
Netty/Redis网络模型——IO多路复用原理(操作系统)
网络模型
BIO-传统阻塞IO
1.单线程阻塞模式(BIO)
整个服务只有一个线程,这个线程不仅负责连接管理(accept)也负责后续的读写操作(read/write)。串行化的操作在有多个连接来临的时候,需要等待上一个连接的读写操作完成,读写操作需要磁盘IO比较耗时,因此性能极其低下,且如果有一个连接或者操作卡住,那么后续所有的操作都会被阻塞。
while(true) {
int connfd = accept(sockfd, ...); // 阻塞,等待新连接
// 有连接到达
while(true) {
int n = read(connfd, buffer, sizeof(buffer)); // 阻塞,等待数据
if (n <= 0) break;
process_command(buffer); // 处理命令
write(connfd, response, strlen(response)); // 发送响应
}
close(connfd);
}
2.多线程/多进程模式
由于单线程容易阻塞,所以可以进行优化,使用多线程来执行,每个线程对应一个连接以及读写操作,但是连接数太多时,线程创建/销毁开销巨大,内存占用高。
while(true) {
int connfd = accept(sockfd, ...); // 阻塞
// 为每个连接创建新线程
pthread_t thread;
pthread_create(&thread, NULL, handle_client, (void*)connfd);
}
void* handle_client(void* arg) {
int connfd = (int)arg;
// 处理这个连接的所有请求
while(true) {
read(connfd, ...);
process_command(...);
write(connfd, ...);
}
}
无论是哪种模式,阻塞IO真正被称之为阻塞IO的原因是,读写操作需要进行等待。
阻塞 IO 的 read() 在没有数据时会一直阻塞,直到:
-
收到数据(内核缓冲区有可读内容)
-
连接关闭(read 返回 -1)
-
被信号打断
在这期间你不能继续做其他事情,线程挂死在 read() 里。
阻塞IO的write()虽然不会需要等待所有数据写完才返回,但是在写缓冲区满的时候,write()会等待可写。
因此,无论是写还是读,都有可能导致线程阻塞,这个线程阻塞指的是大量的线程可能被阻塞在等待读或者写的操作上,即这些线程都被操作系统挂起了,这是严重的资源浪费,甚至有可能拖死线程池。注意每个线程都是独立处理一个连接事件和对应的读写操作,并不是说一个线程卡住了,就阻塞了其余线程。
NIO-非阻塞IO
NIO被称为Non-Blocking IO,即非阻塞IO,是对BIO的改进。非阻塞IO相比传统BIO操作,操作系统内核让IO操作不再等待,调用立即返回。
在这个模式下,read() 在没有数据的时候会直接返回,不会去等待内核缓冲区收到数据。在收到数据的时候,不会把整个TCP协议包的所有数据读完才结束,而是缓冲区有多少数据就把缓冲区的读完就走,剩余的等待下次再读取。NIO并不会要求所有数据写完才返回,而是尽可能地写,如果缓冲区满了,立即返回写了多少字节。
总而言之,NIO不会阻塞是因为内核不会让调用方一直等待,会尽快的返回通知调用方结果。
I/O 多路复用
上面我们讲的是网络IO模型,I/O多路复用不是网络模型,是实现NIO的关键技术,依赖操作系统的底层技术,需要依靠操作系统内核,如select/poll/epoll/kqueue,所以不要混淆了,I/O 多路复用不是NIO的优化,只是一种良好的实践。以Java开发来说,狭义上的NIO我们指的Java的NIO API,N是Non-blocking也是New的含义,Java NIO API 存在不少编程上的难度以及底层存在一些空轮询的Bug等,通常我们很少手动使用NIO API进行网络编程,而是使用Netty来代替,Netty不仅做了很多封装也做了很多优化,Netty 的核心之一实际是就是I/O多路复用。
I/O 多路复用解决了什么问题?
- 解决了一个连接需要一个线程的问题
- 解决了read()阻塞浪费线程资源的问题
- 解决了高并发下线程数过多的问题
I/O 多路复用如何解决的?(核心机制)
I/O 多路复用的核心就是“事件通知”+ 线程一对多连接
// 创建 epoll 实例
int epoll_fd = epoll_create1(0);
// 添加监听 socket 到 epoll
struct epoll_event event;
event.events = EPOLLIN; // 监听可读事件
event.data.fd = sockfd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sockfd, &event);
一个线程如何做到监控多个连接?
