
Pandas数据可视化的备忘录
作者|Rashida Nasrin Sucky
编译|VK
来源|Towards Data Science

我们使用python的pandas库主要用于数据分析中的数据操作,但我们也可以使用Pandas进行数据可视化。你甚至不需要为此导入Matplotlib库。
Pandas本身可以在后端使用Matplotlib并为你呈现可视化效果。它使得使用数据帧列绘制图变得非常容易。Pandas使用比Matplotlib更高级别的API。因此,它可以用更少的代码行来绘制绘图。
我将从使用随机数据从基本的绘图开始,然后转到更高级的带有真实数据集的绘图。
在本教程中,我将使用Jupyter Notebook环境。如果你没有安装,你可以简单地使用谷歌Colab Notebook。你甚至不需要在上面安装Pandas。它已经为我们安装好了。
如果你想安装一个Jupyter Notebook,那也是个好主意。
对于数据科学家来说,这是一个很好的软件包,而且是免费的。
安装pandas使用:
pip install pandas
或者在你的anaconda上
conda install pandas
这样就准备好了
pandas可视化
我们将从最基本的开始。
直线图
首先导入pandas。然后,让我们用pandas做一个基本的系列,画一个直线图。
import pandas as pd
a = pd.Series([40, 34, 30, 22, 28, 17, 19, 20, 13, 9, 15, 10, 7, 3])
a.plot()
最基本最简单的图准备好了!看,这是多么容易。我们可以改进一下。
我将补充:
更改一个图形大小,使图表更大,
更改的默认蓝色
显示标题
更改轴上这些数字的默认字体大小
a.plot(figsize=(8, 6), color='green', title = 'Line Plot', fontsize=12)
在本教程中,我们将学习更多的样式技巧。
面积图
我会用相同的数据a在这里画一个面积图,
我可以使用.plot方法并传递一个参数类型来指定我想要的绘图类型,例如:
a.plot(kind='area')
或者我可以这样写
a.plot.area()
我上面提到的两种方法都将创建此图:
面积图更有意义,而且当其中有多个变量时看起来也更好。所以,我将制作更多Series,制作一个数据框,并从中绘制一个面积图。
b = pd.Series([45, 22, 12, 9, 20, 34, 28, 19, 26, 38, 41, 24, 14, 32])
c = pd.Series([25, 38, 33, 38, 23, 12, 30, 37, 34, 22, 16, 24, 12, 9])
d = pd.DataFrame({'a':a, 'b': b, 'c': c})
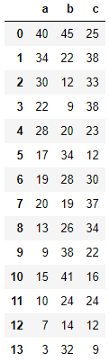
让我们把这个数据框“d”画成面积图,
d.plot.area(figsize=(8, 6), title='Area Plot')
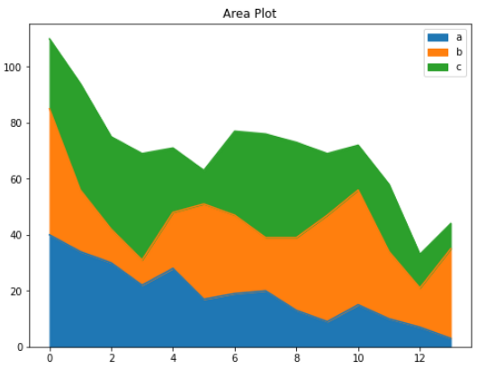
你不必接受这些默认颜色。让我们把这些颜色换一下,再加些样式。
d.plot.area(alpha=0.4, color=['coral', 'purple', 'lightgreen'],figsize=(8, 6), title='Area Plot', fontsize=12)

“alpha”参数为绘图添加了一些半透明的外观。
当我们有重叠的面积图、直方图或密集的散点图时,它似乎非常有用。
plot()可以执行11种类型的绘图:
- line
- area
- bar
- barh
