Quorum Queues - Making RabbitMQ More Competitive In Reliable Messaging
标题:Quorum Queues - Making RabbitMQ More Competitive In Reliable Messaging
原文:https://jack-vanlightly.com/blog/2018/11/20/quorum-queues-making-rabbitmq-more-competitive
时间:2018-11-20
社区对RabbitMQ镜像队列的多个设计缺陷进行了充分的记录,并得到了RabbitMQ团队的认可。在一个新的消息传递系统不断涌现并竞争激烈的时代,RabbitMQ必须改进其复制队列,以便继续在该领域保持竞争力。这就是为什么看到RabbitMQ团队一直在努力基于Raft一致性算法交付一种新的复制队列类型这件事会如此令人兴奋。仲裁队列仍处于测试阶段,因此可能会在发布前进行更改。同样,它们的功能无疑将在未来的版本中不断发展和改进。目前,仲裁队列的功能有一些限制,但如果数据安全是您最重要的要求,那么它们旨在满足您的需求。
在这篇文章中,我们将研究仲裁队列的设计,然后在后面的文章中,我们将进行一系列混沌测试来测试这种新队列类型的耐用性。
首先,我将从较高的层次解释Raft是如何工作的,但不包括协议的所有复杂之处。如果你想了解整个协议及其如何实现安全保证,我郑重建议您阅读Raft论文和其他Raft相关的信息来源。
An Introduction to Raft
Raft共识协议并非微不足道,但同时也不至于复杂到难以理解。这篇文章不会涉及Raft的各个方面,因为Raft论文已经是一份尽可能简洁的文档,所以请一定要读它。
这就是说,我们将简要介绍Raft如何实现其声称的保证(现已由TLA+证明)。
Brief Overview of Raft
所有的写操作都要经过leader,他会将这些写复制给follower。数据始终按以下方向流动:leader -> follower。client可以连接任何节点,但如果节点是follower,它将响应client,通知他们谁是leader,以便client可以向leader发起读写操作。
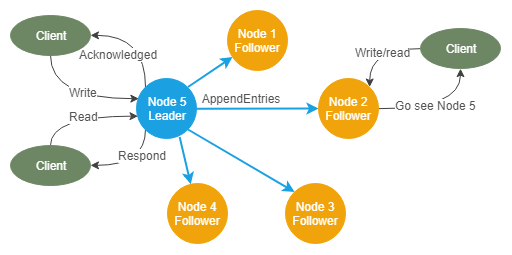
只要follower在一个称为election timeout的时间段内收到来自leader的周期性心跳信号,那么节点就可以保持leader的身份。如果一个follower在这段时间内没有收到心跳信号,那么这个follower就会把自己变成候选人,并试图成为leader。候选人通过对集群中的每个节点进行RequestVote RPC并从大多数节点获得投票,从而成为领导者。
有两件事会阻止多个候选人同时当选leader:
- 需要多数票(因此两名同时参选的候选人不能同时获得多数票);
- Term,也被称为epoch或fencing token,用于防止过时的请求被接受。每当选一位新leader,他们的term就会增加1。当任何节点收到RequestVote RPC时,如果请求中的term小于其当前已知term,则会拒绝该请求。这可以防止过时节点或僵尸节点获得领导权。
当leader失效时,follower将停止接收心跳信号,并将进行leader选举。同样,如果发生网络分区,则来自leader的另一侧的follower将停止接收心跳信号,并且将在其所在的分区上触发leader选举。如果这些现在成为候选人的follower位于分区的少数一边,那么他们将无法当选,因为他们需要大多数节点的投票。这就是Raft避免脑裂的方法。
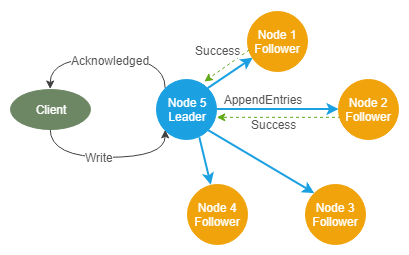
所以心跳很重要,但没有心跳RPC,而是有一个AppendEntries RPC,用于将数据从leader复制到follower。此RPC还充当心跳。每个AppendEntries RPC都包含最新的未复制数据,以及一致性检查所需的元数据(细节请阅读paper原文)。
