使用WSL+Docker进行Spark集群搭建
一.构建集群镜像
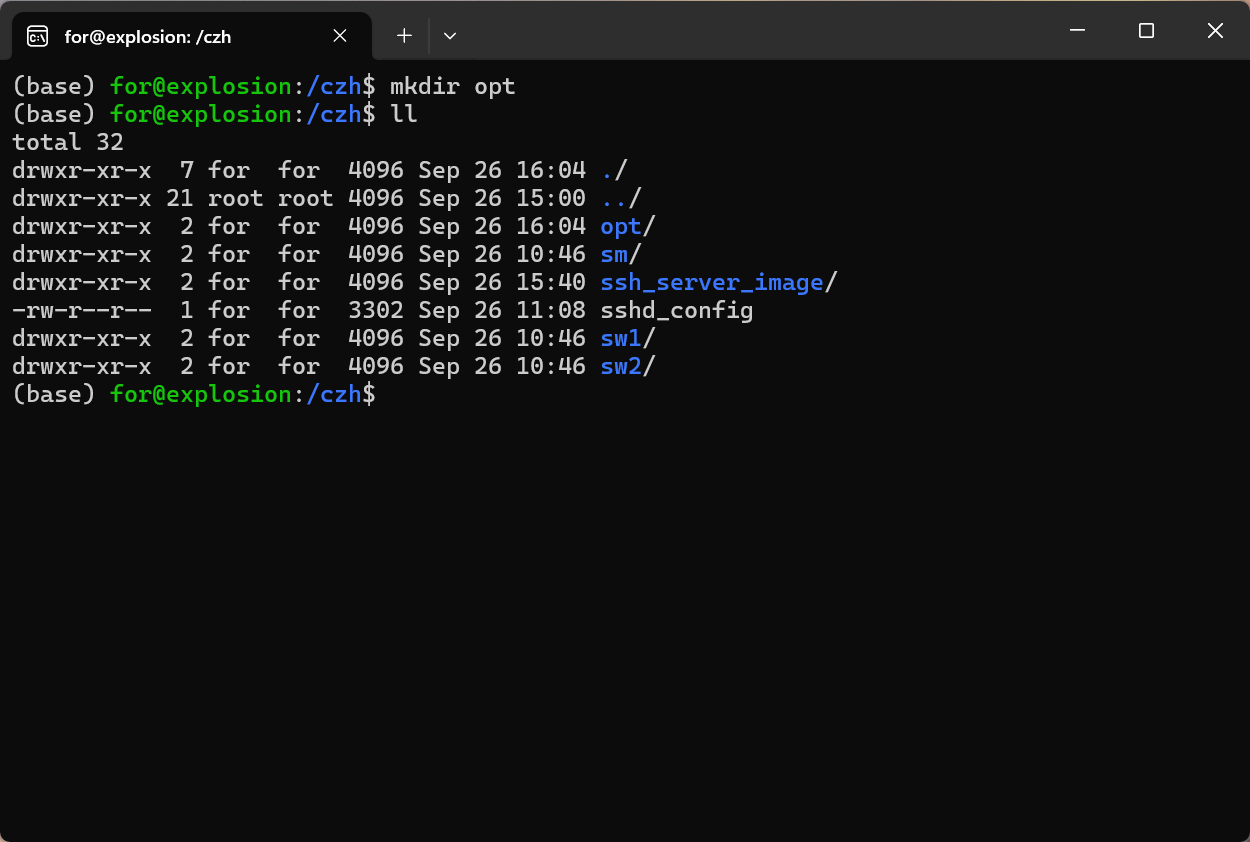
1.创建自己的工作目录,并进入创建相关文件夹(ssh_server_image sm sw1 sw2)
mkdir ./ssh_server_image
mkdir ./sm
mkdir ./sw1
mkdir ./sw2
mkdir ./opt
2.在ssh_server_image文件夹中创建Dockerfile文件,并输入一下配置
FROM ubuntu:latest
RUN apt update && apt install -y openssh-server
RUN apt install -y nano vim
RUN echo "root:root" | chpasswd
RUN mkdir /startup
RUN echo "#!/bin/bash\nservice ssh start\n/bin/bash" > /startup/startup.sh
RUN chmod -R 777 /startup/startup.sh
WORKDIR /root/
CMD ["/startup/startup.sh"]
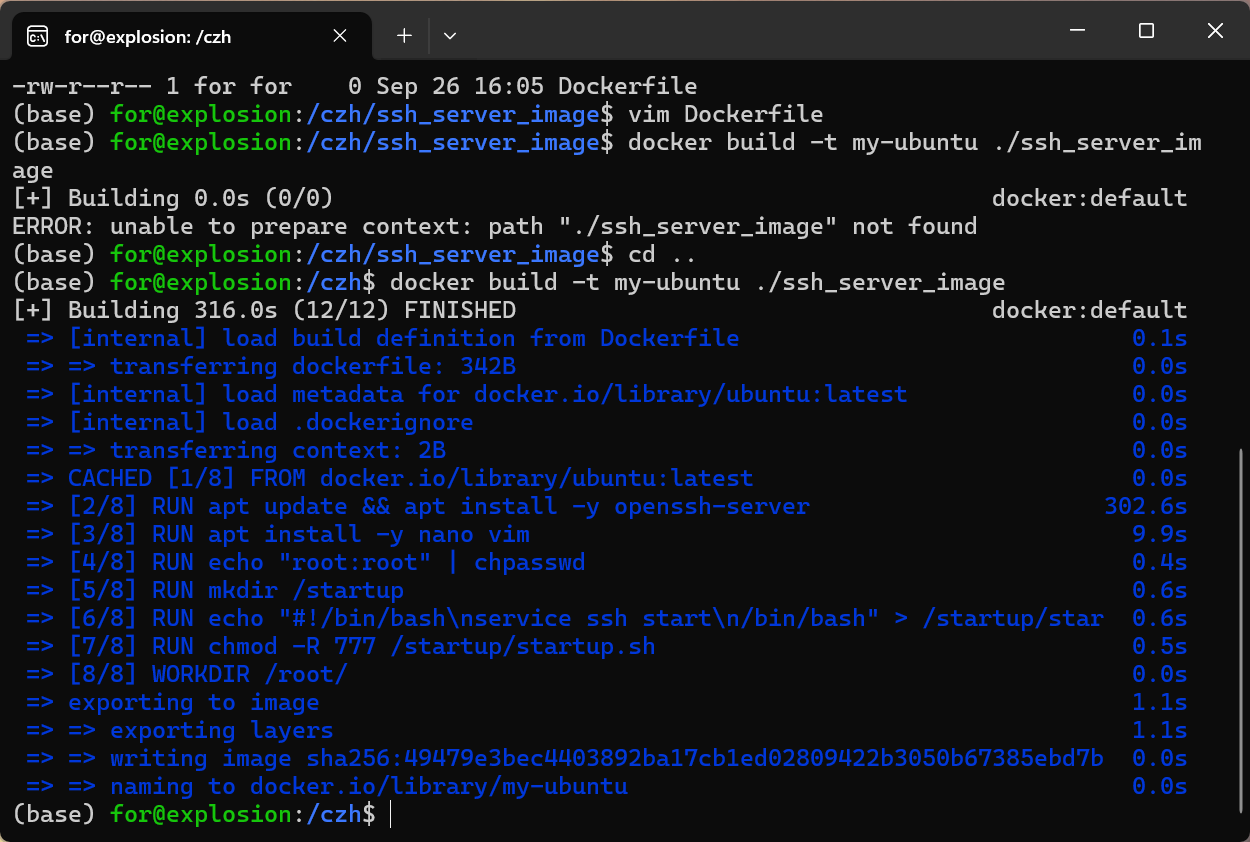
3.构建镜像
docker build -t my-ubuntu ./ssh_server_image
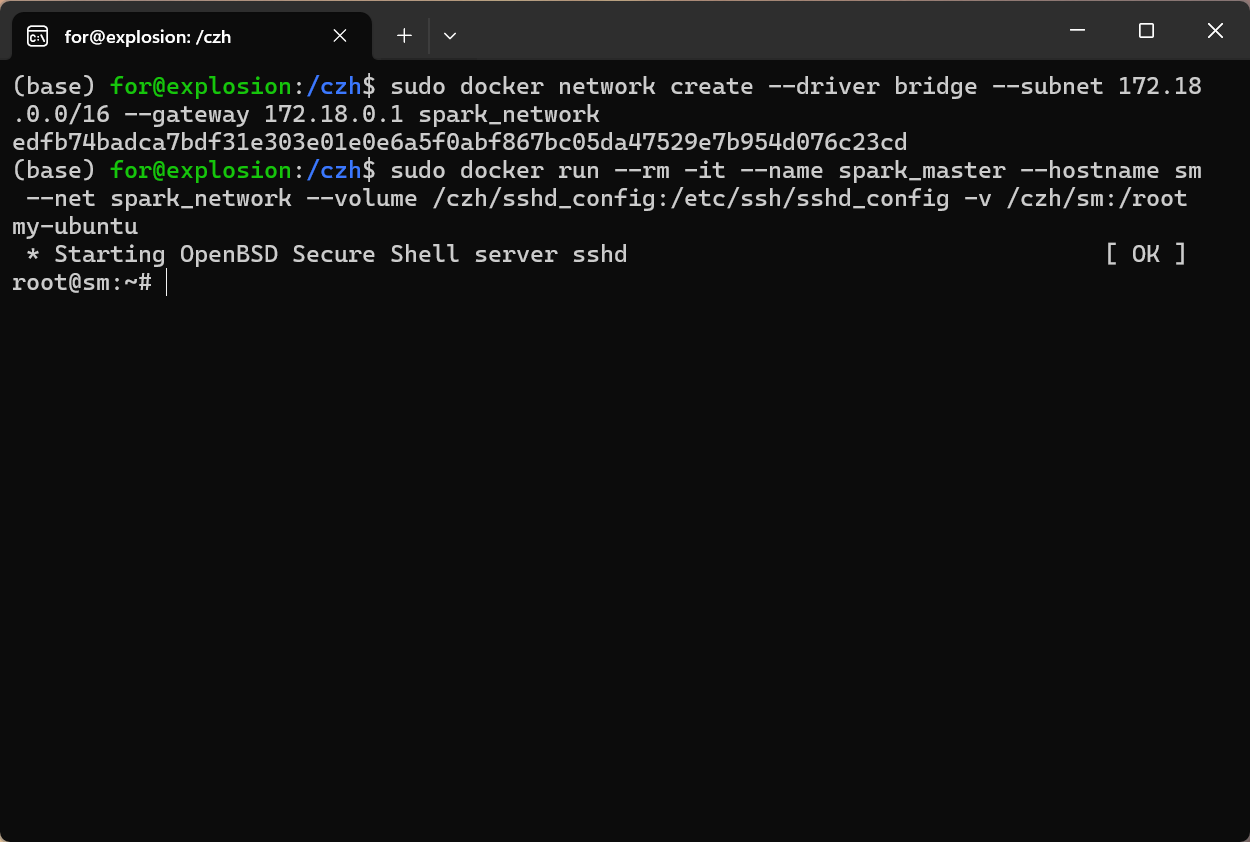
