
MySQL数据模型
-
优点:二分查找
-
缺点:最差情况变成了链表
平衡二叉树:
-
-
缺点:每个节点存储存储的数据太少,每次从磁盘拿数据不够page的16kb,导致树的深度过大(瘦长型)。读不够
多路平衡查找树(B树):分叉数比关键字多1(通过树的合并和分裂来保证新加入的关键字的有序性)
-
优点:每个节点可以存储超过1个关键字
加强版多路平衡查找树(B+树):关键字数=度,非叶子结点不存数据,叶子结点形成有序链表
聚集索引的叶子结点存放完整的数据
二级索引存储索引和主键健值
-
优点:排序能力更强,效率更加稳定,磁盘读写能力、扫表能力更强
回表查询:用二级索引去查询数据的时候,需要多扫描一次自己的B+树,然后再到主键索引的叶子结点中去拿数据
如果select中所有的列都在索引中,则不需要回表查询
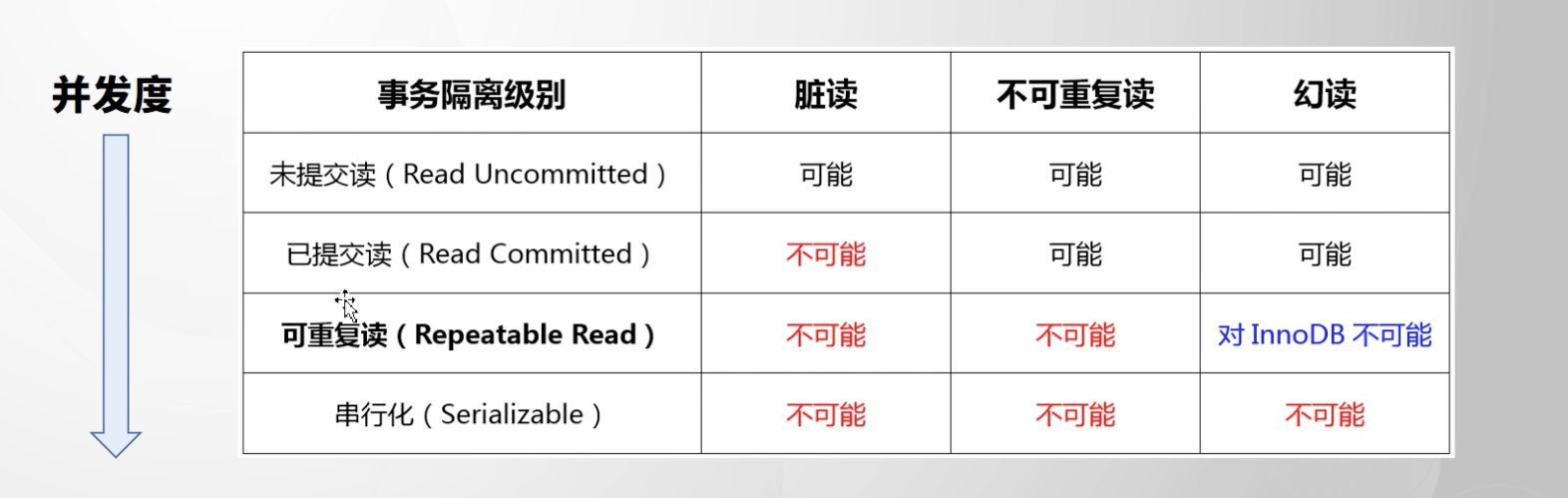
脏读:读到别的事务未提交的数据
不可重复读(针对update和delete):事务过程中读到和事务开始时不一样的数据
幻读(针对insert):事务过程中读到和事务开始时不一样的数据
读一致性:数据库读的事务和其他事务不瓜葛,提高数据库并发性能
例如:A账户原本有1000,现在B和C分别给A账户加100
A:1000
B:1000+100
C:1000+100
这样A就变成1100,和预期结果不一致
MVCC核心思想
效果:建立一个快照,同一个事务无论查询多少次都是相同的数据
一个事务能够看到的数据版本:
1. 第一次查询之前已经提交的事务修改
2. 本事务的修改
一个事务不能看见的数据版本:
1. 在本事务第一次查询之后创建的事务
2. 未提交的事务修改

 浙公网安备 33010602011771号
浙公网安备 33010602011771号