NumPy库入门
import numpy as np
一、简介
ndarray是一个多维数组对象,由两部分构成:
a、实际的数据
b、描述这些数据的元数据(数据维度、数据类型等)
ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始。
In [17]: a = np.array([[0, 1, 2, 3, 4], [9, 8, 7, 6, 5]])
In [18]: a
Out [18]:
'array([[0, 1, 2, 3, 4],
[9, 8, 7, 6, 5]])'
In [19]: print(a)
'[[0 1 2 3 4]
[9 8 7 6 5]]'
np.array()生成一个ndarray数组
ndarray在程序中所谓别名是:array
np.array()输出成[]形式,元素由空格分隔
轴(axis):保存数据的维度
秩(rank):轴的数量
数据的维度:一维、二维、多维、高维
二、ndarray对象的属性
属性 说明
.ndim 秩,即轴的数量或维度的数量
.shape ndarray对象的尺度,对于矩阵,n行m列
.size ndarray对象元素的个数,相当于.shape中n*m的值
.dtype ndarray对象的元素类型
.itemsize ndarray对象中每个元素的大小,以字节为单位
ndarray实例:
In [20]: a = np.array([[0, 1, 2, 3, 4], [9, 8, 7, 6, 5]])
In [21]: a.ndim
Out[21]: 2
In [22]: a.shape
Out[22]: (2, 5)
In [23]: a.size
Out[23]: 10
In [24]: a.dtype
Out[24]: dtype('int32')
In [25]: a.itemsize
Out[25]: 4
三、ndarray的元素类型
数据类型 说明
bool 布尔类型,True或False
intc 与C语言中的int类型一致,一般是int32或int64
intp 用于索引的整数,与C语言中size_t一致,int32或int64
int8 字节长度的整数, 取值:[-128,127]
int16 16位长度整数, 取值:[-32768,32767]
int32 32位长度的整数,取值:[-231,231-1]
int64 64位长度的整数,取值:[-263,263-1]
uint8 8位无符号整数, 取值:[0,255]
uint16 16位无符号整数,取值:[0,65535]
uint32 32位无符号整数,取值:[0,232-1]
uint64 64位无符号整数,取值:[0,264-1]
float16 16位半精度浮点数,1位符号位,5位指数,10位尾数
float32 32位半精度浮点数,1位符号位,8位指数,23位尾数
float64 64位半精度浮点数,1位符号位,11位指数,52位尾数
complex64 复数类型,实部和虚部都是32位浮点数
complex128 复数类型,实部和虚部都是64位浮点数
ndarray为什么要支持这么多种元素类型?
对比:Python语法仅支持整数、浮点数和复数3种类型,而其中整数类型是没有取值范围,
没有具体划分的,浮点数也只有一种浮点数,而复数也只有一种复数。
a、科学计算设计数据较多,对存储和性能都有较高要求。
b、对元素类型精细定义,有助于NumPy合理使用存储空间并优化性能。
c、对元素类型精细定义,有助于程序员对程序规模以及程序运行所需要的资源有合理评估。
在Python语法中,由于整数类型,它涉及到的实际支撑它的存储空间是不确定的,所以
程序员很难去预估一个程序的使用空间,但是经过NumPy的精确定义,这样的空间规模是
可以被预测的。
非同质数据的ndarray实例:
In [27]: x = np.array([[0, 1, 2, 3, 4],[9, 8, 7, 6]])
In [28]: x.shape
Out[28]: (2,)
In [29]: x.dtype
Out[29]: dtype('O') #object类型
In [30]: x
Out[30]: array([list([0, 1, 2, 3, 4]), list([9, 8, 7, 6])], dtype=object)
In [31]: x.itemsize
Out[31]: 4
In [32]: x.size
Out[32]: 2
ndarray数组可以由非同质对象构成
非同质ndarray元素为对象类型
非同质ndarray对象无法有效发挥NumPy优势,尽量避免使用
四、ndarray数组的创建
ndarray数组的创建方法:
1、从Python中的列表、元组等类型创建ndarray数组。
x = np.array(list/tuple)
x = np.array(list/tuple, dtype=np.float32)
注意:可以使用dtype来指定每个元素的数据类型,当np.array()不指定dtype时,NumPy将根据读入的数据情况关联一个dtype类型。
In [33]: x = np.array([0, 1, 2, 3]) #从列表类型创建
In [34]: print(x)
[0 1 2 3]
In [35]: x = np.array((4, 5, 6, 7)) #从元组类型创建
In [36]: print(x)
[4 5 6 7]
In [37]: x = np.array([[1, 2], [9, 8], (0.1, 0.2)]) #从列表和元组混合类型创建
In [38]: print(x)
[[1. 2. ]
[9. 8. ]
[0.1 0.2]]
2、使用NumPy中函数创建ndarray数组,如:arange,ones,zeros等。
函数 说明
np.arange(n) 类似range()函数,返回ndarray类型,元素从0到n-1
np.ones(shape) 根据shape生成一个全1数组,shape是元组类型
np.zeros(shape) 根据shape生成一个全0数组,shape是元组类型
np.full(shape, val) 根据shape生成一个数组,每个元素值都是val
np.eye(n) 创建一个正方形的n*n单位矩阵,对角线为1,其余为0
np.ones_like(a) 根据数组a的形状生成一个全1数组
np.zeros_like(a) 根据数组a的形状生成一个全0数组
np.full_like(a, val) 根据数组a的形状生成一个数组,每个元素值都是val
np.linspace() 根据起止数据等间距地填充数据,形成数组
np.concatenate() 将两个或多个数组合并成一个新的数组
In [47]: np.arange(10) #生成的数组元素类型默认是整数
Out[47]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [48]: np.ones((3,6)) #如果不指定dtype,默认浮点数类型
Out[48]:
array([[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1.]])
