李宏毅Diffusion课程

“雕像其实本来就已经在大理石里面,我只是把不要的部分拿掉”:米开朗琪罗
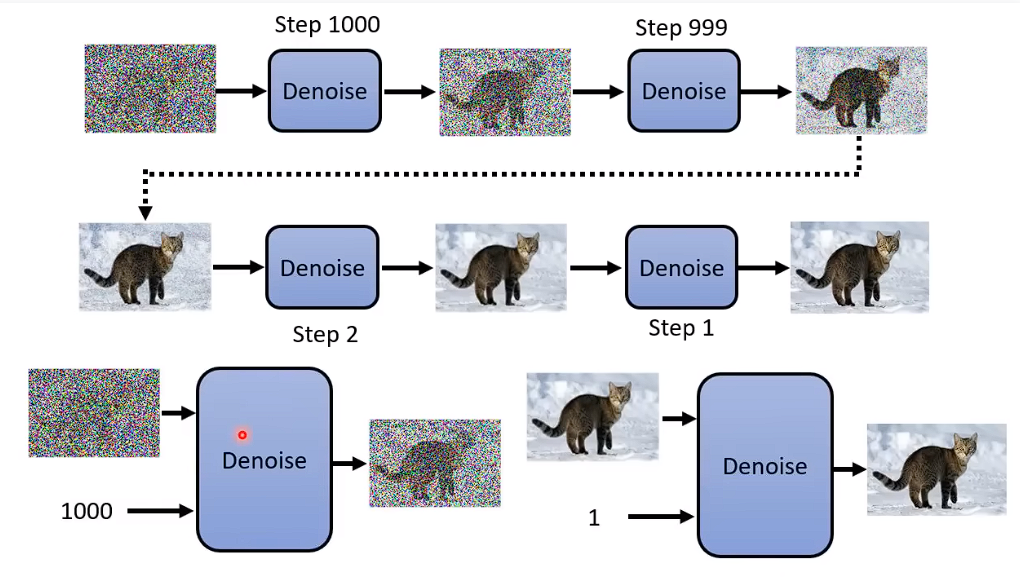
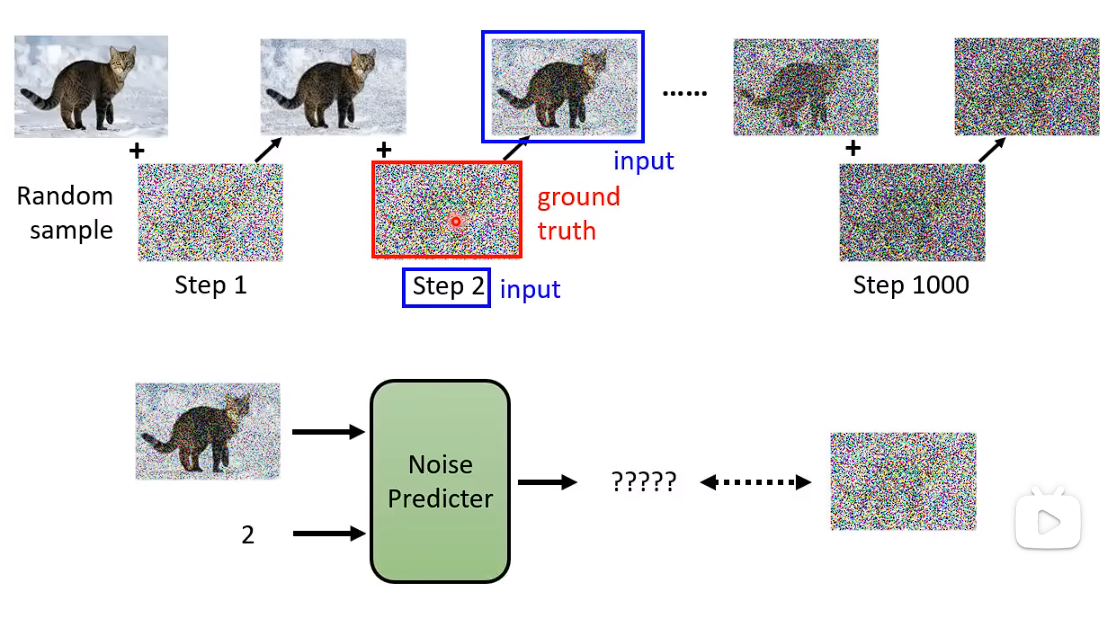
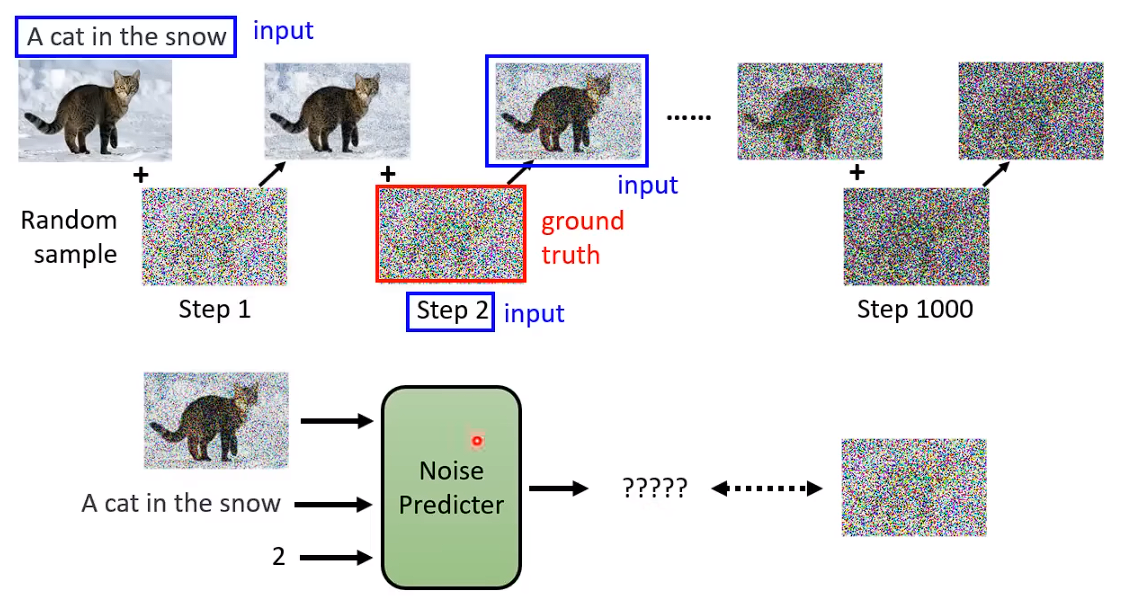
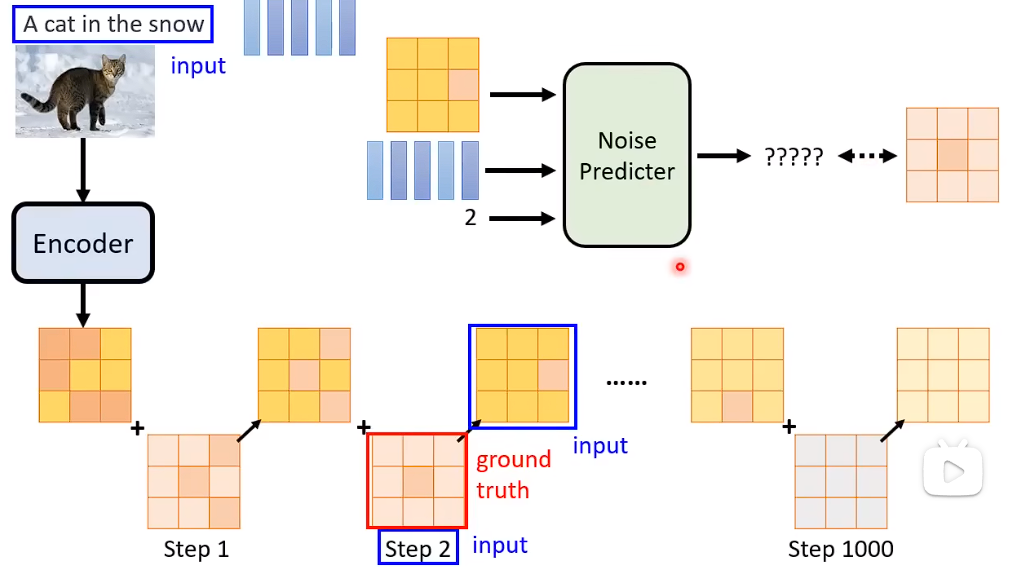
Denoise Model除了要输入 要被输入的那张图片,还要输入这是第几张图片。(即Noise严重的程度)
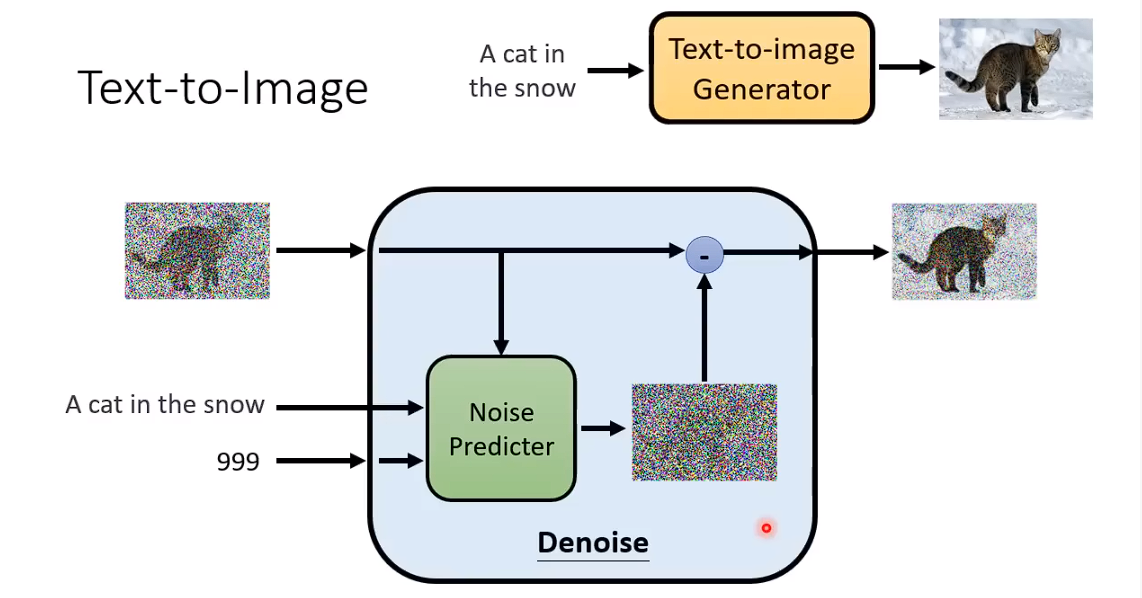
Denoise Model内部实际上是在干什么呢:
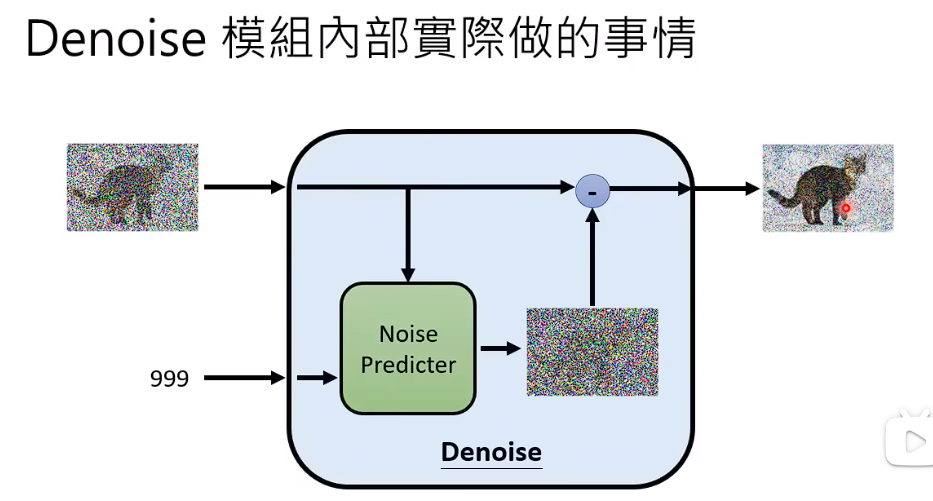
1、Denoise Preidcter除了吃要还原的图片,还要吃一个步骤的数字。 输出一张噪声的图片,即预测出在这张图片中噪声应该长成什么样子。
2、使用要还原的图片,减去预测出来的噪声,得到Denoise后的图片。Noise Predicter学习的是噪声。(学习这张图片中的噪声是比较简单的。直接端到端,学习加噪之后的猫,其实是非常困难的)
如何训练一个Noise Predictor
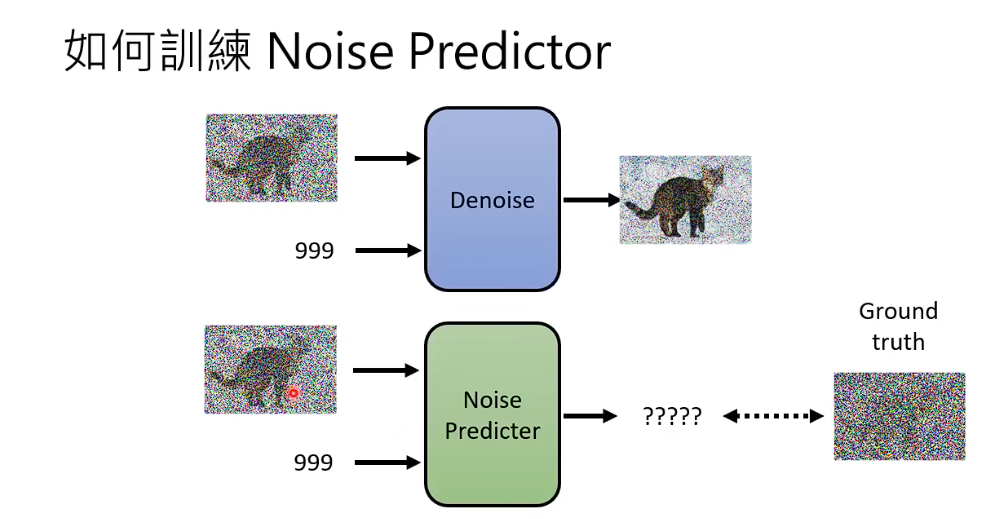
从database 中取一张图片,自己加噪音进去,从Random 噪声中选择采用一组噪音出来加进去。
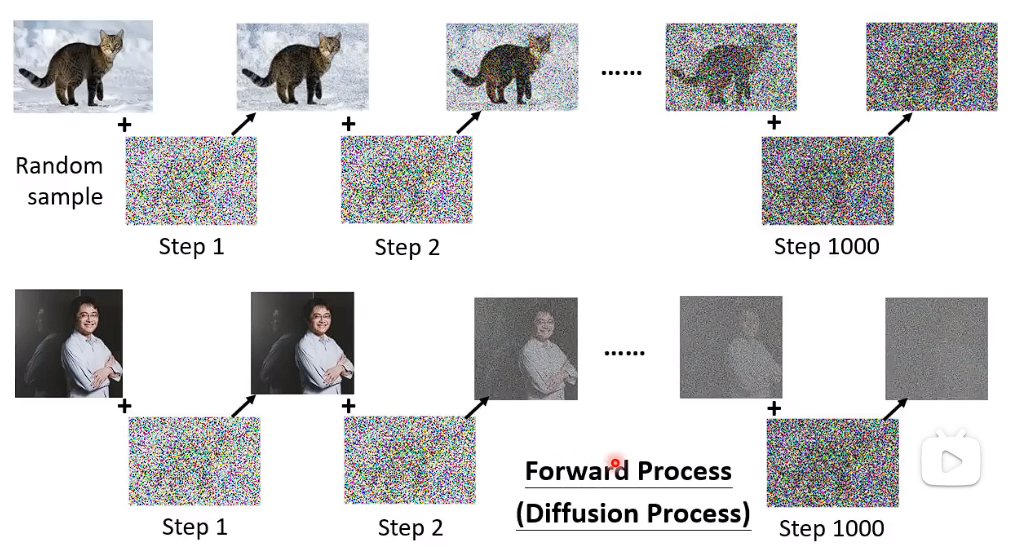
