
数据采集与融合技术_实验四
码云链接:欧翔实验四
1.作业①:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生可自由选择
-
输出信息:
MySQL的输出信息如下

2.解题思路
2.1网页分析与商品定位
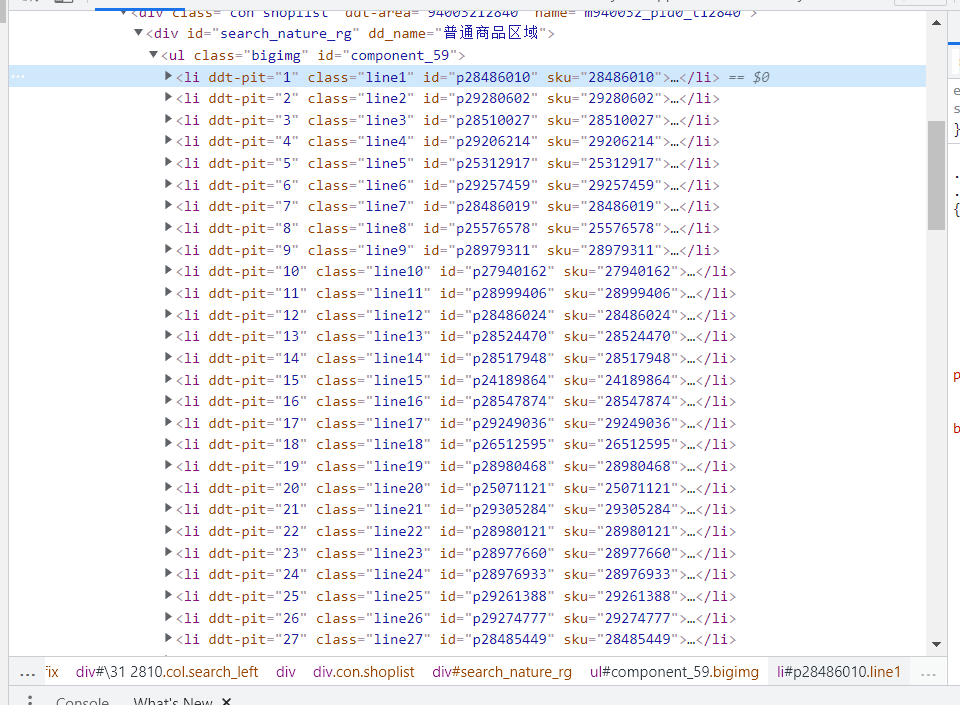
可以发现包含每条商品信息在li标签下,其xpath定位语句为"//ul[@class='bigimg']/li"
2.2信息提取
从每条li中找到所需要的信息
for book in books:
title = book.xpath("./a/@title").extract_first()
price = book.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = book.xpath("./p[@class='search_book_author']/span/a/@title").extract_first()
date = book.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first()
publisher = book.xpath("./p[@class='search_book_author']/span/a[@name='P_cbs']/text()").extract_first()
detail = book.xpath("./p[@class='detail']/text()").extract_first()
2.3写入数据库
pipelines.py
class DdspiderPipeline:
def open_spider(self, spider):