In [49]: np.zeros((3,6),dtype=np.int32) #如果不指定dtype,默认是浮点型
Out[49]:
array([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]])
In [50]: np.eye(5) #如果不指定dtype,默认浮点数类型
Out[50]:
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
#2, 3, 4分别表示的是:
#在最外层的元素中有2个元素,每一个元素又有3个维度,每个维度下又有4个元素
In [51]: x = np.ones((2, 3, 4))
In [52]: print(x)
[[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]]
In [53]: x.shape
Out[53]: (2, 3, 4)
In [63]: a = np.linspace(1, 10, 4)
In [64]: a
Out[64]: array([ 1., 4., 7., 10.])
In [65]: b = np.linspace(1, 10, 4, endpoint=False)
In [66]: b
Out[66]: array([1. , 3.25, 5.5 , 7.75])
In [68]: c = np.concatenate((a, b))
In [69]: c
Out[69]: array([ 1. , 4. , 7. , 10. , 1. , 3.25, 5.5 , 7.75])
3、从字节流(raw bytes)中创建ndarray数组。
4、从文件中读取特定格式,创建ndarray数组。
五、ndarray数组的变换
1、对于创建后的ndarray数组,可以对其进行维度变换和元素类型变换
方法 说明
.reshape(shape) 不改变数组元素,返回一个shape形状的数组,原数组不变
.resize(shape) 与.reshape()功能一致,但修改原数组
.swapaxes(ax1, ax2) 将数组n个维度中两个维度进行调换
.flatten() 将数组进行降维,返回折叠后的一维数组,原数组不变
In [71]: a = np.ones((2, 3, 4), dtype = np.int32)
In [72]: a
Out[72]:
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
In [73]: b = a.reshape((3,8))
In [74]: a
Out[74]:
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
In [75]: b
Out[75]:
array([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
In [76]: a.resize((3, 8))
In [77]: a
Out[77]:
array([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
In [78]: c = a.flatten()
In [79]: a
Out[79]:
array([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]])
In [80]: c
Out[80]:
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1])
2、new_a = a.astype(new_type):
#改变ndarray数组元素类型
In [82]: a = np.ones((2, 3, 4), dtype = np.int)
In [83]: a
Out[83]:
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]])
In [84]: b = a.astype(np.float)
In [85]: b
Out[85]:
array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致。
六、ndarray数组向列表的转换
ls = a.tolist()
In [87]: a = np.full((2, 3, 4), 25, dtype=np.int32)
In [88]: a
Out[88]:
array([[[25, 25, 25, 25],
[25, 25, 25, 25],
[25, 25, 25, 25]],
[[25, 25, 25, 25],
[25, 25, 25, 25],
[25, 25, 25, 25]]])
In [89]: a.tolist()
Out[89]:
[[[25, 25, 25, 25], [25, 25, 25, 25], [25, 25, 25, 25]],
[[25, 25, 25, 25], [25, 25, 25, 25], [25, 25, 25, 25]]]
七、ndarray数组的操作
1、数组的索引和切片
索引:获取数组中特定位置元素的过程
切片:获取数组元素子集的过程
一维数组的索引和切片:与Python的列表类似
In [95]: a = np.array([9, 8, 7, 6, 5])
In [96]: a[2]
Out[96]: 7
In [97]: a[1 : 4 : 2] #起始编号:终止编号(不含):步长,3元素冒号分割
Out[97]: array([8, 6])
多维数组的索引:
In [100]: a = np.arange(24).reshape(2,3,4)
In [101]: a
Out[101]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
In [102]: a[1, 2, 3]
Out[102]: 23
