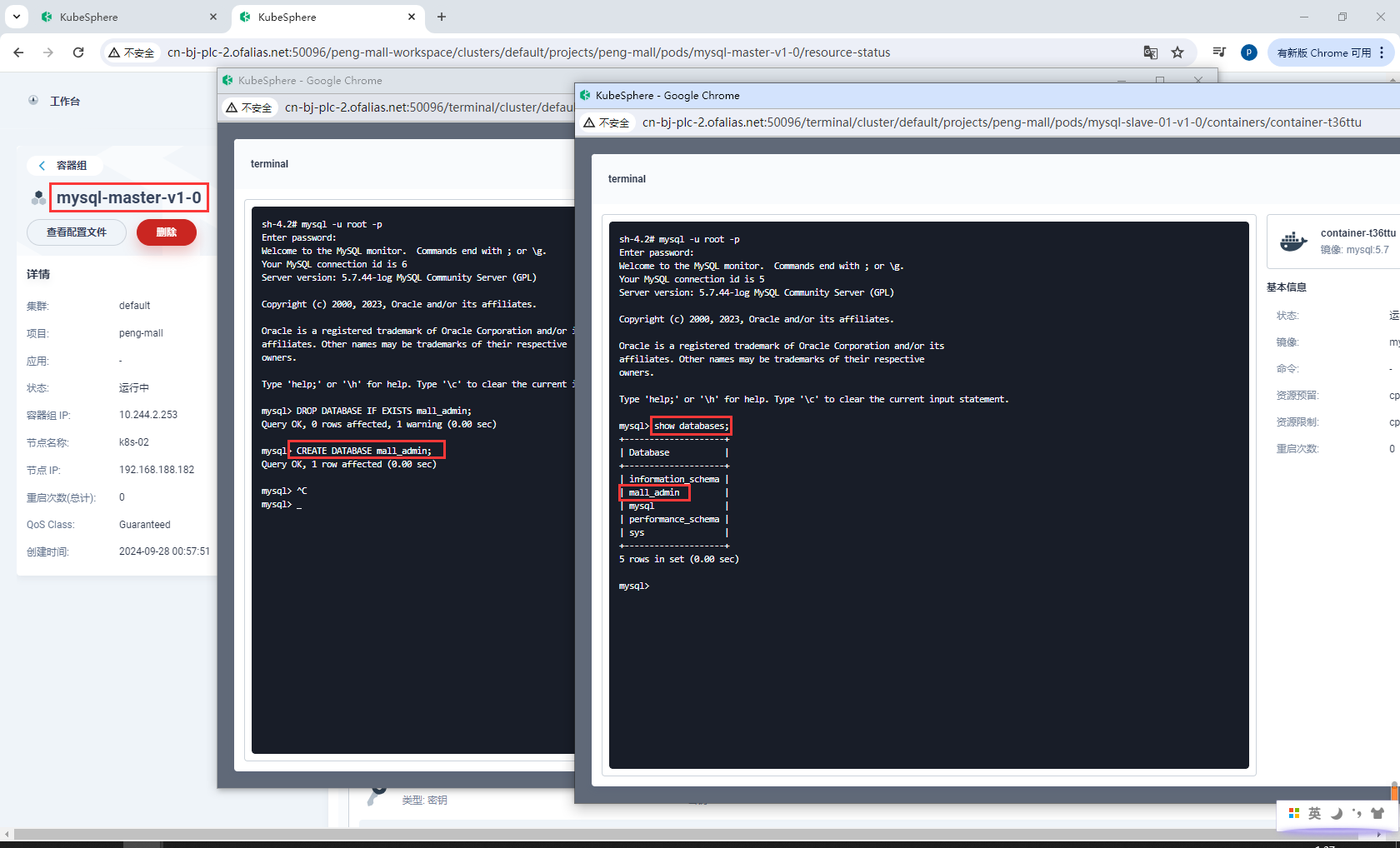
进入容器mysql-master-v1-0创建数据库mall_admin
再次进入容器mysql-slave-01-v1-0,发现数据库mall_admin已同步从库
mysql -u root -p
DROP DATABASE IF EXISTS mall_admin;
CREATE DATABASE mall_admin;
SHOW DATABASES;
USE mall_admin;
CREATE TABLE IF NOT EXISTS test_table (
id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键列
name VARCHAR(100) -- 名称列,不能为空
);
INSERT INTO test_table (name) VALUES ('Alice');
8.3k8s部署Redis
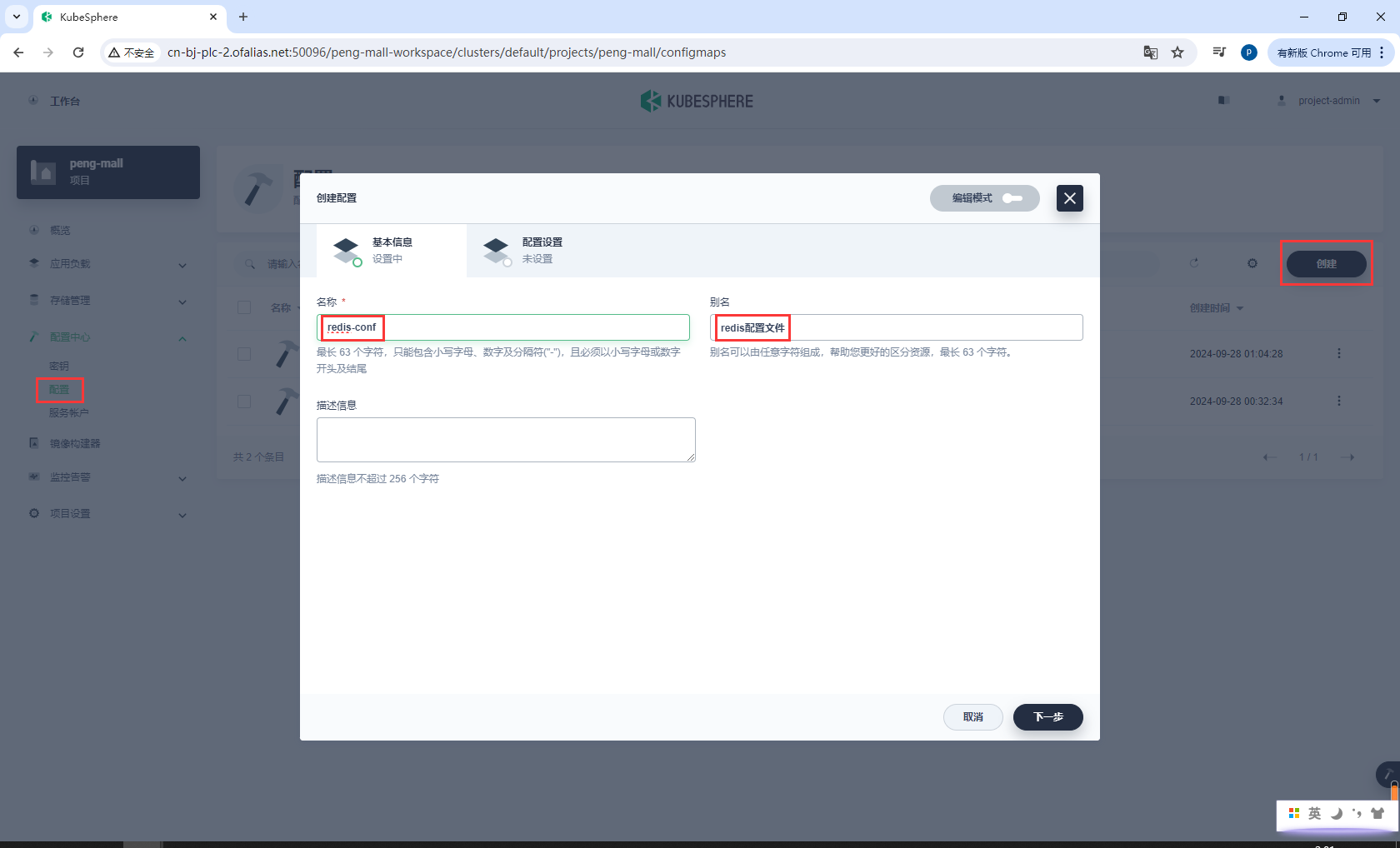
安装:
- 创建配置
redis-conf - 创建存储卷
redis-pvc - 创建有状态服务
创建配置redis-conf
redis-conf
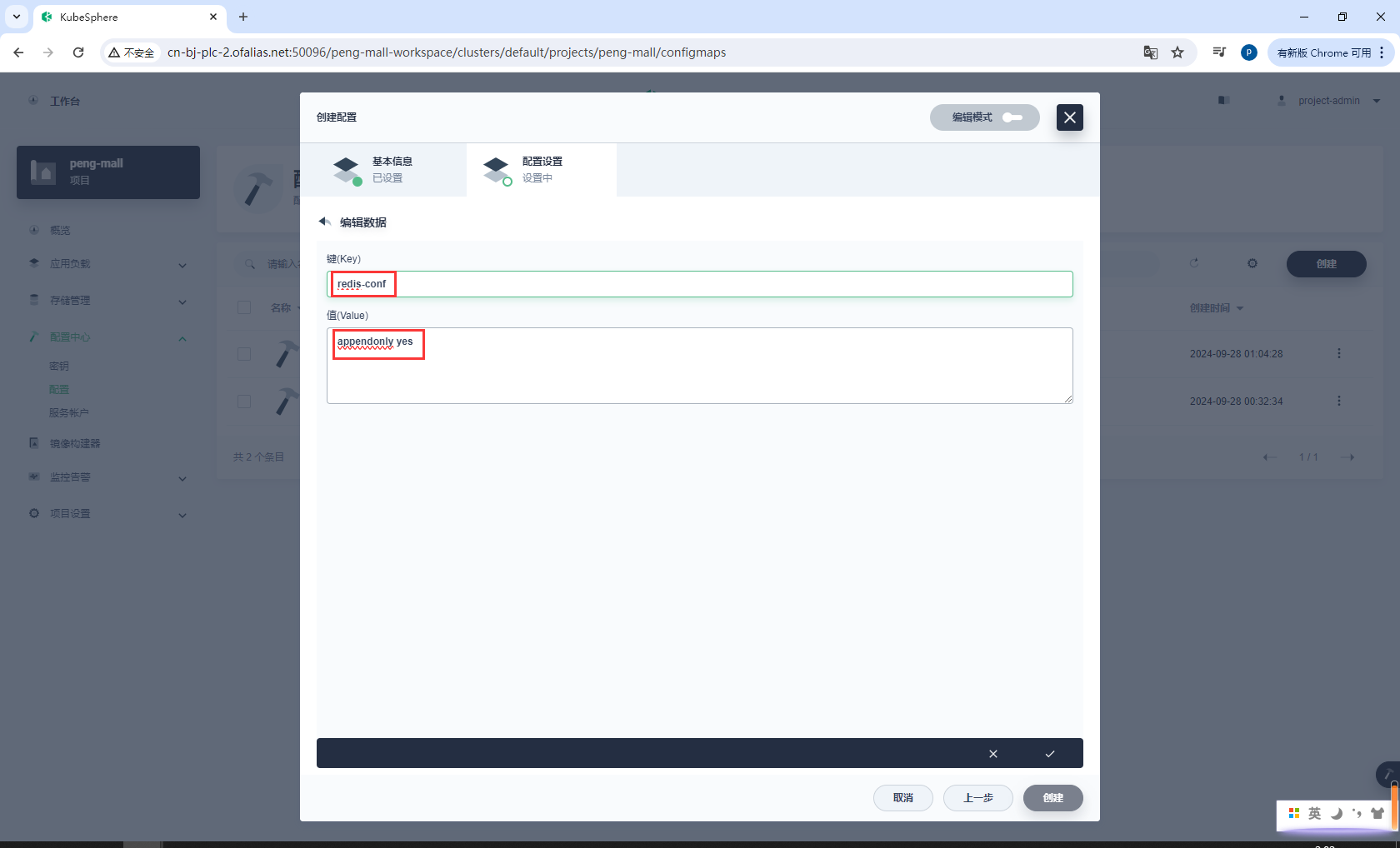
配置设置
redis-conf
appendonly yes
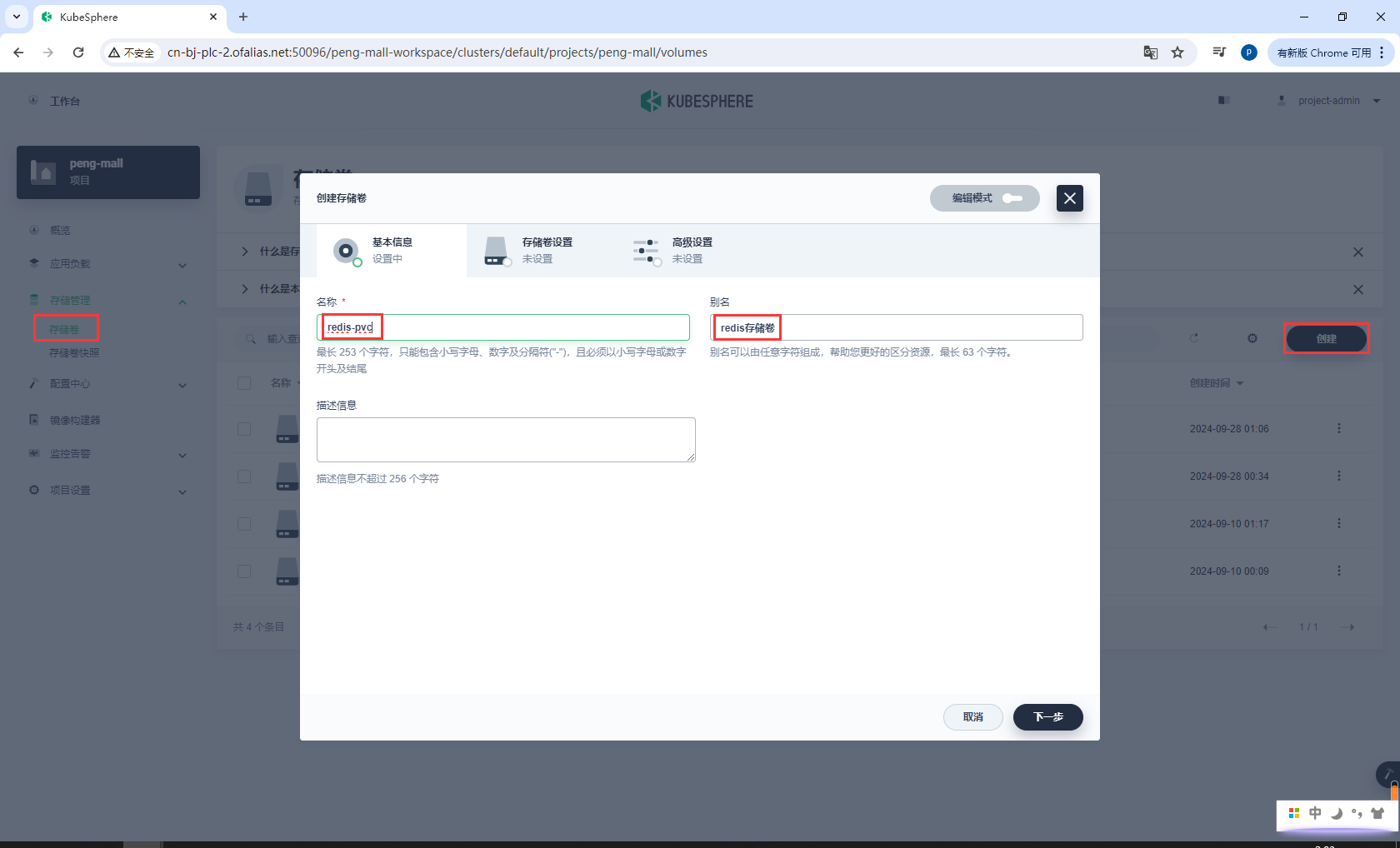
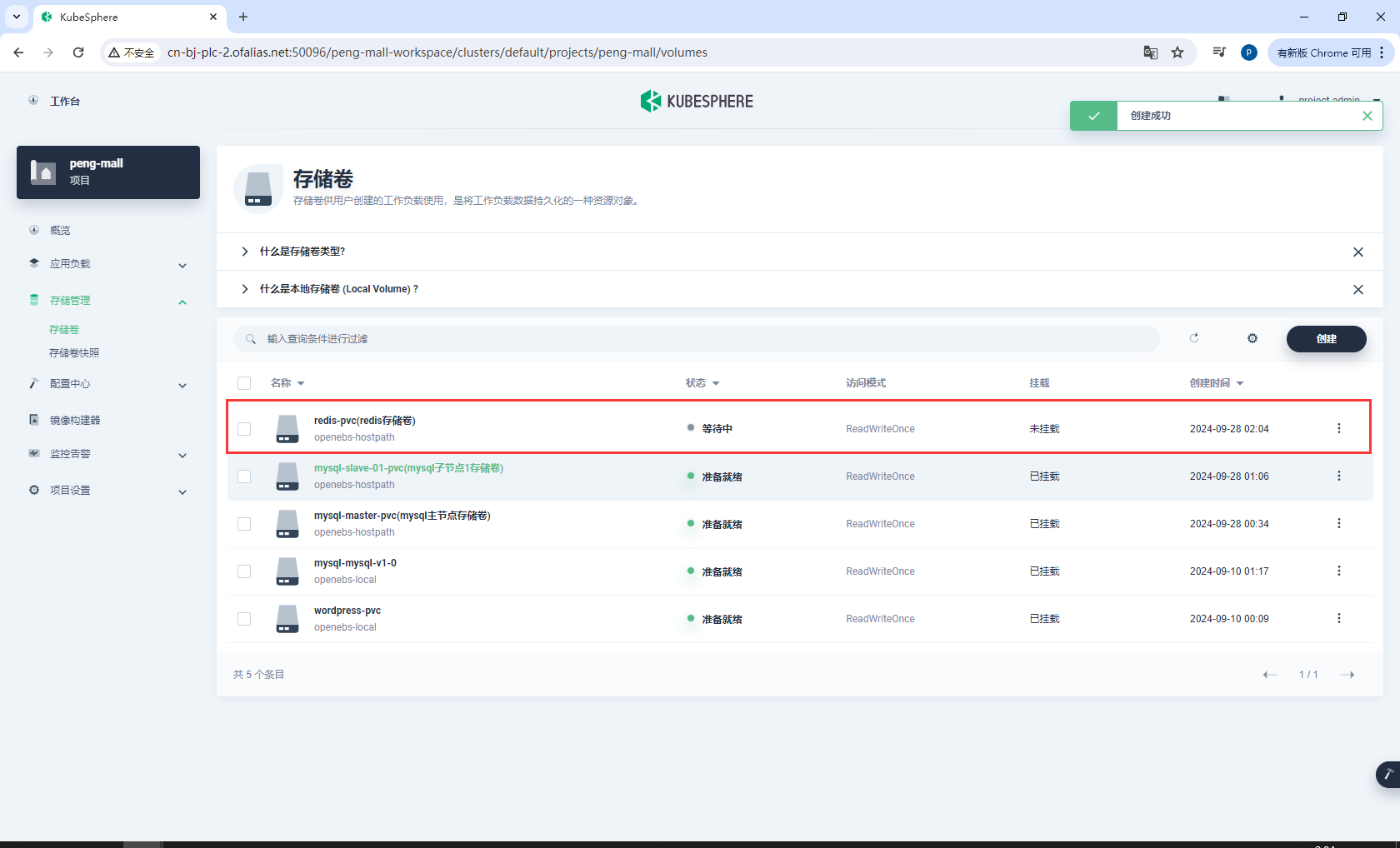
创建存储卷redis-pvc
redis-pvc
基本信息
存储卷设置
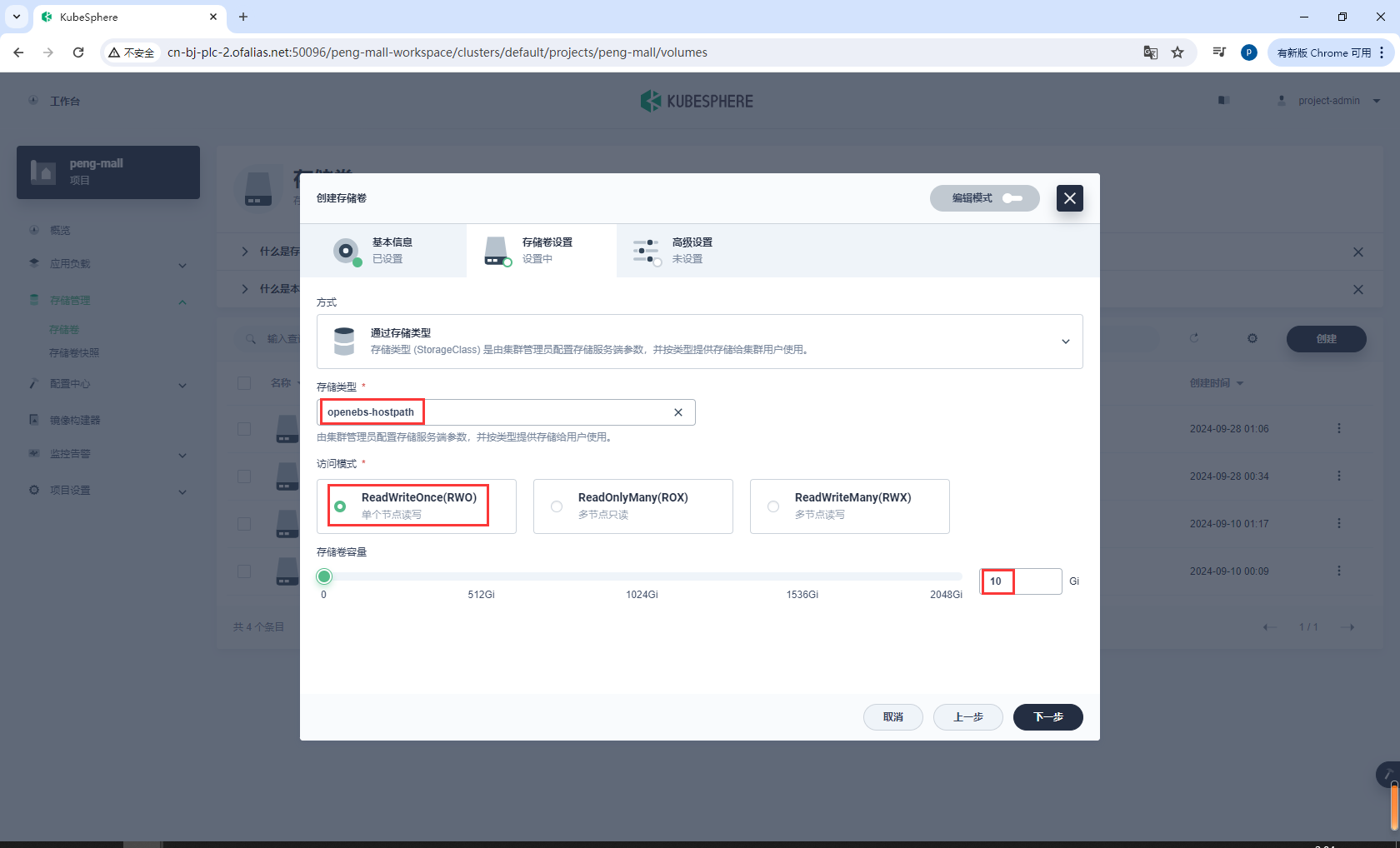
创建完成
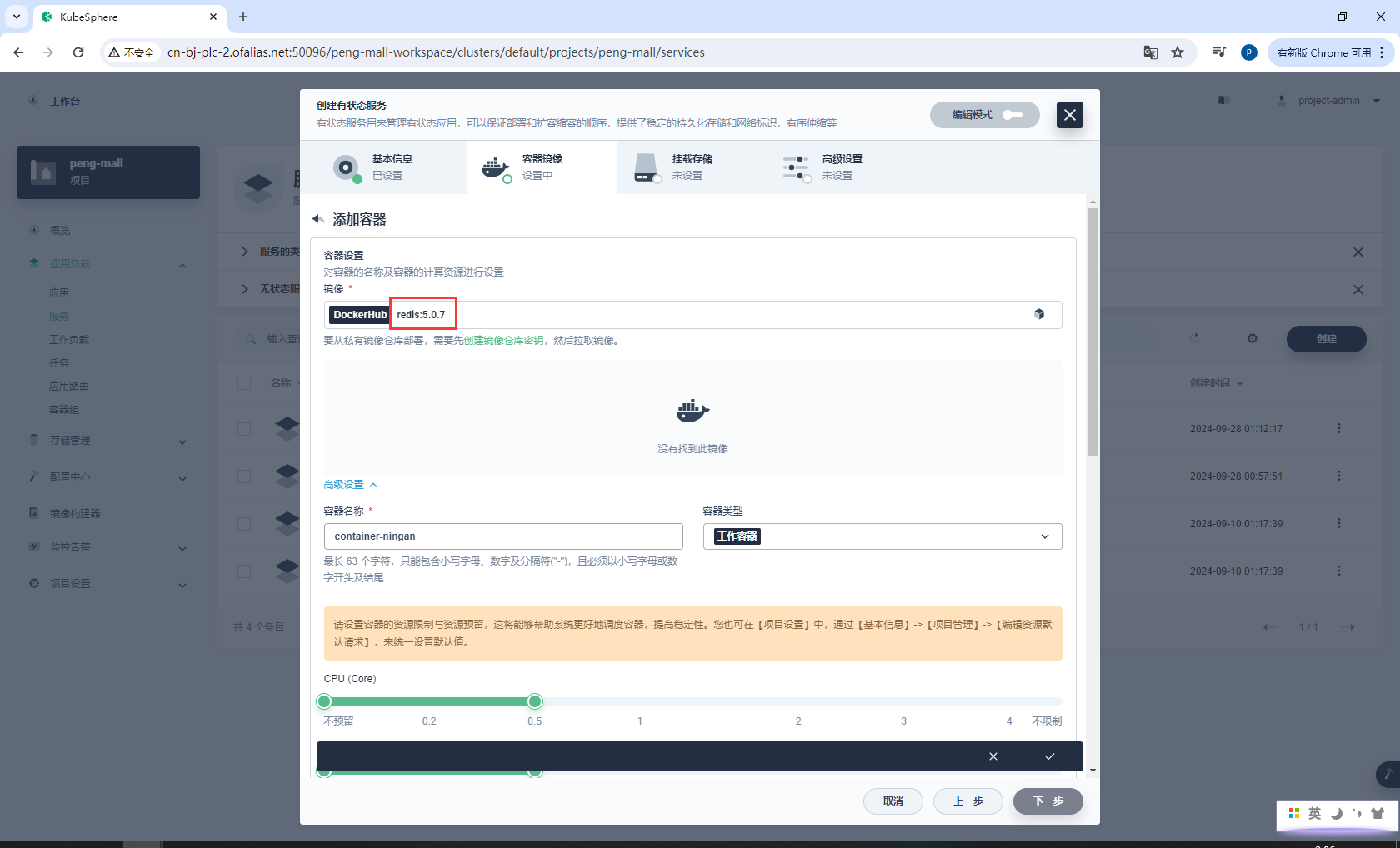
创建有状态服务
redis:5.0.7
# 或者
redis:latest
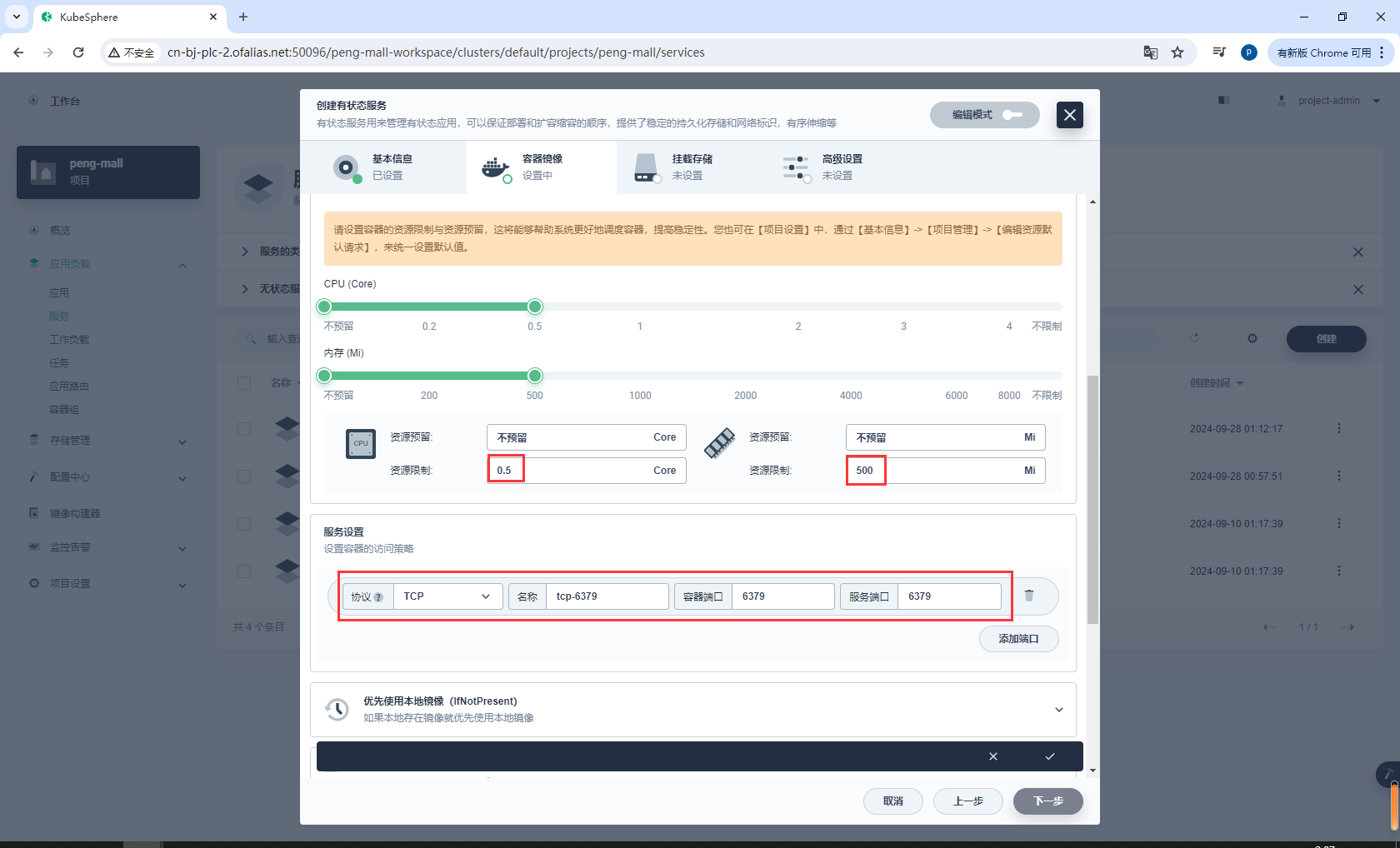
资源、端口配置
6379
添加启动命令
redis-server
/etc/redis/redis.conf
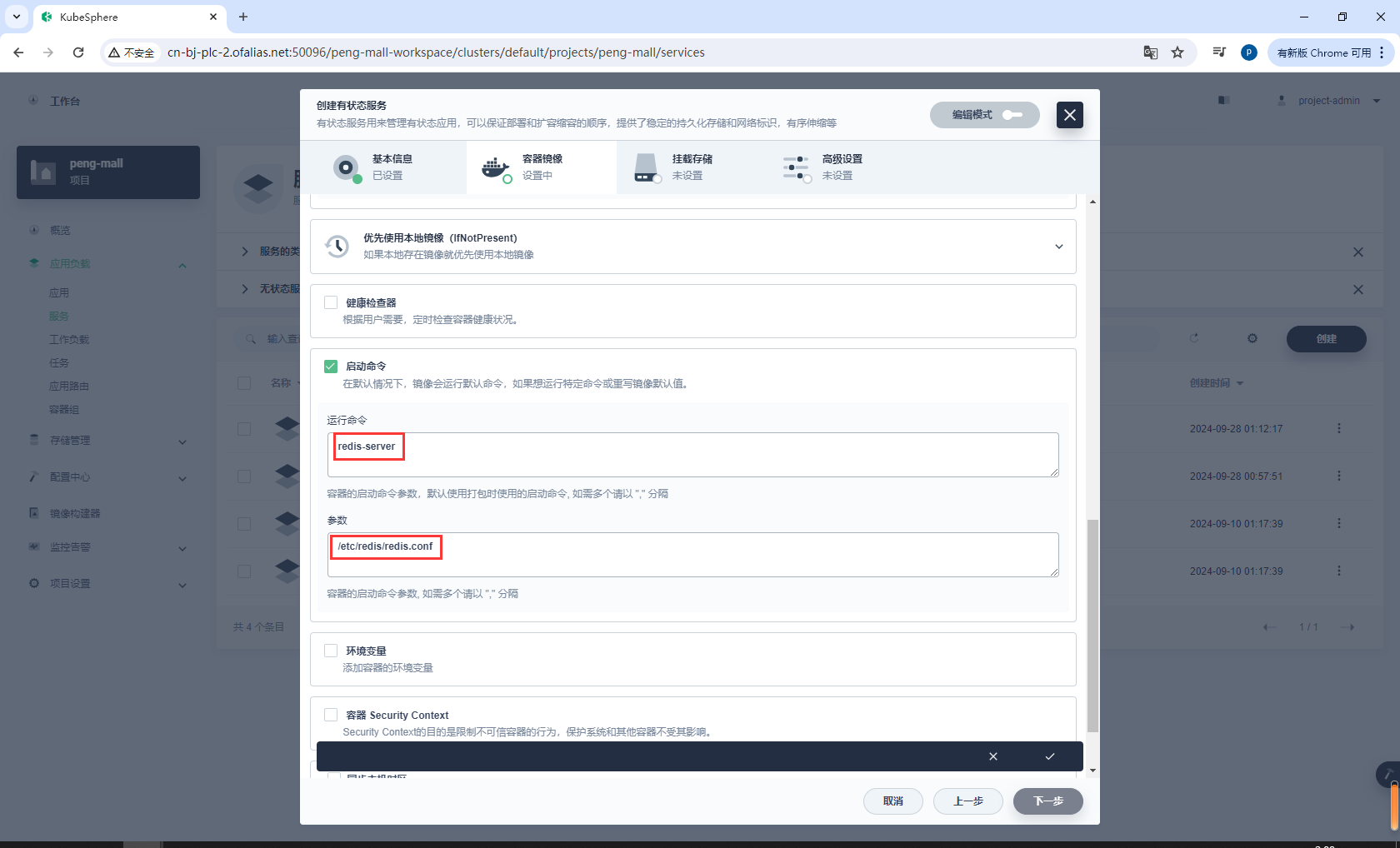
可以提前在主节点使用docker pull redis:5.0.7拉取镜像,这里建议设置优先使用本地镜像
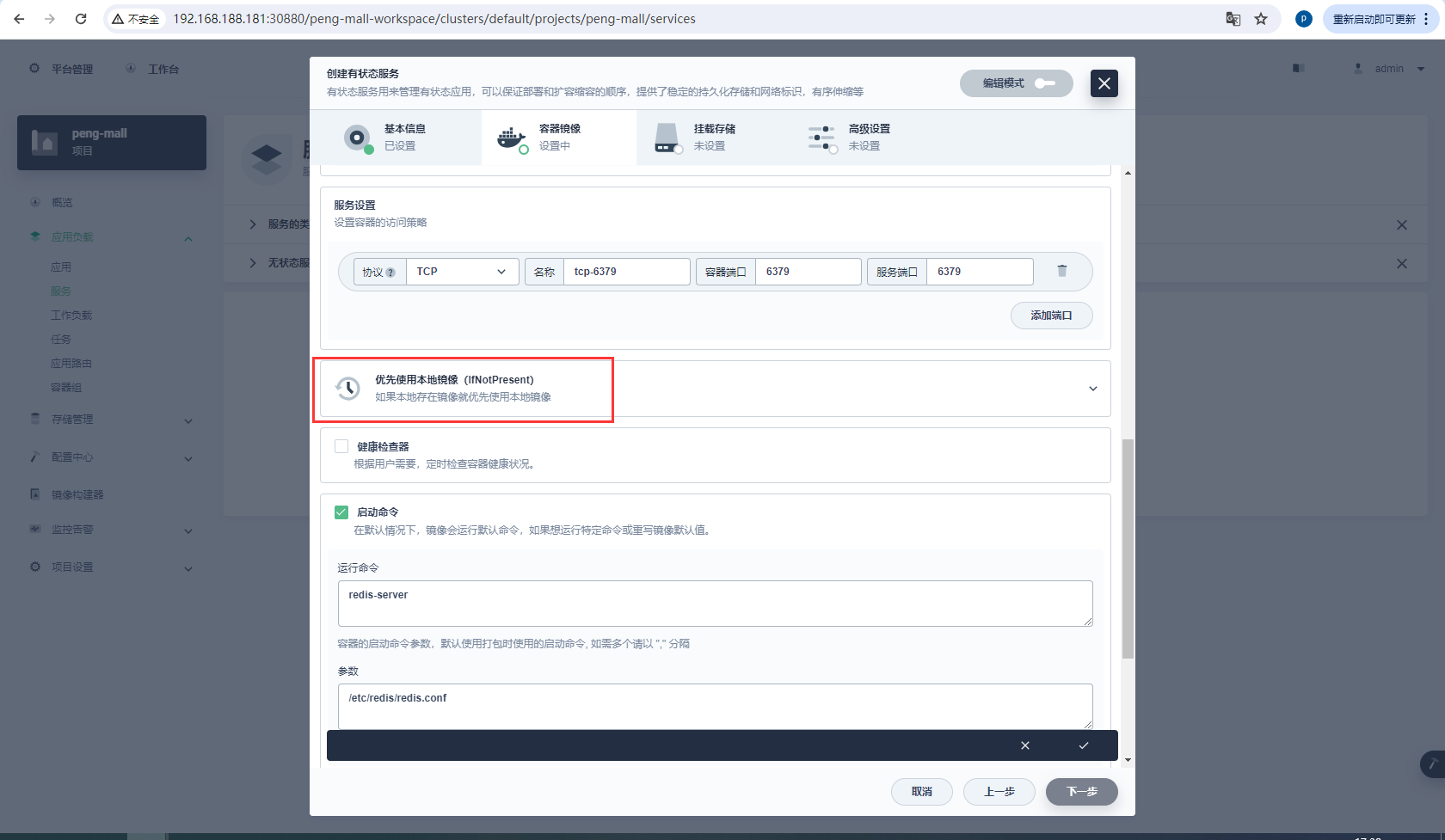
挂载存储
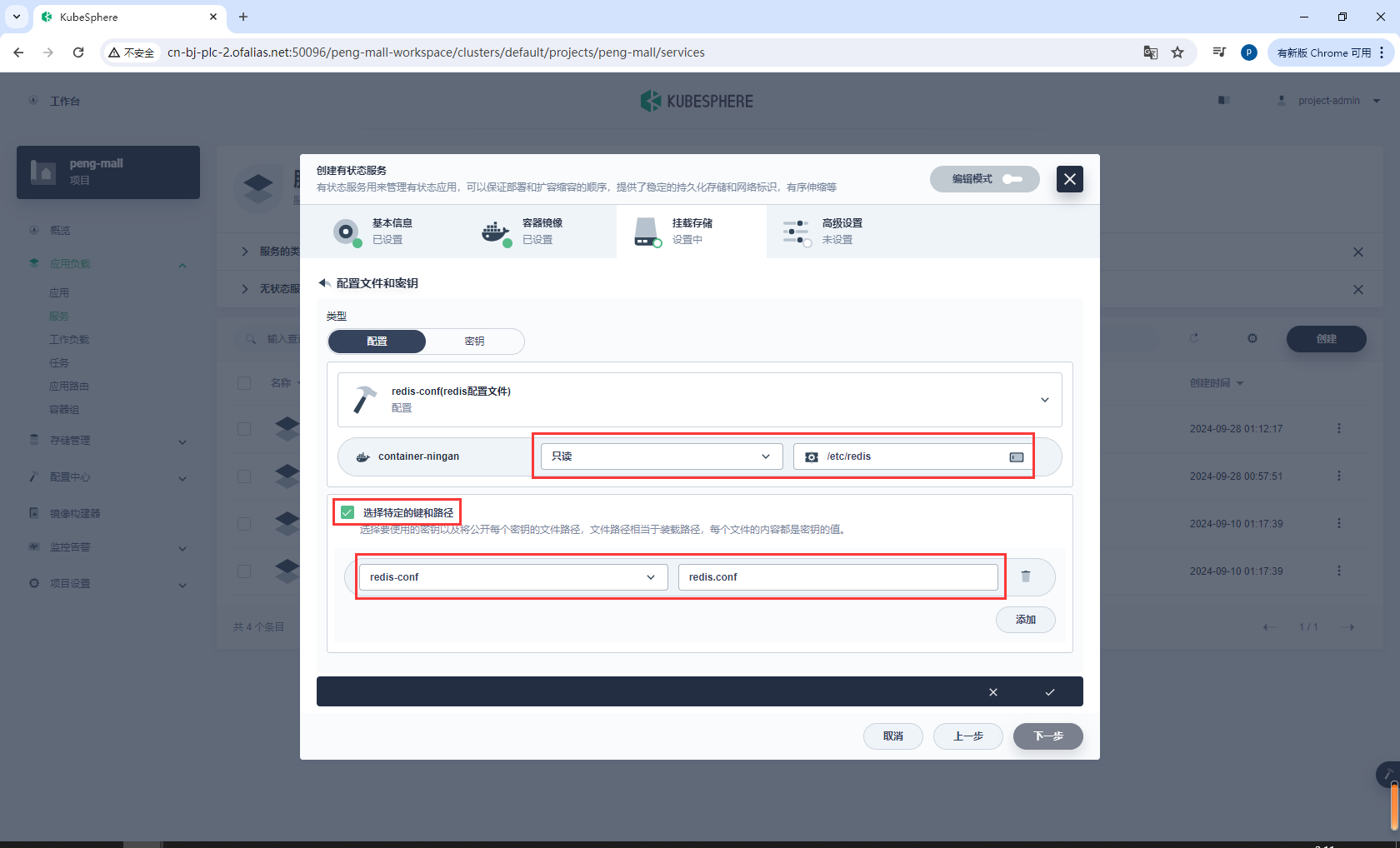
配置指定的配置文件
/etc/redis
redis.conf
redis存储卷和配置文件配置完成
/data
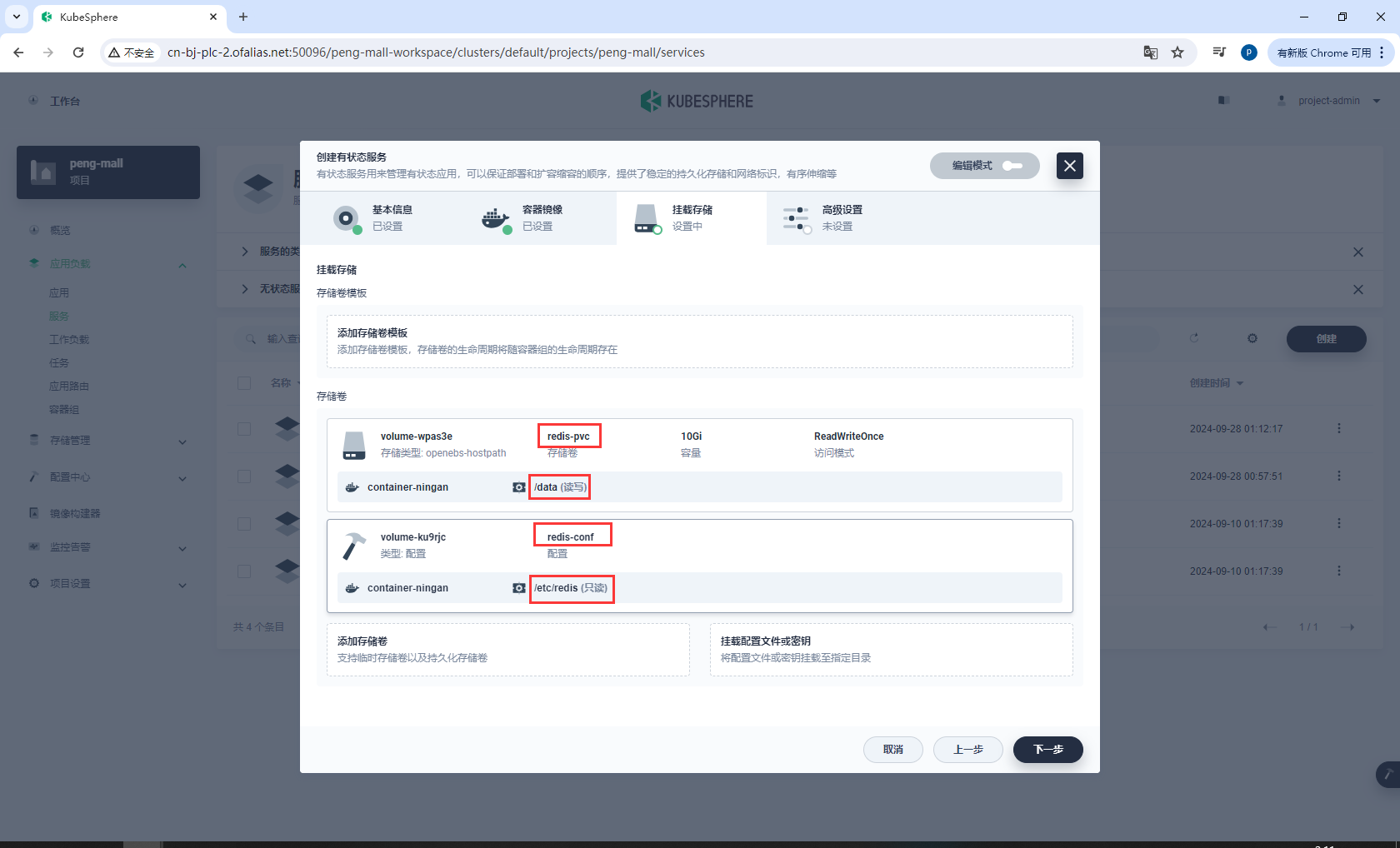
创建完成
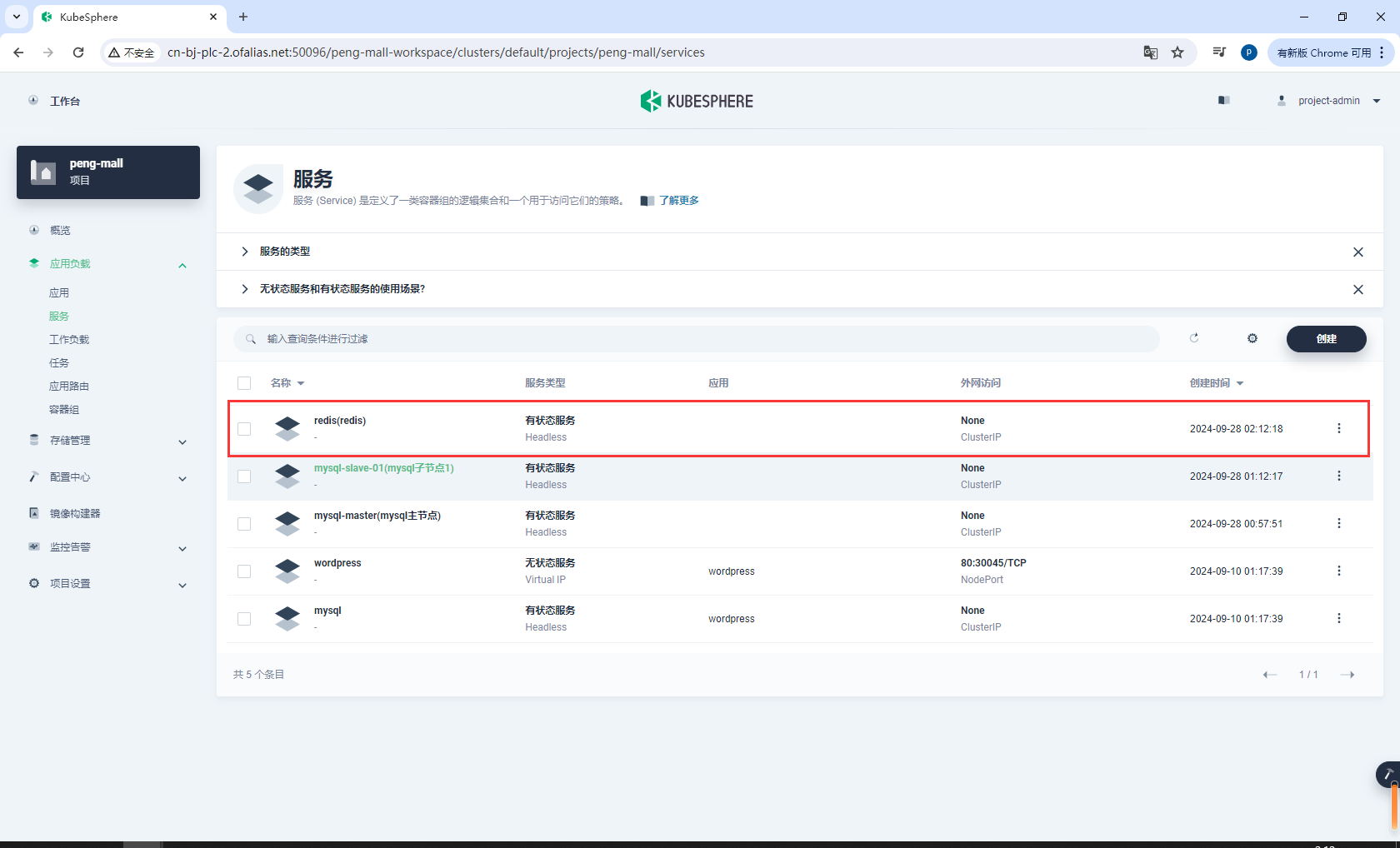
pod一直处于ContainerCreating状态,没有可忽略
pod一直处于ContainerCreating状态,如果之前我们在主节点下载了redis:5.0.7,可以在主节点打包,然后从主节点拷贝到子节点
也可以从有镜像的地方打包,然后直接拷贝到子节点

# 打包
docker save -o /root/k8s/redis_5.0.7.tar redis:5.0.7
# 拷贝
scp /root/k8s/redis_5.0.7.tar root@k8s-03:/root/k8s/

然后到k8s-03子节点
cd k8s/
# 解压镜像
docker load -i /root/k8s/redis_5.0.7.tar

在这里可以确定redis安装在了那个子节点
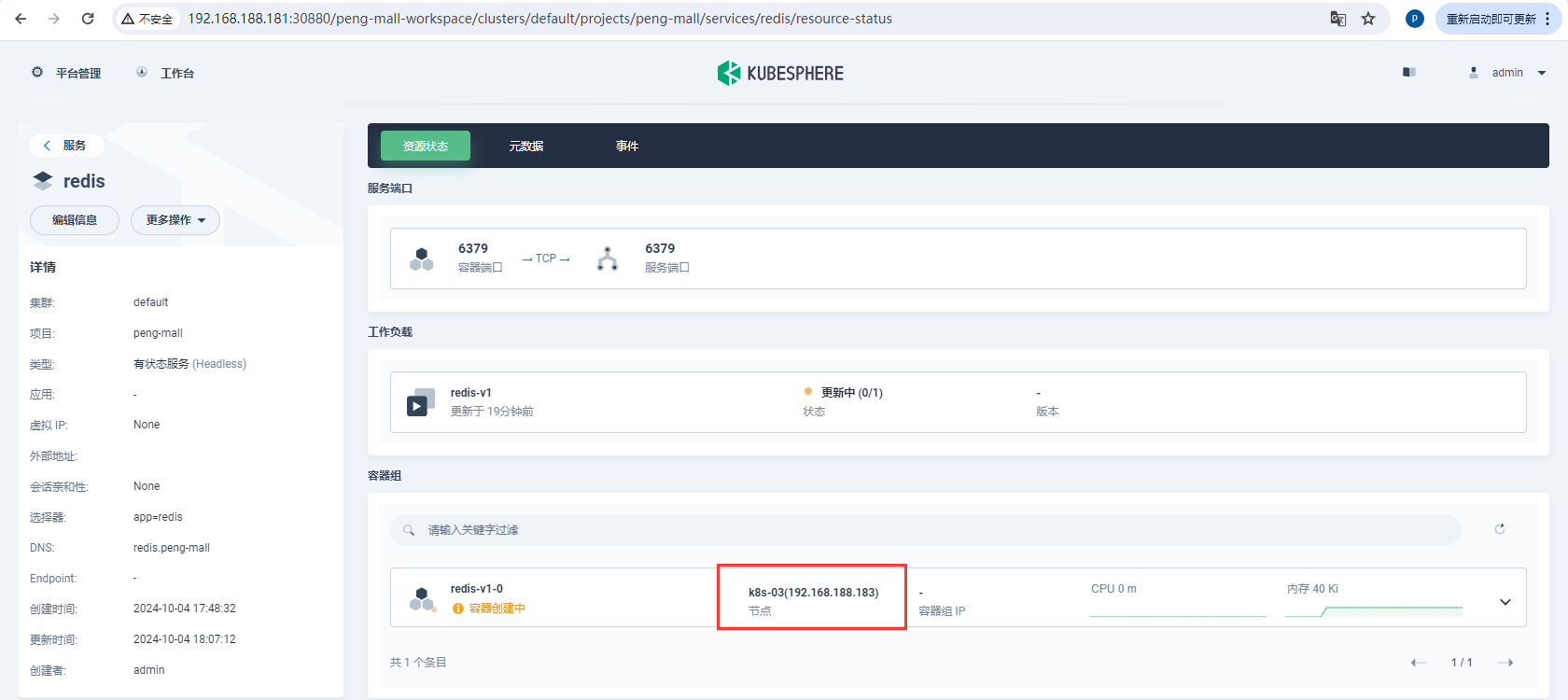
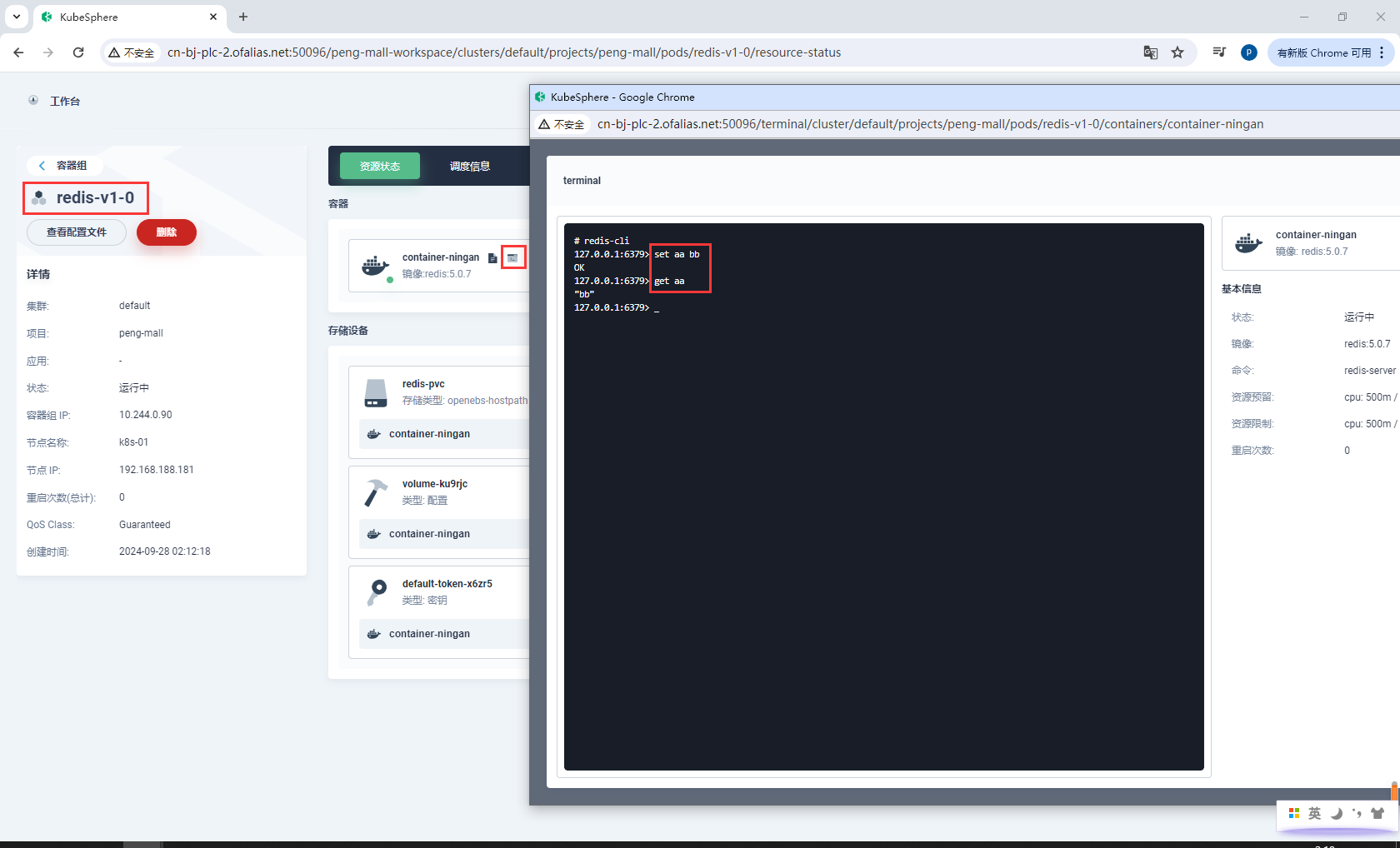
测试
redis-cli