self.count = 1
self.con = pymysql.connect(host='localhost', user='root', password='123456', charset="utf8")
self.cursor = self.con.cursor()
self.cursor.execute("CREATE DATABASE IF NOT EXISTS books")
self.cursor.execute("USE books")
self.cursor.execute("CREATE TABLE IF NOT EXISTS books("
"id int primary key,"
"bTitle varchar(512) ,"
"bAuthor varchar(256),"
"bPublisher varchar(256),"
"bDate varchar(32),"
"bPrice varchar(16),"
"bDetail text)"
"ENGINE=InnoDB DEFAULT CHARSET=utf8")
print("opened")
self.opened = True
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("insert into books (id, bTitle, bAuthor, bPublisher, bDate, bPrice, bDetail) values "
"(%s,%s,%s,%s,%s,%s,%s)", (self.count, item['title'], item['author'], item['publisher'],
item['date'], item['price'], item['detail']))
self.count += 1
return item
except Exception as err:
print(err)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("close")
print("总共爬取:", self.count, "本书籍")
2.4 修改setting.py
BOT_NAME = 'ddSpider'
SPIDER_MODULES = ['ddSpider.spiders']
NEWSPIDER_MODULE = 'ddSpider.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'ddSpider.pipelines.DdspiderPipeline': 300,
}
2.5 结果
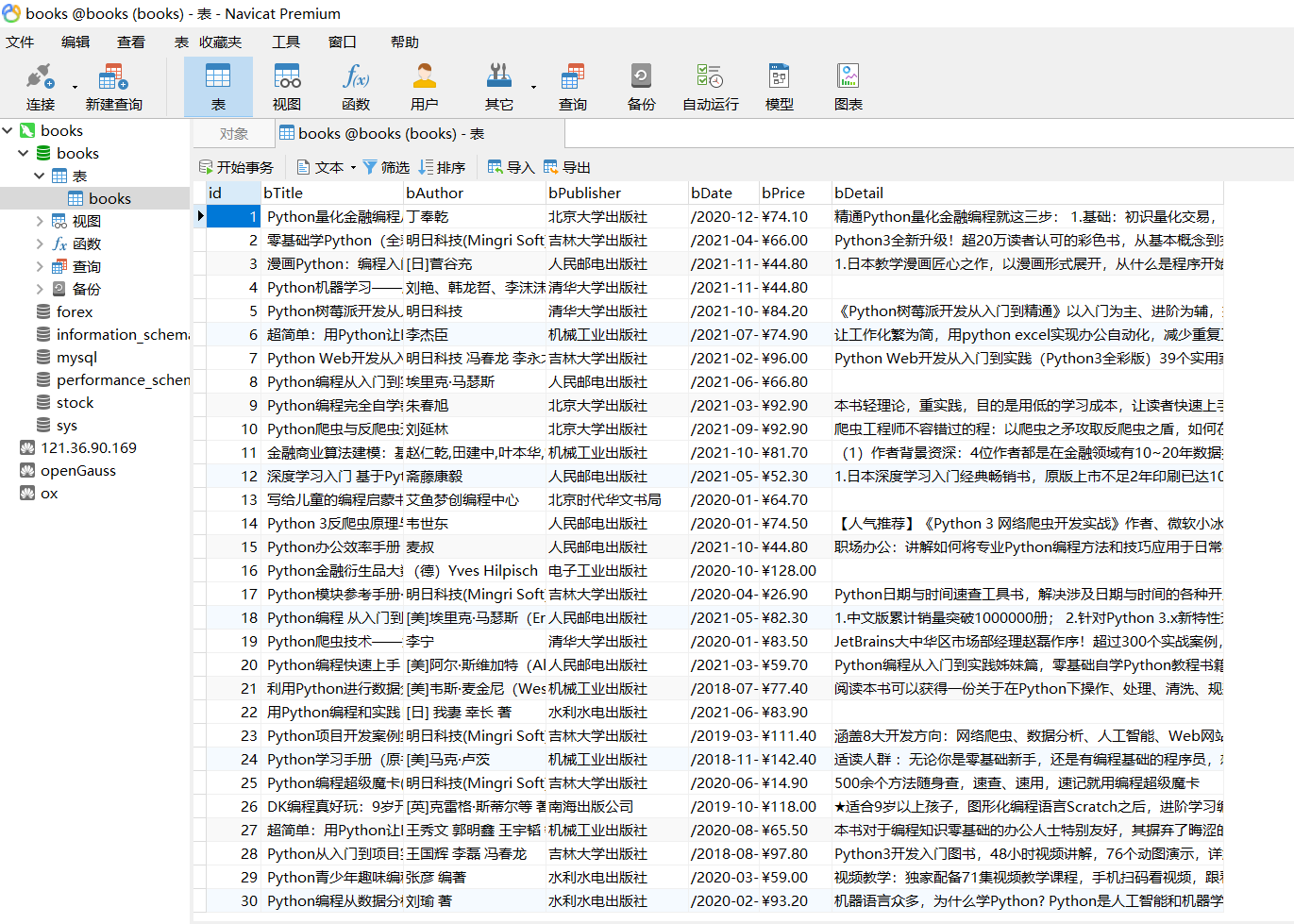
3.心得体会
复现作业难度不大,经过本次实验,我熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法。同时,也是第一次使用mysql,对于python中利用pymysql与MySQL数据库进行交互有了初步理解。对于Xpath的掌握程度也大大加深。
1.作业②:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
-
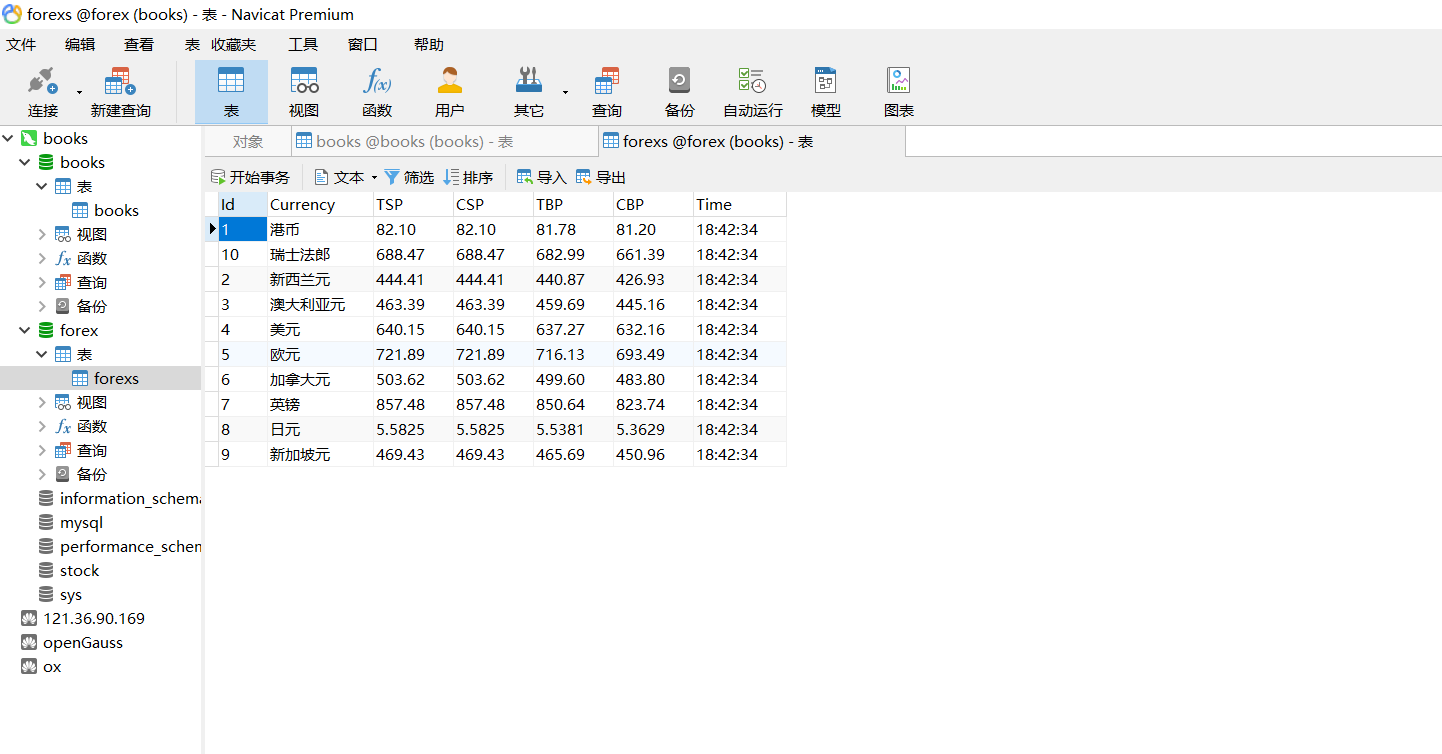
输出信息:MySQL数据库存储和输出格式
Id Currency TSP CSP TBP CBP Time 1 港币 86.60 86.60 86.26 85.65 15:36:30 2......
