linux命令-grep
1.1 grep
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
1.2 选项
grep的常用选项:
-V: 打印grep的版本号
-E: 解释PATTERN作为扩展正则表达式,也就相当于使用egrep。 或操作
-F : 解释PATTERN作为固定字符串的列表,由换行符分隔,其中任何一个都要匹配。也就相当于使用fgrep。
-G: 将范本样式视为普通的表示法来使用。这是默认值。加不加都是使用grep。
匹配控制选项:
-e : 使用PATTERN作为模式。这可以用于指定多个搜索模式,或保护以连字符( - )开头的图案。指定字符串做为查找文件内容的样式。
-f : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-i : 搜索时候忽略大小写
-v: 反转匹配,选择没有被匹配到的内容。
-w:匹配整词,精确地单词,单词的两边必须是非字符符号(即不能是字母数字或下划线)
-x:仅选择与整行完全匹配的匹配项。精确匹配整行内容(包括行首行尾那些看不到的空格内容都要完全匹配)
-y:此参数的效果和指定“-i”参数相同。
一般输出控制选项:
-c: 抑制正常输出;而是为每个输入文件打印匹配线的计数。
--color [= WHEN]:让关键字高亮显示,如--color=auto
-L:列出文件内容不符合指定的范本样式的文件名称
-l : 列出文件内容符合指定的范本样式的文件名称。
-m num:当匹配内容的行数达到num行后,grep停止搜索,并输出停止前搜索到的匹配内容
-o: 只输出匹配的具体字符串,匹配行中其他内容不会输出
-q:安静模式,不会有任何输出内容,查找到匹配内容会返回0,未查找到匹配内容就返回非0
-s:不会输出查找过程中出现的任何错误消息,-q和-s选项因为与其他系统的grep有兼容问题,shell脚本应该避免使用-q和-s,并且应该将标准和错误输出重定向到/dev/null 代替。
输出线前缀控制:
-b:输出每一个匹配行(或匹配的字符串)时在其前附加上偏移量(从文件第一个字符到该匹配内容之间的字节数)
-H:在每一个匹配行之前加上文件名一起输出(针对于查找单个文件),当查找多个文件时默认就会输出文件名
-h:禁止输出上的文件名的前缀。无论查找几个文件都不会在匹配内容前输出文件名
--label = LABEL:显示实际来自标准输入的输入作为来自文件LABEL的输入。这是特别在实现zgrep等工具时非常有用,例如gzip -cd foo.gz | grep --label = foo -H的东西。看到 也是-H选项。
-n:输出匹配内容的同时输出其所在行号。
-T:初始标签确保实际行内容的第一个字符位于制表位上,以便对齐标签看起来很正常。在匹配信息和其前的附加信息之间加入tab以使格式整齐。
上下文线控制选项:
-A num:匹配到搜索到的行以及该行下面的num行
-B num:匹配到搜索到的行以及该行上面的num行
-C num:匹配到搜索到的行以及上下各num行
文件和目录选择选项:
-a: 处理二进制文件,就像它是文本;这相当于--binary-files = text选项。不忽略二进制的数据。
--binary-files = TYPE:如果文件的前几个字节指示文件包含二进制数据,则假定该文件为类型TYPE。默认情况下,TYPE是二进制的,grep通常输出一行消息二进制文件匹配,或者如果没有匹配则没有消息。如果TYPE不匹配,grep假定二进制文件不匹配;这相当于-I选项。如果TYPE是文本,则grep处理a二进制文件,如果它是文本;这相当于-a选项。警告:grep --binary-files = text可能会输出二进制的垃圾,如果输出是一个终端和如果可能有讨厌的副作用终端驱动程序将其中的一些解释为命令。
-D:如果输入文件是设备,FIFO或套接字,请使用ACTION处理。默认情况下,读取ACTION,这意味着设备被读取,就像它们是普通文件一样。如果跳过ACTION,设备为 默默地跳过。
-d: 如果输入文件是目录,请使用ACTION处理它。默认情况下,ACTION是读的,这意味着目录被读取,就像它们是普通文件一样。如果跳过ACTION,目录将静默跳过。如果ACTION是recurse,grep将递归读取每个目录下的所有文件;这是相当于-r选项。