set aa bb
get aa
8.4k8s部署ElasticSearch&Kibana
8.4.1部署ElasticSearch
安装
- 创建
elasticsearch-conf - 创建
elasticsearch-pvc - 创建有状态服务
elasticsearch
创建elasticsearch-conf
elasticsearch-conf
基本信息
配置设置
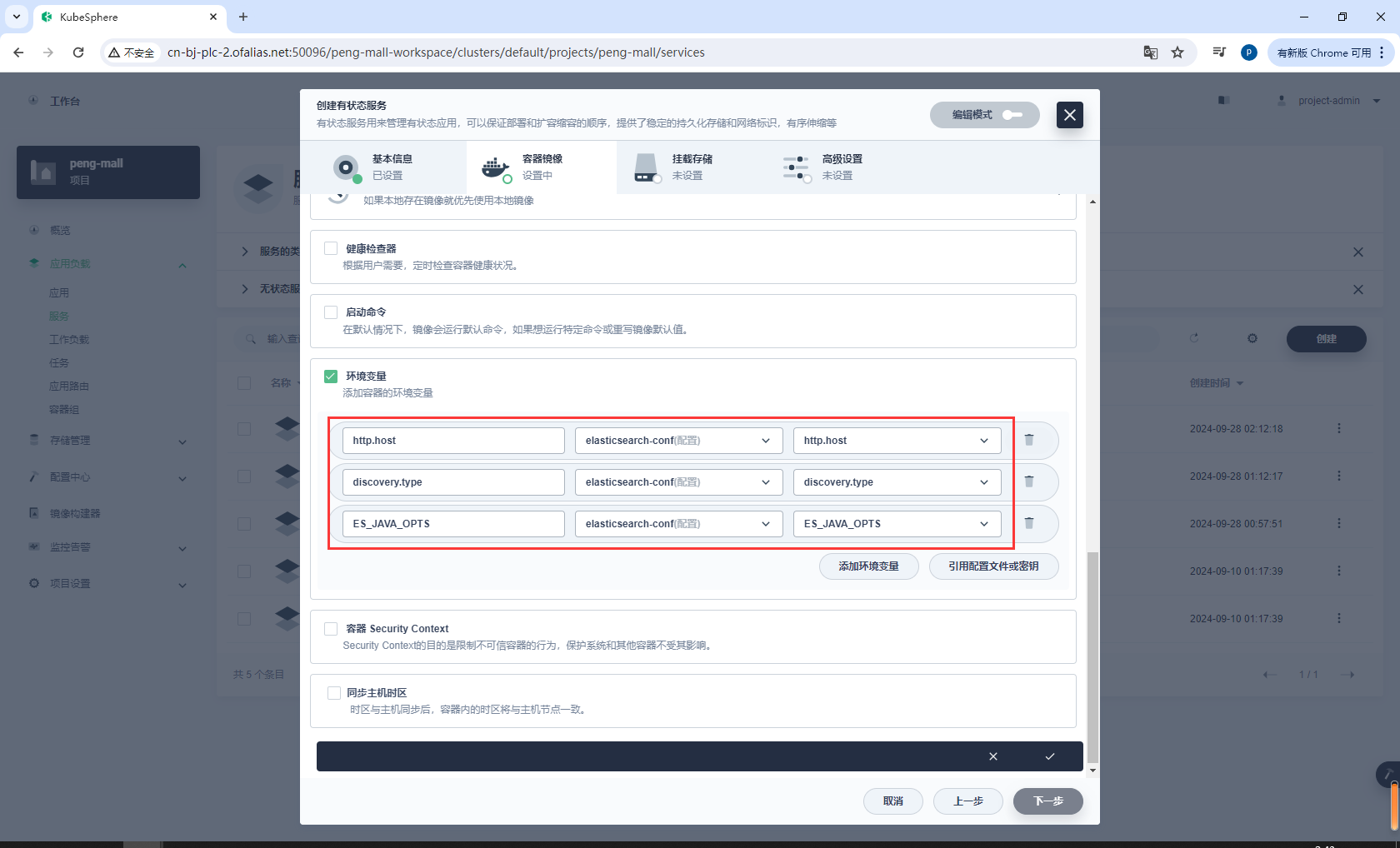
http.host = 0.0.0.0
discovery.type = single-node
ES_JAVA_OPTS = -Xms512m -Xmx512m
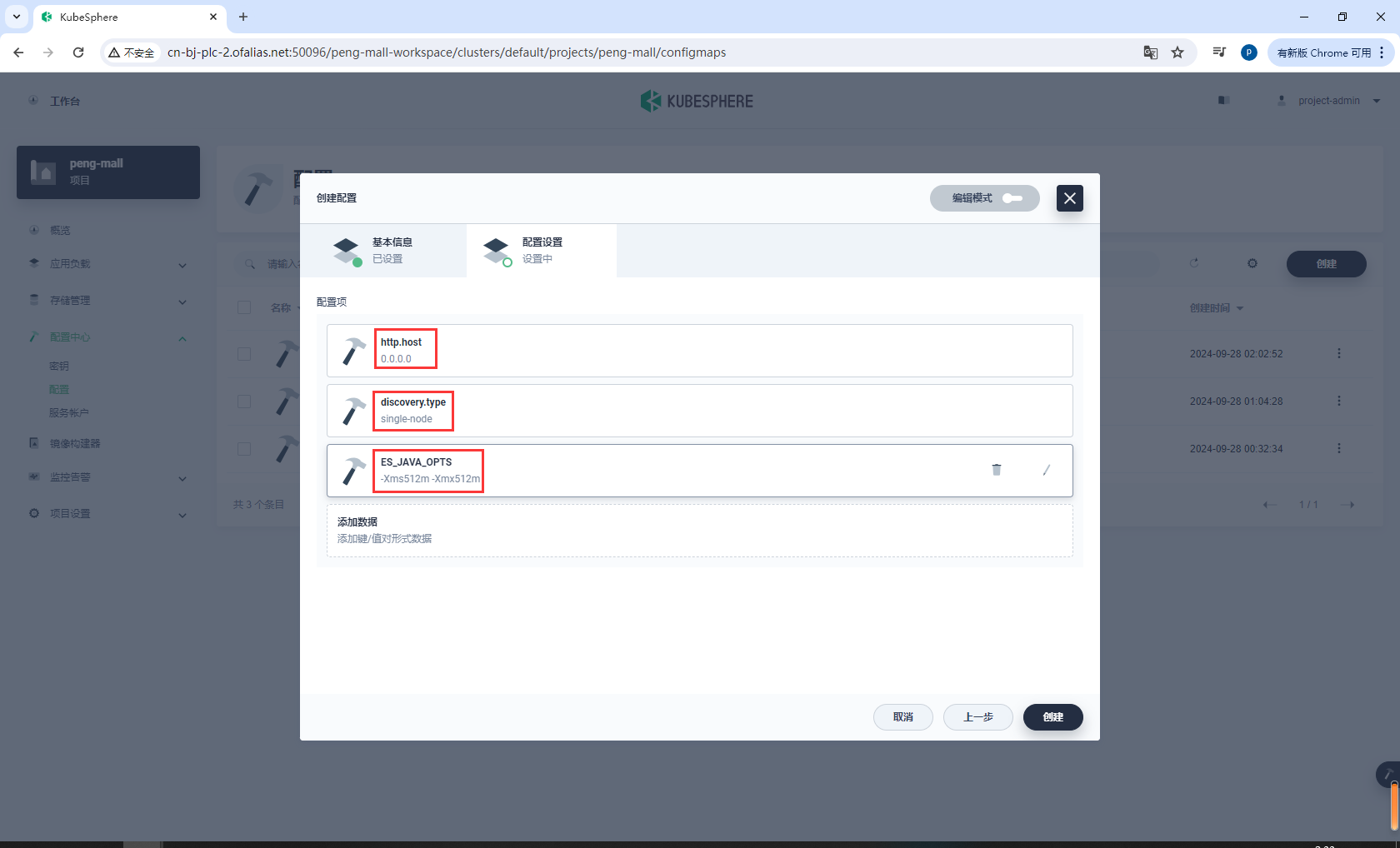
创建elasticsearch-pvc
elasticsearch-pvc
基本信息
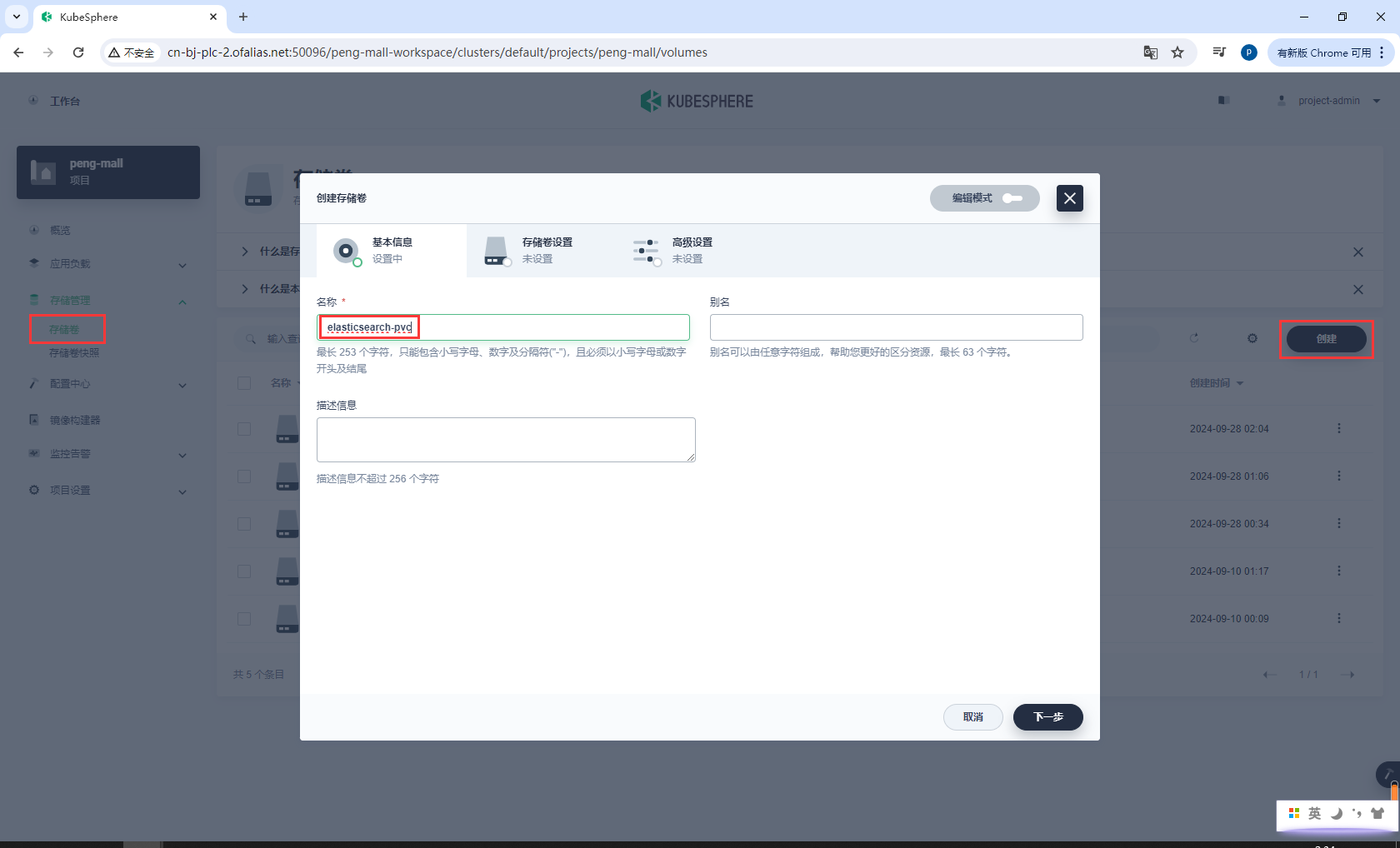
存储卷设置
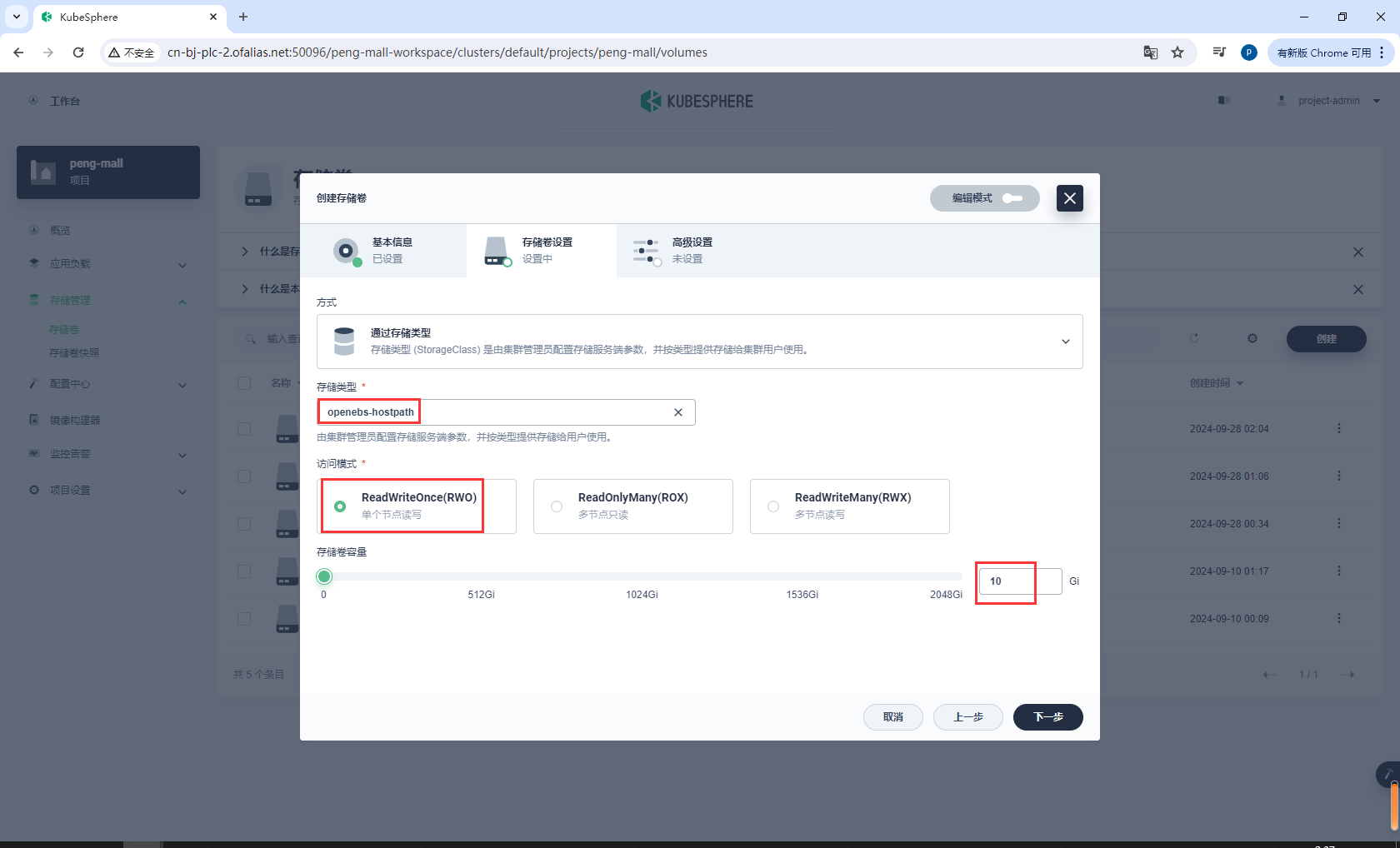
创建有状态服务elasticsearch
elasticsearch:7.12.1
# 或者 我这里下载了这2个镜像
docker.elastic.co/elasticsearch/elasticsearch:7.12.1
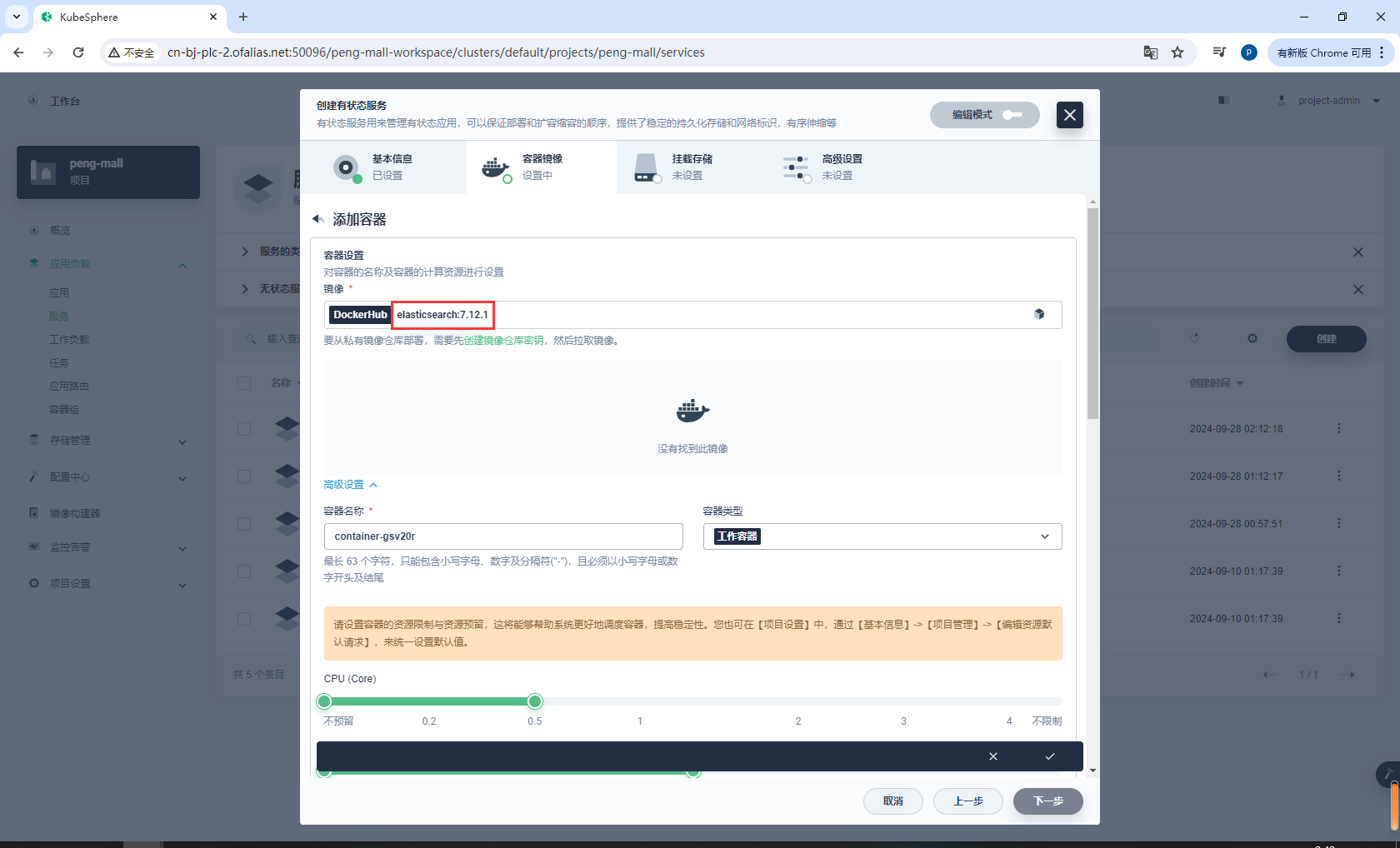
配置资源、端口
9200
9300
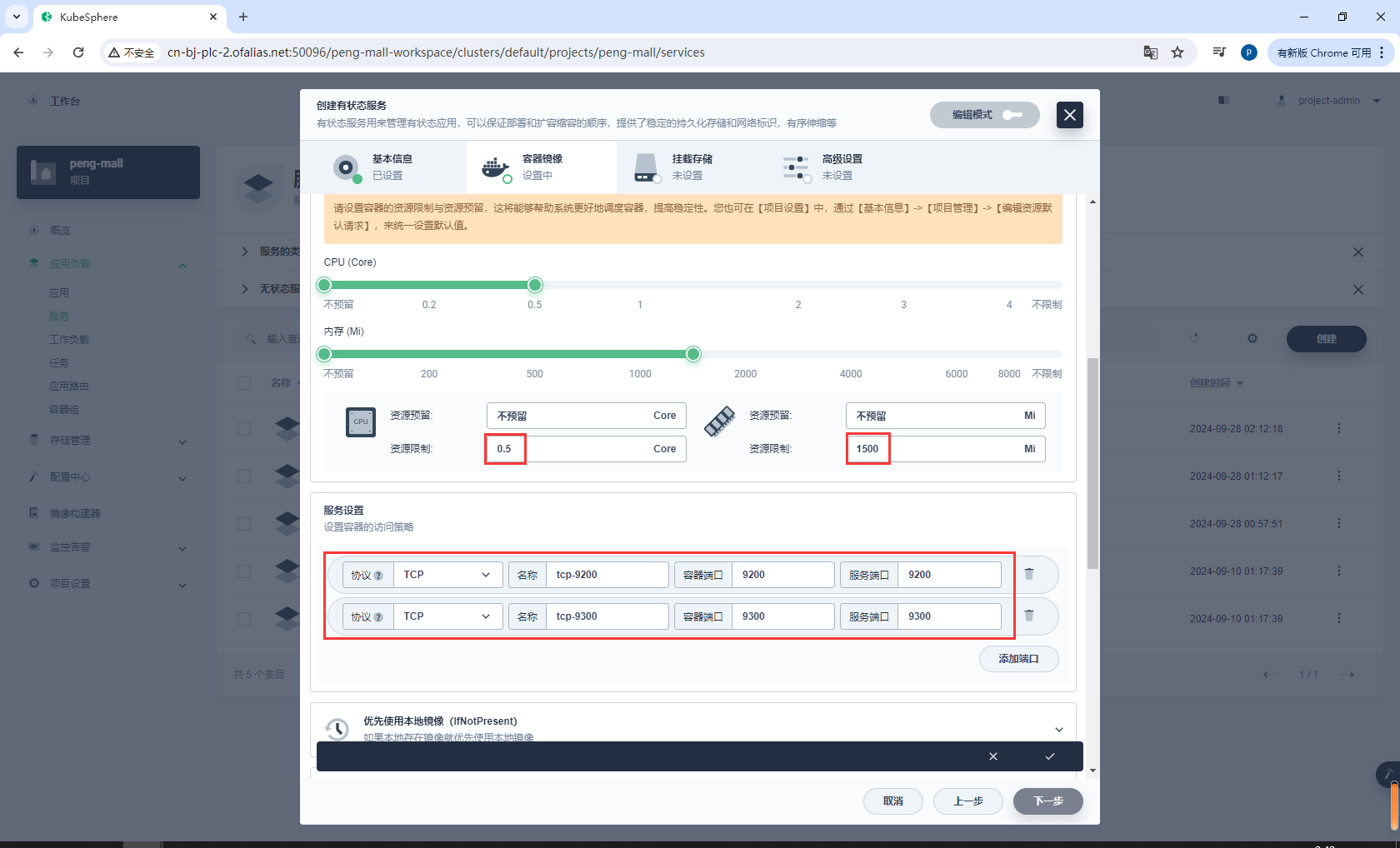
配置环境变量
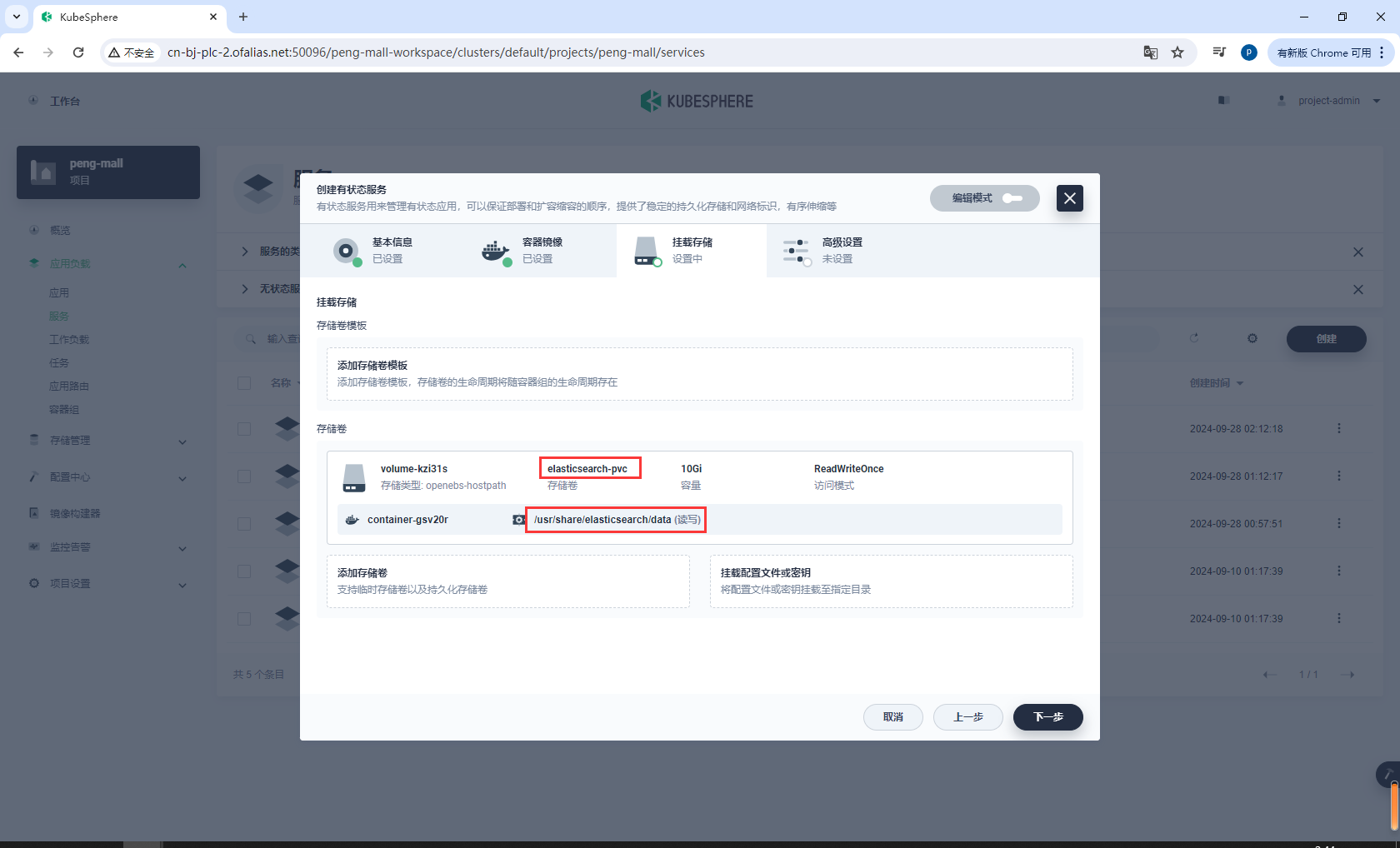
配置存储卷
/usr/share/elasticsearch/data
创建
测试
使用admin登录
访问elasticsearch
curl http://elasticsearch.peng-mall:9200
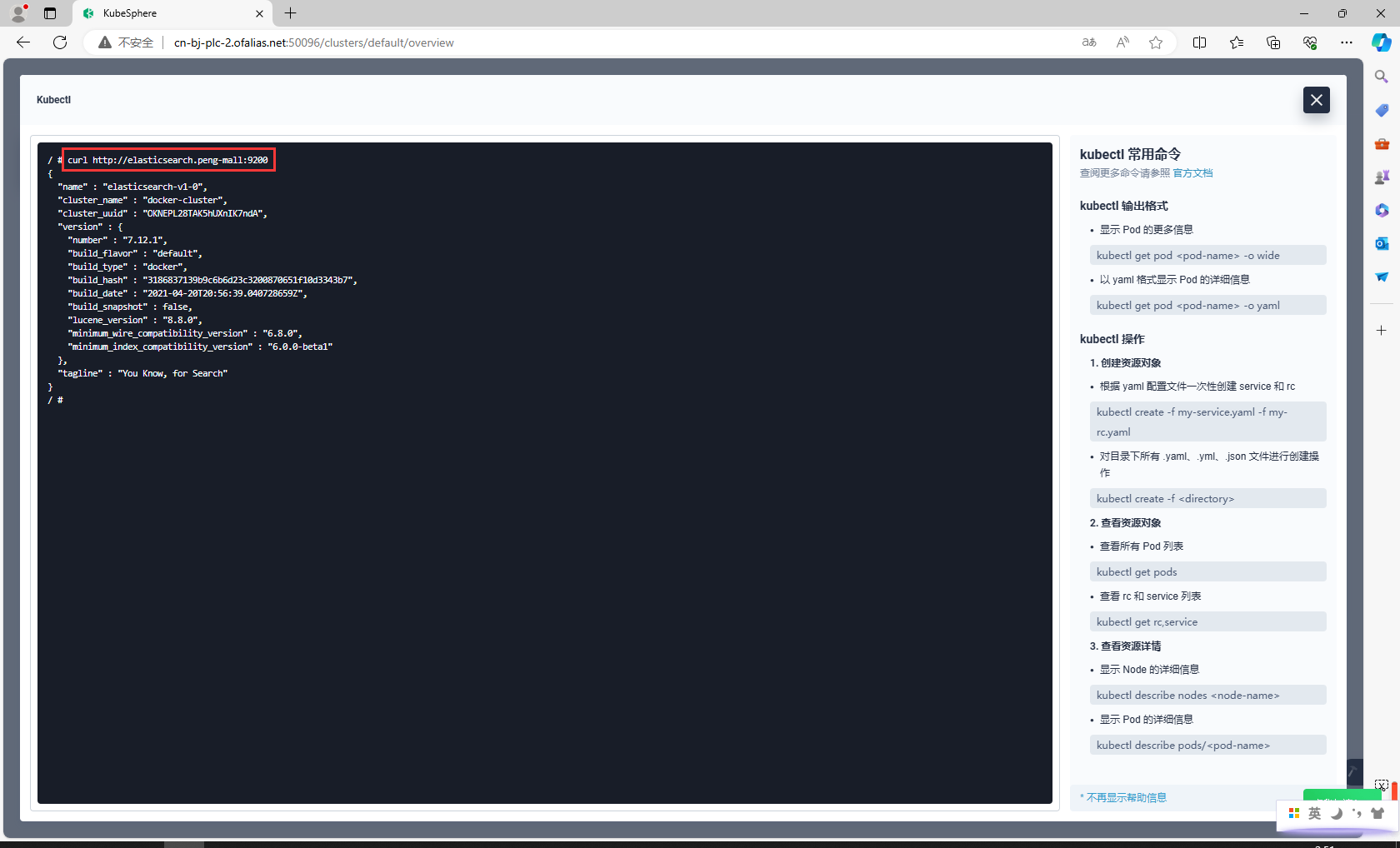
8.4.2部署Kibana
创建无状态服务
基本信息
kibana
设置镜像
kibana:7.12.1
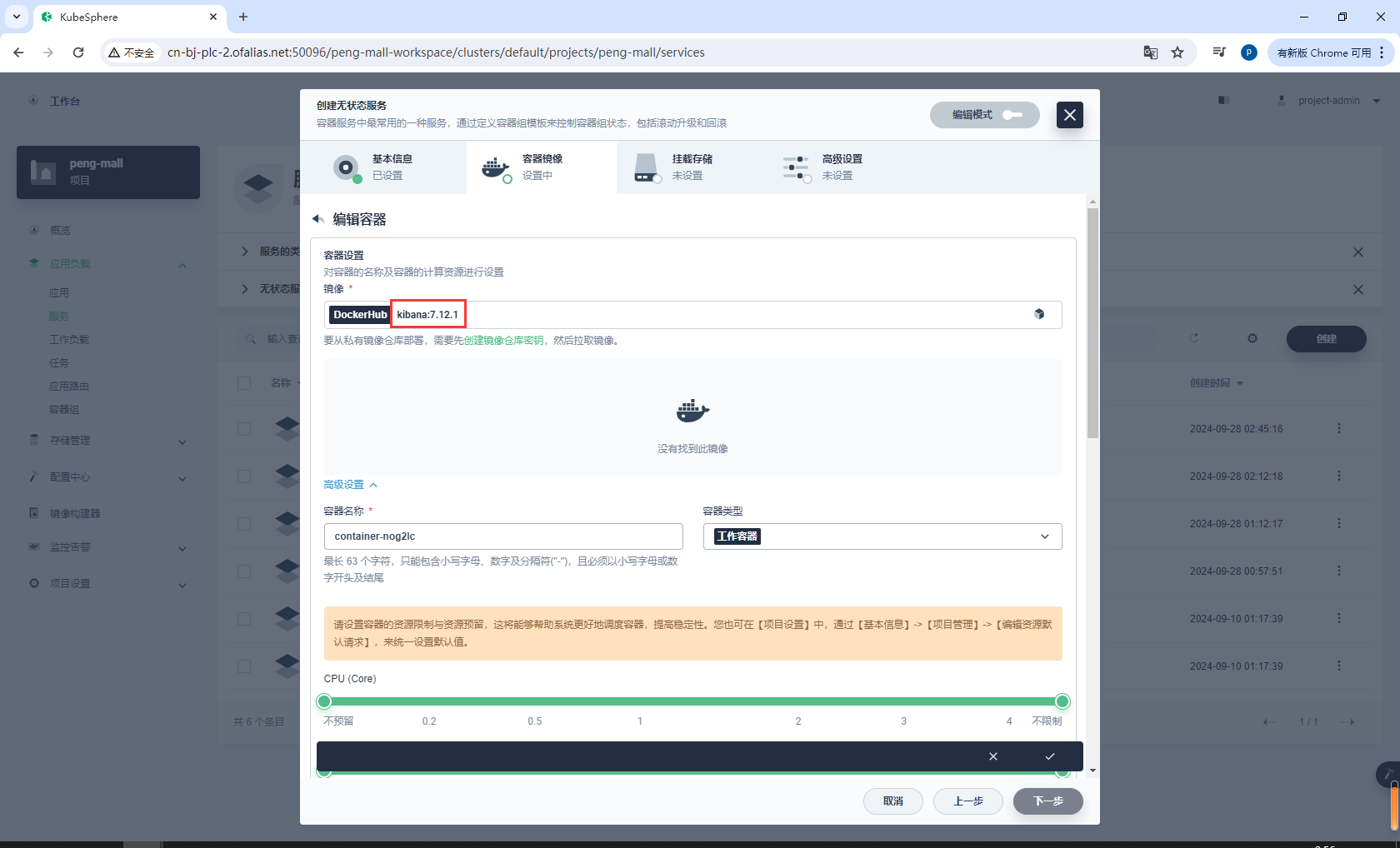
配置端口5601
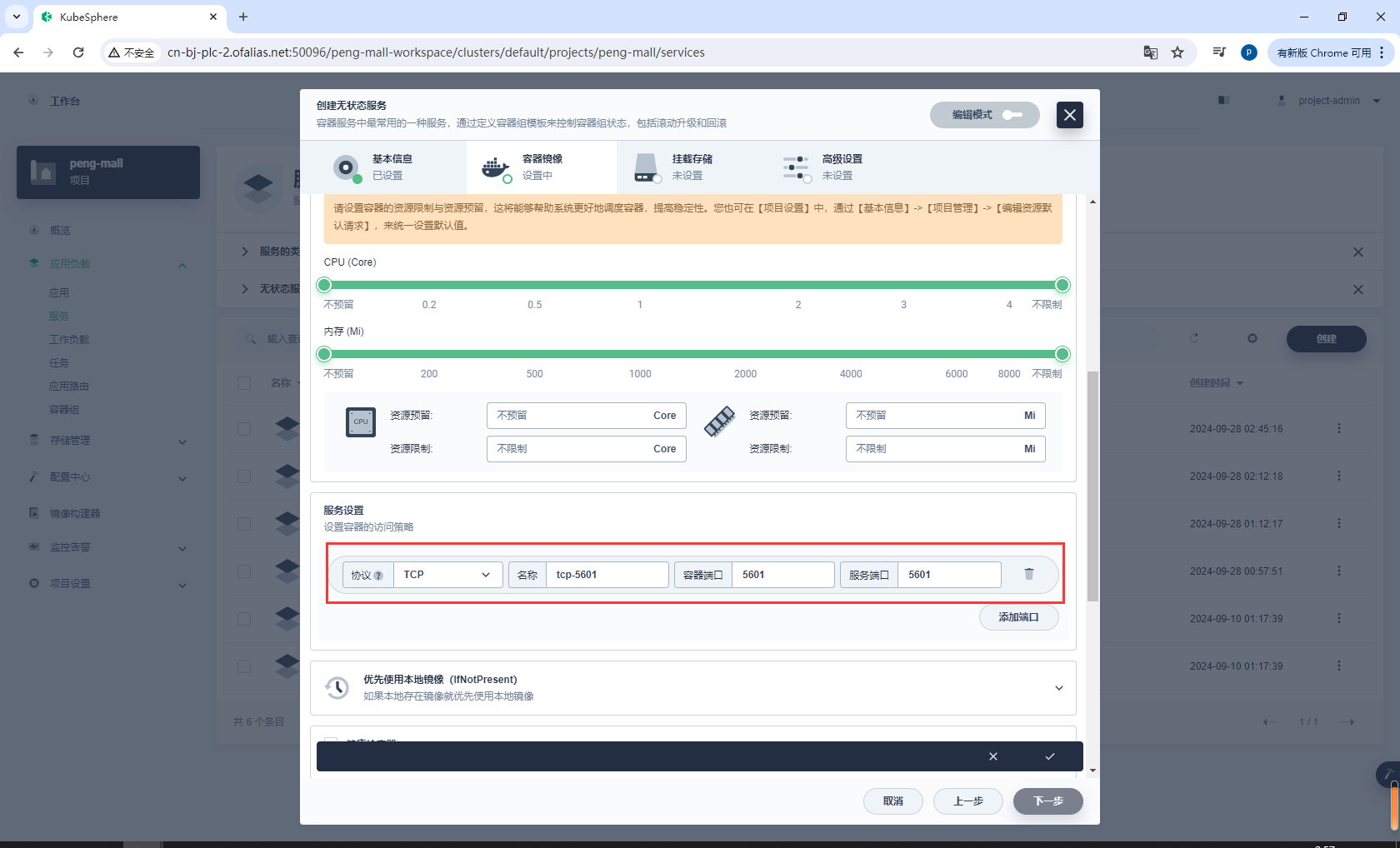
配置环境变量
ELASTICSEARCH_URL = http://elasticsearch.peng-mall:9200
不需要挂载存储
高级设置
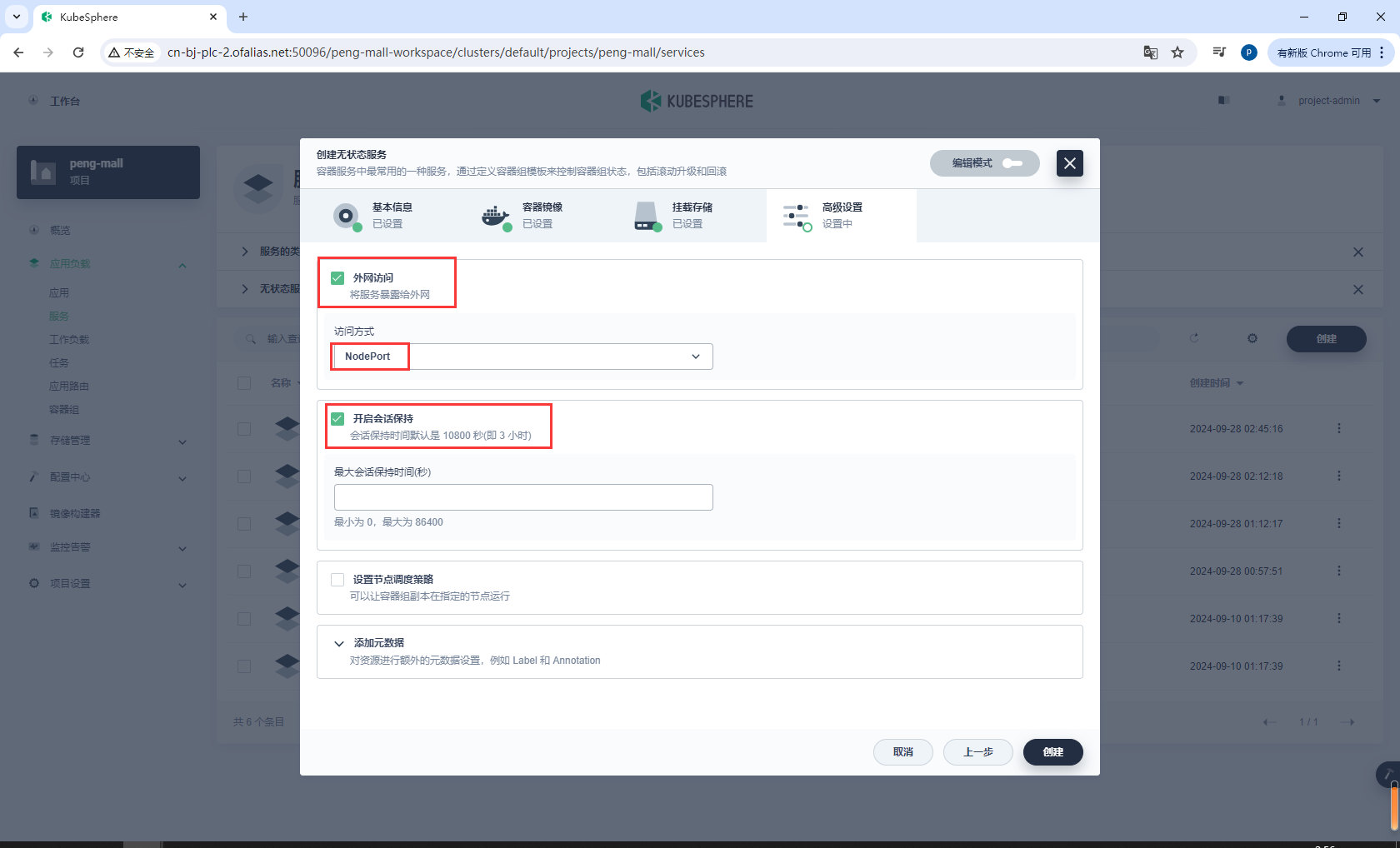
kibana部署完成,我们访问他的端口
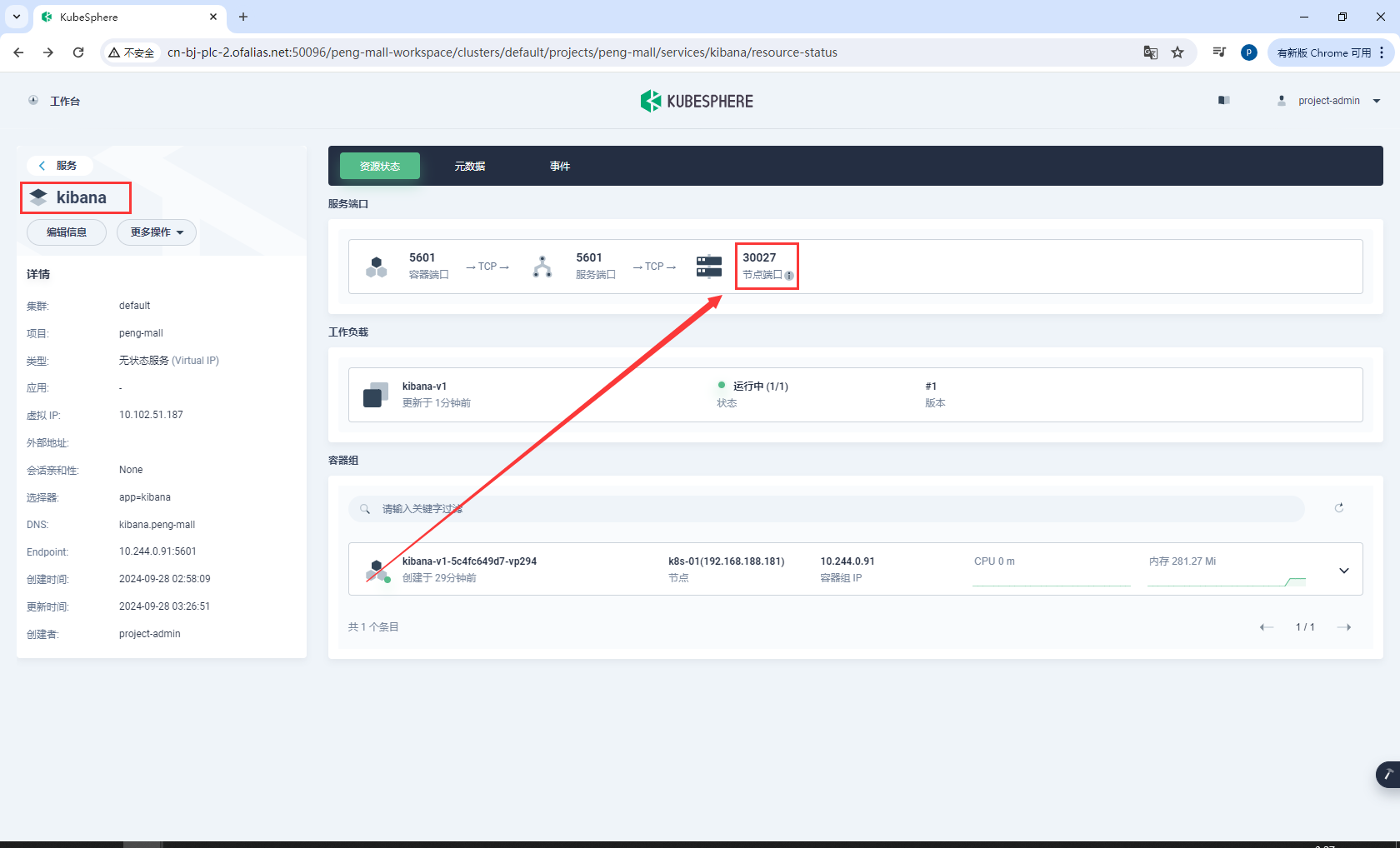
测试,访问自己虚拟机的30027端口,能够发送请求代表部署成功
http://192.168.188.181:30027/app/dev_tools#/console
8.5k8s部署RabbitMQ
安装:
- 创建存储卷
rabbitmq-pvc - 创建有状态服务
rabbitmq
创建存储卷rabbitmq-pvc
创建存储卷-基本信息
rabbitmq-pvc
存储卷设置
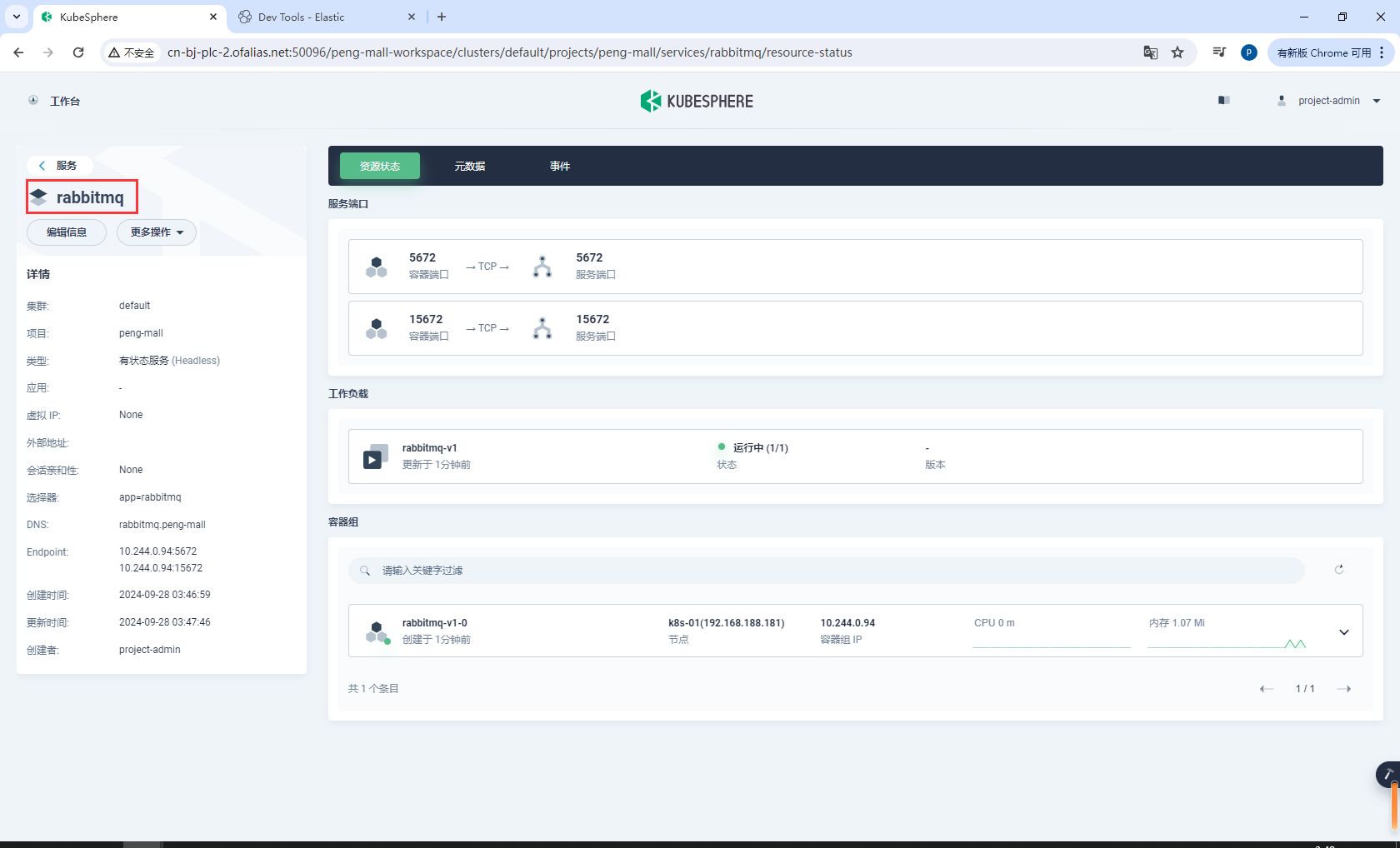
创建有状态服务rabbitmq
基本信息
rabbitmq
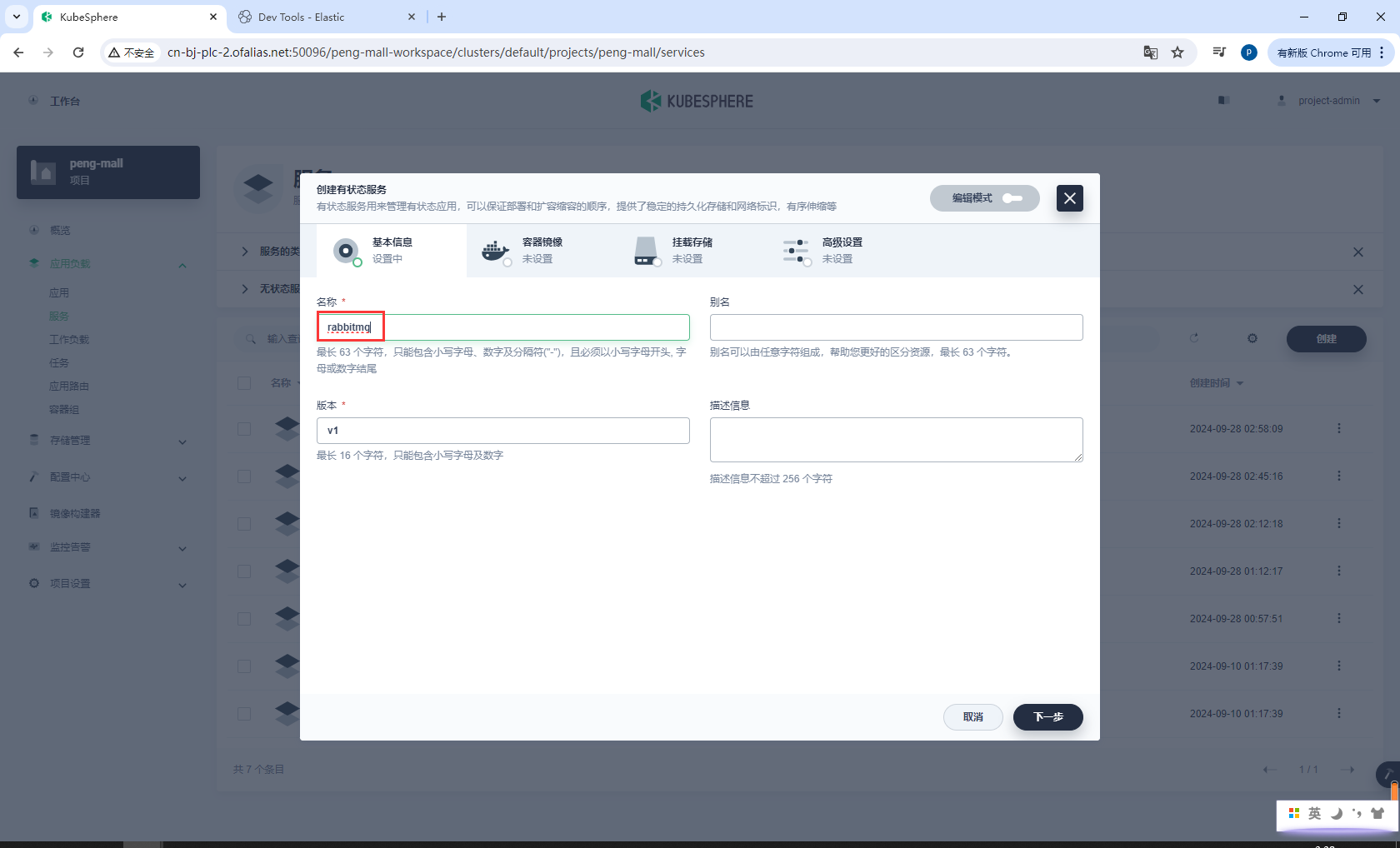
容器镜像
rabbitmq:3.8-management
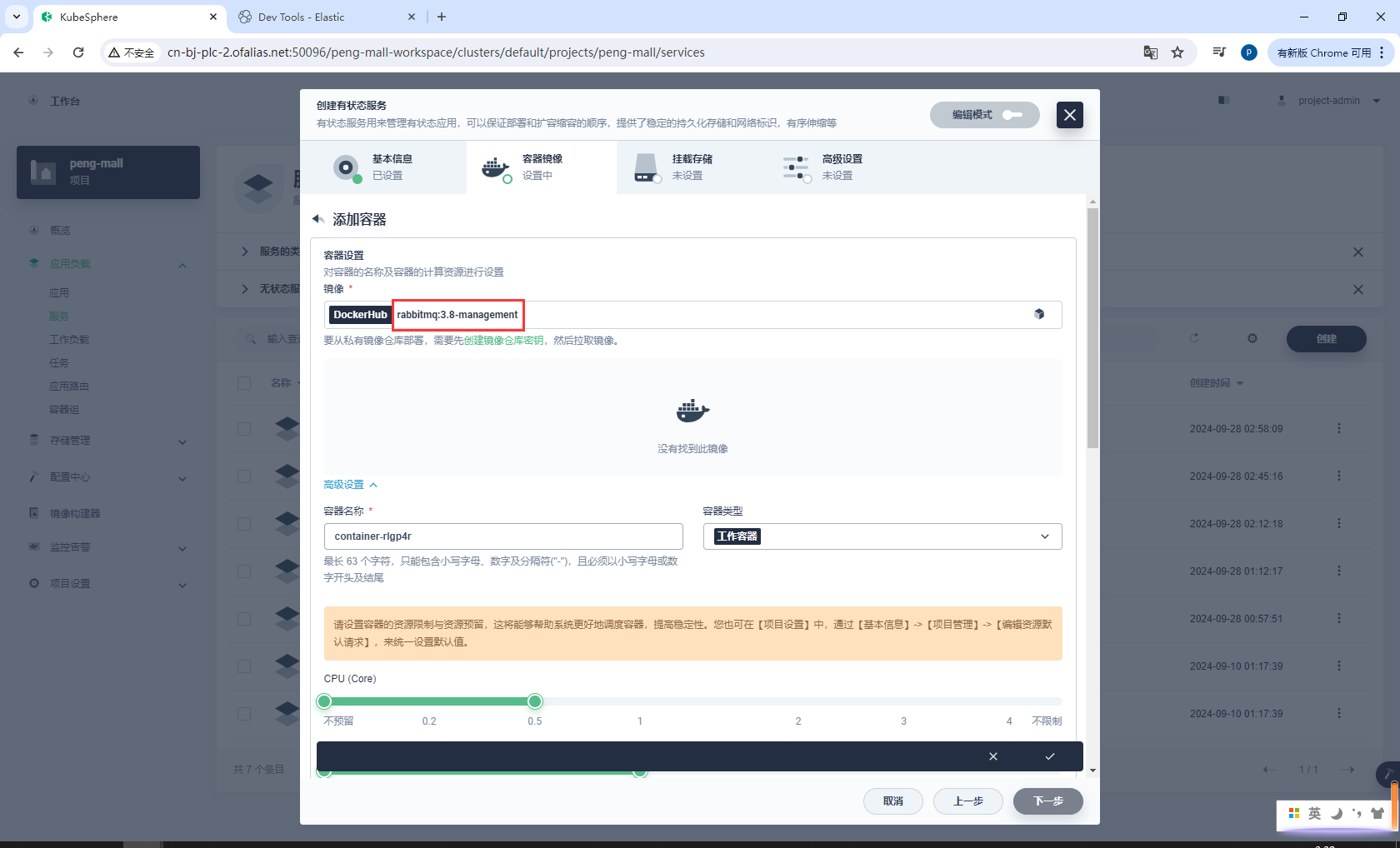
配置资源和端口
ports:
- "5672:5672" # 映射主机的5672端口到容器的5672端口
- "15672:15672" # 映射主机的15672端口到容器的15672端口(管理界面)
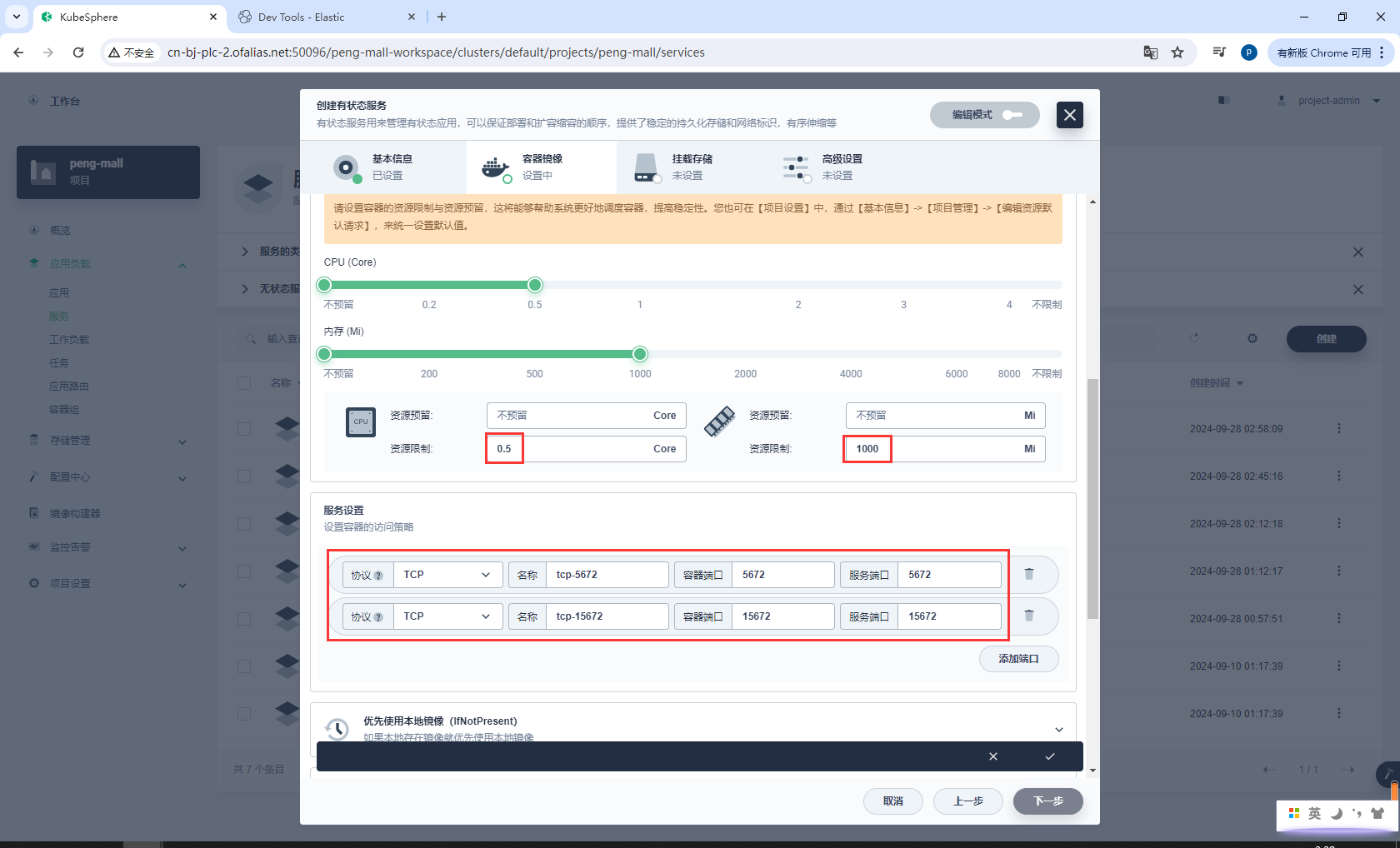