2.解题思路
2.1网页分析与商品定位
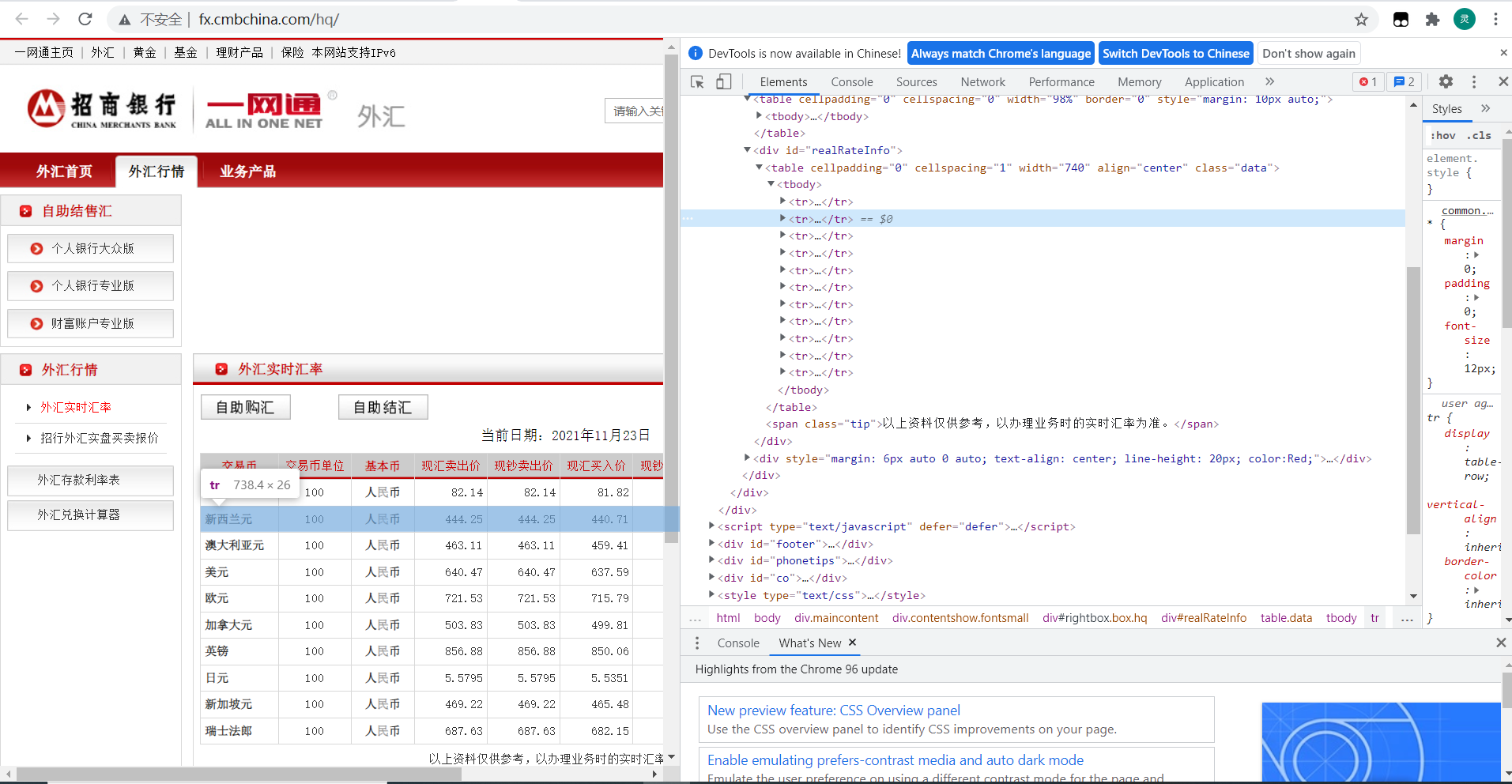
网页比较简洁,可以容易的找到所需数据在tr标签下,但第一条tr为表头,要略过,xpath定位为"//table[@class='data']//tr"
2.2信息提取
从每条tr中找到所需要的汇率信息
for f in forex_data[1:]:
item = forexSpiderItem()
currency = f.xpath("./td[1]/text()").extract_first().strip()
TSP = f.xpath("./td[4]/text()").extract_first().strip()
CSP = f.xpath("./td[5]/text()").extract_first().strip()
TBP = f.xpath("./td[6]/text()").extract_first().strip()
CBP = f.xpath("./td[7]/text()").extract_first().strip()
time = f.xpath("./td[8]/text()").extract_first().strip()
2.3写入数据库
pipelines.py
class ForexspiderPipeline:
def open_spider(self, spider):
try:
self.con = pymysql.connect(host='localhost', port=3306, user='root', password='123456', charset='utf8')
self.cursor = self.con.cursor()
self.cursor.execute("CREATE DATABASE IF NOT EXISTS forex")
self.cursor.execute("USE forex")
self.cursor.execute("CREATE TABLE IF NOT EXISTS forexs(Id varchar(8) primary key, Currency varchar(32), "
"TSP varchar(8),CSP varchar(8), TBP varchar(8), CBP varchar(8), Time varchar(16))"