当client对leader进行写操作时,leader会将该条目附加到自己的日志中,并将该写操作包含在它对follower进行的下一个AppendEntries RPC中。一旦达到法定人数(超过半数)的follower确认他们提交了这些日志条目,leader将立即回复client。
因此,在client收到成功写入的确认时,少数节点可能仍然没有该条目。Leader将继续尝试向给定follower复制尚未提交到其本地日志的所有条目。Paper进一步解释了其中的细微差别。
如果leader在将其所有日志复制到少数节点之前失败,则新当选的leader不能是没有完整日志的少数节点之一。我们在这里讨论的是已确认的写入,因此我们知道大多数节点在leader故障时都有已确认的条目。如果没有完整日志的follower之一成为leader,那么我们将丢失数据。为了防止出现这种情况,最后一个日志条目下标包含在RequestVote RPC中。当一个节点从最后一个日志项下标较低的候选节点接收到RequestVote RPC时,该节点将不会投票给它。因为候选人需要多数票才能获胜,而多数票拥有完整日志,那么没有完整日志的候选人将不能成为leader。
上面解释的关于Raft还有许多细节,例如日志压缩和集群成员更改都没有涉及,可以去读paper。
Write Safety
总之,只要大多数节点继续存在,就可以保证已确认的写操作继续存在。因此,这意味着3节点群集可以容忍1个节点故障,而5节点群集可以容忍2个节点故障。因此,我们不选择偶数集群。一个由4个节点组成的集群仍然只能容忍一个节点故障,此外,在网络分区下可能会降低集群的可用性。
Read Safety
我们尚未涉及读安全性保证,所有读写都交给leader。Leader可以简单地从其本地状态读取提交的条目。然而,仍然存在短期脑裂的风险,即leader L1正在接收读写请求,然后发生网络分区。L1属于少数分区。多数分区的新leader当选,并开始接收读写请求。
在很短的一段时间内,L1不会意识到它位于少数派分区,因此如果它立即响应所有读取请求,它可能会提供过时的数据。为了防止这种情况发生,leader只能在心跳被成功确认后才能为读取请求提供服务。我之前说过,没有显式的心跳RPC,它使用AppendEntries RPC来实现这一点。当leader没有要复制的数据时,它只会使用不包含任何条目的AppendEntries RPC。所有存活的follower都将确认该RPC。Leader在短时间内生成这些AppendEntries RPC。当一个读取请求传入时,它会等待下一个AppendEntries RPC发出,并等待大多数节点的响应,然后再将数据返回给client。这保证了安全性,同时增加了读取请求的延迟。
RabbitMQ Quorum Queues
仲裁队列有一个leader和多个follower,并使用相同的Raft术语。所有的读写都要经过leader。默认情况下,仲裁队列的复制因子为5(如果集群规模小于5,则复制因子也小于5)。因此,如果您有一个由3个节点组成的集群,那么仲裁队列将有三个副本(一个leader,两个follower)。
当client向仲裁队列发送消息时,一旦超过半数节点接受了写入请求,那么broker将会响应client。当client从队列中消费时,队列leader将返回由大多数节点确认过的消息。
同步是镜像队列的痛点之一。对于仲裁队列,故障转移只会发生在完全同步的跟随者身上(根据Raft协议的规定)。新的follower将在后台异步复制(如Raft协议所述),不会导致队列不可用。唯一发生的中断是触发leader选举到选出新leader这段时间。在此期间发送的任何消息都需要client重新发送。
每个仲裁队列(leader及其follower)可以构成一个Raft集群。因此,使用该模型,如果您有100个仲裁队列,那么您将在RabbitMQ节点上有100个Raft集群。RabbitMQ团队不得不稍微调整Raft协议以适应这种情况,因为过多独立Raft集群的通信开销和IO开销太大。相反,队列在RabbitMQ节点级别共享相同的底层存储机制和RPC。