挂载存储
设置存储卷
/var/lib/rabbitmq
高级设置
有时候镜像下载不下来,可以先下载,在设置镜像的时候设置优先选择本地镜像即可
部署完成
8.6k8s部署Nacos
8.6.1部署mysql8
services:
mysql:
image: mysql:latest
container_name: mysql
environment:
MYSQL_ROOT_PASSWORD: root # MySQL 根用户密码
MYSQL_DATABASE: nacos # 默认创建的数据库
MYSQL_PASSWORD: root # MySQL 用户密码
TZ: Asia/Shanghai
ports:
- "3306:3306" # 映射主机的3306端口到容器的3306端口
volumes:
# - mysql_data:/var/lib/mysql # 持久化 MySQL 数据到名为 mysql_data 的卷
- ./mysql/data:/var/lib/mysql
- ./mysql/conf:/etc/mysql/conf.d
# - ./root/mysql/init:/docker-entrypoint-initdb.d
networks:
- peng-net # 指定连接的网络
创建mysql8-conf
mysql8-conf
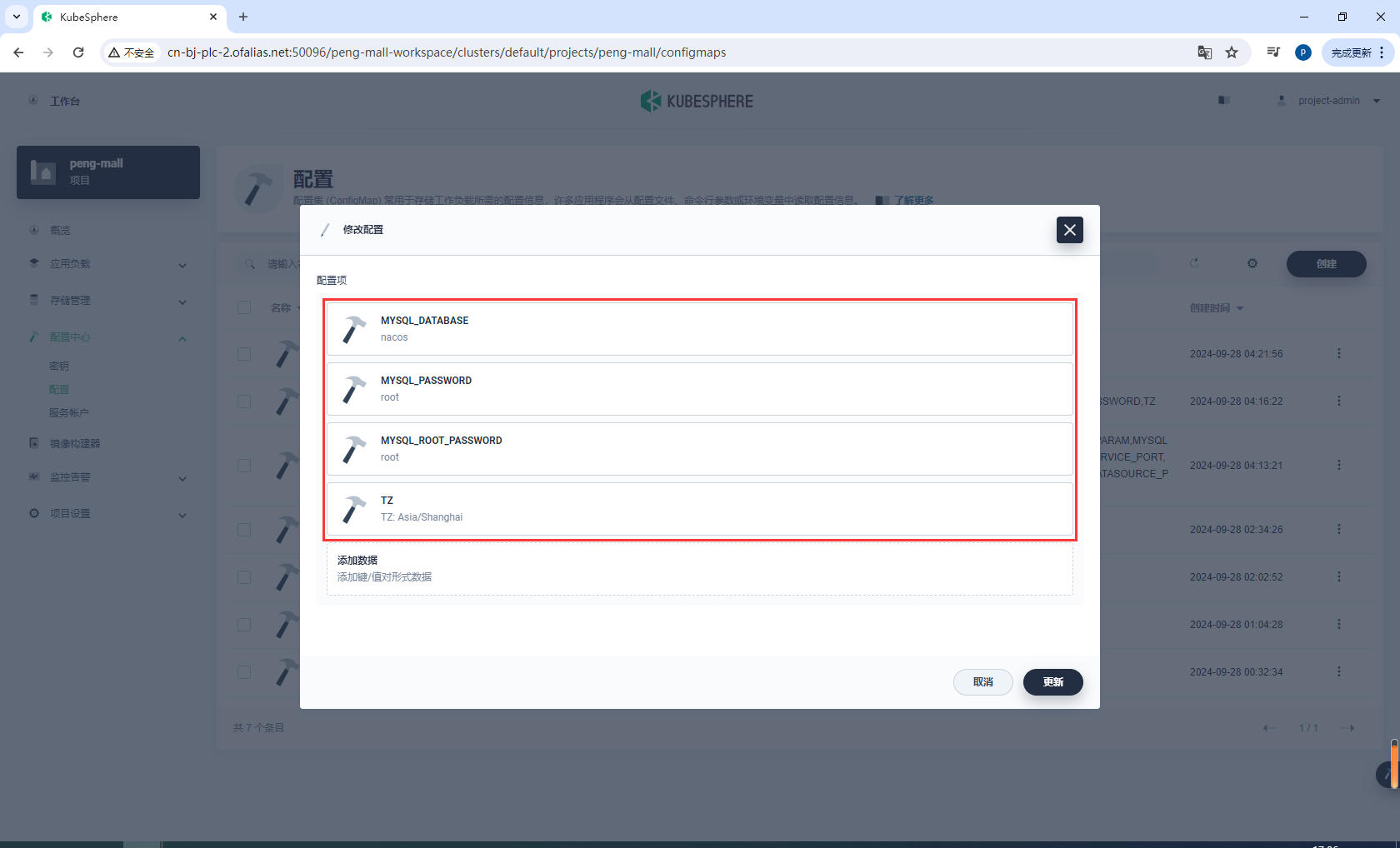
创建mysql8-cnf
键
mysql8.cnf
值
[client]
default_character_set=utf8mb4
[mysql]
default_character_set=utf8mb4
[mysqld]
character_set_server=utf8mb4
collation_server=utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
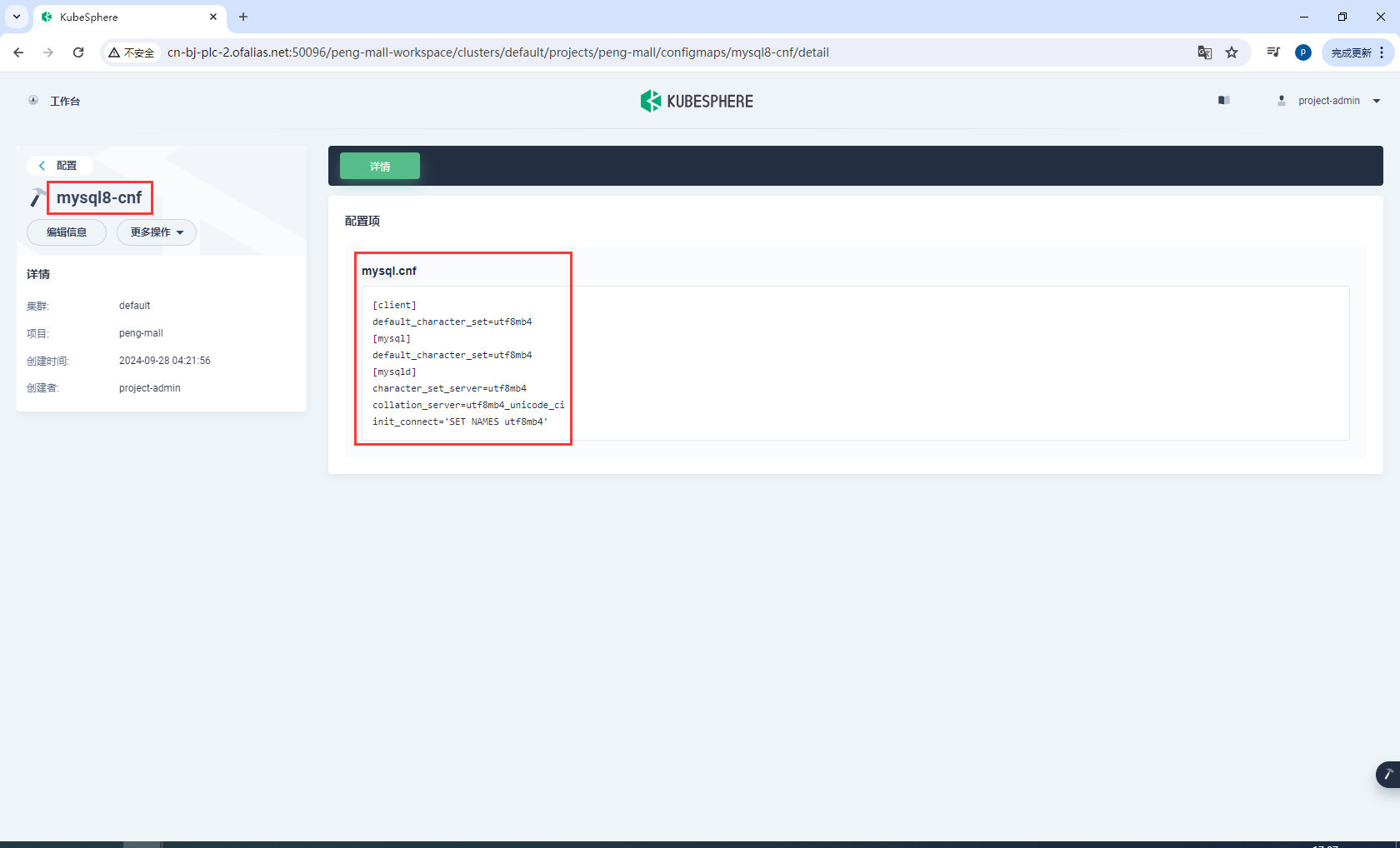
这样就创建完成了mysql8的环境变量和配置
创建mysql8-pvc
mysql8-pvc
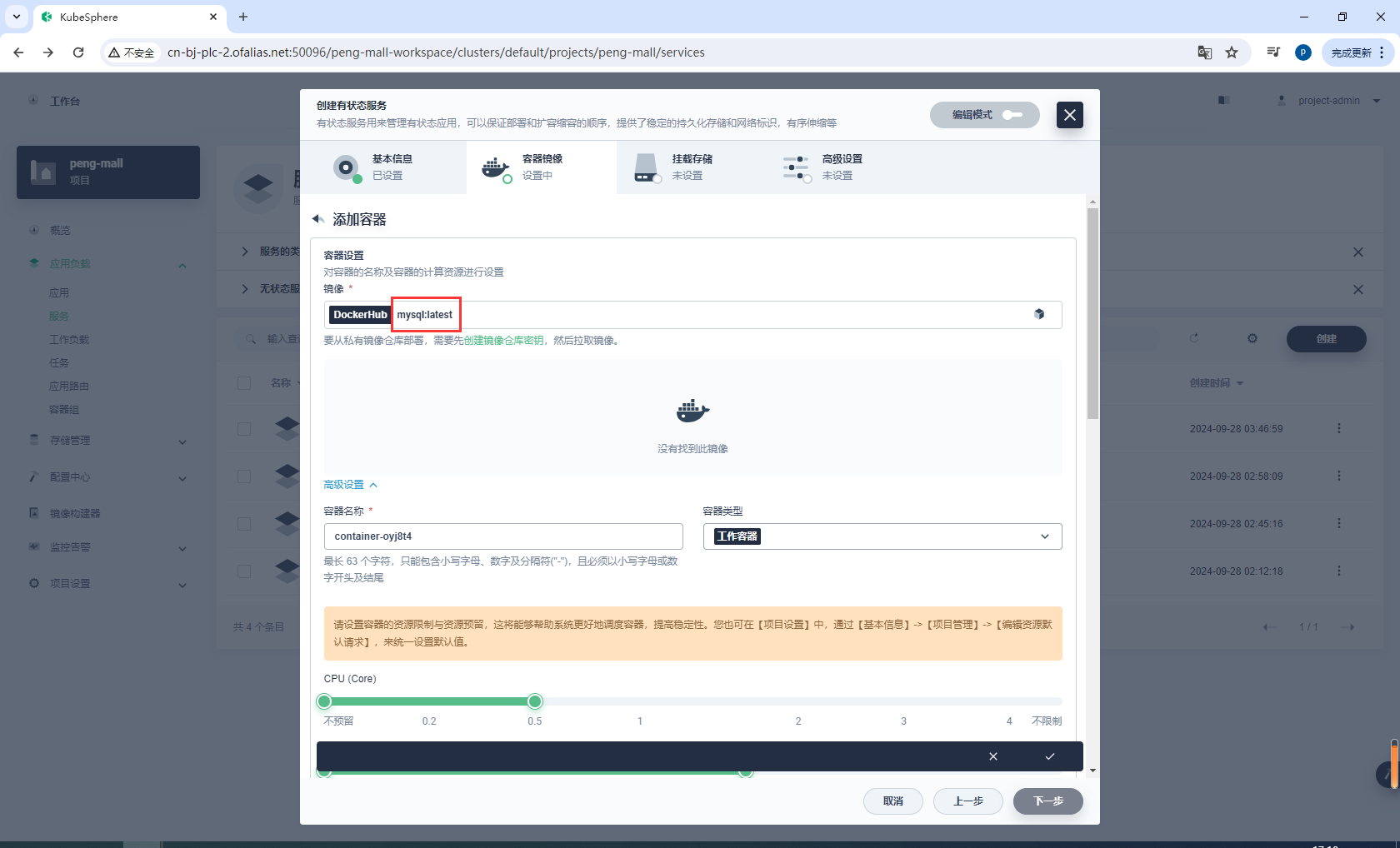
创建有状态服务
mysql8

设置镜像
mysql:latest
配置资源和端口
tcp-3306 3306 3306
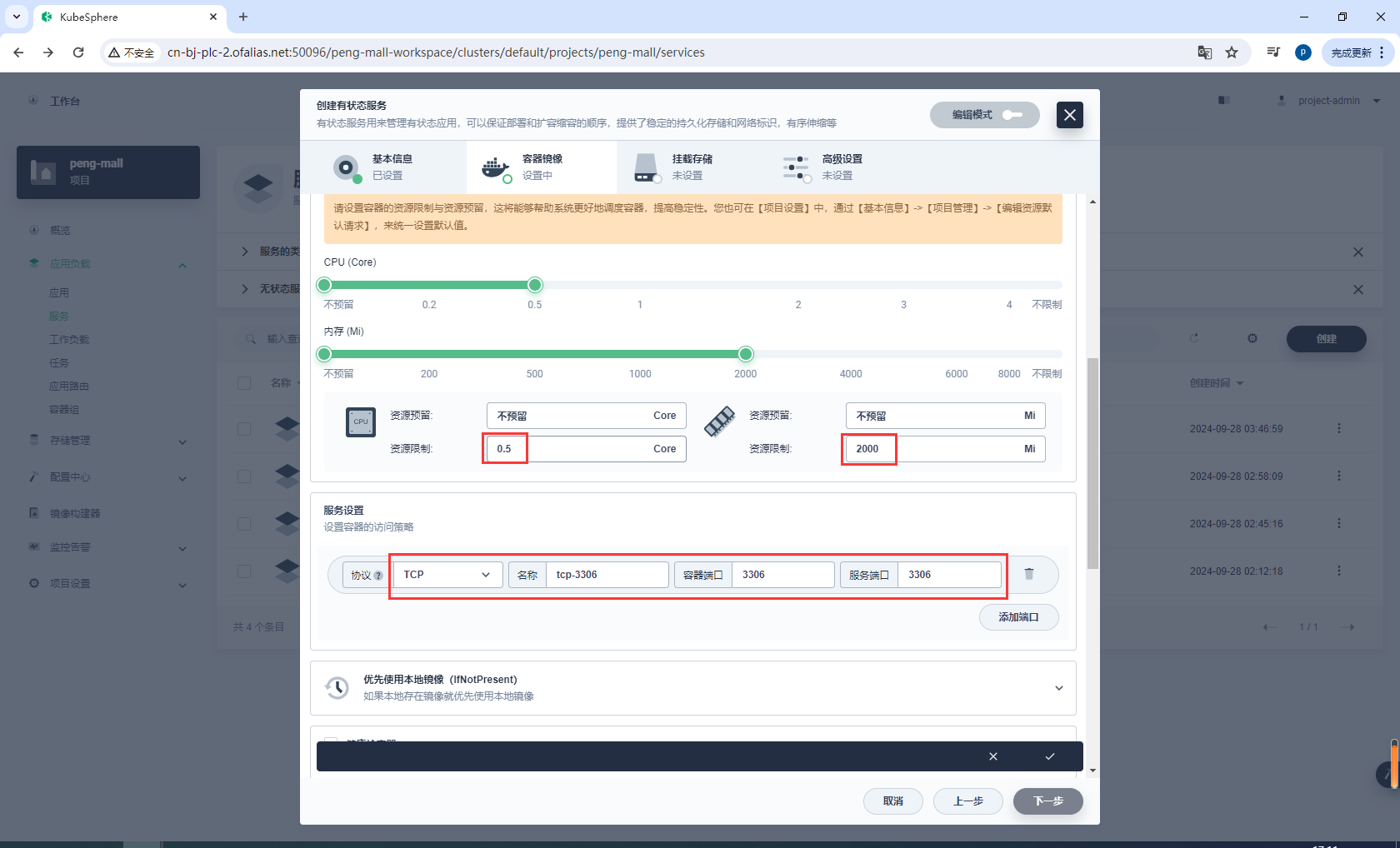
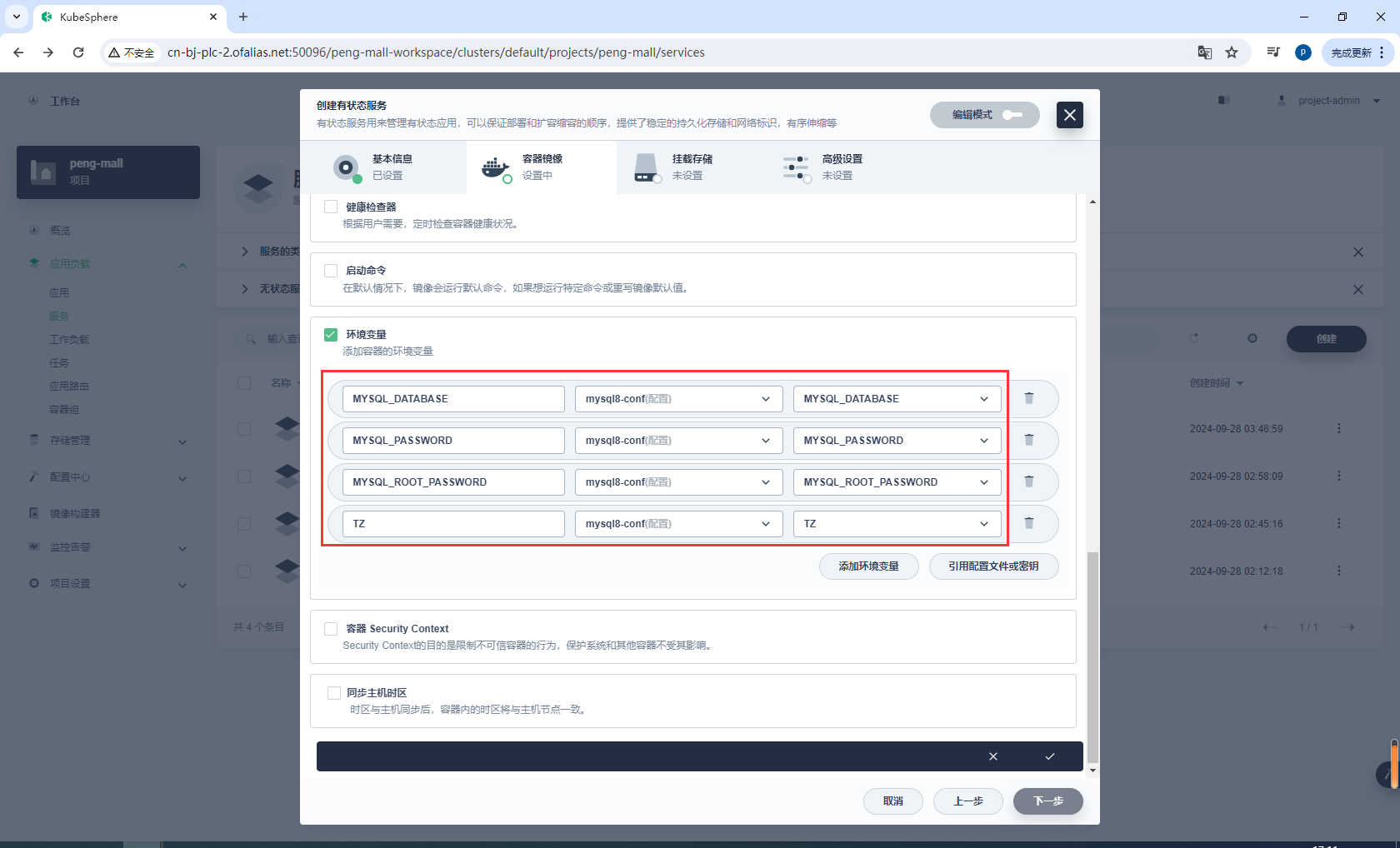
配置环境变量,选择mysql8-conf
mysql8-conf
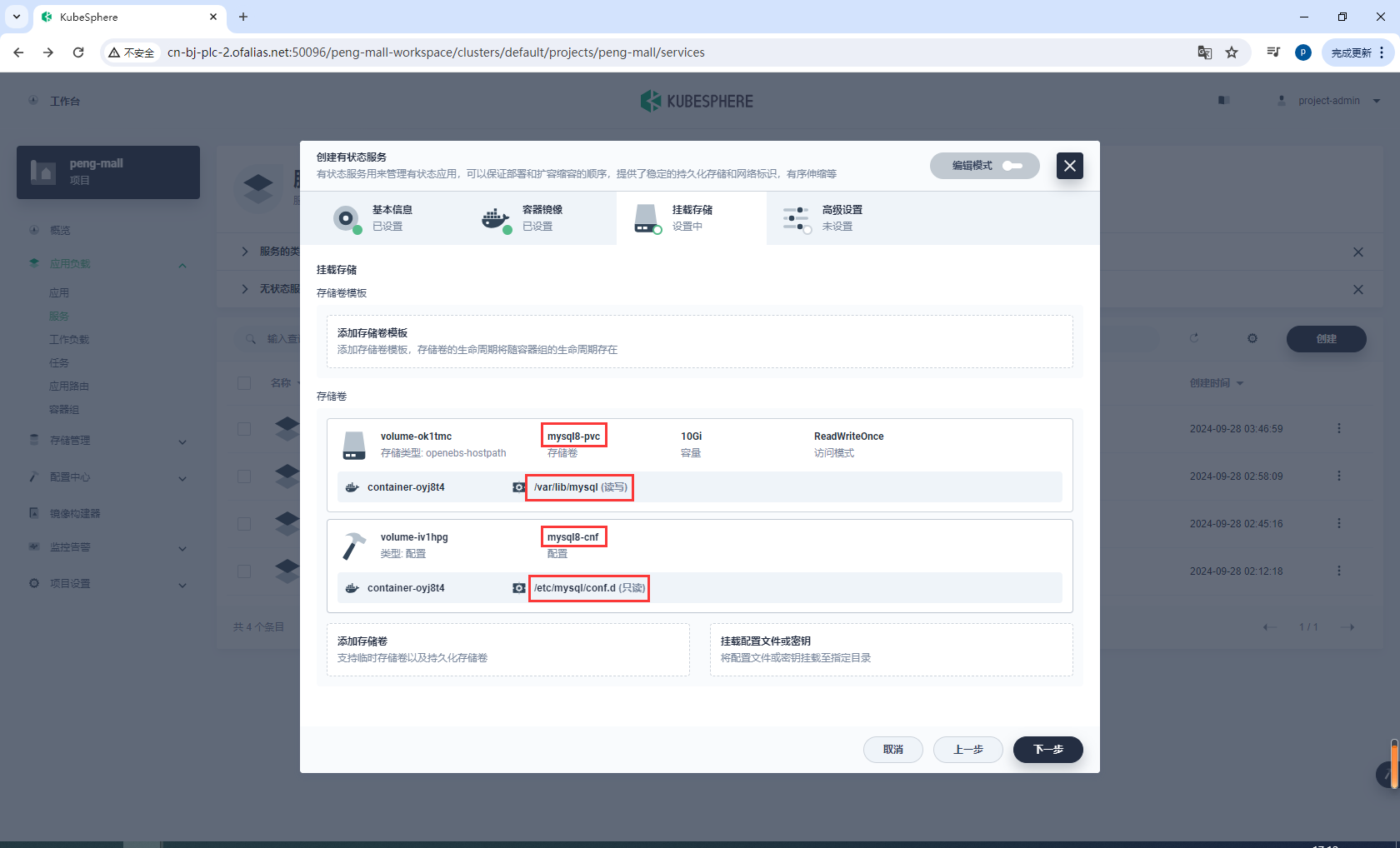
配置挂载存储
mysql8-pvc /var/lib/mysql
mysql8-cnf /etc/mysql/conf.d
高级设置
部署nacos需要的数据
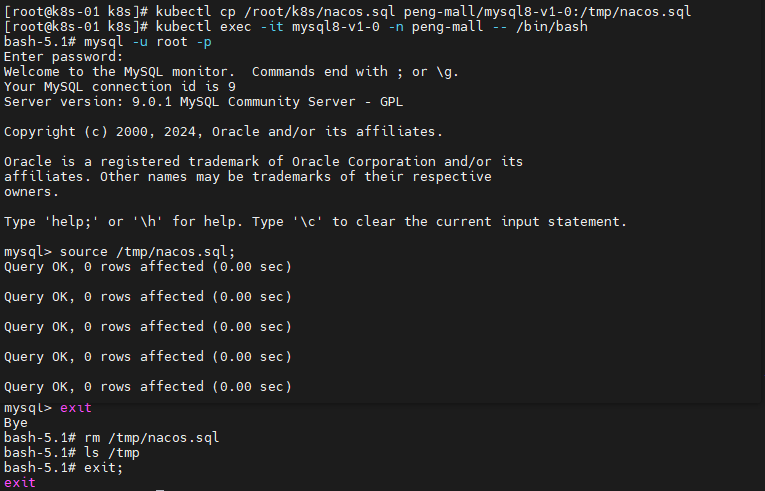
# 将nacos.sql拷贝到容器内
kubectl cp /root/k8s/nacos.sql peng-mall/mysql8-v1-0:/tmp/nacos.sql
# 进入容器
kubectl exec -it mysql8-v1-0 -n peng-mall -- /bin/bash
# 登录mysql
mysql -u root -p
# 执行
source /tmp/nacos.sql;
# 退出mysql
exit;
# 删除
rm /tmp/nacos.sql
# 退出容器
exit;
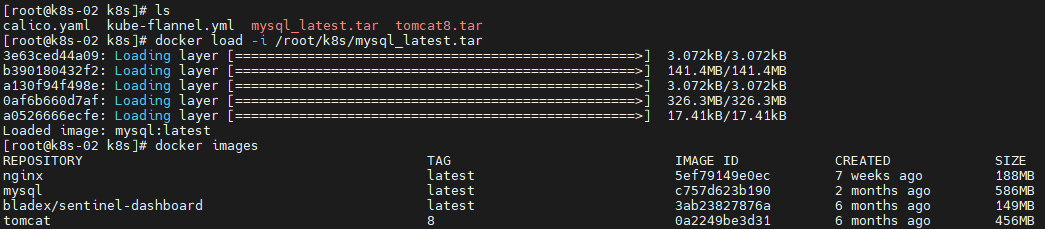
mysql镜像一直不能自动下载,如果主节点有mysql:latest,可以打包,然后复制到子节点重新加载
在k8s-01打包mysql:latest