网络连接是两个进程之间建立的虚拟通信通道,通常通过 TCP 协议实现。在 Linux 中,一切皆文件,网络连接、文件、设备都被抽象为文件描述符, 其具体表征就是文件描述符(fd)。
详细流程:
1. 注册阶段 - 告诉内核要监控什么
// 应用程序:我要监控这些连接的读事件
struct epoll_event event;
event.events = EPOLLIN; // 监听可读事件
event.data.fd = connfd; // 连接的文件描述符
// 把这个连接注册到 epoll 实例
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, connfd, &event);
此时:内核开始在内核空间维护一个"监控列表"。
2. 等待阶段 - 让内核帮忙监控
// 应用程序:我去睡觉了,有事件时叫醒我
int ready_count = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
此时发生什么:
- 应用程序线程进入阻塞状态
- CPU 可以执行其他任务
- 内核网络栈在后台监控所有注册的文件描述符
3. 事件触发阶段 - 内核检测到数据到达
网卡收到数据包 → 产生硬件中断 → 内核网络栈处理 → TCP 协议栈将数据放入接收缓冲区 → 内核标记 fd 为"可读" →
唤醒阻塞在 epoll_wait 的线程
4. 处理阶段 - 应用程序处理就绪事件
// 内核告诉应用程序:这些连接有数据可读了
for (int i = 0; i < ready_count; i++) {
int ready_fd = events[i].data.fd;
// 现在可以立即 read() 而不会阻塞
int n = read(ready_fd, buffer, sizeof(buffer));
process_data(buffer, n);
}
内核如何知道数据到达?
硬件层面:
- 网卡收到数据包
- DMA 将数据直接写入内存(不经过 CPU)
- 网卡发出中断信号
- CPU 执行中断处理程序
操作系统执行监听的时候CPU在做什么?
在等待连接的过程中,发生了什么?
以redis为例:
- Redis 线程从用户态切换到内核态
- 内核将线程标记为休眠状态(TASK_INTERRUPTIBLE)
- 线程让出 CPU,操作系统可以调度其他进程运行
- Redis 线程不再占用 CPU 时间片
也就是说,当你的IO程序正在等待连接的时候,等待事件到来的过程中,是被操作系统挂起的,处于休眠状态,此时的CPU分片分给了其他程序,如果此时IO程序还有后台任务需要处理的时候,CPU分片也可能正好处于当前程序占用时刻。
举例:
时间片1: [Redis] epoll_wait → 进入内核 → 休眠 ⇒ 让出CPU
时间片2: [MySQL] 执行SQL查询(用户态)
时间片3: [Nginx] 处理HTTP请求(用户态)
时间片4: [内核] 处理网络数据包(内核态)
时间片5: [其他] 某个桌面程序(用户态)
...
接下来我们看,当硬件监听到有连接事件的完整链条:
硬件层面:
1. 网卡收到数据包
2. 网卡通过DMA将数据写入内存
3. 网卡发出硬件中断信号
内核层面:
4. CPU暂停当前执行的代码(可能是任何进程)
5. CPU切换到内核态,执行中断处理程序
6. 内核网络栈处理数据包
7. 内核标记对应的socket为"就绪"
8. 唤醒等待在该socket上的Redis线程
9. 中断返回,恢复之前执行的代码
用户层面:
10. 操作系统重新调度,Redis线程变为就绪状态
11. 当Redis获得CPU时间片时,epoll_wait返回
12. Redis处理网络请求
所以这个机制的精妙之处就在于:用休眠代替忙等待,用中断代替轮询,用内核协作代替用户态竞争
Reactor 模型
Reactor 模型是基于 IO 多路复用的高级设计模式:
IO多路复用 (技术基础)
↓
NIO API (编程接口)
↓
Reactor模式 (架构设计)
↓
Netty等框架 (具体实现)
Reactor模型是一种设计模式,用于处理并发I/O请求。所以,NIO并不等同于Reactor模型,但NIO的技术(特别是Selector)是实现Reactor模型的一种常用手段。
Reactor模型的核心思想是将I/O事件分发给相应的处理器(Handler)。它有一个或多个并发的事件源(Event Sources),一个事件分发器(Dispatcher)和多个事件处理器(Event Handlers)。事件分发器等待事件发生,然后将事件分发给对应的事件处理器。
