数据采集与融合技术_实验三
码云链接:实验三
1.作业①
1.1作业内容
- 内容:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位)
- 输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1.2解题思路
1.2.1观察并分析主页面,发现图片在img标签下,同时子网站在a标签的href中
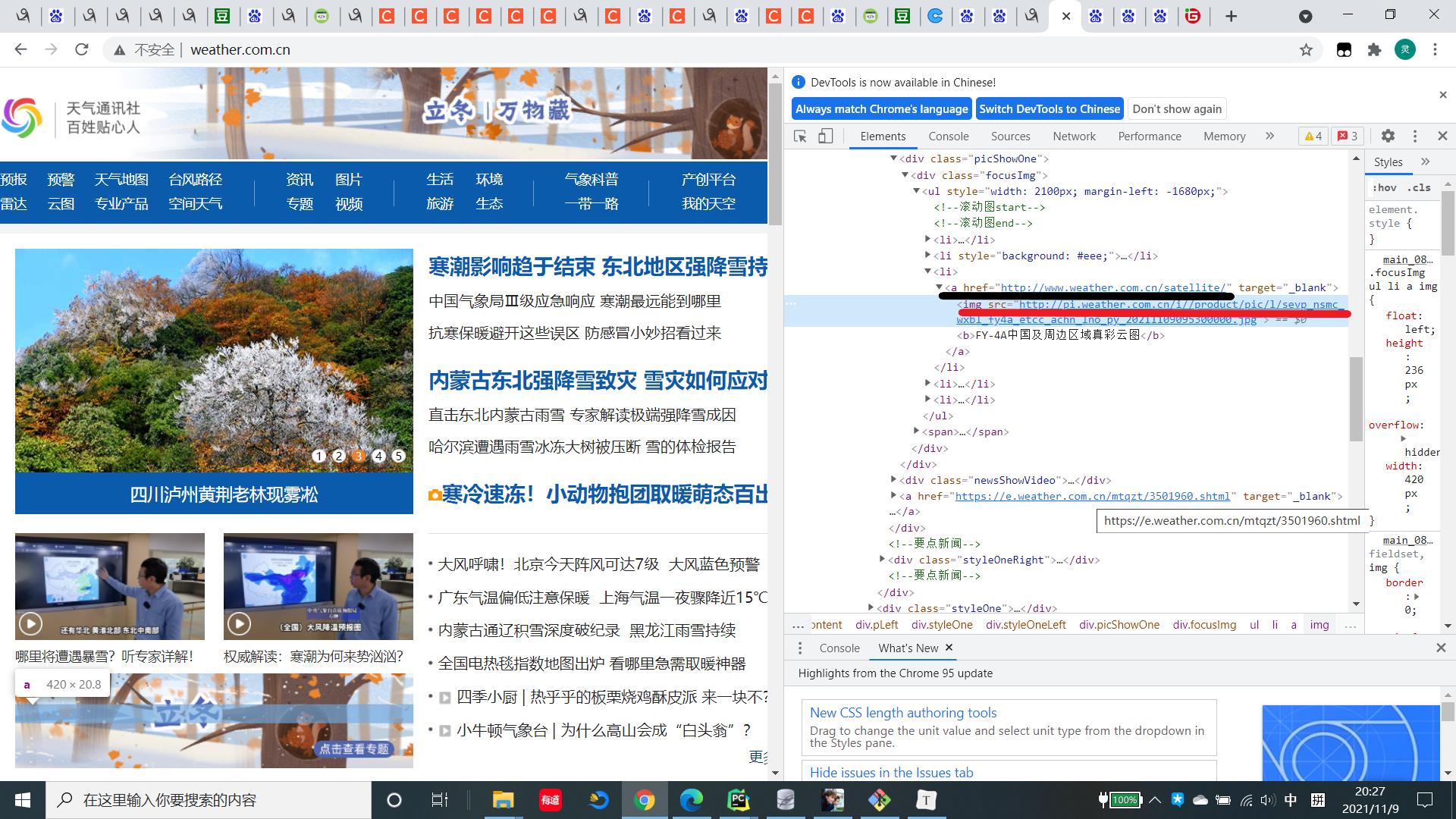
1.2.2进行网站遍历的同时,编写spider函数从每个网站爬取些许图片
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
links = soup.select("a")
if len(images) >= 5:
for i in range(5):
if images[i]["src"].startswith("http") and images[i]["src"] not in imgs:
imgs.append(images[i]["src"])
if len(imgs) >= 121 or deep == 0:
return
for link in links:
if link["href"].startswith("http"):
spider(link["href"],deep-1)
1.2.3 单线程下载图片
def download():
global imgs
for i in range(121):
request.urlretrieve(imgs[i],r"D:\数据采集\demo\实践\3\3.1\images\第"+str(i+1)+"张图.jpg")
print("downloaded ", imgs[i])
1.2.4 多线程下载图片
def download_threads():
global imgs
for i in range(121):
T = threading.Thread(target=download, args=(imgs[i], i+1))
T.setDaemon(False)
T.start()
threads.append(T)
1.2.5 结果
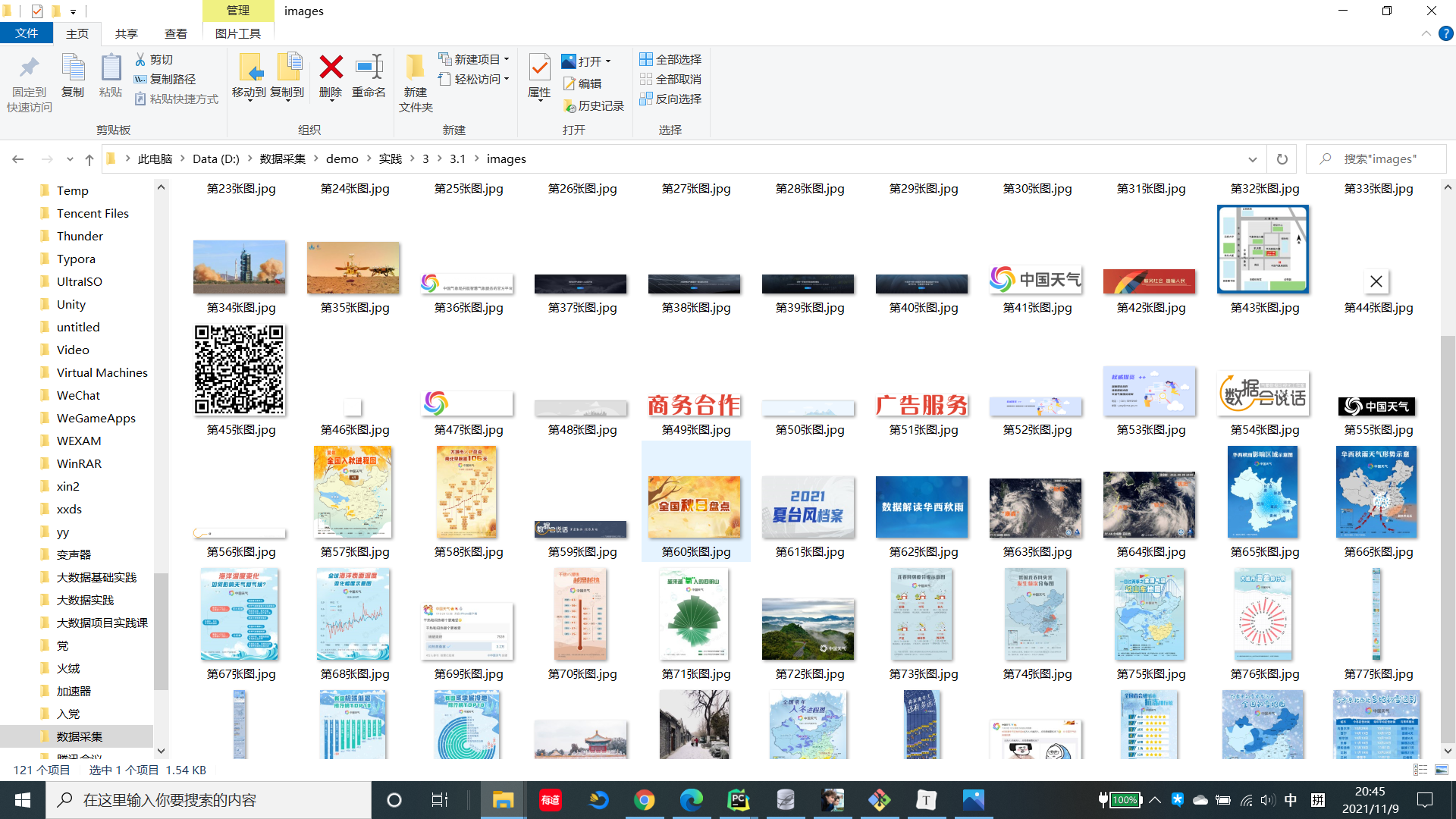
1.3 心得体会
- 单线程按顺序下载图片,非常简单直观,速度较慢,多线程不一定按顺序执行,但是下载速度快
- 熟悉了对网站的遍历,巩固了对多线程爬虫的理解
2.作业②
