Lecture 5 -- 各式各样的Self-Attention
1. How to make self-attention efficent?
当我们的输入序列非常长时,self-attention会主导整个网络的计算!
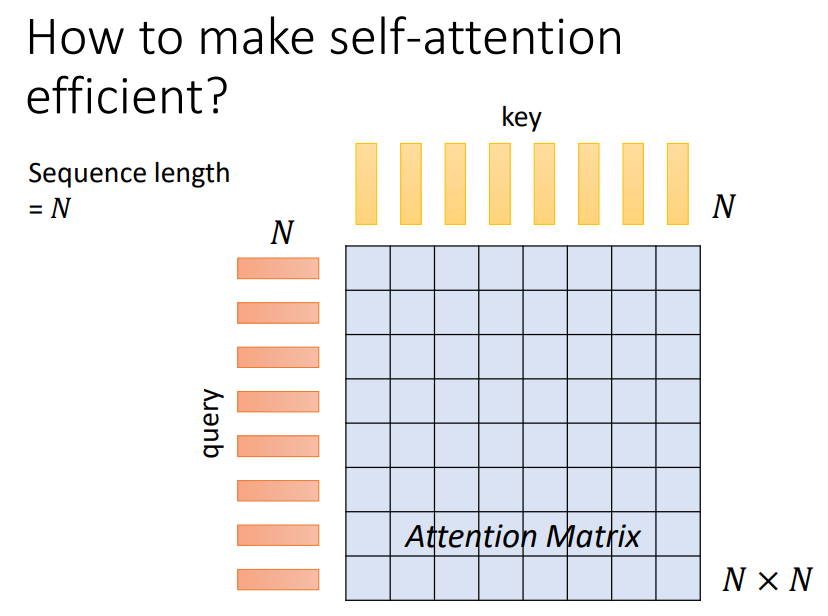
方式一:Local Attention / Truncated Attention

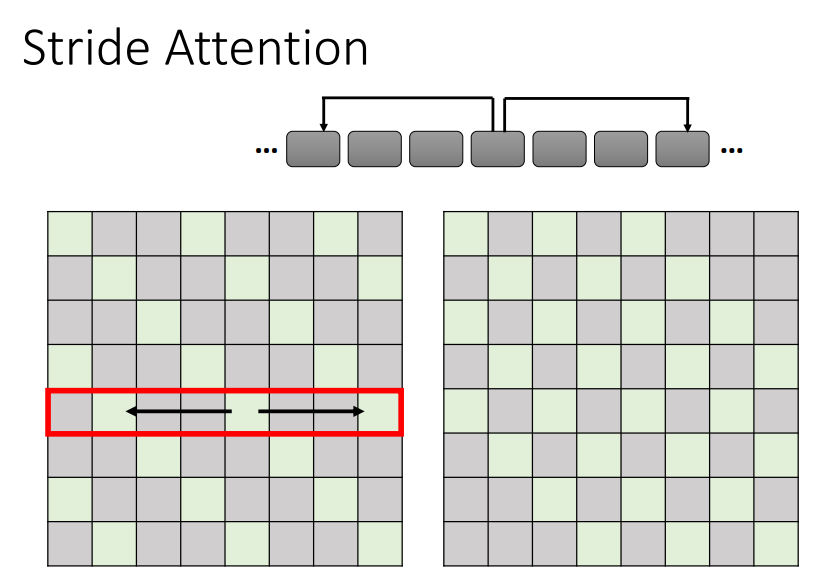
方式二:Stride Attention
方式三:Global Attention
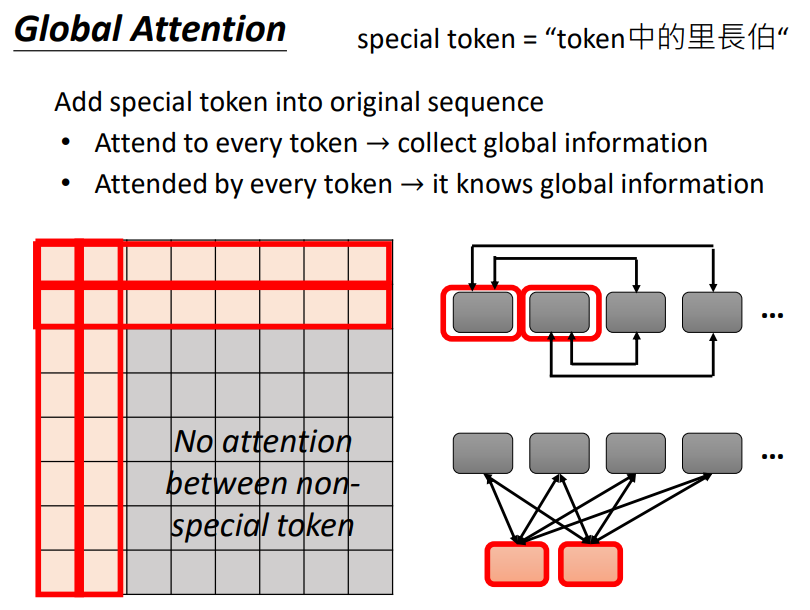
以上三种方式可以同时使用,不同的头使用不同的Attention Matrix处理方式!