New Drawbacks
仲裁队列不会取代镜像队列,因为它带来了新问题,可能不适合你的使用场景。
在存储层,每条消息都存储在每个队列的单独Raft日志中。这会影响fanout exchange,如果10个复制因子为5的仲裁队列绑定到一个fanout exchange上,那么每个消息在磁盘上最终会有50个副本。与此形成对比的是,标准队列(包括镜像队列)具有共享存储模型,其中消息在每个broker中仅保留一次,即使发送到多个队列也是如此。仲裁队列的非共享存储意味着您需要更快的磁盘,或者在消息扇出数较大时不使用仲裁队列。
在Beta 3中,仲裁队列当前始终将其所有消息存储在内存中,但Beta 4承诺使用内存限制配置,这将有助于防止仲裁队列对broker造成太大的内存压力。
你可以在这里了解到一些其他的限制:http://next.rabbitmq.com/quorum-queues.html
Questions and Open Topics
Could the idempotency of writes mentioned in the Raft paper be implemented by the RabbitMQ team?
论文中的内容:
然而,如前所述,Raft可以多次执行一条命令。例如,如果leader提交日志条目后但在响应client之前崩溃,client将会连接新leader重试命令,导致同一条命令处理两次。这个解决方案是为client的每一个命令分配唯一的序列号。然后,状态机跟踪为每个client处理过的最新序列号,以及关联的响应。如果它接收到一个序列号已经执行过的命令,它将立即响应client,而不重新执行请求。
幂等实现可能有不同的方法。例如,Apache Kafka使用生产者Id和一元递增序列号的组合。分区leader跟踪每个生产者确认过的最高序列号,并忽略序列号较低的消息。此外,消息使用生产者Id和序列号进行存储,以便所有分区follower都可以保持相同的状态,当发生故障转移时,消息去重逻辑依然可以正常工作。我在这里写了关于Apache kafka和Apache Pulsar幂等生产者的博客,他们在TCP连接失败和broker故障转移情况下都工作得很好。
我希望RabbitMQ也能这样做,但需要修改各种客户端库以支持它。希望能够在未来的版本中看到这一点。
Memory Alarms
当前仲裁队列不响应内存警报。对仲裁队列功能的大多数限制归结为它们实现了Raft,并且它们不能并且还没有将这些功能与Raft实现集成。
一个有趣的研究领域是仲裁队列在负载和内存压力下的行为。
Testing the Beta Release
实现Raft并不是件小事,实现上存在许多的bug。此外,由于将每个仲裁队列视为一个独立的Raft集群的性能问题,RabbitMQ对Raft的实现不得不有所偏离。
我已经针对仲裁队列的各种beta版本运行了一套测试,稳定性一直在提高。您可以在此处看到测试脚本:https://github.com/Vanlightly/ChaosTestingCode/blob/master/RabbitMqUdn/readme.md.
Summary
仲裁队列特性对RabbitMQ和社区来说是一个好消息,也是RabbitMQ在可靠消息系统领域保持竞争力的必要步骤。它仍然不是镜像队列的替代品,但随着时间的推移,仲裁队列将得到改善,主要是内存使用率,希望还有磁盘存储。
Apache Kafka是RabbitMQ在开源可靠消息领域的第一个大竞争者,我们现在看到Apache Pulsar正在取得进展。也许RabbitMQ在稳定性和可靠性方面无法与Apache Pulsar匹敌,但RabbitMQ的优势并不在于它在特定场景中始终是最好的选择,而是它是一个具有最佳客户端库支持的多功能消息系统。它不一定是目前最可靠的消息系统,但开源可靠消息领域中的赌注越来越高,仲裁队列是向前迈出的另一步。
你可能想查看我在此处对仲裁队列的另一篇总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号