# 打包
docker save -o /root/k8s/mysql_latest.tar mysql:latest
# 复制到k8s-02
scp /root/k8s/mysql_latest.tar root@k8s-02:/root/k8s

在k8s-01
docker load -i /root/k8s/mysql_latest.tar
8.6.2部署nacos
nacos:
image: nacos/nacos-server:v2.1.0-slim
container_name: nacos
environment:
- PREFER_HOST_MODE=hostname # 使用主机名作为偏好模式
- MODE=standalone
- SPRING_DATASOURCE_PLATFORM=mysql
- MYSQL_SERVICE_HOST=192.168.188.180 # MySQL 服务主机名
- MYSQL_SERVICE_DB_NAME=nacos # Nacos 使用的数据库名
- MYSQL_SERVICE_PORT=3306 # MySQL 服务端口
- MYSQL_SERVICE_USER=root # MySQL 用户名
- MYSQL_SERVICE_PASSWORD=root # MySQL 用户密码
- MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
# - NACOS_AUTH_ENABLE=true # 启用 Nacos 认证
ports:
- "8848:8848" # 映射主机的8848端口到容器的8848端口
- "9848:9848"
- "9849:9849"
depends_on:
- mysql # 启动顺序,先启动 mysql 服务
volumes:
- nacos_data:/home/nacos/init.d # 持久化 Nacos 数据到名为 nacos_data 的卷
networks:
- peng-net
基本信息
nacos-conf
配置设置
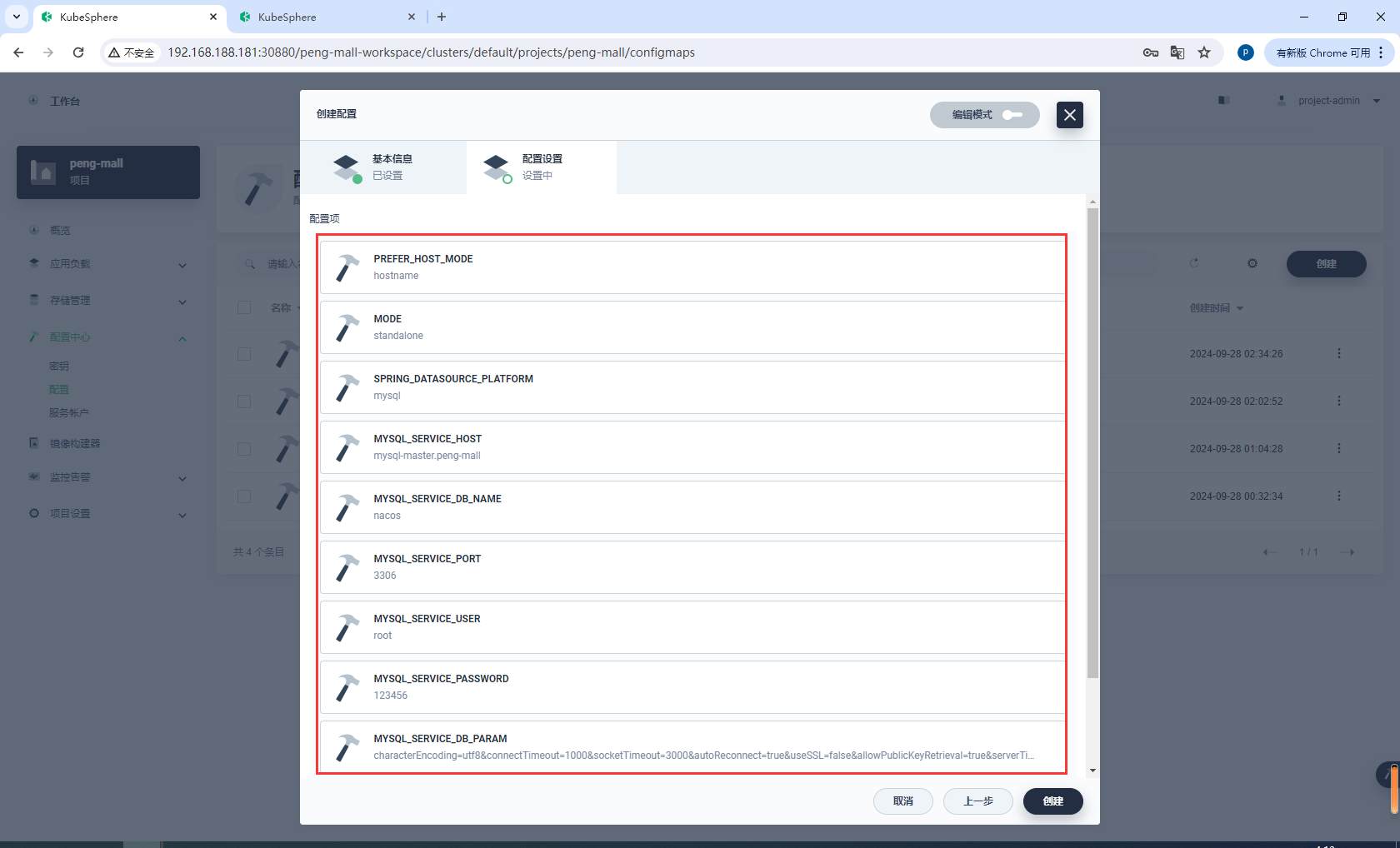
注意MYSQL_SERVICE_HOST配置的是mysql8服务的DNS
mysql8.peng-mall
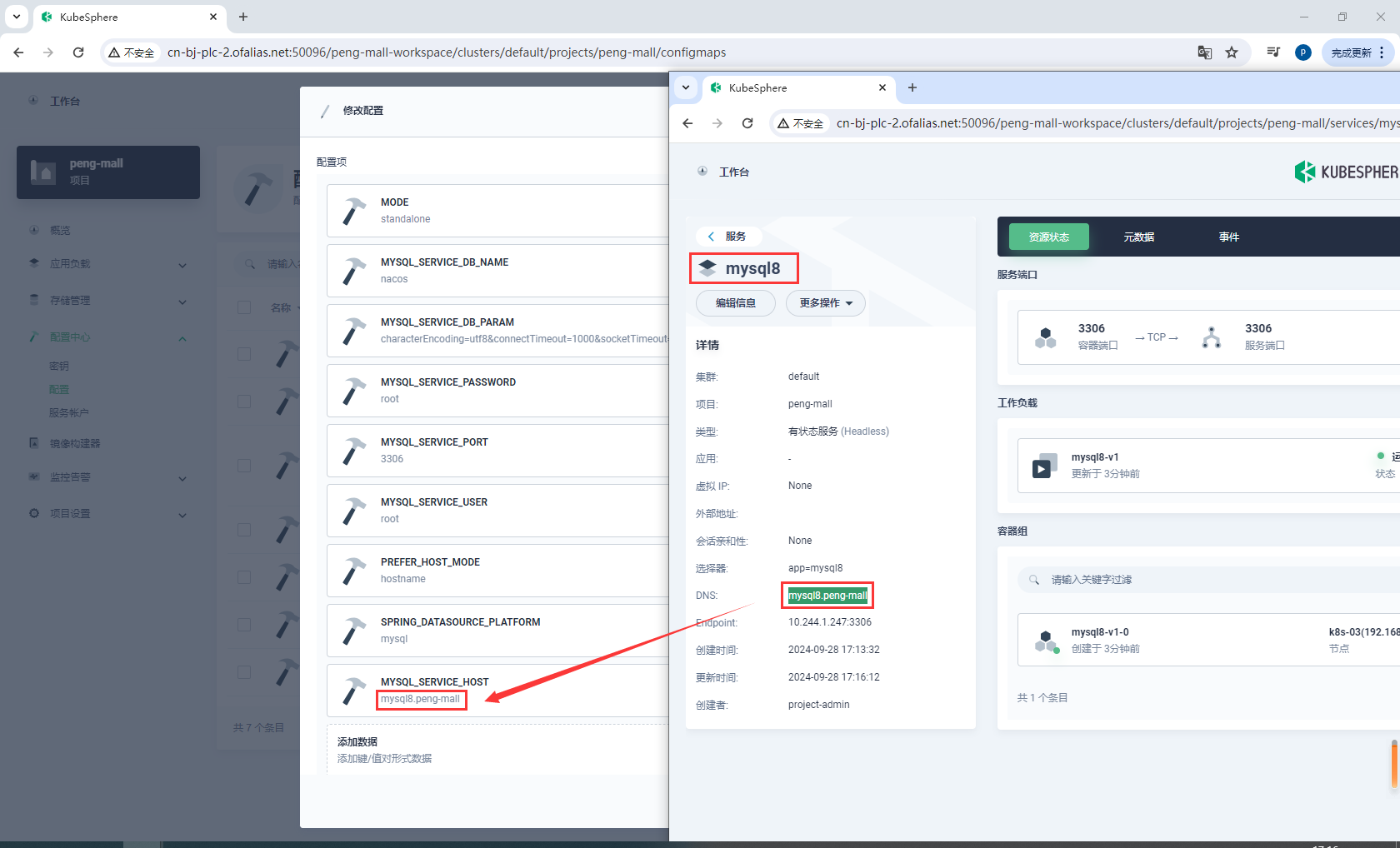
创建有状态服务
nacos
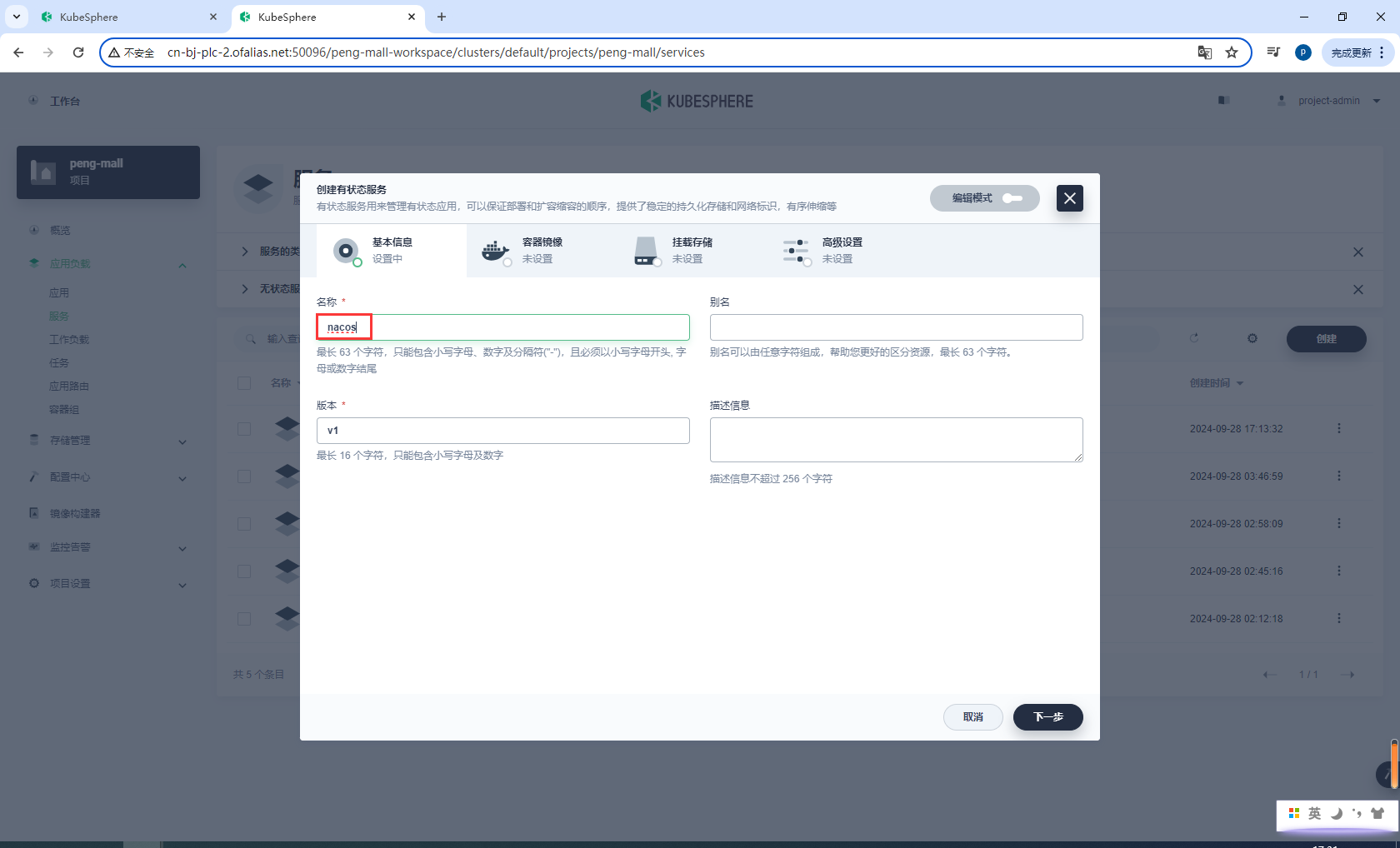
镜像设置
nacos/nacos-server:v2.1.0-slim
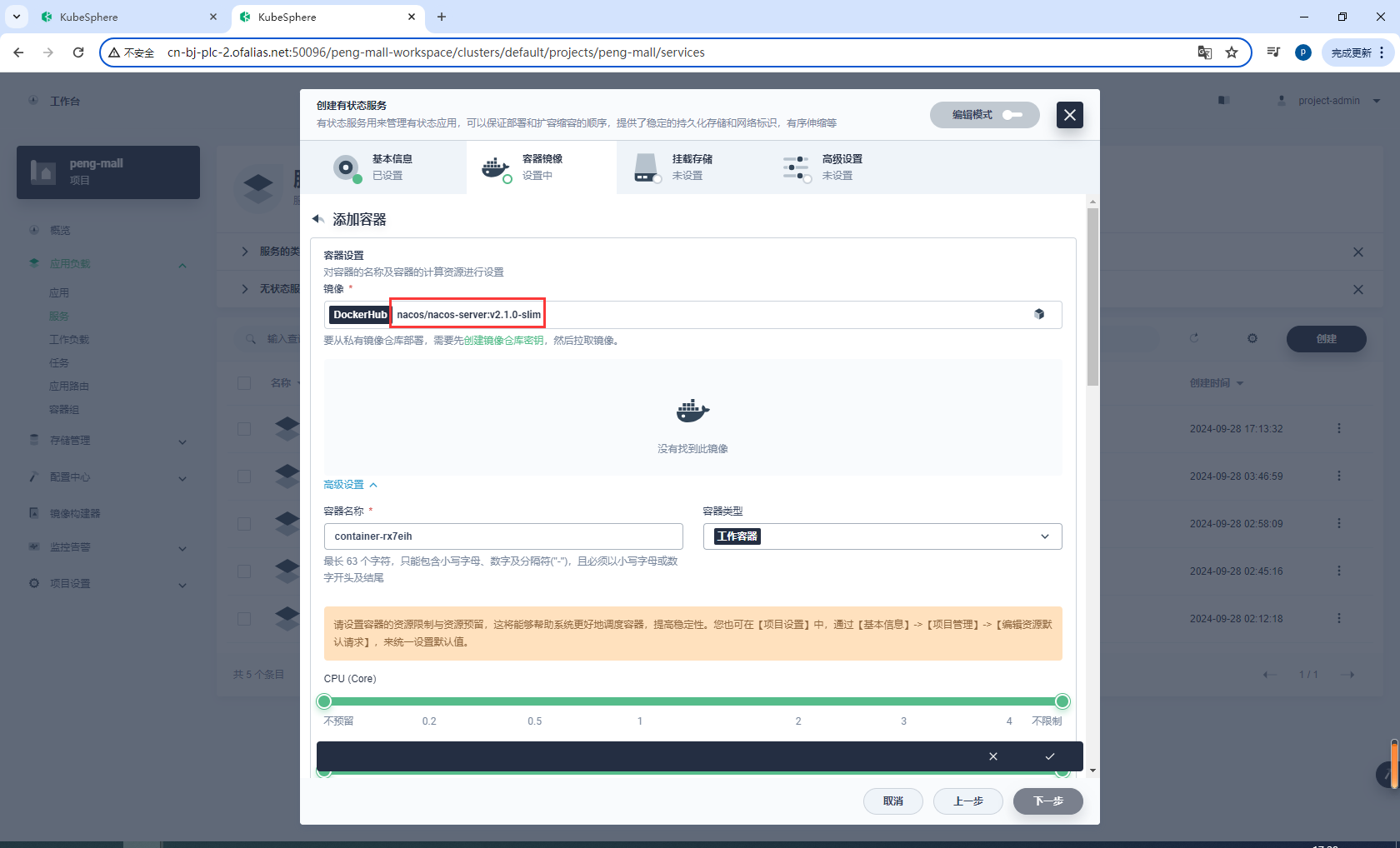
配置资源和端口
- "8848:8848"
- "9848:9848"
- "9849:9849"
环境变量
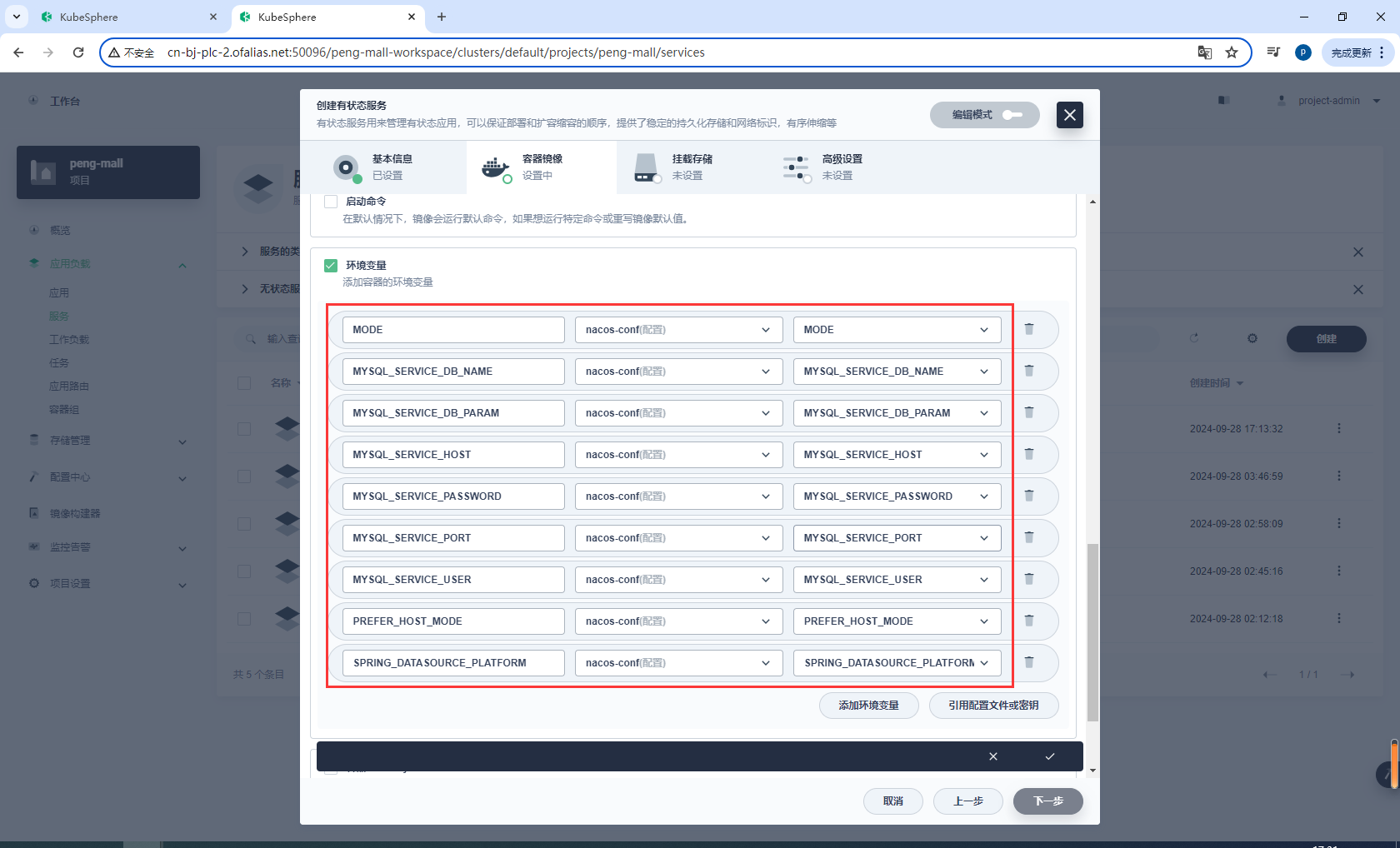
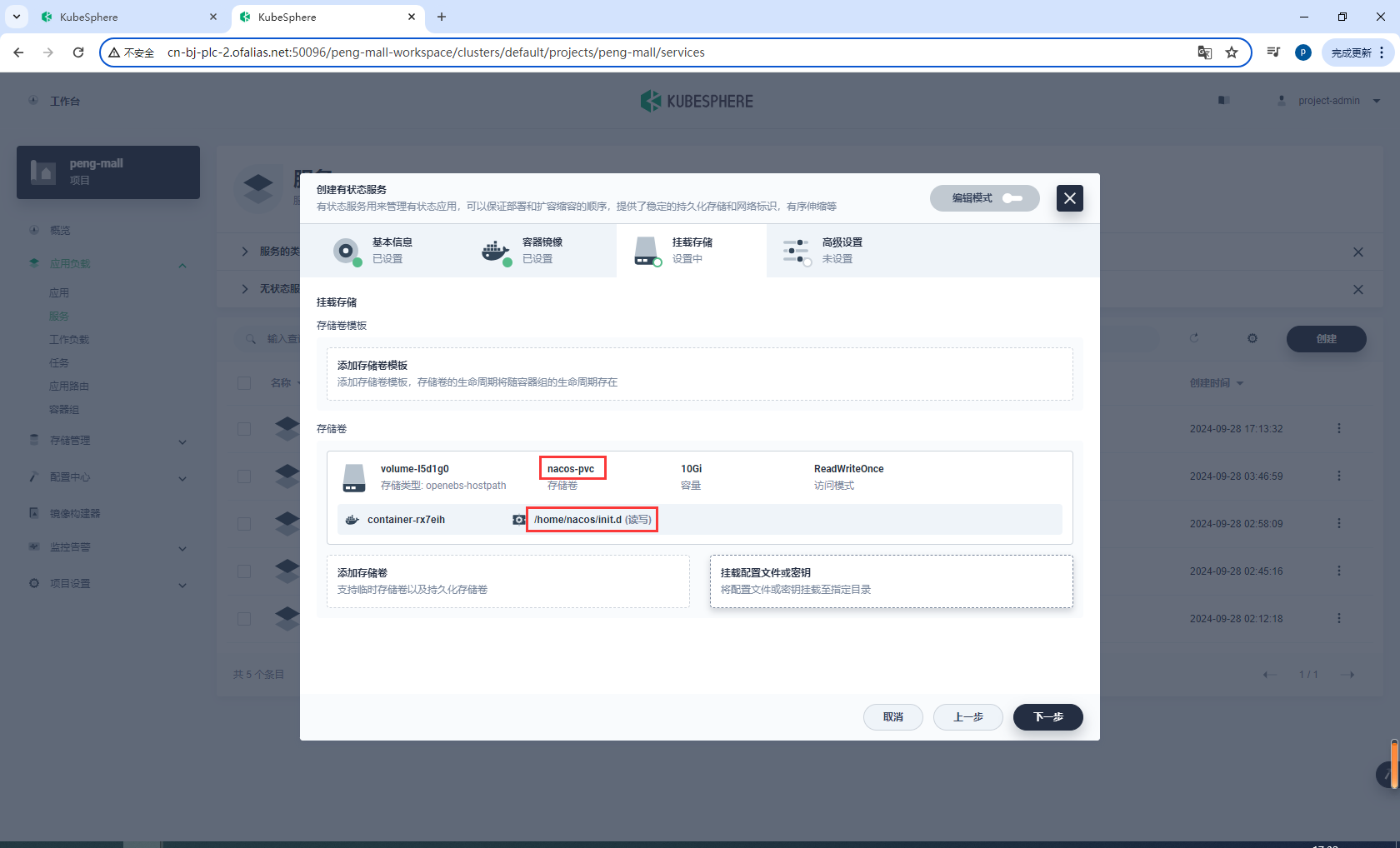
存储卷
nacos-pvc
/home/nacos/init.d
高级设置
8.7k8s部署Zipkin
zipkin:
image: openzipkin/zipkin
container_name: zipkin
environment:
STORAGE_TYPE: elasticsearch
ES_HOST: elasticsearch
ES_PORT: 9200
ES_INDEX: zipkin
ports:
- "9411:9411" # 映射主机的9411端口到容器的9411端口
networks:
创建zipkin-conf
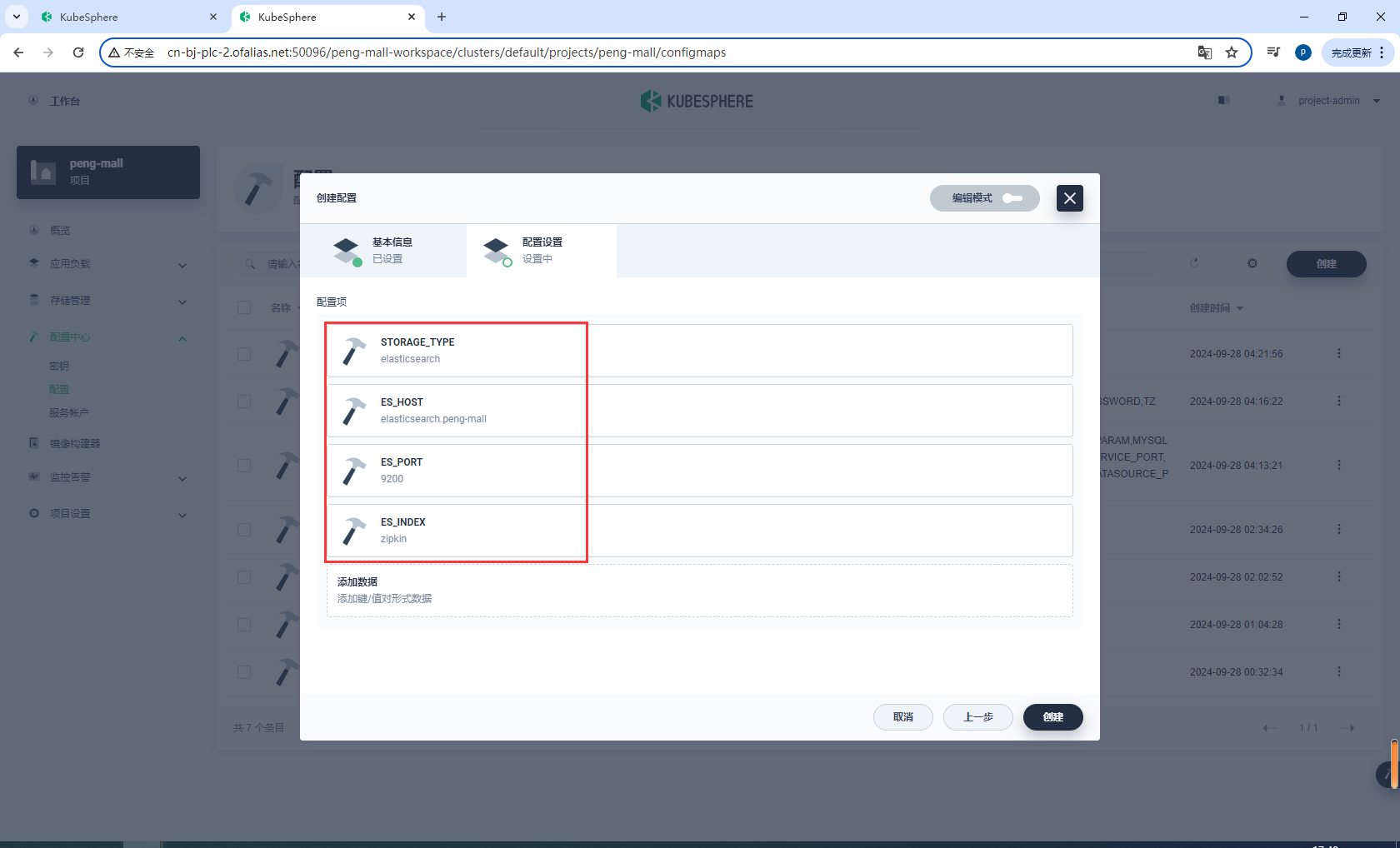
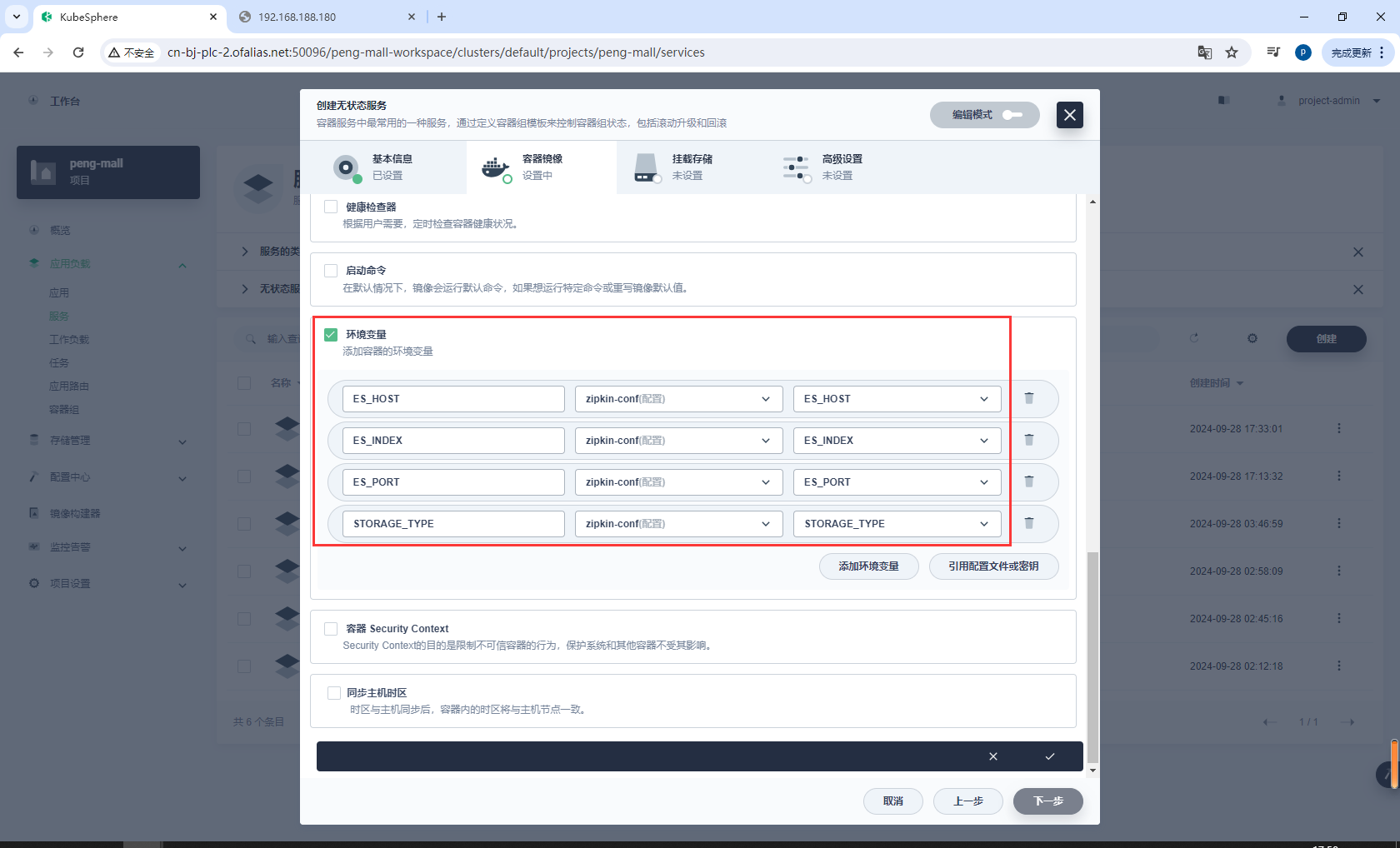
ES_HOST是部署elasticsearch后的域名
elasticsearch.peng-mall

创建无状态服务zipkin
zipkin

