数据的对齐 空间预分配
我是如何实现Go性能5倍提升的? https://mp.weixin.qq.com/s/SlPdSoMs1po1l19uaNMrIQ
01
为什么要进行性能优化
对 Golang 程序进行性能优化,可以在提升业务收益的同时,起到降低成本的作用。笔者在做一次代码重构时发现过一个问题,DeepCopy 占据了大量 CPU 时间,其处理逻辑如下:
x1 := DeepCopy(x) // 对x进行deep copyModify(x) // 对x进行修改Read(x1) // 读取旧x.........
我们完全可以通过简单业务逻辑调整,比如调整处理的先后顺序等移除DeepCopy。优化前后性能对比如下:
性能有5倍左右提升,折算到成本上的收益是巨大的。
02
Go 中如何对性能进行度量与分析
2.1 Benchmark
Benchmark 示例
func BenchmarkConvertReflect(b *testing.B) {var v interface{} = int32(64)for i:=0;i<b.N;i++{f := reflect.ValueOf(v).Int()if f != int64(64){b.Error("errror")}}}
函数固定以 Benchmark 开头,其位于_test.go 文件中,入参为 testing.B 业务逻辑应放在 for 循环中,因为 b.N 会依次取值 1, 2, 3, 5, 10, 20, 30, 50,100.........,直至执行时间超过 1s
可以运行 go test -bench 命令执行 benchmark,其结果如下:
➜ gotest666 go test -bench='BenchmarkConvertReflect' -run=nonegoos: darwingoarch: amd64pkg: gotest666cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkConvertReflect-12 520200014 2.291 ns/op
--bench='BenchmarkConvertReflect', 要执行的 benchmark。需注意:该参数支持模糊匹配,如--bench='Get|Set' ,支持./...-run=none,只进行 Benchmark,不执行单测
BenchmarkConvertReflect, 在12核下,1s内执行了520200014次,每次约2.291ns。
高级用法
➜ gotest666 go test -bench='Convert' -run=none -benchtime=2s -count=3 -cpu='2,4' -benchmem -cpuprofile=cpu.profile -memprofile=mem.profile -blockprofile=blk.profile -trace=trace.out -gcflags=all=-lgoos: darwingoarch: amd64pkg: gotest666cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkConvertReflect-2 1000000000 2.286 ns/op 0 B/op 0 allocs/opBenchmarkConvertReflect-2 1000000000 2.302 ns/op 0 B/op 0 allocs/opBenchmarkConvertReflect-2 1000000000 2.239 ns/op 0 B/op 0 allocs/opBenchmarkConvertReflect-4 1000000000 2.244 ns/op 0 B/op 0 allocs/opBenchmarkConvertReflect-4 1000000000 2.236 ns/op 0 B/op 0 allocs/opBenchmarkConvertReflect-4 1000000000 2.247 ns/op 0 B/op 0 allocs/opPASS
-benchtime=2s', 依次递增 b.N 直至运行时间超过 2s-count=3,执行 3 轮-benchmem,b.ReportAllocs,展示堆分配信息,0 B/op, 0 allos/op 分别代表每次分配了多少空间,每个 op 有多少次空间分配-cpu='2,4',依次在 2 核、4 核下进行测试-cpuprofile=xxxx -memprofile=xxx -trace=trace.out,benmark 时生成 profile、trace 文件-gcflags=all=-l,停止编译器的内联优化b.ResetTimer, b.StartTimer/b.StopItmer,重置定时器b.SetParallelism、b.RunParallel, 并发执行,设置并发的协程数
目前对 Go 性能进行分析的主要工具包含:profile、trace,以下是对二者的介绍。
2.2 profile
go profile 主要是通过对快照中数据进行采样实现,采样命中越多说明函数越是热点 Go 中 profile 包括: cpu、heap、mutex、goroutine。要在 Go 中启用 profile 数据采集,主要包含以下几种方式:
- 通过运行时函数,pprof.StartCPUProfile、pprof.WriteHeapProfile 等;
- 通过导入 net/http/pprof 包,请求相关接口(debug/pprof/*);
- go test 中使用-cpuprofile、-memprofile、-mutexprofile、-blockprofile等。
对 Profile 数据的解析,Go 提供了命令行工具 pprof、web 服务,以命令行工具为例,如下:
go tool pprof cpu.profile(pprof) top 15Showing nodes accounting for 14680ms, 99.46% of 14760ms totalDropped 30 nodes (cum <= 73.80ms)flat flat% sum% cum cum%2900ms 19.65% 19.65% 4590ms 31.10% reflect.unpackEface (inline)2540ms 17.21% 36.86% 13280ms 89.97% gotest666.BenchmarkConvertReflect1680ms 11.38% 48.24% 1680ms 11.38% reflect.(*rtype).Kind (inline)(pprof) list gotest666.BenchmarkConvertReflectTotal: 14.76sROUTINE ======================== gotest666.BenchmarkConvertReflect in /Users/zhangyuxin/go/src/gotest666/a_test.go2.54s 13.28s (flat, cum) 89.97% of Total. . 8:func BenchmarkConvertReflect(b *testing.B) {. . 9: var v interface{} = int32(64)1.30s 1.41s 10: for i:=0;i<b.N;i++{. 10.63s 11: f := reflect.ValueOf(v).Int()1.24s 1.24s 12: if f != int64(64){. . 13: b.Error("errror"). . 14: }. . 15: }. . 16:}. . 17:(pprof)
