指令集架构 x86-64 x86架构的64位拓展,向后兼容于16位及32位的x86架构
指令集架构、机器码与 Go 语言 | Go 语言设计与实现 https://draveness.me/golang/docs/part1-prerequisite/ch02-compile/golang-machinecode/
2.5 机器码生成 #
Go 语言编译的最后一个阶段是根据 SSA 中间代码生成机器码,这里谈的机器码是在目标 CPU 架构上能够运行的二进制代码,中间代码生成一节简单介绍的从抽象语法树到 SSA 中间代码的生成过程,将近 50 个生成中间代码的步骤中有一些过程严格上说是属于机器码生成阶段的。
机器码的生成过程其实是对 SSA 中间代码的降级(lower)过程,在 SSA 中间代码降级的过程中,编译器将一些值重写成了目标 CPU 架构的特定值,降级的过程处理了所有机器特定的重写规则并对代码进行了一定程度的优化;在 SSA 中间代码生成阶段的最后,Go 函数体的代码会被转换成 cmd/compile/internal/obj.Prog 结构。
2.5.1 指令集架构 #
首先需要介绍的就是指令集架构,虽然我们在第一节编译过程概述中曾经讲解过指令集架构,但是在这里还是需要引入更多的指令集架构知识。
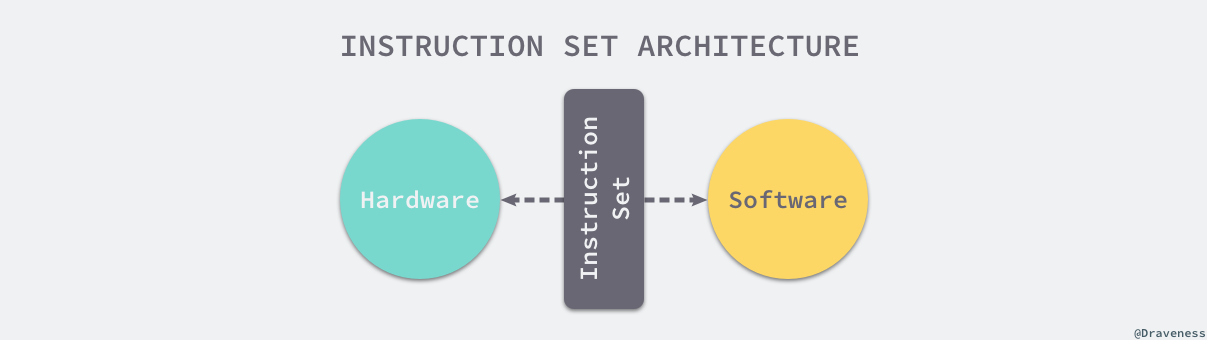
图 2-16 计算机软硬件之间的桥梁
指令集架构是计算机的抽象模型,在很多时候也被称作架构或者计算机架构,它是计算机软件和硬件之间的接口和桥梁1;一个为特定指令集架构编写的应用程序能够运行在所有支持这种指令集架构的机器上,也就是说如果当前应用程序支持 x86 的指令集,那么就可以运行在所有使用 x86 指令集的机器上,这其实就是抽象层的作用,每一个指令集架构都定义了支持的数据结构、寄存器、管理主内存的硬件支持(例如内存一致、地址模型和虚拟内存)、支持的指令集和 IO 模型,它的引入其实就在软件和硬件之间引入了一个抽象层,让同一个二进制文件能够在不同版本的硬件上运行。
如果一个编程语言想要在所有的机器上运行,它就可以将中间代码转换成使用不同指令集架构的机器码,这可比为不同硬件单独移植要简单的太多了。

图 2-17 复杂指令集(CISC)和精简指令集(RISC)
最常见的指令集架构分类方法是根据指令的复杂度将其分为复杂指令集(CISC)和精简指令集(RISC),复杂指令集架构包含了很多特定的指令,但是其中的一些指令很少会被程序使用,而精简指令集只实现了经常被使用的指令,不常用的操作都会通过组合简单指令来实现。
复杂指令集的特点就是指令数目多并且复杂,每条指令的字节长度并不相等,x86 就是常见的复杂指令集处理器,它的指令长度大小范围非常广,从 1 到 15 字节不等,对于长度不固定的指令,计算机必须额外对指令进行判断,这需要付出额外的性能损失2。
而精简指令集对指令的数目和寻址方式做了精简,大大减少指令数量的同时更容易实现,指令集中的每一个指令都使用标准的字节长度、执行时间相比复杂指令集会少很多,处理器在处理指令时也可以流水执行,提高了对并行的支持。作为一种常见的精简指令集处理器,arm 使用 4 个字节作为指令的固定长度,省略了判断指令的性能损失3,精简指令集其实就是利用了我们耳熟能详的 20/80 原则,用 20% 的基础指令和它们的组合来解决问题。
最开始的计算机使用复杂指令集是因为当时计算机的性能和内存比较有限,业界需要尽可能地减少机器需要执行的指令,所以更倾向于高度编码、长度不等以及多操作数的指令。不过随着计算机性能的提升,出现了精简指令集这种牺牲代码密度换取简单实现的设计;除此之外,硬件的飞速提升还带来了更多的寄存器和更高的时钟频率,软件开发人员也不再直接接触汇编代码,而是通过编译器和汇编器生成指令,复杂的机器指令对于编译器来说很难利用,所以精简指令在这种场景下更适合。
复杂指令集和精简指令集的使用是设计上的权衡,经过这么多年的发展,两种指令集也相互借鉴和学习,与最开始刚被设计出来时已经有了较大的差别,对于软件工程师来讲,复杂的硬件设备对于我们来说已经是领域下三层的知识了,其实不太需要掌握太多,但是对指令集架构感兴趣的读者可以找一些资料开拓眼界。
2.5.2 机器码生成 #
机器码的生成在 Go 的编译器中主要由两部分协同工作,其中一部分是负责 SSA 中间代码降级和根据目标架构进行特定处理的 cmd/compile/internal/ssa 包,另一部分是负责生成机器码的 cmd/internal/obj4:
cmd/compile/internal/ssa主要负责对 SSA 中间代码进行降级、执行架构特定的优化和重写并生成cmd/compile/internal/obj.Prog指令;cmd/internal/obj作为汇编器会将这些指令转换成机器码完成这次编译;
SSA 降级 #
SSA 降级是在中间代码生成的过程中完成的,其中将近 50 轮处理的过程中,lower 以及后面的阶段都属于 SSA 降级这一过程,这么多轮的处理会将 SSA 转换成机器特定的操作:
var passes = [...]pass{
...
