Lecture 4 -- Self-Attention
1. 一堆Vector作为Input
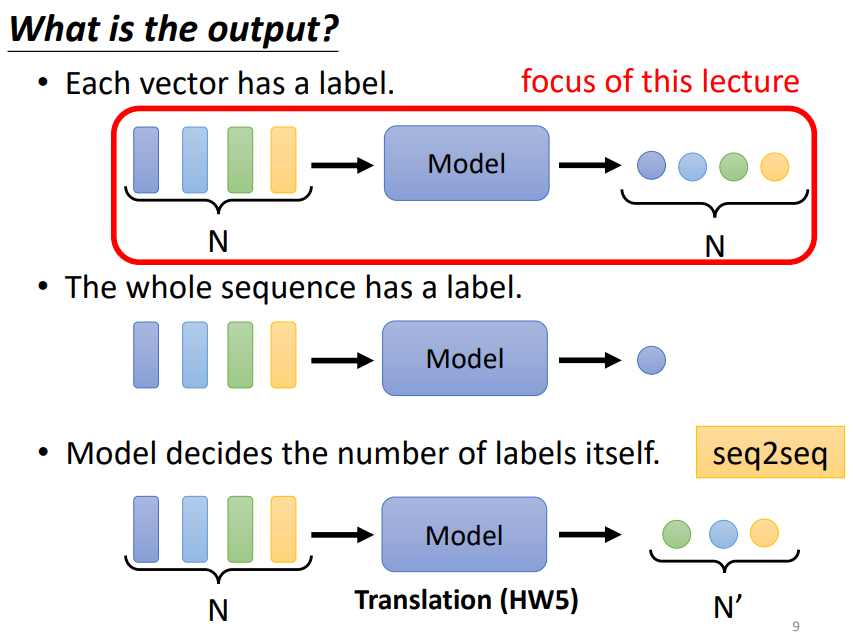
当模型以一堆的向量作为输入时,输出可以是与输入长度相同的一堆向量(focus of this lecture),可以是与输入长度不相同的一堆向量(seq2seq),也可以是一个向量!
2. 为什么要用Self-Attention?
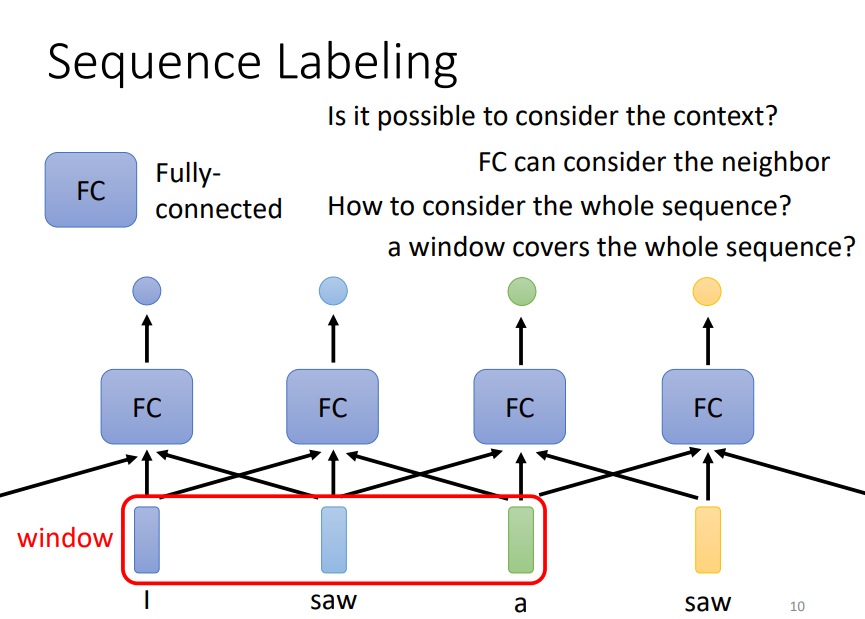
以一个词性标注的任务为例,假如我们要对“I saw a saw”这个句子中的每一个单词做词性标记,很明显,第一个saw为动词,第二个saw为名词,如果我们将每一个词都传入一个全连接层得到输出结果,那么对于全连接层来说,两个saw没有本质上的区别,也就是说,此时全连接层无法捕捉上下文信息。那么我们如何有效的让模型能够理解两个saw的词性不同呢?常见的做法是在判断某个词的词性时,我们将它前面的N个词和后面的N个词一并传入到全连接层中,也就是我们以该词为中心,开一个“窗口”,将这个“窗口”中的所有词都传入全连接层就可以了。但是,如果我们今天一个完整的句子长度非常长,并且我们想要考虑整个句子的语义信息,那么我们就要把“窗口”开的非常大,这就会导致全连接层的参数量暴增,这显然不是一个很好的办法。Self-Attention就可以帮助我们以较少的参数量考虑整个句子的语义信息,进而做出有效的判断!