这样加噪之后,你就有Noise Predictor的训练资料了。
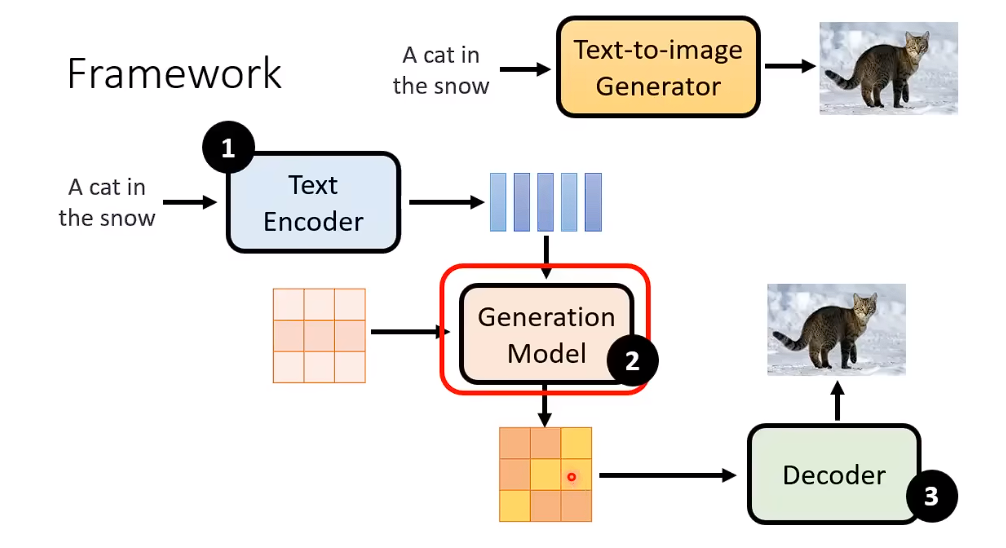
文生图
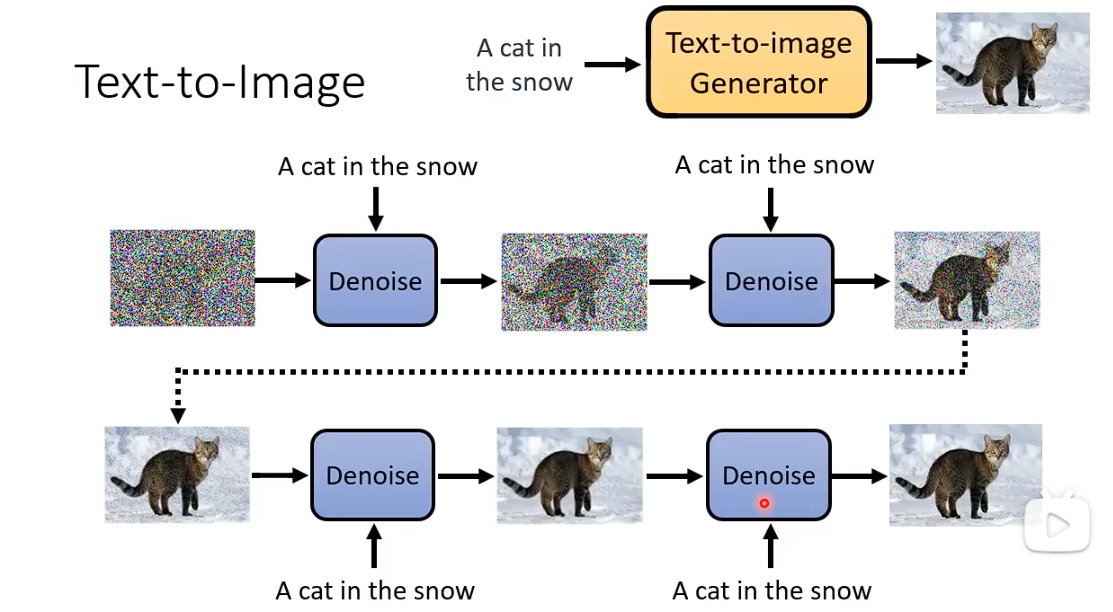
文生图,在denoise的步骤中 每一步增加一个输入。
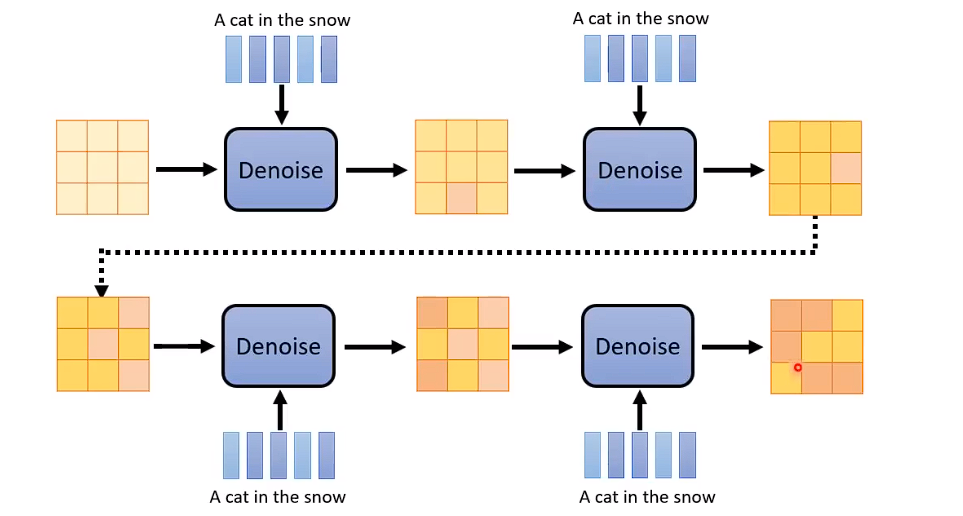
训练过程
DDPM的algorithm。

Stable diffusion
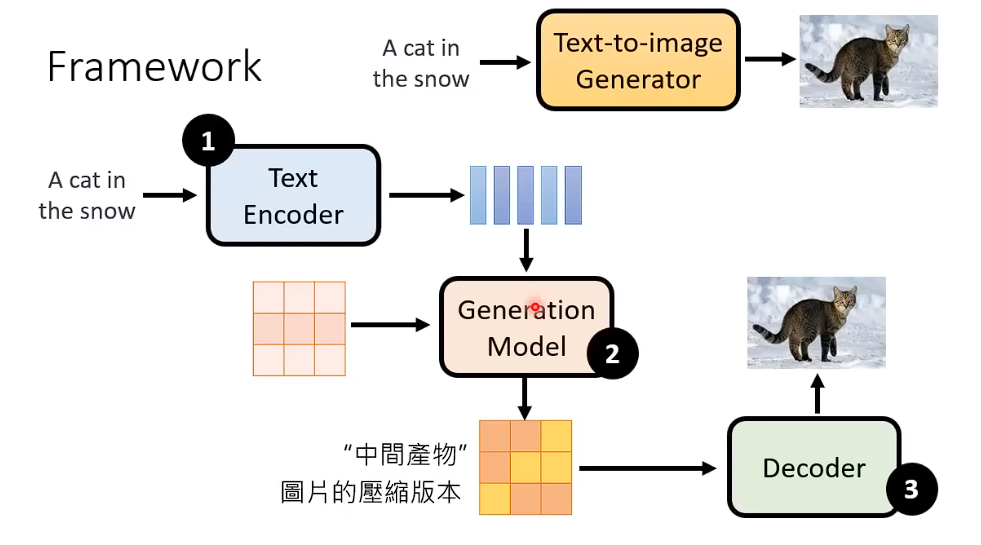
三个比较重要的model 对于 文生图
1、Text Encoder (一个比较好的文本嵌入)