{name: "lower", fn: lower, required: true},
{name: "lowered deadcode for cse", fn: deadcode}, // deadcode immediately before CSE avoids CSE making dead values live again
{name: "lowered cse", fn: cse},
...
{name: "trim", fn: trim}, // remove empty blocks
}
SSA 降级执行的第一个阶段就是 lower,该阶段的入口方法是 cmd/compile/internal/ssa.lower 函数,它会将 SSA 的中间代码转换成机器特定的指令:
func lower(f *Func) {
applyRewrite(f, f.Config.lowerBlock, f.Config.lowerValue)
}
向 cmd/compile/internal/ssa.applyRewrite 传入的两个函数 lowerBlock 和 lowerValue 是在中间代码生成阶段初始化 SSA 配置时确定的,这两个函数会分别转换函数中的代码块和代码块中的值。
假设目标机器使用 x86 的架构,最终会调用 cmd/compile/internal/ssa.rewriteBlock386 和 cmd/compile/internal/ssa.rewriteValue386 两个函数,这两个函数是两个巨大的 switch 语句,前者总共有 2000 多行,后者将近 700 行,用于处理 x86 架构重写的函数总共有将近 30000 行代码,你能在 cmd/compile/internal/ssa/rewrite386.go这里找到文件的全部内容,我们只节选其中的一段展示一下:
func rewriteValue386(v *Value) bool {
switch v.Op {
case Op386ADCL:
return rewriteValue386_Op386ADCL_0(v)
case Op386ADDL:
return rewriteValue386_Op386ADDL_0(v) || rewriteValue386_Op386ADDL_10(v) || rewriteValue386_Op386ADDL_20(v)
...
}
}
func rewriteValue386_Op386ADCL_0(v *Value) bool {
// match: (ADCL x (MOVLconst [c]) f)
// cond:
// result: (ADCLconst [c] x f)
for {
_ = v.Args[2]
x := v.Args[0]
v_1 := v.Args[1]
if v_1.Op != Op386MOVLconst {
break
}
c := v_1.AuxInt
f := v.Args[2]
v.reset(Op386ADCLconst)
v.AuxInt = c
v.AddArg(x)
v.AddArg(f)
return true
}
...
}
重写的过程会将通用的 SSA 中间代码转换成目标架构特定的指令,上述的 rewriteValue386_Op386ADCL_0 函数会使用 ADCLconst 替换 ADCL 和 MOVLconst 两条指令,它能通过对指令的压缩和优化减少在目标硬件上执行所需要的时间和资源。
我们在上一节中间代码生成中已经介绍过 cmd/compile/internal/gc.compileSSA 中调用 cmd/compile/internal/gc.buildssa 的执行过程,我们在这里继续介绍 cmd/compile/internal/gc.buildssa 函数返回后的逻辑:
func compileSSA(fn *Node, worker int) {
f := buildssa(fn, worker)
pp := newProgs(fn, worker)
defer pp.Free()
genssa(f, pp)
pp.Flush()
}
cmd/compile/internal/gc.genssa 函数会创建一个新的 cmd/compile/internal/gc.Progs 结构并将生成的 SSA 中间代码都存入新建的结构体中,我们在上一节得到的 ssa.html 文件就包含最后生成的中间代码:
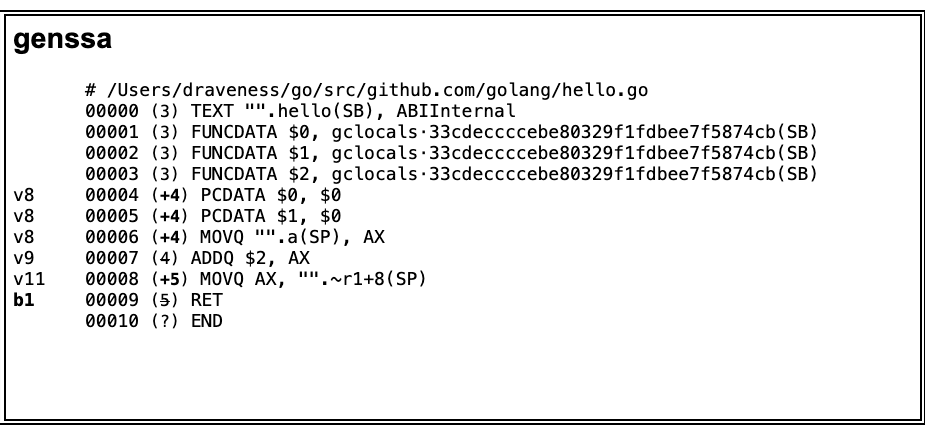
图 2-18 genssa 的执行结果
上述输出结果跟最后生成的汇编代码已经非常相似了,随后调用的 cmd/compile/internal/gc.Progs.Flush 会使用 cmd/internal/obj 包中的汇编器将 SSA 转换成汇编代码:
func (pp *Progs) Flush() {
plist := &obj.Plist{Firstpc: pp.Text, Curfn: pp.curfn}
obj.Flushplist(Ctxt, plist, pp.NewProg, myimportpath)
}
cmd/compile/internal/gc.buildssa 中的 lower 和随后的多个阶段会对 SSA 进行转换、检查和优化,生成机器特定的中间代码,接下来通过 cmd/compile/internal/gc.genssa 将代码输出到 cmd/compile/internal/gc.Progs 对象中,这也是代码进入汇编器前的最后一个步骤。
汇编器 #
汇编器是将汇编语言翻译为机器语言的程序,Go 语言的汇编器是基于 Plan 9 汇编器的输入类型设计的,Go 语言对于汇编语言 Plan 9 和汇编器的资料十分缺乏,网上能够找到的资料也大多都含糊不清,官方对汇编器在不同处理器架构上的实现细节也没有明确定义:
The details vary with architecture, and we apologize for the imprecision; the situation is not well-defined.5
我们在研究汇编器和汇编语言时不应该陷入细节,只需要理解汇编语言的执行逻辑就能够帮助我们快速读懂汇编代码。当我们将如下的代码编译成汇编指令时,会得到如下的内容:
$ cat hello.go
package hello
func hello(a int) int {
c := a + 2
return c
}
$ GOOS=linux GOARCH=amd64 go tool compile -S hello.go
"".hello STEXT nosplit size=15 args=0x10 locals=0x0
0x0000 00000 (main.go:3) TEXT "".hello(SB), NOSPLIT, $0-16
0x0000 00000 (main.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:3) FUNCDATA $3, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:4) PCDATA $2, $0
0x0000 00000 (main.go:4) PCDATA $0, $0
0x0000 00000 (main.go:4) MOVQ "".a+8(SP), AX
0x0005 00005 (main.go:4) ADDQ $2, AX
0x0009 00009 (main.go:5) MOVQ AX, "".~r1+16(SP)
0x000e 00014 (main.go:5) RET
0x0000 48 8b 44 24 08 48 83 c0 02 48 89 44 24 10 c3 H.D$.H...H.D$..
...
上述汇编代码都是由 cmd/internal/obj.Flushplist 这个函数生成的,该函数会调用架构特定的 Preprocess 和 Assemble 方法:
func Flushplist(ctxt *Link, plist *Plist, newprog ProgAlloc, myimportpath string) {
...
for _, s := range text {
mkfwd(s)
linkpatch(ctxt, s, newprog)
ctxt.Arch.Preprocess(ctxt, s, newprog)
ctxt.Arch.Assemble(ctxt, s, newprog)
linkpcln(ctxt, s)
ctxt.populateDWARF(plist.Curfn, s, myimportpath)
}
}
Go 编译器会在最外层的主函数确定调用的 Preprocess 和 Assemble 方法,编译器在 2.1.4 中提到的 cmd/compile.archInits中根据目标硬件初始化当前架构使用的配置。
如果目标机器的架构是 x86,那么这两个函数最终会使用 cmd/internal/obj/x86.preprocess 和 cmd/internal/obj/x86.span6,作者在这里就不展开介绍这两个特别复杂的底层函数了,有兴趣的读者可以通过链接找到目标函数的位置了解预处理和汇编的处理过程,机器码的生成也都是由这两个函数组合完成的。
2.5.3 小结 #
机器码生成作为 Go 语言编译的最后一步,其实已经到了硬件和机器指令这一层,其中对于内存、寄存器的处理非常复杂并且难以阅读,想要真正掌握这里的处理的步骤和原理还是需要耗费很多精力。
作为软件工程师,如果不是 Go 语言编译器的开发者或者需要经常处理汇编语言和机器指令,掌握这些知识的投资回报率实在太低,我们只需要对这个过程有所了解,补全知识上的盲点,在遇到问题时能够快速定位即可。
2.5.4 延伸阅读 #
-
Instruction set architecture https://en.wikipedia.org/wiki/Instruction_set_architecture ↩︎
-
复杂指令集 Complex instruction set computer https://en.wikipedia.org/wiki/Complex_instruction_set_computer ↩︎
-
精简指令集 Reduced instruction set computer https://en.wikipedia.org/wiki/Reduced_instruction_set_computer ↩︎
-
Introduction to the Go compiler https://github.com/golang/go/blob/master/src/cmd/compile/README.md ↩︎
-
A Quick Guide to Go’s Assembler https://golang.org/doc/asm ↩︎
32、64、x86、x64 有什么区别?Win 11 最大的进步是干掉了这个「老破小」 https://mp.weixin.qq.com/s/qXF9zNdY7B33AOLi5zYasw
32、64、x86、x64 有什么区别?Win 11 最大的进步是干掉了这个「老破小」
 关注“脚本之家”,与百万开发者在一起
关注“脚本之家”,与百万开发者在一起 本文来自电手(ID:AoMeiDianShou),未经授权不得二次转载
本文来自电手(ID:AoMeiDianShou),未经授权不得二次转载熟悉计算机的朋友应该都知道,处理器、操作系统、驱动和软件都有 32 位和 64 位之分,一般我们装系统、下软件都会选 64 位版的。但现在仍有很多新开发的软件,仅提供 32 位版本。
32 位和 64 位的真正区别是什么?到底哪种更好?而且不光是 32 位和 64 位,x86 和 x64 在计算机中又代表什么?