--exclude=GLOB:跳过基本名称与GLOB匹配的文件(使用通配符匹配)。文件名glob可以使用*,?和[...]作为通配符,和\引用通配符或反斜杠字符。搜索其文件名和GLOB通配符相匹配的文件的内容来查找匹配使用方法:grep -H --exclude=c* "old" ./* c*是通配文件名的通配符./* 指定需要先通配文件名的文件的范围,必须要给*,不然就匹配不出内容,(如果不给*,带上-r选项也可以匹配)
--exclude-from = FILE:在文件中编写通配方案,grep将不会到匹配方案中文件名的文件去查找匹配内容
--exclude-dir = DIR:匹配一个目录下的很多内容同时还要让一些子目录不接受匹配,就使用此选项。
--include = GLOB:仅搜索其基本名称与GLOB匹配的文件(使用--exclude下所述的通配符匹配)。
-R ,-r :以递归方式读取每个目录下的所有文件; 这相当于-d recurse选项。
其他选项:
--line-buffered: 在输出上使用行缓冲。这可能会导致性能损失。
--mmap:启用mmap系统调用代替read系统调用
-U:将文件视为二进制。
-z:将输入视为一组行,每一行由一个零字节(ASCII NUL字符)而不是a终止新队。与-Z或--null选项一样,此选项可以与排序-z等命令一起使用来处理任意文件名。
————————————————
版权声明:本文为CSDN博主「llljjlj」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/llljjlj/java/article/details/89810340
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
1.3 grep命令常见用法
1.3.1 查找普通文本
grep match_pattern file_name
grep "match_pattern" file_name
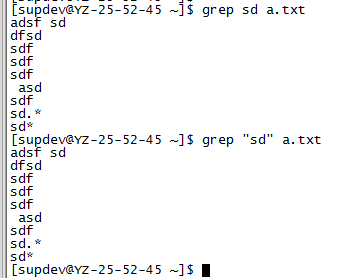
1.3.2 多文件查找文本
grep match_pattern file_name1 file_name2 file_name3
grep "match_pattern" file_name1 file_name2 file_name3
注意文件名之间有空可隔开
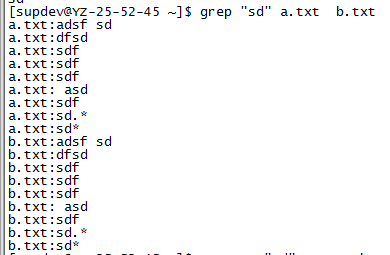
1.3.3 显示文本所在的行号
grep –n match_pattern file_name
grep –n "match_pattern" file_name

1.3.4 不显示匹配的文本行
grep –v match_pattern file_name
grep –v "match_pattern" file_name
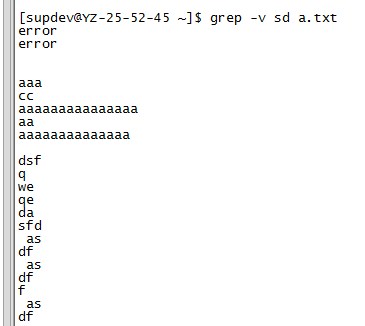
1.3.5 使用正则表达式匹配文本
grep –E match_pattern file_name
grep –E "match_pattern" file_name
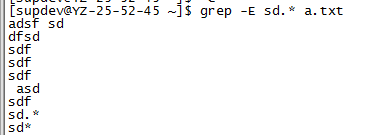
1.3.6 仅显示匹配到的字符串,不是整行
grep –o match_pattern file_name
grep –o "match_pattern" file_name
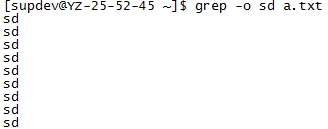
1.3.7 仅显示匹配到的正则字符串,不是整行
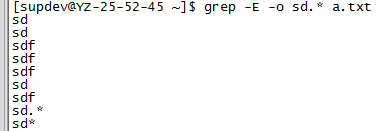
1.3.8 正则表达式为常规字符串,忽略字符的特殊含义
grep –F match_pattern file_name
grep –F "match_pattern" file_name

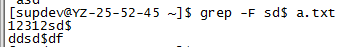
1.3.9 匹配的行数
grep –c match_pattern file_name
grep –c "match_pattern" file_name

1.3.10 忽略大小写
grep –i match_pattern file_name
grep –i "match_pattern" file_name
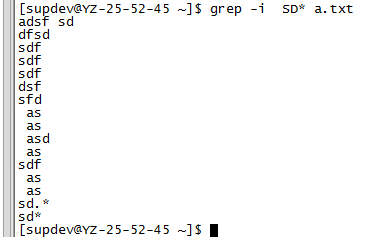