2、Generation Model (一个比较好的,中间生成模型, 生成压缩后的版本)
3、Decoder (一个比较好的Decoder,从输出的图片的压缩版本,还原回图片)
通常来说 这三个Model是分开训练,然后组合起来的
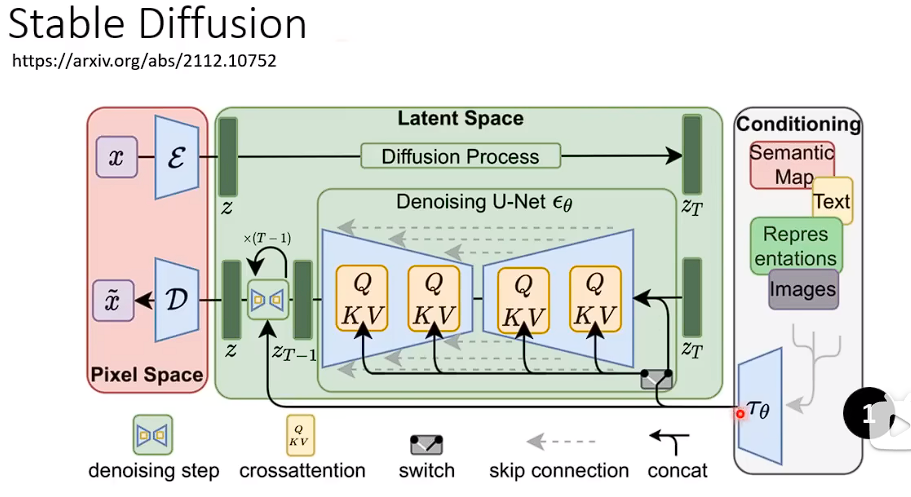
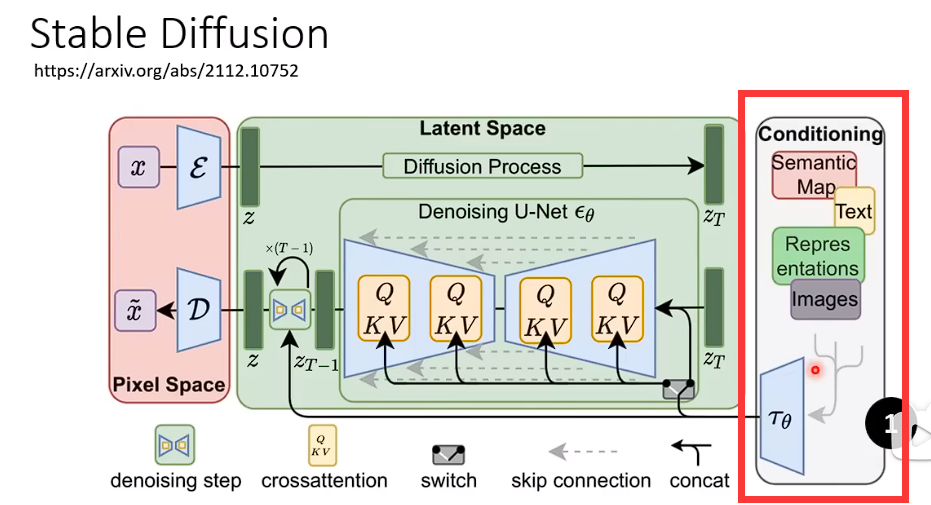
先有一个Encode去处理输入的东西,右侧部分。
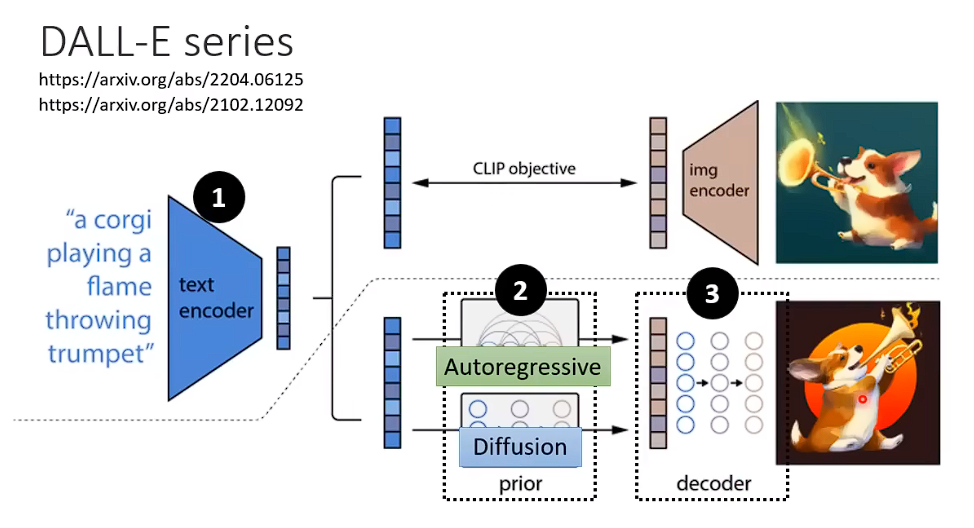
DALL-E 系列 Generation Model 可以考虑使用AR模型或者Diffusion模型
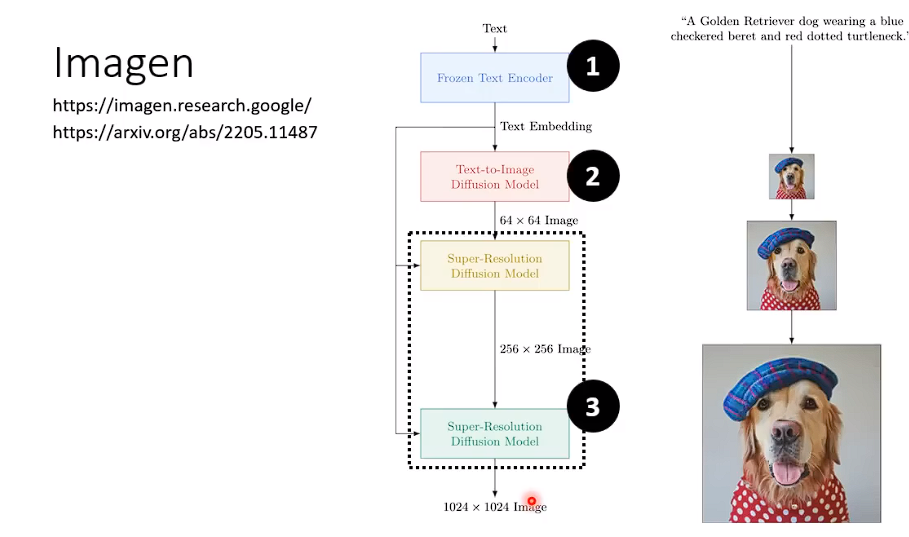
