state checkpoint
state checkpoint
Checkpointing | Apache Flink https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/checkpointing/
每个函数和operator都是有状态的。
检查文件默认存放在任务管理器 JobManager’s heap的 堆上。
检查点增量存储。(全量大小)
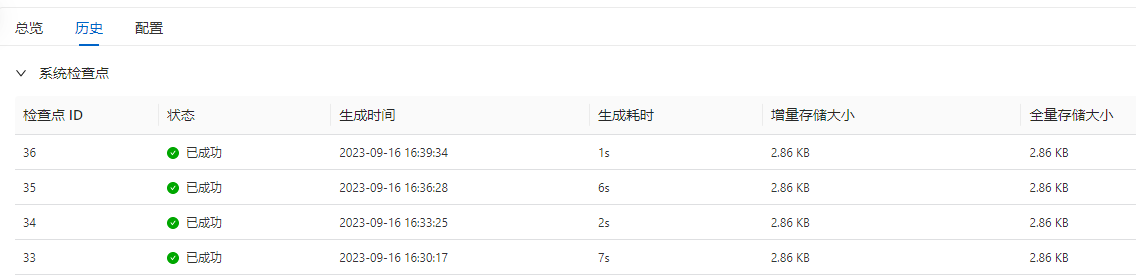
| End to End Duration | Checkpointed Data Size | Full Checkpoint Data Size | Processed (persisted) in-flight data | |
|---|---|---|---|---|
| Minimum | 2s | 3.27 KB | 3.27 KB | 0 B (0 B) |
| Average | 3s | 3.27 KB | 3.27 KB | 0 B (0 B) |
| Maximum | 7s | 3.27 KB | 3.27 KB | 0 B (0 B) |
| Name | Acknowledged | Latest Acknowledgement | End to End Duration | Checkpointed Data Size | Full Checkpoint Data Size | Processed (persisted) in-flight data | |
|---|---|---|---|---|---|---|---|
| Source: app_source[6156… | 2/2 (100%) | 2023-09-16 17:30:25 | 2s | 3.27 KB | 3.27 KB | 0 B (0 B) |
| Option | Value |
|---|---|
| Checkpointing Mode | Exactly Once |
| Interval | 3m 0s |
| Timeout | 10m 0s |
| Minimum Pause Between Checkpoints | 3m 0s |
| Maximum Concurrent Checkpoints | 1 |
| Persist Checkpoints Externally | Enabled (retain on cancellation) |
exactly-once vs. at-least-once 至多一次 至少一次
Checkpointing #
Every function and operator in Flink can be stateful (see working with state for details). Stateful functions store data across the processing of individual elements/events, making state a critical building block for any type of more elaborate operation.
In order to make state fault tolerant, Flink needs to checkpoint the state. Checkpoints allow Flink to recover state and positions in the streams to give the application the same semantics as a failure-free execution.
The documentation on streaming fault tolerance describes in detail the technique behind Flink’s streaming fault tolerance mechanism.
Prerequisites #
Flink’s checkpointing mechanism interacts with durable storage for streams and state. In general, it requires:
- A persistent (or durable) data source that can replay records for a certain amount of time. Examples for such sources are persistent messages queues (e.g., Apache Kafka, RabbitMQ, Amazon Kinesis, Google PubSub) or file systems (e.g., HDFS, S3, GFS, NFS, Ceph, …).
- A persistent storage for state, typically a distributed filesystem (e.g., HDFS, S3, GFS, NFS, Ceph, …)
Enabling and Configuring Checkpointing #
By default, checkpointing is disabled. To enable checkpointing, call enableCheckpointing(n) on the StreamExecutionEnvironment, where n is the checkpoint interval in milliseconds.
Other parameters for checkpointing include:
-
checkpoint storage: You can set the location where checkpoint snapshots are made durable. By default Flink will use the JobManager’s heap. For production deployments it is recommended to instead use a durable filesystem. See checkpoint storage for more details on the available options for job-wide and cluster-wide configuration.
-
exactly-once vs. at-least-once: You can optionally pass a mode to the
enableCheckpointing(n)method to choose between the two guarantee levels. Exactly-once is preferable for most applications. At-least-once may be relevant for certain super-low-latency (consistently few milliseconds) applications. -
checkpoint timeout: The time after which a checkpoint-in-progress is aborted, if it did not complete by then.