1.3.11 打印匹配行上下文信息
-A n打印匹配行及其后n行信息。
-B n打印匹配行及其前n行信息。
-C n 打印匹配行及其前后n行信息。
假设有多重匹配,将使用--隔离。

1.3.12 递规查找
grep -r match_pattern foldername
grep –r "match_pattern" foldername
grep [参数列表] 字符串 目录名 –r
-R与-r一样
1.3.13 高亮加粗显示显示
grep --color match_pattern file_name
grep –color sd a.txt
1.3.14 查询多个关键字|方式
grep -E -i "zhang@jd.com|active" --color tha_ business_man_detail.log.2019032*
1.3.15 查询多个关键字正则表达式
grep -E -i "zhang@jd.com.*active" --color tha_ business_man_detail.log.2019032*
1.3.16 连续查询
grep -E -i "zhang@jd.com" tha_ business_man_detail.log.2019032* | grep "active" --color
1.4 grep –e 与 grep –E的区别
grep –e表示基本正则表达式
grep –E表示扩展正则表达式
参考:https://www.cnblogs.com/franjia/p/4384362.html
1.4.1.1 grep -v、-e、-E
在Linux的grep命令中如何使用OR,AND,NOT操作符呢?
其实,在grep命令中,有OR和NOT操作符的等价选项,但是并没有grep AND这种操作符。不过呢,可以使用patterns来模拟AND操作的。下面会举一些例子来说明在Linux的grep命令中如何使用OR,AND,NOT。
在下面的例子中,会用到这个employee.txt文件,如下:
[plain] view plaincopy
- $ cat employee.txt
- 100 Thomas Manager Sales $5,000
- 200 Jason Developer Technology $5,500
- 300 Raj Sysadmin Technology $7,000
- 400 Nisha Manager Marketing $9,500
- 500 Randy Manager Sales $6,000
(一)Grep OR 操作符
以下四种方法均能实现grep OR的操作。个人推荐方法3.
1.使用 \|
如果不使用grep命令的任何选项,可以通过使用 '\|' 来分割多个pattern,以此实现OR的操作。
[plain] view plaincopy
- grep 'pattern1\|pattern2' filename
例子如下:
[plain] view plaincopy
- $ grep 'Tech\|Sales' employee.txt
- 100 Thomas Manager Sales $5,000
- 200 Jason Developer Technology $5,500
- 300 Raj Sysadmin Technology $7,000
- 500 Randy Manager Sales $6,000
2.使用选项 -E
grep -E 选项可以用来扩展选项为正则表达式。 如果使用了grep 命令的选项-E,则应该使用 | 来分割多个pattern,以此实现OR操作。
[plain] view plaincopy
- grep -E 'pattern1|pattern2' filename
例子如下:
[plain] view plaincopy
- $ grep -E 'Tech|Sales' employee.txt
- 100 Thomas Manager Sales $5,000
- 200 Jason Developer Technology $5,500
- 300 Raj Sysadmin Technology $7,000
- 500 Randy Manager Sales $6,000
3.使用 egrep
egrep 命令等同于‘grep -E’。因此,使用egrep (不带任何选项)命令,以此根据分割的多个Pattern来实现OR操作.
