Java面经整理(二)
1、HashMap
底层数据结构
JDK1.8之前 数组+链表
JDK1.8之后 数组+链表+红黑树
为什么要改成数组+链表+红黑树
主要是为了提升在 hash 冲突严重时(链表过长)的查找性能,使用链表的查找性能是 O(n),而使用红黑树是 O(logn)
什么时候用链表,什么时候用红黑树
对于插入,默认情况下是使用链表节点。当同一个索引位置的节点在新增后达到9个(阈值8):如果此时数组长度大于等于 64,则会触发链表节点转红黑树节点(treeifyBin);而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容,因为此时的数据量还比较小。
对于移除,当同一个索引位置的节点在移除后达到 6 个,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点(untreeify)。
手写HashMap
Map接口
public interface Map<K,V> {
V put(K k, V v);
V get(K k);
int size();
interface Entry<K,V> {
K getKey();
V getValue();
}
}
HashMap
public class HashMap implements Map<K,V> {
private Entry<K,V> table[] = null;
int size = 0;
public HashMap() {
this.table = new Entry[16];
}
@Override
public V put(K k, V v) {
int index = hash(k);
Entry<K,V> entry = table[index];
if (entry == null) {
table[index] = new Entry<>(k,v,index,null);
size++;
}else {
table[index] = new Entry<>(k,v,index,entry);
}
return table[index].getValue();
}
private int hash(K k) {
int index = k.hashCode() % 16;
return index>=0?index:-index;
}
@Override
public V get(K k) {
if (size == 0) {
return null;
}
int index = hash(k);
Entry<K,V> entry = findValue(table[index],k);
return entry==null?null:entry.getValue();
}
private Entry<K,V> findValue(Entry<K,V> entry, K k) {
if (k.equals(entry.getKey())||k == entry.getKey()) {
return entry;
}else {
if (entry.next != null) {
return findValue(entry.next,k);
}
}
return null;
}
@Override
public int size() {
return size;
}
class Entry<K,V> implements Map.Entry<K,V> {
K k;
V v;
int hash;
Entry<K,V> next;
public Entry(K k, V v, int hash, Entry<K,V> next) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}
为什么引入红黑树?
为了解决链表过长查询效率过低的问题
2、重载与重写的区别
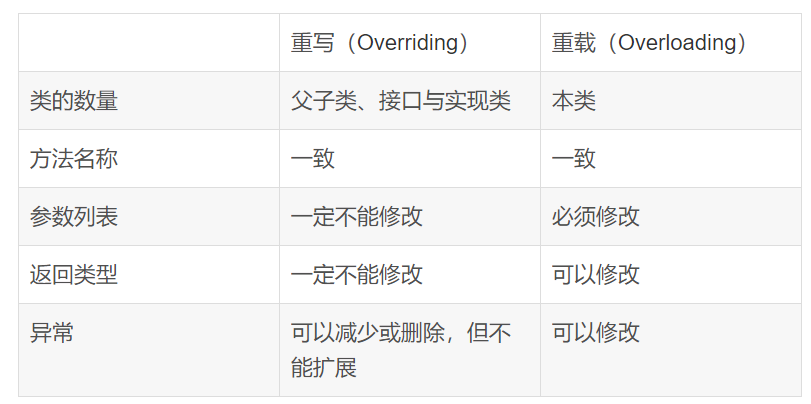
重载(Overloading)
重载发生在本类,方法名相同,参数列表不同,与返回值无关,只和方法名,参数列表,参数的类型有关.
重载(Overload):首先是位于一个类之中或者其子类中,具有相同的方法名,但是方法的参数不同,返回值类型可以相同也可以不同。
(1):方法名必须相同
(2):方法的参数列表一定不一样。
(3):访问修饰符和返回值类型可以相同也可以不同。
其实简单而言:重载就是对于不同的情况写不同的方法。 比如,同一个类中,写不同的构造函数用于初始化不同的参数。
重写(Overriding)
重写发生在父类子类之间,比如所有类都是继承与Object类的,Object类中本身就有equals,hashcode,toString方法等.在任意子类中定义了重名和同样的参数列表就构成方法重写.