"ENGINE=InnoDB DEFAULT CHARSET=utf8")
self.opened = True
print("opened")
except Exception as e:
print(e)
self.opened = False
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("INSERT INTO forexs VALUES (%s,%s,%s,%s,%s,%s,%s)",
(item["id"],item["currency"],item["TSP"],item["CSP"],
item["TBP"],item["CBP"],item["time"]))
print("INSERT INTO forexs VALUES (%s,%s,%s,%s,%s,%s,%s)",
(item["id"],item["currency"],item["TSP"],item["CSP"],
item["TBP"],item["CBP"],item["time"]))
return item
except Exception as e:
print(e)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
2.4 修改setting.py(类似上一题)
2.5结果
id字段设为varchar,表格显示未按id排序
3.心得体会
和第一题大体相同,继续巩固了pymysql与MySQL数据库的使用理解。
1.作业③:
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
2.解题思路
2.1网页分析与商品定位
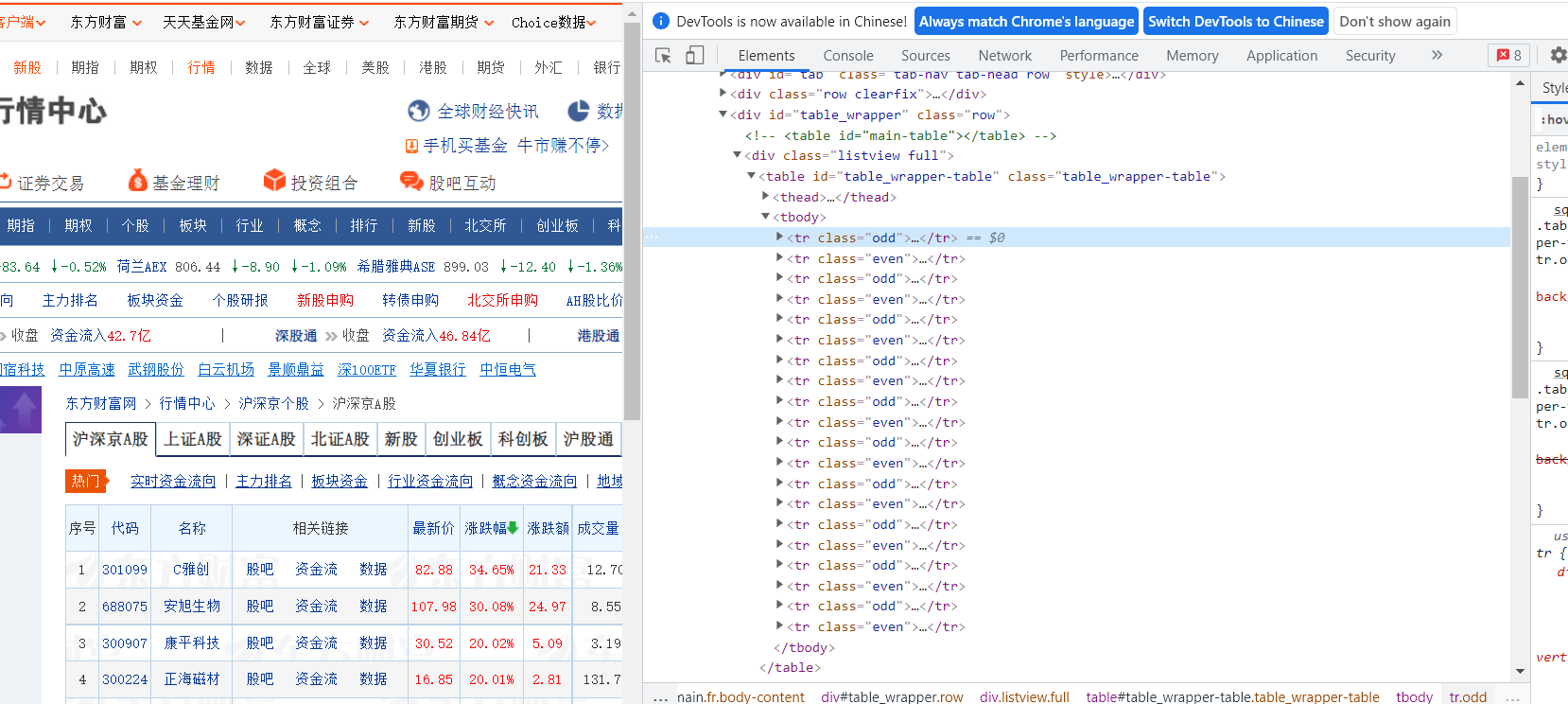
所需股票信息在tr标签下,xpath定位语句为'//tbody/tr',“沪深A股”、“上证A股”、“深证A股””3个板块对应修改url 尾部'hs_a_board','sh_a_board','sz_a_board'
2.2信息提取
stocks = driver.find_elements(By.XPATH, '//tbody/tr')
for s in stocks:
stock_data = []
for i in [1,2,3,5,6,7,8,9,10,11,12,13,14]:
stock_data.append(s.find_element_by_xpath('./td['+str(i)+']').text)
stocks_data.append(stock_data)
2.3翻页处理
# 翻页
driver.find_element_by_xpath('//div[@id="main-table_paginate"]/a[2]').click()
sleep(3)
# 上滚至顶部
driver.execute_script("window.scrollTo(0,0);")
sleep(3)
pages -= 1
2.4代码
spider函数
def spider(key,pages):
stocks_data = []
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get('http://quote.eastmoney.com/center/gridlist.html#'+key)
while pages:
stocks = driver.find_elements(By.XPATH, '//tbody/tr')
for s in stocks:
stock_data = []
for i in [1,2,3,5,6,7,8,9,10,11,12,13,14]:
stock_data.append(s.find_element_by_xpath('./td['+str(i)+']').text)
stocks_data.append(stock_data)
# 翻页
driver.find_element_by_xpath('//div[@id="main-table_paginate"]/a[2]').click()
sleep(3)
# 上滚至顶部
driver.execute_script("window.scrollTo(0,0);")
sleep(3)
pages -= 1
return stocks_data
主函数
def main():
con = pymysql.connect(host='localhost', port=3306, user='root', password='123456', charset='utf8')
cursor = con.cursor()
cursor.execute("CREATE DATABASE IF NOT EXISTS stock")
cursor.execute("USE stock")
print("opened")