由下图可以看到,当我们把一堆向量传入Self-Attention时,它会输出相同数量的一堆向量!
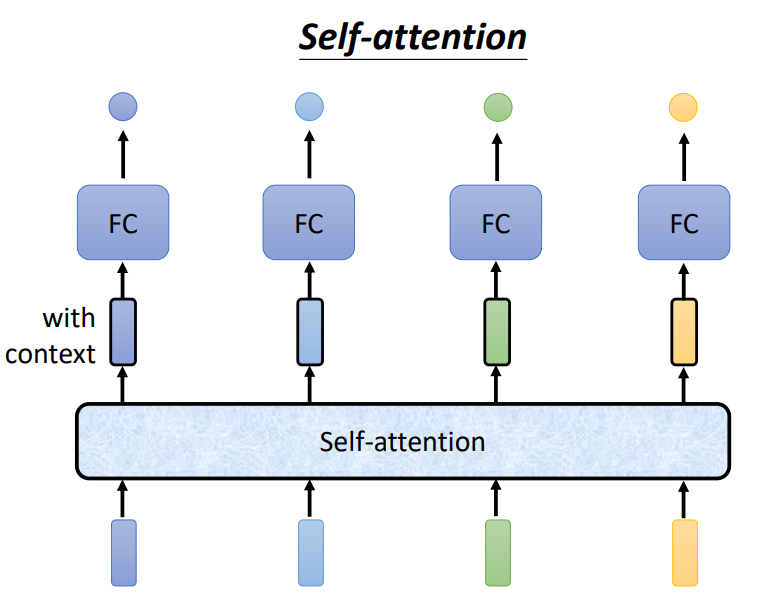
那么,Self-Attention内部究竟是如何工作的呢?
3. Self-Attention是如何工作的?⭐
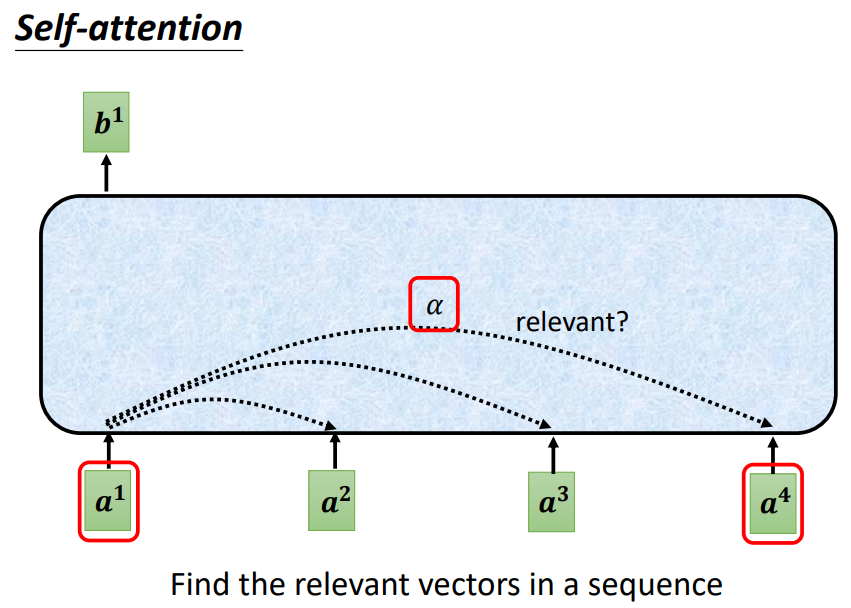
Self-Attention的关键是计算某一个词与周围所有词(包括自己)之间的相关性,这种计算相关性的方式主要有两种:Dot-product(主)和Additive,如下图。
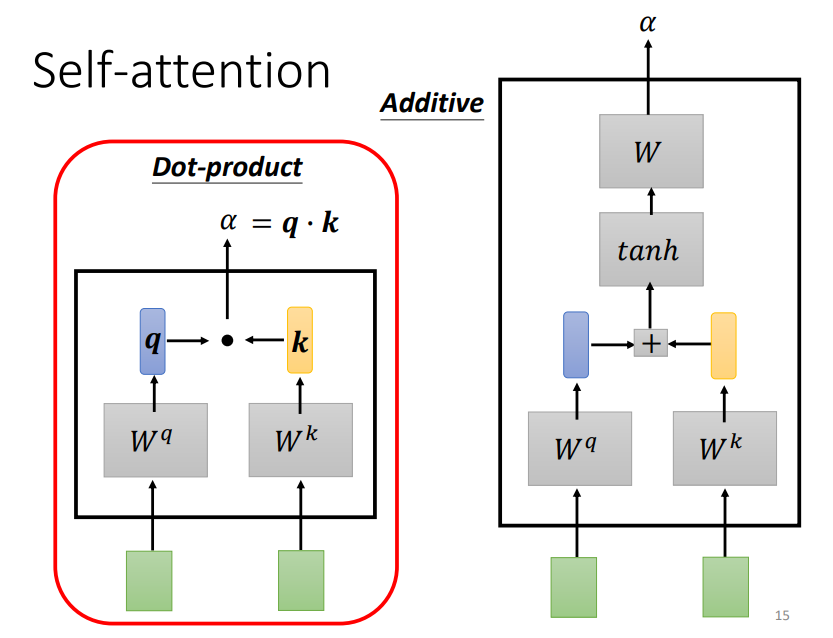
