
掌握Pandas时间序列分析的20个知识点
作者|Soner Yıldırım
编译|VK
来源|Towards Datas Science
时间序列数据有很多种定义,它们以不同的方式表示相同的含义。一个简单的定义是,时间序列数据是包含序列时间戳的数据点。
时间序列数据的来源是周期性测量或观测。我们观察了许多行业的时间序列数据。举几个例子:
-
股票价格随时间变化
-
日、周、月销售额
-
过程中的周期性测量
-
一段时间内的电力或天然气消耗率
在这篇文章中,我将列出20点,这将有助于你全面了解如何处理Pandas的时间序列数据处理。
1.不同形式的时间序列数据
时间序列数据可以是特定日期、持续时间或固定定义间隔的形式。
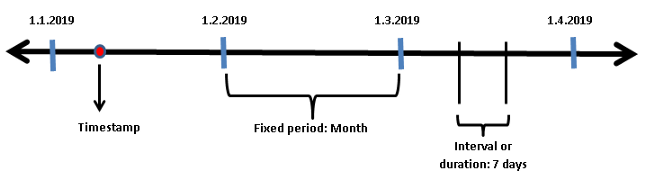
时间戳可以是一天的日期,也可以是给定日期的纳秒,具体取决于精度。例如,“2020–01–01 14:59:30”是基于秒的时间戳。
2.时间序列数据结构
Pandas提供灵活高效的数据结构来处理各种时间序列数据。

除了这三种结构,Pandas还支持日期偏移概念,这是一种考虑日历算法的相对时间长度。
3.创建时间戳
最基本的时间序列数据结构是时间戳,它可以使用to_datetime 或Timestamp 函数创建
import pandas as pd
pd.to_datetime('2020-9-13')
Timestamp('2020-09-13 00:00:00')
pd.Timestamp('2020-9-13')
Timestamp('2020-09-13 00:00:00')
4.访问时间戳的信息
我们可以获得存储在时间戳中的日期、月份和年份的信息。
a = pd.Timestamp('2020-9-13')
a.day_name()
'Sunday'
a.month_name()
'September'
a.day
13
a.month
9
a.year
2020
5.获取不太明显的信息
Timestamp对象还保存有关日期算术的信息。例如,我们可以问一年是否是闰年。以下是我们可以获得的一些更具体的信息:
b = pd.Timestamp('2020-9-30')
b.is_month_end
True
b.is_leap_year
True
b.is_quarter_start
False
b.weekofyear
40
6.欧式日期
我们可以使用to_datetime函数来处理欧式日期(即日期优先)。dayfirst参数设置为True。
pd.to_datetime('10-9-2020', dayfirst=True)
Timestamp('2020-09-10 00:00:00')
pd.to_datetime('10-9-2020')
Timestamp('2020-10-09 00:00:00')
注:如果第一项大于12,Pandas知道它不能是月份。
pd.to_datetime('13-9-2020')
Timestamp('2020-09-13 00:00:00')
7.将数据帧转换为时间序列数据
to_datetime 函数可以将具有适当列的数据帧转换为时间序列。考虑以下数据帧:

pd.to_datetime(df)
0 2020-04-13
1 2020-05-16
2 2019-04-11
dtype: datetime64[ns]
8.时间序列数据
在现实生活中,我们几乎总是处理连续的时间序列数据,而不是单独的日期。Pandas使处理时序数据变得非常简单。
我们可以将日期列表传递给to_datetime函数。
pd.to_datetime(['2020-09-13', '2020-08-12',
'2020-08-04', '2020-09-05'])
DatetimeIndex(['2020-09-13', '2020-08-12', '2020-08-04', '2020-09-05'], dtype='datetime64[ns]', freq=None)
返回的对象是DatetimeIndex。
有更实用的方法来创建日期序列。
9.创建包含to_datetime和to_timedelta的时间序列
可以通过向时间戳添加TimedeltaIndex来创建DatetimeIndex。
pd.to_datetime('10-9-2020') + pd.to_timedelta(np.arange(5), 'D')

“D”表示“day”,但还有许多其他选项可用。你可以在这里查看整个清单:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.to_timedelta.html
10.date_range函数
它提供了一种更灵活的方法来创建DatetimeIndex。
pd.date_range(start='2020-01-10', periods=10, freq='M')

periods参数指定索引中的项数。freq是频率,“M”表示一个月的最后一天。
就freq参数的参数而言,date_range相当灵活。
pd.date_range(start='2020-01-10', periods=10, freq='6D')