2.1作业内容
求:使用scrapy框架复现作业①。 输出信息: 同作业①
2.2解题思路
2.2.1 在 item 中设置唯一参数src_url储存图片地址,编写mySpider
class mySpider(scrapy.Spider):
name = "mySpider"
count = 0
imgs = []
def start_requests(self):
url = "http://www.weather.com.cn/"
yield scrapy.Request(url=url, callback=self.parse, meta={"deep":3})
def parse(self, response):
try:
deep = response.meta["deep"]
if deep <= 0 or self.count >= 121:
return
data = response.body.decode()
selector = scrapy.Selector(text=data)
images = selector.xpath("//img/@src").extract()
n = 0
for i in images:
if i.startswith("http") and i not in self.imgs:
item = DemoItem()
item["src_url"] = i
self.imgs.append(i)
self.count += 1
n += 1
if n > 5:
break
yield item
links = selector.xpath("//a/@href").extract()
for link in links:
if link.startswith("http"):
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse, meta={"deep":deep-1})
except Exception as err:
print(err)
2.2.2 在pipelines中下载图片
class DemoPipeline:
count = 1
def process_item(self, item, spider):
try:
if self.count <= 121:
with open("./images/第" + str(self.count) + "张图.jpg", "wb") as f:
print(str(self.count)+":"+item["src_url"])