具体而言,就是每一个词都会和Wq和Wk矩阵相乘产生q和k向量,如果要计算某一个词与周围所有词之间的关系时,我们只需要将该词产生的q向量与其他所有词(包括自己)产生的k向量做内积,并通过一个softmax层(这里用softmax并没有什么道理而言,当然也可以尝试用ReLU或者其他激活函数,或许会有更好的结果)即可,这里的相关性又称为Attention score!
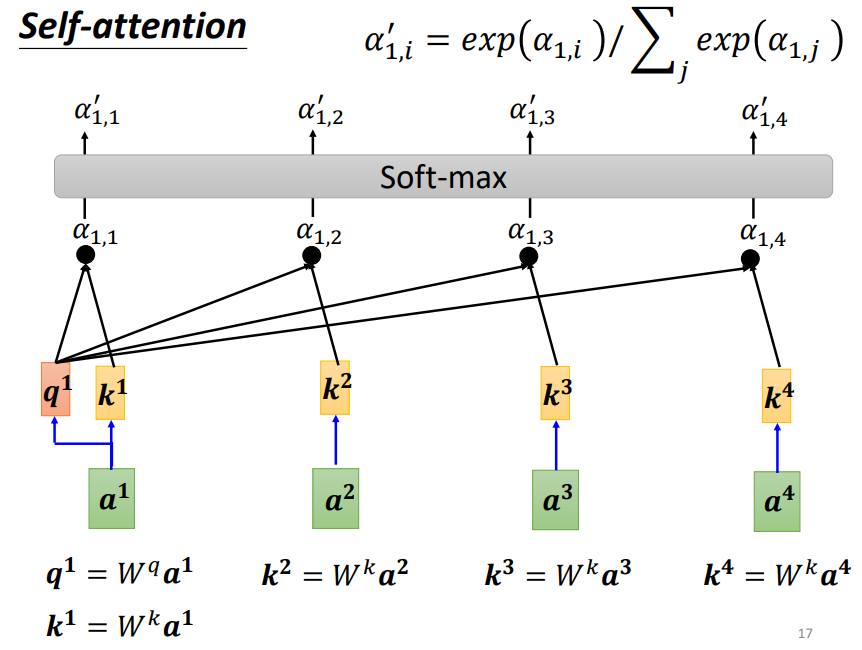
如上图,我们得到了a1与其他所有词(包括自己)的相关性(Attention score),我们接下来如何产生最终的输出呢?
