
aws dynamodb 基础概念和理论
参考资料
- https://amazon-dynamodb-labs.workshop.aws/
- https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/Introduction.html
- AWS DynamoDB Tutorial For Beginners
核心概念
nosql和sql数据库的比较
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/SQLtoNoSQL.WhyDynamoDB.html
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/SQLtoNoSQL.Accessing.html
table、item和attributes是dynamodb的核心组件,可以分别对应关系型数据库中的表,行和列
-
table包含多个item,item是一组attributes,dynamodb没有item的数量的限制
-
item包括attributes,例如People 表中的一个
item包含名为 PersonID、LastName、FirstName 等的属性 -
ddb的表没有固定结构,不需要预先定义,每个项目都能够拥有自己的独特属性
-
ddb最多支持高达 32 级深度的嵌套属性
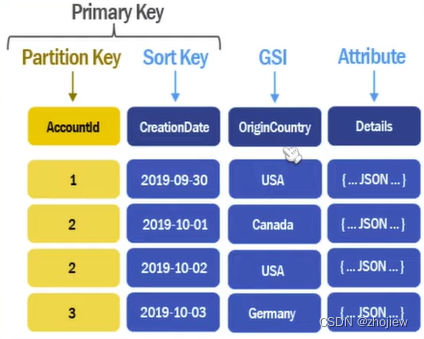
主键和二级索引
分区键和排序键,分区键就是主键,排序键是索引键,通过哈希函数对数据进行分区(具有相同分区键的项目存储在互相紧邻的物理位置)。和mysql函数的逻辑类似,dynamodb中的每个分区默认按照排序键进行排序。复合主键唯一即可
二级索引为数据的查询提供了另一个子树
参考《mysql是怎样运行的?》索引章节内容,聚簇索引通过b+树的方式实现了数据的快速检索
mysql的页按照主键大小顺序排列,每个页内的记录也按照主键的大小顺序排列。
但是dynamodb的item并非按排序顺序存储,具体位置完全由主键哈希决定。决定分区之后再按照排序键有序存储再相邻物理位置
二级索引和聚簇索引的逻辑类似,但是每个页中不再是完整的用户数据,而是索引键+主键的组合,查询的路径变成了二级索引->主键->数据页。联合索引即多个列组成的索引,本质上还是个二级索引
dynamodb的索引可以进行类比
-
全局二级索引,实际上是个联合索引,并且联合索引的内容可以和基表中的分区和排序键不一致
-
本地二级索引,也是个联合索引,但是分区键必须相同,排序键可以不同
注意:每个索引属于一个表,dynamodb在基表的项目进行增删改的时候自动维护索引,存在一定的性能损耗
- dynamodb没有查询优化程序,因此仅在
Query或Scan时使用二级索引
dynamodb启用流时,当对item出现增删改事件是,stream会写入流记录(表名,事件时间戳,元数据),保留24小时后自动删除
典型用法是将dynamodb stream和lambda函数结合,捕获感兴趣的事件并触发对应行为
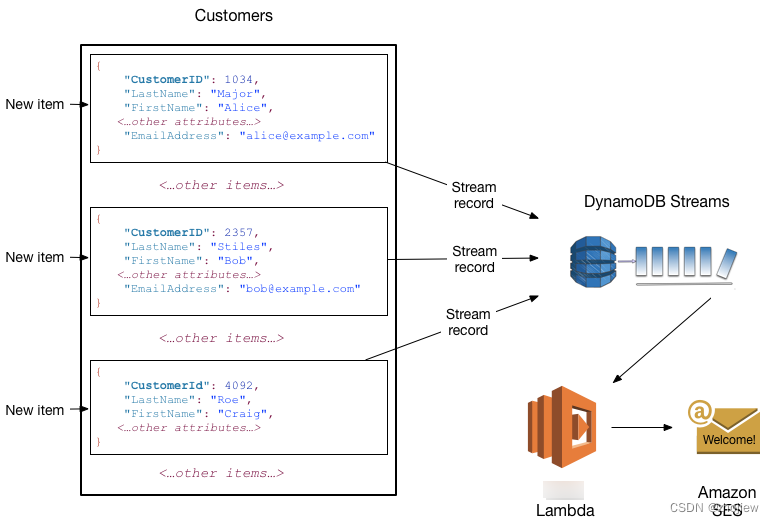
读写一致性
dynamodb 是region隔离的,数据在多可用区中存储,写入数据持久化后,短时间内(1s)最终在所有存储未知保持一致
dynamodb支持最终一致性和强一致性读取
- 最终一致性,当前读数据可能不是最新的
- 强一致性读取,无论何时都读取最新写入的数据,有局限性
- GSI不支持
- 相比最终一致性有更高的吞吐量,但是会收到延迟和终端的影响(500错误)
- 更高的延迟(leader未找到最新数据时)
默认使用最终一致性读取,使用ConsistentRead 将api调用指定为强一致性读取
读写容量问题
(1)读写容量计算(指定的吞吐量是ddb可以交付的最大容量)
- RCU,读取容量单位
- 1单位RCU,4KB及以下的item进行每秒一次强一致性读取