-
minimum time between checkpoints: To make sure that the streaming application makes a certain amount of progress between checkpoints, one can define how much time needs to pass between checkpoints. If this value is set for example to 5000, the next checkpoint will be started no sooner than 5 seconds after the previous checkpoint completed, regardless of the checkpoint duration and the checkpoint interval. Note that this implies that the checkpoint interval will never be smaller than this parameter.
It is often easier to configure applications by defining the “time between checkpoints” than the checkpoint interval, because the “time between checkpoints” is not susceptible to the fact that checkpoints may sometimes take longer than on average (for example if the target storage system is temporarily slow).
Note that this value also implies that the number of concurrent checkpoints is one.
-
tolerable checkpoint failure number: This defines how many consecutive checkpoint failures will be tolerated, before the whole job is failed over. The default value is
0, which means no checkpoint failures will be tolerated, and the job will fail on first reported checkpoint failure. This only applies to the following failure reasons: IOException on the Job Manager, failures in the async phase on the Task Managers and checkpoint expiration due to a timeout. Failures originating from the sync phase on the Task Managers are always forcing failover of an affected task. Other types of checkpoint failures (such as checkpoint being subsumed) are being ignored. -
number of concurrent checkpoints: By default, the system will not trigger another checkpoint while one is still in progress. This ensures that the topology does not spend too much time on checkpoints and not make progress with processing the streams. It is possible to allow for multiple overlapping checkpoints, which is interesting for pipelines that have a certain processing delay (for example because the functions call external services that need some time to respond) but that still want to do very frequent checkpoints (100s of milliseconds) to re-process very little upon failures.
This option cannot be used when a minimum time between checkpoints is defined.
-
externalized checkpoints: You can configure periodic checkpoints to be persisted externally. Externalized checkpoints write their meta data out to persistent storage and are not automatically cleaned up when the job fails. This way, you will have a checkpoint around to resume from if your job fails. There are more details in the deployment notes on externalized checkpoints.
-
unaligned checkpoints: You can enable unaligned checkpoints to greatly reduce checkpointing times under backpressure. This only works for exactly-once checkpoints and with one concurrent checkpoint.
-
checkpoints with finished tasks: By default Flink will continue performing checkpoints even if parts of the DAG have finished processing all of their records. Please refer to important considerations for details.
Stateful Stream Processing | Apache Flink https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/concepts/stateful-stream-processing/
What is State? #
While many operations in a dataflow simply look at one individual event at a time (for example an event parser), some operations remember information across multiple events (for example window operators). These operations are called stateful.
Some examples of stateful operations:
- When an application searches for certain event patterns, the state will store the sequence of events encountered so far.
- When aggregating events per minute/hour/day, the state holds the pending aggregates.
- When training a machine learning model over a stream of data points, the state holds the current version of the model parameters.
- When historic data needs to be managed, the state allows efficient access to events that occurred in the past.
Flink needs to be aware of the state in order to make it fault tolerant using checkpoints and savepoints.
Knowledge about the state also allows for rescaling Flink applications, meaning that Flink takes care of redistributing state across parallel instances.
Queryable state allows you to access state from outside of Flink during runtime.
When working with state, it might also be useful to read about Flink’s state backends. Flink provides different state backends that specify how and where state is stored.
Keyed State #
Keyed state is maintained in what can be thought of as an embedded key/value store. The state is partitioned and distributed strictly together with the streams that are read by the stateful operators. Hence, access to the key/value state is only possible on keyed streams, i.e. after a keyed/partitioned data exchange, and is restricted to the values associated with the current event’s key. Aligning the keys of streams and state makes sure that all state updates are local operations, guaranteeing consistency without transaction overhead. This alignment also allows Flink to redistribute the state and adjust the stream partitioning transparently.
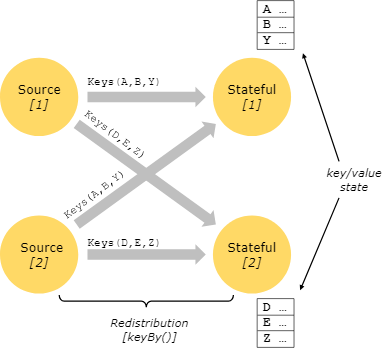
Keyed State is further organized into so-called Key Groups. Key Groups are the atomic unit by which Flink can redistribute Keyed State; there are exactly as many Key Groups as the defined maximum parallelism. During execution each parallel instance of a keyed operator works with the keys for one or more Key Groups.