In [103]: a[0, 1, 2]
Out[103]: 6
In [104]: a[-1, -2, -3]
Out[104]: 17
每个维度一个索引值,逗号分割。
多维数组的切片:
In [106]: a = np.arange(24).reshape(2,3,4)
In [107]: a
Out[107]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
In [108]: a[:, 1, -3] # 选取一个维度用:
Out[108]: array([ 5, 17])
In [109]: a[:, 1:3, :] # 每个维度切片方法与一维数组相同
Out[109]:
array([[[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[16, 17, 18, 19],
[20, 21, 22, 23]]])
In [110]: a[:, :, ::2] # 每个维度可以使用步长跳跃切片
Out[110]:
array([[[ 0, 2],
[ 4, 6],
[ 8, 10]],
[[12, 14],
[16, 18],
[20, 22]]])
八、ndarray数组的运算
1、数组与标量之间的运算
数组与标量之间的运算作用于数组中的每一个元素
实例:计算a与元素平均值的商
In [128]: a = np.arange(24).reshape(2,3,4)
In [129]: a
Out[129]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
In [130]: a.mean()
Out[130]: 11.5
In [131]: a = a / a.mean()
In [132]: a
Out[132]:
array([[[0. , 0.08695652, 0.17391304, 0.26086957],
[0.34782609, 0.43478261, 0.52173913, 0.60869565],
[0.69565217, 0.7826087 , 0.86956522, 0.95652174]],
[[1.04347826, 1.13043478, 1.2173913 , 1.30434783],
[1.39130435, 1.47826087, 1.56521739, 1.65217391],
[1.73913043, 1.82608696, 1.91304348, 2. ]]])
2、NumPy一元函数
对ndarray中的数据执行元素级运算的函数
函数 说明
np.abs(x) np.fabs(x) 计算数组各元素的绝对值
np.sqrt(x) 计算数组各元素的平方根
np.sqyare(x) 计算数组各元素的平方
np.log(x) np.log10(x) 计算数组各元素的自然对数、以10为底对数
np.log2(x) 计算数组各元素的以2为底对数
np.ceil(x) np.floor(x) 分别计算数组各元素的ceiling值和floor值,ceiling表示的是大于元素的最小整数值,
floor表示的是小于元素的最大整数值
np.rint(x) 计算数组各元素的四舍五入值
np.modf(x) 将数组各元素的小数和整数部分以两个独立数组形式返回
np.cos(x) np.cosh(x) 计算数组各元素的普通型和双曲型三角函数
np.sin(x) np.sinh(x) 计算数组各元素的普通型和双曲型三角函数
np.tan(x) np.tanh(x) 计算数组各元素的普通型和双曲型三角函数
np.exp(x) 计算数组各元素的指数值
np.sign(x) 计算数组各元素的符号值,1(+), 0, -1(-)
注意:在运行一元函数时,数组是否被真实改变
In [138]: a = np.arange(24).reshape(2,3,4)
In [139]: np.square(a)
Out[139]:
array([[[ 0, 1, 4, 9],
[ 16, 25, 36, 49],
[ 64, 81, 100, 121]],
[[144, 169, 196, 225],
[256, 289, 324, 361],
[400, 441, 484, 529]]], dtype=int32)
In [140]: a = np.sqrt(a)
In [141]: a
Out[141]:
array([[[0. , 1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974, 2.64575131],
[2.82842712, 3. , 3.16227766, 3.31662479]],
[[3.46410162, 3.60555128, 3.74165739, 3.87298335],
[4. , 4.12310563, 4.24264069, 4.35889894],
[4.47213595, 4.58257569, 4.69041576, 4.79583152]]])
In [142]: np.modf(a)
Out[142]:
(array([[[0. , 0. , 0.41421356, 0.73205081],
[0. , 0.23606798, 0.44948974, 0.64575131],
[0.82842712, 0. , 0.16227766, 0.31662479]],
[[0.46410162, 0.60555128, 0.74165739, 0.87298335],
[0. , 0.12310563, 0.24264069, 0.35889894],
[0.47213595, 0.58257569, 0.69041576, 0.79583152]]]),
array([[[0., 1., 1., 1.],
[2., 2., 2., 2.],
[2., 3., 3., 3.]],
[[3., 3., 3., 3.],
[4., 4., 4., 4.],
[4., 4., 4., 4.]]]))