二.创建网络
sudo docker network create --driver bridge --subnet 172.18.0.0/16 --gateway 172.18.0.1 spark_network

三. 创建集群
1.主节点
sudo docker run --rm -it \
--name spark_master \
--hostname sm \
--net spark_network \
--volume /czh/sshd_config:/etc/ssh/sshd_config \
-v /czh/sm:/root my-ubuntu
chmod 600 ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chown root ~
chgrp root ~
2.在主节点中生成公钥私钥
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #复制
#验证来连接
ssh sm
# or
ssh -p 22 root@sm

3.在wsl中,通过复制文件配置到sw1和sw2中
sudo cp -r sm/.ssh sw1/
sudo cp -r sm/.ssh sw2/
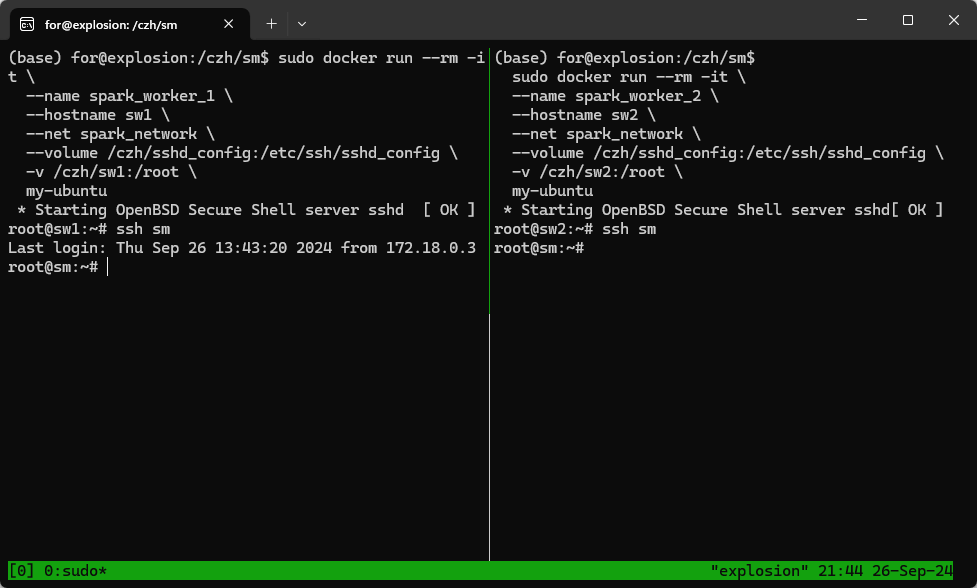
4.创建两个子节点
sudo docker run --rm -it \
--name spark_worker_1 \
--hostname sw1 \