容错实现 流重放、检查点
State Persistence #
Flink implements fault tolerance using a combination of stream replay and checkpointing. A checkpoint marks a specific point in each of the input streams along with the corresponding state for each of the operators. A streaming dataflow can be resumed from a checkpoint while maintaining consistency (exactly-once processing semantics) by restoring the state of the operators and replaying the records from the point of the checkpoint.
The checkpoint interval is a means of trading off the overhead of fault tolerance during execution with the recovery time (the number of records that need to be replayed).
The fault tolerance mechanism continuously draws snapshots of the distributed streaming data flow. For streaming applications with small state, these snapshots are very light-weight and can be drawn frequently without much impact on performance. The state of the streaming applications is stored at a configurable place, usually in a distributed file system.
In case of a program failure (due to machine-, network-, or software failure), Flink stops the distributed streaming dataflow. The system then restarts the operators and resets them to the latest successful checkpoint. The input streams are reset to the point of the state snapshot. Any records that are processed as part of the restarted parallel dataflow are guaranteed to not have affected the previously checkpointed state.
By default, checkpointing is disabled. See Checkpointing for details on how to enable and configure checkpointing.
For this mechanism to realize its full guarantees, the data stream source (such as message queue or broker) needs to be able to rewind the stream to a defined recent point. Apache Kafka has this ability and Flink’s connector to Kafka exploits this. See Fault Tolerance Guarantees of Data Sources and Sinks for more information about the guarantees provided by Flink’s connectors.
Because Flink’s checkpoints are realized through distributed snapshots, we use the words snapshot and checkpoint interchangeably. Often we also use the term snapshot to mean either checkpoint or savepoint.
Checkpointing #
The central part of Flink’s fault tolerance mechanism is drawing consistent snapshots of the distributed data stream and operator state. These snapshots act as consistent checkpoints to which the system can fall back in case of a failure. Flink’s mechanism for drawing these snapshots is described in “Lightweight Asynchronous Snapshots for Distributed Dataflows”. It is inspired by the standard Chandy-Lamport algorithm for distributed snapshots and is specifically tailored to Flink’s execution model.
Keep in mind that everything to do with checkpointing can be done asynchronously. The checkpoint barriers don’t travel in lock step and operations can asynchronously snapshot their state.
Since Flink 1.11, checkpoints can be taken with or without alignment. In this section, we describe aligned checkpoints first.
容错的核心是连续的分布式数据流和操作的快照。
检查点屏障。
Stateful Stream Processing | Apache Flink https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/concepts/stateful-stream-processing/
Barriers #
A core element in Flink’s distributed snapshotting are the stream barriers. These barriers are injected into the data stream and flow with the records as part of the data stream. Barriers never overtake records, they flow strictly in line. A barrier separates the records in the data stream into the set of records that goes into the current snapshot, and the records that go into the next snapshot. Each barrier carries the ID of the snapshot whose records it pushed in front of it. Barriers do not interrupt the flow of the stream and are hence very lightweight. Multiple barriers from different snapshots can be in the stream at the same time, which means that various snapshots may happen concurrently.

Stream barriers are injected into the parallel data flow at the stream sources. The point where the barriers for snapshot n are injected (let’s call it Sn) is the position in the source stream up to which the snapshot covers the data. For example, in Apache Kafka, this position would be the last record’s offset in the partition. This position Sn is reported to the checkpoint coordinator (Flink’s JobManager).
The barriers then flow downstream. When an intermediate operator has received a barrier for snapshot n from all of its input streams, it emits a barrier for snapshot n into all of its outgoing streams. Once a sink operator (the end of a streaming DAG) has received the barrier n from all of its input streams, it acknowledges that snapshot n to the checkpoint coordinator. After all sinks have acknowledged a snapshot, it is considered completed.
Once snapshot n has been completed, the job will never again ask the source for records from before Sn, since at that point these records (and their descendant records) will have passed through the entire data flow topology.

Operators that receive more than one input stream need to align the input streams on the snapshot barriers. The figure above illustrates this:
- As soon as the operator receives snapshot barrier n from an incoming stream, it cannot process any further records from that stream until it has received the barrier n from the other inputs as well. Otherwise, it would mix records that belong to snapshot n and with records that belong to snapshot n+1.