img = requests.get(item["src_url"]).content
f.write(img)
self.count += 1
else:
return
except Exception as err:
print(err)
return item
2.2.3 修改 setting
BOT_NAME = 'demo'
SPIDER_MODULES = ['demo.spiders']
NEWSPIDER_MODULE = 'demo.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
}
2.2.4 输出结果
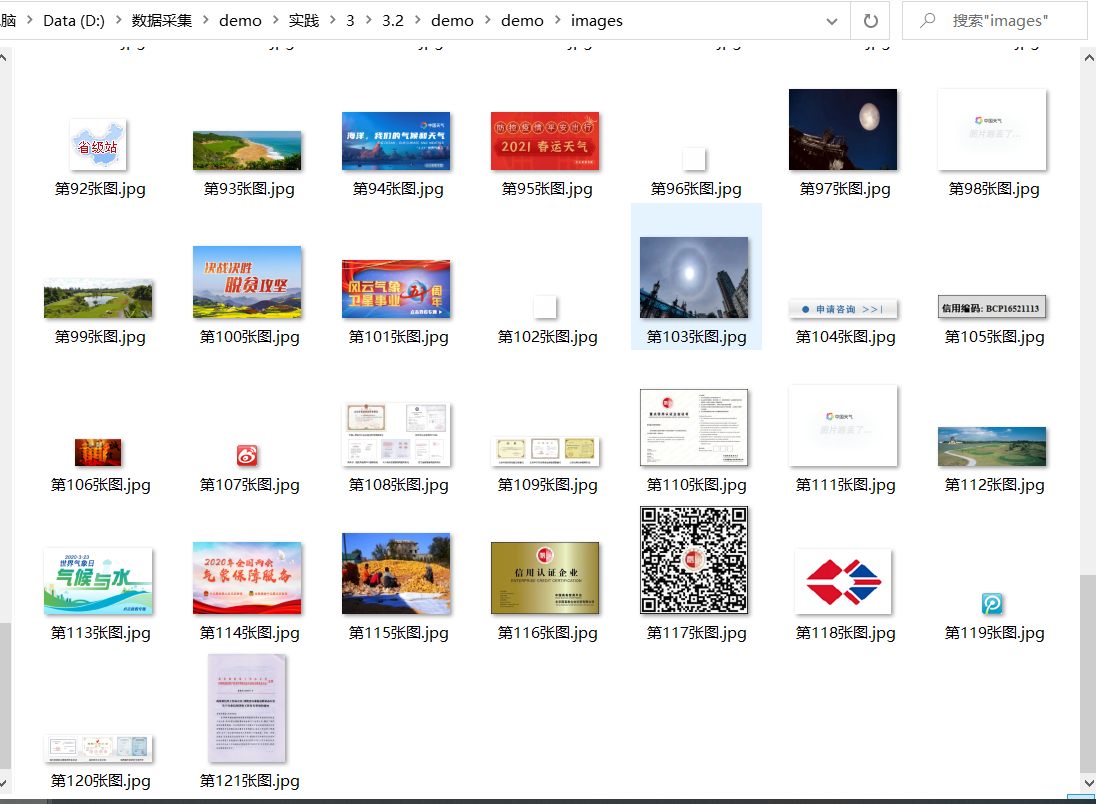
2.3 心得体会
- 复习了scrapy爬虫框架,学会了xpath的使用,感觉熟练后的xpath会比CSS更便利
- 了解了scrapy中parse的传参机制
作业③
3.1作业内容
-
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。 -
输出信息:
序号 电影名称 导演 演员 简介 电影评分 电影封面 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 希望让人自由 9.7 ./imgs/xsk.jpg 2....
3.2 解题思路
3.2.1 网页内容的解析,寻找所需内容的位置

3.2.2 编写movieItem
class MovieItem(scrapy.Item):
rank = scrapy.Field()
name = scrapy.Field()
director = scrapy.Field()
actor = scrapy.Field()
score = scrapy.Field()
img = scrapy.Field()
desp = scrapy.Field()
3.2.3 编写spider
爬取10页
def start_requests(self):
for i in range(10):
url = "https://movie.douban.com/top250?start=" + str(i * 25)
yield scrapy.Request(url=url,callback=self.parse)
parse 函数
def parse(self, response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