Reactor responds to IO events by dispatching the appropriate handler
Handlers perform non-blocking actions
在Java NIO中,Selector正是扮演了事件分发器的角色。我们向Selector注册感兴趣的事件(如连接、读、写等),然后在一个循环中调用Selector的select()方法,等待事件发生。当事件发生时,Selector会返回这些事件,然后我们遍历这些事件并分发给对应的处理器。
NIO Selector 的工作机制——Selector 的 Reactor 本质
public class SelectorReactor {
public void eventLoop() throws IOException {
while (true) {
// 阶段1: 事件等待 (类似 epoll_wait)
int readyChannels = selector.select(); // 阻塞直到事件就绪
if (readyChannels == 0) continue;
// 阶段2: 事件分发
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 阶段3: 事件处理
if (key.isValid()) {
if (key.isAcceptable()) {
// Acceptor 逻辑
} else if (key.isReadable()) {
// Handler 逻辑
} else if (key.isWritable()) {
// Handler 逻辑
}
}
keyIterator.remove(); // 处理完成后移除
}
}
}
}
NIO 的Reactor 模式设计
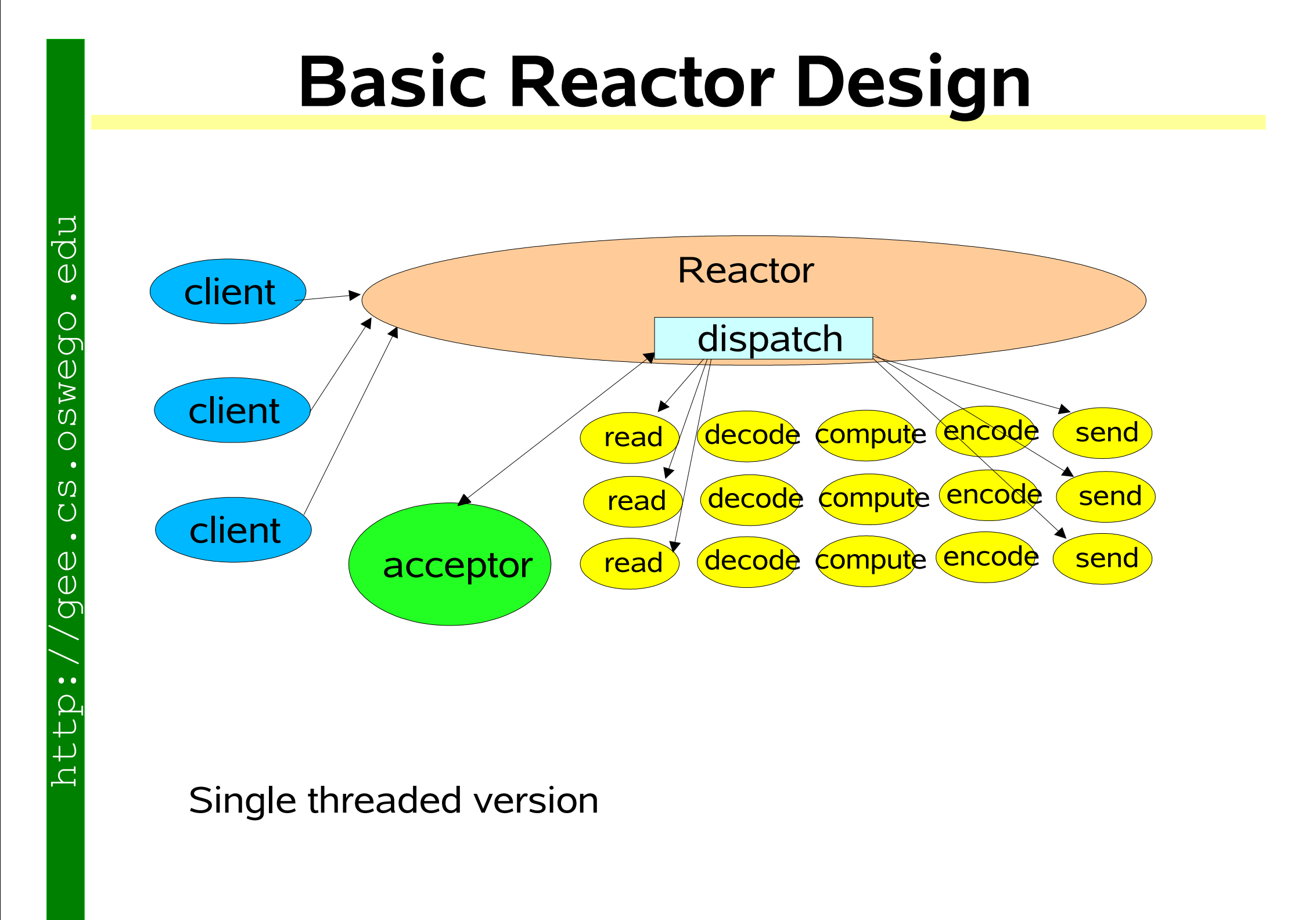
单Reactor 单线程模式
结构
- Reactor:一个线程,负责监听和分发事件(包括连接事件和IO事件)。
- Handler:处理具体的业务逻辑,在同一个线程中完成。