- pie
- box
- hexbin
- hist
- kde
- density
- scatter
我想展示所有这些不同图的用法。为此,我将使用疾病控制和预防中心的NHANES数据集。我下载了这个数据集,并把它和这个Jupyter Notebook放在同一个文件夹里。请随时下载该数据集并跟随:https://github.com/rashida048/Datasets/blob/master/nhanes_2015_2016.csv
在这里导入数据集:
df = pd.read_csv('nhanes_2015_2016.csv')
df.head()

这个数据集有30列5735行。
在开始绘制绘图之前,检查数据集的列很重要:
df.columns
输出:
Index(['SEQN', 'ALQ101', 'ALQ110', 'ALQ130', 'SMQ020', 'RIAGENDR', 'RIDAGEYR', 'RIDRETH1', 'DMDCITZN', 'DMDEDUC2', 'DMDMARTL', 'DMDHHSIZ', 'WTINT2YR', 'SDMVPSU', 'SDMVSTRA', 'INDFMPIR', 'BPXSY1', 'BPXDI1', 'BPXSY2', 'BPXDI2', 'BMXWT', 'BMXHT', 'BMXBMI', 'BMXLEG', 'BMXARML', 'BMXARMC', 'BMXWAIST', 'HIQ210', 'DMDEDUC2x', 'DMDMARTLx'], dtype='object')
列的名称可能看起来很奇怪。但别担心。我将继续解释列的含义。我们不会使用所有列。我们将用其中的一些来练习这些图表。
直方图
我将使用人口的权重来制作一个基本的直方图
df['BMXWT'].hist()
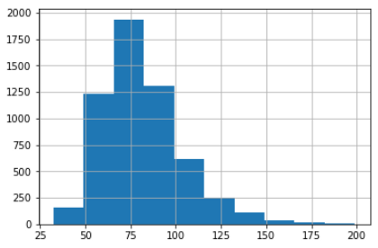
作为提醒,直方图提供了频率分布。上图显示大约1825人体重75。最大的体重在49到99之间。
如果我想把几个柱状图放在一个图上呢?
我将使用体重、身高和体重指数(BMI)在一个图中绘制三个直方图。
df[['BMXWT', 'BMXHT', 'BMXBMI']].plot.hist(stacked=True, bins=20, fontsize=12, figsize=(10, 8))
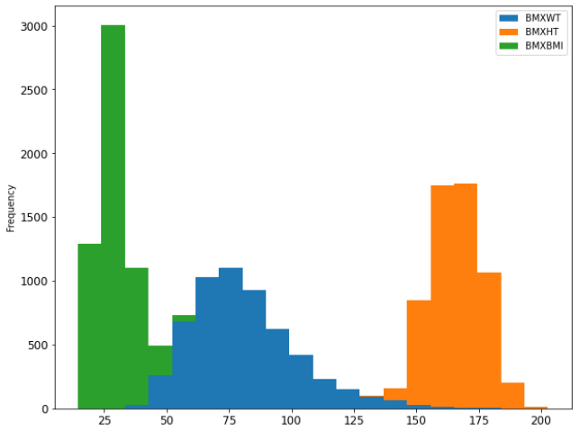
但是如果你想要三个不同的直方图,也可以只使用一行代码,像这样:
df[['BMXWT', 'BMXHT', 'BMXBMI']].hist(bins=20,figsize=(10, 8))
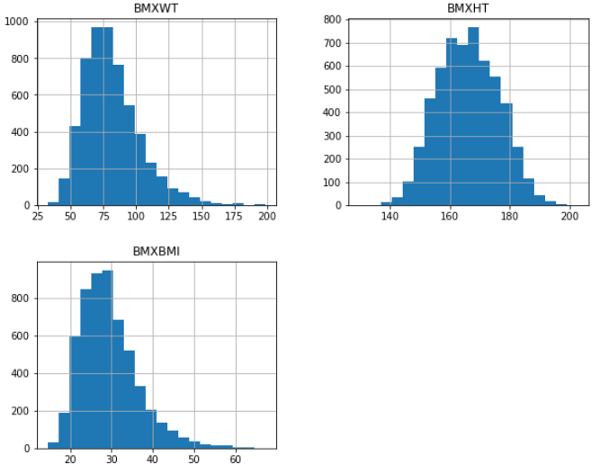
它可以更具活力!
我们在' BPXSY1 '列中有血压数据,在' DMDEDUC2 '列中有教育程度数据。如果我们想检查每个教育水平人群的血压分布,也可以用一行代码完成。
但在此之前,我想用更有意义的字符串值替换'DMDEDUC2'列的数值:
df["DMDEDUC2x"] = df.DMDEDUC2.replace({1: "less than 9", 2: "9-11", 3: "HS/GED", 4: "Some college/AA", 5: "College", 7: "Refused", 9: "Don't know"})
现在做直方图
df[['DMDEDUC2x', 'BPXSY1']].hist(by='DMDEDUC2x', figsize=(18, 12))
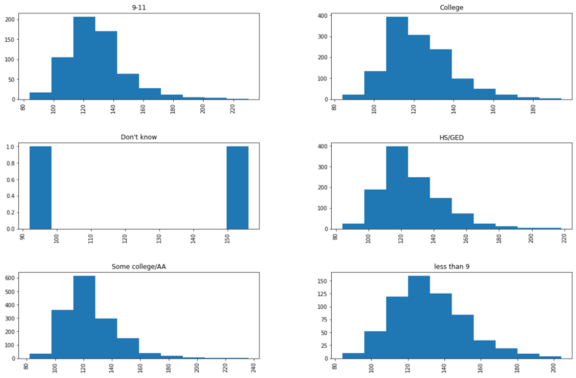
看!我们只需一行代码就可以得到每个教育水平的血压水平分布!