[plain] view plaincopy
- egrep 'pattern1|pattern2' filename
例子如下:
[plain] view plaincopy
- $ egrep 'Tech|Sales' employee.txt
- 100 Thomas Manager Sales $5,000
- 200 Jason Developer Technology $5,500
- 300 Raj Sysadmin Technology $7,000
- 500 Randy Manager Sales $6,000
4.使用选项 -e
使用grep -e 选项,只能传递一个参数。在单条命令中使用多个 -e 选项,得到多个pattern,以此实现OR操作。
[plain] view plaincopy
- grep -e pattern1 -e pattern2 filename
例子如下:
[plain] view plaincopy
- $ grep -e Tech -e Sales employee.txt
- 100 Thomas Manager Sales $5,000
- 200 Jason Developer Technology $5,500
- 300 Raj Sysadmin Technology $7,000
- 500 Randy Manager Sales $6,000
(二)Grep AND 操作
1.使用 -E 'pattern1.*pattern2'
grep命令本身不提供AND功能。但是,使用 -E 选项可以实现AND操作。
[plain] view plaincopy
- grep -E 'pattern1.*pattern2' filename
- grep -E 'pattern1.*pattern2|pattern2.*pattern1' filename
第一个例子如下:(其中两个pattern的顺序是指定的)
[plain] view plaincopy
- $ grep -E 'Dev.*Tech' employee.txt
- 200 Jason Developer Technology $5,500
第二个例子:(两个pattern的顺序不是固定的,可以是乱序的)
[plain] view plaincopy
- $ grep -E 'Manager.*Sales|Sales.*Manager' employee.txt
2.使用多个grep命令
可以使用多个 grep 命令 ,由管道符分割,以此来实现 AND 语义。
[plain] view plaincopy
- grep -E 'pattern1' filename | grep -E 'pattern2'
例子如下:
[plain] view plaincopy
- $ grep Manager employee.txt | grep Sales
- 100 Thomas Manager Sales $5,000
- 500 Randy Manager Sales $6,000
(三)Grep NOT操作
1.使用选项 grep -v
使用 grep -v 可以实现 NOT 操作。 -v 选项用来实现反选匹配的( invert match)。如,可匹配得到除下指定pattern外的所有lines。
[plain] view plaincopy
- grep -v 'pattern1' filename
例子如下:
[plain] view plaincopy
- $ grep -v Sales employee.txt
- 200 Jason Developer Technology $5,500
- 300 Raj Sysadmin Technology $7,000
- 400 Nisha Manager Marketing $9,500
当然,可以将NOT操作与其他操作联合起来,以此实现更强大的功能 组合。
如,这个例子将得到:‘Manager或者Developer,但是不是Sales’的结果:
[plain] view plaincopy
- $ egrep 'Manager|Developer' employee.txt | grep -v Sales
- 200 Jason Developer Technology $5,500
- 400 Nisha Manager Marketing $9,500
2 linux shell 正则表达式(BREs,EREs,PREs)差异比较
则表达式:在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。这些是正则表达式的定义。 由于起源于unix系统,因此很多语法规则一样的。但是随着逐渐发展,后来扩展出以下几个类型。了解这些对于学习正则表达式。
一、正则表达式分类:
1、基本的正则表达式(Basic Regular Expression 又叫 Basic RegEx 简称 BREs)
2、扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs)
