
OO第一单元作业总结
OO第一单元作业总结
程序结构分析
1.第一次作业
第一次作业时我还没有建造者模式这种概念,因此是把字符串处理的工作交给Expr类来处理,在Expr类中调用Term的构造方法,并将Term的系数与指数存放在Expr的容器中。
类图如下:
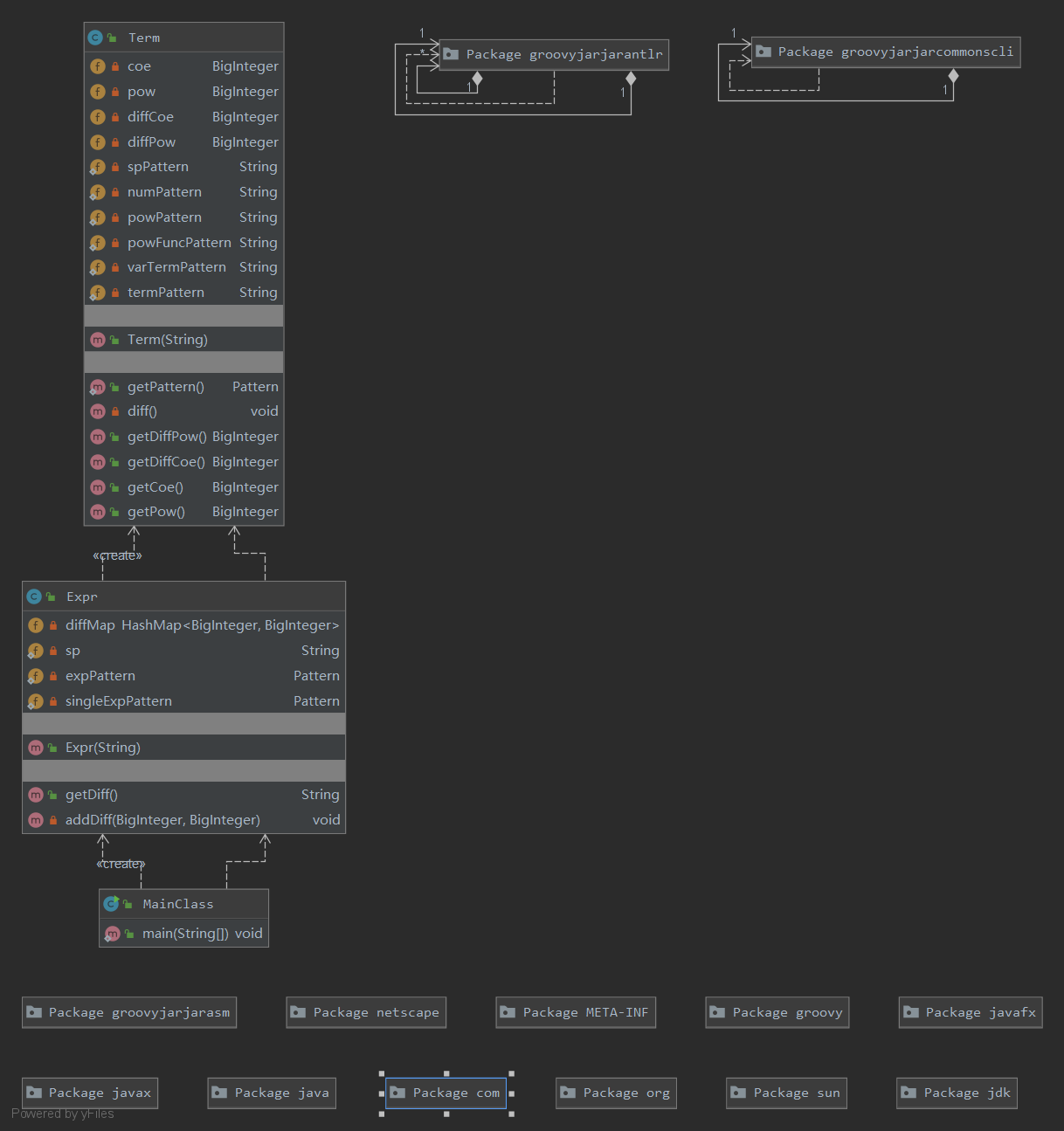
结构比较的简单
下面是复杂度分析:
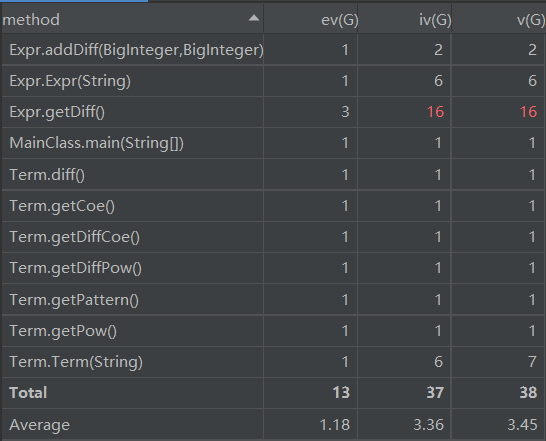
可以看出,在Expr的求导操作中复杂度较高,这是因为我第一次作业中求导时没有用容器来存放求导后的项,而是直接转换成字符串,导致复杂度飙升。下次应该注意。
2.第二次作业
第二次作业抽象出了项和因子的概念,同时也照猫画虎地引入了因子的父类。这次引入了Parser类,集中进行对象的创建,把表达式、项、因子的耦合度降低。在初稿中因为听到了第三次作业的一些消息,所以写了一个扩展性比较好的版本。不过后来为了保险起见,还是采用了范式的方法,即在项中存放系数、幂函数因子、三角函数因子。
类图如下:
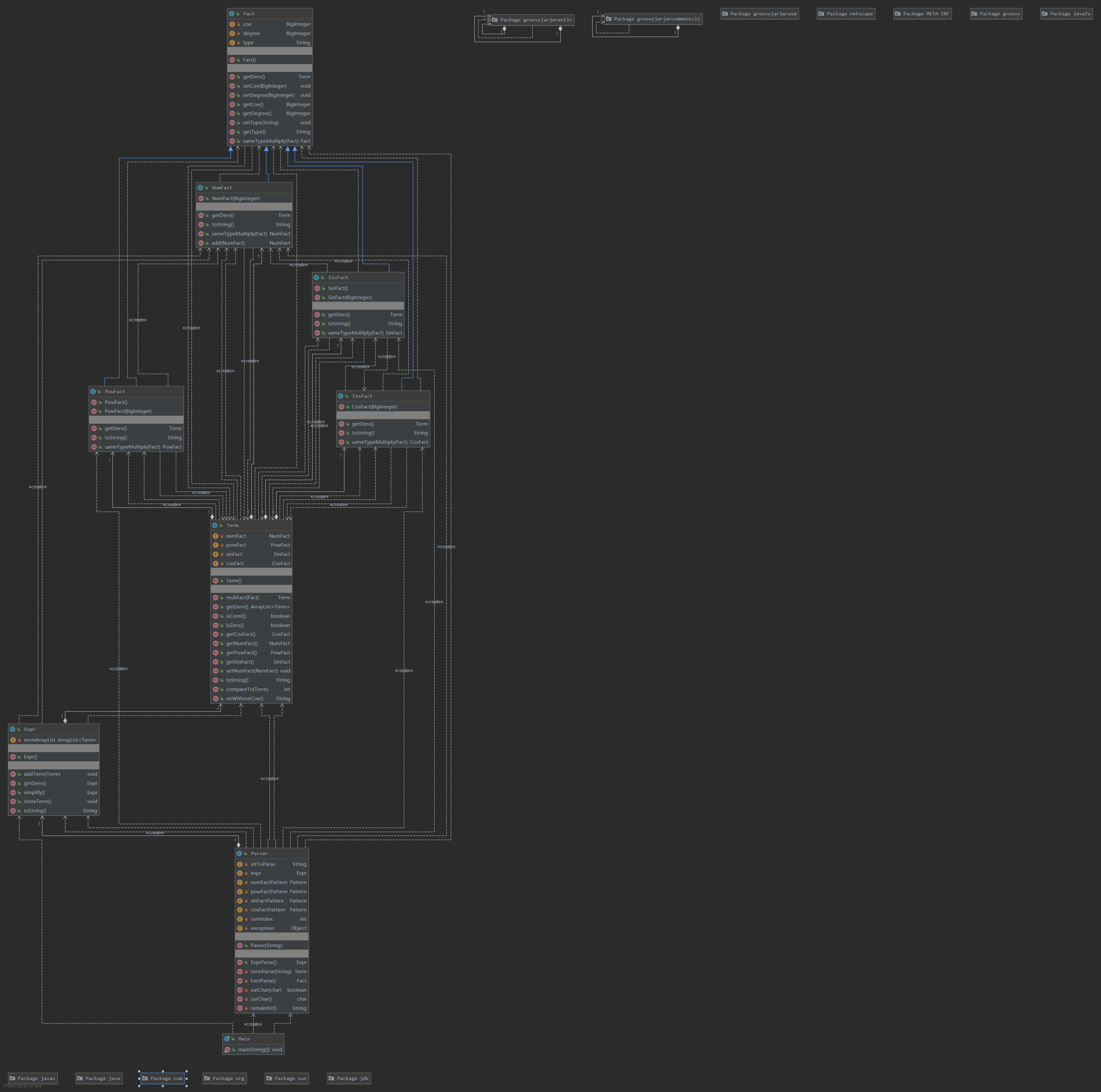
结构还算清晰。
复杂度分析:(只摘取了复杂度标红的部分)