- Once the last stream has received barrier n, the operator emits all pending outgoing records, and then emits snapshot n barriers itself.
- It snapshots the state and resumes processing records from all input streams, processing records from the input buffers before processing the records from the streams.
- Finally, the operator writes the state asynchronously to the state backend.
Note that the alignment is needed for all operators with multiple inputs and for operators after a shuffle when they consume output streams of multiple upstream subtasks.
Snapshotting Operator State #
When operators contain any form of state, this state must be part of the snapshots as well.
Operators snapshot their state at the point in time when they have received all snapshot barriers from their input streams, and before emitting the barriers to their output streams. At that point, all updates to the state from records before the barriers have been made, and no updates that depend on records from after the barriers have been applied. Because the state of a snapshot may be large, it is stored in a configurable state backend. By default, this is the JobManager’s memory, but for production use a distributed reliable storage should be configured (such as HDFS). After the state has been stored, the operator acknowledges the checkpoint, emits the snapshot barrier into the output streams, and proceeds.
The resulting snapshot now contains:
- For each parallel stream data source, the offset/position in the stream when the snapshot was started
- For each operator, a pointer to the state that was stored as part of the snapshot

Recovery #
Recovery under this mechanism is straightforward: Upon a failure, Flink selects the latest completed checkpoint k. The system then re-deploys the entire distributed dataflow, and gives each operator the state that was snapshotted as part of checkpoint k. The sources are set to start reading the stream from position Sk. For example in Apache Kafka, that means telling the consumer to start fetching from offset Sk.
If state was snapshotted incrementally, the operators start with the state of the latest full snapshot and then apply a series of incremental snapshot updates to that state.
See Restart Strategies for more information.
Unaligned Checkpointing #
Checkpointing can also be performed unaligned. The basic idea is that checkpoints can overtake all in-flight data as long as the in-flight data becomes part of the operator state.
Note that this approach is actually closer to the Chandy-Lamport algorithm , but Flink still inserts the barrier in the sources to avoid overloading the checkpoint coordinator.

The figure depicts how an operator handles unaligned checkpoint barriers:
- The operator reacts on the first barrier that is stored in its input buffers.
- It immediately forwards the barrier to the downstream operator by adding it to the end of the output buffers.
- The operator marks all overtaken records to be stored asynchronously and creates a snapshot of its own state.
Consequently, the operator only briefly stops the processing of input to mark the buffers, forwards the barrier, and creates the snapshot of the other state.
Unaligned checkpointing ensures that barriers are arriving at the sink as fast as possible. It’s especially suited for applications with at least one slow moving data path, where alignment times can reach hours. However, since it’s adding additional I/O pressure, it doesn’t help when the I/O to the state backends is the bottleneck. See the more in-depth discussion in ops for other limitations.
Note that savepoints will always be aligned.
Unaligned Recovery #
Operators first recover the in-flight data before starting processing any data from upstream operators in unaligned checkpointing. Aside from that, it performs the same steps as during recovery of aligned checkpoints.
State Backends #
The exact data structures in which the key/values indexes are stored depends on the chosen state backend. One state backend stores data in an in-memory hash map, another state backend uses RocksDB as the key/value store. In addition to defining the data structure that holds the state, the state backends also implement the logic to take a point-in-time snapshot of the key/value state and store that snapshot as part of a checkpoint. State backends can be configured without changing your application logic.

Savepoints #
All programs that use checkpointing can resume execution from a savepoint. Savepoints allow both updating your programs and your Flink cluster without losing any state.
Savepoints are manually triggered checkpoints, which take a snapshot of the program and write it out to a state backend. They rely on the regular checkpointing mechanism for this.
Savepoints are similar to checkpoints except that they are triggered by the user and don’t automatically expire when newer checkpoints are completed. To make proper use of savepoints, it’s important to understand the differences between checkpoints and savepoints which is described in checkpoints vs. savepoints.
Exactly Once vs. At Least Once #
The alignment step may add latency to the streaming program. Usually, this extra latency is on the order of a few milliseconds, but we have seen cases where the latency of some outliers increased noticeably. For applications that require consistently super low latencies (few milliseconds) for all records, Flink has a switch to skip the stream alignment during a checkpoint. Checkpoint snapshots are still drawn as soon as an operator has seen the checkpoint barrier from each input.