条形图
现在让我们看看血压是如何随婚姻状况而变化的。这次我要做一个条形图。与前面一样,我将用更有意义的字符串替换“DMDMARTL”列的数值。
df["DMDMARTLx"] = df.DMDMARTL.replace({1: "Married", 2: "Widowed", 3: "Divorced", 4: "Separated", 5: "Never married", 6: "Living w/partner", 77: "Refused"})
为了绘制条形图,我们需要对数据进行预处理。即根据不同的婚姻状况对数据进行分组,并取每组的平均值。这里我用同一行代码处理数据和绘图。
df.groupby('DMDMARTLx')['BPXSY1'].mean().plot(kind='bar', rot=45, fontsize=10, figsize=(8, 6))
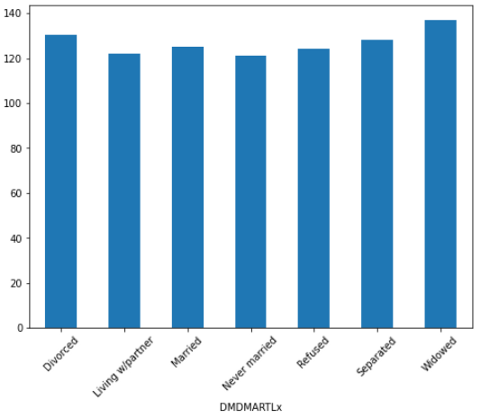
这里我们使用“rot”参数将x记号旋转45度。否则,他们会太混乱。
如果你愿意,你也可以把它弄平,
df.groupby('DMDEDUC2x')['BPXSY1'].mean().plot(kind='barh', rot=45, fontsize=10, figsize=(8, 6))
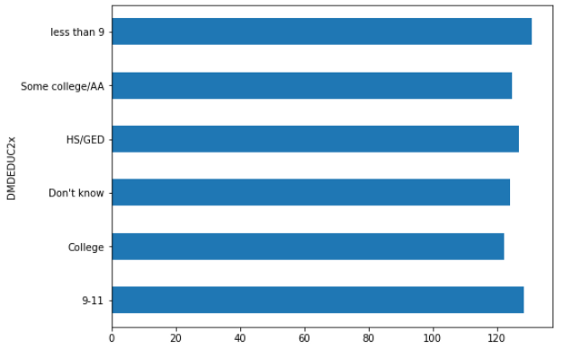
我想用多个变量绘制条形图。我们有一个列,里面有人口的民族血统。看看人们的体重、身高和体重指数是否会随民族血统而变化,这将是一件有趣的事。
为了绘制这个图,我们需要将这三列(体重、身高和体重指数)按民族血统分组并取平均值。
df_bmx = df.groupby('RIDRETH1')['BMXWT', 'BMXHT', 'BMXBMI'].mean().reset_index()
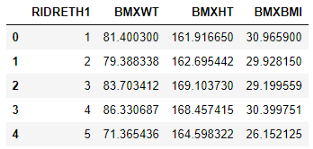
这一次我没有改变民族血统的数据。我保持数值不变。我们现在就开始吧,
df_bmx.plot(x = 'RIDRETH1',
y=['BMXWT', 'BMXHT', 'BMXBMI'],
kind = 'bar',
color = ['lightblue', 'red', 'yellow'],
fontsize=10)

看来第四种族比其他种族高一点。但他们都无显著性差异。
我们也可以将不同的参数(体重、身高和体重指数)叠加在一起。
df_bmx.plot(x = 'RIDRETH1',
y=['BMXWT', 'BMXHT', 'BMXBMI'],
kind = 'bar', stacked=True,
color = ['lightblue', 'red', 'yellow'],
fontsize=10)

饼图
我想看看婚姻状况和受教育程度有没有关系。
我需要按教育程度对婚姻状况进行分组,并按教育程度统计每个婚姻状况组中的人口。听起来太罗嗦了,对吧?让我们看看:
df_edu_marit = df.groupby('DMDEDUC2x')['DMDMARTL'].count()
pd.Series(df_edu_marit)