--net spark_network \
--volume /czh/sshd_config:/etc/ssh/sshd_config \
-v /czh/sw1:/root \
my-ubuntu
sudo docker run --rm -it \
--name spark_worker_2 \
--hostname sw2 \
--net spark_network \
--volume /czh/sshd_config:/etc/ssh/sshd_config \
-v /czh/sw2:/root \
my-ubuntu
5.在两个子节点中,进行权限设置
#都需要进行权限设置
chmod 600 ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chown root ~
chgrp root ~
6.在主节点中测试连接
ssh sm
ssh sw1
ssh sw2
四.运行集群
1. 在wsl中运行三个节点
sudo docker run --rm -it \
--name spark_master \
--hostname sm \
--net spark_network \
--ip 172.18.0.2 \
-v /czh/sm:/root \
-v /czh/hosts:/etc/hosts \
-v /czh/opt:/opt \
-v /czh/sshd_config:/etc/ssh/sshd_config \
-p 9870:9870 -p 8088:8088 -p 8080:8080 -p 4040:4040 -p 19999:19999 \
my-ubuntu:latest
sudo docker run --rm -it \
--name spark_worker_1 \
--hostname sw1 \
--net spark_network \
--ip 172.18.0.3 \
-v/czh/sw1:/root \
-v /czh/hosts:/etc/hosts \
-v /czh/sshd_config:/etc/ssh/sshd_config \
-v /czh/opt:/opt \
my-ubuntu:latest
sudo docker run --rm -it \
--name spark_worker_2 \
--hostname sw2 \
--net spark_network \
--ip 172.18.0.4 \
-v /czh/sw2:/root \
-v /czh/hosts:/etc/hosts \
-v /czh/sshd_config:/etc/ssh/sshd_config \
-v /czh/opt:/opt \
my-ubuntu:latest
5.安装Java、Miniconda3和Scala
配置环境变量
export JAVA_HOME=/opt/jdk1.8.0_421
export PATH=${JAVA_HOME}/bin:$PATH
export SCALA_HOME=/opt/scala-2.12.20