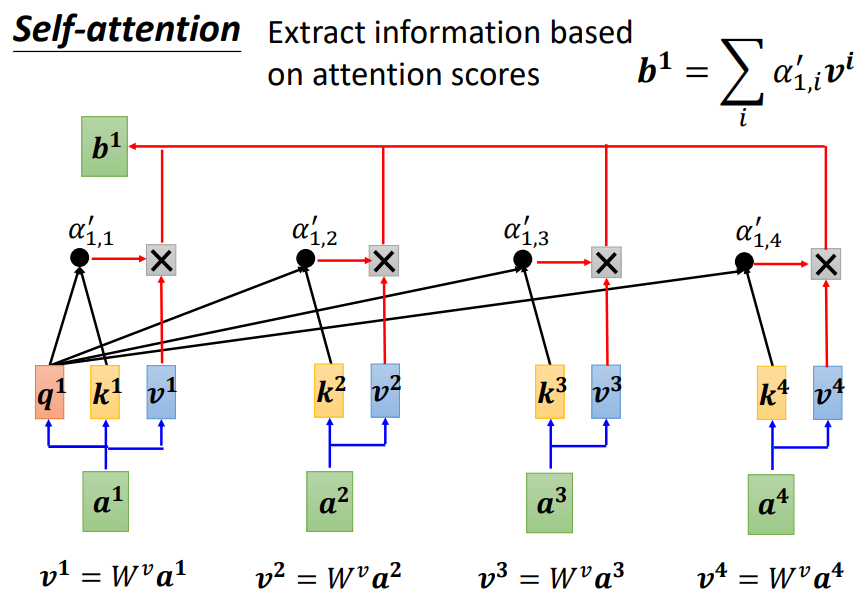
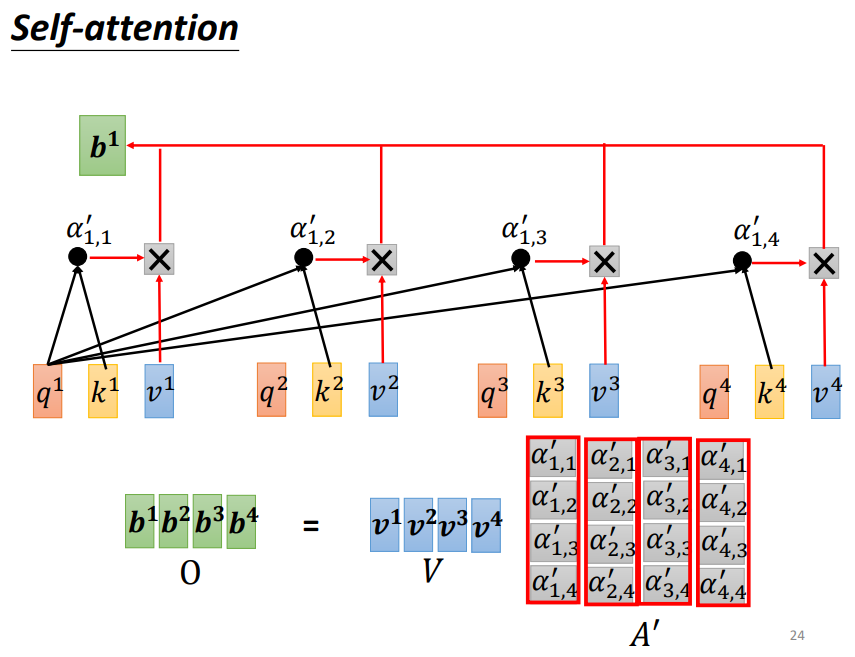
实际上,每一个输入的词还会与Wv矩阵相乘得到v向量,这些v向量与Attention score依次相乘再相加即可得到a1的输出结果b1
值得关注的是,这些输出向量并不是一个一个产生的,而是平行产生的,接下来我们来看看如何向量化表示这个过程。
4. Self-Attention的向量化表示⭐
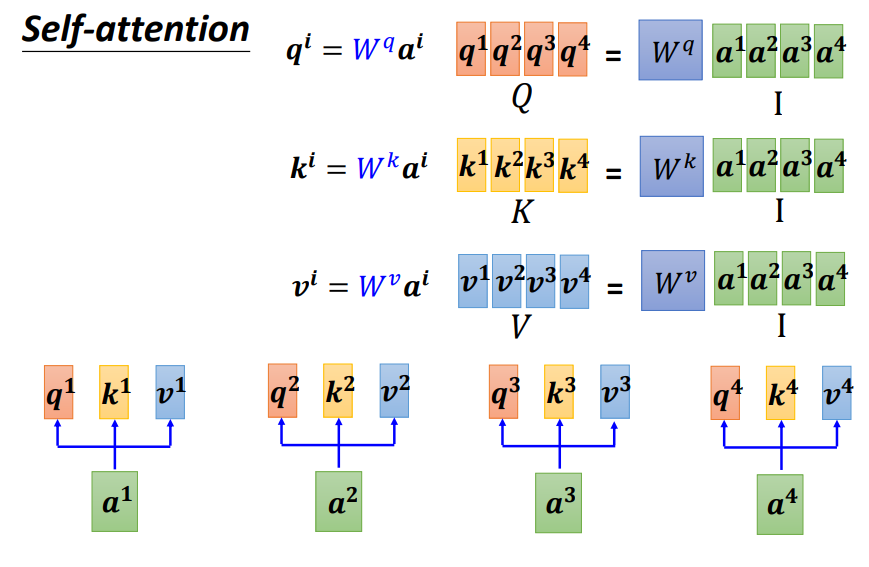
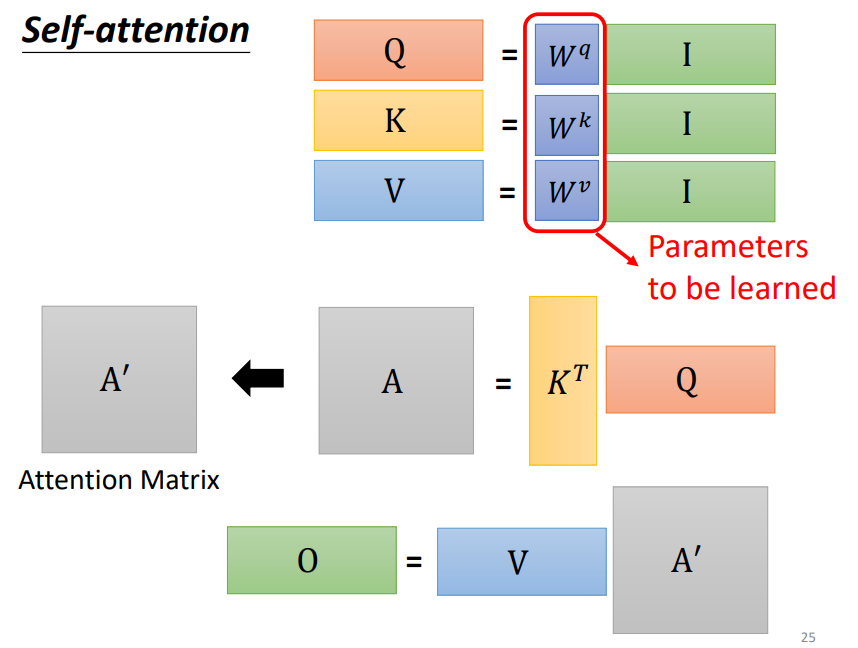
