
为图像识别模型构建图像采集接口应用程序
作者|Andre Ye
编译|Flin
来源|towardsdatascience

通常,数据科学家会建立一个图像识别模型,观察其准确性,如果足够高,就表示工作完成了。自从我13岁开始学习机器学习,我就一直不明白这一点。为什么要花费所有的时间来建立最好的模型——只是为了满足于一个数字?
在本文中,我将提供代码并指导你如何通过构建与模型交互的拍照接口来真正完成项目。
安装cv2(OpenCV)
我们将使用的图像库是cv2。因为cv2不能在Kaggle这样的在线平台上工作,所以它必须在你的计算机上本地完成。然而,模型的权重仍然可以在Kaggle上进行训练,以.h5文件的形式下载(基于Keras/TensorFlow)并加载。
在Anaconda或命令提示符中键入
conda create -n opencv python=3.6
这将在Python版本3.6中创建一个名为opencv的新环境,可以用正在使用的任何版本替换它。

下一步,输入
pip install opencv-python
你已经成功安装了cv2! 现在你可以开始拍照了。
用CV2拍照
首先,导入库。
import cv2
接下来,我们必须创建一个视频捕获实例。你可以测试实例是否能够连接到你的相机(如果没有,请检查你的设置以确保应用程序可以访问它)。
cap = cv2.VideoCapture(0)
if not (cap.isOpened()):
print("Video device not connected.")
最后,是时候拍照了。如果要控制拍摄照片的时间,第一行将指定任意变量和输入。除非输入了某些内容(如按“回车”),然后下一行开始拍照,否则程序无法继续。拍摄图像时,你可能会看到网络摄像头指示灯很快出现。第三行关闭连接,第四行销毁访问相机的所有实例。
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
图像中的数据存储在frame中。可以使用以下代码将其转换为数组:
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
调用cv2_im.shape时,输出为(480640,3)。因此,图像(对于我的相机)是480×640像素(3表示“深度”, 每个像素中有三个值说明创建最终像素颜色需要包含红色、绿色和蓝色)。
现在图像已转换为数组,matplotlib的imshow()可以显示它。
import matplotlib.pyplot as plt
plt.imshow(cv2_im)
plt.show()

完整代码:
import cv2
import matplotlib.pyplot as plt
cap = cv2.VideoCapture(10)
if not (cap.isOpened()):
print("Video device unconnected.")
arb = input('Press enter to take picture.')
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
cv2_im = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
plt.imshow(cv2_im)
plt.show()
格式化为模型标准
卷积神经网络只接受固定大小的图像,例如(100,100,3)。有几种方法可以做到这一点。
为了保持图像的比例长度,可以尝试裁剪图像。
一般语法是:
plt.imshow(cv2_im[y_upper_bound:y_lower_bound,x_lower_bound:x_higher_bound])
其中“upper”和“lower”由图像上的位置确定(y的“upper”表示图像的上方,x的“upper”表示图像的右侧)。
例如,
plt.imshow(cv2_im[100:400,100:400])

这里把照片裁剪成正方形。
但是,尺寸仍然是300×300。为了解决这个问题,我们将再次使用Pillow:
pil_image = Image.fromarray(cv2_im[100:400,100:400])
width = 100
height = 100
pil_image = pil_image.resize((width,height), Image.ANTIALIAS)
NumPy自动将Pillow图像转换为数组。
import numpy as np
cv2_im_new = np.array(pil_image)
查看新图像:
plt.imshow(cv2_im_new)
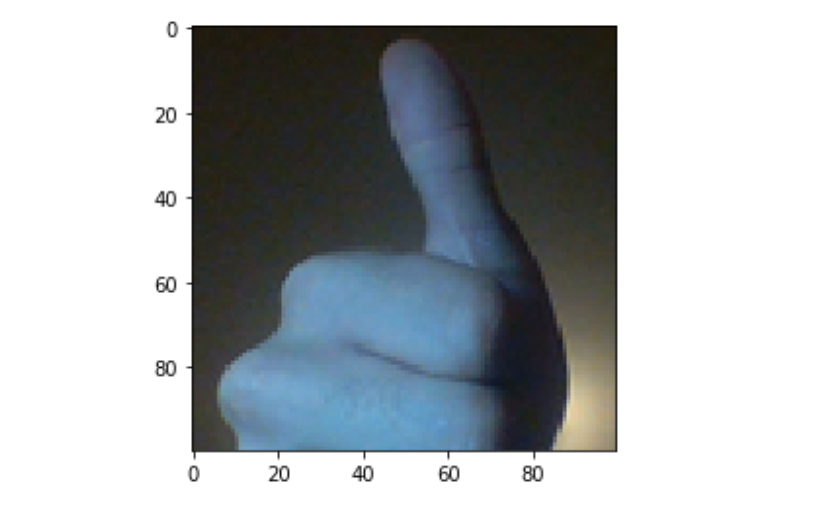
好多了!图像的新形状是(100,100,3), 非常适合我们的模型。
在模型中运行
现在我们有了NumPy数组,只需将其传递到模型中即可。
model.predict(cv2_im_new)
基于此,通过一些手动编码来标记图像的真实标签,可以在title中标记它们:
plt.imshow(cv2_im_new)
plt.title('Hand Gesture: '+classification)

谢谢阅读!
在本教程中,你学习了如何实现一个简单的拍照界面,以查看你的机器学习模型的实际应用程序。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号