Imagen系列的模型,generation model 部分会产生一个人可以辨识的小图,在Decoder的模块,再过一层Diffusion Model去生成最后的图片。
Stable diffusion
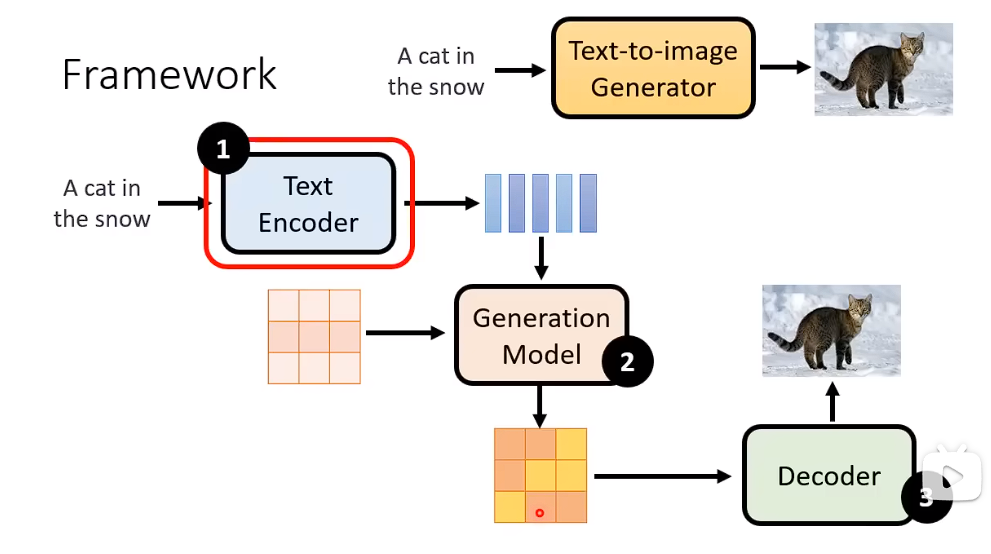
文字Encoder
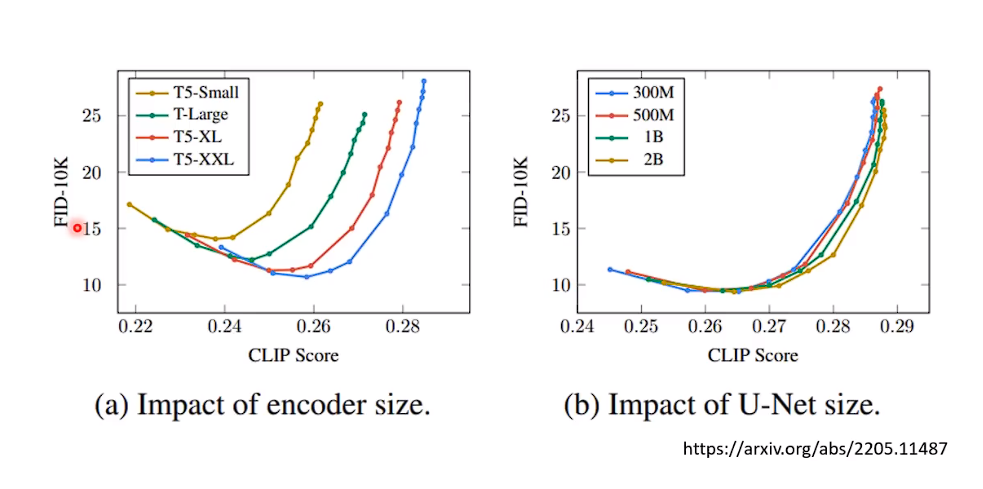
FID越小 生成的效果越好。CLIP Score 越大越好。总之 越往右下角越好。随着使用的Encoder越来越大,他生成的效果越来越好。
文字的Encoder对于生成结果的影响 非常的大。
U-Net大小 指的是Noise Predicter模型的大小。按图说明,增加Diffusion model对于结果影响不大。