镜像设置
openzipkin/zipkin
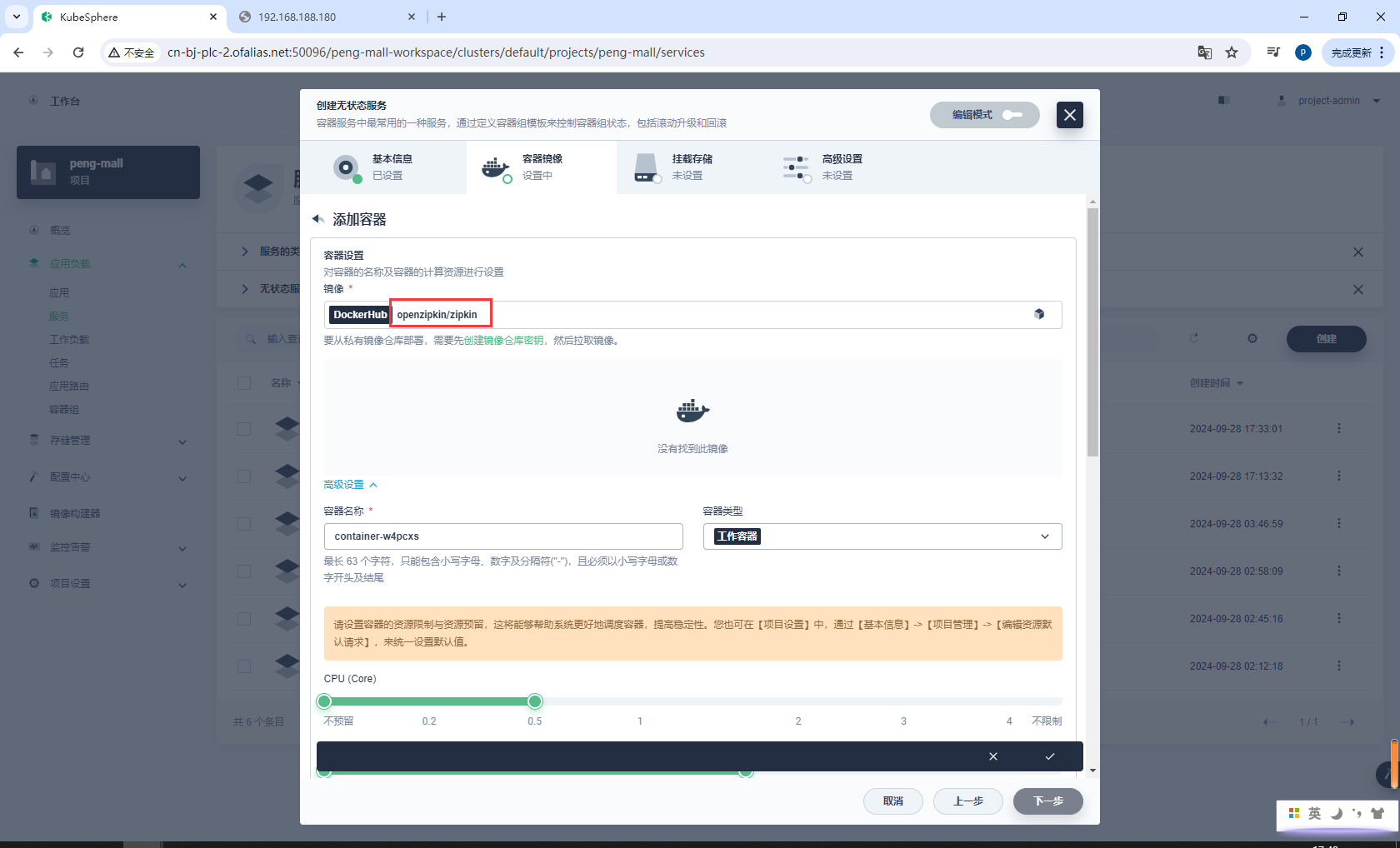
资源、端口配置
9411
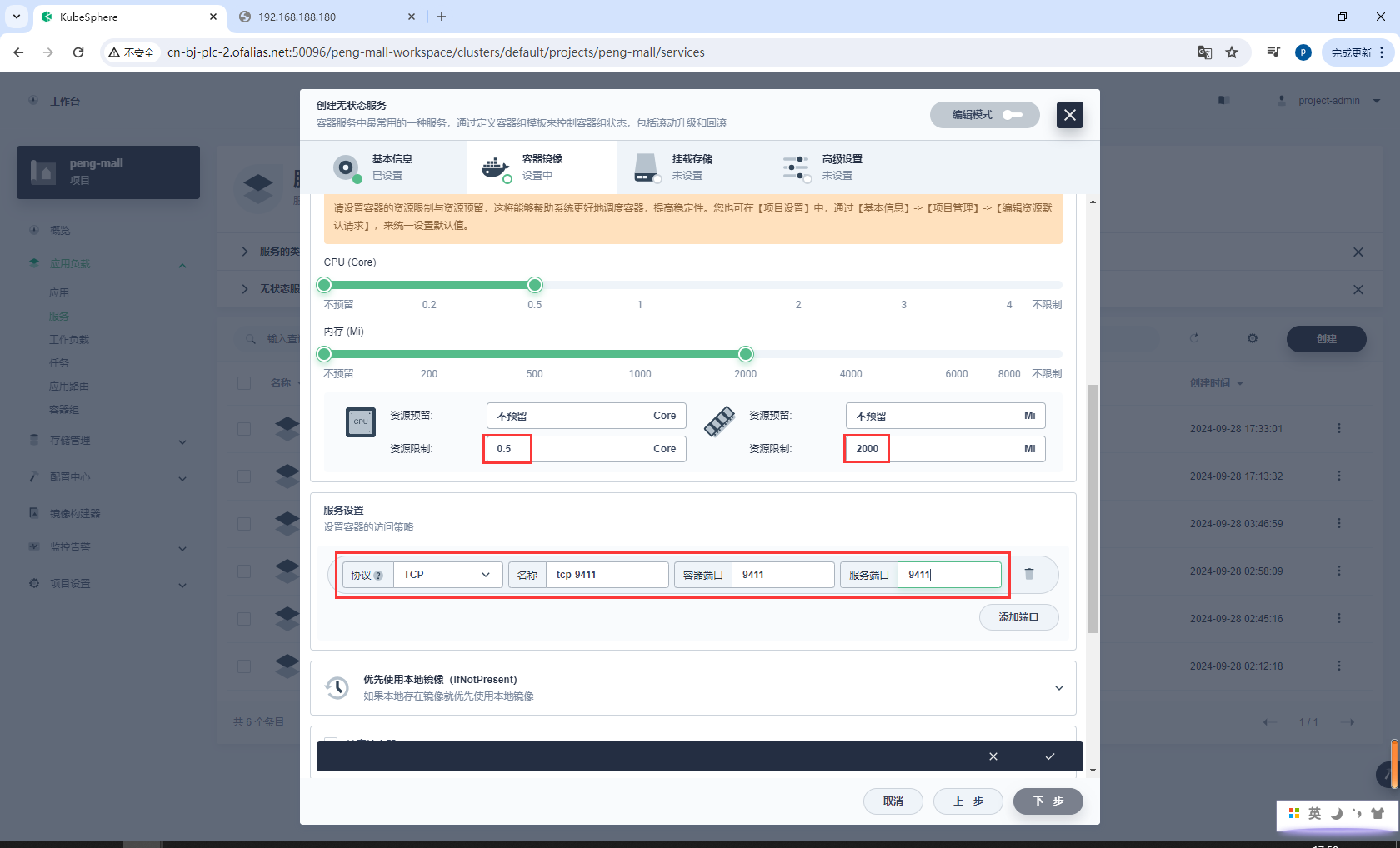
环境配置
不需要配置挂载存储
高级设置
允许外网访问,选择NodePort
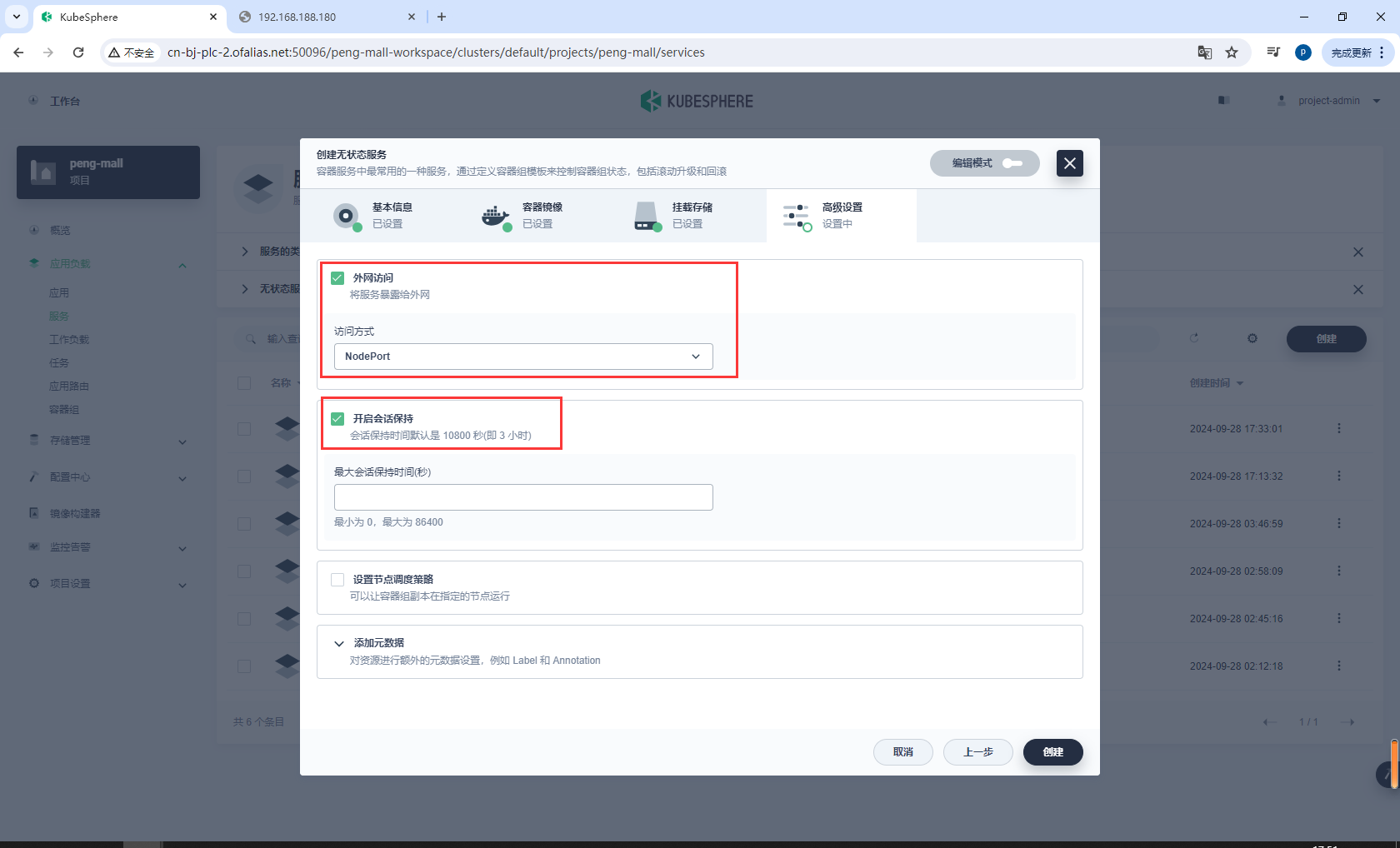
测试访问http://192.168.188.181:30922/zipkin/
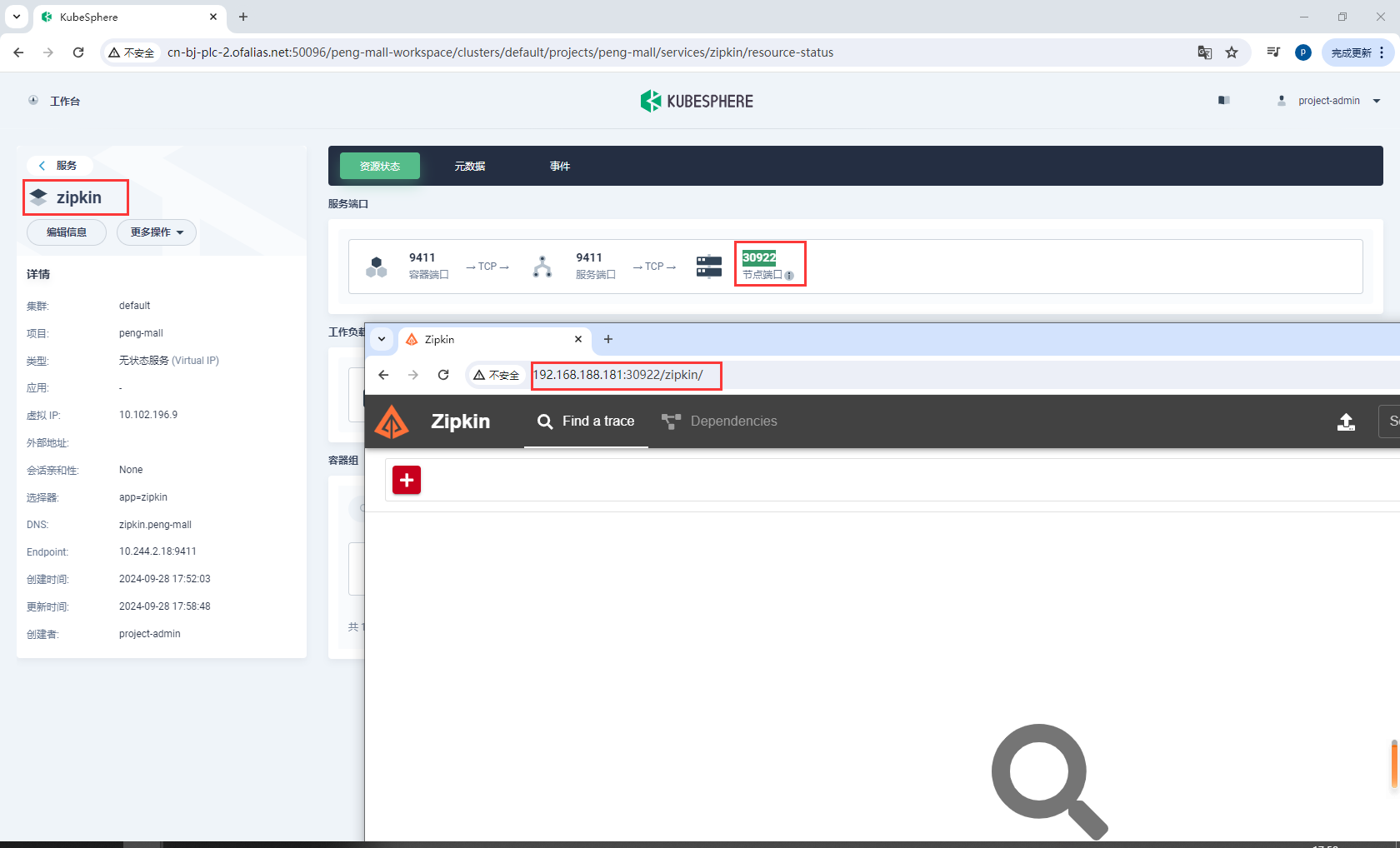
8.8k8s部署Sentinel
sentinel:
image: bladex/sentinel-dashboard
container_name: sentinel
ports:
- "8858:8858" # 映射主机的8858端口到容器的8858端口
networks:
- peng-net # 指定连接的网络
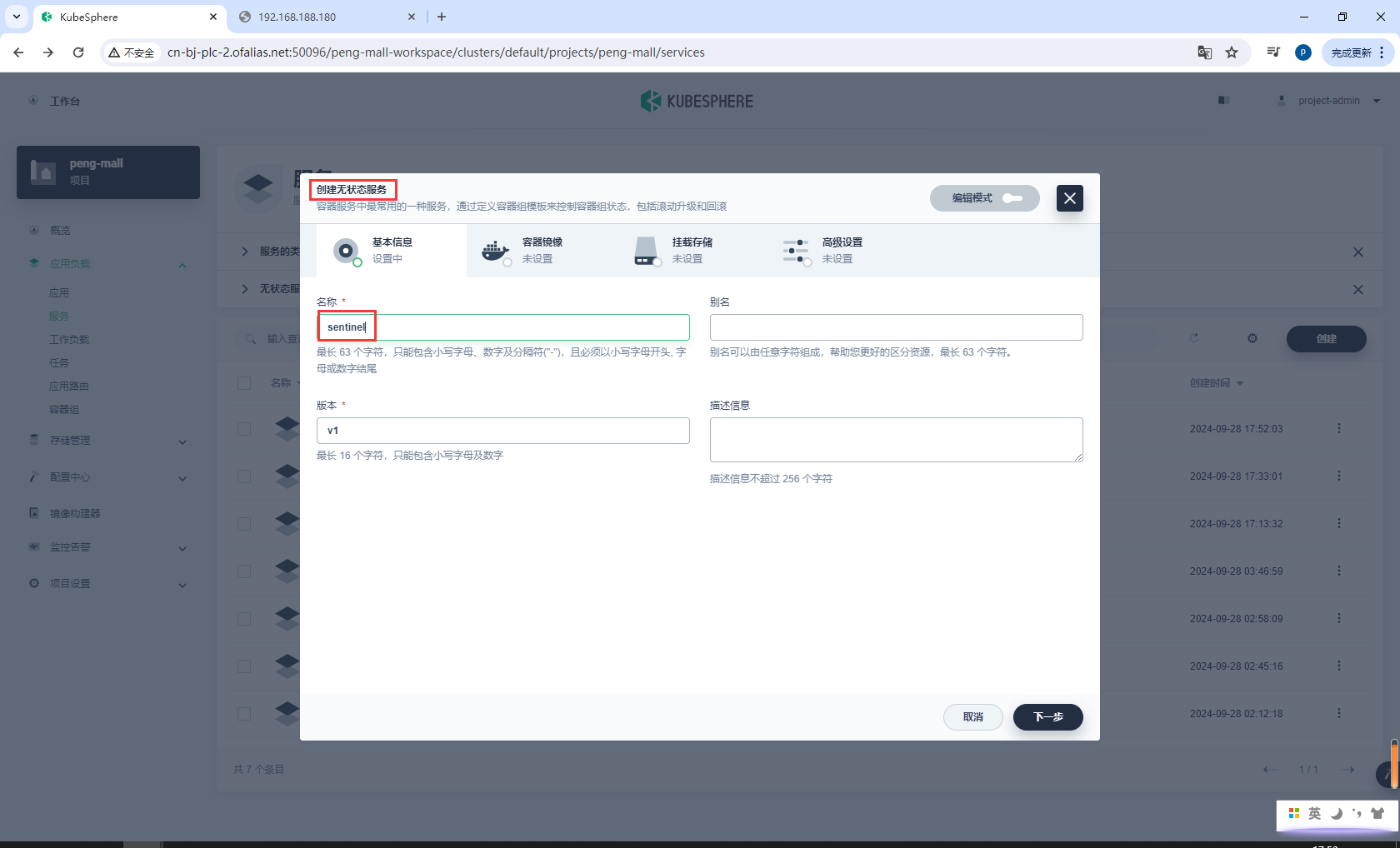
创建无状态服务sentinel
sentinel
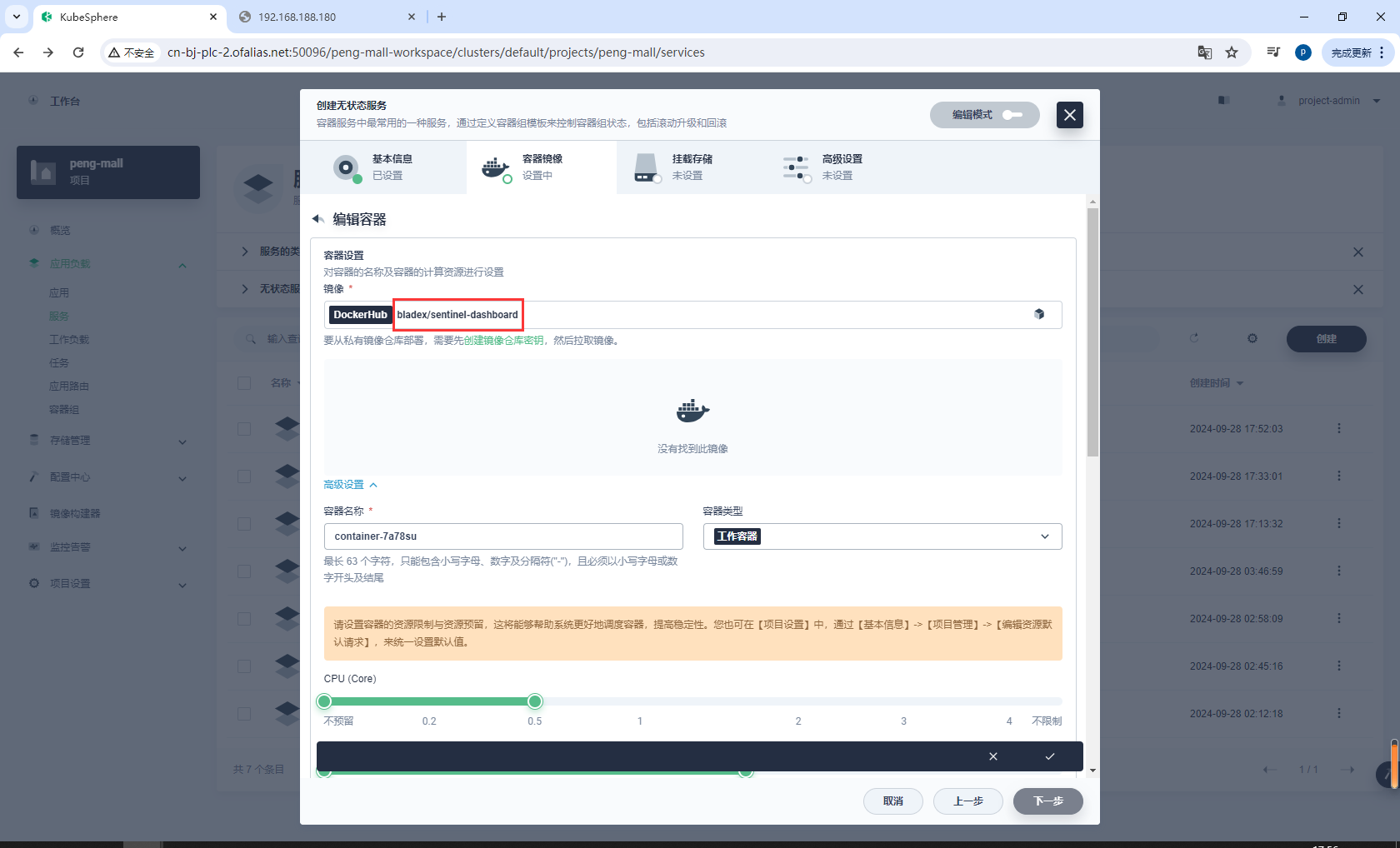
镜像设置
bladex/sentinel-dashboard
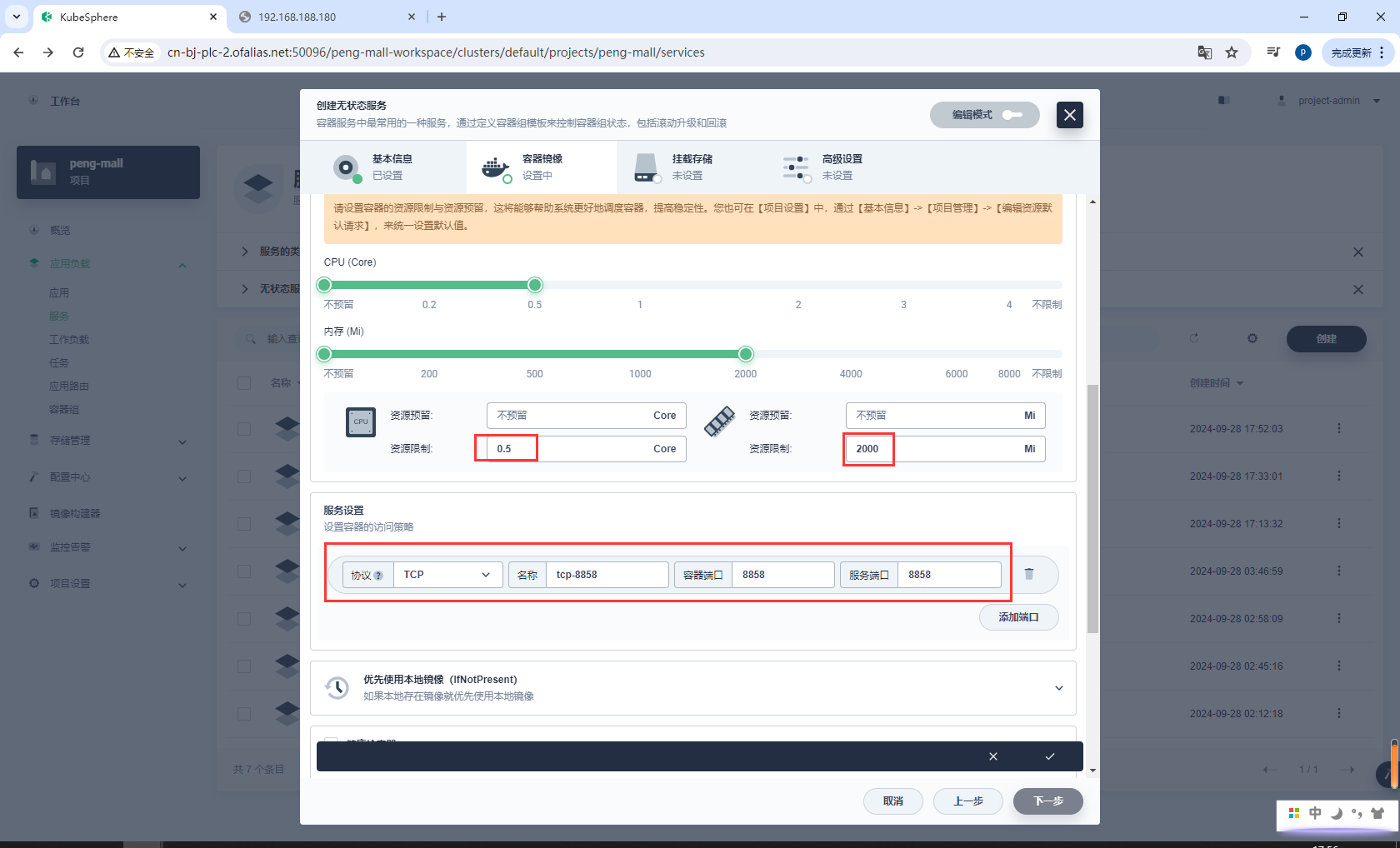
资源、端口配置
8858
无挂载存储
高级设置
开启外网访问,选择NodePort
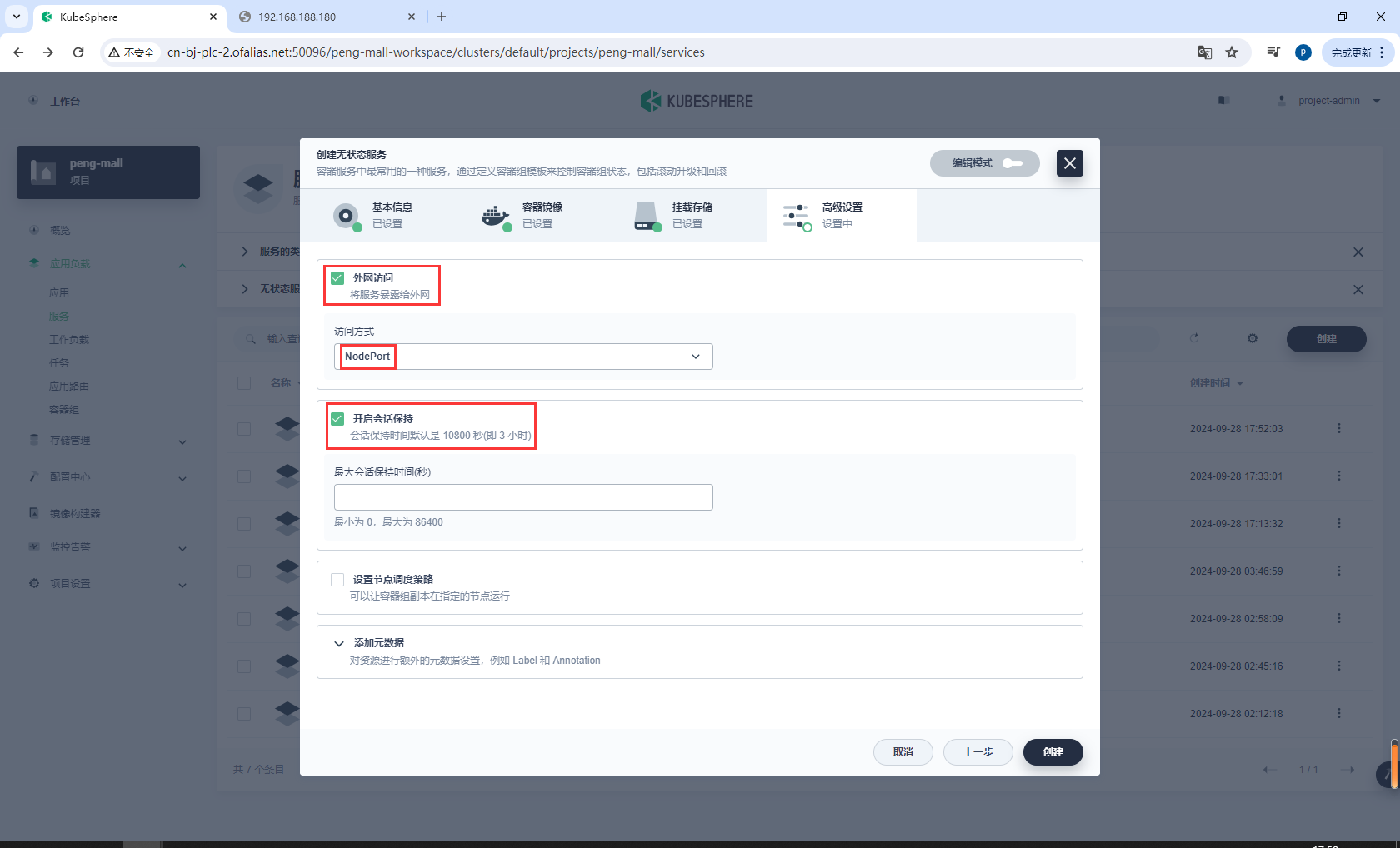
测试访问http://192.168.188.181:30630/#/login

8.9k8s部署应用的流程
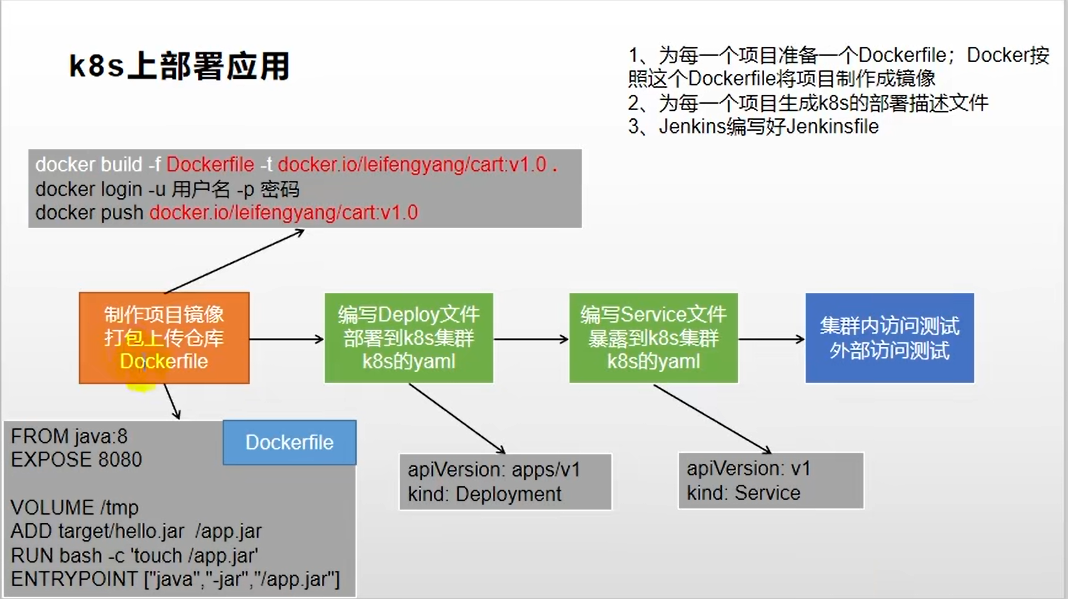
8.10生产环境配置抽取
8.10.1查看服务域名内部是否可以访问
使用admin账号登录,打开kubectl
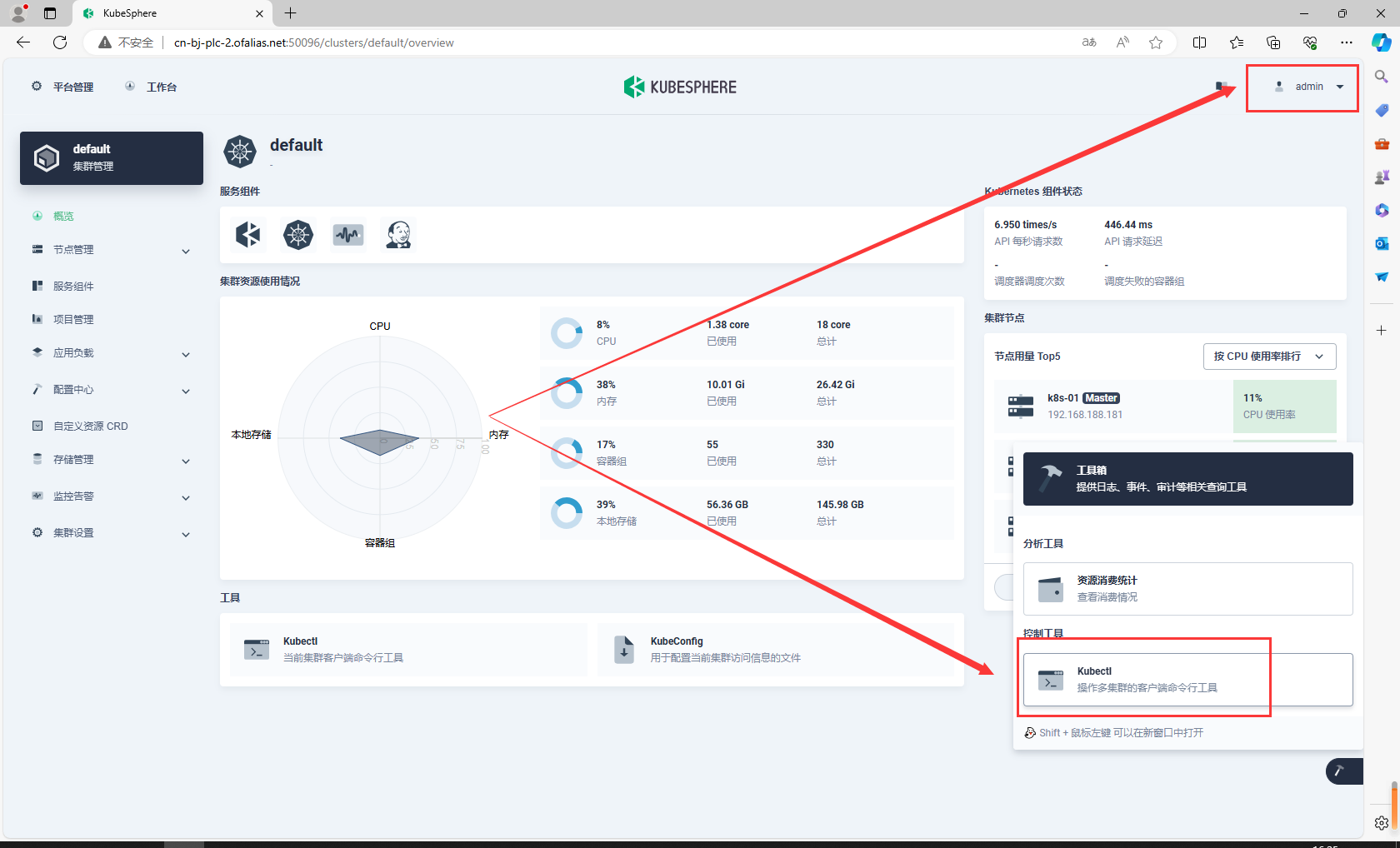
sentinel不可以访问域名
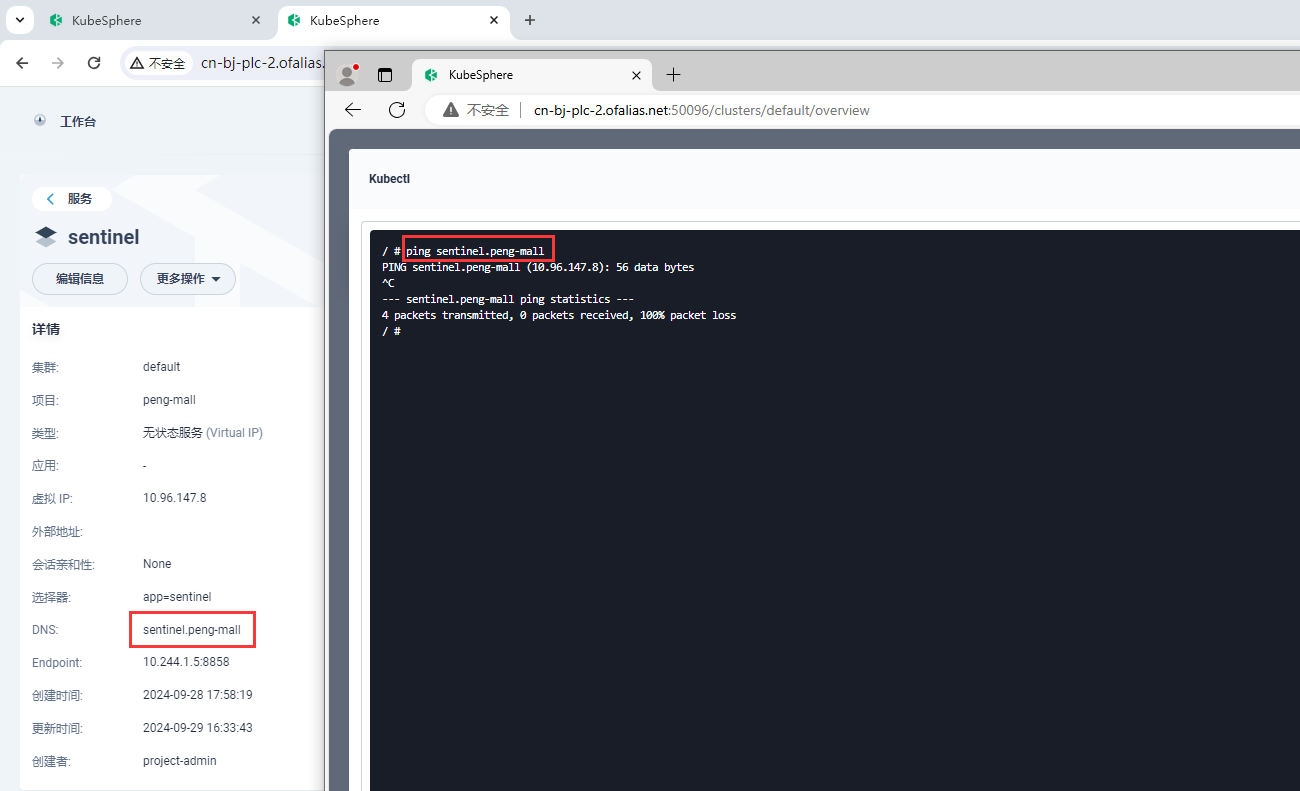
zipkin不可以访问域名
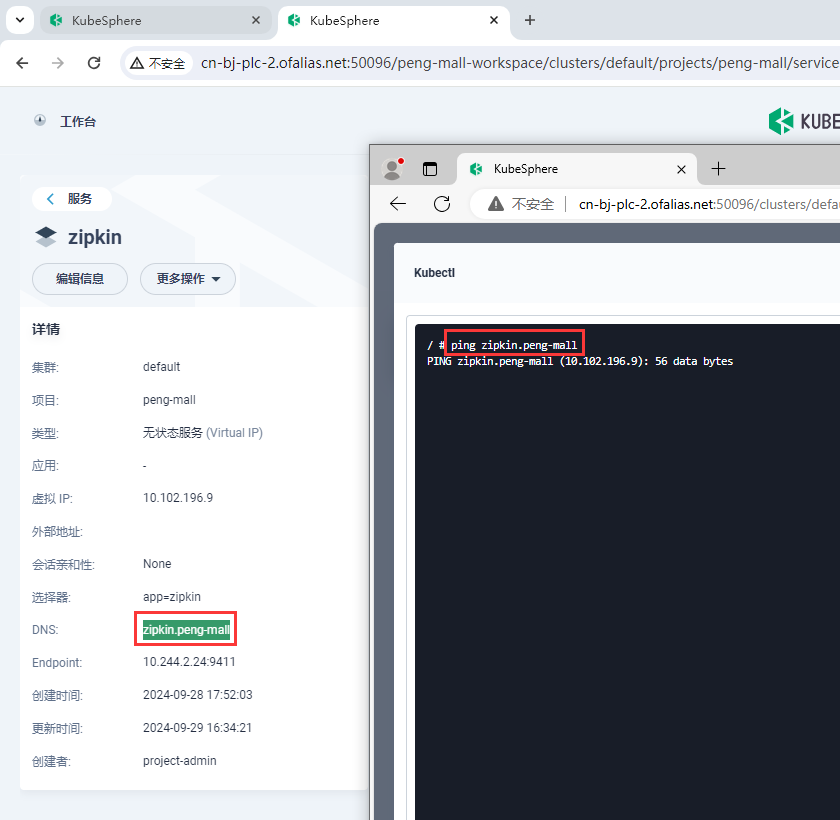
nacos可以访问域名
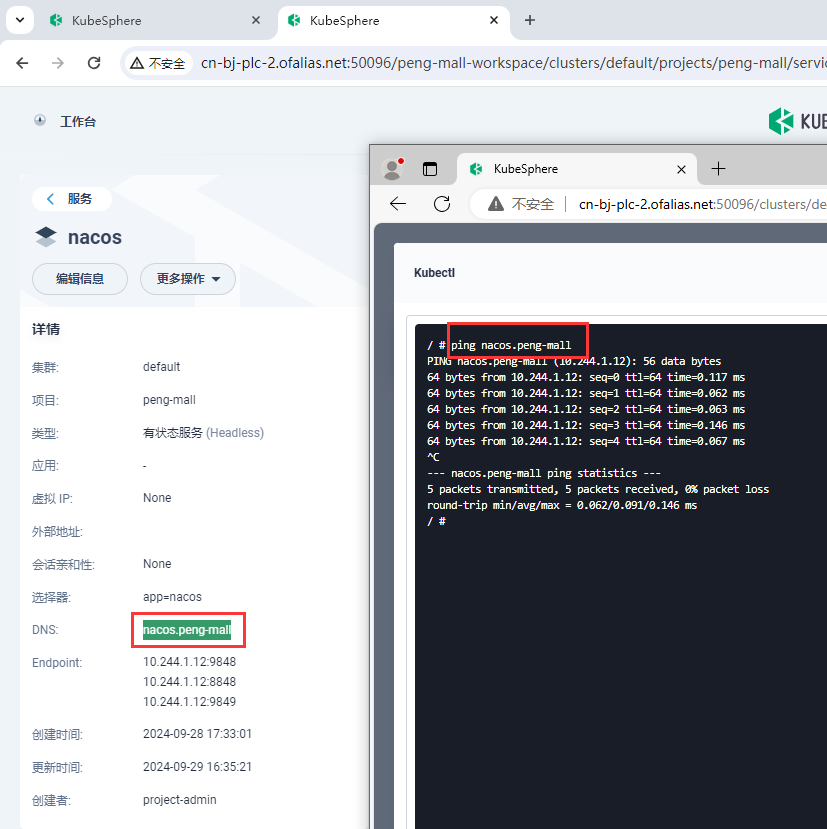
mysql8可以访问域名
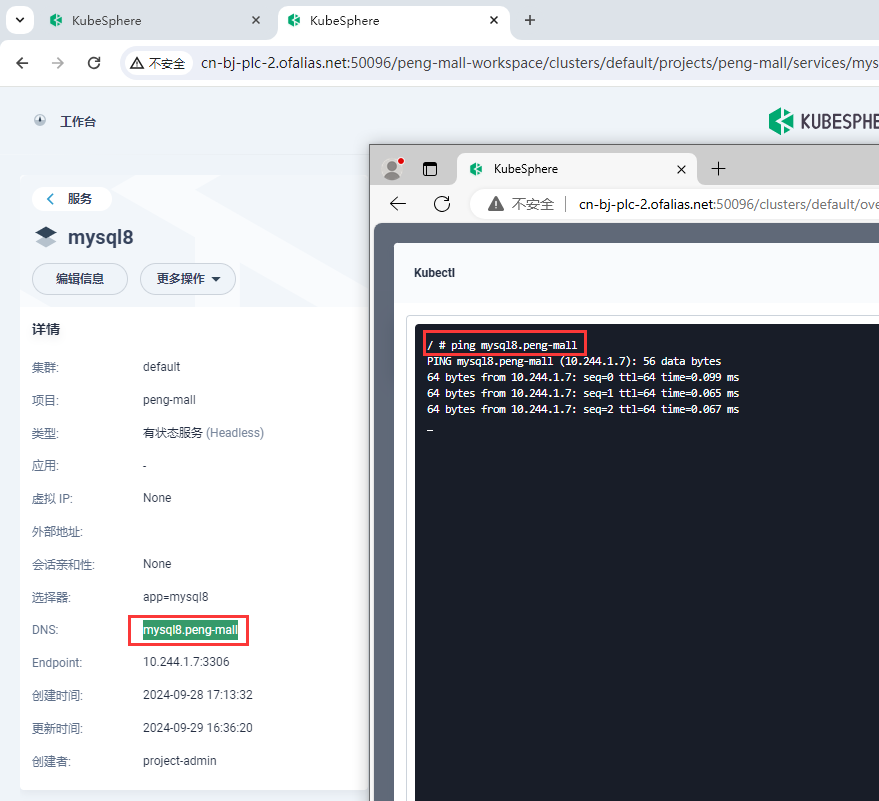
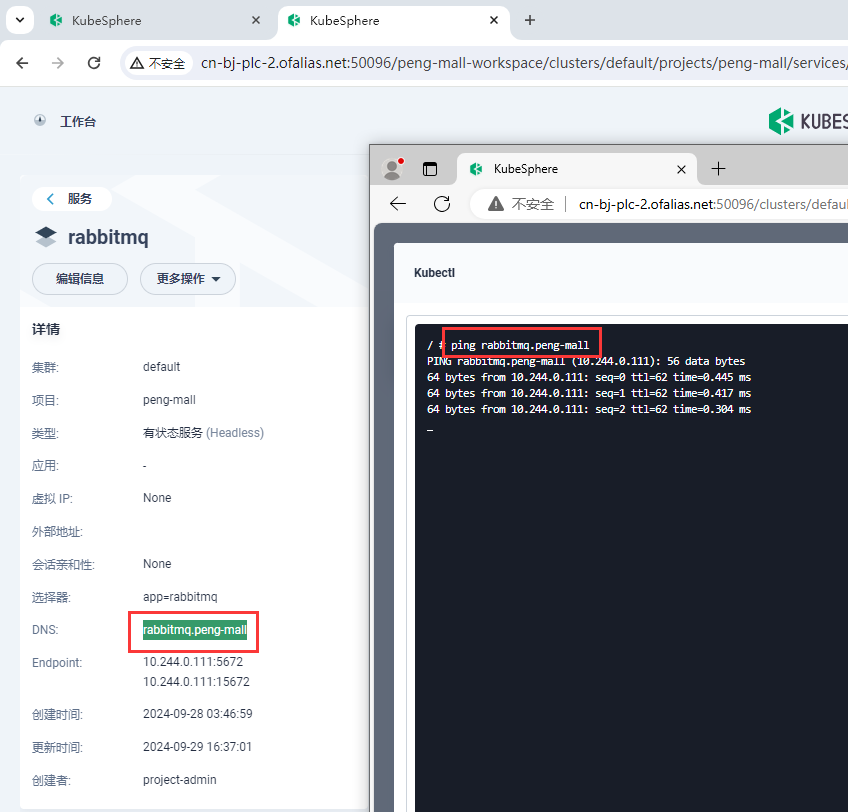
rabbitmq可以访问域名
kibana不可以访问域名
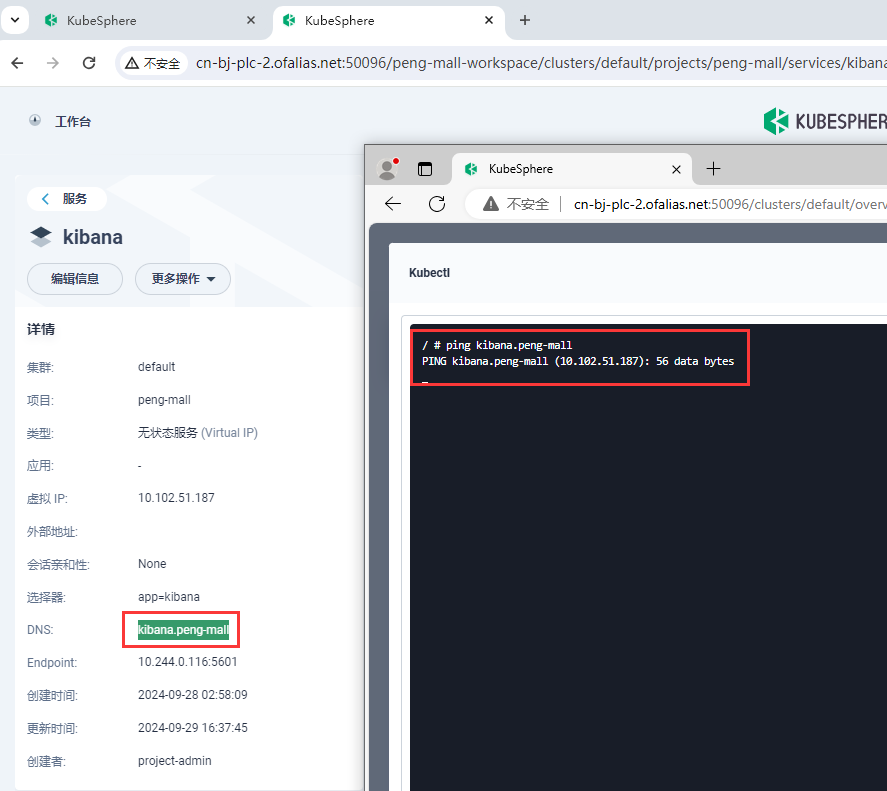
elasticsearch可以访问域名
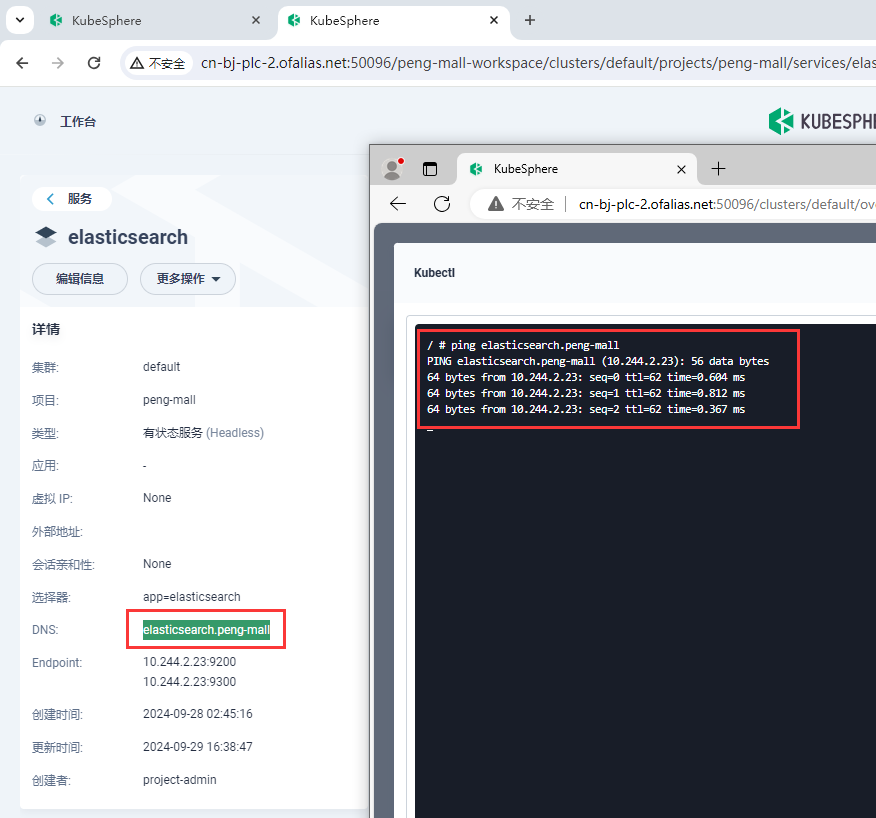
redis可以访问域名
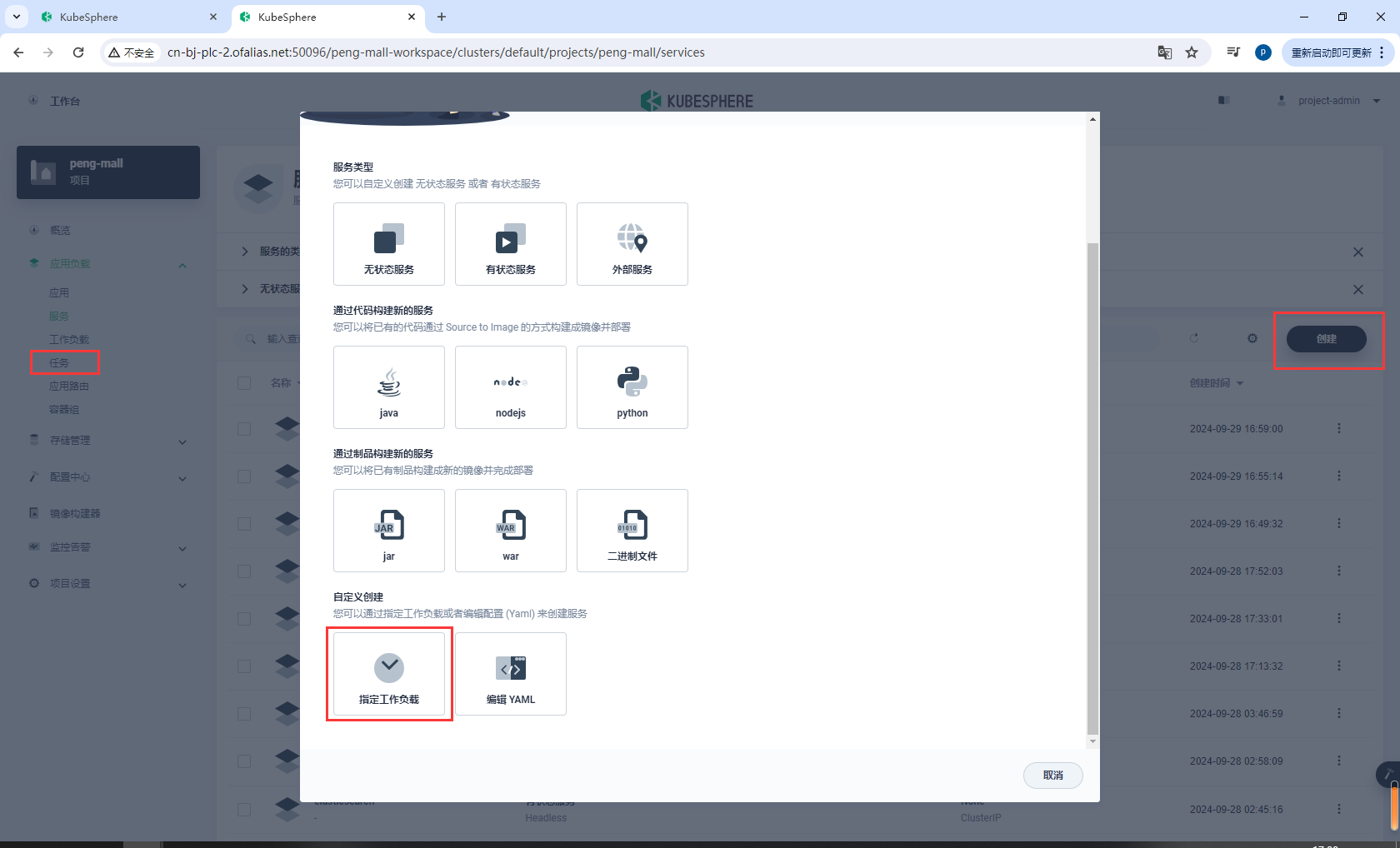
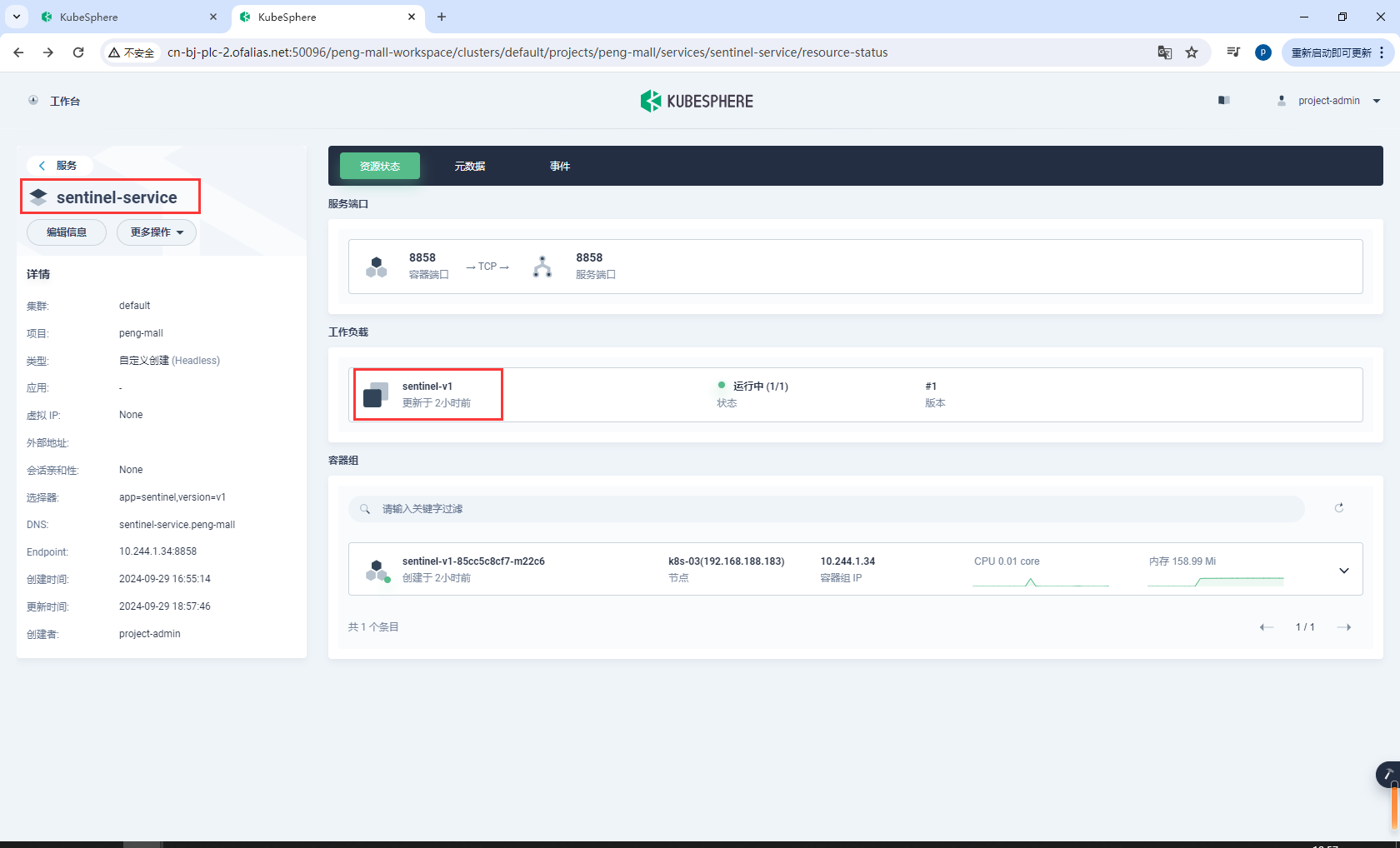
8.10.3sentinel服务指定工作负载
选择指定工作负载
基本信息
sentinel-service
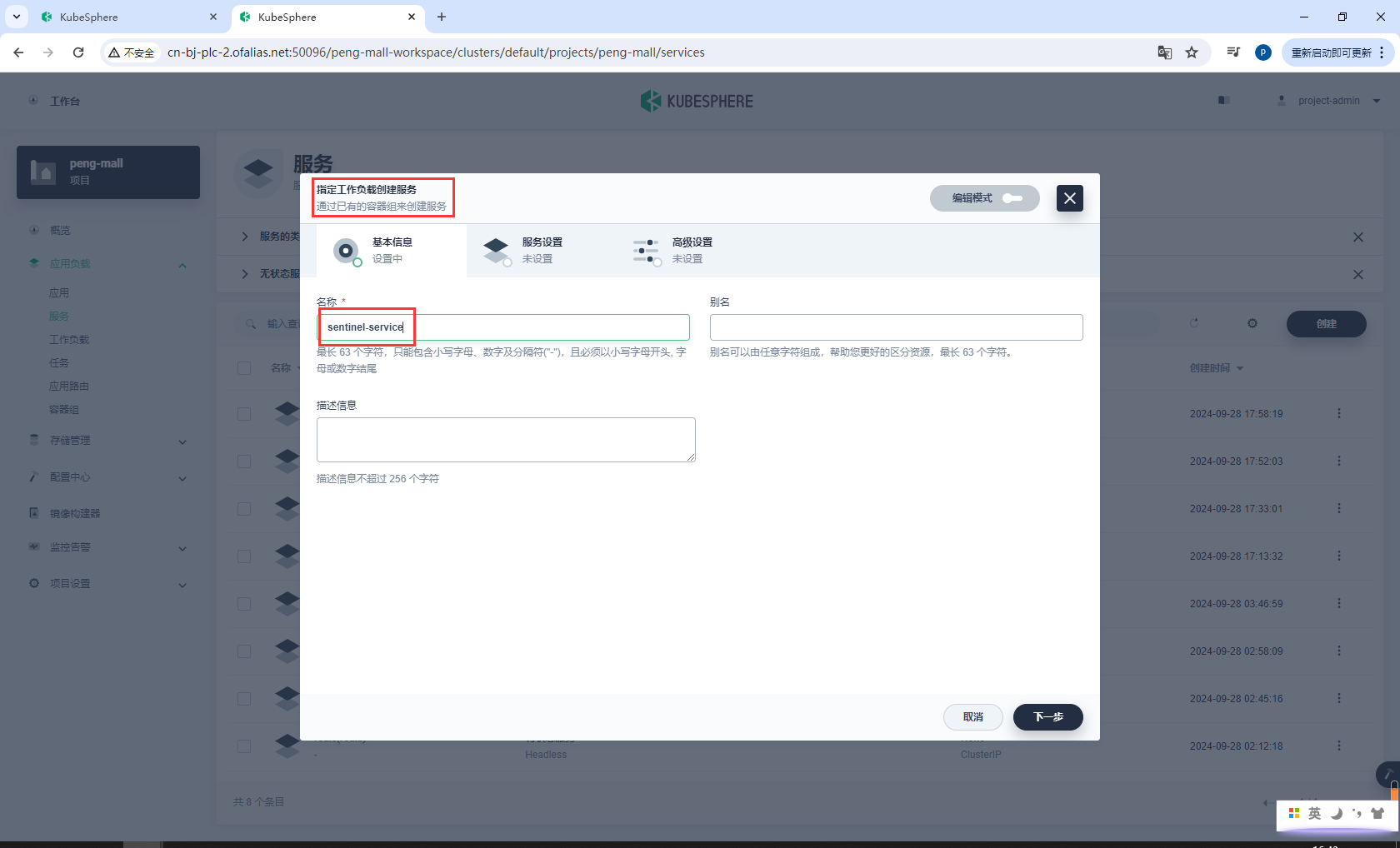
选择EndPoint IP访问
点击指定工作负载,选择sentinel
绑定8858端口
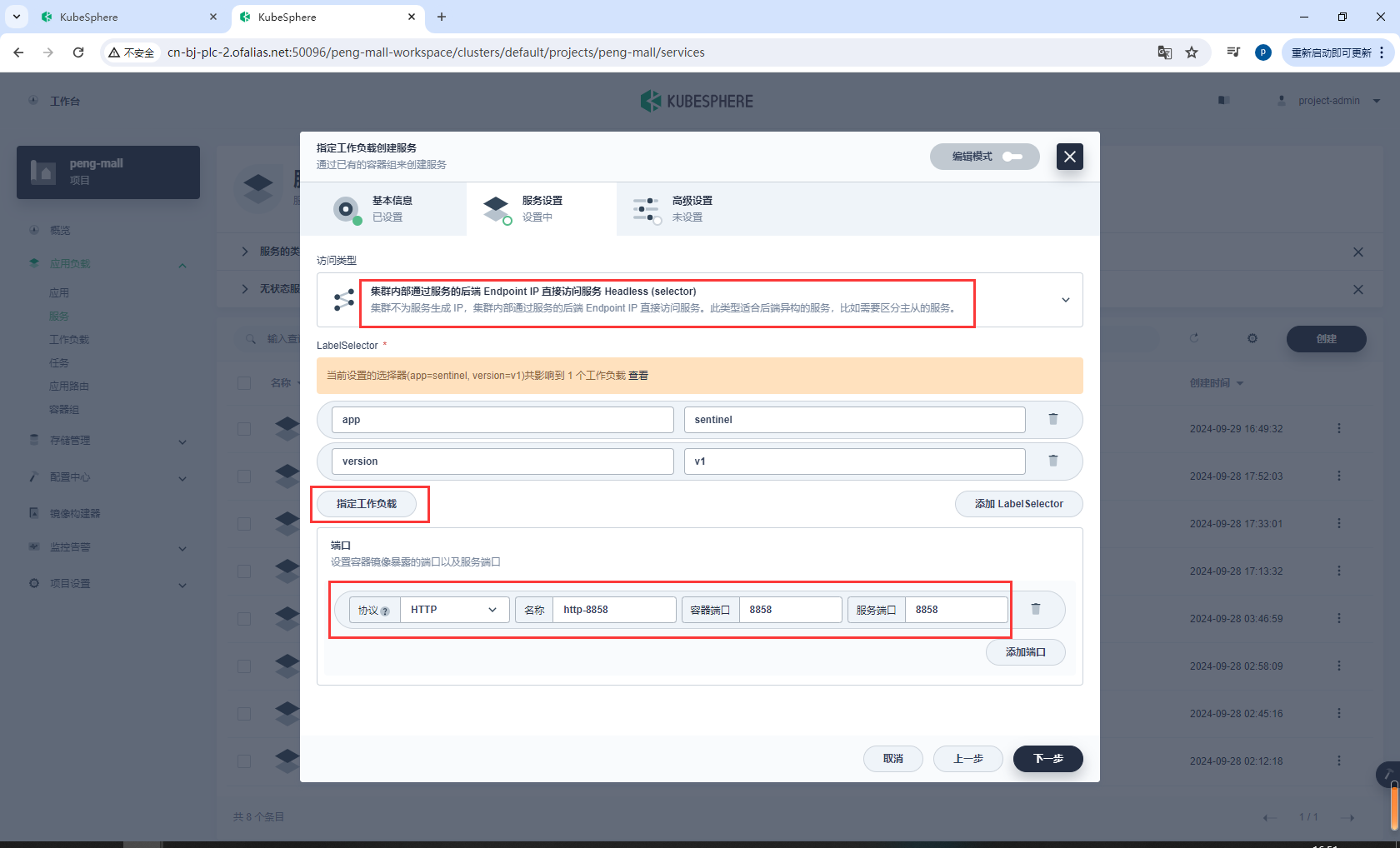
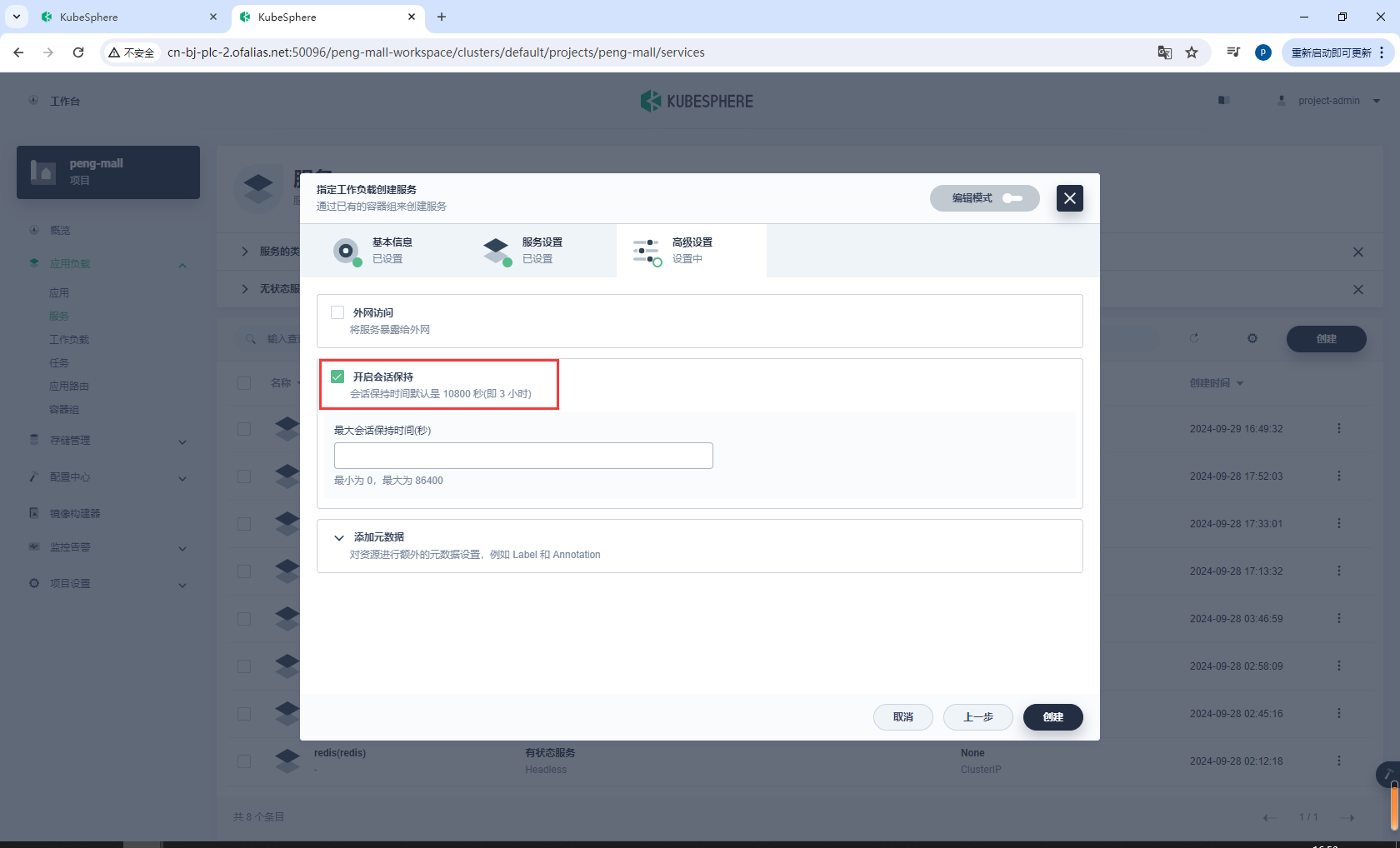
开启会话保持,然后创建
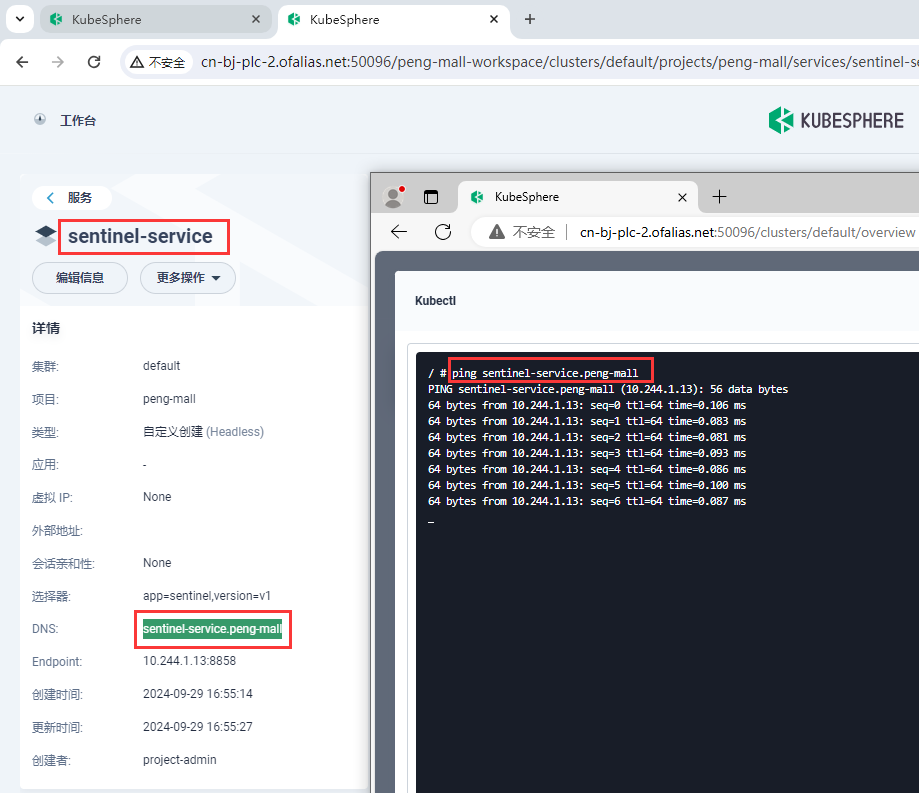
测试sentinel-service内部是否可以访问
8.10.3zipkin服务指定工作负载
选择指定工作负载
基本信息