3、NumPy二元函数
函数 说明
+ - * / ** 两个数组各元素进行对应运算
np.maximum(x,y) np.fmax() 元素级的最大值计算
np.minimum(x,y) np.fmin() 元素级的最小值计算
np.mod(x,y) 元素级的模运算
np.copysign(x,y) 将数组y中各元素值的符号赋值给数组x对应元素
> < >= <= == != 算术比较,产生布尔型数组
In [163]: a = np.arange(24).reshape(2,3,4)
In [164]: b = np.sqrt(a)
In [165]: a
Out[165]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
In [166]: b
Out[166]:
array([[[0. , 1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974, 2.64575131],
[2.82842712, 3. , 3.16227766, 3.31662479]],
[[3.46410162, 3.60555128, 3.74165739, 3.87298335],
[4. , 4.12310563, 4.24264069, 4.35889894],
[4.47213595, 4.58257569, 4.69041576, 4.79583152]]])
In [167]: np.maximum(a, b) #运算结果为浮点数
Out[167]:
array([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]])
In [168]: a > b
Out[168]:
array([[[False, False, True, True],
[ True, True, True, True],
[ True, True, True, True]],
[[ True, True, True, True],
[ True, True, True, True],
[ True, True, True, True]]])
九、数据的CSV文件存取
1、CSV文件
CSV(Comma-Separated Value,逗号分隔值)
CSV是一种常见的文件格式,用来存储批量数据
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
array:要存入文件的数组
fmt:每一个元素写入文件的格式,例如:%d %.2f %.18e(默认科学技术法,保留18位小数)
delimiter:数据写入文件中数据之间的分割字符串,默认是任何空格
In [170]: a = np.arange(100).reshape(5, 20)
In [172]: np.savetxt('a.csv', a, fmt='%d', delimiter=',')
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19
20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39
40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59
60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79
80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
将csv文件中的数据读入到一个NumPy数组类型中
frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
dtype:数据类型,可选
delimiter:读取文件时解析分割字符串,默认是任何空格
unpack:默认False,读入数据写入一个数组,如果True,读入属性将分别写入不同的数组变量
In [174]: b = np.loadtxt('a.csv', delimiter=',')
In [175]: b
Out[175]:
array([[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12.,
13., 14., 15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32.,
33., 34., 35., 36., 37., 38., 39.],
[40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52.,
53., 54., 55., 56., 57., 58., 59.],
[60., 61., 62., 63., 64., 65., 66., 67., 68., 69., 70., 71., 72.,
73., 74., 75., 76., 77., 78., 79.],
[80., 81., 82., 83., 84., 85., 86., 87., 88., 89., 90., 91., 92.,
93., 94., 95., 96., 97., 98., 99.]])
In [177]: b = np.loadtxt('a.csv', dtype = np.int, delimiter=',')
In [178]: b
Out[178]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55,
56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75,
76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95,
96, 97, 98, 99]])
2、CSV文件的局限性
CSV只能有效存储一维和二维数组
np.savetxt() np.loadtxt()只能有效存取一维和二维数组
十、多维数据的存取
a.tofile(frame, sep='', format='%s')
frame:文件、字符串
sep:数据分割字符串,如果空串,写入文件为二进制
format:写入数据的格式
a = np.arange(100).reshape(5, 10, 2)
a.tofile("b.dat", sep=",", format='%d')
0,1,2,3,4,5,6,7,8,9,10,11,...,97,98,99
a.tofile("c.dat", format='%d') #生成一个二进制格式的文件
np.fromfile(frame, dtype=float, count=-1, sep='')
frame:文件、字符串
dtype:读取的数据类型
count:读入元素的个数,-1表示读入整个文件
sep:数据分割字符串,如果是空串,写入文件为二进制
In [185]: a = np.arange(100).reshape(5, 10, 2)
In [186]: a.tofile("b.dat", sep=",", format='%d')
In [187]: c = np.fromfile("b.dat", dtype=np.int, sep=",")
In [189]: c
Out[189]:
array([ 0, 1, 2, ..., 97, 98, 99])
In [190]: c = np.fromfile("b.dat", dtype=np.int, sep=",").reshape(5, 10, 2)
In [191]: c
Out[191]:
array([[[ 0, 1],
[ 2, 3],
[ 4, 5],
...,
[14, 15],
[16, 17],
[18, 19]],
...,
[[80, 81],
[82, 83],
[84, 85],
...,
[94, 95],
[96, 97],
[98, 99]]])
需要注意:
该方法需要读取时知道存入文件时数组的维度和元素类型
a.tofile()和np.fromfile()需要配合使用
可以通过元数据文件来存储额外信息
十一、NumPy的便捷文件存取
np.save(frame, array) 或 np.savez(frame, array)
frame:文件名,以.npy为扩展名,压缩扩展名为.npz
array:数组变量
np.load(frame)