重写(override):一般都是表示子类和父类之间的关系,其主要的特征是:方法名相同,参数相同,但是具体的实现不同。
重写的特征:
(1):方法名必须相同,返回值类型必须相同
(2):参数列表必须相同
(3):访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
(4):子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
(5):构造方法不能被重写,
简单而言:就是具体的实现类对于父类的该方法实现不满意,需要自己在写一个满足于自己要求的方法。
3、TCP和UDP的区别
TCP报文首部格式

- TCP:面向连接,提供可靠的服务,有流量控制,拥塞控制,无重复、无丢失、无差错,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),只能是点对点,首部 20 字节,全双工。
- UDP:无连接,尽最大努力交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对多,首部 8 字节。
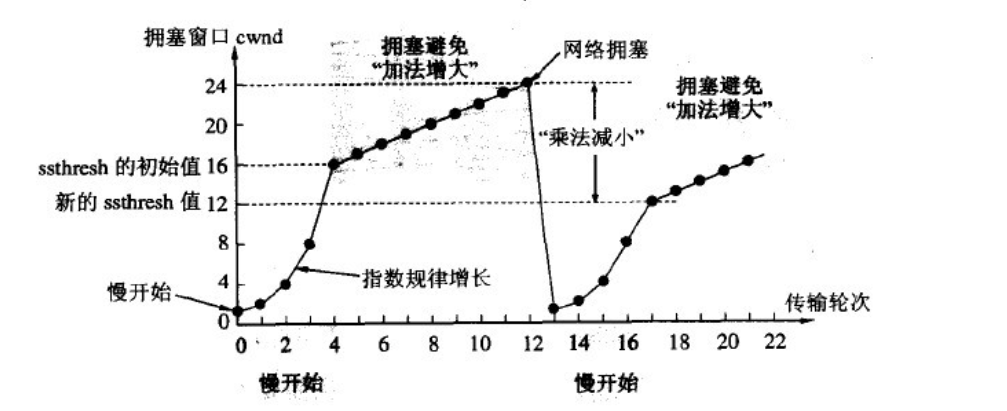
4、TCP拥塞控制
慢开始和拥塞避免
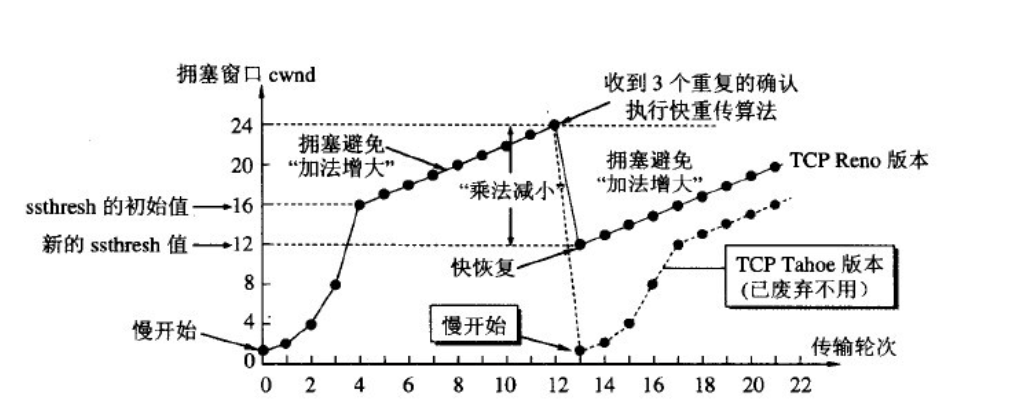
快重传和快恢复
5、hashMap&hashtable&ConcurrentMap
HashTable
继承于Dictionary,实现了Map,Cloneable,Java.io.Serializable接口
- 底层数组+链表实现,无论key还是value都不能为null,同步线程安全,实现线程安全的方式是锁住整个hashtable,效率低,concurrentMap做了相关优化。
- 初始容量为11 扩容:newsize=oldsize*2+1
- 两个参数影响性能:初始容量,加载因子(默认0.75)
- 计算index方法:index=(hash&0x7FFFFFFF)%tab.length
HashMap
- 底层数组+链表实现,可以存在null键和null值,线程不安全
- 初始size为16 扩容:newsize=oldsize*2,size一定为2的n次幂
- 扩容针对整个map,每次和扩容时,原数组的元素重新计算存放位置,并重新插入。
- 插入元素后才判断是否需要扩容,若再无插入,无效扩容
- 加载因子:默认0.75
- 计算index方法:index=hash&(tab.length-1)
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
ConcurrentMap
- 底层采用分段的数组+链表实现,线程安全。
- 通过把整个map分为N个Segment,可以提供相同的线程安全效率提升N倍,默认16倍。
- 读操作不加锁,修改操作加分段锁,允许多个修改操作并行发生。
- 扩容:段内扩容(段内元素超过该段对应的Entry数组的0.75,触发扩容,而不是整段扩容),插入前检测是否需要扩容,避免无效扩容。
- (有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁)。
6、HTTPS的工作原理
1)客户端发起 HTTPS 请求
这个没什么好说的,就是用户在浏览器里输入一个 https 网址,然后连接到 server 的 443 端口。
2)服务端的配置
采用 HTTPS 协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请,区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl 就是个不错的选择,有 1 年的免费服务)。
这套证书其实就是一对公钥和私钥,如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3)传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4)客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。
如果证书没有问题,那么就生成一个随机值,然后用证书对该随机值进行加密,就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5)传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6)服务端解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密,所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7)传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在客户端被还原。
8)客户端解密信息
客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容,整个过程第三方即使监听到了数据,也束手无策。
7、HTTP1.0和HTTP1.1的主要区别
在HTTP/1.0中,默认使用的是短连接,也就是说每次请求都要重新建立一次连接。HTTP 是基于TCP/IP协议的,每一次建立或者断开连接都需要三次握手四次挥手的开销,如果每次请求都要这样的话,开销会比较大。因此最好能维持一个长连接,可以用个长连接来发多个请求。HTTP 1.1起,默认使用长连接 ,默认开启Connection: keep-alive。 HTTP/1.1的持续连接有非流水线方式和流水线方式 。流水线方式是客户在收到HTTP的响应报文之前就能接着发送新的请求报文。与之相对应的非流水线方式是客户在收到前一个响应后才能发送下一个请求。
8、进程间的通信
- 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 命名管道FIFO:命名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
- 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号