flat,cum分别代表了当前函数、当前函数调用函数的统计信息top、list、tree是用的最多的命令
Go 对 profile 进行解析的 web 服务包含调用图、火焰图等,可以通过 -http 参数打开。
go tool pprof -http=":8081" cpu.profile

对于调用图,边框、字体的颜色越深,代表消耗资源越多。实线代表直接调用,虚线代表非直接调用(中间还有其他调用) 火焰图代表了调用层级,函数调用栈越长,火焰越高。同一层级,框越长、颜色越深占用资源越多。
profile 是通过采样实现,存在精度问题、且会对性能有影响。
2.3 trace
profile 工具基于快照的统计信息,存在精度问题。
为此 Go 还提供了 trace 工具,其基于事件的统计能够提供更加详细的信息。此外 trace 还把 P、G、M 等相关信息聚合在一起,从全局对问题进行一个更加直观的解释,如下图: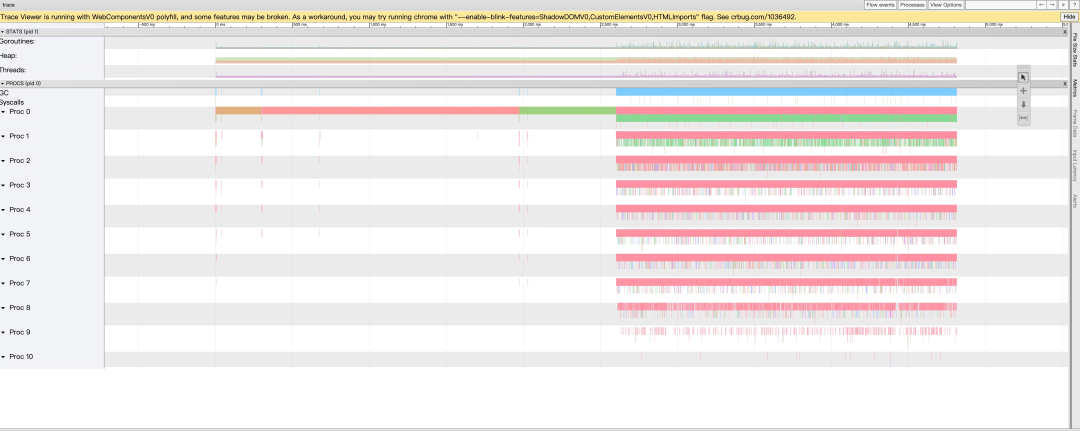
Go 中启用 trace 数据采集,可以通过以下方式:
- 通过runtime/trace函数,trace.Start、trace.Stop;
- 通过导入net/http/pprof,请求debug/pprof/*相关接口;
- 通过 go test 中 trace 参数。
以 runtime/trace 为例,如下:
import ("os""runtime/trace")func main() {f, _ := os.Create("trace.out")trace.Start(f)defer trace.Stop()ch := make(chan string)go func() {ch <- "this is a test"}()<-ch}
go tool trace trace.out,会打开 web 页面,结果包含如下信息:
View trace // 按照时间查看thread、goroutine分析、heap等相关信息Goroutine analysis // goroutine相关分析Syscall blocking profile // syscall 相关Scheduler latency profile // 调度相关........
需要注意,基于事件的数据采集方式,会导致性能有25%左右下降。
03
常用结构、用法背后的故事
3.1 interface、reflect
Go 中较多的 interface、reflect 会对性能有影响,但 interface、reflect 为什么会对性能有影响?
interface
Go 中 interface 包含2种,eface(empty face)、iface, eface 代表了不含方法的 interface 类型、iface 标识包含方法的 interface。
iface、eface 的定义位于 runtime2.go、type.go,其定义如下:
type iface struct {tab *itabdata unsafe.Pointer}type eface struct {_type *_type // 类型信息data unsafe.Pointer // 数据}type itab struct {........_type *_type.......}type _type struct {size uintptr // 大小信息.......hash uint32 // 类型信息tflag tflagalign uint8 // 对齐信息.......}
因为同时包含类型、数据,Go 中所有类型都可以转换为 interface。interface 赋值的过程,即为 iface、eface 生成的过程。如果编译阶段编译器无法确定 interface 类型(比如 :iface 入参)会通过 conv 完成打包,有可能会导致逃逸。conv 系列函数定义位于 iface.go,如下:
// convT converts a value of type t, which is pointed to by v, to a pointer that can// be used as the second word of an interface value.func convT(t *_type, elem unsafe.Pointer) (e eface) {.....x := mallocgc(t.size, t, true) // 空间的分配typedmemmove(t, x, elem) // memovee._type = te.data = xreturn}func convT64(val uint64) (x unsafe.Pointer) {if val < uint64(len(staticuint64s)) {x = unsafe.Pointer(&staticuint64s[val])} else {x = mallocgc(8, uint64Type, false)*(*uint64)(x) = val}return}var staticuint64s = [...]uint64{....} // 长度256的数组
很多对 interface 类型的赋值(并非所有),都会导致空间的分配和拷贝,这也是 Interface 函数为什么可能会导致逃逸的原因 go 这么做的主要原因:逃逸的分析位于编译阶段,对于不确定的类型在堆上分配最为合适。
Reflect.Value
Go 中 reflect 机制涉及到2个类型,reflect.Type、reflect.Value,reflect.Type 是 Interface。
reflect.Value 定义位于 value.go、type.go,其定义与 eface 类似:
type Value struct {typ *rtype // type._typeptr unsafe.Pointerflag}// rtype must be kept in sync with ../runtime/type.go:/^type._type.type rtype struct {....}
相似的实现,即为 interface 和 reflect 可以相互转换的原因。
reflect.Value 是通过 reflect.ValueOf 生成,reflect.ValueOf 也可能会导致数据逃逸,其定义位于 value.go 中,如下:
func ValueOf(i interface{}) Value {if i == nil {return Value{}}// TODO: Maybe allow contents of a Value to live on the stack.// For now we make the contents always escape to the heap.escapes(i) // 逃逸return unpackEface(i) // unpack eface}// dummy为全局变量,作用域不确定可能会逃逸func escapes(x any) {if dummy.b {dummy.x = x}}
再次强调:逃逸的分析是在编译阶段进行的。
一个简单的例子:
func main() {var x = "xxxx"_ = reflect.ValueOf(x)}
结果如下:
➜ gotest666 go build -gcflags="-m -l" main.go# command-line-arguments./main.go:26:21: inlining call to reflect.ValueOf./main.go:26:21: inlining call to reflect.escapes./main.go:26:21: inlining call to reflect.unpackEface./main.go:26:21: inlining call to reflect.(*rtype).Kind./main.go:26:21: inlining call to reflect.ifaceIndir./main.go:26:22: x escapes to heap
需要注意,逃逸的检测是通过-gcflags=-m,一般还需要关闭内联比如-gcflags="-m -l"。
类型的选择:强类型 vs interface
为降低可能的空间分配、拷贝,建议只在必要情况下使用 interface、reflect。
针对函数定义中强类型、interface 的性能对比,测试如下:
type testStruct struct {Data [8192]byte}func StrongType(t testStruct) {t.Data[0] = 1}func InterfaceType(ti interface{}) {ts := ti.(testStruct)ts.Data[0] = 1}func BenchmarkTypeStrong(b *testing.B) {t := testStruct{}t.Data[0] = 2for i := 0; i < b.N; i++ {StrongType(t)}}func BenchmarkTypeInterface(b *testing.B) {t := testStruct{}t.Data[0] = 2for i := 0; i < b.N; i++ {InterfaceType(t)}}
会导致逃逸时(sizeof(testStruct.Dat)==8192):
➜ test go test -bench='Type' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkTypeStrong-12 1000000000 0.2546 ns/op 0 B/op 0 allocs/opBenchmarkTypeInterface-12 799846 1399 ns/op 8192 B/op 1 allocs/opPASS
没有逃逸时(sizeof(testStruct.Dat)==1):
➜ test go test -bench='Type' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkTypeStrong-12 1000000000 0.2549 ns/op 0 B/op 0 allocs/opBenchmarkTypeInterface-12 1000000000 0.2534 ns/op 0 B/op 0 allocs/opPASS
在一些会导致逃逸的情况下,不建议使用 Interface。
目前一些可能会导致逃逸的函数:
| 函数 | 应用场景 |
|---|---|
| fmt系列,包括:fmt.Sprinf、fmt.Sprint等 | 数据转换、格式化打印 |
| binary.Read/binary.Write | 二级制数据读写 |
| Json.Marshal/json.UnMarshal | json相关 |
类型转换: 强转 vs 断言 vs reflect
目前 Go 中数据类型转换,存在以下几种方式:
-
强转,如 int 转 int64,可用 int64(intData)。强转是对底层数据进行语意上的重新解释;
-
interface 的断言,根据已有信息,对变量类型进行断言,如 interfaceData.(int64),会利用 type 中相关信息,对类型进行校验、转换;
-
reflect 相关函数,如 reflect.Valueof(intData).Int(),其中 intData 可以为各种 int 相关类型,具有非常好的灵活性。
针对此的测试如下:
type testStruct struct {Data [8192]byte}func BenchmarkConvertForce(b *testing.B) {for i := 0; i < b.N; i++ {var v = int32(64)f := int64(v)if f != int64(64) {b.Error("errror")}}}func BenchmarkConvertReflect(b *testing.B) {for i := 0; i < b.N; i++ {var v = int32(64)f := reflect.ValueOf(v).Int()if f != int64(64) {b.Error("errror")}}}func BenchmarkConvertAssert(b *testing.B) {for i := 0; i < b.N; i++ {var v interface{} = int32(64)f := v.(int32)if f != int32(64) {b.Error("error")}}}func BenchmarkConvertBigReflect(b *testing.B) {for i := 0; i < b.N; i++ {f := reflect.ValueOf(testStruct{}).Interface().(testStruct)if len(f.Data) <= 0 {b.Error("errror")}}}func BenchmarkConvertBigAssert(b *testing.B) {for i := 0; i < b.N; i++ {var v interface{} = testStruct{}f := v.(testStruct)if len(f.Data) <= 0 {b.Error("error")}}}➜ test go test -bench='Convert' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkConvertForce-12 1000000000 0.2561 ns/op 0 B/op 0 allocs/opBenchmarkConvertReflect-12 259114099 3.892 ns/op 0 B/op 0 allocs/opBenchmarkConvertAssert-12 1000000000 0.5068 ns/op 0 B/op 0 allocs/opBenchmarkConvertBigReflect-12 759171 1595 ns/op 8192 B/op 1 allocs/opBenchmarkConvertBigAssert-12 827790 1593 ns/op 8192 B/op 1 allocs/op
性能上:强类型转换/assert > reflect。
3.2 常用 map
Go 中常用的 map 包含,runtime.map、sync.map 和第三方的 ConcurrentMap。
Go 中 map 的定义位于 map.go,是基于 bucket 的 map的实现,如下:
type hmap struct {......B uint8 // buckets中桶的数目为2的B次方个hash0 uint32 // hash seedbuckets unsafe.Pointer // bucket实现oldbuckets unsafe.Pointer // 旧bucket,主要用于rehash的渐渐式迁移......}
其结构如下:
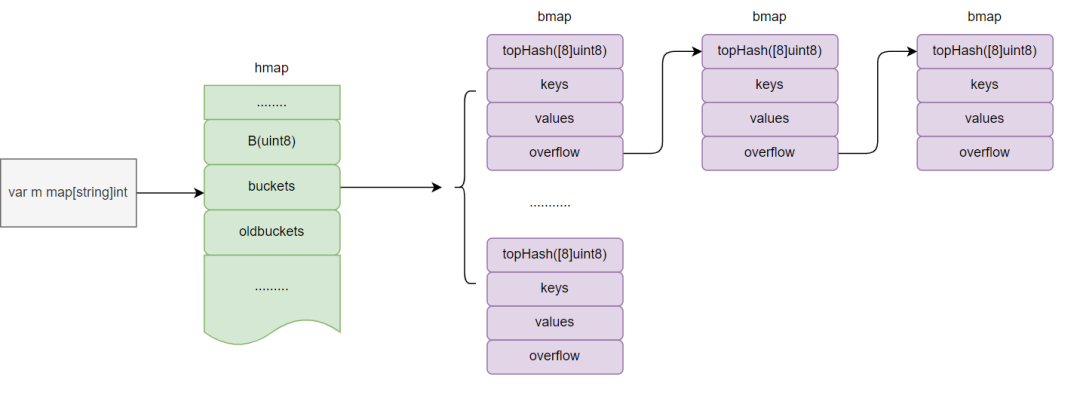
sync.map 定义位于 map.go 中,其是典型的以空间换时间的处理,其以通过 readonly 实现了冗余读,具体如下:
type readOnly struct {m map[interface{}]*entryamended bool // true if the dirty map contains some key not in m.}type entry struct {p unsafe.Pointer // *interface{}}type Map struct {mu Mutexread atomic.Value // readOnly数据dirty map[interface{}]*entrymisses int}
read 中存储的是 dirty 数据的一个指针副本,在读多写少的情况下,可以实现无锁的数据读取,以读取为例其处理逻辑如下:
func (m *Map) Load(key any) (value any, ok bool) {read, _ := m.read.Load().(readOnly)e, ok := read.m[key]if !ok && read.amended {m.mu.Lock()// double checkread, _ = m.read.Load().(readOnly)e, ok = read.m[key]if !ok && read.amended {// 从dirty查询e, ok = m.dirty[key]m.missLocked()}m.mu.Unlock()}if !ok {return nil, false}return e.load()}
ConcurrentMap,其采用分段锁的原理,通过降低锁的粒度提升性能,参见:current-map。
针对 map、sync.map、ConcurrentMap 的测试如下:
const mapCnt = 20func BenchmarkStdMapGetSet(b *testing.B) {mp := map[string]string{}keys := []string{"a", "b", "c", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r"}for i := range keys {mp[keys[i]] = keys[i]}var m sync.Mutexb.ResetTimer()b.RunParallel(func(pb *testing.PB) {for pb.Next() {for i := 0; i < mapCnt; i++ {for j := range keys {m.Lock()_ = mp[keys[j]]m.Unlock()}}m.Lock()mp["d"] = "d"m.Unlock()}})}func BenchmarkSyncMapGetSet(b *testing.B) {var mp sync.Mapkeys := []string{"a", "b", "c", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r"}for i := range keys {mp.Store(keys[i], keys[i])}b.ResetTimer()b.RunParallel(func(pb *testing.PB) {for pb.Next() {for i := 0; i < mapCnt; i++ {for j := range keys {_, _ = mp.Load(keys[j])}}mp.Store("d", "d")}})}func BenchmarkConcurrentMapGetSet(b *testing.B) {m := cmap.New[string]()keys := []string{"a", "b", "c", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r"}for i := range keys {m.Set(keys[i], keys[i])}b.ResetTimer()b.RunParallel(func(pb *testing.PB) {for pb.Next() {for i := 0; i < mapCnt; i++ {for j := range keys {_, _ = m.Get(keys[j])}}m.Set("d", "d")}})}
读写操作比,20:20
➜ test go test -bench='GetSet' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkStdMapGetSet-12 44818 29318 ns/op 0 B/op 0 allocs/opBenchmarkSyncMapGetSet-12 159310 8013 ns/op 320 B/op 20 allocs/opBenchmarkConcurrentMapGetSet-12 155390 8032 ns/op 0 B/op 0 allocs/op
读写操作比,1:20
➜ test go test -bench='GetSet' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkStdMapGetSet-12 466243 2553 ns/op 0 B/op 0 allocs/opBenchmarkSyncMapGetSet-12 255799 4657 ns/op 320 B/op 20 allocs/opBenchmarkConcurrentMapGetSet-12 414024 2721 ns/op 0 B/op 0 allocs/op
读写操作比,20:1
➜ test go test --bench='GetSet' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkStdMapGetSet-12 49065 24976 ns/op 0 B/op 0 allocs/opBenchmarkSyncMapGetSet-12 722704 1756 ns/op 16 B/op 1 allocs/opBenchmarkConcurrentMapGetSet-12 227001 5206 ns/op 0 B/op 0 allocs/opPASS
读>>写时,建议用 sync.Map。写>>读时,建议用 runtime.map。读=写时,建议用 courrentMap
3.3 hash 的实现: index vs map
在使用到 hash 的场景,除了 map,我们还可以基于 slice 或者数组索引的方式实现另外一种 map,即把 index 当做 key、value 当做 hash 的值,如下。
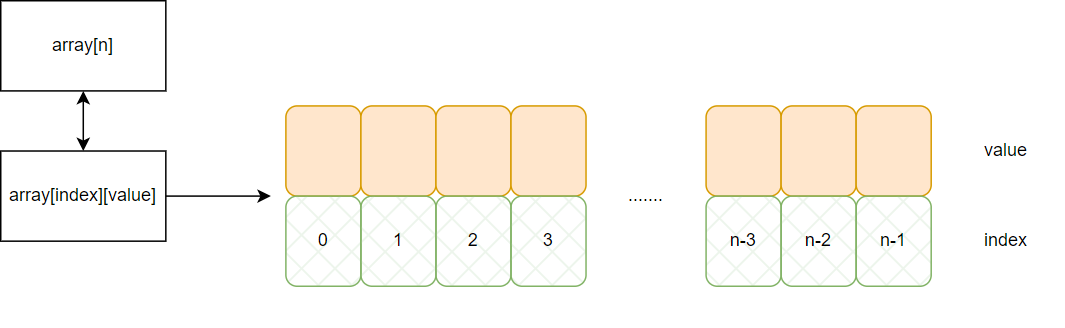
其性能对比如下:
func BenchmarkHashIdx(b *testing.B) {var data = [10]int{0: 1, 1: 1, 2: 2, 3: 3, 4: 4, 5: 5, 6: 6, 7: 7, 8: 8, 9: 9}for i := 0; i < b.N; i++ {tmp := data[b.N%10]_ = tmp}}func BenchmarkHashMap(b *testing.B) {var data = map[int]int{0: 1, 1: 1, 2: 2, 3: 3, 4: 4, 5: 5, 6: 6, 7: 7, 8: 8, 9: 9}for i := 0; i < b.N; i++ {tmp := data[b.N%10]_ = tmp}}➜ test go test --bench='Hash' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkHashIdx-12 1000000000 1.003 ns/op 0 B/op 0 allocs/opBenchmarkHashMap-12 196543544 7.665 ns/op 0 B/op 0 allocs/opPASS
可见其性能会有5倍左右提升。
3.4 string 和 slice
string 和 slice 的定义
Go 中 string、slice 都是基于 buf、len 的元组的定义,二者定义都位于 value.go 中:
type StringHeader structData uintptrLen int}type SliceHeader struct {Data uintptrLen intCap int}
通过二者定义可以得出:
-
在值拷贝背景下,string、slice 的赋值操作代价都不大;
-
slice 因为涉及到 cap,会涉及到预分配、惰性删除,其具体位于 slice.go。
String、[]byte 转换
Go 中 string 和 []byte 间相互转换包含2种:
-
采用原生机制,比如string转slice可采用,[]byte(strData)或者string(byteData);
-
基于二者数据结构,对底层数据重新解释。
以 string 转换为 byte 为例,原生转换的转换会进行如下操作,其位于 string.go 中:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {var b []byteif buf != nil && len(s) <= len(buf) { // 如果可以在tmpBuf中保存*buf = tmpBuf{}b = buf[:len(s)]} else {b = rawbyteslice(len(s)) // 如果32字节不够存储数据,则调用mallocgc分配空间}copy(b, s) // 数据拷贝return b}// rawbyteslice allocates a new byte slice. The byte slice is not zeroed.func rawbyteslice(size int) (b []byte) {cap := roundupsize(uintptr(size))p := mallocgc(cap, nil, false) // 空间分配if cap != uintptr(size) {memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))}*(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}return}
其中 tmpBuf 定义为 type tmpBuf [32]byte。可见当 string 长度超过32字节时,会进行空间的分配、拷贝。
同理,byte 转换为 string,原生处理位于 slicebytetostring 函数,也位于 string.go 中。
针对多余的空间分配、拷贝问题,我们对其进行了封装,该实现通过对底层数据重新解释进行,具有较高的效率。
相关封装、ByteToString 性能对比如下:
// 对底层数据进行重新解释func Bytes2String(b []byte) string {x := (*[3]uintptr)(unsafe.Pointer(&b))s := [2]uintptr{x[0], x[1]}return *(*string)(unsafe.Pointer(&s))}func String2Bytes(s string) []byte {x := (*[2]uintptr)(unsafe.Pointer(&s))b := [3]uintptr{x[0], x[1], x[1]}return *(*[]byte)(unsafe.Pointer(&b))}func BenchmarkByteToStringRaw(b *testing.B) {bytes := getByte(34)b.ResetTimer()for i := 0; i < b.N; i++ {v := string(bytes)if len(v) <= 0 {b.Error("error")}}}func BenchmarkByteToStringPointer(b *testing.B) {bytes := getByte(34)b.ResetTimer()for i := 0; i < b.N; i++ {v := Bytes2String(bytes)if len(v) <= 0 {b.Error("error")}}}➜ gotest666 go test --bench='ByteToString' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkByteToStringRaw-12 47646651 23.37 ns/op 48 B/op 1 allocs/opBenchmarkByteToStringPointer-12 1000000000 0.7539 ns/op 0 B/op 0 allocs/op
其性能提升的主要原因,0gc 0拷贝 需要注意,本处理只针对转换,不涉及 append 等可能引起扩容的处理。
string 的拼接
当前 Golang 中字符串拼接方式,主要包含:
-
使用+连接字符串;
-
使用 fmt.Sprintf;
-
使用运行时提供的工具类,strings.Builder 或者 bytes.Buffer ;
-
预分配机制。
目前对+的处理,编译后其处理函数位于 string.go,当要连接的字符串长度>32时,每次会进行空间的分配和拷贝处理,其处理如下:
func concatstrings(buf *tmpBuf, a []string) string {idx := 0l := 0count := 0for i, x := range a { // 计算+链接字符的长度n := len(x)if n == 0 {continue}if l+n < l {throw("string concatenation too long")}l += ncount++idx = i}if count == 0 {return ""}.....s, b := rawstringtmp(buf, l) // 如果长度小于len(buf)(32),则分配空间,否则使用buffor _, x := range a {copy(b, x)b = b[len(x):]}return s}
需要注意,tmpBuf 定义 type tmpBuf [32]byte。
fmt.Sprinf,涉及逃逸,也会有大量的空间分配、拷贝。
针对+、fmt.Sprintf 等的性能对比测试如下:
func BenchmarkStringJoinAdd(b *testing.B) {var s stringfor i := 0; i < b.N; i++ {for i := 0; i < count; i++ {s += "10"}}}func BenchmarkStringJoinSprintf(b *testing.B) {var s stringfor i := 0; i < b.N; i++ {for i := 0; i < count; i++ {s = fmt.Sprintf("%s%s", s, "10")}}}func BenchmarkStringJoinStringBuilder(b *testing.B) {var sb strings.Buildersb.Grow(count * 2) // 预分配了空间b.ResetTimer()for i := 0; i < b.N; i++ {for i := 0; i < count; i++ {sb.WriteString("10")}}}➜ test go test -bench='StringJoin' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkStringJoinAdd-12 19 864766686 ns/op 7679332420 B/op 20365 allocs/opBenchmarkStringJoinSprintf-12 13 1546112322 ns/op 10474999415 B/op 65459 allocs/opBenchmarkStringJoinStringBuilder-12 10000 205483 ns/op 234915 B/op 0 allocs/opBenchmarkStringJoinStringBuilderPreAlloc-12 21061 139415 ns/op 217885 B/op 0 allocs/op
可以看出,空间预分配拥有最高性能指标。
其他的一些更为详细的测试参见:string连接。
3.5 循环的处理:for vs range
Go 中常用的循环有2种 for index 和 for range 如下:
-
按位置进行遍历,for 和 range 都支持,如 for i:=range a{}, for i:=0;i<len(a);i++。
-
同时对位置、值进行遍历,仅 range 支持,如 for i,v := range a {}。
Go 中循环经过一系列的编译、优化后,伪代码如下:
ta := a // 容器的拷贝i := 0l := len(ta) // 获取长度for ; i < l; i++ {v := ta[i] // 拷贝容器中元素,仅for range value支持}
此处理可能会导致以下问题:
-
遍历前,会进行值的拷贝。如果容器是数组,会有大量数据拷贝,引用类型拷贝较少;
-
for range value 在遍历中存在对容器元素的拷贝;
-
遍历开始,已经确定了容器长度,中间添加的数据,不会遍历到。
针对此测试如下:
type Item struct {id intval [8192]byte}func BenchmarkLoopFor(b *testing.B) {var items [1024]Itemfor i := 0; i < b.N; i++ {length := len(items)var tmp intfor k := 0; k < length; k++ {tmp = items[k].id}_ = tmp}}func BenchmarkLoopRangeIndex(b *testing.B) {var items [1024]Itemfor i := 0; i < b.N; i++ {var tmp intfor k := range items {tmp = items[k].id}_ = tmp}}func BenchmarkLoopRangeValue(b *testing.B) {var items [1024]Itemfor i := 0; i < b.N; i++ {var tmp intfor _, item := range items {tmp = item.id}_ = tmp}}
Sizeof(Item.val)=1
➜ test go test -bench='Loop' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkLoopFor-12 4370520 273.2 ns/op 0 B/op 0 allocs/opBenchmarkLoopRangeIndex-12 4520882 265.6 ns/op 0 B/op 0 allocs/opBenchmarkLoopRangeValue-12 4293848 303.8 ns/op 0 B/op 0 allocs/opPASS
sizeof(Item.val)=8192
➜ test go test --bench='Loop' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkLoopFor-12 4334842 270.8 ns/op 0 B/op 0 allocs/opBenchmarkLoopRangeIndex-12 4436786 272.7 ns/op 0 B/op 0 allocs/opBenchmarkLoopRangeValue-12 7310 211009 ns/op 0 B/op 0 allocs/op
在需要较大存储空间、元素需要较大存储空间时,建议不要采用 for range value 的方式。
3.6 重载
目前 Go 中重载的实现包含2种,泛型(1.18)、基于 interface 的定义。
泛型的优点在于预编译,即编译期间即可确定类型,对比基于 interface 的逃逸会有一定收益。
具体测试如下:
func AddGeneric[T int | int16 | int32 | int64](a, b T) T {return a + b}func AddInterface(a, b interface{}) interface{} {switch a.(type) {case int:return a.(int) + b.(int)case int32:return a.(int32) + b.(int32)case int64:return a.(int64) + b.(int64)}return 0}func BenchmarkOverLoadGeneric(b *testing.B) {for i := 0; i < b.N; i++ {x := AddGeneric(i, i)_ = x}}func BenchmarkOverLoadInterface(b *testing.B) {for i := 0; i < b.N; i++ {x := AddInterface(i, i)_ = x.(int)}}➜ test go test --bench='OverLoad' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkOverLoadGeneric-12 1000000000 0.2778 ns/op 0 B/op 0 allocs/opBenchmarkOverLoadInterface-12 954258690 1.248 ns/op 0 B/op 0 allocs/opPASS
对比 interface 类型的处理,泛型有一定的性能的提升。
04
空间与布局
在栈上分配空间为什么会比堆上快?