如上图,首先得到Q,K,V三个矩阵,需要注意的是:Wq Wk Wv是Self-Attention中仅有的需要学习的参数!
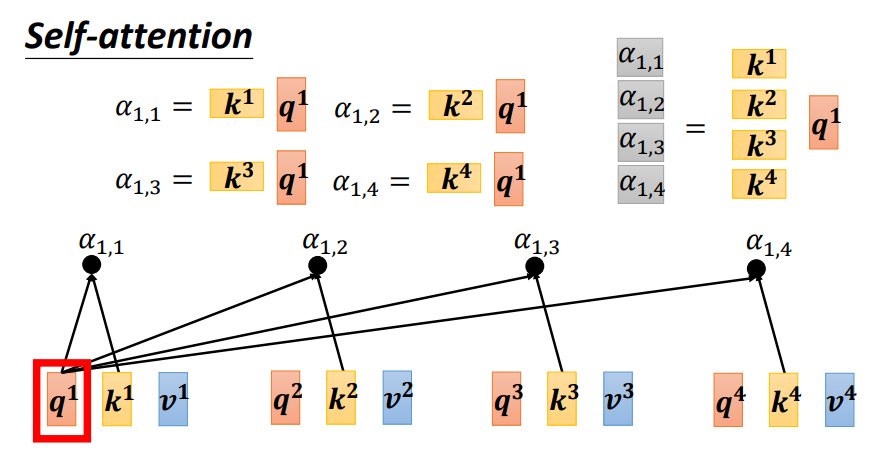
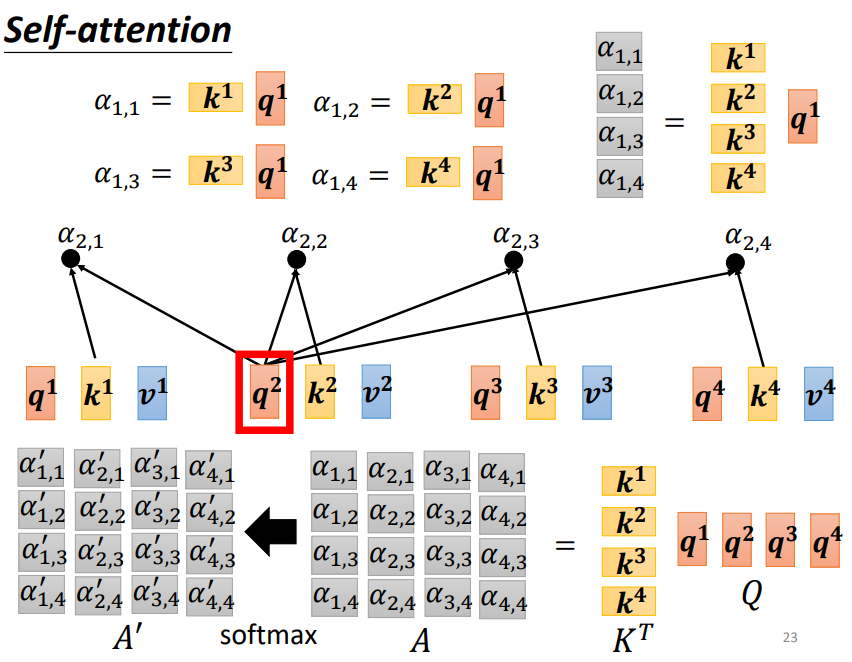
如上图和下图,接着计算Attention score矩阵(KTQ),Attention score矩阵(A矩阵)是一个方阵,其每一列都要经过softmax层,第一列为第一个词与其他所有词之间的Attention score,第二列为第二个词与其他所有词之间的Attention score,以此类推...