01 真正的 x86

一切都要从 1978 年说起,英特尔在这年发布了世界上第一款 x86 指令集架构的处理器「Intel 8086」。
 之后这个系列的处理器名称都以数字 86 作为结尾,比如 Intel 8086、80286、以及 80486,所以慢慢的这个系列就被简称为 x86 了。x86 从 1985 年发布的 Intel 80386 处理器开始使用「32 位架构指令集」,称之为 x86_32(此前都是 16 位)。
之后这个系列的处理器名称都以数字 86 作为结尾,比如 Intel 8086、80286、以及 80486,所以慢慢的这个系列就被简称为 x86 了。x86 从 1985 年发布的 Intel 80386 处理器开始使用「32 位架构指令集」,称之为 x86_32(此前都是 16 位)。
随着 Intel 不断推出新的 32 位处理器,慢慢大家发现 32 位 和 x86 通常指的都是一个东西,所以 32 位也被简称为 x86。
 这也是为什么现在我们看到的 x86 几乎都默认指 32 位。然而
这也是为什么现在我们看到的 x86 几乎都默认指 32 位。然而
谁能想到 AMD 在 2003 年突然一个鲤鱼打挺,抢在英特尔之前发布了 64 位处理器,并将其命名为「AMD 64」,从此 x86 正式进入了 64 位的时代。
 64 位不光数字上领先 32 位,在性能和应用场景上也得到了大幅提升(后面讲),之后英特尔也跟进推出了与之兼容的处理器,命其为「Intel 64」,两者被统称为 x86_64。所以,x86 的本意其实同时包含「32 位和 64位」 。
64 位不光数字上领先 32 位,在性能和应用场景上也得到了大幅提升(后面讲),之后英特尔也跟进推出了与之兼容的处理器,命其为「Intel 64」,两者被统称为 x86_64。所以,x86 的本意其实同时包含「32 位和 64位」 。
历史的经验告诉我们,懒癌不是能接受 x86_32 和 x86_64 这种说法的,于是 x86_64 被简称成了 x64。
02 有什么区别
在硬件上,32 位 软件和 64 位 最大区别,也是当年 64 位被推上舞台的原因,32 位支持的内存是 2^32 Byte,也就是最大只支持 4GB 内存。而 64 位支持 2^64 Byte,也就是 17179869184G=16777216TB ≈ ∞。

1.5 TB 运行内存的 Mac Pro
另外 64 位处理器的「寄存器」也是 64 位,曾经 32 位处理器一次运算需要 4 个「寄存器」,在 64 位处理器上只需要 2 个就够了。好处就是速度更快了。
在 Windows 系统中,32 位系统单个程序进程最多只能使用 2GB 内存空间,这就导致 Adobe 等吃内存的软件几乎无法工作。
所以这些大型软件几乎没有 32 位版本。在 64 位系统则中没有这方面的限制。
另外在 Windows 32 位系统下 C:\ProgramFiles\ 是软件默认安装目录,C:\ System32\ 是系统文件和 DLL 库的目录。
在 64 位系统中,C:\Program Files\ 是 64 位软件的默认安装目录,而C:\Program Files(x86)\ 是 32 位软件的默认安装目录。
因为 DLL 文件也分 32 位和 64 位的缘故,所以 64 位系统中 C:\Windows\System32\ 目录用来放 64 位 DLL 文件,C:\Windows\SysWOW64\ 目录则存放 32 位的 DLL。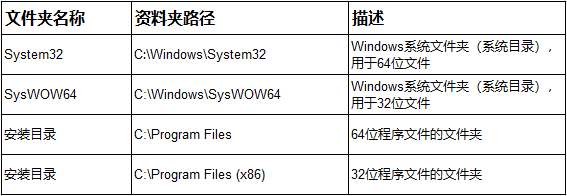
是不是有点绕?System32 是 64 位的,SysWOW64 是 32 位的。
总之,如果你安装了 64 位 Windows 系统,它其实包含了 32 位系统兼容库,并且有 32 位单独的文件夹,可以运行大部分 32 位的软件。
但 32 位却不能使用 64 位的软件。
Windows 系统从 XP 开始便一直有 32 位版和 64 位版,而 macOS 自 v10.8(Mountain Lion)开始就抛弃了 32 位版,只提供 64 位版。
查看系统多少位最简单的办法就是右键桌面上的 此电脑- 属性: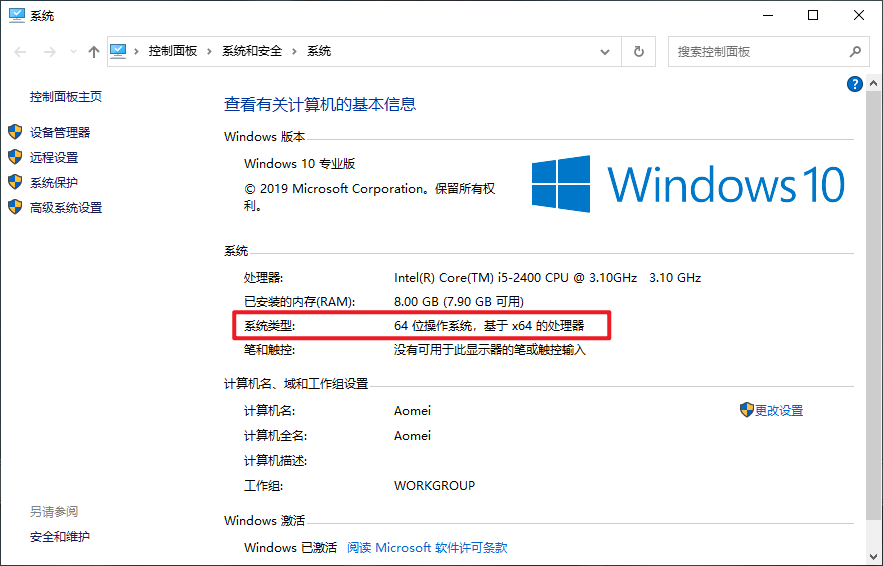