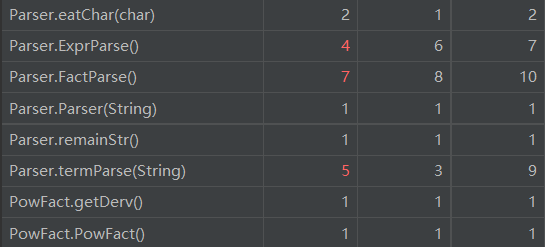
可以看到,复杂度较高的部分集中在字符串处理上。ev较高,主要原因是没有在创建的时候引入工厂模式,把所有的不同因子的创建写在一个函数当中了。这是可以改进的地方。
3.第三次作业
第三次作业难度较大。因为在第二次作业写完之后立即投入到了第三次的企划当中,因此时间一开始还比较充裕,初稿也是进行了很多的优化,挑战了自己。但是后来发现自己的一个严重的BUG,那就是没有进行克隆,修复之后中测直接TLE一个。最后只能忍痛割爱,放弃了绝大部分的优化,可能还是功力不够吧。
结构上与第一次差不多,最主要的区别是第三次作业中有些因子的内部存放的是一个表达式,求导的时候进行递归的求解。第三次的难点对我来说还是在Parser上面。
类图如下:
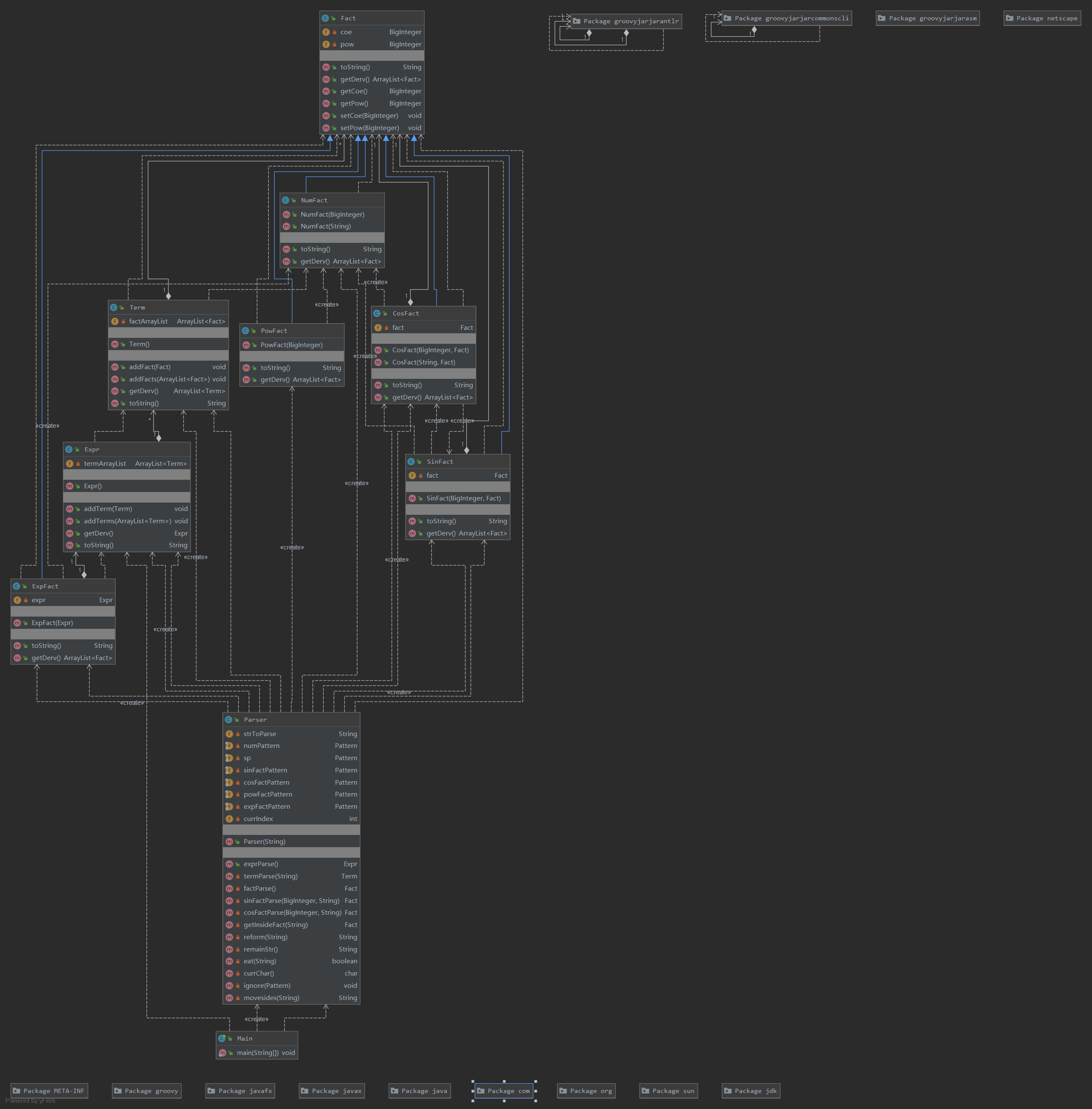
和第二次很相近。
复杂度如下:

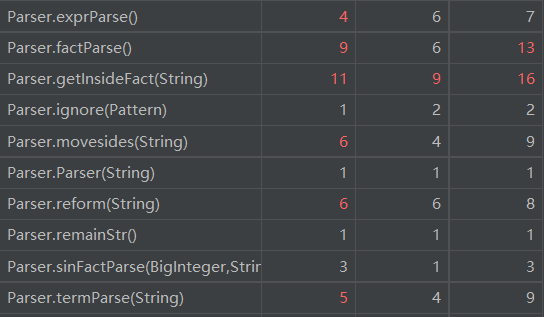

这次标红的地方更多了。实际上,原来优化版本的复杂度比这个还要高。问题还是出在Parse上面。
BUG分析
1.自己的BUG
