机器学习---Kmeans 聚类算法
原理
根据每一个点与聚类簇中心的相对距离,尝试将每一个数据点分组到聚类簇中。
执行过程
我们预先定义好聚类簇的数量,每一轮k均值的过程中,要重新计算每一个数据点和聚类簇的中心的距离。接着将每一个数据点分配到与之最近的聚类簇,分配完之后根据最新的聚类簇中的点计算均值位置作为新的聚类簇中心。
归一化
由于数据的不同维度上的量纲不同,在计算所有维度作用的共同距离时,很有可能会出现维度倾斜。
比如一个维度上的单位为万元,一个维度上的单位为元,另外一个维度上的单位是毫米,三个维度上的数据分别为2,20000,200000。我们计算距离的时候需要计算:
2
∗
2
+
20000
∗
20000
+
200000
∗
200000
\sqrt{2*2+20000*20000+200000*200000}
2∗2+20000∗20000+200000∗200000
这三个不同维度的单位意义不同,也没有很强的联系,很显然,这种距离没有什么意义。我们就需要将这种单位的影响去除才能进行距离计算。
z-score归一化函数
在每一个维度上,每一个数据减去维度上所有数据的均值再除以所有数据的标准差,我们将得到的数据作为我们进行聚类的数据
Z
=
X
−
X
ˉ
s
Z = \frac{X-\bar{X} }{s}
Z=sX−Xˉ
流程
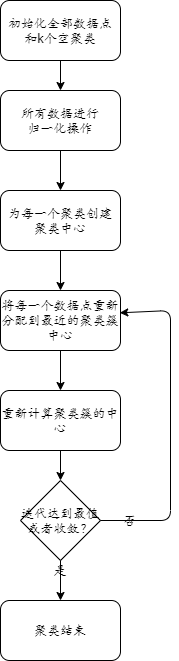
代码
zscore 归一化函数
def zscores(original: Sequence[float]) -> List[float]:
avg: float = mean(original)
std: float = pstdev(original)
if std == 0:
return [0] * len(original)
return [(x - avg) / std for x in original]
归一化替换之前数据
def normalize(self) -> None:
zscored: List[List[float]] = [[] for _ in range(len(self._points))]
for dimension in range(self._points[0].num_dimensions):
dimension_slice: List[float] = self._dimension_slice(dimension)
for index, zscore in enumerate(zscores(dimension_slice)):
zscored[index].append(zscore)
for i in range(len(self._points)):
self._points[i].dimensions = tuple(zscored[i])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号