大家都知道这次 Windows 11 升级了很多硬件要求,其中最大的进步之一就是:Windows 11现在需要 64 位或 ARM64 处理器,对 32 处理器已不再支持。
这可以说是极大的进步,取消对 32 位的支持,也就意味着把老旧的 BIOS(非UEFI)、MBR 分区表格式、32 位发行版、16 位运行环境(NTVDM)等落后技术一并淘汰掉。
但系统中依然保留了 32 位虚拟系统,仍然可以运行 32 位程序。(希望微软提上日程)
这二十年来,苹果从 MacOS9 RISC 到 OSX RISC 到 OSX X86 到 macOS X64 到 macOS ARM,更新了 4 次架构,
Windows 这才终于移除了 32 位处理器和 IE 浏览器,减轻了一点历史包袱。
为什么 Windows 这么先进的系统,直到 Windows 11 才肯放弃 32 位处理器呢?
主要还是用户太多了。
6 年 Windows 10 发布时,前微软的官方负责人回答过这个问题:当时还有大约 1 亿用户在使用 32 位的处理器。
微软并不打算放弃这部分用户。其实 Windows 系统的向下兼容性一直非常好,肯定很多人觉得这话是扯淡,一些软件就不能再 Windows10 上运行嘛。
然而即便如此 Windows 系统的向下兼容性也是业界楷模,达到变态的程度,甚至阻碍其发展。

32位系统装8g内存条能用吗?为什么? https://mp.weixin.qq.com/s/VLPXedDRDKn8l-KCJrYnlw
32位系统装8g内存条能用吗?为什么?
编者荐语:
以下文章来源于小白debug ,作者小白

答应我,关注之后,好好学技术,别只是收藏我的表情包。。

关于32位和64位,这个概念一直让人比较懵。
在买电脑的时候,我们看到过32位和64位CPU。
下软件的时候,我们也看到过32位或64位的软件。
就连装虚拟机的时候,我们也看过32位和64位的系统。
在写代码的时候,我们的数值,也可以定义为int32或者int64。
我们当然很清楚,装软件的时候,一般64位的系统就选64位的软件,肯定不出错,但是这又是为什么呢?既然CPU,软件,操作系统,数值大小都有32位和64位,他们之间就可以随意组合成各种问题,比如32位的系统能装64位的软件吗?32位的系统能计算int64的数值吗?他们之间到底有什么关系?这篇文章会尝试解释清楚。
从代码到到可执行文件
我们从熟悉的场景开始说起,比方说,我们写代码的时候,会在代码编辑器里写入。
// test.c
#include <stdio.h>
int main()
{
int i,j;
i = 3;
j = 2;
return i + j;
}
但这个代码是给人看的,机器可看不懂,于是这段代码,还会经过被编译器转成汇编码。
汇编码就是我们大学的时候学的头秃的这种
// gcc -S test.c
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl $0, -4(%rbp)
movl $3, -8(%rbp)
movl $2, -12(%rbp)
movl -8(%rbp), %eax
addl -12(%rbp), %eax
popq %rbp
retq
大家也别去看上面的内容,没必要。
而汇编,总归还是有各种movl,pushq这些符号,虽然确实不好看,但说到底还是给人看的,而机器cpu要的,说到底还是要0101这样的二进制编码,所以还需要使用汇编器将汇编转成二进制的机器码。我们可以看到下面内容分为3列,左边是指令地址, 右边是汇编码内容,中间的就是指令机器码,是16进制,可以转成二进制01串,这就是机器cpu能认识的内容了。
// objdump -d test
0000000000001125 <main>:
1125: 55 push %rbp
1126: 48 89 e5 mov %rsp,%rbp
1129: c7 45 fc 03 00 00 00 movl $0x3,-0x4(%rbp)
1130: c7 45 f8 02 00 00 00 movl $0x2,-0x8(%rbp)
1137: 8b 55 fc mov -0x4(%rbp),%edx
113a: 8b 45 f8 mov -0x8(%rbp),%eax
113d: 01 d0 add %edx,%eax
113f: 5d pop %rbp
1140: c3 retq