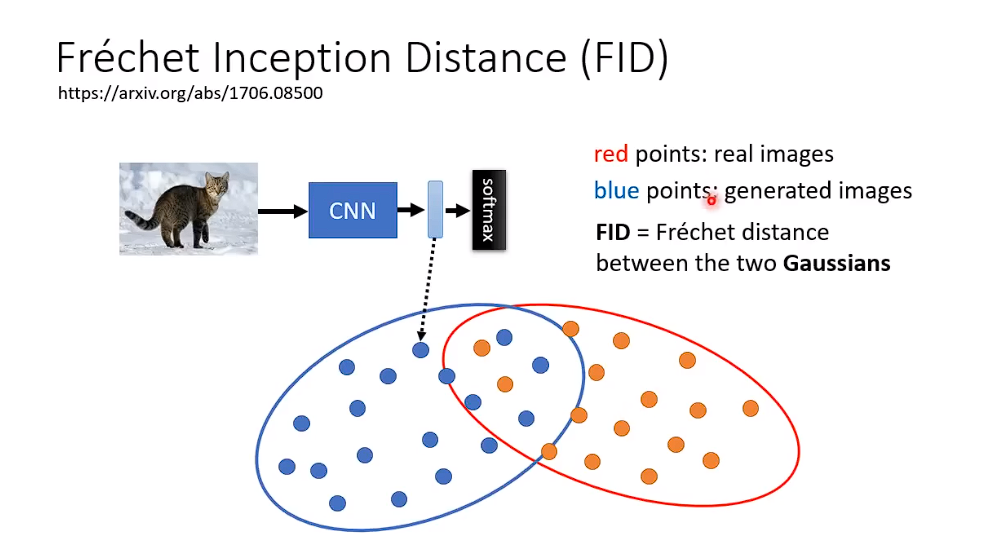
上面这个CNN是Pre-Train过的,
上面蓝色的点,代表生成的图片经过CNN model之后所产生的representation.红色的点,代表真实图片经过CNN model之后所产生的representation,
这两个representation相隔的越接近,说明生成的影像和原始的影像越接近。
这两个representation 离得越远,说明生成的影像和原始影像隔得越远。
怎么看两组representation 之间的距离呢。
使用了比较粗暴的方法:
假设这两组distribution 都是高斯distribution, 就是算这两个Gaussian distribution 的distance.