工作流程
- Reactor通过Select监听事件,收到事件后通过dispatch进行分发。
- 如果是连接建立事件,则由Acceptor处理,接受连接并创建一个Handler来处理后续事件。
- 如果不是连接事件,则Reactor会调用对应的Handler来处理。
- Handler完成读、处理、写等整个业务流程。
优点
- 模型简单,没有多线程竞争和同步问题。
缺点
- 性能瓶颈:只有一个线程,无法充分利用多核CPU。
- 如果Handler处理某个连接上的业务耗时较长,会导致整个服务卡住
单Reactor多线程 模式
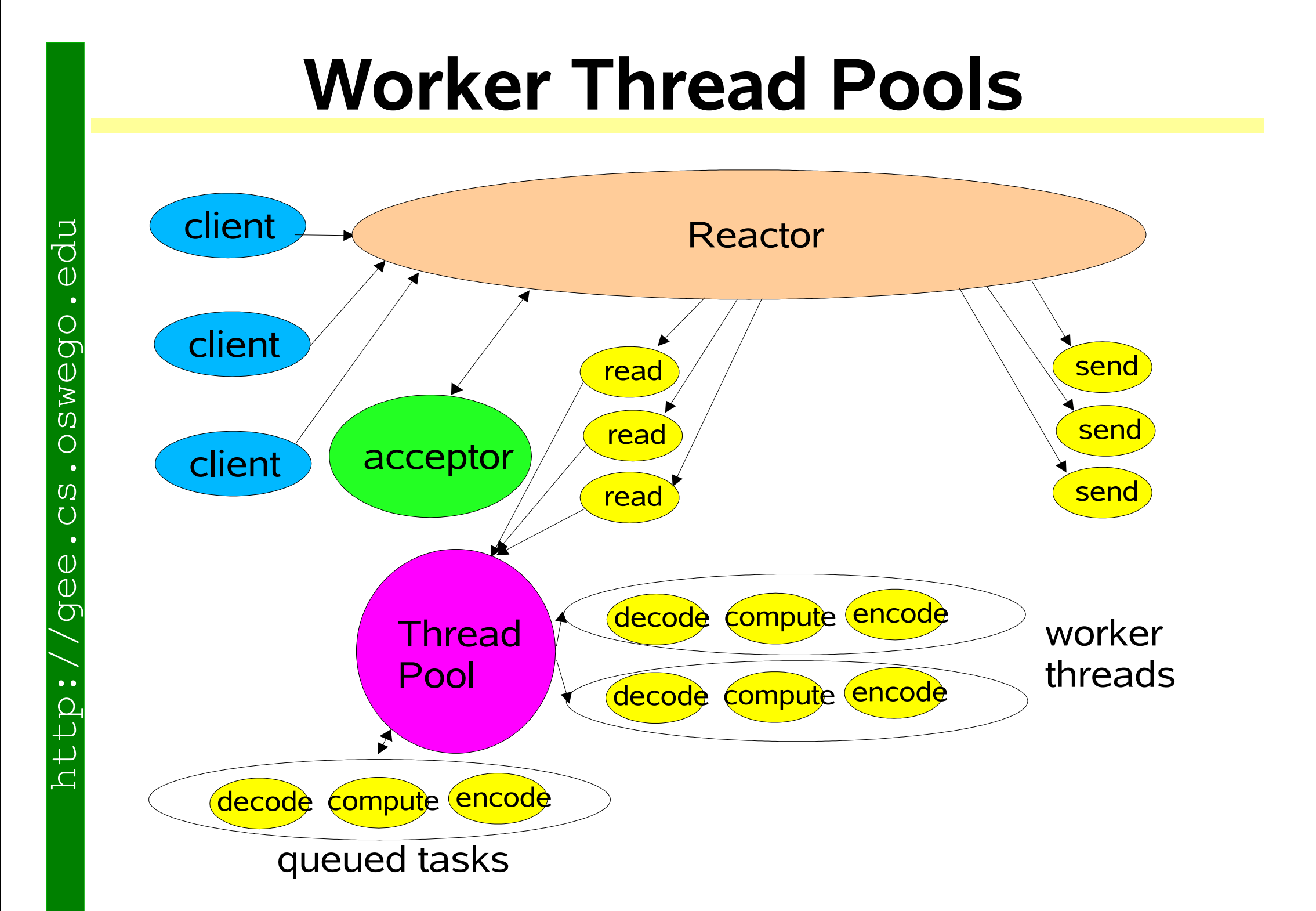
结构
- Reactor:一个线程,负责监听和分发事件(包括连接事件和IO事件)。
- Handler:只负责读取和写入数据,不处理业务逻辑。
- 业务线程池:处理具体的业务逻辑。
工作流程
- Reactor通过Select监听事件,收到事件后通过dispatch进行分发。
- 如果是连接建立事件,则由Acceptor处理,接受连接并创建一个Handler来处理后续事件。
- 如果不是连接事件,则Reactor会调用对应的Handler来处理。
- Handler只负责读取请求和发送响应,而将具体的业务处理交给业务线程池。
- 业务线程池处理完业务后,将结果返回给Handler,然后由Handler发送给客户端。
优点
- 充分利用多核CPU,避免业务处理阻塞Reactor线程。
缺点
-
Reactor线程还是单线程,高并发场景下可能成为瓶颈。
-
多线程数据共享和访问比较复杂,需要注意线程安全。
主从 Reactor 多线程模式 (Netty 采用)
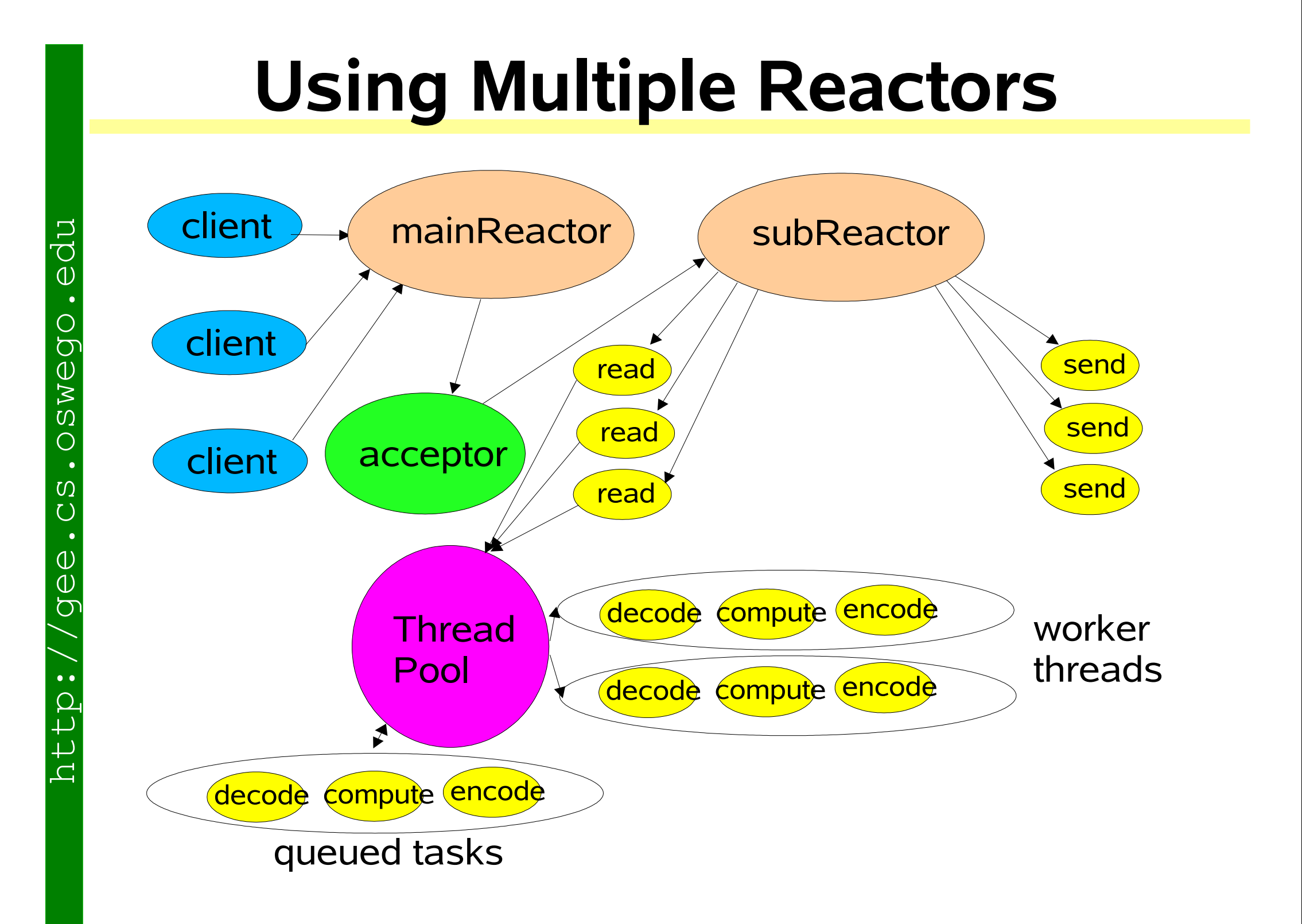
结构
- 主Reactor:一个线程,只负责监听连接建立事件,接受连接后将连接分配给子Reactor。
- 子Reactor:多个线程,每个子Reactor独立运行,监听分配给自己的连接的IO事件。
- Handler:处理具体的业务逻辑,由子Reactor调用,但业务处理交给业务线程池。
工作流程
- 主Reactor监听连接建立事件,收到事件后由Acceptor接受连接。