zipkin-service
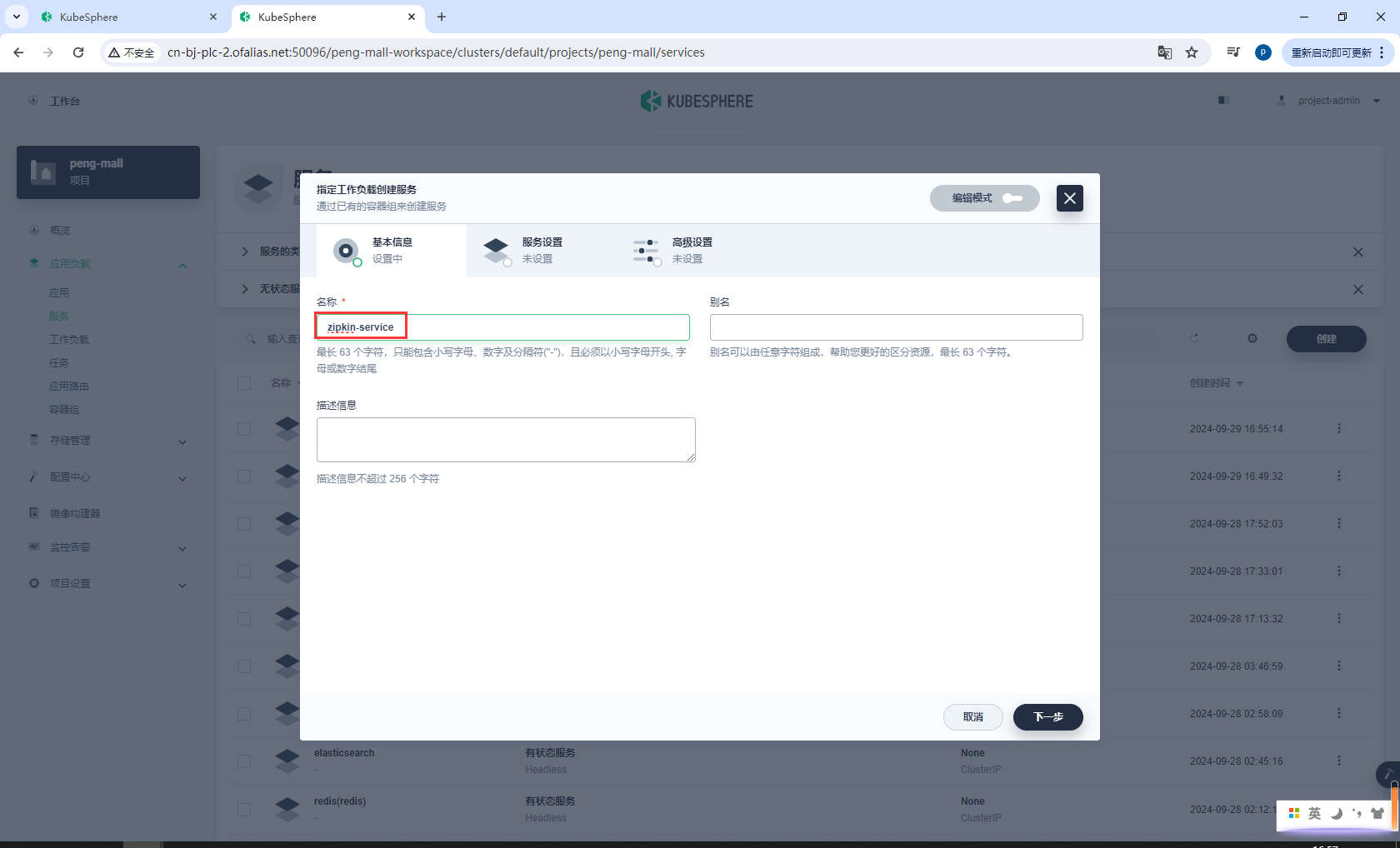
选择EndPoint IP访问
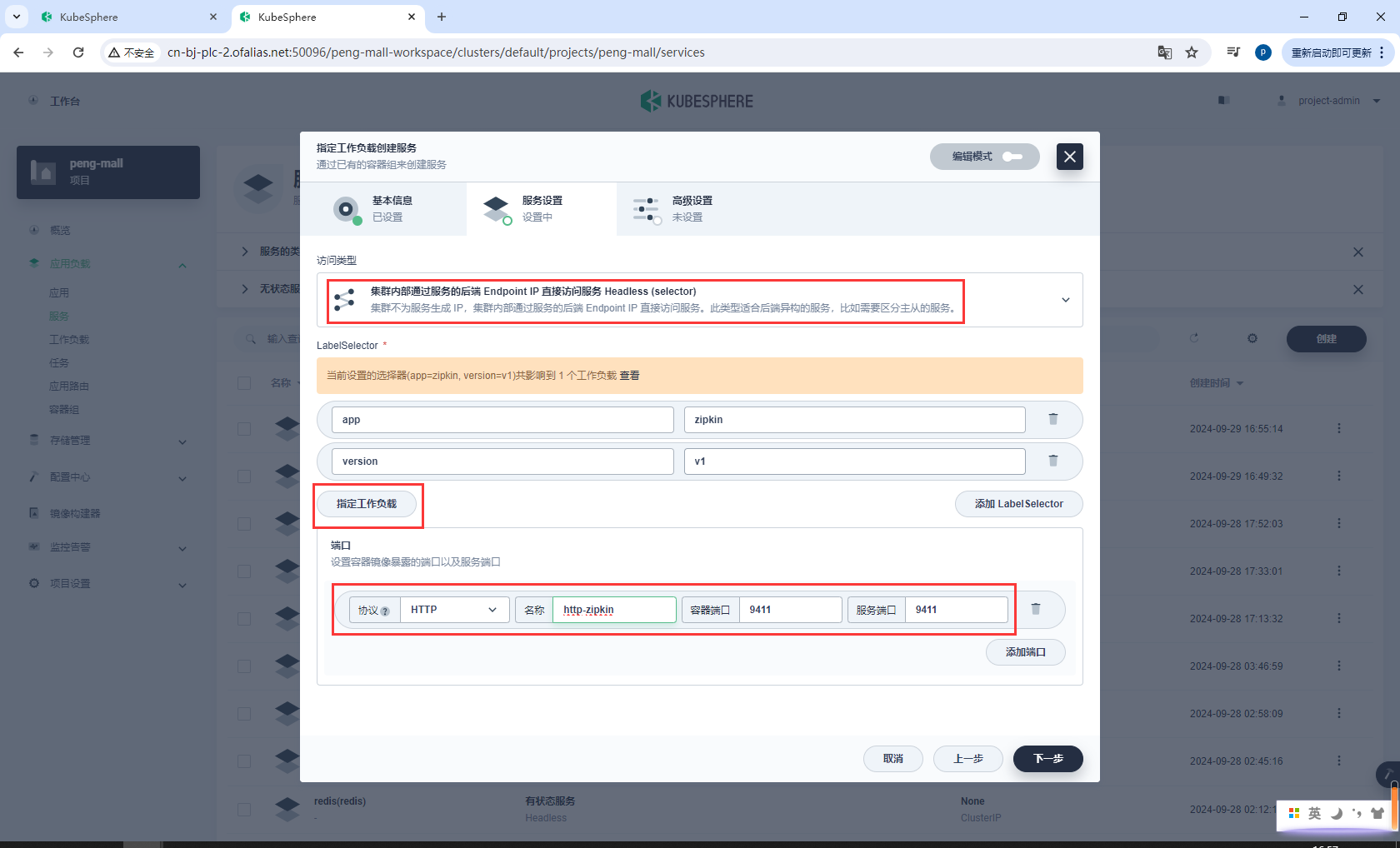
点击指定工作负载,选择zipkin
绑定9411端口
http-zipkin 9411 9411
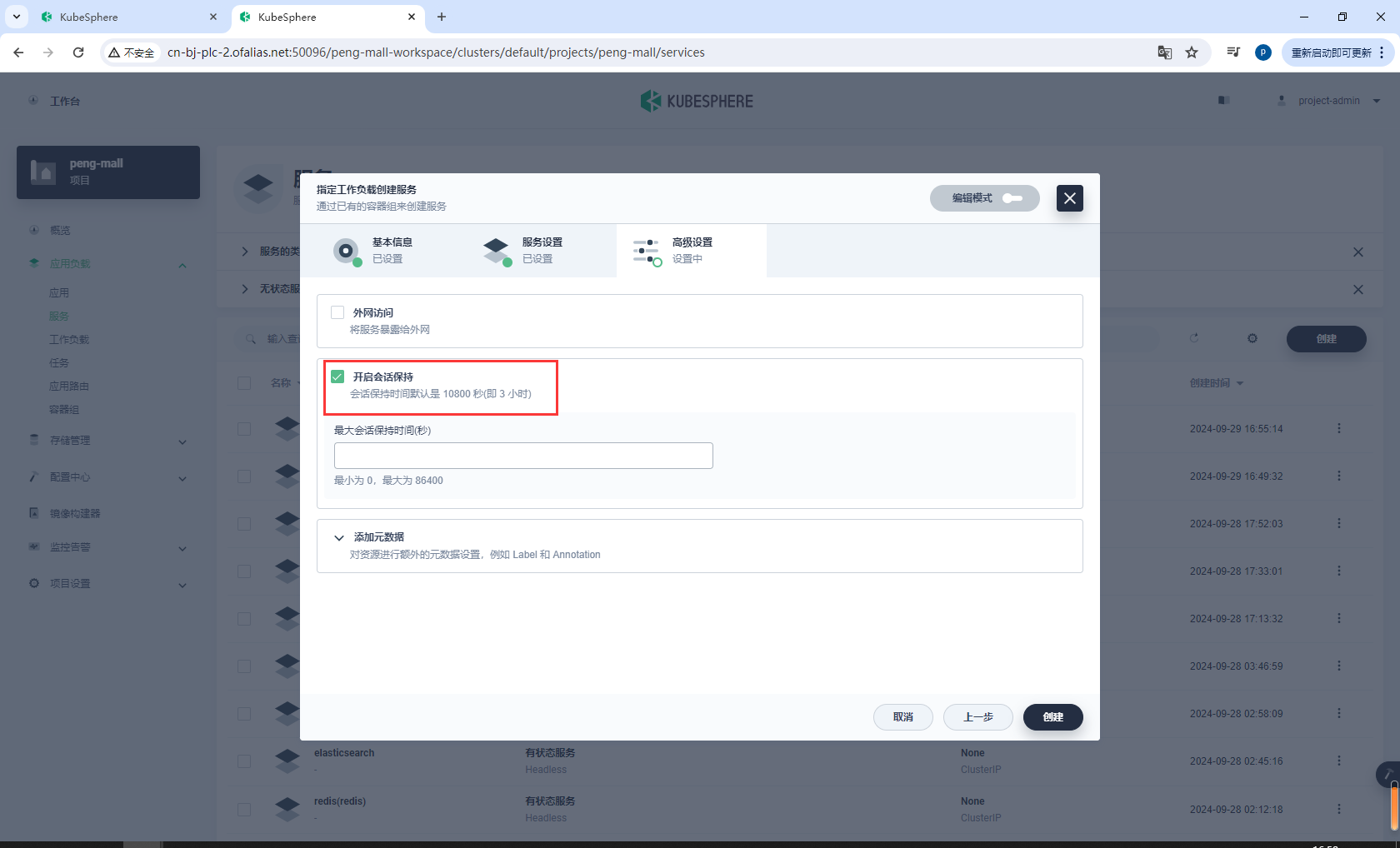
开启会话保持,然后创建
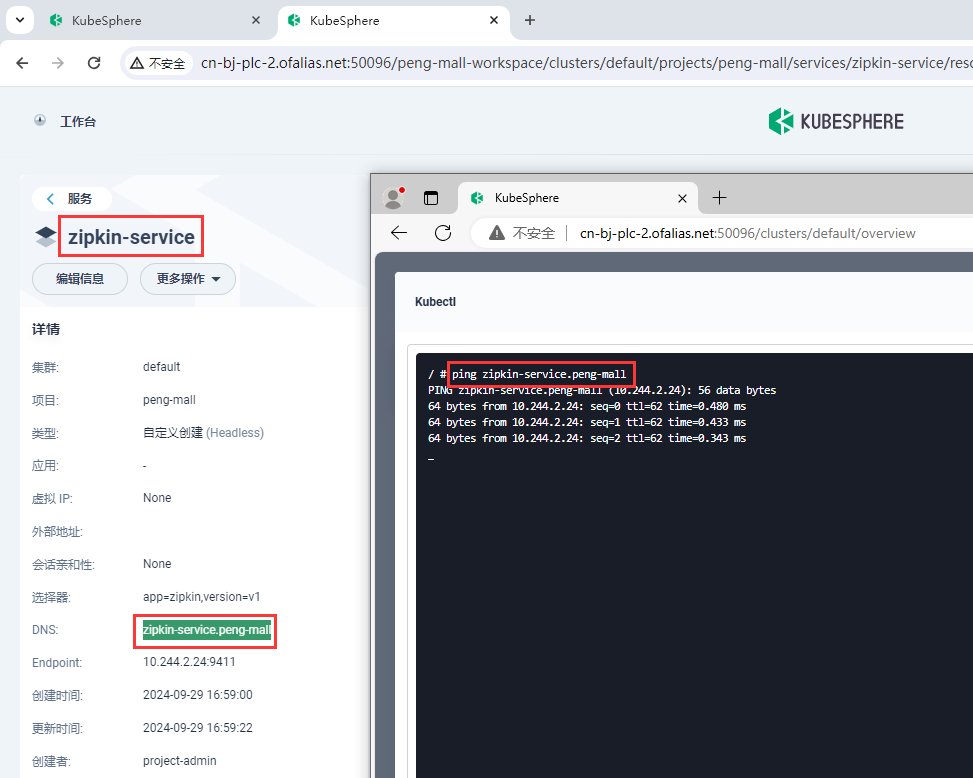
测试zipkin-service内部是否可以访问
8.10.4mysql8服务指定工作负载
mysql8安装后,我们需要初始化数据库
给mysql8创建工作负载
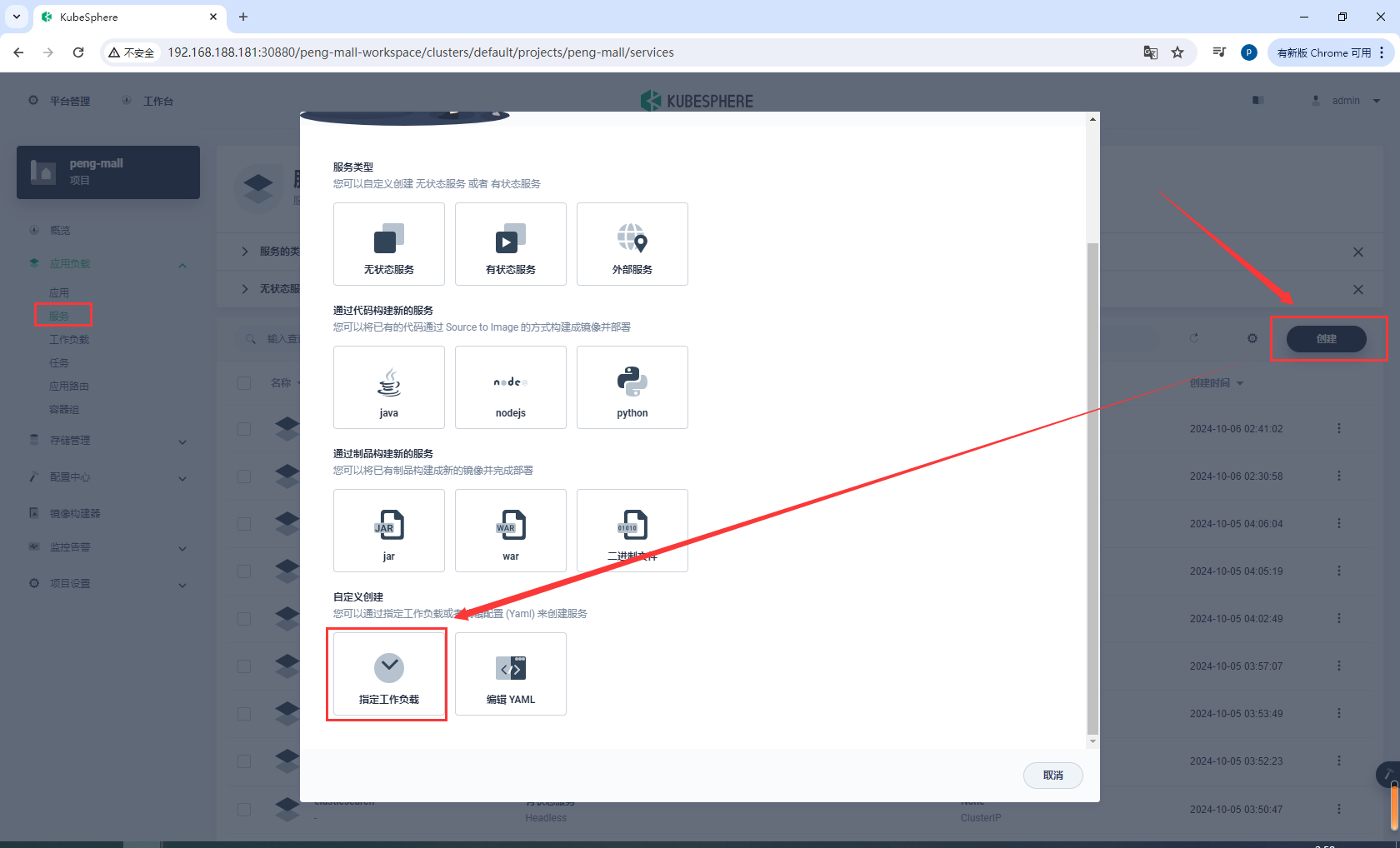
基本信息
mysql8-node-port
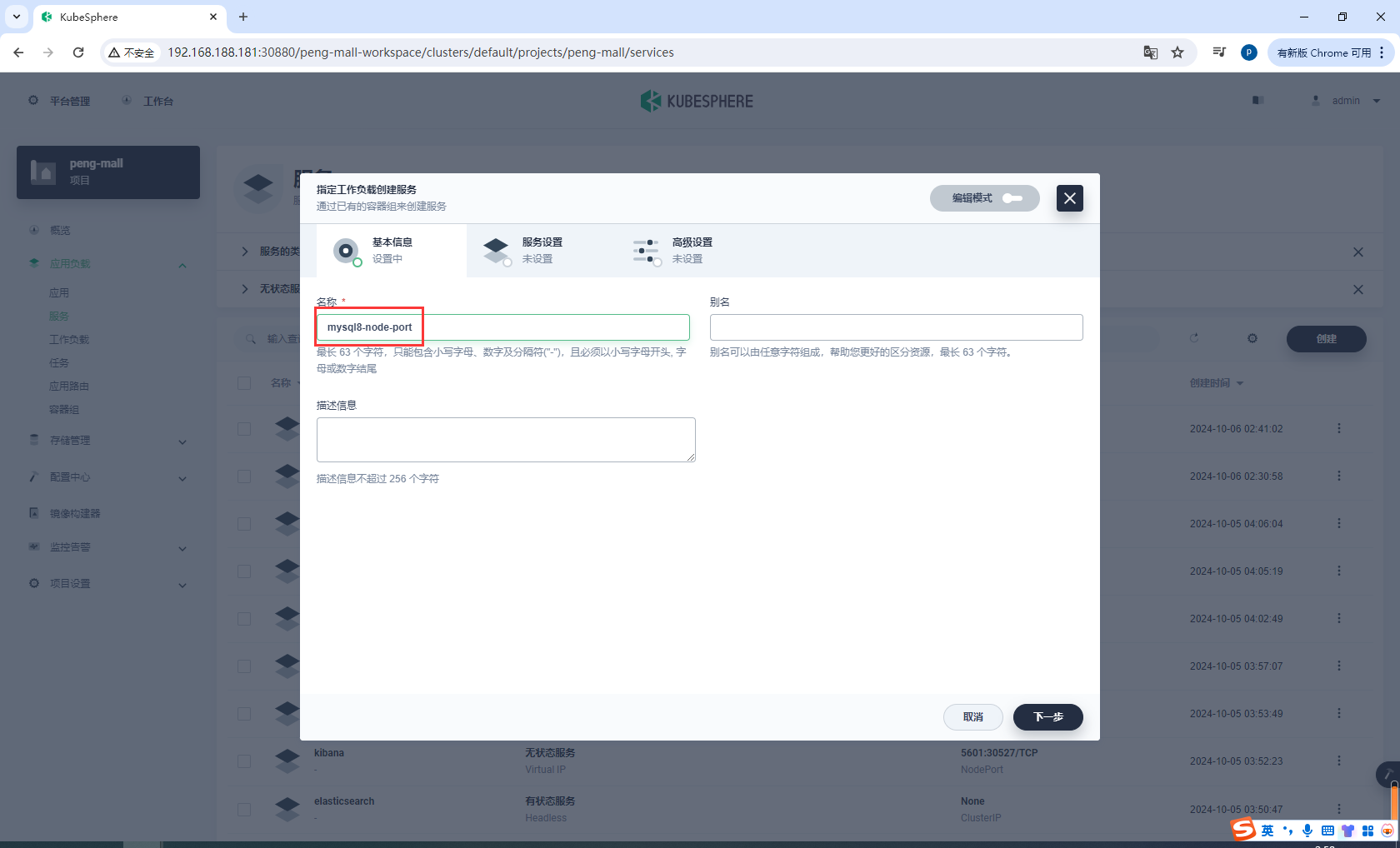
复制设置
选择指定工作负载,选择mysql8-v1
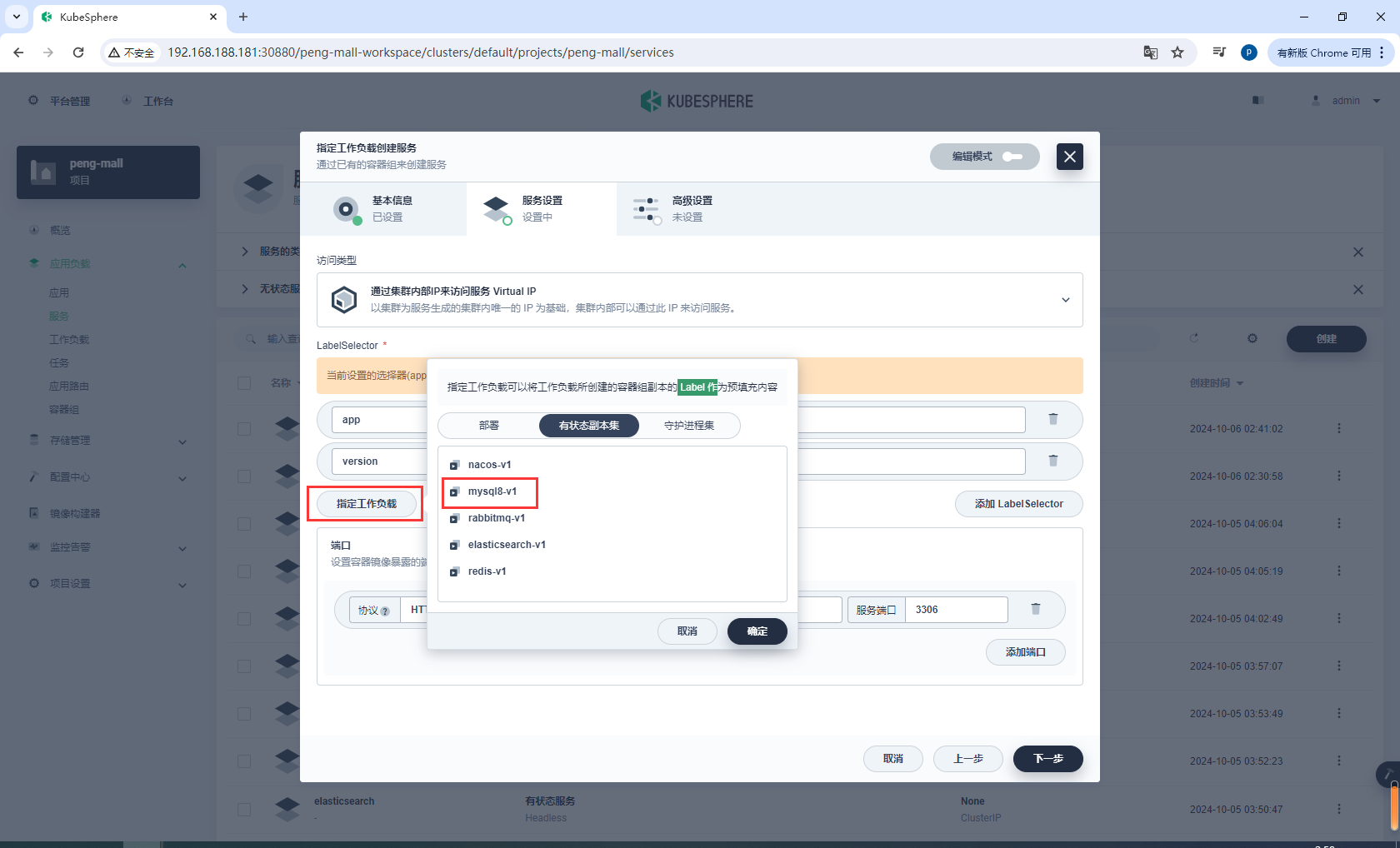
设置端口
http-3306 3306 3306
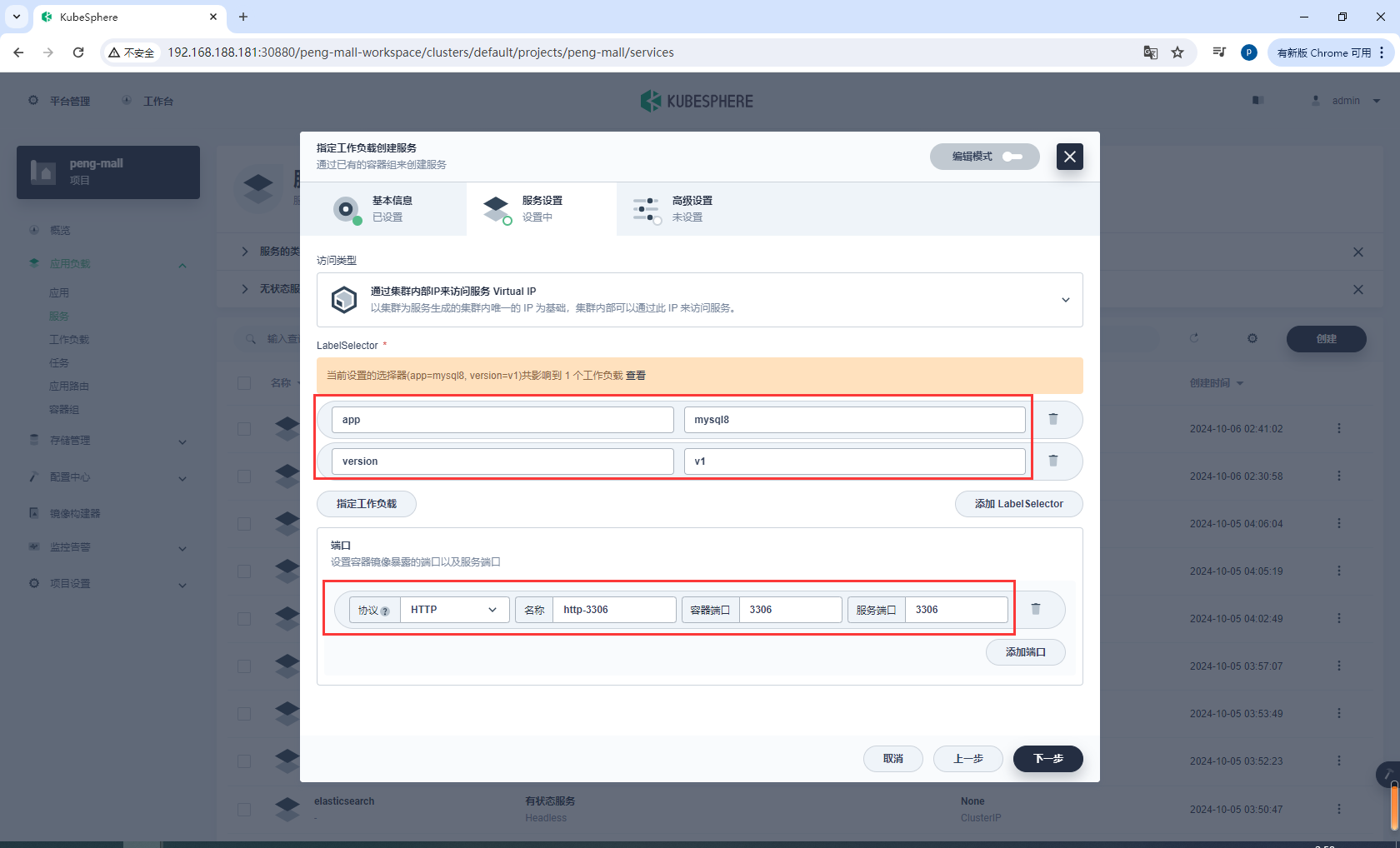
高级设置
选择外网访问,选择NodePort,选择开启会话保持

连接mysql8-node-port,IP任意一个k8s节点ip都可以,端口是随机暴露的端口
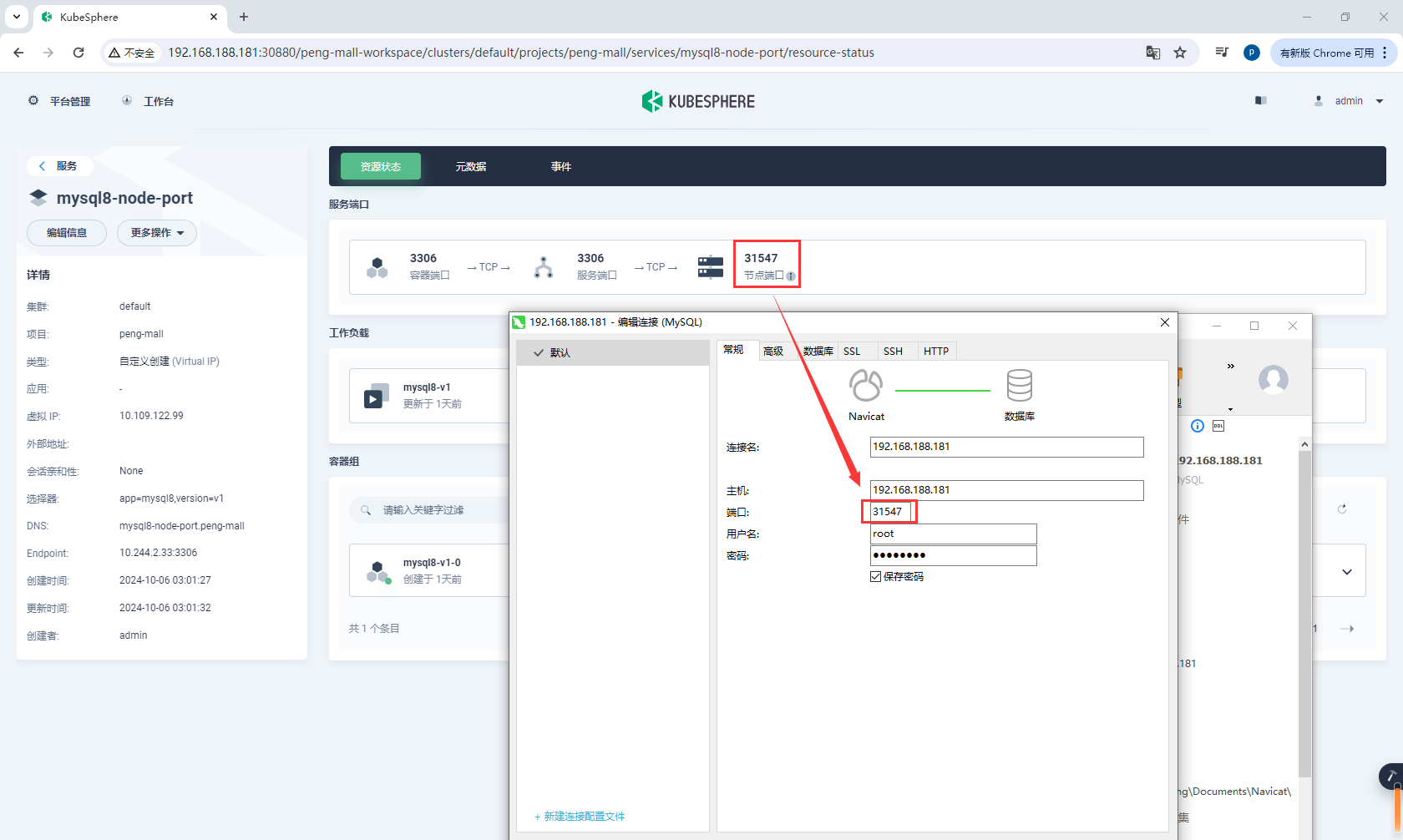
然后导入所有的数据,nacos服务需要连接数据库,如果之前没导入,这里要导入

mall_admin
mall_oms
mall_pms
mall_sms
mall_ums
mall_wms
nacos
# 不使用可以不创建
seata
mysql编码
utf8mb4
utf8mb4_unicode_ci
8.10.5nacos服务指定工作负载
如果我们要使用nacos控制台查看服务状态,需要为nacos创建工作负载,允许外部访问
基本信息
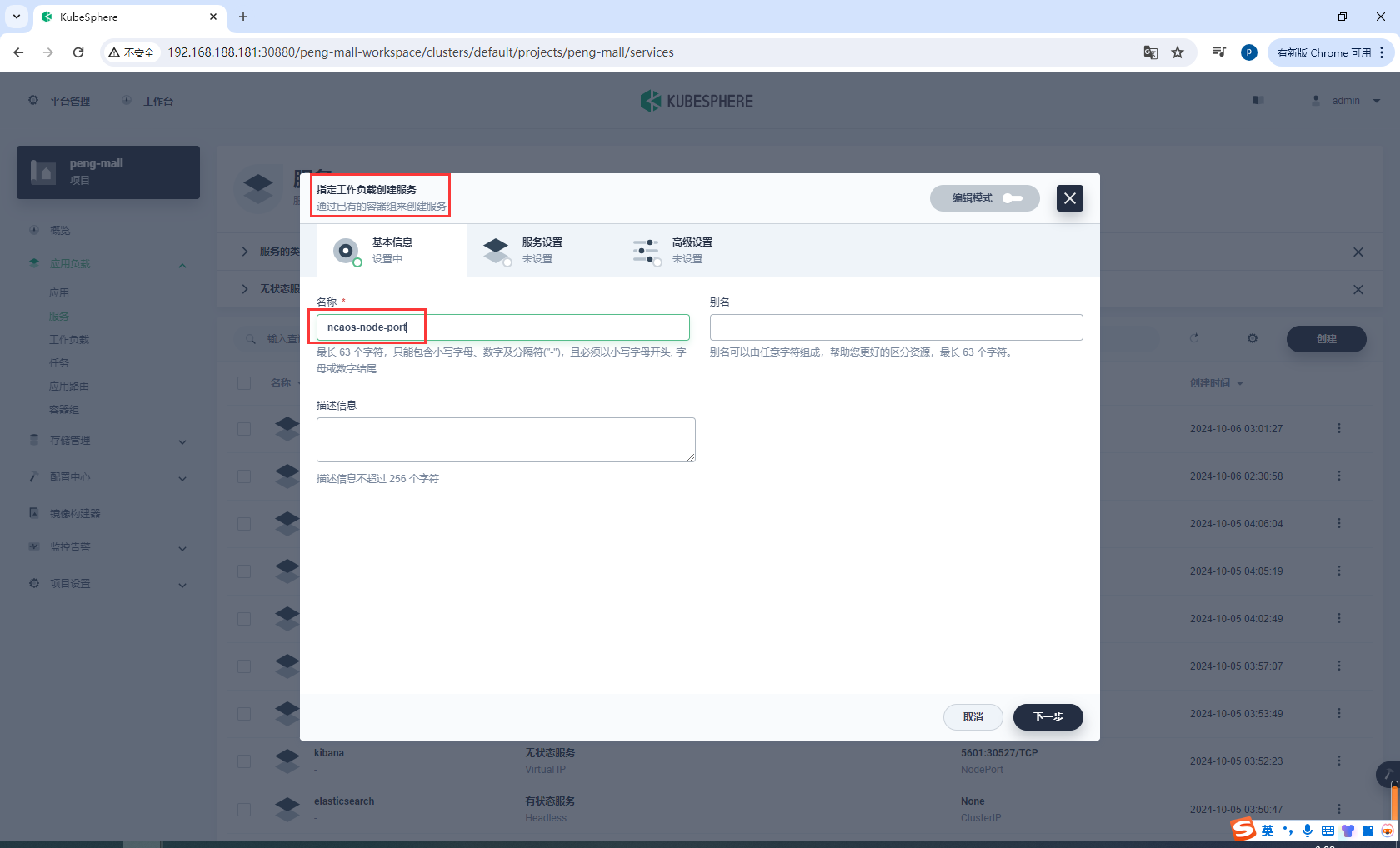
创建ncaos工作负载
nacos-node-port
服务设置
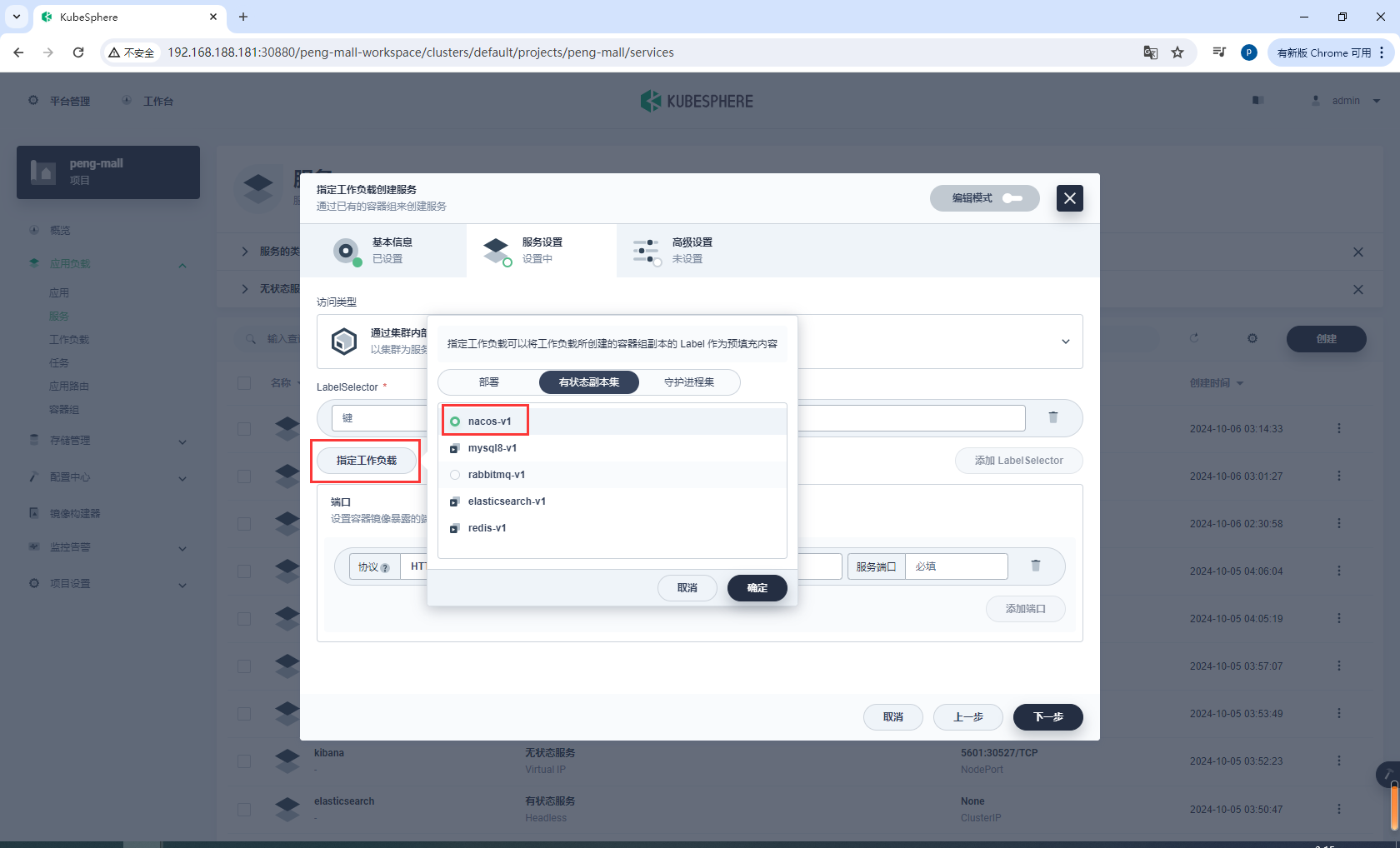
选择指定工作负载,选择nacos-v1
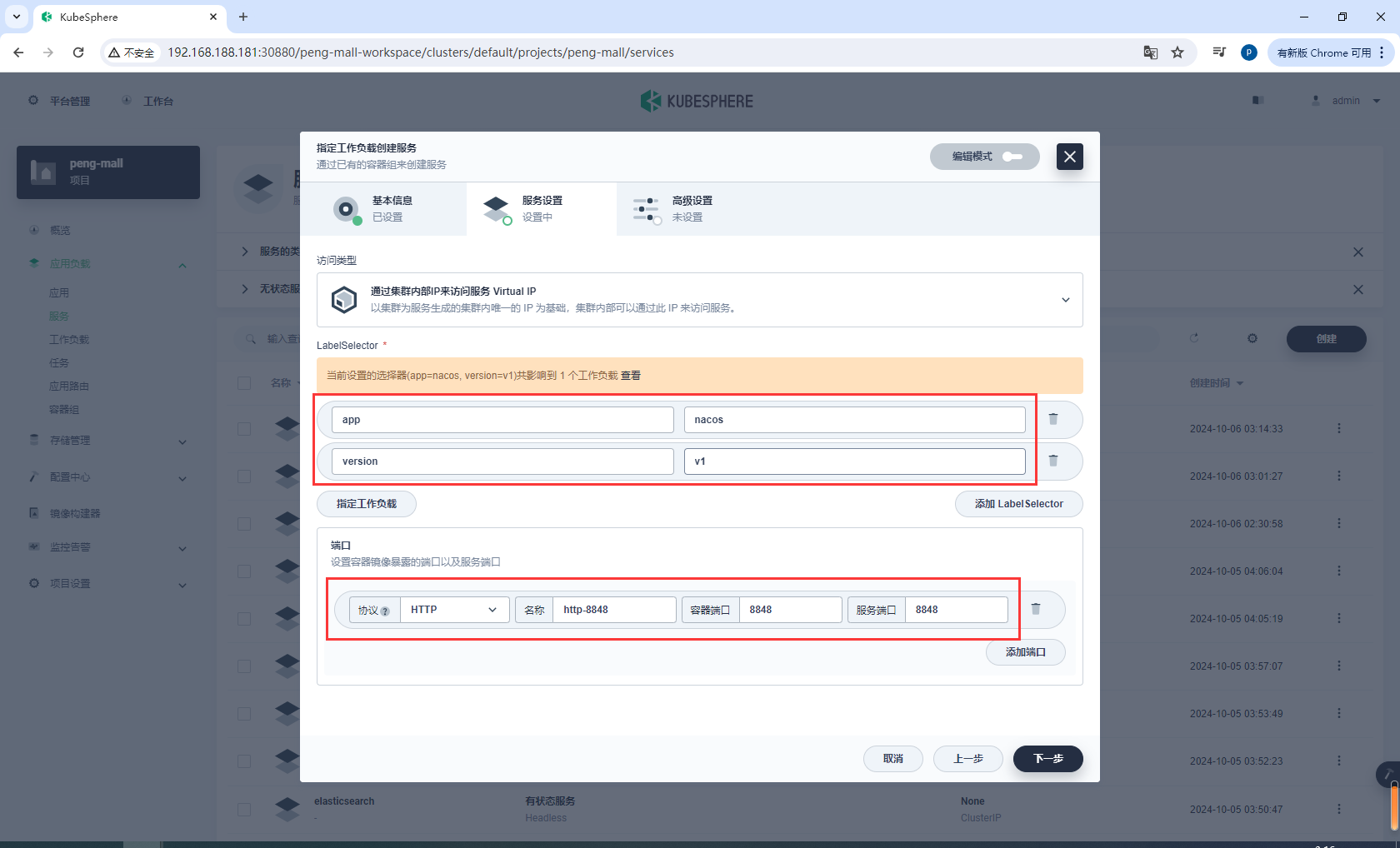
端口
http-8848 8848 8848
高级设置
选择外网访问,选择NodePort,选择开启会话保持
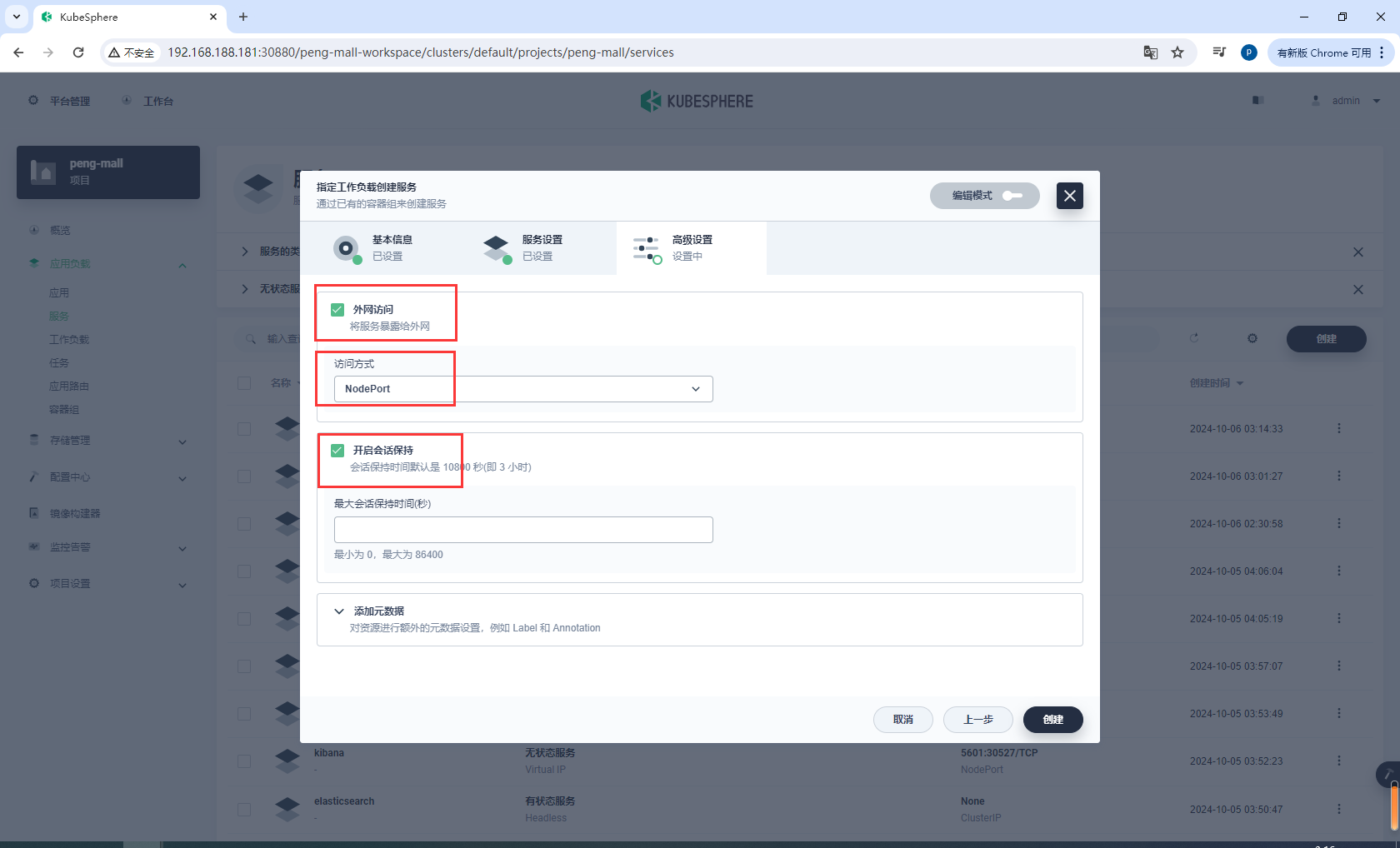
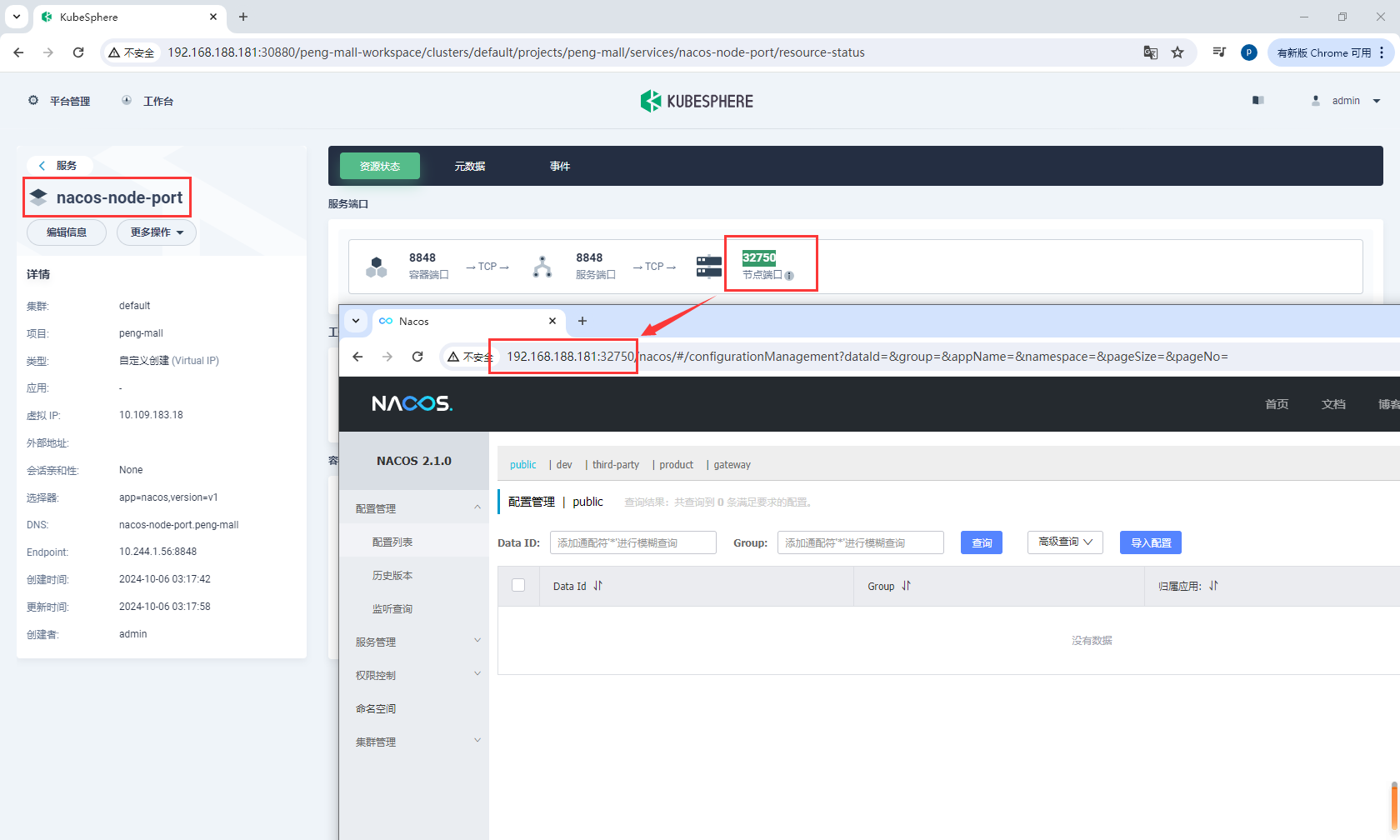
进入nacos-node-port查看访问端口32750,然后访问http://192.168.188.181:32750
8.10.6生产环境配置
所有服务的地址
| 服务 | 域名 |
|---|---|
| zipkin | zipkin-service.peng-mall:9411 |
| sentinel | sentinel-service.peng-mall:8858 |
| mysql8 | mysql8.peng-mall:3306 |
| nacos | nacos.peng-mall:8848 |
| rabbitmq | rabbitmq.peng-mall:5672 |
| kibana | kibana.peng-mall:5601 |
| elasticsearch | elasticsearch.peng-mall:9200 |
| redis | redis.peng-mall:6379 |
给所有的服务添加生产环境配置文件application-prod.yaml
我这里以商品服务gulimall-order为例,然后更新对应的服务地址