2. Can we only focus on Critical Parts?
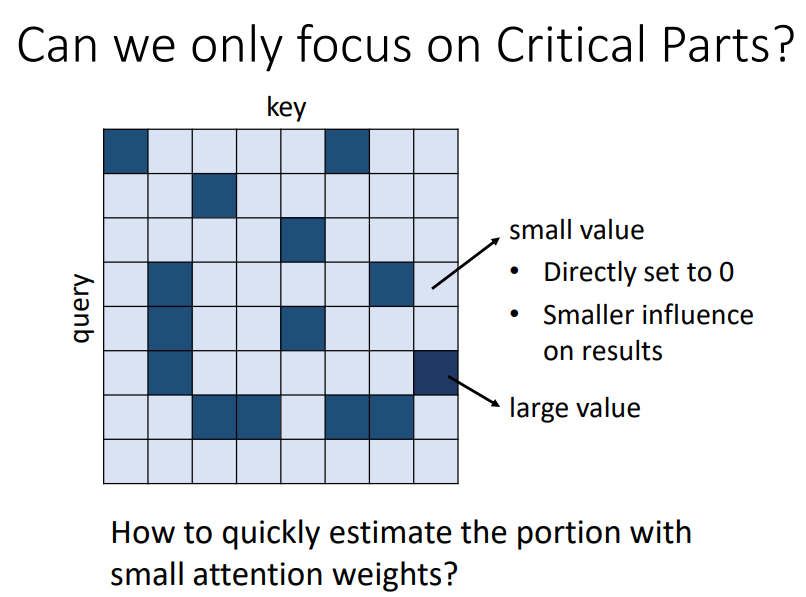
我们是否可以只关注Attention Matrix中数值比较大的相关关系,而数值比较小的相关关系我们直接将其设定为0,不进行计算?
我们如何找到这些重要的部分进行计算?
方式一:Clustering