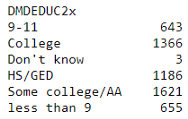
使用此Series可以很容易地绘制饼图:
ax = pd.Series(df_edu_marit).plot.pie(subplots=True, label='',
labels = ['College Education', 'high school',
'less than high school', 'Some college',
'HS/GED', 'Unknown'],
figsize = (8, 6),
colors = ['lightgreen', 'violet', 'coral', 'skyblue', 'yellow', 'purple'], autopct = '%.2f')

这里我添加了一些样式参数。请随时尝试更多的样式参数。
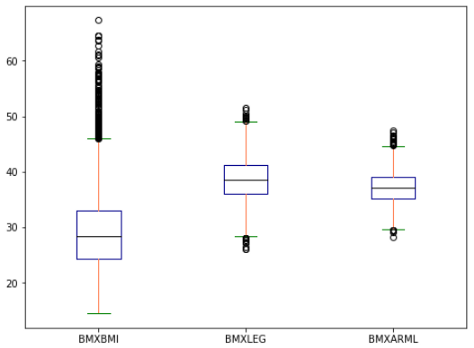
箱线图
例如,我将使用体重指数、腿和臂长数据制作一个箱线图。
color = {'boxes': 'DarkBlue', 'whiskers': 'coral',
'medians': 'Black', 'caps': 'Green'}
df[['BMXBMI', 'BMXLEG', 'BMXARML']].plot.box(figsize=(8, 6),color=color)
散点图
对于一个简单的散点图,我想看看体重指数(“BMXBMI”)和血压(“BPXSY1”)之间是否存在任何关系。
df.head(300).plot(x='BMXBMI', y= 'BPXSY1', kind = 'scatter')
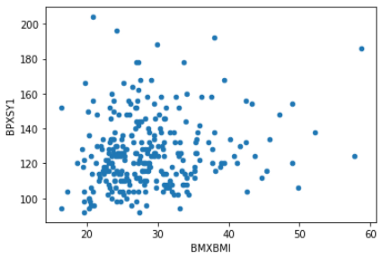
我只使用了300个数据,因为如果我使用所有的数据,散点图变得过于密集,无法理解。但可以使用alpha参数使其半透明。
现在,让我们用同样的一行代码画出一个稍微高级的散点图。
这次我将添加一些颜色的阴影。我将绘制一个散点图,把重量放在x轴上,把高度放在y轴上。
我还要加上腿的长度。但腿的长度会以阴影显示。如果腿的长度较长,则阴影将较暗,否则阴影将较浅。
df.head(500).plot.scatter(x= 'BMXWT', y = 'BMXHT', c ='BMXLEG', s=50, figsize=(8, 6))
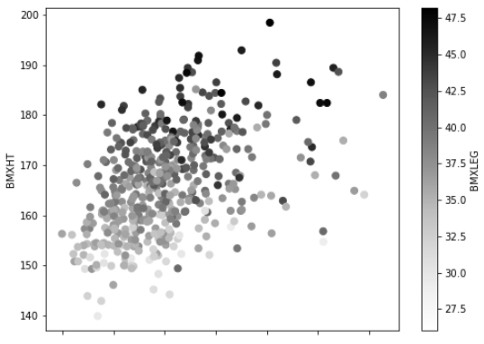
它显示了体重和身高之间的关系。你可以看到腿的长度与身高和体重之间是否有任何关系。
另一种添加第三个参数的方法是增加粒子的大小。在这里,我把高度放在x轴上,重量在y轴上,体重指数作为粒子大小的指标。
df.head(200).plot.scatter(x= 'BMXHT', y = 'BMXWT',
s =df['BMXBMI'][:200] * 7,
alpha=0.5, color='purple',
figsize=(8, 6))
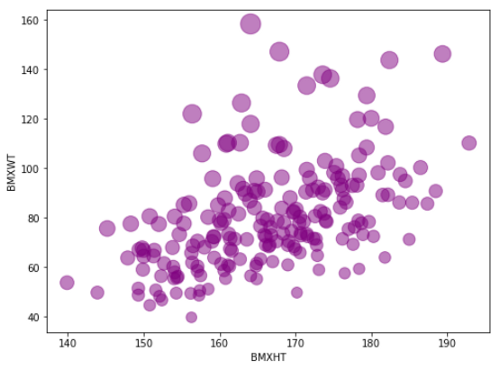
这里的小点表示BMI较低,较大的圆点表示BMI较高。
六边形
