计算机体系结构总结_Pipeline
Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
在前面一节里我们有了一块简单的RISC CPU,包括指令集和各个部件。现在我们来看看怎么在它的基础上构建一个pipeline
pipeline
pipeline的概念本科的时候其实学过了...大意就是把一整个部件(可以理解成电路)分解成多个stage,这样不同stage之间就可以并行的执行不同指令了。
PPT P1-P5 / HI P183
Pipeline Hazards
HI P186
流水线有这样一种情况:在下一个时钟周期中下一条指令不能执行。这种情况叫做冒险。流水线冒险包括以下三种:
1. 结构冒险(structural hazard) PPT P6
如果有两个不同的stage需要访问同一个资源,那它俩就不能并行运行了,这时候有的就只能wait。这叫结构冒险
一个好点的解决方法就是create duplicate resource
2. 数据冒险(data hazard) PPT P7 HI P188
因无法提供指令执行所需数据而导致指令不能在预定的时钟周期内执行。也就是第二条指令需要第一条指令完成后才能运行(比如需要第一步算出来的结果)。这个也叫做data dependence
有三种data dependence:
- Read after Write
- Write after Read(比如 r4=r1+r0 和 r0=r3+4)
- Write after Write(2个指令write the same register)
只有第一种是true dependence,别的都可以通过一些方法解决(比如duplicate resource之类)。
对于Read after Write,就只能确保read指令必须要在write完成之后才能开始。对于存在这种依赖关系的指令,直接按照pipeline的方法执行肯定是不行的。以下面的例子为例:
add $s0, $t0, $t1 //s0:=t0+t1 sub $t2, $s0, $t3 //t2:=s0-t3
这时在两条语句执行的中间就需要Stalling。也就是delay instruction until hazard is resolved。stall的实现是通过对不同部件发送以下三种control signal来实现的:
- “Transfer” (normal operation) indicates should transfer next state to current
- “Stall” indicates that current state should not be changed
- “Bubble” indicates that current state should be set to 0
eg: PPT P8
但是当流水线里的bubble很多的时候,stalling会大幅度降低性能...所以还要用一些别的黑科技来尽量避免stalling
- 1. Forwarding(旁路) PPT P9-13 / HI P187
在解决数据冒险问题之前不需要等待指令的执行结束。对于上述的代码序列, 一旦ALU生成了加法运算的结果,就可以将它用作减法运算的一个输入项。从内部资源中直接提前得到缺少的运算项。例如在这个问题中,ALU data generated at end of EX; consumed at beginning of EX。那么就可以在两个指令的EX阶段之间加个旁路:
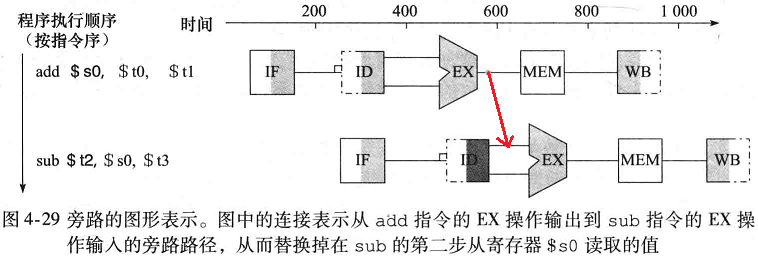
同理,有时候依赖是这样的:第一条指令执行到memory stage了(已经过了EX,显然运算结果已经有了),而此时后面的某一条指令要依赖这个结果。那么也可以在MEM之后到EX之前加个旁路:
而对于一些别的指令,可能还需要加别的旁路。比如下面的例子: PPT P12
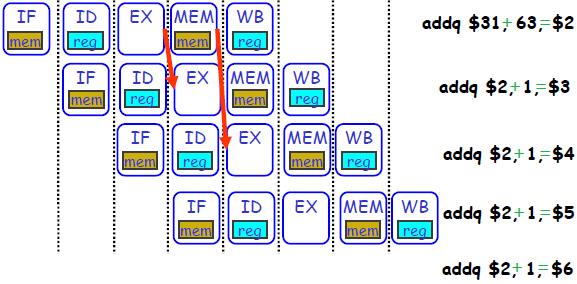
1: $Ra <-- Mem[$Rb +offset] //Load
2: Mem[$Rb +offset] <-- $Ra //Store
它的流水线就简洁一些了,只需要ID(Instruction decode/register fetch)、MEM(读写memory)、WB(写register)三个stage。而在这两条指令之间,1的MEM结束之后其实就已经得到数据了,而2恰好也是在MEM阶段开始前需要数据。因此可以在 MEM的输出 到 MEM的输入 再加个旁路。
其实对于ALU和Load/Store指令,有这三种旁路就够了:
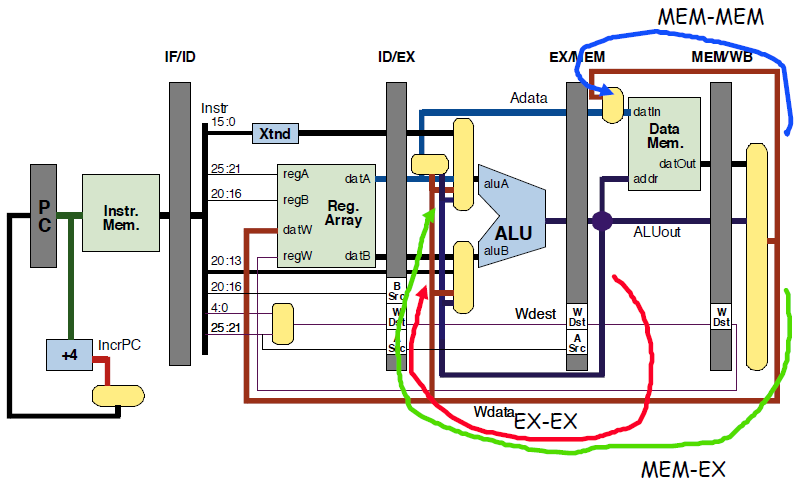
3. 控制冒险(control hazard) PPT P13-25
Conditional branches cause uncertainty to instruction sequencing. 这样只有conditional branch算出来之后才能fetch next instruction。