frame:文件名,以.npy为扩展名,压缩扩展名为.npz
In [193]: a = np.arange(100).reshape(5, 10, 2)
In [194]: np.save("a.npy", a)
In [195]: b = np.load("a.npy")
In [196]: b
Out[196]:
array([[[ 0, 1],
[ 2, 3],
[ 4, 5],
...,
[14, 15],
[16, 17],
[18, 19]],
十二、NumPy的随机数函数
NumPy的随机数函数子库
NumPy的random子库
函数 说明
np.random.rand(d0,d1,...,dn) 根据d0-dn创建随机数数组,浮点数,(0,1),均匀分布
np.random.randn(d0,d1,...,dn) 根据d0-dn创建随机数数组,标准正态分布
np.random.randint(low[,high,shape]) 根据shape创建随机整数或整数数组,范围是[low,high)
np.random.seed(s) 随机数种子,s是给定的种子值
np.random.shuffle(a) 根据数组a的第1轴进行随机排列,改变数组a
np.random.permutation(a) 根据数组a的第1轴产生一个新的乱序数组,不改变数组a
np.random.choice(a[,size,replace,p]) 从一维数组a中以概率p抽取元素,形成size形状新数组,
replace表示是否可以重用元素,默认为True,可以重用
uniform(low,high,size) 产生具有均匀分布的数组,low起始值,high结束值,size形状
normal(loc,scale,size) 产生具有正态分布的数组,loc均值,scale标准差,size形状
poisson(lam,size) 产生具有泊松分布的数组,lam随机事件发生率,size形状
In [198]: a = np.random.rand(3,4,5)
In [199]: a
Out[199]:
array([[[0.25695399, 0.7414277 , 0.75578429, 0.19310308, 0.67073553],
[0.40860825, 0.87833836, 0.46472098, 0.27363694, 0.97506066],
[0.17151599, 0.99350022, 0.60626937, 0.06213282, 0.13644308],
[0.3423731 , 0.15678133, 0.50781854, 0.90444934, 0.7191749 ]],
[[0.11157493, 0.22870048, 0.09568974, 0.94895329, 0.45647719],
[0.75545089, 0.68920971, 0.18417572, 0.04961883, 0.91790802],
[0.10884808, 0.38779379, 0.22143459, 0.45260858, 0.13130334],
[0.26556801, 0.42261478, 0.75213859, 0.28198756, 0.23439392]],
[[0.89788109, 0.76425859, 0.59696053, 0.79930673, 0.06653449],
[0.52984697, 0.37876277, 0.49705969, 0.58775404, 0.19473995],
[0.22031894, 0.3149972 , 0.85039782, 0.75204237, 0.07445696],
[0.26473782, 0.0677433 , 0.06941957, 0.43275848, 0.80160242]]])
In [201]: sn = np.random.randn(3,4,5)
In [202]: sn
Out[202]:
array([[[ 2.02286682, 2.70028453, -0.30458721, 1.80112536,
2.56425348],
[ 0.89540378, -0.45617201, 0.25129778, 0.94339649,
1.24604689],
[ 0.63617271, 1.18732278, -0.73100707, -0.62808357,
-1.53297791],
[-0.57993511, 1.39707776, -1.48818092, 0.90367227,
0.71580174]],
[[ 0.2977844 , -0.04548221, -1.27468596, 1.82508362,
1.39596129],
[-0.10245882, 1.77133131, 0.82661614, -0.53814053,
0.14899324],
[-1.32498978, 0.09505347, -0.41875793, -0.0436812 ,
0.62526278],
[-1.05454191, 0.66238572, -0.42202814, -0.96410311,
-0.45992032]],
[[-1.76423287, -0.22951621, -1.980872 , -0.69703068,
-0.23453545],
[ 0.99584481, -0.8540858 , -1.00657854, -0.26568147,
0.41170017],
[-1.81470821, -0.01276362, 2.16593125, -1.15276026,
1.41373352],
[ 0.48657934, 0.23204144, -0.39321457, 0.93512204,
2.06393063]]])
In [204]: b = np.random.randint(100,200,(3,4))
In [205]: b
Out[205]:
array([[128, 172, 142, 121],
[132, 152, 161, 135],
[143, 116, 162, 197]])
In [207]: np.random.seed(10)
In [208]: np.random.randint(100, 200, (3,4))
Out[208]:
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
In [209]: np.random.seed(10)
In [210]: np.random.randint(100, 200, (3,4))
Out[210]:
array([[109, 115, 164, 128],
[189, 193, 129, 108],
[173, 100, 140, 136]])
In [215]: a = np.random.randint(100, 200, (3,4))
In [216]: a
Out[216]:
array([[169, 113, 125, 113],
[192, 186, 130, 130],
[189, 112, 165, 131]])
In [217]: np.random.shuffle(a)
In [218]: a
Out[218]:
array([[189, 112, 165, 131],
[169, 113, 125, 113],
[192, 186, 130, 130]])
In [219]: np.random.shuffle(a)
In [220]: a
Out[220]:
array([[189, 112, 165, 131],
[169, 113, 125, 113],
[192, 186, 130, 130]])
In [221]: np.random.shuffle(a)
In [222]: a
Out[222]:
array([[192, 186, 130, 130],
[189, 112, 165, 131],
[169, 113, 125, 113]])
In [224]: a = np.random.randint(100, 200, (3,4))
In [225]: a
Out[225]:
array([[123, 194, 111, 128],
[174, 188, 109, 115],
[118, 180, 171, 188]])
In [226]: np.random.permutation(a)
Out[226]:
array([[118, 180, 171, 188],
[123, 194, 111, 128],
[174, 188, 109, 115]])
In [227]: a
Out[227]:
array([[123, 194, 111, 128],
[174, 188, 109, 115],
[118, 180, 171, 188]])
In [229]: b = np.random.randint(100, 200, (8))
In [230]: b
Out[230]: array([107, 175, 128, 133, 184, 196, 188, 144])
In [231]: np.random.choice(b, (3,2))
Out[231]:
array([[196, 184],
[144, 107],
[107, 128]])
In [232]: np.random.choice(b, (3,2), replace=False)
Out[232]:
array([[196, 144],
[175, 133],
[107, 128]])
In [233]: np.random.choice(b, (3,2), p=b/np.sum(b))
Out[233]:
array([[188, 128],
[175, 188],
[196, 196]])
In [234]: import numpy as np
u = np.random.uniform(0, 10, (3,4))
u
Out [234]:
array([[0.19731535, 2.24206179, 7.88888337, 9.76770595],
[5.57983524, 6.39364798, 7.33151281, 9.44251086],
[6.04172762, 5.8557111 , 6.41668698, 8.12397351]])
In [235]: n = np.random.normal(10,5, (3,4))
n
Out [235]:
array([[ 6.38093695, 10.76986348, 1.97497678, -0.7020631 ],
[ 8.29740829, 11.34894364, 2.647922 , 11.10733215],
[ 8.28758304, 16.76092895, 10.34372967, 5.89904158]])
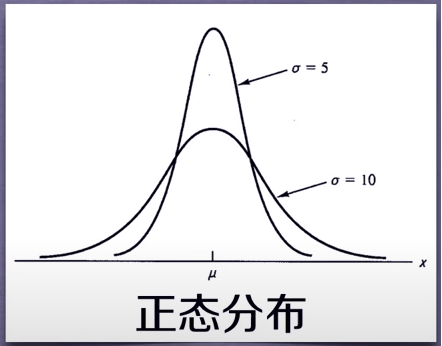
正态分布是围绕某一均值,在特定方差下,一种随机变量的取值的空间可能。
十三、NumPy的统计函
统计函数是对数组中的信息进行统计的函数。
NumPy直接提供的统计函数
np.*
np.std() np.var() np.average()
np.random的统计函数(1)
函数 说明
sum(a, axis=None) 根据给定轴axis计算数组a相关元素之和,axis整数或元组
mean(a, axis=None) 根据给定轴axis计算数组a相关元素的期望,axis整数或元组
average(a, axis=None, weights=None) 根据给定轴axis计算数组a相关元素的加权平均值
std(a, axis=None) 根据给定轴axis计算数组a相关元素的标准差
var(a, axis=None) 根据给定轴axis计算数组a相关元素的方差
axis=None是统计函数的标配参数,默认情况下可以不输入轴的参数,这就是对a中每一个元素
进行累加计算,如果给定了轴,就是对轴上的元素进行计算。
In [244]: import numpy as np
In [245]: a = np.arange(15).reshape(3,5)
In [246]: a
Out[246]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [247]: np.sum(a)
Out[247]: 105
In [248]: np.mean(a, axis=1)
Out[248]: array([ 2., 7., 12.])
In [249]: np.mean(a, axis=0)
Out[249]: array([5., 6., 7., 8., 9.])
In [250]: np.average(a, axis=0, weights=[10,5,1]) #weight 加权平均
Out[250]: array([2.1875, 3.1875, 4.1875, 5.1875, 6.1875]) # (2*10+7*5+1*12)/(10+5+1)=4.1875
In [251]: np.std(a)
Out[251]: 4.320493798938574
In [252]: np.var(a)
Out[252]: 18.666666666666668
np.random的统计函数(2)
函数 说明
min(a) max(a) 计算数组a中元素的最小值、最大值
argmin(a) argmax(a) 计算数组a中元素最小值、最大值的降一维后下标
unravel_index(index,shape) 根据shape将一维下标index转换成多维下标
ptp(a) 计算数组a中元素最大值与最小值的差
median(a) 计算数组a中元素的中位数(中值)
In [254]: b = np.arange(15, 0, -1).reshape(3, 5)
In [255]: b
Out[255]:
array([[15, 14, 13, 12, 11],
[10, 9, 8, 7, 6],
[ 5, 4, 3, 2, 1]])
In [256]: np.max(b)
Out[256]: 15
In [257]: np.argmax(b) #扁平化后的下标
Out[257]: 0
In [258]: np.unravel_index(np.argmax(b), b.shape) #重塑成多维下标
Out[258]: (0, 0)
In [259]: np.ptp(b)
Out[259]: 14
In [260]: np.median(b)
Out[260]: 8.0
十四、NumPy的梯度函数
np.random的梯度函数
函数 说明
np.gradient(f) 计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值之间的变化率,即斜率。
XY坐标轴连续三个X坐标对应的Y轴值:a,b,c,
其中,b的梯度是:(c-a)/2
In [268]: a = np.random.randint(0, 20, (5))
In [269]: a
Out[269]: array([9, 4, 6, 7, 8])
In [270]: np.gradient(a)
Out[270]: array([-5. , -1.5, 1.5, 1. , 1. ]) #1.5,存在两侧值:(7-4)/2;1,只有一侧值:(8-7)/1
In [271]: b = np.random.randint(0, 20, (5))
In [272]: b
Out[272]: array([ 4, 16, 13, 18, 7])
In [273]: np.gradient(b)
Out[273]: array([ 12. , 4.5, 1. , -3. , -11. ]) # 12,只有一侧值:(16-4)/1
In [275]: c = np.random.randint(0 ,50, (3,5))
In [276]: c
Out[276]:
array([[19, 44, 22, 34, 36],
[12, 5, 11, 1, 46],
[15, 12, 47, 23, 19]])
In [277]: np.gradient(c)
Out[277]:
[array([[ -7. , -39. , -11. , -33. , 10. ],
[ -2. , -16. , 12.5, -5.5, -8.5],
[ 3. , 7. , 36. , 22. , -27. ]]), #第一个数组表示元素在最外层维度的梯度
array([[ 25. , 1.5, -5. , 7. , 2. ],
[ -7. , -0.5, -2. , 17.5, 45. ],
[ -3. , 16. , 5.5, -14. , -4. ]])] #第二个数组表示元素在第二层维度的梯度
如果一个数组是n维的,那么gradient会生成n个数组,每个数组代表其中一个元素在第n维维度的梯度值。
梯度的作用?