1141: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
1148: 00 00 00
114b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
 从高级语言到机器码
从高级语言到机器码
而机器码,最后会放在我们编译生成的可执行文件里。
也就是说我们平时写的代码,最后会变成一堆01机器码,放在可执行文件里,躺在磁盘上。
从可执行文件到进程
一旦我们执行以下命令
./可执行文件名
这个可执行文件就会加载进内存中,成为一个进程,运行起来。
可执行文件里的机器码也会被加载到内存中,它就像是一张列满todo list的清单,而CPU就对照着这张清单,一行行的执行上面的机器码。从效果上来看,进程就动起来了。
对CPU来说,它执行到某个特定的编码数值,就会执行特定的操作。比如计算2+3,其实就是通过总线把数据2和3从内存里读入,然后放到寄存器上,再用加法器相加这两个数值并将结果放入到寄存器里,最后将这个数值回写到内存中,以此循环往复,一行行执行机器码直到退出。
 进程内存与CPU的执行逻辑
进程内存与CPU的执行逻辑
CPU位数的含义
上面这个流程里,最重要的几个关键词,分别是CPU寄存器,总线,内存。
CPU的寄存器,说白了就是个存放数值的小盒子,盒子的大小,叫位宽。32位CPU能放入最大2^32的数值。64位就是最大2^64的值。这里的32位位宽的CPU就是我们常说的32位CPU,同理64位CPU也是一样。
而CPU跟内存之间,是用总线来进行信号传输的,总线可以分为数据总线,控制总线,地址总线。功能如其名,举个例子说明下他们的作用吧。在一个进程的运行过程中,CPU会根据进程的机器码一行行执行操作。
比如现在有一行是将A地址的数据与B地址的数据相加,那么CPU就会通过控制总线,发送信号给内存这个设备,告诉它,现在CPU要通过地址总线在内存中找到A数据的地址,然后取得A数据的值,假设是100,那么这个100,就会通过数据总线回传到CPU的某个寄存器中。B也一样,假设B=200,放到另一个寄存器中,此时A和B相加后,结果是300,然后控制CPU通过地址总线找到返回的参数地址,再把数据结果通过数据总线传回内存中。这一存一取,CPU都是通过控制总线对内存发出指令的。
 三类总线
三类总线
而总线,也可以理解为有个宽度,比如宽度是32位,那么一次可以传32个0或1的信号,那么这个宽度能表达的数值范围就是0到2^32这么多。
32位CPU的总线宽度一般是32位,因为刚刚上面提到了,CPU可以利用地址总线在内存中进行寻址操作,那么现在这根地址总线,最大能寻址的范围,也就到2^32,其实就是4G。
64位CPU,按理说总线宽度是64位,但实际上是48位(也有看到说是40位或46位的,没关系,你知道它很大就行了),所以寻址范围能到2^48次方,也就是256T。
系统和软件的位数的含义
上面提到了32位CPU和64位CPU的内存寻址范围,那么相应的操作系统,和软件(其实操作系统也能说是软件),也应该按CPU所能支持的范围去构建自己的寻址范围。
比方说下面这个图,在操作系统上运行一个用户态进程,会分为用户态和内核态,并设定一定的内存布局。操作系统和软件都需要以这个内存布局为基础运行程序。比如32位,内核态分配了1个G,用户态分配了3G,这种时候,你总不能将程序的运行内存边界设定在大于10G的地方。所以,系统和软件的位数,可以理解为,这个系统或软件内存寻址的范围位数。
 32和64位的内存差异
32和64位的内存差异
一般情况下,由于现在我们的CPU架构在设计上都是完全向前兼容的,别说32位了,16位的都还兼容着,因此64位的CPU是能装上32位操作系统的。
同理,64位的操作系统是兼容32位的软件的,所以32位软件能装在64位系统上。
但反过来,因为32位操作系统只支持4g的内存,而64位的软件在编译的时候就设定自己的内存边界不止4个G,并且64位的CPU指令集内容比32位的要多,所以32位操作系统是肯定不能运行64位软件的。
同理,32位CPU也不能装64位的操作系统的。
程序数值int32和int64的含义
这个我们平时写代码接触的最多,比较好理解了。int32也就是用4个字节,32位的内存去存储数据,int64也就是用8个字节,64位去存数据。这个数值就是刚刚CPU运行流程中放在内存里的数据。
那么问题又来了。
32位的CPU能进行int64位的数值计算吗?