3、Perl 的正则表达式(Perl Regular Expression 又叫 Perl RegEx 简称 PREs)
说明:只有掌握了正则表达式,才能全面地掌握 Linux 下的常用文本工具(例如:grep、egrep、GUN sed、 Awk 等) 的用法
二、Linux 中常用文本工具与正则表达式的关系
常握 Linux 下几种常用文本工具的特点,对于我们更好的使用正则表达式是很有帮助的
- grep , egrep 正则表达式特点:
1)grep 支持:BREs、EREs、PREs 正则表达式
grep 指令后不跟任何参数,则表示要使用 ”BREs“
grep 指令后跟 ”-E" 参数,则表示要使用 “EREs“
grep 指令后跟 “-P" 参数,则表示要使用 “PREs"
2)egrep 支持:EREs、PREs 正则表达式
egrep 指令后不跟任何参数,则表示要使用 “EREs”
egrep 指令后跟 “-P" 参数,则表示要使用 “PREs"
3)grep 与 egrep 正则匹配文件,处理文件方法
a. grep 与 egrep 的处理对象:文本文件
b. grep 与 egrep 的处理过程:查找文本文件中是否含要查找的 “关键字”(关键字可以是正则表达式) ,如果含有要查找的 ”关健字“,那么默认返回该文本文件中包含该”关健字“的该行的内容,并在标准输出中显示出来,除非使用了“>" 重定向符号,
c. grep 与 egrep 在处理文本文件时,是按行处理的
- sed 正则表达式特点
1)sed 文本工具支持:BREs、EREs
sed 指令默认是使用"BREs"
sed 命令参数 “-r ” ,则表示要使用“EREs"
2)sed 功能与作用
a. sed 处理的对象:文本文件
b. sed 处理操作:对文本文件的内容进行 --- 查找、替换、删除、增加等操作
c. sed 在处理文本文件的时候,也是按行处理的
- Awk(gawk)正则表达式特点
1)Awk 文本工具支持:EREs
awk 指令默认是使用 “EREs"
2)Awk 文本工具处理文本的特点
a. awk 处理的对象:文本文件
b. awk 处理操作:主要是对列进行操作
三、常见3中类型正则表达式比较
|
字符 |
说明 |
Basic RegEx |
Extended RegEx |
python RegEx |
Perl regEx |
|
转义 |
|
\ |
\ |
\ |
\ |
|
^ |
匹配行首,例如'^dog'匹配以字符串dog开头的行(注意:awk 指令中,'^'则是匹配字符串的开始) |
^ |
^ |
^ |
^ |
|
$ |
匹配行尾,例如:'^、dog$'匹配以字符串 dog 为结尾的行(注意:awk 指令中,'$'则是匹配字符串的结尾) |
$ |
$ |
$ |
$ |
|
^$ |
匹配空行 |
^$ |
^$ |
^$ |
^$ |
|
^string$ |
匹配行,例如:'^dog$'匹配只含一个字符串 dog 的行 |
^string$ |
^string$ |
^string$ |
^string$ |
|
\< |
匹配单词,例如:'\<frog' (等价于'\bfrog'),匹配以 frog 开头的单词 |
\< |
\< |
不支持 |
不支持(但可以使用\b来匹配单词,例如:'\bfrog') |
|
\> |
匹配单词,例如:'frog\>'(等价于'frog\b '),匹配以 frog 结尾的单词 |
\> |
\> |
不支持 |
不支持(但可以使用\b来匹配单词,例如:'frog\b') |
|
\<x\> |
匹配一个单词或者一个特定字符,例如:'\<frog\>'(等价于'\bfrog\b')、'\<G\>' |
\<x\> |
\<x\> |
不支持 |
不支持(但可以使用\b来匹配单词,例如:'\bfrog\b' |
|
() |
匹配表达式,例如:不支持'(frog)' |
不支持(但可以使用\(\),如:\(dog\) |
() |
() |
() |
|
\(\) |
匹配表达式,例如:不支持'(frog)' |
\(\) |
不支持(同()) |
不支持(同()) |
不支持(同()) |
|
? |
匹配前面的子表达式 0 次或 1 次(等价于{0,1}),例如:where(is)?能匹配"where" 以及"whereis" |
不支持(同\?) |
? |
? |
? |
|
\? |
匹配前面的子表达式 0 次或 1 次(等价于'\{0,1\}'),例如:'where\(is\)\? '能匹配 "where"以及"whereis" |
\? |
不支持(同?) |
不支持(同?) |
不支持(同?) |
|
? |
当该字符紧跟在任何一个其他限制符(*, +, ?, {n},{n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个"o",而 'o+' 将匹配所有 'o' |
不支持 |
不支持 |