- Acceptor将连接分配给一个子Reactor(通常通过轮询或哈希等方式)。
- 子Reactor将连接注册到自己的Selector上,监听IO事件。
- 当子Reactor监听到IO事件后,调用对应的Handler进行处理。
- Handler读取请求后,将业务处理交给业务线程池,处理完后将结果返回给Handler,然后由Handler发送响应。
优点
- 主Reactor和子Reactor分工明确,主Reactor只负责连接建立,子Reactor负责IO事件。
- 多个子Reactor可以应对更高的并发连接。
缺点
- 实现复杂。
NIO 的Reactor 模式实现
Netty的主从Reactor模式
Netty的设计基于主从Reactor多线程模式,但做了一些调整。
- BossGroup:相当于主Reactor,负责接收连接。
- WorkerGroup:相当于子Reactor,负责处理IO事件。
- (改变点)每个Channel(连接)只会被分配给一个WorkerGroup中的某个EventLoop(子Reactor)处理,从而避免多线程竞争。
Redis 6.0 的单 Reactor 模式
-
主线程仍然负责接收连接,并将连接分配给I/O线程。
-
I/O线程负责读取命令和发送响应。具体来说:
-
主线程将读任务分配给I/O线程,I/O线程读取客户端发送的命令,并将解析好的命令放入队列。
-
主线程按顺序从队列中取出命令并执行(单线程执行)。
-
主线程将写任务(执行结果)分配给I/O线程,由I/O线程将响应发送给客户端。
-
流程:
- 主线程初始化时,根据配置启动I/O线程(默认不启动,即单线程模式)。
- 主线程负责监听端口,接受连接,并将连接套接字注册到事件循环(epoll)中。
- 当有读事件发生时,主线程将读任务分配给I/O线程(如果有的话),然后主线程等待I/O线程完成读取。
- I/O线程读取数据并解析协议(注意:不执行命令)。
- 主线程执行命令,将响应数据写入输出缓冲区。
- 主线程将写任务分配给I/O线程(如果有的话),由I/O线程将响应数据写回客户端。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号