隐私计算和大模型
观点
-
大模型的崛起,是隐私计算再次发展的绝佳机会。行业已经证明了用隐私计算做大模型的“防火墙”是可行的,全世界范围内大家也已经开始认识到这个方向;(效率又是一大难关)
-
数据要素流通最关键的是模型,以模型为中心,而不是以数据为中心。因为模型与场景强相关,相比数据价值,模型价值更易评估,数据交易所更确切的说应该叫模型交易所,未来模型定价、模型tracking、数据的二次变现能够更容易的成为事实;
-
大模型会导致算力、数据、场景的供需矛盾会更突出,带来更大的分布式需求,这也会对隐私计算提出新的要求;大模型很难独立产生商业价值,联邦大模型是突破点;
-
我们处在这个时代非常的幸运,无论是联邦学习、隐私计算还是MPC,我们有非常庞大的工具箱,战友们为我们做好了准备,现在需要我们发挥聪明才智把这些积累组合成可用的系统;
-
之前我们有两个范式,其一是ToC模式的横向联邦学习,其二是ToB模式的纵向联邦学习。现在我们总结出了第三种范式,即联邦大模型范式。这个范式一旦成立,将大大缓解行业在实践中的众多本地需求;
-
很多人会错误的认为模型性能、隐私保护、算法效率可以同时达到100%。虽然这实际上是一个不可能三角,但是我们只要聪明的运用领域知识,我们就可以把这三方面平衡的非常好。同时,这不是一个单一的技术问题,我们在某些时候可以把优化的任务交给法律来实现;(法律规定了隐私保护范围,技术决定了算法效率和模型性能)
-
联邦学习是隐私计算和AI的交集,是一种分布式AI的隐私计算解决方案,一方面是模型的概念,一方面要运用各种各样的隐私计算的工具箱;
-
可信联邦学习需要是可信的、可解释的、可跟踪的,这些都可以变成数学上的目标,变成标准的数学框架;
-
可信、高效是行业对隐私计算的基本要求;可信、高效的平衡,既是一个学术问题,也是一个商业问题。(可信是目标,高效是难点)
探索
白盒水印、黑盒水印两种模型知识产权的保护手段。通过在模型中嵌入水印,一方面保证模型性能不受影响,另一方面需要的时候能够可靠地提取水印进行验证,实现对模型知识产权的确认和保护。
参考:https://zhuanlan.zhihu.com/p/545282063
神经网络水印是当前DNN模型版权保护方法,分为
- 白盒水印
模型所有者在目标模型的内部嵌入水印。不足之处是提取水印时,目标模型的网络结构和内部权重等信息都是已知的,优点是不损失精度。
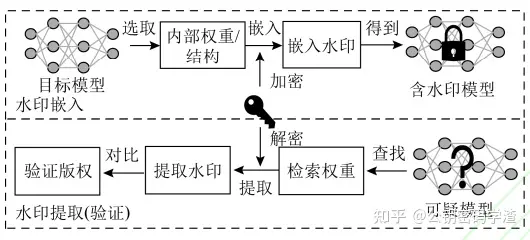
- 黑盒水印
模型所有者不知道目标模型的内部结构和权重,只能通过API来访问目标模型,通常是构造触发数据集(用于实现特定输出的样本及)来验证版权。
由于修改了模型训练数据集,必然会影响模型的准确率。
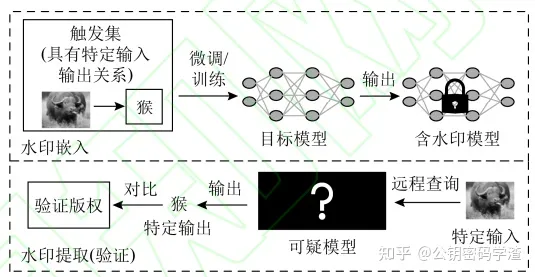
- 灰盒水印
结合了黑盒和白盒水印的特点,但并未有明显优势,所有使用较少。
既通过向模型的内部嵌入信息,又以黑盒的方式获取输出以验证模型版权。
与黑盒水印的嵌入不同,灰盒水印则是在模型内部嵌入信息实现在模型中嵌入水印(白盒思路)。
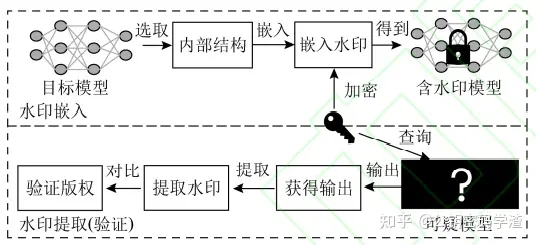
- 无盒水印
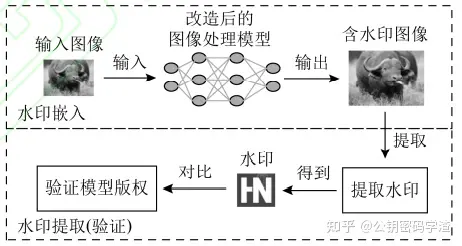
无盒水印区别于另外三种,模型版权验证即不需要在模型内部嵌入水印也不需要构建特定的输入输出对(触发数据集),也不需要模型本身参与。
输入的图像经过模型,输出后会携带水印信息,通过提取输出图像中的水印信息即可验证模型版权。
无盒水印主要应用于图像处理的DNN模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号