不支持 |
不支持 |
|
. |
匹配除换行符('\n')之外的任意单个字符(注意:awk 指令中的句点能匹配换行符) |
. |
.(如果要匹配包括“\n”在内的任何一个字符,请使用:'(^$)|(.) |
. |
.(如果要匹配包括“\n”在内的任何一个字符,请使用:' [.\n] ' |
|
* |
匹配前面的子表达式 0 次或多次(等价于{0, }),例如:zo* 能匹配 "z"以及 "zoo" |
* |
* |
* |
* |
|
\+ |
匹配前面的子表达式 1 次或多次(等价于'\{1, \}'),例如:'where\(is\)\+ '能匹配 "whereis"以及"whereisis" |
\+ |
不支持(同+) |
不支持(同+) |
不支持(同+) |
|
+ |
匹配前面的子表达式 1 次或多次(等价于{1, }),例如:zo+能匹配 "zo"以及 "zoo",但不能匹配 "z" |
不支持(同\+) |
+ |
+ |
+ |
|
{n} |
n 必须是一个 0 或者正整数,匹配子表达式 n 次,例如:zo{2}能匹配 |
不支持(同\{n\}) |
{n} |
{n} |
{n} |
|
{n,} |
"zooz",但不能匹配 "Bob"n 必须是一个 0 或者正整数,匹配子表达式大于等于 n次,例如:go{2,} |
不支持(同\{n,\}) |
{n,} |
{n,} |
{n,} |
|
{n,m} |
能匹配 "good",但不能匹配 godm 和 n 均为非负整数,其中 n <= m,最少匹配 n 次且最多匹配 m 次 ,例如:o{1,3}将配"fooooood" 中的前三个 o(请注意在逗号和两个数之间不能有空格) |
不支持(同\{n,m\}) |
{n,m} |
{n,m} |
{n,m} |
|
x|y |
匹配 x 或 y,例如: 不支持'z|(food)' 能匹配 "z" 或"food";'(z|f)ood' 则匹配"zood" 或 "food" |
不支持(同x\|y) |
x|y |
x|y |
x|y |
|
[0-9] |
匹配从 0 到 9 中的任意一个数字字符(注意:要写成递增) |
[0-9] |
[0-9] |
[0-9] |
[0-9] |
|
[xyz] |
字符集合,匹配所包含的任意一个字符,例如:'[abc]'可以匹配"lay" 中的 'a'(注意:如果元字符,例如:. *等,它们被放在[ ]中,那么它们将变成一个普通字符) |
[xyz] |
[xyz] |
[xyz] |
[xyz] |
|
[^xyz] |
负值字符集合,匹配未包含的任意一个字符(注意:不包括换行符),例如:'[^abc]' 可以匹配 "Lay" 中的'L'(注意:[^xyz]在awk 指令中则是匹配未包含的任意一个字符+换行符) |
[^xyz] |
[^xyz] |
[^xyz] |
[^xyz] |
|
[A-Za-z] |
匹配大写字母或者小写字母中的任意一个字符(注意:要写成递增) |
[A-Za-z] |
[A-Za-z] |
[A-Za-z] |
[A-Za-z] |
|
[^A-Za-z] |
匹配除了大写与小写字母之外的任意一个字符(注意:写成递增) |
[^A-Za-z] |
[^A-Za-z] |
[^A-Za-z] |
[^A-Za-z] |
|
\d |
匹配从 0 到 9 中的任意一个数字字符(等价于 [0-9]) |
不支持 |
不支持 |
\d |
\d |
|
\D |
匹配非数字字符(等价于 [^0-9]) |
不支持 |
不支持 |
\D |
\D |
|
\S |
匹配任何非空白字符(等价于[^\f\n\r\t\v]) |
不支持 |
不支持 |
\S |
\S |
|
\s |
匹配任何空白字符,包括空格、制表符、换页符等等(等价于[ \f\n\r\t\v]) |
不支持 |
不支持 |
\s |
\s |
|
\W |
匹配任何非单词字符 (等价于[^A-Za-z0-9_]) |
\W |
\W |
\W |
\W |
|
\w |
匹配包括下划线的任何单词字符(等价于[A-Za-z0-9_]) |
\w |
\w |
\w |
\w |
|
\B |
匹配非单词边界,例如:'er\B' 能匹配 "verb" 中的'er',但不能匹配"never" 中的'er' |
\B |
\B |
\B |
\B |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置,例如: 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的'er' |
\b |
\b |
\b |
\b |
|
\t |
匹配一个横向制表符(等价于 \x09和 \cI) |
不支持 |
不支持 |
\t |
\t |
|
\v |
匹配一个垂直制表符(等价于 \x0b和 \cK) |
不支持 |
不支持 |
\v |
\v |
|
\n |
匹配一个换行符(等价于 \x0a 和\cJ) |
不支持 |
不支持 |
\n |