# 获取每一个电影信息
movies = selector.xpath("//li/div[@class='item']")
for m in movies:
rank = m.xpath("./div[@class='pic']/em/text()").extract_first()
image = m.xpath("./div[@class='pic']/a/img/@src").extract_first()
name = m.xpath("./div[@class='info']//span[@class='title']/text()").extract_first()
members = m.xpath("./div[@class='info']//p[@class='']/text()").extract_first()
desp = m.xpath("./div[@class='info']//p[@class='quote']/span/text()").extract_first()
score = m.xpath("./div[@class='info']//span[@class='rating_num']/text()").extract_first()
item = MovieItem()
item['rank'] = rank
item['name'] = name
director = re.search(r'导演:(.*?)\s主', members).group(1)
actor = re.search(r'主演:(.*)', members)
item['director'] = director
#由于有动画片没有演员,actor可能为空
if actor == None:
item['actor'] = "null"
else:
item["actor"] = actor.group(1)
item['desp'] = desp
item['score'] = score
item['img'] = image
yield item
except Exception as err:
print(err)
3.2.4 编写数据库类
class MovieDB:
def openDB(self):
self.con = sqlite3.connect("movies.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table movies (Rank int,Name varchar(32),Director varchar(32),"
"Actors varchar(64),Description varchar(64),Score varchar(8),ImgPath varchar(64))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, Rank,Name,Director,Actors,Description,Score,ImgPath):
try:
self.cursor.execute("insert into movies (Rank,Name,Director,Actors,Description,Score,ImgPath) "
"values (?,?,?,?,?,?,?)", (Rank,Name,Director,Actors,Description,Score,ImgPath))
except Exception as err:
print(err)
3.2.5 编写pipelines
class MoviespiderPipeline:
def open_spider(self, spider):
self.db = MovieDB()
self.db.openDB()
def process_item(self, item, spider):
path = r"./images/"+item['name']+".jpg"
url = item['img']
img = requests.get(url).content
with open(path,"wb") as f:
f.write(img)
print("第"+item['rank']+"张封面下载成功")
self.db.insert(int(item['rank']),item['name'],item['director'],item['actor'],item['desp'],item["score"],path)
print("第" + item['rank'] +'部电影数据插入成功')
return item
def close_spider(self, spider):
self.db.closeDB()
print("结束爬取")
3.2.6 修改setting
3.2.7 输出结果
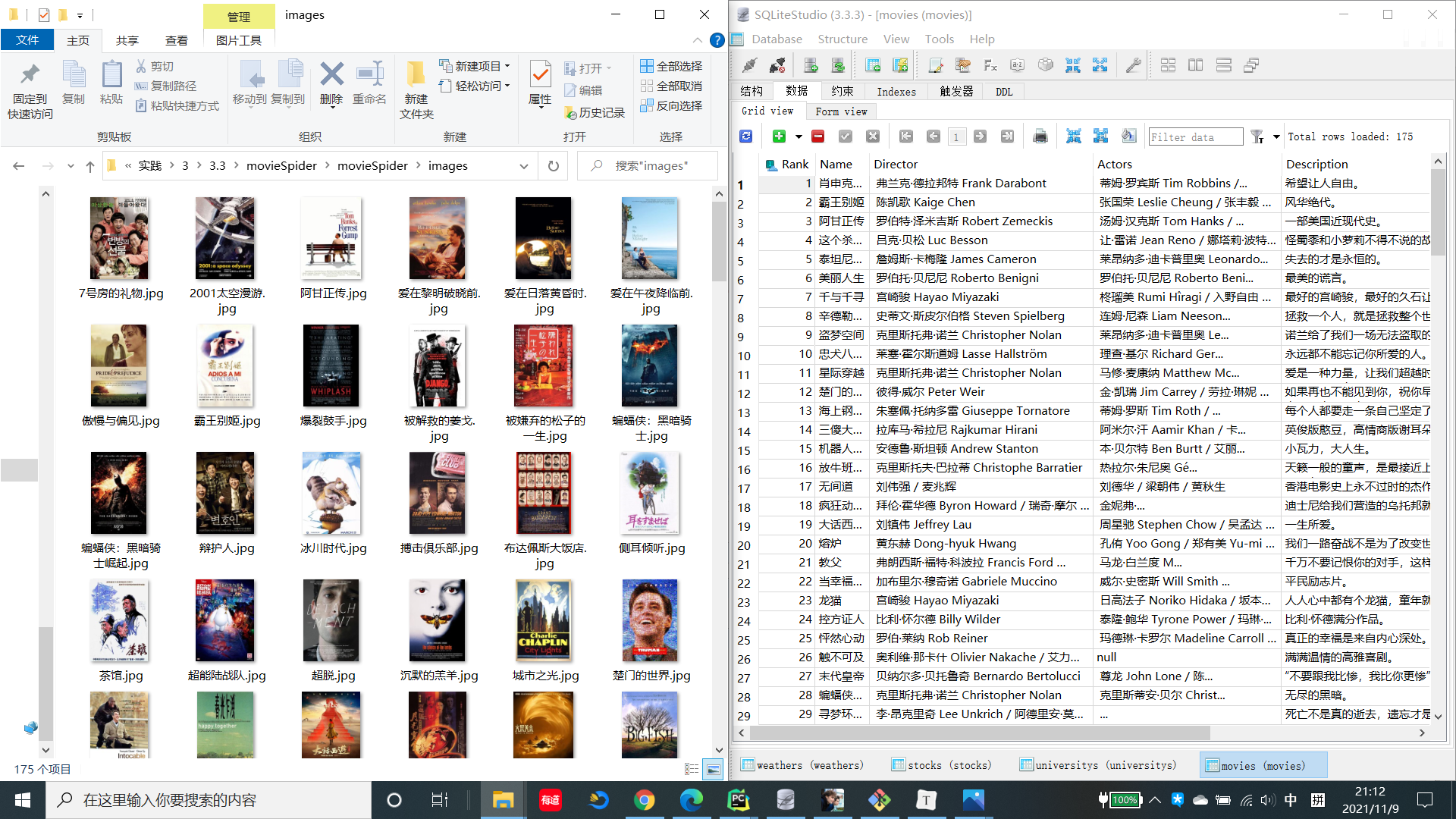
3.3 心得体会
- 对于scrapy和xpath的使用更加熟练

 浙公网安备 33010602011771号
浙公网安备 33010602011771号