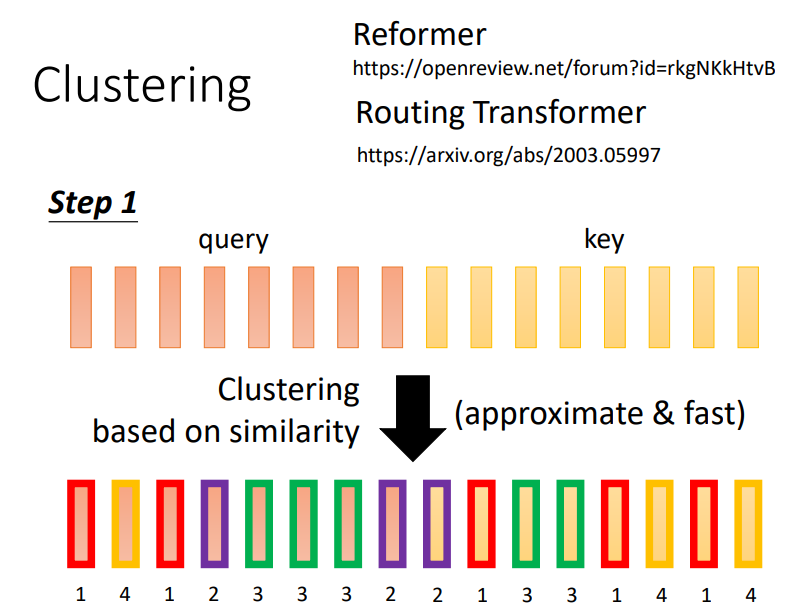
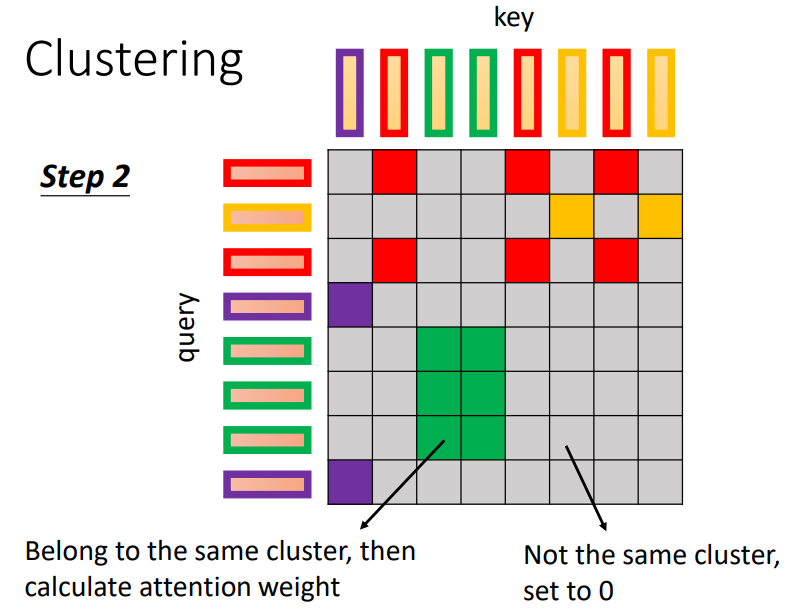
方式二:Learnable Patterns
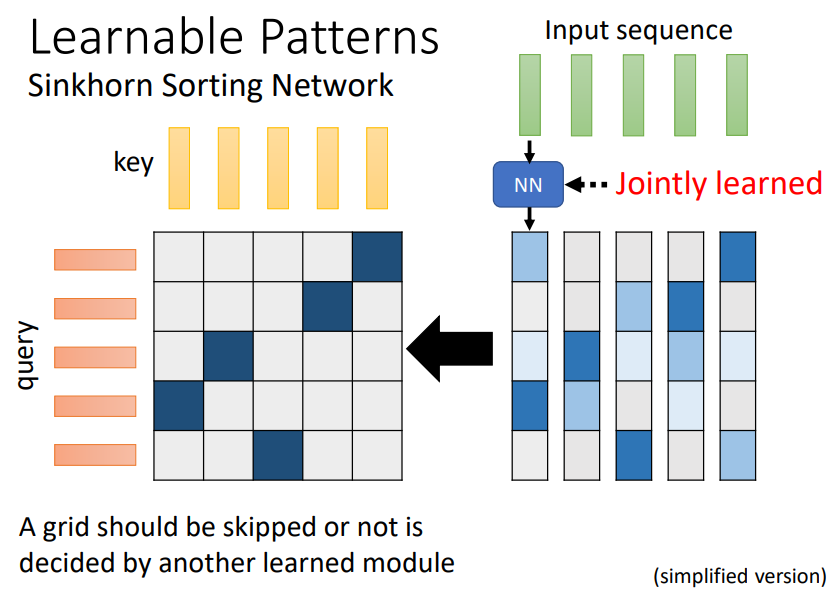
根据输入设计一个模组,决定哪些query和key之间需要计算inner-product!
这个模组是整个网络的一部分,可以跟随整个网络进行训练!