这是另一种漂亮的视觉效果,点是六边形。当数据太密集时,把它们放在箱子里是很有用的。如你所见,在前两个图中,我只使用了500和200个数据,因为如果我将所有数据放入数据集中,则绘图变得过于密集,无法理解或从中获取任何信息。
在这种情况下,使用空间分布是非常有用的。我使用的是hexbin,数据将以六边形表示。每一个六边形都是一个代表箱子密度的箱子。下面是一个最基本的hexpin示例。
df.plot.hexbin(x='BMXARMC', y='BMXLEG', gridsize= 20)
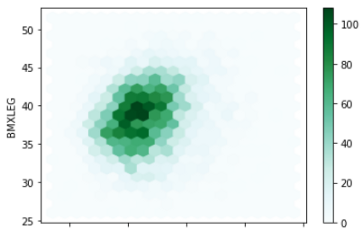
在这里,较深的颜色表示较高的数据密度,而较浅的颜色表示较低的数据密度。
听起来像直方图吗?是的,对吧?它用颜色表示,而不是直方图。
如果我们增加一个额外的参数'C',分布会改变。它不再像直方图了。
参数“C”指定每个(x, y)坐标的位置,对每个六边形箱子进行累加,然后使用reduce_C_function进行reduce。如果没有指定reduce_C_function,默认情况下它使用np.mean。你可以把它定义为np.mean, np.max, np.sum, np.std等等
有关更多信息,请参阅文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.hexbin.html
下面是一个例子:
df.plot.hexbin(x='BMXARMC', y='BMXLEG', C = 'BMXHT',
reduce_C_function=np.max,
gridsize=15,
figsize=(8,6))
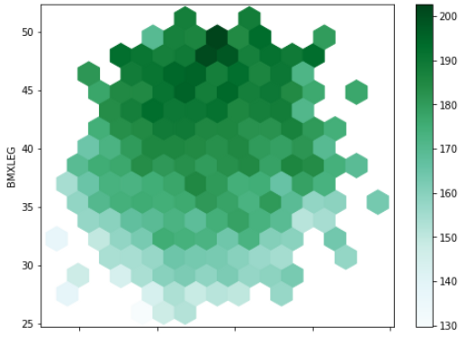
六边形的深色意味着,np.max有一个更高的值,你可以看到我使用np.max作为reduce_C_function。我们可以使用颜色贴图代替颜色的着色:
df.plot.hexbin(x='BMXARMC', y='BMXLEG', C = 'BMXHT',
reduce_C_function=np.max,
gridsize=15,
figsize=(8,6),
cmap = 'viridis')
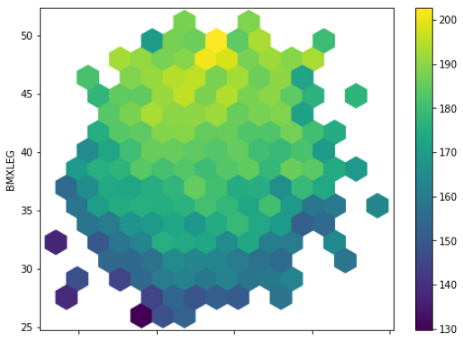
看起来很漂亮,对吧?而且信息量很大。
一些高级可视化
我在上面解释了人们在日常生活中处理数据时使用的一些基本绘图。但数据科学家还需要更多。pandas库也有一些更高级的可视化。它可以在一行代码中提供更多信息。
散点矩阵
散点矩阵非常有用。它在一个图中提供了大量的信息。它可以用于一般的数据分析或机器学习中的特征工程。让我们先看一个例子。之后我再解释。
from pandas.plotting import scatter_matrix
scatter_matrix(df[['BMXWT', 'BMXHT', 'BMXBMI', 'BMXLEG', 'BMXARML']], alpha = 0.2, figsize=(10, 8), diagonal = 'kde')
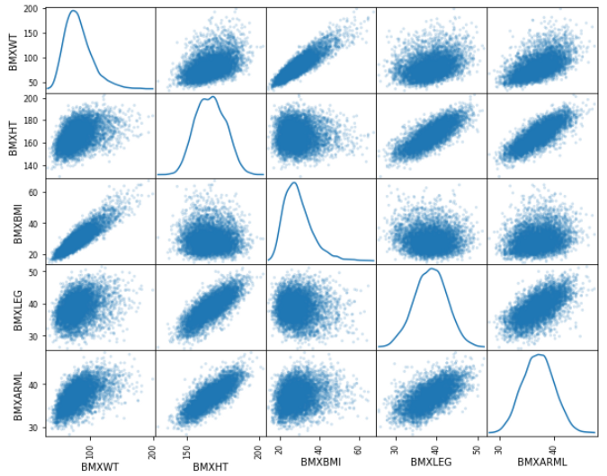