export PATH=${SCALA_HOME}/bin:$PATH
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/opt/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/opt/miniconda3/etc/profile.d/conda.sh" ]; then
. "/opt/miniconda3/etc/profile.d/conda.sh"
else
export PATH="/opt/miniconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
下载相关安装包,解压后配置环境变量
修改环境变量
使环境变量生效
六.安装hadoop
1.解压hadoop
tar -zxvf hadoop-3.3.4.tar.gz
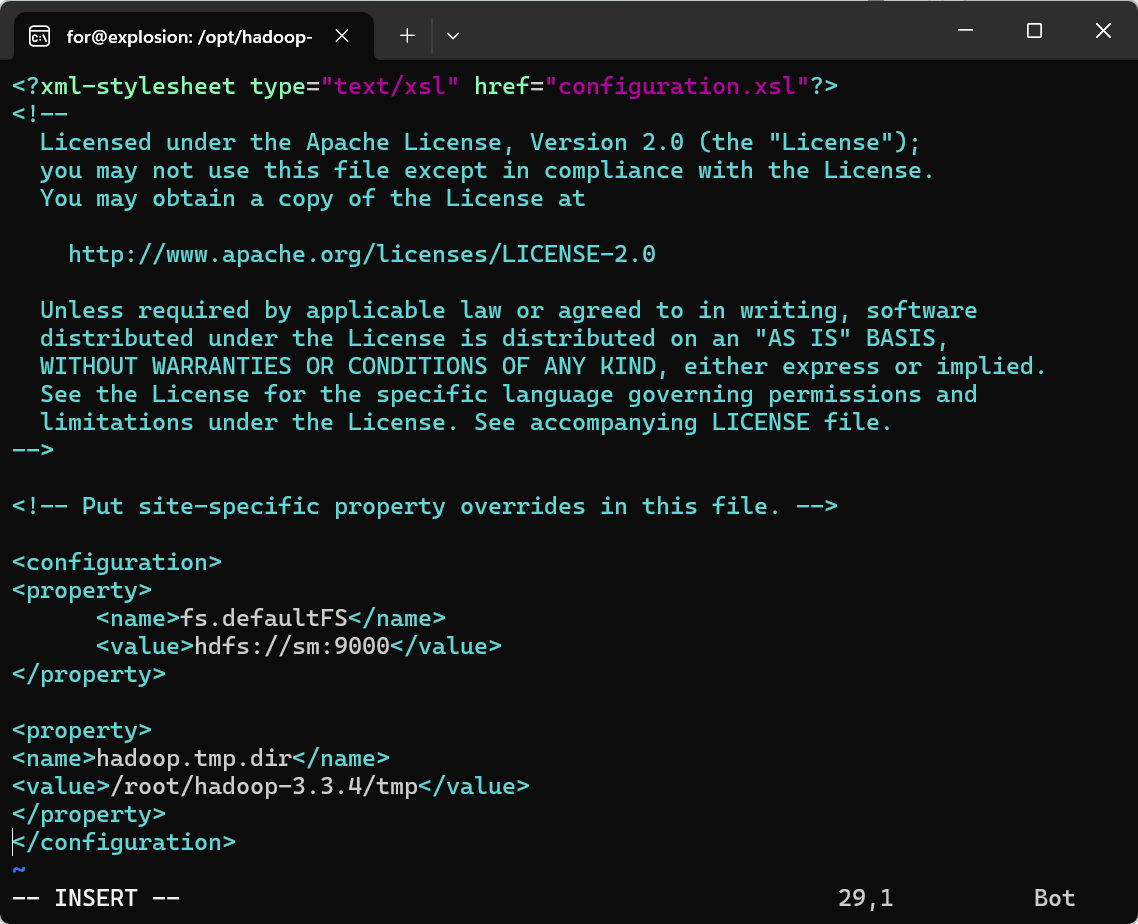
2. 在/opt/hadoop-3.3.4/etc/hadoop/core-site.xml文件中添加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://sm:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-3.3.4/tmp</value>
</property>