3. Do we need full attention matrix?

方式一:Reduce Number of Keys

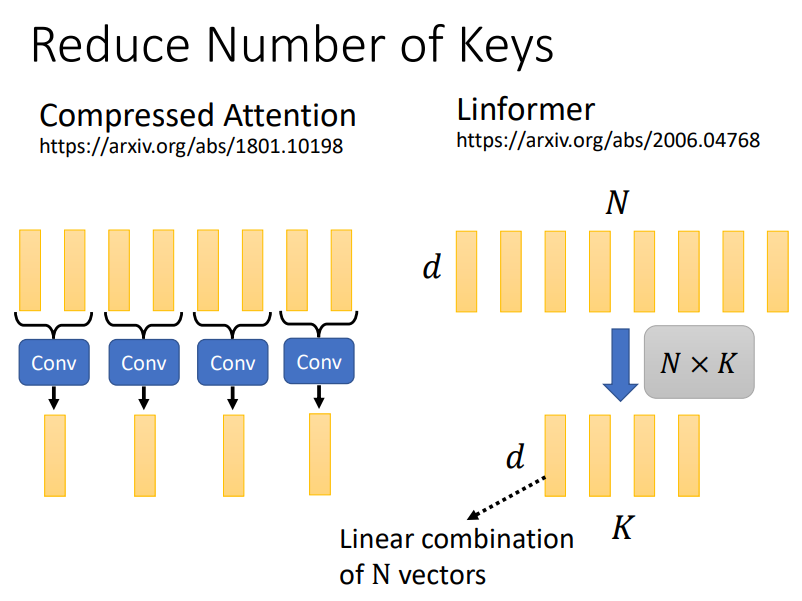
我们可以通过一个卷积神经网络对key的数量进行压缩,或者直接对所有的key进行linear combination!
4. A new view of self-attention
Review:
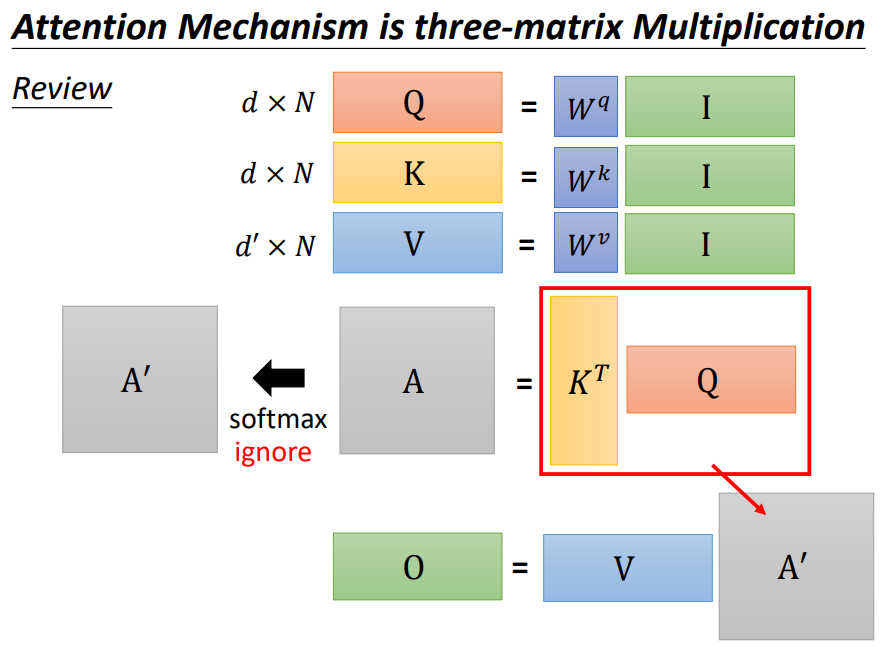