做法看起来很粗糙 但是Imagen仍然使用的是FID这个评价指标。
他需要sample 很多张的图片 来计算FID,
CliP Score 用于计算你输入的文字和图片含义之间的距离
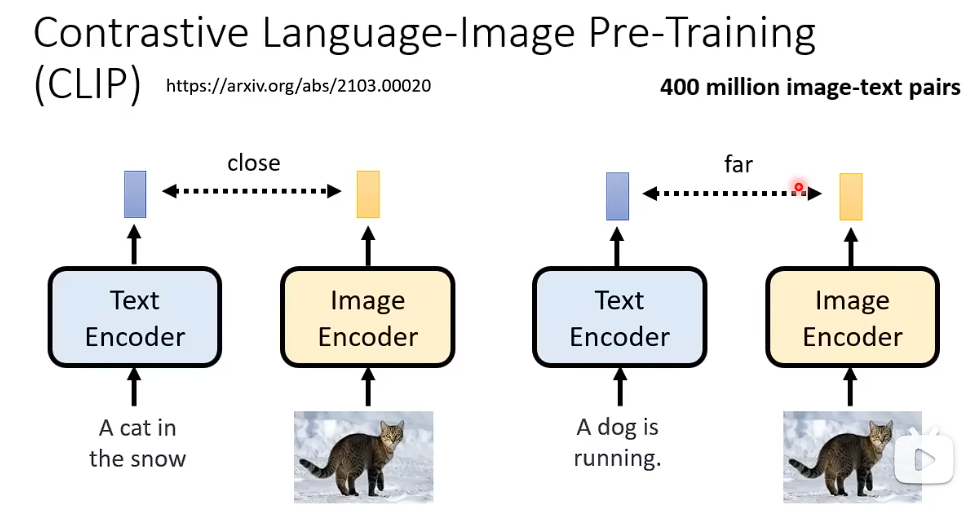
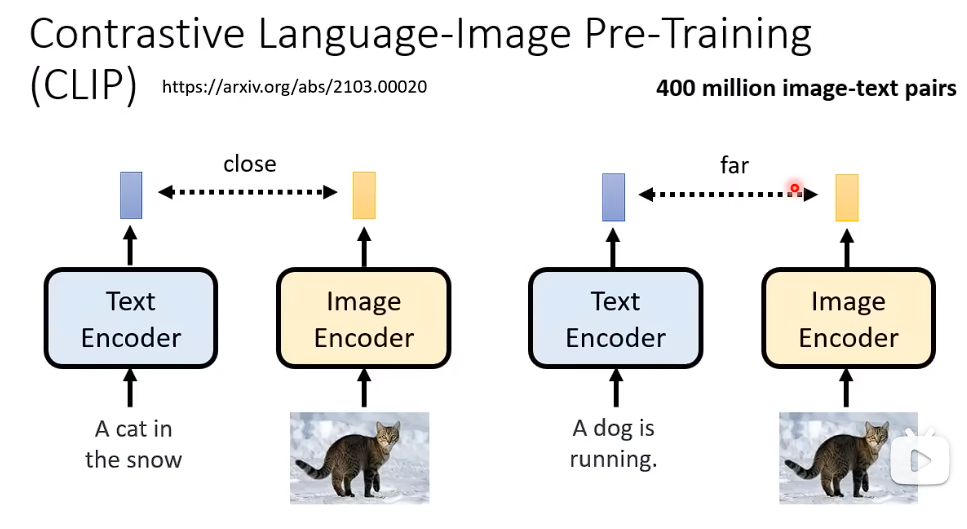
Decoder的训练 不需要 影像和文字匹配的数据。
如果中间产物是小图
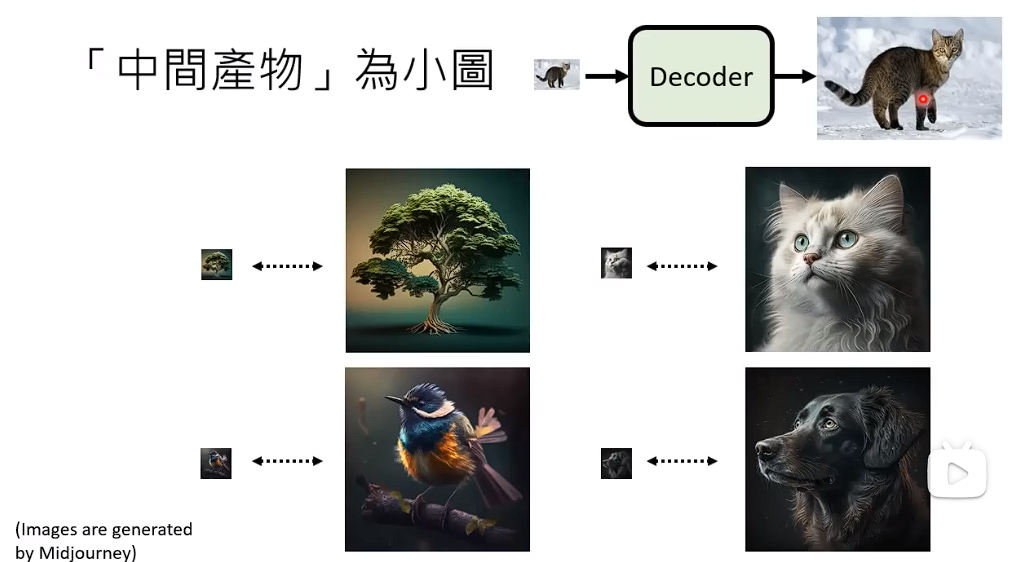
那么Decoder的训练非常的简单,你只需要把你手上的影像都拿出来,然后变成小图, 你就有成对的资料,你就可以把小图变成大图。
如果中间产物是Latent Representation