梯度反应了元素的变化率,尤其是我们在进行图像,声音等批量数据处理的时候,梯度有助于我们发现
图像或声音的边缘,在那些不是变化很平缓的地方,通过梯度可以很容易的发现,所以在我们进行图像
处理,声音处理等多媒体运算的时候,gradient就会发挥很大的作用。
总结:数据存取与函数
CSV文件 多维数据存取
np.loadtxt() a.tofile()
np.savetxt() np.fromfile()
np.save()
np.savez()
np.load()
随机函数
np.random.rand() np.random.randn()
np.random.randint() np.random.seed()
np.random.shuffle() np.random.permutation()
np.random.choice()
NumPy的统计函数
np.sum() np.min()
np.mean() np.max()
np.average() np.argmin()
np.std() np.argmax()
np.var() np.unravel_index()
np.median() np.ptp()
NumPy的梯度函数
np.gradient()
十五、图像的数组表示
图像的RGB色彩模式:
图像一般使用RGB色彩模式,即每个像素点的颜色由红(R)、绿(G)、蓝(B)组成。
RGB三个颜色通道的变化和叠加得到各种颜色,其中
R红色,取值范围,0-255
G绿色,取值范围,0-255
B蓝色,取值范围,0-255
PIL库
PIL,Python Image Library
PIL库是一个具有强大图像处理能力的第三方库
在命令行下的安装方法:pip install pillow
from PIL import Image
Image是PIL库中代表一个图像的类(对象)
在计算机中,图像怎么表示的呢?
图像其实是一个由像素组成的二维矩阵,每个元素是一个RGB值。
可以把图像表示成一个XY轴的图像的像素阵列,其中每一个像素是一个RGB值,
RGB中的每一个是一个字节,所以一个图像就是由3个字节作为元素,形成的一个二维矩阵。
如何表示图像?
可以使用NumPy的数组来表示图像。
In [280]: from PIL import Image
In [281]: import numpy as np
In [282]: im = np.array(Image.open("Lenna_(test_image).png"))
In [283]: im.shape
Out[283]: (512, 512, 3)
In [284]: im.dtype
Out[284]: dtype('uint8')
图像是一个三维数组,维度分别是图像的高度、宽度和像素的RGB值。而在
第三维度的RGB值上,有三个元素,R、G、B分别由一个uint8类型来表示。
图像的变换
a、因为图像是可以表示为数组的,数组又是可以运算的,经过运算后的数组就可以
改变图像的形状,对图像进行变换。
b、图像变换的基本流程
读入图像后,并且将读入的图像变成一种数组,
然后形成像素的RGB值的一种数组表示,修改后保存为新的文件。
变换示例1:
In [290]: from PIL import Image
In [291]: import numpy as np
#将文件中的图像变成一个数组a,它是三维数组,它的三个维度
分别是图像的高度、宽度以及每一个像素的RGB值。
In [292]: a = np.array(Image.open("Lenna_(test_image).png"))
In [293]: a.shape
Out[293]: (512, 512, 3)
In [294]: a.dtype
Out[294]: dtype('uint8')
#将图片的每一个像素去计算RGB三个通道的补值
In [295]: b = [255, 255, 255] - a
#fromarray()将数组b重新生成一个图像对象
In [296]: im = Image.fromarray(b.astype('uint8'))
#保存新图像