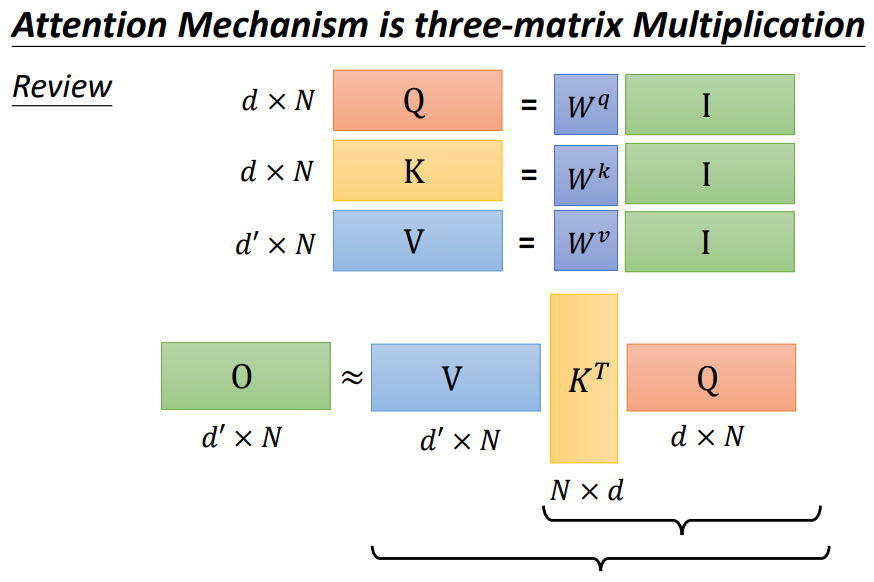
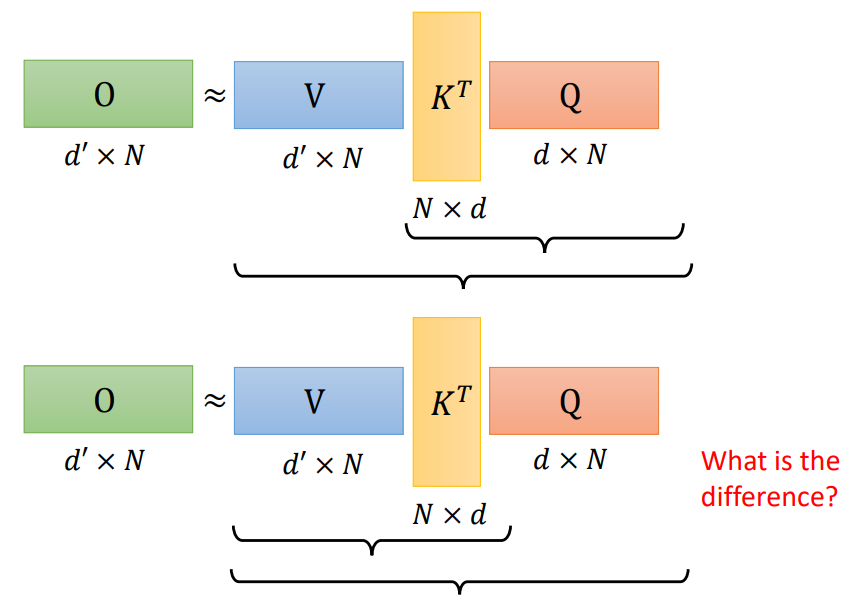
一个self-attention运算加速的方式:先计算VKT!和先计算KTQ有什么区别?需要做的乘法运算数目不同!
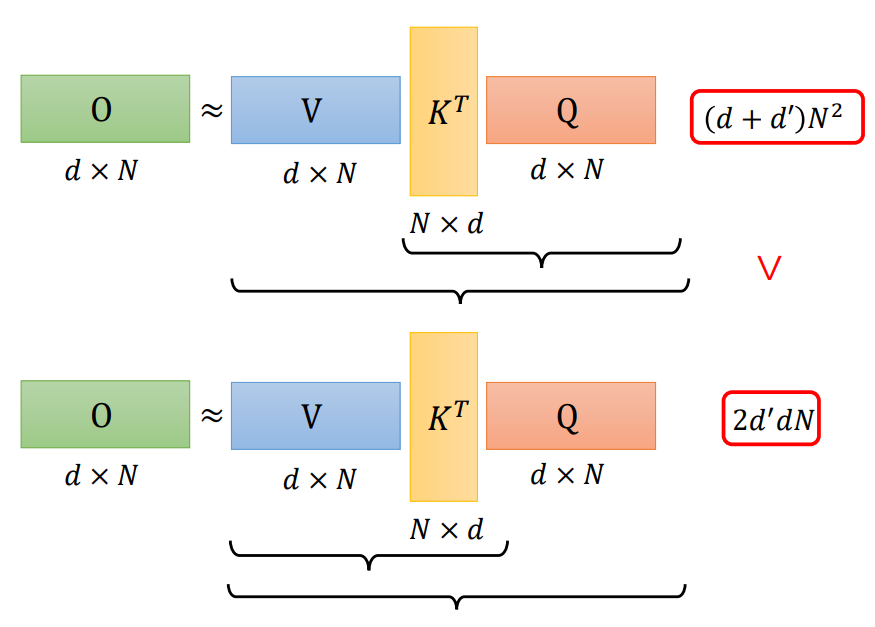
A new view (qk first -- kv first):