如下图,最后我们只需要将A方阵前面乘上V矩阵,即可得到最终的输出结果O矩阵,整个过程都是在做矩阵运算,因此输出结果是平行产生的!
让我们来通览以下该过程👇
5. Multi-head Self-attention⭐

在原先qkv的头上产生多组qkv,以捕捉不同的相关关系!
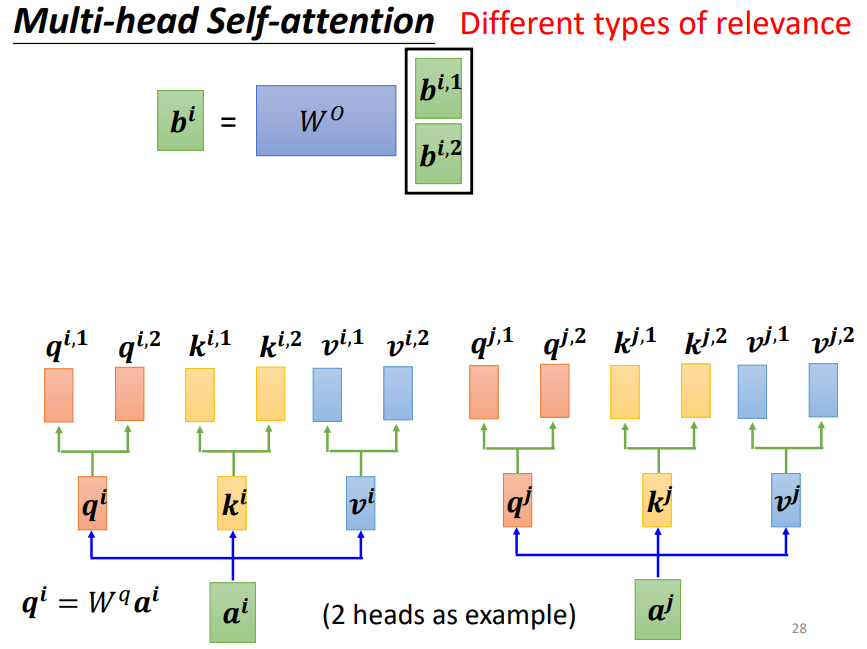
最后将这两种相关关系输出的结果concat起来,通过Wo矩阵产生多头自注意力机制的输出!