\n |
|
\f |
匹配一个换页符(等价于\x0c 和\cL) |
不支持 |
不支持 |
\f |
\f |
|
\r |
匹配一个回车符(等价于 \x0d 和\cM) |
不支持 |
不支持 |
\r |
\r |
|
\\ |
匹配转义字符本身"\" |
\\ |
\\ |
\\ |
\\ |
|
\cx |
匹配由 x 指明的控制字符,例如:\cM匹配一个Control-M 或回车符,x 的值必须为A-Z 或 a-z 之一,否则,将 c 视为一个原义的 'c' 字符 |
不支持 |
不支持 |
|
\cx |
|
\xn |
匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长,例如:'\x41' 匹配 "A"。'\x041' 则等价于'\x04' & "1"。正则表达式中可以使用 ASCII 编码 |
不支持 |
不支持 |
|
\xn |
|
\num |
匹配 num,其中 num是一个正整数。表示对所获取的匹配的引用 |
不支持 |
\num |
\num |
|
|
[:alnum:] |
匹配任何一个字母或数字([A-Za-z0-9]),例如:'[[:alnum:]] ' |
[:alnum:] |
[:alnum:] |
[:alnum:] |
[:alnum:] |
|
[:alpha:] |
匹配任何一个字母([A-Za-z]), 例如:' [[:alpha:]] ' |
[:alpha:] |
[:alpha:] |
[:alpha:] |
[:alpha:] |
|
[:digit:] |
匹配任何一个数字([0-9]),例如:'[[:digit:]] ' |
[:digit:] |
[:digit:] |
[:digit:] |
[:digit:] |
|
[:lower:] |
匹配任何一个小写字母([a-z]), 例如:' [[:lower:]] ' |
[:lower:] |
[:lower:] |
[:lower:] |
[:lower:] |
|
[:upper:] |
匹配任何一个大写字母([A-Z]) |
[:upper:] |
[:upper:] |
[:upper:] |
[:upper:] |
|
[:space:] |
任何一个空白字符: 支持制表符、空格,例如:' [[:space:]] ' |
[:space:] |
[:space:] |
[:space:] |
[:space:] |
|
[:blank:] |
空格和制表符(横向和纵向),例如:'[[:blank:]]'ó'[\s\t\v]' |
[:blank:] |
[:blank:] |
[:blank:] |
[:blank:] |
|
[:graph:] |
任何一个可以看得见的且可以打印的字符(注意:不包括空格和换行符等),例如:'[[:graph:]] ' |
[:graph:] |
[:graph:] |
[:graph:] |
[:graph:] |
|
[:print:] |
任何一个可以打印的字符(注意:不包括:[:cntrl:]、字符串结束符'\0'、EOF 文件结束符(-1), 但包括空格符号),例如:'[[:print:]] ' |
[:print:] |
[:print:] |
[:print:] |
[:print:] |
|
[:cntrl:] |
任何一个控制字符(ASCII 字符集中的前 32 个字符,即:用十进制表示为从 0 到31,例如:换行符、制表符等等),例如:' [[:cntrl:]]' |
[:cntrl:] |
[:cntrl:] |
[:cntrl:] |
[:cntrl:] |
|
[:punct:] |
任何一个标点符号(不包括:[:alnum:]、[:cntrl:]、[:space:]这些字符集) |
[:punct:] |
[:punct:] |
[:punct:] |
[:punct:] |
|
[:xdigit:] |
任何一个十六进制数(即:0-9,a-f,A-F) |
[:xdigit:] |
[:xdigit:] |
[:xdigit:] |
[:xdigit:] |
四、三种不同类型正则表达式比较
注意: 当使用 BERs(基本正则表达式)时,必须在下列这些符号前加上转义字符('\'),屏蔽掉它们的 speical meaning “?,+,|,{,},(,)” 这些字符,需要加入转义符号”\”
注意:修饰符用在正则表达式结尾,例如:/dog/i,其中 “ i “ 就是修饰符,它代表的含义就是:匹配时不区分大小写,那么修饰符有哪些呢?常见的修饰符如下:
g 全局匹配(即:一行上的每个出现,而不只是一行上的第一个出现)
s 把整个匹配串当作一行处理
m 多行匹配
i 忽略大小写
x 允许注释和空格的出现
U 非贪婪匹配
以上就是linux 常见3种类型正则表达式异同之处,整体了解这些,我相信在使用这些工具的时候,就可以更加清楚明晰了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号