4.1 栈与堆空间的分配
通过汇编,可观察栈空间分配机制,如下:
package mainfunc test(a, b int) int {return a + b}
其对应汇编代码如下:
main.test STEXT nosplit size=49 args=0x10 locals=0x10 funcid=0x0 align=0x00x0000 00000 (/Users/zhangyuxin/go/src/gotest666/test.go:3) TEXT main.test(SB), NOSPLIT|ABIInternal, $16-160x0000 00000 (/Users/zhangyuxin/go/src/gotest666/test.go:3) SUBQ $16, SP // 栈扩容......0x002c 00044 (/Users/zhangyuxin/go/src/gotest666/test.go:4) ADDQ $16, SP // 栈释放0x0030 00048 (/Users/zhangyuxin/go/src/gotest666/test.go:4) RET
Go 中栈的扩容、释放只涉及到了 SUBQ、ADDQ 2 条指令。
对应的基于堆的内存分配,位于 malloc.go 中 mallocgc 函数,p 的定义、mheap 的定义分别位于 runtime2.go、mcache.go、mheap.go,其分配流程具体如下(以<32K, >8B为例):
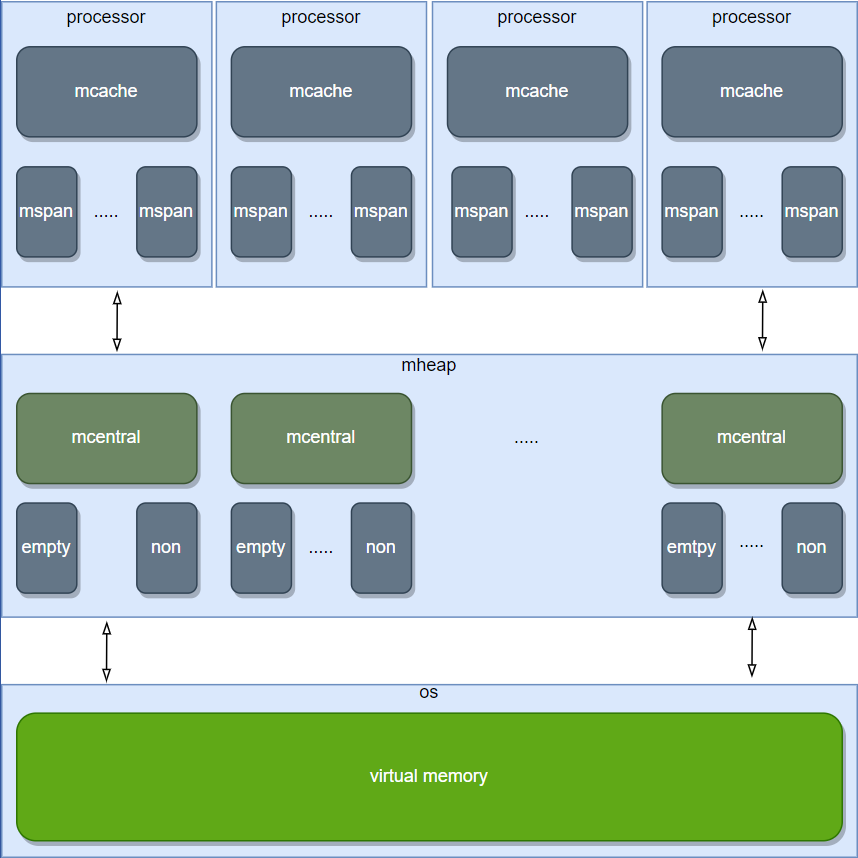
其中,直接从 p.mcache 获取空间不需要加锁(单协程),mheap 为全局变量通过 mheap.mcentral 获取空间需要加锁,从 os 分配空间需要系统调用 mmap。此外,堆上分配还需要考虑 gc 导致的 stw 等的影响,因此建议所需空间不是特别大时还是在栈上进行空间的分配。
4.2 Zero GC
Zero GC 能够避免 gc 带来的扫描、STW 等,具有一定的性能的收益。
当前 zero gc 的处理,主要包含2种:
-
无 gc,通过 mmap 或者 cgo.malloc 分配空间,绕过 Go 的内存分配机制
-
避免或者减少 gc,通过 []byte 等避免因为指针导致的扫描、stw。bigCache 的实现即为此。
在之前的一些开发中,我们使用了大量的基于 0 gc 的库,比如 fastcache 等。也对一些常用函数和机制,如 strings.split 也进行了 0 gc 的优化,其实现如下:
type StringSplitter struct {Idx [8]int // 存储splitter对应的位置信息src stringcnt int}// Split 分割func (s *StringSplitter) Split(str string, sep byte) bool {s.src = strfor i := 0; i < len(str); i++ {if str[i] == sep {s.Idx[s.cnt] = is.cnt++// 超过Idx数据长度则返回空if int(s.cnt) >= len(s.Idx) {return false}}}return true}// At 获得第i个节点数据func (s *StringSplitter) At(idx int) string {// 没有分割,则返回全量数据if s.cnt == 0 {return s.src}if idx == 0 {return s.src[0:s.Idx[idx]]}cnt := s.cntif idx >= cnt {return s.src[s.Idx[cnt-1]+1:]}return s.src[s.Idx[idx-1]+1 : s.Idx[idx]]}
与常规 strings.split 对比如下,其性能有近4倍左右提升。
➜ test go test --bench='Split' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkQSplitRaw-12 13455728 76.43 ns/op 64 B/op 1 allocs/opBenchmarkQSplit-12 59633916 20.08 ns/op 0 B/op 0 allocs/opPASS
4.3 GC 的优化
gc 优化相关,主要涉及 GOGC、GOMEMLIMIT。可以通过调整 GOMEMLIMIT 和 GOGC,降低 GC 频率。参见:GOMEMLIMIT。https://weaviate.io/blog/gomemlimit-a-game-changer-for-high-memory-applications
需要注意,此机制只在1.20以上版本生效。
4.4 逃逸
对于一些比较复杂操作,Go 在编译器会在编译期间将相关变量逃逸至堆上。目前可能导致逃逸的机制包含:
-
函数返回了指针;
-
栈空间超过了 os 的限制8M;
-
闭包;
-
动态类型,如 interface 函数。
目前逃逸分析,可采用 -gcflags="-m -l" 进行查看,如下:
type test1 struct {a int32b intc int32}type test2 struct {a int32c int32b int}func getData() *int {a := 10return &a}func main() {fmt.Println(unsafe.Sizeof(test1{}))fmt.Println(unsafe.Sizeof(test2{}))getData()}➜ gotest666 go build -gcflags="-m -l" main.go# command-line-arguments./main.go:20:6: can inline getData./main.go:26:13: inlining call to fmt.Println./main.go:27:13: inlining call to fmt.Println./main.go:28:9: inlining call to getData./main.go:21:2: moved to heap: a // 返回指针导致逃逸./main.go:26:13: ... argument does not escape./main.go:26:27: unsafe.Sizeof(test1{}) escapes to heap // 动态类型导致逃逸./main.go:27:13: ... argument does not escape./main.go:27:27: unsafe.Sizeof(test2{}) escapes to heap // 动态类型导致逃逸
在日常业务处理过程中,建议尽量避免逃逸到堆上的情况。
4.5 数据的对齐
Go 中同样存在数据对齐,适当的布局调整,能够节省大量的空间,具体如下:
type test1 struct {a int32b intc int32}type test2 struct {a int32c int32b int}func main() {fmt.Println(unsafe.Alignof(test1{}))fmt.Println(unsafe.Alignof(test2{}))fmt.Println(unsafe.Sizeof(test1{}))fmt.Println(unsafe.Sizeof(test2{}))}➜ gotest666 go run main.go882416
4.6 空间预分配
空间预分配,可以避免大量不必要的空间分配、拷贝,目前 slice、map、strings.Builder、byte.Builder 等都提供了预分配机制。
以 map 为例,测试结果如下:
func BenchmarkConcurrentMapAlloc(b *testing.B) {m := map[int]int{}b.ResetTimer()for i := 0; i < b.N; i++ {m[i] = i}}func BenchmarkConcurrentMapPreAlloc(b *testing.B) {m := make(map[int]int, b.N)b.ResetTimer()for i := 0; i < b.N; i++ {m[i] = i}}➜ test go test --bench='Alloc' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkConcurrentMapAlloc-12 6027334 186.0 ns/op 60 B/op 0 allocs/opBenchmarkConcurrentMapPreAlloc-12 15499568 89.68 ns/op 0 B/op 0 allocs/opPASS
预分配能够极大提升,相关性能, 建议在使用时都进行空间的预分配。
05
并发编程
5.1 锁
Golang 中 mutex 定义位于 mutex.go,其定义如下:
type Mutex struct {state int32 // 状态字,标识锁是否被锁定、是否starving等sema uint32 // 信号量}
Golang 的读写锁基于 mutex,其定义位于 rwmutex.go, 其定义如下:
type RWMutex struct {w Mutex // 用于阻塞写writerSem uint32 // 写信号量,用于实现写阻塞队列readerSem uint32 // 读信号量,用于实现读阻塞队列readerCount int32 // 标识当前读操作的个数readerWait int32 // 标识排在写操作前读操作的个数,防止写操作被饿死}
RWMutex 基于 Mutex 实现,在加写锁上,RWMutex 性能略差于 Mutex。但在读操作较多情况下,RWMutex 性能是优于 Mutex 的,因为 RWMutex 对于读的操作只是通过 readerCount 计数进行, 其相关处理位于 rwmutex.go,如下:
func (rw *RWMutex) RLock() {if race.Enabled {_ = rw.w.staterace.Disable()}if rw.readerCount.Add(1) < 0 { // readCount < 0,表示有写操作正在进行runtime_SemacquireRWMutexR(&rw.readerSem, false, 0)}if race.Enabled {race.Enable()race.Acquire(unsafe.Pointer(&rw.readerSem))}}func (rw *RWMutex) Lock() {if race.Enabled {_ = rw.w.staterace.Disable()}rw.w.Lock() // 加写锁r := rw.readerCount.Add(-rwmutexMaxReaders) + rwmutexMaxReaders // 统计当前读操作的个数,if r != 0 && rw.readerWait.Add(r) != 0 { // 并等待读操作runtime_SemacquireRWMutex(&rw.writerSem, false, 0)}if race.Enabled {race.Enable()race.Acquire(unsafe.Pointer(&rw.readerSem))race.Acquire(unsafe.Pointer(&rw.writerSem))}}
按照读写比例的不同,进行了如下测试:
var mut sync.Mutexvar rwMut sync.RWMutexvar t intconst cost = time.Microsecondfunc WRead() {mut.Lock()_ = ttime.Sleep(cost)mut.Unlock()}func WWrite() {mut.Lock()t++time.Sleep(cost)mut.Unlock()}func RWRead() {rwMut.RLock()_ = ttime.Sleep(cost)rwMut.RUnlock()}func RWWrite() {rwMut.Lock()t++time.Sleep(cost)rwMut.Unlock()}func benchmark(b *testing.B, readFunc, writeFunc func(), read, write int) {b.RunParallel(func(pb *testing.PB) {for pb.Next() {var wg sync.WaitGroupfor k := 0; k < read*100; k++ {wg.Add(1)go func() {readFunc()wg.Done()}()}for k := 0; k < write*100; k++ {wg.Add(1)go func() {writeFunc()wg.Done()}()}wg.Wait()}})}func BenchmarkReadMore(b *testing.B) { benchmark(b, WRead, WWrite, 9, 1) }func BenchmarkReadMoreRW(b *testing.B) { benchmark(b, RWRead, RWWrite, 9, 1) }func BenchmarkWriteMore(b *testing.B) { benchmark(b, WRead, WWrite, 1, 9) }func BenchmarkWriteMoreRW(b *testing.B) { benchmark(b, RWRead, RWWrite, 1, 9) }func BenchmarkReadWriteEqual(b *testing.B) { benchmark(b, WRead, WWrite, 5, 5) }func BenchmarkReadWriteEqualRW(b *testing.B) { benchmark(b, RWRead, RWWrite, 5, 5) }➜ test go test --bench='Read|Write' -run=none -benchmemgoos: darwingoarch: amd64pkg: gotest666/testcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzBenchmarkReadMore-12 207 5713542 ns/op 114190 B/op 2086 allocs/opBenchmarkReadMoreRW-12 1237 904307 ns/op 104683 B/op 2007 allocs/opBenchmarkWriteMore-12 211 5799927 ns/op 110360 B/op 2067 allocs/opBenchmarkWriteMoreRW-12 222 5490282 ns/op 110666 B/op 2070 allocs/opBenchmarkReadWriteEqual-12 213 5752311 ns/op 111017 B/op 2065 allocs/opBenchmarkReadWriteEqualRW-12 386 3088603 ns/op 106810 B/op 2030 allocs/op
在读写比例为9:1时,RWMute 性能约为 Mutex 的6倍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号