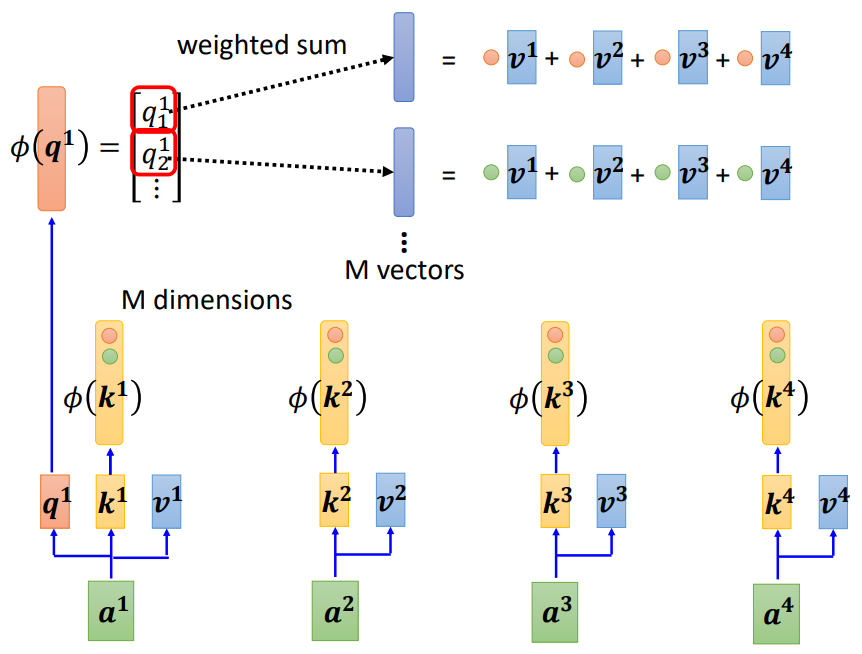
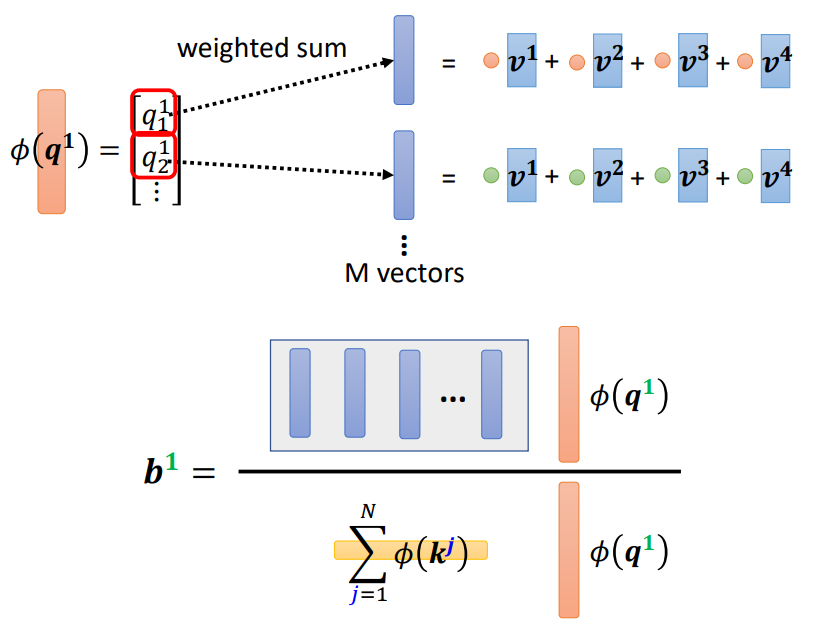
求b1:
首先是k和v进行联动,得到一堆向量,数量与k1的维度一致;
接着是对这堆向量进行线性组合,线性组合的系数是Φ(q1) -- 结果作为分子;
最后是Φ(q1)和所有的Φ(k)求内积并加和 -- 结果作为分母;
分子/分母即为结果b1
理论基础:
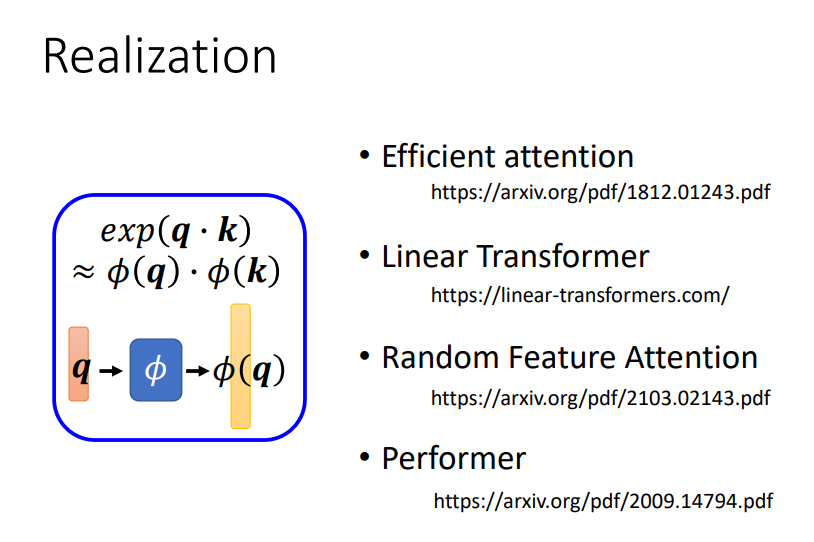
关键是确定Φ的样子!