对于Branch Instructions,zero testing是在EX阶段进行的,因此也是在这个阶段需要data。其他的分析都和前面一样了 PPT P13-14
而有一种Branch Instructions是会修改PC的(比如满足条件时jump到某个指令),这时候问题就来了: PPT P16-21 / HI P215 ch4.8.1
0x0: beq r31, 0x18 # Take: if($r31==0) GOTO 0x18 0x4: r1 <- r31 + 0x3f # Xtra1 0x8: r2 <- r31 + 0x3f # Xtra2 0xc: r3 <- r31 + 0x3f # Xtra3 0x10: r4 <- r31 + 0x3f # Xtra4 ...... 0x18: r5 <- r31 + 0x3f # Target
按照pipeline的方式执行,0x0的beq指令要经过IF ID EX MEM WB五步。那么到beq算出来要不要跳转(EX之后)的时候,后面的Xtra1,Xtra2,Xtra3三个指令也已经在流水线中了。假设此时需要跳转,那么这三条指令就白执行了。对于这里的情况还好,如果Xtra1,Xtra2,Xtra3中有些涉及到写内存的指令,那么已经造成的操作可能就很难复原了......一种方法是当发现branch instruction之后,直接在后面插入2个stall。那么在beq的EX之后,pipeline中就只有fetch Xtra1在执行了。如果要跳转,那就清空流水线重新fetch Target(相当于一共stall了三次);如果不用跳转,就按原计划执行(总共stall两次)。 [PPT P18-20]
经过计算可以发现,这种方法带来的额外时间消耗还是挺多的......(PPT P21)。所以还要想想别的方法。
- 1. Fetch and cancel When Taken
意思就是假设分支不发生,让流水线按顺序往下fetch。如果后来发现真的要branch了,就清空流水线(cancel instructions),相当于插入了三个bubble。如果没branch就按原计划执行,无bubble。
但是这个性能还是不大行的[PPT P24]。而且前面提到过,也不是所有指令都能轻易cancel的...
Scalar Pipeline
PPT P25
前面实现了一个基本的pipeline(scalar pipeline),但它还是有几个缺点:IPC最大只有1、long latency、有时候要stall。有两种改进方案:
1. 超流水线(superpipelining):更多的stage
超级流水线(Super Pipeline) 超级流水线又叫做深度流水线,它是提高cpu速度通常采取的一种技术。CPU处理指令是通过Clock来驱动的,每个clock完成一级流水线操作。每个周期所做的操作越少,那么需要的时间久越短,时间越短,频率就可以提得越高。所以超级流水线就是将cpu处理指令的操作进一步细分,增加流水线级数来提高频率。频率高了,当流水线开足马力运行时平均每个周期完成一条指令(单发射情况下),这样cpu处理得速度久提高了。
当然,这是理想情况下,一般是流水线级数越多,重叠执行的执行就越多,那么发生竞争冲突得可能性就越大,对流水线性能有一定影响。 现在很多cpu都是将超标量和超级流水线技术一起使用,例如pentium IV,流水线达到20级,频率最快已经超过3GHZ.我们教科书上用于教学的经典MIPS只有5级流水。
2. 超标量(superscalar):一次fetch多条指令
超标量(Super Scalar) 将一条指令分成若干个周期处理以达到多条指令重叠处理,从而提高cpu部件利用率的技术叫做标量流水技术。 超级标量是指cpu内一般能有多条流水线,借助硬件资源重复(例如有两套译码器和ALU等)来实现空间的并行操作。在单流水线结构中,指令虽然能够重叠执行,但仍然是顺序的,每个周期只能发射(issue)或退休(retire)一条指令。
超级标量结构的cpu支持指令级并行,每个周期可以发射多条指令(2-4条居多,也叫做多发射[multiple issue])。这样可以使得cpu的IPC(Instruction Per Clock)>1 (也就是CPI<1咯),从而提高cpu处理速度。超级标量机能同时对若干条指令进行译码,将可以并行执行的指令送往不同的执行部件(也就是说执行过程可以是乱序的)。我们熟知的pentium系列(可能是p-II开始),还有SUNSPARC系列的较高级型号,以及MIPS若干型号等都采用了超级标量技术。
指令级并行是一个很重要的研究方向。下一节我们就来看看如何实现指令级并行吧!
...
posted on 2019-10-28 22:35 Pentium.Labs 阅读(6686) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