我们如何训练一个Decoder把 Larent Representation 当成输入,把这些Latent Represention还原成一张图片。
训练一个Auto-encoder 使得输入X 经过AE尽可能的还原出X。
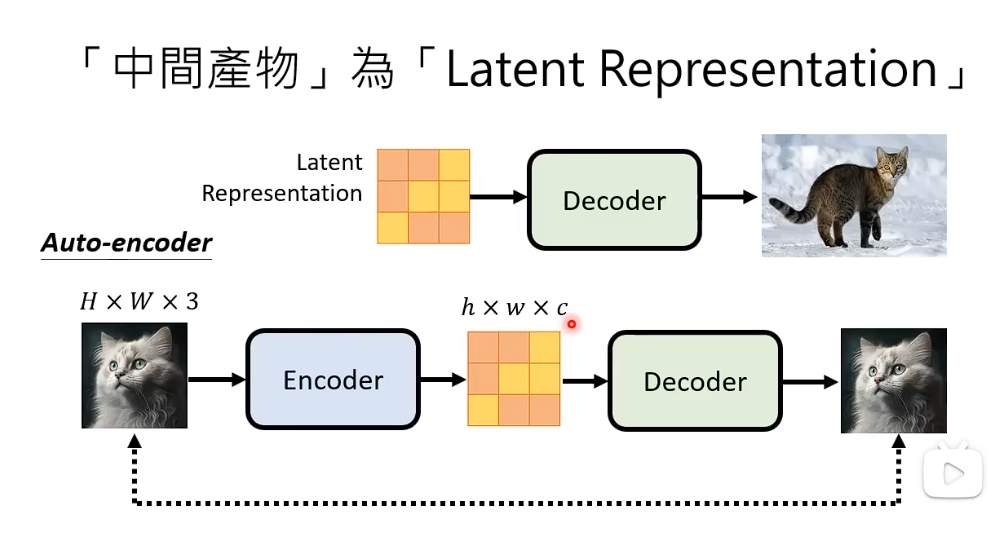
训练完成之后,我们就可以把Decoder拉出来用,给予一个Latent Representation ,就可以还原出X。
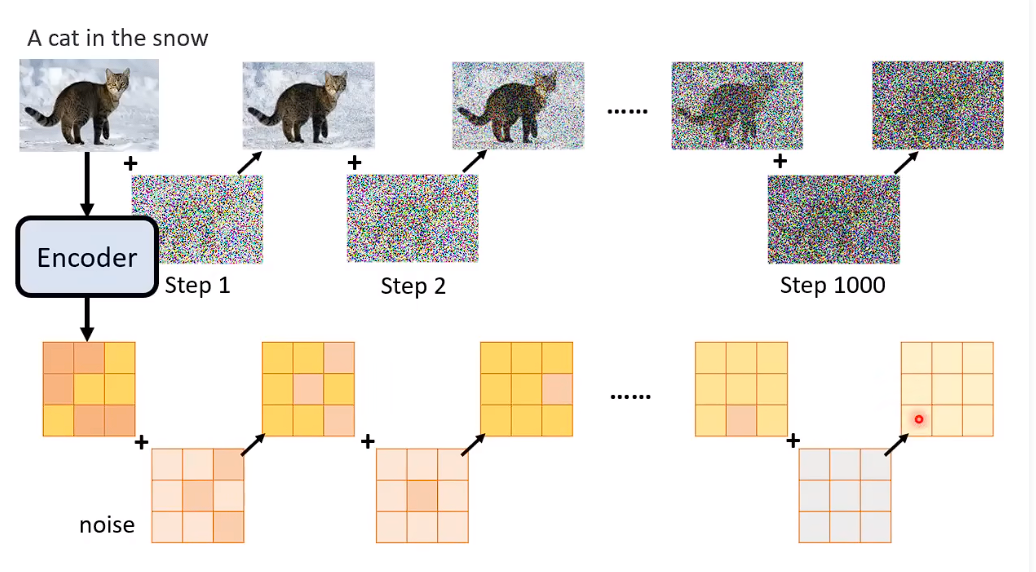
把噪音加入latent reprezatation.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号