先说结论,能。但比起64位的CPU,性能会慢一些。
如果说我用的是64位的CPU,那么我在计算两个int64的数值相加时,我就能将数据通过64位的总线,一次性存入到64位的寄存器,并在进行计算后返回到内存中。整个过程一步到位,一气呵成。
但如果我现在用的是32位的CPU,那就憋屈一点了,我虽然在代码里放了个int64的数值,但实际上CPU的寄存器根本放不下这么大的数据,因此最简单的方法是,将int64的数值,拆成前后两半,现在两个int64相加,就变成了4个int32的数值相加,并且后半部分加好了之后,拿到进位,才能去计算前面的部分,这里光是执行的指令数就比64位的CPU要多。所以理论上,会更慢些。
系统位数会限制内存吗?
上面提到了CPU位数,系统位数,软件位数,以及数值位数之间的区别与联系。
现在,我们回到标题里提到的问题。
32位CPU和系统插8g内存条,能用吗?
系统能正常工作,但一般用不到8G,因为32位系统的总线寻址能力为2的32次方,也就是4G,哪怕装了8G的内存,真正能被用到的其实只有4g,多少有点浪费。
注意上面提到的是一般,为什么这么说,因为这里有例外,32位系统里,有些是可以支持超过4G内存的,比如Windows Server 2003就能最大支持64G的内存,它通过使用 PAE (Intel Physical Address Extension)技术向程序提供更多的物理内存,PAE本质上是通过分页管理的方式将32位的总线寻址能力增加到36位。因此理论上寻址能力达到2的36次方,也就是64G。
 PAE能让32位系统获得大于4G的内存
PAE能让32位系统获得大于4G的内存
至于实现细节大家也不用关心,现在用到这玩意的机器也该淘汰的差不多了,而且都是windows server,注意Windows Server 2003 名字里带个server,是用来做服务器的,我们一般也用不到,知道这件事,除了能帮助我们更好的装x外,就没什么作用了。
所以,你当32位系统最大只能用到4G内存,那也没毛病。
64位CPU装32位操作系统,再插上8g的内存条,寻址能力还是4G吗
上面提到32位CPU就算插上8G内存条,寻址能力也还是4G,那如果说我现在换用64位的CPU,但装了个32位的操作系统,这时候插入8G内存条,寻址能力能超过4G吗?
寻址能力,除了受到cpu的限制外,还受到操作系统的限制,如果操作系统就是按着32位的指令和寻址范围(4G)来编译的话,那么它就会缺少64位系统该有的指令,它在运行软件的时候就不能做到超过这个限制,因此寻址能力还会是4G。
最后留下一个问题吧。
上面提到,我们平时写的代码(也就是C,go,java这些),先转成汇编,再转成机器码。最后CPU执行的是机器码,那么问题来了。
为什么我们平时写的代码不直接转成机器码,而要先转成汇编,这是不是多此一举?
总结
-
CPU位数主要指的是寄存器的位宽,
-
32位CPU只能装32位的系统和软件,且能计算int64,int32的数值。内存寻址范围是4G。
-
64位CPU,同时兼容32位和64位的系统和软件,并且进行int64数值计算的时候,性能比32位CPU更好,内存寻址范围可以达到256T。
-
32位CPU和操作系统,插入8G的内存,会有点浪费,因为总线寻址范围比较有限,它只能用上4G不到的内存。
-
64位CPU,如果装上32位的操作系统,就算插上8G的内存,效果也还是只能用上4G不到的内存。
最后
刚工作的时候一直觉得int32,有21个亿,这么大的数值肯定够用了吧,结果现实好几次打脸。
以前做游戏的时候,血量一开始是定义为int32,游戏设定是可以通过充钱,提升角色的属性,还能提升血量上限,谁也没想到,老板们通过氪金,硬是把血量给打到了int32最大值。于是策划提了个一句话需求:"血量要支持到int64大小",这是我见过最简单的策划案,但也让人加班加的最凶。
那是我第一次感受到了钞能力。
AArch64 - Wikipedia https://en.wikipedia.org/wiki/AArch64
AArch64 or ARM64 is the 64-bit extension of the ARM architecture.

Announced in October 2011,[1] ARMv8-A represents a fundamental change to the ARM architecture. It adds an optional 64-bit architecture, named "AArch64", and the associated new "A64" instruction set. AArch64 provides user-space compatibility with the existing 32-bit architecture ("AArch32" / ARMv7-A), and instruction set ("A32"). The 16-32bit Thumb instruction set is referred to as "T32" and has no 64-bit counterpart. ARMv8-A allows 32-bit applications to be executed in a 64-bit OS, and a 32-bit OS to be under the control of a 64-bit hypervisor.[2] ARM announced their Cortex-A53 and Cortex-A57 cores on 30 October 2012.[3] Apple was the first to release an ARMv8-A compatible core (Apple A7) in a consumer product (iPhone 5S). AppliedMicro, using an FPGA, was the first to demo ARMv8-A.[4] The first ARMv8-A SoC from Samsung is the Exynos 5433 used in the Galaxy Note 4, which features two clusters of four Cortex-A57 and Cortex-A53 cores in a big.LITTLE configuration; but it will run only in AArch32 mode.[5]
To both AArch32 and AArch64, ARMv8-A makes VFPv3/v4 and advanced SIMD (Neon) standard. It also adds cryptography instructions supporting AES, SHA-1/SHA-256 and finite field arithmetic.[6]
It was first introduced with the ARMv8-A architecture.
