K-Means
利用临近信息来标注类别的。是聚类算法中最简单的、搞笑的。
核心思想:指定k个初始质心作为聚类的类别,重复迭代值算法收敛。对于欧式空间的样本,误差平方和作为目标函数。
一、优缺点
优点:简单、快速,效果好,适用于高维;
缺点:很容易受到初始质心的影响,而且初始质心也很难选择。
二、k如何选取?
1、手肘法
随着k的增加,样本划分的越来越细,越来越接近真实类别数,这个时候误差下降的速度会平缓,当等于真实的类别数时,此时的误差是最小的,再继续增加k的时候,由于越来越偏离真实类别墅,误差会增加,此时这个拐弯的地方就是最佳的k值。
2、轮廓系数
簇内不相似度:样本到同簇内其他样本的平均距离,越小说明越应该被分到这个簇;
簇间不相似度:样本到其他簇内样本的平均距离,越大说明越不属于其他簇;
计算簇内不相似度和簇见不相似度,通过公式得到每个样本的轮廓系数:
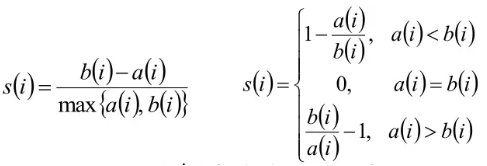
轮廓系数范围在[-1,1]之间,越大越合理;
等于0说明在边界上;
所有样本的轮廓系数均值作为聚类结果的轮廓系数,用来衡量聚类结果的好坏。
三、怎么找这k个中心点?
选择彼此距离最远的k个点。
四、停止条件?
迭代次数,聚类中心移动的距离阈值。
五、如何处理空聚类?
找一个分布最散的簇,找一个替补质心,就能消除这个空簇。重复多次,如果噪点或者孤立点还很多要考虑更换算法,例如密度算法。
六、如何快速收敛超大的kmeans?
前m次迭代正常进行,m次之后,就只计算离他最近的几个质心的距离就行了,远的质心不用计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号