5. Shortcoming & Positional Encoding
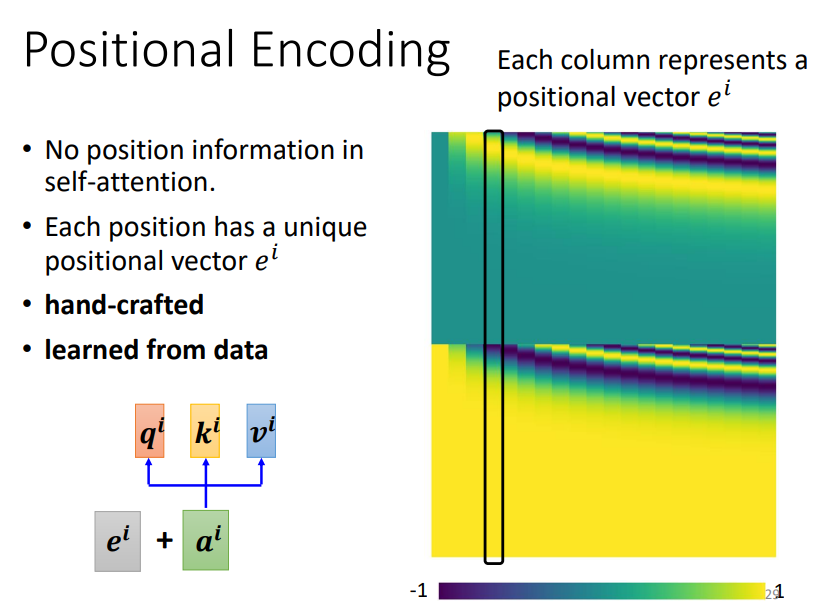
Self-Attention无法表示出不同词之间的位置信息,因此需要对不同词进行位置编码,每一个词都会有一个位置编码向量;
这个向量可以通过人工设计,也可以从数据中自动学习!
6. Appilications
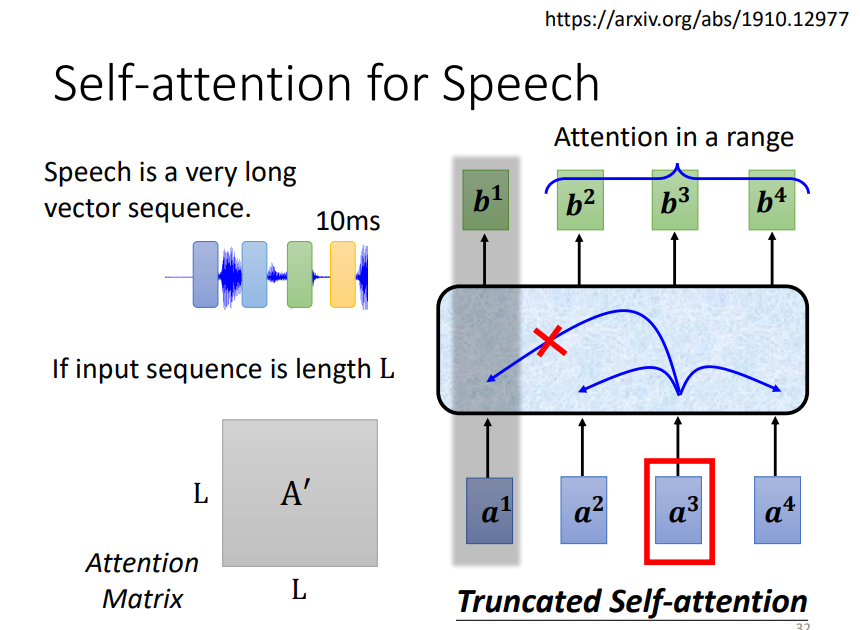
Truncated Self-attention是指不计算某个词与所有词之间的关系,而是计算与相邻词之间的关系,这样做的目的是为了减少参数,降低Attention Matrix的维度!
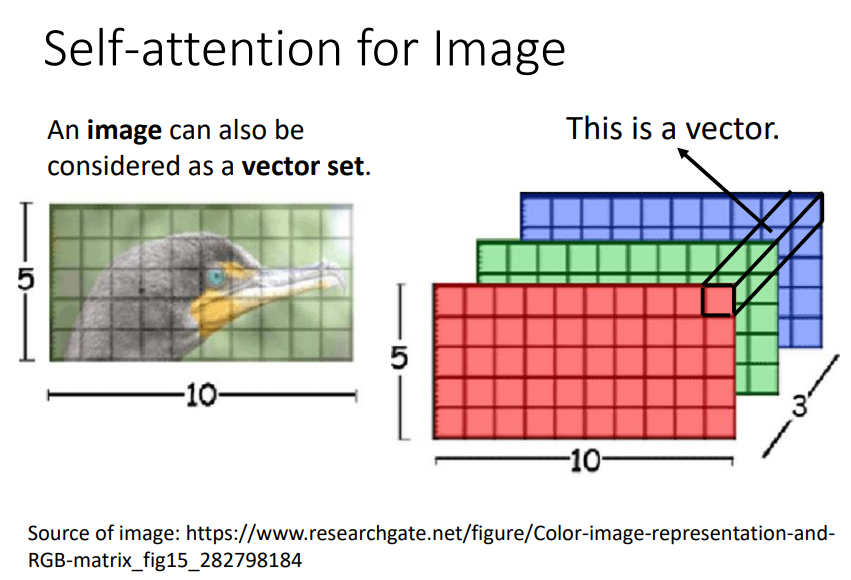
Self-Attention也可以用在图像中,如何把一张图像表示成一堆向量呢?