What is the difference between X64 and ARM64 - Microsoft Q&A https://docs.microsoft.com/en-us/answers/questions/10614/what-is-the-difference-between-x64-and-arm64.html
Like x86 and x64, ARM is a different processor (CPU) architecture. The ARM architecture is typically used to build CPUs for a mobile device, ARM64 is simply an extension or evolution of the ARM architecture that supports 64-bit processing. Devices built on the ARM64 architecture include desktop PCs, mobile devices, and some IoT Core devices (Rasperry Pi 2, Raspberry Pi 3, and DragonBoard). For example the Microsoft HoloLens 2 uses an ARM64 processor.
App package architectures - MSIX | Microsoft Docs https://docs.microsoft.com/en-US/windows/msix/package/device-architecture
App packages are configured to run on a specific processor architecture. By selecting an architecture, you are specifying which device(s) you want your app to run on. Universal Windows Platform (UWP) apps can be configured to run on the following architectures:
- x86
- x64
- ARM
- ARM64
It is highly recommended that you build your app package to target all architectures. By deselecting a device architecture, you are limiting the number of devices your app can run on, which in turn will limit the amount of people who can use your app!
Windows 10 devices and architectures
| UWP Architecture | Desktop (x86) | Desktop (x64) | Desktop (ARM) | Mobile | Windows Mixed Reality and HoloLens | Xbox | IoT Core (Device dependent) | Surface Hub |
|---|---|---|---|---|---|---|---|---|
| x86 | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ❌ | ✔️ | ✔️ |
| x64 | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
| ARM | ❌ | ❌ | ✔️ | ✔️ | ❌ | ❌ | ✔️ | ❌ |
| ARM64 | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ❌ |
Let’s talk about these architectures in more detail.
x86
Choosing x86 is generally the safest configuration for an app package since it will run on nearly every device. On some devices, an app package with the x86 configuration won't run, such as the Xbox or some IoT Core devices. However, for a PC, an x86 package is the safest choice and has the largest reach for device deployment. A substantial portion of Windows 10 devices continue to run the x86 version of Windows.
x64
This configuration is used less frequently than the x86 configuration. It should be noted that this configuation is reserved for desktops using 64-bit versions of Windows 10, UWP apps on Xbox, and Windows 10 IoT Core on the Intel Joule.
ARM and ARM64
The Windows 10 on ARM configuration includes desktop PCs, mobile devices, and some IoT Core devices (Rasperry Pi 2, Raspberry Pi 3, and DragonBoard). Windows 10 on ARM desktop PCs are a new addition to the Windows family, so if you are UWP app developer, you should submit ARM packages to the Store for the best experience on these PCs.
https://zh.wikipedia.org/wiki/X86
x86泛指一系列英特尔公司用于开发处理器的指令集架构,这类处理器最早为1978年面市的“Intel 8086”CPU。
该系列较早期的处理器名称是以数字来表示80x86。由于以“86”作为结尾,包括Intel 8086、80186、80286、80386以及80486,因此其架构被称为“x86”。由于数字并不能作为注册商标,因此Intel及其竞争者均在新一代处理器使用可注册的名称,如Pentium。现时英特尔将其称为IA-32,全名为“Intel Architecture, 32-bit”,一般情形下指代32位的架构。
https://zh.wikipedia.org/wiki/X86-64
x86-64( 又称x64,即英文词64-bit extended,64位拓展 的简写)是x86架构的64位拓展,向后兼容于16位及32位的x86架构。x64于1999年由AMD设计,AMD首次公开64位集以扩展给x86,称为“AMD64”。其后也为英特尔所采用,现时英特尔称之为“Intel 64”,在之前曾使用过“Clackamas Technology” (CT)、“IA-32e”及“EM64T”。
苹果公司和RPM包管理员以“x86-64”或“x86_64”称呼此64位架构。甲骨文公司及Microsoft称之为“x64”。BSD家族及其他Linux发行版则使用“amd64”,32位版本则称为“i386”(或 i486/586/686),Arch Linux用x86_64称呼此64位架构。
Intel 64可使处理器直接访问超过4GB的存储器,容许运行更大的应用程序。而x86-64架构也加入了额外的寄存器及其他改良在指令集上。透过64位的存储器地址上限,其理论存储器大小上限达16,000,000TB(16EB),不过在初期的应用上并未能支持完整的64位地址。
https://en.wikipedia.org/wiki/X86
x86 is a family of instruction set architectures[a] initially developed by Intel based on the Intel 8086 microprocessor and its 8088 variant. The 8086 was introduced in 1978 as a fully 16-bit extension of Intel's 8-bit 8080 microprocessor, with memory segmentation as a solution for addressing more memory than can be covered by a plain 16-bit address. The term "x86" came into being because the names of several successors to Intel's 8086 processor end in "86", including the 80186, 80286, 80386 and 80486 processors.
https://baike.baidu.com/item/64位处理器/2354951
所谓32位处理器就是一次只能处理32位,也就是4个字节的数据,而64位处理器一次就能处理64位,即8个字节的数据。
Like x86 and x64, ARM is a different processor (CPU) architecture. The ARM architecture is typically used to build CPUs for a mobile device, ARM64 is simply an extension or evolution of the ARM architecture that supports 64-bit processing. Devices built on the ARM64 architecture include desktop PCs, mobile devices, and some IoT Core devices (Rasperry Pi 2, Raspberry Pi 3, and DragonBoard). For example the Microsoft HoloLens 2 uses an ARM64 processor.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号