我们创建了一个频率为6天的索引。
11.period_range 函数
它返回一个周期索引。语法类似于date_range函数。
pd.period_range('2018', periods=10, freq='M')

12.timedelta_range 函数
返回TimedeltaIndex。
pd.timedelta_range(start='0', periods=24, freq='H')

13时区
默认情况下,pandas的时间序列对象没有指定的时区。
dates = pd.date_range('2019-01-01','2019-01-10')
dates.tz is None
True
我们可以使用tz_localize方法为这些对象指定一个时区。
dates_lcz = dates.tz_localize('Europe/Berlin')
dates_lcz.tz
<DstTzInfo 'Europe/Berlin' LMT+0:53:00 STD>
14.创建具有指定时区的时间序列
我们还可以使用tz关键字参数创建一个带有时区的时间序列对象。
pd.date_range('2020-01-01', periods = 5, freq = 'D', tz='US/Eastern')

15.偏移量
假设我们有一个时间序列索引,并希望偏移特定时间的所有日期。
A = pd.date_range('2020-01-01', periods=10, freq='D')
A

让我们在这个序列中增加一周的偏移量。
A + pd.offsets.Week()

16.移动时间序列数据
时间序列数据分析可能需要移动数据点来进行比较。shift函数可及时移动数据。

A.shift(10, freq='M')

17.shift与tshift
-
shift:移动数据
-
tshift:改变时间索引
让我们创建一个带有时间序列索引的数据帧,并对其进行绘图,以查看shift和tshift之间的差异。
dates = pd.date_range('2020-03-01', periods=30, freq='D')
values = np.random.randint(10, size=30)
df = pd.DataFrame({'values':values}, index=dates)
df.head()

让我们将原始时间序列与移位的时间序列一起绘制出来。
import matplotlib.pyplot as plt
fig, axs = plt.subplots(nrows=3, figsize=(10,6), sharey=True)
plt.tight_layout(pad=4)
df.plot(ax=axs[0], legend=None)
df.shift(10).plot(ax=axs[1], legend=None)
df.tshift(10).plot(ax=axs[2], legend=None)

18.使用重采样功能重新采样
时间序列数据的另一个常见操作是重采样。根据任务的不同,我们可能需要以更高或更低的频率重新采样数据。
重采样创建指定内部的组,并允许你对组进行聚合。
让我们创建一个包含30个值和时间序列索引的Pandas序列。
A = pd.date_range('2020-01-01', periods=30, freq='D')
values = np.random.randint(10, size=30)
S = pd.Series(values, index=A)
下面将返回3天周期的平均值。
S.resample('3D').mean()

19.Asfreq函数
在某些情况下,我们可能对某些频率下的值感兴趣。Asfreq函数返回指定间隔结束时的值。例如,在上一步创建的序列中,我们可能只需要每隔3天(而不是3天平均值)的值。
S.asfreq('3D')

20.滚动
滚动是时间序列数据的一种非常有用的操作。滚动意味着创建一个具有指定大小的滚动窗口,并对该窗口中的数据执行计算,当然,该窗口会滚动数据。下图解释了滚动的概念。
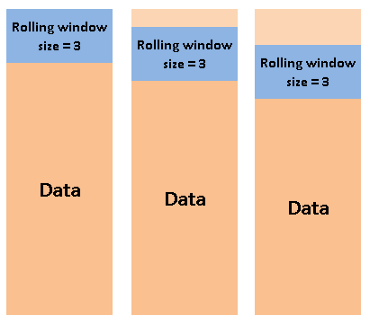
值得注意的是,当整个窗口都在数据中时,计算就开始了。换句话说,如果窗口的大小为3,则第一次聚合将在第三行完成。
让我们将3天的滚动窗口应用到我们的序列中。
S.rolling(3).mean()[:10]

结论
我们已经全面介绍了Pandas的时间序列分析。值得注意的是,Pandas提供了更多的时间序列分析。
官方文档涵盖了时间序列的所有功能和方法。乍一看似乎详尽无遗,但通过练习你会感到有所成长。
官方文档:https://pandas.pydata.org/docs/user_guide/timeseries.html
谢谢你的阅读。如果你有任何反馈,请告诉我。
原文链接:https://towardsdatascience.com/20-points-to-master-pandas-time-series-analysis-f90155ee0e8a
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号