In [297]: im.save("Lenna_(test_image)-1.png")
 |
 |
变换示例2:
#convert('L')是将一个彩色图片变成为一个灰度值的图片
#此时a不再是一个三维数组,而是一个二维数组
#数组中的每一个元素并不对应RGB的一个值而是对应一个灰度值
In [305]: a = np.array(Image.open("Lenna_(test_image).png").convert('L'))
In [306]: b = 255 - a
In [307]: im = Image.fromarray(b.astype('uint8'))
In [308]: im.save("Lenna_(test_image)-2.png")
 |
 |
变换示例3:
In [316]: a = np.array(Image.open("Lenna_(test_image).png").convert('L'))
#a*(100/255):把当前图片的灰度值做一个区间压缩
#+150扩充一个区间范围
In [317]: c = (100/255)*a + 150 #区间变换
In [318]: im = Image.fromarray(c.astype('uint8'))
In [319]: im.save("Lenna_(test_image)-3.png")
 |
 |
变换示例4:
In [323]: a = np.array(Image.open("Lenna_(test_image).png").convert('L'))
In [324]: d = 255 * (a/255)**2 #像素平方
In [325]: im = Image.fromarray(d.astype('uint8'))
In [326]: im.save("Lenna_(test_image)-4.png")
 |
 |
“图像的手绘效果”实例分析
手绘效果的几个特征:
a、黑白灰色
b、边界线条较重
c、相同或相近色彩趋于白色
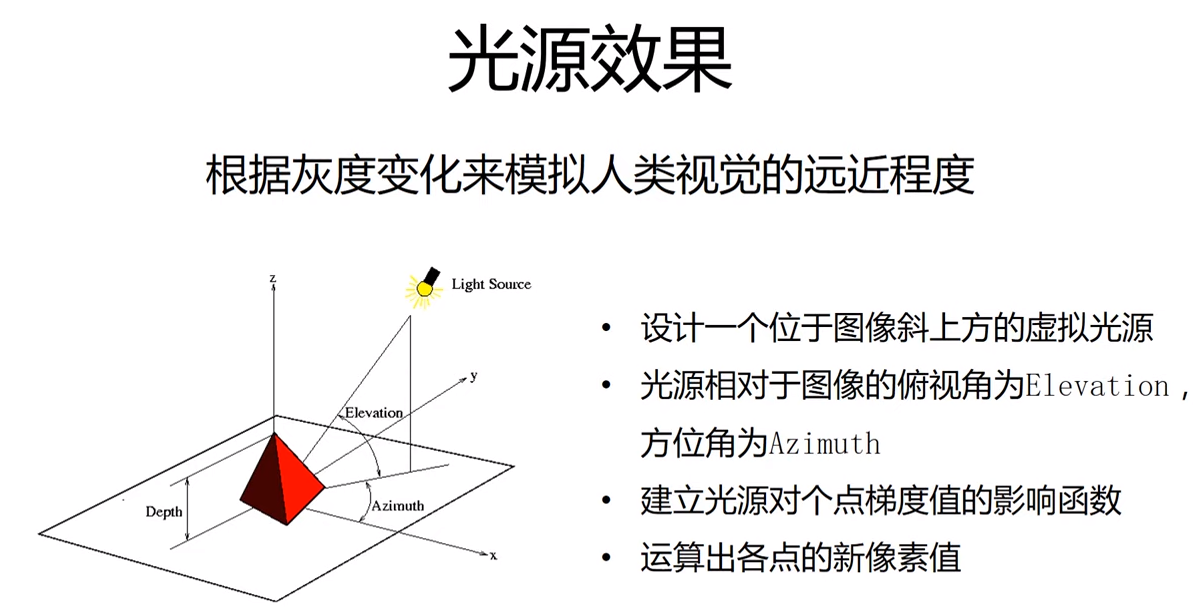
d、略有光源效果
“图像的手绘效果”代码
1、

2、
3、

4、

5、

from PIL import Image
import numpy as np
a = np.asarray(Image.open("Lenna_(test_image).png").convert('L')).astype('float')
depth = 10. #(0-100)
grad = np.gradient(a) #取图像灰度的梯度值
grad_x,grad_y = grad #分别取横纵图像梯度值
grad_x = grad_x * depth/100.
grad_y = grad_y * depth/100.
A = np.sqrt(grad_x **2 + grad_y **2 +1.)
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
vec_el = np.pi/2.2 #光源的俯视角度,弧度制
vec_az = np.pi/4. #光源的方位角度,弧度制
dx = np.cos(vec_el)*np.cos(vec_az) #光源对X轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对Y轴的影响
dz = np.sin(vec_el) #光源对Z轴的影响
b = 255*(dx*uni_x + dy*uni_y + dz*uni_z) #光源归一化
b = b.clip(0, 255)
im = Image.fromarray(b.astype('uint8')) #重构图像
im.save("Lenna_(test_image-5).png")
 |
 |
posted on 2020-06-26 21:36 pencil2001 阅读(144) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号