
学习笔记之Data Science
Data science - Wikipedia
- https://en.wikipedia.org/wiki/Data_science
- Data science, also known as data-driven science, is an interdisciplinary field of scientific methods, processes, algorithms and systems to extract knowledge or insights from data in various forms, either structured or unstructured, similar to data mining.
数据学和数据科学_百度百科
- https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E5%AD%A6%E5%92%8C%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6/3565373?fr=aladdin
- 数据学(Dataology)和数据科学(DataScience)是关于数据的科学,定义为研究探索Cyberspace中数据界奥秘的理论、方法和技术。
- 主要有两个内涵:一个是研究数据本身;另一个是为自然科学和社会科学研究提供一种新方法,称为科学研究的数据方法。
面试总结之Data Science - 浩然119 - 博客园 (cnblogs.com)
ETL v.s. ELT
- Extract, transform, load - Wikipedia
- In computing, extract, transform, load (ETL) is the general procedure of copying data from one or more sources into a destination system which represents the data differently from the source(s) or in a different context than the source(s). The ETL process became a popular concept in the 1970s and is often used in data warehousing.[1]
- Data extraction involves extracting data from homogeneous or heterogeneous sources; data transformation processes data by data cleaning and transforming them into a proper storage format/structure for the purposes of querying and analysis; finally, data loading describes the insertion of data into the final target database such as an operational data store, a data mart, data lake or a data warehouse.[2][3]
- A properly designed ETL system extracts data from the source systems, enforces data quality and consistency standards, conforms data so that separate sources can be used together, and finally delivers data in a presentation-ready format so that application developers can build applications and end users can make decisions.[4]
- Since the data extraction takes time, it is common to execute the three phases in pipeline. While the data is being extracted, another transformation process executes while processing the data already received and prepares it for loading while the data loading begins without waiting for the completion of the previous phases.
- ETL systems commonly integrate data from multiple applications (systems), typically developed and supported by different vendors or hosted on separate computer hardware. The separate systems containing the original data are frequently managed and operated by different employees. For example, a cost accounting system may combine data from payroll, sales, and purchasing.
- Extract, load, transform - Wikipedia
- Extract, load, transform (ELT) is an alternative to extract, transform, load (ETL) used with data lake implementations. In contrast to ETL, in ELT models the data is not transformed on entry to the data lake, but stored in its original raw format. This enables faster loading times. However, ELT requires sufficient processing power within the data processing engine to carry out the transformation on demand, to return the results in a timely manner. Since the data is not processed on entry to the data lake, the query and schema do not need to be defined a priori (although often the schema will be available during load since many data sources are extracts from databases or similar structured data systems and hence have an associated schema). ELT is a data pipeline model.[1]
- Data lake - Wikipedia
- A data lake is a system or repository of data stored in its natural/raw format,[1] usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc.,[2] and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).[3] A data lake can be established "on premises" (within an organization's data centers) or "in the cloud" (using cloud services from vendors such as Amazon, Microsoft, or Google).
- A data swamp is a deteriorated and unmanaged data lake that is either inaccessible to its intended users or is providing little value.[4]
ETL vs ELT: Key Differences, Side-by-Side Comparisons, & Use Cases (rivery.io)
什么是数据仓库?什么是数据湖?什么是智能湖仓? (qq.com)
什么是数据科学?数据科学的基本内容 - CSDN博客
- https://blog.csdn.net/op07p6aaqo9u71/article/details/78373737
- 什么是数据科学?它和已有的信息科学、统计学、机器学习等学科有什么不同?作为一门新兴的学科,数据科学依赖两个因素:一是数据的广泛性和多样性;二是数据研究的共性。现代社会的各行各业都充满了数据,这些数据的类型多种多样,不仅包括传统的结构化数据,也包括网页、文本、图像、视频、语音等非结构化数据。数据分析本质上都是在解反问题,而且通常是随机模型的反问题,因此对它们的研究有很多共性。例如,自然语言处理和生物大分子模型都用到隐马尔科夫过程和动态规划方法,其最根本的原因是它们处理的都是一维随机信号;再如,图像处理和统计学习中都用到的正则化方法,也是处理反问题的数学模型中最常用的一种。
- 数据科学主要包括两个方面:用数据的方法研究科学和用科学的方法研究数据。前者包括生物信息学、天体信息学、数字地球等领域;后者包括统计学、机器学习、数据挖掘、数据库等领域。这些学科都是数据科学的重要组成部分,只有把它们有机地整合在一起,才能形成整个数据科学的全貌。
学习笔记之入行数据科学,这些书一定要看 - 浩然119 - 博客园
- https://www.cnblogs.com/pegasus923/p/9591291.html
- https://mp.weixin.qq.com/s/m_HyN47zsBsfW84Y5HjNFg
- https://anvaka.github.io/greview/hands-on-ml/1/
Python数据科学超强阵容书单 - Python编程
- https://mp.weixin.qq.com/s/gmaCGWzF3KzX3hmTlua2Zw
- 1. 为什么数据科学青睐 Python?