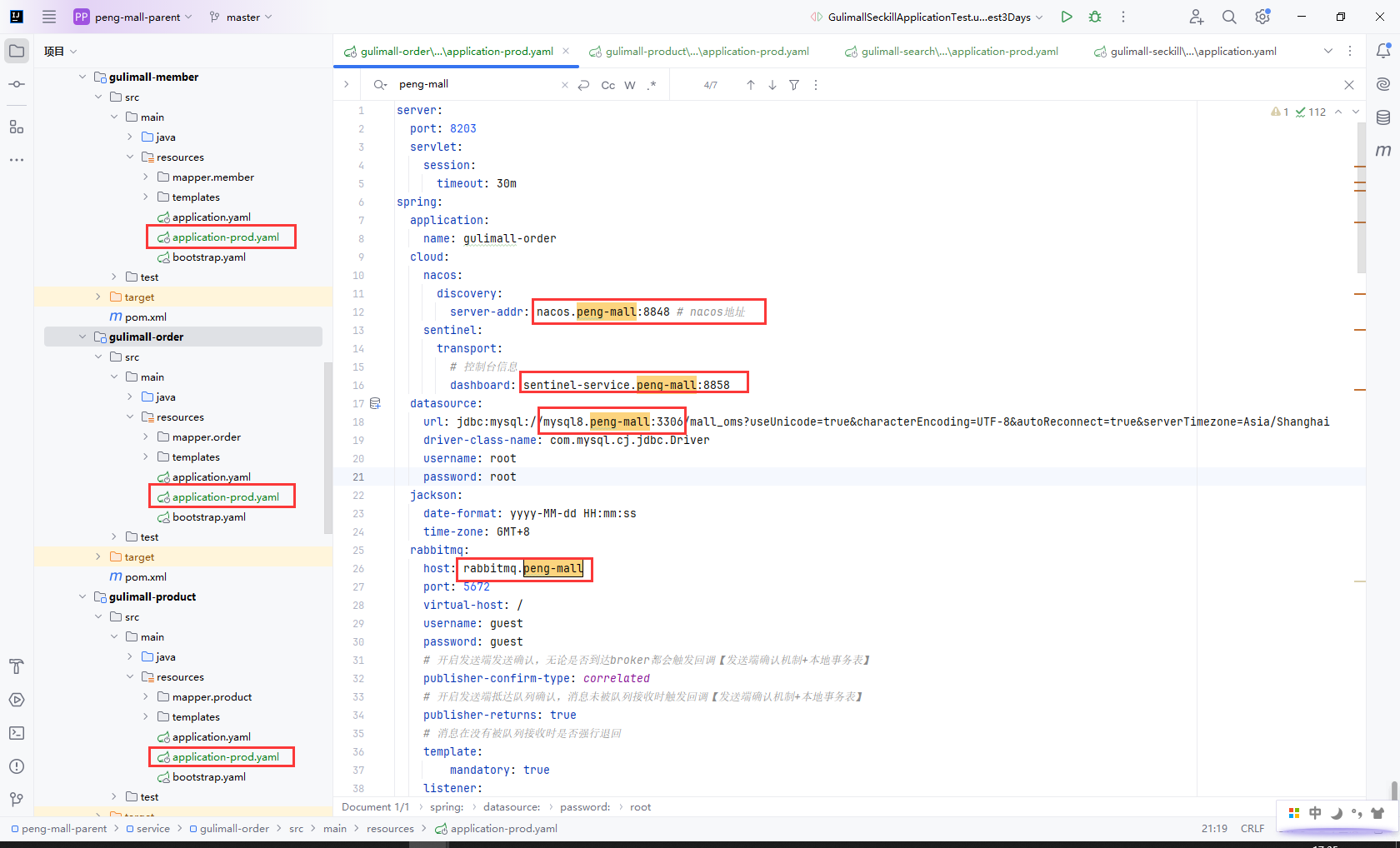
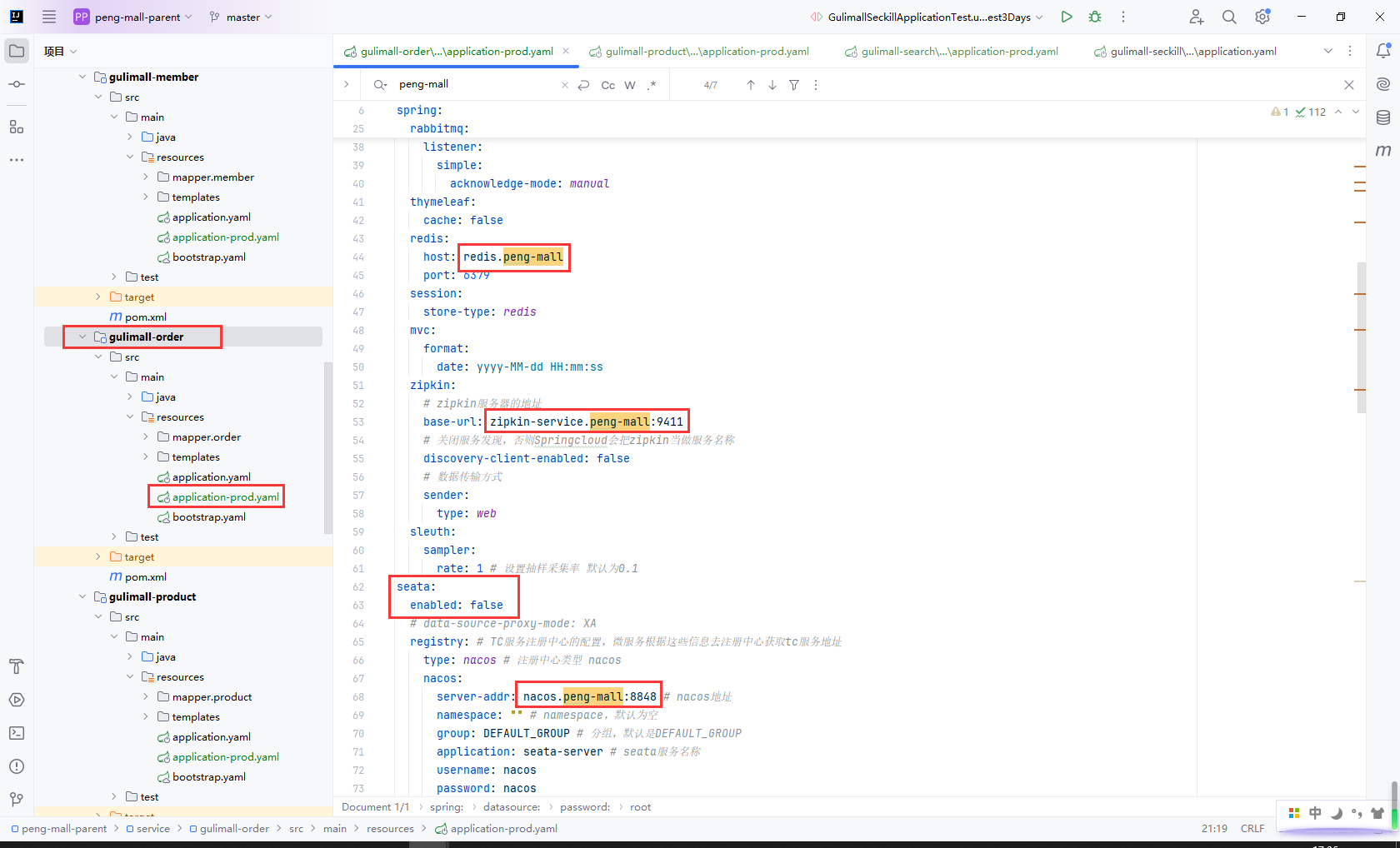
这里需要留意的是我们不考虑强一致性的seata事务解决办法,而且我们没有在k8s上部署seata,这里把seata服务关闭了
8.11创建微服务Dockfile
所有服务的application-prod.yaml的启动端口都改成8080
因为每个服务都一个独立的容器,他们在容器内部运行8080没有问题,对外映射的端口不一样即可
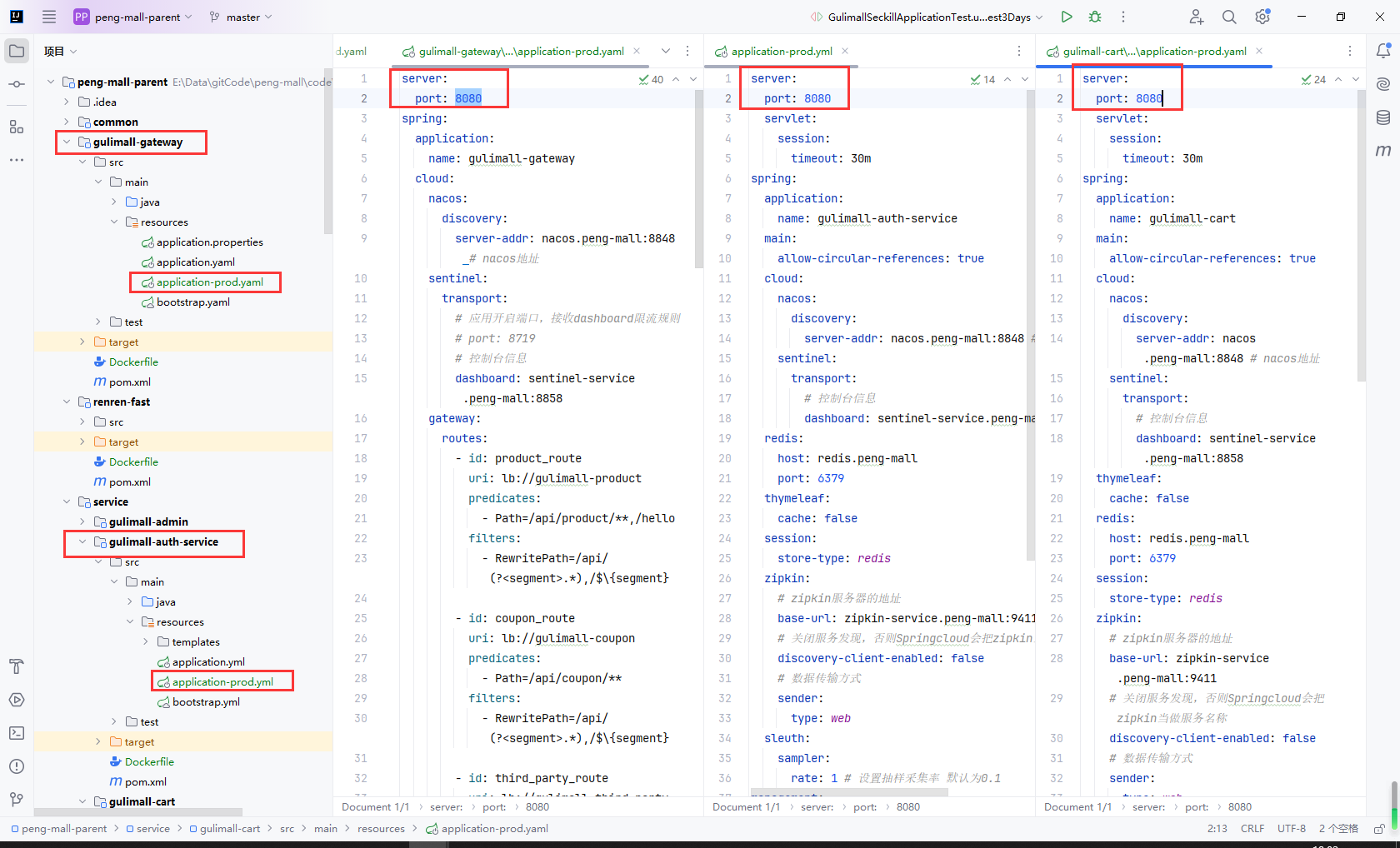
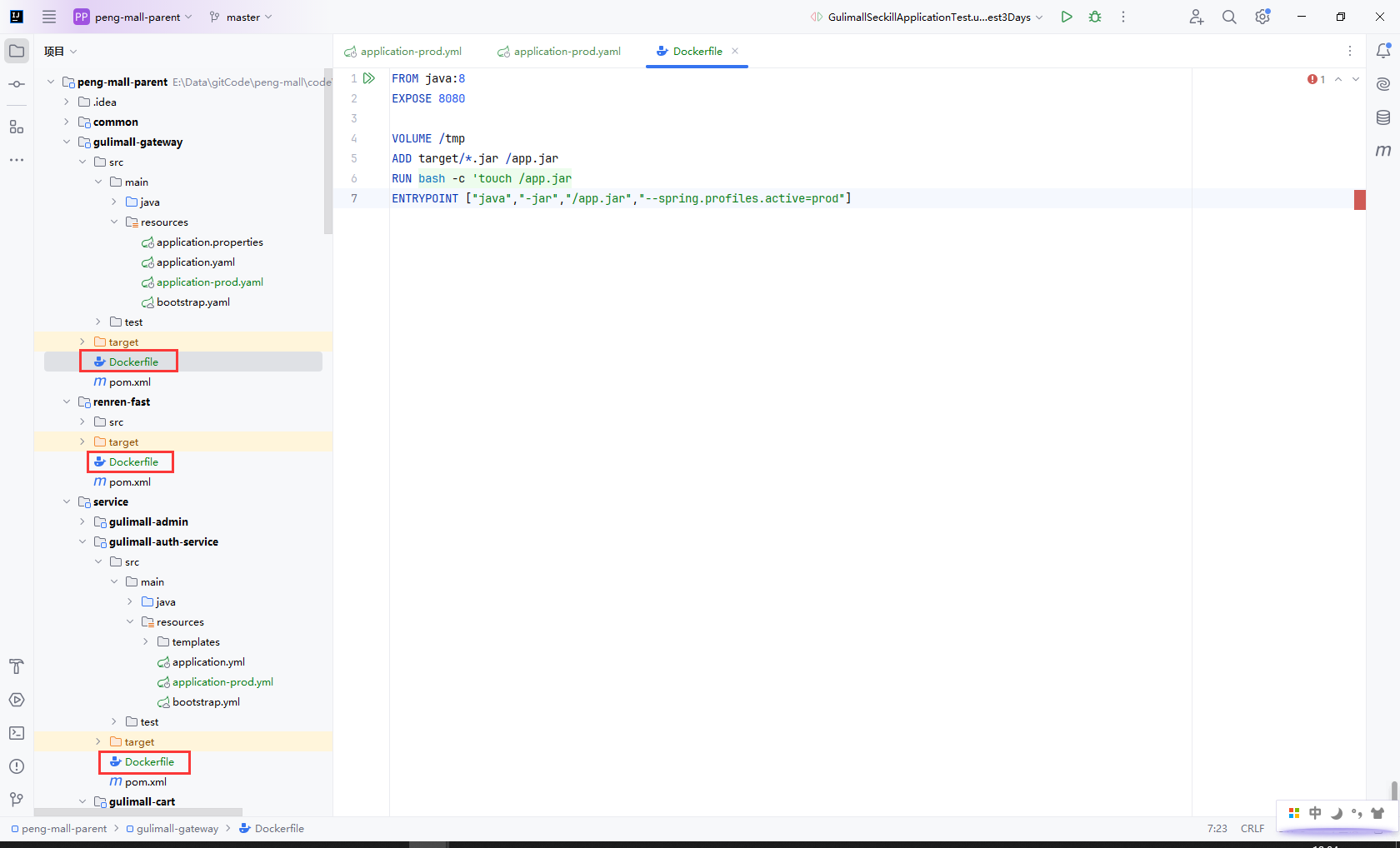
所有的服务添加Dockerfile,内容如下
- FROM: 指定基础镜像。在这里,使用的是 Java 8 的官方 Docker 镜像。这意味着构建的镜像将基于这个 Java 8 镜像。
- EXPOSE: 告诉 Docker 容器内部的应用会使用 8080 端口进行通信。这并不会直接开放端口,只是为文档和将来的网络配置提供参考。
- VOLUME: 创建一个挂载点,容器运行时会将
/tmp目录标记为持久化存储。这样,在容器重启时,存储在/tmp中的数据不会丢失。 - ADD: 将构建上下文中的文件(在这个例子中是
target目录下的.jar文件)复制到容器中的/app.jar路径。这一命令不仅可以复制文件,还可以自动解压归档文件。 - RUN: 在构建镜像时执行命令。在这里,它用于创建或更新
/app.jar文件的时间戳。这一命令通常用于确保该文件在容器运行时被重新加载。 - ENTRYPOINT: 设置容器启动时运行的命令。在这里,指定了使用 Java 命令来运行
/app.jar,并传递参数--spring.profiles.active=prod,这意味着 Spring 应用将以prod(生产)配置文件启动。
FROM java:8
EXPOSE 8080
VOLUME /tmp
ADD target/*.jar /app.jar
RUN bash -c 'touch /app.jar'
ENTRYPOINT ["java", "-jar", "/app.jar", "--spring.profiles.active=prod"]
8.12创建微服务k8s部署描述文件
8.12.1Deployment
官方demo地址:https://github.com/kubesphere/devops-java-sample/tree/master/deploy/prod-ol
选择sentinel-service,选择工作负载,点击该服务
选择编辑文件,复制sentinel-service的配置
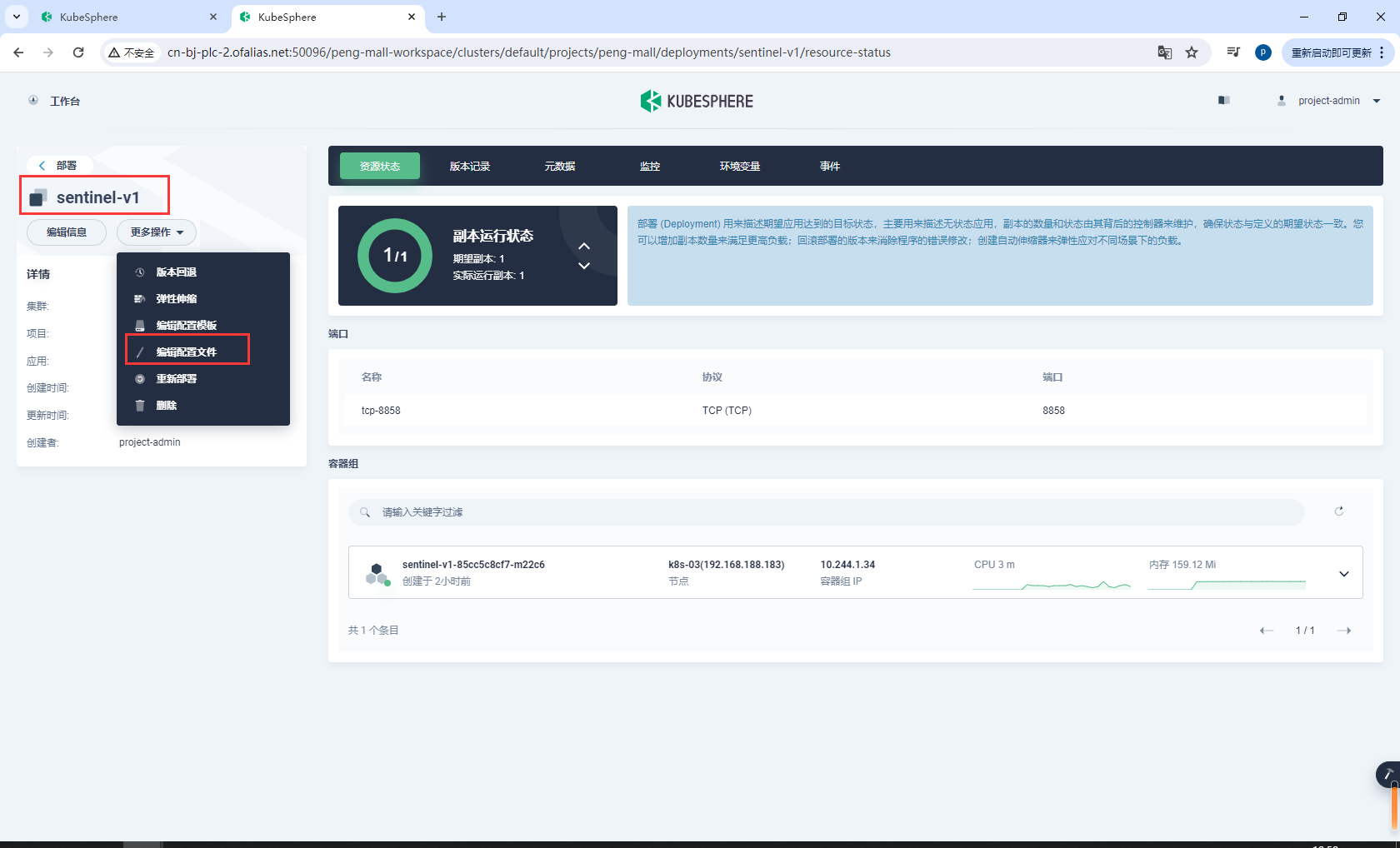
把所有app: sentinel替换为自己的微服务名称app: gulimall-auth-service
app: sentinel
app: gulimall-auth-service
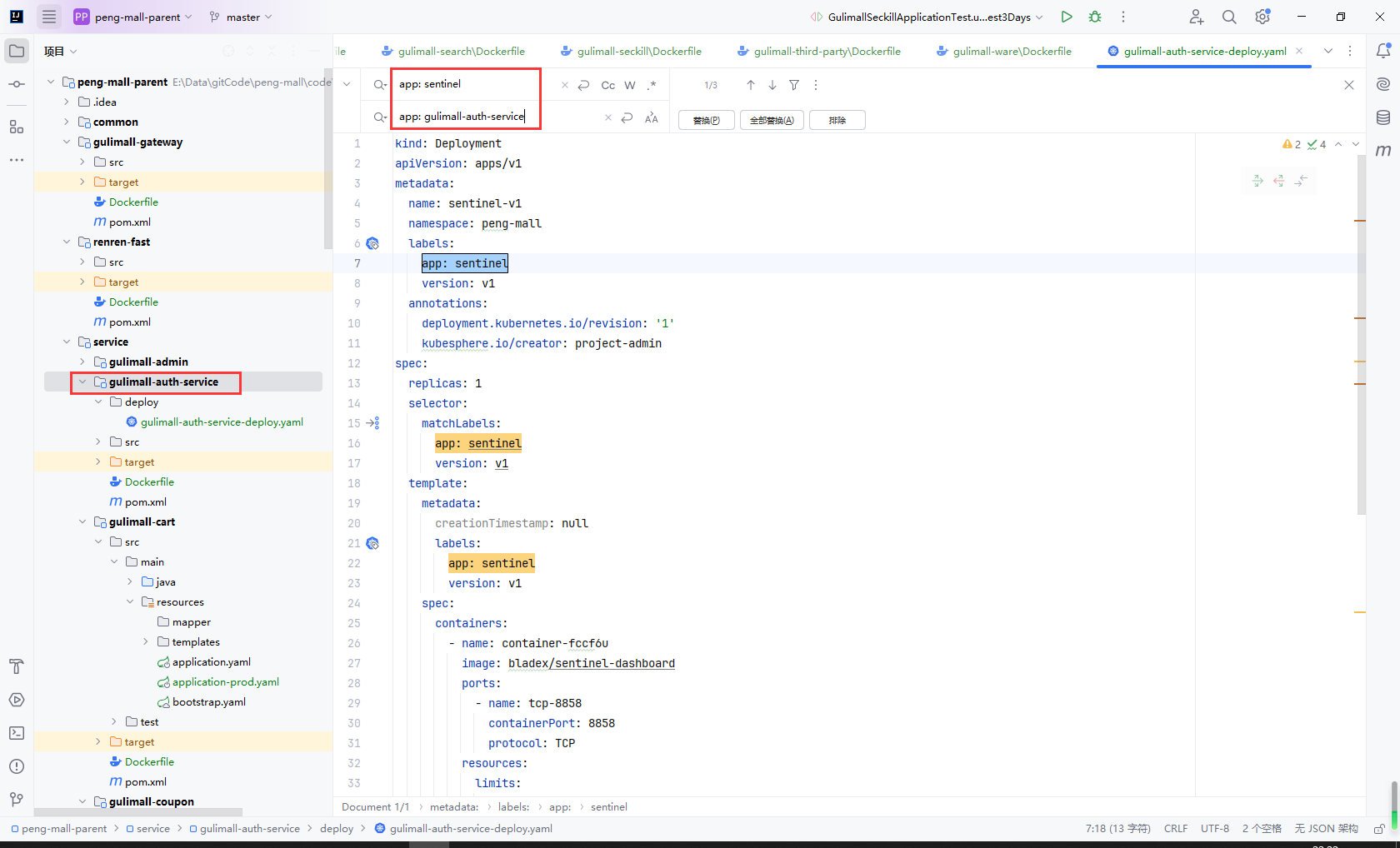
8.12.2Service
官方demo地址:https://github.com/kubesphere/devops-java-sample/blob/master/deploy/prod-ol/devops-sample-svc.yaml
选择一个无状态服务,这里选择的是sentinel,选择编辑配置文件,把配置文件复制出来进行修改
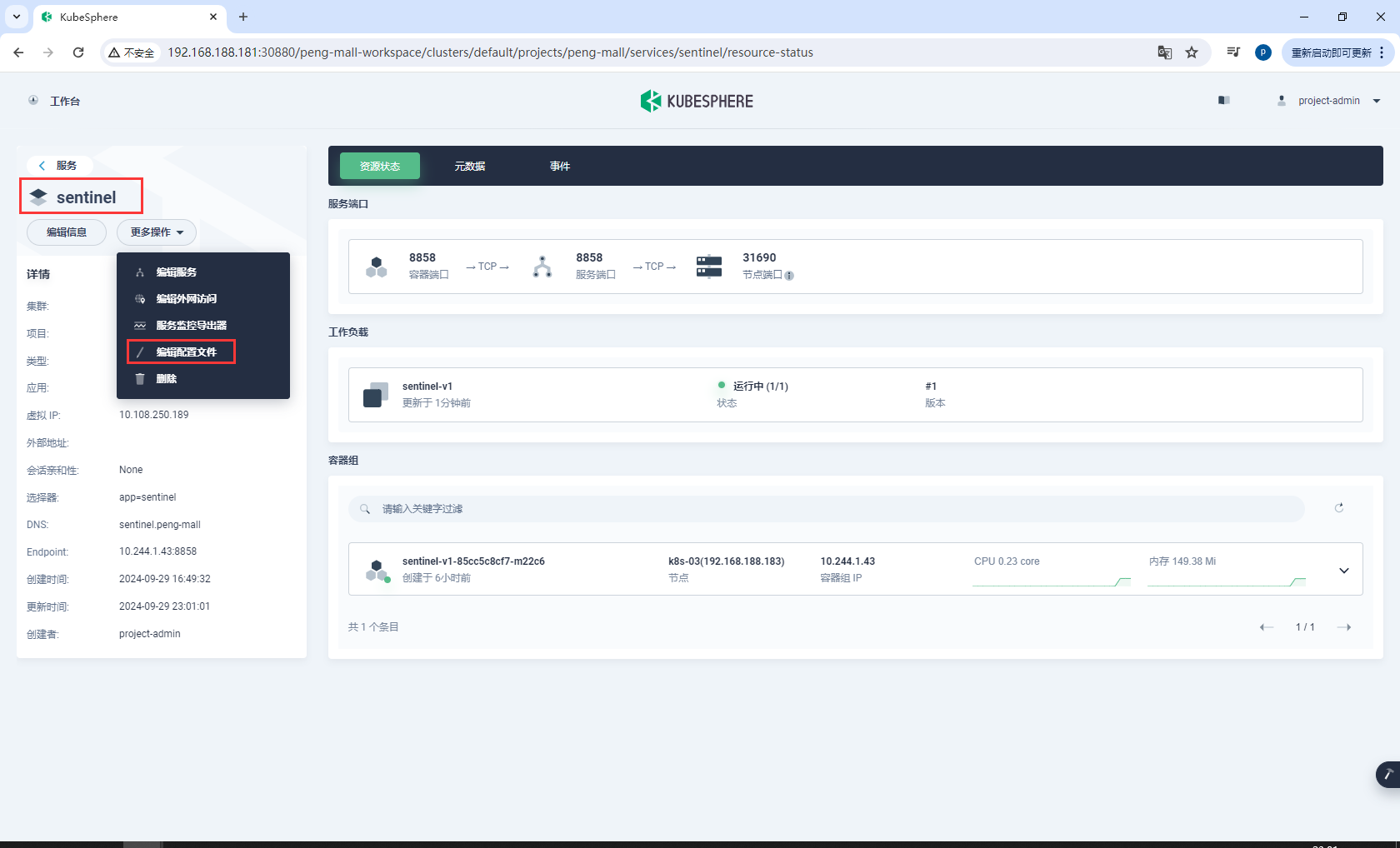
把所有app: sentinel替换为自己的微服务名称app: gulimall-auth-service
app: sentinel
app: gulimall-auth-service
把所有 name: sentinel替换为自己的微服务名称name: gulimall-auth-service