我们把每一个pixel视为一个向量即可!
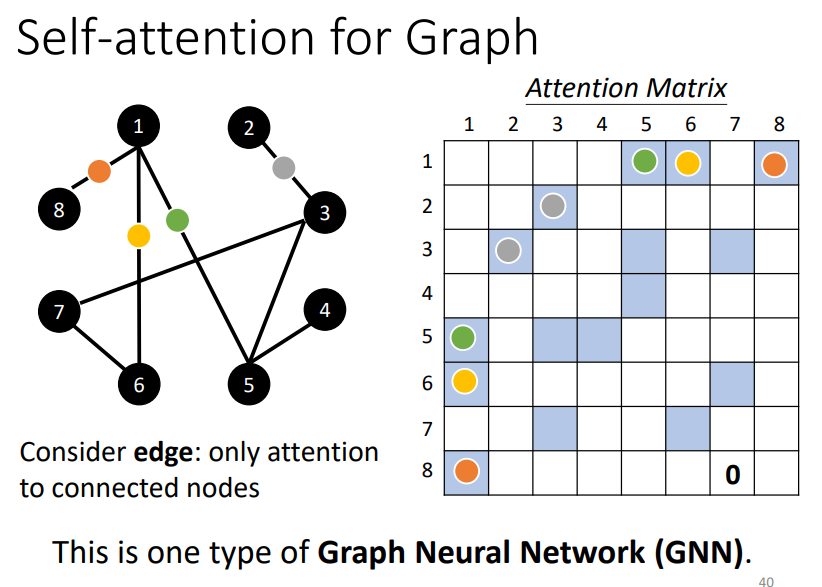
Self-Attention也可以用于Graph中,属于GNN的一种。
具体而言就是指我们只考虑有边相连的节点之间的相关关系,如上图。
7. Self-attention v.s. CNN & RNN

CNN可以视为一个简化版的Self-attention,CNN的模型弹性没有Self-Attention大!
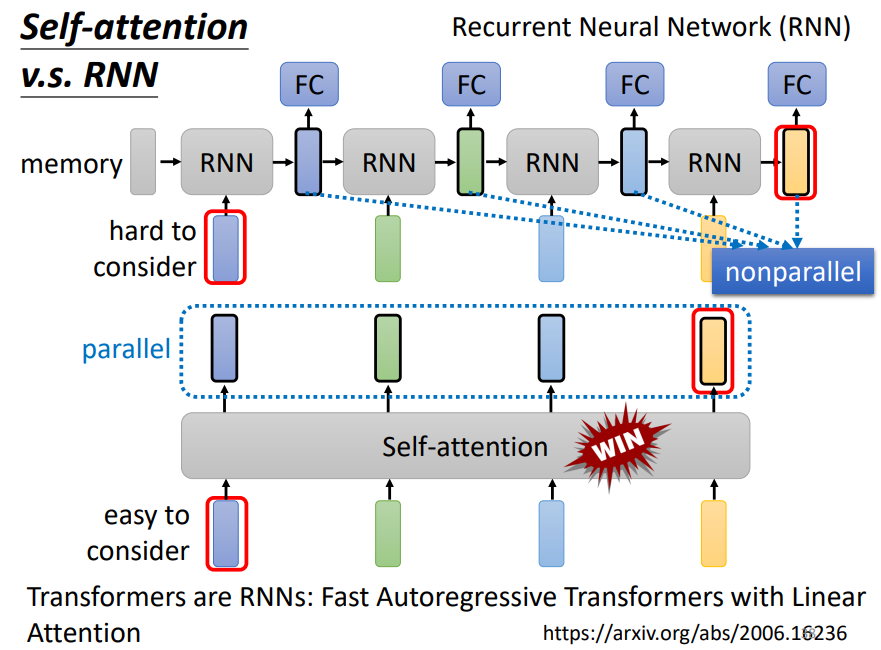
和RNN相比,
相同的是:它们都是输入一堆向量,并输出一堆向量
不同的是:RNN的输出向量之间不能平行产生,而是一个一个产生;并且如果RNN最后一个BLOCK的输出需要考虑与第一个词之间的关系是非常困难的,它需要把第一个词储存在memory中,并且要保证在传输的过程中不会被遗忘!
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号