
Spring data redis 使用 pipelined 批量操作
需求说明
当用到数据的时候,将项目中数据放到redis中,这些数据预计会达到十几万。
方案一
// 这样最简单
list.forEach(s -> redisTemplate.opsForSet().add("key", s));
如上代码很简单,遍历集合放入redis,但是这样效率低,每次都要获取一次连接,十几万的连接,大部分时间都在创建销毁连接了,真正执行任务的时间相对来说要少很多。
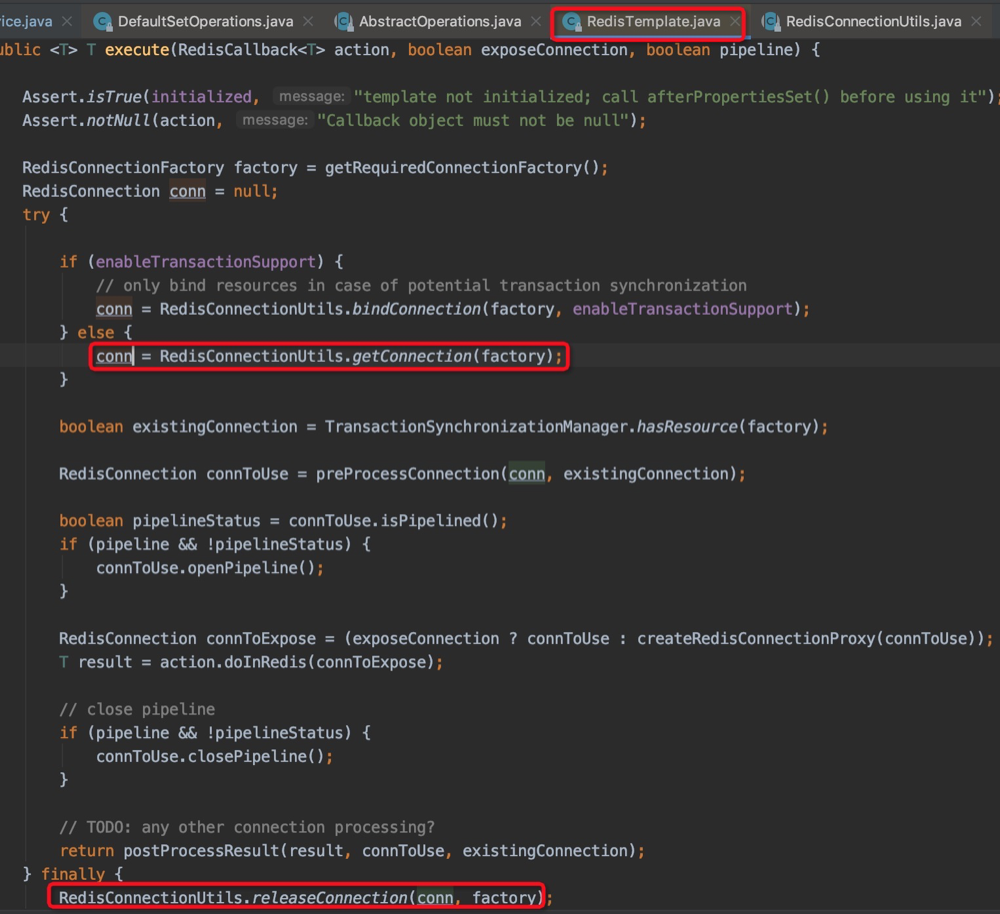
看上面进来执行任务的时候要先获取一次连接,finally里面释放了(如果你使用了事务那么就不会重新获取连接,不过这不是本文要讲的,如果想了解自己可以看看。)所以方案一要优化。
方案二
RedisSerializer keyS = redisTemplate.getKeySerializer();
RedisSerializer valueS = redisTemplate.getValueSerializer();
byte[] key = keyS.serialize("key");
redisTemplate.executePipelined((RedisCallback<String>) connection -> {
list.stream().forEach(s -> connection.sAdd(key, valueS.serialize(s)));
// 设置过期时间
connection.expire(key, 60L);
return null;
});
redis提供了批量操作方式执行命令,就是pipeline。使用方式如上,方法内所有命令都是在一个连接内。这样就完美解决了我们的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号