5. Attention free? new framework!

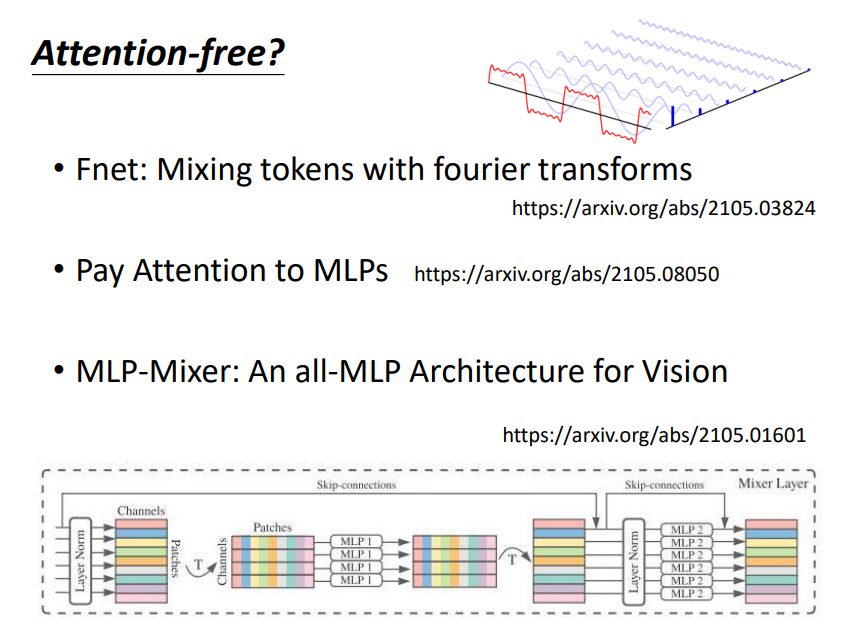
Attention matrix不一定要由q和k计算而来,可以作为网络的参数进行学习!
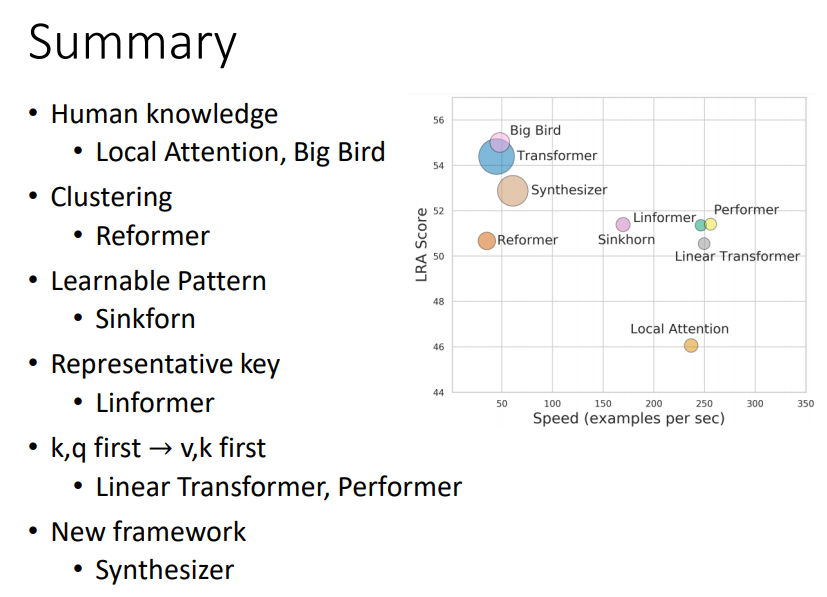
6. Summary
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号