Hinge Loss
The hinge loss is a convex function, so many of the usual convex optimizers used in machine learning can work with it. It is not differentiable, but has a subgradient with respect to model parameters w of a linear SVM with score function  that is given by
that is given by

The hinge loss is a convex function, so many of the usual convex optimizers used in machine learning can work with it. It is not differentiable, but has a subgradient with respect to model parameters w of a linear SVM with score function that is given by
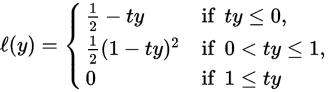
or the quadratically smoothed
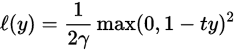
suggested by Zhang.[6] The modified Huber loss is a special case of this loss function with  .[6]
.[6]
https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Hinge_loss.html

http://www1.inf.tu-dresden.de/~ds24/lehre/ml_ws_2013/ml_11_hinge.pdf



 浙公网安备 33010602011771号
浙公网安备 33010602011771号