name: sentinel
name: gulimall-auth-service
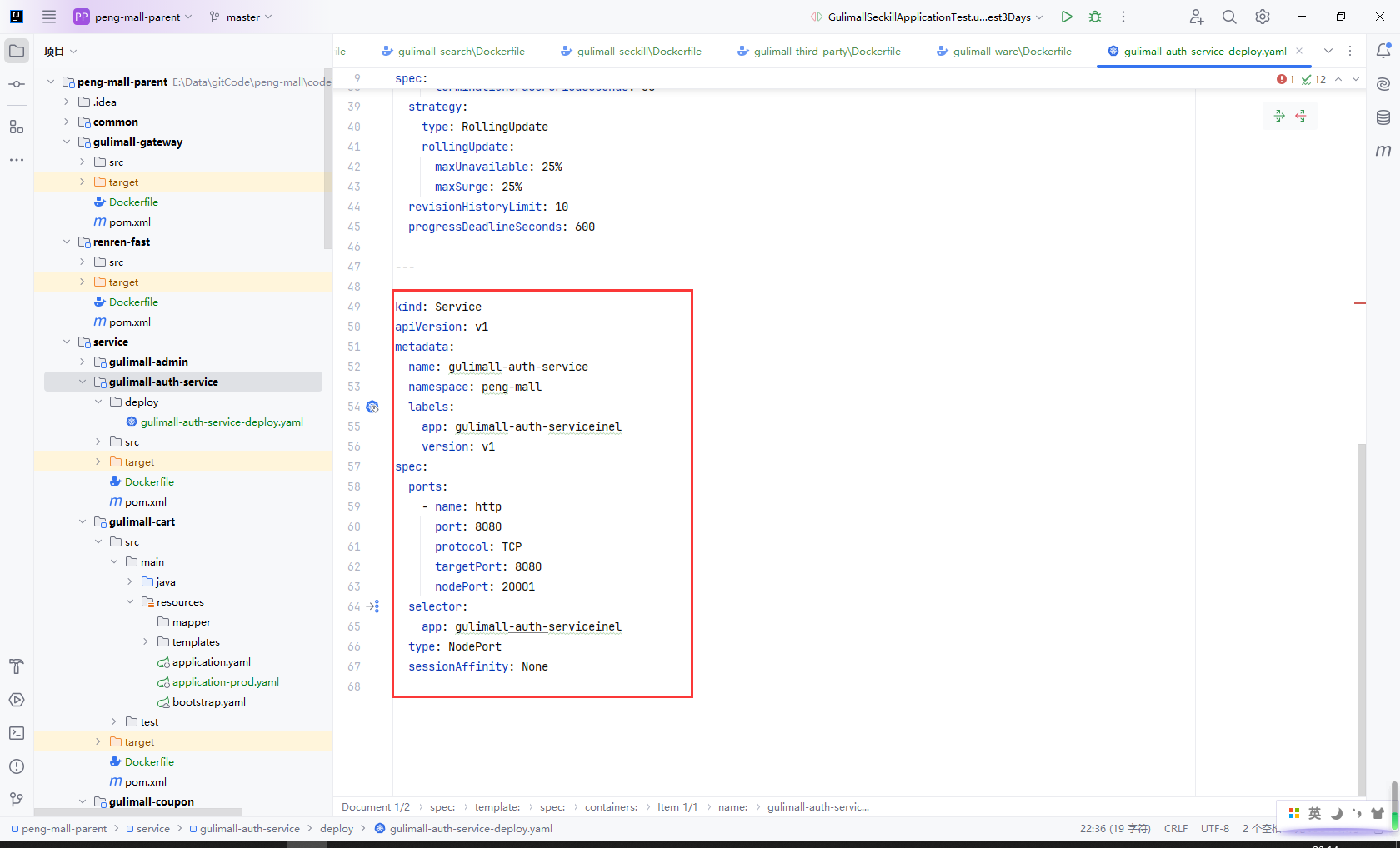
8.12.3完整配置
kind: Deployment
apiVersion: apps/v1
metadata:
name: gulimall-auth-service
namespace: peng-mall
labels:
app: gulimall-auth-service
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: gulimall-auth-service
version: v1
template:
metadata:
labels:
app: gulimall-auth-service
version: v1
spec:
containers:
- name: gulimall-auth-service
image: $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:$TAG_NAME
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: 1000m
memory: 500Mi
requests:
cpu: 10m
memory: 10Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
---
kind: Service
apiVersion: v1
metadata:
name: gulimall-auth-service
namespace: peng-mall
labels:
app: gulimall-auth-serviceinel
version: v1
spec:
ports:
- name: http
port: 8080
protocol: TCP
targetPort: 8080
nodePort: 20001
selector:
app: gulimall-auth-serviceinel
type: NodePort
sessionAffinity: None
8.12.4为所有服务添加deploy
把gulimall-auth-service的deploy文件夹拷贝到所有服务
把所有app: sentinel替换为自己的微服务名称app: 微服务名称
app: sentinel
app: 微服务名称
把所有 name: sentinel替换为自己的微服务名称name: 微服务名称
name: sentinel
name: 微服务名称
修改端口号,从200001开始+2
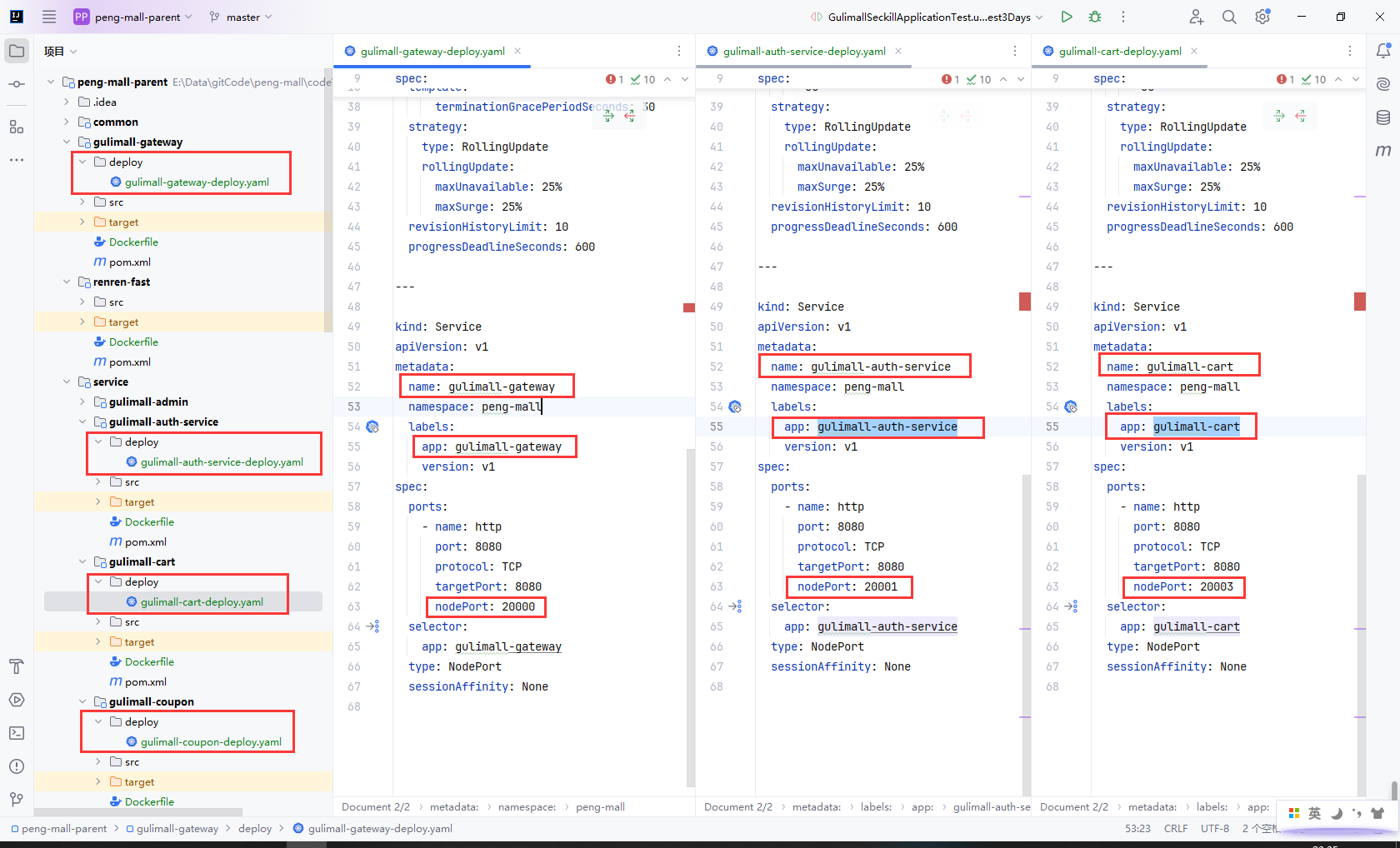
8.13理解targetPort、Port、NodePort
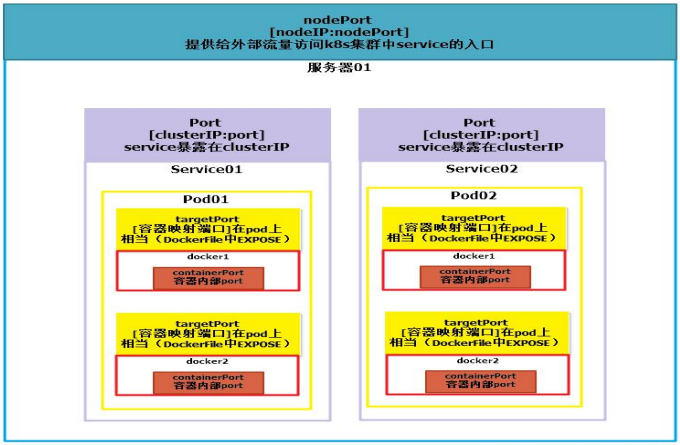
targetPort:
- 这是指向容器内部服务的端口。当服务接收到请求时,它会将请求转发到指定的
targetPort。 - 可以是容器内部的端口号,也可以是名称(如 "http" 或 "mysql"),表示容器内定义的端口。
port:
- 这是服务在 Kubernetes 中暴露的端口,外部的请求通过这个端口访问服务。
port是服务的虚拟端口,通常用于集群内部的通信。
nodePort:
- 这是一个可选字段,用于将服务暴露给外部流量。Kubernetes 会在每个节点的指定端口上监听并转发请求到
port。 nodePort的值必须在 30000 到 32767 之间(默认情况下)。外部请求可以通过NodeIP:nodePort访问服务。
8.14备份
商城运行的基本程序都搭建完成的话记得备份
创作不易,感谢支持。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号