这一单元整体表现都不是很好。在第一次作业中,虽然并不是超长正则表达式匹配的,但是却写了一个超长的正则(后来加了个注释符就解决了),导致强测TLE一个,在互测中也是在这里被输出;第二次作业也很可笑,明明放弃了很多优化,最后还是想占个小便宜,在输出的时候将x2替换成x*x,结果就出现了x241变成x*x41的尴尬局面,互测时也是被精准发现;第三次更加难受,因为在最后一个小时内发现了BUG,(就是在sin与cos内部对是否是表达式因子进行判断的地方),然后急速DEBUG,结果引入了一个更大的BUG:对于sin或者cos内部的两层及以上的括号,我均未返回表达式因子,返回的是一个null,可笑的是竟然苟过了中测,甚至竟然进入了互测(当然互测的时候被捅成了筛子,几乎随便写一个复杂一点的样例都能刀中我),强测更是直接挂掉5个。可以看到,我每次任务均没有做到极致,每次均是因为一些这样那样的原因而无法全部通过。教训就是以后每一个版本均要在本地做足测试,同时,一定要把握住每一个细节,不能让差一点点成为一个坏习惯。
2.他人的BUG
找他人的BUG主要来自两方面,第一是用python写了个随机生成数据的程序(但是完整的评测机还是不会写),通过这种方法找到了些许BUG;第二种方法是阅读代码。其实OS实验课的主要内容也是阅读代码,阅读代码还是很有趣的,很像解谜,遇到好的代码还能拜读(如果不是一味地想找BUG的话)。前两次作业中我每次均挑了一份较好的代码进行了阅读,然后找到了BUG,第三次因为心里实在五味杂陈、没有心情所以就没有很积极地参与到圣杯战争当中。以后为了阅读到更好的代码应该把自身的段位提高。
应用创建对象模式重构
目前学到的创建模式只有工厂模式。在这三次作业当中,后两次作业的parser可用说是有了些创建模式的影子,但是更好的解决办法是将创建对象的部分再分出来,用一个工厂来创建不同的因子。具体做法是当一种matcher匹配到后,找到工厂声明需要哪种的因子。这么做应该可以比较好地降低耦合度。
对比和心得体会
与自身对比的话,确实是在进步,但是每一次都不能做到没有瑕疵也是顽疾;与他人对比的话,自己还是太菜了。面对这种菜一是要产生动力,二是不要被搞坏了心态,尽力去做就好了。
心得来讲,通过这三次作业我算是入了一个门,同时也意识到了差距与难点所在。虽然分数不是很理想,但是也可以称得上是一个良好的开端。还有一点很深的体会是:不要过分地纠结于分数,每次的目标应该是写出更好的代码,这个目标达到了,分数只是一种认可形式。另外在互测的时候,不要被搞坏了心态,糟蹋一整个周末。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号