- 1单位RCU,4KB及以下的item进行每秒两次最终一致性读取
- 1单位RCU,4KB及以下的item每秒一次事务读取需要2个RCU
- WCU,写入容量单位
- 1单位WCU,1KB 及以下的item每秒一次写入
- 1单位WCU,1KB及以下的item每秒一次事务写入需要2个WCU
具体的例子如下
创建一个具有 6 个读取容量单位和 6 个写入容量单位的预置表
- 执行高达每秒 24KB 的强一致性读取(4KB x 6 个读取容量单位)。
- 执行高达每秒 48KB 的最终一致性读取(读取吞吐量的两倍)。
- 执行高达每秒 12 KB 的事务读取请求。
- 每秒写入高达 6KB(1 KB × 6 个写入容量单位)。
- 执行高达每秒 3KB 的事务写入请求。
(2)dynamodb支持两个读写容量模式处理表操作:按需模式,预置模式(默认)
读写容量模式在创建表时设置,也可以之后进行修改
- 24小时内可以修改两次
- 从预置模式更新为按需模式无需额外配置
- 从按需模式更新为预置模式,控制台会按照GSI过去30分钟的读写容量设置预置的值,sdk和cli需要手动设置
- 其他控制台和cli工具操作的区别,区别比较大
- 对表和分区的结构进行若干更改,持续数分钟
- 切换到按需容量时,保持之前预置的读写吞吐量。切换到预置容量时,保持之前按需的峰值吞吐量
比较两个读写模式
| 按需模式 | 预置模式 | |
|---|---|---|
| 描述 | 每秒处理数千个请求,随着工作负载的增减,动态调整工作负载 | 需要指定应用程序所需每秒读取和写入次数(预置吞吐量 是应用程序可以从表或索引中消耗的最大容量,超过会发生throttle 报错为400 ProvisionedThroughputExceededException) |
| 场景 | 工作负载未知,应用程序流量无法预测,按需付费 | 可预测的应用程序流量,流量比较稳定或逐渐增加,按需控制成本 |
| 问题 | 按需模式会自适应流量大小,并将负载流量扩展为原来的2倍。如果流量短时间内超过原来的2倍,则可能会出现throttle | 可以使用autoscaling自动调整预置容量,以及预留容量(和预留实例的概念类似,成本折扣) |
表类和分区
表类类似s3存储类的IA概念,主要是针对成本进行优化。表类默认为standard,可以更改。
分区是table数据存储的位置(SSD固态硬盘)由aws维护,以下场景会发生分区扩展:
- 预置吞吐量设置超出了现有分区的支持能力
- 现有分区达到容量上限,需要更多存储空间
主键的哈希决定了数据存储的分区,项目并非按排序顺序存储的。决定分区之后再按照排序键有序存储再相邻物理位置
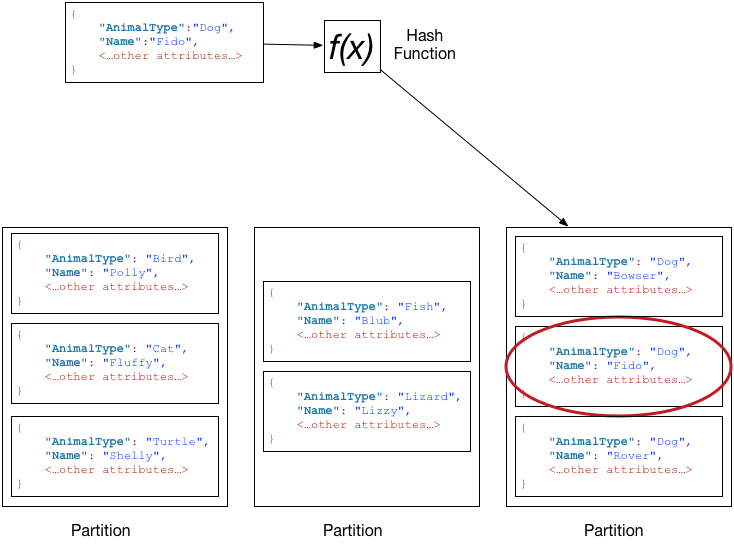
dynamodb的api操作(DDL和DML)
官方文档给出的sdk example实在是太全了
DynamoDB 代码示例:Node.js、Java、Python、.Net、Go , Rust
https://github.com/awsdocs/aws-doc-sdk-examples
关于sdk使用的一些问题
对于dynamodb的api接口,官方提供了不同级别的实现
这里需要注意的是,由于不同语言的特性,并不一定拥有以上的全部级别api接口
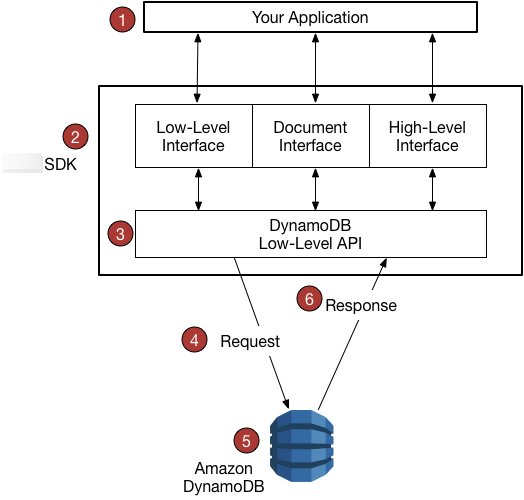
官方为java和.NET(最完善)提供了最完善的api接口类型
使用低级数据库接口,开发人员必须编写向数据库表读取或写入对象数据的方法。对象类型和数据库表的每个组合所需的额外代码量非常庞大。
为了简化开发,适用于 Java 和 .NET 的 Amazon SDK 提供更高级别抽象
之后可能会在单独的文章中涉及到具体的api使用
- 高等级api,使用java测试
- 低等级api和文档级别api,使用java或rust测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号