我在这里使用了五个特征。我得到了所有五个变量之间的关系。在对角线中,它给出了每个单独特征的密度图。在我的下一个例子中,我们将进一步讨论密度图。
KDE或密度图
构建KDE图或核密度图是为了提供数据帧中序列或列的概率分布。让我们看看权重变量(“BMXWT”)的概率分布。
df['BMXWT'].plot.kde()
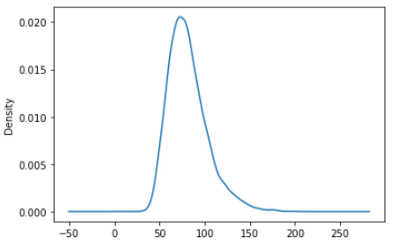
你可以在一个图中看到几个概率分布。在这里,我在同一个图中给出了身高、体重和BMI的概率分布:
df[['BMXWT', 'BMXHT', 'BMXBMI']].plot.kde(figsize = (8, 6))
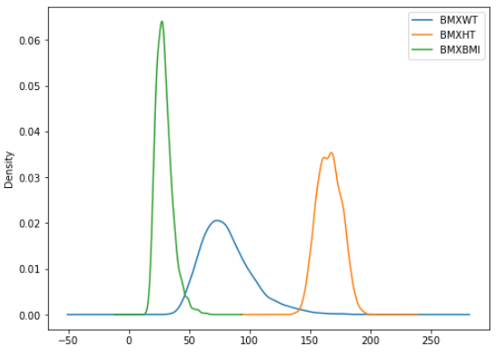
你也可以使用前面描述的其他样式参数。我喜欢保持简单。
Parallel_coordinates
这是一种显示多维数据的好方法。它清楚地显示了簇(如果有)。例如,我想看看男性和女性在身高、体重和体重指数上是否有什么不同。让我们检查一下。
from pandas.plotting import parallel_coordinates
parallel_coordinates(df[['BMXWT', 'BMXHT', 'BMXBMI', 'RIAGENDR']].dropna().head(200), 'RIAGENDR', color=['blue', 'violet'])
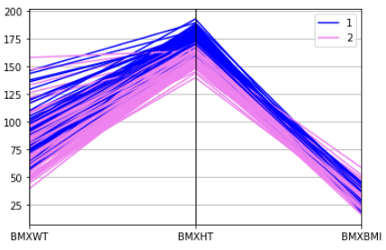
你可以看到男性和女性在体重、身高和BMI上的明显差异。这里,1是男人,2是女人。
Bootstrap_plot
这是一个非常重要的研究和统计分析图。这将节省大量的统计分析时间。Bootstrap_plot用于评估给定数据集的不确定性。
此函数获取指定大小的随机样本。然后计算该样本的平均值、中位数和中位数。此过程重复指定次数。
这里我用BMI数据创建了一个Bootstrap_plot:
from pandas.plotting import bootstrap_plot
bootstrap_plot(df['BMXBMI'], size=100, samples=1000, color='skyblue')
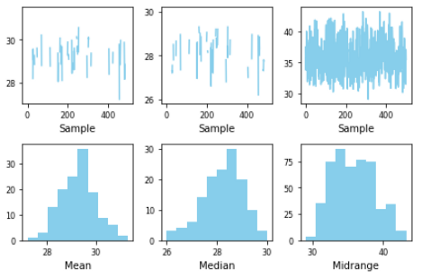
这里,样本量是100,样本数是1000。所以,我们随机抽取100个数据样本来计算平均值、中位数和中位数。这个过程重复1000次。
对于统计学家和研究人员来说,这是一个极其重要的过程,也是一个节省时间的过程。
结论
我想为pandas的数据可视化制作一份备忘单。不过,如果使用matplotlib和seaborn,则有更多的选项或可视化类型。但是如果你处理数据,我们在日常生活中使用这些基本类型的可视化。将pandas用于此可视化将使你的代码更简单,并节省大量代码。
原文链接:https://towardsdatascience.com/an-ultimate-cheat-sheet-for-data-visualization-in-pandas-4010e1b16b5c
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号