When the alignment is skipped, an operator keeps processing all inputs, even after some checkpoint barriers for checkpoint n arrived. That way, the operator also processes elements that belong to checkpoint n+1 before the state snapshot for checkpoint n was taken. On a restore, these records will occur as duplicates, because they are both included in the state snapshot of checkpoint n, and will be replayed as part of the data after checkpoint n.
Alignment happens only for operators with multiple predecessors (joins) as well as operators with multiple senders (after a stream repartitioning/shuffle). Because of that, dataflows with only embarrassingly parallel streaming operations (map(),flatMap(),filter(), …) actually give exactly once guarantees even in at least once mode.
State and Fault Tolerance in Batch Programs #
Flink executes batch programs as a special case of streaming programs, where the streams are bounded (finite number of elements). A DataSet is treated internally as a stream of data. The concepts above thus apply to batch programs in the same way as well as they apply to streaming programs, with minor exceptions:
-
Fault tolerance for batch programs does not use checkpointing. Recovery happens by fully replaying the streams. That is possible, because inputs are bounded. This pushes the cost more towards the recovery, but makes the regular processing cheaper, because it avoids checkpoints.
-
Stateful operations in the DataSet API use simplified in-memory/out-of-core data structures, rather than key/value indexes.
-
The DataSet API introduces special synchronized (superstep-based) iterations, which are only possible on bounded streams. For details, check out the iteration docs.
Queryable State | Apache Flink https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/queryable_state/
Queryable State #
The client APIs for queryable state are currently in an evolving state and there are no guarantees made about stability of the provided interfaces. It is likely that there will be breaking API changes on the client side in the upcoming Flink versions.
In a nutshell, this feature exposes Flink’s managed keyed (partitioned) state (see Working with State) to the outside world and allows the user to query a job’s state from outside Flink. For some scenarios, queryable state eliminates the need for distributed operations/transactions with external systems such as key-value stores which are often the bottleneck in practice. In addition, this feature may be particularly useful for debugging purposes.
When querying a state object, that object is accessed from a concurrent thread without any synchronization or copying. This is a design choice, as any of the above would lead to increased job latency, which we wanted to avoid. Since any state backend using Java heap space, e.g.HashMapStateBackend, does not work with copies when retrieving values but instead directly references the stored values, read-modify-write patterns are unsafe and may cause the queryable state server to fail due to concurrent modifications. TheEmbeddedRocksDBStateBackendis safe from these issues.
Architecture #
Before showing how to use the Queryable State, it is useful to briefly describe the entities that compose it. The Queryable State feature consists of three main entities:
- the
QueryableStateClient, which (potentially) runs outside the Flink cluster and submits the user queries, - the
QueryableStateClientProxy, which runs on eachTaskManager(i.e. inside the Flink cluster) and is responsible for receiving the client’s queries, fetching the requested state from the responsible Task Manager on his behalf, and returning it to the client, and - the
QueryableStateServerwhich runs on eachTaskManagerand is responsible for serving the locally stored state.
The client connects to one of the proxies and sends a request for the state associated with a specific key, k. As stated in Working with State, keyed state is organized in Key Groups, and each TaskManager is assigned a number of these key groups. To discover which TaskManager is responsible for the key group holding k, the proxy will ask the JobManager. Based on the answer, the proxy will then query the QueryableStateServer running on that TaskManager for the state associated with k, and forward the response back to the client.
Activating Queryable State #
To enable queryable state on your Flink cluster, you need to do the following:
- copy the
flink-queryable-state-runtime-1.17.1.jarfrom theopt/folder of your Flink distribution, to thelib/folder. - set the property
queryable-state.enabletotrue. See the Configuration documentation for details and additional parameters.
To verify that your cluster is running with queryable state enabled, check the logs of any task manager for the line: "Started the Queryable State Proxy Server @ ...".
状态存哪里 堆上 或堆外
State Backends #
Flink provides different state backends that specify how and where state is stored.
State can be located on Java’s heap or off-heap. Depending on your state backend, Flink can also manage the state for the application, meaning Flink deals with the memory management (possibly spilling to disk if necessary) to allow applications to hold very large state. By default, the configuration file flink-conf.yaml determines the state backend for all Flink jobs.
However, the default state backend can be overridden on a per-job basis, as shown below.
For more information about the available state backends, their advantages, limitations, and configuration parameters see the corresponding section in Deployment & Operations.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号