keys = ['hs_a_board','sh_a_board','sz_a_board']
names = ['沪深A股','上证A股','深证A股']
for i in range(3):
cursor.execute("CREATE TABLE IF NOT EXISTS " +names[i]+"(sNo varchar(8) , sId varchar(16) primary key, "
"sName varchar(32), sPrice varchar(8), sChangePer varchar(8), sChangeAmount varchar(8), "
"sTransactionVolume varchar(16), sTradingVolume varchar(16), sAmplitude varchar(8), sHigh varchar(8), "
"sLow varchar(8), sToday varchar(8), sYesterday varchar(8))"
"ENGINE=InnoDB DEFAULT CHARSET=utf8")
stocks = spider(keys[i],3)#爬取3页
print(len(stocks))
for s in stocks:
print(s[0], s[1], s[2], s[3], s[4], s[5], s[6], s[7], s[8], s[9], s[10], s[11], s[12])
cursor.execute("INSERT INTO " +names[i]+" VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(s[0], s[1], s[2], s[3], s[4], s[5], s[6], s[7], s[8], s[9], s[10], s[11], s[12]))
con.commit()
con.close()
print("closed")
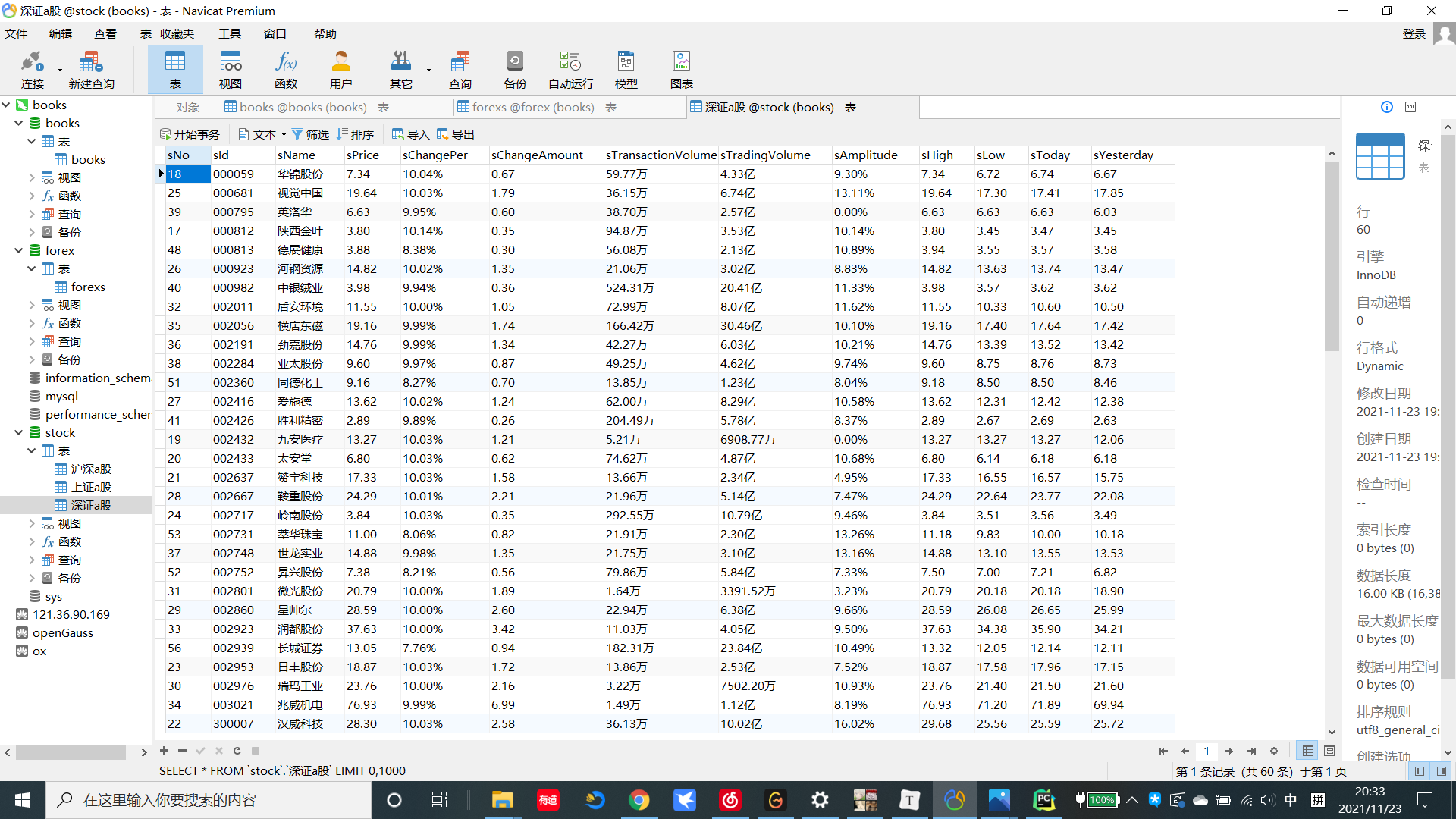
2.5结果
深证A股
3.心得体会
更加理解了selenium的使用,虽然selenium速度很慢,但其直接运行在浏览器之中的。用户可以非常清楚地看到浏览器执行的每一步操作,功能也更多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号