3. 在/opt/hadoop-3.3.4/etc/hadoop/yarn-site.xml文件中添加以下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sm</value>
</property>

4. 在/opt/hadoop-3.3.4/etc/hadoop/mapred-site.xml文件中添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value>
</property>

5.hdfs-site.xml
<property>
<name>dfs.blocksize</name>
<value>8388608</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/nn</value>
</property>
6.yarn-env.sh
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
7. hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_421
export HADOOP_HOME=/opt/hadoop-3.3.4
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export HADOOP_PID_DIR=${HADOOP_HOME}/${HOSTNAME}-pid
export HADOOP_PIexport HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
8.修改文件worker内容为:
sw1
sw2
9.运行
cd /opt/hadoop-3.3.4
#初始化
./bin/hdfs namenode -format
#开始
./sbin/start-dfs.sh
./sbin/start-yarn.sh
#停止
./sbin/stop-dfs.sh
./sbin/stop-yarn.sh
七.安装spark
1.在workers中添加从节点
sw1
sw2
2.在spark-env.sh中配置环境目录
JAVA_HOME=/opt/jdk1.8.0_421
HADOOP_CONF_DIR=/opt/hadoop-3.3.4/etc/hadoop
YARN_CONF_DIR=/opt/hadoop-3.3.4/etc/hadoop
SPARK_PID_DIR=/root/spark-3.3.1-bin-hadoop3/${HOSTNAME}-pid
3.运行
cd /opt/spark-3.3.1-bin-hadoop3
./sbin/start-all.sh
./sbin/stop-all.sh
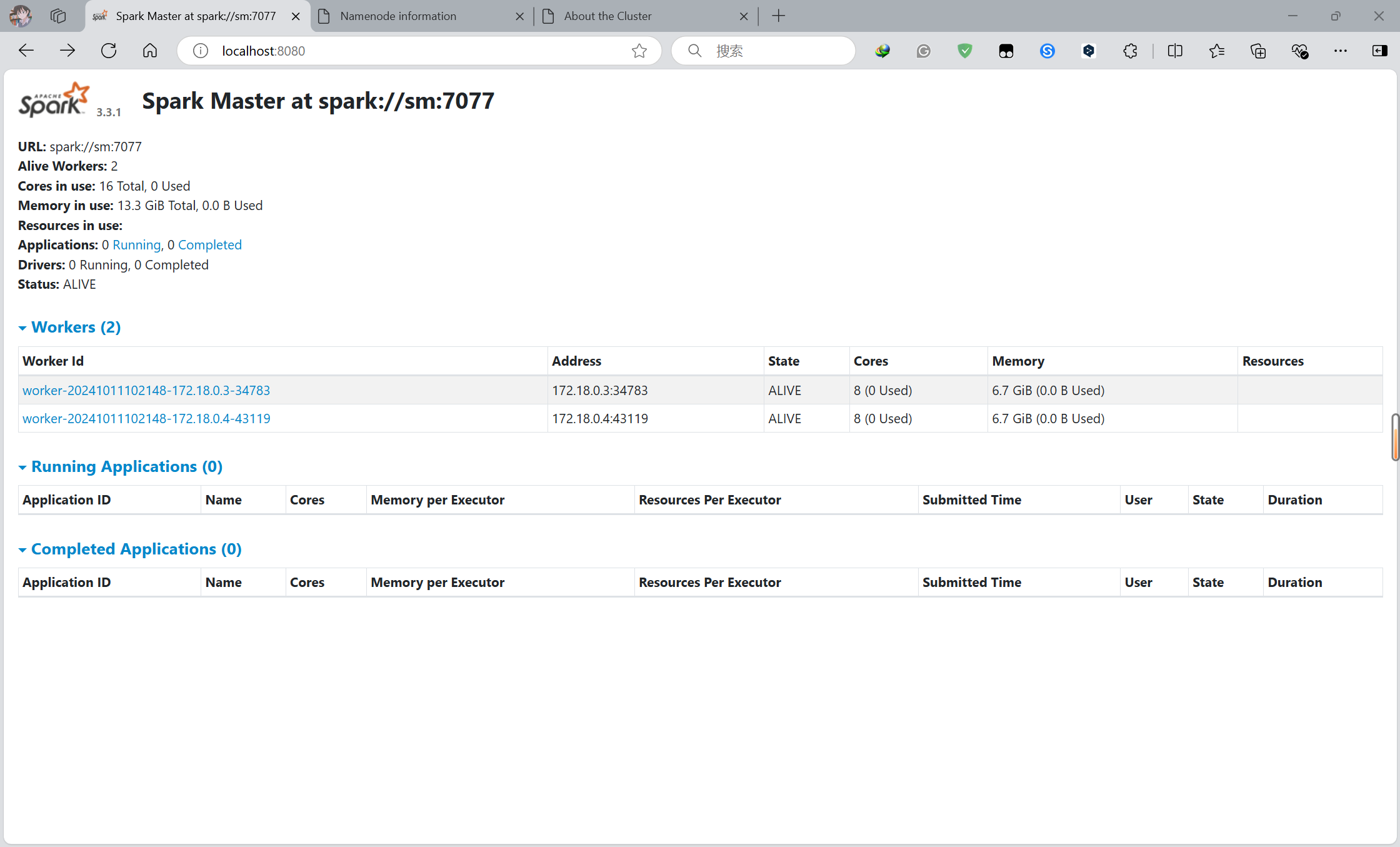

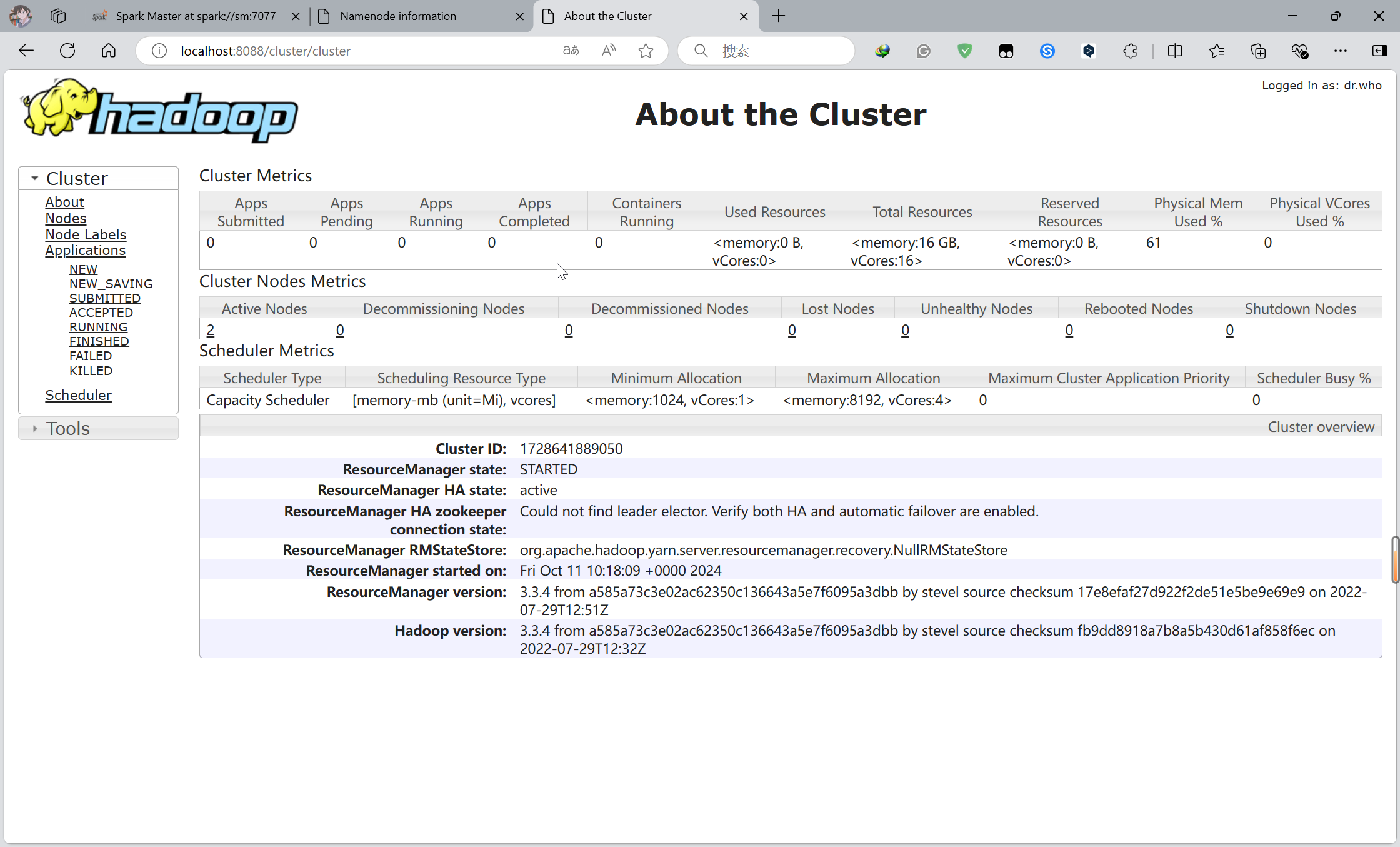
#安装spark
pip install pyspark==3.5.0


 浙公网安备 33010602011771号
浙公网安备 33010602011771号