- 2. 那么,简单回顾一下常用的 Python 库。
- 核心库
- NumPy
- Pandas
- SciPy
- 绘图以及可视化
- Matplotlib
- Seaborn
- 机器学习
- Scikit-Learn
- TensorFlow
- 核心库
- 3. 数据科学三剑客
- 《Python数据科学手册》
- 《数据科学入门》
- 《数据科学实战》
数据科学 20 个最好的 Python 库 - 数据分析与开发
- https://mp.weixin.qq.com/s/x2Zk-O7oeFvqmSw0QMqc8w
- 核心库和统计数据
- 1. NumPy (Commits: 17911, Contributors: 641)
- 2. SciPy (Commits: 19150, Contributors: 608)
- 3. Pandas (Commits: 17144, Contributors: 1165)
- 4. StatsModels (Commits: 10067, Contributors: 153)
- 可视化
- 5. Matplotlib (Commits: 25747, Contributors: 725)
- 6. Seaborn (Commits: 2044, Contributors: 83)
- 7. Plotly (Commits: 2906, Contributors: 48)
- 8. Bokeh (Commits: 16983, Contributors: 294)
- 9. Pydot (Commits: 169, Contributors: 12)
- 机器学习
- 10. Scikit-learn (Commits: 22753, Contributors: 1084)
- 11. XGBoost / LightGBM / CatBoost (Commits: 3277 / 1083 / 1509, Contributors: 280 / 79 / 61)
- 12. Eli5 (Commits: 922, Contributors: 6)
- 深度学习
- 13. TensorFlow (Commits: 33339, Contributors: 1469)
- 14. PyTorch (Commits: 11306, Contributors: 635)
- 15. Keras (Commits: 4539, Contributors: 671)
- 分布式深度学习
- 16. Dist-keras / elephas / spark-deep-learning (Commits: 1125 / 170 / 67, Contributors: 5 / 13 / 11)
- 自然语言处理
- 17. NLTK (Commits: 13041, Contributors: 236)
- 18. SpaCy (Commits: 8623, Contributors: 215)
- 19. Gensim (Commits: 3603, Contributors: 273)
- 数据采集
- 20. Scrapy (Commits: 6625, Contributors: 281)
资源|超全数据科学速查工具手册
数据科学入门数学指南
- https://mp.weixin.qq.com/s/Ht-u_ZN4jb9zutOuAk978g
- https://www.dataquest.io/blog/math-in-data-science/
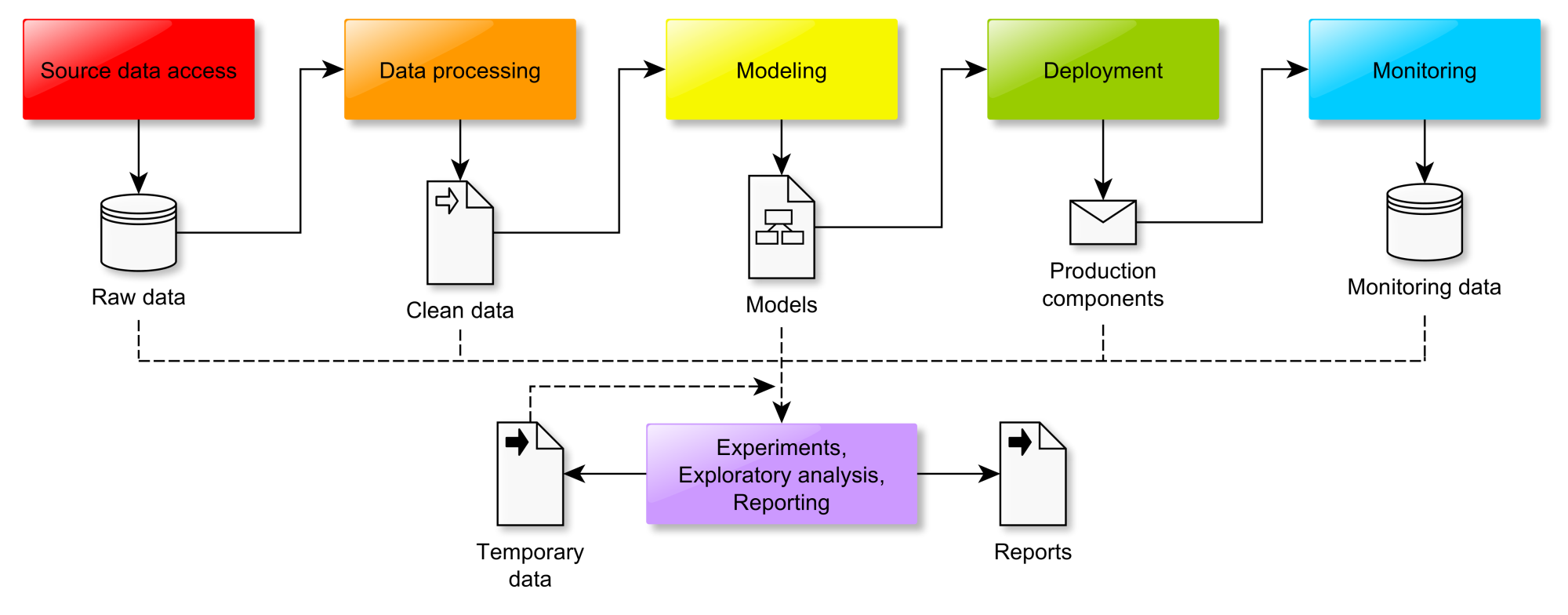
BEST PRACTICE
数据科学中必须熟知的5种聚类算法 - 机器学习算法与自然语言处理
- https://mp.weixin.qq.com/s/6jfE2kAjjeSXTS1US7_ktw
- 聚类算法是机器学习中涉及对数据进行分组的一种算法,本文详尽的介绍了5种常用的聚类算法。
数据科学中的6个基本算法,掌握它们要学习哪些知识
Command Line Tricks For Data Scientists - 人工智能爱好者社区
- https://mp.weixin.qq.com/s/B-7ORQDBXAf0YlZhaBTIUQ
- https://www.oschina.net/translate/cli-4-ds
- https://kadekillary.work/post/cli-4-ds/
盘一盘 Python 系列 3 - SciPy
数据科学家常犯的 10 个编程错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号